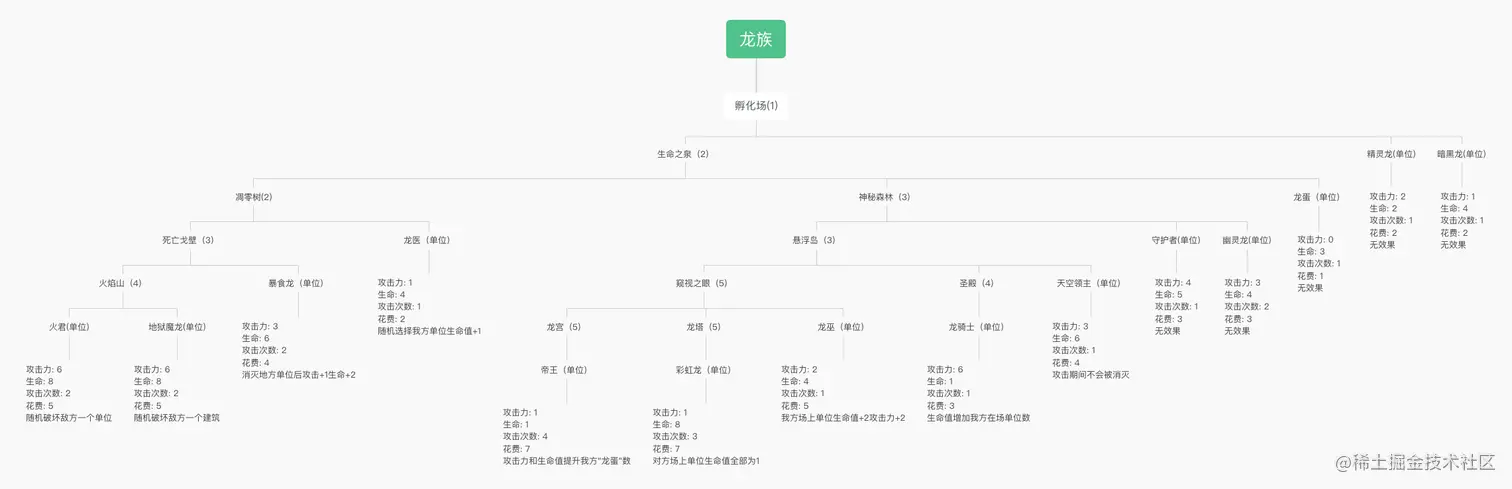
用户登录之后,会返回一个用户的标识,之后带上这个标识请求别的接口,就能识别出该用户。
标识登录状态的方案有两种: session 和 jwt。
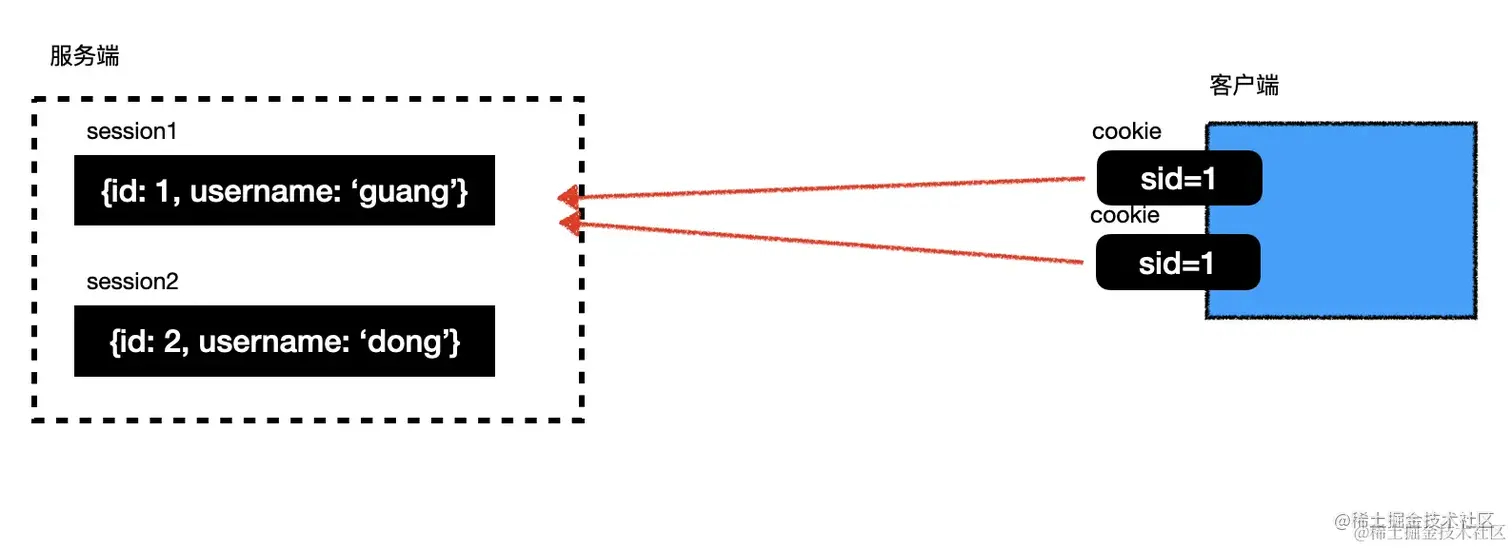
session 是通过 cookie 返回一个 id,关联服务端内存里保存的 session 对象,请求时服务端取出 cookie 里 id 对应的 session 对象,就可以拿到用户信息。
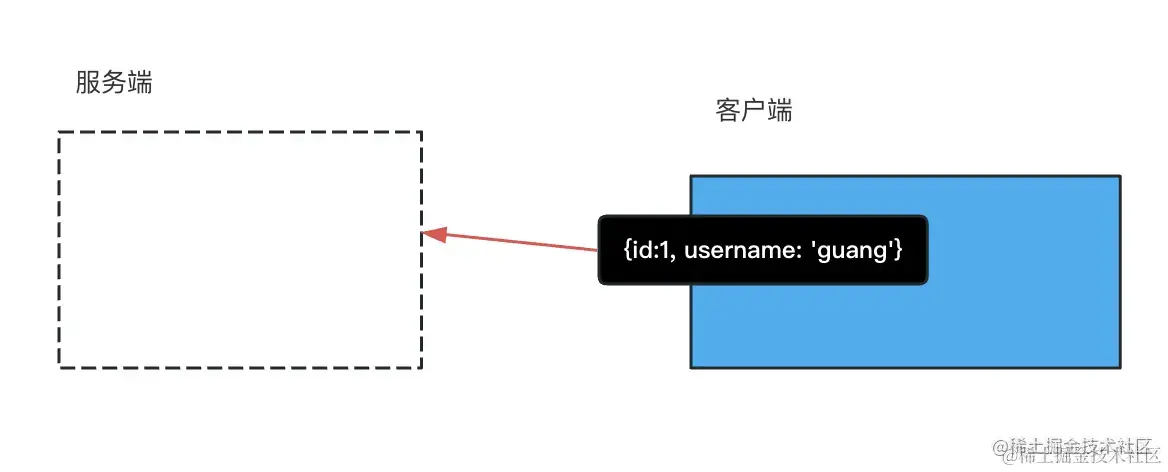
jwt 不在服务端存储,会直接把用户信息放到 token 里返回,每次请求带上这个 token,服务端就能从中取出用户信息。
这个 token 一般是放在一个叫 authorization 的 header 里。
这两种方案一个服务端存储,通过 cookie 携带标识,一个在客户端存储,通过 header 携带标识。
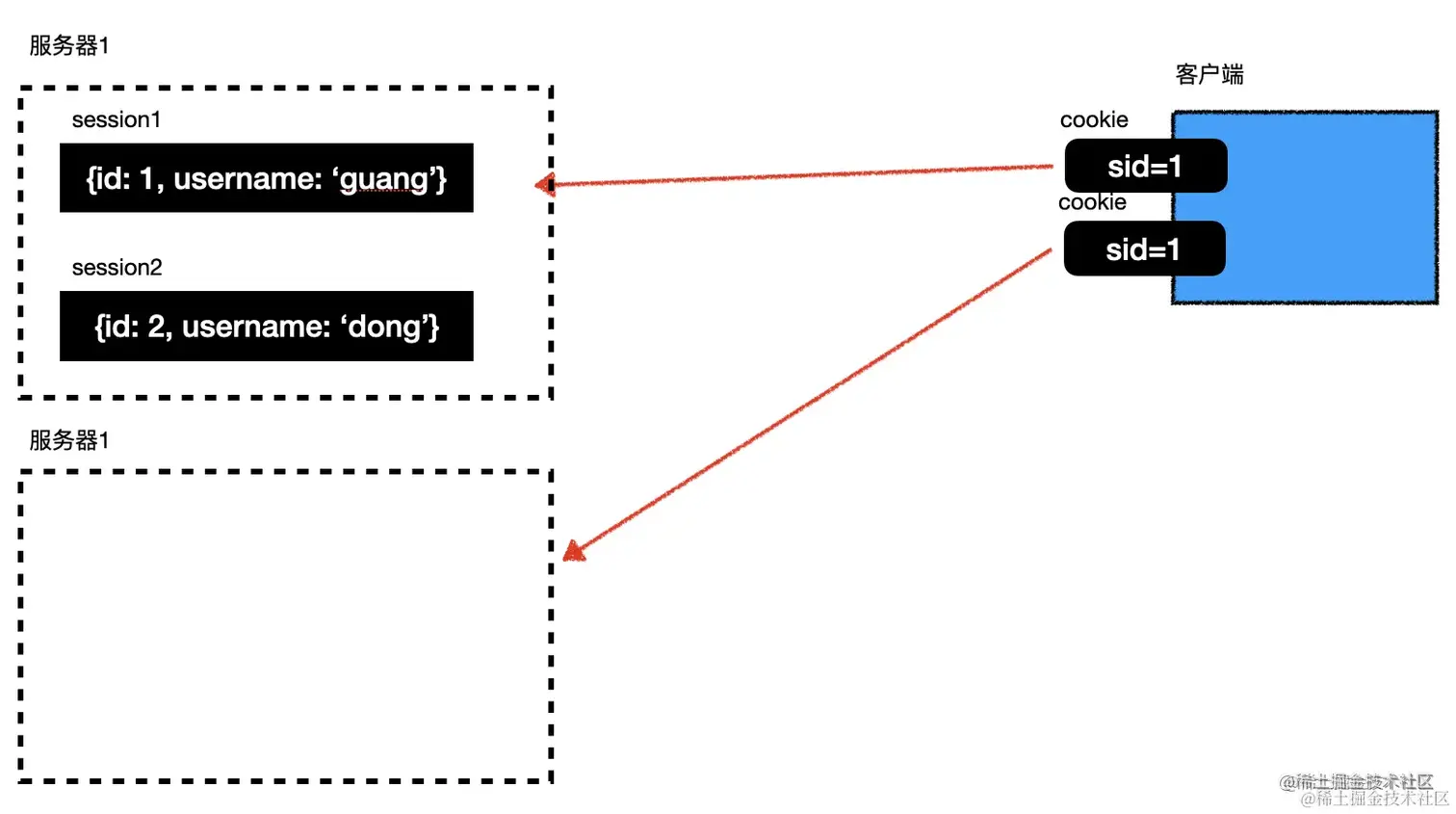
session 的方案默认不支持分布式,因为是保存在一台服务器的内存的,另一台服务器没有。
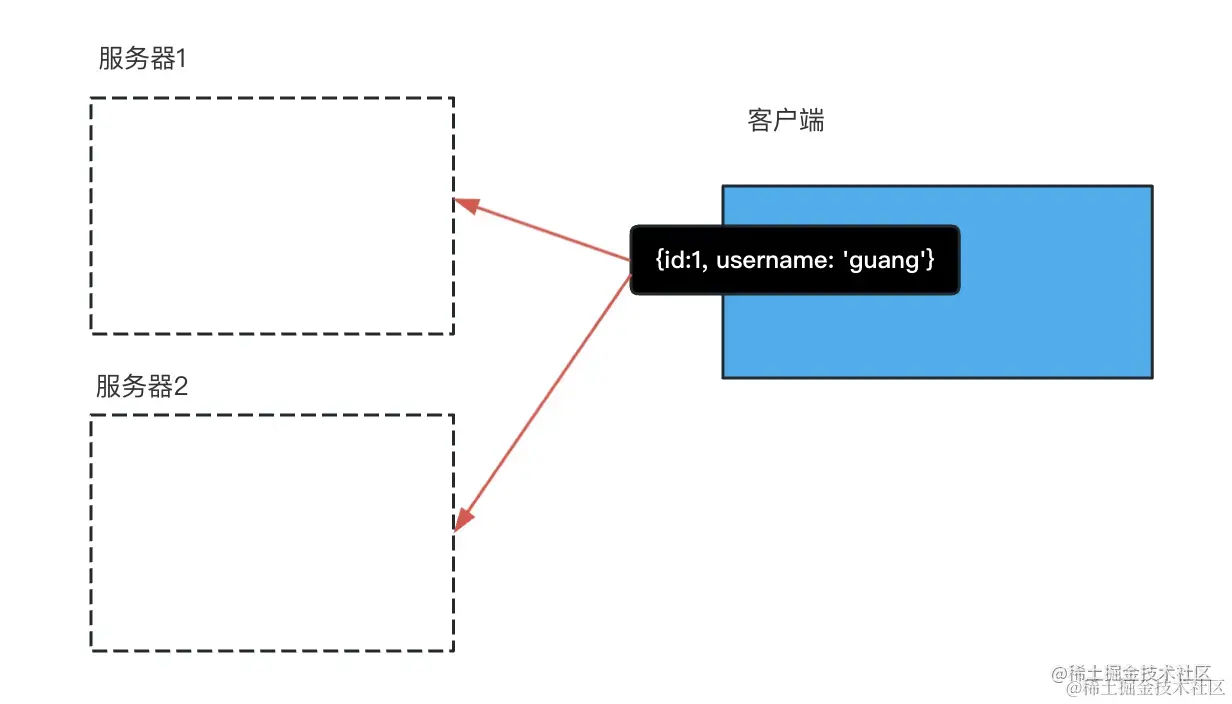
jwt 的方案天然支持分布式,因为信息保存在 token 里,只要从中取出来就行。
所以 jwt 的方案用的还是很多的。
服务端把用户信息放入 token 里,设置一个过期时间,客户端请求的时候通过 authorization 的 header 携带 token,服务端验证通过,就可以从中取到用户信息。
但是这样有个问题:
token 是有过期时间的,比如 3 天,那过期后再访问就需要重新登录了。
这样体验并不好。
想想你在用某个 app 的时候,用着用着突然跳到登录页了,告诉你需要重新登录了。
是不是体验很差?
所以要加上续签机制,也就是延长 token 过期时间。
主流的方案是通过双 token,一个 access_token、一个 refresh_token。
登录成功之后,返回这两个 token:
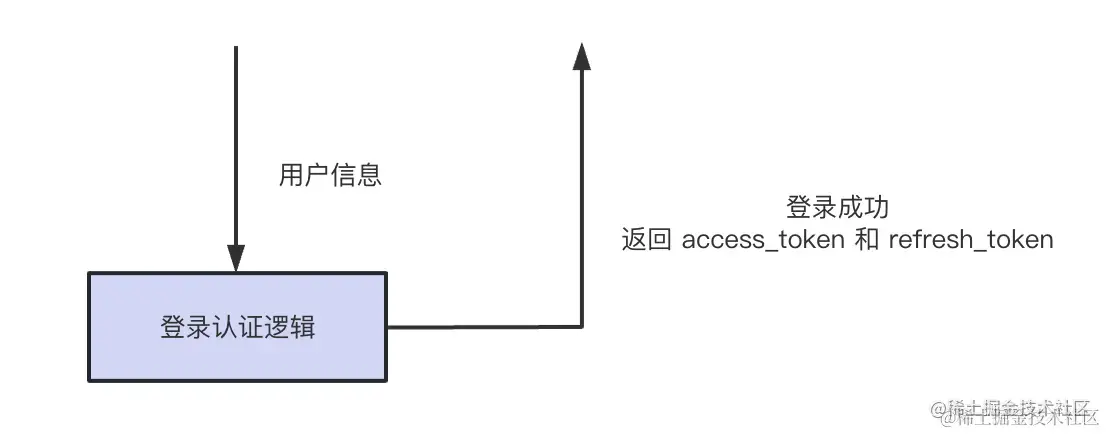
访问接口时带上 access_token 访问:
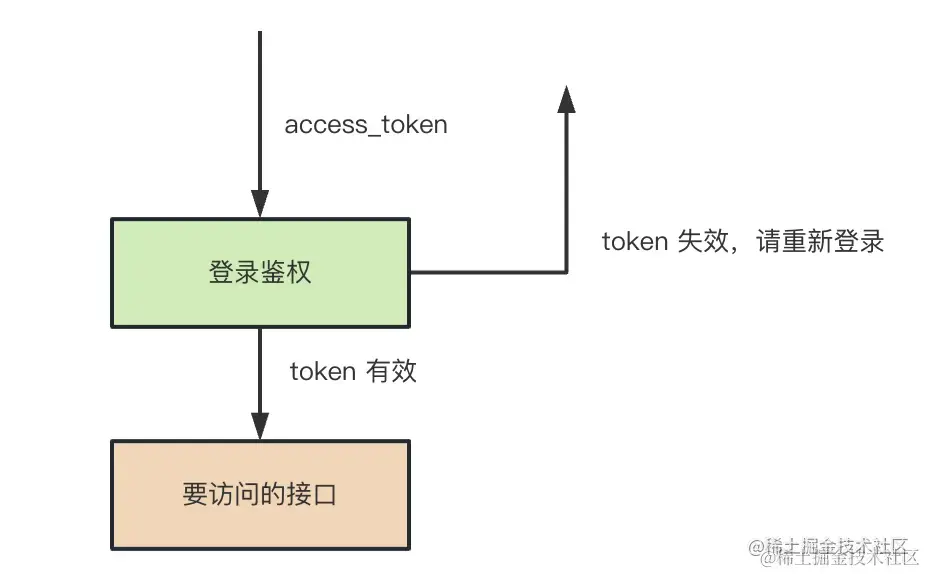
当 access_token 过期时,通过 refresh_token 来刷新,拿到新的 access_token 和 refresh_token
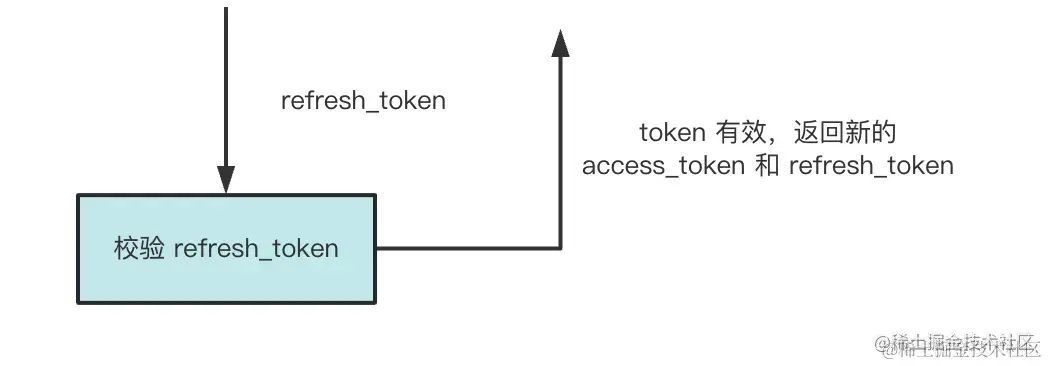
这里的 access_token 就是我们之前的 token。
为什么多了个 refresh_token 就能简化呢?
因为如果你重新登录,是不是需要再填一遍用户名密码?而有了 refresh_token 之后,只要带上这个 token 就能标识用户,不需要传用户名密码就能拿到新 token。
而 access_token 一般过期时间设置的比较短,比如 30 分钟,refresh_token 设置的过期时间比较长,比如 7 天。
这样,只要你 7 天内访问一次,就能刷新 token,再续 7 天,一直不需要登录。
但如果你超过 7 天没访问,那 refresh_token 也过期了,就需要重新登录了。
想想你常用的 APP,是不是没再重新登录过?
而不常用的 APP,再次打开是不是就又要重新登录了?
这种一般都是双 token 做的。
知道了什么是双 token,以及它解决的问题,我们来实现一下。
新建个 nest 项目:
npx nest new token-test
进入项目,把它跑起来:
npm run start:dev
访问 http://localhost:3000 可以看到 hello world,代表服务跑成功了:
在 AppController 添加一个 login 的 post 接口:
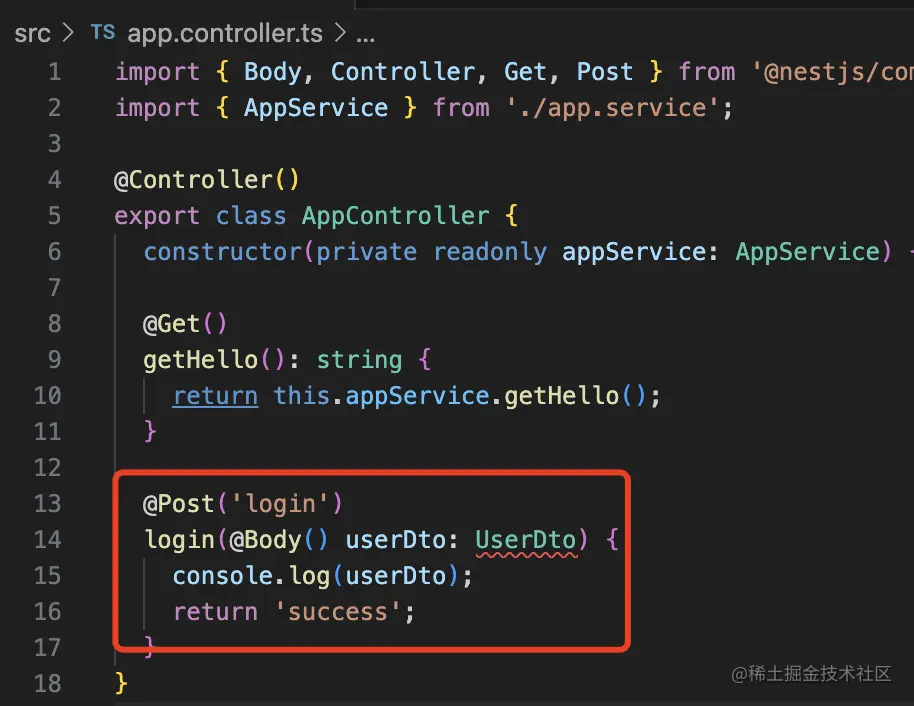
@Post('login')
login(@Body() userDto: UserDto) {
console.log(userDto);
return 'success';
}
这里通过 @Body 取出请求体的内容,设置到 dto 中。
dto 是 data transfer object,数据传输对象,用来保存参数的。
我们创建 src/user.dto.ts
export class UserDto {
username: string;
password: string;
}
在 postman 里访问下这个接口:
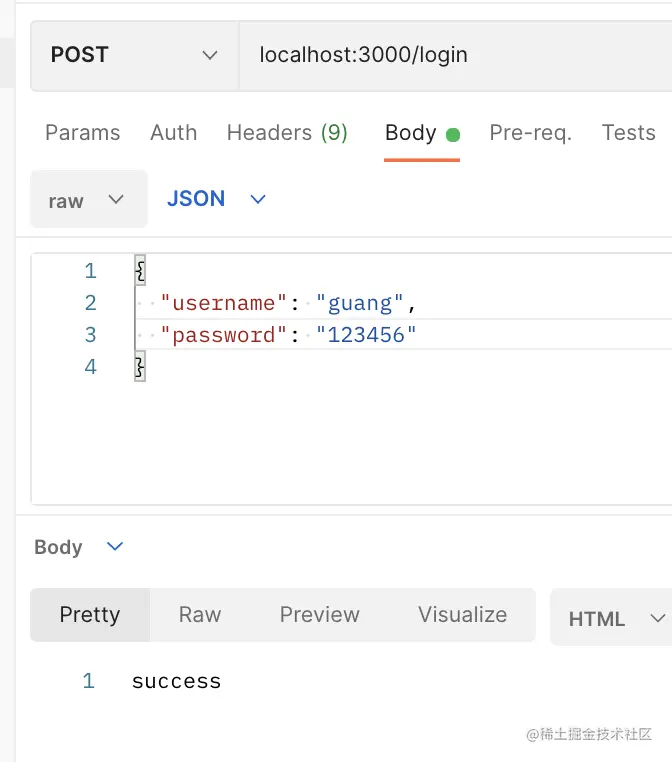
返回了 success,服务端也打印了收到的参数:
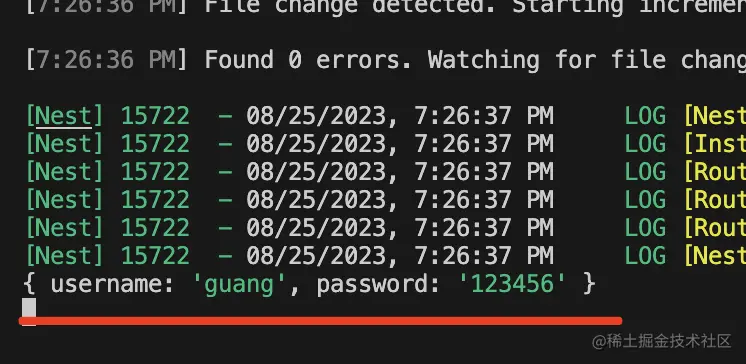
然后我们实现下登录逻辑:
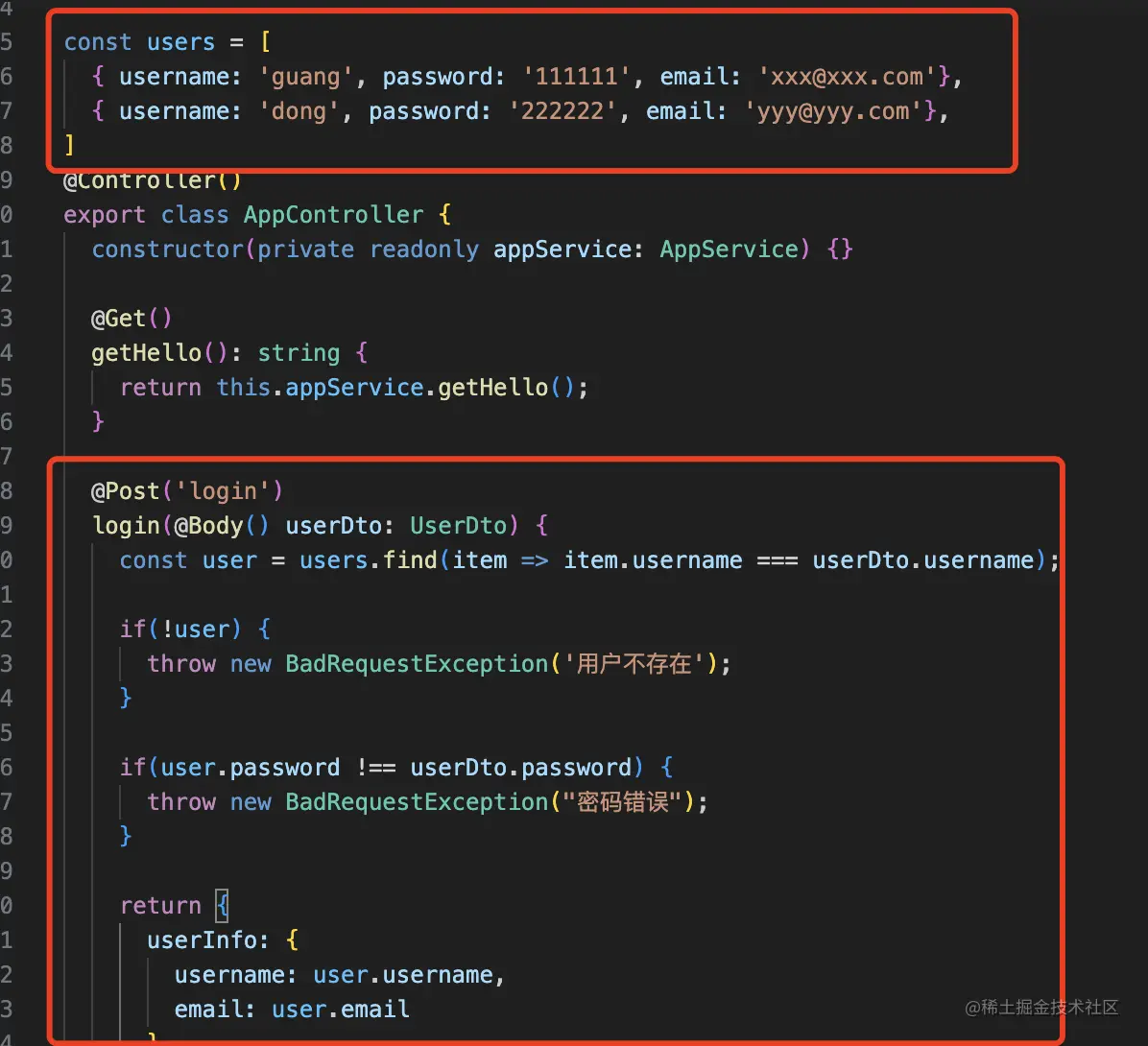
这里我们就不连接数据库了,就是内置几个用户,匹配下信息。
const users = [
{ username: 'guang', password: '111111', email: 'xxx@xxx.com'},
{ username: 'dong', password: '222222', email: 'yyy@yyy.com'},
]
@Post('login')
login(@Body() userDto: UserDto) {
const user = users.find(item => item.username === userDto.username);
if(!user) {
throw new BadRequestException('用户不存在');
}
if(user.password !== userDto.password) {
throw new BadRequestException("密码错误");
}
return {
userInfo: {
username: user.username,
email: user.email
},
accessToken: 'xxx',
refreshToken: 'yyy'
};
}
如果没找到,就返回用户不存在。
找到了但是密码不对,就返回密码错误。
否则返回用户信息和 token。
测试下:
当 username 不存在时:
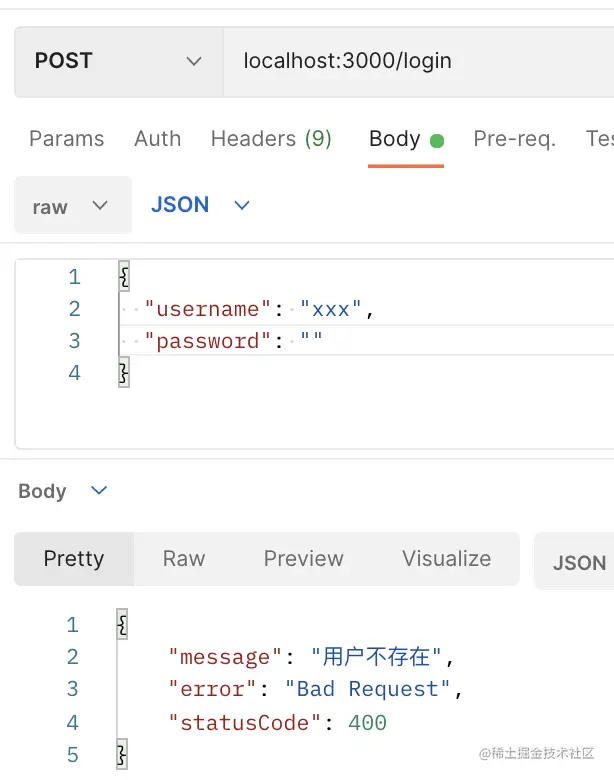
当 password 不对时:
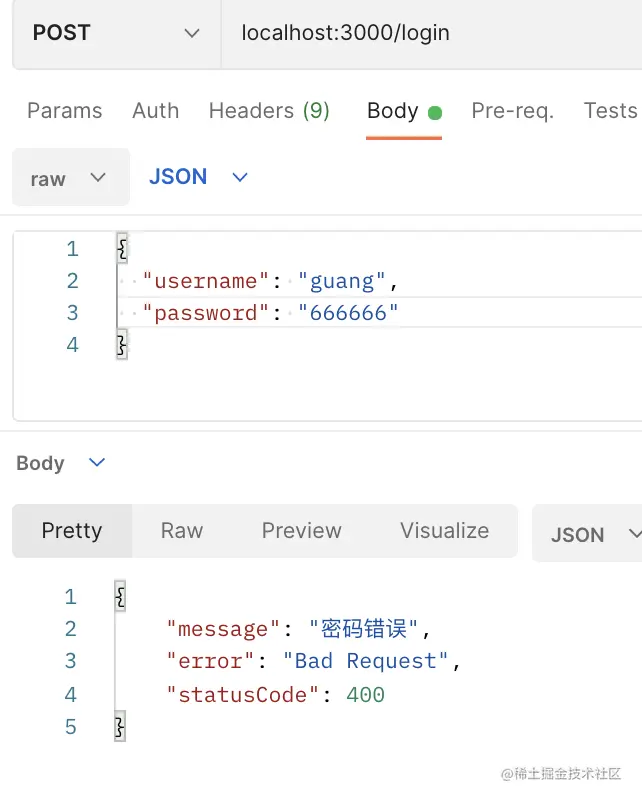
登录成功时:
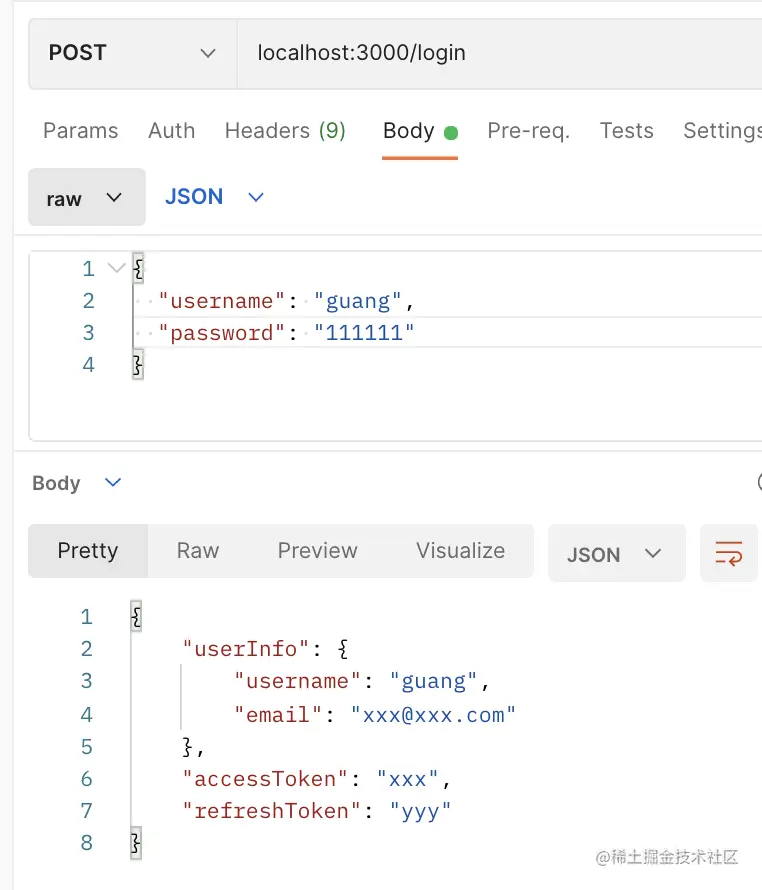
然后我们引入 jwt 模块来生成 token:
npm install @nestjs/jwt
在 AppModule 里注册下这个模块:
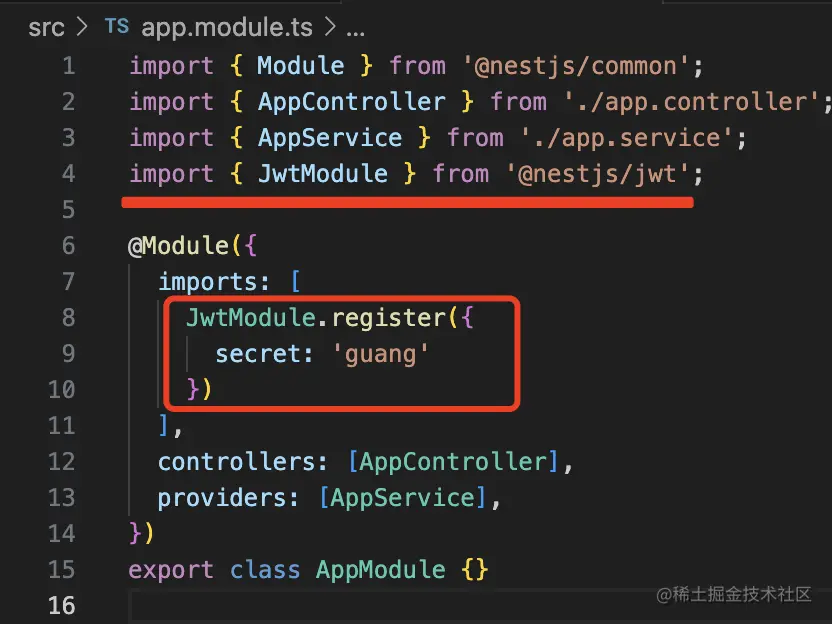
JwtModule.register({
secret: 'guang'
})
然后在 AppController 里就可以注入 JwtService 来用了:
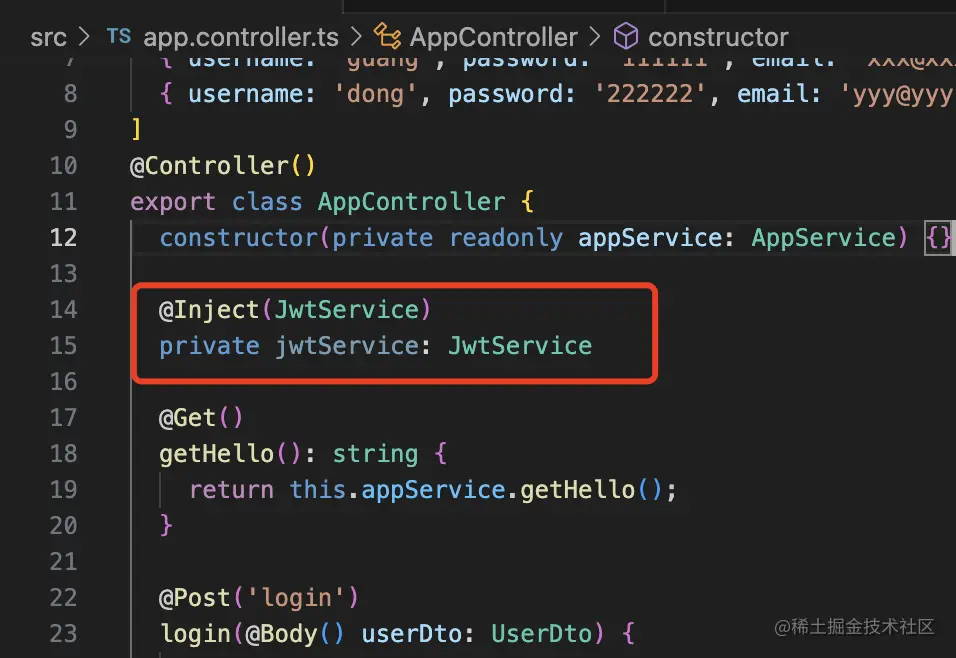
@Inject(JwtService)
private jwtService: JwtService
这个是 nest 的依赖注入功能。
然后用这个 jwtService 生成 access_token 和 refresh_token:
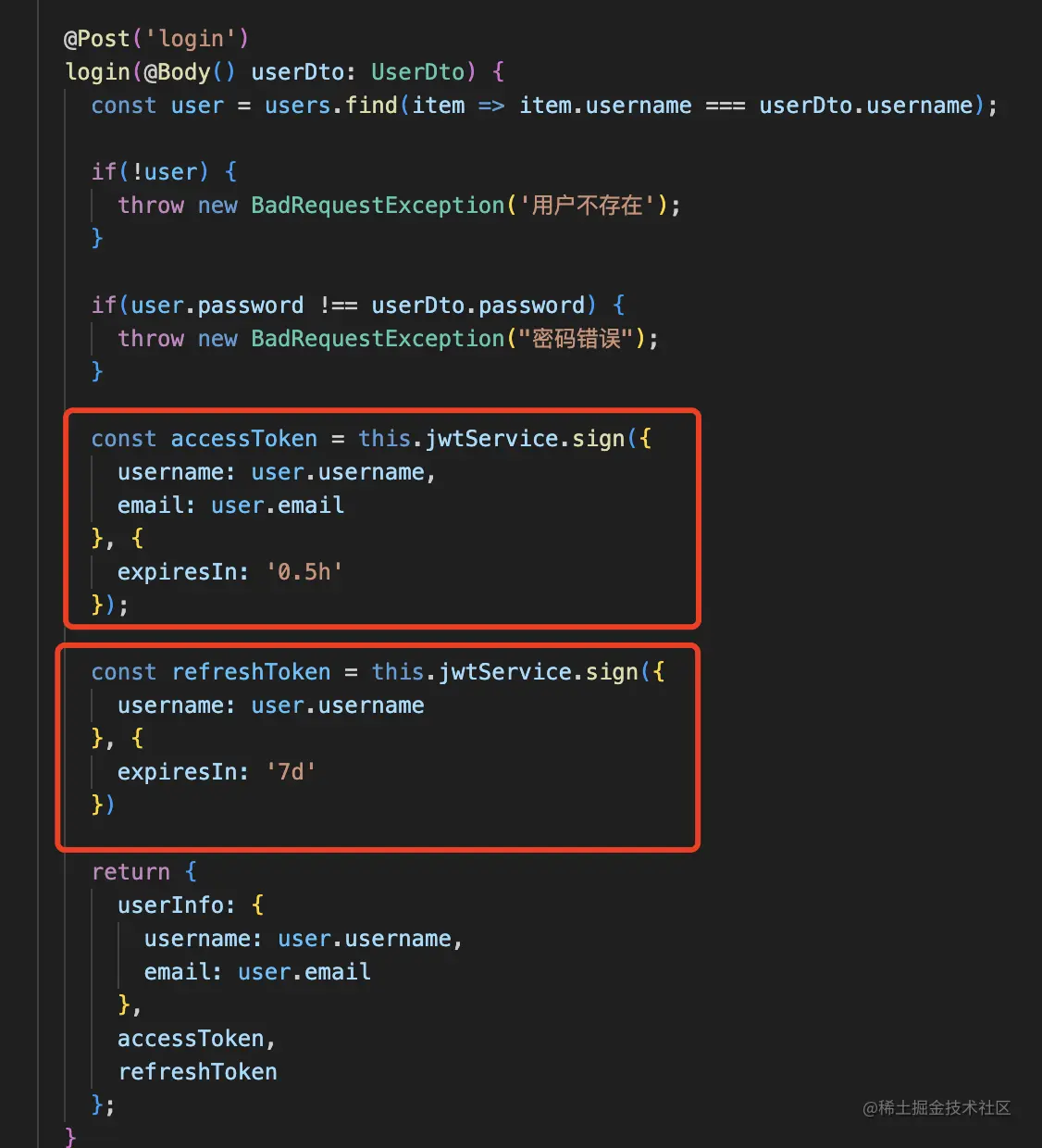
const accessToken = this.jwtService.sign({
username: user.username,
email: user.email
}, {
expiresIn: '0.5h'
});
const refreshToken = this.jwtService.sign({
username: user.username
}, {
expiresIn: '7d'
})
access_token 过期时间半小时,refresh_token 过期时间 7 天。
测试下:
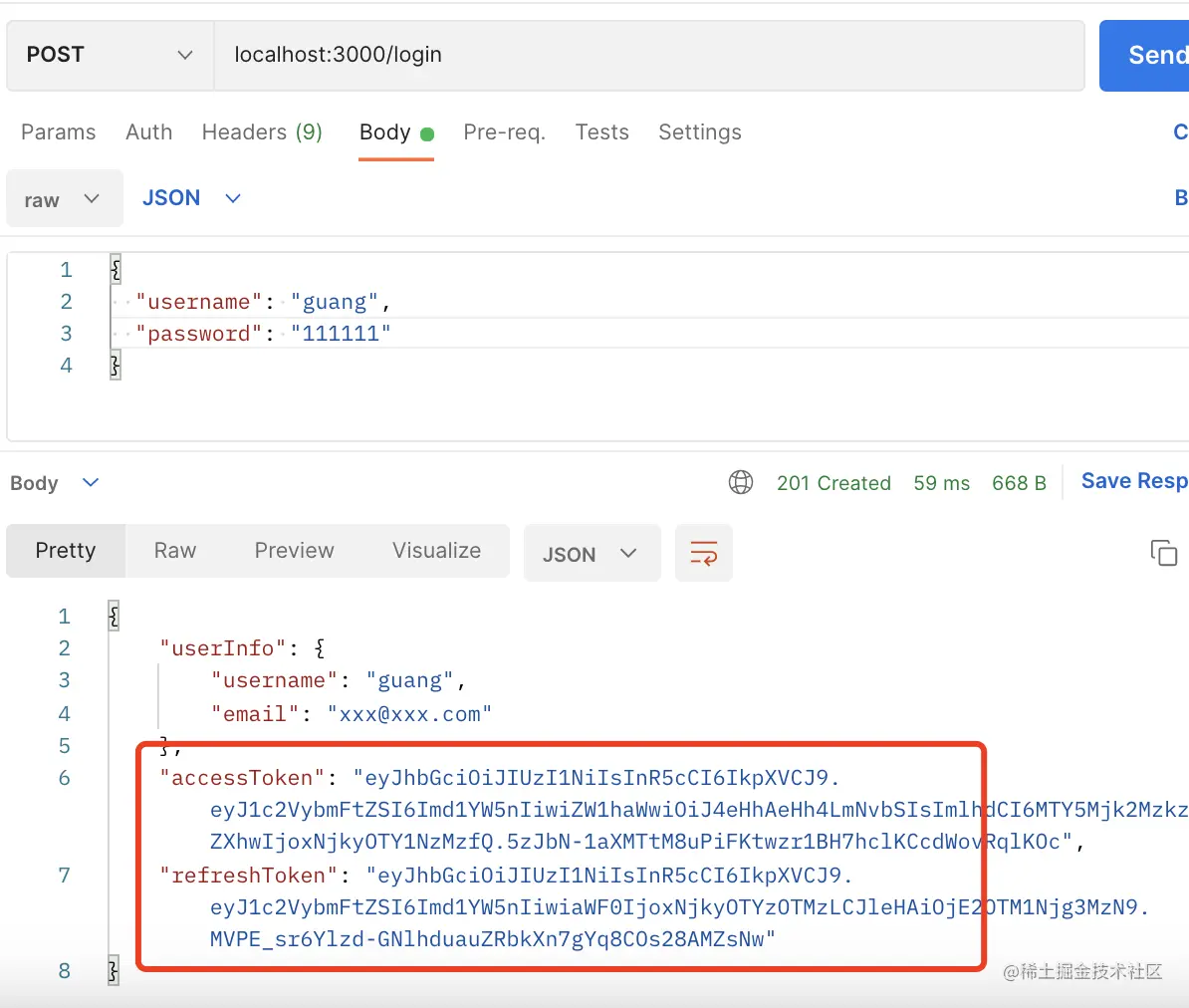
登录之后,访问别的接口只要带上这个 access_token 就好了。
前面讲过,jwt 是通过 authorization 的 header 携带 token,格式是 Bearer xxxx
也就是这样:
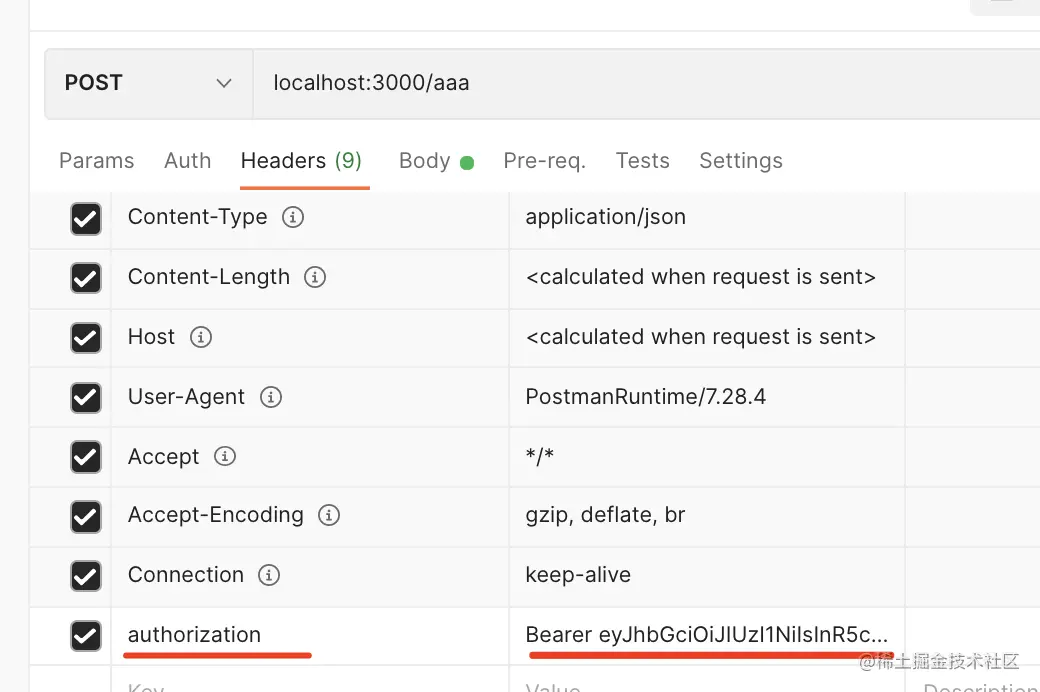
我们再定义个需要登录访问的接口:
@Get('aaa')
aaa(@Req() req: Request) {
const authorization = req.headers['authorization'];
if(!authorization) {
throw new UnauthorizedException('用户未登录');
}
try{
const token = authorization.split(' ')[1];
const data = this.jwtService.verify(token);
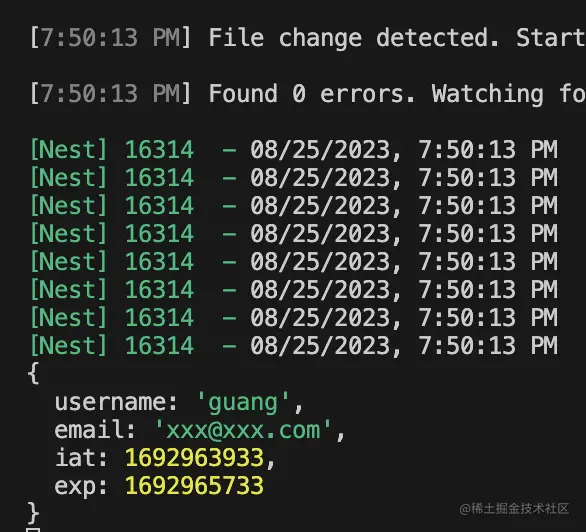
console.log(data);
} catch(e) {
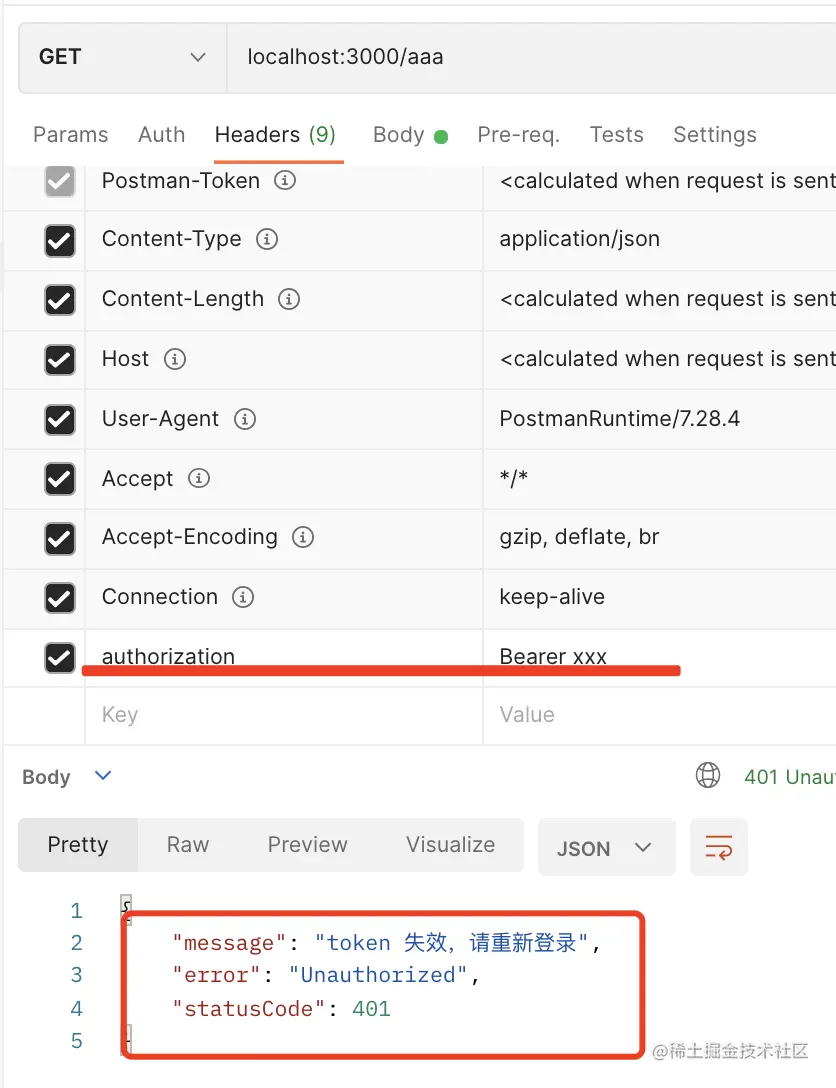
throw new UnauthorizedException('token 失效,请重新登录');
}
}
接口里取出 authorization 的 header,如果没有,说明没登录。
然后从中取出 token,用 jwtService.verify 校验下。
如果校验失败,返回 token 失效的错误,否则打印其中的信息。
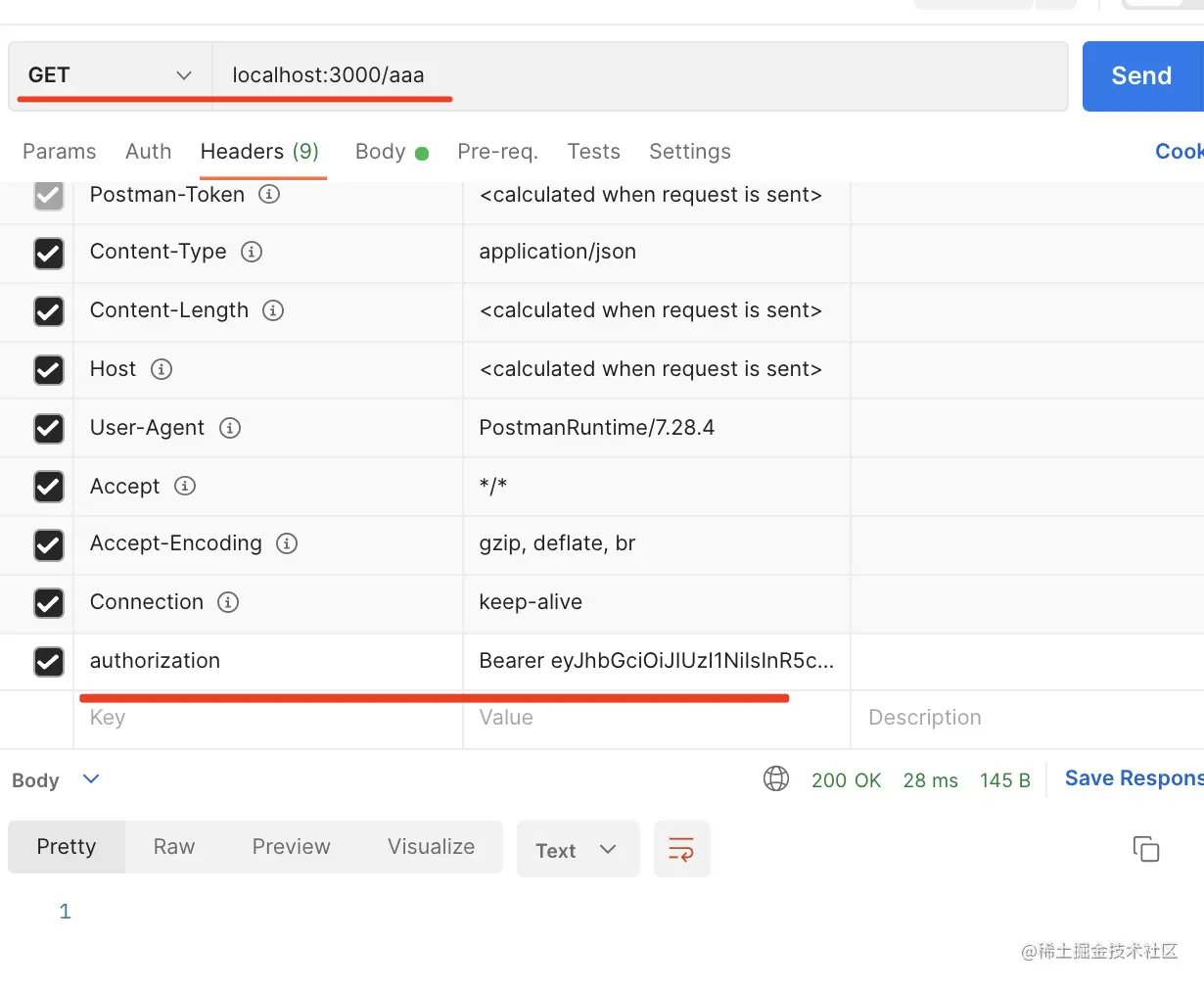
试一下:
带上 token 访问这个接口:
服务端打印了 token 中的信息,这就是我们登录时放到里面的:
试一下错误的 token:
然后我们实现刷新 token 的接口:
@Get('refresh')
refresh(@Query('token') token: string) {
try{
const data = this.jwtService.verify(token);
const user = users.find(item => item.username === data.username);
const accessToken = this.jwtService.sign({
username: user.username,
email: user.email
}, {
expiresIn: '0.5h'
});
const refreshToken = this.jwtService.sign({
username: user.username
}, {
expiresIn: '7d'
})
return {
accessToken,
refreshToken
};
} catch(e) {
throw new UnauthorizedException('token 失效,请重新登录');
}
}
定义了个 get 接口,参数是 refresh_token。
从 token 中取出 username,然后查询对应的 user 信息,再重新生成双 token 返回。
测试下:
登录之后拿到 refreshToken:
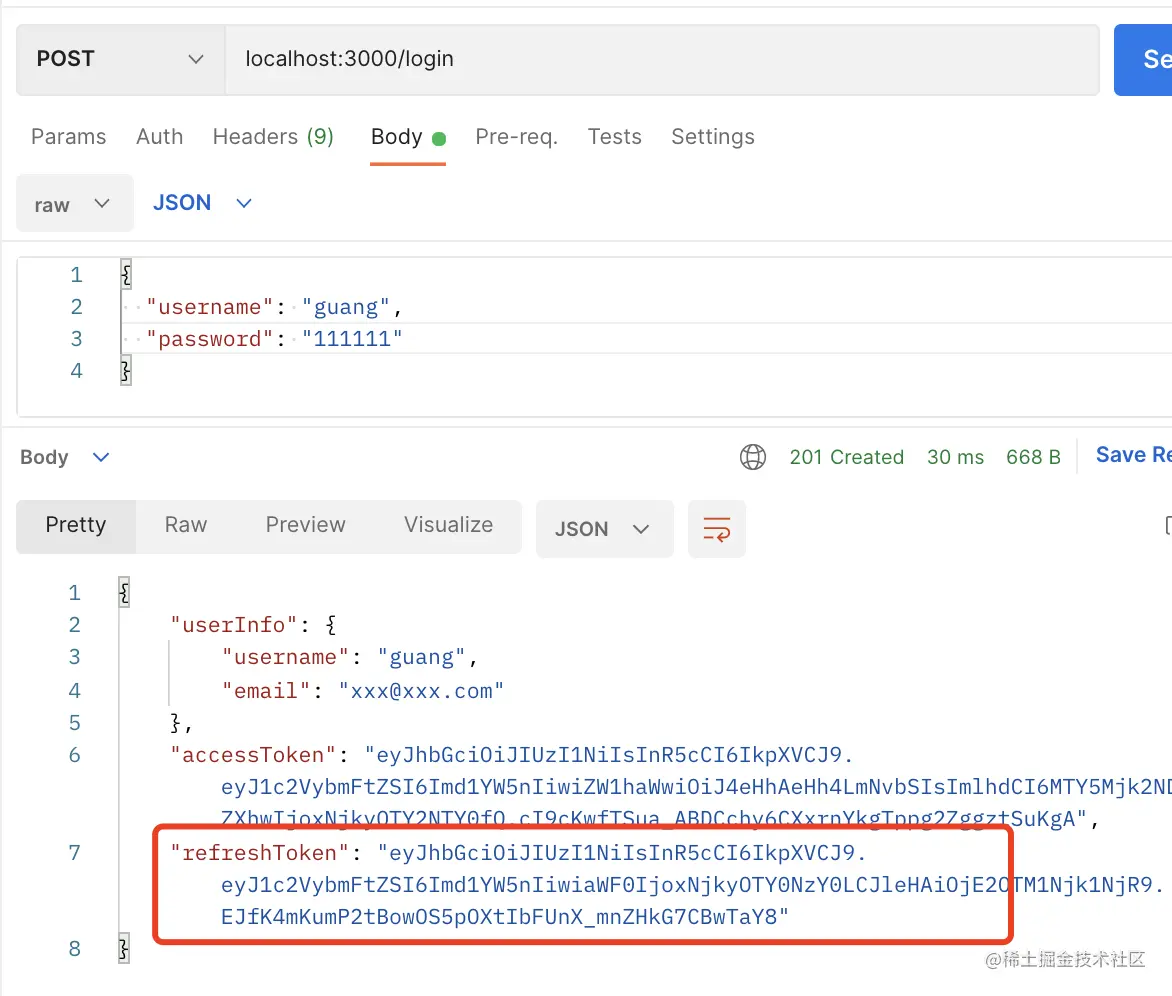
然后带上这个 token 访问刷新接口:
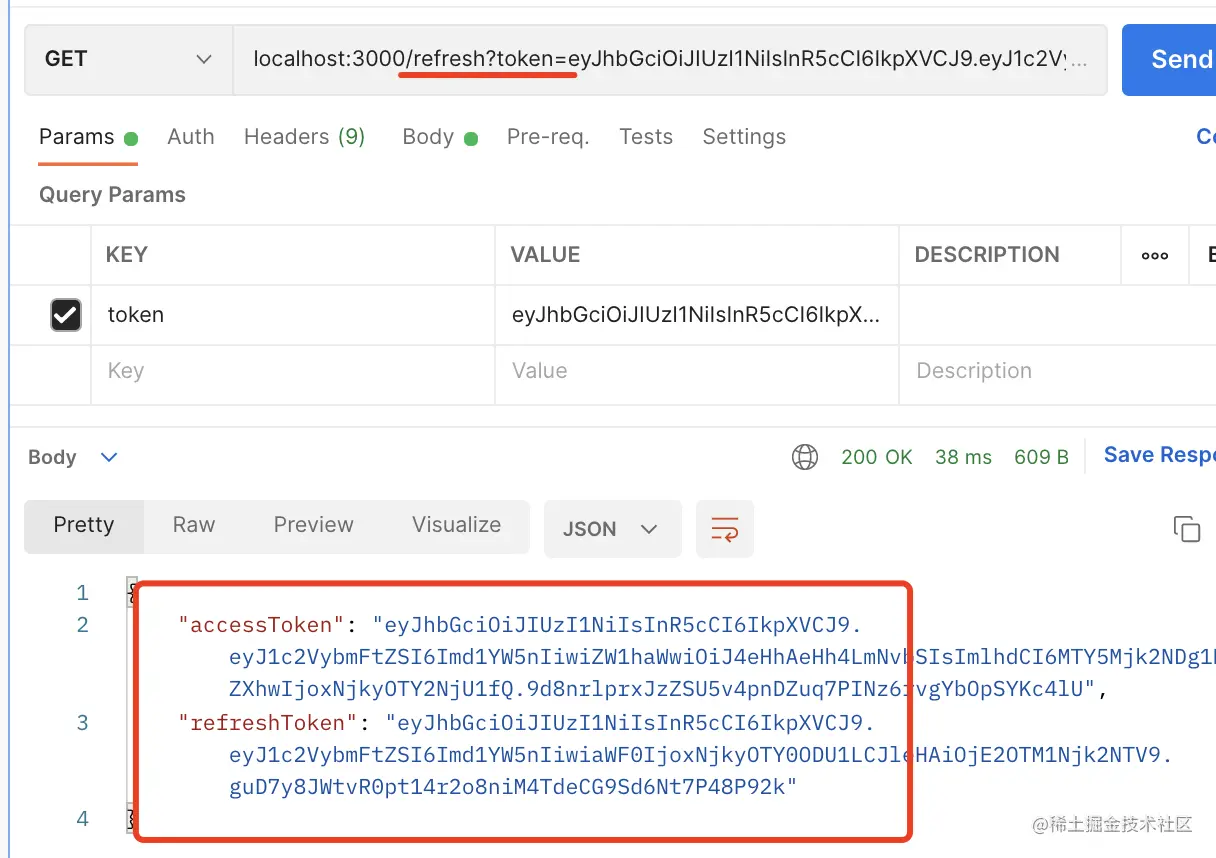
返回了新的 token,这种方式也叫做无感刷新。
那在前端项目里怎么用呢?
我们新建个 react 项目试试:
npx create-react-app
把它跑起来:
npm run start
因为 3000 端口被占用了,这里跑在了 3001 端口。
成功跑起来了。
我们改下 App.tsx
import { useCallback, useState } from "react";
interface User {
username: string;
email?: string;
}
function App() {
const [user, setUser] = useState<User>();
const login = useCallback(() => {
setUser({username: 'guang', email: 'xx@xx.com'});
}, []);
return (
<div className="App">
{
user?.username
? `当前登录用户: ${ user?.username }`
: <button onClick={login}>登录button>
}
div>
);
}
export default App;
如果已经登录,就显示用户信息,否则显示登录按钮。
点击登录按钮,会设置用户信息。
这里的 login 方法因为作为参数了,所以用 useCallback 包裹下,避免不必要的渲染。
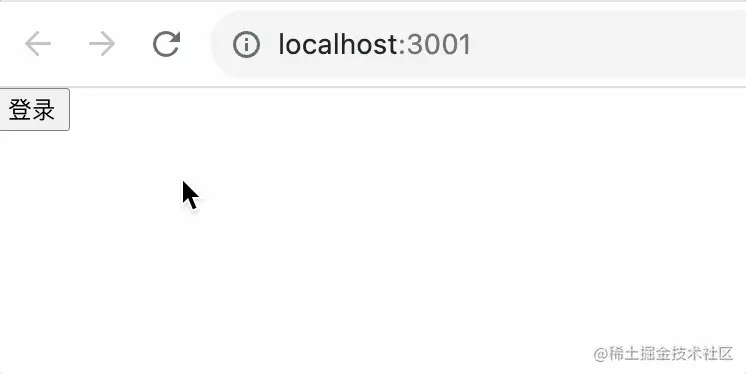
然后我们在 login 方法里访问登录接口。
首先要在 nest 服务里开启跨域支持:
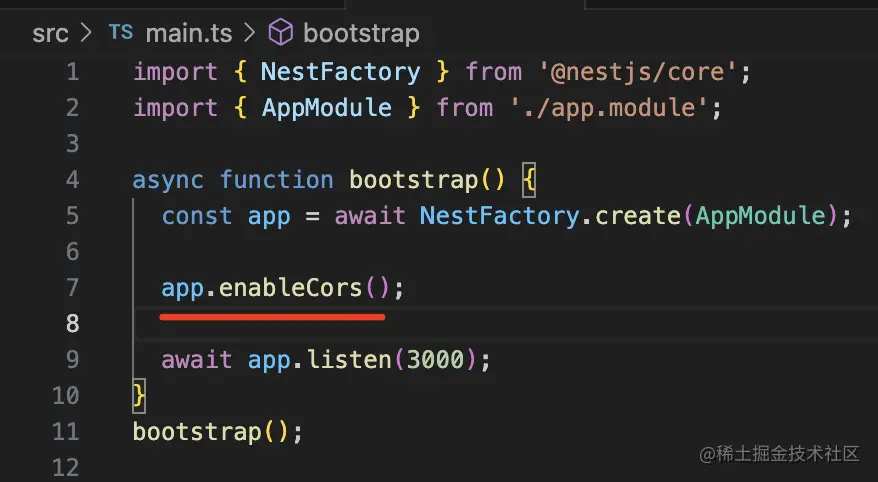
在 main.ts 里调用 enbalbeCors 开启跨域。
然后在前端代码里访问下这个接口:
先安装 axios
npm install
然后创建个 interface.ts 来管理所有接口:
import axios from "axios";
const axiosInstance = axios.create({
baseURL: 'http://localhost:3000/',
timeout: 3000
});
export async function userLogin(username: string, password: string) {
return await axiosInstance.post('/login', {
username,
password
});
}
async function refreshToken() {
}
async function aaa() {
}
在 App 组件里调用下:
const login = useCallback(async () => {
const res = await userLogin('guang', '111111');
console.log(res.data);
}, []);
接口调用成功了,我们拿到了 userInfo、access_token、refresh_token
然后我们把 token 存到 localStorage 里,因为后面还要用。
const login = useCallback(async () => {
const res = await userLogin('guang', '111111');
const { userInfo, accessToken, refreshToken } = res.data;
setUser(userInfo);
localStorage.setItem('access_token', accessToken);
localStorage.setItem('refresh_token', refreshToken);
}, []);
在 interface.ts 里添加 aaa 接口:
export async function aaa() {
return await axiosInstance.get('/aaa');
}
组件里访问下:
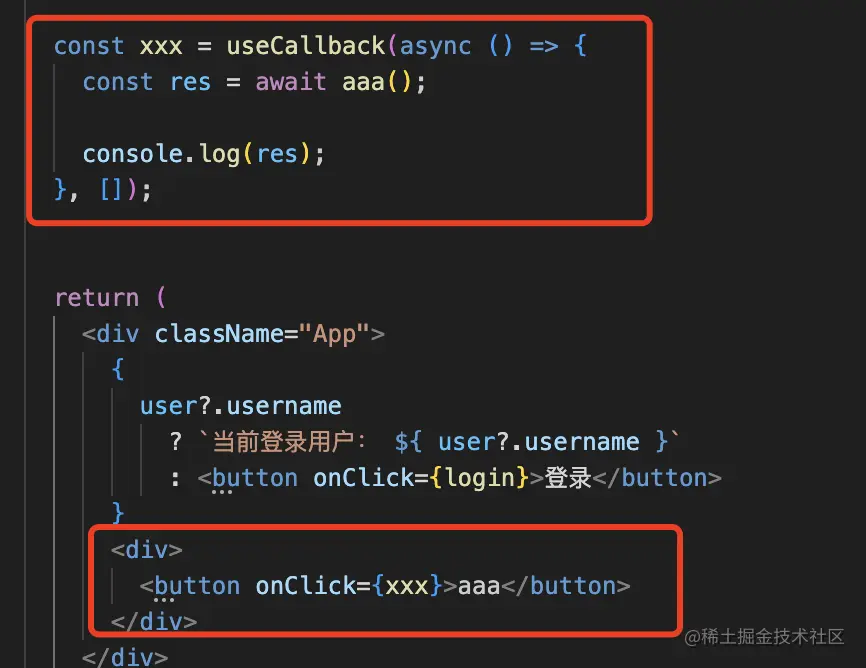
const xxx = useCallback(async () => {
const res = await aaa();
console.log(res);
}, []);
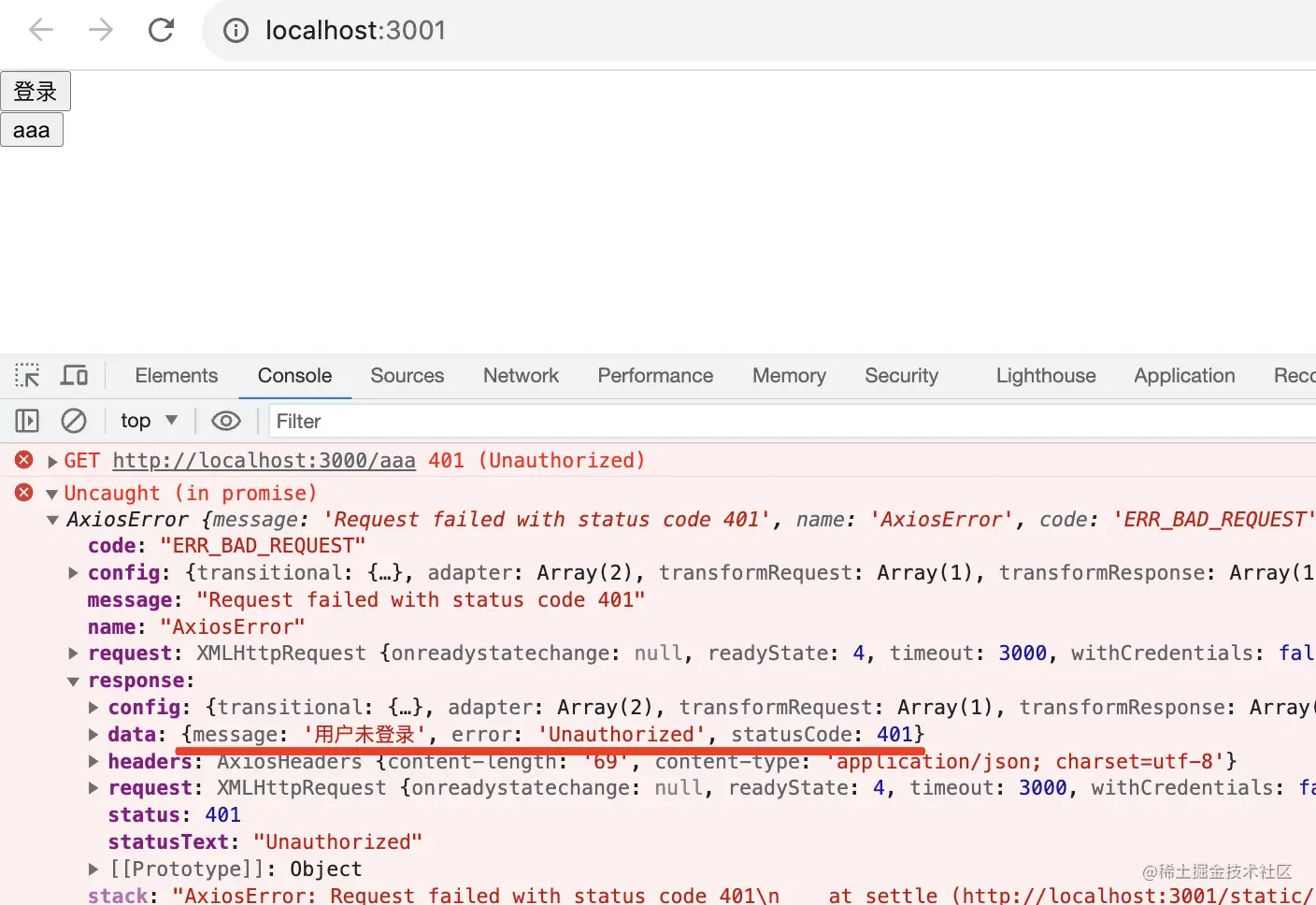
点击 aaa 按钮,报错了,因为接口返回了 401。
因为访问接口时没带上 token,我们可以在 interceptor 里做这个。
interceptor 是 axios 提供的机制,可以在请求前、响应后加上一些通用处理逻辑:
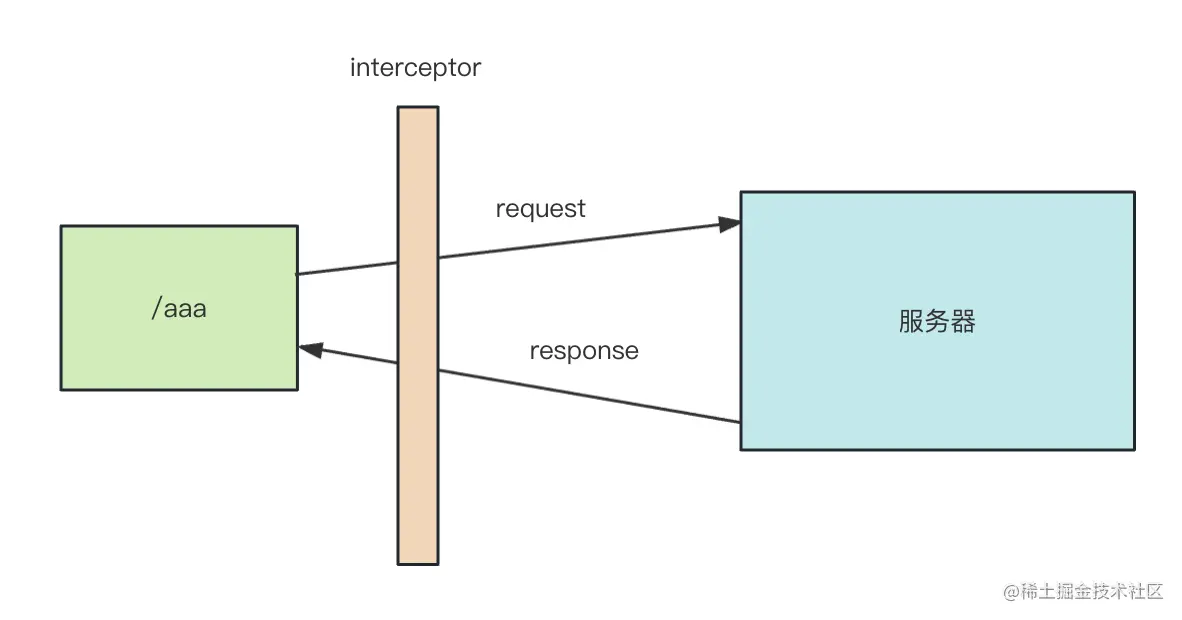
添加 token 的逻辑就很适合放在 interceptor 里:
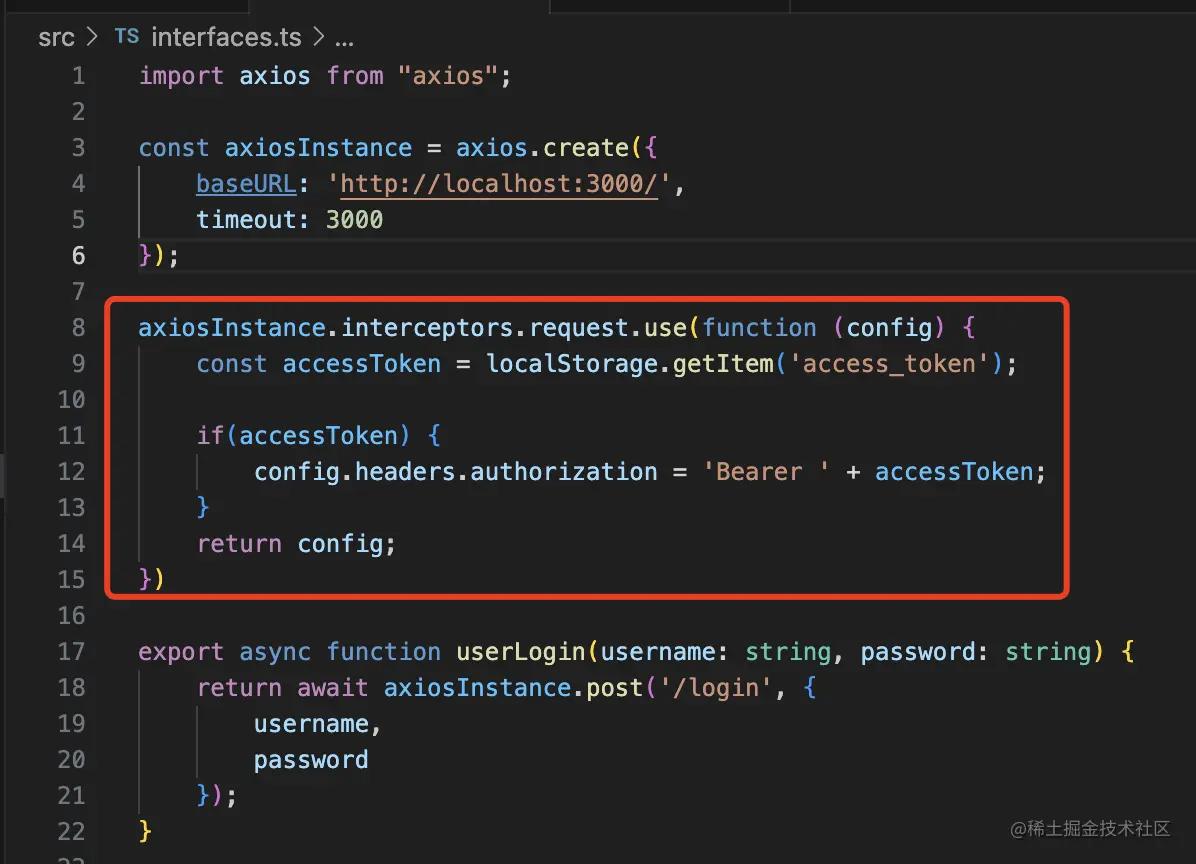
axiosInstance.interceptors.request.use(function (config) {
const accessToken = localStorage.getItem('access_token');
if(accessToken) {
config.headers.authorization = 'Bearer ' + accessToken;
}
return config;
})
现在再点击 aaa 按钮,接口就正常响应了:
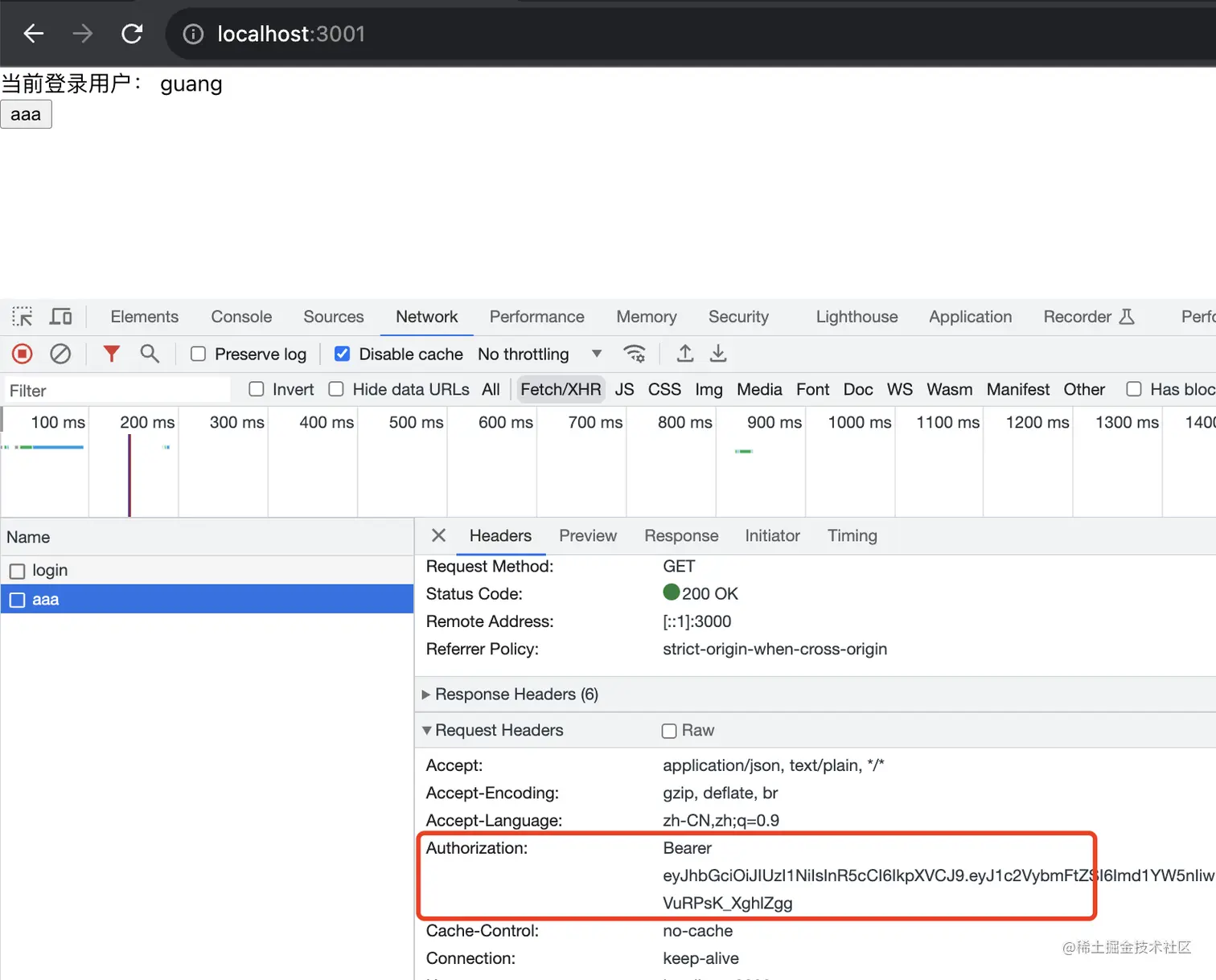
因为 axios 的拦截器里给它带上了 token:
那当 token 失效的时候,刷新 token 的逻辑在哪里做呢?
很明显,也可以放在 interceptor 里。
比如我们改下 localStorage 里的 access_token,手动让它失效。
这时候再点击 aaa 按钮,提示的就是 token 失效的错误了:
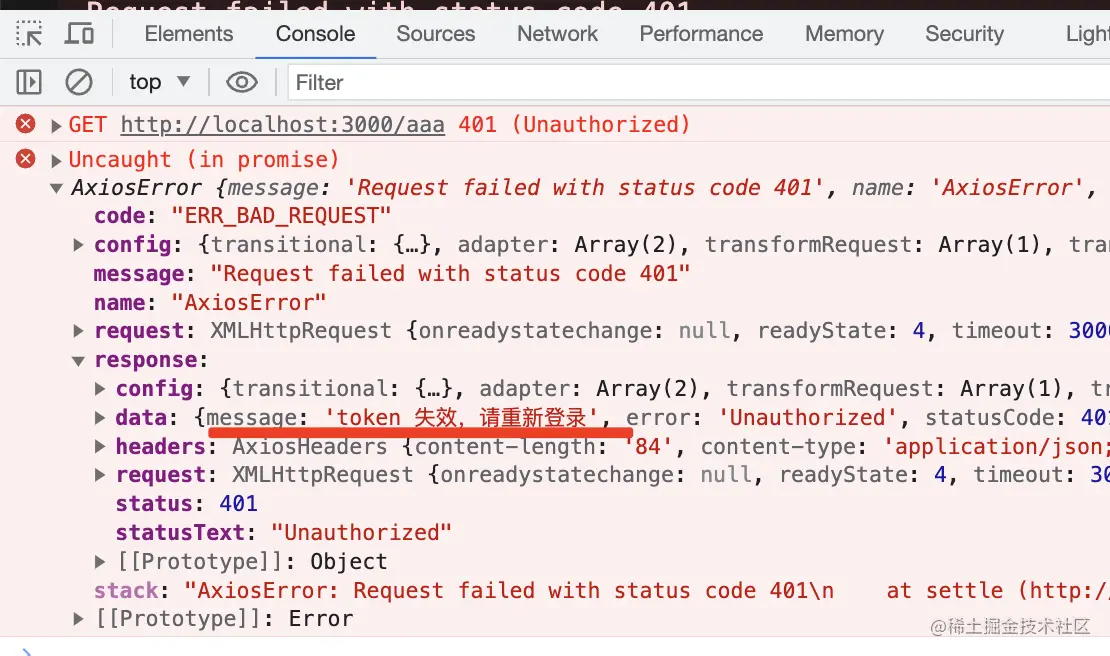
我们在 interceptor 里判断下,如果失效了就刷新 token:
axiosInstance.interceptors.response.use(
(response) => {
return response;
},
async (error) => {
let { data, config } = error.response;
if (data.statusCode === 401 && !config.url.includes('/refresh')) {
const res = await refreshToken();
if(res.status === 200) {
return axiosInstance(config);
} else {
alert(data || '登录过期,请重新登录');
}
} else {
return error.response;
}
}
)
async function refreshToken() {
const res = await axiosInstance.get('/refresh', {
params: {
token: localStorage.getItem('refresh_token')
}
});
localStorage.setItem('access_token', res.data.accessToken);
localStorage.setItem('refresh_token', res.data.refreshToken);
return res;
}
响应的 interceptor 有两个参数,当返回 200 时,走第一个处理函数,直接返回 response。
当返回的不是 200 时,走第二个处理函数 ,判断下如果返回的是 401,就调用刷新 token 的接口。
这里还要排除下 /refresh 接口,也就是刷新失败不继续刷新。
刷新 token 成功,就重发之前的请求,否则,提示重新登录。
其他错误直接返回。
刷新 token 的接口里,我们拿到新的 access_token 和 refresh_token 后,更新本地的 token。
测试下:
我手动改了 access_token 让它失效后,点击 aaa 按钮,发现发了三个请求:
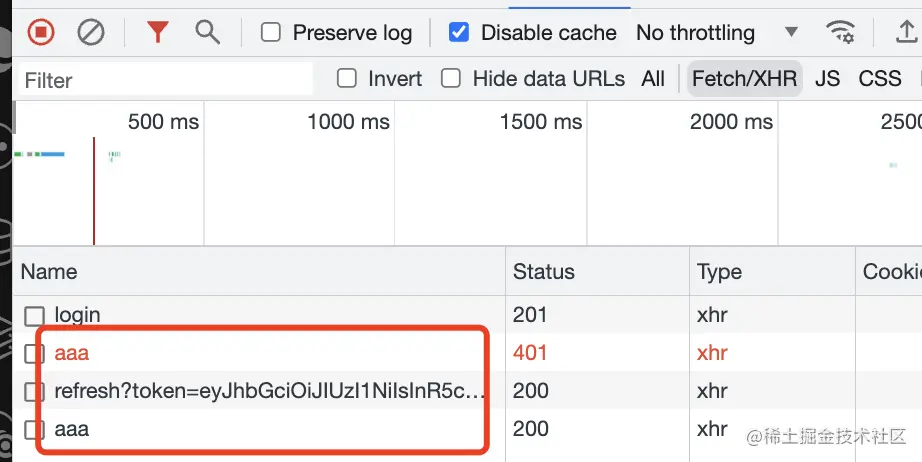
第一次访问 aaa 接口返回 401,自动调了 refresh 接口来刷新,之后又重新访问了 aaa 接口。
这样,基于 axios interceptor 的无感刷新 token 就完成了。
但现在还不完美,比如点击按钮的时候,我同时调用了 3 次 aaa 接口:
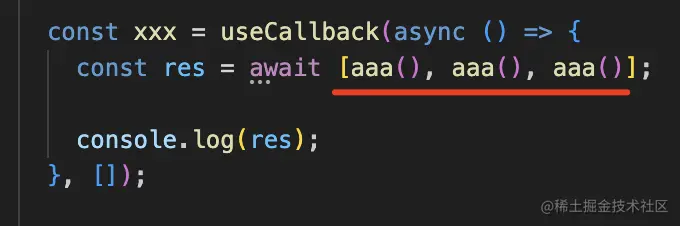
这时候三个接口用的 token 都失效了,会刷新几次呢?
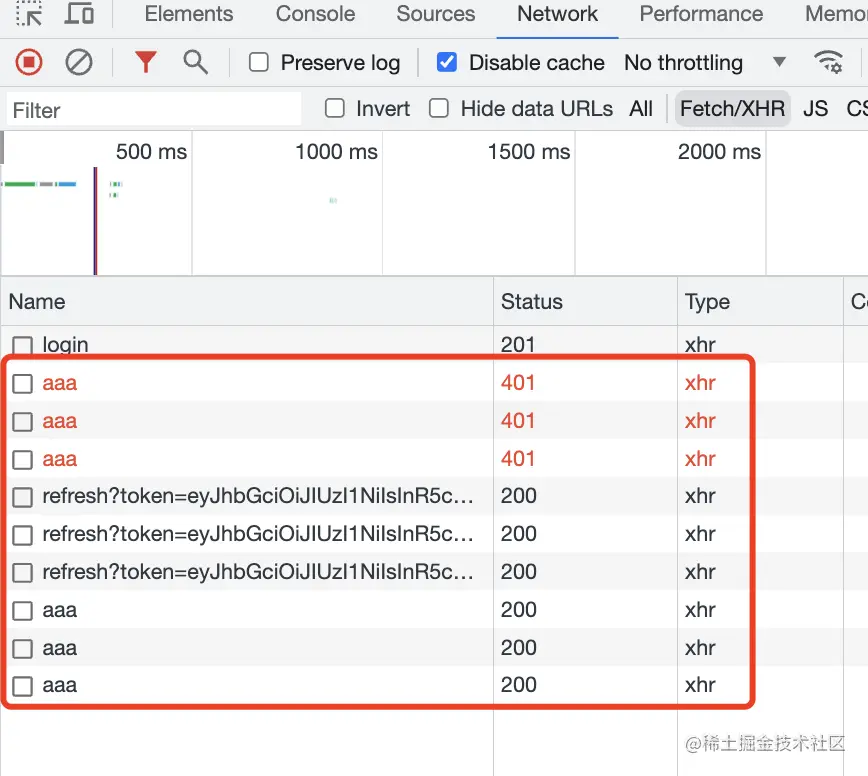
是 3 次。
多刷新几次也没啥,不影响功能。
但做的再完美一点可以处理下:
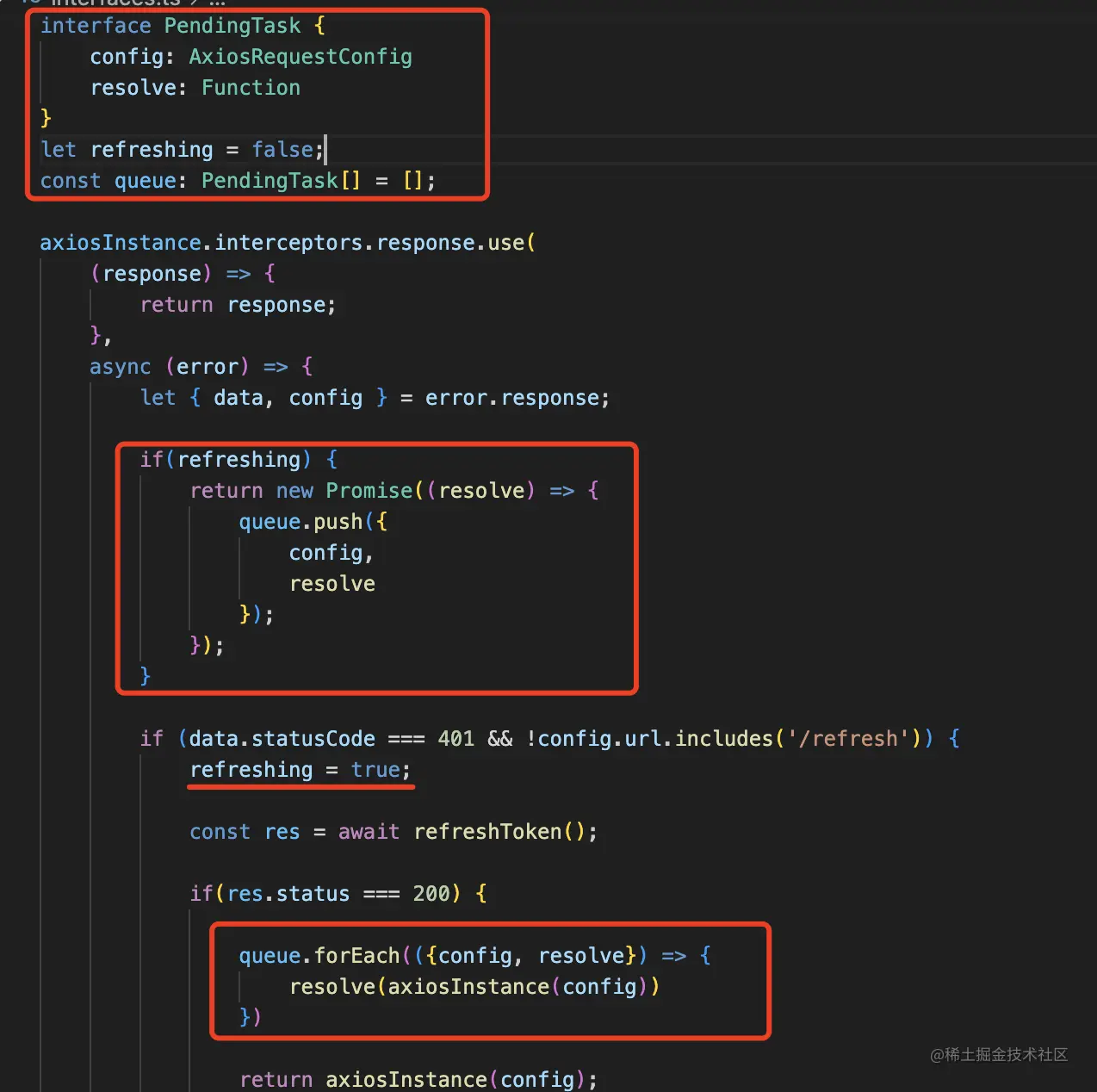
加一个 refreshing 的标记,如果在刷新,那就返回一个 promise,并且把它的 resolve 方法还有 config 加到队列里。
当 refresh 成功之后,重新发送队列中的请求,并且把结果通过 resolve 返回。
interface PendingTask {
config: AxiosRequestConfig
resolve: Function
}
let refreshing = false;
const queue: PendingTask[] = [];
axiosInstance.interceptors.response.use(
(response) => {
return response;
},
async (error) => {
let { data, config } = error.response;
if(refreshing) {
return new Promise((resolve) => {
queue.push({
config,
resolve
});
});
}
if (data.statusCode === 401 && !config.url.includes('/refresh')) {
refreshing = true;
const res = await refreshToken();
refreshing = false;
if(res.status === 200) {
queue.forEach(({config, resolve}) => {
resolve(axiosInstance(config))
})
return axiosInstance(config);
} else {
alert(data || '登录过期,请重新登录');
}
} else {
return error.response;
}
}
)
axiosInstance.interceptors.request.use(function (config) {
const accessToken = localStorage.getItem('access_token');
if(accessToken) {
config.headers.authorization = 'Bearer ' + accessToken;
}
return config;
})
测试下:
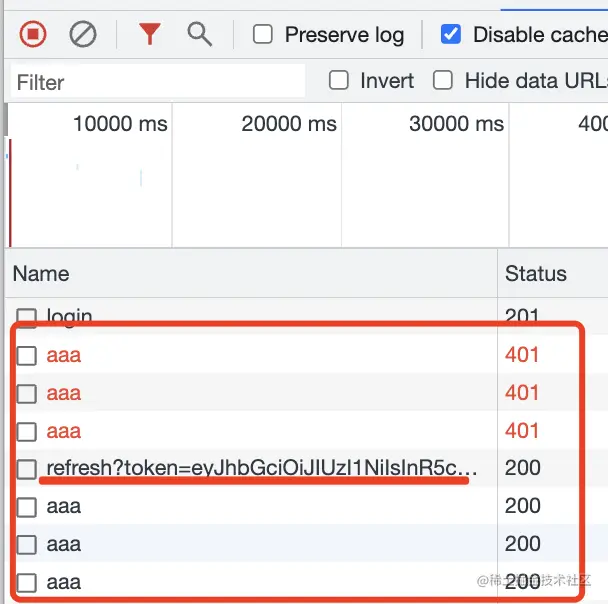
现在就是并发请求只 refresh 一次了。
这样,我们就基于 axios 的 interceptor 实现了完美的双 token 无感刷新机制。
总结
登录状态的标识有 session 和 jwt 两种方案。
session 是通过 cookie 携带 sid,关联服务端的 session,用户信息保存在服务端。
jwt 是 token 保存用户信息,在 authorization 的 header 里通过 Bearer xxx 的方式携带,用户信息保存在客户端。
jwt 的方式因为天然支持分布式,用的比较多。
但是只有一个 token 会有过期后需要重新登录的问题,为了更好的体验,一般都是通过双 token 来做无感刷新。
也就是通过 access_token 标识用户身份,过期时通过 refresh_token 刷新,拿到新 token。
我们通过 nest 实现了这种双 token 机制,在 postman 里测试了一下。
在 react 项目里访问这些接口,也需要双 token 机制。我们通过 axios 的 interceptor 对它做了封装。
axios.request.interceptor 里,读取 localStorage 里的 access_token 放到 header 里。
axios.response.interceptor 里,判断返回的如果是 401 就调用刷新接口刷新 token,之后重发请求。
我们还支持了并发请求时,如果 token 过期,会把请求放到队列里,只刷新一次,刷新完批量重发请求。
这样,就是一个基于 Axios 的完美的双 token 无感刷新了。
作者:zxg_神说要有光
来源:juejin.cn/post/7271139265442021391






























































































 可以看到,这就是
可以看到,这就是