你好呀,我是歪歪。
这次来盘个小伙伴分享给我的一个面试题,他说面试的过程中面试官的问了一个比较开放的问题:
请谈谈你对于请求合并和分治的看法。
他觉得自己没有答的特别好,主要是没找到合适的角度来答题,跑来问我怎么看。
我能怎么看?
我也不知道面试官想问啥角度啊。但是这种开放题,只要回答的不太离谱,应该都能混得过去。
比如,如果你回答一个:我认为合并和分治,这二者之间是辩证的关系,得用辩证的眼光看问题,它们是你中有我,我中有你~
那凉了,拿着简历回家吧。

我也想了一下,如果让我来回答这个问题,我就用这篇文章来回答一下。
有广义上的实际应用场景,也有狭义上的源代码体现对应的思想。
让面试官自己挑吧。

铺垫一下
首先回答之前肯定不能干聊,所以我们铺垫一下,先带入一个场景:热点账户。
什么是热点账户呢?
在第三方支付系统或者银行这类交易机构中,每产生一笔转入或者转出的交易,就需要对交易涉及的账户进行记账操作。
记账粗略的来说涉及到两个部分。
- 交易系统记录这一笔交易的信息。
- 账户系统需要增加或减少对应的账户余额。
如果对于某个账户操作非常的频繁,那么当我们对账户余额进行操作的时候,肯定就会涉及到并发处理的问题。
并发了怎么办?
我们可以对账户进行加锁处理嘛。但是这样一来,这个账户就涉及到频繁的加锁解锁操作。
虽然这样我们可以保证数据不出问题,但是随之带来的问题是随着并发的提高,账户系统性能下降。
极少数的账户在短时间内出现了极大量的余额更新请求,这类账户就是热点账户,就是性能瓶颈点。
热点账户是业界的一个非常常见的问题。
而且根据热点账户的特性,也可以分为不同的类型。
如果余额的变动是在频繁的增加,比如头部主播带货,只要一喊 321,上链接,那订单就排山倒海的来了,钱就一笔笔的打到账户里面去了。这种账户,就是非常多的人在给这个账户打款,频率非常高,账户余额一直在增加。
这种账户叫做“加余额频繁的热点账户”。
如果余额的变动是在频繁的减少,比如常见的某流量平台广告位曝光,这种属于扣费场景。
商家先充值一笔钱到平台上,然后平台给商家一顿咔咔曝光,接着账户上的钱就像是流水一样哗啦啦啦的就没了。
这种预充值,然后再扣减频繁的账户,这种账户叫做“减余额频繁的热点账户”。
还有一种,是加余额,减余额都很频繁的账户。
你细细的嗦一下,什么账户一边加一遍减呢,怎么感觉像是个二手贩子在左手倒右手呢?
这种账户一般不能细琢磨,琢磨多了,就有点灰色地带了,点到为止。

先说请求合并
针对“加余额频繁的热点账户”我们就可以采取请求合并的思路。
假设有个歪师傅是个正经的带货主播,在直播间穿着女装卖女装,我只要喊“321,上链接”姐妹们就开始冲了。

随着歪师傅生意越来越好,有的姐妹们就反馈下单越来越慢。
后来一分析,哦,原来是更新账户余额那个地方是个性能瓶颈,大量的单子都在这里排着队,等着更新余额。
怎么办呢?
针对这种情况,我们就可以把多笔调整账务余额的请求合并成一笔处理。

当记录进入缓冲流水记录表之后,我就可以告知姐妹下单成功了,虽然钱还没有真的到我的账户中来,但是你放心,有定时任务保证,钱一会就到账。
所以当姐妹们下单之后,我们只是先记录数据,并不去实际动账户。等着定时任务去触发记账,进行多笔合并一笔的操作。
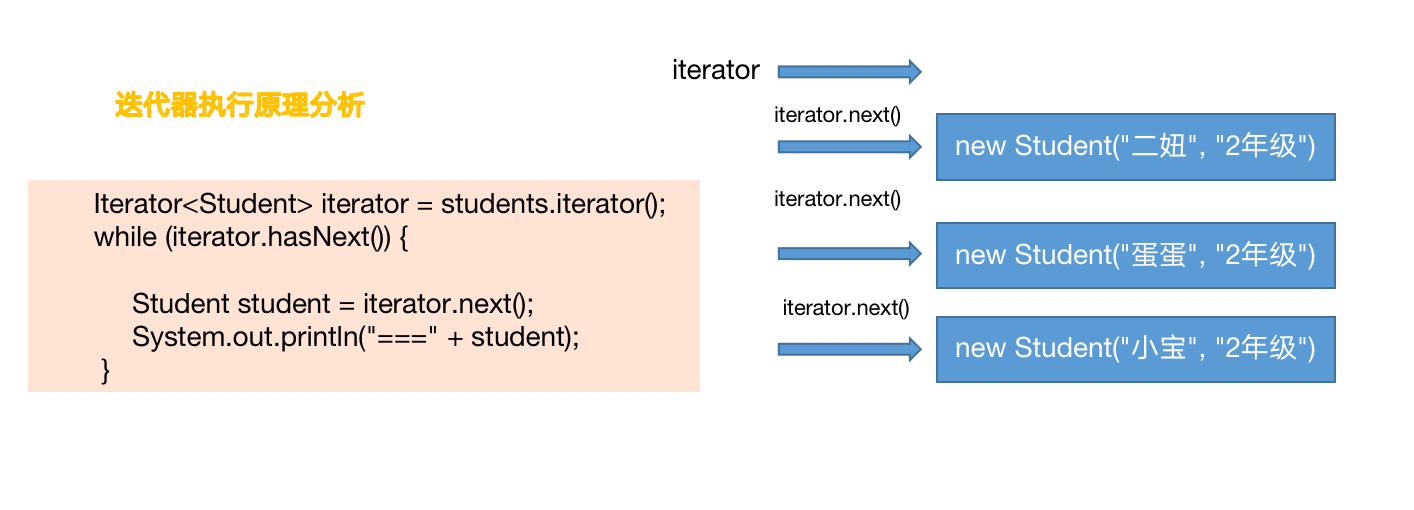
比如下面的这个示意图:

对于歪师傅来说,实际有 6 个姐妹的支付记录,但是只有一次余额调整。
而我拿着这一次余额调整的账户流水,也是可以追溯到这 6 笔交易记录的详情。
这样的好处是吞吐量上来了,用户体验也好了。但是带来的弊端是余额并不是一个准确的值。
假设我们的定时任务是一小时汇总一次,那么歪师傅在后端看到的交易金额可能是一小时之前的数据。
但是歪师傅觉得没关系,总比姐妹们下不了单强。

如果我们把缓冲流水记录表看作是一个队列。那么这个方案抽象出来就是队列加上定时任务。
所以,请求合并的关键点也是队列加上定时任务。
除了我上面的例子外,比如还有 redis 里面的 mget,数据库里面的批量插入,这玩意不就是一个请求合并的真实场景吗?
比如 redis 把多个 get 合并起来,然后调用 mget。多次请求合并成一次请求,节约的是网络传输时间。
还有真实的案例是转账的场景,有的转账渠道是按次收费的,那么作为第三方公司,我们就可以把用户的请求先放到表里记录着,等一小时之后,一起汇总发起,假设这一小时内发生了 10 次转账,那么 10 次收费就变成了 1 次收费,虽然让客户等的稍微久了点,但还是在可以接受的范围内,这操作节约的就是真金白银了。
请求合并,说穿了,就这么一点事儿,一点也不复杂。
那么如果我在请求合并的前面,加上“高并发”这三个字...

首先不论是在请求合并的前面加上多么狂拽炫酷吊炸天的形容词,说的多么的天花乱坠,它也还是一个请求合并。
那么队列和定时任务的这个基础结构肯定是不会变的。
高并发的情况下,就是请求量非常的大嘛,那我们把定时任务的频率调高一点不就行了?
以前 100ms 内就会过来 50 笔请求,我每收到一笔就是立即处理了。
现在我们把请求先放到队列里面缓存着,然后每 100ms 就执行一次定时任务。
100ms 到了之后,就会有定时任务把这 100ms 内的所有请求取走,统一处理。
同时,我们还可以控制队列的长度,比如只要 50ms 队列的长度就达到了 50,这个时候我也进行合并处理。不需要等待到 100ms 之后。
其实写到这里,高并发的请求合并的答案已经出来了。
关键点就三个:
- 一是需要借助队列加定时任务实现。
- 二是控制定时任务的执行时间.
- 三是控制缓冲队列的任务长度。
方案都想到了,把代码写出来岂不是很容易的事情。而且对于这种面试的场景图,一般都是讨论技术方案,而不太会去讨论具体的代码。
当讨论到具体的代码的时候,要么是对你的方案存疑,想具体的探讨一下落地的可行性。要么就是你答对了,他要准备从代码的交易开始衍生另外的面试题了。
总之,大部分情况下,不会在你给了一个面试官觉得错误的方案之后,他还和你讨论代码细节。你们都不在一个频道了,赶紧换题吧,还聊啥啊。
实在要往代码实现上聊,那么大概率他是在等着你说出一个框架:Hystrix。
其实这题,你要是知道 Hystrix,很容易就能给出一个比较完美的回答。
因为 Hystrix 就有请求合并的功能。
通过一个实际的例子,给大家演示一下。
假设我们有一个学生信息查询接口,调用频率非常的高。对于这个接口我们需要做请求合并处理。
做请求合并,我们至少对应着两个接口,一个是接收单个请求的接口,一个处理把单个请求汇总之后的请求接口。
所以我们需要先提供两个 service:

其中根据指定 id 查询的接口,对应的 Controller 是这样的:

服务启动起来后,我们用线程池结合 CountDownLatch 模拟 20 个并发请求:

从控制台可以看到,瞬间接受到了 20 个请求,执行了 20 次查询 sql:

很明显,这个时候我们就可以做请求合并。每收到 10 次请求,合并为一次处理,结合 Hystrix 代码就是这样的,为了代码的简洁性,我采用的是注解方式:

在上面的图片中,有两个方法,一个是 getUserId,直接返回的是null,因为这个方法体不重要,根本就不会执行。
在 @HystrixCollapser 里面可以看到有一个 batchMethod 的属性,其值是 getUserBatchById。
也就是说这个方法对应的批量处理方法就是 getUserBatchById。当我们请求 getUserById 方法的时候,Hystrix 会通过一定的逻辑,帮我们转发到 getUserBatchById 上。
所以我们调用的还是 getUserById 方法:

同样,我们用线程池结合 CountDownLatch 模拟 20 个并发请求,只是变换了请求地址:

调用之后,神奇的事情就出现了,我们看看日志:

同样是接受到了 20 个请求,但是每 10 个一批,只执行了两个sql语句。
从 20 个 sql 到 2 个 sql,这就是请求合并的威力。请求合并的处理速度甚至比单个处理还快,这也是性能的提升。
那假设我们只有 5 个请求过来,不满足 10 个这个条件呢?
别忘了,我们还有定时任务呢。
在 Hystrix 中,定时任务默认是每 10ms 执行一次:
同时我们可以看到,如果不设置 maxRequestsInBatch,那么默认是 Integer.MAX_VALUE。
也就是说,在 Hystrix 中做请求合并,它更加侧重的是时间方面。
功能演示,其实就这么简单,代码量也不多,有兴趣的朋友可以直接搭个 Demo 跑跑看。看看 Hystrix 的源码。
我这里只是给大家指几个关键点吧。
第一个肯定是我们需要找到方法入口。
你想,我们的 getUserById 方法的方法体里面直接是 return null,也就是说这个方法体是什么根本就不重要,因为不会去执行方法体中的代码。它只需要拦截到方法入参,并缓存起来,然后转发到批量方法中去即可。
然后方法体上面有一个 @HystrixCollapser 注解。
那么其对应的实现方式你能想到什么?
肯定是 AOP 了嘛。
所以,我们拿着这个注解的全路径,进行搜索,啪的一下,很快啊,就能找到方法的入口:
com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect#methodsAnnotatedWithHystrixCommand

在入口处打上断点,就可以开始调试了:

第二个我们看看定时任务是在哪儿进行注册的。
这个就很好找了。我们已经知道默认参数是 10ms 了,只需要顺着链路看一下,哪里的代码调用了其对应的 get 方法即可:

同时,我们可以看到,其定时功能是基于 scheduleAtFixedRate 实现的。
第三个我们看看是怎么控制超过指定数量后,就不等待定时任务执行,而是直接发起汇总操作的:

可以看到,在com.netflix.hystrix.collapser.RequestBatch#offer方法中,当 argumentMap 的 size 大于我们指定的 maxBatchSize 的时候返回了 null。
如果,返回为 null ,那么说明已经不能接受请求了,需要立即处理,代码里面的注释也说的很清楚了:

以上就是三个关键的地方,Hystrix 的源码读起来,需要下点功夫,大家自己研究的时候需要做好心理准备。
最后再贴一个官方的请求合并工作流程图:

再说请求分治
还是回到最开始我们提出的热点账户问题中的“减余额频繁的热点账户”。
请求分治和请求合并,就是针对“热点账户”这同一个问题的完全不同方向的两个回答。
分治,它的思想是拆分。
再说拆分之前,我们先聊一个更熟悉的东西:AtomicLong。
AtomicLong,这玩意是可以实现原子性的增减操作,但是当竞争非常大的时候,被操作的“值”就是一个热点数据,所有线程都要去对其进行争抢,导致并发修改时冲突很大。
那么 AtomicLong 是靠什么解决这个冲突的呢?
看一下它的 getAndAdd 方法:

可以看到这里面还是有一个 do-while 的循环:

里面调用了 compareAndSwapLong 方法。
do-while,就是自旋。
compareAndSwapLong,就是 CAS。
所以 AtomicLong 靠的是自旋 CAS 来解决竞争大的时候的这个冲突。
你看这个场景,是不是和我们开篇提到的热点账户有点类似?
热点账户,在并发大的时候我们可以对账户进行加锁操作,让其他请求进行排队。
而它这里用的是 CAS,一种乐观锁的机制。
但是也还是要排队,不够优雅。
什么是优雅的?
LongAdder 是优雅的。
有点小伙伴就有点疑问了:歪师傅,不是要讲热点账户吗,怎么扯到 LongAdder 上了呢?
闭嘴,往下看就行了。

首先,我们先看一下官网上的介绍:

上面的截图一共两段话,是对 LongAdder 的简介,我给大家翻译并解读一下。

首先第一段:当有多线程竞争的情况下,有个叫做变量集合(set of variables)的东西会动态的增加,以减少竞争。
sum 方法返回的是某个时刻的这些变量的总和。
所以,我们知道了它的返回值,不论是 sum 方法还是 longValue 方法,都是那个时刻的,不是一个准确的值。
意思就是你拿到这个值的那一刻,这个值其实已经变了。
这点是非常重要的,为什么会是这样呢?
我们对比一下 AtomicLong 和 LongAdder 的自增方法就可以知道了:

AtomicLong 的自增是有返回值的,就是一个这次调用之后的准确的值,这是一个原子性的操作。
LongAdder 的自增是没有返回值的,你要获取当前值的时候,只能调用 sum 方法。
你想这个操作:先自增,再获取值,这就不是原子操作了。
所以,当多线程并发调用的时候,sum 方法返回的值必定不是一个准确的值。除非你加锁。
该方法上的说明也是这样的:

至于为什么不能返回一个准确的值,这就是和它的设计相关了,这点放在后面去说。

然后第二段:当在多线程的情况下对一个共享数据进行更新(写)操作,比如实现一些统计信息类的需求,LongAdder 的表现比它的老大哥 AtomicLong 表现的更好。在并发不高的时候,两个类都差不多。但是高并发时 LongAdder 的吞吐量明显高一点,它也占用更多的空间。这是一种空间换时间的思想。
这段话其实是接着第一段话在进行描述的。
因为它在多线程并发情况下,没有一个准确的返回值,所以当你需要根据返回值去搞事情的时候,你就要仔细思考思考,这个返回值你是要精准的,还是大概的统计类的数据就行。
比如说,如果你是用来做序号生成器,所以你需要一个准确的返回值,那么还是用 AtomicLong 更加合适。
如果你是用来做计数器,这种写多读少的场景。比如接口访问次数的统计类需求,不需要时时刻刻的返回一个准确的值,那就上 LongAdder 吧。
总之,AtomicLong 是可以保证每次都有准确值,而 LongAdder 是可以保证最终数据是准确的。高并发的场景下 LongAdder 的写性能比 AtomicLong 高。
接下来探讨三个问题:
- LongAdder 是怎么解决多线程操作热点 value 导致并发修改冲突很大这个问题的?
- 为什么高并发场景下 LongAdder 的 sum 方法不能返回一个准确的值?
- 为什么高并发场景下 LongAdder 的写性能比 AtomicLong 高?
先带你上个图片,看不懂没有关系,先有个大概的印象:

接下来我们就去探索源码,源码之下无秘密。
从源码我们可以看到 add 方法是关键:

里面有 cells 、base 这样的变量,所以在解释 add 方法之前,我们先看一下 这几个成员变量。
这几个变量是 Striped64 里面的。
LongAdder 是 Striped64 的子类:

其中的四个变量如下:

- NCPU:cpu 的个数,用来决定 cells 数组的大小。
- cells:一个数组,当不为 null 的时候大小是 2 的次幂。里面放的是 cell 对象。
- base : 基数值,当没有竞争的时候直接把值累加到 base 里面。还有一个作用就是在 cells 初始化时,由于 cells 只能初始化一次,所以其他竞争初始化操作失败线程会把值累加到 base 里面。
- cellsBusy:当 cells 在扩容或者初始化的时候的锁标识。
之前,文档里面说的 set of variables 就是这里的 cells。

好了,我们再回到 add 方法里面:

cells 没有被初始化过,说明是第一次调用或者竞争不大,导致 CAS 操作每次都是成功的。
casBase 方法就是进行 CAS 操作。
当由于竞争激烈导致 casBase 方法返回了 false 后,进入 if 分支判断。
这个 if 分子判断有 4 个条件,做了 3 种情况的判断

- 标号为 ① 的地方是再次判断 cells 数组是否为 null 或者 size 为 0 。as 就是 cells 数组。
- 标号为 ② 的地方是判断当前线程对 cells 数组大小取模后的值,在 cells 数组里面是否能取到 cell 对象。
- 标号为 ③ 的地方是对取到的 cell 对象进行 CAS 操作是否能成功。
这三个操作的含义为:当 cells 数组里面有东西,并且通过 getProbe() & m算出来的值,在 cells 数组里面能取到东西(cell)时,就再次对取到的 cell 对象进行 CAS 操作。
如果不满足上面的条件,则进入 longAccumulate 函数。
这个方法主要是对 cells 数组进行操作,你想一个数组它可以有三个状态:未初始化、初始化中、已初始化,所以下面就是对这三种状态的分别处理:

- 标号为 ① 的地方是 cells 已经初始化过了,那么这个里面可以进行在 cell 里面累加的操作,或者扩容的操作。
- 标号为 ② 的地方是 cells 没有初始化,也还没有被加锁,那就对 cellsBusy 标识进行 CAS 操作,尝试加锁。加锁成功了就可以在这里面进行一些初始化的事情。
- 标号为 ③ 的地方是 cells 正在进行初始化,这个时候就在 base 基数上进行 CAS 的累加操作。
上面三步是在一个死循环里面的。
所以如果 cells 还没有进行初始化,由于有锁的标志位,所以就算并发非常大的时候一定只有一个线程去做初始化 cells 的操作,然后对 cells 进行初始化或者扩容的时候,其他线程的值就在 base 上进行累加操作。
上面就是 sum 方法的工作过程。
感受到了吗,其实这就是一个分段操作的思想,不知道你有没有想到 ConcurrentHashMap,也不奇怪,毕竟这两个东西都是 Doug Lea 写的。
总的来说,就是当没有冲突的时候 LongAdder 表现的和 AtomicLong 一样。当有冲突的时候,才是 LongAdder 表现的时候,然后我们再回去看这个图,就能明白怎么回事了:

好了,现在我们回到前面提出的三个问题:
- LongAdder 是怎么解决多线程操作热点 value 导致并发修改冲突很大这个问题的?
- 为什么高并发场景下 LongAdder 的 sum 方法不能返回一个准确的值?
- 为什么高并发场景下 LongAdder 的写性能比 AtomicLong 高?
它们其实是一个问题。
因为 LongAdder 把热点 value 拆分了,放到了各个 cell 里面去操作。这样就相当于把冲突分散到了 cell 里面。所以解决了并发修改冲突很大这个问题。
当发生冲突时 sum= base+cells。高并发的情况下当你获取 sum 的时候,cells 极有可能正在被其他的线程改变。一个在高并发场景下实时变化的值,你要它怎么给你个准确值?
当然,你也可以通过加锁操作拿到当前的一个准确值,但是这种场景你还用啥 LongAdder,是 AtomicLong 不香了吗?
为什么高并发场景下 LongAdder 的写性能比 AtomicLong 高?
你发动你的小脑壳想一想,朋友。
AtomicLong 不管有没有冲突,它写的都是一个共享的 value,有冲突的时候它就在自旋。
LongAdder 没有冲突的时候表现的和 AtomicLong 一样,有冲突的时候就把冲突分散到各个 cell 里面了,冲突分散了,写的当然更快了。
我强调一次:有冲突的时候就把冲突分散到各个 cell 里面了,冲突分散了,写的当然更快了。
你注意这句话里面的“各个 cell”。
这是什么?
这个东西本质上就是 sum 值的一部分。
如果用热点账户去套的话,那么“各个 cell”就是热点账户下的影子账户。
热点账户说到底还是一个单点问题,那么对于单点问题,我们用微服务的思想去解决的话是什么方案?
就是拆分。
假设这个热点账户上有 100w,我设立 10 个影子账户,每个账户 10w ,那么是不是我们的流量就分散了?
从一个账户变成了 10 个账户,压力也就进行了分摊。
但是同时带来的问题也很明显。
比如,获取账户余额的时候需要把所有的影子账户进行汇总操作。但是每个影子账户上的余额是时刻在变化的,所以我们不能保证余额是一个实时准确的值。
但是相比于下单的量来说,大部分商户并不关心“账上的实时余额”这个点。
他只关心上日余额是准确的,每日对账都能对上就行了。
这就是分治。
其实我浅显的觉得分布式、高并发都是基于分治,或者拆分思想的。
本文的 LongAdder 就不说了。
微服务化、分库分表、读写分离......这些东西都是在分治,在拆分,把集中的压力分散开来。
这就算是我对于“请求合并和分治”的理解、
好了,到这里本文就算是结束了。
针对"热点账户"这同一个问题,细化了问题方向,定义了加余额频繁和减余额频繁的两种热点账户,然后给出了两个完全不同方向的回答。
这个时候,我就可以把文章开头的那句话拿出来说了:
综上,我认为合并和分治,这二者之间是辩证的关系,得用辩证的眼光看问题,它们是你中有我,我中有你~

作者:why技术
来源:juejin.cn/post/7292955463954563072

























![newTable[i] = e](https://www.imgeek.net/uploads/article/20231110/6856d678fdd79e1340d490511038f830.jpg)