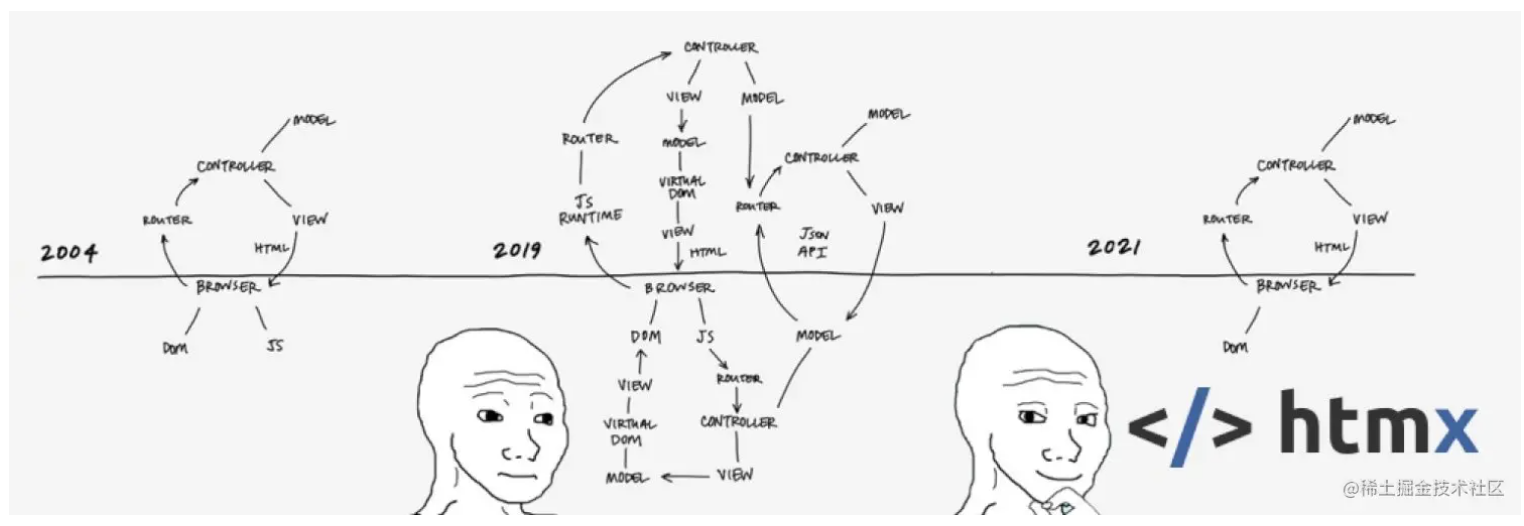
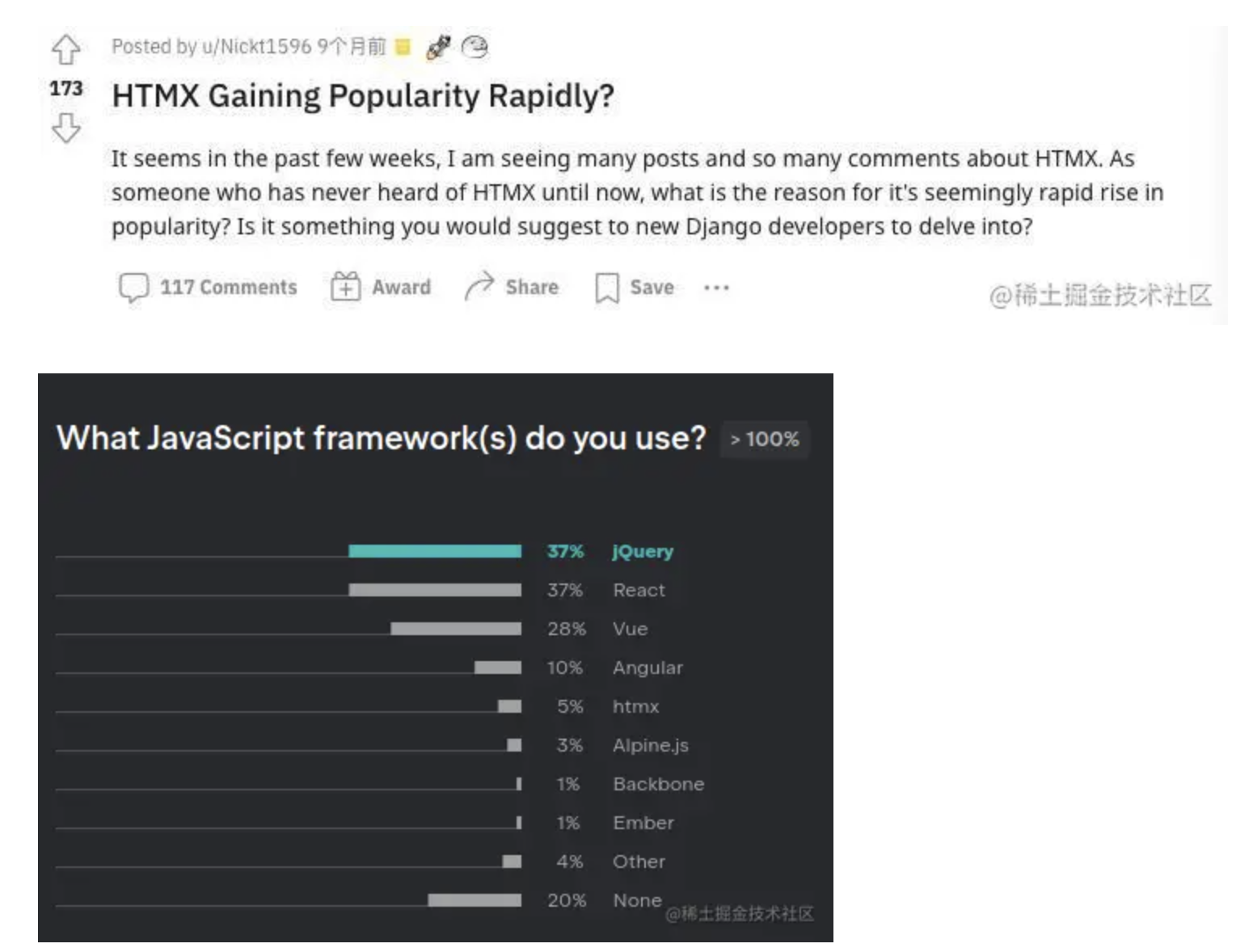
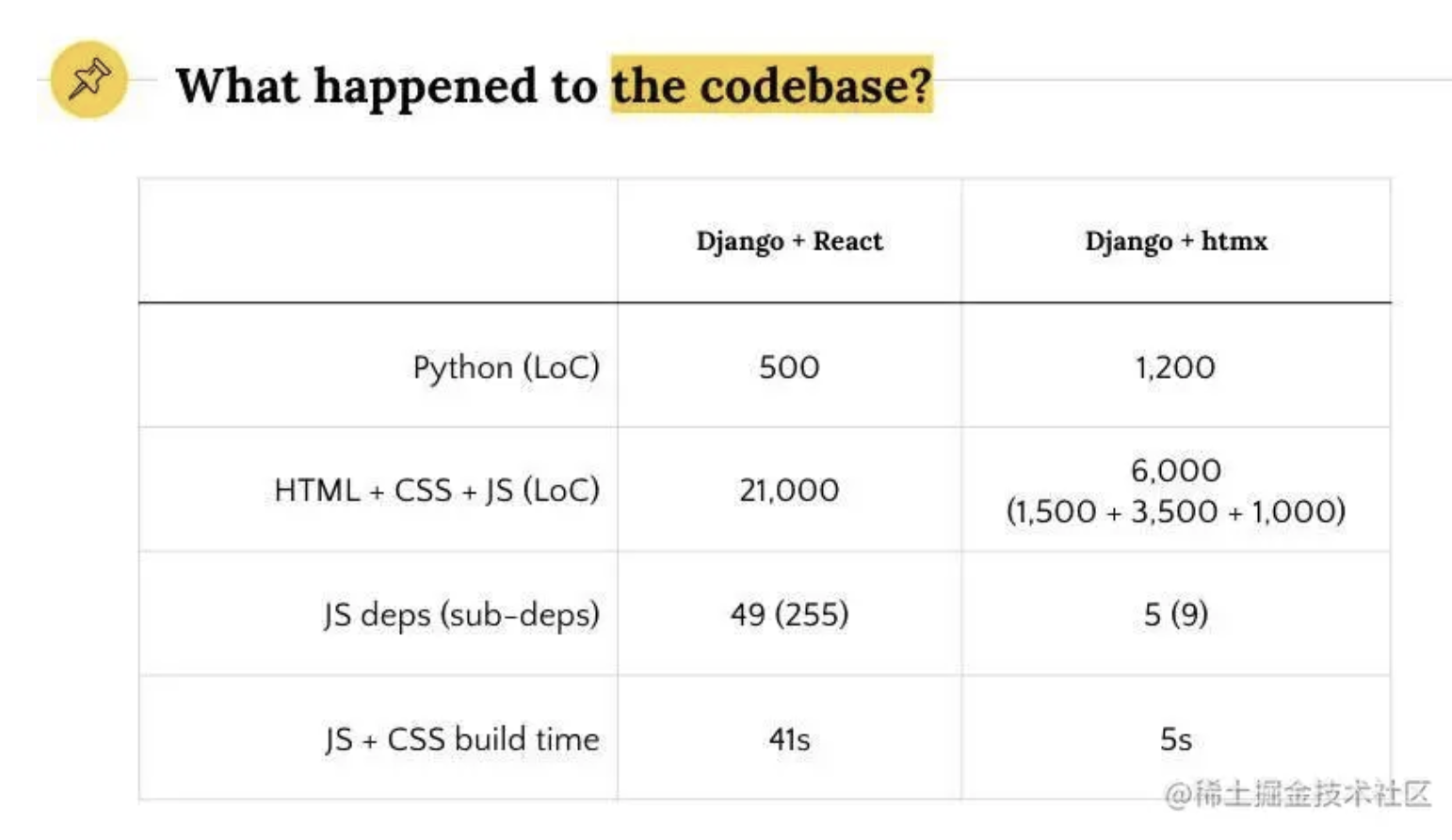
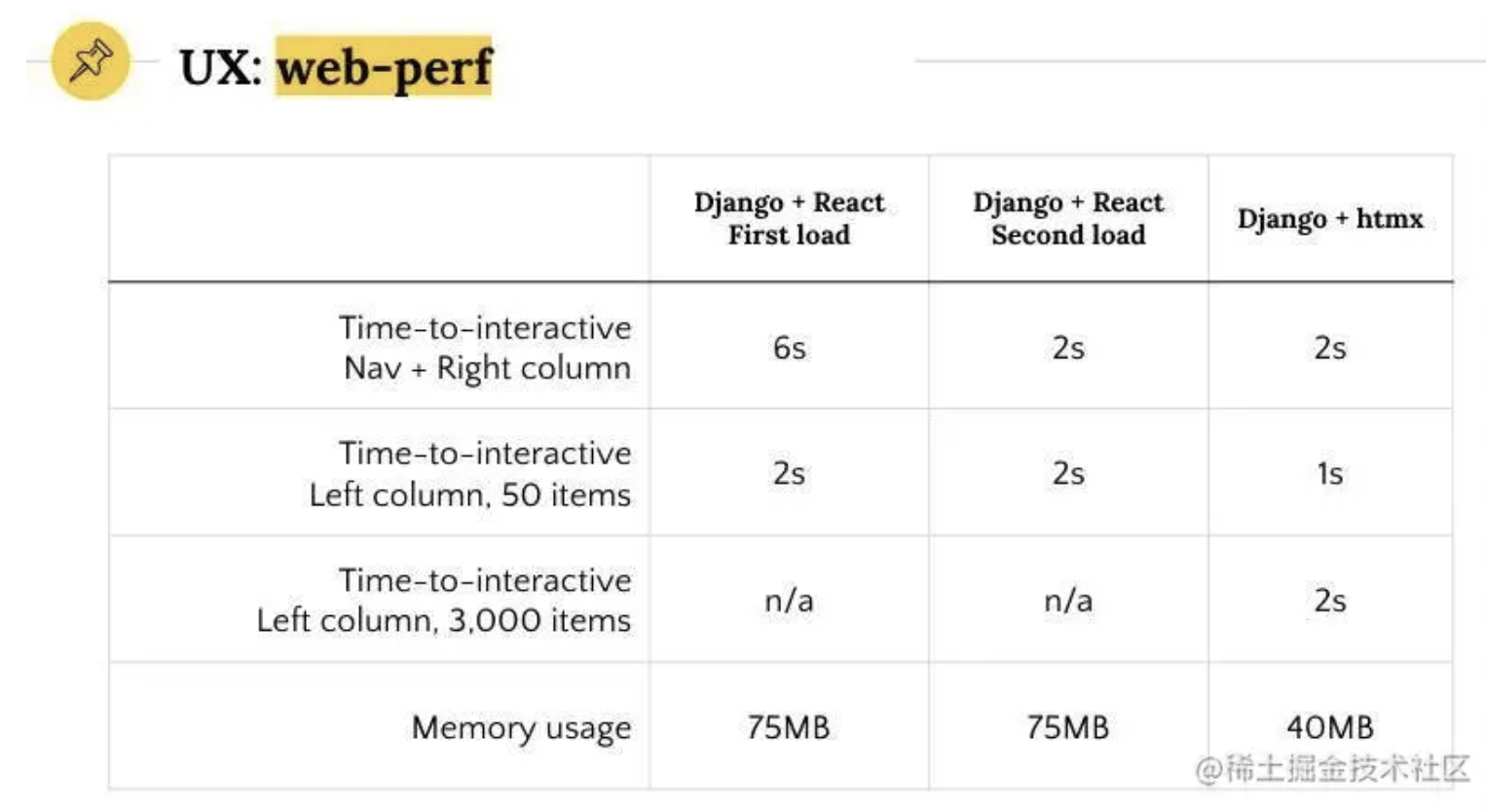
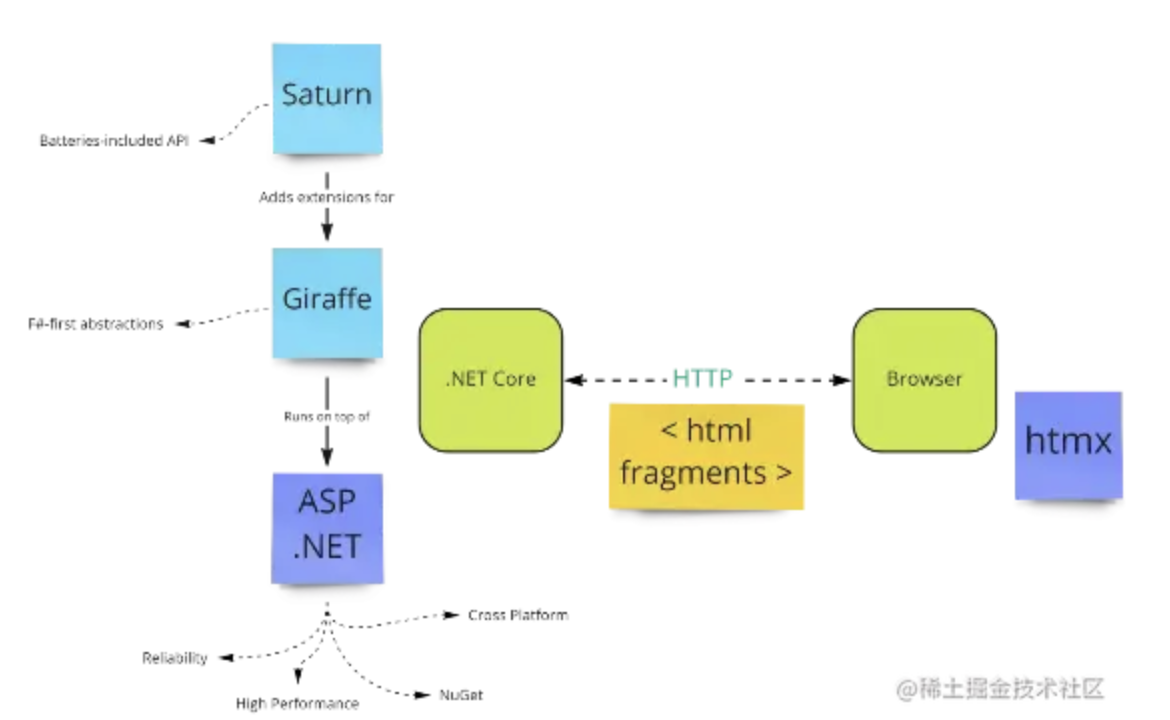
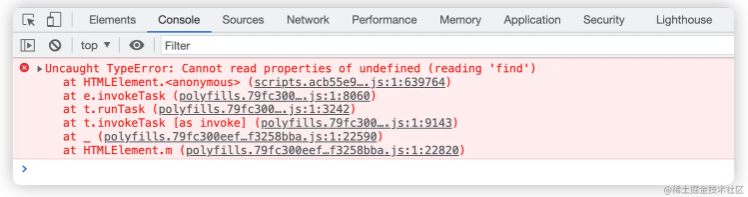
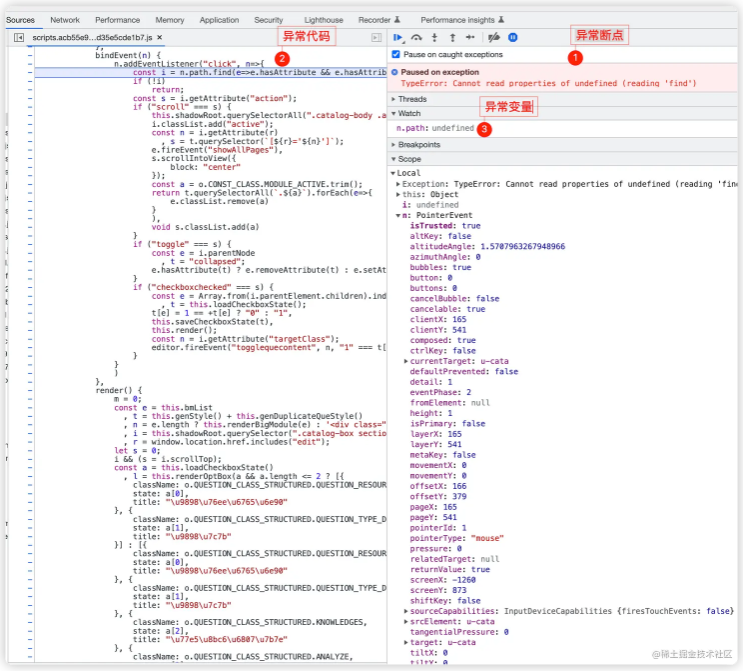
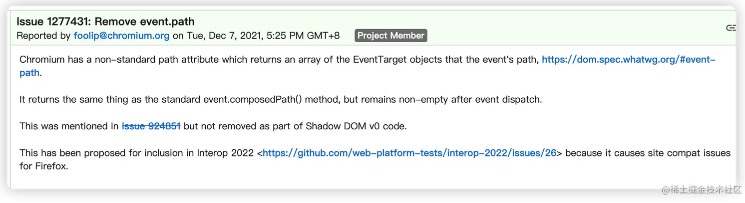
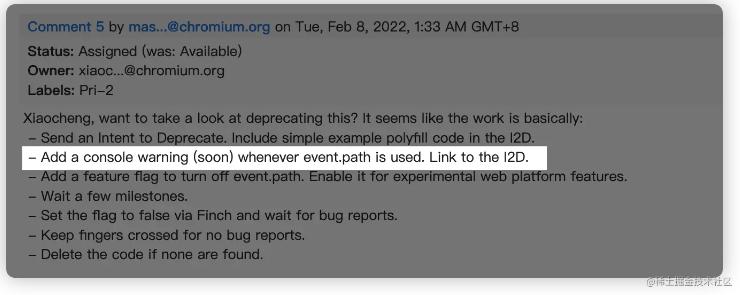
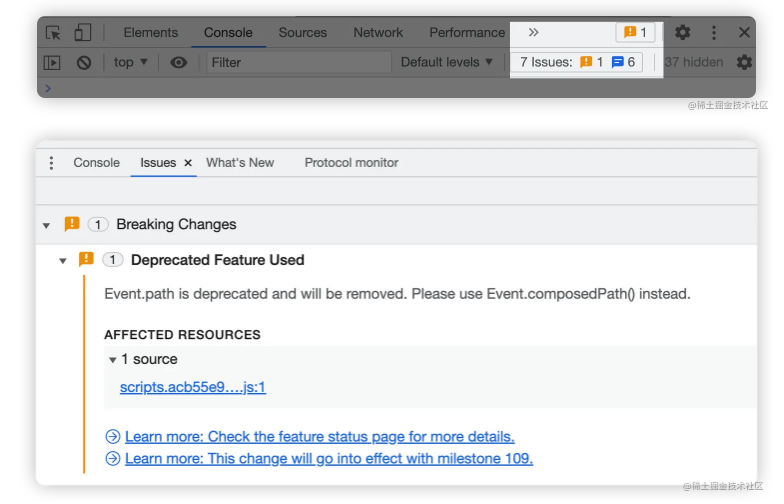
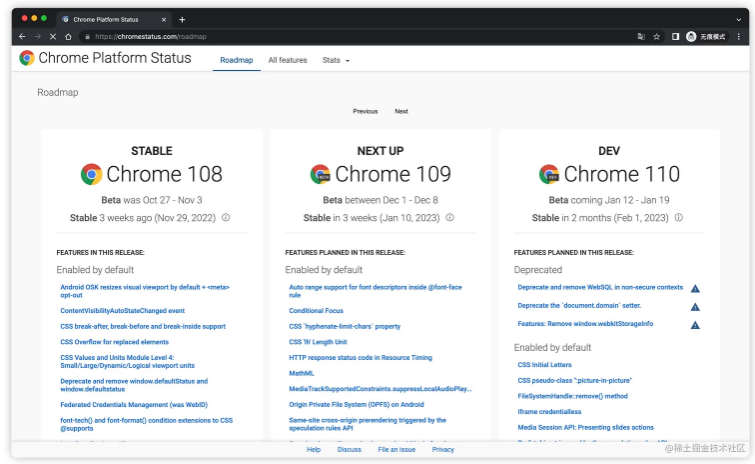
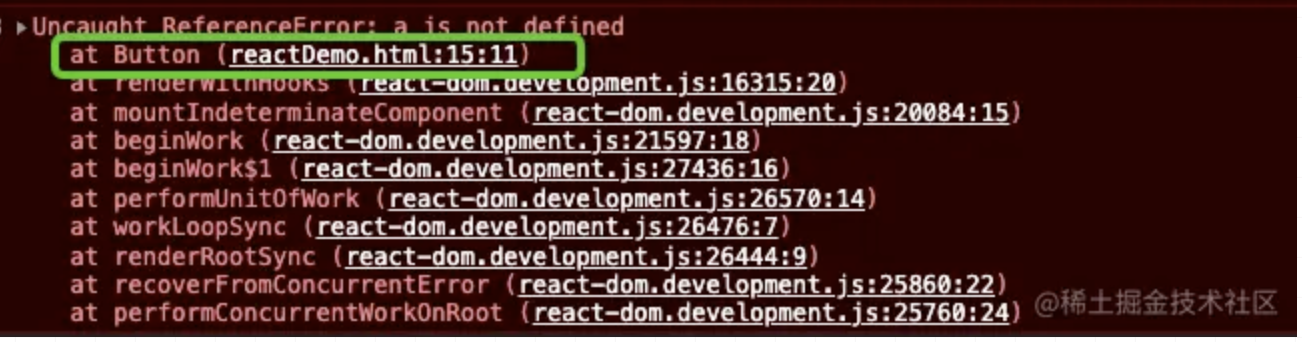
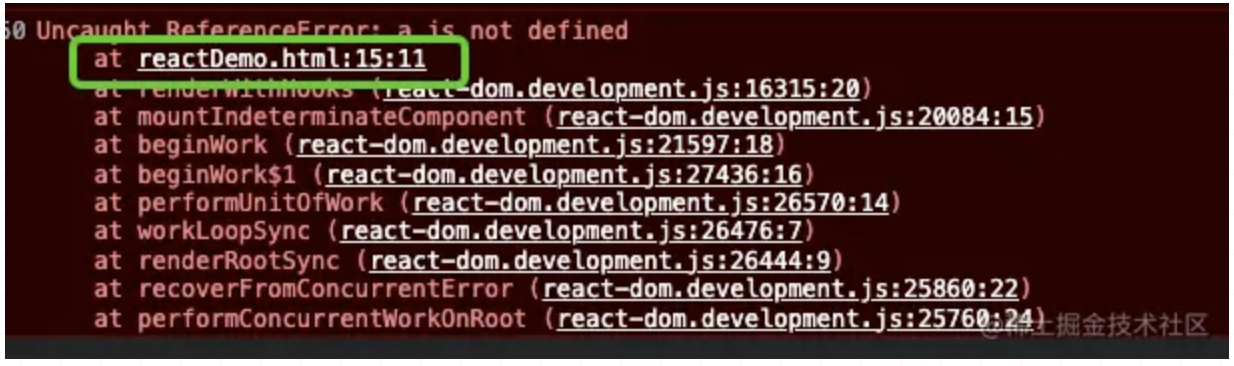
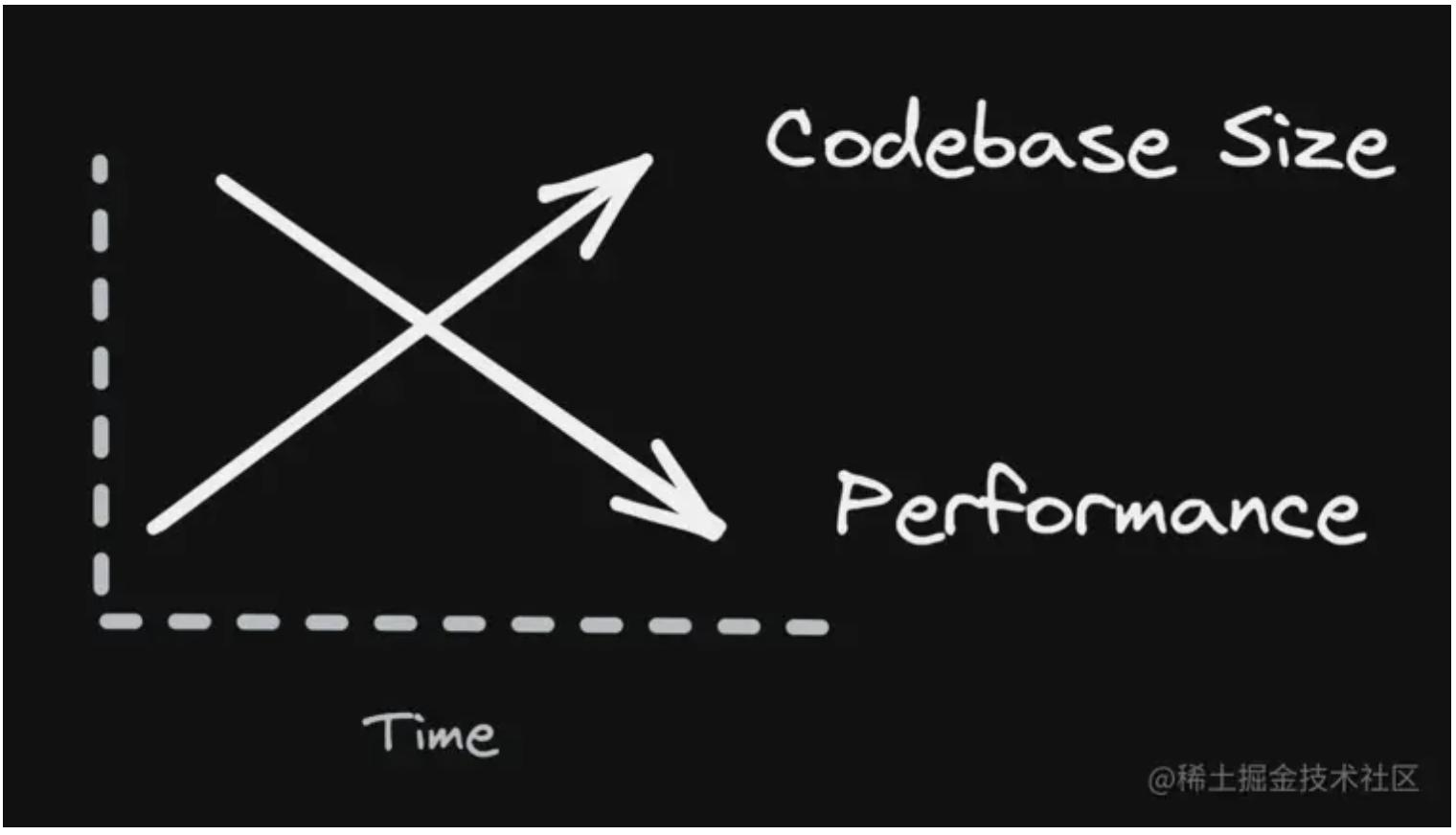
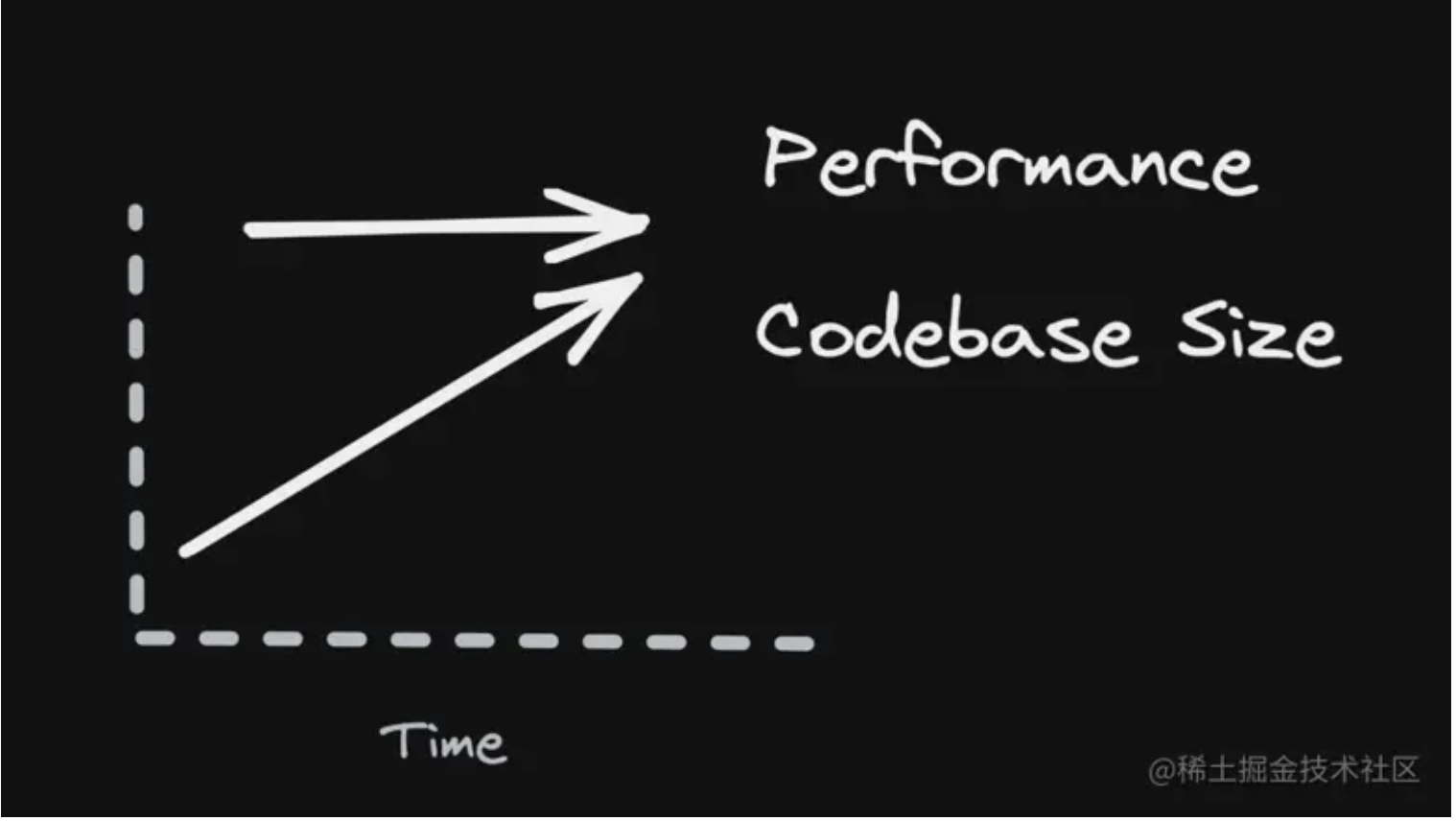
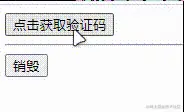
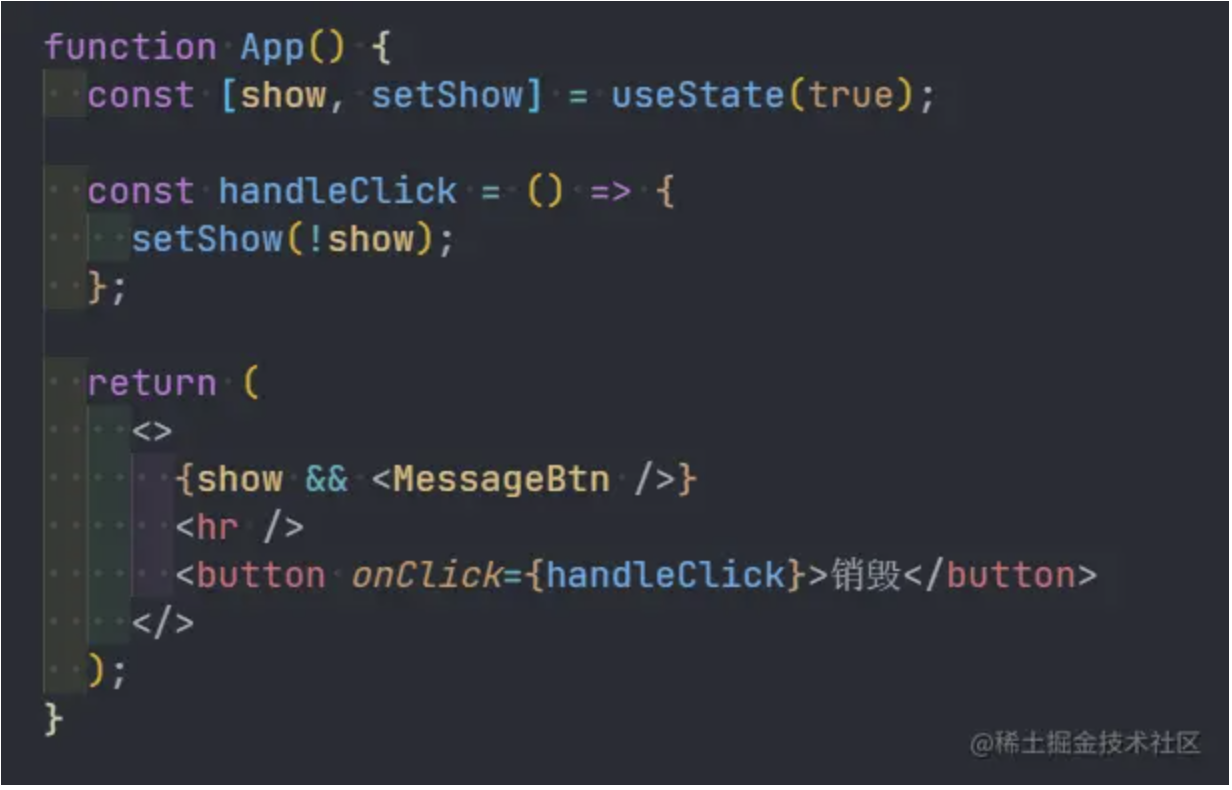
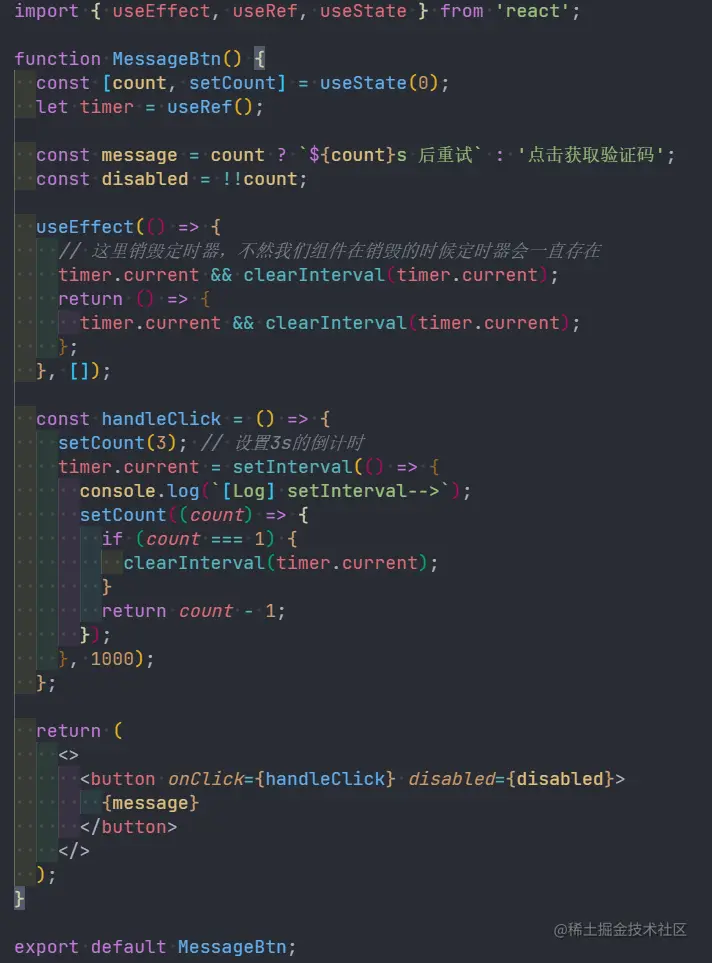
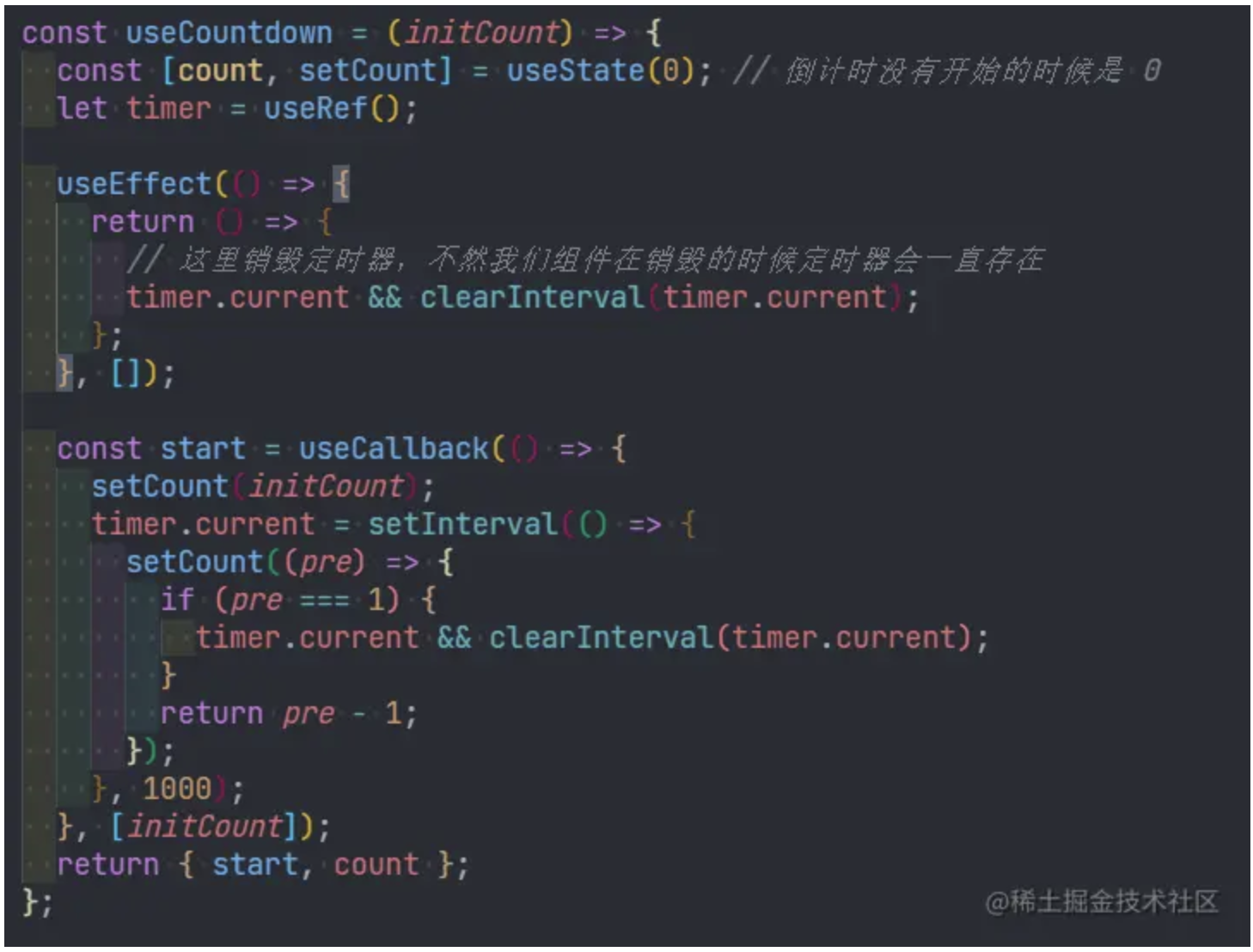
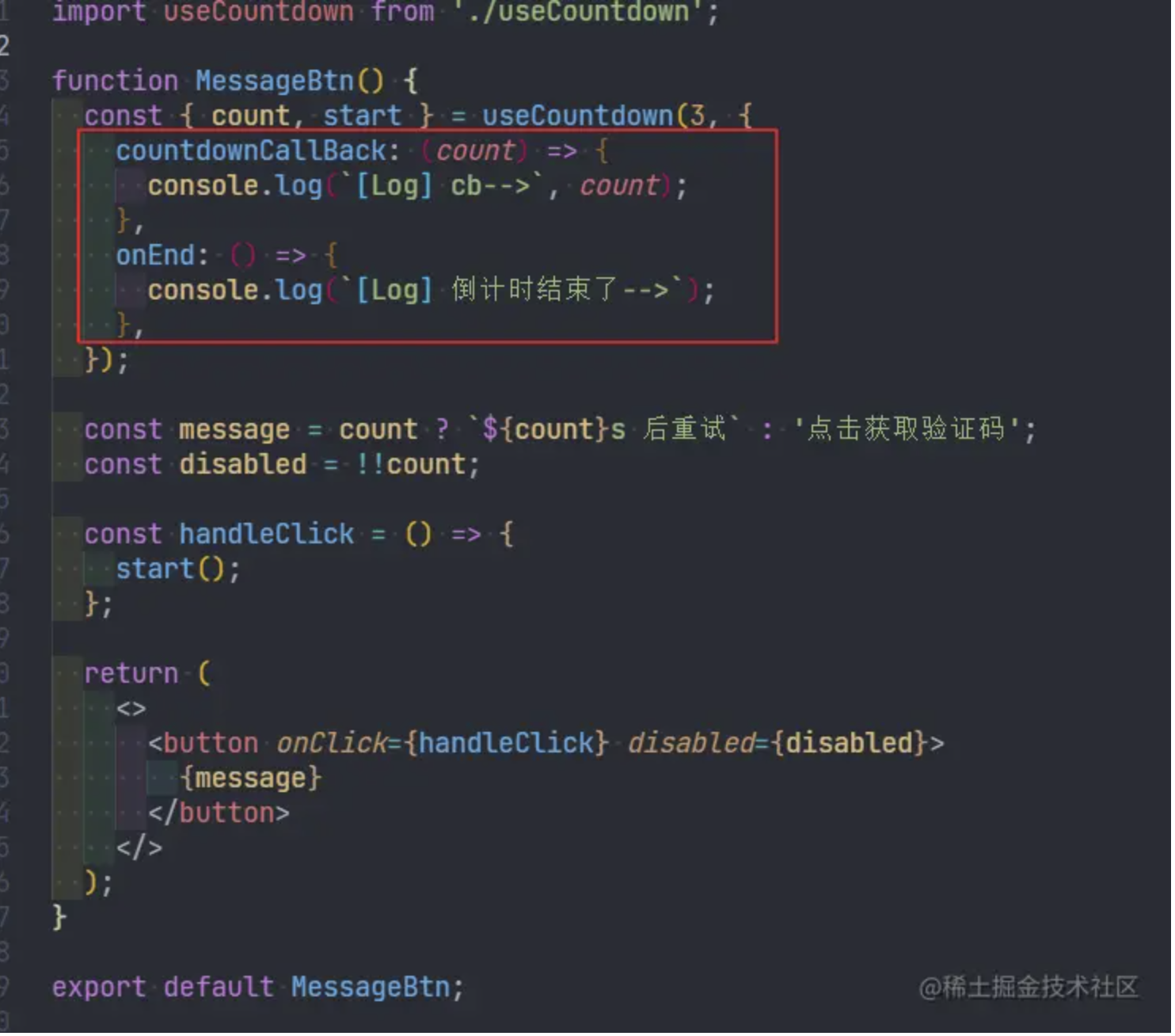
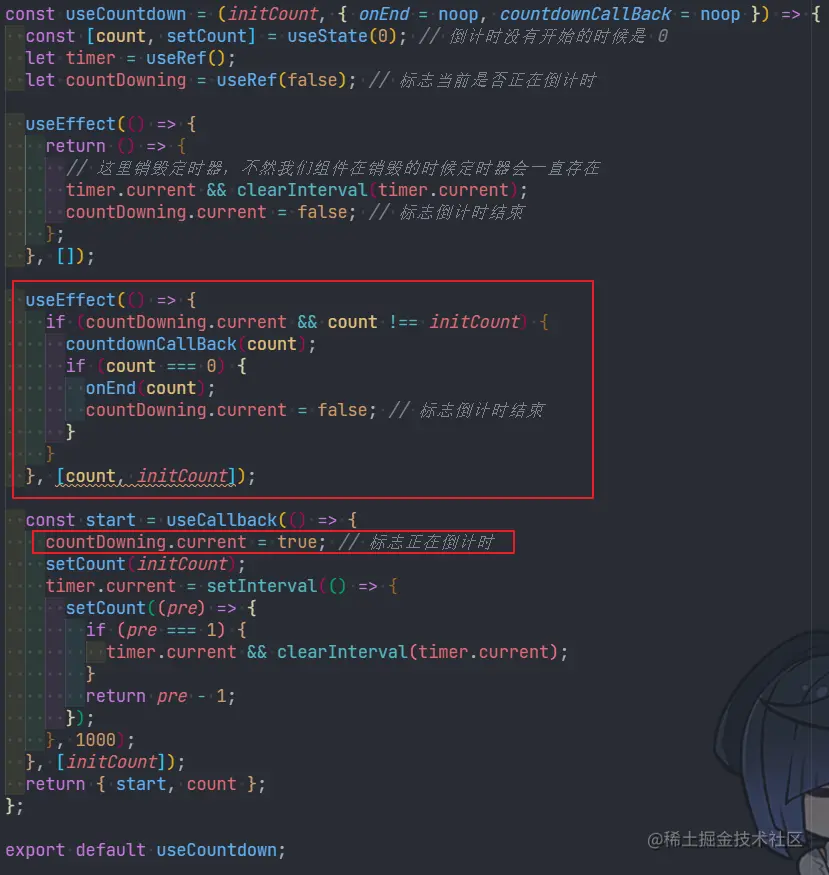
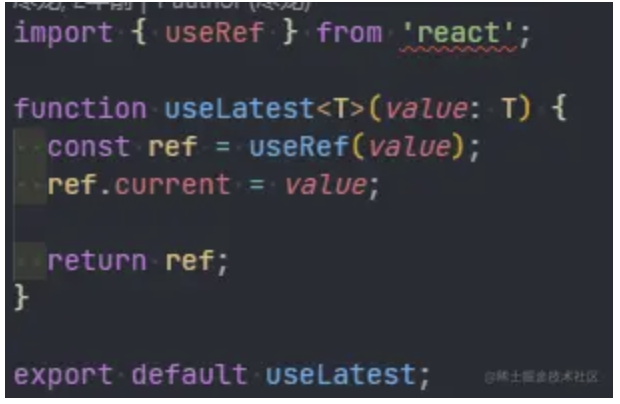
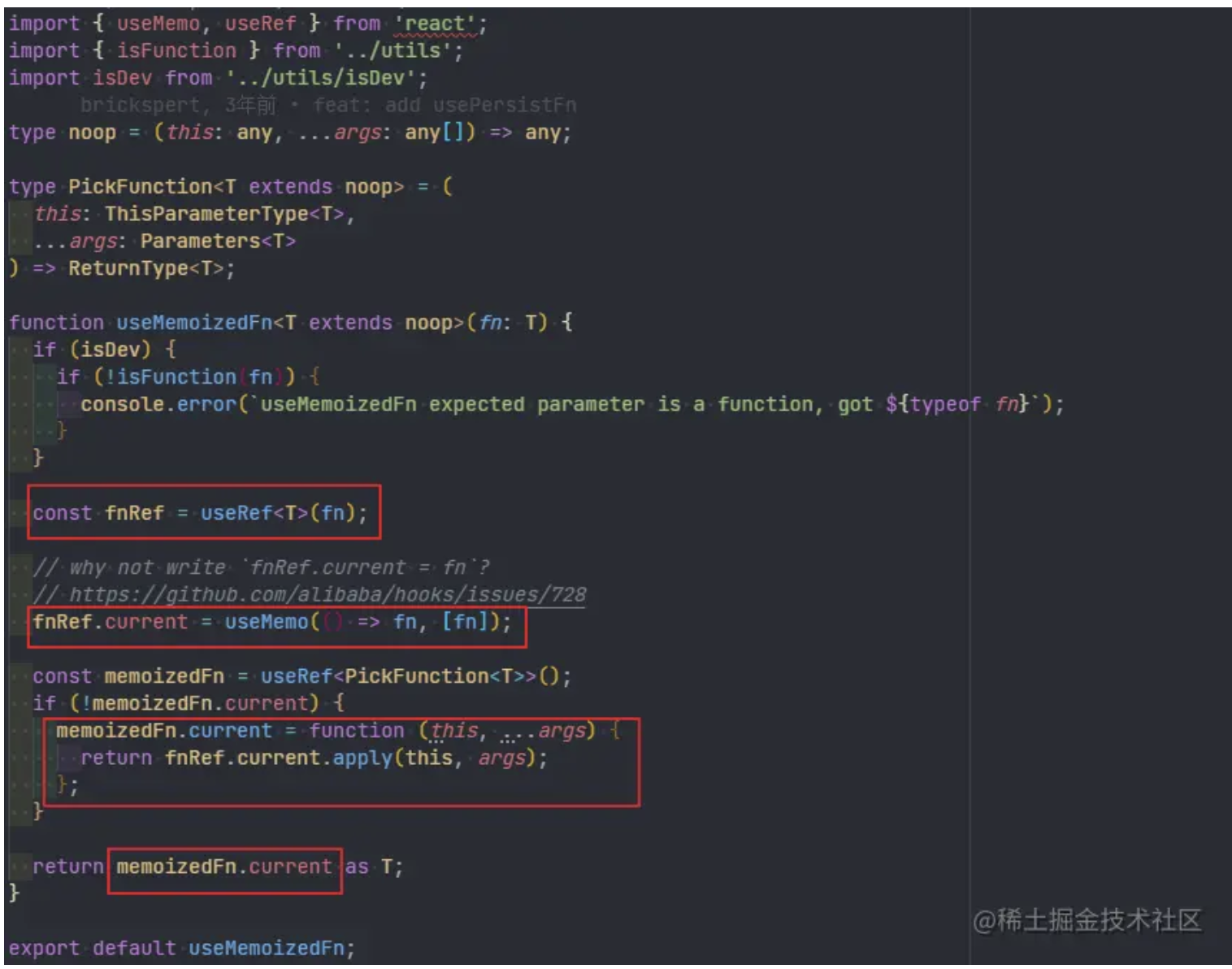
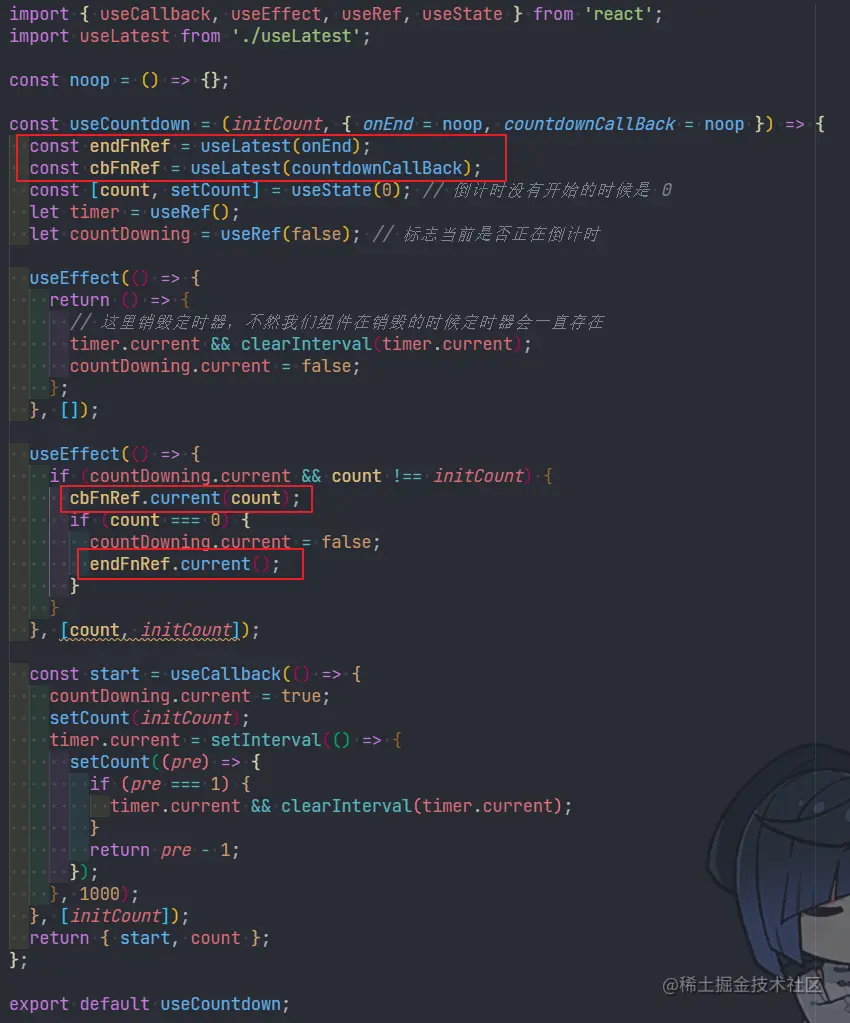
完成最后的性能飞跃,实际上我只改了 3 个字符,就是把 with 里的 var 换成了 const,这是为什么呢?
其实我之前的这篇文章早就告诉了我答案: ES 拾遗之 with 声明与 var 变量赋值
里面有一个重要的结论:
因为 windowProxy 里有所有的全局变量,那么我们之前使用 var 去尝试做作用域缓存的方案其实是无效的,声明的变量实际还是在全局的词法环境中的,也就避免不了作用域链的查找。而换成 const,就可以顺利的将变量写到 with 下的词法环境了。
延迟更新:组件更新的前面几步都是一样,有一个异步队列,但是延迟更新模式中有一个priority属性,当组件 effect 拥有这种属性的时候会自动根据这批组件的更新时间,或者用户操作来中断队列中后续任务的更新,当浏览器告诉我们,现在有空闲了可以继续任务时再继续未更新的任务。其实这种模式还可以更进一步,设定一个冷却时间,在冷却时间内再次发现相同的任务直接抛弃上一次相同的任务(根据任务 ID 来区分),这样做可以减少浏览器开销,因为这些任务在下一个周期中肯定会被覆盖。我们有计划的去实现这个内容,但不是现在。
这其中还有一个问题,我在组件函数中访问 props 状态也无法保证是最新的,这时候就需要使用Gyron.js提供的onBeforeUpdate方法,这个方法会在组件更新之前调用,然后我们需要把组件函数中定义的 props 全部放进这个函数中,然后根据函数的 new props 去更新用户定义的 props。但是真实的使用场景比较复杂,比如可以这样定义({ a, ...b }) => {},将 props 的 a 单独拎出来,然后其余部分全部归纳到 b 中。
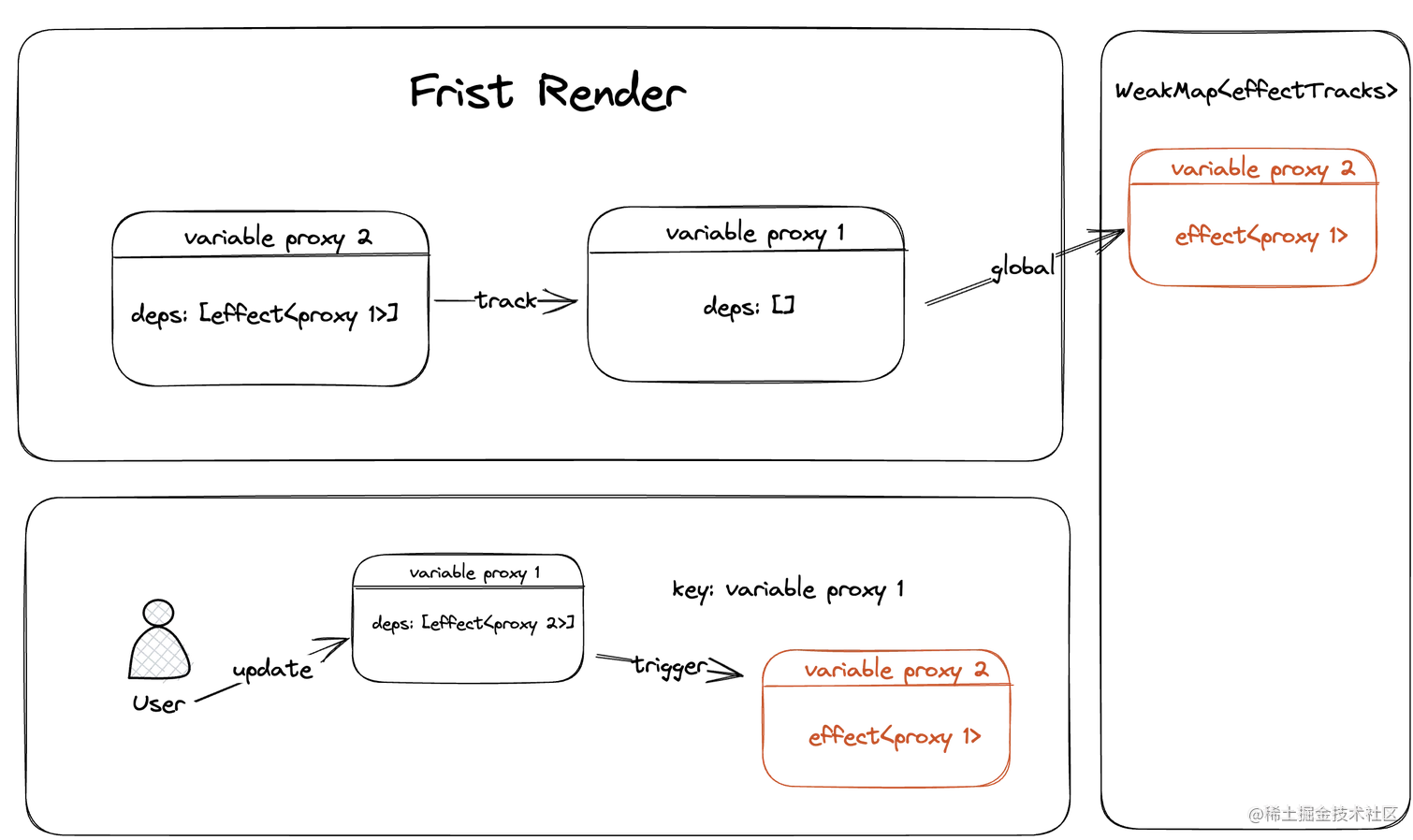
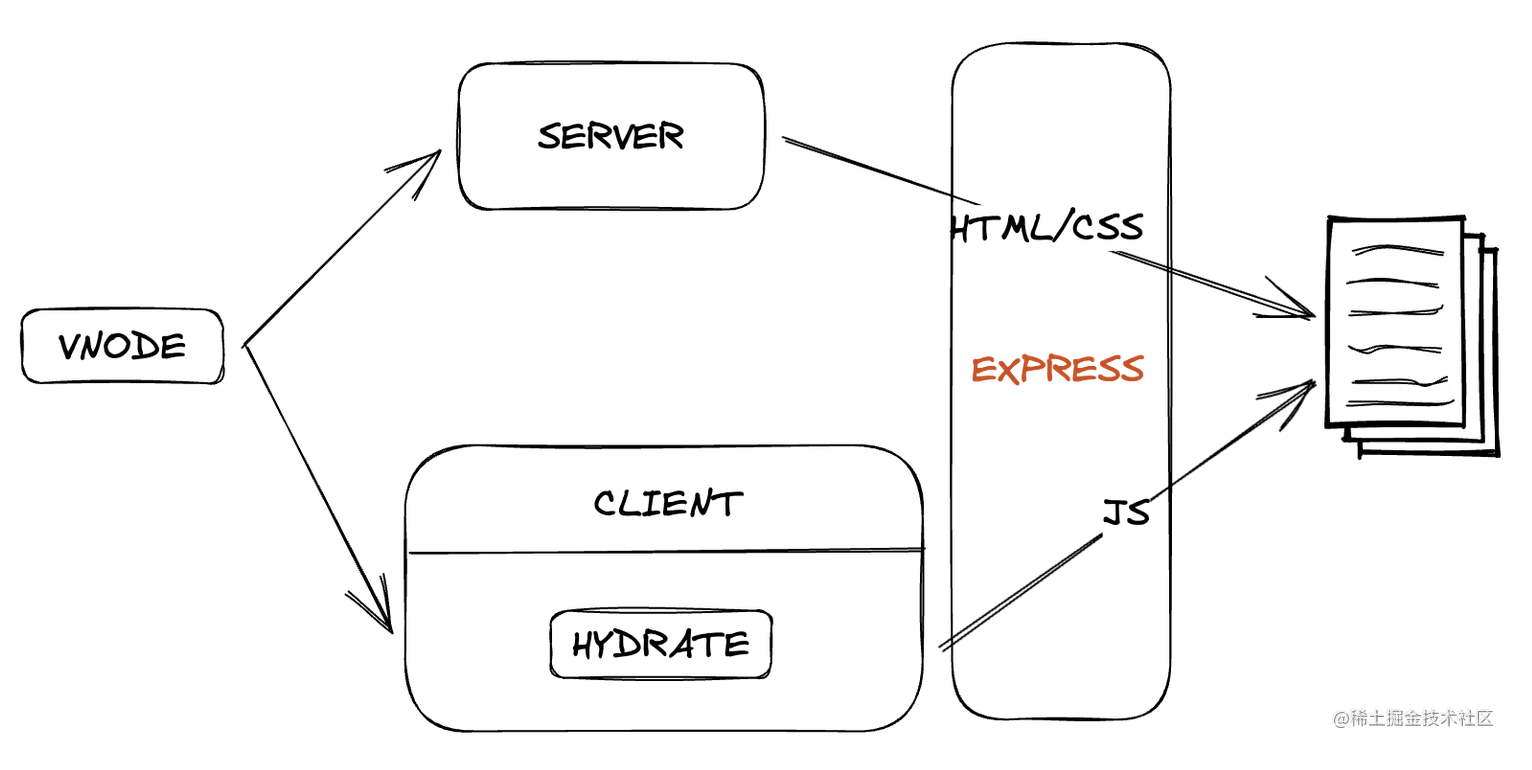
其实这段内容和Gyron.js本身关系不太大,但是没有Gyron.js提供的能力也很难办到。Gyron.js提供了 SSR(Server Side Render)的渲染模式,也就是我们熟知的服务端渲染。其中大致的原理就是服务端将实例渲染成字符串之后返回给浏览器,然后再通过客户端的hydrate功能让“静态”文本变的可响应。
const filters = { keyword: 'john', createdAt: new Date('2020-02-10') };
另一方面,我们不知道这些过滤器应该如何传递给 API,但是我们可以假设(跟 API 提供方进行约定)每一个过滤器在列表 API 中都有一个相应的参数,可以以'key=value'URL 查询参数的形式被传递。
因此我们需要知道如何将应用的过滤器转换成相对应的 API 参数来创建我们的 list 函数。这可以通过将 transformFilters 参数传递给 crudBuilder() 来完成。举一个用户的例子:
function transformUserFilters(filters) { const params = []; if (filters.keyword) { params.push(`keyword=${filters.keyword}`); } if (filters.createdAt) { params.push(`create_at=${dateUtility.format(filters.createdAt)}`); }
return params; }
现在我们可以使用这个参数来创建 list 函数了。
export function crudBuilder(baseRoute, transformFilters) { function list(filters) { let params = transformFilters(filters)?.join('&'); if (params) { params += '?'; }
return fetch(`${baseRoute}${params}`); } }
转换和分页
从 API 接收的数据可能需要进行一些转换才能在我们的应用程序中使用。例如,我们可能需要将 snake_case 转换成驼峰命名或将一些日期字符串转换成用户时区。
getUserInfo () { return http.get('/user/info').then(response => { let data = response.data if (data && typeof data === 'object') { // 获取用户信息成功则保存到全局 this.globalData.userInfo = data return data
} returnPromise.reject(response)
})
}
专为小程序发请求设计的库
小程序代码通过 http.get, http.post 这样的 api 来发请求, 背后使用了一个请求库
app
.post('/user/bindinfo', (req, res) => { var user = req.user if (user) { var {encryptedData, iv} = req.body var pc = new WXBizDataCrypt(config.appId, user.sessionKey) var data = pc.decryptData(encryptedData, iv) Object.assign(user, data) return res.send({ code: 0
})
} thrownewError('用户未登录')
})
.post('/user/bindphone', (req, res) => { var user = req.user if (user) { var {encryptedData, iv} = req.body var pc = new WXBizDataCrypt(config.appId, user.sessionKey) var data = pc.decryptData(encryptedData, iv) Object.assign(user, data) return res.send({ code: 0
})
} thrownewError('用户未登录')
})
bun build index.ts // index.ts var release = await"bun-v1.0.0";
Bun:可以做更多事
Bun 在 macOS 和 Linux 上提供了原生构建支持,但 Windows 一直是一个明显的缺失。以前,在 Windows 上运行 Bun 需要安装 Windows 子系统来运行Linux系统,但现在不再需要。
Bun 首次发布了一个实验性的、专为Windows平台的本地版本的 Bun。这意味着Windows用户现在可以直接在其操作系统上使用 Bun,而无需额外的配置。
尽管Bun的macOS和Linux版本已经可以用于生产环境,但Windows版本目前仍然处于高度实验阶段。目前只支持JavaScript运行时,而包管理器、测试运行器和打包工具在稳定性更高之前都将被禁用。性能方面也还未进行优化。
Bun:面向未来
Bun 1.0 只是一个开始。Bun 团队正在开发一种全新的部署JavaScript和TypeScript到生产环境的方式,期待 Bun 未来更好的表现!
// 截取图片的一部分,这里示例截取左上角的100x100像素区域 var startX = 0; var startY = 0; var width = 100; var height = 100; var croppedData = ctx.getImageData(startX, startY, width, height);
// 创建一个新的canvas用于显示截取的部分 var croppedCanvas = document.createElement('canvas');
croppedCanvas.width = width;
croppedCanvas.height = height; var croppedCtx = croppedCanvas.getContext('2d');
croppedCtx.putImageData(croppedData, 0, 0);
// 将截取的部分显示在页面上 var croppedImage = document.getElementById('croppedImage');
croppedImage.src = croppedCanvas.toDataURL();
};
在整个定价页面上,大部分文案都集中在最后一点上。React Flow 不是一个容易用其他东西替代的库,所以公司很可能有兴趣确保它得到良好的维护,并继续使用 MIT 许可。
John 在他们的博客上写了一篇优秀的文章,名为“Dear Open Source: let’s do a better job of asking for money”,我建议你阅读一下。我对此非常着迷,所以给 John 发了一封邮件,提出了一些后续问题,他非常友善地回答了我关于这个话题的许多宝贵的知识。
要从头开始创建英文字体,需要大约230个字形——字形是给定字母的单个表示(A a a算作3个字形)——或者如果想覆盖所有基于拉丁字母表的语言,则需要840个字形。对于日语而言,由于其三种不同的书写系统和无数的汉字,需要7,000至16,000个字形甚至更多。因此,在日语中创建新字体需要有组织的团队合作和比其拉丁字母表的同行们更多的时间。
const book = { title: 'In Search of Lost Time', author: 'Marcel Proust', get description() { return `${this.title} by ${this.author}`; }, set description(value) { [this.title, this.author] = value.split(' by '); } };
book.description = '1984 by George Orwell'; console.log(book.title); // Outputs: 1984
var formId = event.target.getAttribute("id"); var formData = new FormData(event.target); var timestamp = new Date().getTime(); var userData = { eventType: "formSubmit", formId: formId, formData: Object.fromEntries(formData.entries()), timestamp: timestamp // 其他需要收集的用户数据 };
const list = [1,2,3] //🔴 Bad Case //不能添加key { list.map(v=><> <div>1-1</div> <div>1-2</div> </>) } //🔴 Bad Case //创建了额外的div节点 { list.map(v=><div key={v}> <div>1-1</div> <div>1-2</div> <div/>) } //✅ Good Case { list.map(v=><Fragment key={v}> <div>1-1</div> <div>1-2</div> </Fragment>) }
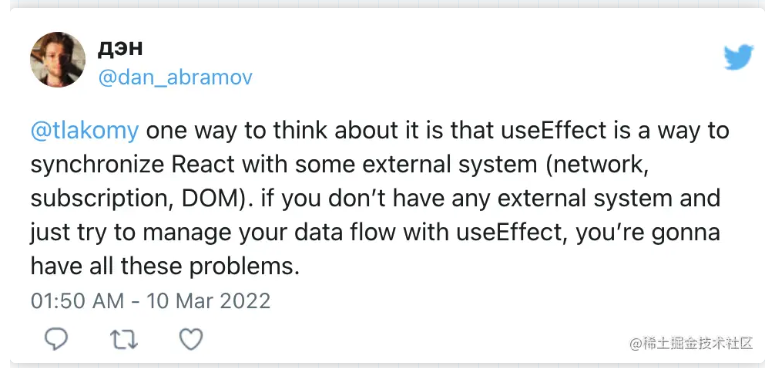
//🔴 Bad Case function useOnlineStatus() { // Not ideal: Manual store subscription in an Effect const [isOnline, setIsOnline] = useState(true); useEffect(() => { function updateState() { setIsOnline(navigator.onLine); }
// ✅ GoodCase function useOnlineStatus() { return useSyncExternalStore( subscribe, // React won't resubscribe for as long as you pass the same function () => navigator.onLine, // How to get the value on the client () => true // How to get the value on the server ); }
function ChatIndicator() { const isOnline = useOnlineStatus(); // ... }
functiongetPageHeight() { var g = document,
a = g.body,
f = g.documentElement,
d = g.compatMode == "BackCompat" ? a : g.documentElement; returnMath.max(f.scrollHeight, a.scrollHeight, d.clientHeight);
}
获取页面scrollLeft
functiongetPageScrollLeft() { var a = document; return a.documentElement.scrollLeft || a.body.scrollLeft;
}
获取页面scrollTop
functiongetPageScrollTop() { var a = document; return a.documentElement.scrollTop || a.body.scrollTop;
}
获取页面可视宽度
functiongetPageViewWidth() { var d = document,
a = d.compatMode == "BackCompat" ? d.body : d.documentElement; return a.clientWidth;
}
获取页面可视高度
functiongetPageViewHeight() { var d = document,
a = d.compatMode == "BackCompat" ? d.body : d.documentElement; return a.clientHeight;
}
获取页面宽度
functiongetPageWidth() { var g = document,
a = g.body,
f = g.documentElement,
d = g.compatMode == "BackCompat" ? a : g.documentElement; returnMath.max(f.scrollWidth, a.scrollWidth, d.clientWidth);
}























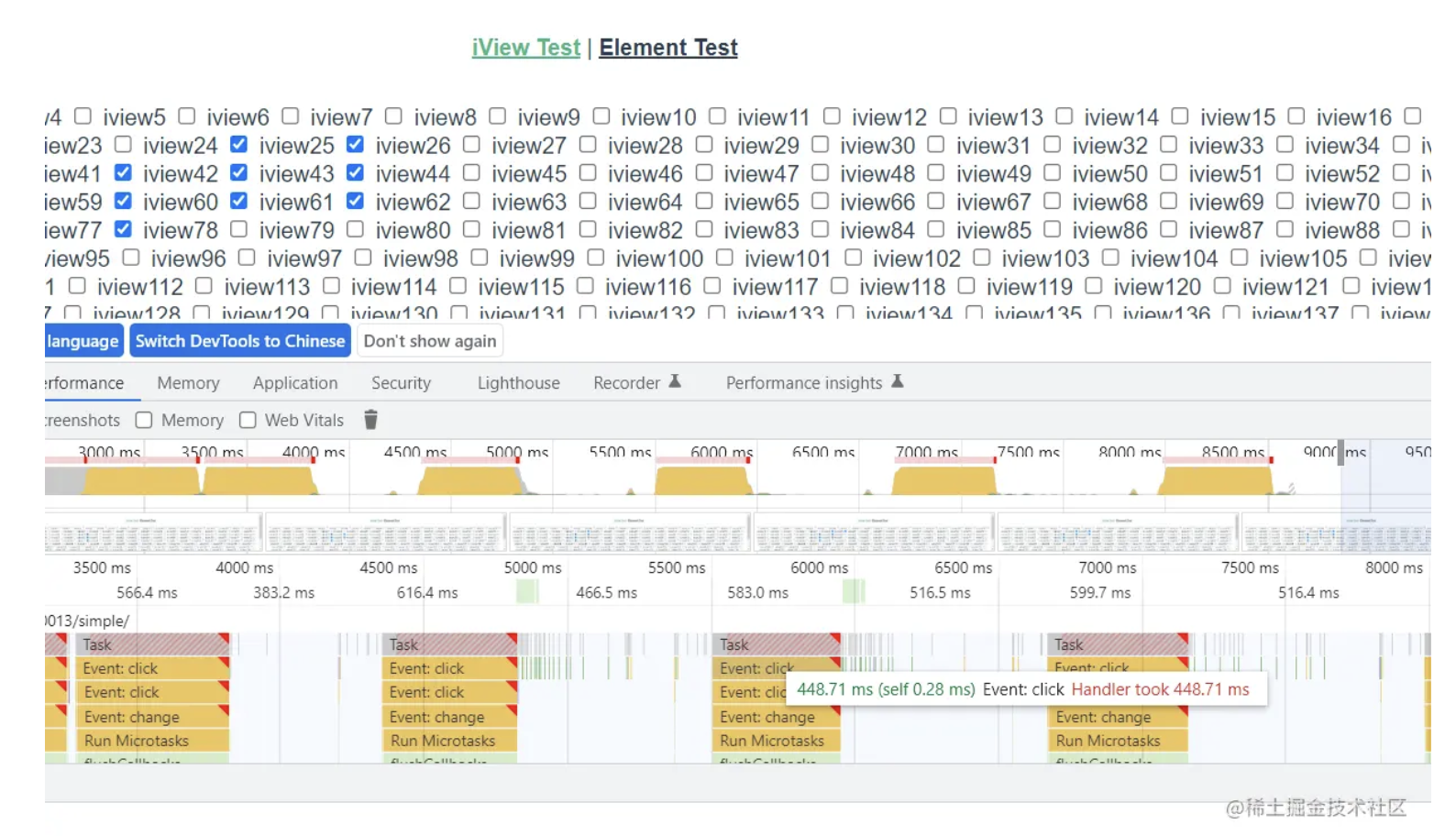
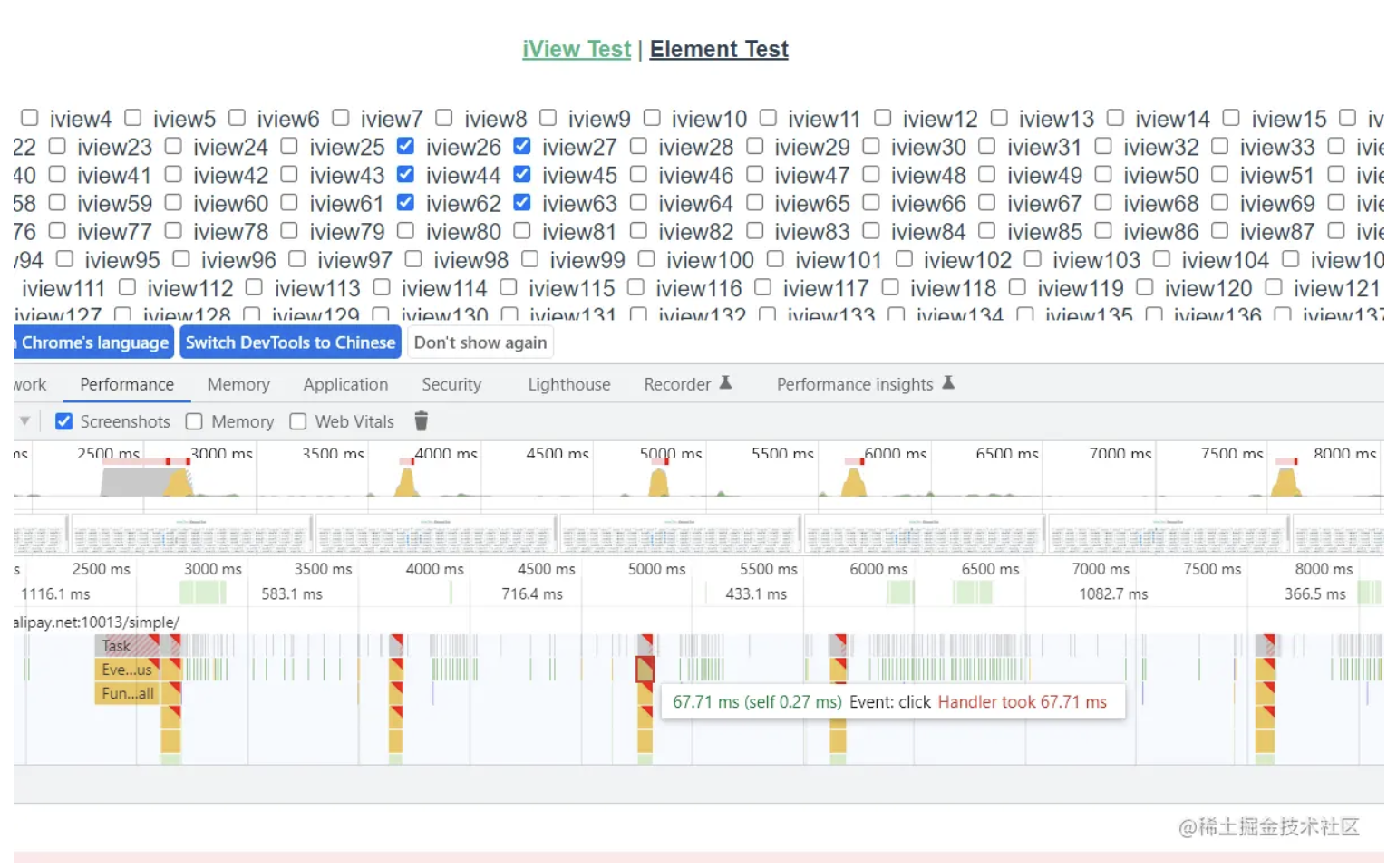




















 而使用
而使用