








整洁的 Table View 代码
Table view 是 iOS 应用程序中非常通用的组件。许多代码和 table view 都有直接或间接的关系,随便举几个例子,比如提供数据、更新 table view,控制它的行为以及响应选择事件。在这篇文章中,我们将会展示保持 table view 相关代码的整洁和良好组织的技术。
UITableViewController vs. UIViewController
Apple 提供了 UITableViewController 作为 table views 专属的 view controller 类。Table view controllers 实现了一些非常有用的特性,来帮你避免一遍又一遍地写那些死板的代码!但是话又说回来,table view controller 只限于管理一个全屏展示的 table view。大多数情况下,这就是你想要的,但如果不是,还有其他方法来解决这个问题,就像下面我们展示的那样。
Table View Controllers 的特性
Table view controllers 会在第一次显示 table view 的时候帮你加载其数据。另外,它还会帮你切换 table view 的编辑模式、响应键盘通知、以及一些小任务,比如闪现侧边的滑动提示条和清除选中时的背景色。为了让这些特性生效,当你在子类中覆写类似 viewWillAppear: 或者 viewDidAppear: 等事件方法时,需要调用 super 版本。
Table view controllers 相对于标准 view controllers 的一个特别的好处是它支持 Apple 实现的“下拉刷新”。目前,文档中唯一的使用 UIRefreshControl 的方式就是通过 table view controller ,虽然通过努力在其他地方也能让它工作(见此处),但很可能在下一次 iOS 更新的时候就不行了。
这些要素加一起,为我们提供了大部分 Apple 所定义的标准 table view 交互行为,如果你的应用恰好符合这些标准,那么直接使用 table view controllers 来避免写那些死板的代码是个很好的方法。
Table View Controllers 的限制
Table view controllers 的 view 属性永远都是一个 table view。如果你稍后决定在 table view 旁边显示一些东西(比如一个地图),如果不依赖于那些奇怪的 hacks,估计就没什么办法了。
如果你是用代码或 .xib 文件来定义的界面,那么迁移到一个标准 view controller 将会非常简单。但是如果你使用了 storyboards,那么这个过程要多包含几个步骤。除非重新创建,否则你并不能在 storyboards 中将 table view controller 改成一个标准的 view controller。这意味着你必须将所有内容拷贝到新的 view controller,然后再重新连接一遍。
最后,你需要把迁移后丢失的 table view controller 的特性给补回来。大多数都是 viewWillAppear: 或 viewDidAppear: 中简单的一条语句。切换编辑模式需要实现一个 action 方法,用来切换 table view 的 editing 属性。大多数工作来自重新创建对键盘的支持。
在选择这条路之前,其实还有一个更轻松的选择,它可以通过分离我们需要关心的功能(关注点分离),让你获得额外的好处:
使用 Child View Controllers
和完全抛弃 table view controller 不同,你还可以将它作为 child view controller 添加到其他 view controller 中(关于此话题的文章)。这样,parent view controller 在管理其他的你需要的新加的界面元素的同时,table view controller 还可以继续管理它的 table view。
- (void)addPhotoDetailsTableView
{
DetailsViewController *details = [[DetailsViewController alloc] init];
details.photo = self.photo;
details.delegate = self;
[self addChildViewController:details];
CGRect frame = self.view.bounds;
frame.origin.y = 110;
details.view.frame = frame;
[self.view addSubview:details.view];
[details didMoveToParentViewController:self];
}如果你使用这个解决方案,你就必须在 child view controller 和 parent view controller 之间建立消息传递的渠道。比如,如果用户选择了一个 table view 中的 cell,parent view controller 需要知道这个事件来推入其他 view controller。根据使用习惯,通常最清晰的方式是为这个 table view controller 定义一个 delegate protocol,然后到 parent view controller 中去实现。
@protocol DetailsViewControllerDelegate
- (void)didSelectPhotoAttributeWithKey:(NSString *)key;
@end
@interface PhotoViewController ()
@end
@implementation PhotoViewController
// ...
- (void)didSelectPhotoAttributeWithKey:(NSString *)key
{
DetailViewController *controller = [[DetailViewController alloc] init];
controller.key = key;
[self.navigationController pushViewController:controller animated:YES];
}
@end就像你看到的那样,这种结构为 view controller 之间的消息传递带来了额外的开销,但是作为回报,代码封装和分离非常清晰,有更好的复用性。根据实际情况的不同,这既可能让事情变得更简单,也可能会更复杂,需要读者自行斟酌和决定。
分离关注点(Separating Concerns)
当处理 table views 的时候,有许多各种各样的任务,这些任务穿梭于 models,controllers 和 views 之间。为了避免让 view controllers 做所有的事,我们将尽可能地把这些任务划分到合适的地方,这样有利于阅读、维护和测试。
这里描述的技术是文章更轻量的 View Controllers 中的概念的延伸,请参考这篇文章来理解如何重构 data source 和 model 的逻辑。结合 table views,我们来具体看看如何在 view controllers 和 views 之间分离关注点。
搭建 Model 对象和 Cells 之间的桥梁
有时我们需要将想显示的 model 层中的数据传到 view 层中去显示。由于我们同时也希望让 model 和 view 之间明确分离,所以通常把这个任务转移到 table view 的 data source 中去处理:
- (UITableViewCell *)tableView:(UITableView *)tableView
cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
PhotoCell *cell = [tableView dequeueReusableCellWithIdentifier:@"PhotoCell"];
Photo *photo = [self itemAtIndexPath:indexPath];
cell.photoTitleLabel.text = photo.name;
NSString* date = [self.dateFormatter stringFromDate:photo.creationDate];
cell.photoDateLabel.text = date;
}但是这样的代码会让 data source 变得混乱,因为它向 data source 暴露了 cell 的设计。最好分解出来,放到 cell 类的一个 category 中。
@implementation PhotoCell (ConfigureForPhoto)
- (void)configureForPhoto:(Photo *)photo
{
self.photoTitleLabel.text = photo.name;
NSString* date = [self.dateFormatter stringFromDate:photo.creationDate];
self.photoDateLabel.text = date;
}
@end有了上述代码后,我们的 data source 方法就变得简单了。
- (UITableViewCell *)tableView:(UITableView *)tableView
cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
PhotoCell *cell = [tableView dequeueReusableCellWithIdentifier:PhotoCellIdentifier];
[cell configureForPhoto:[self itemAtIndexPath:indexPath]];
return cell;
}在我们的示例代码中,table view 的 data source 已经分解到单独的类中了,它用一个设置 cell 的 block 来初始化。这时,这个 block 就变得这样简单了:
TableViewCellConfigureBlock block = ^(PhotoCell *cell, Photo *photo) {
[cell configureForPhoto:photo];
};让 Cells 可复用
有时多种 model 对象需要用同一类型的 cell 来表示,这种情况下,我们可以进一步让 cell 可以复用。首先,我们给 cell 定义一个 protocol,需要用这个 cell 显示的对象必须遵循这个 protocol。然后简单修改 category 中的设置方法,让它可以接受遵循这个 protocol 的任何对象。这些简单的步骤让 cell 和任何特殊的 model 对象之间得以解耦,让它可适应不同的数据类型。
在 Cell 内部控制 Cell 的状态
如果你想自定义 table views 默认的高亮或选择行为,你可以实现两个 delegate 方法,把点击的 cell 修改成我们想要的样子。例如:
- (void)tableView:(UITableView *)tableView
didHighlightRowAtIndexPath:(NSIndexPath *)indexPath
{
PhotoCell *cell = [tableView cellForRowAtIndexPath:indexPath];
cell.photoTitleLabel.shadowColor = [UIColor darkGrayColor];
cell.photoTitleLabel.shadowOffset = CGSizeMake(3, 3);
}
- (void)tableView:(UITableView *)tableView
didUnhighlightRowAtIndexPath:(NSIndexPath *)indexPath
{
PhotoCell *cell = [tableView cellForRowAtIndexPath:indexPath];
cell.photoTitleLabel.shadowColor = nil;
}然而,这两个 delegate 方法的实现又基于了 view controller 知晓 cell 实现的具体细节。如果我们想替换或重新设计 cell,我们必须改写 delegate 代码。View 的实现细节和 delegate 的实现交织在一起了。我们应该把这些细节移到 cell 自身中去。
@implementation PhotoCell
// ...
- (void)setHighlighted:(BOOL)highlighted animated:(BOOL)animated
{
[super setHighlighted:highlighted animated:animated];
if (highlighted) {
self.photoTitleLabel.shadowColor = [UIColor darkGrayColor];
self.photoTitleLabel.shadowOffset = CGSizeMake(3, 3);
} else {
self.photoTitleLabel.shadowColor = nil;
}
}
@end总的来说,我们在努力把 view 层和 controller 层的实现细节分离开。delegate 肯定得清楚一个 view 该显示什么状态,但是它不应该了解如何修改 view 结构或者给某些 subviews 设置某些属性以获得正确的状态。所有这些逻辑都应该封装到 view 内部,然后给外部提供一个简单的 API。
控制多个 Cell 类型
如果一个 table view 里面有多种类型的 cell,data source 方法很快就难以控制了。在我们示例程序中,photo details table 有两种不同类型的 cell:一种用于显示几个星,另一种用来显示一个键值对。为了划分处理不同 cell 类型的代码,data source 方法简单地通过判断 cell 的类型,把任务派发给其他指定的方法。
- (UITableViewCell *)tableView:(UITableView *)tableView
cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
NSString *key = self.keys[(NSUInteger) indexPath.row];
id value = [self.photo valueForKey:key];
UITableViewCell *cell;
if ([key isEqual:PhotoRatingKey]) {
cell = [self cellForRating:value indexPath:indexPath];
} else {
cell = [self detailCellForKey:key value:value];
}
return cell;
}
- (RatingCell *)cellForRating:(NSNumber *)rating
indexPath:(NSIndexPath *)indexPath
{
// ...
}
- (UITableViewCell *)detailCellForKey:(NSString *)key
value:(id)value
{
// ...
}编辑 Table View
Table view 提供了易于使用的编辑特性,允许你对 cell 进行删除或重新排序。这些事件都可以让 table view 的 data source 通过 delegate 方法得到通知。因此,通常我们能在这些 delegate 方法中看到对数据的进行修改的操作。
修改数据很明显是属于 model 层的任务。Model 应该为诸如删除或重新排序等操作暴露一个 API,然后我们可以在 data source 方法中调用它。这样,controller 就可以扮演 view 和 model 之间的协调者,而不需要知道 model 层的实现细节。并且还有额外的好处,model 的逻辑也变得更容易测试,因为它不再和 view controllers 的任务混杂在一起了。
总结
Table view controllers(以及其他的 controller 对象!)应该在 model 和 view 对象之间扮演协调者和调解者的角色。它不应该关心明显属于 view 层或 model 层的任务。你应该始终记住这点,这样 delegate 和 data source 方法会变得更小巧,最多包含一些简单的样板代码。
这不仅减少了 table view controllers 那样的大小和复杂性,而且还把业务逻辑和 view 的逻辑放到了更合适的地方。Controller 层的里里外外的实现细节都被封装成了简单的 API,最终,它变得更加容易理解,也更利于团队协作。
转自:https://www.jianshu.com/p/22df7a214b49
收起阅读 »Core Image 和视频
在这篇文章中,我们将研究如何将 Core Image 应用到实时视频上去。我们会看两个例子:首先,我们把这个效果加到相机拍摄的影片上去。之后,我们会将这个影响作用于拍摄好的视频文件。它也可以做到离线渲染,它会把渲染结果返回给视频,而不是直接显示在屏幕上。两个例子的完整源代码,请点击这里。
总览
当涉及到处理视频的时候,性能就会变得非常重要。而且了解黑箱下的原理 —— 也就是 Core Image 是如何工作的 —— 也很重要,这样我们才能达到足够的性能。在 GPU 上面做尽可能多的工作,并且最大限度的减少 GPU 和 CPU 之间的数据传送是非常重要的。之后的例子中,我们将看看这个细节。
想对 Core Image 有个初步认识的话,可以读读 Warren 的这篇文章 Core Image 介绍。我们将使用 Swift 的函数式 API 中介绍的基于 CIFilter 的 API 封装。想要了解更多关于 AVFoundation 的知识,可以看看本期话题中 Adriaan 的文章,还有话题 #21 中的 iOS 上的相机捕捉。
优化资源的 OpenGL ES
CPU 和 GPU 都可以运行 Core Image,我们将会在 下面 详细介绍这两个的细节。在这个例子中,我们要使用 GPU,我们做如下几样事情。
我们首先创建一个自定义的 UIView,它允许我们把 Core Image 的结果直接渲染成 OpenGL。我们可以新建一个 GLKView 并且用一个 EAGLContext 来初始化它。我们需要指定 OpenGL ES 2 作为渲染 API,在这两个例子中,我们要自己触发 drawing 事件 (而不是在 -drawRect: 中触发),所以在初始化 GLKView 的时候,我们将 enableSetNeedsDisplay 设置为 false。之后我们有可用新图像的时候,我们需要主动去调用 -display。
在这个视图里,我们保持一个对 CIContext 的引用,它提供一个桥梁来连接我们的 Core Image 对象和 OpenGL 上下文。我们创建一次就可以一直使用它。这个上下文允许 Core Image 在后台做优化,比如缓存和重用纹理之类的资源等。重要的是这个上下文我们一直在重复使用。
上下文中有一个方法,-drawImage:inRect:fromRect:,作用是绘制出来一个 CIImage。如果你想画出来一个完整的图像,最容易的方法是使用图像的 extent。但是请注意,这可能是无限大的,所以一定要事先裁剪或者提供有限大小的矩形。一个警告:因为我们处理的是 Core Image,绘制的目标以像素为单位,而不是点。由于大部分新的 iOS 设备配备 Retina 屏幕,我们在绘制的时候需要考虑这一点。如果我们想填充整个视图,最简单的办法是获取视图边界,并且按照屏幕的 scale 来缩放图片 (Retina 屏幕的 scale 是 2)。
完整的代码示例在这里:CoreImageView.swift
从相机获取像素数据
对于 AVFoundation 如何工作的概述,请看 Adriaan 的文章 和 Matteo 的文章 iOS 上的相机捕捉。对于我们而言,我们想从镜头获得 raw 格式的数据。我们可以通过创建一个 AVCaptureDeviceInput 对象来选定一个摄像头。使用 AVCaptureSession,我们可以把它连接到一个 AVCaptureVideoDataOutput。这个 data output 对象有一个遵守 AVCaptureVideoDataOutputSampleBufferDelegate 协议的代理对象。这个代理每一帧将接收到一个消息:
func captureOutput(captureOutput: AVCaptureOutput!,
didOutputSampleBuffer: CMSampleBuffer!,
fromConnection: AVCaptureConnection!) {我们将用它来驱动我们的图像渲染。在我们的示例代码中,我们已经将配置,初始化以及代理对象都打包到了一个叫做 CaptureBufferSource 的简单接口中去。我们可以使用前置或者后置摄像头以及一个回调来初始化它。对于每个样本缓存区,这个回调都会被调用,并且参数是缓冲区和对应摄像头的 transform:
source = CaptureBufferSource(position: AVCaptureDevicePosition.Front) {
(buffer, transform) in
...
}我们需要对相机返回的数据进行变换。无论你如何转动 iPhone,相机的像素数据的方向总是相同的。在我们的例子中,我们将 UI 锁定在竖直方向,我们希望屏幕上显示的图像符合照相机拍摄时的方向,为此我们需要后置摄像头拍摄出的图片旋转 -π/2。前置摄像头需要旋转 -π/2 并且加一个镜像效果。我们可以用一个 CGAffineTransform 来表达这种变换。请注意如果 UI 是不同的方向 (比如横屏),我们的变换也将是不同的。还要注意,这种变换的代价其实是非常小的,因为它是在 Core Image渲染管线中完成的。
接着,要把 CMSampleBuffer转换成 CIImage,我们首先需要将它转换成一个 CVPixelBuffer。我们可以写一个方便的初始化方法来为我们做这件事:
extension CIImage {
convenience init(buffer: CMSampleBuffer) {
self.init(CVPixelBuffer: CMSampleBufferGetImageBuffer(buffer))
}
}现在我们可以用三个步骤来处理我们的图像。首先,把我们的 CMSampleBuffer 转换成 CIImage,并且应用一个形变,使图像旋转到正确的方向。接下来,我们用一个 CIFilter 滤镜来得到一个新的 CIImage 输出。我们使用了 Florian 的文章 提到的创建滤镜的方式。在这个例子中,我们使用色调调整滤镜,并且传入一个依赖于时间而变化的调整角度。最终,我们使用之前定义的 View,通过 CIContext 来渲染 CIImage。这个流程非常简单,看起来是这样的:
source = CaptureBufferSource(position: AVCaptureDevicePosition.Front) {
[unowned self] (buffer, transform) in
let input = CIImage(buffer: buffer).imageByApplyingTransform(transform)
let filter = hueAdjust(self.angleForCurrentTime)
self.coreImageView?.image = filter(input)
}当你运行它时,你可能会因为如此低的 CPU 使用率感到吃惊。这其中的奥秘是 GPU 做了几乎所有的工作。尽管我们创建了一个 CIImage,应用了一个滤镜,并输出一个 CIImage,最终输出的结果是一个 promise:直到实际渲染才会去进行计算。一个 CIImage 对象可以是黑箱里的很多东西,它可以是 GPU 算出来的像素数据,也可以是如何创建像素数据的一个说明 (比如使用一个滤镜生成器),或者它也可以是直接从 OpenGL 纹理中创建出来的图像。
从影片中获取像素数据
我们可以做的另一件事是通过 Core Image 把这个滤镜加到一个视频中。和实时拍摄不同,我们现在从影片的每一帧中生成像素缓冲区,在这里我们将采用略有不同的方法。对于相机,它会推送每一帧给我们,但是对于已有的影片,我们使用拉取的方式:通过 display link,我们可以向 AVFoundation 请求在某个特定时间的一帧。
display link 对象负责在每帧需要绘制的时候给我们发送消息,这个消息是按照显示器的刷新频率同步进行发送的。这通常用来做 自定义动画,但也可以用来播放和操作视频。我们要做的第一件事就是创建一个 AVPlayer和一个视频输出:
player = AVPlayer(URL: url)
videoOutput = AVPlayerItemVideoOutput(pixelBufferAttributes: pixelBufferDict)
player.currentItem.addOutput(videoOutput)接下来,我们要创建 display link。方法很简单,只要创建一个 CADisplayLink 对象,并将其添加到 run loop。
let displayLink = CADisplayLink(target: self, selector: "displayLinkDidRefresh:")
displayLink.addToRunLoop(NSRunLoop.mainRunLoop(), forMode: NSRunLoopCommonModes)现在,唯一剩下的就是在 displayLinkDidRefresh: 调用的时候获取视频每一帧。首先,我们获取当前的时间,并且将它转换成当前播放项目里的时间比。然后我们询问 videoOutput,如果当前时间有一个可用的新的像素缓存区,我们把它复制一下并且调用回调方法:
func displayLinkDidRefresh(link: CADisplayLink) {
let itemTime = videoOutput.itemTimeForHostTime(CACurrentMediaTime())
if videoOutput.hasNewPixelBufferForItemTime(itemTime) {
let pixelBuffer = videoOutput.copyPixelBufferForItemTime(itemTime, itemTimeForDisplay: nil)
consumer(pixelBuffer)
}
}我们从一个视频输出获得的像素缓冲是一个 CVPixelBuffer,我们可以把它直接转换成 CIImage。正如上面的例子,我们会加上一个滤镜。在这个例子里,我们将组合多个滤镜:我们使用一个万花筒的效果,然后用渐变遮罩把原始图像和过滤图像相结合,这个操作是非常轻量级的。
创意地使用滤镜
大家都知道流行的照片效果。虽然我们可以将这些应用到视频,但 Core Image 还可以做得更多。
Core Image 里所谓的滤镜有不同的类别。其中一些是传统的类型,输入一张图片并且输出一张新的图片。但有些需要两个 (或者更多) 的输入图像并且混合生成一张新的图像。另外甚至有完全不输入图片,而是基于参数的生成图像的滤镜。
通过混合这些不同的类型,我们可以创建意想不到的效果。
混合图片
在这个例子中,我们使用这些东西:
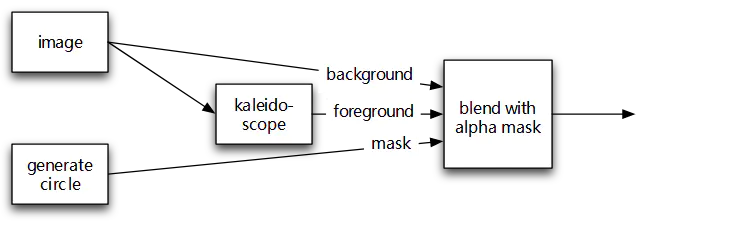
上面的例子可以将图像的一个圆形区域像素化。
它也可以创建交互,我们可以使用触摸事件来改变所产生的圆的位置。
Core Image Filter Reference 按类别列出了所有可用的滤镜。请注意,有一部分只能用在 OS X。
生成器和渐变滤镜可以不需要输入就能生成图像。它们很少自己单独使用,但是作为蒙版的时候会非常强大,就像我们例子中的 CIBlendWithMask 那样。
混合操作和 CIBlendWithAlphaMask 还有 CIBlendWithMask 允许将两个图像合并成一个。
CPU vs. GPU
我们在话题 #3 的文章,绘制像素到屏幕上里,介绍了 iOS 和 OS X 的图形栈。需要注意的是 CPU 和 GPU 的概念,以及两者之间数据的移动方式。
在处理实时视频的时候,我们面临着性能的挑战。
首先,我们需要能在每一帧的时间内处理完所有的图像数据。我们的样本中采用 24 帧每秒的视频,这意味着我们有 41 毫秒 (1/24 秒) 的时间来解码,处理以及渲染每一帧中的百万像素。
其次,我们需要能够从 CPU 或者 GPU 上面得到这些数据。我们从视频文件读取的字节数最终会到达 CPU 里。但是这个数据还需要移动到 GPU 上,以便在显示器上可见。
避免转移
一个非常致命的问题是,在渲染管线中,代码可能会把图像数据在 CPU 和 GPU 之间来回移动好几次。确保像素数据仅在一个方向移动是很重要的,应该保证数据只从 CPU 移动到 GPU,如果能让数据完全只在 GPU 上那就更好。
如果我们想渲染 24 fps 的视频,我们有 41 毫秒;如果我们渲染 60 fps 的视频,我们只有 16 毫秒,如果我们不小心从 GPU 下载了一个像素缓冲到 CPU 里,然后再上传回 GPU,对于一张全屏的 iPhone 6 图像来说,我们在每个方向将要移动 3.8 MB 的数据,这将使帧率无法达标。
当我们使用 CVPixelBuffer 时,我们希望这样的流程:
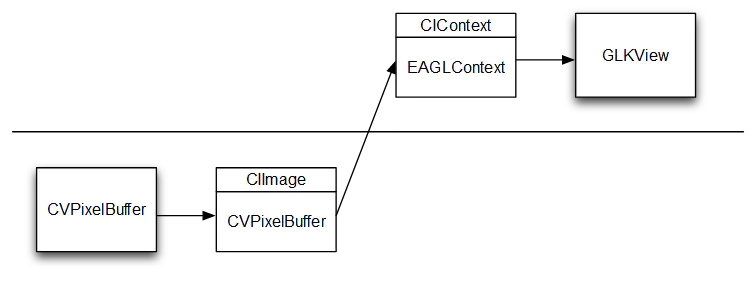
CVPixelBuffer 是基于 CPU 的 (见下文),我们用 CIImage 来包装它。构建滤镜链不会移动任何数据;它只是建立了一个流程。一旦我们绘制图像,我们使用了基于 EAGL 上下文的 Core Image 上下文,而这个 EAGL 上下文也是 GLKView 进行图像显示所使用的上下文。EAGL 上下文是基于 GPU 的。请注意,我们是如何只穿越 GPU-CPU 边界一次的,这是至关重要的部分。
工作和目标
Core Image 的图形上下文可以通过两种方式创建:使用 EAGLContext 的 GPU 上下文,或者是基于 CPU 的上下文。
这个定义了 Core Image 工作的地方,也就是像素数据将被处理的地方。与工作区域无关,基于 GPU 和基于 CPU 的图形上下文都可以通过执行 createCGImage(…),render(, toBitmap, …) 和 render(, toCVPixelBuffer, …),以及相关的命令来向 CPU 进行渲染。
重要的是要理解如何在 CPU 和 GPU 之间移动像素数据,或者是让数据保持在 CPU 或者 GPU 里。将数据移过这个边界是需要很大的代价的。
缓冲区和图像
在我们的例子中,我们使用了几个不同的缓冲区和图像。这可能有点混乱。这样做的原因很简单,不同的框架对于这些“图像”有不同的用途。下面有一个快速总览,以显示哪些是以基于 CPU 或者基于 GPU 的:

结论
Core Image 是操纵实时视频的一大利器。只要你适当的配置下,性能将会是强劲的 —— 只要确保 CPU 和 GPU 之间没有数据的转移。创意地使用滤镜,你可以实现一些非常炫酷的效果,神马简单色调,褐色滤镜都弱爆啦。所有的这些代码都很容易抽象出来,深入了解下不同的对象的作用区域 (GPU 还是 CPU) 可以帮助你提高代码的性能。
转自:https://www.jianshu.com/p/6c4118290a56
收起阅读 »GCD你会用吗?GCD扫盲之dispatch_semaphore
本文是GCD多线程编程中dispatch_semaphore内容的小结,通过本文,你可以了解到:
1、信号量的基本概念与基本使用
2、信号量在线程同步与资源加锁方面的应用
3、信号量释放时的小陷阱
今天我来讲解一下dispatch_semaphore在我们平常开发中的一些基本概念与基本使用,dispatch_semaphore俗称信号量,也称为信号锁,在多线程编程中主要用于控制多线程下访问资源的数量,比如系统有两个资源可以使用,但同时有三个线程要访问,所以只能允许两个线程访问,第三个应当等待资源被释放后再访问,这时我们就可以使用dispatch_semaphore。
与dispatch_semaphore相关的共有3个方法,分别是dispatch_semaphore_create,dispatch_semaphore_wait,dispatch_semaphore_signal下面我们逐一了解一下这三个方法。
semaphore的三个方法
dispatch_semaphore_create
/*!
* @function dispatch_semaphore_create
*
* @abstract
* Creates new counting semaphore with an initial value.
*
* @discussion
* Passing zero for the value is useful for when two threads need to reconcile
* the completion of a particular event. Passing a value greater than zero is
* useful for managing a finite pool of resources, where the pool size is equal
* to the value.
*
* @param value
* The starting value for the semaphore. Passing a value less than zero will
* cause NULL to be returned.
*
* @result
* The newly created semaphore, or NULL on failure.
*/
API_AVAILABLE(macos(10.6), ios(4.0))
DISPATCH_EXPORT DISPATCH_MALLOC DISPATCH_RETURNS_RETAINED DISPATCH_WARN_RESULT
DISPATCH_NOTHROW
dispatch_semaphore_t
dispatch_semaphore_create(long value);dispatch_semaphore_create方法用于创建一个带有初始值的信号量dispatch_semaphore_t。
对于这个方法的参数信号量的初始值,这里有2种情况:
1、信号量初始值为0时:这种情况主要用于两个线程需要协调特定事件的完成时,即线程同步。
2、信号量初始值为大于0时:这种情况主要用于管理有限的资源池,其中池大小等于这个值,即资源加锁。
上面的2种情况(线程同步、资源加锁),我们在后续的使用篇中会详细讲解。
dispatch_semaphore_wait
/*!
* @function dispatch_semaphore_wait
*
* @abstract
* Wait (decrement) for a semaphore.
*
* @discussion
* Decrement the counting semaphore. If the resulting value is less than zero,
* this function waits for a signal to occur before returning.
*
* @param dsema
* The semaphore. The result of passing NULL in this parameter is undefined.
*
* @param timeout
* When to timeout (see dispatch_time). As a convenience, there are the
* DISPATCH_TIME_NOW and DISPATCH_TIME_FOREVER constants.
*
* @result
* Returns zero on success, or non-zero if the timeout occurred.
*/
API_AVAILABLE(macos(10.6), ios(4.0))
DISPATCH_EXPORT DISPATCH_NONNULL_ALL DISPATCH_NOTHROW
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout);dispatch_semaphore_wait这个方法主要用于等待或减少信号量,每次调用这个方法,信号量的值都会减一,然后根据减一后的信号量的值的大小,来决定这个方法的使用情况,所以这个方法的使用同样也分为2种情况:
1、当减一后的值小于0时,这个方法会一直等待,即阻塞当前线程,直到信号量+1或者直到超时。
2、当减一后的值大于或等于0时,这个方法会直接返回,不会阻塞当前线程。
上面2种方式,放到我们日常的开发中就是下面2种使用情况:
· 当我们只需要同步线程时,我们可以使用dispatch_semaphore_create(0)初始化信号量为0,然后使用dispatch_semaphore_wait方法让信号量减一,这时就属于第一种减一后小于0的情况,这时就会阻塞当前线程,直到另一个线程调用dispatch_semaphore_signal这个让信号量加1的方法后,当前线程才会被唤醒,然后执行当前线程中的代码,这时就起到一个线程同步的作用。
· 当我们需要对资源加锁,控制同时能访问资源的最大数量(假设为n)时,我们就需要使用dispatch_semaphore_create(n)方法来初始化信号量为n,然后使用dispatch_semaphore_wait方法将信号量减一,然后访问我们的资源,然后使用dispatch_semaphore_signal方法将信号量加一。如果有n个线程来访问这个资源,当这n个资源访问都还没有结束时,就会阻塞当前线程,第n+1个线程的访问就必须等待,直到前n个的某一个的资源访问结束,这就是我们很常见的资源加锁的情况。
dispatch_semaphore_signal
/*!
* @function dispatch_semaphore_signal
*
* @abstract
* Signal (increment) a semaphore.
*
* @discussion
* Increment the counting semaphore. If the previous value was less than zero,
* this function wakes a waiting thread before returning.
*
* @param dsema The counting semaphore.
* The result of passing NULL in this parameter is undefined.
*
* @result
* This function returns non-zero if a thread is woken. Otherwise, zero is
* returned.
*/
API_AVAILABLE(macos(10.6), ios(4.0))
DISPATCH_EXPORT DISPATCH_NONNULL_ALL DISPATCH_NOTHROW
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema);dispatch_semaphore_signal方法用于让信号量的值加一,然后直接返回。如果先前信号量的值小于0,那么这个方法还会唤醒先前等待的线程。
semaphore使用篇
线程同步
这种情况在我们的开发中也是挺常见的,当主线程中有一个异步网络任务,我们需要等这个网络请求成功拿到数据后,才能继续做后面的处理,这时我们就可以使用信号量这种方式来进行线程同步。
我们首先看看完整测试代码:
- (IBAction)threadSyncTask:(UIButton *)sender {
NSLog(@"threadSyncTask start --- thread:%@",[NSThread currentThread]);
//1.创建一个初始值为0的信号量
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
//2.定制一个异步任务
//开启一个异步网络请求
NSLog(@"开启一个异步网络请求");
NSURLSession *session = [NSURLSession sharedSession];
NSURL *url =
[NSURL URLWithString:[@"https://www.baidu.com/" stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]]];
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
request.HTTPMethod = @"GET";
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
if (error) {
NSLog(@"%@", [error localizedDescription]);
}
if (data) {
NSDictionary *dict = [NSJSONSerialization JSONObjectWithData:data options:NSJSONReadingMutableContainers error:nil];
NSLog(@"%@", dict);
}
NSLog(@"异步网络任务完成---%@",[NSThread currentThread]);
//4.调用signal方法,让信号量+1,然后唤醒先前被阻塞的线程
NSLog(@"调用dispatch_semaphore_signal方法");
dispatch_semaphore_signal(semaphore);
}];
[dataTask resume];
//3.调用wait方法让信号量-1,这时信号量小于0,这个方法会阻塞当前线程,直到信号量等于0时,唤醒当前线程
NSLog(@"调用dispatch_semaphore_wait方法");
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
NSLog(@"threadSyncTask end --- thread:%@",[NSThread currentThread]);
}运行之后的log如下:
2019-04-27 17:24:27.050077+0800 GCD(四) dispatch_semaphore[34482:6102243] threadSyncTask end --- thread:<NSThread: 0x6000028aa7c0>{number = 1, name = main}
2019-04-27 17:24:27.050227+0800 GCD(四) dispatch_semaphore[34482:6102243] 开启一个异步网络请求
2019-04-27 17:24:27.050571+0800 GCD(四) dispatch_semaphore[34482:6102243] 调用dispatch_semaphore_wait方法
2019-04-27 17:24:27.105069+0800 GCD(四) dispatch_semaphore[34482:6105851] (null)
2019-04-27 17:24:27.105262+0800 GCD(四) dispatch_semaphore[34482:6105851] 异步网络任务完成---<NSThread: 0x6000028c6ec0>{number = 6, name = (null)}
2019-04-27 17:24:27.105401+0800 GCD(四) dispatch_semaphore[34482:6105851] 调用dispatch_semaphore_signal方法
2019-04-27 17:24:27.105550+0800 GCD(四) dispatch_semaphore[34482:6102243] threadSyncTask end --- thread:<NSThread: 0x6000028aa7c0>{number = 1, name = main}从log中我们可以看出,wait方法会阻塞主线程,直到异步任务完成调用signal方法,才会继续回到主线程执行后面的任务。
资源加锁
当一个资源可以被多个线程读取修改时,就会很容易出现多线程访问修改数据出现结果不一致甚至崩溃的问题。为了处理这个问题,我们通常使用的办法,就是使用NSLock,@synchronized给这个资源加锁,让它在同一时间只允许一个线程访问资源。其实信号量也可以当做一个锁来使用,而且比NSLock还有@synchronized代价更低一些,接下来我们来看看它的基本使用
第一步,定义2个宏,将wait与signal方法包起来,方便下面的使用
#ifndef ZED_LOCK
#define ZED_LOCK(lock) dispatch_semaphore_wait(lock, DISPATCH_TIME_FOREVER);
#endif
#ifndef ZED_UNLOCK
#define ZED_UNLOCK(lock) dispatch_semaphore_signal(lock);
#endif第二步,声明与创建共享资源与信号锁
/* 需要加锁的资源 **/
@property (nonatomic, strong) NSMutableDictionary *dict;
/* 信号锁 **/
@property (nonatomic, strong) dispatch_semaphore_t lock;//创建共享资源
self.dict = [NSMutableDictionary dictionary];
//初始化信号量,设置初始值为1
self.lock = dispatch_semaphore_create(1);第三步,在即将使用共享资源的地方添加ZED_LOCK宏,进行信号量减一操作,在共享资源使用完成的时候添加ZED_UNLOCK,进行信号量加一操作。
- (IBAction)resourceLockTask:(UIButton *)sender {
NSLog(@"resourceLockTask start --- thread:%@",[NSThread currentThread]);
//使用异步执行并发任务会开辟新的线程的特性,来模拟开辟多个线程访问贡献资源的场景
for (int i = 0; i < 3; i++) {
NSLog(@"异步添加任务:%d",i);
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
ZED_LOCK(self.lock);
//模拟对共享资源处理的耗时
[NSThread sleepForTimeInterval:1];
NSLog(@"i:%d --- thread:%@ --- 将要处理共享资源",i,[NSThread currentThread]);
[self.dict setObject:@"semaphore" forKey:@"key"];
NSLog(@"i:%d --- thread:%@ --- 共享资源处理完成",i,[NSThread currentThread]);
ZED_UNLOCK(self.lock);
});
}
NSLog(@"resourceLockTask end --- thread:%@",[NSThread currentThread]);
}在这一步中,我们使用异步执行并发任务会开辟新的线程的特性,来模拟开辟多个线程访问贡献资源的场景,同时使用了线程休眠的API来模拟对共享资源处理的耗时。这里我们开辟了3个线程来并发访问这个共享资源,代码运行的log如下:
2019-04-27 18:36:25.275060+0800 GCD(四) dispatch_semaphore[35944:6315957] resourceLockTask start --- thread:<NSThread: 0x60000130e940>{number = 1, name = main}
2019-04-27 18:36:25.275312+0800 GCD(四) dispatch_semaphore[35944:6315957] 异步添加任务:0
2019-04-27 18:36:25.275508+0800 GCD(四) dispatch_semaphore[35944:6315957] 异步添加任务:1
2019-04-27 18:36:25.275680+0800 GCD(四) dispatch_semaphore[35944:6315957] 异步添加任务:2
2019-04-27 18:36:25.275891+0800 GCD(四) dispatch_semaphore[35944:6315957] resourceLockTask end --- thread:<NSThread: 0x60000130e940>{number = 1, name = main}
2019-04-27 18:36:26.276757+0800 GCD(四) dispatch_semaphore[35944:6316211] i:0 --- thread:<NSThread: 0x6000013575c0>{number = 3, name = (null)} --- 将要处理共享资源
2019-04-27 18:36:26.277004+0800 GCD(四) dispatch_semaphore[35944:6316211] i:0 --- thread:<NSThread: 0x6000013575c0>{number = 3, name = (null)} --- 共享资源处理完成
2019-04-27 18:36:27.282099+0800 GCD(四) dispatch_semaphore[35944:6316212] i:1 --- thread:<NSThread: 0x600001357800>{number = 4, name = (null)} --- 将要处理共享资源
2019-04-27 18:36:27.282357+0800 GCD(四) dispatch_semaphore[35944:6316212] i:1 --- thread:<NSThread: 0x600001357800>{number = 4, name = (null)} --- 共享资源处理完成
2019-04-27 18:36:28.283769+0800 GCD(四) dispatch_semaphore[35944:6316214] i:2 --- thread:<NSThread: 0x600001369280>{number = 5, name = (null)} --- 将要处理共享资源
2019-04-27 18:36:28.284041+0800 GCD(四) dispatch_semaphore[35944:6316214] i:2 --- thread:<NSThread: 0x600001369280>{number = 5, name = (null)} --- 共享资源处理完成从多次log中我们可以看出:
添加信号锁之后,每个线程对于共享资源的操作都是有序的,并不会出现2个线程同时访问锁中的代码区域。
我把上面的实现代码简化一下,方便分析这种锁的实现原理:
//step_1
ZED_LOCK(self.lock);
//step_2
NSLog(@"执行任务");
//step_3
ZED_UNLOCK(self.lock);1、信号量初始化的值为1,当一个线程过来执行step_1的代码时,会调用信号量的值减一的方法,这时,信号量的值为0,它会直接返回,然后执行step_2的代码去完成去共享资源的访问,然后再使用step_3中的signal方法让信号量加一,信号量的值又会回归到初始值1。这就是一个线程过来访问的调用流程。
2、当线程1过来执行到step_2的时候,这时又有一个线程2它也从step_1处来调用这段代码,由于线程1已经调用过step_1的wait方法将信号量的值减一,这时信号量的值为0。同时线程2进入然后调用了step_1的wait方法又将信号量的值减一,这时的信号量的值为-1,由于信号量的值小于0时会阻塞当前线程(线程2),所以,线程2就会一直等待,直到线程1执行完step_3中的方法,将信号量加一,才会唤醒线程2,继续执行下面的代码。这就是为什么信号量可以对共享资源加锁的原因,如果我们可以允许n个线程同时访问,我们就需要在初始化这个信号量时把信号量的值设为n,这样就限制了访问共享资源的线程数。
通过上面的分析,我们可以知道,如果我们使用信号量来进行线程同步时,我们需要把信号量的初始值设为0,如果要对资源加锁,限制同时只有n个线程可以访问的时候,我们就需要把信号量的初始值设为n。
semaphore的释放
在我们平常的开发过程中,如果对semaphore使用不当,就会在它释放的时候遇到奔溃问题。
首先我们来看2个例子:
- (IBAction)crashScene1:(UIButton *)sender {
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
//在使用过程中将semaphore置为nil
semaphore = nil;
}- (IBAction)crashScene2:(UIButton *)sender {
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
//在使用过程中对semaphore进行重新赋值
semaphore = dispatch_semaphore_create(3);
}我们打开测试代码,找到semaphore对应的target,然后运行一下代码,然后点击后面2个按钮调用一下上面的代码,然后我们可以发现,代码在运行到semaphore = nil;与semaphore = dispatch_semaphore_create(3);时奔溃了。然后我们使用lldb的bt命令查看一下调用栈。
(lldb) bt
* thread #1, queue = 'com.apple.main-thread', stop reason = EXC_BAD_INSTRUCTION (code=EXC_I386_INVOP, subcode=0x0)
frame #0: 0x0000000111c31309 libdispatch.dylib`_dispatch_semaphore_dispose + 59
frame #1: 0x0000000111c2fb06 libdispatch.dylib`_dispatch_dispose + 97
* frame #2: 0x000000010efb113b GCD(四) dispatch_semaphore`-[ZEDDispatchSemaphoreViewController crashScene1:](self=0x00007fdcfdf0add0, _cmd="crashScene1:", sender=0x00007fdcfdd0a3d0) at ZEDDispatchSemaphoreViewController.m:117
frame #3: 0x0000000113198ecb UIKitCore`-[UIApplication sendAction:to:from:forEvent:] + 83
frame #4: 0x0000000112bd40bd UIKitCore`-[UIControl sendAction:to:forEvent:] + 67
frame #5: 0x0000000112bd43da UIKitCore`-[UIControl _sendActionsForEvents:withEvent:] + 450
frame #6: 0x0000000112bd331e UIKitCore`-[UIControl touchesEnded:withEvent:] + 583
frame #7: 0x00000001131d40a4 UIKitCore`-[UIWindow _sendTouchesForEvent:] + 2729
frame #8: 0x00000001131d57a0 UIKitCore`-[UIWindow sendEvent:] + 4080
frame #9: 0x00000001131b3394 UIKitCore`-[UIApplication sendEvent:] + 352
frame #10: 0x00000001132885a9 UIKitCore`__dispatchPreprocessedEventFromEventQueue + 3054
frame #11: 0x000000011328b1cb UIKitCore`__handleEventQueueInternal + 5948
frame #12: 0x0000000110297721 CoreFoundation`__CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE0_PERFORM_FUNCTION__ + 17
frame #13: 0x0000000110296f93 CoreFoundation`__CFRunLoopDoSources0 + 243
frame #14: 0x000000011029163f CoreFoundation`__CFRunLoopRun + 1263
frame #15: 0x0000000110290e11 CoreFoundation`CFRunLoopRunSpecific + 625
frame #16: 0x00000001189281dd GraphicsServices`GSEventRunModal + 62
frame #17: 0x000000011319781d UIKitCore`UIApplicationMain + 140
frame #18: 0x000000010efb06a0 GCD(四) dispatch_semaphore`main(argc=1, argv=0x00007ffee0c4efc8) at main.m:14
frame #19: 0x0000000111ca6575 libdyld.dylib`start + 1
frame #20: 0x0000000111ca6575 libdyld.dylib`start + 1
(lldb)从上面的调用栈我们可以看出,奔溃的地方都处于libdispatch库调用dispatch_semaphore_dispose方法释放信号量的时候,为什么在信号量使用过程中对信号量进行重新赋值或置空操作会crash呢,这个我们就需要从GCD的源码层面来分析了,GCD的源码库libdispatch在苹果的开源代码库可以下载,我在自己的Github也放了一份libdispatch-187.10版本的,下面的源码分析都是基于这个版本的。
首先我们来看一下dispatch_semaphore_t的结构体dispatch_semaphore_s的结构体定义
struct dispatch_semaphore_s {
DISPATCH_STRUCT_HEADER(dispatch_semaphore_s, dispatch_semaphore_vtable_s);
long dsema_value; //当前的信号值
long dsema_orig; //初始化的信号值
size_t dsema_sent_ksignals;
#if USE_MACH_SEM && USE_POSIX_SEM
#error "Too many supported semaphore types"
#elif USE_MACH_SEM
semaphore_t dsema_port; //当前mach_port_t信号
semaphore_t dsema_waiter_port; //休眠时mach_port_t信号
#elif USE_POSIX_SEM
sem_t dsema_sem;
#else
#error "No supported semaphore type"
#endif
size_t dsema_group_waiters;
struct dispatch_sema_notify_s *dsema_notify_head;//链表头部
struct dispatch_sema_notify_s *dsema_notify_tail;//链表尾部
};这里我们需要关注2个值的变化,dsema_value与dsema_orig,它们分别代表当前的信号值与初始化时的信号值。
当我们调用dispatch_semaphore_create方法创建信号量时,这个方法内部会把传入的参数存储到dsema_value(当前的value)和dsema_orig(初始value)中,条件是value的值必须大于或等于0。
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {//初始值不能小于0
return NULL;
}
dsema = calloc(1, sizeof(struct dispatch_semaphore_s));//申请信号量的内存
if (fastpath(dsema)) {//信号量初始化赋值
dsema->do_vtable = &_dispatch_semaphore_vtable;
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_ref_cnt = 1;
dsema->do_xref_cnt = 1;
dsema->do_targetq = dispatch_get_global_queue(
DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dsema->dsema_value = value;//当前的值
dsema->dsema_orig = value;//初始值
#if USE_POSIX_SEM
int ret = sem_init(&dsema->dsema_sem, 0, 0);//内存空间映射
DISPATCH_SEMAPHORE_VERIFY_RET(ret);
#endif
}
return dsema;
}然后调用dispatch_semaphore_wait与dispatch_semaphore_signal时会对dsema_value做加一或减一操作。当我们对信号量置空或者重新赋值操作时,会调用dispatch_semaphore_dispose释放信号量,我们来看看对应的源码
static void
_dispatch_semaphore_dispose(dispatch_semaphore_t dsema)
{
if (dsema->dsema_value < dsema->dsema_orig) {//当前的信号值如果小于初始值就会crash
DISPATCH_CLIENT_CRASH(
"Semaphore/group object deallocated while in use");
}
#if USE_MACH_SEM
kern_return_t kr;
if (dsema->dsema_port) {
kr = semaphore_destroy(mach_task_self(), dsema->dsema_port);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}
if (dsema->dsema_waiter_port) {
kr = semaphore_destroy(mach_task_self(), dsema->dsema_waiter_port);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}
#elif USE_POSIX_SEM
int ret = sem_destroy(&dsema->dsema_sem);
DISPATCH_SEMAPHORE_VERIFY_RET(ret);
#endif
_dispatch_dispose(dsema);
}从源码中我们可以看出,当dsema_value小于dsema_orig时,即信号量还在使用时,会直接调用DISPATCH_CLIENT_CRASH让APP奔溃。
所以,我们在使用信号量的时候,不能在它还在使用的时候,进行赋值或者置空的操作。
如果文中有错误的地方,或者与你的想法相悖的地方,请在评论区告知我,我会继续改进,如果你觉得这个篇文章总结的还不错,麻烦动动小手,给我的文章与Git代码样例点个✨
链接:https://www.jianshu.com/p/7981e3357fe9
收起阅读 »探究iOS鲜为人知的小秘密一一__attribute__运用
Clang Attributes是Clang提供的一种源码注解,方便开发者向编译器表达某种要求,参与控制如Static Analyzer、Name Mangling、Code Generation等过程,一般以attribute(xxx)的形式出现在代码中;为方便使用,一些常用属性也被Cocoa定义成宏,比如在系统头文件中经常出现的NS_CLASS_AVAILABLE_IOS(9_0)就是attribute(availability(...))这个属性的简单写法。
※unavailable
#define UNAVAILABLE_ATTRIBUTE __attribute__((unavailable))
可以加在方法声明的后面,告诉编译器该方法不可用
Swift中
@available(*, unavailable)
func foo() {}
@available(iOS, unavailable, message="you can't call this")
func foo2() {}※availability
#define NS_DEPRECATED_IOS(_iosIntro,_iosDep,...) CF_DEPRECATED_IOS(_iosIntro,_iosDep,__VA_ARGS__)
展开看
#define CF_DEPRECATED_IOS(_iosIntro, _iosDep, ...) __attribute__((availability(ios,introduced=_iosIntro,deprecated=_iosDep,message="" __VA_ARGS__)))
再展开看
__attribute__((availability(ios,introduced=2_0,deprecated=7_0,message=""__VA_ARGS__)))
iOS即是iOS平台
introduced从哪个版本开始使用
deprecated从哪个版本开始弃用
message警告的信息
其实还可以再加一个参数例子:
void f(void) __attribute__((availability(macosx,introduced=10.4,deprecated=10.6,obsoleted=10.7)));
obsoleted完全禁止使用的版本
NS_AVAILABLE_IOS(7_0) iOS7.0或之后才能使用
NS_DEPRECATED_IOS(2_0,6_0) iOS2.0开始使用6.0废弃
Swift中:
@available(iOS 6.0, *)
public var minimumScaleFactor: CGFloat
@available(OSX, introduced=10.4, deprecated=10.6, obsoleted=10.10)
@available(iOS, introduced=5.0, deprecated=7.0)
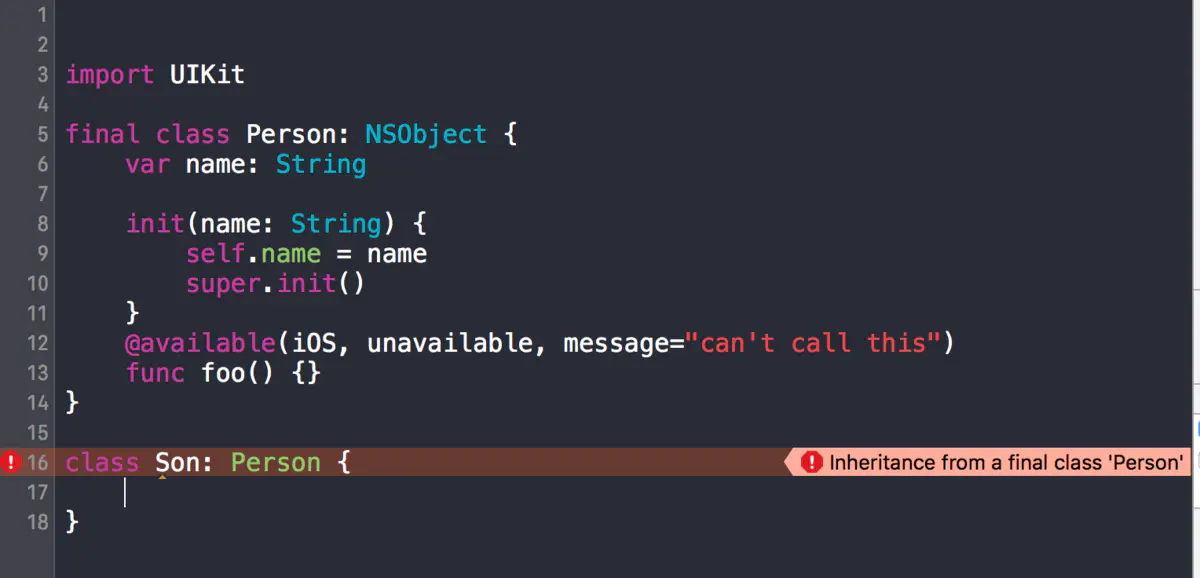
func foo3() {}※objc_subclassing_restricted
一句话就是使用这个属性可以定义一个不可被继承的类
__attribute__((objc_subclassing_restricted))
@interface Eunuch : NSObject
@end
@interface Child : Eunuch//如果继承它会报错
@end在Swift中对原来的很多attribute的支持现在还缺失中,为了达到类似的目的,我们可以使用一个final关键词
※objc_requires_super
使用这个属性标志子类继承这个方法时需要调用super,否则给出编译警告,来让父类中有一些关键代码是在被继承重写后必须执行
#define NS_REQUIRES_SUPER __attribute__((objc_requires_super))
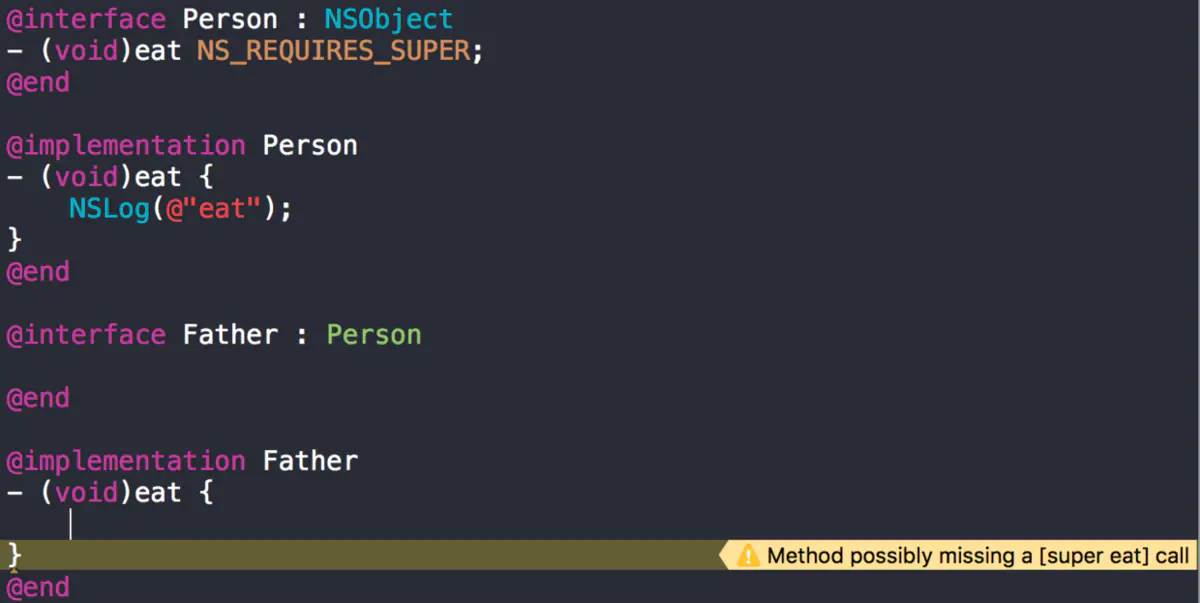
在Switf中也还是可以用final的方法来达到这个目的

Swift equivalent to __attribute((objc_requires_super))?(stackoverflow)
※overloadable
用于C函数,可以定义若干个相同函数名,但参数不同的方法,调用时编译器会自动根据参数选择函数去调用
__attribute__((overloadable))
void logAnything(id obj) {
NSLog(@"%@", obj);
}
__attribute__((overloadable)) void logAnything(int number) {
NSLog(@"%@", @(number));
}
__attribute__((overloadable)) void logAnything(CGRect rect) {
NSLog(@"%@", NSStringFromCGRect(rect));
}
// Tests
logAnything(@[@"1", @"2"]);
logAnything(233);
logAnything(CGRectMake(1, 2, 3, 4));有兴趣的可以写一个自定义的Log免去用NSLog要写@""等格式的麻烦
※cleanup
__attribute__((cleanup(...))),用于修饰一个变量,在它的作用域结束时可以自动执行一个指定的方法,个人感觉这个真的很方便

一个对象可以这样用,那么block实际也是一个对象,这样就可以写一个宏,实际上就是ReactiveCocoa中神奇的@onExit
#define onExit\
__strong void(^block)(void) __attribute__((cleanup(blockCleanUp), unused)) = ^有时候我们需要用到锁这个东西,或者一些CoreFoundation的对象有时候最后需要释放,用这个宏就很方便了
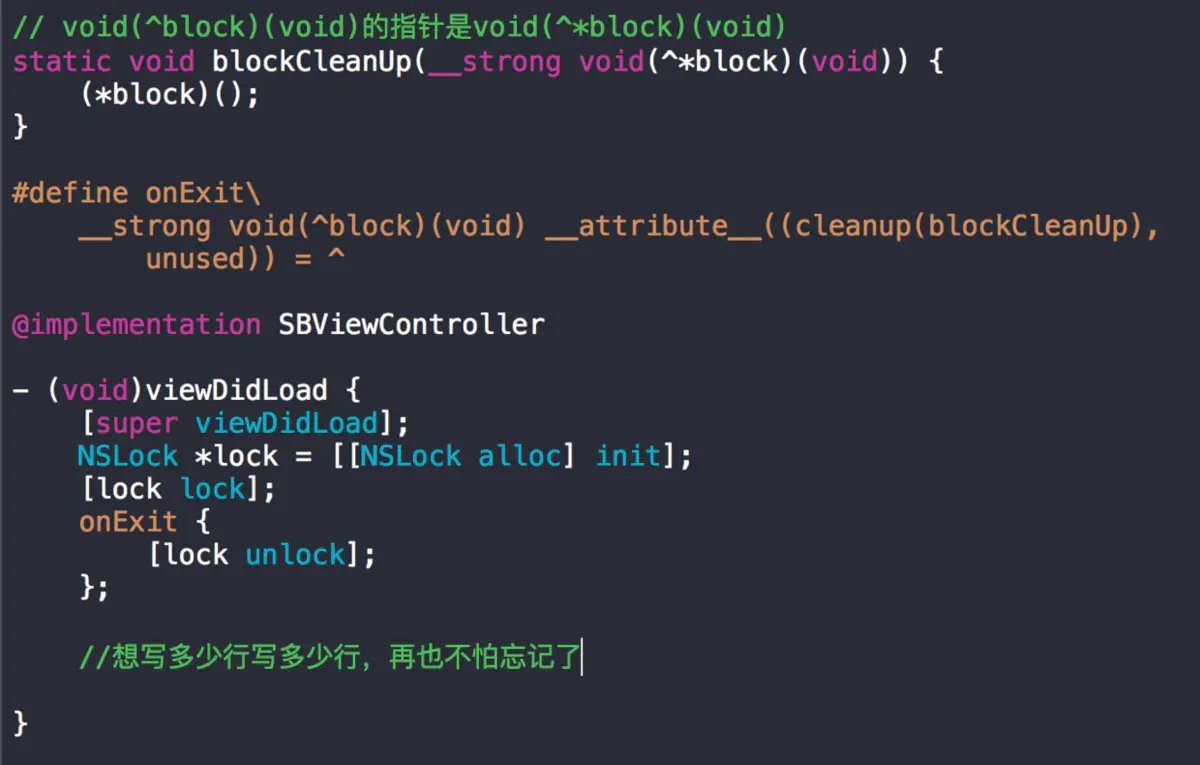
为了好看用这个宏的时候加个@就加个释放池就可以了

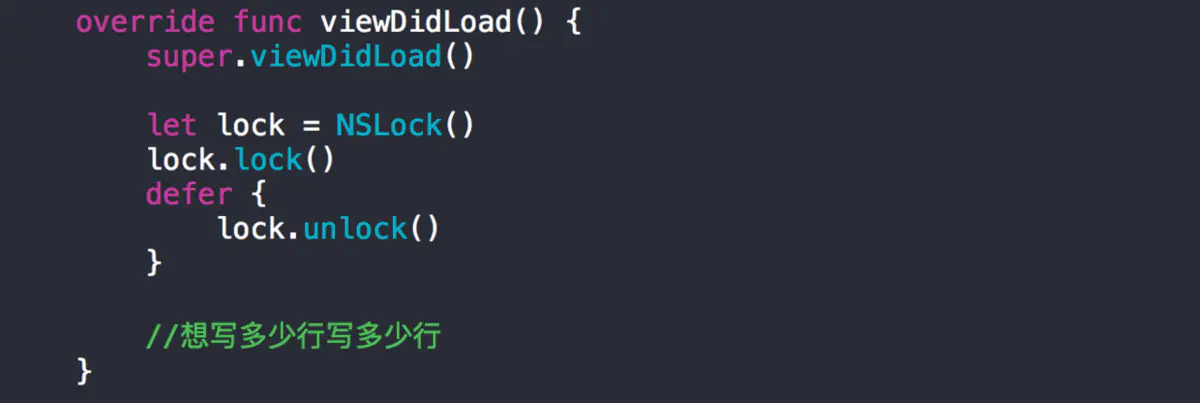
Swift中:可以用defer
还有一些format, const, noreturn, aligned , packed, objc_boxable, constructor / destructor, enable_if, objc_runtime_name可以看这两篇文章:
链接:https://www.jianshu.com/p/33d7d0596028
收起阅读 »iOS-拍照后裁剪,不可拖动照片的问题
问题
在项目中,选择照片或拍照的功能很长见,由于我之前采用系统自带的UIimagePickViewController遇到一点问题:
1、使用拍照功能,进行截取时(allowEditing = YES)时,拍照完成的图片无法拖动,没有办法进行选择性的截取图片
2、如果使用选择相册功能,进入裁剪界面,图片是可以拖动的,唯独拍照之后进入裁剪界面无法拖动
3、微信头像更换拍照好像也无法拖动,初步推测可能使用的系统自带的裁剪界面
所以想来仔细研究一下UIImagePickViewController的属性和使用方法
UIImagePickViewController
UIImagePickerController是iOS系统提供的和系统的相册和相机交互的一个类,可以用来获取相册的照片,也可以调用系统的相机拍摄照片或者视频。该类的继承结构是:
UIImagePickerController-->UINavigationController-->UIViewController-->UIResponder-->NSObject
官方文档中对于该类的说明是:
该类只支持竖屏模式,为了保证该类被原样使用,它不支持子类,并且它的视图层次是私有的不能被修改,只支持自定义cameraOverlayView属性来展示更多信息以及和用户的交互。
由于该类继承自UINavgationController,所以在使用过程中一般实现UIImagePickerControllerDelegate和UINavigationControllerDelegate这两个代理,可以利用navgation的push 和pop操作自定义界面实现更复杂的交互效果。
下面具体分析该类的一些方法和属性.
UIImagePickViewController之常用属性
@property (nullable, nonatomic, weak) id <UINavigationControllerDelegate, UIImagePickerControllerDelegate> delegate;该对象的代理需要实现UINavigationControllerDelegate和UIImagePickerControllerDelegate协议,nullable是xcode6.3之后引入的nullability annotations特性,主要用于在OC和swift之间的转换。这一特性主要包含两个新的类型注释nullable和nonnull,用于表示对象是否可以是NULL或nil
@property (nonatomic) UIImagePickerControllerSourceType sourceType; // default value is UIImagePickerControllerSourceTypePhotoLibrary.sourceType用于指定要访问的系统的媒体类型。UIImagePickerControllerSourceType支持以下3种枚举类型,默认值是图片库
typedef NS_ENUM(NSInteger, UIImagePickerControllerSourceType) { UIImagePickerControllerSourceTypePhotoLibrary,//照片库模式。图像选取控制器以该模式显示时会浏览系统照片库的根目录。 UIImagePickerControllerSourceTypeCamera, //相机模式,图像选取控制器以该模式显示时可以进行拍照或摄像。 UIImagePickerControllerSourceTypeSavedPhotosAlbum //相机胶卷模式,图像选取控制器以该模式显示时会浏览相机胶卷目录。};1、PhotoLibrary代表系统照片应用对应的相薄,包含照片流和其它自定义的相册
2、PhotosAlbum则对应系统照片应用的照片,包含用设备拍摄的所有照片流。
3、Camera则代表相机的摄像头。
@property (nonatomic, copy) NSArray<NSString *> *mediaTypes;mediaTypes用于设置相机支持的功能,拍照或者是视频,返回值类型可以是kUTTypeMovie视频和kUTTypeImage拍照
1、kUTTypeMovie包含
const CFStringRef kUTTypeAudiovisualContent ;抽象的声音视频
const CFStringRef kUTTypeMovie ;抽象的媒体格式(声音和视频)
const CFStringRef kUTTypeVideo ;只有视频没有声音
const CFStringRef kUTTypeAudio ;只有声音没有视频
const CFStringRef kUTTypeQuickTimeMovie ;
const CFStringRef kUTTypeMPEG ;
const CFStringRef kUTTypeMPEG4 ;
const CFStringRef kUTTypeMP3 ;
const CFStringRef kUTTypeMPEG4Audio ;
const CFStringRef kUTTypeAppleProtectedMPEG4Audio;2、kUTTypeImage包含
const CFStringRef kUTTypeImage ;抽象的图片类型
const CFStringRef kUTTypeJPEG ;
const CFStringRef kUTTypeJPEG2000 ;
const CFStringRef kUTTypeTIFF ;
const CFStringRef kUTTypePICT ;
const CFStringRef kUTTypeGIF ;
const CFStringRef kUTTypePNG ;
const CFStringRef kUTTypeQuickTimeImage ;
const CFStringRef kUTTypeAppleICNS const CFStringRef kUTTypeBMP;
const CFStringRef kUTTypeICO;@property (nonatomic) BOOL showsCameraControls NS_AVAILABLE_IOS(3_1);
@property (nonatomic) BOOL allowsEditing NS_AVAILABLE_IOS(3_1); // replacement for -allowsImageEditing; default value is NO.
@property (nonatomic) BOOL allowsImageEditing NS_DEPRECATED_IOS(2_0, 3_1);1、showsCameraControls用于指定拍照时下方的工具栏是否显示
2、allowImageEditing在iOS3.1就已废弃,取而代之的是allowEditing,
3、allowEditing表示拍完照片或者从相册选完照片后,是否跳转到编辑模式对图片裁剪,只有在showsCameraControls为YES时才有效果。
@property (nonatomic) UIImagePickerControllerCameraCaptureMode cameraCaptureMode NS_AVAILABLE_IOS(4_0); // default is UIImagePickerControllerCameraCaptureModePhoto
@property (nonatomic) UIImagePickerControllerCameraDevice cameraDevice NS_AVAILABLE_IOS(4_0); // default is UIImagePickerControllerCameraDeviceRear
@property (nonatomic) UIImagePickerControllerCameraFlashMode cameraFlashMode
@property (nonatomic) CGAffineTransform cameraViewTransform NS_AVAILABLE_IOS(3_1); // set the transform of the preview view.
@property (nullable, nonatomic,strong) __kindof UIView *cameraOverlayView NS_AVAILABLE_IOS(3_1); // set a view to overlay the preview view.当sourceType是camera的时候,这几个属性有效,否则抛出异常。
· cameraCaptureMode捕捉模式指定的是相机是拍摄照片还是视频,它的枚举类型如下:
NS_ENUM(NSInteger, UIImagePickerControllerCameraCaptureMode) {
UIImagePickerControllerCameraCaptureModePhoto,//photo
UIImagePickerControllerCameraCaptureModeVideo//video
};· cameraDevice指定拍摄的摄像头位置,是使用前置摄像头还是后置摄像头,它的枚举类型有:
typedef NS_ENUM(NSInteger, UIImagePickerControllerCameraDevice) {
UIImagePickerControllerCameraDeviceRear,//后摄像头(默认)
UIImagePickerControllerCameraDeviceFront//前摄像头
};· cameraFlashMode用于指定闪光灯模式,它的枚举类型如下:
typedef NS_ENUM(NSInteger, UIImagePickerControllerCameraFlashMode) {
UIImagePickerControllerCameraFlashModeOff = -1,//关闭闪关灯
UIImagePickerControllerCameraFlashModeAuto = 0,//自动
UIImagePickerControllerCameraFlashModeOn = 1//开启闪关灯
};· cameraViewTransform该结构体可以用于指定拍摄时View的一些形变属性,如旋转缩放等。当showsCameraControls为NO,系统的工具栏隐藏时,我们可以自定义背景View赋值给cameraOverlayView添加到拍摄时的预览视图之上。
@property(nonatomic) NSTimeInterval videoMaximumDuration NS_AVAILABLE_IOS(3_1); // default value is 10 minutes.
@property(nonatomic) UIImagePickerControllerQualityType videoQuality NS_AVAILABLE_IOS(3_1);· videoMaximumDuration用于设置视频拍摄模式下最大拍摄时长,默认值是10分钟。
· videoQuality表示拍摄的视频质量设置,默认是Medium即表示中等质量。 videoQuality支持的枚举类型如下:
typedef NS_ENUM(NSInteger, UIImagePickerControllerQualityType) {
UIImagePickerControllerQualityTypeHigh = 0, // 高清模式
UIImagePickerControllerQualityTypeMedium = 1, //中等质量,适于WIFI传播
UIImagePickerControllerQualityTypeLow = 2, //低等质量,适于蜂窝网络传输
UIImagePickerControllerQualityType640x480 NS_ENUM_AVAILABLE_IOS(4_0) = 3, // VGA 质量
UIImagePickerControllerQualityTypeIFrame1280x720 NS_ENUM_AVAILABLE_IOS(5_0) = 4,//1280*720的分辨率
UIImagePickerControllerQualityTypeIFrame960x540 NS_ENUM_AVAILABLE_IOS(5_0) = 5,//960*540分辨率
};UIImagePickViewController之类方法
@interface UIImagePickerController : UINavigationController <NSCoding>
+ (BOOL)isSourceTypeAvailable:(UIImagePickerControllerSourceType)sourceType; // returns YES if source is available (i.e. camera present)
+ (nullable NSArray<NSString *> *)availableMediaTypesForSourceType:(UIImagePickerControllerSourceType)sourceType; // returns array of available media types (i.e. kUTTypeImage)
+ (BOOL)isCameraDeviceAvailable:(UIImagePickerControllerCameraDevice)cameraDevice NS_AVAILABLE_IOS(4_0); // returns YES if camera device is available
+ (BOOL)isFlashAvailableForCameraDevice:(UIImagePickerControllerCameraDevice)cameraDevice NS_AVAILABLE_IOS(4_0); // returns YES if camera device supports flash and torch.
+ (nullable NSArray<NSNumber *> *)availableCaptureModesForCameraDevice:(UIImagePickerControllerCameraDevice)cameraDevice NS_AVAILABLE_IOS(4_0);isSourceTypeAvailable用于判断当前设备是否支持指定的sourceType,可以是照片库/相册/相机.
isCameraDeviceAvailable判断当前设备是否支持前置摄像头或者后置摄像头
isFlashAvailableForCameraDevice是否支持前置摄像头闪光灯或者后置摄像头闪光灯
availableMediaTypesForSourceType方法返回所特定的媒体如相册/图片库/相机所支持的媒体类型数组,元素值可以是kUTTypeImage类型或者kUTTypeMovie类型的静态字符串,所以是NSString类型的数组
availableCaptureModesForCameraDevice返回特定的摄像头(前置摄像头/后置摄像头)所支持的拍摄模式数值数组,元素值可以是UIImagePickerControllerCameraCaptureMode枚举里面的video或者photo,所以是NSNumber类型的数组
UIImagePickViewController之对象方法
- (void)takePicture NS_AVAILABLE_IOS(3_1);
- (BOOL)startVideoCapture NS_AVAILABLE_IOS(4_0);
- (void)stopVideoCapture NS_AVAILABLE_IOS(4_0);1、takePicture可以用来实现照片的连续拍摄,需要自己自定义拍摄的背景视图来赋值给cameraOverlayView,结合自定义overlayView实现多张照片的采集,在收到代理的didFinishPickingMediaWithInfo方法之后可以启动额外的捕捉。
2、startVideoCapture用来判断当前是否可以开始录制视频,当视频正在拍摄中,设备不支持视频拍摄,磁盘空间不足等情况,该方法会返回NO.该方法结合自定义overlayView可以拍摄多部视频
3、stopVideoCapture当你调用此方法停止视频拍摄时,它会调用代理的imagePickerController:didFinishPickingMediaWithInfo:方法
UIImagePickViewController之代理方法
@protocol UIImagePickerControllerDelegate<NSObject>
@optional
- (void)imagePickerController:(UIImagePickerController *)picker didFinishPickingImage:(UIImage *)image editingInfo:(nullable NSDictionary<NSString *,id> *)editingInfo NS_DEPRECATED_IOS(2_0, 3_0);
- (void)imagePickerController:(UIImagePickerController *)picker didFinishPickingMediaWithInfo:(NSDictionary<NSString *,id> *)info;
- (void)imagePickerControllerDidCancel:(UIImagePickerController *)picker;
@end1、imagePickerController:didFinishPickingImage:editingInfo:在iOS3.0中已废弃,不再使用。
2、当用户取消选取的内容时会调用DidCancel方法,默认实现销毁弹出的视图。
3、当完成内容的选取时会调用didFinishPickingMediaWithInfo方法,默认info字典的key值可以是以下类型:
UIKIT_EXTERN NSString *const UIImagePickerControllerMediaType; //指定用户选择的媒体类型
UIKIT_EXTERN NSString *const UIImagePickerControllerOriginalImage; // 原始图片
UIKIT_EXTERN NSString *const UIImagePickerControllerEditedImage; // 修改后的图片
UIKIT_EXTERN NSString *const UIImagePickerControllerCropRect; // 裁剪尺寸
UIKIT_EXTERN NSString *const UIImagePickerControllerMediaURL; // 媒体的URL
UIKIT_EXTERN NSString *const UIImagePickerControllerReferenceURL NS_AVAILABLE_IOS(4_1); // 原件的URL
UIKIT_EXTERN NSString *const UIImagePickerControllerMediaMetadata //当数据来源是相机的时候获取到的静态图像元数据,可以使用phtoho框架进行处理UIImagePickViewController之C语言函数(保存图片或视频)
UIKIT_EXTERN void UIImageWriteToSavedPhotosAlbum(UIImage *image, __nullable id completionTarget, __nullable SEL completionSelector, void * __nullable contextInfo);
UIKIT_EXTERN BOOL UIVideoAtPathIsCompatibleWithSavedPhotosAlbum(NSString *videoPath) NS_AVAILABLE_IOS(3_1);
UIKIT_EXTERN void UISaveVideoAtPathToSavedPhotosAlbum(NSString *videoPath, __nullable id completionTarget, __nullable SEL completionSelector, void * __nullable contextInfo) NS_AVAILABLE_IOS(3_1);1、UIImageWriteToSavedPhotosAlbum用来保存照片到相册,seletor应该设置为- (void)image:(UIImage )image didFinishSavingWithError:(NSError )error contextInfo:(void )contextInfo;当照片保存到相册完成时,会调用该方法通知你。
2、UIVideoAtPathIsCompatibleWithSavedPhotosAlbum会返回布尔类型的值判断该路径下的视频能否保存到相册,视频需要先存储到沙盒文件再保存到相册,而照片是可以直接从代理完成的回调info字典里面获取到。
3、UISaveVideoAtPathToSavedPhotosAlbum用来保存视频到相册,seletor应该设置为- (void)video:(NSString )videoPath didFinishSavingWithError:(NSError )error contextInfo:(void )contextInfo;当视频保存到相册或出错时会调用该方法通知你。
这三个方法一般是在代理的完成方法didFinishPickingMediaWithInfo里面配合使用。
以上便是系统UIImagePickViewController的所有属性和方法的简单介绍
问题解决方案
由于使用设置allowEditing = YES属性后,开启摄像头拍照后直接进入系统自定义的裁剪界面,但是在这个界面,从摄像头拍摄过来的照片无法拖动裁剪,仅仅从相册选择过来的照片是可以拖动进行裁剪的,那么我们就决定裁剪界面不使用系统自带的,而自定义一个裁剪界面.
在UIImagePickViewController的代理方法里
#pragma UIImagePickerController Delegate
- (void)imagePickerController:(UIImagePickerController *)picker didFinishPickingMediaWithInfo:(NSDictionary *)info
{
UIImage *portraitImg = [info objectForKey:@"UIImagePickerControllerOriginalImage"];
YYImageClipViewController *imgClipVC = [[YYImageClipViewController alloc] initWithImage:portraitImg cropFrame:CGRectMake(0, 100.0f, self.view.frame.size.width, self.view.frame.size.width) limitScaleRatio:3.0];
imgClipVC.delegate = self;
[picker pushViewController:imgClipVC animated:NO];
}
- (void)imagePickerControllerDidCancel:(UIImagePickerController *)picker
{
[picker dismissViewControllerAnimated:YES completion:nil];
}HZImageCropperViewController是我自定义的一个裁剪界面,通过这个控制器的两个代理方法,得到裁剪后的照片
- (void)imageClip:(YYImageClipViewController *)clipViewController didFinished:(UIImage *)editedImage
{
//保存图片
NSString *imageFilePath = [UIImage saveImage:editedImage];
//上传七牛服务器
[self upImageFilePath:imageFilePath];
//隐藏裁剪界面
[clipViewController dismissViewControllerAnimated:YES completion:nil];
}
- (void)imageClipDidCancel:(YYImageClipViewController *)clipViewController
{
[clipViewController dismissViewControllerAnimated:YES completion:nil];
}下面附上一个demo,里面包含裁剪界面的源代码,可供大家参考
自定义裁剪界面demo
转自:https://www.jianshu.com/p/9474ca73e269
收起阅读 »
iOS 详解socket编程[oc]粘包、半包处理
在做socket编程时,如果是做tcp连接,那就不可避免的会遇到粘包与半包的问题。
粘包 就是多组数据被一并接收了,粘在了一起,无法做划分;
半包 就是有数据接收不完整,无法处理。
要解决粘包、半包的问题,一般在设计数据(消息)格式时会约定好一个字段专门用于描述数据包的长度,这样就使数据有了边界,依靠这个边界,就能把每组数据划分出来,数据不完整时也能获知数据的缺失。
(当然也可以把数据设计成定长数据,但这样不够灵活;或者用\n,\r这类字符作为数据划分依据,但不直观、不明确,同时也不灵活)
举个栗子:
消息=消息头+消息体。消息头用于描述消息本身的基本信息,消息体则为消息的具体内容
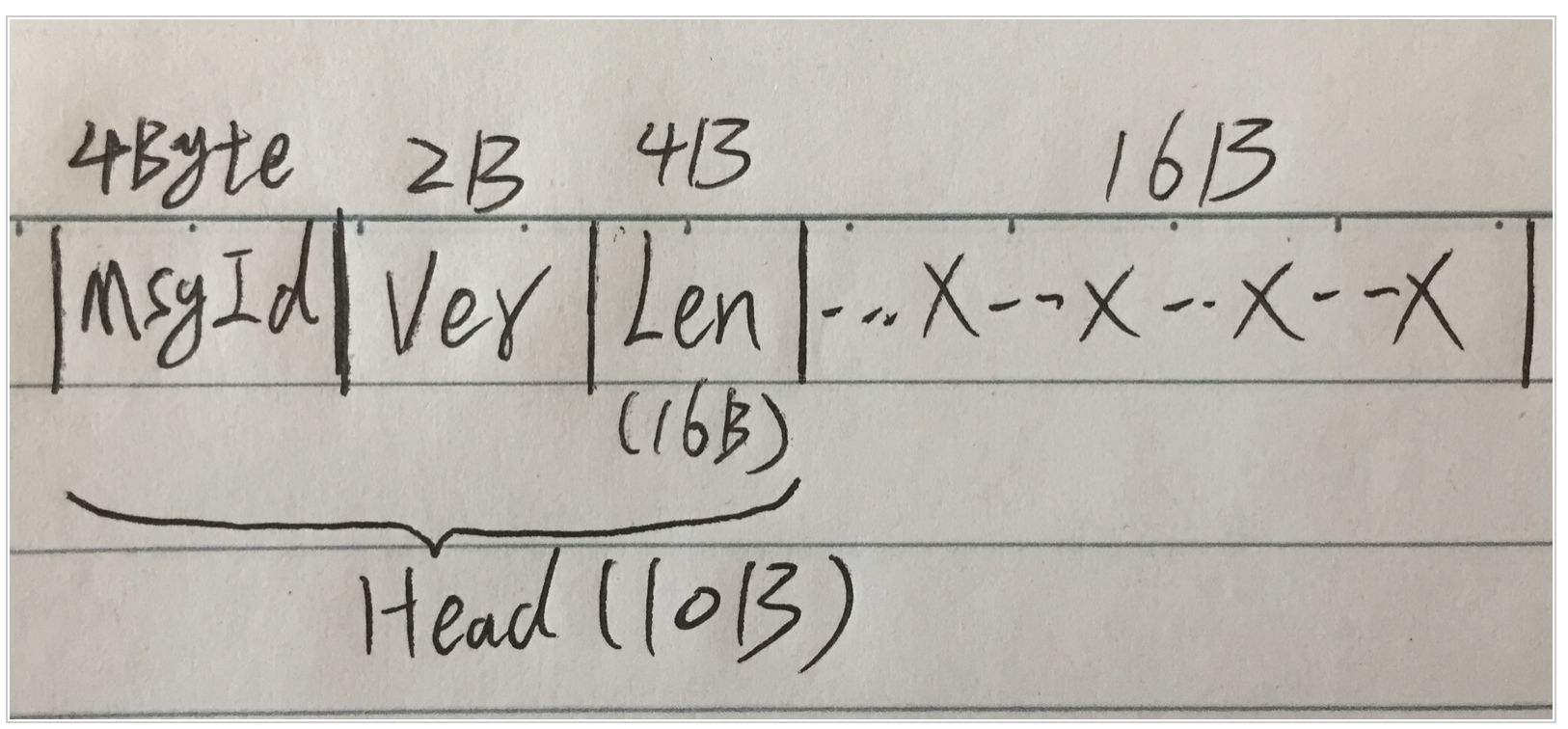
如上图所示,假如我们的一个消息是这么定义的
消息头 = msgId(4B)+version(2B)+len(4B),共占用10字节
消息体 = len中描述的16字节长
所以这条消息的长度就是 26字节
可以看到,要想知道一条完整数据的边界,关键就是消息头中的len字段
假如我们现在接收到的数据是这样的:
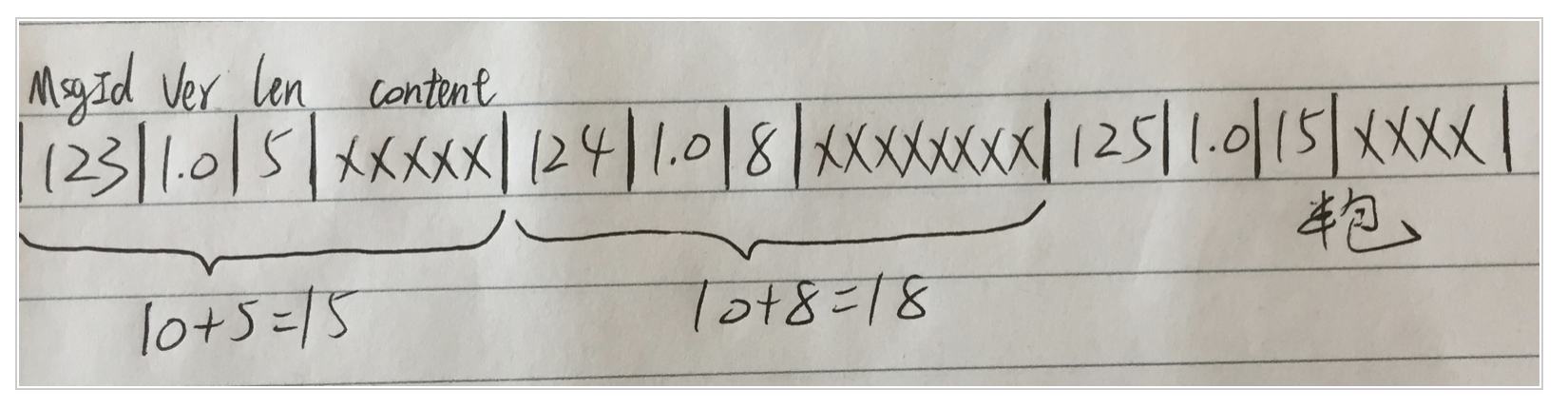
这个情况下即包含了粘包,也出现了半包的情况,三个数据包粘在了一起,最后一个数据包没有接收完全,出现了半包的情况,看看代码如何处理
- (void)onSocket:(AsyncSocket *)sock didReadData:(NSData *)data withTag:(long)tag
{
while (_readBuf.length >= 10)//因为头部固定10个字节,数据长度至少要大于10个字节,我们才能得到完整的消息描述信息
{
NSData *head = [_readBuf subdataWithRange:NSMakeRange(0, 10)];//取得头部数据
NSData *lengthData = [head subdataWithRange:NSMakeRange(6, 4)];//取得长度数据
NSInteger length = [[[NSString alloc] initWithData:lengthData encoding:NSUTF8StringEncoding] integerValue];//得出内容长度
NSInteger complateDataLength = length + 10;//算出一个包完整的长度(内容长度+头长度)
if (_readBuf.length >= complateDataLength)//如果缓存中数据够一个整包的长度
{
NSData *data = [_readBuf subdataWithRange:NSMakeRange(0, complateDataLength)];//截取一个包的长度(处理粘包)
[self handleTcpResponseData:data];//处理包数据
//从缓存中截掉处理完的数据,继续循环
_readBuf = [NSMutableData dataWithData:[_readBuf subdataWithRange:NSMakeRange(complateDataLength, _readBuf.length - complateDataLength)]];
}
else//如果缓存中的数据长度不够一个包的长度,则包不完整(处理半包,继续读取)
{
[_socket readDataWithTimeout:-1 buffer:_readBuf bufferOffset:_readBuf.length tag:0];//继续读取数据
return;
}
}
//缓存中数据都处理完了,继续读取新数据
[_socket readDataWithTimeout:-1 buffer:_readBuf bufferOffset:_readBuf.length tag:0];//继续读取数据
}摘自:https://www.jb51.net/article/105278.htm
Socket简析与iOS实现
Socket的基本概念
1.定义
网络上两个程序通过一个双向通信连接实现数据交互,这种双向通信的连接叫做Socket(套接字)。
2.本质
网络模型中应用层与TCP/IP协议族通信的中间软件抽象层,是它的一组编程接口(API),也即对TCP/IP的封装。TCP/IP也要提供可供程序员做网络开发所用的接口,即Socket编程接口。
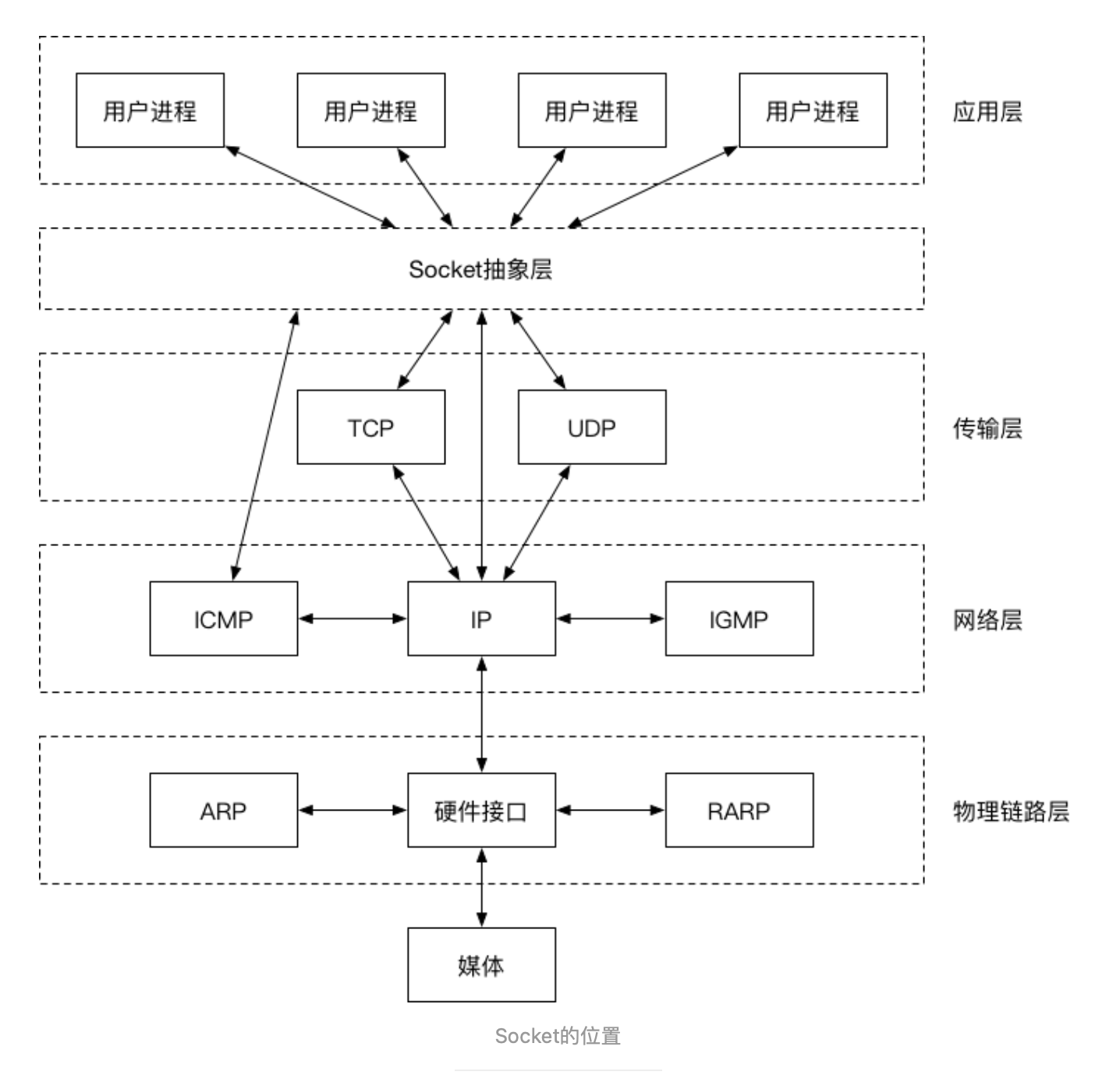
3.要素
Socket是网络通信的基石,是支持TCP/IP协议的网络通信的基本操作单元,包含进行网络通信的必须的五种信息:
- 连接使用的协议
- 本地主机的IP地址
- 本地进程的协议端口
- 远程主机的IP地址
- 远程进程的协议端口
4.特性
Socket可以支持不同的传输协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接;同理,当使用UDP协议进行连接时,该Socket连接就是一个UDP连接。
多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。5.连接
建立Socket连接至少需要一对套接字,分别运行于服务端(ServerSocket)和客户端(ClientSocket)。套接字直接的连接过程氛围三个步骤:
Step 1 服务器监听
服务端Socket始终处于等待连接状态,实时监听是否有客户端请求连接。
Step 2 客户端请求
客户端Socket提出连接请求,指定服务端Socket的地址和端口号,这时就可以向对应的服务端提出Socket连接请求。
Step 3 连接确认
当服务端Socket监听到客户端Socket提出的连接请求时作出响应,建立一个新的进程,把服务端Socket的描述发送给客户端,该描述得到客户端确认后就可建立起Socket连接。而服务端Socket则继续处于监听状态,继续接收其他客户端Socket的请求。
iOS客户端Socket的实现
1. 数据流方式
- (IBAction)connectToServer:(id)sender {
// 1.与服务器通过三次握手建立连接
NSString *host = @"192.168.1.58";
int port = 1212;
//创建一个socket对象
_socket = [[GCDAsyncSocket alloc] initWithDelegate:self
delegateQueue:dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)];
NSError *error = nil;
// 开始连接
[_socket connectToHost:host
onPort:port
error:&error];
if (error) {
NSLog(@"%@",error);
}
}
#pragma mark - Socket代理方法
// 连接成功
- (void)socket:(GCDAsyncSocket *)sock
didConnectToHost:(NSString *)host
port:(uint16_t)port {
NSLog(@"%s",__func__);
}
// 断开连接
- (void)socketDidDisconnect:(GCDAsyncSocket *)sock
withError:(NSError *)err {
if (err) {
NSLog(@"连接失败");
} else {
NSLog(@"正常断开");
}
}
// 发送数据
- (void)socket:(GCDAsyncSocket *)sock
didWriteDataWithTag:(long)tag {
NSLog(@"%s",__func__);
//发送完数据手动读取,-1不设置超时
[sock readDataWithTimeout:-1
tag:tag];
}
// 读取数据
-(void)socket:(GCDAsyncSocket *)sock
didReadData:(NSData *)data
withTag:(long)tag {
NSString *receiverStr = [[NSString alloc] initWithData:data
encoding:NSUTF8StringEncoding];
NSLog(@"%s %@",__func__,receiverStr);
}2.基于第三方开源库CocoaAsyncSocket
2.1客户端通过地址和端口号与服务端建立Socket连接,并写入相关数据。
- (void)connectToServerWithCommand:(NSString *)command
{
_socket = [[GCDAsyncSocket alloc] initWithDelegate:self delegateQueue:dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)];
[_socket setUserData:command];
NSError *error = nil;
[_socket connectToHost:WIFI_DIRECT_HOST onPort:WIFI_DIRECT_PORT error:&error];
if (error) {
NSLog(@"__connect error:%@",error.userInfo);
}
[_socket writeData:[command dataUsingEncoding:NSUTF8StringEncoding] withTimeout:10.0f tag:6];
}2.2 实现CocoaAsyncSocket的代理方法
#pragma mark - Socket Delegate
- (void)socket:(GCDAsyncSocket *)sock didConnectToHost:(NSString *)host port:(uint16_t)port
{
NSLog(@"Socket连接成功:%s",__func__);
}
-(void)socketDidDisconnect:(GCDAsyncSocket *)sock withError:(NSError *)err{
if (err) {
NSLog(@"连接失败");
}else{
NSLog(@"正常断开");
}
if ([sock.userData isEqualToString:[NSString stringWithFormat:@"%d",SOCKET_CONNECT_SERVER]])
{
//服务器掉线 重新连接
[self connectToServerWithCommand:@"battery"];
}else
{
return;
}
}
-(void)socket:(GCDAsyncSocket *)sock didWriteDataWithTag:(long)tag {
NSLog(@"数据发送成功:%s",__func__);
//发送完数据手动读取,-1不设置超时
[sock readDataWithTimeout:-1 tag:tag];
}
-(void)socket:(GCDAsyncSocket *)sock didReadData:(NSData *)data withTag:(long)tag {
NSString *receiverStr = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
NSLog(@"读取数据:%s %@",__func__,receiverStr);
}摘自:https://www.jianshu.com/p/8e599ca5dfe8
收起阅读 »iOS 接入WebSocket
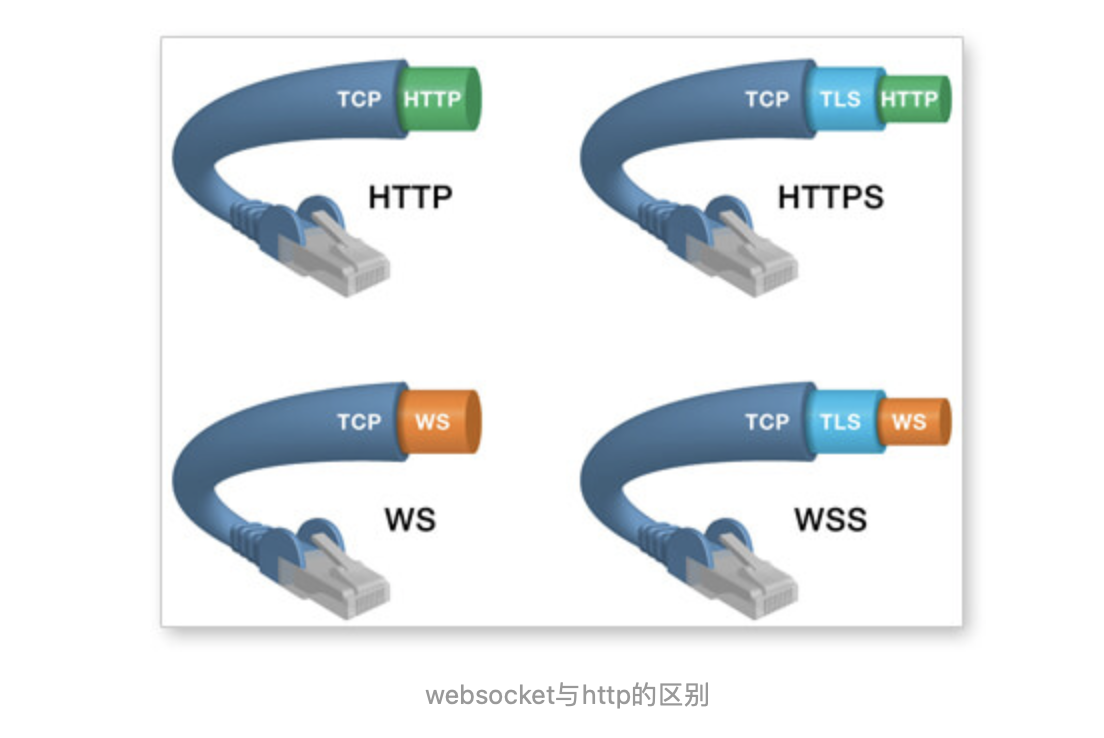
WebSocket是什么
WebSocket协议是 基于TCP 的一种网络协议。
它实现了浏览器与服务器全双工(full-duplex)通信——允许服务器主动发送信息给客户端。
WebSocket基本原理
帧协议:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+- fin(1 bit):指示该帧是否构成该消息的最终帧。大多数情况下,消息适合于一个单一的帧,这一点总是默认设置的。实验表明,Firefox 在 32K 之后创建了第二个帧。
rsv1,rsv2,rsv3(1 bit each):必须为0,除非扩展里协商定义了非零值的含义。如果收到一个非零值,并且协商的扩展中没有一个定义这个非零值的含义,那么接收端必须抛出失败连接。
- opcode(4bits):展示了帧表示什么。以下值目前正在使用:
0x00:这个帧继续前面的有效载荷。
0x01:此帧包含文本数据。
0x02:这个帧包含二进制数据。
0x08:这个帧终止连接。
0x09:这个帧是一个 ping 。
0x0a:这个帧是一个 pong 。
(正如你所看到的,有足够的值未被使用,它们已被保留供将来使用)。 - payload:最可能被掩盖的实际数据。它的长度是 payload_len 的长度。
- masking-key(32 bits):从客户端发送到服务器的所有帧都被帧中包含的 32 位值掩盖。
- 0-125 表示有效载荷的长度。 126 表示以下两个字节表示长度,127 表示接下来的 8 个字节表示长度。所以有效负载的长度在 〜7bit,16bit 和 64bit 括号内。
- payload_len(7 bits):有效载荷的长度。 WebSocket 的帧有以下长度括号:
- mask(1 bit):指示连接是否掩盖。就目前而言,从客户端到服务器的每条消息都必须掩盖,如果规范没有掩盖,规范就会终止连接。
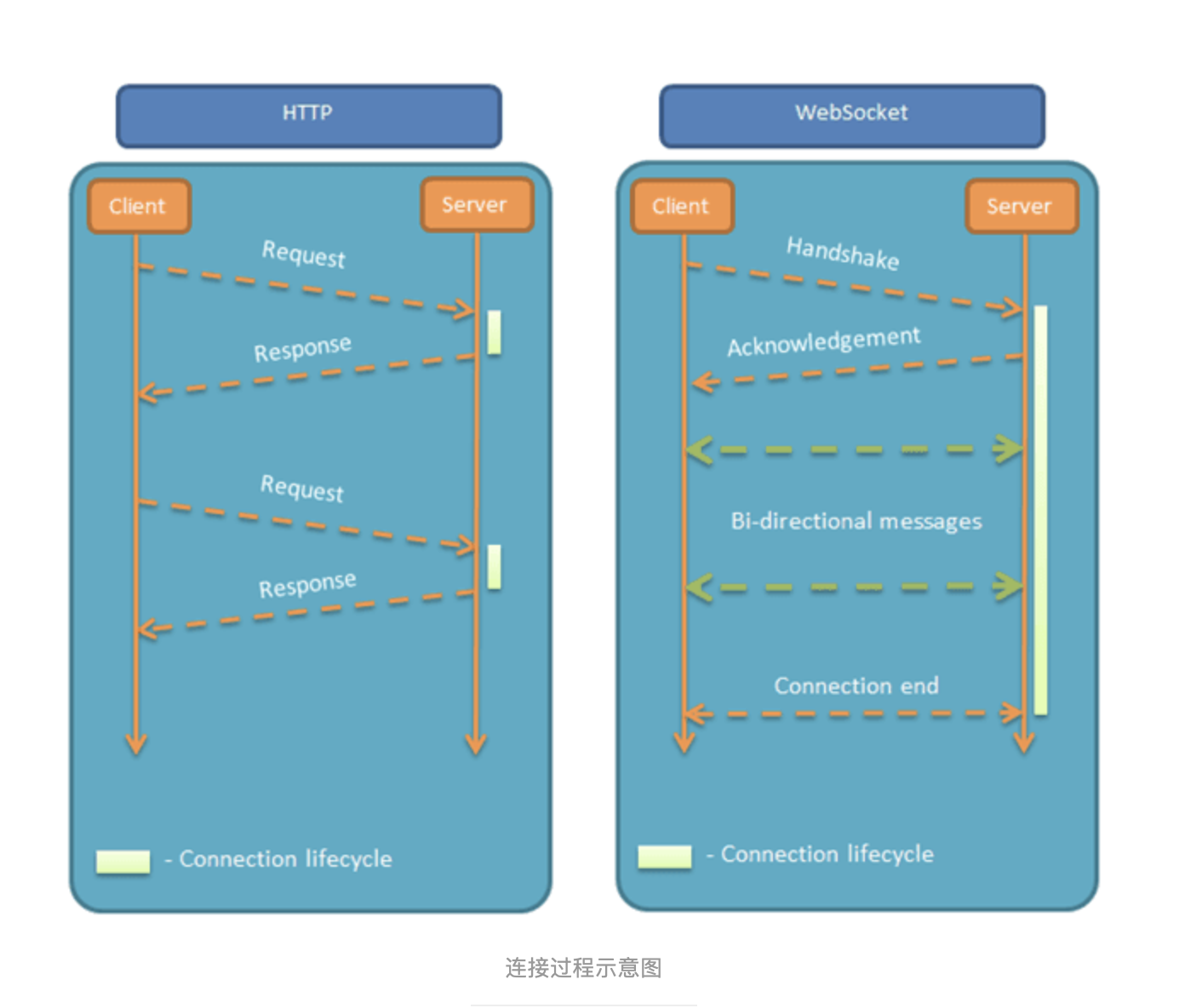
其他特点包括:
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
WebSocket常见的使用场景
要求服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息。(也可以采用HTTP/2)
iOS端实现WebSocket连接的参考方案
SocketRocket
SocketRocket是facebook封装的websocket开源库,采用纯Objective-C编写。
使用者需要自己实现心跳机制,以及适配断网重连等情况。
SocketIO
SocketIO将WebSocket、AJAX和其它的通信方式全部封装成了统一的通信接口,也就是说,我们在使用SocketIO时,不用担心兼容问题,底层会自动选用最佳的通信方式。因此说,WebSocket是SocketIO的一个子集。
另外,如果后端采用的是原生WebSocket,不建议大家使用SocketIO。因为SocketIO定制了专有的协议,并不是纯粹的WebSocket,可能会遭遇适配问题。
不过,SocketIO的API极其易用!!!
Starscream
采用Swift编写,不过笔者暂时还没有用过,不发表任何评论。
iOS端利用SocketRocket实现WebSocket连接
示例代码如下,欢迎指正:
import Foundation
import SocketRocket
import Alamofire
/// Websocket连接中的通知
let FSWebSocketConnectingNotification = NSNotification.Name.init("FSWebSocketConnectingNotification")
/// Websocket连接成功的通知
let FSWebSocketDidOpenNotification = NSNotification.Name.init("FSWebSocketDidOpenNotification")
/// Websocket连接收到新消息的通知
let FSWebSocketDidReceiveMessageNotification = NSNotification.Name.init("FSWebSocketDidReceiveMessageNotification")
/// Websocket连接失败的通知
let FSWebSocketFailWithErrorNotification = NSNotification.Name.init("FSWebSocketFailWithErrorNotification")
/// Websocket连接已关闭的通知
let FSWebSocketDidCloseNotification = NSNotification.Name.init("FSWebSocketDidCloseNotification")
/// websocket连接地址,请输入有效的websocket地址!
let WSAddr = "ws://host:port/ws"
/// 心跳包发送间隔,3分钟
let PingDuration = 180
/// Websocket连接对象
class FSWebsocket: NSObject,SRWebSocketDelegate {
static let `default` = FSWebsocket.init()
/// 是否在断开连接后自动重连
var autoReconnect = true
private var reachabilityManager = NetworkReachabilityManager.init(host: "www.baidu.com")
/// websocket连接地址
private var addr = WSAddr
/// websocket连接
private var ws:SRWebSocket?
/// 心跳包定时发送计时器
private var heartbeatTimer:Timer?
/// 重连计数器
private var reconnectCount = 0
override init() {
super.init()
NotificationCenter.default.addObserver(self, selector: #selector(appWillEnterForeground), name: NSNotification.Name.UIApplicationWillEnterForeground, object: nil)
NotificationCenter.default.addObserver(self, selector: #selector(appDidEnterBackground), name: NSNotification.Name.UIApplicationDidEnterBackground, object: nil)
// 切换网络自动重连
reachabilityManager?.listener = { [weak self] (networkReachabilityStatus) in
// 正在连接中或已经连接成功,不需要重连
if self?.ws?.readyState == .CONNECTING || self?.ws?.readyState == .OPEN{
return
}
// 设置自动重连才会进行自动重连
if let s = self, s.autoReconnect{
self?.reconnect()
}
}
reachabilityManager?.startListening()
}
deinit {
NotificationCenter.default.removeObserver(self)
}
@objc func appDidEnterBackground(){
close()
}
@objc func appWillEnterForeground(){
reconnect()
}
// MARK: - Send Message
@discardableResult
func sendJSON(_ json:[AnyHashable : Any]) -> NSError?{
let jsonData = try? JSONSerialization.data(withJSONObject: json, options: JSONSerialization.WritingOptions.prettyPrinted)
return self.sendData(jsonData)
}
@discardableResult
func sendData(_ data:Data?) -> NSError?{
guard ws?.readyState == SRReadyState.OPEN else{
return NSError.init(domain: "FSWebsocket", code: SRStatusCodeGoingAway.rawValue, userInfo: nil)
}
ws?.send(data)
return nil
}
// MARK: - Connection Management
/// 连接websocket服务器
func open(){
let url = URL(string: self.addr)
assert(url != nil)
self.ws = SRWebSocket.init(url: url!)
ws?.delegate = self
ws?.open()
NotificationCenter.default.post(name: FSWebSocketConnectingNotification, object: self)
}
/// 重新连接
private func reconnect(){
if !autoReconnect{
return
}
if reconnectCount > 64 {
return
}
let seconds = DispatchTime.now().uptimeNanoseconds + UInt64(reconnectCount) * NSEC_PER_SEC
let time = DispatchTime.init(uptimeNanoseconds: seconds)
DispatchQueue.main.asyncAfter(deadline: time) {
self.ws?.close()
self.ws = nil
self.open()
}
if reconnectCount == 0 {
reconnectCount = 1
}
reconnectCount *= 2
}
/// 关闭连接
func close(){
self.destroyHeartbeat()
self.ws?.close()
self.ws = nil
resetConnectCount()
}
/// 发送心跳包
@objc func heartbeat(){
guard ws?.readyState == SRReadyState.OPEN else{
return
}
self.ws?.sendPing(nil)
}
/// 启动心跳
private func startHeartbeat(){
let timer = Timer.init(timeInterval: TimeInterval(PingDuration), target: self, selector: #selector(heartbeat), userInfo: nil, repeats: true)
self.heartbeatTimer = timer
RunLoop.current.add(timer, forMode: RunLoopMode.commonModes)
}
/// 停止心跳
private func destroyHeartbeat(){
self.heartbeatTimer?.invalidate()
self.heartbeatTimer = nil
}
/// 重置重连尝试次数
private func resetConnectCount(){
reconnectCount = 0
}
// MARK: - SRWebSocketDelegate
func webSocketDidOpen(_ webSocket: SRWebSocket!) {
self.resetConnectCount()
self.startHeartbeat()
NotificationCenter.default.post(name: FSWebSocketDidOpenNotification, object: self)
}
func webSocket(_ webSocket: SRWebSocket!, didReceiveMessage message: Any!) {
guard let msgString = message as? NSString else{
return
}
guard let msgData = msgString.data(using: String.Encoding.utf8.rawValue) else{
return
}
// 如果传输的是JSON数据,可以使用JSONSerialization将JSON字符串转换为字典
guard let msgJSON = try? JSONSerialization.jsonObject(with: msgData, options: JSONSerialization.ReadingOptions.allowFragments) else{
return
}
NotificationCenter.default.post(name: FSWebSocketDidReceiveMessageNotification, object: self, userInfo: ["message":msgJSON])
}
func webSocket(_ webSocket: SRWebSocket!, didFailWithError error: Error!) {
NotificationCenter.default.post(name: FSWebSocketFailWithErrorNotification, object: self, userInfo: ["error": error])
// 连接失败:
if (error as NSError).code == 50{
// 断网,不重连
return
}
// 当前页面不需要使用websocket,不重连
// 重连次数超过限制,不重连
reconnect()
}
func webSocket(_ webSocket: SRWebSocket!, didReceivePong pongPayload: Data!) {
// 心跳包响应回调
}
func webSocket(_ webSocket: SRWebSocket!, didCloseWithCode code: Int, reason: String!, wasClean: Bool) {
// 连接被关闭
NotificationCenter.default.post(name: FSWebSocketDidCloseNotification, object: self, userInfo: ["code": code, "reason": reason, "wasClean": wasClean])
close()
}
}摘自链接:https://www.jianshu.com/p/934c0d79f75e
任意组合判断还在用Switch?位运算符了解一下~
情景再现
很多时候,当我们写程序都会有这样的情况,就是代码多选操作.例如下面的操作.
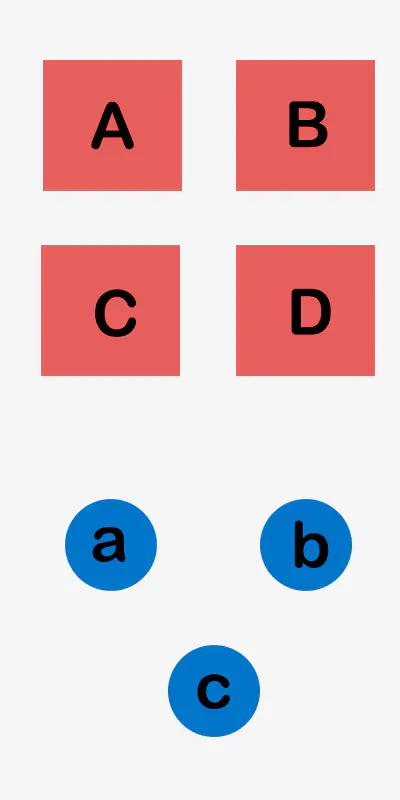
比如有四个视图View(分别为A,B,C,D);
当点击按钮a的时候,视图A,B背景色发生改变;
当点击按钮b的时候,视图A,B,D背景色发生改变;
当点击按钮c的时候,视图B,C,D背景色发生改变;
后续开发中可能有很多按钮和不同的组合形式.
这时候你会怎么办?
第一种方案: 所有的按钮就响应一个方法,里面使用if else等模块来区分不同的按钮事件.
思考问题: 后期如果增加一种按钮.你就需要增加一个if else,代码增加的同时,if else逻辑层级太多也不利于阅读.
第二种方案: if else性能太低?我们就使用Switch.配合着枚举值或者按钮的Tag值来做区别判断,枚举值可以定义成每一种组合形式都是一个枚举值.不同按钮相同的组合形式进入同样的模块.
思考问题: 虽然Switch使用break关键词相对于普通的if else有很大的性能提高,但是后期如果增加一种情况,仍然需要添加代码块.还是会增加代码量.
这时候我们总结一下上面倒是需要干什么,以及出现的问题.
需求: 组合是具有不确定性的,但是组合中的基本元素是确定的(A,B,C,D中的任意组合).
问题: 普通的方式不管if else或者Switch都可能会需要罗列出所有的组合形式,代码量很大,不符合代码规范.阅读起来也是相当的困难.
难道就没有更加优雅的方式来解决这个问题吗?这当然是有的,那就是我们的今天猪脚 位运算符.使用位运算符可以很好的帮助我们解决这一问题.但是在此之前我们需要先了解什么叫做位移运算符.
位运算符
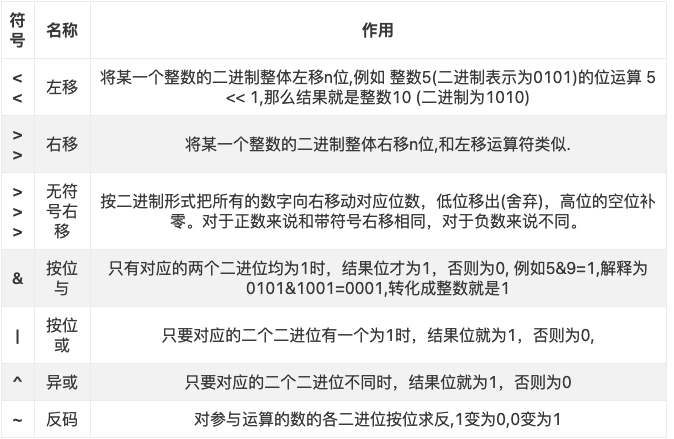
按位与和按位或举个例子来看下.
按位与
1001
&
0101
=0001按位或
1001
&
0101
=1101按位异或
1001
^
0101
=1100我们了解了位运算符,我们该如何解决最开始的那种问题呢?我们接着看~
解决问题
解决这种问题我们会用到 << 和& 以及 | 这三种位运算符.
首先定义一个ColorView视图,继承于UIView,然后在 .h 头文件定义枚举,并且ColorView持有枚举的属性.代码如下所示.
#import <UIKit/UIKit.h>
typedef enum : NSUInteger {
ColorViewStyleA = 1<<0,
ColorViewStyleB = 1<<1,
ColorViewStyleC = 1<<2,
ColorViewStyleD = 1<<3,
} ColorViewStyle;
@interface ColorView : UIView
@property(nonatomic,assign)ColorViewStyle style;
@property(nonatomic,copy)NSString *title;
@end然后在ViewController导入ColorView,并且声明一个属性needChangeColorStyle.用于判断需要做出修改的视图.
#import "ColorView.h"
@interface ViewController ()
@property(nonatomic,assign)ColorViewStyle needChangeColorStyle;
@end然后在ViewController创建ColorView和Button,这里由于时间原因,我就简写了.主要要给每种视图设置一个枚举值,作为识别码.
//创建ColorView
for (int i = 0; i < 4; i++) {
ColorView *colorView = [[ColorView alloc] initWithFrame:CGRectMake(viewWidth * i + distance *(i+1), 100, viewWidth, 100)];
............
switch (i) {
case 0:
colorView.style = ColorViewStyleA;
break;
case 1:
colorView.style = ColorViewStyleB;
break;
case 2:
colorView.style = ColorViewStyleC;
break;
case 3:
colorView.style = ColorViewStyleD;
break;
}
............
}
//创建按钮
for (int i = 0; i < 4; i++) {
............
}然后在按钮的点击方法 buttonAction 里面重置needChangeColorStyle的值,这里就需要使用到按位或进行枚举值的组合了.如下所示.
- (void)buttonAction:(UIButton *)sender {
//对 needChangeColorStyle 进行赋值,其实这步操作应该在一开始做的,这里是Demo,所以这么做了.
//赋值过程中使用了按位或运算符.整合可响应的View类型.
NSInteger tagIndex = sender.tag - 10000;
switch (tagIndex) {
case 0:
_needChangeColorStyle = ColorViewStyleA|ColorViewStyleB|ColorViewStyleD;
break;
case 1:
_needChangeColorStyle = ColorViewStyleB|ColorViewStyleC|ColorViewStyleD;
break;
case 2:
_needChangeColorStyle = ColorViewStyleA|ColorViewStyleB;
break;
case 3:
_needChangeColorStyle = ColorViewStyleD;
break;
}
[self colorViewsChangAction];
}最后在colorViewsChangAction方法中进行视图的操作选择.使用到了按位与运算.只要视图的style和_needChangeColorStyle有相交部分,那么两者按位与出来的数值一定是大于等于1的.这样就可以做包含操作了.代码日下所示.
- (void)colorViewsChangAction {
//遍历ColorView视图数组
for (ColorView *colorView in self.colorViews) {
//使用了按位与,查看两者是否具有相交部分.
if (_needChangeColorStyle & colorView.style) {
NSLog(@"%@ 做出了响应",colorView.title);
colorView.backgroundColor = [UIColor redColor];
} else {
colorView.backgroundColor = [UIColor orangeColor];
}
}
}这样我们就完成了使用位运算做任何组合判断的操作了,后期我们加一种按钮或者组合形式,只需要在 buttonAction 添加三行代码即可.其他都不用了,而且代码结构读起来非常的舒服.
当然了,在iOS原生框架也是有这样的操作的,例如对于贝塞尔曲线的指定角进行切边操作.枚举值也是带有位移运算的,枚举值如下所示.这时候可以仍然可以使用按位或组合任意形式的角.
typedef NS_OPTIONS(NSUInteger, UIRectCorner) {
UIRectCornerTopLeft = 1 << 0,
UIRectCornerTopRight = 1 << 1,
UIRectCornerBottomLeft = 1 << 2,
UIRectCornerBottomRight = 1 << 3,
UIRectCornerAllCorners = ~0UL
};总结
位运算符还有很多用途,这是最简单的用途而已,在安卓那边的话,如果枚举有性能问题,可以使用定义常量的形式来实现该目的,整体上是一致的,好了就说到这里,如果有任何问题,欢迎批评指导,谢谢.最后再把Demo发一遍.
转自:https://www.jianshu.com/p/5ed73f85ac37
收起阅读 »作为iOSer,你还不会适配暗黑模式吗 ---- 如何适配暗黑模式(Dark Mode)
原理
1、将同一个资源,创建出两种模式的样式。系统根据当前选择的样式,自动获取该样式的资源
2、每次系统更新样式时,应用会调用当前所有存在的元素调用对应的一些重新方法,进行重绘视图,可以在对应的方法做相应的改动
资源文件适配
1、创建一个Assets文件(或在现有的Assets文件中)
2、新建一个图片资源文件(或者颜色资源文件、或者其他资源文件)
3、选中该资源文件, 打开 Xcode ->View ->Inspectors ->Show Attributes Inspectors (或者Option+Command+4)视图,将Apperances 选项 改为Any,Dark
4、执行完第三步,资源文件将会有多个容器框,分别为 Any Apperance 和 Dark Apperance. Any Apperance 应用于默认情况(Unspecified)与高亮情况(Light), Dark Apperance 应用于暗黑模式(Dark)
5、代码默认执行时,就可以正常通过名字使用了,系统会根据当前模式自动获取对应的资源文件
注意
同一工程内多个Assets文件在打包后,就会生成一个Assets.car 文件,所以要保证Assets内资源文件的名字不能相同
如何在代码里进行适配颜色(UIColor)
如何在代码里进行适配颜色(UIColor)
+ (UIColor *)colorWithDynamicProvider:(UIColor * (^)(UITraitCollection *))dynamicProvider API_AVAILABLE(ios(13.0), tvos(13.0)) API_UNAVAILABLE(watchos);
- (UIColor *)initWithDynamicProvider:(UIColor * (^)(UITraitCollection *))dynamicProvider API_AVAILABLE(ios(13.0), tvos(13.0)) API_UNAVAILABLE(watchos);eg.
[UIColor colorWithDynamicProvider:^UIColor * _Nonnull(UITraitCollection * _Nonnull trait) {
if (trait.userInterfaceStyle == UIUserInterfaceStyleDark) {
return UIColorRGB(0x000000);
} else {
return UIColorRGB(0xFFFFFF);
}
}];系统调用更新方法,自定义重绘视图
当用户更改外观时,系统会通知所有window与View需要更新样式,在此过程中iOS会触发以下方法, 完整的触发方法文档
UIView
traitCollectionDidChange(_:)
layoutSubviews()
draw(_:)
updateConstraints()
tintColorDidChange()UIViewController
traitCollectionDidChange(_:)
updateViewConstraints()
viewWillLayoutSubviews()
viewDidLayoutSubviews()UIPresentationController
traitCollectionDidChange(_:)
containerViewWillLayoutSubviews()
containerViewDidLayoutSubviews()如何不进行系统切换样式的适配
注意
苹果官方强烈建议适配 暗黑模式(Dark Mode)此功能也是为了开发者能慢慢将应用适配暗黑模式
所以想通过此功能不进行适配暗黑模式,预计将会被拒
全局关闭暗黑模式
1、在Info.plist 文件中,添加UIUserInterfaceStyle key 名字为 User Interface Style 值为String,
2、将UIUserInterfaceStyle key 的值设置为 Light
单个界面不遵循暗黑模式
1、UIViewController与UIView 都新增一个属性 overrideUserInterfaceStyle
2、将 overrideUserInterfaceStyle 设置为对应的模式,则强制限制该元素与其子元素以设置的模式进行展示,不跟随系统模式改变进行改变
1、设置 ViewController 的该属性, 将会影响视图控制器的视图和子视图控制器采用该样式
2、设置 View 的该属性, 将会影响视图及其所有子视图采用该样式
3、设置 Window 的该属性, 将会影响窗口中的所有内容都采用样式,包括根视图控制器和在该窗口中显示内容的所有演示控制器(UIPresentationController)
转自:https://www.jianshu.com/p/7925bd51d2d6
收起阅读 »SwiftUI-如何创建一个工程
2019年度WWDC全球开发者大会,更新旗下用于手机、电脑、智能手表和电视机顶盒的软件操作系统。此外还发布了计算机编程语言框架SwiftUI。SwiftUI是基于开发语言Swift建立的框架——SwiftUI。全新的SwiftUI可以用于watchOS、tvOS、macOS等苹果旗下系统。
在本文对于SwiftUI使用做一个简介。😊
环境:
1、macOS 15 Beta
2、Xcode 11.0 Beta
3、iOS 13.0 Beta
接下来我们尝试体验一下SwiftUI功能,如何使用SwiftUI实现一个TableView呢?
import SwiftUI
struct Hero: Identifiable {
let id: UUID = UUID()
let name: String
}
struct ContentView : View {
let heros = [
Hero(name: "邱少云"),
Hero(name: "黄继光"),
Hero(name: "董存瑞"),
Hero(name: "杨宝山"),
Hero(name: "毛岸英")
]
var body: some View {
List(heros) {
hero in
Text(hero.name)
}
}
}
#if DEBUG
struct ContentView_Previews : PreviewProvider {
static var previews: some View {
ContentView()
}
}
#endif
以上是我们实现的第一个SwiftUI程序是不是很直观?
接下来我们来了解一下程序的入口,同时解释一下他们之间如何联系的。
1、创建一个SwiftUI 工程
在Xcode-Beta 里创建工程和之前Xcode版本是一样的,我们选择 Single View App:
给工程命名同时选择使用SwiftUI
2、了解程序的入口
让我们从项目中删除尽可能多的代码和文件,看到什么程度还可以让它跑起来。刚开始创建工程是这样的:
我们将AppDelegate.swift和ContentView.swift删除并移进回收站。并在SceneDelegate类的顶部添加@UIApplicationMain,让这个类遵循UIApplicationDelegate,删除SceneDelegate中除func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions)以外的方法,func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions)是程序的主入口。
现在如果选择iPhone XR进行运行,会显示黑屏。
3、创建一个新的Swift File或者直接选择SwiftUI View
我们将新创建的Swift文件命名为 AwesomeView.swift,内部代码如下,和我们最初删除的ContentView.swift内容一样:
import SwiftUI
struct AwesomeView : View {
var body: some View {
Text(/*@START_MENU_TOKEN@*/"Hello World!"/*@END_MENU_TOKEN@*/)
}
}
#if DEBUG
struct AwesomeView_Previews : PreviewProvider {
static var previews: some View {
AwesomeView()
}
}
#endifAwesomeView.swift中有一个实现View协议的AwesomeView结构体,根据View协议,我们实现了body属性,Swift5.1中,我们不需要添加return关键字,函数或者闭包最后一行将自动返回。
这是我们写的第一个SwiftUI试图,接下来选择右上角,点击一个多条线按钮,选择Editor and Canvas
接下来点击Resume 或者 Try again 查看试图状态。
预览里将展示AwesomeView_Previews 结构体中闭包返回的所有试图预览。
在PreviewProvider里我们可以看到这段注释
Xcode statically discovers types that conform to `PreviewProvider` and
generates previews in the canvas for each provider it discovers.通过Xcode静态发现符合PreviewProvider协议的类型,并在画布中为它发现的每个provider生成预览。所以我们可以随意命名xxx_Previews并遵循PreviewProvider协议,就可以在画布上预览我们的视图。
我们可以编辑左边的代码,看右侧的画布是不是可以重载。😍
4、将SwiftUI View 定义为程序启动图
之前我们的跑起来的程序是黑屏,目前重新启动程序依然是黑屏。如何将我们定义的为根视图呢?其实我们之前删除代码是我们就注意到了在SceneDelegate.swift中有以下代码:
import UIKit
import SwiftUI
@UIApplicationMain
class SceneDelegate: UIResponder, UIWindowSceneDelegate, UIApplicationDelegate {
var window: UIWindow?
func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) {
// 实例化一个手机屏幕大小window
let window = UIWindow(frame: UIScreen.main.bounds)
// 实例化一个UIHostingController作为rootViewController
// UIHostingController保存SwiftUI视图,将AwesomeView作为根视图
window.rootViewController = UIHostingController(rootView: AwesomeView())
self.window = window
window.makeKeyAndVisible()
}
}现在运行程序我们就可以在模拟器中看到我们写的AwesomeView了。。。。
Xcode 是如何知道SceneDelegate.swift中的SceneDelegate作为程序启动根视图的类的呢?我们看一下工程中的info.plist
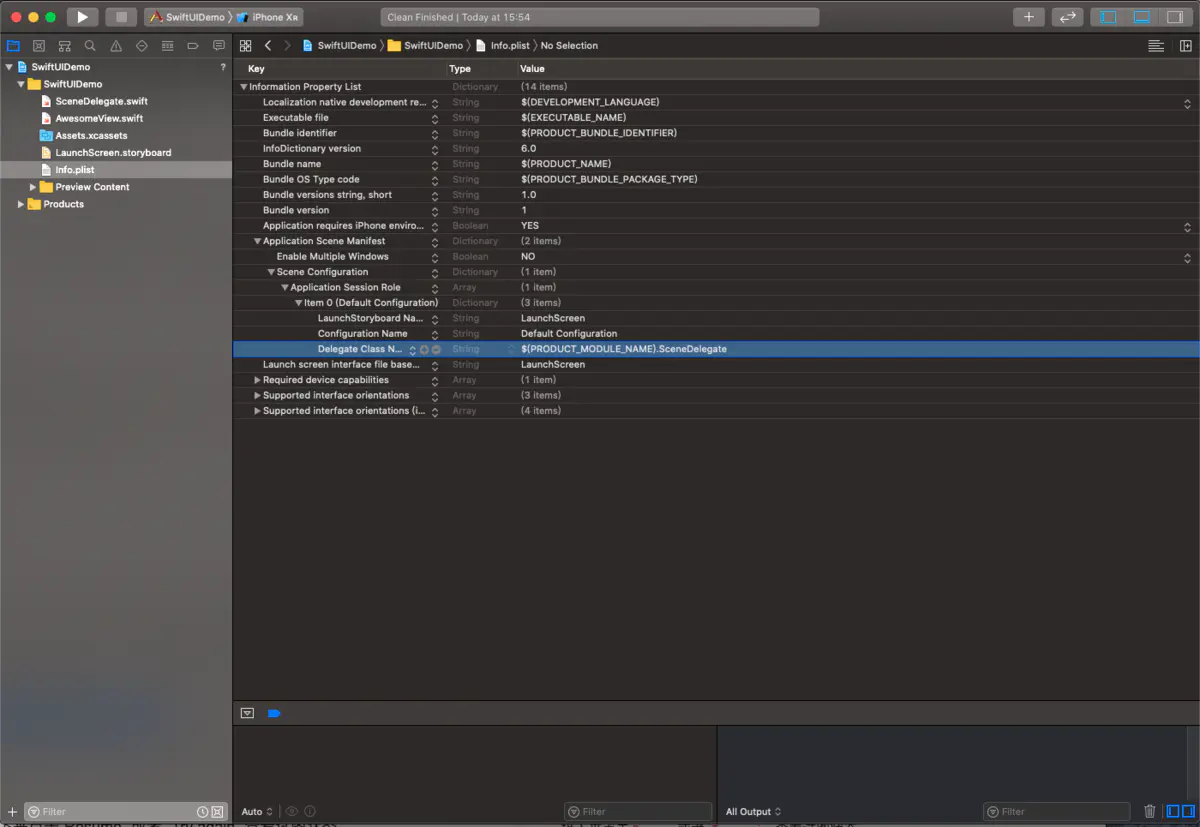
我们尝试修改一下Delegate Class Name将(PRODUCT_MODULE_NAME).SceneDelegate改为$(PRODUCT_MODULE_NAME).martinlasek,此时我们运行将会出现之前的黑屏情况,因为程序找不到martinlasek,
现在我们将SceneDelegate.swift中的SceneDelegate类重命名为martinlasek。然后我们再运行一次。在模拟器中我们再次看到了AwesomeView。
也就是说info.plist中的Delegate Class Name定义了根视图的类。
通过上面的一段内容你可以很轻松实现一个SwiftUI小程序。从现在开始你可以开启你的SwiftUI之旅了。
链接:https://www.jianshu.com/p/b4509d3d9766
收起阅读 »SwiftUI 入门指引教程
这是 WWDC2019 发布的 SwiftUI 布局框架的一些官方示例。
首先为了保证项目的正常运行,需要升级 Mac OS 至 10.15 beta 版,以及 Xcode 使用 Xcode 11 beta。
1.创建项目运行
首先创建一个新的项目,模板可以使用第一个Single View App,项目名称官方的Demo叫做Landmarks,勾选上Use SwiftUI如图。
然后创建项目,点击打开 ContentView.swift,代码如下:
import SwiftUI
struct ContentView: View {
var body: some View {
Text("Hello World")
}
}
struct ContentView_Preview: PreviewProvider {
static var previews: some View {
ContentView()
}
}目前该类声明了两个 struct,第一个是该 View 的实现,第二个是为了实现该 View 的浏览。
然后在 canvas 视图上点击 Resume(如果找不到,打开 Editor > Editor and Canvas )。
然后修改 View 实现的代码,可以实时看到效果
struct ContentView: View {
var body: some View {
Text("Hello SwiftUI!")
}
}2、定制TextView
在之前的基础上,按住Command,并单击 Hello SwiftUI!,会弹出菜单,选择Inspect修改属性。
点击之后
修改 Font 为 title。
然后手动修改UI代码,添加颜色为绿色:
struct ContentView: View {
var body: some View {
Text("Turtle Rock")
.font(.title)
.color(.green)
}
}接下来在代码中单击文本的声明Text("Turtle Rock"),可以看到弹出的菜单,点击检查器inspect,把颜色再改回黑色。
这个时候你会发现,Xcode会删除Text("Turtle Rock")这一行。
3、使用 Stack 去组合 View
这一部分会添加几个视图,并使用 Stack去组合。
单击 Text("Turtle Rock"),弹出的菜单中选择 Embed in VStack。
单击Xcode窗口右上角的加号按钮(+)打开库,然后在“Turtle Rock”文本视图后将Text视图拖到代码中的位置。
替换文本为 Joshua Tree National Park,设置字体为.subheadline。
然后编辑VStack的初始化方法,代码修改为 VStack(alignment: .leading) { 使得它左对齐。
然后在 canvas 里面 command 并单击 Joshua Tree National Park,选择 Embed in HStack 添加一个新的 textView,输入内容 California,设置字体为 .subheadline。
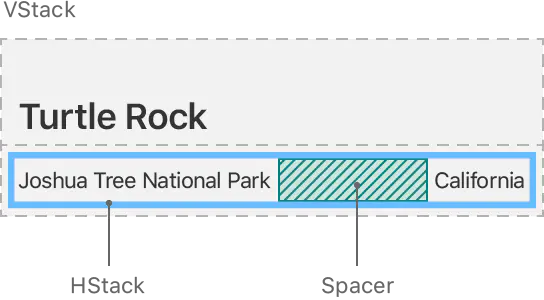
通过将 Spacer 添加到包含两个 Text 的水平堆栈,使得布局使用设备的整个宽度,如下:
struct ContentView: View {
var body: some View {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
}
}Spacer 会使用俯视图所有的空间,彻底的展开,不需要通过指定内容大小等属性。
最后,使用 padding()修饰符,添加到Stack的实现结束的地方,给界面留一些呼吸的空间。
struct ContentView: View {
var body: some View {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
}
}4、Image 添加图片
这一部分会添加一个独立的原型的自定义图片视图,将遮罩,边框和阴影应用于图像。
将图片添加到资源 asset 目录下。
创建一个新的额 SwiftUI 类,命名为 CircleImage.swift,并替换其实现如下,使用Image 的初始化方法 Image(_:)。
struct CircleImage: View {
var body: some View {
Image("turtlerock")
}
}Image初始化方法之后添加圆形剪裁形状,Circle 可以像这样用做于一个蒙版,或者用作一个试图内的原型的填充。
struct CircleImage: View {
var body: some View {
Image("turtlerock")
.clipShape(Circle())
}
}然后添加其余的属性,颜色,线宽和半径为10个单位的阴影:
struct CircleImage: View {
var body: some View {
Image("turtlerock")
.clipShape(Circle())
.overlay(
Circle().stroke(Color.gray, lineWidth: 4))
.shadow(radius: 10)
}
}5.组合成详情 View
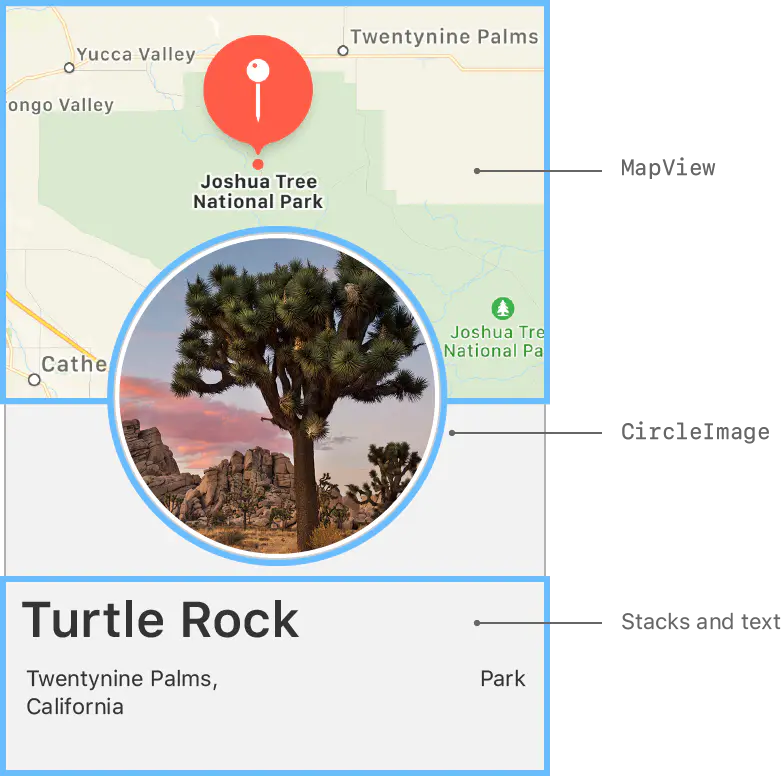
在第一个 ContentView 类中插入一个新的 VStack 视图,位置如下:
struct ContentView: View {
var body: some View {
VStack {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack(alignment: .top) {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
}
}
}添加一个 MapView,在新添加的 VStack 的下面,设置 MapView 的 Size, 如下:
struct ContentView: View {
var body: some View {
VStack {
MapView()
.frame(height: 300)
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)仅指定 height 参数的话,View 会自动调整其内容的宽度。在这种情况下,MapView 会扩展以填充可用空间。
点击 Live Preview 实时预览视图。
然后在 MapView 的下方,添加我们上一步实现的 CircleImage,并且设置向上的位置偏移量。
CircleImage()
.offset(y: -130)
.padding(.bottom, -130)在最外面的 VStack 的底部添加一个 spacer,把内容整个推到屏幕的上面。
最后:让 MapView 忽略上面的安全距离,在MapView下面插入 .edgesIgnoringSafeArea(.top),完整的类实现代码如下:
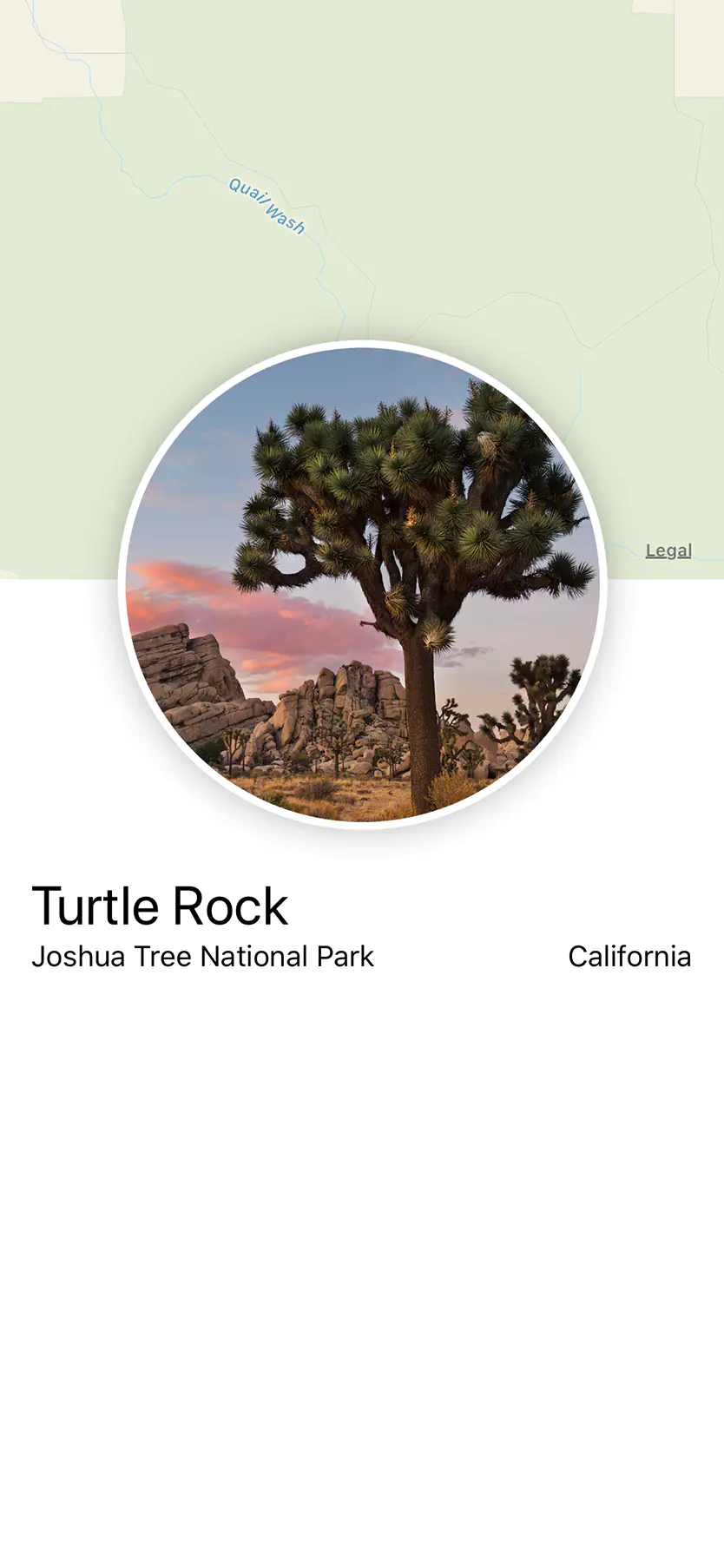
struct ContentView: View {
var body: some View {
VStack {
MapView()
.edgesIgnoringSafeArea(.top)
.frame(height: 300)
CircleImage()
.offset(y: -130)
.padding(.bottom, -130)
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack(alignment: .top) {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
Spacer()
}
}
}
转自:https://www.jianshu.com/p/82524bf00b35
收起阅读 »SwiftUI官方教程解读
SwiftUI简介
SwiftUI是wwdc2019发布的一个新的UI框架,通过声明和修改视图来布局UI和创建流畅的动画效果。并且我们可以通过状态变量来进行数据绑定实现一次性布局;Xcode 11 内建了直观的新设计工具canvus,在整个开发过程中,预览可视化与代码可编辑性能同时支持并交互,让我们可以体验到代码和布局同步的乐趣;同时支持和UIkit的交互.
设计工具canvus
1、开发者可以在canvus中拖拽控件来构建界面, 所编辑的内容会立刻反应到代码上
2、切换不同的视图文件时canvus会切换到不同的界面
3、点击左下角的按钮钉我们可以把视图固定在活跃页面
4、选中canvus中的控件command+click可以调出inspect布局控件的属性
5、点击右上角的+可以获取新的控件并拖拽到对应的位置
6、在live状态下我们可以在canvus中调试点击等可交互效果 但不能缩放视图大小
每次修改或者增加属性需要点击resume刷新canvus
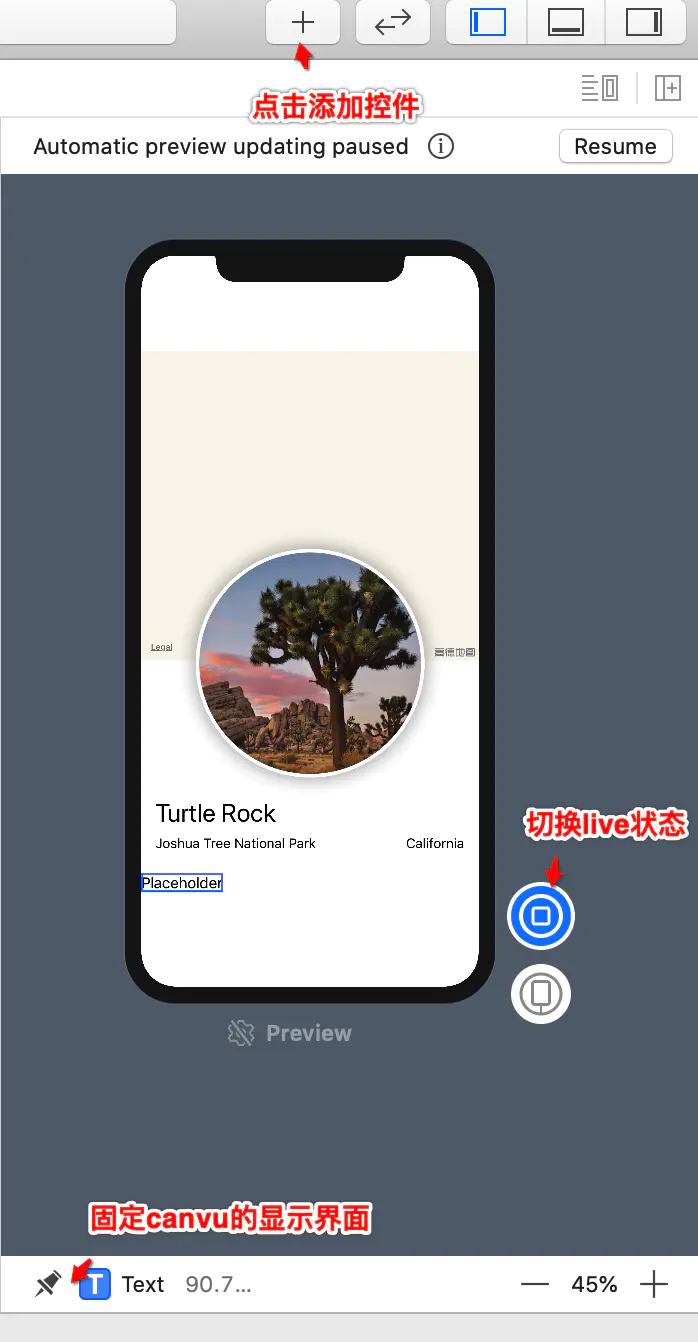
文件结构
创建一个SwiftUI文件,默认生成两个结构体。一个实现view的协议,在body属性里描述内容和布局;一个结构体声明预览的view 并进行初始化等信息,预览view是控制器的view时可以显示在多个模拟器设备,是控件view时可以设置frame,预览view是提供给canvus展示的,使用了#if DEBUG 指令,编译器会删除代码,不会随应用程序一起发布
struct LandmarksList_Previews: PreviewProvider {
static var previews: some View {
ForEach(["iPhone SE", "iPhone XS Max"].identified(by: \.self)) { deviceName in
LandmarkList()
.previewDevice(PreviewDevice(rawValue: deviceName))
.previewDisplayName(deviceName)
//.previewLayout(.fixed(width: 300, height: 70)) 设置view控件大小
}
.environmentObject(UserData())
}
}
#endif布局
普通的view:将多个视图组合并嵌入到堆栈中,这些堆栈将视图水平、垂直或者前后组合在一起
VStack { //这里的布局实现的是上图canvus中landMarkDetail的效果
MapView(coordinate: landmark.locationCoordinate)
.frame(height: 300)//不传width默认长度为整个界面
CircleImage(image: landmark.image(forSize: 250))
.offset(x: 0, y: -130)
.padding(.bottom, -130)
VStack(alignment: .leading) {
Text(landmark.name)
.font(.title)
HStack(alignment: .top) {
Text(landmark.park)
.font(.subheadline)
Spacer() //将水平的两个控件撑开
Text(landmark.state)
.font(.subheadline)
}
}
.padding()
Spacer()
}列表的布局:要求数据是可被标识的
(1)唯一标识每个元素的主键路径
List(landmarkData.identified(by: \.id)) { landmark in
LandmarkRow(landmark: landmark)
}(2)数据类型实现Identifiable protocol,持有一个id 属性
struct Landmark: Hashable, Codable, Identifiable {
var id: Int //
var name: String
fileprivate var imageName: String
fileprivate var coordinates: Coordinates
var state: String
var park: String
var category: Category
}
List(landmarkData) { landmark in
LandmarkRow(landmark: landmark)
} //直接传数据源导航
添加导航栏是将其嵌入到NavigationView中,点击跳转的控件包装在navigationButton中,以设置到目标视图的换位。navigationBarTitle设置导航栏的标题,navigationBarItems设置导航栏右边的item
NavigationView {//显示导航view
List {
//SwiftUI里面的类似switch的控件,可以在list中直接组合布局
Toggle(isOn: $showFavoritesOnly) {
Text("Favorites only")
}
ForEach(landmarkData) { landmark in
if !self.showFavoritesOnly || landmark.isFavorite {
//跳转到地标详细页面
NavigationButton(destination: LandmarkDetail(landmark: landmark)) {
LandmarkRow(landmark: landmark)
}
}
}
}
.navigationBarTitle(Text("Landmarks"))//导航标题
}
}实现modal出一个view
.navigationBarItems(trailing:
//点击navigationBarItems modal出profileHost页面
PresentationButton(
Image(systemName: "person.crop.circle")
.imageScale(.large)
.accessibility(label: Text("User Profile"))
.padding(),
destination: ProfileHost()
)
)程序运行是从sceneDelegate定义的根视图开始的, UIhostingController 是UIViewController的子类
动画效果
SwiftUI包括带有预定义或自定义的基本动画 以及弹簧和流体动画,可以调整动画速度,设置延迟,重复动画等等
可以通过在一个动画修改器后面添加另一个动画修改器来关闭动画
1、转场动画
系统转场动画调用: hikeDetail(hike.hike).transition(.slide)
自定义的转场动画:把转场动画作为AnyTransition类的类型属性 (方便点语法设置丰富自定义动画)
extension AnyTransition {
static var moveAndFade: AnyTransition {
let insertion = AnyTransition.move(edge: .trailing)
.combined(with: .opacity)
let removal = AnyTransition.scale()
.combined(with: .opacity)
return .asymmetric(insertion: insertion, removal: removal)
}
}HikeDetail(hike: hike).transition(.moveAndFade)调用转场动画;move(edge:)方法是让视图从同一边滑出来以及消失;asymmetric(insertion:removal:)设置出现和小时的不同的动画效果
2、阻尼动画
var animation: Animation { //定义成存储属性方便调用
Animation.spring(initialVelocity: 5)//重力效果,值越大,弹性越大
.speed(2)//动画时间,值越大动画速度越快
.delay(0.03 * Double(index))
}3、基础动画
Button(action: //点击按钮显示一个view带转场的动画效果
withAnimation {
self.showDetail.toggle()
}
}) {
Image(systemName: "chevron.right.circle")
.imageScale(.large)
//旋转90度
.rotationEffect(.degrees(showDetail ? 90 : 0))
//.animation(nil) //关闭前面的旋转90度的动画效果,只显示下面的动画
//选中的时候放大为原来的1.5倍
.scaleEffect(showDetail ? 1.5 : 1)
.padding()
// .animation(.basic()) 实现简单的基础动画
//.animation(.spring()) 阻尼动画
}给图片按钮加动画效果, 对应的会有旋转和缩放会有动画;加到action时,即使点击完成后的显示没有给image的可做动画属性加动画效果,全部都有动画,包含旋转缩放和转场动画
数据流
利用SwiftUI环境中的存储 ,把自定义数据对象绑定到view ,SwiftUI监视到可绑对象任何影响视图的更改并在更改后显示正确的视图
1、自定义绑定类型
声明为绑定类型 BindableObject ,PassthroughSubject是Combine框架的消息发布者, SwiftUI通过这个消息发布者订阅对象,并在数据发生变化的时候更新任何需要刷新的视图
import Combine
import SwiftUI
final class UserData: BindableObject {
let didChange = PassthroughSubject()
var showFavoritesOnly = false {
didSet {
didChange.send(self)
}
}
var landmarks = landmarkData {
didSet {
didChange.send(self)
}
}
} 当客户机需要更新数据的时候,可绑定对象通知其订阅者
eg:当其中一个属性发生更改时,在属性的didset里面通过didchange发布者发布更改
2、绑定属性
(1)state
@State var profile = Profile.default状态是随时间变化影响页面布局内容和行为的值
给定类型的持久值,视图通过该持久值读取和监视该值。状态实例不是值本身;它是读取和修改值的一种方法。若要访问状态的基础值,请使用其值属性。
(2)binding
@Binding var profile: Profile//向子视图传递数据(3)environmentObject :
@EnvironmentObject var userData: UserData存储在当前环境中的数据,跨视图传递,在初始化持有对象的时候使用environmentObject(_:)赋值可以和前面的自定义绑定类型一起使用
let window = UIWindow(frame: UIScreen.main.bounds)
window.rootViewController = UIHostingController(rootView: CategoryHome().environmentObject(UserData()))3、绑定行为
是对可变状态或数据的引用,用$的前缀访问状态变量或者其属性之一实现绑定控件 也可以访问绑定属性来实现绑定
与UIkit的交互
表示UIkit的view和controller 需要创建遵UIViewRepresentable或者UIViewControllerRepresentable协议的结构体,SwiftUI管理他们的生命周期并在需要的时候更新
实现协议方法:
//创建展示的UIViewController,调用一次
func makeUIViewController(context: Self.Context) -> Self.UIViewControllerType
//将展示的UIViewController更新到最新的版本
func updateUIViewController(_ uiViewController: Self.UIViewControllerType, context: Self.Context)
//创建协调器
func makeCoordinator() -> Self.Coordinator在结构体内嵌套定义一个coordinator类。SwiftUI管理coordinator并把它提供给context ,在makeUIView(context:)之前调用这个makeCoordinator()方法创建协调器,以便在配置视图控制器的时候可以访问coordinator对象
我们可以使用这个协调器来实现常见的Cocoa模式,例如委托、数据源和通过目标操作响应用户事件。
这里以用UIPageViewController实现轮播图为例,要注意其中的更新页面的逻辑~
pageview作为主view,组合一个PageControl 和 PageViewController实现图片轮播效果
PageView: @State var currentPage = 1 定义绑定属性 ,$currentPage实现绑定到PageViewController
PageViewController: @Binding var currentPage: Int 定义绑定属性,在更新的方法updateUIViewController里面绑定显示,点击pagecontrol的更新页面时pageviewcontroller可以更新到最新的页面
pagecontrol: @Binding var currentPage: Int定义绑定属性 ,updateUIView 绑定显示,pageview滑动更新页面 pagecontrol可以更新到正确的显示
struct PageView: View {
var viewControllers: [UIHostingController]
@State var currentPage = 1
init(_ views: [Page]) {//传入的view用SwiftUI的controller包装好后面传给pagecontroller
self.viewControllers = views.map { UIHostingController(rootView: $0) }
}
var body: some View {
ZStack(alignment: .bottomTrailing) {//将currentpage绑定起来了
PageViewController(controllers: viewControllers, currentPage: $currentPage)
PageControl(numberOfPages: viewControllers.count, currentPage: $currentPage)
.padding()
//Text("Current Page: \(currentPage)").padding(.trailing,30)
}
}
} import SwiftUI
import UIKit
struct PageViewController: UIViewControllerRepresentable {
var controllers: [UIViewController]
@Binding var currentPage: Int
func makeCoordinator() -> Coordinator {
Coordinator(self)
}
func makeUIViewController(context: Context) -> UIPageViewController {
let pageViewController = UIPageViewController(
transitionStyle: .scroll,
navigationOrientation: .horizontal)
pageViewController.dataSource = context.coordinator
pageViewController.delegate = context.coordinator
return pageViewController
}
func updateUIViewController(_ pageViewController: UIPageViewController, context: Context) {
//pageviewcontroller绑定currentpage显示当前的页面,pageView变化的时候,page更新页面
pageViewController.setViewControllers(
[controllers[currentPage]], direction: .forward, animated: true)
}
class Coordinator: NSObject, UIPageViewControllerDataSource, UIPageViewControllerDelegate {
var parent: PageViewController
init(_ pageViewController: PageViewController) {
self.parent = pageViewController
}
//左滑显示控制
func pageViewController(
_ pageViewController: UIPageViewController,
viewControllerBefore viewController: UIViewController) -> UIViewController? {
guard let index = parent.controllers.firstIndex(of: viewController) else {
return nil
}
if index == 0 {
return parent.controllers.last
}
return parent.controllers[index - 1]
}
// 右滑动显示控制
func pageViewController(
_ pageViewController: UIPageViewController,
viewControllerAfter viewController: UIViewController) -> UIViewController? {
guard let index = parent.controllers.firstIndex(of: viewController) else {
return nil
}
if index + 1 == parent.controllers.count {
return parent.controllers.first
}
return parent.controllers[index + 1]
}
func pageViewController(_ pageViewController: UIPageViewController, didFinishAnimating finished: Bool, previousViewControllers: [UIViewController], transitionCompleted completed: Bool) {
if completed,
let visibleViewController = pageViewController.viewControllers?.first,
let index = parent.controllers.firstIndex(of: visibleViewController) {
//当view滑动停止的时候告诉pageview当前页面的index(数据变化 pageview更新pagecontrol的展示)
parent.currentPage = index
}
}
}
}struct PageControl: UIViewRepresentable {
var numberOfPages: Int
@Binding var currentPage: Int
func makeCoordinator() -> Coordinator {
Coordinator(self)
}
func makeUIView(context: Context) -> UIPageControl {
let control = UIPageControl()
control.numberOfPages = numberOfPages
control.addTarget(
context.coordinator,
action: #selector(Coordinator.updateCurrentPage(sender:)),
for: .valueChanged)
return control
}
func updateUIView(_ uiView: UIPageControl, context: Context) {
uiView.currentPage = currentPage
}
class Coordinator: NSObject {
var control: PageControl
init(_ control: PageControl) {
self.control = control
}
@objc
func updateCurrentPage(sender: UIPageControl) {
control.currentPage = sender.currentPage
}
}
}: 当我们编辑一部分用户数据的时候,我们不希望在编辑数据完成的时候影响到其他的页面 那么我们需要创建一个副本数据, 当副本数据编辑完成的时候 用副本数据更新真正的数据, 使相关的页面变化 这部分的内容参见demo中profiles的部分;对于画图的部分demo中也有非常酷炫的示例,详情参见 HikeGraph、Badge(徽章)
参考资料
Apple官网教程 :https://developer.apple.com/tutorials/swiftui/creating-and-combining-views
demo下载
SwiftUI documentation
作者简介
就职于甜橙金融(翼支付)信息技术部,负责 iOS 客户端开发
转自:https://www.jianshu.com/p/ecfdbea7a0ed
收起阅读 »Swift 5—表达通过字符串插值
Swift的设计 - 首先是 - 是一种安全的语言。检查数字和集合是否有溢出,变量总是在第一次使用之前初始化,选项确保正确处理非值,并且相应地命名任何可能不安全的操作。
这些语言功能在很大程度上消除了一些最常见的编程错误,但我们不得不让我们guard失望。
今天,我想谈谈Swift 5中最激动人心的新功能之一:对字符串文字中的值如何通过协议进行插值的大修。很多人都对你可以用它做的很酷的事感到兴奋。(理所当然!我们将在短时间内完成所有这些工作)但我认为重要的是要更广泛地了解这一功能,以了解其影响的全部范围。ExpressibleByStringInterpolation
格式字符串很糟糕。
在不正确的NULL处理,缓冲区溢出和未初始化的变量之后, printf/scanf -style格式字符串可以说是C风格编程语言中最有问题的延迟。
在过去的20年中,安全专业人员已经记录了 数百个与格式字符串漏洞相关的漏洞。它是如此普遍,它被赋予了自己的 Common Weakness Enumeration常见的弱点列举类别。
他们不仅不安全,而且难以使用。是的,很难用。
考虑属性on ,它采用 格式字符串。如果我们想要创建一个包含其年份的日期的字符串表示,我们将使用,就像年份一样...... 对吗 dateFormat DateFormatter strftime "Y" "Y"
import Foundation
let formatter = DateFormatter()
formatter.dateFormat = "M/d/Y"
formatter.string(from: Date()) // "2/4/2019"这看起来确实如此,至少在今年的第一个360天。但是当我们跳到今年的最后一天时会发生什么?
let dateComponents = DateComponents(year: 2019,
month: 12,
day: 31)
let date = Calendar.current.date(from: dateComponents)!
formatter.string(from: date) // "12/31/2020" (😱)啊,啥? 结果"Y"是ISO周编号年的格式 ,它将在2019年12月31日返回2020,因为第二天是新年第一周的星期三。
我们真正想要的是"y"。
formatter.dateFormat = "M/d/y"
formatter.string(from: date) // 12/31/2019 (😄)格式化字符串是最难以使用的类型,因为它们很容易被错误地使用。日期格式字符串是最糟糕的,因为可能不清楚你做错了,直到为时已晚。它们是你的代码库中的字面时间炸弹。
现在花点时间(如果您还没有),"Y"在实际意图使用时,审核您的代码库以使用日期格式字符串"y"。
到目前为止,问题一直是API必须在危险但富有表现力的特定于域的语言特定领域的语言之间进行选择,例如格式字符串,以及正确但灵活性较低的方法调用。
Swift 5中的新功能,该协议允许这些类型的API既正确又富有表现力。在这样做的过程中,它推翻了几十年来有问题的行为。ExpressibleByStringInterpolation
所以不用多说,让我们来看看它是什么以及它是如何工作的:ExpressibleByStringInterpolation
ExpressibleByStringInterpolation
符合协议的类型可以自定义字符串文字中的内插值(即,转义的值)。
ExpressibleByStringInterpolation \(...)
您可以通过扩展默认String插值类型()或创建符合的新类型来利用此新协议。DefaultStringInterpolation ExpressibleByStringInterpolation
有关更多信息,请参阅Swift Evolution提议 SE-0228:“Fix ExpressibleByStringInterpolation”
扩展默认字符串插值
默认情况下,在Swift 5之前,字符串文字中的所有插值都直接发送到String初始值设定项。现在,您可以指定其他参数,就像调用方法一样(实际上,这就是您在幕后所做的事情)。ExpressibleByStringInterpolation
作为一个例子,让我们回顾以前的mixup "Y"和"y" ,看看这种混乱可能与避免。ExpressibleByStringInterpolation
通过扩展String默认插值类型(aptly-named ),我们可以定义一个名为的新方法。第一个未命名参数的类型确定哪些插值方法可用于要插值的值。在我们的例子中,我们将定义一个方法,该方法接受一个参数和一个 我们将用来指定哪个类型的附加参数DefaultStringInterpolation appendingInterpolation appendInterpolation Date component Calendar.Component
import Foundation
#if swift(<5)
#error("Download Xcode 10.2 Beta 2 to see this in action")
#endif
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
component: Calendar.Component)
{
let dateComponents =
Calendar.current.dateComponents([component],
from: value)
self.appendInterpolation(
dateComponents.value(for: component)!
)
}
}现在我们可以为每个单独的组件插入日期:
"\(date, component: .month)/\(date, component: .day)/\(date, component: .year)"
// "12/31/2019" (😊)这很冗长,是的。但是你永远不会误认为日历组件等同于你真正想要的东西:。.yearForWeekOfYear "Y" .year
但实际上,我们不应该像这样手工格式化日期。我们应该将责任委托给:DateFormatter
您可以像任何其他Swift方法一样重载插值,并使多个具有相同名称但不同类型的签名。例如,我们可以formatter为采用相应类型的日期和数字定义插值器。
import Foundation
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
formatter: DateFormatter)
{
self.appendInterpolation(
formatter.string(from: value)
)
}
mutating func appendInterpolation<T>(_ value: T,
formatter: NumberFormatter)
where T : Numeric
{
self.appendInterpolation(
formatter.string(from: value as! NSNumber)!
)
}
}这允许与等效功能的一致接口,例如格式化插值日期和数字。
let dateFormatter = DateFormatter()
dateFormatter.dateStyle = .full
dateFormatter.timeStyle = .none
"Today is \(Date(), formatter: dateFormatter)"
// "Today is Monday, February 4, 2019"
let numberformatter = NumberFormatter()
numberformatter.numberStyle = .spellOut
"one plus one is \(1 + 1, formatter: numberformatter)"
// "one plus one is two"实现自定义字符串插值类型
除了扩展,您还可以在符合的自定义类型上定义自定义字符串插值行为。如果满足以下任何条件,您可以这样做:
DefaultStringInterpolation ExpressibleByStringInterpolation
1、您希望区分文字和插值段
2、您想限制可以插入的类型
3、您希望支持与默认情况下提供的不同的插值行为
3、您希望避免使用过多的API表面区域来增加内置字符串插值类型的负担
对于一个简单的例子,考虑一个转义XML中的值的自定义类型,类似于我们上周描述的一个记录器。我们的目标:提供了一个很好的模板的API,允许我们编写XML / HTML和在自动转义字符一样的方式插入值<和>。
我们将简单地用一个包含单个String值的包装器开始。
struct XMLEscapedString: LosslessStringConvertible {
var value: String
init?(_ value: String) {
self.value = value
}
var description: String {
return self.value
}
}我们在扩展中添加一致性,就像任何其他协议一样。它继承自,需要初始化程序。 本身需要一个初始化程序,它接受所需的关联类型的实例。ExpressibleByStringInterpolation ExpressibleByStringLiteral init(stringLiteral:) ExpressibleByStringInterpolation init(stringInterpolation:) StringInterpolation
此关联类型负责从字符串文字中收集所有文字段和插值。所有文字段都传递给方法。对于插值,编译器会找到与指定参数匹配的方法。在这种情况下,文字和插值都被收集到一个可变的字符串中。
StringInterpolation appendLiteral(_:)``appendInterpolation
这需要一个初始化器; 作为可选的优化,容量和插值计数可用于,例如,分配足够的空间来保存结果字符串。
StringInterpolationProtocol init(literalCapacity:interpolationCount:)
import Foundation
extension XMLEscapedString: ExpressibleByStringInterpolation {
init(stringLiteral value: String) {
self.init(value)!
}
init(stringInterpolation: StringInterpolation) {
self.init(stringInterpolation.value)!
}
struct StringInterpolation: StringInterpolationProtocol {
var value: String = ""
init(literalCapacity: Int, interpolationCount: Int) {
self.value.reserveCapacity(literalCapacity)
}
mutating func appendLiteral(_ literal: String) {
self.value.append(literal)
}
mutating func appendInterpolation<T>(_ value: T)
where T: CustomStringConvertible
{
let escaped = CFXMLCreateStringByEscapingEntities(
nil, value.description as NSString, nil
)! as NSString
self.value.append(escaped as String)
}
}
}完成所有这些后,我们现在可以使用自动转义插值的字符串文字进行初始化。(没有XSS漏洞利用给我们,谢谢!)XMLEscapedString
let name = "<bobby>"
let markup: XMLEscapedString = """
<p>Hello, \(name)!</p>
"""
print(markup)
// <p>Hello, <bobby>!</p>此功能的最佳部分之一是其实现的透明度。对于感觉非常神奇的行为,你永远不会想知道它是如何工作的。
将上面的字符串文字与下面的等效API调用进行比较:
var interpolation =
XMLEscapedString.StringInterpolation(literalCapacity: 15,
interpolationCount: 1)
interpolation.appendLiteral("<p>Hello, ")
interpolation.appendInterpolation(name)
interpolation.appendLiteral("!</p>")
let markup = XMLEscapedString(stringInterpolation: interpolation)
// <p>Hello, <bobby>!</p>阅读就像诗歌一样,不是吗?
有关更高级的示例,请查看Swift Strings Flight School指南示例代码中包含 的 Unicode样式操场
看看它是如何运作的,很难不去环顾四周,找到无数机会可以使用它:ExpressibleByStringInterpolation
1、格式化 字符串插值为日期和数字格式字符串提供了更安全,更易于理解的替代方法。
2、转义 无论是URL中的转义实体,XML文档,shell命令参数还是SQL查询中的值,可扩展字符串插值都可以无缝且自动地进行正确的行为。
3、装饰 使用字符串插值创建类型安全的DSL,用于为应用程序和终端输出创建属性字符串,使用ANSI控制序列来显示颜色和效果,或填充未加修饰的文本以匹配所需的对齐方式。
4、本地化 而不是依赖于扫描源代码以查找“NSLocalizedString”匹配的脚本,字符串插值允许我们构建利用编译器查找本地化字符串的所有实例的工具。
如果您考虑所有这些因素并考虑将来可能支持 编译时常量表达式,那么您发现Swift 5可能只是偶然发现了处理格式化的新方法。
转自:https://www.jianshu.com/p/14cb3d70d133
收起阅读 »Swift—文本输出流
print是Swift标准库中最常用的函数之一。实际上,这是程序员在编写“Hello,world!”时学习的第一个函数。令人惊讶的是,我们很少有人熟悉其他形式。
例如,您是否知道实际的签名print是 print(_:separator:terminator:)?或者它有一个名为print(_:separator:terminator:to:)?的变体 ?
令人震惊,我知道。
这就像了解你最好的朋友“Chaz” 的中间名,并且他的完整法定名称实际上是 “R”。巴克敏斯特小查尔斯拉格兰德“ - 哦,而且,他们一直都有一个完全相同的双胞胎。
一旦你花了一些时间来收集自己,请继续阅读,找出你之前认为不需要进一步介绍的功能的全部真相。
让我们首先仔细看看之前的函数声明:
func print<Target>(_ items: Any...,
separator: String = default,
terminator: String = default,
to output: inout Target)
where Target : TextOutputStream这个重载print 采用可变长度的参数列表,后跟separator和terminator参数 - 两者都有默认值。
1、separator是用于将每个元素的表示连接items 成单个字符串的字符串。默认情况下,这是一个空格(" ")。
2、terminator是附加到打印表示的末尾的字符串。默认情况下,这是换行符(\ n "\n")。
最后一个参数output 采用Target符合协议的泛型类型的可变实例。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
符合的类型的实例 可以传递给函数以从标准输出中捕获和重定向字符串。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream``print(_:to:)
实现自定义文本输出流类型
由于Unicode的多变性,您无法通过查看字符串来了解字符串中潜伏的字符。在 组合标记, 格式字符, 不支持的字符, 变体序列, 连字,有向图和其他表现形式之间,单个扩展字形集群可以包含远远超过眼睛的东西。
举个例子,让我们创建一个符合的自定义类型。我们不会逐字地将字符串写入标准输出,而是检查每个组成<dfn style="box-sizing: border-box;">代码点</dfn>。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
符合协议只是满足方法要求的问题。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream``write(_:)
protocol TextOutputStream {
mutating func write(_ string: String)
}在我们的实现中,我们迭代Unicode.Scalar传递的字符串中的每个值; 的enumerated()收集方法提供当前在每次循环偏移。在方法的顶部,guard如果字符串为空或换行符,则语句会提前解除(这会减少控制台中的噪音量)。
struct UnicodeLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n" else {
return
}
for (index, unicodeScalar) in
string.unicodeScalars.lazy.enumerated()
{
let name = unicodeScalar.name ?? ""
let codePoint = String(format: "U+X", unicodeScalar.value)
print("\(index): \(unicodeScalar) \(codePoint)\t\(name)")
}
}
}要使用我们的新类型,请初始化它并将其分配给变量(with ),以便它可以作为参数传递。任何时候我们想要获得字符串的X射线而不是仅仅打印它的表面表示,我们可以在我们的声明中添加一个额外的参数。Unicode<wbr style="box-sizing: border-box;">Logger``var``inout``print
这样做可以让我们揭示关于表情符号字符的秘密👨👩👧👧:它实际上是 由<abbr title="零宽度木匠" style="box-sizing: border-box;">ZWJ</abbr>字符加入的四个单独表情符号的 序列 - 总共七个代码点!<abbr title="零宽度木匠" style="box-sizing: border-box;"></abbr>
print("👨👩👧👧")
// Prints: "👨👩👧👧"
var logger = UnicodeLogger()
print("👨👩👧👧", to: &logger)
// Prints:
// 0: 👨 U+1F468 MAN
// 1: U+200D ZERO WIDTH JOINER
// 2: 👩 U+1F469 WOMAN
// 3: U+200D ZERO WIDTH JOINER
// 4: 👧 U+1F467 GIRL
// 5: U+200D ZERO WIDTH JOINER
// 6: 👧 U+1F467 GIRL在Swift 5.0中,您可以通过其Unicode properties属性访问标量值的名称。与此同时,我们可以使用 字符串变换 来为我们提取名称(我们只需要在两端去掉一些残骸)。
import Foundation
extension Unicode.Scalar {
var name: String? {
guard var escapedName =
"\(self)".applyingTransform(.toUnicodeName,
reverse: false)
else {
return nil
}
escapedName.removeFirst(3) // remove "\\N{"
escapedName.removeLast(1) // remove "}"
return escapedName
}
}有关更多信息,请参阅 SE-0211:“将Unicode属性添加到Unicode.Scalar”。
使用自定义文本输出流的想法
现在我们知道Swift标准库的一个不起眼的部分,我们可以用它做什么?
事实证明,有很多潜在的用例。为了更好地了解它们是什么,请考虑以下示例:Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
记录到标准错误
默认情况下,Swift print语句指向 <dfn style="box-sizing: border-box;">标准输出(stdout)</dfn>。如果您希望改为指向 <dfn style="box-sizing: border-box;">标准error(stderr)</dfn>,则可以创建新的文本输出流类型并按以下方式使用它:
import func Darwin.fputs
import var Darwin.stderr
struct StderrOutputStream: TextOutputStream {
mutating func write(_ string: String) {
fputs(string, stderr)
}
}
var standardError = StderrOutputStream()
print("Error!", to: &standardError)将输出写入文件
前面的写入示例stderr 可以概括为写入任何流或文件,而是通过创建输出流 (可以通过类型属性访问标准错误)。File<wbr style="box-sizing: border-box;">Handle
import Foundation
struct FileHandlerOutputStream: TextOutputStream {
private let fileHandle: FileHandle
let encoding: String.Encoding
init(_ fileHandle: FileHandle, encoding: String.Encoding = .utf8) {
self.fileHandle = fileHandle
self.encoding = encoding
}
mutating func write(_ string: String) {
if let data = string.data(using: encoding) {
fileHandle.write(data)
}
}
}按照这种方法,您可以自定义print写入文件而不是流。
let url = URL(fileURLWithPath: "/path/to/file.txt")
let fileHandle = try FileHandle(forWritingTo: url)
var output = FileHandlerOutputStream(fileHandle)
print("\(Date())", to: &output)转发流输出
作为最后一个例子,让我们想象一下你会发现自己经常将控制台输出复制粘贴到某个网站上的表单中的情况。不幸的是,该网站有试图解析无益的行为<,并>就好像它们是HTML。
每次发布到网站时,您都可以创建一个 自动处理该文本的内容,而不是采取额外的步骤来逃避文本(在这种情况下,我们使用我们发现深埋在Core Foundation中的XML转义函数)。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
import Foundation
struct XMLEscapingLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n",
let xmlEscaped = CFXMLCreateStringByEscapingEntities(nil, string as NSString, nil)
else {
return
}
print(xmlEscaped)
}
}
var logger = XMLEscapingLogger()
print("<3", to: &logger)
// Prints "<3"对于开发人员来说,打印是一种熟悉且便捷的方式,可以了解其代码的行为。它补充了更全面的技术,如日志框架和调试器,并且 - 在Swift的情况下 - 证明它本身就非常强大。
转自:https://www.jianshu.com/p/4901641b9c38
收起阅读 »知乎 iOS 客户端工程化工具 Venom
前言
知乎 iOS 客户端从一开始围绕问答社区到目前涵盖 Feed,会员,商业,文章,想法等多个业务线的综合内容生产与消费平台。项目的复杂程度已经在超级 App 的范畴。单周发布与业务并行开发也逐渐变成主流。同时在知乎 iOS 平台,技术选型一直也都比较开(sui)放(yi)。较早了引入了 Swift 进行业务开发,列表引入了需要 OC++ 的 ComponentKit 作为核心引擎。所以在这种多业务方团队,技术形态复杂,组件仓库数量多等场景下,也同样遇到了各种超级 App 团队都面临的一些问题。
问题如下:
如何统一开发环境
提高编译速度
提高打包速度
二进制组件调试
多组件联合调试
多组件联合打包
约束组件依赖关系等
当然在思考解决上面这些问题前,知乎 iOS 项目也同样经历过组件化的工作。与众多组件化拆分方案殊途同归,进行了业务划分,主仓库代码清空,业务线及 SDK 进行独立仓库管理。引入基于路由,基于协议声明的组件间通信等机制等,这里就不多赘述了。
简介
核心介绍的项目名称为 Venom,灵感来源于电影《毒液》。Venom 的用户端是一款为开发人员打造 Mac App,应用内置了工程构建需要的全套 Ruby Gem 和 Cocoapods 等其相关构建环境。核心目标是解决工程构建,二进制构建,组件管理,调试工具等一系列开发过程中的繁琐耗时任务。
所以当一台全新的 Mac 电脑希望运行工程时, 只需要 3 步:
1、安装 Venom For Mac 客户端。
2、使用 Venom 打开工程点击 Make 按钮。
3、构建完成点击 XCode 按钮打开工程。(当然默认己装 XCode )
从此告别 ruby,cocoapods 版本不对,gem 问题,bundle 问题以及权限问题等困扰。因为构建环境内置,使得构建环境与工程师本地环境隔离,极大的降低了工程 setup 的成本。
完整的 Venom 包含了 3 个部分:
1、Venom App
2、Venom 内核
3、Venom Server
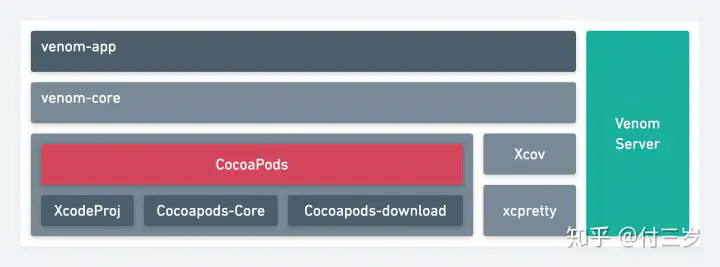
下面会着重介绍客户端和内核相关的技术方案,数据服务目前仅为组件的附加信息提供 API 支持。
Venom 内核介绍
在引入 Venom 前,一直使用 Cocoapods 的 Podfile 进行组件的引用。但如果希望对 pod 命令的 DSL 进行扩展,发现是不够方便的。索性在 Cocoapods 上层建立自己的组件描述文件,每一个描述文件最终都会被转化为一次 podfile 的 pod 调用。

如上图,使用 Venom 方式集成的项目,由在 VenomFiles 目录内的组建描述文件组成。
组件描述文件
VenomFile.new do |v| v.name = 'XXModuleA' v.git = 'git@git.abc.abc.com:Team-iOS-Module/XXModule.git' v.tag = '1.0.0' v.binary = false v.use_module_map = true v.XX...end组件描述文件可以理解是 pod 命令的一个超集,在包含了 pod 的原有功能基础上,扩展其他功能(胶水代码创建,二进制化与源码切换等)。
组件调试
同时在与 VenomFile 同级别还设计了一个 Customization.yml 的文件。当开发过程中,需要对某个组件进行源码二进制的切换,或者源码路径的切换,版本引用的切换等,不会直接改动 VenomFile,会改动 Customization.yml 来进行。在构建过程中的优先,Customization.yml > Venomfile 。为了每个工程师的改动不会互相影响,Customization.yml 是非 git 托管的。而 VenomFiles 内的文件只有更新版本号或其他配置改动,才会更新。
构建过程
所有组件都通过一个个 Venomfile 文件方式管理在主工程仓库中,通过目录对组件进行层级划分管理。

原来的 Podfile 文件通过嵌入 Venom 进行构建职责的接管。
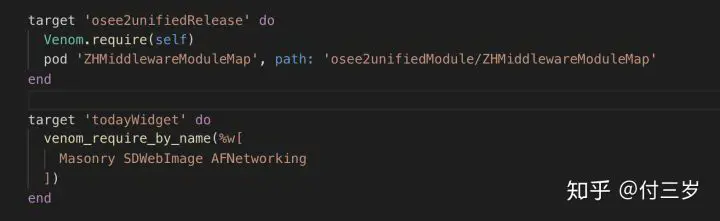
使用 Venom 后 pod install 的实际过程就如下图:
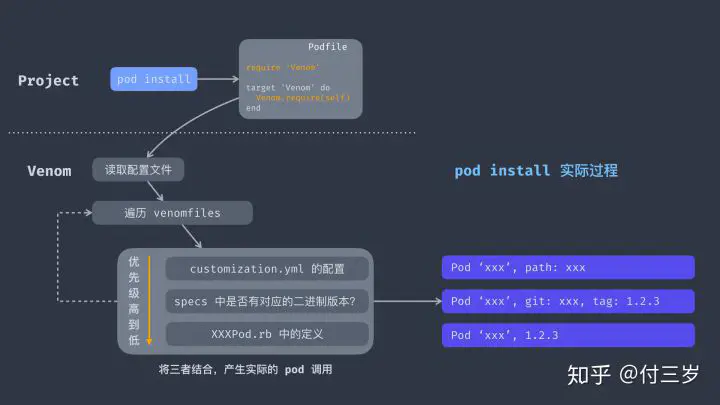
整体上来看, Venom 内核提供了一套扩展 pod 属性的描述文件,开发阶段通过 customization.yml 进行可配置的构建。构建过程中,依赖 Venomfile 文件的唯一标识进行二进制库和源码的关联。通过对 Cocoapods 构建过程的 hook 实现二进制与源码的引用切换。二进制化方案可参考 :
Xinyu Zhao:知乎 iOS 基于 CocoaPods 实现的二进制化方案
命令接口
Venom 内核除了主要的构建职责,还提供了一系列的 ipc 命令。通过这些 ipc 命令,上层的 Venom 客户端就可以更容易的操作每个组件,进行定制化的开发组织。来构建工程。
例如:
// 修改组件二进制使用方式,使用二进制venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --binary// 修改组件二进制使用方式,使用源码venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --source// 修改 yml 文件中指定组件的路径venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --pod_path /path/to/ZHModuleABC// reset 某个组件在 customization 中的 change,不指定 name 参数会给整个文件置成空venom ipc customization \ --path /xxx \ --reset \ --name ZHModuleABCVenom App 介绍
通过对 Venom 内核的简单介绍,其实可以认为,只通过命令行版的工具,就可以达到用到的大部分功能。但因为实际开发情况一般不会一个人一次只处理一个模块,所以希望以一种所见即所得方式来让业务工程师不用关心下层的逻辑,学习命令。可以快速建立起开发环境是我们的主要目标。
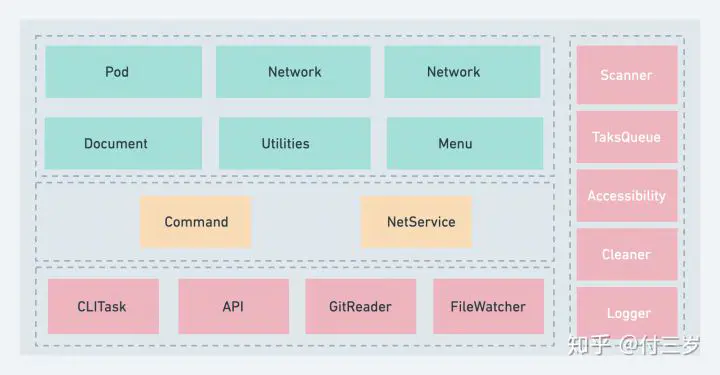
<center style="color: rgb(74, 74, 74); font-family: Avenir, Tahoma, Arial, "PingFang SC", "Lantinghei SC", "Microsoft Yahei", "Hiragino Sans GB", "Microsoft Sans Serif", "WenQuanYi Micro Hei", Helvetica, sans-serif; font-size: 16px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;">客户端主要模块</center>
Venom App 内置了全套的 guby gem 环境来运行命令。通过 CLITask 来访问 Venom-core 以及 git 等其他命令(venom 内核一样内置在 Venom App 内)。
核心功能
开发组件关联
正常情况下 clone 下来的主工程(壳工程)内是没有代码的,只有空的工程文件和组件描述文件。Venom 工具划分了 2 个区域,普通组件和定制组件。
因为每个开发者维护的组件其实是有限的几个,一般都会将源码放在固定目录,所以通过设置客户端的自动扫描路径。在 Venom 界面上,如果在扫码路径下发现了相关组件,则可以一键关联本地目录组件,这样组件会切换到定制组件的模式进行开发。
特定版本关联
在开发过程中,有时需要对某一个依赖库的特定版本进行调试或连调。所以也支持通过 tag,commit,branch 等方式,进行特定源码的切换和关联。
源码与二进制切换

某些特殊场景下,可能希望工程以所有组件都是源代码方式构建,排查问题。那么也可以通过 2 种不同的构建模式一键切换。(当然全源码构建一次需要十足的耐心)
二进制模式下搜索与调试
二进制化后,大部分情况下都工作在二进制模式下,但有时在进行源码搜索时,希望可以全局搜索。所以在构建过程中,会把当前版本的源码目录也引用到工程目录下。

所以在工程进行检索代码时,是完全没问题的。有了源码,在云端进行二进制打包时,通过 fdebug-prefix-map ( Clang command line argument reference )这个参数重新在二进制文件中改写 Debug 模式的源代码路径。这样即使在二进制模式下,也可以直接关联源码进行断点调试。
组件依赖关系分析
当组件很多后,就会出现一些工程师对组件所处层级不够了解,导致出现依赖混乱的问题。所以在构建结束后会通过对组件层级的检查,进行组件依赖层级的判断。
总结
在推进所有工程师使用 Venom 客户端后,相当于在开发环节有了一个强有力的抓手。由于 App 的自动更新功能,可以在平台下提供给开发者更多的工具,而开发者只需要更新客户端使用。通过工具化客户端的开发,我们重构了原有散落在各处的脚步,工具集中整合在一起。使得开发工具维护更统一,更新也更及时,开发人员上手成本也更低。
Venom 核心承担的是开发环境管理,工程组织与构建管理,提高工程效率工作。但上线后,我们还陆续在此基础上提供了一些其他功能。
1、多仓库 MR 自动填充提交
2、本地非独立业务仓库单元测试
3、个人开发者账号真机调试
4、无用图片扫描工具
5、轻量的 app 网络和日志查看等
转自:https://www.jianshu.com/p/b65d7bb7fa32
Runtime底层原理--动态方法解析总结
方法的底层会编译成消息,消息进行递归,先从实例方法开始查找,到父类最后到NSObject。如果在汇编部分快速查找没有找到IMP,就会进入C/C++中的动态方法解析进入lookUpImpOrForward方法进行递归。
动态方法解析
动态方法解析分为实例方法和类方法两种。
实例方法查找imp流程和动态方法解析
比如执行一个Student实例方法eat,会先去这个类中查找是否有该方法(sel),如果有则进行存储以便下次直接从汇编部分快速查找。
// Try this class's cache.
// Student元类 - 父类 (根元类) -- NSObject
// resovleInstance 防止递归 --
imp = cache_getImp(cls, sel);
if (imp) goto done;
// Try this class's method lists.
{
Method meth = getMethodNoSuper_nolock(cls, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, cls);
imp = meth->imp;
goto done;
}
}如果没有sel那么接下来去父类(直到NSObject)的缓存和方法列表找查找。如果在父类中找到先缓存再执行done.
// 元类的父类 - NSObject 是否有 实例方法
for (Class curClass = cls->superclass;
curClass != nil;
curClass = curClass->superclass)
{
// Halt if there is a cycle in the superclass chain.
if (--attempts == 0) {
_objc_fatal("Memory corruption in class list.");
}
// Superclass cache.
imp = cache_getImp(curClass, sel);
if (imp) {
if (imp != (IMP)_objc_msgForward_impcache) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, imp, sel, inst, curClass);
goto done;
}如果最终还是没找到,则会进入动态方法解析_class_resolveMethod,先判断当前cls对象是不是元类,也就是如果是对象方法会走到_class_resolveInstanceMethod方法,
/***********************************************************************
* _class_resolveMethod
* Call +resolveClassMethod or +resolveInstanceMethod.
* Returns nothing; any result would be potentially out-of-date already.
* Does not check if the method already exists.
**********************************************************************/
void _class_resolveMethod(Class cls, SEL sel, id inst)
{
if (! cls->isMetaClass()) {
// try [cls resolveInstanceMethod:sel]
_class_resolveInstanceMethod(cls, sel, inst);
}
else {
// try [nonMetaClass resolveClassMethod:sel]
// and [cls resolveInstanceMethod:sel]
_class_resolveClassMethod(cls, sel, inst);
if (!lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
_class_resolveInstanceMethod(cls, sel, inst);
}
}
}如果元类,那么执行_class_resolveInstanceMethod(cls, sel, inst)方法,该方法会执行lookUpImpOrNil(cls->ISA(), SEL_resolveInstanceMethod, cls, NO/*initialize*/, YES/*cache*/, NO/*resolver*/),查找当前的cls的isa是否实现了resolveInstanceMethod,也就是是否有自定义实现、是否重写了。如果查到了就会给类对象发送消息objc_msgSend,调起resolveInstanceMethod方法
/***********************************************************************
* lookUpImpOrNil.
* Like lookUpImpOrForward, but returns nil instead of _objc_msgForward_impcache
**********************************************************************/
IMP lookUpImpOrNil(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
IMP imp = lookUpImpOrForward(cls, sel, inst, initialize, cache, resolver);
if (imp == _objc_msgForward_impcache) return nil;
else return imp;
}lookUpImpOrNil的内部是通过lookUpImpOrForward方法进行查找,再次回到递归调用。
如果还是没查到,这里就不会再次进入动态方法解析(注:如果再次进入动态方法解析会形成死递归),首先对cls的元类进行查找,然后元类的父类,也就是根元类(系统默认实现的虚拟的)进行查找、最终到NSObjece,只不过NSObjece中默认实现resolveInstanceMethod方法返回NO,也就是此时在元类进行查找的时候找到了resolveInstanceMethod方法,并停止继续查找,这就是为什么动态方法解析后的递归没有再次进入动态方法解析的原因。如果最终还是没有找到SEL_resolveInstanceMethod则说明程序有问题,直接返回。下面是isa走位图:

如果找到的imp不是转发的imp,则返回imp。
举个例子:
在Student中有个对象run方法,但是并没有实现,当调用run方法时,最终没有找到imp会崩溃。通过动态方法解析,实现run方法
#pragma mark - 动态方法解析
+ (BOOL)resolveInstanceMethod:(SEL)sel {
NSLog(@"动态方法解析 - %@",self);
if (sel == @selector(run)) {
// 我们动态解析对象方法
NSLog(@"对象方法 run 解析走这里");
SEL readSEL = @selector(readBook);
Method readM= class_getInstanceMethod(self, readSEL);
IMP readImp = method_getImplementation(readM);
const char *type = method_getTypeEncoding(readM);
return class_addMethod(self, sel, readImp, type);
}
return [super resolveInstanceMethod:sel];
}此时只是给对象方法添加了一个imp,接下来再次进入查找imp流程,重复之前的操作,只不过现在对象方法已经有了imp。
/***********************************************************************
* _class_resolveInstanceMethod
* Call +resolveInstanceMethod, looking for a method to be added to class cls.
* cls may be a metaclass or a non-meta class.
* Does not check if the method already exists.
**********************************************************************/
static void _class_resolveInstanceMethod(Class cls, SEL sel, id inst)
{
if (! lookUpImpOrNil(cls->ISA(), SEL_resolveInstanceMethod, cls,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
// Resolver not implemented.
return;
}
BOOL (*msg)(Class, SEL, SEL) = (typeof(msg))objc_msgSend;
bool resolved = msg(cls, SEL_resolveInstanceMethod, sel);
// Cache the result (good or bad) so the resolver doesn't fire next time.
// +resolveInstanceMethod adds to self a.k.a. cls
IMP imp = lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/);
// ...省略N行代码动态方法解析的实质: 经过漫长的查找并没有找到sel的imp,系统会发送resolveInstanceMethod消息,为了防止系统崩溃,可以在该方法内对sel添加imp,系统会自动再次查找imp。
类方法查找imp流程和动态方法解析
类方法查找imp流程和实例方法查找imp前面流程一样,也是从汇编部分快速查找,之后判断cls是不是元类,在元类方法列表中查找,如果元类中没有当前的sel,就去元类的父类中查找,还没有就去根元类的父类NSObject中查找,此时查找的就是NSObject中是否有这个实例对象方法,如果NSObject中也没有就会进入动态方法解析_class_resolveMethod。类对象这里的cls和对象方法不一样,因为cls是元类所以直接走_class_resolveClassMethod方法。进入_class_resolveClassMethod方法还是先判断resolveClassMethod方法是否有实现,之后发送消息objc_msgSend,这里和实例方法有所区别,类方法会执行_class_getNonMetaClass方法,内部实现getNonMetaClass,getNonMetaClass会判断当前cls是不是NSObject,判断当前的cls是不是根元类,也就是自己,接下来判断inst类对象,判断inst类对象的isa如果不是元类,那么返回类对象的父类,不是就返回类对象。在_class_resolveClassMethod方法中添加了imp后还是和实例方法一样,再次进入重新查找流程,此时如果还是没有,那么类方法还会再一次的进入_class_resolveInstanceMethod方法,和实例方法不同的是resolveInstanceMethod方法内部的cls是元类,所以找的方法也就是- (BOOL)resolveClassMethod:(SEL)sel,可以在NSObject中添加+ (BOOL)resolveClassMethod:(SEL)sel方法,这样无论类方法还是实例方法都会走到这里,可以作为防崩溃的处理。
/***********************************************************************
* getNonMetaClass
* Return the ordinary class for this class or metaclass.
* `inst` is an instance of `cls` or a subclass thereof, or nil.
* Non-nil inst is faster.
* Used by +initialize.
* Locking: runtimeLock must be read- or write-locked by the caller
**********************************************************************/
static Class getNonMetaClass(Class metacls, id inst)
{
static int total, named, secondary, sharedcache;
runtimeLock.assertLocked();
realizeClass(metacls);
total++;
// return cls itself if it's already a non-meta class
if (!metacls->isMetaClass()) return metacls;
// metacls really is a metaclass
// special case for root metaclass
// where inst == inst->ISA() == metacls is possible
if (metacls->ISA() == metacls) {
Class cls = metacls->superclass;
assert(cls->isRealized());
assert(!cls->isMetaClass());
assert(cls->ISA() == metacls);
if (cls->ISA() == metacls) return cls;
}
// use inst if available
if (inst) {
Class cls = (Class)inst;
realizeClass(cls);
// cls may be a subclass - find the real class for metacls
while (cls && cls->ISA() != metacls) {
cls = cls->superclass;
realizeClass(cls);
}
if (cls) {
assert(!cls->isMetaClass());
assert(cls->ISA() == metacls);
return cls;
}我们在Student类中添加未实现的类方法walk,在NSObject类中添加一个对象方法walk,运行程序不会崩溃。类方法先递归,开始找父类,最终在NSObject类中好到对象方法walk。
TIP:对象方法存储在类中,类方法存储在元类里面,类对象以实例方法的形式存储在元类中。可以通过输出class_getInstanceMethod方法和class_getClassMethod方法的imp指针来验证,当然源码也可以解释在cls的元类中查找实例方法
/***********************************************************************
* class_getClassMethod. Return the class method for the specified
* class and selector.
**********************************************************************/
Method class_getClassMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
return class_getInstanceMethod(cls->getMeta(), sel);
}还可以通过LLDB进行验证,动态方法解析的时候执行lookUpImpOrForward(Class cls, SEL sel, id inst, bool initialize, bool cache, bool resolver)方法,这里的cls就是inst的元类
# define ISA_MASK 0x00007ffffffffff8ULL
// -------------------------------------------------
#if SUPPORT_NONPOINTER_ISA
inline Class
objc_object::ISA()
{
assert(!isTaggedPointer());
#if SUPPORT_INDEXED_ISA
if (isa.nonpointer) {
uintptr_t slot = isa.indexcls;
return classForIndex((unsigned)slot);
}
return (Class)isa.bits;
#else
return (Class)(isa.bits & ISA_MASK);
#endif
}这里看到初始化的时候isa.bits & ISA_MASK,我们先后打印cls和inst的信息,也可以验证当前指针指向当前的元类。

动态方法解析作用
适用于重定向,也可以做防崩溃处理,也可以做一些错误日志收集等等。动态方法解析本质就是提供机会(任何没有实现的方法都可以重新实现)。
转自:https://www.jianshu.com/p/a7db9f0c82d6
收起阅读 »iOS Files文件应用程序开发
前言:
最近在做一个项目,需要用到文件选取、上传、下载功能,首先想到的就是iOS11自带的“文件”应用。“文件”算是一个中转站,是iOS系统的文件管理器,可以为各个项目提供私有的文件夹,进行文件管理。
iOS11已经提供了相当完善的接口,本文基于此开发过程的总结,给出iOS11的桌面“文件”应用程序进行相关开发的经验。文中若有错漏之处,恳请大家批评指正。
两种开发模式
1、将qq或微信的文档拷贝到自己项目中,即拷贝模式;
2、将qq或微信的文档存储到“文件”中,即存储模式
拷贝模式开发步骤:
(1)打开项目中的info.plist,添加“Document Types”键值:
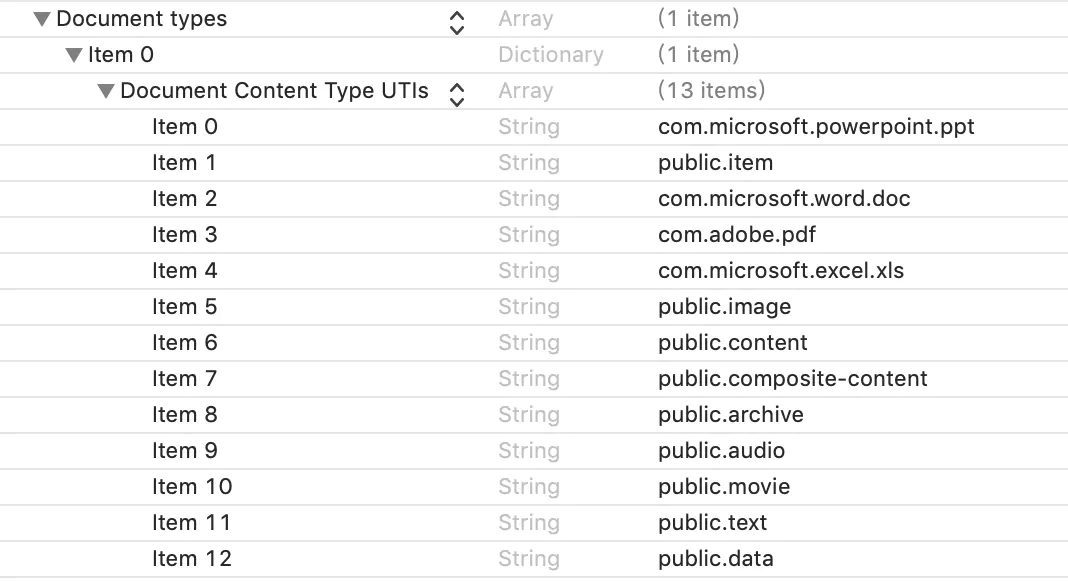
(2)项目运行安装到真机上。打开微信或qq里的文档,从右上角的“...”按钮选择“用其他应用打开”;

(3)此时将看到自己的项目已经存在其他应用的列表上,选择“拷贝到xxx”,选择拷贝到自己开发的项目;
(4)点击“拷贝到xxx”后,将跳转到自己项目中。需要在自己项目的AppDelegate.m文件中处理回调;
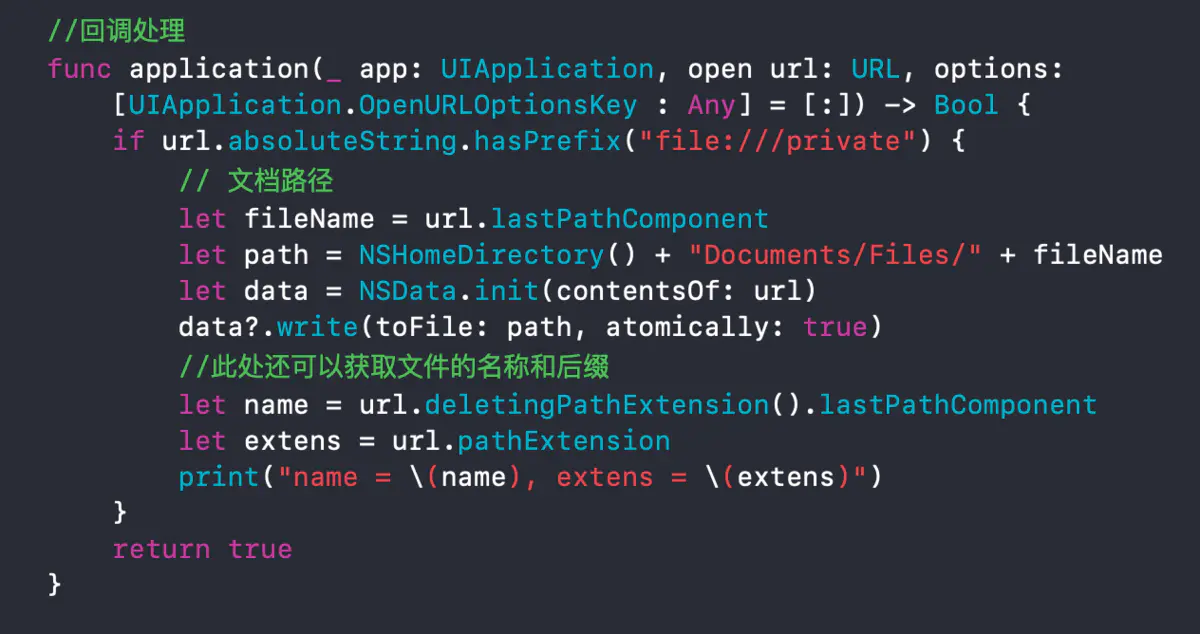
(5)后续步骤可以做一个本地文件管理界面(类似相册图片的九宫格展示,或者列表形式),进行本地文件管理,读取、上传、下载,这里就不展开讨论了。
存储模式的开发步骤:
(1)打开项目中的info.plist,添加“Supports Document Browser”键值:

(2)项目运行安装到真机上。打开微信或qq里的文档,从右上角的“...”按钮选择“用其他应用打开”;
(3)在弹窗中选择存储到“文件”,将文件存储到系统的“文件”应用程序;
(4)在打开的“文件”应用程序中,选择添加到自己的项目;
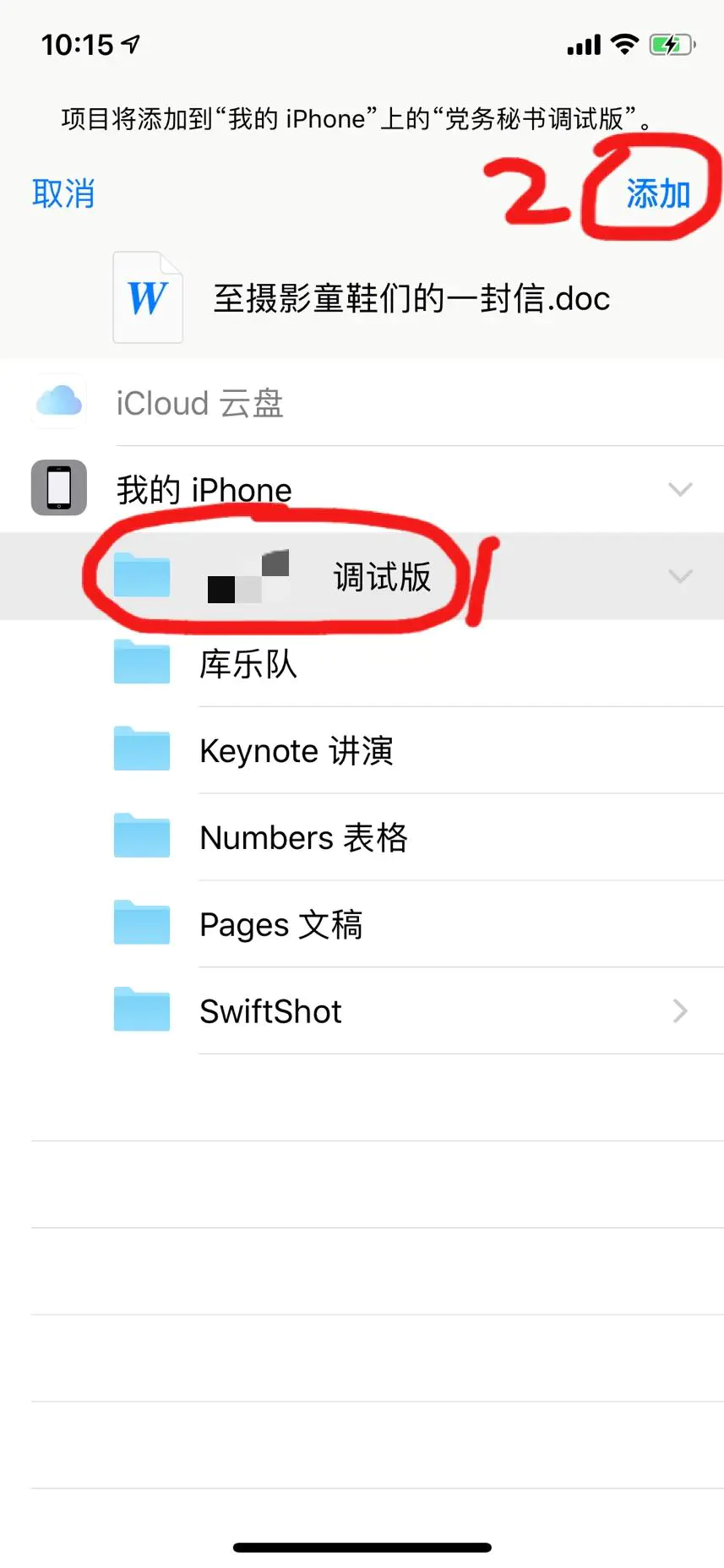
(5)在项目中编写代码,获取“文件”应用程序中刚刚的存储文件,代码如下:
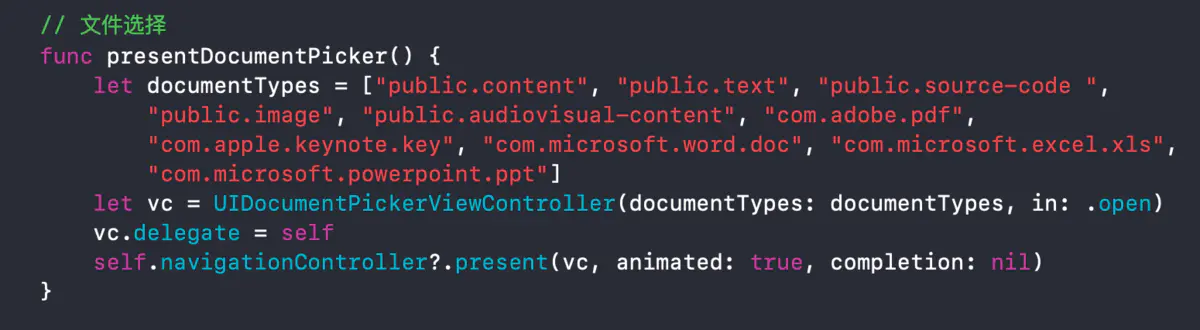
(6)运行代码,将项目安装到真机上,进入代码所在的页面,打开“文件”面板,即可看到在“文件”里的本项目名称的文件夹,选择刚才的文件即可。
转自:https://www.jianshu.com/p/e1e57f8e86c5
收起阅读 »iOS timer定时器正确使用方式
1. 初始化,添加定时器前先移除
[self.timer invalidate];
self.timer = nil;
self.timer = [NSTimer scheduledTimerWithTimeInterval:2.f target:self selector:@selector(lookforCard:) userInfo:nil repeats:YES];
[[NSRunLoop currentRunLoop] addTimer:self.timer forMode:NSRunLoopCommonModes];2. 释放timer
[self.timer invalidate];
self.timer = nil;3. NSTimer不释放原因
原因是 Timer 添加到 Runloop 的时候,会被 Runloop 强引用;然后 Timer 又会有一个对 Target 的强引用(也就是 self )
注意target参数的描述:
The object to which to send the message specified by aSelector when the timer fires. The timer maintains a strong reference to target until it (the timer) is invalidated.
注意:文档中写的很清楚,timer对target会有一个强引用,直到timer is invalidated。也就是说,在timer调用 invalidate方法之前,timer对target一直都有一个强引用。这也是为什么控制器的dealloc 方法不会被调用的原因。
方法的文档介绍:
The receiver retains aTimer. To remove a timer from all run loop modes on which it is installed, send an invalidate message to the timer.
也就是说,runLoop会对timer有强引用,因此,timer修饰符是weak,timer还是不能释放,timer的target也就不能释放。
4. 解决办法
viewWillDisappear或viewDidDisappear中 invalidate
这种方式是可以释放掉的,但如果我只是想在离开此页时要释放,进入下一页时不要释放,场景就不适用了
- (void)viewWillDisappear:(BOOL)animated
- (void)viewDidDisappear:(BOOL)animated添加一个NSTimer的分类,把target指给[NSTimer class],事件由加方法接收,然后把事件通过block传递出来
@interface NSTimer (Block)
+ (instancetype)scheduledTimerWithTimeInterval:(NSTimeInterval)interval repeats:(BOOL)repeats block:(void(^)(NSTimer *timer))block;
@end
@implementation NSTimer (Block)
+ (instancetype)scheduledTimerWithTimeInterval:(NSTimeInterval)interval repeats:(BOOL)repeats block:(void(^)(NSTimer *timer))block{
NSTimer *timer = [NSTimer scheduledTimerWithTimeInterval:interval target:self selector:@selector(trigger:) userInfo:[block copy] repeats:repeats];
return timer;
}
+ (void)trigger:(NSTimer *)timer{
void(^block)(NSTimer *timer) = [timer userInfo];
if (block) {
block(timer);
}
}
@end使用示例
@interface SecondViewController ()
@property (nonatomic, strong) NSTimer *timer;
@end
@implementation SecondViewController
- (void)viewDidLoad {
[super viewDidLoad];
__weak typeof(self) weakSelf = self;
self.timer = [NSTimer scheduledTimerWithTimeInterval:0.5 repeats:YES block:^(NSTimer * _Nonnull timer) {
[weakSelf doSomeThing];
}];
[[NSRunLoop currentRunLoop] addTimer:self.timer forMode:NSRunLoopCommonModes];
}
- (void)dealloc {
[self.timer invalidate];
}
@end5. invalidate方法注意事项
invalidate方法的介绍:
(1)This method is the only way to remove a timer from an NSRunLoop object. The NSRunLoop object removes its strong reference to the timer, either just before the invalidate method returns or at some later point.
(2)You must send this message from the thread on which the timer was installed. If you send this message from another thread, the input source associated with the timer may not be removed from its run loop, which could prevent the thread from exiting properly.
两点:
(1)invalidate方法是唯一能从runloop中移除timer的方式,调用invalidate方法后,runloop会移除对timer的强引用
(2)timer的添加和timer的移除(invalidate)需要在同一个线程中,否则timer可能不能正确的移除,线程不能正确退出
链接:https://www.jianshu.com/p/a05c556f2a8a
收起阅读 »“小家碧玉”中的UIStackView
KeyWords
AutoLayout UIStackView
背景
随着需求的迭代,项目中在列表的同一个区域新增业务标签貌似成了每个产品经理的“特殊嗜好”。如下图中的区域
(其实本人的项目中在箭头区域大概有7个类似的标签,当然在业务上不会同时出现,能同时出现的时候最多会有四个),随着标签的增加,势必会造成繁重的视图维护工作,再加上要控制优先级之类的,估计头都大了,好在apple给咱们提供了强大的视图管理:UIStackView。我們可以透过它轻易的定义好在 UIStackView 中元件的布局,不需对于所有元件进行 AutoLayout 的约束设置,UIStackView会处理大部分的工作。
正文
apple官方文档对UIStackView的描述是:用于在列或行中布置视图集合
UIStackView要点
UIStackView是在iOS 9中引入的, 是Cocoa Touch中UI控件分类的最新成员。
通过UIStackView,你可以利用 AutoLayout 的強大功能,创建用户视图,可以动态适应设备方向,屏幕大小和可用空间任何变化的用户界面。UIStackView 管理其 arrangeSubviews 属性中所有视图的布局。這些视图基于它們在 arrangeSubviews 阵列中的順序,沿著 UIStackView 的 axis 排列。最终精确的布局依赖于 UIStackView 的 axis、distribution、alignment、spacing 以及其他属性。
我们只需要负责 UIStackView 的位置和尺寸,然后 UIStackView 就会管理其內容的布局和尺寸。
注意:放到 StackView ≠ 完成 AutoLayout
所以你还必須設定 StackView 的位置和尺寸(可選)才算是完成。StackView 只有為其 arrangeSubviews 做佈局
虽然堆栈视图允许您直接布局其内容而不直接使用“自动布局”,但仍需要使用“自动布局”来定位堆栈视图本身。通常,这意味着定位堆叠视图的至少两个相邻边缘以限定其位置。如果没有其他约束,系统将根据其内容计算堆栈视图的大小。
1、沿着堆栈视图的轴,其拟合大小等于所有排列视图的大小加上视图之间的空间的总和。
2、垂直于堆栈视图的轴,其拟合大小等于最大排列视图的大小。
3、如果堆栈视图的属性设置为,则堆栈视图的拟合大小会增加,以包含边距的空间。layoutMarginsRelativeArrangement
您可以提供其他约束来指定堆栈视图的高度,宽度或两者。在这些情况下,堆栈视图会调整其排列视图的布局和大小以填充指定区域。确切的布局根据堆栈视图的属性而有所不同。有关堆栈视图如何处理其内容的额外空间或空间不足的完整说明,请参阅和枚举。UIStackViewDistribution 、UIStackViewAlignment
您还可以基于其第一个或最后一个基线定位堆栈视图,而不是使用顶部,底部或中心Y位置。与堆栈视图的拟合大小一样,这些基线是根据堆栈视图的内容计算的。
1、水平堆栈视图返回其和方法的最高视图。如果最高视图也是堆栈视图,则返回调用结果或嵌套堆栈视图。
2、垂直堆栈视图返回其第一个排列的视图以及其最后排列的视图。如果这些视图中的任何一个也是堆栈视图,则它返回调用的结果或嵌套堆栈视图。
创建一个StackView
UILabel * main = [[UILabel alloc]init];
main.text = @"Learn More";
main.font = [UIFont boldSystemFontOfSize:28];
main.translatesAutoresizingMaskIntoConstraints = false;
main.backgroundColor = [UIColor redColor];
UILabel * sub = [[UILabel alloc]init];
sub.translatesAutoresizingMaskIntoConstraints = false;
sub.numberOfLines = 0;
sub.text = @"[self.collectionView.topAnchor constraintEqualToAnchor:self.view.topAnchor constant:40].active = true";
sub.font = [UIFont systemFontOfSize:18];
sub.backgroundColor = [UIColor greenColor];
UILabel * third = [[UILabel alloc]init];
third.translatesAutoresizingMaskIntoConstraints = false;
third.numberOfLines = 0;
third.text = @"Object_C";
third.font = [UIFont systemFontOfSize:18];
third.backgroundColor = [UIColor brownColor];
UIStackView * stackView = [[UIStackView alloc]initWithArrangedSubviews:@[main,sub,third]];
stackView.translatesAutoresizingMaskIntoConstraints = false;
stackView.axis = UILayoutConstraintAxisVertical;
stackView.distribution = UIStackViewDistributionFillProportionally;
stackView.alignment = UIStackViewAlignmentFill;
stackView.spacing = 10;
[stackView.topAnchor constraintEqualToAnchor:self.view.topAnchor constant:100].active = true;
[stackView.leadingAnchor constraintEqualToAnchor:self.view.leadingAnchor constant:12].active = true;
[stackView.trailingAnchor constraintEqualToAnchor:self.view.trailingAnchor constant:-12].active = true;效果图如下:

这样一个简单的堆叠视图就创建出来了,然后咱们沿着这段代码逐一分解下
Axis
配置视图的轴线,简单说就是 UIStackView 整体的排列方式(行或列)
UILayoutConstraintAxisVertical
UILayoutConstraintAxisHorizontal

Distribution
确定沿堆栈轴排列的视图的布局
這个属性算是比较难以理解的属性,所以我下面一样用特殊的图形來表示,希望大家能理解。
UIStackViewDistributionFill
如同前面的 Fill 类似,一樣是把自身的范围給占满。
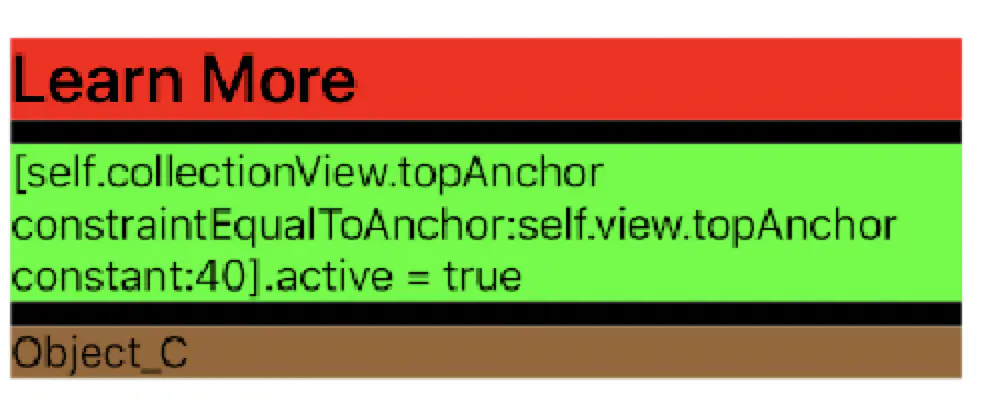
UIStackViewDistributionFillEqually
StackView 会平均分配各個子视图的配置,例如下面的 StackView 垂直排列时,高度则会为其子视图最高的高度。反之,水平排列则取其子视图最寬的寬度。
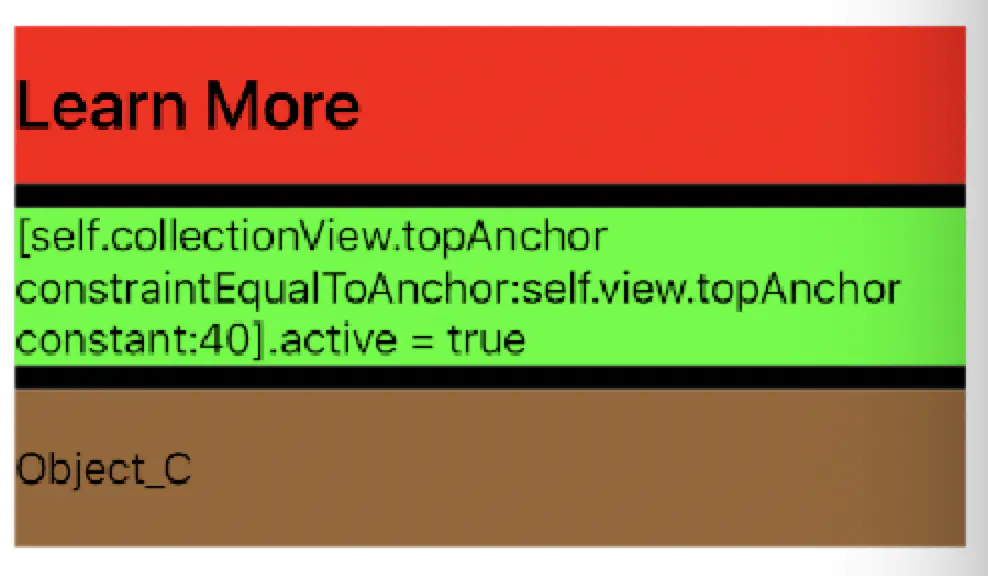
UIStackViewDistributionFillProportionally
你可能会觉得此属性与 Fill 属性沒有差异,但兩者的差异在于 Fill 会根据自身的尺寸來決定在 StackView 中的尺寸,而 Fill Proportionally 則是會根据 StackView 的寬或高按比例分配給其中的子视图。
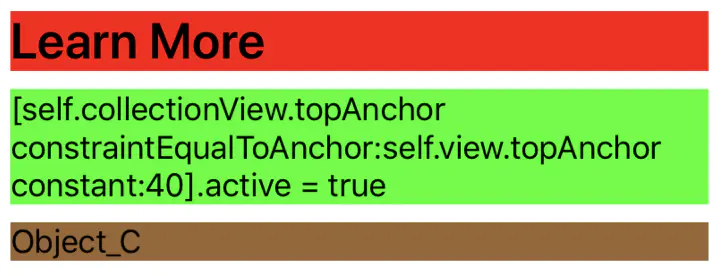
UIStackViewDistributionEqualSpacing
此属性简单來說就会根据 StackView 剩余可用空間的尺寸,來分配 StackView 子视图间的间隔。
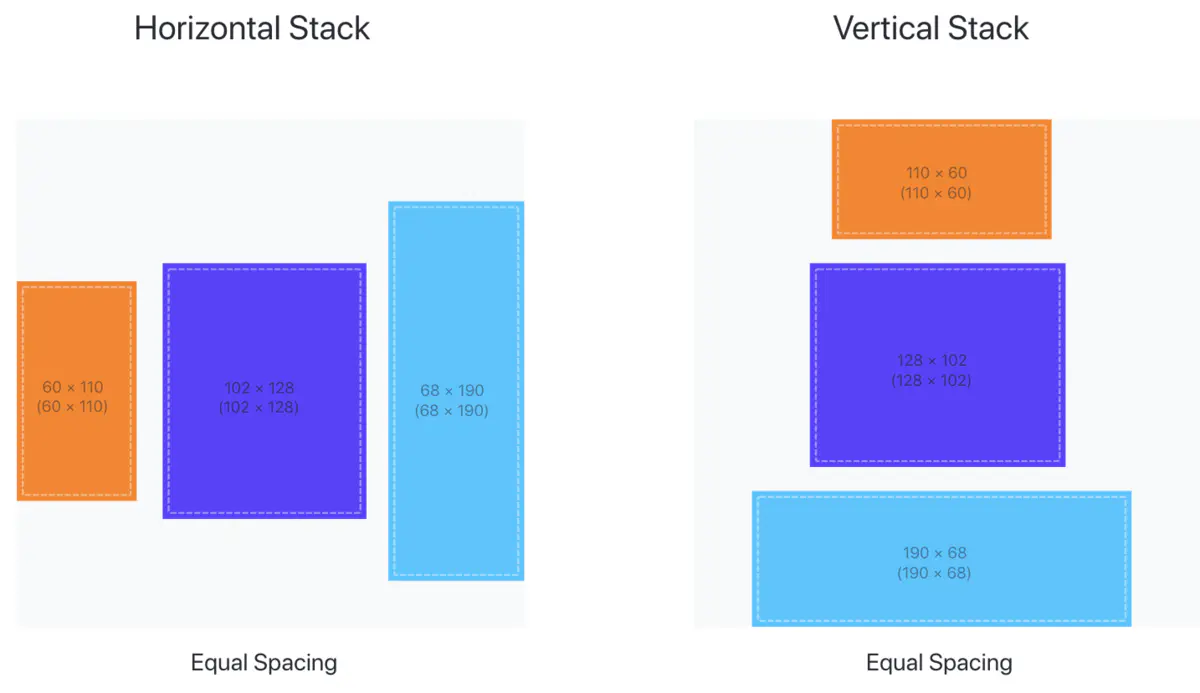
UIStackViewDistributionEqualCentering
此属性与上面的 Equal Spacing 意思类似,只是它是以其子视图中心點的中心与中心距離是相同來做為配置。
若說明得還不夠清楚可以看看這篇文章,了解當中的差异。
Alignment
确定垂直于堆栈轴的排列视图的布局
在 Axis 为 Vertical 下,各个状态下的对齐方式:
在 Axis 為 Horizontal 下,各个状态下的对齐方式:
Spacing
這個属性就不用多加以赘述了,就是可以自定义 StackView 的間隔大小,但是这边要注意,如果你沒有限制 StackView 的尺寸,那么就會加長或加寬 StackView。但是如果你有限制 StackView 的尺寸,那麼就會在限制尺寸下增加间隔(可能會造成跑版或失敗)。
baselineRelativeArrangement
该属性确定视图之间的垂直间距是否从基线测量。
layoutMarginsRelativeArrangement
该属性确定堆栈视图是否相对于其布局边距布置其排列的视图
注意
详情参考
从堆栈视图中删除子视图时,堆栈视图也会将其从数组中删除
从数组中删除视图不会将其作为子视图删除。堆栈视图不再管理视图的大小和位置,但视图仍然是视图层次结构的一部分,并且如果可见,则在屏幕上呈现
无论何时添加,删除或插入视图,或者每当其中一个已排列的子视图的属性发生更改时,堆栈视图都会自动更新其布局(比如hidden,更改布局方向...)
后记
堆栈视图为我们执行的自动布局计算会带来性能成本。在大多数情况下,它可以忽略不计。但是当堆栈视图嵌套超过两层时,可能会变得明显。
为了安全起见,请避免使用深层嵌套的堆栈视图,尤其是在可重用的视图(如表和集合视图单元格)中。
链接:https://www.jianshu.com/p/7920d287c13b
收起阅读 »Swift5.0的Runtime机制浅析
导读:你想知道Swift内部对象是如何创建的吗?方法以及函数调用又是如何实现的吗?成员变量的访问以及对象内存布局又是怎样的吗?这些问题都会在这篇文章中得到解答。为了更好的让大家理解这些内部实现,我会将源代码翻译为用C语言表示的伪代码来实现。
Objective-C语言是一门以C语言为基础的面向对象编程语言,其提供的运行时(Runtime)机制使得它也可以被认为是一种动态语言。运行时的特征之一就是对象方法的调用是在程序运行时才被确定和执行的。系统提供的开放接口使得我们可以在程序运行的时候执行方法替换以便实现一些诸如系统监控、对象行为改变、Hook等等的操作处理。然而这种开放性也存在着安全的隐患,我们可以借助Runtime在AOP层面上做一些额外的操作,而这些额外的操作因为无法进行管控, 所以有可能会输出未知的结果。
可能是苹果意识到了这个问题,所以在推出的Swift语言中Runtime的能力得到了限制,甚至可以说是取消了这个能力,这就使得Swift成为了一门静态语言。Swift语言中对象的方法调用机制和OC语言完全不同,Swift语言的对象方法调用基本上是在编译链接时刻就被确定的,可以看做是一种硬编码形式的调用实现。
Swfit中的对象方法调用机制加快了程序的运行速度,同时减少了程序包体积的大小。但是从另外一个层面来看当编译链接优化功能开启时反而又会出现包体积增大的情况。Swift在编译链接期间采用的是空间换时间的优化策略,是以提高运行速度为主要优化考虑点。具体这些我会在后面详细谈到。
通过程序运行时汇编代码分析Swift中的对象方法调用,发现其在Debug模式下和Release模式下的实现差异巨大。其原因是在Release模式下还同时会把编译链接优化选项打开。因此更加确切的说是在编译链接优化选项开启与否的情况下二者的实现差异巨大。
在这之前先介绍一下OC和Swift两种语言对象方法调用的一般实现。
OC类的对象方法调用
对于OC语言来说对象方法调用的实现机制有很多文章都进行了深入的介绍。所有OC类中定义的方法函数的实现都隐藏了两个参数:一个是对象本身,一个是对象方法的名称。每次对象方法调用都会至少传递对象和对象方法名称作为开始的两个参数,方法的调用过程都会通过一个被称为消息发送的C函数objc_msgSend来完成。objc_msgSend函数是OC对象方法调用的总引擎,这个函数内部会根据第一个参数中对象所保存的类结构信息以及第二个参数中的方法名来找到最终要调用的方法函数的地址并执行函数调用。这也是OC语言Runtime的实现机制,同时也是OC语言对多态的支持实现。整个流程就如下表述:
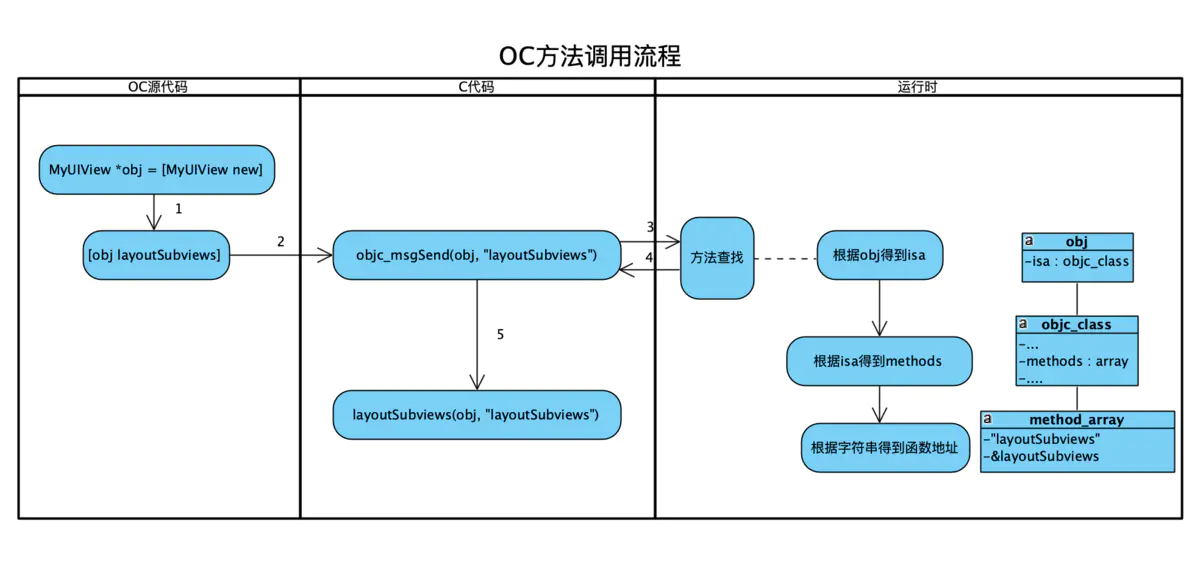
Swift类的对象创建和销毁
在Swift中可以定义两种类:一种是从NSObject或者派生类派生的类,一类是从系统Swift基类SwiftObject派生的类。对于后者来说如果在定义类时没有指定基类则默认会从基类SwiftObject派生。SwiftObject是一个隐藏的基类,不会在源代码中体现。
Swift类对象的内存布局和OC类对象的内存布局相似。二者对象的最开始部分都有一个isa成员变量指向类的描述信息。Swift类的描述信息结构继承自OC类的描述信息,但是并没有完全使用里面定义的属性,对于方法的调用则主要是使用其中扩展了一个所谓的虚函数表的区域,关于这部分会在后续中详细介绍。
Swift类的对象实例都是在堆内存中创建,这和OC语言的对象实例创建方式相似。系统会为类提供一个默认的init构造函数,如果想自定义构造函数则需要重写和重载init函数。一个Swift类的对象实例的构建分为两部分:首先是进行堆内存的分配,然后才是调用init构造函数。在源代码编写中不会像OC语言那样明确的分为alloc和init两个分离的调用步骤,而是直接采用:类名(初始化参数)这种方式来完成对象实例的创建。在编译时系统会为每个类的初始化方法生成一个:模块名.类名.__allocating_init(类名,初始化参数)的函数,这个函数的伪代码实现如下:
//假设定义了一个CA类。
class CA {
init(_ a:Int){}
}//编译生成的对象内存分配创建和初始化函数代码
CA * XXX.CA.__allocating_init(swift_class classCA, int a)
{
CA *obj = swift_allocObject(classCA); //分配内存。
obj->init(a); //调用初始化函数。
}
//编译时还会生成对象的析构和内存销毁函数代码
XXX.CA.__deallocating_deinit(CA *obj)
{
obj->deinit() //调用析构函数
swift_deallocClassInstance(obj); //销毁对象分配的内存。
}其中的swift_class 就是从objc_class派生出来,用于描述类信息的结构体。
Swift对象的生命周期也和OC对象的生命周期一样是通过引用计数来进行控制的。当对象初次创建时引用计数被设置为1,每次进行对象赋值操作都会调用swift_retain函数来增加引用计数,而每次对象不再被访问时都会调用swift_release函数来减少引用计数。当引用计数变为0后就会调用编译时为每个类生成的析构和销毁函数:模块名.类名.__deallocating_deinit(对象)。这个函数的定义实现在前面有说明。
这就是Swift对象的创建和销毁以及生命周期的管理过程,这些C函数都是在编译链接时插入到代码中并形成机器代码的,整个过程对源代码透明。下面的例子展示了对象创建和销毁的过程。
////////Swift源代码
let obj1:CA = CA(20);
let obj2 = obj1///////C伪代码
CA *obj1 = XXX.CA. __allocating_init(classCA, 20);
CA *obj2 = obj1;
swift_retain(obj1);
swift_release(obj1);
swift_release(obj2);swift_release函数内部会在引用计数为0时调用模块名.类名.__deallocating_deinit(对象)函数进行对象的析构和销毁。这个函数的指针保存在swift类描述信息结构体中,以便swift_release函数内部能够访问得到。
Swift类的对象方法调用
Swift语言中对象的方法调用的实现机制和C++语言中对虚函数调用的机制是非常相似的。(需要注意的是我这里所说的调用实现只是在编译链接优化选项开关在关闭的时候是这样的,在优化开关打开时这个结论并不正确)。
Swift语言中类定义的方法可以分为三种:OC类的派生类并且重写了基类的方法、extension中定义的方法、类中定义的常规方法。针对这三种方法定义和实现,系统采用的处理和调用机制是完全不一样的。
OC类的派生类并且重写了基类的方法
如果在Swift中的使用了OC类,比如还在使用的UIViewController、UIView等等。并且还重写了基类的方法,比如一定会重写UIViewController的viewDidLoad方法。对于这些类的重写的方法定义信息还是会保存在类的Class结构体中,而在调用上还是采用OC语言的Runtime机制来实现,即通过objc_msgSend来调用。而如果在OC派生类中定义了一个新的方法的话则实现和调用机制就不会再采用OC的Runtime机制来完成了,比如说在UIView的派生类中定义了一个新方法foo,那么这个新方法的调用和实现将与OC的Runtime机制没有任何关系了! 它的处理和实现机制会变成我下面要说到的第三种方式。下面的Swift源代码以及C伪代码实现说明了这个情况:
////////Swift源代码
//类定义
class MyUIView:UIView {
open func foo(){} //常规方法
override func layoutSubviews() {} //重写OC方法
}
func main(){
let obj = MyUIView()
obj.layoutSubviews() //调用OC类重写的方法
obj.foo() //调用常规的方法。
}////////C伪代码
//...........................................运行时定义部分
//OC类的方法结构体
struct method_t {
SEL name;
IMP imp;
};
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
struct method_t methods[1];
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct MyUIView {
struct swift_class *isa;
}
//类的方法函数的实现
void layoutSubviews(id self, SEL _cmd){}
void foo(){} //Swift类的常规方法中和源代码的参数保持一致。
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classMyUIView;
classMyUIView.methods[0] = {"layoutSubviews", &layoutSubviews};
classMyUIView.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
void main(){
MyUIView *obj = MyUIView.__allocating_init(classMyUIView);
obj->isa = &classMyUIView;
//OC类重写的方法layoutSubviews调用还是用objc_msgSend来实现
objc_msgSend(obj, @selector(layoutSubviews);
//Swift方法调用时对象参数被放到x20寄存器中
asm("mov x20, obj");
//Swift的方法foo调用采用间接调用实现
obj->isa->vtable[0]();
}extension中定义的方法
如果是在Swift类的extension中定义的方法(重写OC基类的方法除外)。那么针对这个方法的调用总是会在编译时就决定,也就是说在调用这类对象方法时,方法调用指令中的函数地址将会以硬编码的形式存在。在extension中定义的方法无法在运行时做任何的替换和改变!而且方法函数的符号信息都不会保存到类的描述信息中去。这也就解释了在Swift中派生类无法重写一个基类中extension定义的方法的原因了。因为extension中的方法调用是硬编码完成,无法支持多态!下面的Swift源代码以及C伪代码实现说明了这个情况:
////////Swift源代码
//类定义
class CA {
open func foo(){}
}
//类的extension定义
extension CA {
open func extfoo(){}
}
func main() {
let obj = CA()
obj.foo()
obj.extfoo()
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
}
//类的方法函数的实现定义
void foo(){}
//类的extension的方法函数实现定义
void extfoo(){}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
//extension中定义的函数不会保存到虚函数表中。
struct swift_class classCA;
classCA.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
void main(){
CA *obj = CA.__allocating_init(classCA)
obj->isa = &classCA;
asm("mov x20, obj");
//Swift中常规方法foo调用采用间接调用实现
obj->isa->vtable[0]();
//Swift中extension方法extfoo调用直接硬编码调用,而不是间接调用实现
extfoo();
}需要注意的是extension中是可以重写OC基类的方法,但是不能重写Swift类中的定义的方法。具体原因根据上面的解释就非常清楚了。
类中定义的常规方法
如果是在Swift中定义的常规方法,方法的调用机制和C++中的虚函数的调用机制是非常相似的。Swift为每个类都建立了一个被称之为虚表的数组结构,这个数组会保存着类中所有定义的常规成员方法函数的地址。每个Swift类对象实例的内存布局中的第一个数据成员和OC对象相似,保存有一个类似isa的数据成员。isa中保存着Swift类的描述信息。对于Swift类的类描述结构苹果并未公开(也许有我并不知道),类的虚函数表保存在类描述结构的第0x50个字节的偏移处,每个虚表条目中保存着一个常规方法的函数地址指针。每一个对象方法调用的源代码在编译时就会转化为从虚表中取对应偏移位置的函数地址来实现间接的函数调用。下面是对于常规方法的调用Swift语言源代码和C语言伪代码实现:
////////Swift源代码
//基类定义
class CA {
open func foo1(_ a:Int){}
open func foo1(_ a:Int, _ b:Int){}
open func foo2(){}
}
//扩展
extension CA{
open func extfoo(){}
}
//派生类定义
class CB:CA{
open func foo3(){}
override open func foo1(_ a:Int){}
}
func testfunc(_ obj:CA){
obj.foo1(10)
}
func main() {
let objA = A()
objA.foo1(10)
objA.foo1(10,20)
objA.foo2()
objA.extfoo()
let objB = B()
objB.foo1(10)
objB.foo1(10,20)
objB.foo2()
objB.foo3()
objB.extfoo()
testfunc(objA)
testfunc(objB)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[0];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//基类定义
struct CA {
struct swift_class *isa;
};
//派生类定义
struct CB {
struct swift_class *isa;
};
//基类CA的方法函数的实现,这里对所有方法名都进行修饰命名
void _$s3XXX2CAC4foo1yySiF(int a){} //CA类中的foo1
void _$s3XXX2CAC4foo1yySi_SitF(int a, int b){} //CA类中的两个参数的foo1
void _$s3XXX2CAC4foo2yyF(){} //CA类中的foo2
void _$s3XXX2CAC6extfooyyF(){} //CA类中的extfoo函数
//派生类CB的方法函数的实现。
void _$s3XXX2CBC4foo1yySiF(int a){} //CB类中的foo1,重写了基类的方法,但是名字不一样了。
void _$s3XXX2CBC4foo3yyF(){} //CB类中的foo3
//构造基类的描述信息以及虚函数表
struct swift_class classCA;
classCA.vtable[3] = {&_$s3XXX2CAC4foo1yySiF, &_$s3XXX2CAC4foo1yySi_SitF, &_$s3XXX2CAC4foo2yyF};
//构造派生类的描述信息以及虚函数表,注意这里虚函数表会将基类的函数也添加进来而且排列在前面。
struct swift_class classCB;
classCB.vtable[4] = {&_$s3XXX2CBC4foo1yySiF, &_$s3XXX2CAC4foo1yySi_SitF, &_$s3XXX2CAC4foo2yyF, &_$s3XXX2CBC4foo3yyF};
void testfunc(A *obj){
obj->isa->vtable[0](10); //间接调用实现多态的能力。
}
//...........................................源代码中程序运行的部分
void main(){
CA *objA = CA.__allocating_init(classCA);
objA->isa = &classCA;
asm("mov x20, objA")
objA->isa->vtable[0](10);
objA->isa->vtable[1](10,20);
objA->isa->vtable[2]();
_$s3XXX2CAC6extfooyyF()
CB *objB = CB.__allocating_init(classCB);
objB->isa = &classCB;
asm("mov x20, objB");
objB->isa->vtable[0](10);
objB->isa->vtable[1](10,20);
objB->isa->vtable[2]();
objB->isa->vtable[3]();
_$s3XXX2CAC6extfooyyF();
testfunc(objA);
testfunc(objB);
}从上面的代码中可以看出一些特点:
1、Swift类的常规方法中不会再有两个隐藏的参数了,而是和字面定义保持一致。那么问题就来了,方法调用时对象如何被引用和传递呢?在其他语言中一般情况下对象总是会作为方法的第一个参数,在编译阶段生成的机器码中,将对象存放在x0这个寄存器中(本文以arm64体系结构为例)。而Swift则不同,对象不再作为第一个参数来进行传递了,而是在编译阶段生成的机器码中,将对象存放在x20这个寄存器中(本文以arm64体系结构为例)。这样设计的一个目的使得代码更加安全。
2、每一个方法调用都是通过读取方法在虚表中的索引获取到了方法函数的真实地址,然后再执行间接调用。在这个过程虚表索引的值是在编译时就确定了,因此不再需要通过方法名来在运行时动态的去查找真实的地址来实现函数调用了。虽然索引的位置在编译时确定的,但是基类和派生类虚表中相同索引处的函数的地址确可以不一致,当派生类重写了父类的某个方法时,因为会分别生成两个类的虚表,在相同索引位置保存不同的函数地址来实现多态的能力。
3、每个方法函数名字都和源代码中不一样了,原因在于在编译链接是系统对所有的方法名称进行了重命名处理,这个处理称为命名修饰。之所以这样做是为了解决方法重载和运算符重载的问题。因为源代码中重载的方法函数名称都一样只是参数和返回类型不一样,因此无法简单的通过名字进行区分,而只能对名字进行修饰重命名。另外一个原因是Swift还提供了命名空间的概念,也就是使得可以支持不同模块之间是可以存在相同名称的方法或者函数。因为整个重命名中是会带上模块名称的。下面就是Swift中对类的对象方法的重命名修饰规则:
_$s<模块名长度><模块名><类名长度><类名>C<方法名长度><方法名>yy<参数类型1>_<参数类型2>_<参数类型N>F
就比如上面的CA类中的foo1两个同名函数在编译链接时刻就会被分别重命名为:
//这里面的XXX就是你工程模块的名称。
void _$s3XXX2CAC4foo1yySiF(int a){} //CA类中的foo1
void _$s3XXX2CAC4foo1yySi_SitF(int a, int b){} //CA类中的两个参数的foo1下面这张图就清晰的描述了Swift类的对象方法调用以及类描述信息。
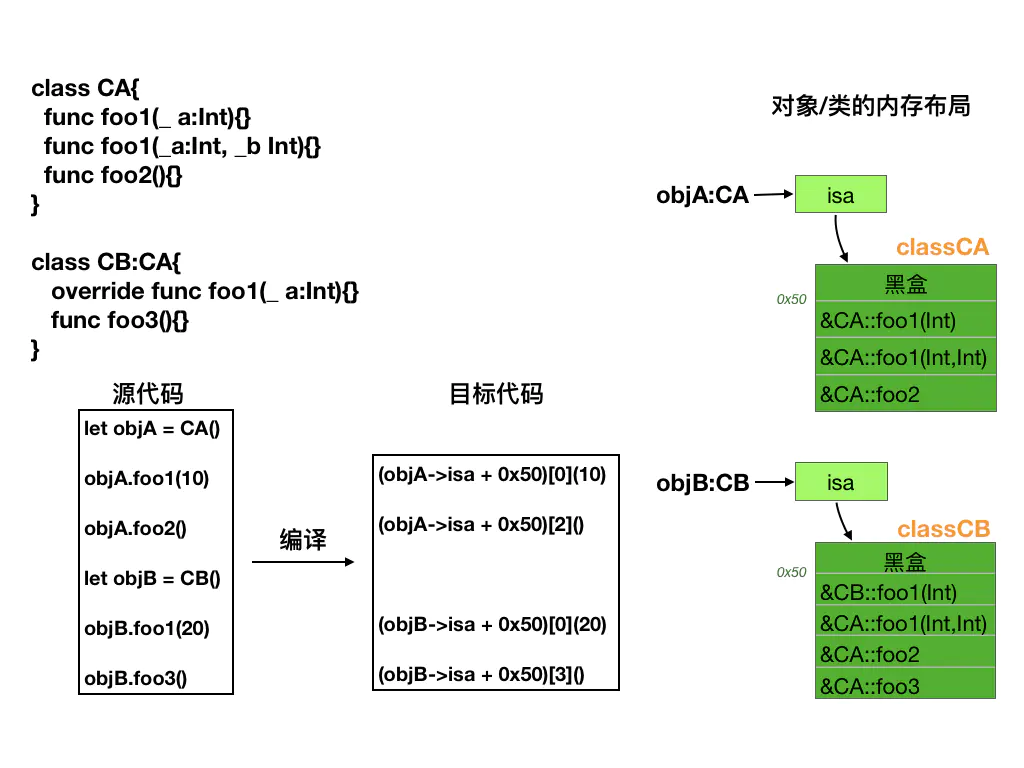
Swift类中成员变量的访问
虽然说OC类和Swift类的对象内存布局非常相似,每个对象实例的开始部分都是一个isa数据成员指向类的描述信息,而类中定义的属性或者变量则一般会根据定义的顺序依次排列在isa的后面。OC类还会为所有成员变量,生成一张变量表信息,变量表的每个条目记录着每个成员变量在对象内存中的偏移量。这样在访问对象的属性时会通过偏移表中的偏移量来读取偏移信息,然后再根据偏移量来读取或设置对象的成员变量数据。在每个OC类的get和set两个属性方法的实现中,对于属性在类中的偏移量值的获取都是通过硬编码来完成,也就是说是在编译链接时刻决定的。
对于Swift来说,对成员变量的访问得到更加的简化。系统会对每个成员变量生成get/set两个函数来实现成员变量的访问。系统不会再为类的成员变量生成变量偏移信息表,因此对于成员变量的访问就是直接在编译链接时确定成员变量在对象的偏移位置,这个偏移位置是硬编码来确定的。下面展示Swift源代码和C伪代码对数据成员访问的实现:
////////Swift源代码
class CA
{
var a:Int = 10
var b:Int = 20
}
void main()
{
let obj = CA()
obj.b = obj.a
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[4];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//CA类的结构体定义也是CA类对象在内存中的布局。
struct CA
{
struct swift_class *isa;
long reserve; //这里的值目前总是2
int a;
int b;
};
//类CA的方法函数的实现。
int getA(){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
return obj->a;
}
void setA(int a){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
obj->a = a;
}
int getB(){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
return obj->b;
}
void setB(int b){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
obj->b = b;
}
struct swift_class classCA;
classCA.vtable[4] = {&getA,&setA,&getB, &setB};
//...........................................源代码中程序运行的部分
void main(){
CA *obj = CA.__allocating_init(classCA);
obj->isa = &classCA;
obj->reserve = 2;
obj->a = 10;
obj->b = 20;
asm("mov x20, obj");
obj->isa->vtable[3](obj->isa->vtable[0]()); // obj.b = obj.a的实现
}从上面的代码可以看出,Swift类会为每个定义的成员变量都生成一对get/set方法并保存到虚函数表中。所有对对象成员变量的方法的代码都会转化为通过虚函数表来执行get/set相对应的方法。 下面是Swift类中成员变量的实现和内存结构布局图:
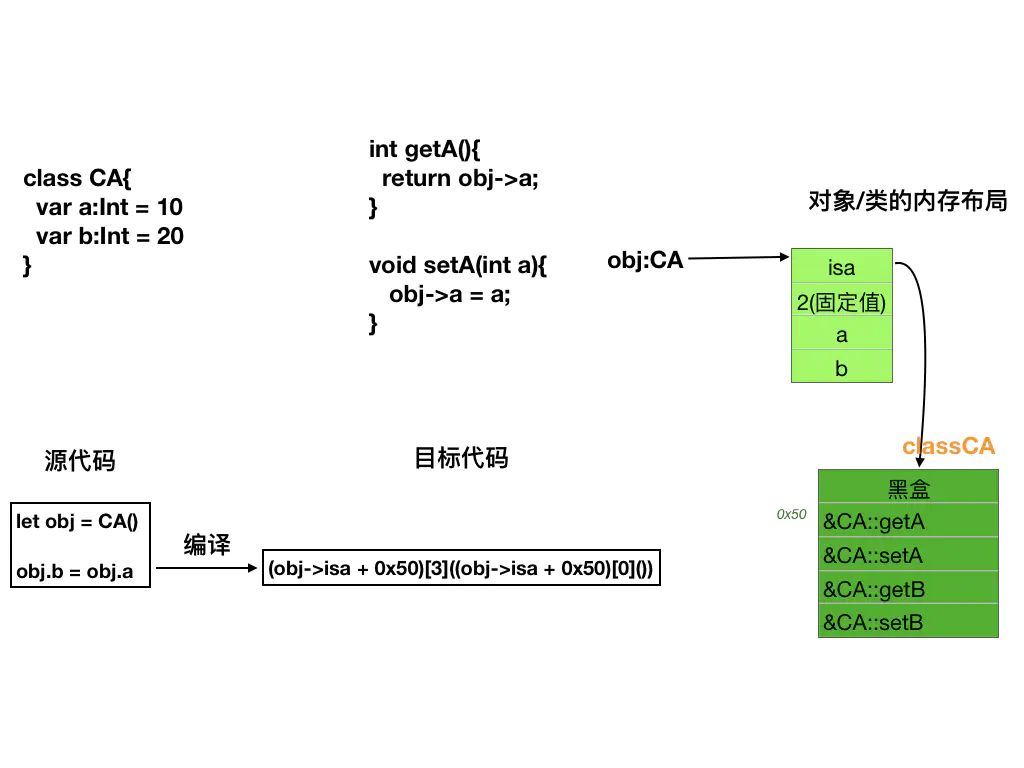
结构体中的方法
在Swift结构体中也可以定义方法,因为结构体的内存结构中并没有地方保存结构体的信息(不存在isa数据成员),因此结构体中的方法是不支持多态的,同时结构体中的所有方法调用都是在编译时硬编码来实现的。这也解释了为什么结构体不支持派生,以及结构体中的方法不支持override关键字的原因。
类的方法以及全局函数
Swift类中定义的类方法和全局函数一样,因为不存在对象作为参数,因此在调用此类函数时也不会存在将对象保存到x20寄存器中这么一说。同时源代码中定义的函数的参数在编译时也不会插入附加的参数。Swift语言会对所有符号进行重命名修饰,类方法和全局函数也不例外。这也就使得全局函数和类方法也支持名称相同但是参数不同的函数定义。简单的说就是类方法和全局函数就像C语言的普通函数一样被实现和定义,所有对类方法和全局函数的调用都是在编译链接时刻硬编码为函数地址调用来处理的。
OC调用Swift类中的方法
如果应用程序是通过OC和Swift两种语言混合开发完成的。那就一定会存在着OC语言代码调用Swift语言代码以及相反调用的情况。对于Swift语言调用OC的代码的处理方法是系统会为工程建立一个桥声明头文件:项目工程名-Bridging-Header.h,所有Swift需要调用的OC语言方法都需要在这个头文件中声明。而对于OC语言调用Swift语言来说,则有一定的限制。因为Swift和OC的函数调用ABI规则不相同,OC语言只能创建Swift中从NSObject类中派生类对象,而方法调用则只能调用原NSObject类以及派生类中的所有方法以及被声明为@objc关键字的Swift对象方法。如果需要在OC语言中调用Swift语言定义的类和方法,则需要在OC语言文件中添加:#import "项目名-Swift.h"。当某个Swift方法被声明为@objc关键字时,在编译时刻会生成两个函数,一个是本体函数供Swift内部调用,另外一个是跳板函数(trampoline)是供OC语言进行调用的。这个跳板函数信息会记录在OC类的运行时类结构中,跳板函数的实现会对参数的传递规则进行转换:把x0寄存器的值赋值给x20寄存器,然后把其他参数依次转化为Swift的函数参数传递规则要求,最后再执行本地函数调用。整个过程的实现如下:
////////Swift源代码
//Swift类定义
class MyUIView:UIView {
@objc
open func foo(){}
}
func main() {
let obj = MyUIView()
obj.foo()
}
//////// OC源代码
#import "工程-Swift.h"
void main() {
MyUIView *obj = [MyUIView new];
[obj foo];
}////////C伪代码
//...........................................运行时定义部分
//OC类的方法结构体
struct method_t {
SEL name;
IMP imp;
};
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
struct method_t methods[1];
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct MyUIView {
struct swift_class *isa;
}
//类的方法函数的实现
//本体函数foo的实现
void foo(){}
//跳板函数的实现
void trampoline_foo(id self, SEL _cmd){
asm("mov x20, x0");
self->isa->vtable[0](); //这里调用本体函数foo
}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classMyUIView;
classMyUIView.methods[0] = {"foo", &trampoline_foo};
classMyUIView.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
//Swift代码部分
void main()
{
MyUIView *obj = MyUIView.__allocating_init(classMyUIView);
obj->isa = &classMyUIView;
asm("mov x20, obj");
//Swift方法foo的调用采用间接调用实现。
obj->isa->vtable[0]();
}
//OC代码部分
void main()
{
MyUIView *obj = objc_msgSend(objc_msgSend(classMyUIView, "alloc"), "init");
obj->isa = &classMyUIView;
//OC语言对foo的调用还是用objc_msgSend来执行调用。
//因为objc_msgSend最终会找到methods中的方法结构并调用trampoline_foo
//而trampoline_foo内部则直接调用foo来实现真实的调用。
objc_msgSend(obj, @selector(foo));
}下面的图形展示了Swift中带@objc关键字的方法实现,以及OC语言调用Swift对象方法的实现:
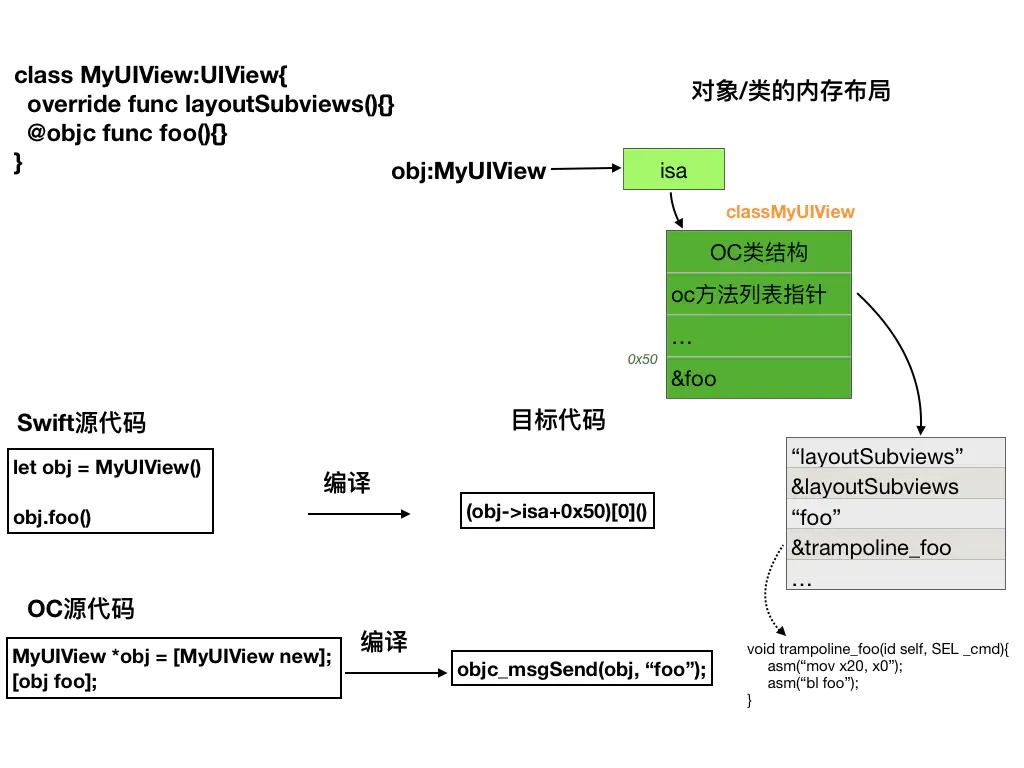
Swift类方法的运行时替换实现的可行性
从上面的介绍中我们已经了解到了Swift类的常规方法定义和调用实现的机制,同样了解到Swift对象实例的开头部分也有和OC类似的isa数据,用来指向类的信息结构。一个令人高兴的事情就是Swift类的结构定义部分是存放在可读写的数据段中,这似乎给了我们一个提示是说可以在运行时通过修改一个Swift类的虚函数表的内容来达到运行时对象行为改变的能力。要实现这种机制有三个难点需要解决:
1、一个是Swift对内存和指针的操作进行了极大的封装,同时Swift中也不再支持简单直接的对内存进行操作的机制了。这样就使得我们很难像OC那样直接修改类结构的内存信息来进行运行时的更新处理,因为Swift不再公开运行时的相关接口了。虽然可以将方法函数名称赋值给某个变量,但是这个变量的值并非是类方法函数的真实地址,而是一个包装函数的地址。
2、第二个就是Swift中的类方法调用和参数传递的ABI规则和其他语言不一致。在OC类的对象方法中,对象是作为方法函数的第一个参数传递的。在机器指令层面以arm64体系结构为例,对象是保存在x0寄存器作为参数进行传递。而在Swift的对象方法中这个规则变为对象不再作为第一个参数传递了,而是统一改为通过寄存器x20来进行传递。需要明确的是这个规则不会针对普通的Swift函数。因此当我们想将一个普通的函数来替换类定义的对象方法实现时就几乎变得不太可能了,除非借助一些OC到Swift的桥的技术和跳板技术来实现这个功能也许能够成功。
当然我们也可以通过为类定义一个extension方法,然后将这个extension方法函数的指针来替换掉虚函数表中类的某个原始方法的函数指针地址,这样能够解决对象作为参数传递的寄存器的问题。但是这里仍然需要面临两个问题:一是如何获取得到extension中的方法函数的地址,二是在替换完成后如何能在合适的时机调用原始的方法。
3、第三是Swift语言将不再支持内嵌汇编代码了,所以我们很难在Swift中通过汇编来写一些跳板程序了。
因为Swift具有比较强的静态语言的特性,外加上函数调用的规则特点使得我们很难在运行时进行对象方法行为的改变。还有一个非常大的因素是当编译链接优化开关打开时,上述的对象方法调用规则还将进一步被打破,这样就导致我们在运行时进行对象方法行为的替换变得几乎不可能或者不可行。
编译链接优化开启后的Swift方法定义和调用
一个不幸的事实是,当我们开启了编译链接的优化选项后,Swift的对象方法的调用机制做了非常大的改进。最主要的就是进一步弱化了通过虚函数表来进行间接方法调用的实现,而是大量的改用了一些内联的方式来处理方法函数调用。同时对多态的支持也采用了一些别的策略。具体用了如下一些策略:
1、大量的将函数实现换成了内联函数模式,也就是对于大部分类中定义的源代码比较少的方法函数都统一换成内联。这样对象方法的调用将不再通过虚函数表来间接调用,而是简单粗暴的将函数的调用改为直接将内联函数生成的机器码进行拷贝处理。这样的一个好处就是由于没有函数调用的跳转指令,而是直接执行方法中定义的指令,从而极大的加速了程序的运行速度。另外一个就是使得整个程序更加安全,因为此时函数的实现逻辑已经散布到各处了,除非恶意修改者改动了所有的指令,否则都只会影响局部程序的运行。内联的一个的缺点就是使得整个程序的体积会增大很多。比如下面的类代码在优化模式下的Swift语言源代码和C语言伪代码实现:
////////Swift源代码
//类定义
class CA {
open func foo(_ a:Int, _ b:Int) ->Int {
return a + b
}
func main() {
let obj = CA()
let a = obj.foo(10,20)
let b = obj.foo(a, 40)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//这里也没有虚表的信息。
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
};
//这里没有方法实现,因为短方法被内联了。
struct swift_class classCA;
//...........................................源代码中程序运行的部分
void main() {
CA *obj = CA.__allocating_init(classCA);
obj->isa = &classCA;
int a = 10 + 20; //代码被内联优化
int b = a + 40; //代码被内联优化
}2、就是对多态的支持,也可能不是通过虚函数来处理了,而是通过类型判断采用条件语句来实现方法的调用。就比如下面Swift语言源代码和C语言伪代码:
////////Swift源代码
//基类
class CA{
@inline(never)
open func foo(){}
}
//派生类
class CB:CA{
@inline(never)
override open func foo(){}
}
//全局函数接收对象作为参数
@inline(never)
func testfunc(_ obj:CA){
obj.foo()
}
func main() {
//对象的创建以及方法调用
let objA = CA()
let objB = CB()
testfunc(objA)
testfunc(objB)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//这里也没有虚表的信息。
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
};
struct CB {
struct swift_class *isa;
};
//Swift类的方法的实现
//基类CA的foo方法实现
void fooForA(){}
//派生类CB的foo方法实现
void fooForB(){}
//全局函数方法的实现
void testfunc(CA *obj)
{
//这里并不是通过虚表来进行间接调用而实现多态,而是直接硬编码通过类型判断来进行函数调用从而实现多态的能力。
asm("mov x20, obj");
if (obj->isa == &classCA)
fooForA();
else if (obj->isa == &classCB)
fooForB();
}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classCA;
struct swift_class classCB;
//...........................................源代码中程序运行的部分
void main() {
//对象实例创建以及方法调用的代码。
CA *objA = CA.__allocating_init(classCA);
objA->isa = &classCA;
CB *objB = CB.__allocating_init(classCB);
objB->isa = &classCB;
testfunc(objA);
testfunc(objB);
}也许你会觉得这不是一个最优的解决方案,而且如果当再次出现一个派生类时,还会继续增加条件分支的判断。 这是一个多么低级的优化啊!但是为什么还是要这么做呢?个人觉得还是性能和包大小的问题。对于性能来说如果我们通过间接调用的形式可能需要增加更多的指令以及进行间接的寻址处理和指令跳转,而如果采用简单的类型判断则只需要更少的指令就可以解决多态调用的问题了,这样性能就会得到提升。至于第二个包大小的问题这里有必要重点说一下。
编译链接优化的一个非常重要的能力就是减少程序的体积,其中一个点即是链接时如果发现某个一个函数没有被任何地方调用或者引用,链接器就会把这个函数的实现代码整体删除掉。这也是符合逻辑以及正确的优化方式。回过头来Swift函数调用的虚函数表方式,因为根据虚函数表的定义需要把一个类的所有方法函数地址都存放到类的虚函数表中,而不管类中的函数是否有被调用或者使用。而通过虚函数表的形式间接调用时是无法在编译链接时明确哪个函数是否会被调用的,所以当采用虚函数表时就不得不把类中的所有方法的实现都链接到可执行程序中去,这样就有可能无形中增加了程序的体积。而前面提供的当编译链接优化打开后,系统尽可能的对对象的方法调用改为内联,同时对多态的支持改为根据类型来进行条件判断处理,这样就可以减少对虚函数表的使用,一者加快了程序运行速度,二者删除了程序中那些永远不会调用的代码从而减少程序包的体积。但是这种减少包体积的行为又因为内联的引入也许反而增加了程序包的体积。而这二者之间的平衡对于链接优化器是如何决策的我们就不得而知了。
综上所述,在编译器优化模式下虚函数调用的间接模式改变为直接模式了,所以我们几乎很难在运行时通过修改虚表来实现方法调用的替换。而且Swift本身又不再支持运行时从方法名到方法实现地址的映射处理,所有的机制都是在编译时静态决定了。正是因为Swift语言的特性,使得原本在OC中可以做的很多事情在Swift中都难以实现,尤其是一些公司的无痕埋点日志系统的建设,APM的建设,以及各种监控系统的建设,以及模拟系统的建设都将失效,或者说需要寻找另外一些途径去做这些事情。对于这些来说,您准备好了吗?
链接:https://www.jianshu.com/p/158574ab8809
收起阅读 »iOS的异步处理神器——Promises
前言
你是否因为多任务的依赖而头疼?你是否被一个个嵌套的block回调弄得晕头转向?
快来投入Promises的怀抱吧。
正文
回调任务是很正常的现象,比如说购买一个商品,需要下单,然后等后台返回。
单一任务,通常只需要一个block,非常清晰;
以上面的下单为例,传给网络层一个block,购买完成之后回调即可。
但是出现多个任务的时候,逻辑就开始有分支,同样以购买商品为例,在下单完成后,需要和SDK发起支付,然后根据支付结果再进行一些提示:
任务1是下单,执行完回调error指针(或者状态码)表示完成状态,同时待会下单信息,此时产生一个分支,成功继续下一步,失败执行错误block;
然后是执行任务2购买,执行异步的支付,根据支付结果又会产生一个分支。
当连续的任务超过2个之后,分支会导致代码逻辑非常混乱。
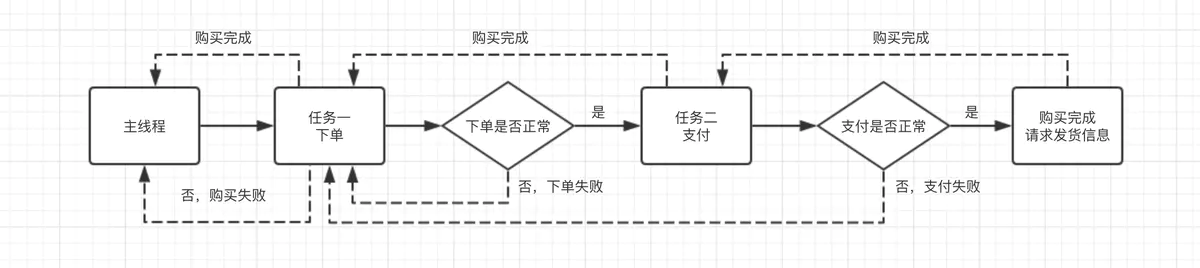
简单画一个流程图来分析,上述的逻辑变得复杂的原因是因为每一级的block需要处理下一级block的失败情况,导致逻辑分支的增多。
其实所有的失败处理都是类似的:打日志、提示用户,可以放在一起统一处理。
然后把任务一、任务二等串行执行,流程就非常清晰。
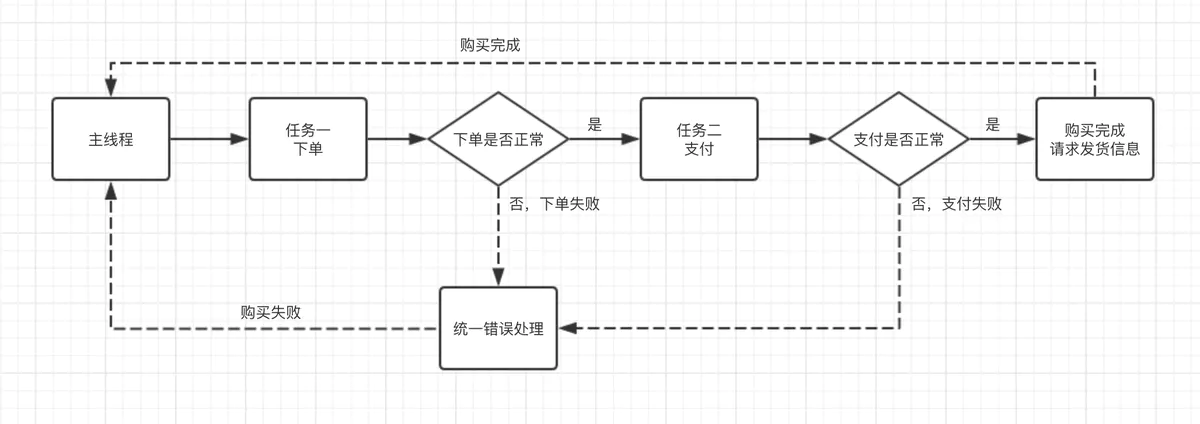
Promises就是用来辅助实现这样设计的库。
实现的代码效果如下:
- (void)workflow {
[[[[self order:@"order_id"] then:^id _Nullable(NSString * _Nullable value) {
return [self pay:value];
}] then:^id _Nullable(id _Nullable value) {
return [self check:value];
}] catch:^(NSError * _Nonnull error) {
NSLog(@"error: %@", error);
}];
}Promises的使用
Promises库的引入非常简单,可以使用CocoaPod,Podfile如下:
pod 'PromisesObjC'也可以到GitHub手动下载。
按照Promise设计模式的规范,每一个Promise应该有三种状态:pending(等待)、fulfilled(完成)、rejected(失败);
对应到Promises分别是:
[FBLPromise pendingPromise]; // pending等待
[FBLPromise resolvedWith:@"anyString"]; // fulfilled完成
[FBLPromise resolvedWith:[NSError new]]; // rejected失败实际使用中,我们更多使用的Promises库已经提供好的便捷函数:
启动一个异步任务 :
[FBLPromise onQueue:dispatch_get_main_queue()
async:^(FBLPromiseFulfillBlock fulfill,
FBLPromiseRejectBlock reject) {
BOOL success = arc4random() % 2;
if (success) {
fulfill(@"success");
}
else {
reject([NSError errorWithDomain:@"learn_promises_error" code:-1 userInfo:nil]);
}
}];或者简单使用do方法:
[FBLPromise do:^id _Nullable{
BOOL success = random() % 2;
if (success) {
return @"success";
}
else {
return [NSError errorWithDomain:@"learn_promises_error" code:-1 userInfo:nil];
}
}];不管是async方法还是do方法,他们的返回值都是创建一个Promise对象,可以在Promise对象后面挂一个then方法,表示这个Promise执行完毕之后,要继续执行的任务:
[[[FBLPromise do:^id _Nullable{
BOOL success = arc4random() % 2;
return success ? @"do_success" : [NSError errorWithDomain:@"learn_promises_do_error" code:-1 userInfo:nil];
}] then:^id _Nullable(id _Nullable value) {
BOOL success = arc4random() % 2;
return success ? @"then_success" : [NSError errorWithDomain:@"learn_promises_then_error" code:-1 userInfo:nil];
}] catch:^(NSError * _Nonnull error) {
NSLog(@"error: %@", error);
}];上面的catch方法表示统一的error处理。
promise在完成任务之后,如果满足下面的条件会调用then的方法:
1、直接调用fulfill;
2、在do方法中返回一个值(不能为error);
3、在then方法中返回一个值;
调用reject方法或者返回一个NSError对象,都会转到catch方法处理。
用上面的do、then、catch方法组合,就完成多个异步任务的依赖执行:
- (void)workflow {
[[[[self order:@"order_id"] then:^id _Nullable(NSString * _Nullable value) {
return [self pay:value];
}] then:^id _Nullable(id _Nullable value) {
return [self check:value];
}] catch:^(NSError * _Nonnull error) {
NSLog(@"error: %@", error);
}];
}
- (FBLPromise<NSString *> *)order:(NSString *)orderParam {
return [FBLPromise do:^id _Nullable{
return @"order_success";
}];
}
- (FBLPromise<NSString *> *)pay:(NSString *)payParam {
return [FBLPromise do:^id _Nullable{
BOOL success = arc4random() % 2;
return success ? @"pay_success" : [NSError errorWithDomain:@"pay_error" code:-1 userInfo:nil];
}];
}
- (FBLPromise<NSString *> *)check:(NSString *)checkParam {
return [FBLPromise do:^id _Nullable{
return @"check success";
}];
}Promises还提供了很多附加特性,以All和Any为例:
All是所有Promise都fulfill才算完成;
Any是任何一个Promise完成都会执行fulfill;
- (void)testAllAndAny {
NSMutableArray *arr = [NSMutableArray new];
[arr addObject:[self work1]];
[arr addObject:[self work2]];
[[[FBLPromise all:arr] then:^id _Nullable(NSArray * _Nullable value) {
NSLog(@"then, value:%@", value);
return value;
}] catch:^(NSError * _Nonnull error) {
NSLog(@"all error:%@", error);
}];
[[[FBLPromise any:arr] then:^id _Nullable(NSArray * _Nullable value) {
NSLog(@"then, value:%@", value);
return value;
}] catch:^(NSError * _Nonnull error) {
NSLog(@"any error:%@", error);
}];
}
- (FBLPromise<NSString *> *)work1 {
return [FBLPromise do:^id _Nullable{
BOOL success = arc4random() % 2;
return success ? @"work1 success" : [NSError errorWithDomain:@"work1_error" code:-1 userInfo:nil];
}];
}
- (FBLPromise<NSNumber *> *)work2 {
return [FBLPromise do:^id _Nullable{
BOOL success = arc4random() % 2;
return success ? @"work2 success" : [NSError errorWithDomain:@"work2_error" code:-1 userInfo:nil];
}];
}Promises原理解析
Promises库的设计很简单,基于Promise设计模式和iOS的GCD来实现。
整个库由Promise.m/.h和他的Catagory组成。Catagory都是附加特性,基于Promise.m/.h提供的方法做扩展,所以这里重点解析下Promise.m/h。
Promise类public头文件只有寥寥数个方法:
// 静态方法
[FBLPromise pendingPromise]; // pending等待
[FBLPromise resolvedWith:@"anyString"]; // fulfilled完成
[FBLPromise resolvedWith:[NSError new]]; // rejected失败
// 实例方法
- (void)fulfill:(nullable Value)value; // 完成一个promise
- (void)reject:(NSError *)error;// rejected一个promise重点在于private.h提供的两个方法:
/**
对一个promise添加fulfill和reject的回调
*/
- (void)observeOnQueue:(dispatch_queue_t)queue
fulfill:(FBLPromiseOnFulfillBlock)onFulfill
reject:(FBLPromiseOnRejectBlock)onReject NS_SWIFT_UNAVAILABLE("");
/**
创建一个promise,并设置fulfill、reject方法为传进来的block
*/
- (FBLPromise *)chainOnQueue:(dispatch_queue_t)queue
chainedFulfill:(FBLPromiseChainedFulfillBlock)chainedFulfill
chainedReject:(FBLPromiseChainedRejectBlock)chainedReject NS_SWIFT_UNAVAILABLE("");observeOnQueue方法是promise的实例方法,根据promise当前的状态,如果是fulfilled或者rejected状态则会dispatch_group_async到下一次执行对应的onFulfill和onReject回调;如果是pending状态则会创建_observers数组,往_observers数组中添加一个block回调,当promise执行完毕的时候,根据state选择onFulfill或者onReject回调。
chainOnQueue方法同样是promise的实例方法,返回的是一个FBLPromise的对象(状态是pending)。
方法首先创建的是promise对象,接着创建了resolver的回调,然后调用observeOnQueue方法。
当self(也是一个promise)执行完毕后,会根据fulfill、reject回调类型接着执行chainedFulfill、chainedReject;
最后将结果抛给resolver执行,resolver会根据返回值value进行判断,如果仍是promise则递归执行,否则直接调用fulfill方法。
fulfill方法则会判断value是否为NSError,如果是NSError则转为reject,否则将状态改为Fulfilled,并且通知observer数组。
- (FBLPromise *)chainOnQueue:(dispatch_queue_t)queue
chainedFulfill:(FBLPromiseChainedFulfillBlock)chainedFulfill
chainedReject:(FBLPromiseChainedRejectBlock)chainedReject {
NSParameterAssert(queue);
FBLPromise *promise = [[FBLPromise alloc] initPending];
__auto_type resolver = ^(id __nullable value) {
if ([value isKindOfClass:[FBLPromise class]]) {
[(FBLPromise *)value observeOnQueue:queue
fulfill:^(id __nullable value) {
[promise fulfill:value];
}
reject:^(NSError *error) {
[promise reject:error];
}];
} else {
[promise fulfill:value];
}
};
[self observeOnQueue:queue
fulfill:^(id __nullable value) {
value = chainedFulfill ? chainedFulfill(value) : value;
resolver(value);
}
reject:^(NSError *error) {
id value = chainedReject ? chainedReject(error) : error;
resolver(value);
}];
return promise;
}Promises中的dispatch_group_enter() 和 dispatch_group_leave() 是成对使用,但是和平时使用GCD不同,这里并没有用到dispath_group_notify方法。
在刚开始看Promises源码时,产生过一个疑问,为什么所有Promises的操作要放在同一个group内?
+ (dispatch_group_t)dispatchGroup {
static dispatch_group_t gDispatchGroup;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
gDispatchGroup = dispatch_group_create();
});
return gDispatchGroup;
}直到发现FBLWaitForPromisesWithTimeout方法,里面有一个dispatch_group_wait方法(等待group中所有block执行完毕,或者在指定时间结束后回调)。
dispatch_group_wait方法与dispath_group_notify方法类似,只是多了一个超时时间,如果调用dispatch_group_wait(DISPATCH_TIME_FOREVER)则和dispath_group_notify方法一样。
总结
附加的特性有很多,类似Retry、Delay等,但实际使用中Promise用do、then、catch、async等少数几个已经可以满足需求。
能够实现Promise设计模式的库比较多,Promises是性能和接口调用清晰度都比较不错的。
使用设计模式可以简化逻辑代码,同时也使得代码的健壮性更强。
链接:https://www.jianshu.com/p/d62ef7bec77e
在Swift中自定义Codable类型
大多数现代应用程序的共同点是,它们需要对各种形式的数据进行编码或解码。无论是通过网络下载的JSON数据,还是本地存储的模型的某种形式的序列化表示 - 能够可靠地编码和解码不同的数据对于或多或少的任何Swift代码库都是必不可少的。
这是Swift的Codable API在作为Swift 4.0的一部分引入时如此重要的新功能的一个重要原因 - 从那时起它已经发展成为几种不同类型的编码和解码的标准,强大的机制 - 在Apple的平台,以及服务器端Swift。
使Codable如此出色的原因在于它与Swift工具链紧密集成,使编译器能够自动合成编码和解码各种值所需的大量代码。但是,有时我们确实需要自定义序列化时我们的值的表示方式 - 所以本周,我们来看看我们可以通过几种不同的方式调整我们的Codable实现来做到这一点。
改变钥匙
让我们从一种基本方法开始,我们可以自定义类型的编码和解码方式 - 通过修改用作序列化表示的一部分的键。假设我们正在开发一个用于阅读文章的应用程序,我们的核心数据模型之一如下所示:
struct Article: Codable {
var url: URL
var title: String
var body: String
}我们的模型当前使用完全自动合成的Codable实现,这意味着它的所有序列化键都将匹配其属性的名称。但是,我们将解码Article值的数据(例如从服务器下载的JSON)可能使用稍微不同的命名约定,导致默认解码失败。
谢天谢地,这很容易修复。我们需要做的就是自定义Codable在解码(或编码)我们Article类型的实例时将使用的键是在其中定义CodingKeys枚举 - 并将自定义原始值分配给匹配我们希望自定义的键的案例 - 像这样:
extension Article {
enum CodingKeys: String, CodingKey {
case url = "source_link"
case title = "content_name"
case body
}
}执行上述操作后,我们可以继续利用编译器生成的默认实现进行实际的编码工作,同时仍然允许我们更改将用于序列化的键的名称。
虽然上述技术非常适合我们想要使用完全自定义的键名称,但如果我们只想让Codable使用snake_case我们的属性名称版本(例如backgroundColor转入background_color) - 那么我们可以简单地改变我们的JSON解码器keyDecodingStrategy:
var decoder = JSONDecoder()
decoder.keyDecodingStrategy = .convertFromSnakeCase上述两个API的优点在于它们使我们能够解决Swift模型与用于表示它们的数据之间的不匹配问题,而无需我们修改属性的名称。
忽略键
虽然能够自定义编码密钥的名称非常有用,但有时我们可能希望完全忽略某些密钥。例如,我们现在说我们正在制作一个笔记记录应用程序 - 并且我们允许用户将各种笔记组合在一起形成一个NoteCollection,其中可以包括本地草稿:
struct NoteCollection: Codable {
var name: String
var notes: [Note]
var localDrafts = [Note]()
}然而,尽管成为localDrafts我们NoteCollection模型的一部分真的很方便- 但是我们说在序列化或反序列化这样的集合时我们不希望包含这些草稿。这样做的原因可能是每次启动应用程序时给用户一个干净的名单,或者因为我们的服务器不支持草稿。
幸运的是,这也可以轻松完成,而无需更改实际的Codable实现NoteCollection。如果我们CodingKeys像之前一样定义枚举,并且只是省略localDrafts- 那么在编码或解码NoteCollection值时不会考虑该属性:
extension NoteCollection {
enum CodingKeys: CodingKey {
case name
case notes
}
}为了使上述工作,我们省略的属性必须具有默认值 - localDrafts在这种情况下已经具有。
创建匹配结构
到目前为止,我们只调整了一个类型的编码键 - 虽然我们通常可以做到这一点,但有时我们需要在Codable自定义方面更进一步。
假设我们正在构建一个包含货币转换功能的应用程序,并且我们将给定货币的当前汇率作为JSON数据下载,如下所示:
{
"currency": "PLN",
"rates": {
"USD": 3.76,
"EUR": 4.24,
"SEK": 0.41
}
}在我们的Swift代码中,我们希望将这些JSON响应转换为CurrencyConversion实例 - 每个实例包含一个ExchangeRate条目数组- 每种货币对应一个:
struct CurrencyConversion {
var currency: Currency
var exchangeRates: [ExchangeRate]
}
struct ExchangeRate {
let currency: Currency
let rate: Double
}但是,如果我们只是继续使上述两个模型都符合Codable,我们再次得出我们的Swift代码和我们想要解码的JSON数据之间的不匹配。但这一次,它不仅仅是关键名称的问题 - 结构上存在根本区别。
当然,我们可以修改我们的Swift模型的结构以完全匹配我们的JSON数据的结构 - 但这并不总是实用的。虽然拥有正确的序列化代码很重要,但拥有适合我们实际代码库的模型结构同样重要。
相反,让我们创建一个新的专用类型 - 它将充当我们的JSON数据中使用的格式与Swift代码结构之间的桥梁。在该类型中,我们将能够封装将汇率的JSON字典转换为ExchangeRate模型数组所需的所有逻辑- 如下所示:
private extension ExchangeRate {
struct List: Decodable {
let values: [ExchangeRate]
init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let dictionary = try container.decode([String : Double].self)
values = dictionary.map { key, value in
ExchangeRate(currency: Currency(key), rate: value)
}
}
}
}使用上面的类型,我们现在可以定义一个私有属性,该属性与用于其数据的JSON密钥匹配 - 并且我们的exchangeRates属性只是充当该私有属性的面向公众的代理:
struct CurrencyConversion: Decodable {
var currency: Currency
var exchangeRates: [ExchangeRate] {
return rates.values
}
private var rates: ExchangeRate.List
}上述工作的原因是因为在编码或解码值时从不考虑计算属性。
当我们想要使Swift代码与使用非常不同结构的JSON API兼容时,上述技术可以成为一个很好的工具 - 再次无需Codable从头开始实现。
转变价值观
在解码时,尤其是在使用我们无法控制的外部JSON API时,一个非常常见的问题是,类型的编码方式与Swift的严格类型系统不兼容。例如,我们要解码的JSON数据可能使用字符串来表示整数或其他类型的数字。
让我们看看一种可以让我们处理这些值的方法,再次以一种自包含的方式,不需要我们编写完全自定义的Codable实现。
我们在这里要做的就是将字符串值转换为另一种类型 - 让我们Int以此为例。我们首先定义一个协议,让我们将任何类型标记为StringRepresentable- 意味着它可以从字符串表示转换为字符串表示:
protocol StringRepresentable: CustomStringConvertible {
init?(_ string: String)
}
extension Int: StringRepresentable {}我们将上述协议基于CustomStringConvertible标准库,因为它已经包含了将值描述为字符串的属性要求。有关将协议定义为其他协议的特殊方法的更多信息,请查看“Swift中的专业协议”。
接下来,让我们创建另一个专用类型 - 这次是任何可以由字符串支持的值- 并且它包含解码和编码字符串值所需的所有代码:
struct StringBacked: Codable {
var value: Value
init(from decoder: Decoder) throws {
let container = try decoder.singleValueContainer()
let string = try container.decode(String.self)
guard let value = Value(string) else {
throw DecodingError.dataCorruptedError(
in: container,
debugDescription: """
Failed to convert an instance of \(Value.self) from "\(string)"
"""
)
}
self.value = value
}
func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
try container.encode(value.description)
}
} 就像我们之前为我们的JSON兼容的底层存储创建私有属性一样,我们现在可以对编码时由字符串后端的任何属性执行相同的操作 - 同时仍然将该数据暴露给我们的其余Swift代码类型。这是一个为Video类型的numberOfLikes属性做这样的例子:
struct Video: Codable {
var title: String
var description: String
var url: URL
var thumbnailImageURL: URL
var numberOfLikes: Int {
get { return likes.value }
set { likes.value = newValue }
}
private var likes: StringBacked
}在必须为属性手动定义setter和getter的复杂性以及必须回退到完全自定义Codable实现的复杂性之间肯定存在权衡- 但对于类似上述Video结构的类型,其仅具有需要的一个属性使用私有支持属性进行自定义可能是一个很好的选择。
结论
虽然编译器能够自动合成所有Codable不需要任何形式定制的一致性,但真正太棒了- 我们能够在需要时自定义事物同样非常棒。
更妙的是,这样做往往并不真正需要我们赞成手工执行的彻底抛弃自动生成的代码-这是很多次可能只是稍微调整一个类型的编码或解码的方式,同时还让编译器做大部分繁重的工作。
链接:https://www.jianshu.com/p/62162d01d1df
收起阅读 »CocoaPod知识整理
前言
Pod库是很重要的组成部分,大部分第三方库都是通过CocoaPod的方式引入和管理,同时项目中的部分功能也可以用Pod库来做模块化。
本文是对CocoaPod的一些探究。
XS项目中的Pod库是很重要的组成部分,目前阅读器模块正在进行SDK化,需要用Pod库来管理,同时未来会做一些模块化的功能,同样需要用Pod库来处理。
本文对CocoaPods的一些内容进行探究。
正文
CocoaPods是为iOS工程提供第三方依赖库管理的工具,用CocoaPods可以更方便地管理第三方库:把依赖库统一放在Pods工程中,同时让主工程依赖Pods工程。Pods工程的target是libPods-targetName.a静态库,主工程会依赖这个.a静态库。 (下面会详细剖析这个处理过程)
CocoaPods相比手动引入framework或者子工程依赖的方式,有两个便捷之处:
所有Pod库集中管理,版本更新只需Podfile配置文件;
依赖关系的自动解析;
同时CocoaPods的使用流程很简单:(假设已经安装CocoaPods)
1、在xcodeproj所在目录下,新建Podfile文件;
2、描述依赖信息,以demo为例,有AFNetworking和SDWebImage两个第三方库:
target 'LearnPod' do
pod 'AFNetworking'
pod 'SDWebImage'
end3、打开命令行,执行pod install ;
4、打开生成xcworkspace,就可以继续开发;
一、Podfile的写法
1、普通的写法;
pod 'AFNetworking' 或者 pod 'AFNetworking', '3.2.1',前者是下载最新版本,后者是下载指定版本。
2、指向本地的代码分支;
pod 'AFNetworking', :path => '/Users/loyinglin/Documents/Learn/AFNetworking'指向的本地目录要带有podspec文件。
3、指定远端的代码分支;
pod 'AFNetworking', :git => 'https://github.com/AFNetworking/AFNetworking.git', :branch => 'master'
指向的repo仓库要带有podspec文件。

4、针对特定的configurations用不同的依赖库
`pod 'AFNetworking', :configurations => ['Release']`如上,只有Release的configurations生效;(同理,可以设置Debug)

5、一些其他的feature
优化pod install速度,可以进行依赖打平:将pod库的依赖库明确的写在Podfile,主端已经提供对应的工具。
`require "bd_pod_extentions"`
`bytedanceAnalyzeSpeed(true)`
`bd_use_app('toutiao','thirdParty','public')`post install的脚本,修改安装后的Pod库工程中的target设置;同理,可以修改其他属性的设置。
post_install do |installer_representation|
installer_representation.pods_project.targets.each do |target|
target.build_configurations.each do |config|
config.build_settings['ONLY_ACTIVE_ARCH'] = 'NO'`
end
end
end类似的还有pre_install的脚本;(但是install之前可能都没有pods_project,所以用处也比较少;具体的参数意义可自查,以pods_project为例)
puts只有在添加--verbose参数可以看到,Pod::UI.puts则是全文可见。
pre_install do |installer|
puts "pre install hook"
Pod::UI.puts "pre install hook puts"
endPodfile还可以设置一些警告提示的去除,第一行是去掉pod install时候的警告信息,第二行是去掉build时候的警告信息。
# 去掉pod install时候的警告信息
install! 'cocoapods', :warn_for_multiple_pod_sources => false
inhibit_all_warnings二、Pods目录
Pods目录是pod install之后CocoaPod生成的目录。
目录的组成部分:
1、Pods.xcodeproj,Pods库的工程;每个Pod库会对应其中某个target,每个target都会打包出来一个.a文件;
2、依赖库的文件目录;以SDWebImage为例,会有个SDWebImage目录存放文件;
3、manifest.lock,Pods目录中的Pod库版本信息;每次pod install的时候会检查manifest.lock和Podfile.lock的版本是否一致,不一致的则会更新;
4、Target Support Files、Headers、Local Podspecs目录等;Target Support Files里面是一些target的工程设置xcconifg以及脚本等,Headers里面有Public和Private的头文件目录,Local Podspecs是存放从本地Pod库install时的podspec;
三、CocoaPods的其他重要部分
1.Podfile.lock文件
pod install会解析依赖并生成Podfile.lock文件;如果Podfile.lock存在时执行pod install,则不会修改已经install的pod库。(注意,pod update则会忽视Podfile.lock进行依赖解析,最后重新install所有的Pod库,生成新的Podfile.lock)
在多人开发的项目中,Pods目录由于体积较大,往往不会放在Git仓库中,Podfile.lock文件则建议添加到Git仓库。当其他人修改Podfile时,pod install生成新的Podfile.lock文件也会同步到Git。这样能保证拉下来的版本库是其他人一致的。
实际开发中,也会通过依赖打平来避免多人协作的Pod版本不一致问题。
pod install的时候,Pods目录下生成一个Manifest.lock文件,内容与.lock文件完全一致;在每次build工程的时候,会检查这两个文件是否一致。
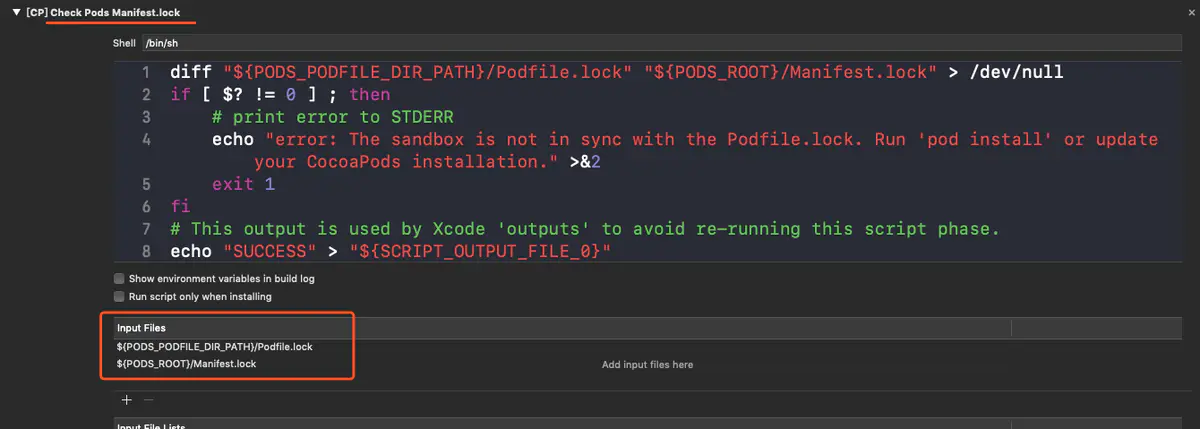
2、Pod库的podspec文件
在每个Pod库的仓库中,都会有一个podspec文件,描述Pod库的版本、依赖等信息。
如下,是一个普通的Pod库的podspec:

3、Pod库依赖解析
CocoaPod的依赖管理相对第三方库手动管理更加便捷。
在手动管理第三方库中,如果库A集成了库F,库B也集成了库F ,就会遇到库F符号冲突的问题,需要将库A/B和库F的代码分开,手动添加库F;后续如果库A/B版本有更新,也需要手动去处理。
而在CocoaPod依赖解析中,可以把每个Pod库都看成一个节点,Pod库的依赖是它的子节点; 依赖解析的过程,就是在一个有向图中找到一个拓扑序列。
一个合法的Podfile描述的应该是一个有向无环图,可以通过拓扑排序的方式,得到一个AOV网。
按照这个拓扑序列中的顶点次序,可以依次install所有的Pod库并且保证其依赖的库已经install。
有时候会陷入循环依赖的怪圈,就是因为在有向图中出现环,则无法通过算法得到一个拓扑排序。
四、Pods工程和主工程的关系
在实际的开发过程,容易知道Pods工程是先编译,编译完再执行主工程的编译;因为主工程的Linked Libraries里面有libPods-LearnPod.a的文件。(LearnPod是target的名字,下面的示例图都是用LearnPod作为target名)

那么Pod库中的target编译顺序是如何决定?
打开workspace,选择Pods工程。从上图分析我们知道,主工程最终需要的是libPods-LearnPod.a这一个静态库文件。
我们通常打包,最终名字都是target的名字;而静态库通常会在前面加上lib的前缀。所以libPods-LearnPod.a这个静态库的target名字应该是Pods-LearnPod。
从下图我们也可以确定,确实是在前面添加了lib的前缀。
看看Pods-LearnPod的Build Phases选项,从target依赖中可以看到其他两个target。
分析至此,我们可以知道这里的编译顺序是AFNetworking、SDWebImage、Pods-LearnPod、LeanPod(主工程target)。
接下来我们分析编译过程。AFNetworking因为没有依赖,所以编译的时候只需要知道自己的.h/.m文件。
对于Pods-LearnPod,其有两个依赖,分别是AFNetworking和SDWebImage;所以在Header Search Paths中需要设置这两个库的Public头文件地址。
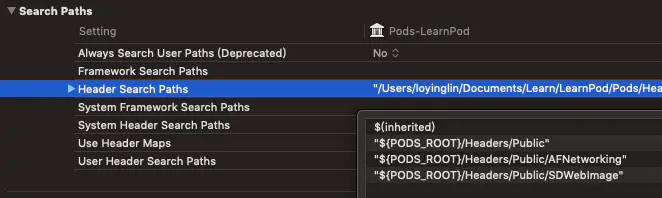
编译的结果是3个.a文件(libPods-LearnPod.a、libAFNetworking.a、libSDWebImage.a),只有libPods-LearnPod.a是主工程的编译依赖。那么libPods-LearnPod.a是否为多个.a文件的集合?
从libPods-LearnPod.a的大小,我们可以知道libPods-LearnPod不是多个.a的集合,仅仅是作为主工程的一个依赖,使得Pod库工程能先于主工程编译。
那么,主工程编译的时候如何去找到AFNetworking的头文件和.a文件?
从主工程的Search Paths我们可以看到,Header是有说明具体的位置;
同时Library也有相对应的Paths,在对应的位置放着libAFNetworking.a文件;
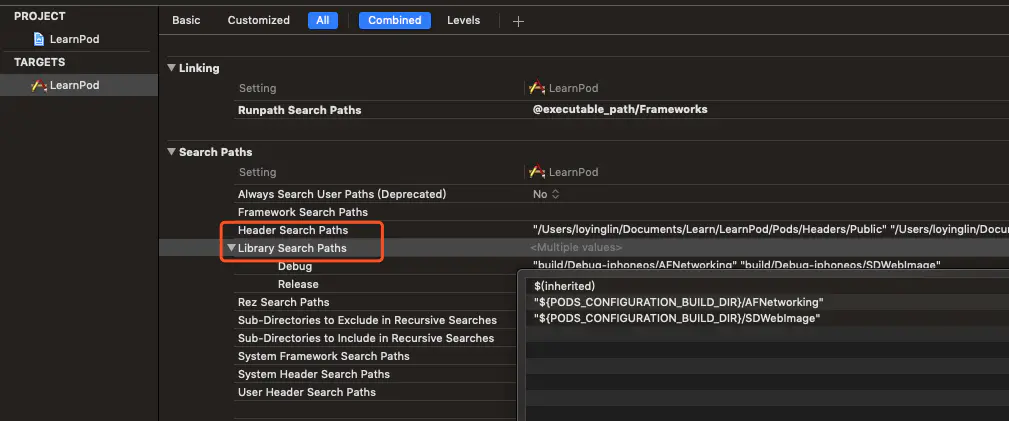
这些信息是CocoaPod生成的一份xcconfig,里面的HEADER_SEARCH_PATHS和LIBRARY_SEARCH_PATHS会指明这两个地址。
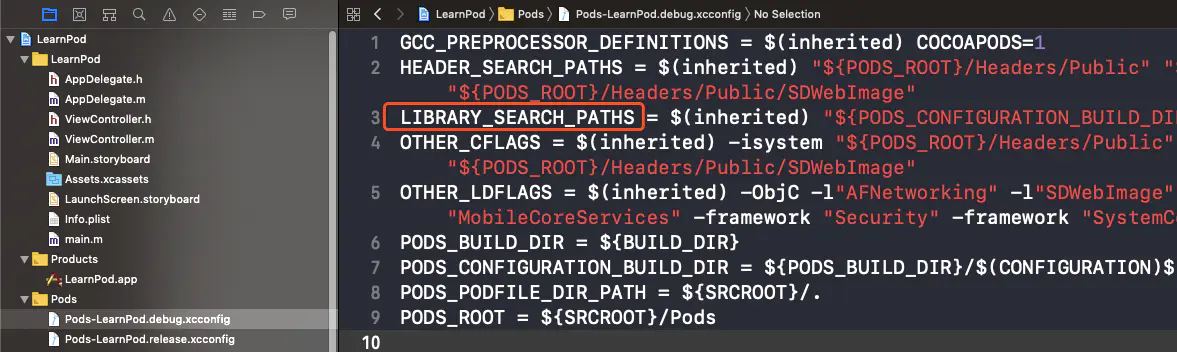
对于资源文件,CocoaPods 提供了一个名为 Pods-resources.sh 的 bash 脚本,该脚本在每次项目编译的时候都会执行,将第三方库的各种资源文件复制到目标目录中。
CocoaPods 通过一个名为 Pods.xcconfig 的文件来在编译时设置所有的依赖和参数。
在编译之前会检查pod的版本是否发生变化(manifest和.lock文件对比),以及执行一些自定义的脚本。
Pod库的子target在指定armv7和arm64两个架构的时候,会分别编译生成armv7和arm64的.a文件;然后再进行一次合并操作,得到一个.a文件。
编译完成后进行链接,在armv7和arm64都指定时,会分别进行链接,最后合并得到可执行文件。
得到可执行文件后,会进行asset、storyboard等资源文件的处理;还会执行pod的脚本,把pod的资源复制过来。
全部准备就绪,就会生成符号表,包括.a文件里面的符号。
最后进行签名、校验,得到.app文件。
五、常用Pod指令
pod install,最常用的指令;
pod update,更新repo并重新解析依赖;
pod install --repo-update,类似pod update;
pod install --no-repo-update,忽略Pod库更新,直接用本地repo进行install;
pod update --no-repo-update,类似pod install;
pod update AFNetworking,更新指定库;
以上所有指令都可以添加 --verbose ,查看更详细的信息;
xcconfig在新增configuration之后,需要重新pod install,并修改xcconfig。
转自:https://www.jianshu.com/p/07ddbd829efc
收起阅读 »可变共享结构(第二部分)
我们改进了新数据类型的观察能力。
在上一章中,我们构建了一个名为的struct / class混合类型 Var。今天我们将继续实验。
Var类包含一个结构,我们可以利用关键路径寻找到的结构。如果我们有一个people内部的阵列Var,我们希望采取先Person出数组,那么我们得到另一个Var与 Person。更新它Person会修改原始数组,这样我们就会给出Var引用语义。但是如果我们需要的话,我们仍然可以获得结构的复制行为:我们可以将结构值取出Var并具有本地副本。
我们也深入观察。只要有任何变化,根变量就会知道它。我们仍然有一个有点笨拙的API,因为我们Var使用observe闭包初始化,这意味着我们只能在初始化时在根级别添加一个观察者。我们想用一种addObserver方法改进这个API,并且如果我们想要观察根结构或任何其他属性,请使用它。
添加观察者
我们从初始化程序中删除观察者闭包并设置一个新addObserver方法。因为我们将大量使用观察者闭包,所以我们可以为它创建一个类型别名:
final class Var {
// ...
init(initialValue: A) {
var value: A = initialValue {
didSet {
}
}
_get = { value }
_set = { newValue in value = newValue }
}
typealias Observer = (A) -> ()
func addObserver(_ observer: @escaping Observer) {
}
// ... }以前,我们将一个观察者闭包连接到初始化器中的struct值,但现在我们无法访问那里的观察者。我们需要将所有观察者存储在一个地方,从一个空数组开始,然后连接观察者和结构值:
final class Var {
// ...
init(initialValue: A) {
var observers: [Observer] = []
var value: A = initialValue {
didSet {
for o in observers {
o(value)
}
}
}
_get = { value }
_set = { newValue in value = newValue }
}
// ... }现在我们仍然需要一种方法来向数组中添加一个观察者。我们重申我们做与技巧get,并set与转addObserver成一个属性,而不是一个方法:
final class Var {
let addObserver: (_ observer: @escaping Observer) -> ()
// ...
init(initialValue: A) {
var observers: [Observer] = []
var value: A = initialValue {
didSet {
for o in observers {
o(value)
}
}
}
_get = { value }
_set = { newValue in value = newValue }
addObserver = { observer in observers.append(observer) }
}
// ... }在我们可以使用之前addObserver,我们必须将它设置在我们的其他私有初始化程序中。为此,我们将从外部传入一个闭包,以便我们可以在下标实现中定义闭包:
fileprivate init(get: @escaping () -> A, set: @escaping (A) -> (), addObserver: @escaping (@escaping Observer) -> ()) {
_get = get
_set = set
self.addObserver = addObserver
}subscript(keyPath: WritableKeyPath) -> Var {
return Var(get: {
self.value[keyPath: keyPath]
}, set: { newValue in
self.value[keyPath: keyPath] = newValue
}, addObserver: { observer in
self.addObserver { newValue in
observer(newValue[keyPath: keyPath])
}
})
} 我们还在addObserver集合的下标中传递了一个类似的闭包:
extension Var where A: MutableCollection {
subscript(index: A.Index) -> Var {
return Var(get: {
self.value[index]
}, set: { newValue in
self.value[index] = newValue
}, addObserver: { observer in
self.addObserver { newValue in
observer(newValue[index])
}
})
}
} let peopleVar: Var<[Person]> = Var(initialValue: people)
peopleVar.addObserver { p in
print("peoplevar changed: \(p)")
}
let vc = PersonViewController(person: peopleVar[0])
vc.update()这会将peopleVar更改打印到控制台。但是,我们现在也可以添加一个观察者到Var
final class PersonViewController {
let person: Var
init(person: Var) {
self.person = person
self.person.addObserver { newPerson in
print(newPerson)
}
}
func update() {
person.value.last = "changed"
}
} 我们现在可以添加观察者,但我们无法删除它们。如果视图控制器因为其观察者仍然在那里而消失,这就成了问题。
我们可以采取类似于反应性图书馆工作方式的方法。添加观察者时,将返回不透明对象。通过保持对该对象的引用,我们保持观察者活着。当我们丢弃对象时,观察者将被删除。
我们使用一个名为的辅助类,Disposable它接受一个在对象取消时调用的dispose函数:
final class Disposable {
private let dispose: () -> ()
init(_ dispose: @escaping () -> ()) {
self.dispose = dispose
}
deinit {
dispose()
}
}我们更新签名addObserver返回Disposable:
final class Var {
private let _get: () -> A
private let _set: (A) -> ()
let addObserver: (_ observer: @escaping Observer) -> Disposable
// ... }如果我们想要删除观察者,我们必须改变观察者商店的数据结构。数组不再有效,因为无法比较函数以找到要删除的数组。相反,我们可以使用由唯一整数键入的字典:
final class Var {
// ...
init(initialValue: A) {
var observers: [Int:Observer] = [:]
// ...
}
// ... }final class Var {
// ...
init(initialValue: A) {
var observers: [Int:Observer] = [:]
// ...
var freshInt = (0...).makeIterator()
addObserver = { observer in
let id = freshInt.next()!
observers[id] = observer
// ...
}
}
// ... }我们现在将观察者存储在字典中。当我们不再使用它们时,剩下要做的就是丢弃观察者。我们返回一个Disposable 带有dispose函数的函数,该函数从字典中删除观察者:
final class Var {
// ...
init(initialValue: A) {
var observers: [Int:Observer] = [:]
// ...
var freshInt = (0...).makeIterator()
addObserver = { observer in
let id = freshInt.next()!
observers[id] = observer
return Disposable { observers[id] = nil }
}
}
// ... }最后,我们必须addObserver在私有初始化程序中修复签名,它仍然声明返回void而不是Disposable:
fileprivate init(get: @escaping () -> A, set: @escaping (A) -> (), addObserver: @escaping (@escaping Observer) -> Disposable) { /*...*/ }final class PersonViewController {
let person: Var
let disposable: Any?
init(person: Var) {
self.person = person
disposable = self.person.addObserver { newPerson in
print(newPerson)
}
}
func update() {
person.value.last = "changed"
}
} 注意:如果我们想self在观察者中使用,我们必须使它成为弱引用,以避免创建引用循环。
我们实现的一个重要方面是观察者不仅在观察到的Var变化时触发,而且在整个数据结构发生任何变化时触发。
如果PersonViewController想要确定它已经Person 改变了,它应该能够将新值与旧值进行比较。因此,我们将更改Observer类型别名以提供新值和旧值
typealias Observer = (A, A) -> ()这意味着使用新版本和旧版本调用观察者 A。为了明确这一点,我们应该将值包装在一个结构中,并在两个字段中描述它们是什么,但我们正在跳过该部分。
init(initialValue: A) {
// ...
var value: A = initialValue {
didSet {
for o in observers.values {
o(value, oldValue)
}
}
}
// ... }
subscript(keyPath: WritableKeyPath) -> Var {
return Var(get: {
self.value[keyPath: keyPath]
}, set: { newValue in
self.value[keyPath: keyPath] = newValue
}, addObserver: { observer in
self.addObserver { newValue, oldValue in
observer(newValue[keyPath: keyPath], oldValue[keyPath: keyPath])
}
})
} 而在MutableCollection标,我们也应该通过旧值观察员:
extension Var where A: MutableCollection {
subscript(index: A.Index) -> Var {
return Var(get: {
self.value[index]
}, set: { newValue in
self.value[index] = newValue
}, addObserver: { observer in
self.addObserver { newValue, oldValue in
observer(newValue[index], oldValue[index])
}
})
}
} 观察者PersonViewController可以比较新旧版本,看看它的模型是否确实改变了:
final class PersonViewController {
// ...
init(person: Var) {
self.person = person
disposable = self.person.addObserver { newPerson, oldPerson in
guard newPerson != oldPerson else { return }
print(newPerson)
}
}
// ... } peopleVar.addObserver { newPeople, oldPeople in
print("peoplevar changed: \(newPeople)")
}通过对视图控制器中的人进行更改,我们测试视图控制器的观察者忽略它:
peopleVar[1].value.first = "Test"在这段代码中还有一个令人惊讶的等待。我们将第一个Person从数组移交给视图控制器。如果我们然后删除people数组的第一个元素,视图控制器突然有一个不同的 Person:
peopleVar.value.removeFirst()的第一个元素是从阵列中删除,但Var在 PersonViewController仍然指向peopleVar[0]因为我们使用一个动态评估标。在大多数情况下,这是不希望的行为。一个可以改善这种行为的例子是有一个first(where:)允许我们通过标识符选择元素的方法。
到目前为止,我们对我们的建设感到兴奋。也许它可能改变我们编写应用程序的方式。或者,它可能仍然太实验性:我们设法编译代码,但我们不确定该技术将在何处以及如何破解。
即使我们不在Var实践中使用,我们也结合了很多有趣的功能,这些功能可以很好地展示Swift的强大功能:泛型,关键路径,闭包,变量捕获,协议和扩展。
将来,尝试只部分应用方面可能会很酷Var。假设我们有一个数据库接口,它从数据库中读取一个人模型并将其作为a返回Var。我们可以使用它自动将结构的更改保存回数据库。似乎会有像这样的例子,其中Var技术可能是有用的。
被忽视了的NSDataDetector
keywords
NSDataDetector NSRegularExpression NSTextCheckingResult
在日常开发场景中经常会遇到,在一段文本中检测一些半结构化的信息,比如:日期、地址段、链接、电话号码、交通信息、航班号、奇怪的格式化了的数字、甚至是相对的指示语等等。
如果这些需求在一个项目中出现,在不知道NSDataDetector这个类之前,可能要头皮发麻,之后开始自己编制一些正则,再加上国际化的需求,可能对编制好的正则需要大量的单元测试用例的介入。(估计好多小盆友要被这些东西整自闭了...)
幸运的是,对于 Cocoa 开发者来说,有一个简单的解决方案:NSDataDetector。
关于NSDataDetector
NSDataDetector 是 NSRegularExpression 的子类,而不只是一个 ICU 的模式匹配,它可以检测半结构化的信息:日期,地址,链接,电话号码和交通信息。
它以惊人的准确度完成这一切。NSDataDetector 可以匹配航班号,地址段,奇怪的格式化了的数字,甚至是相对的指示语,如 “下周六五点”。
你可以把它看成是一个有着复杂的令人难以置信的正则表达式匹配,可以从自然语言提取信息(尽管实际的实现细节可能比这个复杂得多)。
NSDataDetector 对象用一个需要检查的信息的位掩码类型来初始化,然后传入一个需要匹配的字符串。像 NSRegularExpression 一样,在一个字符串中找到的每个匹配是用 NSTextCheckingResult 来表示的,它有诸如字符范围和匹配类型的详细信息。然而,NSDataDetector 的特定类型也可以包含元数据,如地址或日期组件。
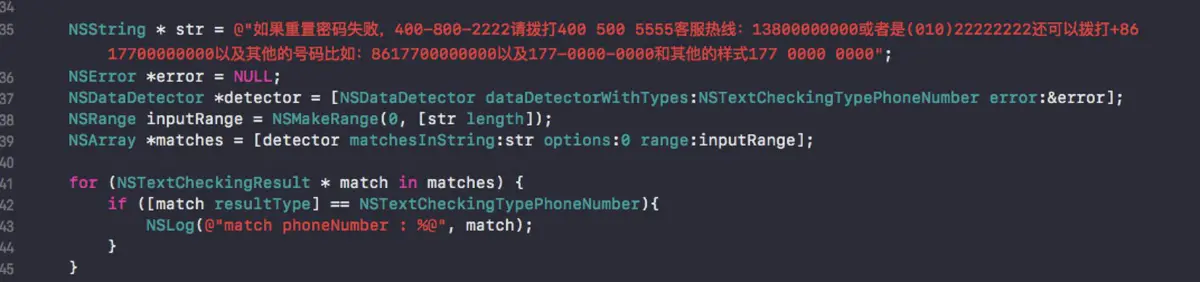
当然你也可以结合 YYKit 中的YYLabel进行文本的高亮展示,并且添加点击事件(以下是我项目中需要匹配文本中的手机号码):
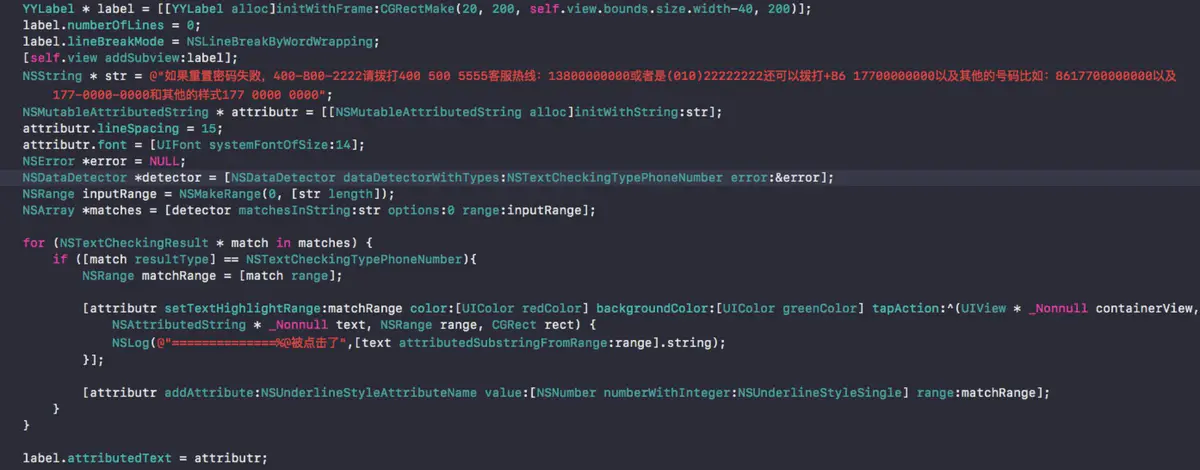
当初始化 NSDataDetector 的时候,确保只指定你感兴趣的类型。每当增加一个需要检查的类型,随着而来的是不小的性能损失为代价。
数据检测器匹配类型
NSDataDetector 的各种 NSTextCheckingTypes 匹配,及其相关属性表:
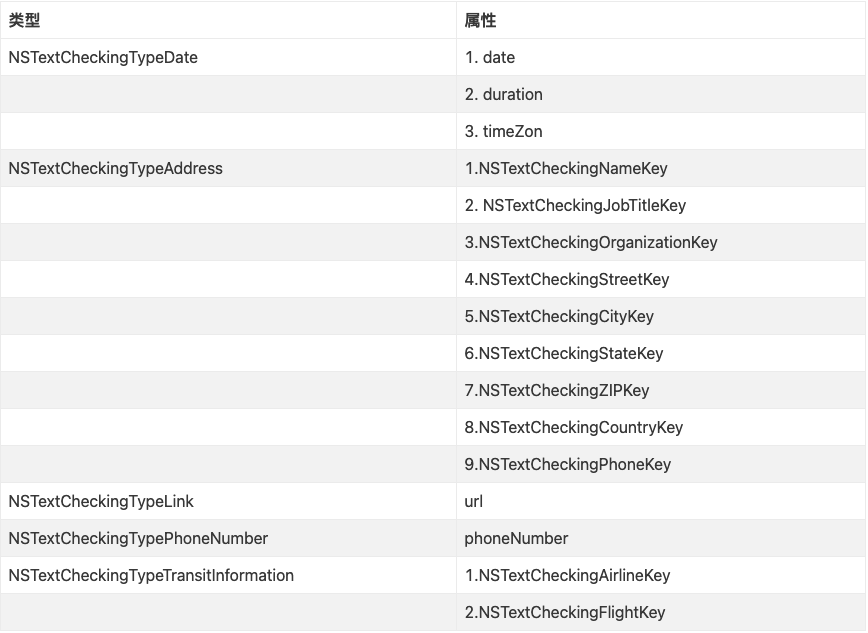
其他的一些注意事项可以自行参考 Mattt 的文章NSDataDetector自行进行查阅。
好了,大家可以进行尝试一下,在你的应用程序里充分利用 NSDataDetector 解锁那些已经隐藏在众目睽睽下的结构化信息吧。
参考自: https://developer.apple.com/documentation/foundation/nsregularexpression
https://developer.apple.com/documentation/foundation/nstextcheckingresult
https://nshipster.com/nsdatadetector
转自:https://www.jianshu.com/p/91daa300da26
收起阅读 »iOS完整文件拉流解析解码同步渲染音视频流
需求
解析文件中的音视频流以解码同步并将视频渲染到屏幕上,音频通过扬声器输出.对于仅仅需要单纯播放一个视频文件可直接使用AVFoundation中上层播放器,这里是用最底层的方式实现,可获取原始音视频帧数据.
实现原理
本文主要分为三大块,解析模块使用FFmpeg parse文件中的音视频流,解码模块使用FFmpeg或苹果原生解码器解码音视频,渲染模块使用OpenGL将视频流渲染到屏幕,使用Audio Queue Player将音频以扬声器形式输出.
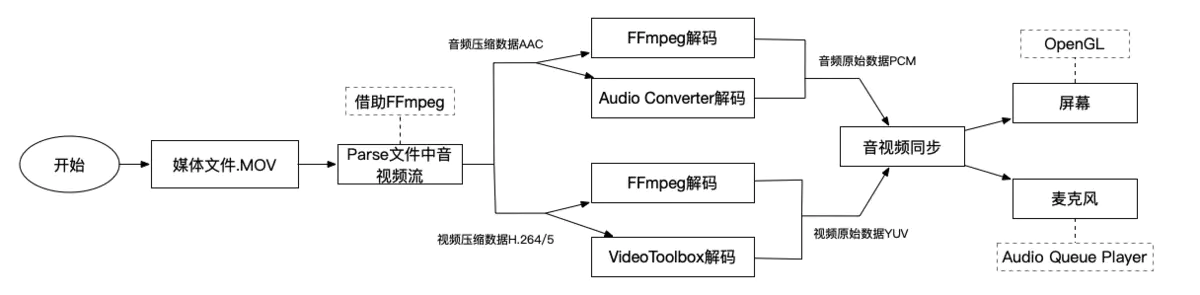
本文以解码一个.MOV媒体文件为例, 该文件中包含H.264编码的视频数据, AAC编码的音频数据,首先要通过FFmpeg去parse文件中的音视频流信息,parse出来的结果保存在AVPacket结构体中,然后分别提取音视频帧数据,音频帧通过FFmpeg解码器或苹果原生框架中的Audio Converter进行解码,视频通过FFmpeg或苹果原生框架VideoToolbox中的解码器可将数据解码,解码后的音频数据格式为PCM,解码后的视频数据格式为YUV原始数据,根据时间戳对音视频数据进行同步,最后将PCM数据音频传给Audio Queue以实现音频的播放,将YUV视频原始数据封装为CMSampleBufferRef数据结构并传给OpenGL以将视频渲染到屏幕上,至此一个完整拉取文件视频流的操作完成.
注意: 通过网址拉取一个RTMP流进行解码播放的流程与拉取文件流基本相同, 只是需要通过socket接收音视频数据后再完成解码及后续流程.
简易流程
Parse
创建AVFormatContext上下文对象: AVFormatContext *avformat_alloc_context(void);
从文件中获取上下文对象并赋值给指定对象: int avformat_open_input(AVFormatContext **ps, const char *url, AVInputFormat *fmt, AVDictionary **options)
读取文件中的流信息: int avformat_find_stream_info(AVFormatContext *ic, AVDictionary **options);
获取文件中音视频流: m_formatContext->streams[audio/video index]e
开始parse以获取文件中视频帧帧: int av_read_frame(AVFormatContext *s, AVPacket *pkt);
如果是视频帧通过av_bitstream_filter_filter生成sps,pps等关键信息.
读取到的AVPacket即包含文件中所有的音视频压缩数据.
解码
通过FFmpeg解码
获取文件流的解码器上下文: formatContext->streams[a/v index]->codec;
通过解码器上下文找到解码器: AVCodec *avcodec_find_decoder(enum AVCodecID id);
打开解码器: int avcodec_open2(AVCodecContext *avctx, const AVCodec *codec, AVDictionary **options);
将文件中音视频数据发送给解码器: int avcodec_send_packet(AVCodecContext *avctx, const AVPacket *avpkt);
循环接收解码后的音视频数据: int avcodec_receive_frame(AVCodecContext *avctx, AVFrame *frame);
如果是音频数据可能需要重新采样以便转成设备支持的格式播放.(借助SwrContext)
通过VideoToolbox解码视频
将从FFmpeg中parse到的extra data中分离提取中NALU头关键信息sps,pps等
通过上面提取的关键信息创建视频描述信息:CMVideoFormatDescriptionRef, CMVideoFormatDescriptionCreateFromH264ParameterSets / CMVideoFormatDescriptionCreateFromHEVCParameterSets
创建解码器:VTDecompressionSessionCreate,并指定一系列相关参数.
将压缩数据放入CMBlockBufferRef中:CMBlockBufferCreateWithMemoryBlock
开始解码: VTDecompressionSessionDecodeFrame
在回调中接收解码后的视频数据
通过AudioConvert解码音频
通过原始数据与解码后数据格式的ASBD结构体创建解码器: AudioConverterNewSpecific
指定解码器类型AudioClassDescription
开始解码: AudioConverterFillComplexBuffer
注意: 解码的前提是每次需要有1024个采样点才能完成一次解码操作.
同步
因为这里解码的是本地文件中的音视频, 也就是说只要本地文件中音视频的时间戳打的完全正确,我们解码出来的数据是可以直接播放以实现同步的效果.而我们要做的仅仅是保证音视频解码后同时渲染.
注意: 比如通过一个RTMP地址拉取的流因为存在网络原因可能造成某个时间段数据丢失,造成音视频不同步,所以需要有一套机制来纠正时间戳.大体机制即为视频追赶音频,后面会有文件专门介绍,这里不作过多说明.
渲染
通过上面的步骤获取到的视频原始数据即可通过封装好的OpenGL ES直接渲染到屏幕上,苹果原生框架中也有GLKViewController可以完成屏幕渲染.音频这里通过Audio Queue接收音频帧数据以完成播放.
文件结构
快速使用
使用FFmpeg解码
首先根据文件地址初始化FFmpeg以实现parse音视频流.然后利用FFmpeg中的解码器解码音视频数据,这里需要注意的是,我们将从读取到的第一个I帧开始作为起点,以实现音视频同步.解码后的音频要先装入传输队列中,因为audio queue player设计模式是不断从传输队列中取数据以实现播放.视频数据即可直接进行渲染.
- (void)startRenderAVByFFmpegWithFileName:(NSString *)fileName {
NSString *path = [[NSBundle mainBundle] pathForResource:fileName ofType:@"MOV"];
XDXAVParseHandler *parseHandler = [[XDXAVParseHandler alloc] initWithPath:path];
XDXFFmpegVideoDecoder *videoDecoder = [[XDXFFmpegVideoDecoder alloc] initWithFormatContext:[parseHandler getFormatContext] videoStreamIndex:[parseHandler getVideoStreamIndex]];
videoDecoder.delegate = self;
XDXFFmpegAudioDecoder *audioDecoder = [[XDXFFmpegAudioDecoder alloc] initWithFormatContext:[parseHandler getFormatContext] audioStreamIndex:[parseHandler getAudioStreamIndex]];
audioDecoder.delegate = self;
static BOOL isFindIDR = NO;
[parseHandler startParseGetAVPackeWithCompletionHandler:^(BOOL isVideoFrame, BOOL isFinish, AVPacket packet) {
if (isFinish) {
isFindIDR = NO;
[videoDecoder stopDecoder];
[audioDecoder stopDecoder];
dispatch_async(dispatch_get_main_queue(), ^{
self.startWorkBtn.hidden = NO;
});
return;
}
if (isVideoFrame) { // Video
if (packet.flags == 1 && isFindIDR == NO) {
isFindIDR = YES;
}
if (!isFindIDR) {
return;
}
[videoDecoder startDecodeVideoDataWithAVPacket:packet];
}else { // Audio
[audioDecoder startDecodeAudioDataWithAVPacket:packet];
}
}];
}
-(void)getDecodeVideoDataByFFmpeg:(CMSampleBufferRef)sampleBuffer {
CVPixelBufferRef pix = CMSampleBufferGetImageBuffer(sampleBuffer);
[self.previewView displayPixelBuffer:pix];
}
- (void)getDecodeAudioDataByFFmpeg:(void *)data size:(int)size pts:(int64_t)pts isFirstFrame:(BOOL)isFirstFrame {
// NSLog(@"demon test - %d",size);
// Put audio data from audio file into audio data queue
[self addBufferToWorkQueueWithAudioData:data size:size pts:pts];
// control rate
usleep(14.5*1000);
}使用原生框架解码
首先根据文件地址初始化FFmpeg以实现parse音视频流.这里首先根据文件中实际的音频流数据构造ASBD结构体以初始化音频解码器,然后将解码后的音视频数据分别渲染即可.这里需要注意的是,如果要拉取的文件视频是H.265编码格式的,解码出来的数据的因为含有B帧所以时间戳是乱序的,我们需要借助一个链表对其排序,然后再将排序后的数据渲染到屏幕上.
- (void)startRenderAVByOriginWithFileName:(NSString *)fileName {
NSString *path = [[NSBundle mainBundle] pathForResource:fileName ofType:@"MOV"];
XDXAVParseHandler *parseHandler = [[XDXAVParseHandler alloc] initWithPath:path];
XDXVideoDecoder *videoDecoder = [[XDXVideoDecoder alloc] init];
videoDecoder.delegate = self;
// Origin file aac format
AudioStreamBasicDescription audioFormat = {
.mSampleRate = 48000,
.mFormatID = kAudioFormatMPEG4AAC,
.mChannelsPerFrame = 2,
.mFramesPerPacket = 1024,
};
XDXAduioDecoder *audioDecoder = [[XDXAduioDecoder alloc] initWithSourceFormat:audioFormat
destFormatID:kAudioFormatLinearPCM
sampleRate:48000
isUseHardwareDecode:YES];
[parseHandler startParseWithCompletionHandler:^(BOOL isVideoFrame, BOOL isFinish, struct XDXParseVideoDataInfo *videoInfo, struct XDXParseAudioDataInfo *audioInfo) {
if (isFinish) {
[videoDecoder stopDecoder];
[audioDecoder freeDecoder];
dispatch_async(dispatch_get_main_queue(), ^{
self.startWorkBtn.hidden = NO;
});
return;
}
if (isVideoFrame) {
[videoDecoder startDecodeVideoData:videoInfo];
}else {
[audioDecoder decodeAudioWithSourceBuffer:audioInfo->data
sourceBufferSize:audioInfo->dataSize
completeHandler:^(AudioBufferList * _Nonnull destBufferList, UInt32 outputPackets, AudioStreamPacketDescription * _Nonnull outputPacketDescriptions) {
// Put audio data from audio file into audio data queue
[self addBufferToWorkQueueWithAudioData:destBufferList->mBuffers->mData size:destBufferList->mBuffers->mDataByteSize pts:audioInfo->pts];
// control rate
usleep(16.8*1000);
}];
}
}];
}
- (void)getVideoDecodeDataCallback:(CMSampleBufferRef)sampleBuffer isFirstFrame:(BOOL)isFirstFrame {
if (self.hasBFrame) {
// Note : the first frame not need to sort.
if (isFirstFrame) {
CVPixelBufferRef pix = CMSampleBufferGetImageBuffer(sampleBuffer);
[self.previewView displayPixelBuffer:pix];
return;
}
[self.sortHandler addDataToLinkList:sampleBuffer];
}else {
CVPixelBufferRef pix = CMSampleBufferGetImageBuffer(sampleBuffer);
[self.previewView displayPixelBuffer:pix];
}
}
#pragma mark - Sort Callback
- (void)getSortedVideoNode:(CMSampleBufferRef)sampleBuffer {
int64_t pts = (int64_t)(CMTimeGetSeconds(CMSampleBufferGetPresentationTimeStamp(sampleBuffer)) * 1000);
static int64_t lastpts = 0;
// NSLog(@"Test marigin - %lld",pts - lastpts);
lastpts = pts;
[self.previewView displayPixelBuffer:CMSampleBufferGetImageBuffer(sampleBuffer)];
}具体实现
本文中每一部分的具体实现均有详细介绍, 如需帮助请参考阅读前提中附带的链接地址.
注意
因为不同文件中压缩的音视频数据格式不同,这里仅仅兼容部分格式,可自定义进行扩展.
转自:https://www.jianshu.com/p/854a1bb47173
收起阅读 »SDWebImage加载多张高分辨图片crash
项目中有一个控制器里的图片服务器那边没有进行压缩 所以使用SDWebImage显示在collectionView/tableView的时候有时会crash(及时没有反复进几次就会crash了)。网上查了很多资料,大致总结有一下几种方法:
1、每次加载高清图片时清空memcache
[[SDImageCache sharedImageCache] setValue:nil forKey:@"memCache"];但是这种方法会产生一个效果:当滑动tableView的时候 cell消失在屏幕中再滑回来图片会从新加载。
2.取消解压缩
[SDImageCache sharedImageCache].shouldDecompressImages = NO;
[SDWebImageDownloader sharedDownloader].shouldDecompressImages = NO;之所以产生crash的原因,是因为在SDWebImage里的这个方法decodedImageWithImage在加载高清图片是占用了大量内存。所以上面的两行代码就禁止调用了这个方法,那么问题来了,那这个方法存在的意义又是什么呢?
因为我们对图片的展示大部分是在tableviews/collectionview里 其实decodedImageWithImage方法是对图片进行解压缩并且缓存起来,以提高流畅度。但是加载高分辨率的图片就会起到适得其反的效果。所以在加载高分辨率图片的地方调用以上两个方法,其他地方仍然保持为YES就可以了。如果再限制图片内存缓存最高限制就更安全了

3.对图片进行等比例压缩(需修改源码)
这里面对图片的处理是直接按照原大小进行的,如果分辨率很大这里导致占用了大量内存。所以我们需要在这里对图片做一次等比的压缩。
在UIImage+MultiFormat这个类里面添加如下压缩方法
+(UIImage *)compressImageWith:(UIImage *)image{
float imageWidth = image.size.width;
float imageHeight = image.size.height;
float width = 640;
float height = image.size.height/(image.size.width/width);
float widthScale = imageWidth /width;
float heightScale = imageHeight /height;
// 创建一个bitmap的context
// 并把它设置成为当前正在使用的context
UIGraphicsBeginImageContext(CGSizeMake(width, height));
if (widthScale > heightScale) {
[image drawInRect:CGRectMake(0, 0, imageWidth /heightScale , height)];
}
else {
image drawInRect:CGRectMake(0, 0, width , imageHeight /widthScale)];
}
// 从当前context中创建一个改变大小后的图片
UIImage *newImage = UIGraphicsGetImageFromCurrentImageContext();
// 使当前的context出堆栈
UIGraphicsEndImageContext();
return newImage;
}在上图箭头位置这样调用
image = [[UIImage alloc] initWithData:data];
if (data.length/1024 > 128) {
image = [self compressImageWith:image];
}到了这里还需要进行最后一步。就是在SDWebImageDownloaderOperation的connectionDidFinishLoading方法里面的:
UIImage *image = [UIImage sd_imageWithData:self.imageData];
//将等比压缩过的image在赋在转成data赋给self.imageData
NSData *data = UIImageJPEGRepresentation(image, 1);
self.imageData = [NSMutableData dataWithData:data];但是我在尝试这个方法的时候只这样操作的话还是会crash,所以还是要配合下面这个方法使用,所以那个郁闷啊!!!!大家也可以尝试一下
[[SDImageCache sharedImageCache] setValue:nil forKey:@"memCache"];
最终我是选择了第二种。欢迎补充!
链接:https://www.jianshu.com/p/7013919c03eb
收起阅读 »优雅的处理 iOS 中复杂的 Table Views
Table views 是 iOS 开发中最重要的布局组件之一。通常我们的一些最重要的页面都是 table views:feed 流,设置页,条目列表等。
每个开发复杂的 table view 的 iOS 开发者都知道这样的 table view 会使代码很快就变的很粗糙。这样会产生包含大量 UITableViewDataSource 方法和大量 if 和 switch 语句的巨大的 view controller。加上数组索引计算和偶尔的越界错误,你会在这些代码中遭受很多挫折。
我会给出一些我认为有益(至少在现在是有益)的原则,它们帮助我解决了很多问题。这些建议并不仅仅针对复杂的 table view,对你所有的 table view 来说它们都能适用。
我们来看一下一个复杂的 UITableView 的例子。

这是 PokeBall,一个为 Pokémon 定制的社交网络。像其它社交网络一样,它需要一个 feed 流来显示跟用户相关的不同事件。这些事件包括新的照片和状态信息,按天进行分组。所以,现在我们有两个需要担心的问题:一是 table view 有不同的状态,二是多个 cell 和 section。
1. 让 cell 处理一些逻辑
我见过很多开发者将 cell 的配置逻辑放到 cellForRowAt: 方法中。仔细思考一下,这个方法的目的是创建一个 cell。UITableViewDataSource 的目的是提供数据。数据源的作用不是用来设置按钮字体的。
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(
withIdentifier: identifier,
for: indexPath) as! StatusTableViewCell
let status = statuses[indexPath.row]
cell.statusLabel.text = status.text
cell.usernameLabel.text = status.user.name
cell.statusLabel.font = .boldSystemFont(ofSize: 16)
return cell
}你应该把配置和设置 cell 样式的代码放到 cell 中。如果是一些在 cell 的整个生命周期都存在的东西,例如一个 label 的字体,就应该把它放在 awakeFromNib 方法中。
class StatusTableViewCell: UITableViewCell {
@IBOutlet weak var statusLabel: UILabel!
@IBOutlet weak var usernameLabel: UILabel!
override func awakeFromNib() {
super.awakeFromNib()
statusLabel.font = .boldSystemFont(ofSize: 16)
}
}另外你也可以给属性添加观察者来设置 cell 的数据。
var status: Status! {
didSet {
statusLabel.text = status.text
usernameLabel.text = status.user.name
}
}那样的话你的 cellForRow 方法就变得简洁易读了。
func tableView(_ tableView: UITableView,
cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(
withIdentifier: identifier,
for: indexPath) as! StatusTableViewCell
cell.status = statuses[indexPath.row]
return cell
}此外,cell 的设置逻辑现在被放置在一个单独的地方,而不是散落在 cell 和 view controller 中。
2. 让 model 处理一些逻辑
通常,你会用从某个后台服务中获取的一组 model 对象来填充一个 table view。然后 cell 需要根据 model 来显示不同的内容。
var status: Status! {
didSet {
statusLabel.text = status.text
usernameLabel.text = status.user.name
if status.comments.isEmpty {
commentIconImageView.image = UIImage(named: "no-comment")
} else {
commentIconImageView.image = UIImage(named: "comment-icon")
}
if status.isFavorite {
favoriteButton.setTitle("Unfavorite", for: .normal)
} else {
favoriteButton.setTitle("Favorite", for: .normal)
}
}
}你可以创建一个适配 cell 的对象,传入上文提到的 model 对象来初始化它,在其中计算 cell 中需要的标题,图片以及其它属性。
class StatusCellModel {
let commentIcon: UIImage
let favoriteButtonTitle: String
let statusText: String
let usernameText: String
init(_ status: Status) {
statusText = status.text
usernameText = status.user.name
if status.comments.isEmpty {
commentIcon = UIImage(named: "no-comments-icon")!
} else {
commentIcon = UIImage(named: "comments-icon")!
}
favoriteButtonTitle = status.isFavorite ? "Unfavorite" : "Favorite"
}
}现在你可以将大量的展示 cell 的逻辑移到 model 中。你可以独立地实例化并单元测试你的 model 了,不需要在单元测试中做复杂的数据模拟和 cell 获取了。这也意味着你的 cell 会变得非常简单易读。
var model: StatusCellModel! {
didSet {
statusLabel.text = model.statusText
usernameLabel.text = model.usernameText
commentIconImageView.image = model.commentIcon
favoriteButton.setTitle(model.favoriteButtonTitle, for: .normal)
}
}这是一种类似于 MVVM 的模式,只是应用在一个单独的 table view 的 cell 中。
3. 使用矩阵(但是把它弄得漂亮点)
分组的 table view 经常乱成一团。你见过下面这种情况吗?
func tableView(_ tableView: UITableView, titleForHeaderInSection section: Int) -> String? {
switch section {
case 0: return "Today"
case 1: return "Yesterday"
default: return nil
}
}这一大团代码中,使用了大量的硬编码的索引,而这些索引本应该是简单并且易于改变和转换的。对这个问题有一个简单的解决方案:矩阵。
记得矩阵么?搞机器学习的人以及一年级的计算机科学专业的学生会经常用到它,但是应用开发者通常不会用到。如果你考虑一个分组的 table view,其实你是在展示分组的列表。每个分组是一个 cell 的列表。听起来像是一个数组的数组,或者说矩阵。

矩阵才是你组织分组 table view 的正确姿势。用数组的数组来替代一维的数组。 UITableViewDataSource 的方法也是这样组织的:你被要求返回第 m 组的第 n 个 cell,而不是 table view 的第 n 个 cell。
var cells: [[Status]] = [[]]
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(
withIdentifier: identifier,
for: indexPath) as! StatusTableViewCell
cell.status = statuses[indexPath.section][indexPath.row]
return cell
}我们可以通过定义一个分组容器类型来扩展这个思路。这个类型不仅持有一个特定分组的 cell,也持有像分组标题之类的信息。
struct Section {
let title: String
let cells: [Status]
}
var sections: [Section] = []现在我们可以避免之前 switch 中使用的硬编码索引了,我们定义一个分组的数组并直接返回它们的标题。
func tableView(_ tableView: UITableView,
titleForHeaderInSection section: Int) -> String? {
return sections[section].title
}这样在我们的数据源方法中代码更少了,相应地也减少了越界错误的风险。代码的表达力和可读性也变得更好。
4. 枚举是你的朋友
处理多种 cell 的类型有时候会很棘手。例如在某种 feed 流中,你不得不展示不同类型的 cell,像是图片和状态信息。为了保持代码优雅以及避免奇怪的数组索引计算,你应该将各种类型的数据存储到同一个数组中。
然而数组是同质的,意味着你不能在同一个数组中存储不同的类型。面对这个问题首先想到的解决方案是协议。毕竟 Swift 是面向协议的。
你可以定义一个 FeedItem 协议,并且让我们的 cell 的 model 对象都遵守这个协议。
protocol FeedItem {}
struct Status: FeedItem { ... }
struct Photo: FeedItem { ... }然后定义一个持有 FeedItem 类型对象的数组。
var cells: [FeedItem] = []但是,用这个方案实现 cellForRowAt: 方法时,会有一个小问题。
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cellModel = cells[indexPath.row]
if let model = cellModel as? Status {
let cell = ...
return cell
} else if let model = cellModel as? Photo {
let cell = ...
return cell
} else {
fatalError()
}
}在让 model 对象遵守协议的同时,你丢失了大量你实际上需要的信息。你对 cell 进行了抽象,但是实际上你需要的是具体的实例。所以,你最终必须检查是否可以将 model 对象转换成某个类型,然后才能据此显示 cell。
这样也能达到目的,但是还不够好。向下转换对象类型内在就是不安全的,而且会产生可选类型。你也无法得知是否覆盖了所有的情况,因为有无限的类型可以遵守你的协议。所以你还需要调用 fatalError 方法来处理意外的类型。
当你试图把一个协议类型的实例转化成具体的类型时,代码的味道就不对了。使用协议是在你不需要具体的信息时,只要有原始数据的一个子集就能完成任务。
更好的实现是使用枚举。那样你可以用 switch 来处理它,而当你没有处理全部情况时代码就无法编译通过。
enum FeedItem {
case status(Status)
case photo(Photo)
}枚举也可以具有关联的值,所以也可以在实际的值中放入需要的数据。
数组依然是那样定义,但你的 cellForRowAt: 方法会变的清爽很多:
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cellModel = cells[indexPath.row]
switch cellModel {
case .status(let status):
let cell = ...
return cell
case .photo(let photo):
let cell = ...
return cell
}
}这样你就没有类型转换,没有可选类型,没有未处理的情况,所以也不会有 bug。
5. 让状态变得明确

空白的页面可能会使用户困惑,所以我们一般在 table view 为空时在页面上显示一些消息。我们也会在加载数据时显示一个加载标记。但是如果页面出了问题,我们最好告诉用户发生了什么,以便他们知道如何解决问题。
我们的 table view 通常拥有所有的这些状态,有时候还会更多。管理这些状态就有些痛苦了。
我们假设你有两种可能的状态:显示数据,或者一个提示用户没有数据的视图。初级开发者可能会简单的通过隐藏 table view,显示无数据视图来表明“无数据”的状态。
noDataView.isHidden = false
tableView.isHidden = true在这种情况下改变状态意味着你要修改两个布尔值属性。在 view controller 的另一部分中,你可能想修改这个状态,你必须牢记你要同时修改这两个属性。
实际上,这两个布尔值总是同步变化的。不能显示着无数据视图的时候,又在列表里显示一些数据。
我们有必要思考一下实际中状态的数值和应用中可能出现的状态数值有何不同。两个布尔值有四种可能的组合。这表示你有两种无效的状态,在某些情况下你可能会变成这些无效的状态值,你必须处理这种意外情况。
你可以通过定义一个 State 枚举来解决这个问题,枚举中只列举你的页面可能出现的状态。
enum State {
case noData
case loaded
}
var state: State = .noData你也可以定义一个单独的 state 属性,来作为修改页面状态的唯一入口。每当该属性变化时,你就更新页面到相应的状态。
var state: State = .noData {
didSet {
switch state {
case .noData:
noDataView.isHidden = false
tableView.isHidden = true
case .loaded:
noDataView.isHidden = false
tableView.isHidden = true
}
}
}如果你只通过这个属性来修改状态,就能保证不会忘记修改某个布尔值属性,也就不会使页面处于无效的状态中。现在改变页面状态就变得简单了。
self.state = .noData可能的状态数量越多,这种模式就越有用。
你甚至可以通过关联值将错误信息和列表数据都放置在枚举中。
enum State {
case noData
case loaded([Cell])
case error(String)
}
var state: State = .noData {
didSet {
switch state {
case .noData:
noDataView.isHidden = false
tableView.isHidden = true
errorView.isHidden = true
case .loaded(let cells):
self.cells = cells
noDataView.isHidden = true
tableView.isHidden = false
errorView.isHidden = true
case .error(let error):
errorView.errorLabel.text = error
noDataView.isHidden = true
tableView.isHidden = true
errorView.isHidden = false
}
}
}至此你定义了一个单独的数据结构,它完全满足了整个 table view controller 的数据需求。它 易于测试(因为它是一个纯 Swift 值),为 table view 提供了一个唯一更新入口和唯一数据源。欢迎来到易于调试的新世界!
几点建议
还有几点不值得单独写一节的小建议,但是它们依然很有用:
响应式!
确保你的 table view 总是展示数据源的当前状态。使用一个属性观察者来刷新 table view,不要试图手动控制刷新。
var cells: [Cell] = [] {
didSet {
tableView.reloadData()
}
}Delegate != View Controller
任何对象和结构都可以实现某个协议!你下次写一个复杂的 table view 的数据源或者代理时一定要记住这一点。有效而且更优的做法是定义一个类型专门用作 table view 的数据源。这样会使你的 view controller 保持整洁,把逻辑和责任分离到各自的对象中。
不要操作具体的索引值!
如果你发现自己在处理某个特定的索引值,在分组中使用 switch 语句以区别索引值,或者其它类似的逻辑,那么你很有可能做了错误的设计。如果你在特定的位置需要特定的 cell,你应该在源数据的数组中体现出来。不要在代码中手动地隐藏这些 cell。
牢记迪米特法则
简而言之,迪米特法则(或者最少知识原则)指出,在程序设计中,实例应该只和它的朋友交谈,而不能和朋友的朋友交谈。等等,这是说的啥?
换句话说,一个对象只应访问它自身的属性。不应该访问其属性的属性。因此, UITableViewDataSource 不应该设置 cell 的 label 的 text 属性。如果你看见一个表达式中有两个点(cell.label.text = ...),通常说明你的对象访问的太深入了。
如果你不遵循迪米特法则,当你修改 cell 的时候你也不得不同时修改数据源。将 cell 和数据源解耦使得你在修改其中一项时不会影响另一项。
小心错误的抽象
有时候,多个相近的 UITableViewCell 类 会比一个包含大量 if 语句的 cell 类要好得多。你不知道未来它们会如何分歧,抽象它们可能会是设计上的陷阱。YAGNI(你不会需要它)是个好的原则,但有时候你会实现成 YJMNI(你只是可能需要它)。
链接:https://www.jianshu.com/p/9417d01d7841
收起阅读 »数据时代之非侵入式埋点方案
在发展日新月异的移动互联网时代,数据扮演着极其重要的角色。埋点作为一种最简单最直接的用户行为统计方式,能够全面精确的采集用户的使用习惯以及各功能点的迭代反馈等等,有了这些数据才能更好的驱动产品的决策设计和新业务场景的规划。本文旨在提出一种轻量级非侵入式的埋点方案,其主要有以下三方面优势
支持动态下发埋点配置
物理隔离埋点代码和业务代码
插件式的埋点功能实现
该方案通过维护一个JSON文件来指定埋点所在的类和方法,继而利用AOP的方式在对应的类和方法执行时动态嵌入埋点代码。对于需要逻辑判断来确定埋点值的场景,提供hook方法的入参,以及所在类的属性值读取,根据相应的状态值设置不同的埋点
埋点配置
埋点配置JSON表中包含需要hook的类名class和具体的事件event信息,event中包括hook的方法和对应的埋点值。如下所示
{
"version": "0.1.0",
"tracking": [
{
"class": "RJMainViewController",
"event": {
"rj_main_tracking": [
"tripTypeViewChangedWithIndex:",
"tripLabClickWithLabKey:"
],
"user_fp_slide_click": "clickNavLeftBtn",
"user_fp_reflocate_click": "clickLocationBtn"
}
},
{
"class": "RJTripHistoryViewModel",
"event": {
"user_mytrip_show": "tableView:didSelectRowAtIndexPath:"
}
},
{
"class": "RJTripViewController",
"event": {
"rj_trip_tracking": "callServiceEvent"
}
}
]
}简单来说就是本来埋点需要手动在该方法写入埋点代码来记录埋点值,现在通过AOP的方式物理隔离埋点代码和业务代码,避免埋点的逻辑侵入污染业务逻辑。埋点包括固定埋点和需要逻辑判断的场景化埋点,固定埋点如下所示
{
"class": "RJTripHistoryViewModel",
"event": {
"user_mytrip_show": "tableView:didSelectRowAtIndexPath:"
}
}RJTripHistoryViewModel为类名,tableView:didSelectRowAtIndexPath:为需要hook的该类中的方法,而user_mytrip_show则是具体的埋点值,也就是当RJTripHistoryViewModel中的tableView:didSelectRowAtIndexPath:方法执行的时候记录埋点值user_mytrip_show
{
"class": "RJTripViewController",
"event": {
"rj_trip_tracking": "callServiceEvent"
}
},对于场景化埋点,则需要提供一个impl类来提供相应的逻辑判断。比如上述配置表中的rj_trip_tracking为场景埋点的实现类,在该类中根据状态量返回对应的埋点值,即当callServiceEvent方法执行时会去找rj_trip_tracking这个埋点impl同名类,取该类返回的埋点值记录埋点。需要注意到是event中的key值既可以作为埋点值也可以作为impl的类名,埋点库会首先判断是否存在对应的类,存在即认为是impl实现类,从该类中取具体的埋点值。反之,则认为是固定埋点值
配置表中的类名和方法名需要对应,在hook的时候会去匹配,如果发现类中不存在对应的方法,则会自动触发断言
固定埋点
对于固定的埋点,只需要在对应的方法执行时直接记录埋点,利用Aspects来hook指定的类和方法,代码如下所示
[class aspect_hookSelector:sel withOptions:AspectPositionBefore usingBlock:^(id<AspectInfo> info) {
[events enumerateObjectsUsingBlock:^(NSString *name, NSUInteger idx, BOOL *stop) {
NSLog(@"<RJEventTracking> - %@", ename);
}];
} error:&error];为了便于检测无效的埋点,还需对hook的类和方法进行匹配校验,若类中没有对应的方法,则抛出断言
+ (void)checkValidWithClass:(NSString *)class method:(NSString *)method {
SEL sel = NSSelectorFromString(method);
Class c = NSClassFromString(class);
BOOL respond = [c respondsToSelector:sel] || [c instancesRespondToSelector:sel];
NSString *err = [NSString stringWithFormat:@"<RJEventTracking> - no specified method: %@ found on class: %@, please check", method, class];
NSAssert(respond, err);
}场景埋点
场景化埋点主要为同一事件但是在多种状态或逻辑下不同埋点的情况,比如同是联系客服的操作,在各种订单类型以及订单状态下所设置的埋点是不同的。这个情况下,埋点库通过提供一个protocol由埋点impl类来实现,根据不同的逻辑判断,返回对应的埋点值
@protocol RJEventTracking <NSObject>
- (NSString *)trackingMethod:(NSString *)method instance:(id)instance arguments:(NSArray *)arguments;
@end比如上文的rj_trip_tracking类需要遵循RJEventTracking协议,并根据相关逻辑判断返回对应的埋点值
埋点实现类的类名需要与埋点配置JSON中的event里的key保持一致,因为埋点库会通过检测是否有同名的类来实现插件式的埋点规则。另外,一个impl可以对应多个method方法
状态判断
根据状态量来确定埋点值。还是联系客服埋点的例子,根据订单种类和订单状态来返回对应的埋点值,首先定义JSON表中同名的impl类,并遵循RJEventTracking协议
#import "RJEventTracking.h"
NS_ASSUME_NONNULL_BEGIN
@interface rj_trip_tracking : NSObject <RJEventTracking>
@end
NS_ASSUME_NONNULL_END在.m文件中实现自定义埋点的协议方法trackingMethod:instance:arguments:
#import "rj_trip_tracking.h"
@implementation rj_trip_tracking
- (NSString *)trackingMethod:(NSString *)method instance:(id)instance arguments:(NSArray *)arguments {
id dataManager = [instance property:@"dataManager"];
NSInteger orderStatus = [[dataManager property:@"orderStatus"] integerValue];
NSInteger orderType = [[dataManager property:@"orderType"] integerValue];
if ([method isEqualToString:@"callServiceEvent"]) {
if (orderType == 1) {
if (orderStatus == 1) {
return @"user_inbook_psgservice_click";
} else if (orderStatus == 2) {
return @"user_finishbook_psgservice_click";
}
} else {
return @"user_psgservice_click";
}
}
return nil;
}
@end在协议方法中,可以获取当前的实例(在这个示例下为RJTripViewController)和入参数组。订单的类型和状态是存储在RJTripViewController中的dataManager属性中的,所以可以通过埋点库封装好的property:方法来获取属性值,并根据属性值返回对应的埋点名称
@interface NSObject (RJEventTracking)
- (id)property:(NSString *)property;
@end属性值读取的实现为
- (id)property:(NSString *)property {
return [NSObject runMethodWithObject:self selector:property arguments:nil];
}其中的原理很简单,就是将getter方法封装到NSInvocation中并invoke读取返回值即可
+ (id)runMethodWithObject:(id)object selector:(NSString *)selector arguments:(NSArray *)arguments {
if (!object) return nil;
if (arguments && [arguments isKindOfClass:NSArray.class] == NO) {
arguments = @[arguments];
}
SEL sel = NSSelectorFromString(selector);
NSMethodSignature *signature = [object methodSignatureForSelector:sel];
if (!signature) {
return nil;
}
NSInvocation *invocation = [NSInvocation invocationWithMethodSignature:signature];
invocation.selector = sel;
invocation.arguments = arguments;
[invocation invokeWithTarget:object];
return invocation.returnValue_obj;
}入参判断
需要根据JSON中设置的所hook方法的入参来确定埋点名称的情况。比如在订单列表中点击全部,进行中,待支付,待评价,已完成等菜单项时分别埋点。被hook的方法为tripLabClickWithLabKey:其参数为UILabel,原先代码中通过Label的tag判断是点击的哪个子项,同样,我们也可以获取到Label的入参然后据此判断。由于参数只有一个,所以可以直接取arguments第一个值
#import "rj_main_tracking.h"
#import <UIKit/UIKit.h>
static NSString *order_types[5] = { @"user_order_all_click", @"user_order_ongoing_click",
@"user_order_unpay_click", @"user_order_unmark_click",
@"user_order_finish_click" };
@implementation rj_main_tracking
- (NSString *)trackingMethod:(NSString *)method instance:(id)instance arguments:(NSArray *)arguments {
if ([method isEqualToString:@"tripLabClickWithLabKey:"]) {
UILabel *label = arguments[0];
if (!label || label.tag > 4) {
return nil;
}
return order_types[label.tag];
} else if ([method isEqualToString:@"tripTypeViewChangedWithIndex:"]) {
return @"xx_ryan_jin";
}
}
@end通过AOP来hook方法时,可以获取到当前hook方法所对应的实例对象和入参,在调用协议方法时,直接传给协议实现类
方法调用
和读取属性值类似,也是在不同场景下同一事件不同埋点名称的情况,但获取的状态量不是当前实例对象的,而是某个方法的返回值,这种情况下可以通过埋点库提供的方法调用函数来实现
@interface NSObject (RJEventTracking)
- (id)performSelector:(NSString *)selector arguments:(nullable NSArray *)arguments;
@end比如获取某个页面的视图类型,而这个视图类型存储于单例对象中
[RJViewTypeModel sharedInstance].viewType该场景下则根据viewType的类型,来返回相应的埋点名称
- (NSString *)trackingMethod:(NSString *)method instance:(id)instance arguments:(NSArray *)arguments {
NSString *labKey = [instance property:@"labKey"];
id viewTypeModel = [NSClassFromString(@"RJViewTypeModel") performSelector:@"sharedInstance"
arguments:nil];
NSInteger viewType = [[viewTypeModel property:@"viewType"] integerValue];
if (viewType == 0) {
if ([labKey isEqualToString:@"rj_view_begin_add"]) {
return @"user_fp_book_on_click";
}
if ([labKey isEqualToString:@"rj_view_end_add"]) {
return @"user_fp_book_off_click";
}
}
if (viewType == 1) {
if ([labKey isEqualToString:@"rj_view_begin_add"]) {
return @"user_fr_on_click";
}
if ([labKey isEqualToString:@"rj_view_end_add"]) {
return @"user_fr_off_click";
}
}
return nil;
}逻辑判断
需要额外添加逻辑判断的场景,比如在订单详情页需要统计用户进入页面的查看行为,但是详情页的类型需要在网络请求后才能获取,而且该网络请求会定时触发,所以埋点hook的方法会走多次,该情况下,需要添加一个属性用来标记是否已记录埋点 。故而埋点库需要提供动态添加属性的功能
@interface NSObject (RJEventTracking)
- (id)extraProperty:(NSString *)property;
- (void)addExtraProperty:(NSString *)property defaultValue:(id)value;
@end在埋点实现impl类里面,添加额外的属性来标记是否已记录过埋点
@implementation user_orderdetail_show
- (NSString *)trackingMethod:(NSString *)method instance:(id)instance arguments:(NSArray *)arguments {
if ([instance extraProperty:@"isRecorded"]) {
return nil;
}
[instance addExtraProperty:@"isRecorded" defaultValue:@(YES)];
return @"user_orderdetail_show";
}
@end使用addExtraProperty:defaultValue:来给当前实例动态添加属性,而extraProperty:方法则用来获取实例的某个额外属性。如果isRecorded返回YES代表已经记录过该埋点,返回nil值来忽略该次埋点
上面示例中添加的isRecorded属性是因为埋点的需求,和业务逻辑无关,所以比较合理的方式是在埋点的插件impl类中添加,避免影响业务代码
埋点库动态添加属性的原理也很简单,利用runtime的objc_setAssociatedObject和objc_getAssociatedObject方法来绑定属性到实例对象
- (id)extraProperty:(NSString *)property {
return objc_getAssociatedObject(self, NSSelectorFromString(property));
}
- (void)addExtraProperty:(NSString *)property defaultValue:(id)value {
objc_setAssociatedObject(self, NSSelectorFromString(property), value, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}动态下发
埋点JSON配置表可以由服务器提供接口,客户端在每次启动时通过接口获取最新埋点配置表,从而达到动态下发的目的,客户端拿到JSON后,读取埋点信息并生效
[RJEventTracking loadConfiguration:[[NSBundle mainBundle] pathForResource:@"RJUserTracking" ofType:@"json"]];读取的代码如下所示,主要逻辑为遍历埋点中的类和hook的方法,并检测是固定埋点还是场景化埋点,对于场景化埋点的情况查询是否有对应的埋点impl实现类。当然,还需检测JSON配置表的合法性,每个类和其中的方法是否匹配
+ (void)loadConfiguration:(NSString *)path {
NSData *data = [NSData dataWithContentsOfFile:path];
if (!data) {
return;
}
NSDictionary *dict = [NSJSONSerialization JSONObjectWithData:data options:NSJSONReadingMutableLeaves error:nil];
NSString *version = dict[@"version"];
NSArray *ts = dict[@"tracking"];
[ts enumerateObjectsUsingBlock:^(NSDictionary *obj, NSUInteger idx, BOOL *stop) {
Class class = NSClassFromString(obj[@"class"]);
NSDictionary *ed = obj[@"event"];
NSMutableDictionary *td = [NSMutableDictionary dictionaryWithCapacity:0];
[ed enumerateKeysAndObjectsUsingBlock:^(NSString *key, id obj, BOOL *stop) {
NSMutableArray *tArr = [NSMutableArray arrayWithCapacity:0];
[tArr addObjectsFromArray:[obj isKindOfClass:[NSArray class]] ? obj : @[obj]];
[tArr enumerateObjectsUsingBlock:^(NSString *m, NSUInteger idx, BOOL *stop) {
if ([td.allKeys containsObject:m]) {
NSMutableArray *ms = [td[m] mutableCopy];
if (![ms containsObject:key]) [ms addObject:key];
td[m] = ms;
} else {
td[m] = @[key];
}
}];
}];
[td enumerateKeysAndObjectsUsingBlock:^(NSString *kmethod, NSArray <NSString *> *tArr, BOOL *stop) {
SEL sel = NSSelectorFromString(kmethod);
NSError *error = nil;
[self checkValidWithClass:obj[@"class"] method:kmethod];
[class aspect_hookSelector:sel withOptions:AspectPositionBefore usingBlock:^(id<AspectInfo> info) {
[tArr enumerateObjectsUsingBlock:^(NSString *name, NSUInteger idx, BOOL *stop) {
NSString *ename = name;
id<RJEventTracking> t = [NSClassFromString(name) new];
if (t && [t respondsToSelector:@selector(trackingMethod:instance:arguments:)]) {
ename = [t trackingMethod:kmethod instance:info.instance
arguments:info.arguments];
}
if ([ename length]) {
NSLog(@"<RJEventTracking> - %@", ename);
}
}];
} error:&error];
[self checkHookStatusWithClass:obj[@"class"] method:kmethod error:error];
}];
}];
}最后附上源码地址: https://github.com/rjinxx/RJEventTracking,
pod 'RJEventTracking'在使用RJEventTracking的过程中中有遇到什么问题或者优化建议欢迎留言PR,谢谢。
转自:https://www.jianshu.com/p/cdf61602316e
收起阅读 »探究产生离屏渲染的秘密
一.渲染机制
CPU将计算好的需要显示的内容提交给GPU,GPU渲染完成后将渲染结果放入帧缓冲区,随后视频控制器会按照Vsync(垂直脉冲)信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器进行显示。
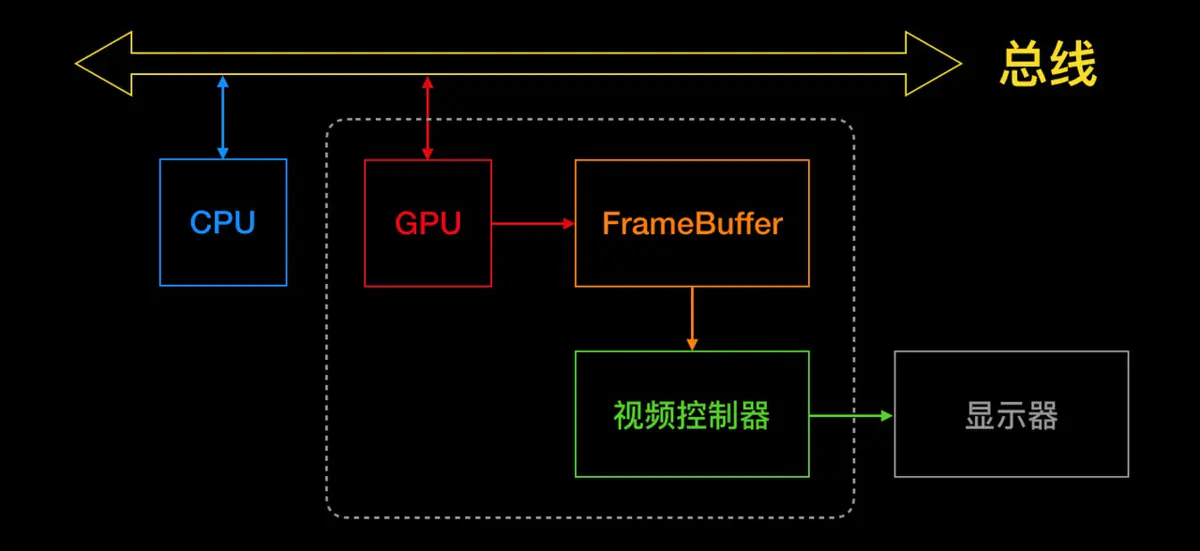
二.GPU屏幕渲染两种方式
1.On-Screen Rendering:当前屏幕渲染
指GPU的渲染操作是在当前用于显示的屏幕缓冲区中进行。
2.Off-Screen Rendering:离屏渲染
指GPU在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作。
三.两种渲染方式比较
相比于当前屏幕渲染,离屏渲染的代价很高,主要体现在以下两个方面:
1.创建新缓冲区
要想进行离屏渲染,首先需要创建一个新的缓冲区。
2.上下文切换
离屏渲染的整个过程,需要多次进行上下文切换:先从当前屏幕(On-Screen)到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕。而上下文环境的切换回导致GPU产生空闲,而GPU拥有大量的并行计算的处理单元,这些处理单元都空闲,会产生巨大的浪费。
四.特殊的离屏渲染:CPU渲染
如果重写了drawRect方法,并且使用任何Core Graphics 的技术进行了绘制操作,就涉及到CPU渲染。整个渲染过程由CPU在App内同步完成,渲染得到的bitmap(位图)最后再交由GPU用于显示。
CoreGraphic通常是线程安全的,所以可以进行一步绘制,显示的时候再回主线程,一个简单异步绘制内容如下:
- (void)display {
dispatch_async(backgroundQueue, ^{
CGContextRef ctx = CGBitmapContextCreate(...);
// draw in context...
CGImageRef img = CGBitmapContextCreateImage(ctx);
CFRelease(ctx);
dispatch_async(mainQueue, ^{
layer.contents = img;
});
});
}五.为什么产生离屏渲染
离屏渲染产生的原因主要有两方面:
1.在VSync(垂直脉冲)信号作用下,视频控制器每隔16.67ms就会去帧缓冲区(当前屏幕缓冲区)读取渲染后的数据;但是有些效果被认为不能直接呈现于屏幕前,而需要在别的地方做额外的处理,进行预合成。
比如图层属性的混合体再没有预合成之前不能直接在屏幕中绘制,所以就需要屏幕外渲染。屏幕外渲染并不意味着软件绘制,但是它意味着图层必须在被显示之前必须在一个屏幕外上下文中被渲染(不论CPU还是GPU)。
举个🌰:
UIView *AView = [[UIView alloc] initWithFrame:CGRectMake(100, 100, 200, 200)];
AView.backgroundColor = [UIColor redColor];
AView.alpha = 0.5;
[self.view addSubview:AView];
UIView *BView = [[UIView alloc] initWithFrame:CGRectMake(50, 50, 100, 100)];
BView.backgroundColor = [UIColor blackColor];
BView.alpha = 0.5;
[AView addSubview:BView];效果图:
如上代码所示:
AView 视图包含BView视图,AView视图是红色,透明度为0.5;BView视图为黑色,透明度也为0.5,那么在渲染阶段,就会对AView和BView图层重叠的部分进行混合操作,但是这个过程并不适合直接显示在屏幕上,因此需要开辟屏幕外的缓存,对这两个图层进行屏幕外的渲染,然后将渲染的结果写回到当前屏幕缓存区。
这里有些人会有疑问,那如果能保证图层在16.67ms里完成渲染,视频控制器去读取的时候能读取到渲染完成的数据,不就可以了。
理论上,确实可以这样理解,但是图层之间的混合、渲染这个过程所耗费的时间是不固定的,跟多个维度相关,比如图层数量、重叠区域、GPU处理器性能等,因此底层设计的时候,应该是将不能够直接呈现在屏幕上的效果,都通过离屏渲染来操作。
2.有些视图渲染后的纹理需要被多次复用,但屏幕内的渲染缓冲区是实时更新的,所以需要通过开辟屏幕外的渲染缓冲区,将视图的内容渲染成纹理并缓存,然后再需要的时候在调入屏幕缓冲区,可以避免多次渲染的开销。
典型的例子就是光栅化。光栅化就是通过把视图的内容渲染成纹理并缓存,等到下次调用的时候直接去缓存的取出纹理,但是更新内容时候,会启用离屏渲染,所以更新的代价比较大,只能用于静态内容;而且如果光栅化的元素100ms没有被使用,也将被移除,故而不常用元素的光栅化并不会优化显示。
注意:光栅化的元素,总大小限制为2.5倍的屏幕。
六.如何检测离屏渲染
1.模拟器
模拟器在工作栏上面的Debug -> Color Off-Screen Rendered
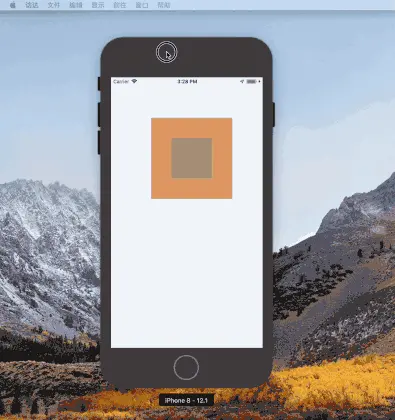
2.真机
真机在工作栏上面的Debug -> View Debugging -> Rendering -> Color Off-Screen Rendered Yellow
七.引起离屏渲染操作和怎样优化
关于这方面的资料,可以参考文章:
如果想更深入的了解,可以了解下OpenGL、Metal、计算机图形学这方面的知识。
八.延伸阅读
链接:https://www.jianshu.com/p/aa8dc1a61c91
收起阅读 »iOS — Swift高级分享:SWIFT协议的替代方案
毫无疑问,协议是SWIFT总体设计的主要部分-并且可以提供一种很好的方法来创建抽象、分离关注点和提高系统或功能的整体灵活性。通过不强烈地将类型绑定在一起,而是通过更抽象的接口连接代码库的各个部分,我们通常会得到一个更加解耦的体系结构,它允许我们孤立地迭代每个单独的特性。
然而,虽然协议在许多不同的情况下都是一个很好的工具,但它们也有各自的缺点和权衡。本周,让我们来看看其中的一些特性,并探索几种在SWIFT中抽象代码的替代方法-看看它们与使用协议相比如何。
使用闭包的单个需求
使用协议抽象代码的优点之一是它允许我们对多个代码进行分组。所需在一起。例如,PersistedValue协议可能需要两个save和一个load方法-这两种方法都使我们能够在所有这些值之间强制执行一定程度的一致性,并编写用于保存和加载数据的共享实用程序。
然而,并不是所有的抽象都涉及多个需求,并且非常常见的协议只有一个方法或属性-比如这个:
protocol ModelProvider {
associatedtype Model: ModelProtocol
func provideModel() -> Model
}假设上面的ModelProvider协议用于抽象我们在代码库中加载和提供模型的方式。它使用关联类型,以便让每个实现以非常类型安全的方式声明它提供的模型类型,这是很棒的,因为它使我们能够编写通用代码来执行常见任务,例如为给定模型呈现详细视图:
class DetailViewController<Model: ModelProtocol>: UIViewController {
private let modelProvider: AnyModelProvider<Model>
init<T: ModelProvider>(modelProvider: T) where T.Model == Model {
// We wrap the injected provider in an AnyModelProvider
// instance to be able to store a reference to it.
self.modelProvider = AnyModelProvider(modelProvider)
super.init(nibName: nil, bundle: nil)
}
override func viewDidLoad() {
super.viewDidLoad()
let model = modelProvider.provideModel()
...
}
...
}虽然上面的代码可以工作,但它说明了使用具有关联类型的协议的缺点之一-我们不能将引用存储到ModelProvider直接。相反,我们必须首先执行类型擦除将我们的协议引用转换成一个具体的类型,这两种类型都会使我们的代码混乱,并要求我们实现其他类型,以便能够使用我们的协议。
因为我们所处理的协议只有一个要求,所以问题是-我们真的需要吗?毕竟,我们ModelProvider协议没有添加任何额外的分组或结构,因此让我们取消它的唯一要求,将其转化为闭包-然后可以直接注入,如下所示:
class DetailViewController<Model: ModelProtocol>: UIViewController {
private let modelProvider: () -> Model
init(modelProvider: @escaping () -> Model) {
self.modelProvider = modelProvider
super.init(nibName: nil, bundle: nil)
}
override func viewDidLoad() {
super.viewDidLoad()
let model = modelProvider()
...
}
...
}通过直接注入我们需要的功能,而不是要求类型符合协议,我们还大大提高了代码的灵活性-因为我们现在可以自由地注入任何东西,从空闲函数到内联定义的闭包,再到实例方法。我们也不再需要执行任何类型删除,留给我们的代码要简单得多。
使用泛型类型
虽然闭包和函数是建模单个需求抽象的好方法,但是如果我们开始添加额外的需求,那么使用它们可能会变得有点混乱。例如,假设我们希望扩展上面的内容DetailViewController也支持书签和删除模型。如果我们坚持基于闭包的方法,我们最终会得到这样的结果:
class DetailViewController<Model: ModelProtocol>: UIViewController {
private let modelProvider: () -> Model
private let modelBookmarker: (Model) -> Void
private let modelDeleter: (Model) -> Void
init(modelProvider: @escaping () -> Model,
modelBookmarker: @escaping (Model) -> Void,
modelDeleter: @escaping (Model) -> Void) {
self.modelProvider = modelProvider
self.modelBookmarker = modelBookmarker
self.modelDeleter = modelDeleter
super.init(nibName: nil, bundle: nil)
}
...
}上述设置不仅要求我们跟踪多个独立闭包,而且还会出现大量重复的闭包。“模型”前缀-(使用“三人规则”)告诉我们,我们这里有一些结构性问题。而我们能回到将上述所有闭包封装到一个协议中去,这再次要求我们执行类型擦除,并失去我们在开始使用闭包时获得的一些灵活性。
相反,让我们使用泛型类型将我们的需求组合在一起-这两种类型都允许我们保留使用闭包的灵活性,同时在代码中添加一些额外的结构:
struct ModelHandling<Model: ModelProtocol> {
var provide: () -> Model
var bookmark: (Model) -> Void
var delete: (Model) -> Void
}因为上面是一个具体的类型,所以它不需要任何形式的类型擦除(实际上,它看起来非常类似于我们在使用带关联类型的协议时经常被迫编写的类型擦除包装)。因此,就像闭包一样,它可以直接使用和存储-如下所示:
class DetailViewController<Model: ModelProtocol>: UIViewController {
private let modelHandler: ModelHandling<Model>
private lazy var model = modelHandler.provide()
init(modelHandler: ModelHandling<Model>) {
self.modelHandler = modelHandler
super.init(nibName: nil, bundle: nil)
}
@objc private func bookmarkButtonTapped() {
modelHandler.bookmark(model)
}
@objc private func deleteButtonTapped() {
modelHandler.delete(model)
dismiss(animated: true)
}
...
}而具有关联类型的协议在定义更高级别的需求时非常有用(就像标准库的Equatable和Collection),当这样的协议需要直接使用时,使用独立闭包或泛型类型通常可以给我们相同的封装级别,但通过一个简单得多的抽象。
使用枚举分离要求
在设计任何类型的抽象时,一个常见的挑战是不要。“过于抽象”通过添加太多的需求。例如,现在假设我们正在开发一个应用程序,它允许用户使用多种媒体-比如文章、播客、视频等等-我们希望为所有这些不同的格式创建一个共享的抽象。如果我们再次从面向协议的方法开始,我们可能会得到这样的结果:
protocol Media {
var id: UUID { get }
var title: String { get }
var description: String { get }
var text: String? { get }
var url: URL? { get }
var duration: TimeInterval? { get }
var resolution: Resolution? { get }
}由于上面的协议需要与所有不同类型的媒体一起工作,我们最终得到了多个仅与某些格式相关的属性。例如,Article类型没有任何概念持续时间或分辨力-留给我们一些我们必须实现的属性,因为我们的协议要求我们:
struct Article: Media {
let id: UUID
var title: String
var description: String
var text: String?
var url: URL? { return nil }
var duration: TimeInterval? { return nil }
var resolution: Resolution? { return nil }
}上面的设置不仅要求我们在符合标准的类型中添加不必要的样板,还可能是歧义的来源-因为我们无法强制规定一篇文章实际上包含文本,或者应该支持URL、持续时间或解析的类型实际上携带了该数据-因为所有这些属性都是选项。
我们可以通过多种方法解决上述问题,从将协议拆分为多个协议开始,每个方法都具有提高专业化程度-像这样:
protocol Media {
var id: UUID { get }
var title: String { get }
var description: String { get }
}
protocol ReadableMedia: Media {
var text: String { get }
}
protocol PlayableMedia: Media {
var url: URL { get }
var duration: TimeInterval { get }
var resolution: Resolution? { get }
}以上所述无疑是一种改进,因为它将使我们能够拥有以下类型Article符合ReadableMedia,和可玩类型(如Audio和Video)符合PlayableMedia-减少歧义和样板,因为每种类型都可以选择哪一种专门版本的Media它想要遵守的。
但是,由于上述协议都是关于数据的,因此使用实际数据类型相反,这既可以减少重复实现的需要,也可以让我们通过单一的具体类型来处理任何媒体格式:
struct Media {
let id: UUID
var title: String
var description: String
var content: Content
}上面的结构现在只包含我们所有媒体格式之间共享的数据,除了content属性-这就是我们将用于专门化的内容。但这一次,而不是Content一个协议,让我们使用枚举-它将使我们能够通过关联的值为每种格式定义一组量身定做的属性:
extension Media {
enum Content {
case article(text: String)
case audio(Playable)
case video(Playable, resolution: Resolution)
}
struct Playable {
var url: URL
var duration: TimeInterval
}
}选项已经消失,我们现在已经在共享抽象和启用特定于格式的专门化之间取得了很好的平衡。枚举的美妙之处还在于,它使我们能够表达数据变化,而不必使用泛型或协议-只要我们预先知道变体的数量,一切都可以封装在相同的具体类型中。
类和继承
另一种方法在SWIFT中可能不像在其他语言中那么流行,但仍然值得考虑,那就是使用通过继承专门化的类来创建抽象。例如,而不是使用Content为了实现上述媒体格式,我们可以使用Media基类,然后将其子类化,以添加特定于格式的属性,如下所示:
class Media {
let id: UUID
var title: String
var description: String
init(id: UUID, title: String, description: String) {
self.id = id
self.title = title
self.description = description
}
}
class PlayableMedia: Media {
var url: URL
var duration: TimeInterval
init(id: UUID,
title: String,
description: String,
url: URL,
duration: TimeInterval) {
self.url = url
self.duration = duration
super.init(id: id, title: title, description: description)
}
}然而,尽管从结构的角度来看,上述方法是完全有意义的-但它也有一些不利之处。首先,由于类还不支持按成员划分的初始化器,所以我们必须自己定义所有初始化器-我们还必须通过调用super.init..但也许更重要的是,课程是参考类型,这意味着在共享时,我们必须小心避免执行任何意外的突变。Media跨代码库的实例。
但这并不意味着SWIFT中没有有效的继承用例。例如,在“在未来的引擎盖下&斯威夫特的承诺”,继承提供了一种公开只读的好方法。Future类型到api用户-同时仍然允许通过Promise子类:
class Future<Value> {
fileprivate var result: Result<Value, Error>? {
didSet { result.map(report) }
}
...
}
class Promise<Value>: Future<Value> {
func resolve(with value: Value) {
result = .success(value)
}
func reject(with error: Error) {
result = .failure(error)
}
}
func loadCachedData() -> Future<Data> {
let promise = Promise<Data>()
cache.load { promise.resolve(with: $0) }
return promise
}使用上面的设置,我们可以让同一个实例在不同的上下文中公开不同的API集,当我们只允许其中一个上下文对给定的对象进行变异时,这是非常有用的。在使用泛型代码时尤其如此,因为如果我们尝试使用一个协议来实现相同的目标,我们将再次遇到关联类型问题。
结语
在可预见的将来,协议是很棒的,并且很可能仍然是在SWIFT中定义抽象的最常用的方式。然而,这并不意味着使用协议永远是最好的解决方案-有时会超越流行的范围“面向协议的编程”MARRA可以产生更简单、更健壮的代码-特别是当我们想要定义的协议要求我们使用关联类型的时候。
链接:https://www.jianshu.com/p/74d511140089
收起阅读 »iOS OC开发 BTC、ETH、区块链钱包
ETH钱包部分:
功能有:
1、创建钱包
2、通过助记词导入钱包
3、通过KeyStore导入钱包
4、通过私钥导入钱包
5、查询余额
6、查询以太坊系代币余额
7、转账


BTC钱包部分:
功能:
1、创建钱包
2、通过私钥导入钱包
3、通过助记词导入钱包
4、查询余额
5、查询交易记录
6、发起交易
项目连接:
ETH钱包Demo:https://github.com/Ccct/CCTEthereum/
BTC钱包Demo:https://github.com/Ccct/CCTBTC
ARC对init方法的处理
前言
此文源于前几日工作中遇到的一个问题,并跟同事就init方法进行了相关讨论。相关代码如下:
Person *myPerson = [Person alloc];
NSMethodSignature *signature = [NSMethodSignature signatureWithObjCTypes:"@16@0:8"];
NSInvocation *invocation = [NSInvocation invocationWithMethodSignature:signature];
invocation.target = myPerson;
invocation.selector = @selector(initPerson);
[invocation invoke];
__unsafe_unretained id retValue;
[invocation getReturnValue:&retValue];正常来说,这段代码运行起来没有任何问题。然而,当Person的initPerson方法返回nil或者返回子类对象时,上述代码就会EXC_BAD_ACCESS。但如果我们把initPerson方法前缀改成其他(比如:createPerson),就不会crash。为了查清原因,便对init方法进行了一次探索(说探索多少有些夸张)。
通过符号断点及反汇编等调试手段,发现在initPerson方法结束的时候,person对象调用了一次release,而上述示例代码执行完,ARC为了抵消[Person alloc]这步操作,会对myPerson进行一次release。也就是说,过渡释放引起了crash。
那么接下来,我们就看下init方法结束的时候,为什么要调用那次看似多余的release?
原因分析
在clang文档中找到这么两个东西:__attribute__((ns_consumes_self))、__attribute((ns_returns_retained))。
据文档描述,前者的作用是将ownership从主调方转移到被调方;而后者的作用是把ownership从被调方转移到主调方。具体原理如下:
0x1. __attribute__((ns_consumes_self))
若某个方法被标记这个特性,调用方会在方法调用前对receiver进行一次retain(也可能会被编译器优化掉),而被调方会在方法结束的时候对self进行一次release。比如下面代码
// 主调方
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
Person *myPerson = [[Person alloc] init];
[myPerson noninitPerson]; // 以非init方法来测试
return YES;
}
// 被调方
@interface Person : NSObject
- (void)noninitPerson __attribute__((ns_consumes_self));
@end
@implementation Person
- (void)noninitPerson {
}
@end通过Hopper反汇编,伪代码如下:
// 主调方
bool -[AppDelegate application:didFinishLaunchingWithOptions:](void * self, void * _cmd, void * arg2, void * arg3) {
var_28 = [[Person alloc] init];
rax = [var_28 retain]; // 调用前retain
[rax noninitPerson]; // 开始调用
objc_storeStrong(var_28, 0x0);
return rax;
}
// 被调方
void -[Person noninitPerson](void * self, void * _cmd {
objc_storeStrong(self, 0x0); // 调用完被调方负责release
return;
}而init开头的方法会被隐式地标记这个特性,文档中有描述:
The implicit self parameter of a method may be marked as consumed by adding __ attribute __((ns_consumes_self)) to the method declaration. Methods in theinitfamily are treated as if they were implicitly marked with this attribute.
0x2. __attribute__((ns_returns_retained))
若方法标记这个特性,表示主调方希望得到一个retainCount+1的对象,即被调方可能会进行一次retain将所有权移交给主调方,主调方会进行一次release(可能会被编译器优化掉)来负责释放。
伪代码如下:
// 主调方
var_28 = [[Person alloc] init];
rax = [var_28 running];
[rax release]; // 主调方负责释放
// 被调方
void * -[Person running](void * self, void * _cmd) {
rax = [self retain]; // 若这里返回一个新分配的对象,则无需retain
return rax;
}同样地,init开头的方法也会被标记这个特性,文档里亦有体现:
Methods in the alloc, copy, init, mutableCopy, and new families are implicitly marked __ attribute __((ns_returns_retained)).
这么多的retain、release,多少有些凌乱,既然已知init方法会被标记__attribute__((ns_returns_retained))和__attribute__((ns_consumes_self)),那我们干脆看下init方法反汇编后的代码:
// 主调方
bool -[AppDelegate application:didFinishLaunchingWithOptions:](void * self, void * _cmd, void * arg2, void * arg3) {
var_28 = [[Person alloc] init];
objc_storeStrong(var_28, 0x0);
// 优化掉了一对retain/release
return rax;
}
// 被调方
void * -[Person init](void * self, void * _cmd) {
// 忽略一些无关指令
var_18 = [self retain]; // 对应__attribute__((ns_returns_retained))
objc_storeStrong(self, 0x0); // 对应__attribute__((ns_consumes_self))
rax = var_18;
return rax;
}到这里,我们基本了解了init方法原理,那么离文章开头那段代码crash又如何解释呢?我们对代码稍作修改,让init方法返回nil,再看下:
// 主调方
bool -[AppDelegate application:didFinishLaunchingWithOptions:](void * self, void * _cmd, void * arg2, void * arg3) {
var_28 = [[Person alloc] init];
objc_storeStrong(var_28, 0x0);
return rax;
}
// 被调方
void * -[Person init](void * self, void * _cmd) {
// 因为返回nil,所以这里的retain不存在了,而下面的self依然要消费掉
objc_storeStrong(self, 0x0); // 对应__attribute__((ns_consumes_self))
return 0x0;
}至此,过度释放的原因也就清楚了,那么该怎么解决呢?
解决方案
回到文章开头,再看下代码,不难发现,我们只要模仿ARC在init方法调用前插入个retain,并在主调方快结束的时候再插入个release即可。
Person *myPerson = [Person alloc];
NSMethodSignature *signature = [NSMethodSignature signatureWithObjCTypes:"@16@0:8"];
NSInvocation *invocation = [NSInvocation invocationWithMethodSignature:signature];
invocation.target = myPerson;
invocation.selector = @selector(initPerson);
CFBridgingRetain(myPerson); // 代替ARC将owneship将传递给被调方
[invocation invoke];
__unsafe_unretained id retValue;
[invocation getReturnValue:&retValue];
CFBridgingRelease((__bridge CFTypeRef)retValue); // 代替ARC来释放ns_returns_retained结果如果init方法返回nil,即retValue=nil,则CFBridgingRelease不会生效,上面插的那个CFBridgingRetain也就完美抵消掉了init方法结束时的release。
链接:https://www.jianshu.com/p/51adf5b44588
收起阅读 »iOS 开发:『Crash 防护系统』(二)KVO 防护
1. KVO Crash 的常见原因
KVO(Key Value Observing) 翻译过来就是键值对观察,是 iOS 观察者模式的一种实现。KVO 允许一个对象监听另一个对象特定属性的改变,并在改变时接收到事件。但是 KVO API 的设计,我个人觉得不是很合理。被观察者需要做的工作太多,日常使用时稍不注意就会导致崩溃。
KVO 日常使用造成崩溃的原因通常有以下几个:
1. KVO 添加次数和移除次数不匹配:
移除了未注册的观察者,导致崩溃。
重复移除多次,移除次数多于添加次数,导致崩溃。
重复添加多次,虽然不会崩溃,但是发生改变时,也同时会被观察多次。
2. 被观察者提前被释放,被观察者在 dealloc 时仍然注册着 KVO,导致崩溃。 例如:被观察者是局部变量的情况(iOS 10 及之前会崩溃)。
3. 添加了观察者,但未实现 observeValueForKeyPath:ofObject:change:context: 方法,导致崩溃。
4. 添加或者移除时 keypath == nil,导致崩溃。
2. KVO 防止 Crash 常见方案
为了避免上面提到的使用 KVO 造成崩溃的问题,于是出现了很多关于 KVO 的第三方库,比如最出名的就是 FaceBook 开源的第三方库 facebook / KVOController。
FBKVOController 对 KVO 机制进行了额外的一层封装,框架不但可以自动帮我们移除观察者,还提供了 block 或者 selector 的方式供我们进行观察处理。不可否认的是,FBKVOController 为我们的开发提供了很大的便利性。但是相对而言,这种方式对项目代码的侵入性比较大,必须依靠编码规范来强制约束团队人员使用这种方式。
那么有没有一种对项目代码侵入性小,同时还能有效防护 KVO 崩溃的防护机制呢?
网上有很多类似的方案可以参考一下。
方案一:大白健康系统 -- iOS APP运行时 Crash 自动修复系统
1. 首先为 NSObject 建立一个分类,利用 Method Swizzling,实现自定义的 BMP_addObserver:forKeyPath:options:context:、BMP_removeObserver:forKeyPath:、BMP_removeObserver:forKeyPath:context:、BMPKVO_dealloc 方法,用来替换系统原生的添加移除观察者方法的实现。
2. 然后在观察者和被观察者之间建立一个 KVODelegate 对象,两者之间通过 KVODelegate 对象 建立联系。然后在添加和移除操作时,将 KVO 的相关信息例如 observer、keyPath、options、context 保存为 KVOInfo 对象,并添加到 KVODelegate 对象 中对应 的 关系哈希表 中,对应原有的添加观察者。关系哈希表的数据结构:{keypath : [KVOInfo 对象1, KVOInfo 对象2, ... ]}
3. 在添加和移除操作的时候,利用 KVODelegate 对象 做转发,把真正的观察者变为 KVODelegate 对象,而当被观察者的特定属性发生了改变,再由 KVODelegate 对象 分发到原有的观察者上。
那么,BayMax 系统是如何避免 KVO 崩溃的呢?
1. 添加观察者时:通过关系哈希表判断是否重复添加,只添加一次。
2. 移除观察者时:通过关系哈希表是否已经进行过移除操作,避免多次移除。
3. 观察键值改变时:同样通过关系哈希表判断,将改变操作分发到原有的观察者上。
另外,为了避免被观察者提前被释放,被观察者在 dealloc 时仍然注册着 KVO 导致崩溃。BayMax 系统还利用 Method Swizzling 实现了自定义的 dealloc,在系统 dealloc 调用之前,将多余的观察者移除掉。
方案二: ValiantCat / XXShield(第三方框架)
XXShield 实现方案和 BayMax 系统类似。也是利用一个 Proxy 对象用来做转发, 真正的观察者是 Proxy,被观察者出现了通知信息,由 Proxy 做分发。不过不同点是 Proxy 里面保存的内容没有前者多。只保存了 _observed(被观察者) 和关系哈希表,这个关系哈希表中只维护了 keyPath 和 observer 的关系。
关系哈希表的数据结构:{keypath : [observer1, observer2 , ...](NSHashTable)} 。
XXShield 在 dealloc 中也做了类似将多余观察者移除掉的操作,是通过关系数据结构和 _observed ,然后调用原生移除观察者操作实现的。
方案三: JackLee18 / JKCrashProtect(第三方框架)
JKCrashProtect 相对于前两个方案来讲,看上去更加的简洁明了。他的不同点在于没有使用 delegate。而是直接在分类中建立了一个关系哈希表,用来保存 {keypath : [observer1, observer2 , ...](NSHashTable)} 的关系。
添加的时候,如果关系哈希表中与 keyPath 对应的已经有了相关的观察者,就不再进行添加。同样移除观察者的时候,也在哈希表中进行查找,如果存在 observer、keyPath 的信息,就移除掉,否则就不进行移除操作。
不过,这个框架并没有对被观察者在 dealloc 时仍然注册着 KVO ,造成崩溃的情况进行处理。
3. 我的 KVO 防护实现
参考了这几个方法的实现后,分别实现了一下之后,最终还是选择了 方案一、方案二 这两种方案的实现思路。
1. 我使用了 YSCKVOProxy 对象,在 YSCKVOProxy 对象 中使用 {keypath : [observer1, observer2 , ...](NSHashTable)} 结构的 关系哈希表 进行 observer、keyPath 之间的维护。
2. 然后利用 YSCKVOProxy 对象 对添加、移除、观察方法进行分发处理。
3. 在分类中自定义了 dealloc 的实现,移除了多余的观察者。
代码如下所示:
#import "NSObject+KVODefender.h"
#import "NSObject+MethodSwizzling.h"
#import <objc/runtime.h>
// 判断是否是系统类
static inline BOOL IsSystemClass(Class cls){
BOOL isSystem = NO;
NSString *className = NSStringFromClass(cls);
if ([className hasPrefix:@"NS"] || [className hasPrefix:@"__NS"] || [className hasPrefix:@"OS_xpc"]) {
isSystem = YES;
return isSystem;
}
NSBundle *mainBundle = [NSBundle bundleForClass:cls];
if (mainBundle == [NSBundle mainBundle]) {
isSystem = NO;
}else{
isSystem = YES;
}
return isSystem;
}
#pragma mark - YSCKVOProxy 相关
@interface YSCKVOProxy : NSObject
// 获取所有被观察的 keyPaths
- (NSArray *)getAllKeyPaths;
@end
@implementation YSCKVOProxy
{
// 关系数据表结构:{keypath : [observer1, observer2 , ...](NSHashTable)}
@private
NSMutableDictionary<NSString *, NSHashTable<NSObject *> *> *_kvoInfoMap;
}
- (instancetype)init {
self = [super init];
if (self) {
_kvoInfoMap = [NSMutableDictionary dictionary];
}
return self;
}
// 添加 KVO 信息操作, 添加成功返回 YES
- (BOOL)addInfoToMapWithObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath
options:(NSKeyValueObservingOptions)options
context:(void *)context {
@synchronized (self) {
if (!observer || !keyPath ||
([keyPath isKindOfClass:[NSString class]] && keyPath.length <= 0)) {
return NO;
}
NSHashTable<NSObject *> *info = _kvoInfoMap[keyPath];
if (info.count == 0) {
info = [[NSHashTable alloc] initWithOptions:(NSPointerFunctionsWeakMemory) capacity:0];
[info addObject:observer];
_kvoInfoMap[keyPath] = info;
return YES;
}
if (![info containsObject:observer]) {
[info addObject:observer];
}
return NO;
}
}
// 移除 KVO 信息操作, 添加成功返回 YES
- (BOOL)removeInfoInMapWithObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath {
@synchronized (self) {
if (!observer || !keyPath ||
([keyPath isKindOfClass:[NSString class]] && keyPath.length <= 0)) {
return NO;
}
NSHashTable<NSObject *> *info = _kvoInfoMap[keyPath];
if (info.count == 0) {
return NO;
}
[info removeObject:observer];
if (info.count == 0) {
[_kvoInfoMap removeObjectForKey:keyPath];
return YES;
}
return NO;
}
}
// 添加 KVO 信息操作, 添加成功返回 YES
- (BOOL)removeInfoInMapWithObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath
context:(void *)context {
@synchronized (self) {
if (!observer || !keyPath ||
([keyPath isKindOfClass:[NSString class]] && keyPath.length <= 0)) {
return NO;
}
NSHashTable<NSObject *> *info = _kvoInfoMap[keyPath];
if (info.count == 0) {
return NO;
}
[info removeObject:observer];
if (info.count == 0) {
[_kvoInfoMap removeObjectForKey:keyPath];
return YES;
}
return NO;
}
}
// 实际观察者 yscKVOProxy 进行监听,并分发
- (void)observeValueForKeyPath:(NSString *)keyPath
ofObject:(id)object
change:(NSDictionary<NSKeyValueChangeKey,id> *)change
context:(void *)context {
NSHashTable<NSObject *> *info = _kvoInfoMap[keyPath];
for (NSObject *observer in info) {
@try {
[observer observeValueForKeyPath:keyPath ofObject:object change:change context:context];
} @catch (NSException *exception) {
NSString *reason = [NSString stringWithFormat:@"KVO Warning : %@",[exception description]];
NSLog(@"%@",reason);
}
}
}
// 获取所有被观察的 keyPaths
- (NSArray *)getAllKeyPaths {
NSArray <NSString *>*keyPaths = _kvoInfoMap.allKeys;
return keyPaths;
}
@end
#pragma mark - NSObject+KVODefender 分类
@implementation NSObject (KVODefender)
+ (void)load {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 拦截 `addObserver:forKeyPath:options:context:` 方法,替换自定义实现
[NSObject yscDefenderSwizzlingInstanceMethod: @selector(addObserver:forKeyPath:options:context:)
withMethod: @selector(ysc_addObserver:forKeyPath:options:context:)
withClass: [NSObject class]];
// 拦截 `removeObserver:forKeyPath:` 方法,替换自定义实现
[NSObject yscDefenderSwizzlingInstanceMethod: @selector(removeObserver:forKeyPath:)
withMethod: @selector(ysc_removeObserver:forKeyPath:)
withClass: [NSObject class]];
// 拦截 `removeObserver:forKeyPath:context:` 方法,替换自定义实现
[NSObject yscDefenderSwizzlingInstanceMethod: @selector(removeObserver:forKeyPath:context:)
withMethod: @selector(ysc_removeObserver:forKeyPath:context:)
withClass: [NSObject class]];
// 拦截 `dealloc` 方法,替换自定义实现
[NSObject yscDefenderSwizzlingInstanceMethod: NSSelectorFromString(@"dealloc")
withMethod: @selector(ysc_kvodealloc)
withClass: [NSObject class]];
});
}
static void *YSCKVOProxyKey = &YSCKVOProxyKey;
static NSString *const KVODefenderValue = @"YSC_KVODefender";
static void *KVODefenderKey = &KVODefenderKey;
// YSCKVOProxy setter 方法
- (void)setYscKVOProxy:(YSCKVOProxy *)yscKVOProxy {
objc_setAssociatedObject(self, YSCKVOProxyKey, yscKVOProxy, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
// YSCKVOProxy getter 方法
- (YSCKVOProxy *)yscKVOProxy {
id yscKVOProxy = objc_getAssociatedObject(self, YSCKVOProxyKey);
if (yscKVOProxy == nil) {
yscKVOProxy = [[YSCKVOProxy alloc] init];
self.yscKVOProxy = yscKVOProxy;
}
return yscKVOProxy;
}
// 自定义 addObserver:forKeyPath:options:context: 实现方法
- (void)ysc_addObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath
options:(NSKeyValueObservingOptions)options
context:(void *)context {
if (!IsSystemClass(self.class)) {
objc_setAssociatedObject(self, KVODefenderKey, KVODefenderValue, OBJC_ASSOCIATION_RETAIN);
if ([self.yscKVOProxy addInfoToMapWithObserver:observer forKeyPath:keyPath options:options context:context]) {
// 如果添加 KVO 信息操作成功,则调用系统添加方法
[self ysc_addObserver:self.yscKVOProxy forKeyPath:keyPath options:options context:context];
} else {
// 添加 KVO 信息操作失败:重复添加
NSString *className = (NSStringFromClass(self.class) == nil) ? @"" : NSStringFromClass(self.class);
NSString *reason = [NSString stringWithFormat:@"KVO Warning : Repeated additions to the observer:%@ for the key path:'%@' from %@",
observer, keyPath, className];
NSLog(@"%@",reason);
}
} else {
[self ysc_addObserver:observer forKeyPath:keyPath options:options context:context];
}
}
// 自定义 removeObserver:forKeyPath:context: 实现方法
- (void)ysc_removeObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath
context:(void *)context {
if (!IsSystemClass(self.class)) {
if ([self.yscKVOProxy removeInfoInMapWithObserver:observer forKeyPath:keyPath context:context]) {
// 如果移除 KVO 信息操作成功,则调用系统移除方法
[self ysc_removeObserver:self.yscKVOProxy forKeyPath:keyPath context:context];
} else {
// 移除 KVO 信息操作失败:移除了未注册的观察者
NSString *className = NSStringFromClass(self.class) == nil ? @"" : NSStringFromClass(self.class);
NSString *reason = [NSString stringWithFormat:@"KVO Warning : Cannot remove an observer %@ for the key path '%@' from %@ , because it is not registered as an observer", observer, keyPath, className];
NSLog(@"%@",reason);
}
} else {
[self ysc_removeObserver:observer forKeyPath:keyPath context:context];
}
}
// 自定义 removeObserver:forKeyPath: 实现方法
- (void)ysc_removeObserver:(NSObject *)observer
forKeyPath:(NSString *)keyPath {
if (!IsSystemClass(self.class)) {
if ([self.yscKVOProxy removeInfoInMapWithObserver:observer forKeyPath:keyPath]) {
// 如果移除 KVO 信息操作成功,则调用系统移除方法
[self ysc_removeObserver:self.yscKVOProxy forKeyPath:keyPath];
} else {
// 移除 KVO 信息操作失败:移除了未注册的观察者
NSString *className = NSStringFromClass(self.class) == nil ? @"" : NSStringFromClass(self.class);
NSString *reason = [NSString stringWithFormat:@"KVO Warning : Cannot remove an observer %@ for the key path '%@' from %@ , because it is not registered as an observer", observer, keyPath, className];
NSLog(@"%@",reason);
}
} else {
[self ysc_removeObserver:observer forKeyPath:keyPath];
}
}
// 自定义 dealloc 实现方法
- (void)ysc_kvodealloc {
@autoreleasepool {
if (!IsSystemClass(self.class)) {
NSString *value = (NSString *)objc_getAssociatedObject(self, KVODefenderKey);
if ([value isEqualToString:KVODefenderValue]) {
NSArray *keyPaths = [self.yscKVOProxy getAllKeyPaths];
// 被观察者在 dealloc 时仍然注册着 KVO
if (keyPaths.count > 0) {
NSString *reason = [NSString stringWithFormat:@"KVO Warning : An instance %@ was deallocated while key value observers were still registered with it. The Keypaths is:'%@'", self, [keyPaths componentsJoinedByString:@","]];
NSLog(@"%@",reason);
}
// 移除多余的观察者
for (NSString *keyPath in keyPaths) {
[self ysc_removeObserver:self.yscKVOProxy forKeyPath:keyPath];
}
}
}
}
[self ysc_kvodealloc];
}
@end4. 测试 KVO 防护效果
这里提供一下相关崩溃的测试代码:
/********************* KVOCrashObject.h 文件 *********************/
#import <Foundation/Foundation.h>
@interface KVOCrashObject : NSObject
@property (nonatomic, copy) NSString *name;
@end
/********************* KVOCrashObject.m 文件 *********************/
#import "KVOCrashObject.h"
@implementation KVOCrashObject
@end
/********************* ViewController.m 文件 *********************/
#import "ViewController.h"
#import "KVOCrashObject.h"
@interface ViewController ()
@property (nonatomic, strong) KVOCrashObject *objc;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
// Do any additional setup after loading the view.
self.objc = [[KVOCrashObject alloc] init];
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event {
// 1.1 移除了未注册的观察者,导致崩溃
[self testKVOCrash11];
// 1.2 重复移除多次,移除次数多于添加次数,导致崩溃
// [self testKVOCrash12];
// 1.3 重复添加多次,虽然不会崩溃,但是发生改变时,也同时会被观察多次。
// [self testKVOCrash13];
// 2. 被观察者 dealloc 时仍然注册着 KVO,导致崩溃
// [self testKVOCrash2];
// 3. 观察者没有实现 -observeValueForKeyPath:ofObject:change:context:导致崩溃
// [self testKVOCrash3];
// 4. 添加或者移除时 keypath == nil,导致崩溃。
// [self testKVOCrash4];
}
/**
1.1 移除了未注册的观察者,导致崩溃
*/
- (void)testKVOCrash11 {
// 崩溃日志:Cannot remove an observer XXX for the key path "xxx" from XXX because it is not registered as an observer.
[self.objc removeObserver:self forKeyPath:@"name"];
}
/**
1.2 重复移除多次,移除次数多于添加次数,导致崩溃
*/
- (void)testKVOCrash12 {
// 崩溃日志:Cannot remove an observer XXX for the key path "xxx" from XXX because it is not registered as an observer.
[self.objc addObserver:self forKeyPath:@"name" options:NSKeyValueObservingOptionNew context:NULL];
self.objc.name = @"0";
[self.objc removeObserver:self forKeyPath:@"name"];
[self.objc removeObserver:self forKeyPath:@"name"];
}
/**
1.3 重复添加多次,虽然不会崩溃,但是发生改变时,也同时会被观察多次。
*/
- (void)testKVOCrash13 {
[self.objc addObserver:self forKeyPath:@"name" options:NSKeyValueObservingOptionNew context:NULL];
[self.objc addObserver:self forKeyPath:@"name" options:NSKeyValueObservingOptionNew context:NULL];
self.objc.name = @"0";
}
/**
2. 被观察者 dealloc 时仍然注册着 KVO,导致崩溃
*/
- (void)testKVOCrash2 {
// 崩溃日志:An instance xxx of class xxx was deallocated while key value observers were still registered with it.
// iOS 10 及以下会导致崩溃,iOS 11 之后就不会崩溃了
KVOCrashObject *obj = [[KVOCrashObject alloc] init];
[obj addObserver: self
forKeyPath: @"name"
options: NSKeyValueObservingOptionNew
context: nil];
}
/**
3. 观察者没有实现 -observeValueForKeyPath:ofObject:change:context:导致崩溃
*/
- (void)testKVOCrash3 {
// 崩溃日志:An -observeValueForKeyPath:ofObject:change:context: message was received but not handled.
KVOCrashObject *obj = [[KVOCrashObject alloc] init];
[self addObserver: obj
forKeyPath: @"title"
options: NSKeyValueObservingOptionNew
context: nil];
self.title = @"111";
}
/**
4. 添加或者移除时 keypath == nil,导致崩溃。
*/
- (void)testKVOCrash4 {
// 崩溃日志: -[__NSCFConstantString characterAtIndex:]: Range or index out of bounds
KVOCrashObject *obj = [[KVOCrashObject alloc] init];
[self addObserver: obj
forKeyPath: @""
options: NSKeyValueObservingOptionNew
context: nil];
// [self removeObserver:obj forKeyPath:@""];
}
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary*)change context:(void *)context {
NSLog(@"object = %@, keyPath = %@", object, keyPath);
}
@end可以将示例项目 NSObject+KVODefender.m 中的 + (void)load; 方法注释掉或打开进行防护前后的测试。
经测试可以发现,成功的拦截了这几种因为 KVO 使用不当导致的崩溃。
链接:https://www.jianshu.com/p/e3713d309283
收起阅读 »Swift高级分享 - 在Swift中构建模型数据
在代码库中建立可靠的结构通常是必不可少的,以便更容易使用。然而,实现一个既足够严格以防止错误和问题的结构 - 以及对现有功能足够灵活的结构以及我们想要的任何未来变化 - 都可能非常棘手。
对于模型代码而言尤其如此,模型代码通常由许多不同的功能使用,每个功能都有自己的一组要求。本周,让我们来看看构建核心模型的数据的几种不同技术,以及如何改进该结构对我们的其余代码库产生重大积极影响。
形成层次结构
在项目开始时,模型通常可以保持非常简单。由于我们尚未实现许多功能,因此我们的模型很可能不需要包含太多数据。然而,随着我们的代码库的增长,我们的模型经常发生变化 - 并且很容易达到一个简单的模型最终成为各种相关数据的“全能”的程度。
例如,假设我们正在构建一个电子邮件客户端,它使用Message模型来跟踪每条消息。最初,该模型可能只包含给定消息的主题行和正文,但此后逐渐增长为包含各种其他数据:
struct Message {
var subject: String
var body: String
let date: Date
var tags: [Tag]
var replySent: Bool
let senderName: String
let senderImage: UIImage?
let senderAddress: String
}虽然为了呈现消息需要所有上述数据,但是直接将其保留在Message类型本身中会使事情变得有点混乱 - 并且很可能使消息更难以使用,尤其是当我们创建新实例时 - 撰写新邮件时或编写单元测试时。
缓解上述问题的一种方法是将数据分解为多个专用类型 - 然后我们可以使用它们来形成模型层次结构。例如,我们可能会将有关消息发送者的所有数据提取到Person结构中,并将所有元数据(例如消息的标记和日期)提取到Metadata类型中,如下所示:
struct Person {
var name: String
var image: UIImage?
var address: String
}
extension Message {
struct Metadata {
let date: Date
var tags: [Tag]
var replySent: Bool
}
}现在,有了上述内容,我们可以为我们的Message类型提供一个更清晰的结构 - 因为每个数据不直接作为消息本身的一部分现在包含在更具上下文的专用类型中:
struct Message {
var subject: String
var body: String
var metadata: Metadata
let sender: Person
}上述方法的另一个好处是,我们现在可以更容易地在不同的上下文中重用部分数据。例如,我们可以使用我们的新Person类型来实现联系人列表等功能,或者允许用户定义组 - 因为该数据不再直接绑定到该Message类型。
减少重复
除了用于更好地组织我们的代码之外,可靠的结构还可以帮助减少项目中的重复。假设我们的电子邮件应用程序使用事件驱动的方法来处理不同的用户操作 - 使用如下所示的Event枚举:
enum Event {
case add(Message)
case update(Message)
case delete(Message)
case move(Message, to: Folder)
}使用枚举来定义各种代码需要处理的有限事件列表,这是在应用程序中建立更清晰数据流的好方法 - 但是我们当前的实现要求每个案例都包含Message事件所针对的事件 - 领先在Event类型本身内复制,以及在我们想要从事件的消息中提取信息时。
由于每个事件的操作都是对消息执行的,所以让我们将两者分开,并创建一个更简单的枚举类型,它将包含我们的所有操作:
enum Action {
case add
case update
case delete
case move(to: Folder)
}然后,让我们再次形成一个层次结构 - 这一次通过重构我们的Event类型成为一个包含a Action和Message它将被应用于的包装器- 如下所示:
struct Event {
let message: Message
let action: Action
}上述方法为我们提供了两全其美 - 处理事件现在只需要切换事件Action,现在可以使用message属性直接从事件的消息中提取数据。
递归结构
到目前为止,我们已经形成了层次结构,其中每个孩子和父母都是完全独立的类型 - 但这并不总是最优雅,或最方便的解决方案。假设我们正在开发一个显示各种内容的应用程序,例如文本和图像,并且我们再次使用枚举来定义每个内容 - 如下所示:
enum Content {
case text(String)
case image(UIImage)
case video(Video)
}现在让我们说我们希望让用户能够形成一组内容 - 例如,通过创建收藏列表,或使用文件夹来组织内容。最初的想法可能是寻找一个专用Group类型,它包含组的名称和属于它的内容:
struct Group {
var name: String
var content: [Content]
}然而,尽管上述内容看起来优雅且结构合理,但在这种情况下它有一些缺点。通过引入一种新的专用类型,我们将需要单独处理各个内容组 - 使得构建列表之类的内容变得更加困难 - 而且我们也无法轻松支持嵌套组。
因为在这种情况下,一个组只不过是构造内容的另一种方式,所以让它改为Content枚举本身的第一类成员,只需为它添加一个新的例子 - 就像这样:
enum Content {
case text(String)
case image(UIImage)
case video(Video)
case group(name: String, content: [Content])
}我们上面基本上做的是创建Content一个递归数据结构。这种方法的优点在于我们现在可以重用我们用于处理内容的大部分相同代码来处理组,并且我们可以自动支持任意数量的嵌套组。
例如,以下是我们如何处理显示内容列表的表视图的单元格选择:
extension ListViewController: UITableViewDelegate {
func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
let content = contentList[indexPath.row]
switch content {
case .text(let string):
navigator.showText(string)
case .image(let image):
navigator.showImage(image)
case .video(let video):
navigator.openPlayer(for: video)
case .group(let name, let content):
navigator.openList(withTitle: name, content: content)
}
}
}上面我们使用导航器模式导航到新目的地。您可以在“Swift中的导航”中找到更多相关信息。
由于Content现在是递归的,因此navigator.openList在处理组时调用现在只需创建一个ListViewController包含该组内容列表的新实例,使用户能够轻松地创建和导航任何内容层次结构,而我们只需要很少的努力。
专业模特
虽然能够重用代码通常是件好事,但有时最好创建一个更专业的新版本的模型,而不是尝试在非常不同的上下文中重用它。
回到之前的电子邮件应用程序示例,假设我们希望用户能够保存部分撰写的邮件草稿。而不是让该功能处理完整的Message实例,这需要不能用于草稿的数据 - 例如发件人的姓名或收到邮件的日期 - 让我们创建一个更简单的Draft类型,我们将嵌套在Message其他上下文中:
extension Message {
struct Draft {
var subject: String?
var body: String?
var recipients: [Person]
}
}这样,我们可以自由地将某些属性作为选项,并减少加载和保存草稿时我们需要处理的数据量 - 而不会影响我们处理正确消息的任何代码。
结论
虽然哪种模型结构最适合每种情况,但在很大程度上取决于所需的数据类型以及数据的使用方式 - 在能够重用代码和不创建模型之间取得平衡太复杂,往往是关键。
形成清晰的层次结构 - 无论是使用专用类型还是通过创建递归数据结构 - 同时仍然偶尔为特定用例创建模型的专用版本,可以在我们的模型代码中形成更清晰的结构 - 并且像往常一样,常量重构和小改进通常是达到目的的方式。
链接:https://www.jianshu.com/p/06e7d171dd99
收起阅读 »iOS开发性能监控
App 的性能问题虽然不会导致 App不可用,但依然会影响到用户体验。如果这个性能问题不断累积,达到临界点以后,问题就会爆发出来。这时,影响到的就不仅仅是用户了,还有负责App开发的你。
线下性能监控
其中线下监控使用的还是Instruments,Instruments功能很强大,下图是Instruments的各种性能检测工具。
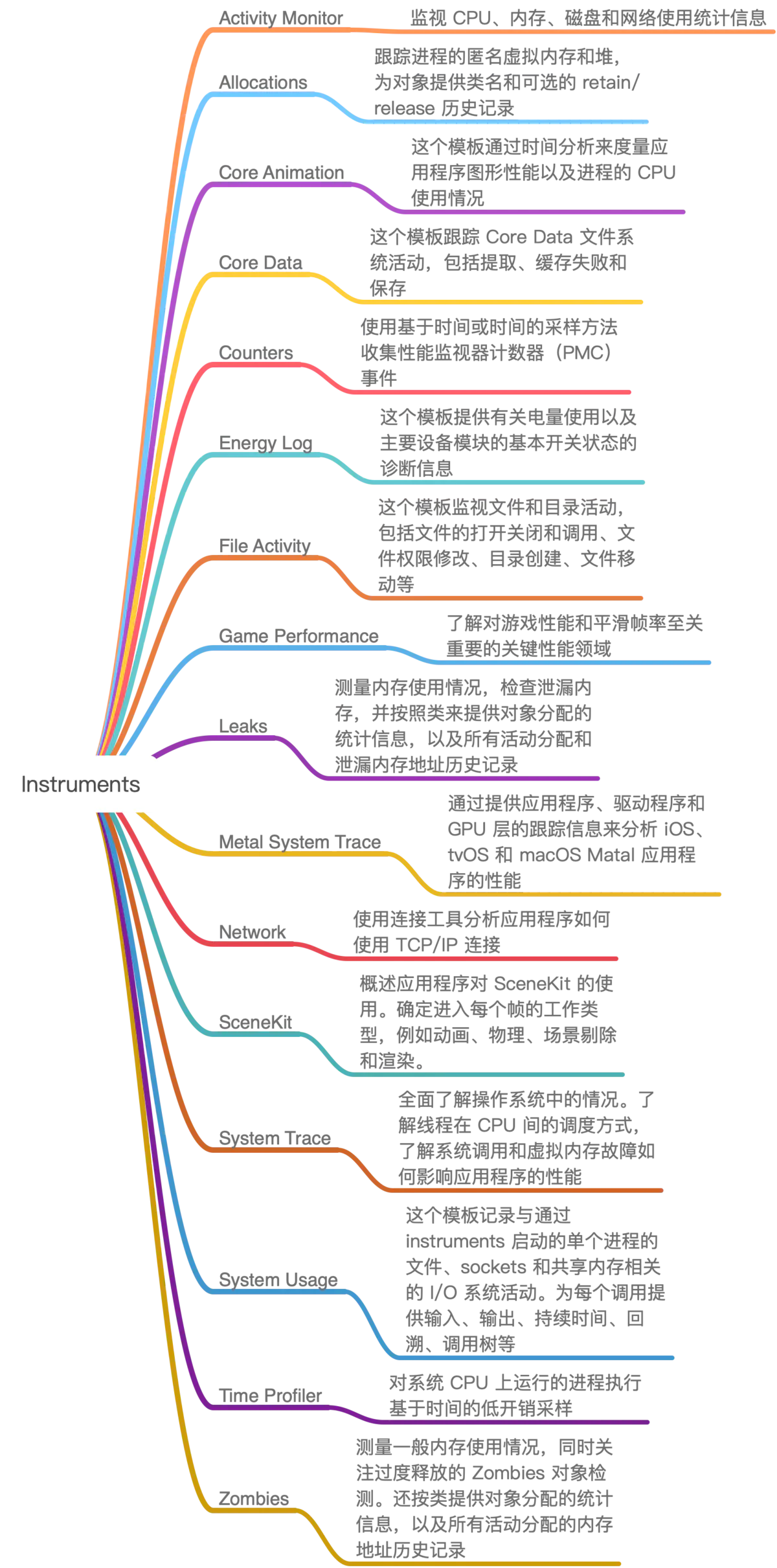
最新版本的Instruments 10还有以下两大优势:
1.Instruments基于os_signpost 架构,可以支持所有平台。
2.Instruments由于标准界面(Standard UI)和分析核心(Analysis Core)技术,使得我们可以非常方便地进行自定义性能监测工具的开发。当你想要给Instruments内置的工具换个交互界面,或者新创建一个工具的时候,都可以通过自定义工具这个功能来实现。
从整体架构来看,Instruments 包括Standard UI 和 Analysis Core 两个组件,它的所有工具都是基于这两个组件开发的。而且,你如果要开发自定义的性能分析工具的话,完全基于这两个组件就可以实现。
开发一款自定义Instruments工具,主要包括以下这几个步骤:
1.在Xcode中,点击File > New > Project;
2.在弹出的Project模板选择界面,将其设置为macOS;
3.选择 Instruments Package,点击后即可开始自定义工具的开发了。如下图所示。
经过上面的三步之后,会在新创建的工程里面生成一个.instrpkg 文件,接下来的开发过程主要就是对这个文件的配置工作了。这些配置工作中最主要的是要完成Standard UI 和 Analysis Core 的配置。
上面这些内容,就是你在开发一个自定义Instruments工具时,需要完成的编码工作了。可以看到,Instruments 10版本的自定义工具开发还是比较简单的。与此同时,苹果公司还提供了大量的代码片段,帮助你进行个性化的配置。你可以点击这个链接,查看官方指南中的详细教程。
再说一下,线上性能监控
对于线上性能监控,我们需要先明白两个原则:
1、监控代码不要侵入到业务代码中;
2、采用性能消耗最小的监控方案。
接下来我们从CPU使用率、FPS的帧率和内存这三个方面,说一下线上性能监控
CPU使用率的线上监控方法
App作为进程运行起来后会有多个线程,每个线程对CPU 的使用率不同。各个线程对CPU使用率的总和,就是当前App对CPU 的使用率。明白了这一点以后,我们也就摸清楚了对CPU使用率进行线上监控的思路。
在iOS系统中,你可以在 usr/include/mach/thread_info.h 里看到线程基本信息的结构体,其中的cpu_usage 就是 CPU使用率。结构体的完整代码如下所示:
struct thread_basic_info {
time_value_t user_time; // 用户运行时长
time_value_t system_time; // 系统运行时长
integer_t cpu_usage; // CPU 使用率
policy_t policy; // 调度策略
integer_t run_state; // 运行状态
integer_t flags; // 各种标记
integer_t suspend_count; // 暂停线程的计数
integer_t sleep_time; // 休眠的时间
};因为每个线程都会有这个 thread_basic_info 结构体,所以接下来的事情就好办了,你只需要定时(比如,将定时间隔设置为2s)去遍历每个线程,累加每个线程的 cpu_usage 字段的值,就能够得到当前App所在进程的 CPU 使用率了。实现代码如下:
- (integer_t)cpuUsage {
thread_act_array_t threads; //int 组成的数组比如 thread[1] = 5635
mach_msg_type_number_t threadCount = 0; //mach_msg_type_number_t 是 int 类型
const task_t thisTask = mach_task_self();
//根据当前 task 获取所有线程
kern_return_t kr = task_threads(thisTask, &threads, &threadCount);
if (kr != KERN_SUCCESS) {
return 0;
}
integer_t cpuUsage = 0;
// 遍历所有线程
for (int i = 0; i < threadCount; i++) {
thread_info_data_t threadInfo;
thread_basic_info_t threadBaseInfo;
mach_msg_type_number_t threadInfoCount = THREAD_INFO_MAX;
if (thread_info((thread_act_t)threads[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount) == KERN_SUCCESS) {
// 获取 CPU 使用率
threadBaseInfo = (thread_basic_info_t)threadInfo;
if (!(threadBaseInfo->flags & TH_FLAGS_IDLE)) {
cpuUsage += threadBaseInfo->cpu_usage;
}
}
}
assert(vm_deallocate(mach_task_self(), (vm_address_t)threads, threadCount * sizeof(thread_t)) == KERN_SUCCESS);
return cpuUsage;
}在上面这段代码中,task_threads 方法能够取到当前进程中的线程总数 threadCount 和所有线程的数组 threads。
接下来,我们就可以通过遍历这个数组来获取单个线程的基本信息。其中,线程基本信息的结构体是 thread_basic_info_t,这个结构体里就包含了我们需要的 CPU 使用率的字段 cpu_usage。然后,我们累加这个字段就能够获取到当前的整体 CPU 使用率。
接下来我们说说关于FPS的监控
FPS 线上监控方法
FPS 是指图像连续在显示设备上出现的频率。FPS低,表示App不够流畅,还需要进行优化。
但是,和前面对CPU使用率和内存使用量的监控不同,iOS系统中没有一个专门的结构体,用来记录与FPS相关的数据。但是,对FPS的监控也可以比较简单的实现:通过注册 CADisplayLink 得到屏幕的同步刷新率,记录每次刷新时间,然后就可以得到 FPS。具体的实现代码如下:
- (void)startMonitoring {
if (_link) {
[_link removeFromRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
[_link invalidate];
_link = nil;
}
_link = [CADisplayLink displayLinkWithTarget:self selector:@selector(fpsDisplayLinkAction:)];
[_link addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
}
- (void)fpsDisplayLinkAction:(CADisplayLink *)link {
if (_lastTime == 0) {
_lastTime = link.timestamp;
return;
}
self.count++;
NSTimeInterval delta = link.timestamp - _lastTime;
if (delta < 1) return;
_lastTime = link.timestamp;
_fps = _count / delta;
NSLog(@"count = %d, delta = %f,_lastTime = %f, _fps = %.0f",_count, delta, _lastTime, _fps);
self.count = 0;
}
内存使用量的线上监控方法
通常情况下,我们在获取 iOS 应用内存使用量时,都是使用task_basic_info 里的 resident_size 字段信息。但是,我们发现这样获得的内存使用量和 Instruments 里看到的相差很大。后来,在 2018 WWDC Session 416 iOS Memory Deep Dive中,苹果公司介绍说 phys_footprint 才是实际使用的物理内存。
内存信息存在 task_info.h (完整路径 usr/include/mach/task.info.h)文件的 task_vm_info 结构体中,其中phys_footprint 就是物理内存的使用,而不是驻留内存 resident_size。结构体里和内存相关的代码如下:
struct task_vm_info {
mach_vm_size_t virtual_size; // 虚拟内存大小
integer_t region_count; // 内存区域的数量
integer_t page_size;
mach_vm_size_t resident_size; // 驻留内存大小
mach_vm_size_t resident_size_peak; // 驻留内存峰值
...
/* added for rev1 */
mach_vm_size_t phys_footprint; // 物理内存
...我们只要从这个结构体里取出phys_footprint 字段的值,就能够监控到实际物理内存的使用情况了。具体实现代码如下:
- (unsigned long)memoryUsage {
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t result = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if (result != KERN_SUCCESS)
return 0;
return vmInfo.phys_footprint;
}从以上三个线上性能监控方案可以看出,它们的代码和业务逻辑是完全解耦的,监控时基本都是直接获取系统本身提供的数据,没有额外的计算量,因此对 App 本身的性能影响也非常小,满足了我们要考虑的两个原则。
你可以点击这个链接,查看具体demo,欢迎大家点赞。
链接:https://www.jianshu.com/p/cc02a1e1e019
iOS-编译过程
编译器
iOS编译和打包时,编译器直接将代码编译成机器码,然后直接在CPU上运行。而不用使用解释器运行代码。因为这样执行效率更高,运行速度更快。C,C++,OC都是使用的编译器生成相关的可执行文件。
解释器:解释器会在运行时解释执行代码,获取一段代码后就会将其翻译成目标代码(就是字节码(Bytecode)),然后一句一句地执行目标代码。也就是说是在运行时才去解析代码,比直接运行编译好的可执行文件自然效率就低,但是跑起来之后可以不用重启启动编译,直接修改代码即可看到效果,类似热更新,可以帮我们缩短整个程序的开发周期和功能更新周期。
编译器:把一种编程语言(原始语言)转换为另一种编程语言(目标语言)的程序叫做编译器
采用编译器生成机器码执行的好处是效率高,缺点是调试周期长。
解释器执行的好处是编写调试方便,缺点是执行效率低。
编译器分为前端和后端
- 前端:前端负责语法分析、词法分析,生成中间代码
- 后端:后端以中间代码作为输入,进行架构无关的代码优化,接着针对不同架构生成不同的机器码
在2007年之前LLVM使用GCC作为前端来对用户程序进行语义分析产生 IF(Intermidiate Format)。GCC系统庞大而笨重,因此,Apple决定从零开始写C、C++、Objective-C语言的前端Clang,以求完全替代掉GCC。
对于Apple来说Objective C/C/C++使用的编译器前端是clang,后端都是LLVM
LLVM 是编译器工具链技术的一个集合。而其中的 lld 项目,就是内置链接器。编译器会对每个文件进行编译,生成 Mach-O(可执行文件);链接器会将项目中的多个 Mach-O 文件合并成一个。
编译过程
- 预处理:Clang会预处理你的代码,比如把宏嵌入到对应的位置、注释被删除,条件编译被处理
- 词法分析:词法分析器读入源文件的字符流,将他们组织称有意义的词素(lexeme)序列,对于每个词素,此法分析器产生词法单元(token)作为输出。并且会用Loc来记录位置。
- 语法分析:这一步是把词法分析生成的标记流,解析成一个抽象语法树(abstract syntax tree -- AST),同样地,在这里面每一节点也都标记了其在源码中的位置。
AST 是抽象语法树,结构上比代码更精简,遍历起来更快,所以使用 AST 能够更快速地进行静态检查。 - 静态分析:把源码转化为抽象语法树之后,编译器就可以对这个树进行静态分析处理。静态分析会对代码进行错误检查,如出现方法被调用但是未定义、定义但是未使用的变量等,以此提高代码质量。当然,还可以通过使用 Xcode 自带的静态分析工具(Product -> Analyze)进行手动分析。最后 AST 会生成 IR,IR 是一种更接近机器码的语言,区别在于和平台无关,通过 IR 可以生成多份适合不同平台的机器码。静态分析的阶段会进行类型检查,比如给属性设置一个与其自身类型不相符的对象,编译器会给出一个可能使用不正确的警告。在此阶段也会检查时候有未使用过的变量等。
- 中间代码生成和优化:此阶段LLVM 会对代码进行编译优化,例如针对全局变量优化、循环优化、尾递归优化等,最后输出汇编代码xx.ll文件。
生成汇编代码: 汇编器LLVM会将汇编码转为机器码。此时的代码就是.o文件,即二进制文件。 - 链接:连接器把编译产生的.o文件和(dylib,a,tbd)文件,生成一个mach-o文件。mach-o文件级可执行文件。编译过程全部结束,生成了可执行文件Mach-O

连接器
Mach-O 文件里面的内容,主要就是代码和数据:代码是函数的定义;数据是全局变量的定义,包括全局变量的初始值。不管是代码还是数据,它们的实例都需要由符号将其关联起来。
为什么呢?因为 Mach-O 文件里的那些代码,比如 if、for、while 生成的机器指令序列,要操作的数据会存储在某个地方,变量符号就需要绑定到数据的存储地址。你写的代码还会引用其他的代码,引用的函数符号也需要绑定到该函数的地址上。而链接器的作用,就是完成变量、函数符号和其地址绑定这样的任务。而这里我们所说的符号,就可以理解为变量名和函数名。那为什么要让链接器做符号和地址绑定这样一件事儿呢?
如果地址和符号不做绑定的话,要让机器知道你在操作什么内存地址,你就需要在写代码时给每个指令设好内存地址。写这样的代码的过程,就像你直接在和不同平台的机器沟通,连编译生成 AST 和 IR 的步骤都省掉了,甚至优化平台相关的代码都需要你自己编写。
可读性和可维护性都会很差,比如修改代码后对地址的维护就会让你崩溃。而这种“崩溃”的罪魁祸首就是代码和内存地址绑定得太早。链接器为什么还要把项目中的多个 Mach-O 文件合并成一个
项目中文件之间的变量和接口函数都是相互依赖的,所以这时我们就需要通过链接器将项目中生成的多个 Mach-O 文件的符号和地址绑定起来。
没有这个绑定过程的话,单个文件生成的 Mach-O 文件是无法正常运行起来的。因为,如果运行时碰到调用在其他文件中实现的函数的情况时,就会找不到这个调用函数的地址,从而无法继续执行。
链接器在链接多个目标文件的过程中,会创建一个符号表,用于记录所有已定义的和所有未定义的符号。链接时如果出现相同符号的情况,就会出现“ld: dumplicate symbols”的错误信息;如果在其他目标文件里没有找到符号,就会提示“Undefined symbols”的错误信息。
链接器做了什么
- 在项目文件中查找目标代码文件里没有定义的变量
- 扫描项目中的不同文件,将所有符号定义和引用地址收集起来,并放到全局符号表中
- 计算合并后长度及位置,生成同类型的段进行合并,建立绑定
- 对项目中不同文件里的变量进行地址重定位
- 去除无用函数:链接器在整理函数的调用关系时,会以 main 函数为源头,跟随每个引用,并将其标记为 live。跟随完成后,那些未被标记 live 的函数,就是无用函数。然后,链接器可以通过打开 Dead code stripping 开关,来开启自动去除无用代码的功能。并且,这个开关是默认开启的。
动态库链接
在真实的 iOS 开发中,你会发现很多功能都是现成可用的,比如 系统库、GUI 框架、I/O、网络等。链接这些共享库到你的 Mach-O 文件,也是通过链接器来完成的。
链接的共用库分为静态库和动态库:静态库是编译时链接的库,需要链接进你的 Mach-O 文件里,如果需要更新就要重新编译一次,无法动态加载和更新;而动态库是运行时链接的库,使用 dyld 就可以实现动态加载。加载过程开始会修正地址偏移,iOS 会用 ASLR 来做地址偏移避免攻击,确定 Non-Lazy Pointer 地址进行符号地址绑定,加载所有类,最后执行 load 方法和 Clang Attribute 的 constructor 修饰函数。每个函数、全局变量和类都是通过符号的形式定义和使用的,当把目标文件链接成一个 Mach-O 文件时,链接器在目标文件和动态库之间对符号做解析处理。
编译和启动速度
编译阶段由于有了链接器,代码可以写在不同的文件里,每个文件都能够独立编成 Mach-O 文件进行标记。编译器可以根据你修改的文件范围来减少编译,通过这种方式提高每次编译的速度。
这也是为什么文件越多,链接器链接 Mach-O 文件所需绑定的遍历操作就会越多,编译速度也会越慢。iOS- 核心动画分类以及基本使用
1、UIView和核心动画区别?
核心动画只能添加到CALayer, 核心动画一切都是假象,并不会改变真实的值。如果需要与用户交互就使用UIView的动画. 不需要与用户交互可以使用核心动画。
在转场动画中,核心动画的类型比较多。根据⼀个路径做动画,只能用核心动画(帧动画) 、动画组:同时做多个动画。
2、核心动画的分类
核心动画继承结构
图中的黑色虚线代表“继承”某个类,红色虚线代表“遵守”某个协议
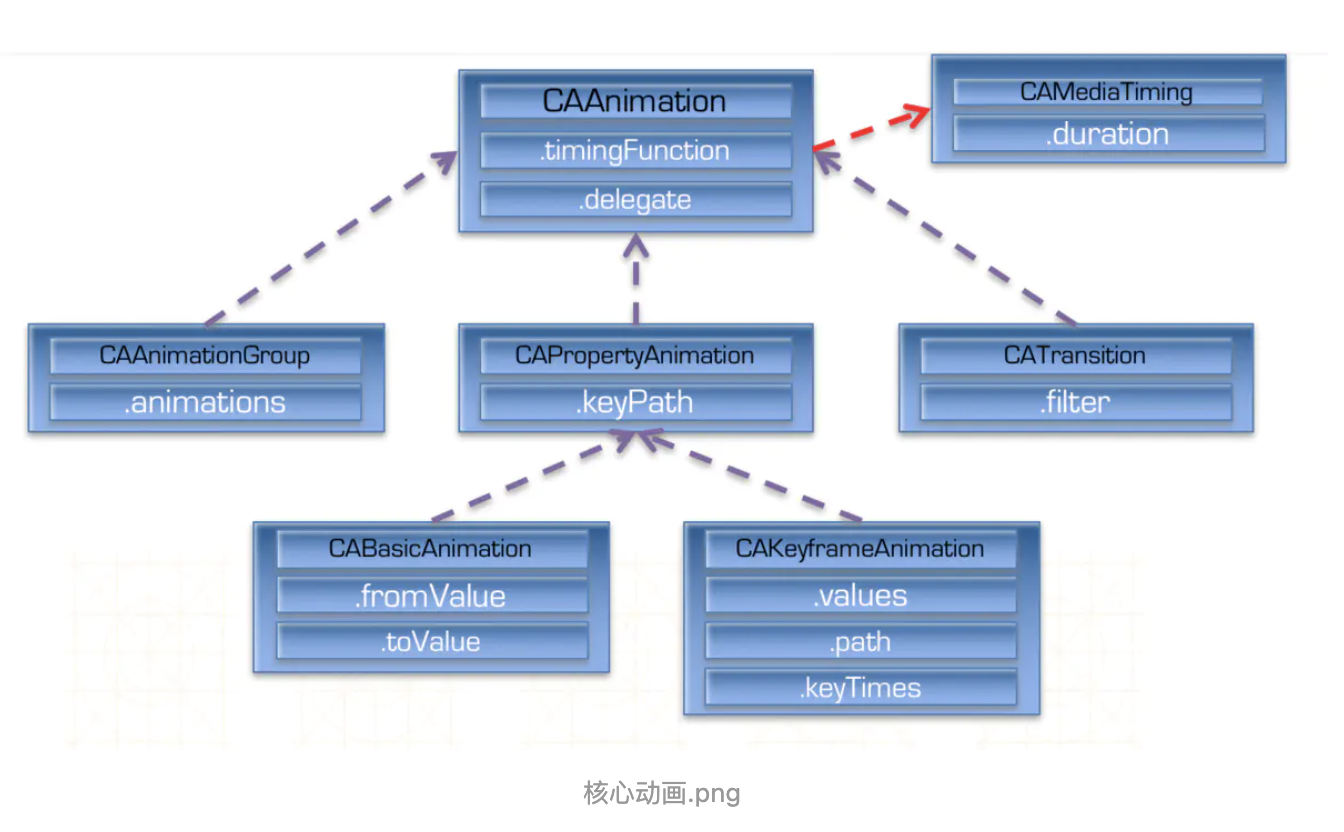
CAAnimation是所有动画对象的父类,负责控制动画的持续时间和速度,是个抽象类,不能直接使用,应该使用它具体的子类
属性说明:(红色代表来自CAMediaTiming协议的属性)
duration:动画的持续时间repeatCount:重复次数,无限循环可以设置HUGE_VALF或者MAXFLOATrepeatDuration:重复时间removedOnCompletion:默认为YES,代表动画执行完毕后就从图层上移除,图形会恢复到动画执行前的状态。如果想让图层保持显示动画执行后的状态,那就设置为NO,不过还要设置fillMode为kCAFillModeForwards
-fillMode:决定当前对象在非active时间段的行为。比如动画开始之前或者动画结束之后
beginTime:可以用来设置动画延迟执行时间,若想延迟2s,就设置为CACurrentMediaTime()+2,CACurrentMediaTime()为图层的当前时间
timingFunction:速度控制函数,控制动画运行的节奏
delegate:动画代理fillMode属性值(要想fillMode有效,最好设置removedOnCompletion = NO)kCAFillModeRemoved这个是默认值,也就是说当动画开始前和动画结束后,动画对layer都没有影响,动画结束后,layer会恢复到之前的状态kCAFillModeForwards当动画结束后,layer会一直保持着动画最后的状态kCAFillModeBackwards在动画开始前,只需要将动画加入了一个layer,layer便立即进入动画的初始状态并等待动画开始。kCAFillModeBoth这个其实就是上面两个的合成.动画加入后开始之前,layer便处于动画初始状态,动画结束后layer保持动画最后的状态速度控制函数(
CAAnimationDelegate代理方法只是监听动画的开始和结束CAMediaTimingFunction)kCAMediaTimingFunctionLinear(线性):匀速,给你一个相对静态的感觉kCAMediaTimingFunctionEaseIn(渐进):动画缓慢进入,然后加速离开kCAMediaTimingFunctionEaseOut(渐出):动画全速进入,然后减速的到达目的地kCAMediaTimingFunctionEaseInEaseOut(渐进渐出):动画缓慢的进入,中间加速,然后减速的到达目的地。这个是默认的动画行为。@protocol CAAnimationDelegate <NSObject>
@optional
/* Called when the animation begins its active duration. */
- (void)animationDidStart:(CAAnimation *)anim;
/* Called when the animation either completes its active duration or
* is removed from the object it is attached to (i.e. the layer). 'flag'
* is true if the animation reached the end of its active duration
* without being removed. */
- (void)animationDidStop:(CAAnimation *)anim finished:(BOOL)flag;
@endCALayer上动画的暂停和恢复
- (void)pauseLayerAnimation:(CALayer *)layer {
CFTimeInterval pauseTimes = [layer convertTime:CACurrentMediaTime() fromLayer:nil];
// speed动画的运行速度,当为0时会停止动画,speed越大说明动画执行速度越快
layer.speed = 0.0;
// 让layer的时间停留在pauseTimes
// 动画的时间偏移,也就是上次动画的暂停/继续 距离本次动画的继续/暂停的时间差
layer.timeOffset = pauseTimes;
NSLog(@":pauseTimes:%f", pauseTimes);
}
- (void)resumeLayerAnimation:(CALayer *)layer {
CFTimeInterval pauseTimes = layer.timeOffset;
//让CALayer的时间继续行走
layer.speed = 1;
// 取消上次记录的停留时刻
layer.timeOffset = 0.0;
//取消上次设置的时间
layer.beginTime = 0.0;
CFTimeInterval timeSincePause = CACurrentMediaTime()-pauseTimes;
layer.beginTime = timeSincePause;
NSLog(@":timeSincePause:%f", timeSincePause);
}第一次暂停和开始是正常的,之后就会出现偏移,暂时搞不清楚是什么原因???????????????
原因:
-(CFTimeInterval)convertTime:(CFTimeInterval)t fromLayer:(CALayer)l; -(CFTimeInterval)convertTime:(CFTimeInterval)t toLayer:(CALayer)l;这两个方法混用了2、CABasicAnimation——基本动画
基本动画,是
CAPropertyAnimation的子类
属性说明:
fromValue:keyPath相应属性的初始值
toValue:keyPath相应属性的结束值动画过程说明:
随着动画的进行,在长度为duration的持续时间内,keyPath相应属性的值从fromValue渐渐地变为toValue
keyPath内容是CALayer的可动画Animatable属性
如果fillMode==kCAFillModeForwards同时removedOnComletion=NO,那么在动画执行完毕后,图层会保持显示动画执行后的状态。但在实质上,图层的属性值还是动画执行前的初始值,并没有真正被改变。CABasicAnimation *basicAnim = [CABasicAnimation animation];
basicAnim.keyPath = @"position.y";
basicAnim.fromValue = @(self.redView.layer.position.y);
basicAnim.toValue = @(self.redView.layer.position.y + 300);
basicAnim.duration = 2.0;
// 动画完成时不移除动画
basicAnim.removedOnCompletion = NO;
// 动画完成时保持最后的状态
/**
kCAFillModeRemoved 这个是默认值,也就是说当动画开始前和动画结束后,动画对layer都没有影响,动画结束后,layer会恢复到之前的状态
kCAFillModeForwards 当动画结束后,layer会一直保持着动画最后的状态
kCAFillModeBackwards 在动画开始前,只需要将动画加入了一个layer,layer便立即进入动画的初始状态并等待动画开始。
kCAFillModeBoth 这个其实就是上面两个的合成.动画加入后开始之前,layer便处于动画初始状态,动画结束后layer保持动画最后的状态
*/
basicAnim.fillMode = kCAFillModeForwards;
// 动画重复次数
basicAnim.repeatCount = MAXFLOAT;
// 自动返转(怎么去,怎么返回)
basicAnim.autoreverses = YES;
basicAnim.delegate = self;
// 延迟2S开始动画
basicAnim.beginTime = CACurrentMediaTime()+2;
[self.redView.layer addAnimation:basicAnim forKey:nil];3、CAKeyframeAnimation——关键帧动画
关键帧动画,也是
CAPropertyAnimation的子类,与CABasicAnimation的区别是:
CABasicAnimation只能从一个数值(fromValue)变到另一个数值(toValue),而CAKeyframeAnimation会使用一个NSArray保存这些数值。属性说明:
values:上述的·NSArray·对象。里面的元素称为“关键帧”(keyframe)。动画对象会在指定的时间(duration)内,依次显示values数组中的每一个关键帧
path:可以设置一个CGPathRef、CGMutablePathRef,让图层按照路径轨迹移动。path只对CALayer的anchorPoint和position起作用。如果设置了path,那么values将被忽略keyTimes:可以为对应的关键帧指定对应的时间点,其取值范围为0到1.0,keyTimes中的每一个时间值都对应values中的每一帧。如果没有设置keyTimes,各个关键帧的时间是平分的CABasicAnimation可看做是只有2个关键帧的CAKeyframeAnimation
UIBezierPath *path = [UIBezierPath bezierPathWithArcCenter:self.iconImageView.center radius:100 startAngle:0 endAngle:M_PI clockwise:YES];
CAKeyframeAnimation *keyFrameAnima = [CAKeyframeAnimation animation];
keyFrameAnima.path = path.CGPath;
keyFrameAnima.keyPath = @"position";
keyFrameAnima.duration = 2;
keyFrameAnima.repeatCount = MAXFLOAT;
keyFrameAnima.autoreverses = YES;
[self.iconImageView.layer addAnimation:keyFrameAnima forKey:nil];4、CAAnimationGroup——动画组
动画组,是CAAnimation的子类,可以保存一组动画对象,将CAAnimationGroup对象加入层后,组中所有动画对象可以同时并发运行
- 属性说明:
animations:用来保存一组动画对象的NSArray
默认情况下,一组动画对象是同时运行的,也可以通过设置动画对象的beginTime属性来更改动画的开始时间
- (void)addAnimationGrounp {
// 创建一个基础动画
CABasicAnimation *basicAnima = [CABasicAnimation animation];
basicAnima.keyPath = @"transform.scale";
basicAnima.fromValue = @1.0;
basicAnima.toValue = @0;
// 创建一个帧动画
CAKeyframeAnimation *keyframeAnim = [CAKeyframeAnimation animation];
keyframeAnim.path = [UIBezierPath bezierPathWithArcCenter:CGPointMake(170, self.redView.center.y) radius:100 startAngle:M_PI endAngle:M_PI*2 clockwise:YES].CGPath;
keyframeAnim.keyPath = @"position";
// 动画组
CAAnimationGroup *animGroup = [CAAnimationGroup animation];
animGroup.animations = @[basicAnima,keyframeAnim];
animGroup.duration = 2.0;
animGroup.repeatCount = MAXFLOAT;
animGroup.autoreverses = YES;
[self.redView.layer addAnimation:animGroup forKey:nil];
}5、CATransition——转场动画
CATransition是CAAnimation的子类,用于做转场动画,能够为层提供移出屏幕和移入屏幕的动画效果。UINavigationController就是通过CATransition`实现了将控制器的视图推入屏幕的动画效果
如果父视图中的两个子视图互相切换,转场动画应加给父视图!
动画属性:
type:动画过渡类型subtype:动画过渡方向startProgress:动画起点(在整体动画的百分比)endProgress:动画终点(在整体动画的百分比)
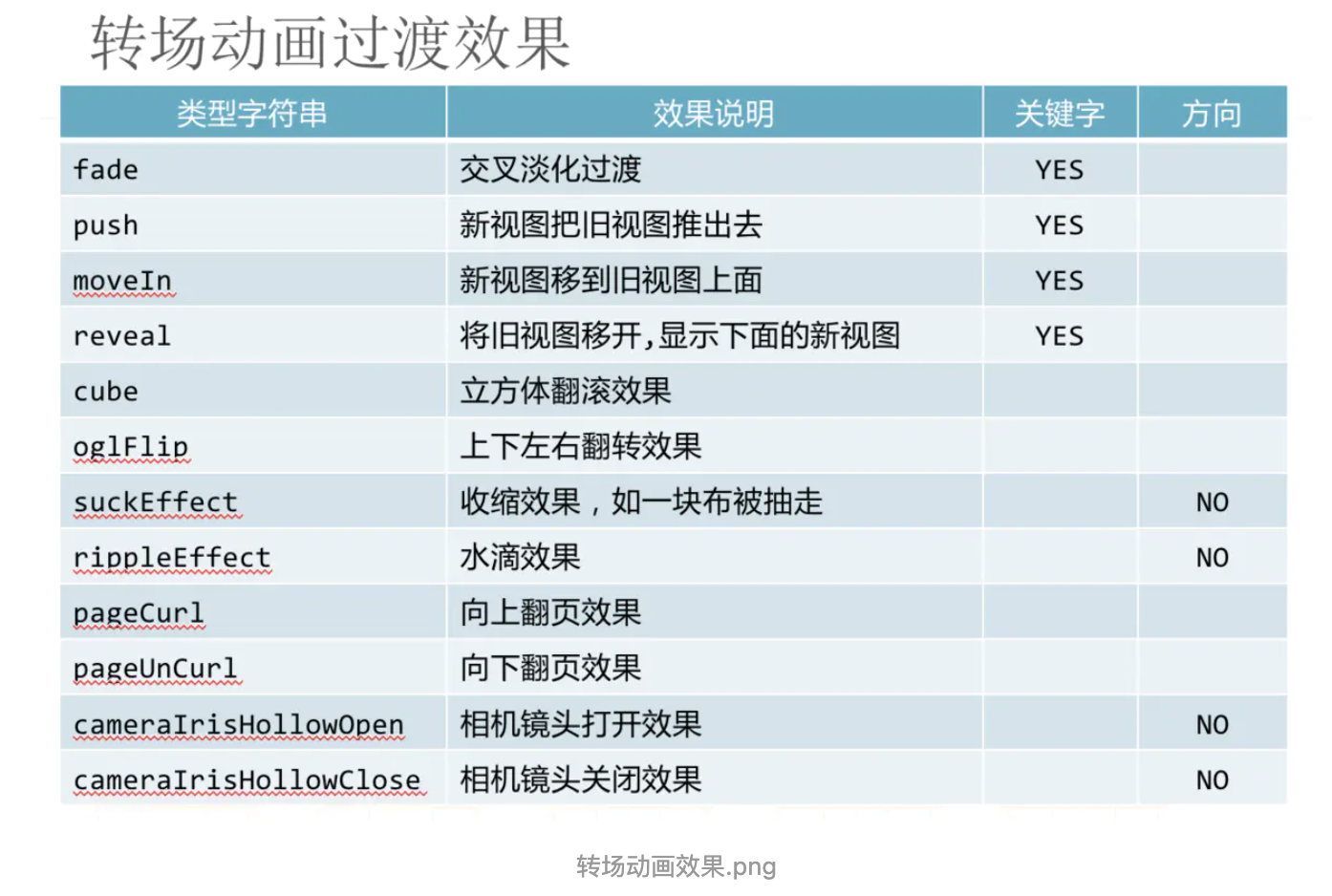
iOS--开发中遇到的der,csr,crt,p12,pem文件到底是什么
关于pem文件的话,上一篇文章已经有提到:iOS---利用OpenSSL演示RSA加密解密,PEM
在工作中,pem文件,我们是不会直接使用的,需要从pem文件里面提取csr文件。
csr文件
步骤1:从private.pem文件里,提取rsacert.csr文件,终端命令“openssl req -new -key private.pem -out rsacert.csr”

这个步骤是不是似曾相识,这个步骤我们也可以在钥匙串里面,从证书颁发机构创建这个文件。
总结。csr文件,:是请求证书文件,是用于从证书颁发机构请求证书用的文件。
(趣味:麻省理工设计RSA算法的三位数学家成立了一个机构,收费帮别的组织签名赚钱,一般收费是5000一年)
crt文件
步骤2:利用命令“openssl x509 -req -days 3650 -in rsacert.csr -signkey private.pem -out rsacert.crt”自己签名。
-days 3650 代表有效期10年,(5万块到手)
-in rsacert.csr 传递一个文件
-signkey private.pem 代表用私钥private.pem文件进行签名。
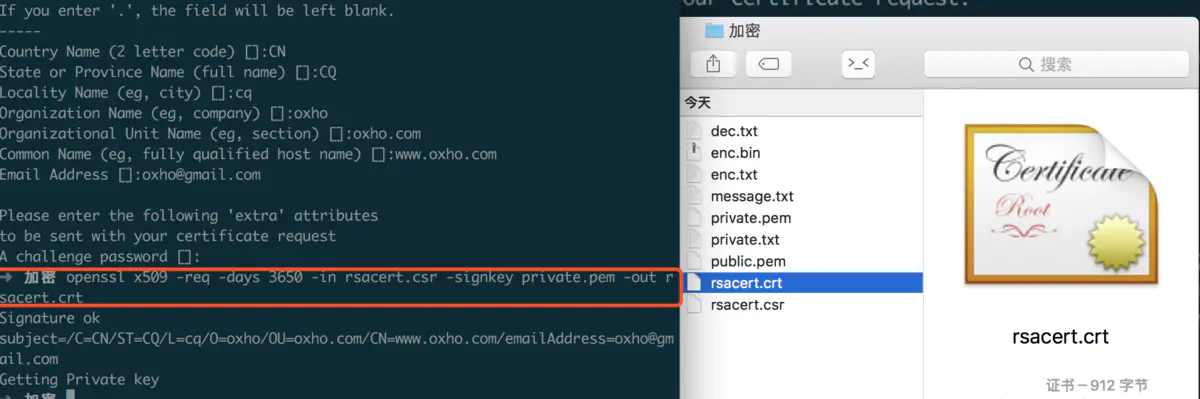
总结。crt文件,是用于从证书颁发机构签过名的文件。https就需要这个文件,放在自己服务器上用于别人接收。是一个base64格式的。
der文件
步骤3:利用命令“openssl x509 -outform der -in rsacert.crt -out rsacert.der”生成一个rsacert.der文件

总结。der文件主要包括就是公钥和一些信息。
p12文件
步骤4:利用命令“openssl pkcs12 -export -out p.p12 -inkey private.pem -in rsacert.crt”生成一个p.p12文件
-in rsacert.crt 我们从rsacert.crt 生成了 der文件, 同时,也从rsacert.crt 里面生成p12文件。
pkcs12 原来,p12是pkcs12的缩写。
输入密码的时候,是不是想起来,导出p12文件的时候,有一个输入密码的操作。

总结。p12文件主要包括就是私钥和一些信息。
这便是我们经常接触到的,钥匙串帮我们做的事情,通过命令行演示,如果有问题,请指出来,及时修改。
转自:https://www.jianshu.com/p/83b67244458a
收起阅读 »Swift高级分享 - 在Swift中提取视图控制器操作
视图控制器往往在为Apple平台构建的大多数应用程序中起着非常重要的作用。他们管理我们UI的关键方面,提供系统功能的桥梁,如设备方向和状态栏外观,并经常响应用户交互 - 如按钮点击和文本输入。
由于它们通常具有这样的关键作用,因此许多视图控制器最终遭受常见的大规模视图控制器问题并不奇怪- 当它们最终承担太多责任时,导致大量交织在一起的逻辑,通常与视图混合在一起和布局代码。
虽然我们已经探索了多种减轻和分解大视图控制器的方法 - 例如使用合成,将导航代码移动到专用类型,重用数据源和使用逻辑控制器 - 本周,我们来看一下技术这让我们可以提取视图控制器的核心操作,而无需引入任何其他抽象或架构概念。
尴尬的意识
许多类型的架构和结构问题的一个非常常见的根本原因是某些类型只是意识到太多的域和细节。当给定类型的“意识领域”增长时,通常会履行其职责,并且 - 作为直接影响 - 它包含的代码量。
假设我们正在为消息传递应用程序构建一个作曲家视图,为了能够从用户的联系人中添加收件人并启用消息发送,我们目前允许我们的视图控制器直接访问我们的数据库和网络代码:
class MessageComposerViewController: UIViewController {
private var message: Message
private let userDatabase: UserDatabase
private let networking: Networking
init(recipients: [Recipient],
userDatabase: UserDatabase,
networking: Networking) {
self.message = Message(recipients: recipients)
self.userDatabase = userDatabase
self.networking = networking
super.init(nibName: nil, bundle: nil)
}
}上面可能看起来不是什么大问题 - 我们使用依赖注入,并不像我们的视图控制器有大量依赖。然而,当我们的视图控制器还没有变成一个巨大的一个,只是还没有,它确实有它需要处理的动作相当多的数量-如添加收件人,取消和发送邮件-它目前正在对所有的它自己的:
private extension MessageComposerViewController {
func handleAddRecipientButtonTap() {
let picker = RecipientPicker(database: userDatabase)
picker.present(in: self) { [weak self] recipient in
self?.message.recipients.append(recipient)
self?.renderRecipientsView()
}
}
func handleCancelButtonTap() {
if message.text.isEmpty {
dismiss(animated: true)
} else {
dismissAfterAskingForConfirmation()
}
}
func handleSendButtonTap() {
let sender = MessageSender(networking: networking)
sender.send(message) { [weak self] error in
if let error = error {
self?.display(error)
} else {
self?.dismiss(animated: true)
}
}
}
}让视图控制器执行自己的操作可能非常方便,对于更简单的视图控制器,它很可能不会导致任何问题 - 但正如我们只看到上面的摘录所看到的那样MessageComposerViewController,它通常需要我们的视图控制器知道他们理想情况下不应过于关注的事情 - 例如网络,创建逻辑对象,以及对父母如何呈现它们做出假设。
由于大多数视图控制器已经非常忙于创建和管理视图,设置布局约束以及检测用户交互等内容 - 让我们看看我们是否可以提取上述操作,并使我们的视图控制器更简单(并且不太清楚)处理。
操作
动作通常有两种不同的变体 - 同步和异步。某些操作只需要我们快速处理或转换给定值,并直接返回,而其他操作则需要更多时间来执行。
为了对这两种动作进行建模,让我们创建一个通用Action枚举 - 实际上并没有任何情况 - 但是包含两个类型别名,一个用于同步动作,一个用于异步动作:
enum Action<I, O> {
typealias Sync = (UIViewController, I) -> O
typealias Async = (UIViewController, I, @escaping (O) -> Void) -> Void
}我们使用的原因,enum我们的Action包装上面,以防止它被实例化的类型,而不是只充当一个“抽象的命名空间”。
使用上面的类型别名,我们现在可以定义一个元组,其中包含我们MessageComposerViewController可以执行的所有操作- 如下所示:
private extension MessageComposerViewController {
func handleAddRecipientButtonTap() {
actions.addRecipient(self, message) { [weak self] newMessage in
self?.message = newMessage
self?.renderRecipientsView()
}
}
func handleCancelButtonTap() {
actions.cancel(self, message)
}
func handleSendButtonTap() {
let loadingVC = add(LoadingViewController())
actions.finish(self, message) { [weak self] error in
loadingVC.remove()
error.map { self?.display($0) }
}
}
}值得注意的是,作为此重构的一部分,我们还改进了收件人添加到邮件的方式。我们不是让视图控制器本身执行其模型的变异,而是简单地返回一个新Message值作为其addRecipient动作的结果。
上述方法的优点在于我们的视图控制器现在可以专注于视图控制器最擅长的 - 控制视图 - 并让创建它的上下文处理网络和呈现等细节RecipientPicker。以下是我们现在可以在另一个视图控制器上呈现消息编写器的方法,例如在协调器或导航器中:
func presentMessageComposerViewController(
for recipients: [Recipient],
in presentingViewController: UIViewController
) {
let composer = MessageComposerViewController(
recipients: recipients,
actions: (
addRecipient: { [userDatabase] vc, message, handler in
let picker = RecipientPicker(database: userDatabase)
picker.present(in: vc) { recipient in
var message = message
message.recipients.append(recipient)
handler(message)
}
},
cancel: { vc, message in
if message.text.isEmpty {
vc.dismiss(animated: true)
} else {
vc.dismissAfterAskingForConfirmation()
}
},
finish: { [networking] vc, message, handler in
let sender = MessageSender(networking: networking)
sender.send(message) { error in
handler(error)
if error == nil {
vc.dismiss(animated: true)
}
}
}
)
)
presentingViewController.present(composer, animated: true)
}太可爱了!由于我们所有的视图控制器的操作现在都只是函数,因此我们的代码变得更加灵活,更容易测试 - 因为我们可以轻松地模拟行为并验证在各种情况下调用正确的操作。
可操作的概述
从私有方法和专用集合中提取操作的另一大好处是,可以更容易地了解给定视图控制器执行的操作类型 - 例如ProductViewController,这具有四个同步的非常清晰的列表和异步操作:
extension ProductViewController {
typealias Actions = (
load: Action<Product.ID, Result<Product, Error>>.Async,
purchase: Action<Product.ID, Error?>.Async,
favorite: Action<Product.ID, Void>.Sync,
share: Action<Product, Void>.Sync
)
}添加对新操作的支持通常也变得非常简单,因为我们不必为每个视图控制器注入新的依赖项并编写特定的实现,我们可以更轻松地利用共享逻辑并简单地向我们的Actions元组添加新成员- 然后在调用时调用它发生了相应的用户交互。
最后,操作可以实现类型自定义和更简单的重构等功能,而无需通常需要的“仪式”来解锁此类功能 - 例如,在使用协议时,或切换到新的,更严格的架构设计模式时。
例如,假设我们想要MessageComposerViewController从之前返回到我们,并添加对保存未完成消息草稿的支持。我们现在可以实现整个功能,甚至无需触及我们的实际视图控制器代码 - 我们所要做的就是更新其cancel操作:
let composer = MessageComposerViewController(
recipients: recipients,
actions: (
...
cancel: { [draftManager] vc, message in
if message.text.isEmpty {
vc.dismiss(animated: true)
} else {
vc.presentConfirmation(forReason: .saveDraft) {
outcome in
switch outcome {
case .accepted:
draftManager.saveDraft(message)
vc.dismiss(animated: true)
case .rejected:
vc.dismiss(animated: true)
case .cancelled:
break
}
}
}
},
...
)
)iOS 列表界面如何优雅实现模块化与动态化
前言
去年做了一个小组件,前些时间考虑到项目中可能会大规模实施,完善简化后新开了一个 repo: YBHandyList 。
有些朋友抛出了 nimbus、IGListKit 等业界应用很广的库,前些时间网易工程师也推出了 M80TableViewComponent。理论上这些组件的原理大同小异,虽然它们各有优势,但却不太能满足笔者对架构清晰度的要求。
本文分析 YBHandyList 的应用价值,希望能解开一些朋友的疑惑。
业务痛点
iOS 界面开发中 UITableView / UICollectionView 的出场率极高,它们都是使用代理方法配置数据源,虽然这样的设计理念符合了单一职责原则,但在列表变得复杂时代理方法的处理将变得力不从心:
同一个 Cell / Header / Footer 处理逻辑分散在各个代理方法中,不便于管理。
当列表数据动态变化时,每一个代理方法里的判断逻辑都将变得复杂,且这些逻辑很可能会相互关联。
显然,在这样的场景下将是维护的灾难,特别是当你接手别人的代码发现每个 UITableView 代理方法里都有几十个if-else,它们人多势众,量你不敢动它们任何一个。
由此可见,若想维护性高需要解开每一个 Cell 之间的逻辑耦合,也就是通常意义的模块化,由此才能更轻易的实现动态化。解决方案其实很简单,只需要一个中间类,将分散的配置集中起来(在代理方法里取这个中间类的对应值):
@interface Config : NSObject
@property (nonatomic, assign) CGFloat height;
@property (nonatomic, strong) Class cls;
@property (nonatomic, strong) id model;
@end然而对于业务工程师来说,每次写这样的代码都意味着时间成本,所以制作一个基础组件是很有必要的,它需要满足以下特性:
模块化配置 Cell / Header / Footer。
更容易实施列表动态化。
能拓展原生能实现的所有场景。
为此,YBHandyList 应运而生,它足够简单以至于从设计到编码基本就花了一天时间。
YBHandyList 的优势
原理:

代码简单轻量
YBHandyList 保留最小功能,代码量很少,核心思路就一句话:将 UITableView / UICollectionView 的数据源从代理方法配置转化为数组配置。
在其它库当中可以看到高度缓存、访问迭代器等逻辑,笔者认为这样的基础设施不应该侵入过多业务,它们本应该是业务关注的逻辑,这样的语法糖只能在简单场景下少写些代码,当业务变得复杂时往往这样的优势就不存在了。
YBHandyList 的语法糖非常收敛,简单的一个延展,你甚至可以选择不使用语法糖,直接使用代理实现类。
由此,新手工程师也能对实施代码充满信心。
业务侵入性低
YBHandyList 采用 IOP 设计,最大限度的降低了业务侵入性,只需要在 Cell / Header / Footer 中实现几个代理方法就行了。
去基类化设计让数据流动过程更加纯粹,不需要考虑父类做了什么,没做什么。在老业务中可能存在类似BaseTableViewCell 的东西,YBHandyList 也能优雅的接入,这种场景下继承的设计范式将力不从心。
这种架构规范类组件接入的成本非常重要,而舍弃的成本也不容忽视,由于 IOP 天然的优势,YBHandyList 结构代码的舍弃将轻而易举,不拖泥带水。
直观的动态化控制
构建界面只需要关注所有id<Config>在数据源数组中的顺序,就像搭积木一样拼接起来,数组中的顺序就是对应 Cell 在界面中的显示顺序,由此就能通过改变数据源数组的顺序轻易的实现动态化控制。
在 MVVM 架构中实施
YBHandyList 的设计方式让它在各种架构中都能无障碍实施,下面以 MVVM 举例(仅说明 UITableViewCell 的实施,具体可以看 DEMO):
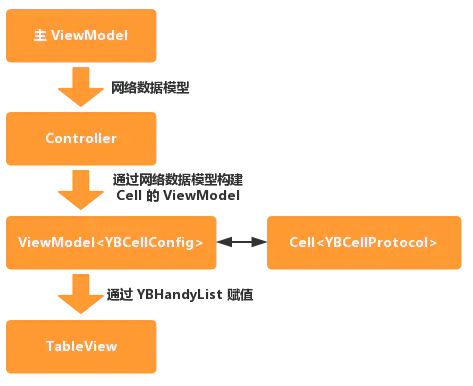
可以看到,Cell 与 UITableView 非直接耦合,所以若需要将 Cell 的事件传递出来最好通过 Cell 的 ViewModel,ViewModel 作为连接 Cell 与外界的桥梁。
Cell 的 ViewModel 也可以在主 ViewModel 中构建,这样 Controller 中就不用导入这些类,不过当 Cell 的 ViewModel 需要将事件传递到 Controller 时,就会需要一些胶水代码通过主 ViewModel 间接传递。
数据绑定并非必须做的事情,你可以用 RAC,或者另外一个选择:EasyReact,可以参考笔者的文章:美团 EasyReact 源码剖析:图论与响应式编程。
更安全和优雅的复用
很多时候,我们会将具体业务的处理逻辑放 Cell 中或者其 ViewModel 中,那么它们就很难复用,因为复用是建立在无具体业务侵入的前提下。
实际上只需要将具体业务的处理逻辑抽离出来,处理过后再放在 ViewModel 中,Cell 拿到 ViewModel 再进行具体业务无关的界面刷新。如此,ViewModel 将可以在任何地方复用。
使用 YBHandyList 后,ViewModel 把 Cell 与外部业务解开耦合,只把需要暴露的东西写在ViewModel .h中,外部业务无需导入 Cell 便能通过 ViewModel 直接复用,更加的安全。
能拓展原生支持的场景
一个基础设施最怕的就是不能满足所有场景的情况下还封闭了拓展的入口。YBHandyList 通过继承默认代理实现类就能拓展实现其它的 UITableView / UICollectionView 代理方法。
这看起来有些繁琐,使用多代理技术能避免额外的创建代理实现类,但这样会导致代码不再简单和透明。换个角度想,代理实现类中将大量复杂逻辑处理过后,仅仅回调给外部业务一个简单的方法,达到为外部模块瘦身的目的。
后语
笔者一直偏好简洁的代码设计,让核心功能最小化实现,当它无法覆盖所有的场景时一定要有原生拓展能力。语法糖的主要意义是减少使用者的思考成本而不单单是为了少写两句代码,它不应该侵入功能收敛的核心代码。要做好这一切,就一定要透过现象看清问题的本质。
链接:https://www.jianshu.com/p/f0a74d5744b8
iOS 应用内打开三方地图app直接导航
当然因为有需求喽。
疯狂试探
- (BOOL)canOpenURL:(NSURL *)url NS_AVAILABLE_IOS(3_0);
常用地图应用的url Scheme:
//百度地图
baidumap
//高德地图
iosamap
//谷歌地图
comgooglemaps
//腾讯地图
qqmap
//其他地图省略
….苹果地图不需要,iOS API提供了一个跳转打开方法。
注意IOS9之后,plist里面设置url scheme白名单
<key>LSApplicationQueriesSchemes</key>
<array>
<string>qqmap</string>
<string>comgooglemaps</string>
<string>iosamap</string>
<string>baidumap</string>
</array>在下用的是高德坐标
高德转坐标类型枚举
// AMapCoordinateTypeBaidu = 0, ///<Baidu
// AMapCoordinateTypeMapBar, ///<MapBar
// AMapCoordinateTypeMapABC, ///<MapABC
// AMapCoordinateTypeSoSoMap, ///<SoSoMap
// AMapCoordinateTypeAliYun, ///<AliYun
// AMapCoordinateTypeGoogle, ///<Google
// AMapCoordinateTypeGPS, ///<GPS在下试过转百度用AMapCoordinateTypeBaidu,这样一一对应的方式转,但跳转之后误差很大,后来我试着杂交匹配一下,所有地图使用Google转法最准,所以除高德地图都用了Google转出的坐标
重点来了!!!!
- (void)pushMapLan:(CGFloat)lan Lon:(CGFloat)lon pointName:(NSString *)title {
UIAlertController *alertSheet = [UIAlertController alertControllerWithTitle:title message:@"请选择以下驾车导航方式" preferredStyle:UIAlertControllerStyleActionSheet];
// 高德坐标转换百度坐标
CLLocationCoordinate2D gps = AMapCoordinateConvert(CLLocationCoordinate2DMake(lan,lon), AMapCoordinateTypeGoogle);
// --------------------------------------------------
if ([[UIApplication sharedApplication] canOpenURL:[NSURL URLWithString:@"baidumap://"]]) {
NSMutableDictionary *baiduMapDic = [NSMutableDictionary dictionary];
baiduMapDic[@"title"] = @"百度地图";
NSString *urlString = [[NSString stringWithFormat:@"baidumap://map/direction?origin={{我的位置}}&destination=latlng:%f,%f|name=北京&mode=driving&coord_type=gcj02",gps.latitude,gps.longitude] stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
baiduMapDic[@"url"] = urlString;
[alertSheet addAction:[UIAlertAction actionWithTitle:baiduMapDic[@"title"] style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action) {
[[UIApplication sharedApplication] openURL:[NSURL URLWithString:baiduMapDic[@"url"]]];
}]];
}
//高德地图
if ([[UIApplication sharedApplication] canOpenURL:[NSURL URLWithString:@"iosamap://"]]) {
NSMutableDictionary *gaodeMapDic = [NSMutableDictionary dictionary];
gaodeMapDic[@"title"] = @"高德地图";
NSString *urlString = [[NSString stringWithFormat:@"iosamap://navi?sourceApplication=%@&backScheme=%@&lat=%f&lon=%f&dev=0&style=2",@"导航功能",@"poapoaaldoerccbadersvsruhdk",lan,lon] stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
gaodeMapDic[@"url"] = urlString;
[alertSheet addAction:[UIAlertAction actionWithTitle:gaodeMapDic[@"title"] style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action) {
[[UIApplication sharedApplication] openURL:[NSURL URLWithString:gaodeMapDic[@"url"]]];
}]];
}
//谷歌地图
if ([[UIApplication sharedApplication] canOpenURL:[NSURL URLWithString:@"comgooglemaps://"]]) {
NSMutableDictionary *googleMapDic = [NSMutableDictionary dictionary];
googleMapDic[@"title"] = @"谷歌地图";
NSString *urlString = [[NSString stringWithFormat:@"comgooglemaps://?x-source=%@&x-success=%@&saddr=&daddr=%f,%f&directionsmode=driving",@"驾车导航",@"poapoaaldoerccbadersvsruhdk",gps.latitude,gps.longitude] stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
googleMapDic[@"url"] = urlString;
[alertSheet addAction:[UIAlertAction actionWithTitle:googleMapDic[@"title"] style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action) {
[[UIApplication sharedApplication] openURL:[NSURL URLWithString:googleMapDic[@"url"]]];
}]];
}
//腾讯地图
if ([[UIApplication sharedApplication] canOpenURL:[NSURL URLWithString:@"qqmap://"]]) {
NSMutableDictionary *qqMapDic = [NSMutableDictionary dictionary];
qqMapDic[@"title"] = @"腾讯地图";
NSString *urlString = [[NSString stringWithFormat:@"qqmap://map/routeplan?from=我的位置&type=drive&tocoord=%f,%f&to=终点&coord_type=1&policy=0",gps.latitude,gps.longitude] stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
qqMapDic[@"url"] = urlString;
[alertSheet addAction:[UIAlertAction actionWithTitle:qqMapDic[@"title"] style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action) {
[[UIApplication sharedApplication] openURL:[NSURL URLWithString:qqMapDic[@"url"]]];
}]];
}
NSMutableDictionary *iosMapDic = [NSMutableDictionary dictionary];
iosMapDic[@"title"] = @"苹果地图";
[alertSheet addAction:[UIAlertAction actionWithTitle:iosMapDic[@"title"] style:UIAlertActionStyleDestructive handler:^(UIAlertAction * _Nonnull action) {
CLLocationCoordinate2D gps = AMapCoordinateConvert(CLLocationCoordinate2DMake(lan,lon), AMapCoordinateTypeGoogle);
MKMapItem *currentLoc = [MKMapItem mapItemForCurrentLocation];
MKMapItem *toLocation = [[MKMapItem alloc] initWithPlacemark:[[MKPlacemark alloc] initWithCoordinate:gps addressDictionary:nil]];
toLocation.name = title;
NSArray *items = @[currentLoc,toLocation];
NSDictionary *dic = @{
MKLaunchOptionsDirectionsModeKey : MKLaunchOptionsDirectionsModeDriving,
MKLaunchOptionsMapTypeKey : @(MKMapTypeStandard),
MKLaunchOptionsShowsTrafficKey : @(YES)
};
[MKMapItem openMapsWithItems:items launchOptions:dic];
}]];
[alertSheet addAction:[UIAlertAction actionWithTitle:@"取消" style:UIAlertActionStyleCancel handler:^(UIAlertAction * _Nonnull action) {
}]];
[self presentViewController:alertSheet animated:YES completion:nil];
}关于转换坐标,如果你用的是高德坐标系,除了高德地图不用转坐标系外,其他的都以高德sdk里转Google的方式转,保证目的地精确。
其他的就自己探索咯!
建议 第三方的转换方法【github】地址,找不到合适的尝试这个。
链接:https://www.jianshu.com/p/8622b6ff83b3
Swift之构建非常优雅的便利API—Swift中的计算属性
使Swift成为如此强大且通用的语言的主要原因在于,当我们选择在为特定问题形成解决方案时选择使用哪种语言功能时,我们通常可以使用多种选项。然而,这种多样性也可能引起混淆和争论,特别是当我们正在考虑的功能的关键用例之间没有明确的界限时。
本周,我们来看看一个这样的语言特性 - 计算属性 - 以及它们如何让我们构建非常优雅的便利API,如何避免在部署它们时意外隐藏性能问题,以及在计算属性之间进行选择的一些不同策略和方法。
属性用于数据
理想情况下,属性是计算还是存储应该只是一个实现细节 - 特别是因为只要查看它所使用的代码就无法确切地知道属性是如何存储的。因此,就像存储的属性如何构成类型存储的数据一样,计算属性可以被视为在需要时计算类型数据的方法。
假设我们正在制作一个用于收听播客的应用程序,并且使用如下所示的State枚举来模拟给定播客剧集所处的状态(是否已经下载,收听等)。
extension Episode {
enum State {
case awaitingDownload
case downloaded
case listening(progress: Double)
case finished
}
}然后,我们为我们的Episode模型提供一个存储的state属性,我们可以根据给定的剧集状态来制作决策 - 例如,能够向用户显示是否已经下载了一集。但是,由于该特定用例在我们的代码库中非常常见,我们不希望必须state在许多不同的地方手动打开- 所以我们还提供Episode了一个isDownloaded我们可以在需要的地方重用的计算属性:
extension Episode {
var isDownloaded: Bool {
switch state {
case .awaitingDownload:
return false
case .downloaded, .listening, .finished:
return true
}
}
}我们在state上面开启而不是使用if或guard声明的原因是,如果我们在我们的State枚举中添加一个新案例,那么“强迫”我们自己更新这个代码- 否则我们可能会以不正确的方式处理这个新案例了解它。
上面的实现可以说是计算属性的一个很好的用例 - 它消除了样板,增加了便利性,并且就像它是一个只读存储属性一样 - 它的全部意义在于让我们访问模型数据的特定部分。
意外瓶颈
现在让我们来看看硬币的另一面 - 如果我们不小心,计算属性虽然非常方便,但有时最终会导致意外的性能瓶颈。继续上面的播客应用程序示例,假设我们为用户的播客订阅库建模的方式是通过Library结构,该结构还包含类似上次服务器同步发生时的元数据:
struct Library {
var lastSyncDate: Date
var downloadNewEpisodes: Bool
var podcasts: [Podcast]
}虽然Podcast我们需要在我们的应用程序中呈现上述大多数视图的所有模型,但我们确实有一些地方可以将所有用户的播客显示为平面列表。就像我们之前Episode使用isDownloaded属性扩展一样,最初的想法可能是在这里做同样的事情 - 添加一个计算allEpisodes属性,收集用户库中每个播客的所有剧集 - 如下所示:
extension Library {
var allEpisodes: [Episode] {
return podcasts.flatMap { $0.episodes }
}
}要了解更多信息flatMap,请查看“Map,FlatMap和CompactMap”基础知识文章。
上面的API可能看起来非常简单 - 但它有一个相当大的缺陷 - 它的时间复杂度是线性的(或O(N)),因为为了计算我们的allEpisodes属性,我们需要一次遍历所有播客。一开始这似乎不是什么大不了的事 - 但是在我们每次我们在一个单元格中出列单元格时访问上述属性时,在这种情况下可能会出现问题UITableView:
class AllEpisodesViewController: UITableViewController {
...
override func tableView(
_ tableView: UITableView,
cellForRowAt indexPath: IndexPath
) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(
withIdentifier: reuseIdentifier,
for: indexPath
)
// Here we're accessing allEpisodes just as if it was a
// stored property, and there's no way of telling that this
// will actually cause an O(N) evaluation under the hood:
let episode = library.allEpisodes[indexPath.row]
cell.textLabel?.text = episode.title
cell.detailTextLabel?.text = episode.duration
return cell
}
}由于表格视图单元格可以以非常快的速度出列 - 当用户滚动时 - 上述代码迟早会成为性能瓶颈,因为我们当前的allEpisodes实现将在每次访问时不断迭代所有播客。不是很好。
虽然收集每个播客的所有剧集本身就是O(N)我们当前模型结构的一个操作,但我们可以改进我们通过API 发出复杂信号的方式。我们不是将它allEpisodes看作另一个属性,而是让它成为一种方法。这样一来,它看起来更像是一个行动正在执行(这是),而不是访问一个数据块的只是一个快速的方法:
extension Library {
func allEpisodes() -> [Episode] {
return podcasts.flatMap { $0.episodes }
}
}如果我们还更新我们AllEpisodesViewController接受一组剧集作为其初始化程序的一部分,而不是Library直接访问我们的模型,那么我们得到以下调用站点 - 它看起来比我们之前的实现更清晰:
let vc = AllEpisodesViewController(episodes: library.allEpisodes())在我们的视图控制器中,我们仍然可以像以前一样继续访问所有剧集 - 只是现在该阵列只构建一次,而不是每次单元格出列时都是如此,这是一个很大的胜利。
方便懒惰
将任何无法在常规时间内执行的计算属性转换为方法通常会提高API的整体清晰度 - 因为我们现在强烈表示存在与访问它们相关的某种形式的成本。但在这样做的过程中,我们也失去了一些使用属性给我们带来的“优雅”。
然而,在许多这样的情况下,实际上有一种方法可以实现清晰,优雅和性能 - 所有这些都在同一时间。为了能够继续使用属性,而不必通过使用延迟评估来预先完成所有处理工作。
就像我们在“Swift序列:懒惰的艺术”和“Swift中的字符串解析”中看到的那样,推迟迭代序列直到它实际需要可以给我们带来显着的性能提升 - 所以让我们来看看如何我们可以使用该技术将其allEpisodes转变为属性。
我们将首先Library使用两种新类型扩展我们的模型 - 一种用于我们的剧集序列,另一种用于迭代该序列中的元素:
extension Library {
struct AllEpisodesSequence {
fileprivate let library: Library
}
struct AllEpisodesIterator {
private let library: Library
private var podcastIndex = 0
private var episodeIndex = 0
fileprivate init(library: Library) {
self.library = library
}
}
}要变成AllEpisodesSequence第一类Swift序列,我们所要做的就是Sequence通过实现makeIterator工厂方法使其符合:
extension Library.AllEpisodesSequence: Sequence {
func makeIterator() -> Library.AllEpisodesIterator {
return Library.AllEpisodesIterator(library: library)
}
}接下来,让我们的迭代器符合要求IteratorProtocol,并实现我们的实际迭代代码。我们将通过阅读播客中的每一集来做到这一点,当没有更多的剧集可以找到时,我们将继续播放下一个播客 - 直到所有剧集都被退回,如下所示:
extension Library.AllEpisodesIterator: IteratorProtocol {
mutating func next() -> Episode? {
guard podcastIndex < library.podcasts.count else {
return nil
}
let podcast = library.podcasts[podcastIndex]
guard episodeIndex < podcast.episodes.count else {
episodeIndex = 0
podcastIndex += 1
return next()
}
let episode = podcast.episodes[episodeIndex]
episodeIndex += 1
return episode
}
}有了上述内容,我们现在可以自由地allEpisodes转回计算属性 - 因为它不再需要任何前期评估,只需AllEpisodesSequence在常量时间内返回一个新实例:
extension Library {
var allEpisodes: AllEpisodesSequence {
return AllEpisodesSequence(library: self)
}
}虽然上述方法需要的代码多于我们之前的代码,但它有一些关键的好处。第一个是现在完全不可能简单地下标到allEpisodes返回的序列,因为Sequence这并不意味着随机访问任何底层元素:
// Compiler error: Library.AllEpisodesSequence has no subscripts
let episode = library.allEpisodes[indexPath.row]这看起来似乎不是一个好处,但它阻止我们意外地造成我们之前遇到的那种性能瓶颈 - 迫使我们将我们的allEpisodes序列复制到一个Array之前我们将能够随机访问其中的剧集它:
let episodes = Array(library.allEpisodes)
let vc = AllEpisodesViewController(episodes: episodes)虽然每次我们想要阅读一集时都没有什么能阻止我们执行上面的数组转换 - 但是当我们意外地订阅一个看起来像是存储的数组时,这是一个更加慎重的选择。比计算的。
另一个好处是,如果我们所寻找的只是一小部分,我们不再需要从每个播客中不必要地收集所有剧集。例如,如果我们只想向用户展示他们下一个即将到来的剧集 - 我们现在可以简单地这样做:
let nextEpisode = library.allEpisodes.first使用延迟评估的好处在于,即使allEpisodes返回序列,上述操作也具有恒定的时间复杂度 - 就像您期望访问first任何其他序列一样。太棒了!
这都是关于语义的
既然我们能够将复杂的操作转换为计算属性,而无需任何前期评估,那么最大的问题是 - 无参数方法的剩余用例是什么?
答案很大程度上取决于我们希望给定API具有哪种语义。属性非常意味着某种形式的访问值或对象的当前状态 - 而不更改它。所以修改状态的任何东西,例如通过返回一个新值,很可能更好地用一个方法表示 - 比如这个,它更新了state我们Episode之前的一个模型:
extension Episode {
func finished() -> Episode {
var episode = self
episode.state = .finished
return episode
}
}将上述API与使用属性的情况进行比较 - 很明显,一种方法为这种情况提供了恰当的语义:
// Looks like we're performing an action to finish the episode:
let finishedEpisode = episode.finished()
// Looks like we're accessing some form of "finished" data:
let finishedEpisode = episode.finished许多相同的逻辑也可以应用于静态API,但我们可能会选择做出某些例外,特别是如果我们要优化使用点语法调用的API 。有关设计此类静态API的一些示例,请参阅“Swift中的静态工厂方法”和Swift中基于规则的逻辑”。
结论
计算属性非常有用 - 并且可以使我们能够设计更简单,更轻量级的API。但是,重要的是要确保这种简单性不仅被感知,而且还反映在底层实现中。否则,我们冒着隐藏性能瓶颈的风险,在这种情况下,通常更好的选择方法 - 或者在适当时部署延迟评估。
链接:https://www.jianshu.com/p/315e4522c7c8
iOS -开发SDK的技巧
本文目标:掌握封装及开发SDK的全部技巧
内容提要:不同场景下如何封装及开发SDK
.a静态库创建
直接创建Framework库
在已有工程中创建
创建Framework工程进行封装
创建Bundle资源库文件
含界面SDK如何进行依赖开发
使用脚本创建Framework库,解决合并的烦恼
Swift 如何创建Framework库
知识准备
- 终端命令
真机和模拟器上的库文件合并
Framework库合并的是Framework内包含的二进制文件,合并后替换库中的文件,没有.a后缀
lipo -create xxx.a(真机) xxx.a(模拟器) -output 新名字.a
查看SDK支持的架构
lipo -info XXX.a 输出: i386 armv7 x86_64 arm64arm7: 在最老的支持iOS7的设备上使用
arm7s: 在iPhone5和5C上使用
arm64: 运行于iPhone5S的64位 ARM 处理器 上
i386: 32位模拟器上使用
x86_64: 64为模拟器上使用
注意: 高位兼容地位(32位兼容16位),arm7版本可以在arm7s上运行
需要在对应架构设备上运行,才能生成对应架构的包
- category的处理
category是项目开发中经常用到的,把category打包成静态库是没有问题的,但是在使用这个静态库时,
调用category中的方法时会发生找不到该方法的运行时错误(selector not recognized),解决的办法是在使用静态库的工程中配置other linker flags的值为 -ObjC -all_load
- 对图片资源和UI界面xib或nib文件的处理
.a和.framework两种静态库,通常都是把需要用的到图片或者xib文件存放在一个bundle文件中,而该bundle文件的名字和.a或.framework的名字相同。
.a文件中无法存放图片或xib文件,很容易理解,但是.framework从本质上说也是一个bundle文件,为什么不把图片或者xib文件直接放在.framework中而单独再创建个bundle文件呢?那是因为iOS系统不会去扫描.framework下的图片等资源文件,也不会在项目中显示,也就是说即使放在 .framework目录下,系统根本就不会去扫描,因此也无法发现使用
- Debug和Release
Debug和Release,在我看来主要是针对其面向的目标不同的而进行区分的。
Debug通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,以为开发人员提供强大的应用程序调试能力。
Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利
开发指南
一、.a静态库创建
- 创建静态库工程 >> 删除自动创建的.m文件 >> 清空头文件里的信息 >> 导入你要封装的系统库文件



- 点击目标工程 >> Build Phases >> Editor >> add build Phases(是否公开头文件选项) >> 设置公开访问的头文件(或在Target Membership中直接设置)
或
目标工程 > Build Phases > 点击左侧加号 > add build Phases(是否公开头文件选项) > 设置公开访问的头文件(或在Target Membership中直接设置)










- 合并Debug模式下的真机和模拟器下的静态库文件
使用终端进行合并
cd 文件保存目录
lipo -create 模拟器.a(路径) 真机.a(路径) -output 重命名.a
查看架构模式
lipo -info XXX.a 查看是否满足运行要求- 使用.a库文件
创建文件夹libAdvanced用于保存静态库信息 >> 替换刚刚合并的.a文件 >> 添加用到的图片等资源文件 >> 导入工程验证

- 创建新工程验证
- 如果架构报错 Build Settings >> BuildActiveArchitecture Only Debug改为NO
二、直接创建Framework库
Framework是资源的集合,将静态库和其头文件包含到一个结构中,让Xcode可以方便地把它纳入到你的项目中。本质也是一个bundle文件
在已有工程中创建
创建Framework
点击目标工程 >> 点击下面左下角加号 >> 创建

- 参数配置
点击目标工程 >> 选择你创建的Framework >> 点击工程设置 >> 做出如下修改
Build Settings >> Dead Code Stripping >> 设置为NO
Build Settings >> Strip Debug Symbol During Copy >> 全部设置为NO
Build Settings >> Strip Style >> 设置为Non-Global Symbols
Build Settings >> Base SDK >> Latest iOS(iOS 选择最新的)
Build Settings >> Link With Standard Libraries >> 设置为 NO
Build Settings >> Mach-O Type >> Static Library
对于Mach-O Type有两种情况:(1)选择 Static Library 打出来的是静态库;(2)选择 Relocatable Object File 打出来是动态库。
选择framework支持的系统版本
将需要打包的文件拖入到Framework中


选择运行模式(debug 或 Release)分别在真机和模拟器下common + B 编译生成对应的Framework库
合并二进制文件并替换












iOS 类簇(class clusters)
类簇(class clusters)
类簇是Foundation framework框架下广泛使用的一种设计模式。它管理了一组隐藏在公共抽象父类下的具体私有子类。
没有使用类簇(Simple Concept but Complex Interface)
为了说明类簇的结构体系和好处,我们先思考一个问题:如何构建一个类的结构体系用它来定义一个对象存储不同数据类型的数字(char,int, float, double)。因为不同数据类型的数字有很多共同点(例如:它们都能从一种类型转换成另一种类型,都能用字符串表示),所以可以用一个类来表示它们。然而,不同的数据类型的数字的存储空间是不同的,所以用一个类来表示它们是很低效的。考虑到这个问题,我们设计了如下图1-1的结构解决这个问题。
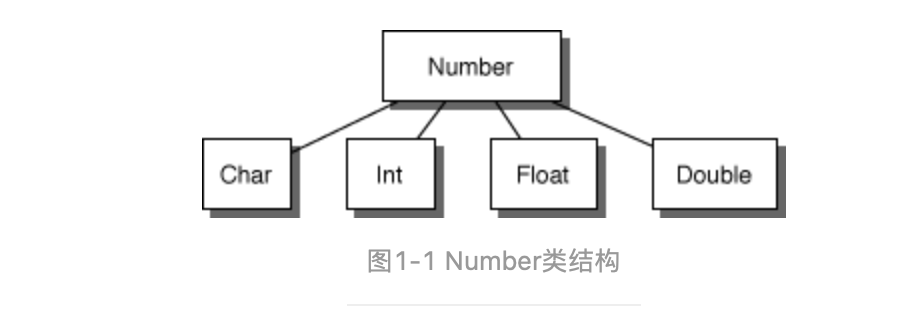
Number是一个抽象父类,在其方法声明中声明了子类的共有操作。但是,Number不会声明一个实例变量存储不同类型的数据,而是由其子类创建对应类型的实例变量并将调用接口共享给抽象父类Number。到目前为止,这个类结构的设计十分简单。然而,如果C语言的基本数据类型被修改了(例如:加入了些新的数据类型),那么我们Number类结构如下图1-2所示:
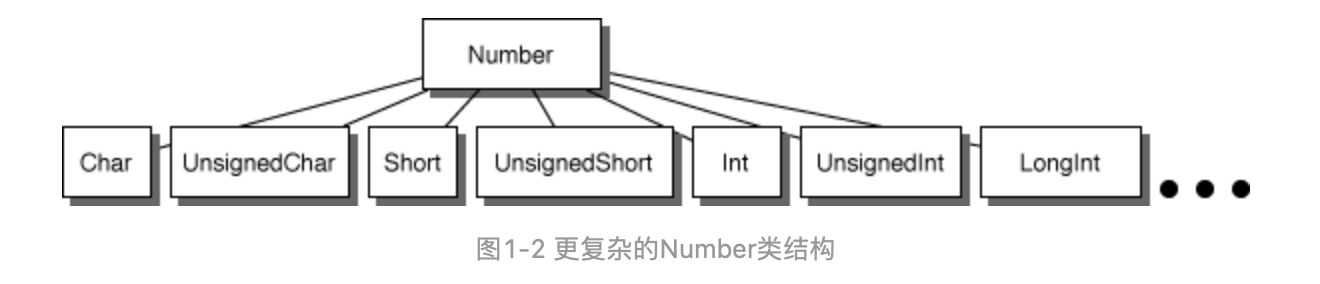
这种创建一个类保存一种类型数据的概念很容易扩展成十几个类。类簇的体系结构展示了一种概念简洁性的设计。
使用类簇(Simple Concept and Simple Interface)
使用类簇的设计模式来解决这个问题,类结构设计如图1-3所示:
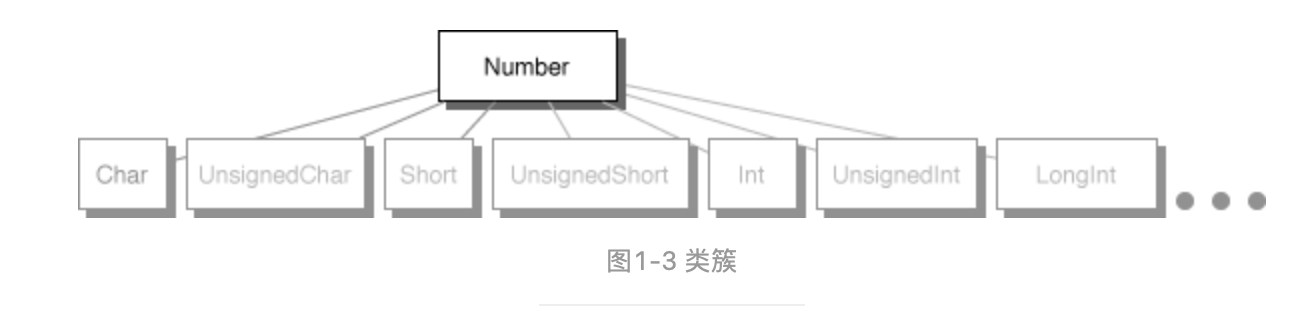
使用类簇我们只能看到一个公共父类Number,它是如何创建正确子类的实例的呢?解决方式是利用抽象父类来处理实例化。
创建实例(Creating Instances)
在类簇中的抽象父类必须声明创建私有子类变量的方法。抽象父类的主要职责是当调用创建实例对象的方法时,根据调用的方法去分配合适的子类对象(不能选择创建实例对象的类)。
在Foundation framework中,你可能调用类方法或者alloc和init创建对象。以Foundation framework的NSNumber创建数字对象为例:
NSNumber *aChar = [NSNumber numberWithChar:’a’];
NSNumber *anInt = [NSNumber numberWithInt:1];
NSNumber *aFloat = [NSNumber numberWithFloat:1.0];
NSNumber *aDouble = [NSNumber numberWithDouble:1.0];使用上面方法返回的对象aChar, anInt, aFloat, aDouble是由不同的私有字类创建的。尽管每个对象的从属关系(class membership)被隐藏了,但是它的接口是公开的,能够通过抽象父类NSNumber声明的接口来访问。当然这种做法是及其不严谨的,某种意义上是不正确的,因为用NSNumber方法创建的对象并不是一个NSNumber的对象,而是返回了一个被隐藏了的私有子类的对象。但是我们可以很方便的使用抽象类NSNumber接口中声明的方法来实例化对象和操作它们。
拥有多个公共抽象父类的类簇(Class Clusters with Multiple Public Superclasses)
在上面的例子中,使用一个公共抽象父类声明多个私有子类的接口。但是在Foundation framework框架中也有很多使用两个或两个以上的公共抽象父类声明私有子类接口的例子,如表1-1所示:
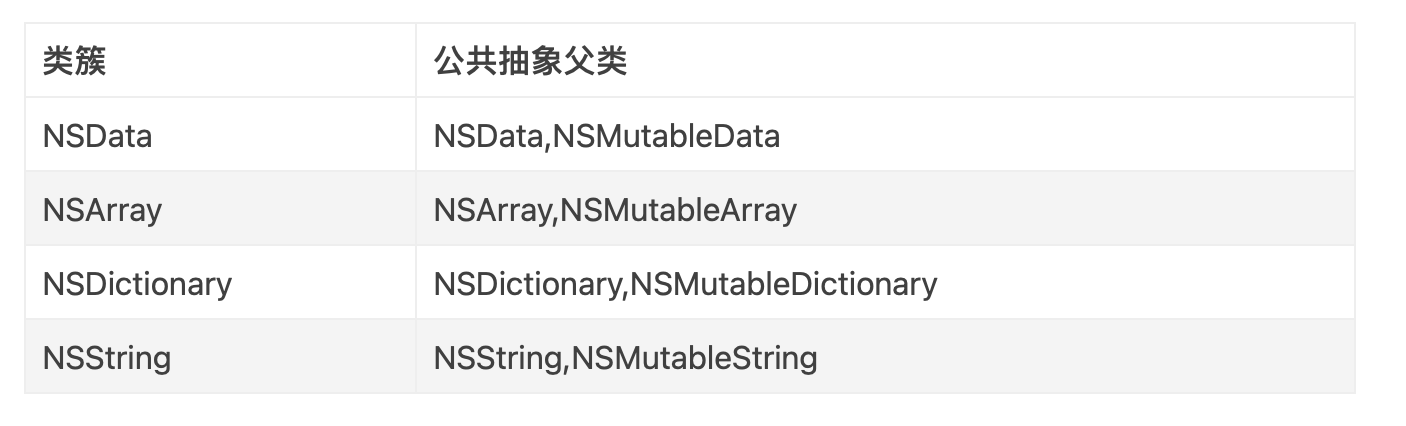
还存在这种类型的类簇,但这些清楚说明了两个公共抽象父类是如何协同工作来声明类簇的编程接口的。一个公共抽象父类声明了所有类簇对象都能相应的方法,而另一个公共抽象父类声明的方法只适合允许修改内容的类簇对象。
创建子类(Creating Subclasses Within a Class Cluster)
类蔟的体系结构是在易用性和可扩展性之间均衡的结果:类簇的应用使得学习和使用框架中的类十分简单,但是在类簇中创建子类是困难的。但是很少情况下需要在类簇中创建子类,因为类簇的好处是显而易见的。
如果你发现类簇提供的功能不能满足你的变成需要,那么在类簇创建子类是一种选择。例如:假如你想在NSArray的类簇中创建一个基于文件存储而不是基于内存存储的数组。因为改变了类的底层存储机制,就不得不在类簇中创建子类。
另一方面,在某些情况下我们创建一个类内嵌类簇对象就足够了。例如:如果你的程序需要被提醒,当某些数据没被修改的时候。在这种情况下,创建一个包装Foundation framework框架定义的数据对象的类可能是最好的方法。这个类的对象能干预修改数据的消息,拦截这个消息,对这个消息采取相应的行动,然后重定向给内嵌的数据对象。
真正子类(A True Subclass)
在类簇中创建一个子类,你必须:
- 创建类簇中抽象超类的子类
- 声明自己的存储空间
- 重写父类的所有初始化方法
- 重写父类的所有原始方法(primitive methods)
第一点:因为在类簇的体系结构中只有类簇中的抽象父类是公开可见的节点。第二点:子类会继承类簇的接口但没有实例变量,因为抽象父类没有声明,所以子类必须声明它所需要的任意实例变量。最后:子类必须重写继承的所有方法。
一个类的原始方法(primitive methods)是构成其接口的基础。拿NSArray为例,它声明类管理数组对象的接口。在概念上,一个数据保存了很多数据项,它们都能通过下标(index)访问。NSArray通过这两个原始方法表达了这一抽象概念,count和objectAtIndex:,以这些方法为基础可以实现其它派生方法。

原始方法(primitive methods)和派生方法(derived methods)的接口区分使创建子类更简单。子类必须重写所有继承的原始方法(primitive methods),这样做可以确保所有继承的派生方法(derived methods)都能正常运行。
原始和派生的区别同样适用于完全初始化对象接口。子类中需要解决如何处理init…方法的问题。
通常,一个类簇的抽象父类方法声明了一系列init…方法和+ className类方法。基于你选择的init…方法或+ className类方法,抽象类决定用哪个具体的子类来实例化。你可以认为抽象类是为子类服务的,因为抽象类没有实例变量,它也不需要初始化方法。
自定义的子类应该声明自己的init…和+ className方法,不应该依赖继承的方法。为了保持初始化链,它应该在自己的指定初始化函数里调用父类的指定初始化函数(designated initializers)。在类簇中它也应该以合理方式重写继承的所有初始化方法,抽象父类的指定初始化函数总是init。
复合对象(A Composite Object)
在你自定义的对象中内嵌一个私有的类簇对象称为复合对象。复合对象可以利用类簇对象来实现基本的功能,只拦截复合对象想要特殊处理的消息。这种结构减少了代码量,利用了Foundation framework的测试代码。如图1-4所示:
复合对象必须声明它自己是类簇抽象父类的子类,必须重写父类的所有原始方法,也可以重写派生方法但不是必须的。
总结
在Cocoa中,实际上许多类都是以类簇的方式实现的,即它们是一群隐藏在通用接口之下与实现相关的类。例如创建数组时可能是__NSArray0,__NSSingleObjectArray, __NSArrayI,所以请不要轻易尝试创建NSString,NSArray,NSDictionary的子类。对类簇使用isKindOfClass和isMemberOfClass的结果可能是不正确的。因为类簇是由公共抽象类管理的一组私有类,公共抽象类并不是实例对应的真正的类,类簇中真正的类的从属关系被隐藏了。
转自链接:https://www.jianshu.com/p/86ef3ca9810d
Swift的高级技巧 - 动态注入和更改代码
虽然Xcode为lldb命令提供了几个可视化抽象,例如通过单击代码行添加断点并通过单击播放按钮来运行,但lldb提供了一些Xcode UI中不存在的有用命令。这可以是从即时创建方法到甚至更改CPU的寄存器以强制应用程序上的特定流而无需重新编译它,并且了解它们可以极大地改善您的调试体验。
并非所有Swift都是在Xcode中开发的 - 像Swift编译器或Apple的SourceKit-LSP这样的东西通过其他方式更好地工作,这些方法通常最终会让你手动使用lldb 。如果没有Xcode来帮助您,其中一些技巧可能会阻止您再次编译应用程序以测试某些更改。
注入属性和方法
您可能已经知道po(“打印对象”的缩写) - 通常用于打印属性内容的友好命令:
func foo() {
var myProperty = 0
} // a breakpointpo myProperty
0然而,po比这更强大 - 尽管名称暗示它打印的东西,po是一个别名,更原始(或只是)命令的论证版本,使输出更加开放:expression --object-description -- expression e
e myProperty
(Int) $R4 = 0 // not very pretty!因为它是别名,po所以可以做任何事情e。e用于评估表达式,表达式的范围可以从打印属性到更改其值,甚至可以定义新类。作为一个简单的用法,我们可以在代码中更改属性的值以强制新流而无需重新编译代码:
po myProperty
0
po myProperty = 1
po myProperty
1除此之外,如果你po单独写,你将能够编写这样的多线表达式。我们可以使用它在我们的调试会话中创建全新的方法和类:
po
Enter expressions, then terminate with an empty line to evaluate:
1 class $BreakpointUtils {
2 static var $counter = 0
3 }
4 func $increaseCounter() {
5 $BreakpointUtils.$counter += 1
6 print("Times I've hit this breakpoint: \($BreakpointUtils.$counter)")
7 }
8(这里使用美元符号表示这些属性和方法属于lldb,而不是实际代码。)
前面的例子允许我直接从lldb 调用,这将在我的“我无法处理这个bug”计数器上加1。$increaseCounter()
po $increaseCounter()
Times I've hit this breakpoint: 1
po $increaseCounter()
Times I've hit this breakpoint: 2这样做的能力可以与lldb导入插件的能力相结合,这可以大大增强您的调试体验。一个很好的例子就是Chisel,这是一个由Facebook制作的工具,它包含许多lldb插件 - 就像border命令一样,它增加了一个明亮的边框,UIView这样你就可以在屏幕上快速定位它们,并且它们都通过巧妙的用法来实现。e/ po。
然后,您可以使用lldb的断点操作在命中断点时自动触发这些方法。结合po的属性更改功能,您可以创建特殊的断点,这些断点将改变您尝试执行的测试的应用流程。
通常,所有高级断点命令都非常痛苦地在lldb中手动编写(这就是为什么我会在本文中避免它们),但幸运的是,您可以轻松地在Xcode中设置断点操作:
v- 避免po动态
如果你已经使用po了一段时间,你可能在过去看到过这样一个神秘的错误信息:
error: Couldn't lookup symbols:
$myProperty #1 : Swift.Int in __lldb_expr_26.$__lldb_expr(Swift.UnsafeMutablePointer<Any>) -> ()这是因为po通过编译来评估您的代码,不幸的是,即使您尝试访问的代码是正确的,仍然存在可能出错的情况。
如果你正在处理不需要评估的东西(比如静态属性而不是方法或闭包),你可以使用v命令(简称frame variable)作为打印的替代,po以便立即获取内容。宾语。
v myProperty
(Int) myProperty = 1disassemble - 打破内存地址以更改其内容
注意:以下命令仅在极端情况下有用。你不会在这里学习一个新的Swift技巧,但你可能会学到一些有趣的软件工程!
我通过使用越狱的iPad来使用流行的应用程序进入逆向工程,当你这样做时,你没有选择重新编译代码 - 你需要动态地改变它。例如,如果我无法重新编译代码,isSubscribed即使我没有订阅,如何强制以下方法进入条件?
var isSubscribed = false
func run() {
if isSubscribed {
print("Subscribed!")
} else {
print("Not subscribed.")
}
}我们可以通过使用应用程序的内存来解决 - 在任何堆栈框架内,您可以调用该disassemble命令来查看该堆栈的完整指令集:
myapp`run():
-> 0x100000d60 <+0>: push rbp
0x100000d61 <+1>: mov rbp, rsp
0x100000d64 <+4>: sub rsp, 0x70
0x100000d68 <+8>: lea rax, [rip + 0x319]
0x100000d6f <+15>: mov ecx, 0x20
...
0x100000d9c <+60>: test r8, 0x1
0x100000da0 <+64>: jne 0x100000da7
0x100000da2 <+66>: jmp 0x100000e3c
0x100000da7 <+71>: mov eax, 0x1
0x100000dac <+76>: mov edi, eax
...
0x100000ec7 <+359>: call 0x100000f36
0x100000ecc <+364>: add rsp, 0x70
0x100000ed0 <+368>: pop rbp
0x100000ed1 <+369>: ret这里整洁的东西不是命令本身,而是你可以用这些信息做些什么。我们习惯在Xcode中设置断点到代码行和特定选择器,但在lldb的控制台中你也可以使用断点特定的内存地址。
我们需要知道一些汇编来解决这个问题:如果我的代码包含一个if,那么该代码的结果汇编肯定会有一个跳转指令。在这种情况下,跳转指令将跳转到存储器地址,如果寄存器(在前一条指令中设置)不等于零(那么,为真)。由于我没有订阅,肯定会为零,这将阻止该指令被触发。0x100000da0 <+64>: jne0x100000da7 0x100000da7 r8 0x100000d9c <+60>: test r8, 0x1 r8
要看到这种情况发生并修复它,让我们首先断点并将应用程序放在jne指令处:
b 0x100000da0
continue
//Breakpoint hits the specific memory address如果我disassemble再次运行,小箭头将显示我们在正确的内存地址处开始操作。
-> 0x100000da0 <+64>: jne 0x100000da7有两种方法可以解决这个问题:
方法1:更改CPU寄存器的内容
该register read和register write命令由LLDB提供,让您检查和修改的CPU寄存器的内容,并解决这个问题的第一种方式是简单地改变的内容r8。
通过定位jne指令,register read将返回以下内容:
General Purpose Registers:
rax = 0x000000010295ddb0
rbx = 0x0000000000000000
rcx = 0x00007ffeefbff508
rdx = 0x0000000000000000
rdi = 0x00007ffeefbff508
rsi = 0x0000000010000000
rbp = 0x00007ffeefbff520
rsp = 0x00007ffeefbff4b0
r8 = 0x0000000000000000General Purpose Registers:因为r8为零,jne指令不会触发,从而使代码输出"Not subscribed."。但是,这是一个简单的修复 - 我们可以r8通过运行register write和恢复应用程序设置为不为零的东西:
register write r8 0x1
continue
"Subscribed!"在日常的iOS开发中,register write可以用来替换代码中的整个对象。如果某个方法要返回你不想要的东西,你可以在lldb中创建一个新对象,获取其内存地址e并将其注入所需的寄存器。
方法2:更改指令本身
解决这个问题的第二种也可能是最疯狂的方法是实时重写应用程序本身。
就像寄存器一样,lldb提供memory read并memory write允许您更改应用程序使用的任何内存地址的内容。这可以用作动态更改属性内容的替代方法,但在这种情况下,我们可以使用它来更改指令本身。
这里可以做两件事:如果我们想要反转if指令的逻辑,我们可以改为(所以它检查一个条件),或者(跳空不是)to (跳空,或)。我发现后者更容易,所以这就是我要遵循的。如果我们阅读该指令的内容,我们会看到如下内容:test r8, 0x1 test r8, 0x0 false jne 0x100000da7 je 0x100000da7 if!condition
memory read 0x100000da0
0x100000da0: 75 05 e9 95 00 00 00 b8 01 00 00 00 89 c7 e8 71这看起来很疯狂,但我们不需要了解所有这些 - 我们只需要知道指令的OPCODE对应于开头的两位(75)。按照这个图表,我们可以看到OPCODE for je是74,所以如果我们想要jne成为je,我们需要将前两位与74交换。
为此,我们可以使用memory write与该地址完全相同的内容,但前两位更改为74。
memory write 0x100000da0 74 05 e9 95 00 00 00 b8 01 00 00 00 89 c7 e8 71
dis0x100000da0 <+64>: je 0x100000da7现在,运行应用程序将导致"Subscribed!"打印。
结论
虽然拆解和写入内存对于日常开发来说可能过于极端,但您可以使用一些更高级的lldb技巧来提高工作效率。更改属性,定义辅助方法并将它们与断点操作混合将允许您更快地导航和测试代码,而无需重新编译它。
转自:https://www.jianshu.com/p/281a2f61937e
收起阅读 »iOS KVO 与 readonly的讨论 (数组array & setter)
在开发过程中,可能会有这样的需求:当数据源变动的时候及时刷新显示的列表。
期望是去监听数据源数组的count,当count有变动就刷新UI,可是实际操作中却发现了不少的问题。
例如:
self.propertyArray = [NSMutableArray array];
[self.propertyArray addObserver:self forKeyPath:@"count" options:NSKeyValueObservingOptionNew|NSKeyValueObservingOptionOld context:nil];直接就报错了,信息如下:
Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '[<__NSArrayM 0x6000033db450> addObserver:forKeyPath:options:context:] is not supported. Key path: count'字面意思是,不支持对数组count的监听。
回到问题的本质。
我们知道KVO是在属性的setter方法上做文章,进入到数组的类中看一下,发现count属性是readonly
@interface NSArray<__covariant ObjectType> : NSObject <NSCopying, NSMutableCopying, NSSecureCoding, NSFastEnumeration>
@property (readonly) NSUInteger count;readonly不会自动生成setter方法,但是可以手动添加setter方法。
我们来验证一下 例如:
创建一个people类 添加一个属性 readonly count
@interface People : NSObject
@property (nonatomic, readonly) NSInteger count;
@end
@implementation People
@end我们来试一下 监听它的count属性会怎样
People *peo = [People new];
[peo addObserver:self forKeyPath:@"count" options:NSKeyValueObservingOptionNew|NSKeyValueObservingOptionOld context:nil];我们发现 并没有报错。
我们来看一下People的方法列表
const char *className = "People";
Class NSKVONotifying_People = objc_getClass(className);
unsigned int methodCount =0;
Method* methodList = class_copyMethodList(NSKVONotifying_People,&methodCount);
NSMutableArray *methodsArray = [NSMutableArray arrayWithCapacity:methodCount];
for(int i=0;i<methodCount;i++)
{
Method temp = methodList[i];
const char* name_s =sel_getName(method_getName(temp));
[methodsArray addObject:[NSString stringWithUTF8String:name_s]];
}
NSLog(@"%@",methodsArray);通过打印我们可以看到 People中只有两个方法
(
dealloc,
count,
)我们知道,KVO监听某个对象时,会动态生成名字叫做NSKVONotifying_XX的类,并且重写监听对象的setter方法。下面 我们来看下NSKVONotifying_People的方法列表:
const char *className = "NSKVONotifying_People";
Class NSKVONotifying_People = objc_getClass(className);
unsigned int methodCount =0;
Method* methodList = class_copyMethodList(NSKVONotifying_People,&methodCount);
NSMutableArray *methodsArray = [NSMutableArray arrayWithCapacity:methodCount];
for(int i=0;i<methodCount;i++)
{
Method temp = methodList[i];
const char* name_s =sel_getName(method_getName(temp));
[methodsArray addObject:[NSString stringWithUTF8String:name_s]];
}
NSLog(@"%@",methodsArray);打印结果如下:
(
class,
dealloc,
"_isKVOA"
)可以看到,里面没有count的getter方法,多了个class和isKVO, 当然也没有我们需要的setter方法。但是这样并不会导致crash。
下面我们再试一下,手动在People的.m中 添加上setter方法会怎么样:
@implementation People
- (void)setCount:(NSInteger)count{
_count = count;
}
@end再次查看People和NSKVONotifying_People的方法列表,会发现多了一个count的setter方法。(如下所示)
(
dealloc,
count,
"setCount:"
)
(
"setCount:",
class,
dealloc,
"_isKVOA"
)这样我们就可以得出一个结论:
KVO动态生成的类,重写setter方法的前提是:原来的类中,要有对应的setter方法。即便是readonly修饰,只要.m中有对应属性的setter方法,都是可以的。
OK 说了这么多,好像还是没有解决我们的问题。 为什么监听数组count就抛异常了呢? 带着这个问题 继续往下走。
通过点击array的监听方法 进入到ArrayObserving类中,我们发现,系统给出了注释:NSArrays are not observable, so these methods raise exceptions when invoked on NSArrays.
系统也不期望我们去监听数组的属性。is not supported. Key path: count' 应该就是系统在实现监听方法时,抛出的异常。
最后,我从网上找到了另一个方法
[self mutableArrayValueForKey:@"propertyArray"]我们可以转换一个思路,不再监听count,选择监听数组本身,当数组变动时刷新页面。
[self addObserver:self forKeyPath:@"propertyArray" options:NSKeyValueObservingOptionNew|NSKeyValueObservingOptionOld context:nil];
[[self mutableArrayValueForKey:@"propertyArray"] addObject:@"a"];这个方法的具体实现,没有看到源码,但是看到有人说,这个方法会生成一个可变数组,添加完元素后,会将这个生成的数组赋值给叫做Key的数组。我试了一下,确实是有效果的,这里就不做考究了。
转自:https://www.jianshu.com/p/688c2512be01
收起阅读 »避免 iOS 组件依赖冲突的小技巧
问题缘由
本文以 YBImageBrowser 组件举例。
YBImageBrowser 依赖了 SDWebImage,在使用 CocoaPods 集成到项目中时,可能会出现一些依赖冲突的问题,最近社区提了多个 Issues 并且在 Insights -> Traffic -> Popular content 中看到了此类问题很高的关注度,所以不得不着手解决。
严格的版本限制
一个开源组件的迭代过程中,保证上层接口的向下兼容就不错了。为了优化性能并且控制内存,YBImageBrowser 没有直接用其最上层的接口,而是单独使用了下载模块和缓存模块,SDWebImage 的迭代升级很容易导致笔者的组件兼容不了,所以之前一直是类似这样依赖的:
s.dependency 'SDWebImage', '~> 5.0.0'这样做的好处是限制足够小版本范围,降低 SDWebImage 接口变动导致组件代码错误的风险。但如果 SDWebImage 升级到 5.1.0,不管相关 API 是否变动,CocoaPods 都视为依赖冲突。
其它组件依赖了不同版本的 SDWebImage
当两个组件依赖了同一个组件的不同版本,并且依赖的版本没有交集,比如:
A.dependency 'SDWebImage', '~> 4.0.0'
B.dependency 'SDWebImage', '~> 5.0.0'那么 A 和 B 同时集成进项目会出现依赖冲突。
解决方案
使用 CocoaPods 集成项目非常便捷,对于组件使用者来说,总是想在任何场景下都能轻易集成,并且能在将来享受组件的更新优化,显然前面提到的问题可能会影响集成的便捷性。
更模糊的版本限制
很多时候一个大版本的组件不会改动 API,并且对于社区流行的组件我们可以寄一定希望于其做好向下兼容,所以放宽依赖的版本限制能覆盖将来更多的版本(规则参考:podspec dependency):
s.dependency 'SDWebImage', '>= 5.0.0'为什么不干脆去掉版本限制呢?
因为 YBImageBrowser 3.x 是基于 SDWebImage 5.0.0 开发的,笔者可以明确不兼容 5.0.0 之前的版本,所以在 SDWebImage 将来迭代版本出现相关 API 不兼容之前,这个限制都是“完美”覆盖所有版本的。
避免依赖冲突的暴力方案
当有其它组件依赖了不同版本的 SDWebImage,粗暴的解决方案如下:
直接修改其它组件依赖的 SDWebImage 版本。
将 YBImageBrowser 手动导入项目,并且修改代码去适应当前的 SDWebImage 版本。
社区朋友一个 Issue 中提到的方法:在 ~/.cocoapods/repos 目录下找到 YBImageBrowser 文件夹,更改对应版本的 podspec.json 文件里对 SDWebImage 的依赖版本。
显然,上面的几种方案不太优雅,手动导入项目难以享受组件的更新优化,修改本地 repo 信息会因为 repo 列表的更新而复位。
避免依赖冲突的优雅方案
出现依赖冲突是必须要解决的问题,其它组件依赖的版本限制可以视为不变量,解决方案可以从组件的制作方面考虑。
要做到的目标是,既满足部分用户快速集成组件,又能让部分用户解决依赖冲突的前提下保证能享受组件将来的更新优化。
答案就是subspec,以下是 YBImageBrowser.podspec 部分代码(完整代码):
s.subspec "Core" do |core|
core.source_files = "YBImageBrowser/**/*.{h,m}"
core.dependency 'SDWebImage', '>= 5.0.0'
end
s.subspec "NOSD" do |core|
core.source_files = "YBImageBrowser/**/*.{h,m}"
core.exclude_files = "YBImageBrowser/WebImageMediator/YBIBDefaultWebImageMediator.{h,m}"
end由此,用户可以自由的选择是否需要依赖 SDWebImage,在 Podfile 里的观感大致是这样:
// 依赖 SDWebImage
pod 'YBImageBrowser'
// 不依赖 SDWebImage
pod 'YBImageBrowser/NOSD'那么在 YBImageBrowser 代码中应该如何区分是否依赖了 SDWebImage 并且提供默认实现呢?
第一步是设计一个抽象接口(这个接口不依赖 SDWebImage):
@protocol YBIBWebImageMediator <NSObject>
// Download methode, caching methode, and so on.
@end第二步是在YBImageBrowser.h中定义一个遵循该接口的属性:
/// 图片下载缓存相关的中介者(赋值可自定义)
@property (nonatomic, strong) id<YBIBWebImageMediator> webImageMediator;第三步是实现一个默认的中介者(这个类依赖了 SDWebImage):
@interface YBIBDefaultWebImageMediator : NSObject <YBIBWebImageMediator>
@end
@implementation YBIBDefaultWebImageMediator
//通过 SDWebImage 的 API 实现 <YBIBWebImageMediator> 协议方法
@end第四步是在内部代码中通过条件编译导入并初始化默认中介者:
#if __has_include("YBIBDefaultWebImageMediator.h")
#import "YBIBDefaultWebImageMediator.h"
#endif
...
#if __has_include("YBIBDefaultWebImageMediator.h")
_webImageMediator = [YBIBDefaultWebImageMediator new];
#endif第五步在 YBImageBrowser.podspec 中也可以看到,在不依赖 SDWebImage 的集成方式时排除了两个文件:YBIBDefaultWebImageMediator.{h.m}。
由此便实现了目标:
用依赖 SDWebImage 的集成方式快速集成。
使用不依赖 SDWebImage 的集成方式避免各种情况下的依赖冲突,但注意这种情况需要自行实现一个遵循<YBIBWebImageMediator>协议的中介者。
以上便是避免依赖冲突的小技巧,希望读者朋友能提出更好的建议或意见😁。
链接:https://www.jianshu.com/p/0e3283275300




