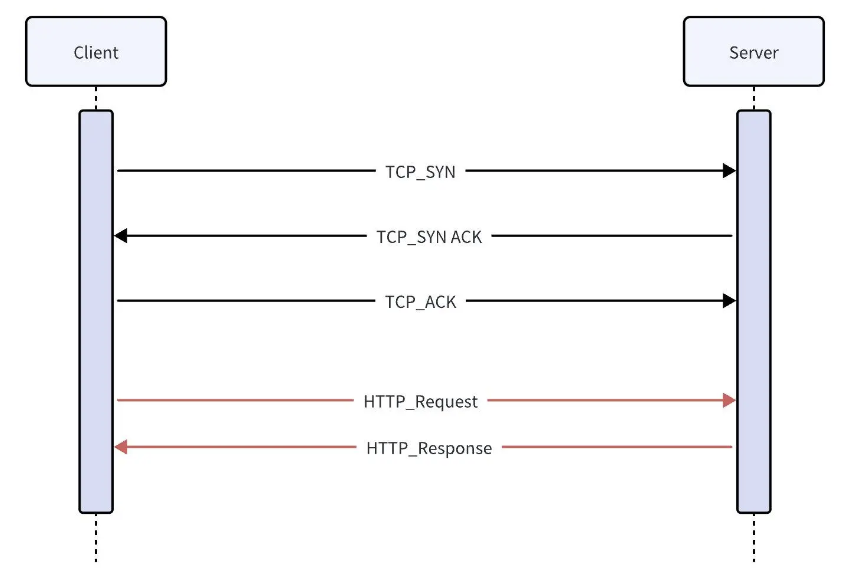
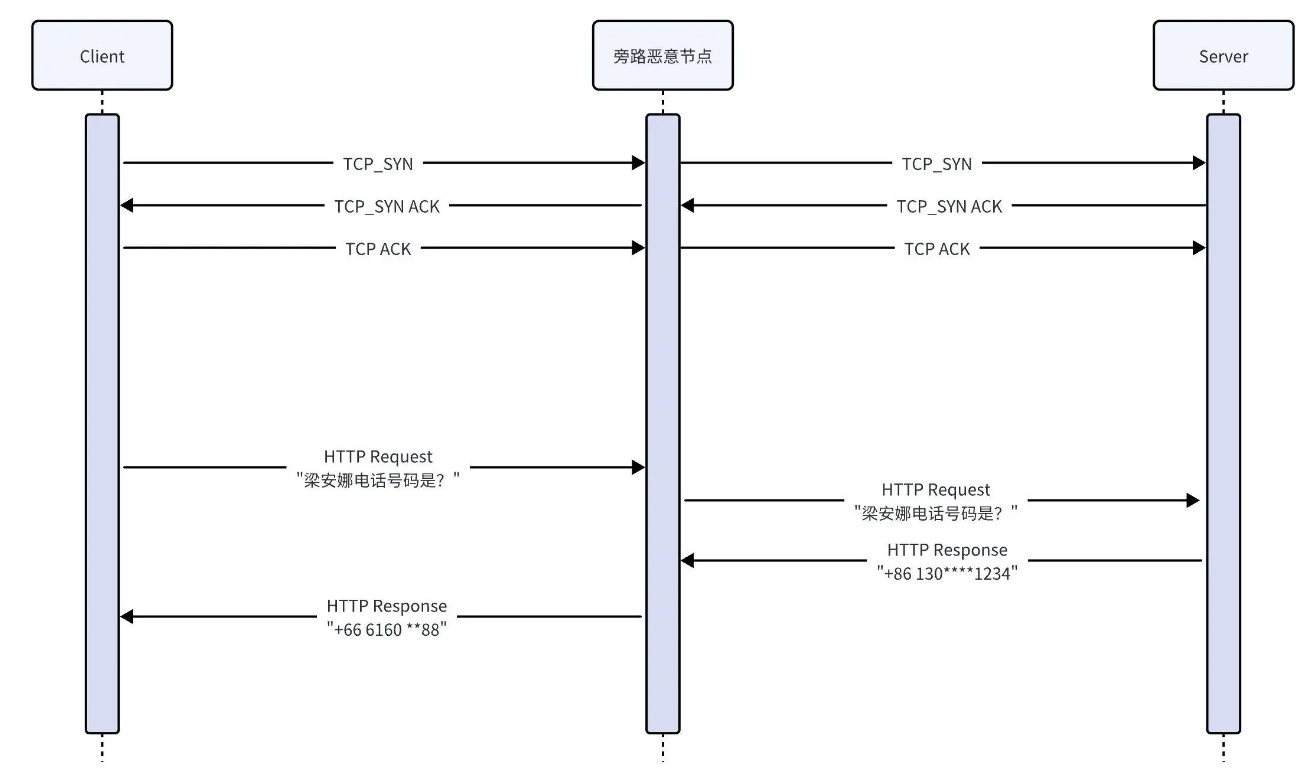
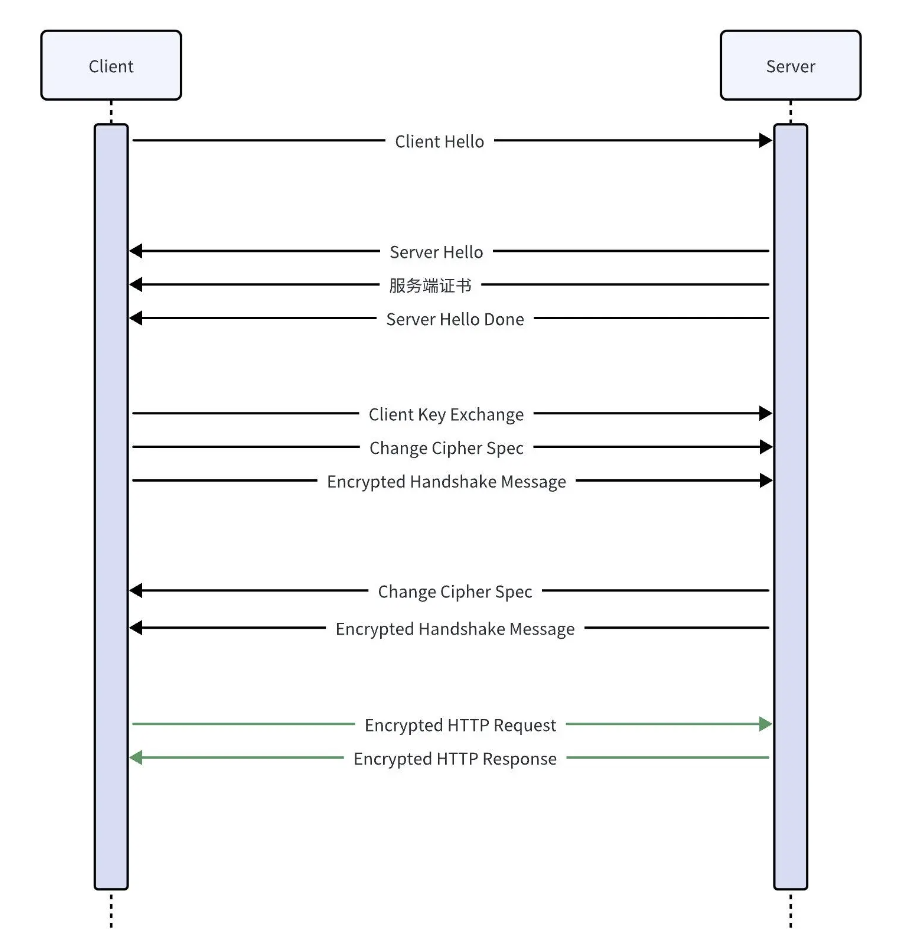
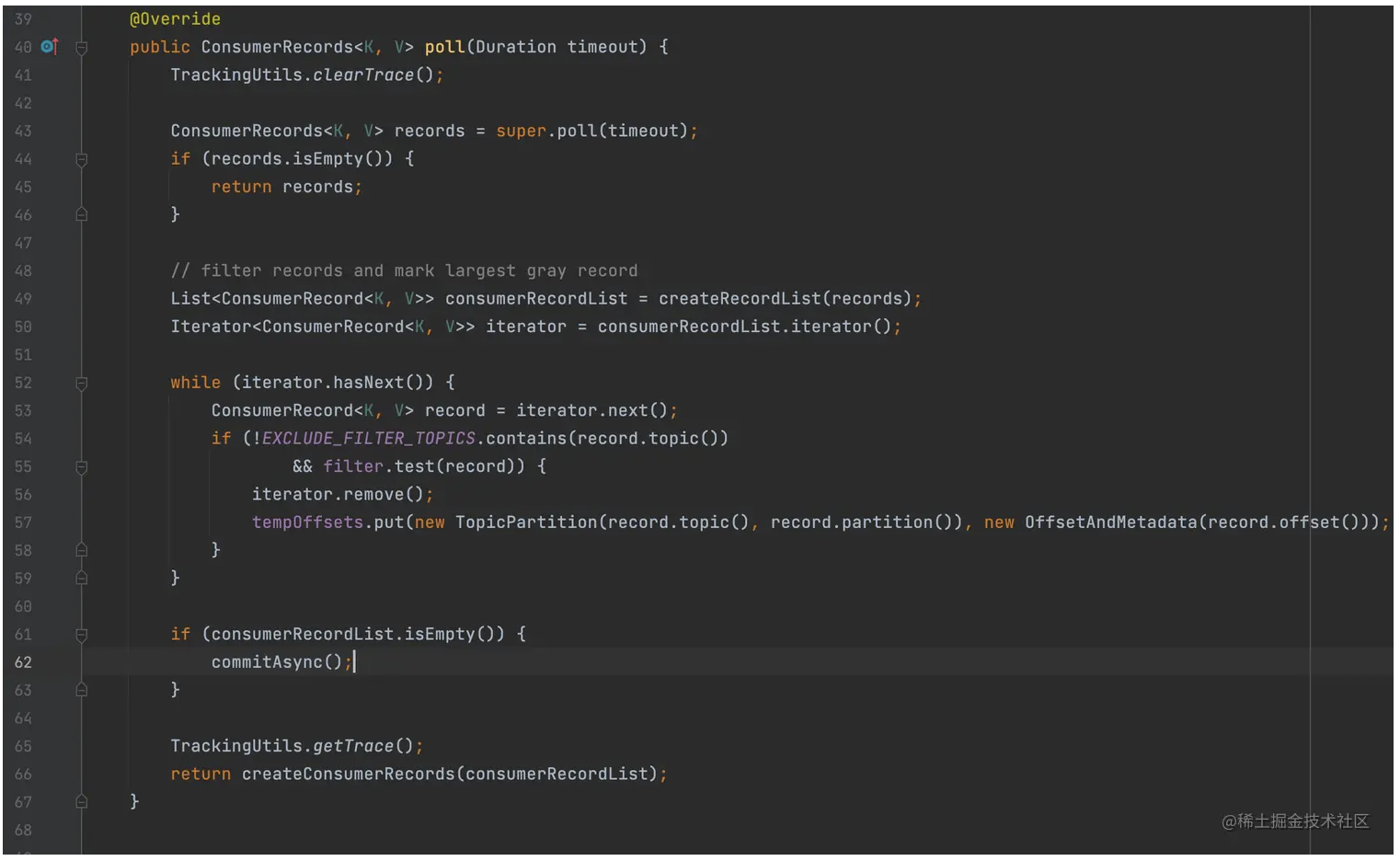
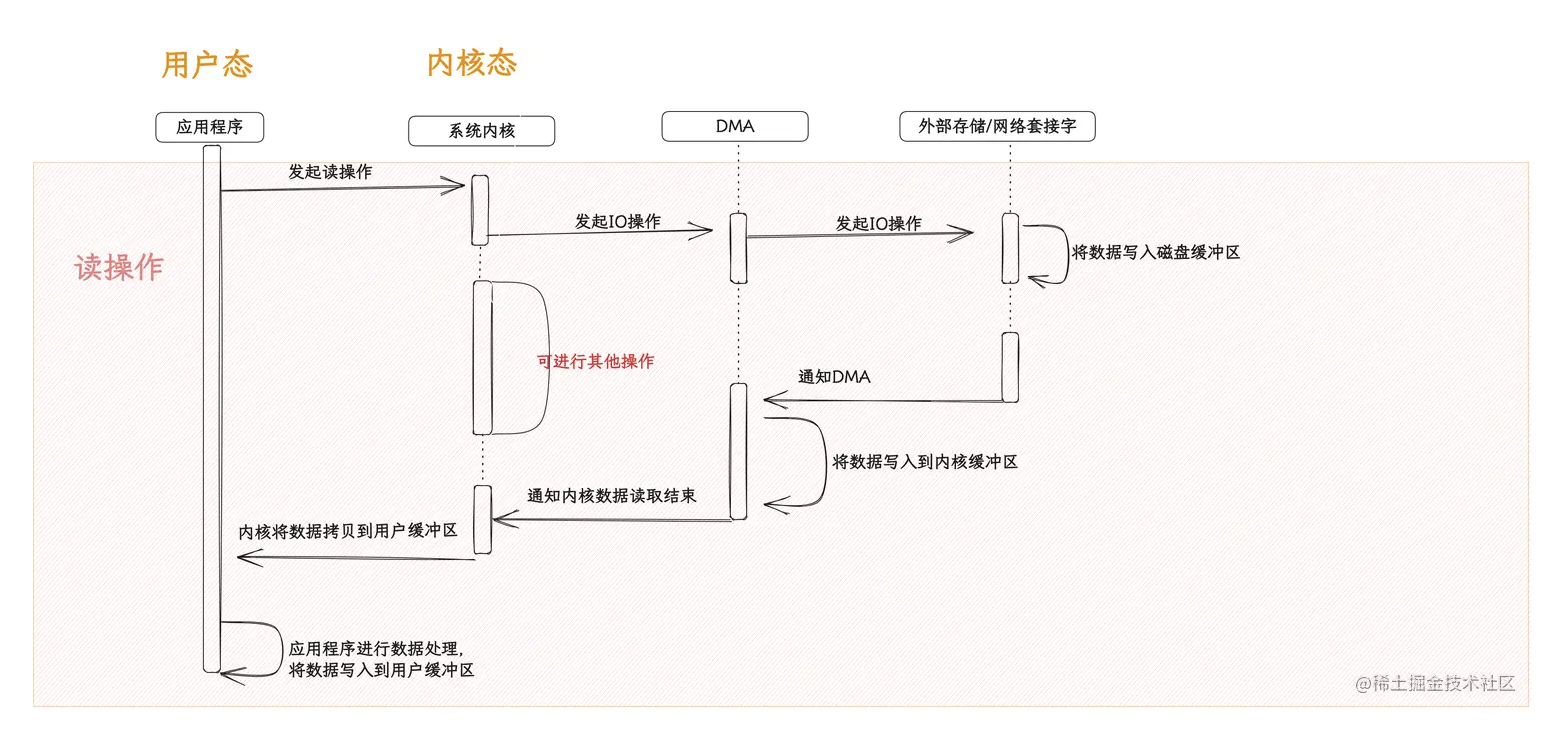
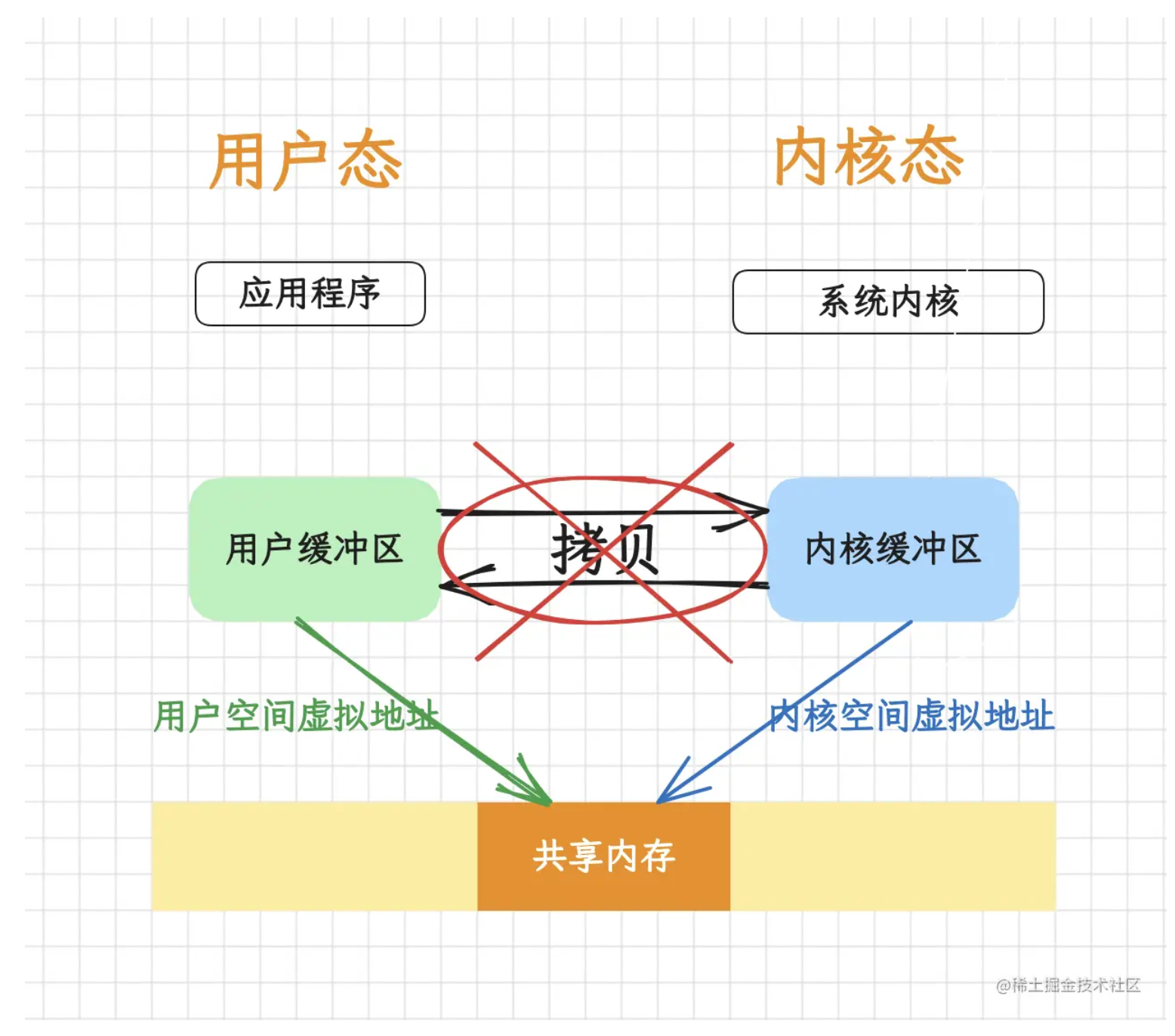
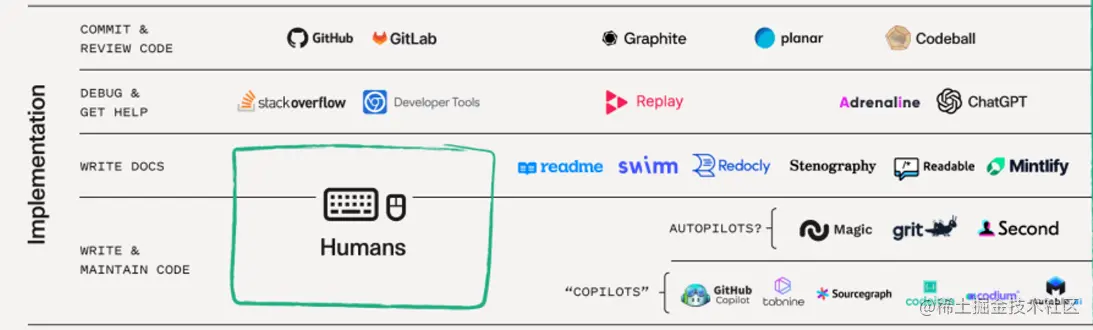
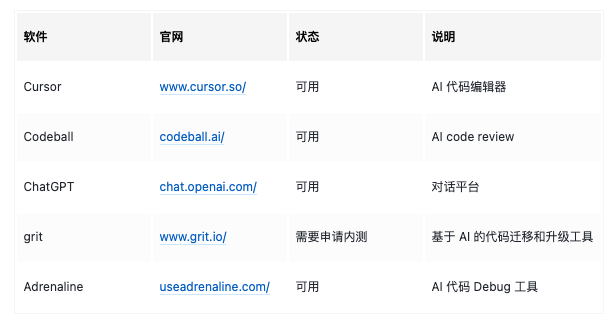
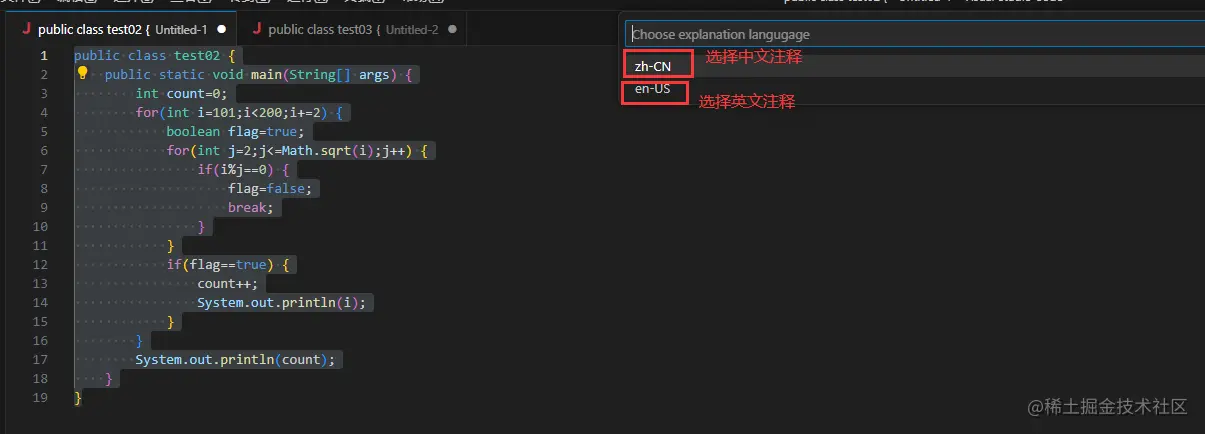
在王者荣耀中,我们会打排位赛,而且大家最关注的往往都是你的段位,还有在好友中的排名。
作为程序员的你,思考过吗,这个段位排行榜是怎么实现的?了解它的实现原理,会不会对上分有所帮助?
看看我的排名,你就知道了,答案是否定的,哈哈。

一、排行榜设计方案
从技术角度而言,我们可以根据排行榜的类型来选择不同技术方案来进行排行榜设计。
1、数据库直接排序
在低数据量场景中,用数据库直接排序做排行榜的,有很多。
举个栗子,比如要做一个程序员薪资排行榜,看看哪个城市的程序员最有钱。
根据某招聘网站的数据,2023年中国国内程序员的平均月薪为1.2万元,其中最高的是北京,达到了2.1万元,最低的是西安,只有0.7万元。
以下是几个主要城市的程序员平均月薪排行榜:
- 北京:2.1万元
- 上海:1.9万元
- 深圳:1.8万元
- 杭州:1.6万元
- 广州:1.5万元
- 成都:1.3万元
- 南京:1.2万元
- 武汉:1.1万元
- 西安:0.7万元
从这个榜单中可以看出,我拖了大家的后腿,抱歉了。

这个就可以用数据库来做,一共也没有多少个城市,来个百大,撑死了。
对于这种量级的数据,加好索引,用好top,都不会超过100ms,在请求量小、数据量小的情况下,用数据库做排行榜是完全没有问题的。
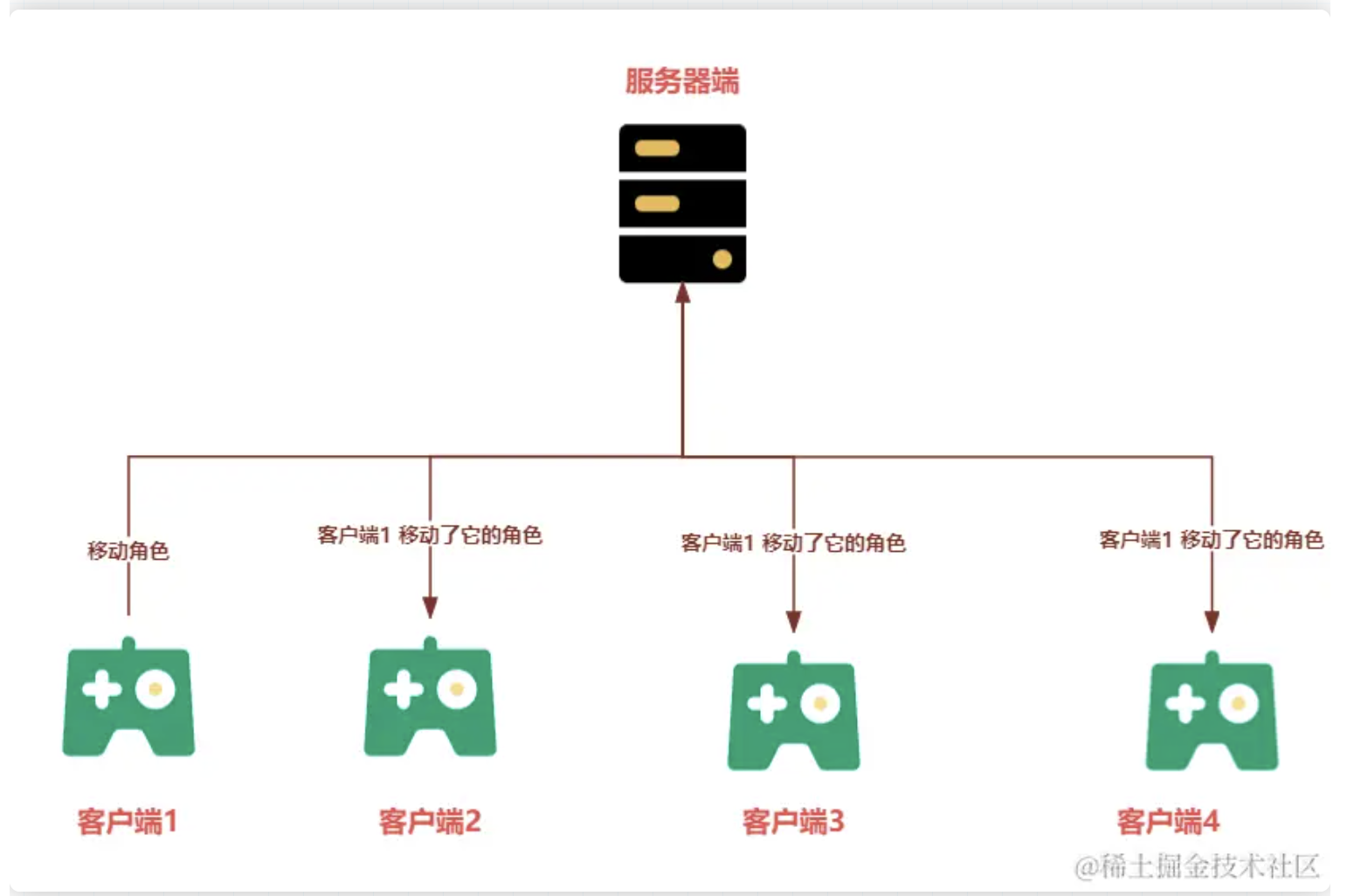
2、王者荣耀好友排行
这类榜单是根据自己好友数据来进行排行的,这类榜单不用将每位好友的数据都存储在数据库中,而是通过获取自己的好友列表,获取好友的实时分数,在客户端本地进行本地排序,展现出王者荣耀好友排行榜,因为向数据库拉取数据是需要时间的,比如一分钟拉取一次,因为并非实时拉取,这类榜单对数据库的压力还是较小的。
下面探索一下在Java中使用Redis实现高性能的排行榜是如何实现的?
二、Redis实现计数器
1、什么是计数器功能?
计数器是一种常见的功能,用于记录某种事件的发生次数。在应用中,计数器可以用来跟踪用户行为、统计点击次数、浏览次数等。
例如,您可以使用计数器来记录一篇文章被阅读的次数,或者统计某个产品被购买的次数。通过跟踪计数,您可以了解数据的变化趋势,从而做出更明智的决策。
2、Redis实现计数器的原理
Redis是一款高性能的内存数据库,提供了丰富的数据结构和命令,非常适合实现计数器功能。在Redis中,我们可以使用字符串数据类型以及相关的命令来实现计数器。
(1)使用INCR命令实现计数器
Redis的INCR命令是一个原子操作,用于将存储在键中的数字递增1。如果键不存在,将会创建并初始化为0,然后再执行递增操作。这使得我们可以轻松地实现计数器功能。
让我们通过Java代码来演示如何使用Redis的INCR命令实现计数器:
import redis.clients.jedis.Jedis;
public class CounterExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String articleId = "article:123";
String viewsKey = "views:" + articleId;
long views = jedis.incr(viewsKey);
System.out.println("Article views: " + views);
jedis.close();
}
}
在上面的代码中,我们使用了Jedis客户端库来连接Redis服务器,并使用INCR命令递增一个存储在views:article:123键中的计数器。每次执行该代码,计数器的值都会递增,并且我们可以轻松地获取到文章的浏览次数。
(2)使用INCRBY命令实现计数器
除了单次递增1,我们还可以使用INCRBY命令一次性增加指定的数量。这对于一些需要一次性增加较大数量的场景非常有用。
让我们继续使用上面的例子,但这次我们使用INCRBY命令来增加浏览次数:
import redis.clients.jedis.Jedis;
public class CounterExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String articleId = "article:123";
String viewsKey = "views:" + articleId;
long views = jedis.incrBy(viewsKey, 10);
System.out.println("Article views: " + views);
jedis.close();
}
}
在上述代码中,我们使用了INCRBY命令将文章浏览次数一次性增加了10。这在统计需要一次性增加较多计数的场景中非常有用。
通过使用Redis的INCR和INCRBY命令,我们可以轻松实现高性能的计数器功能。这些命令的原子性操作保证了计数的准确性,而且非常适用于需要频繁更新计数的场景。
三、通过Redis实现“王者荣耀”排行榜?
王者荣耀的排行榜是不是用Redis做的,我不得而知,但,我的项目中,排行榜确实是用Redis做的,这是实打实的。
看见了吗?掌握算法的男人,到哪里都是无敌的。

1、什么是排行榜功能?
排行榜是一种常见的功能,用于记录某种项目的排名情况,通常按照某种规则对项目进行排序。在社交媒体、游戏、电商等领域,排行榜功能广泛应用,可以增强用户的参与度和竞争性。例如,社交媒体平台可以通过排行榜展示最活跃的用户,游戏中可以展示玩家的分数排名等。
2、Redis实现排行榜的原理
在Redis中,我们可以使用有序集合(Sorted Set)数据结构来实现高效的排行榜功能。有序集合是一种键值对的集合,每个成员都与一个分数相关联,Redis会根据成员的分数进行排序。这使得我们能够轻松地实现排行榜功能。
(1)使用ZADD命令添加成员和分数
Redis的ZADD命令用于向有序集合中添加成员和对应的分数。如果成员已存在,可以更新其分数。让我们通过Java代码演示如何使用ZADD命令来添加成员和分数到排行榜:
import redis.clients.jedis.Jedis;
public class LeaderboardExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String leaderboardKey = "leaderboard";
String player1 = "PlayerA";
String player2 = "PlayerB";
jedis.zadd(leaderboardKey, 1000, player1);
jedis.zadd(leaderboardKey, 800, player2);
jedis.close();
}
}
在上述代码中,我们使用ZADD命令将PlayerA和PlayerB作为成员添加到leaderboard有序集合中,并分别赋予分数。这样,我们就在排行榜中创建了两名玩家的记录。
(2)使用ZINCRBY命令更新成员分数
除了添加成员,我们还可以使用ZINCRBY命令更新已有成员的分数。这在实时更新排行榜中的分数非常有用。
让我们继续使用上面的例子,但这次我们将使用ZINCRBY命令来增加玩家的分数:
import redis.clients.jedis.Jedis;
public class LeaderboardExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String leaderboardKey = "leaderboard";
String player1 = "PlayerA";
String player2 = "PlayerB";
jedis.zincrby(leaderboardKey, 200, player1);
jedis.close();
}
}
在上述代码中,我们使用了ZINCRBY命令将PlayerA的分数增加了200分。这种方式可以用于记录玩家的得分、积分等变化,从而实时更新排行榜数据。
通过使用Redis的有序集合以及ZADD、ZINCRBY等命令,我们可以轻松实现高性能的排行榜功能。这些命令的原子性操作保证了排行的准确性和一致性,非常适用于需要频繁更新排行榜的场景。
我的最强百里,12-5-6,这都能输?肯定是哪里出问题了,服务器性能?

四、计数器与排行榜的性能优化
在本节中,我们将重点讨论如何在高并发场景下优化计数器和排行榜功能的性能。通过合理的策略和技巧,我们可以确保系统在处理大量数据和用户请求时依然保持高性能。
1、如何优化计数器的性能?
(1)使用Redis事务
在高并发场景下,多个用户可能同时对同一个计数器进行操作,这可能引发并发冲突。为了避免这种情况,可以使用Redis的事务来确保原子性操作。事务将一组命令包装在一个原子性的操作中,保证这些命令要么全部执行成功,要么全部不执行。
下面是一个示例,演示如何使用Redis事务进行计数器操作:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
import redis.clients.jedis.exceptions.JedisException;
public class CounterOptimizationExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String counterKey = "view_count";
try {
Transaction tx = jedis.multi();
tx.incr(counterKey);
tx.exec();
} catch (JedisException e) {
e.printStackTrace();
} finally {
jedis.close();
}
}
}
在上述代码中,我们使用了Jedis客户端库,通过MULTI命令开启一个事务,然后在事务中执行INCR命令来增加计数器的值。最后,使用EXEC命令执行事务。如果在事务执行期间出现错误,我们可以通过捕获JedisException来处理异常。
(2)使用分布式锁
另一种优化计数器性能的方法是使用分布式锁。分布式锁可以确保在同一时刻只有一个线程能够对计数器进行操作,避免了并发冲突。这种机制可以保证计数器的更新是串行化的,从而避免了竞争条件。
以下是一个使用Redisson框架实现分布式锁的示例:
import org.redisson.Redisson;
import org.redisson.api.RLock;
public class CounterOptimizationWithLockExample {
public static void main(String[] args) {
Redisson redisson = Redisson.create();
RLock lock = redisson.getLock("counter_lock");
try {
lock.lock();
} finally {
lock.unlock();
redisson.shutdown();
}
}
}
在上述代码中,我们使用了Redisson框架来创建一个分布式锁。通过调用lock.lock()获取锁,然后执行计数器操作,最后通过lock.unlock()释放锁。这样可以保证在同一时间只有一个线程能够执行计数器操作。

2、如何优化排行榜的性能?
(1)分页查询
在排行榜中,通常会有大量的数据,如果一次性查询所有数据,可能会影响性能。为了解决这个问题,可以使用分页查询。将排行榜数据分成多个页,每次查询一小部分数据,以减轻数据库的负担。
以下是一个分页查询排行榜的示例:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Tuple;
import java.util.Set;
public class LeaderboardPaginationExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String leaderboardKey = "leaderboard";
int pageSize = 10;
int pageIndex = 1;
Set<Tuple> leaderboardPage = jedis.zrevrangeWithScores(leaderboardKey, (pageIndex - 1) * pageSize, pageIndex * pageSize - 1);
for (Tuple tuple : leaderboardPage) {
String member = tuple.getElement();
double score = tuple.getScore();
System.out.println("Member: " + member + ", Score: " + score);
}
jedis.close();
}
}
在上述代码中,我们使用zrevrangeWithScores命令来获取指定页的排行榜数据。通过计算起始索引和结束索引,我们可以实现分页查询功能。
(2)使用缓存
为了进一步提高排行榜的查询性能,可以将排行榜数据缓存起来,减少对数据库的访问。例如,可以使用Redis缓存最近的排行榜数据,定期更新缓存以保持数据的新鲜性。
以下是一个缓存排行榜数据的示例:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Tuple;
import java.util.Set;
public class LeaderboardCachingExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String leaderboardKey = "leaderboard";
String cacheKey = "cached_leaderboard";
int cacheExpiration = 300;
Set<Tuple> cachedLeaderboard = jedis.zrevrangeWithScores(cacheKey, 0, -1);
if (cachedLeaderboard.isEmpty()) {
Set<Tuple> leaderboardData = jedis.zrevrangeWithScores(leaderboardKey, 0, -1);
jedis.zadd(cacheKey, leaderboardData);
jedis.expire(cacheKey, cacheExpiration);
cachedLeaderboard = leaderboardData;
}
for
(Tuple tuple : cachedLeaderboard) {
String member = tuple.getElement();
double score = tuple.getScore();
System.out.println("Member: " + member + ", Score: " + score);
}
jedis.close();
}
}
在上述代码中,我们首先尝试从缓存中获取排行榜数据。如果缓存为空,我们从数据库获取数据,并将数据存入缓存。使用expire命令来设置缓存的过期时间,以保持数据的新鲜性。
五、实际应用案例
在本节中,我们将通过两个实际的案例,展示如何使用Redis的计数器和排行榜功能来构建社交媒体点赞系统和游戏玩家排行榜系统。这些案例将帮助您更好地理解如何将Redis的功能应用于实际场景中。
1、社交媒体点赞系统案例
(1)问题背景
假设我们要构建一个社交媒体平台,用户可以在文章、照片等内容上点赞。我们希望能够统计每个内容的点赞数量,并实时显示最受欢迎的内容。
(2)系统架构
- 每个内容的点赞数可以使用Redis的计数器功能进行维护。
- 我们可以使用有序集合(Sorted Set)来维护内容的排名信息,将内容的点赞数作为分数。
(3)数据模型
- 每个内容都有一个唯一的标识,如文章ID或照片ID。
- 使用一个计数器来记录每个内容的点赞数。
- 使用一个有序集合来记录内容的排名,以及与内容标识关联的分数。
(4)Redis操作步骤
- 用户点赞时,使用Redis的
INCR命令增加对应内容的点赞数。
- 使用
ZADD命令将内容的标识和点赞数作为分数添加到有序集合中。
Java代码示例
import redis.clients.jedis.Jedis;
public class SocialMediaLikeSystem {
private Jedis jedis;
public SocialMediaLikeSystem() {
jedis = new Jedis("localhost", 6379);
}
public void likeContent(String contentId) {
jedis.incr("likes:" + contentId);
jedis.zincrby("rankings", 1, contentId);
}
public long getLikes(String contentId) {
return Long.parseLong(jedis.get("likes:" + contentId));
}
public void showRankings() {
System.out.println("Top content rankings:");
jedis.zrevrangeWithScores("rankings", 0, 4)
.forEach(tuple -> System.out.println(tuple.getElement() + ": " + tuple.getScore()));
}
public static void main(String[] args) {
SocialMediaLikeSystem system = new SocialMediaLikeSystem();
system.likeContent("post123");
system.likeContent("post456");
system.likeContent("post123");
System.out.println("Likes for post123: " + system.getLikes("post123"));
System.out.println("Likes for post456: " + system.getLikes("post456"));
system.showRankings();
}
}
在上述代码中,我们创建了一个名为SocialMediaLikeSystem的类来模拟社交媒体点赞系统。我们使用了Jedis客户端库来连接到Redis服务器,并实现了点赞、获取点赞数和展示排名的功能。每当用户点赞时,我们会使用INCR命令递增点赞数,并使用ZINCRBY命令更新有序集合中的排名信息。通过调用zrevrangeWithScores命令,我们可以获取到点赞数排名前几的内容。

2、游戏玩家排行榜案例
(1)问题背景
在一个多人在线游戏中,我们希望能够实时追踪和显示玩家的排行榜,以鼓励玩家参与并提升游戏的竞争性。
(2)系统架构
- 每个玩家的得分可以使用Redis的计数器功能进行维护。
- 我们可以使用有序集合来维护玩家的排名,将玩家的得分作为分数。
(3)数据模型
- 每个玩家都有一个唯一的ID。
- 使用一个计数器来记录每个玩家的得分。
- 使用一个有序集合来记录玩家的排名,以及与玩家ID关联的得分。
(4)Redis操作步骤
- 玩家完成游戏时,使用Redis的
ZINCRBY命令增加玩家的得分。
- 使用
ZREVRANK命令获取玩家的排名。
(5)Java代码示例
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Tuple;
import java.util.Set;
public class GameLeaderboard {
private Jedis jedis;
public GameLeaderboard() {
jedis = new Jedis("localhost", 6379);
}
public void updateScore(String playerId, double score) {
jedis.zincrby("leaderboard", score, playerId);
}
public Long getPlayerRank(String playerId) {
return jedis.zrevrank("leaderboard", playerId);
}
public Set<Tuple> getTopPlayers(int count) {
return jedis.zrevrangeWithScores("leaderboard", 0, count - 1);
}
public static void main(String[] args) {
GameLeaderboard leaderboard = new GameLeaderboard();
leaderboard.updateScore("player123", 1500);
leaderboard.updateScore("player456", 1800);
leaderboard.updateScore("player789", 1600);
Long rank = leaderboard.getPlayerRank("player456");
System.out.println("Rank of player456: " + (rank != null ? rank + 1 : "Not ranked"));
Set<Tuple> topPlayers = leaderboard.getTopPlayers(3);
System.out.println("Top players:");
topPlayers.forEach(tuple -> System.out.println(tuple.getElement() + ": " + tuple.getScore()));
}
}
在上述代码中,我们创建了一个名为GameLeaderboard的类来模拟游戏玩家排行榜系统。我们同样使用Jedis客户端库来连接到Redis服务器,并实现了更新玩家得分、获取玩家排名和获取排名前几名玩家的功能。使用zincrby命令可以更新玩家的得分,而zrevrank命令则用于
获取玩家的排名,注意排名从0开始计数。通过调用zrevrangeWithScores命令,我们可以获取到排名前几名玩家以及他们的得分。
六、总结与最佳实践
在本篇博客中,我们深入探讨了如何使用Redis构建高性能的计数器和排行榜功能。通过实际案例和详细的Java代码示例,我们了解了如何在实际应用中应用这些功能,提升系统性能和用户体验。让我们在这一节总结Redis在计数器和排行榜功能中的价值,并提供一些最佳实践指南。
1、Redis在计数器和排行榜中的价值
通过使用Redis的计数器和排行榜功能,我们可以实现以下价值:
实时性和高性能:Redis的内存存储和优化的数据结构使得计数器和排行榜功能能够以极高的性能实现。这对于需要实时更新和查询数据的场景非常重要。
用户参与度提升:在社交媒体和游戏等应用中,计数器和排行榜功能可以激励用户参与。通过显示点赞数量或排行榜,用户感受到了更强的互动性和竞争性,从而增加了用户参与度。
数据统计和分析:通过统计计数和排行数据,我们可以获得有价值的数据洞察。这些数据可以用于分析用户行为、优化内容推荐等,从而指导业务决策。
2、最佳实践指南
以下是一些使用Redis构建计数器和排行榜功能的最佳实践指南:
合适的数据结构选择:根据实际需求,选择合适的数据结构。计数器可以使用简单的String类型,而排行榜可以使用有序集合(Sorted Set)来存储数据。
保证数据准确性:在高并发环境下,使用Redis的事务、管道和分布式锁来保证计数器和排行榜的数据准确性。避免并发写入导致的竞争条件。
定期数据清理:定期清理不再需要的计数器和排行数据,以减小数据量和提高查询效率。可以使用ZREMRANGEBYRANK命令来移除排行榜中的过期数据。
适度的缓存:对于排行榜数据,可以考虑添加适度的缓存以提高查询效率。但要注意平衡缓存的更新和数据的一致性。
通过遵循这些最佳实践,您可以更好地应用Redis的计数器和排行榜功能,为您的应
作者:哪吒编程
来源:juejin.cn/post/7271908000414351400
用程序带来更好的性能和用户体验。