摘要:什么是“元宇宙”,1000个人眼里有1000个“元宇宙”。
本文分享自华为云社区《【云驻共创】年轻人如何入场元宇宙?未来已来!》,作者:启明。
近期,Facebook把自己公司更名为Meta(元),上了一波热搜;而前段时间国内的阿里腾讯,国外的谷歌等巨头纷纷宣布入局元宇宙;行业“冥”灯罗永浩也宣布要入局元宇宙,这个词汇出现的越来越频繁,而未来会更频繁。
那么“元宇宙”究竟是什么呢?
1000个人眼里有1000个“元宇宙”
什么是“元宇宙”,1000个人眼里有1000个“元宇宙”。
不同的媒体、公司、个人等,对“元宇宙”都有着自己的理解:
有的人认为“元宇宙”代表着人类文明的未来;而还有些人觉得“元宇宙”代表着虚拟世界的“躺平”,是个“邪恶”的东西,Elon Musk的冲向太空,才是人类文明的未来.....
而在这两种观点之间,还有一种观点:“元宇宙”和互联网一样,本身是不带任何属性的,重点还是看我们如何使用它。
要探讨什么是“元宇宙”,我们需要探索人类需求的本源。
影视文学中的元宇宙
首先,我们从影视文学中的元宇宙的角度来挖掘一下:
《雪崩》
对于元宇宙的解释,目前公认翻译自1992年斯蒂芬森科幻小说《雪崩》中“Metaverse”(也译为超元域)一词。元宇宙简单来说,就是现实世界中的所有人和事都被数字化投射在了这个网络云端世界里,你可以在这个世界里做任何你在真实世界中可以做的事情。与此同时,你还可能做你在真实世界里做不到的事情。
《庄周梦蝶》
而在中国2300多年前的百家争鸣时代,庄子梦到了自己变成了蝴蝶在翩翩飞舞,醒来之后不知身在何处,就产生了这样的思考:到底是庄子变成了蝴蝶,还是蝴蝶变成了庄子呢?哪个才是真是的存在?还有《枕中记》一书中的“黄粱一梦”等成语也是类似的哲思探索。
《星球大战》
在《星球大战》中我们看到具备三维全息投影功能的R2D2机器人;以及目前在游戏玩家中很流行的玩意儿:由一个全视角显示头盔和一套感应服构成,感应服可以使玩家从肉体上感觉到游戏中的击打、刀刺和火烧,能产生出酷热和严寒,甚至还能逼真地模拟出身体暴露在风雪中的感觉。在《三体》改编的同名游戏中提到,汪淼走到她后面,由于游戏是在头盔中以全视角方式显示的,在显示器上什么都看不到。
《王牌特工》
在美国影视剧《王牌特工》中,当你带上王牌特工的专属AR眼镜,其他与会人哪怕身在不同国家地区,都能就在身边一样,开一个全息会议。
《阿凡达》
在《阿凡达》影视剧中,科学家尝试将人类DNA和纳威人的DNA结合在一起,制造出一个克隆纳威人。而最神奇的地方在于克隆纳威人可以让人类的意识入驻其中,从而成为人类在这个星球上活动的“化身”(Avatar)。
《黑镜》
在《黑镜》第二季第一集当中,名为“Be Right Back·马上回来”,讲述了一对情侣Martha和Ash搬去了Ash父母居住的远离尘嚣的小镇生活,但是社交网络狂人Ash却在归还搬家租赁的货车时死于非命。在Ash的葬礼上,Martha的朋友Sarah告诉了她一种和死去的人建立联系的新方法,就是用Ash在社交网络中留下的所有信息、状态,更新和Like,Martha可以创造出一个新的“真”Ash,从而帮助她减轻伤痛。
《刀剑神域》
在《刀剑神域》中,当你带上脑机接口设备时,你在游戏中死亡,那么在现实中也将死亡。
《太空堡垒》
《太空堡垒》有3个非常了不起的设定:
1、全息眼镜Holoband和虚拟paradise
2、意识上传到云端
3、意识下载到机器人的身体中,成为第一代具备真正“智慧”的机器人
《头号玩家》
2045年,处于混乱和崩溃边缘的现实世界令人失望,人们将救赎的希望寄托于“绿洲”,一个由鬼才詹姆斯·哈利迪一手打造的虚拟游戏世界。人们只要戴上VR设备,就可以进入这个与现实世界形成强烈反差的虚拟世界。在这个世界中,有繁华的都市,形象各异、光彩照人的玩家,而不同次元的影视游戏中的经典角色也可以在这里齐聚。就算你在现实中是一个挣扎在社会边缘的失败者,在“绿洲”里也依然可以成为超级英雄,再遥远的梦想都变得触手可及。
《失控玩家》
今年上映的一个新的影视剧。其中的主角以为自己是生活的主角,其实只不是这个世界的一个NPC,这个舞台上的提线木偶。
《UPLOAD》
《UPLOAD》中的精彩设定:
1、死前将意识上传到虚拟天堂
2、死后的世界也有2G和5G之分
3、死后通过全息方式参加自己的葬礼
《黑客帝国》
未来的人类生活在机器人所制造的矩阵(Matrix)虚拟世界中,而机器人则得以从人体获取所需的生物能源。但生活在虚拟世界中的人类丝毫没有意识到自己的世界是虚拟的,知道“救世主”的出现。
我们并不是来讲解这个科幻影视作品的,我们要做的,是从中这些科幻影视作品中,看看人们的需求。
一提到需求,我们可能会立刻想到马斯克的“需求层次论”,但是在这里,我们更加抽象一下:
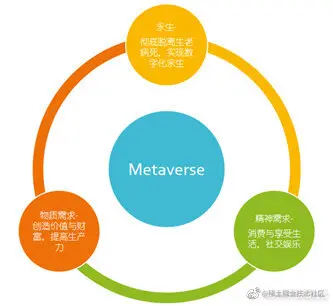
**物质需求:**创造价值与财富,提高生产力
**精神需求:**消费与享受生活,社交娱乐
**永生:**彻底脱离生老病死,实现数字化永生
当然,按照目前科技的发展进程,如果想实现人类生物身体的永生不老是非常难的,但是通过Metaverse的技术未来我们有可能会实现一种数字化的永生。
巨头眼中的元宇宙
介绍完影视剧中的“元宇宙”,我们来看看巨头眼中的元宇宙:
Facebook?Meta!
首先我们来看的是Meta,也就是之前的Facebook。对Meta来说,今年是一个非常重要的一年,因为今年它改元。当然我们都知道在中国的历史上,某个帝王更改自己的年号叫“改元”,其实对Facebook对Meta来说,2021年也是它的改元之年。我们可以看一看在它改元之前,它的虚拟现实以及在元宇宙做了哪些布局。
2014年的时候,其用20亿美元将股份收购了OculusVR。在收购的时候,扎克伯格在自己的Facebook主页上说了这样一句话:沉浸式的虚拟现实游戏,将是虚拟现实第一个重大应用,但是这仅仅只是一个起点,虚拟现实绝不仅仅是游戏,我们希望把它打造成下一个计算和通讯平台。
2018年9月,Facebook在OculusConnect开发者大会上宣布推出独立虚拟现实(VR)头盔Oculus Quest,跟Oculus Go类似,这种头盔无需PC或手机即可提供虚拟现实功能。但是它提供了6自由度的游戏控制器,可以让玩家更愉快的玩耍。
2020年9月,Facebook在开发者大会上宣布推出OculusQuest 2代,定价仅299美元。2021年11月17日,根据高通CEO透露的数据,Oculus Quest2代的累积销量已经突破1000万台!!!
那么1000万台意味着什么?意味着 VR头显的设备已经跨越了所谓的第一个极限点,即将迈向真正的星辰大海。
往后接下来几年还会陆续还有Oculus的3代和4代,而这些都在开发之中,而且价格肯定不会比二代贵,也会解决诸多的技术问题,但是具体的发布时间(可能在2022年圣诞节前)还在猜测当中。除了3代和4代之外,还有传闻中的PRO版本,也就是性能更强,价格更高,那么它可能会对标传说中要发布的苹果的新品。当然Meta也就是之前的Facebook,除了现有的Oculus这条产品之外,还在积极的研发AR眼镜。
看完上述的这些产品之外,我们也来看一看Meta还有其他哪些布局:2018年的Facebook F8大会上,Oculus首席科学家Michael Abrash宣布Oculus研发部门Oculus Research重新命名为Facebook Reality Labs,并同时涉足VR与AR技术的研发。
Facebook AR/VR部门在2021年总人数已逾1万人,占总员工人数的近20%,而2017年该部门仅为1000人。
Facebook有两个开发者的大会是值得我们关注的,分别是每年5月到6月的F8大会,以及每年10月底左右的XR开发者大会。
Facebook于2017年发布了名为AR Studio的AR套件,并一直与全球社区合作,共同塑造和定义Spark AR平台。
2021年8月20日,Facebook推出测试性的VR远程办公APP,名为HorizonWorkrooms,有了该软件,Oculus Quest 2用户可以用虚拟化身参与会议。
2021年11月11日,Meta宣布与微软合作,将Meta旗下的WorkPlace功能与微软的Teams整合,发展元宇宙办公室。
我们可以看到,现在虚拟现实和原有的产品和技术的布局,从之前的以数年为单位,现在已经大大的提速,增加到了一年半年甚至几个月都会有一个新的产品新的功能出来。
那么在内容生态上,Meta一是推出Oculus Store,目前已有超过60款Oculus Quest 游戏的营收超过100万美元;二是和第三方平台SideQuest合作。
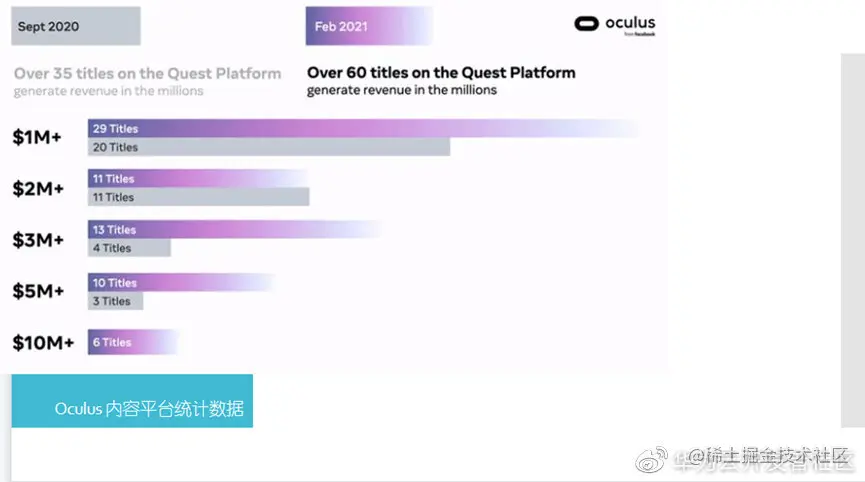
其还成立了Oculus Studio,并且收购多家VR内容公司,包括Beat Games、Downpour、Ready at Dawn、Sanzaru Games、BigBox VR。
根据Steam VR平台的统计数据,我们可以看到OcQ设备的市场占有率是非常的高:
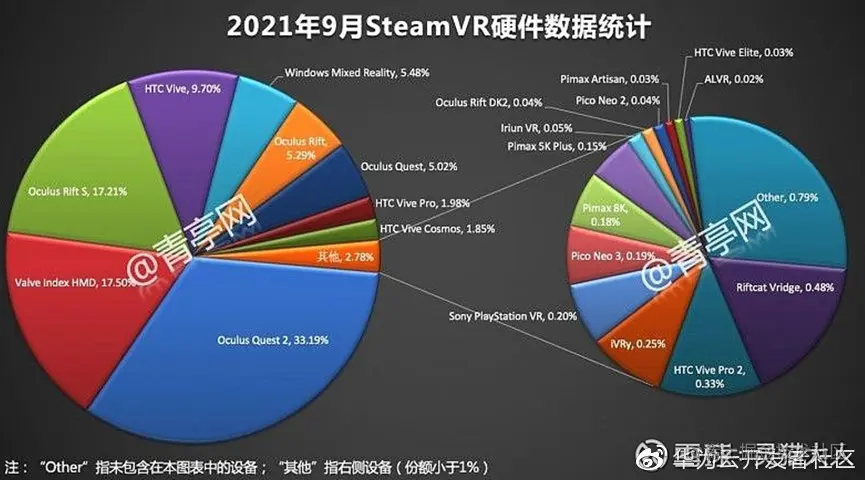
那么目前在这个市场上我们可以看到,整个平台已经有了一定数量的相关的VR内容,包括支持各个设备的,但是还仅仅是在以千为单位。
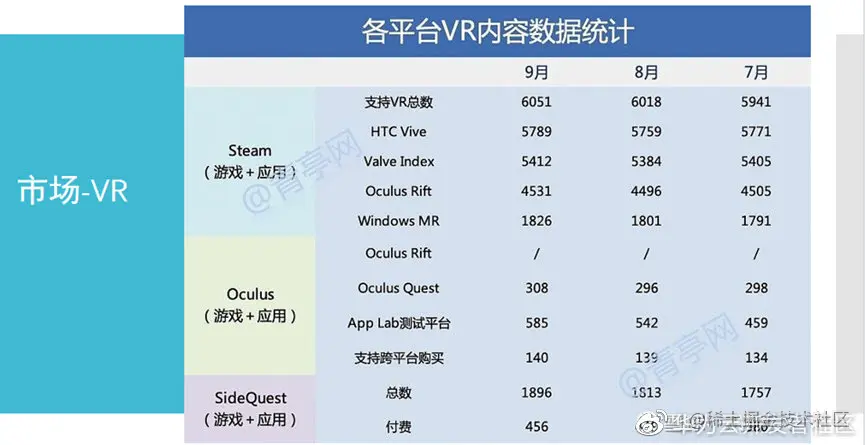
我们都知道,比如说苹果的App Store或者是安卓商城上的应用,都已经是突破上百万甚至几百万个,那么现在目前 VR的应用还处于非常的早期。
所以对于Meta来说,也就对于之前的Facebook来说,最重要的事情就是上个月28号扎克伯格宣布它正式更名成Meta,从此迈向未来的星辰大海。
微软
同样是元宇宙,我们可以看到Meta,也就是Facebook它更偏重于其社交属性。而对于微软来说,它更多是从企业办公、企业生产力方面来看,也就是所谓的“企业元宇宙”。
2015的开发者大会,微软与WIN10一起推出黑科技产品HoloLens;
2019年2月的MWC(世界移动通信大会)上,微软发布HoloLens 2代;
2021年4月,微软拿下美军218.8亿美元的军工版HoloLens合同。
除设备之外,
2018年10月,微软首次启动AzureDigital Twins平台预览版;
2020年12月,微软宣布AzureDigital Twins全面上市;
2021年3月,微软推出了一款具有3D化身和其他XR功能的虚拟平台Mesh,旨在打造能让人们通过AR/VR技术进行远程协作的应用。微软团队将会推出全新的3D虚拟化身,无须使用VR/AR头盔,用户将能够以虚拟任务或动画卡通的形式出现在视频会议中,且通过人工智能能够解读声音,让头像变得活灵活现。
可以看到微软的动作也是不断的加快:11月2日,微软在Ignite大会上宣布,计划将旗下聊天和会议应用Microsoft Teams打造成元宇宙,把混合现实会议平台Microsoft Mesh融入Microsoft Teams中。此外,Xbox游戏平台将来也要加入元宇宙。
萨提亚·纳德拉表示,微软的元宇宙最初专注于企业级应用。
微软(中国)首席技术官官韦青表示,没必要去纠结现在流行的技术叫什么词,无论是叫元宇宙也好,叫数字孪生也罢。永远不要忘记,创造虚拟空间的初衷是为了强化物理世界,让我们在现实生活提高生产效率,降低生产成本。
官韦青指出,像微软、苹果等科技公司的业务是虚拟空间、物理世界两方面业务皆有覆盖,两方面互补,而不是单方面地陷入到某一个领域。元宇宙构筑的逻辑,都是将物理世界的对象和现象变成模型,放到虚拟空间中,进行仿真、预测,最终反馈到物理空间,来强化我们的物理世界。
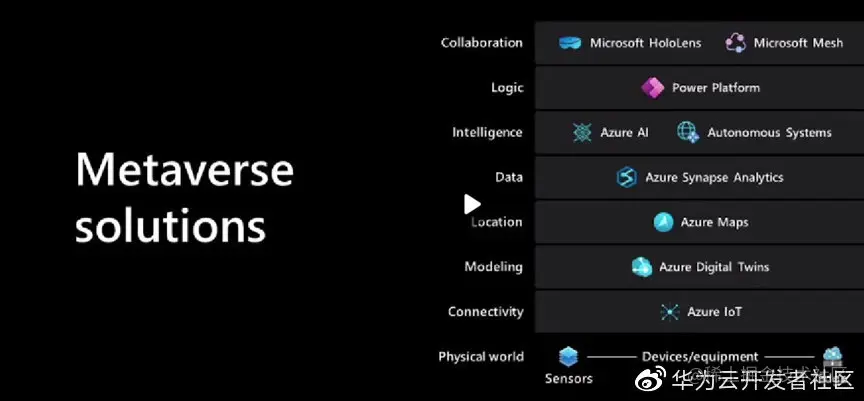
下图是微软的Metaverse解决方案,包括它的物理世界、连接、建模、位置、数据,还有智能逻辑以及协作平台等等,可以看到它是偏向于提高生产力。
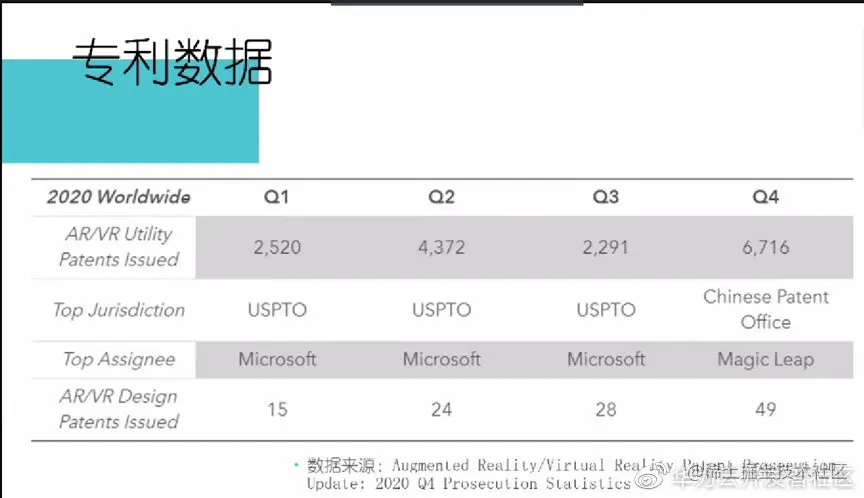
下图是微软去年在AR/VR领域的专利,可以看到在Q1至Q3它都是排在第一的,Q4是Magic Leap跃居第一。
在Meta的眼中,元宇宙可能更多的是社交娱乐,也就是满足我们的精神需求,而在微软的眼中元宇宙做更多的是提升生产效率,满足物质层面的需求,那么,英伟达眼中的元宇宙又是什么呢?
英伟达-OmniVerse
英伟达提出自己的元宇宙叫OmniVerse。它在元宇宙相关的布局及相关产品:
1、NVIDIA RTX系统显卡和虚拟工作站;
2、NVIDIA CloudXR-XR串流平台(和微软Azure以及Amazon AWS开展合作,主要兼容AR和VR设备,包括不限于:1、大部分PCVR、HoloLens 2、VR一体机、支持AR的安卓和iOS设备等);
3、OmniVerse元宇宙平台-数字版老黄
2021年11月9日GTC大会再次升级Omniverse平台,发布了OmniverseAvatar和Omniverse Replicator。Omniverse Avatar是一个用于生成交互式AI化身的技术平台。它集合了英伟达在语音AI、计算机视觉、自然语言理解、推荐引擎和模拟技术方面积累的技术,为创建人工智能助手打开了大门,可以帮助处理数十亿的日常客户服务互动。Omniverse Replicator则是一种合成数据生成引擎,可以基于现有数据持续生成用于训练的合成数据。
Omniverse的门户是USD(通用场景描述)黄仁勋认为Omniverse的本质是一个数字虫洞。未来任何计算机都可以连接到Omniverse就像HTML(一种标记语言,可将网络上的文档格式统一)基于网站。
黄仁勋表示:“如何使用OmniVerse模拟仓库、工厂、物理和生物系统、5G边缘、机器人、自动驾驶汽车,甚至是虚拟形象的数字孪生,是一个永恒的主题。”
总结来说,在英伟达眼中,那么不管是叫OmniVerse,还是MetaVerse也好,它百分之八九十的功能是为了提升生产力。具体的细节大家可以去相关的英伟达的开发网站去看详细的细节(http:developer.nvidia.com/nvidia-omniverse-platform)。
苹果
苹果虽然目前还没有推出相关的产品,但是他在不断的收购相关的公司以及部署了非常多的专利。那么在各个场合其CEO库克也表达了他对元宇宙以及对虚拟现实的一些看法。
I think AR is big and profound. This is oneof those huge thing that we'll look back at and marved at the stat of it. Ithink customers are going to see it in a variety of ways anfd it feeld great toget AR going at a level that can get all of the developers behind it.
Tim Cook, Apple CEO
库克认为,AI,也就是增强现实是一个非常巨大的市场。
在苹果WWDC 2017大会上,苹果发布了AR开发工具ARKit,具备SLAM、平面检测、光照估计、环境理解、图像识别等功能;
2017年9月12日,苹果正式发布的iPhoneX系列手机中使用了A11 Bionic芯片,首次集成了神经网络引擎;以及3D结构光技术FaceID,通过iPhone X的Face ID可以制作3D表情Animoji;
2019年9月11日,苹果发布的iPhone11首次使用了UWB超宽频芯片U1,超宽频技术让iPhone 11系列更具空间感知能力,可精确定位其他配备U1的苹果设备;
2019年10月29日,苹果发布的AirpodsPro无线降噪耳机首次使用了“空间音频”功能,2020年9月苹果发布的iOS 14为AirPods Pro新增了“空间音频”功能;
2020年1月14日,苹果推出USDZ3D格式转换工具Reality Converter;2020年3月18日,苹果官网发布了iPad Pro 2020,首次使用了dTOF激光雷达(LiDAR);
2021年4月21日,苹果春季发布会上推出的iPad Pro 2021搭载M1芯片,令世人震惊;
2021年秋季发布会,苹果推出搭载M1X芯片的14寸和16寸Macbook Pro;
根据彭博社的报告透露,苹果未来的AR/VR设备将集成M系列芯片的高端版本。
那么产业链的消息是2022年的秋季,苹果很可能会发布自己的首款AR/MR头显。与此同时2025年的时候有可能会推出苹果首款AI眼镜。
当然前面也提到了,其实苹果虽然没有推出产品,但是它已经布局了非常多的专利,包括收购了大大小小的各种相关的公司,其实都是公开可以查询到的(http://www.fastscience.tv/collections…
谷歌
看完苹果之后,我们再来看一下谷歌。谷歌在这个领域的布局和定位,可能是没有那么的清晰。比如说我们都知道,Meta的定位是做社交元宇宙;微软做的就是企业元宇宙;苹果面向于 C端消费者市场,定位是做增强现实。
谷歌做了很多尝试性的工作,包括Google DayDream和Google Glass等,但是延续性都不是很强。所以对于谷歌今后将推出什么样的产品,我们无从知晓,目前来说延续性比较好的是ARCORE这一块。
当然它在相关技术的前沿研究上还是做的比较到位的,比如Project Starline,就是一个仿真、全新的社交。“Project Starline”是一个结合了硬件和软件技术进步的技术项目,旨在帮助相隔两地的朋友、家人和同事共聚一起。想象一下,透过一扇神奇的窗户,你可以看到另一个人,真人大小,三维形式。你们可以自然地对话,做手势和进行眼神交流。
华为
2019年推出VR Glass;2021年11月17日推出VR Glass 6dof 游戏套装版本;
2019年11月开源数据虚拟化引擎华为河图Cyberverse, 目的是打造一个“地球级、不断演进,与现实无缝融合的数字新世界”。华为河图有四个核心能力:1、3D高精地图能力;2、全场景空间计算能力;3、强环境理解功能;4、虚拟现实融合渲染能力。
其他公司
**字节跳动:**2021年8月29日字节跳动官宣90亿元人民币收购Pico。
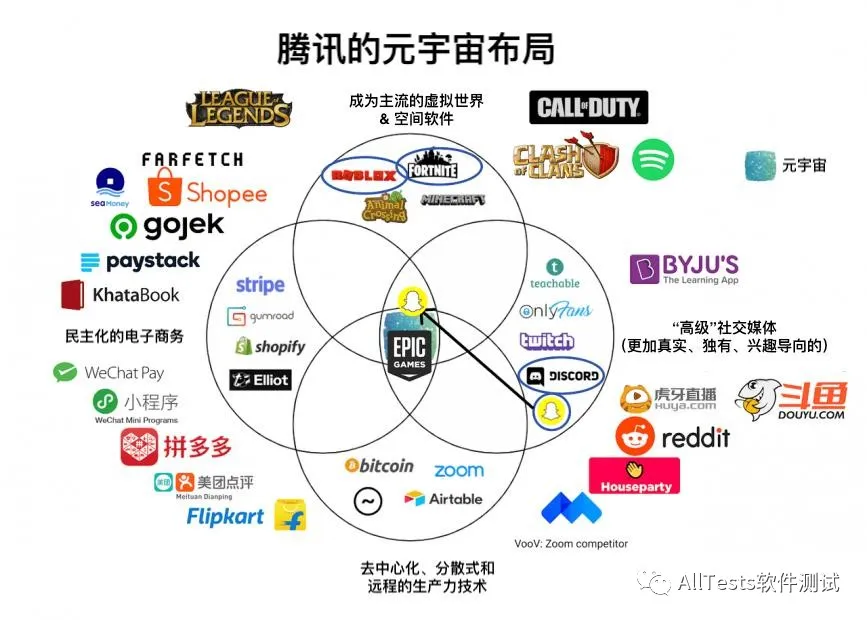
腾讯:提出全真互联网概念。当然他在这个领域的更多是通过投融资投资来布局,比如说投资虚幻引擎,以及做上周又投了一家做触觉手套相关技术的公司。
HTC:
2015年3月在MWC 2015上发布HTC Vive,并于2016年上市;
2017年HTC 将部分手机业务出售给Google后,全面转型VR市场,曾一度占领市场先机。但是近两年C端市场的表现远远落后于Facebook,2021年6月宣布重心转向B端;
2021年5月发布HTC VIVEFocus3商业版和HTC VIVE PRO 2。
Sony:
2016年10月,Sony正式开始发售PSVR,并搭配PS4和下一代的PS5使用;2018年8月,PSVR销售突破了300万台;根据Sony官方透露的消息,PSVR2预计2022年发布
元宇宙百科词典
我们看完了科幻影视作品里面元宇宙,以及巨头对元宇宙之后的看法,接下来我们就看几个关键的核心的名词。
首先是3个R:

VR=一切皆梦幻泡影
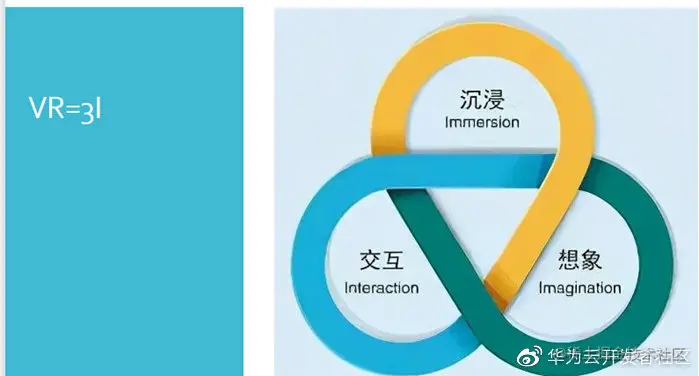
VR(Immersive Virtual Reality)= 虚拟世界,沉浸式虚拟现实,忘了现实世界的一切~
VR满足3个特性,分别是沉浸、交互和想象。
AR=向左是真实,向右是虚幻
AR(Augmented Reality)=真实世界 + 数字化信息
MR=真实虚幻傻傻分不清
MR(Mixed Reality)=真实世界 + 虚拟世界+ 数字化信息,假作真时真亦假,无为有处有还无
**数字人:**什么是数字人,什么是虚拟偶像?通过建模、3D扫描以及动作捕捉,把类似真实的人的形象做成一个虚拟的数字人,然后让他做很多相关的初步动作。待会我们会在技术环节给大家讲述数字人是如何实现的。
**数字孪生(Digital Twin):**虚拟和现实的高度融合互通(现实世界的数字复刻)
1.最早用于NASA阿波罗项目,对飞行中的空间飞行器进行实时仿真;
2.实现物理工厂/系统和数字工厂/系统的交互和融合;
3.面向B端-用于工业4.0、智能制造、智慧城市等;
4.AR/VR、IoT、AI是重要的技术支撑。
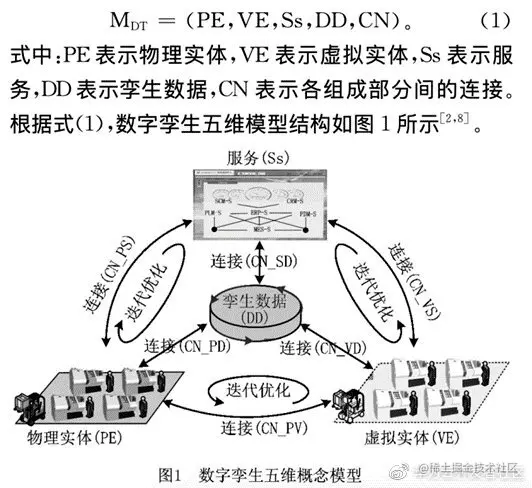
下图是北京航空航天的陶飞等人从车间组成的角度给出了车间数字孪生的定义,然后提出了车间数字孪生的组成,主要包括:物理车间、虚拟车间、车间服务系统、车间孪生数据几部分。物理车间是真实存在的车间,主要从车间服务系统接收生产任务,并按照虚拟车间仿真优化后的执行策略,执行完成任务;虚拟车间是物理车间的计算机内的等价映射,主要负责对生产活动进行仿真分析和优化,并对物理车间的生产活动进行实时的监测、预测和调控;车间服务系统是车间各类软件系统的总称,主要负责车间数字孪生驱动物理车间的运行,和接受物理车间的生产反馈。
**全真网:**马化腾于2020年底在腾讯集团官方年度特刊《三观》提出
1.移动互联网的接替者;
2.虚拟世界和真实世界的全面融合;
3.全面+真实(全面= 消费互联网+产业互联网 真实= AR/VR交互技术)。
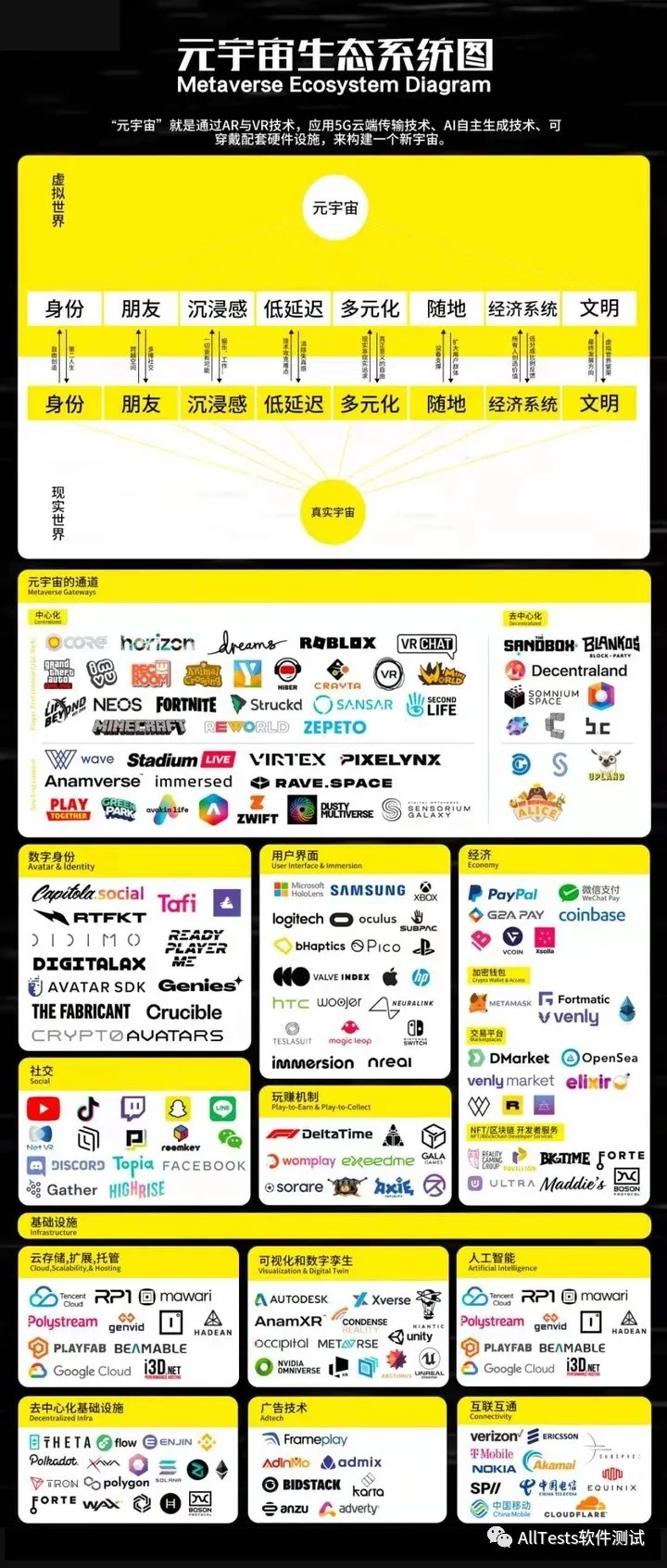
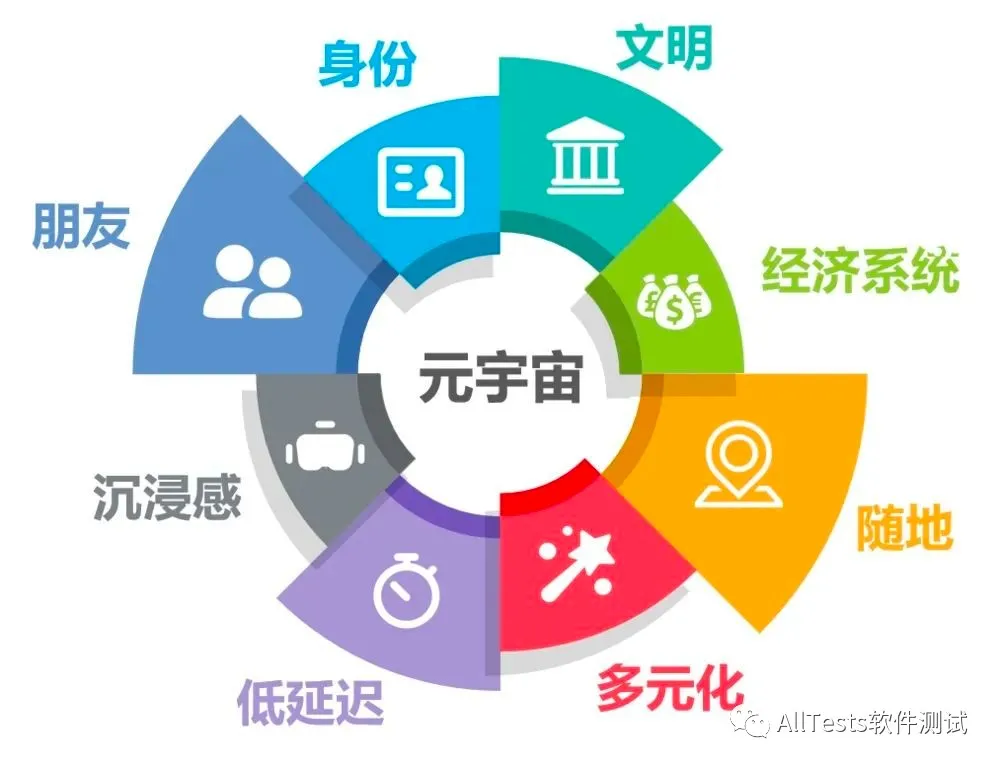
**元宇宙:**源自科幻作品《雪崩》,⼀个⼈们以虚拟形象在三维空间与各种软件进⾏交互的世界。其真正为人所知是今年Roblox上市的时候,把MetaVerse加到了招股说明书,并且提出了元宇宙的八大要素:身份、朋友、沉浸感、低延迟、多元化、随地、经济系统、文明。
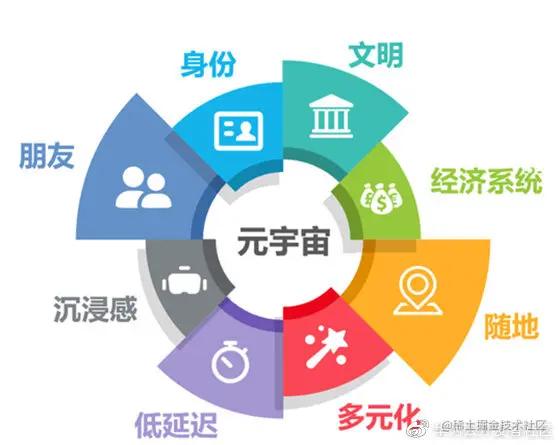
可以看出,其对元宇宙的理解,更多也是一个社交娱乐层面的。而维基百科之中,对元宇宙的定义更加的精准和全面:The metaverse (a portmanteau of "" and"universe") is a hypothesized iteration of the internet, supportingpersistent online 3-D virtual environments through conventional personalcomputing, as well as virtual and augmented reality headsets.
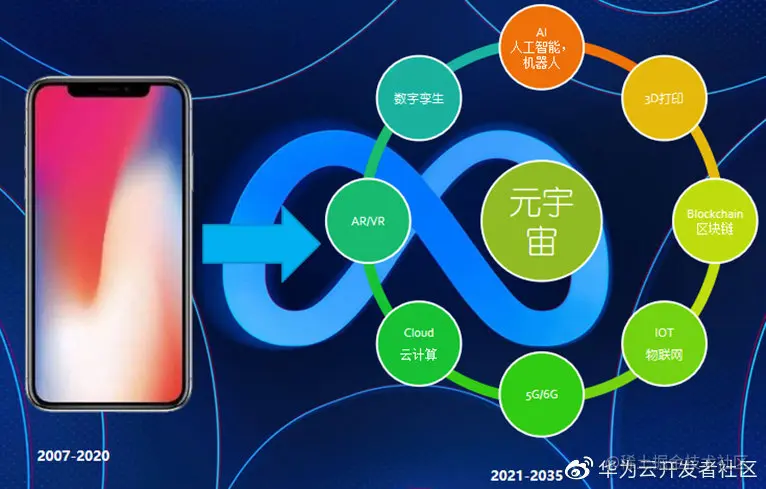
一句话概述:元宇宙就是下一代互联网。
元宇宙的技术基础
那么接下来我们来一起看一看元宇宙就是如何构建的,也就是元宇宙的技术基础。
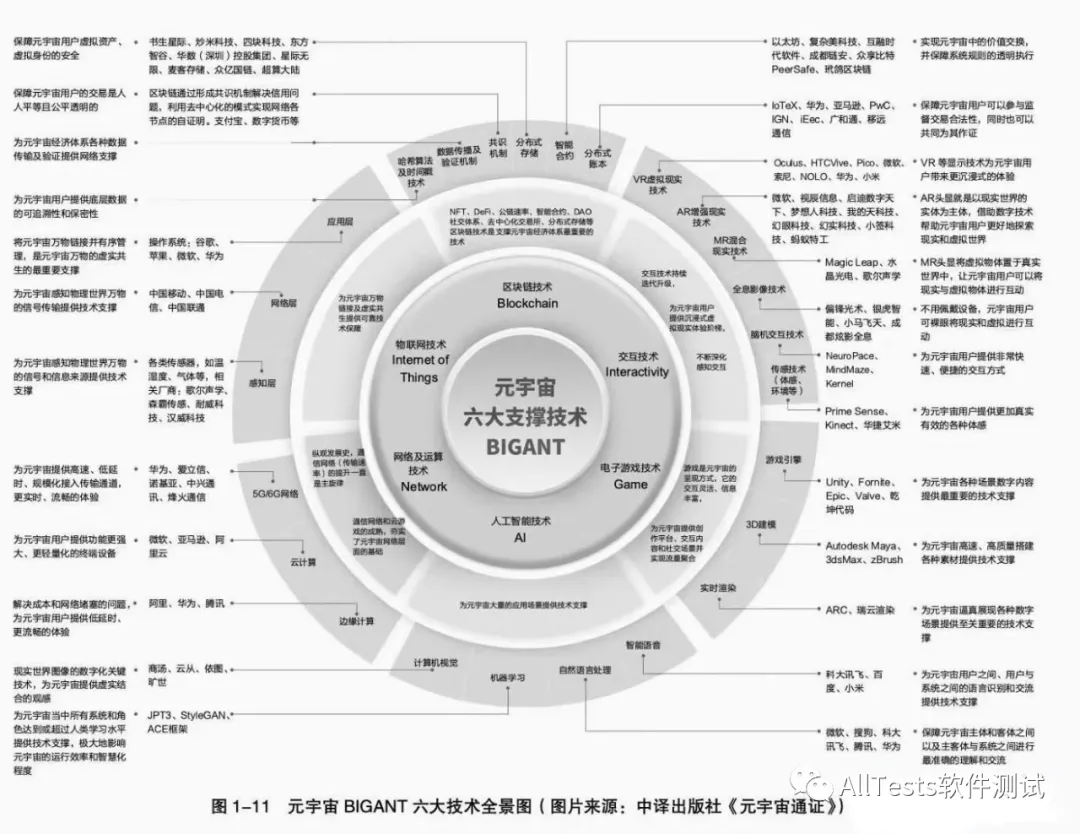
元宇宙的构成技术是非常的多,包括虚拟现实、区块链、AI+人工智能等等.
我们本次重点从虚拟现实和大家分享一下。AR/VR技术的科技树,也就是五大核心技术:近眼显示技术、内容创建技术、网络传输技术、渲染技术、感知和自然交互技术。
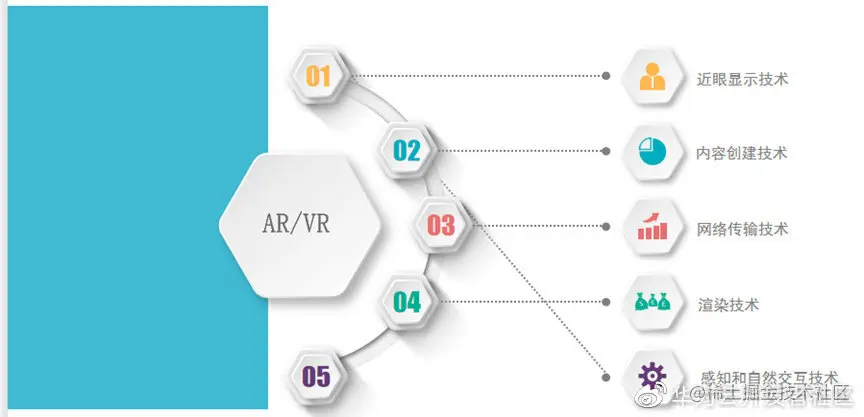
1.Near-eye display(近眼显示技术)包括传统的屏幕显示技术(LCOS/OLED/可折叠的AMOLED/Micro LED)和光学技术(光场显示/波导技术等等。
2.Content creation(内容创作技术)包括虚拟角色和场景构建、动作捕捉、全景视频拍摄与编辑等等。
3.Network communication(网络传输技术)
这方面最受人关注的当然就是即将商用的5G技术,以及传说中传输速率可达每秒1T的下一代6G技术了。当然还有一系列的其它技术有待发展。
4.Rendering Processing(渲染技术)包括本地渲染、云渲染、光场渲染、多重视角渲染,以及硬件渲染加速等等技术。
5.Perception&interaction(感知和自然交互)
包括跟踪定位技术、多感官自然交互技术(脑波、语音交互、触感交互等等)、机器视觉技术(SLAM/场景分离与识别等)
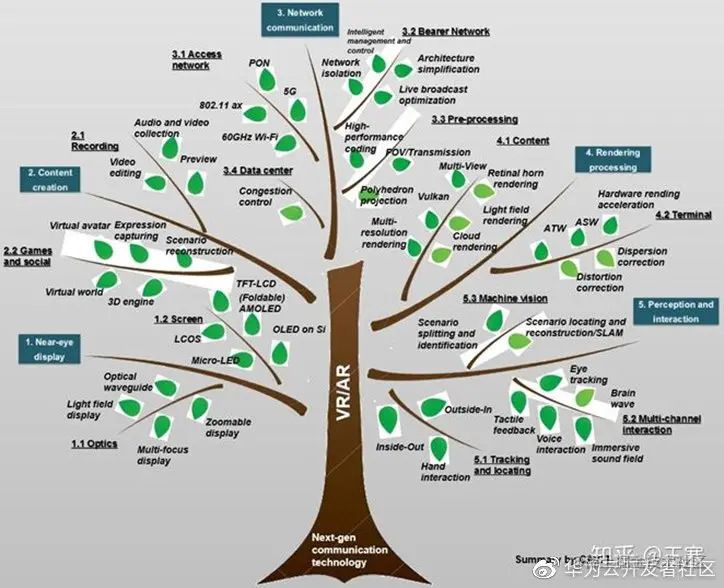
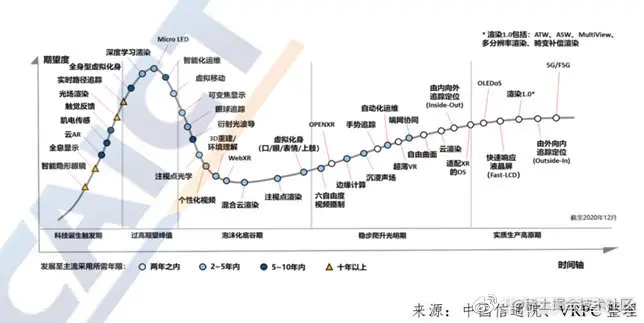
AR/VR技术有一个非常著名的科技树(如下图),我们可以看到刚才提到的五大技术都有一个科技树展开,然后每个树也有自己的树干,每个树干上也有非常多的分支和树叶。毫不夸张的说,在其中的任何一个树干,甚至任何一个树叶之上,如果去做深入的研究,都可以在这个领域成为一个非常资深的专家。
下图是AR/VR技术成熟度曲线,可以看到类似跟踪定位、液晶屏显示、云渲染以及OS相关等技术基本上都是属于两年之内可以商用的。
类似另外一些,比如说自由曲面、虚拟化身、混合云渲染等这些可能要2~5年。
接下来我们快速的带大家来一起过一下5大核心技术。
近眼显示技术
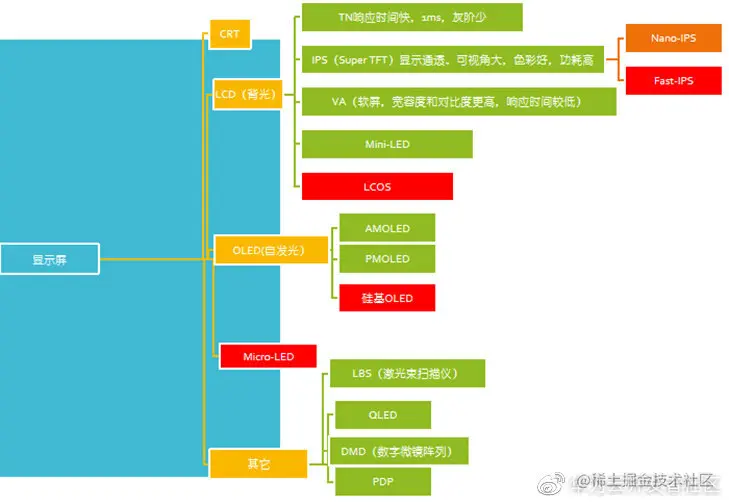
首先是**近眼显示技术。**近眼显示技术分两个部分,分别是显示技术以及光学技术。
显示技术其实就指的各种各样的显示屏,比如LED、MicroLED等等。
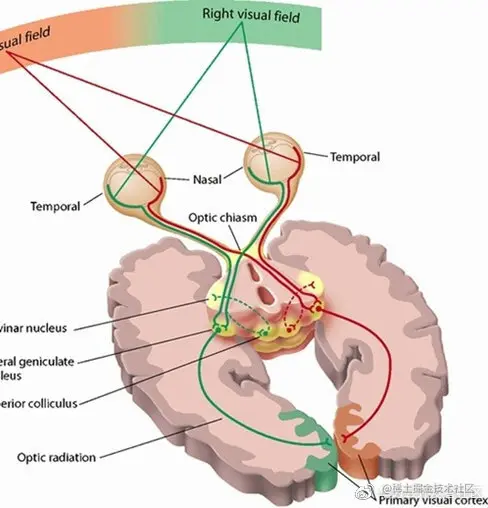
而对于光学技术,我们可能首先想到就是双眼视差原理。人眼是如何实现立体视觉呢?其实最简单就是因为每个人都有两只眼睛,每个眼睛之间都有一定的间隔,通过间隔每个眼睛看到的图像有所差别,再通过我们的大脑的这种判断,最终都形成了一个立体视觉。
同时,AR/VR的光学系统,包括 Pancake,折返式、自由曲面以及光波导。
然后我们再来看一下还有全息投影技术,3D全息投影技术可以分为投射全息投影和反射全息投影两种,是全息摄影技术的逆向展示。
目前我们经常看到的各类表演中所使用的全息投影技术都需要用到全息膜这种特殊的介质,而且需要提前在舞台上做各种精密的光学布置。虽然看起来效果绚丽无比,但成本高昂,操作复杂,需要专业训练,并非每个普通人都可以轻松享受到的。从某种程度上来说,目前的主流商用全息投影技术只能被称作“伪全息投影”。
内容创建技术
内容创建技术分成360全景拍摄、传统3D建模和3D重建。
全景拍摄,其实也就是全景相机还有全景摄像机。
优点:百分百真实
缺点:无法切换焦点,无法和场景及人物互动
3D建模就是大家熟悉的3D MAX、玛雅等。
优点:精度高,流程成熟
缺点:耗费大量人力、时间、精力
3D重建主要是针对于小物体以及人物角色。它本身就分成基于2D图像、基于3D扫描、基于红外TOF。
惯性动作捕捉技术也是比较主流的动作捕捉技术之一。其基本原理是通过惯性导航传感器和IMU(惯性测量单元)来测量演员动作的加速度、方位、倾斜角等特性。惯性动作捕捉技术的特点是不受环境干扰,不怕遮挡,采样速度高,精度高。2015年10月由奥飞动漫参与B轮投资的诺亦腾就是一家提供惯性动作捕捉技术的国内科技创业公司,其动作捕捉设备曾用在2015年最热门的美剧《冰与火之歌:权力的游戏》中,并帮助该剧勇夺第67届艾美奖的“最佳特效奖”。
我们以英伟达的“虚拟发布会”为例,来讲一下怎么搭建一个虚拟场景。
详细的步骤可以参考下图:

第一步:使用3D扫描构建虚拟场景
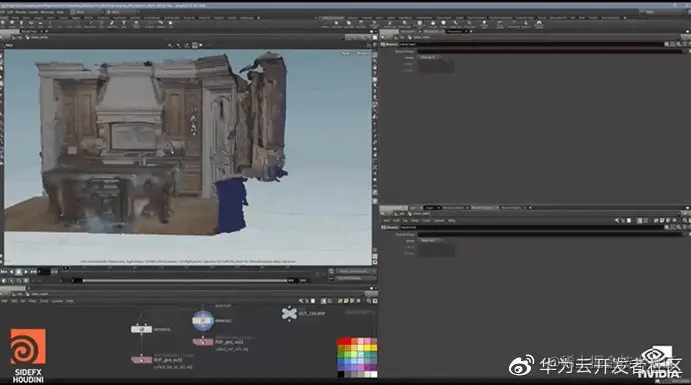
第二步:使用体积摄影进行全身3D建模

第三步:使用AI Audio2Face让口型和面部肌肉变化随语音变动

第四步:使用动作捕捉获取身体姿态动画

第五步:使用RTX渲染器进行实时光线追踪
在了解前述知识点之后,我们再来看看3D引擎和SDK技术。当然在这个领域AR/VR里面最常用的3D引擎无非也就是虚幻和Unity。
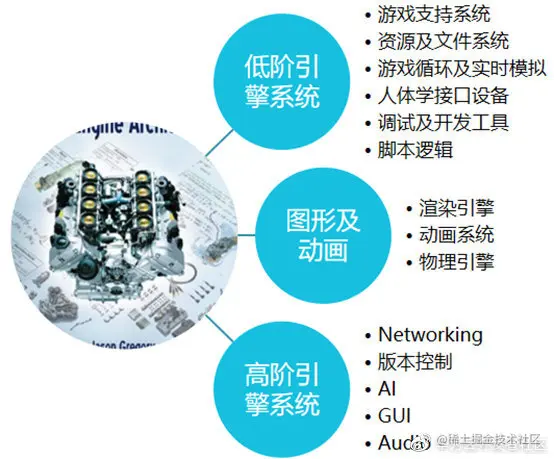
在此,推荐一本非常经典的书叫《游戏引擎架构》。书里对游戏引擎,从低阶到图形动画,再到高阶的构成做了非常详细的描述和解释说明,目前已经是出到第三版了。
AR/VR相关的SDK比如说Vuforia、APPLE ARKit,GOOGLEARCORE等等。
网络传输技术
我们再来看一下网络传输技术。网络传输技术是虚拟现实的支撑技术。
渲染技术渲染技术包括本地渲染、云渲染、光场渲染、多重视角渲染,以及硬件渲染加速等等技术。
本地的VR渲染流程如下:
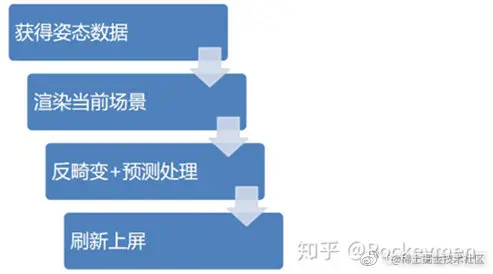
云VR渲染流程:
在本地VR渲染的基础上额外增加三个环节(比本地渲染增加20ms左右的延迟):
1.图像压缩编码
2.网络传输
3.图像解压缩
云VR渲染的利弊:
好处:
1.降低对本地硬件处理能力的要求
包括存储空间、性能、散热等,从而让设备增加轻便
缺点:
1.额外增加延迟,影响实际体验
2.清晰度经压缩和传输后无法保证
端云渲染的配合使用
1.对于不追求及时响应的应用
如3dof游戏、VR看房、旅游景点观赏、全景视频播放等,通过ATW+云渲染+本地观看的方式可以获得比较好的效果。
2.对于追求及时响应的6dof游戏和社交互动应用
渲染处理更多还是需要在本地进行,云端用于处理指令型数据(参考大型多人在线游戏MMORPG)。
3.当前的5G网络和设备硬件性能无法支撑强互动型的云VR渲染和数据传输,未来的6G可以完全实现。
感知和自然交互技术
Inside-out技术
基于单目/双目/多目视觉+IMU的inside-out技术取代早期的Outside-in技术开始产品化,特别是在VR一体机设备,如Oculus Quest /Oculus Quest 2,HTC Vive Focus等。
可以实现:
1.追踪定位
2.手势动作识别
FOV眼动追踪技术
眼动追踪的原理其实很简单,就是使用红外摄像头和LED捕捉人眼或脸部的图像,然后用算法实现人脸和人眼的检测、定位和跟踪,从而估算用户的视线变化。目前主要使用光谱成像和红外光谱成像两种图像处理方法,前一种需要捕捉虹膜和巩膜之间的轮廓,而后一种则跟踪瞳孔轮廓。
SLAM
基于RGBD相机和红外TOF、激光雷达和AI算法等实现实时场景3D重建,在机器人、无人机和AR/VR设备如HoloLens中得到普遍应用,
除此之外,还有语音交互和语义理解、触觉反馈,嗅觉及其它感觉及模拟器。
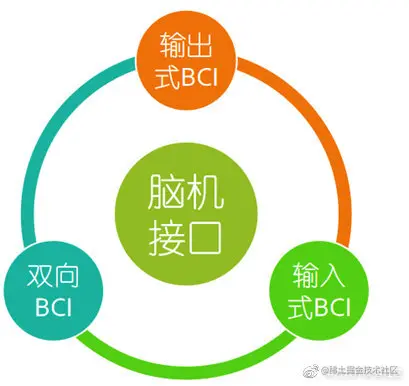
另外还有一个非常亮的亮点——脑机接口(大脑和计算机直接进行交互,有时候又被称为意识-机器交互,神经直连。脑机接口是人或者动物大脑和外部设备间建立的直接连接通道,又分为单向脑机接口和双向脑机接口)。
单向脑机接口只允许单向的信息通讯,比如只允许计算机接受大脑传来的命令,或者只允许计算机向大脑发送信号(比如重建影像)。而双向脑机接口则允许大脑和外部计算机设备间实现双向的信息交换。
如何参与元宇宙
作为开发者也好,作为兴趣者也好,我们如何来参与元宇宙呢?
未来5年产业发展预测
首先看一下产业链的构成,它包括硬件、平台、工具、内容、行业应用,还有服务。
硬件有分很多分支,比如终端设备,还有其中的零部件等等,其中:
1.2022年将是AR/VR行业真正爆发的元年,特别是VR;
2.VR设备从2021年OCQ2代单款突破千万销量后,将开始爆发式增长;
3.苹果新品将让AR/VR从小众精英人群的玩具走向大众,其行业影响力不容小觑;
4.终端设备从2022年开始将成为巨头逐鹿的市场,小型创业团队的窗口期接近关闭,从2021年下半年开始会看到更为密集的战略型投融资或并购事件发生;
5.AR设备在接近诸多技术问题之前,主要仍将面向2B市场,在2025年可能迎来爆发;
6.核心器件方面(芯片、显示屏、光学器件、声光电传感器等模组)投入巨大,不适合初创型团队,目前仍然是巨头以及上市公司体量团队的天下。但该部分也是构成终端设备比例最大的部分;
7.感知交互方面,目前并没有统一的行业标准,空间定位、手势交互、眼动追踪、全身动捕、语音交互、脑机交互都处于发展的早期阶段,该领域有众多的初创企业。而Facebook、苹果等公司收购的重点也在该领域的领先技术团队;
8.其它配套外设,目前全景相机领域已有脱颖而出的领先者,如Insta360,其它领域因生态系统尚未标准化,有较大的空间。
工具平台
1.工具平台中的系统级平台(操作系统/UI)仍将由巨头把控,特别是苹果、Facebook,国内厂商如能接受移动互联网时代的教训,应在第一时间切入底层系统平台的打造,否则仍将受制于人
2.AR/VR内容创建工具目前虽然已经有Unity/UE4等市场领先产品,但是因为设备平台的独特性,仍然有巨大的潜力空间,包括SDK、3D开发引擎、基于AI技术的自动化3D场景和角色建模工具、基于AI技术的高效渲染软件等,都有足够的空间。该部分也给初创型团队留下了足够的机会。
内容-内容创作
随着三大核心产品的爆发,以及C端的量级突破,内容创作方面将迎来全面繁荣,包括影视、游戏、直播、社交、3D/全景等。而内容创作因为其创意和开放性属性,一向是初创团队的首选,在硬件和工具平台领域形成各自王者之后,将有越来越多的团队加入该领域。内容创作和工具平台的交集是类似Roblox的“元宇宙”大型多人在线社交类产品。
内容-内容分发
1.系统级别的内容分发和流量入口仍将占据首要地位,特别是后续的苹果生态
2.类似移动互联网的安卓商城生态,将有众多的第三方内容分发平台涌现,比如专门针对Oculus Quest的SideQuest平台。3.类似于移动互联网时代的微信,后续也将有类似微信的超级APP出现,同样可以扮演内容分发的角色。
行业应用
1.在国内市场,行业应用领域短期内仍将是VR的主要商业变现应用场景,如面向职业教育的教育培训、医疗健康、军事训练等。
2.在可预见的5年周期内,AR的主要应用场景仍然集中在行业领域,特别是智能制造、数字孪生等。
服务
随着行业的爆发式增长,相关的媒体、协会、线下活动等也会更加活跃起来,并逐渐形成集媒体、投融资服务、产品推介等为一体的综合服务,类似移动互联网时代的36kr等。部分媒体也会朝内容分发的方向去尝试。
总结
我们见证了历史,也步入了未来。人人皆可改变世界。