








环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
设置界面
我们来贴代码
跟我们平常写的什么我的界面是大同小异的。主要有这些,其大多设置与demoModel有关
零钱
使用扬声器播放语音
环信官方Demo源码分析及SDK简单应用-EaseUI 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
设置界面
我们来贴代码
跟我们平常写的什么我的界面是大同小异的。主要有这些,其大多设置与demoModel有关
零钱
RedPacketUtil.startChangeActivity(getActivity());接受新消息通知
settingsModel.setSettingMsgNotification(false);
声音
PreferenceManager.getInstance().setSettingMsgNotification(paramBoolean);
valueCache.put(Key.VibrateAndPlayToneOn, paramBoolean);
settingsModel.setSettingMsgSound(false);震动
settingsModel.setSettingMsgVibrate(false);消息推送设置
使用扬声器播放语音
settingsModel.setSettingMsgSpeaker(false);自定义AppKey
settingsModel.enableCustomAppkey(false);自定义server
settingsModel.enableCustomServer(false); settingsModel.enableCustomServer(false);个人资料
startActivity(new Intent(getActivity(), UserProfileActivity.class).putExtra("setting", true)
.putExtra("username", EMClient.getInstance().getCurrentUser()));通讯录黑名单startActivity(new Intent(getActivity(), BlacklistActivity.class));诊断
startActivity(new Intent(getActivity(), DiagnoseActivity.class));IOS离线推送昵称
startActivity(new Intent(getActivity(), OfflinePushNickActivity.class));通话设置
startActivity(new Intent(getActivity(), CallOptionActivity.class));允许聊天室群主离开
settingsModel.allowChatroomOwnerLeave(false);退出群组时删除聊天数据
chatOptions.allowChatroomOwnerLeave(false);
settingsModel.setDeleteMessagesAsExitGroup(false);自动同意群组加群邀请
chatOptions.setDeleteMessagesAsExitGroup(false);
settingsModel.setAutoAcceptGroupInvitation(false);视频自适应编码
chatOptions.setAutoAcceptGroupInvitation(false);
settingsModel.setAdaptiveVideoEncode(false);退出登录
EMClient.getInstance().callManager().getCallOptions().enableFixedVideoResolution(true);
DemoHelper.getInstance().logout(false,new EMCallBack() {
@Override
public void onSuccess() {
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
// show login screen
((MainActivity) getActivity()).finish();
startActivity(new Intent(getActivity(), LoginActivity.class));
}
});
}
@Override
public void onProgress(int progress, String status) {
}
@Override
public void onError(int code, String message) {
getActivity().runOnUiThread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
pd.dismiss();
Toast.makeText(getActivity(), "unbind devicetokens failed", Toast.LENGTH_SHORT).show();
}
});
}
});到这里主界面的三个fragment就都讲完了,我们来看重头戏。环信官方Demo源码分析及SDK简单应用-EaseUI 收起阅读 »
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
刚才我们看了主界面的三个fragment中的第一个界面-会话界面,再来看通讯录界面。
通讯录界面
ContactListFragment
照例,我们来贴代码:
我们先来一个直观的界面感受。
首先是干嘛,是填充了该ListView的头部。

刷新联系人
刷新联系人及邀请信息。
注册同步监听
比较有趣的是如下的操作。
两个方法。
我们再来看其他的方法。
注册同步监听
删除联系人及其他监听实现
下面,我们来看他爹。
EaseContactListFragment
照例的填充布局

我们看到就一个search。
继续看其他的方法
初始化view
拉黑及刷新
联系人排序
各种点击监听
他爷爷是EaseBaseFragment之前分析过就不分析了。 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
刚才我们看了主界面的三个fragment中的第一个界面-会话界面,再来看通讯录界面。
通讯录界面
ContactListFragment
照例,我们来贴代码:
/**界面及初始化
* Copyright (C) 2016 Hyphenate Inc. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.hyphenate.chatuidemo.ui;
import java.util.Hashtable;
import java.util.Map;
import com.hyphenate.chat.EMClient;
import com.hyphenate.chatuidemo.DemoHelper;
import com.hyphenate.chatuidemo.DemoHelper.DataSyncListener;
import com.hyphenate.chatuidemo.R;
import com.hyphenate.chatuidemo.db.InviteMessgeDao;
import com.hyphenate.chatuidemo.db.UserDao;
import com.hyphenate.chatuidemo.widget.ContactItemView;
import com.hyphenate.easeui.domain.EaseUser;
import com.hyphenate.easeui.ui.EaseContactListFragment;
import com.hyphenate.util.EMLog;
import com.hyphenate.util.NetUtils;
import android.annotation.SuppressLint;
import android.app.ProgressDialog;
import android.content.Intent;
import android.view.ContextMenu;
import android.view.ContextMenu.ContextMenuInfo;
import android.view.LayoutInflater;
import android.view.MenuItem;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.AdapterView;
import android.widget.AdapterView.AdapterContextMenuInfo;
import android.widget.AdapterView.OnItemClickListener;
import android.widget.Toast;
/**
* contact list
*
*/
public class ContactListFragment extends EaseContactListFragment {
private static final String TAG = ContactListFragment.class.getSimpleName();
private ContactSyncListener contactSyncListener;
private BlackListSyncListener blackListSyncListener;
private ContactInfoSyncListener contactInfoSyncListener;
private View loadingView;
private ContactItemView applicationItem;
private InviteMessgeDao inviteMessgeDao;
@SuppressLint("InflateParams")
@Override
protected void initView() {
super.initView();
@SuppressLint("InflateParams") View headerView = LayoutInflater.from(getActivity()).inflate(R.layout.em_contacts_header, null);
HeaderItemClickListener clickListener = new HeaderItemClickListener();
applicationItem = (ContactItemView) headerView.findViewById(R.id.application_item);
applicationItem.setOnClickListener(clickListener);
headerView.findViewById(R.id.group_item).setOnClickListener(clickListener);
headerView.findViewById(R.id.chat_room_item).setOnClickListener(clickListener);
headerView.findViewById(R.id.robot_item).setOnClickListener(clickListener);
listView.addHeaderView(headerView);
//add loading view
loadingView = LayoutInflater.from(getActivity()).inflate(R.layout.em_layout_loading_data, null);
contentContainer.addView(loadingView);
registerForContextMenu(listView);
}
@Override
public void refresh() {
Map<String, EaseUser> m = DemoHelper.getInstance().getContactList();
if (m instanceof Hashtable<?, ?>) {
//noinspection unchecked
m = (Map<String, EaseUser>) ((Hashtable<String, EaseUser>)m).clone();
}
setContactsMap(m);
super.refresh();
if(inviteMessgeDao == null){
inviteMessgeDao = new InviteMessgeDao(getActivity());
}
if(inviteMessgeDao.getUnreadMessagesCount() > 0){
applicationItem.showUnreadMsgView();
}else{
applicationItem.hideUnreadMsgView();
}
}
@SuppressWarnings("unchecked")
@Override
protected void setUpView() {
titleBar.setRightImageResource(R.drawable.em_add);
titleBar.setRightLayoutClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
// startActivity(new Intent(getActivity(), AddContactActivity.class));
NetUtils.hasDataConnection(getActivity());
}
});
//设置联系人数据
Map<String, EaseUser> m = DemoHelper.getInstance().getContactList();
if (m instanceof Hashtable<?, ?>) {
m = (Map<String, EaseUser>) ((Hashtable<String, EaseUser>)m).clone();
}
setContactsMap(m);
super.setUpView();
listView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EaseUser user = (EaseUser)listView.getItemAtPosition(position);
if (user != null) {
String username = user.getUsername();
// demo中直接进入聊天页面,实际一般是进入用户详情页
startActivity(new Intent(getActivity(), ChatActivity.class).putExtra("userId", username));
}
}
});
// 进入添加好友页
titleBar.getRightLayout().setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
startActivity(new Intent(getActivity(), AddContactActivity.class));
}
});
contactSyncListener = new ContactSyncListener();
DemoHelper.getInstance().addSyncContactListener(contactSyncListener);
blackListSyncListener = new BlackListSyncListener();
DemoHelper.getInstance().addSyncBlackListListener(blackListSyncListener);
contactInfoSyncListener = new ContactInfoSyncListener();
DemoHelper.getInstance().getUserProfileManager().addSyncContactInfoListener(contactInfoSyncListener);
if (DemoHelper.getInstance().isContactsSyncedWithServer()) {
loadingView.setVisibility(View.GONE);
} else if (DemoHelper.getInstance().isSyncingContactsWithServer()) {
loadingView.setVisibility(View.VISIBLE);
}
}
@Override
public void onDestroy() {
super.onDestroy();
if (contactSyncListener != null) {
DemoHelper.getInstance().removeSyncContactListener(contactSyncListener);
contactSyncListener = null;
}
if(blackListSyncListener != null){
DemoHelper.getInstance().removeSyncBlackListListener(blackListSyncListener);
}
if(contactInfoSyncListener != null){
DemoHelper.getInstance().getUserProfileManager().removeSyncContactInfoListener(contactInfoSyncListener);
}
}
protected class HeaderItemClickListener implements OnClickListener{
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.application_item:
// 进入申请与通知页面
startActivity(new Intent(getActivity(), NewFriendsMsgActivity.class));
break;
case R.id.group_item:
// 进入群聊列表页面
startActivity(new Intent(getActivity(), GroupsActivity.class));
break;
case R.id.chat_room_item:
//进入聊天室列表页面
startActivity(new Intent(getActivity(), PublicChatRoomsActivity.class));
break;
case R.id.robot_item:
//进入Robot列表页面
startActivity(new Intent(getActivity(), RobotsActivity.class));
break;
default:
break;
}
}
}
@Override
public void onCreateContextMenu(ContextMenu menu, View v, ContextMenuInfo menuInfo) {
super.onCreateContextMenu(menu, v, menuInfo);
toBeProcessUser = (EaseUser) listView.getItemAtPosition(((AdapterContextMenuInfo) menuInfo).position);
toBeProcessUsername = toBeProcessUser.getUsername();
getActivity().getMenuInflater().inflate(R.menu.em_context_contact_list, menu);
}
@Override
public boolean onContextItemSelected(MenuItem item) {
if (item.getItemId() == R.id.delete_contact) {
try {
// delete contact
deleteContact(toBeProcessUser);
// remove invitation message
InviteMessgeDao dao = new InviteMessgeDao(getActivity());
dao.deleteMessage(toBeProcessUser.getUsername());
} catch (Exception e) {
e.printStackTrace();
}
return true;
}else if(item.getItemId() == R.id.add_to_blacklist){
moveToBlacklist(toBeProcessUsername);
return true;
}
return super.onContextItemSelected(item);
}
/**
* delete contact
*
* @param toDeleteUser
*/
public void deleteContact(final EaseUser tobeDeleteUser) {
String st1 = getResources().getString(R.string.deleting);
final String st2 = getResources().getString(R.string.Delete_failed);
final ProgressDialog pd = new ProgressDialog(getActivity());
pd.setMessage(st1);
pd.setCanceledOnTouchOutside(false);
pd.show();
new Thread(new Runnable() {
public void run() {
try {
EMClient.getInstance().contactManager().deleteContact(tobeDeleteUser.getUsername());
// remove user from memory and database
UserDao dao = new UserDao(getActivity());
dao.deleteContact(tobeDeleteUser.getUsername());
DemoHelper.getInstance().getContactList().remove(tobeDeleteUser.getUsername());
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
contactList.remove(tobeDeleteUser);
contactListLayout.refresh();
}
});
} catch (final Exception e) {
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st2 + e.getMessage(), Toast.LENGTH_LONG).show();
}
});
}
}
}).start();
}
class ContactSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(final boolean success) {
EMLog.d(TAG, "on contact list sync success:" + success);
getActivity().runOnUiThread(new Runnable() {
public void run() {
getActivity().runOnUiThread(new Runnable(){
@Override
public void run() {
if(success){
loadingView.setVisibility(View.GONE);
refresh();
}else{
String s1 = getResources().getString(R.string.get_failed_please_check);
Toast.makeText(getActivity(), s1, Toast.LENGTH_LONG).show();
loadingView.setVisibility(View.GONE);
}
}
});
}
});
}
}
class BlackListSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(boolean success) {
getActivity().runOnUiThread(new Runnable(){
@Override
public void run() {
refresh();
}
});
}
}
class ContactInfoSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(final boolean success) {
EMLog.d(TAG, "on contactinfo list sync success:" + success);
getActivity().runOnUiThread(new Runnable() {
@Override
public void run() {
loadingView.setVisibility(View.GONE);
if(success){
refresh();
}
}
});
}
}
}
我们先来一个直观的界面感受。
首先是干嘛,是填充了该ListView的头部。
接着我们来看其他方法。
@SuppressLint("InflateParams")
@Override
protected void initView() {
super.initView();
@SuppressLint("InflateParams") View headerView = LayoutInflater.from(getActivity()).inflate(R.layout.em_contacts_header, null);
HeaderItemClickListener clickListener = new HeaderItemClickListener();
applicationItem = (ContactItemView) headerView.findViewById(R.id.application_item);
applicationItem.setOnClickListener(clickListener);
headerView.findViewById(R.id.group_item).setOnClickListener(clickListener);
headerView.findViewById(R.id.chat_room_item).setOnClickListener(clickListener);
headerView.findViewById(R.id.robot_item).setOnClickListener(clickListener);
listView.addHeaderView(headerView);
//add loading view
loadingView = LayoutInflater.from(getActivity()).inflate(R.layout.em_layout_loading_data, null);
contentContainer.addView(loadingView);
registerForContextMenu(listView);
}
刷新联系人
刷新联系人及邀请信息。
@SuppressWarnings("unchecked")
@Override
protected void setUpView() {
titleBar.setRightImageResource(R.drawable.em_add);
titleBar.setRightLayoutClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
// startActivity(new Intent(getActivity(), AddContactActivity.class));
NetUtils.hasDataConnection(getActivity());
}
});
//设置联系人数据
Map<String, EaseUser> m = DemoHelper.getInstance().getContactList();
if (m instanceof Hashtable<?, ?>) {
m = (Map<String, EaseUser>) ((Hashtable<String, EaseUser>)m).clone();
}
setContactsMap(m);
super.setUpView();
listView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EaseUser user = (EaseUser)listView.getItemAtPosition(position);
if (user != null) {
String username = user.getUsername();
// demo中直接进入聊天页面,实际一般是进入用户详情页
startActivity(new Intent(getActivity(), ChatActivity.class).putExtra("userId", username));
}
}
});
// 进入添加好友页
titleBar.getRightLayout().setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
startActivity(new Intent(getActivity(), AddContactActivity.class));
}
});
contactSyncListener = new ContactSyncListener();
DemoHelper.getInstance().addSyncContactListener(contactSyncListener);
blackListSyncListener = new BlackListSyncListener();
DemoHelper.getInstance().addSyncBlackListListener(blackListSyncListener);
contactInfoSyncListener = new ContactInfoSyncListener();
DemoHelper.getInstance().getUserProfileManager().addSyncContactInfoListener(contactInfoSyncListener);
if (DemoHelper.getInstance().isContactsSyncedWithServer()) {
loadingView.setVisibility(View.GONE);
} else if (DemoHelper.getInstance().isSyncingContactsWithServer()) {
loadingView.setVisibility(View.VISIBLE);
}
}常规的一些界面操作。注册同步监听
比较有趣的是如下的操作。
contactSyncListener = new ContactSyncListener();添加了三个同步监听。
DemoHelper.getInstance().addSyncContactListener(contactSyncListener);
blackListSyncListener = new BlackListSyncListener();
DemoHelper.getInstance().addSyncBlackListListener(blackListSyncListener);
contactInfoSyncListener = new ContactInfoSyncListener();
DemoHelper.getInstance().getUserProfileManager().addSyncContactInfoListener(contactInfoSyncListener);
if (DemoHelper.getInstance().isContactsSyncedWithServer()) {
loadingView.setVisibility(View.GONE);
} else if (DemoHelper.getInstance().isSyncingContactsWithServer()) {
loadingView.setVisibility(View.VISIBLE);
}
- addSyncContactListener 同步联系人监听
- addSyncBlackListListener 同步黑名单监听
- addSyncContactInfoListener 同步联系人信息监听
- isContactsSyncedWithServer
- isSyncingContactsWithServer
两个方法。
我们再来看其他的方法。
注册同步监听
注销四个监听。
@Override
public void onDestroy() {
super.onDestroy();
if (contactSyncListener != null) {
DemoHelper.getInstance().removeSyncContactListener(contactSyncListener);
contactSyncListener = null;
}
if(blackListSyncListener != null){
DemoHelper.getInstance().removeSyncBlackListListener(blackListSyncListener);
}
if(contactInfoSyncListener != null){
DemoHelper.getInstance().getUserProfileManager().removeSyncContactInfoListener(contactInfoSyncListener);
}
headview四条目监听。
protected class HeaderItemClickListener implements OnClickListener{
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.application_item:
// 进入申请与通知页面
startActivity(new Intent(getActivity(), NewFriendsMsgActivity.class));
break;
case R.id.group_item:
// 进入群聊列表页面
startActivity(new Intent(getActivity(), GroupsActivity.class));
break;
case R.id.chat_room_item:
//进入聊天室列表页面
startActivity(new Intent(getActivity(), PublicChatRoomsActivity.class));
break;
case R.id.robot_item:
//进入Robot列表页面
startActivity(new Intent(getActivity(), RobotsActivity.class));
break;
default:
break;
}
}
删除联系人及其他监听实现
/**删除联系人,主要两句话。
* delete contact
*
* @param toDeleteUser
*/
public void deleteContact(final EaseUser tobeDeleteUser) {
String st1 = getResources().getString(R.string.deleting);
final String st2 = getResources().getString(R.string.Delete_failed);
final ProgressDialog pd = new ProgressDialog(getActivity());
pd.setMessage(st1);
pd.setCanceledOnTouchOutside(false);
pd.show();
new Thread(new Runnable() {
public void run() {
try {
EMClient.getInstance().contactManager().deleteContact(tobeDeleteUser.getUsername());
// remove user from memory and database
UserDao dao = new UserDao(getActivity());
dao.deleteContact(tobeDeleteUser.getUsername());
DemoHelper.getInstance().getContactList().remove(tobeDeleteUser.getUsername());
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
contactList.remove(tobeDeleteUser);
contactListLayout.refresh();
}
});
} catch (final Exception e) {
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st2 + e.getMessage(), Toast.LENGTH_LONG).show();
}
});
}
}
}).start();
}
class ContactSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(final boolean success) {
EMLog.d(TAG, "on contact list sync success:" + success);
getActivity().runOnUiThread(new Runnable() {
public void run() {
getActivity().runOnUiThread(new Runnable(){
@Override
public void run() {
if(success){
loadingView.setVisibility(View.GONE);
refresh();
}else{
String s1 = getResources().getString(R.string.get_failed_please_check);
Toast.makeText(getActivity(), s1, Toast.LENGTH_LONG).show();
loadingView.setVisibility(View.GONE);
}
}
});
}
});
}
}
class BlackListSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(boolean success) {
getActivity().runOnUiThread(new Runnable(){
@Override
public void run() {
refresh();
}
});
}
}
class ContactInfoSyncListener implements DataSyncListener{
@Override
public void onSyncComplete(final boolean success) {
EMLog.d(TAG, "on contactinfo list sync success:" + success);
getActivity().runOnUiThread(new Runnable() {
@Override
public void run() {
loadingView.setVisibility(View.GONE);
if(success){
refresh();
}
}
});
}
}
EMClient.getInstance().contactManager().deleteContact以及
DemoHelper.getInstance().getContactList().remove(tobeDeleteUser.getUsername());其他监听均实现了DataSyncListener接口。
下面,我们来看他爹。
EaseContactListFragment
/**填充布局
* Copyright (C) 2016 Hyphenate Inc. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.hyphenate.easeui.ui;
import android.app.ProgressDialog;
import android.os.Bundle;
import android.os.Handler;
import android.text.Editable;
import android.text.TextWatcher;
import android.view.LayoutInflater;
import android.view.MotionEvent;
import android.view.View;
import android.view.View.OnClickListener;
import android.view.View.OnTouchListener;
import android.view.ViewGroup;
import android.widget.AdapterView;
import android.widget.AdapterView.OnItemClickListener;
import android.widget.EditText;
import android.widget.FrameLayout;
import android.widget.ImageButton;
import android.widget.ListView;
import android.widget.Toast;
import com.hyphenate.EMConnectionListener;
import com.hyphenate.EMError;
import com.hyphenate.chat.EMClient;
import com.hyphenate.easeui.R;
import com.hyphenate.easeui.domain.EaseUser;
import com.hyphenate.easeui.utils.EaseCommonUtils;
import com.hyphenate.easeui.widget.EaseContactList;
import com.hyphenate.exceptions.HyphenateException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
/**
* contact list
*
*/
public class EaseContactListFragment extends EaseBaseFragment {
private static final String TAG = "EaseContactListFragment";
protected List<EaseUser> contactList;
protected ListView listView;
protected boolean hidden;
protected ImageButton clearSearch;
protected EditText query;
protected Handler handler = new Handler();
protected EaseUser toBeProcessUser;
protected String toBeProcessUsername;
protected EaseContactList contactListLayout;
protected boolean isConflict;
protected FrameLayout contentContainer;
private Map<String, EaseUser> contactsMap;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
return inflater.inflate(R.layout.ease_fragment_contact_list, container, false);
}
@Override
public void onActivityCreated(Bundle savedInstanceState) {
//to avoid crash when open app after long time stay in background after user logged into another device
if(savedInstanceState != null && savedInstanceState.getBoolean("isConflict", false))
return;
super.onActivityCreated(savedInstanceState);
}
@Override
protected void initView() {
contentContainer = (FrameLayout) getView().findViewById(R.id.content_container);
contactListLayout = (EaseContactList) getView().findViewById(R.id.contact_list);
listView = contactListLayout.getListView();
//search
query = (EditText) getView().findViewById(R.id.query);
clearSearch = (ImageButton) getView().findViewById(R.id.search_clear);
}
@Override
protected void setUpView() {
EMClient.getInstance().addConnectionListener(connectionListener);
contactList = new ArrayList<EaseUser>();
getContactList();
//init list
contactListLayout.init(contactList);
if(listItemClickListener != null){
listView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EaseUser user = (EaseUser)listView.getItemAtPosition(position);
listItemClickListener.onListItemClicked(user);
}
});
}
query.addTextChangedListener(new TextWatcher() {
public void onTextChanged(CharSequence s, int start, int before, int count) {
contactListLayout.filter(s);
if (s.length() > 0) {
clearSearch.setVisibility(View.VISIBLE);
} else {
clearSearch.setVisibility(View.INVISIBLE);
}
}
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
public void afterTextChanged(Editable s) {
}
});
clearSearch.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
query.getText().clear();
hideSoftKeyboard();
}
});
listView.setOnTouchListener(new OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
hideSoftKeyboard();
return false;
}
});
}
@Override
public void onHiddenChanged(boolean hidden) {
super.onHiddenChanged(hidden);
this.hidden = hidden;
if (!hidden) {
refresh();
}
}
@Override
public void onResume() {
super.onResume();
if (!hidden) {
refresh();
}
}
/**
* move user to blacklist
*/
protected void moveToBlacklist(final String username){
final ProgressDialog pd = new ProgressDialog(getActivity());
String st1 = getResources().getString(R.string.Is_moved_into_blacklist);
final String st2 = getResources().getString(R.string.Move_into_blacklist_success);
final String st3 = getResources().getString(R.string.Move_into_blacklist_failure);
pd.setMessage(st1);
pd.setCanceledOnTouchOutside(false);
pd.show();
new Thread(new Runnable() {
public void run() {
try {
//move to blacklist
EMClient.getInstance().contactManager().addUserToBlackList(username,false);
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st2, Toast.LENGTH_SHORT).show();
refresh();
}
});
} catch (HyphenateException e) {
e.printStackTrace();
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st3, Toast.LENGTH_SHORT).show();
}
});
}
}
}).start();
}
// refresh ui
public void refresh() {
getContactList();
contactListLayout.refresh();
}
@Override
public void onDestroy() {
EMClient.getInstance().removeConnectionListener(connectionListener);
super.onDestroy();
}
/**
* get contact list and sort, will filter out users in blacklist
*/
protected void getContactList() {
contactList.clear();
if(contactsMap == null){
return;
}
synchronized (this.contactsMap) {
Iterator<Entry<String, EaseUser>> iterator = contactsMap.entrySet().iterator();
List<String> blackList = EMClient.getInstance().contactManager().getBlackListUsernames();
while (iterator.hasNext()) {
Entry<String, EaseUser> entry = iterator.next();
// to make it compatible with data in previous version, you can remove this check if this is new app
if (!entry.getKey().equals("item_new_friends")
&& !entry.getKey().equals("item_groups")
&& !entry.getKey().equals("item_chatroom")
&& !entry.getKey().equals("item_robots")){
if(!blackList.contains(entry.getKey())){
//filter out users in blacklist
EaseUser user = entry.getValue();
EaseCommonUtils.setUserInitialLetter(user);
contactList.add(user);
}
}
}
}
// sorting
Collections.sort(contactList, new Comparator<EaseUser>() {
@Override
public int compare(EaseUser lhs, EaseUser rhs) {
if(lhs.getInitialLetter().equals(rhs.getInitialLetter())){
return lhs.getNick().compareTo(rhs.getNick());
}else{
if("#".equals(lhs.getInitialLetter())){
return 1;
}else if("#".equals(rhs.getInitialLetter())){
return -1;
}
return lhs.getInitialLetter().compareTo(rhs.getInitialLetter());
}
}
});
}
protected EMConnectionListener connectionListener = new EMConnectionListener() {
@Override
public void onDisconnected(int error) {
if (error == EMError.USER_REMOVED || error == EMError.USER_LOGIN_ANOTHER_DEVICE || error == EMError.SERVER_SERVICE_RESTRICTED) {
isConflict = true;
} else {
getActivity().runOnUiThread(new Runnable() {
public void run() {
onConnectionDisconnected();
}
});
}
}
@Override
public void onConnected() {
getActivity().runOnUiThread(new Runnable() {
public void run() {
onConnectionConnected();
}
});
}
};
private EaseContactListItemClickListener listItemClickListener;
protected void onConnectionDisconnected() {
}
protected void onConnectionConnected() {
}
/**
* set contacts map, key is the hyphenate id
* @param contactsMap
*/
public void setContactsMap(Map<String, EaseUser> contactsMap){
this.contactsMap = contactsMap;
}
public interface EaseContactListItemClickListener {
/**
* on click event for item in contact list
* @param user --the user of item
*/
void onListItemClicked(EaseUser user);
}
/**
* set contact list item click listener
* @param listItemClickListener
*/
public void setContactListItemClickListener(EaseContactListItemClickListener listItemClickListener){
this.listItemClickListener = listItemClickListener;
}
}
照例的填充布局
我们看到就一个search。
继续看其他的方法
@Override照例的填充,冲突标志位,初始化view。
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
return inflater.inflate(R.layout.ease_fragment_contact_list, container, false);
}
@Override
public void onActivityCreated(Bundle savedInstanceState) {
//to avoid crash when open app after long time stay in background after user logged into another device
if(savedInstanceState != null && savedInstanceState.getBoolean("isConflict", false))
return;
super.onActivityCreated(savedInstanceState);
}
@Override
protected void initView() {
contentContainer = (FrameLayout) getView().findViewById(R.id.content_container);
contactListLayout = (EaseContactList) getView().findViewById(R.id.contact_list);
listView = contactListLayout.getListView();
//search
query = (EditText) getView().findViewById(R.id.query);
clearSearch = (ImageButton) getView().findViewById(R.id.search_clear);
}
初始化view
@Override寻常的初始化。
protected void setUpView() {
EMClient.getInstance().addConnectionListener(connectionListener);
contactList = new ArrayList<EaseUser>();
getContactList();
//init list
contactListLayout.init(contactList);
if(listItemClickListener != null){
listView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EaseUser user = (EaseUser)listView.getItemAtPosition(position);
listItemClickListener.onListItemClicked(user);
}
});
}
query.addTextChangedListener(new TextWatcher() {
public void onTextChanged(CharSequence s, int start, int before, int count) {
contactListLayout.filter(s);
if (s.length() > 0) {
clearSearch.setVisibility(View.VISIBLE);
} else {
clearSearch.setVisibility(View.INVISIBLE);
}
}
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
public void afterTextChanged(Editable s) {
}
});
clearSearch.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
query.getText().clear();
hideSoftKeyboard();
}
});
listView.setOnTouchListener(new OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
hideSoftKeyboard();
return false;
}
});
}
拉黑及刷新
@Override拉黑,以及刷新。
public void onHiddenChanged(boolean hidden) {
super.onHiddenChanged(hidden);
this.hidden = hidden;
if (!hidden) {
refresh();
}
}
@Override
public void onResume() {
super.onResume();
if (!hidden) {
refresh();
}
}
/**
* move user to blacklist
*/
protected void moveToBlacklist(final String username){
final ProgressDialog pd = new ProgressDialog(getActivity());
String st1 = getResources().getString(R.string.Is_moved_into_blacklist);
final String st2 = getResources().getString(R.string.Move_into_blacklist_success);
final String st3 = getResources().getString(R.string.Move_into_blacklist_failure);
pd.setMessage(st1);
pd.setCanceledOnTouchOutside(false);
pd.show();
new Thread(new Runnable() {
public void run() {
try {
//move to blacklist
EMClient.getInstance().contactManager().addUserToBlackList(username,false);
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st2, Toast.LENGTH_SHORT).show();
refresh();
}
});
} catch (HyphenateException e) {
e.printStackTrace();
getActivity().runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getActivity(), st3, Toast.LENGTH_SHORT).show();
}
});
}
}
}).start();
}
// refresh ui
public void refresh() {
getContactList();
contactListLayout.refresh();
}
@Override
public void onDestroy() {
EMClient.getInstance().removeConnectionListener(connectionListener);
super.onDestroy();
}
联系人排序
/**联系人的排序,将会过滤掉黑名单人员。
* get contact list and sort, will filter out users in blacklist
*/
protected void getContactList() {
contactList.clear();
if(contactsMap == null){
return;
}
synchronized (this.contactsMap) {
Iterator<Entry<String, EaseUser>> iterator = contactsMap.entrySet().iterator();
List<String> blackList = EMClient.getInstance().contactManager().getBlackListUsernames();
while (iterator.hasNext()) {
Entry<String, EaseUser> entry = iterator.next();
// to make it compatible with data in previous version, you can remove this check if this is new app
if (!entry.getKey().equals("item_new_friends")
&& !entry.getKey().equals("item_groups")
&& !entry.getKey().equals("item_chatroom")
&& !entry.getKey().equals("item_robots")){
if(!blackList.contains(entry.getKey())){
//filter out users in blacklist
EaseUser user = entry.getValue();
EaseCommonUtils.setUserInitialLetter(user);
contactList.add(user);
}
}
}
}
// sorting
Collections.sort(contactList, new Comparator<EaseUser>() {
@Override
public int compare(EaseUser lhs, EaseUser rhs) {
if(lhs.getInitialLetter().equals(rhs.getInitialLetter())){
return lhs.getNick().compareTo(rhs.getNick());
}else{
if("#".equals(lhs.getInitialLetter())){
return 1;
}else if("#".equals(rhs.getInitialLetter())){
return -1;
}
return lhs.getInitialLetter().compareTo(rhs.getInitialLetter());
}
}
});
}
各种点击监听
protected EMConnectionListener connectionListener = new EMConnectionListener() {
@Override
public void onDisconnected(int error) {
if (error == EMError.USER_REMOVED || error == EMError.USER_LOGIN_ANOTHER_DEVICE || error == EMError.SERVER_SERVICE_RESTRICTED) {
isConflict = true;
} else {
getActivity().runOnUiThread(new Runnable() {
public void run() {
onConnectionDisconnected();
}
});
}
}
@Override
public void onConnected() {
getActivity().runOnUiThread(new Runnable() {
public void run() {
onConnectionConnected();
}
});
}
};
private EaseContactListItemClickListener listItemClickListener;
protected void onConnectionDisconnected() {
}
protected void onConnectionConnected() {
}
/**
* set contacts map, key is the hyphenate id
* @param contactsMap
*/
public void setContactsMap(Map<String, EaseUser> contactsMap){
this.contactsMap = contactsMap;
}
public interface EaseContactListItemClickListener {
/**
* on click event for item in contact list
* @param user --the user of item
*/
void onListItemClicked(EaseUser user);
}
/**
* set contact list item click listener
* @param listItemClickListener
*/
public void setContactListItemClickListener(EaseContactListItemClickListener listItemClickListener){
this.listItemClickListener = listItemClickListener;
}正常的点击事件。他爷爷是EaseBaseFragment之前分析过就不分析了。 收起阅读 »
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
现在来看具体的主界面的三个Fragment
主界面的三个fragment
会话界面
我们来看会话界面的代码
EaseBaseFragment
看到inputmethdManager要干嘛啊,隐藏键盘。果不其然。
初始化标题头
隐藏和显示标题头
其中还提供了两个方法,隐藏和显示标题头
EaseConversationListFragment
我们来看代码
首先onCreateView(),正常的填充了布局
覆写爷爷的家规,初始化View输入法管理器
我们接着看其他的方法
删除消息并更新未读消息。
好,至此,第一个界面,会话界面到此结束。
我们再来看通讯录界面。
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
现在来看具体的主界面的三个Fragment
主界面的三个fragment
会话界面
我们来看会话界面的代码
我们还是挨个来读代码
package com.hyphenate.chatuidemo.ui;
import android.content.Intent;
import android.view.ContextMenu;
import android.view.ContextMenu.ContextMenuInfo;
import android.view.MenuItem;
import android.view.View;
import android.widget.AdapterView;
import android.widget.AdapterView.AdapterContextMenuInfo;
import android.widget.AdapterView.OnItemClickListener;
import android.widget.LinearLayout;
import android.widget.TextView;
import android.widget.Toast;
import com.easemob.redpacketsdk.constant.RPConstant;
import com.hyphenate.chat.EMClient;
import com.hyphenate.chat.EMConversation;
import com.hyphenate.chat.EMConversation.EMConversationType;
import com.hyphenate.chat.EMMessage;
import com.hyphenate.chatuidemo.Constant;
import com.hyphenate.chatuidemo.R;
import com.hyphenate.chatuidemo.db.InviteMessgeDao;
import com.hyphenate.easeui.model.EaseAtMessageHelper;
import com.hyphenate.easeui.ui.EaseConversationListFragment;
import com.hyphenate.easeui.widget.EaseConversationList.EaseConversationListHelper;
import com.hyphenate.util.NetUtils;
public class ConversationListFragment extends EaseConversationListFragment{
private TextView errorText;
@Override
protected void initView() {
super.initView();
View errorView = (LinearLayout) View.inflate(getActivity(),R.layout.em_chat_neterror_item, null);
errorItemContainer.addView(errorView);
errorText = (TextView) errorView.findViewById(R.id.tv_connect_errormsg);
}
@Override
protected void setUpView() {
super.setUpView();
// register context menu
registerForContextMenu(conversationListView);
conversationListView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EMConversation conversation = conversationListView.getItem(position);
String username = conversation.conversationId();
if (username.equals(EMClient.getInstance().getCurrentUser()))
Toast.makeText(getActivity(), R.string.Cant_chat_with_yourself, Toast.LENGTH_SHORT).show();
else {
// start chat acitivity
Intent intent = new Intent(getActivity(), ChatActivity.class);
if(conversation.isGroup()){
if(conversation.getType() == EMConversationType.ChatRoom){
// it's group chat
intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_CHATROOM);
}else{
intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_GROUP);
}
}
// it's single chat
intent.putExtra(Constant.EXTRA_USER_ID, username);
startActivity(intent);
}
}
});
//red packet code : 红包回执消息在会话列表最后一条消息的展示
conversationListView.setConversationListHelper(new EaseConversationListHelper() {
@Override
public String onSetItemSecondaryText(EMMessage lastMessage) {
if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_RED_PACKET_ACK_MESSAGE, false)) {
String sendNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_SENDER_NAME, "");
String receiveNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_RECEIVER_NAME, "");
String msg;
if (lastMessage.direct() == EMMessage.Direct.RECEIVE) {
msg = String.format(getResources().getString(R.string.msg_someone_take_red_packet), receiveNick);
} else {
if (sendNick.equals(receiveNick)) {
msg = getResources().getString(R.string.msg_take_red_packet);
} else {
msg = String.format(getResources().getString(R.string.msg_take_someone_red_packet), sendNick);
}
}
return msg;
} else if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_TRANSFER_PACKET_MESSAGE, false)) {
String transferAmount = lastMessage.getStringAttribute(RPConstant.EXTRA_TRANSFER_AMOUNT, "");
String msg;
if (lastMessage.direct() == EMMessage.Direct.RECEIVE) {
msg = String.format(getResources().getString(R.string.msg_transfer_to_you), transferAmount);
} else {
msg = String.format(getResources().getString(R.string.msg_transfer_from_you),transferAmount);
}
return msg;
}
return null;
}
});
super.setUpView();
//end of red packet code
}
@Override
protected void onConnectionDisconnected() {
super.onConnectionDisconnected();
if (NetUtils.hasNetwork(getActivity())){
errorText.setText(R.string.can_not_connect_chat_server_connection);
} else {
errorText.setText(R.string.the_current_network);
}
}
@Override
public void onCreateContextMenu(ContextMenu menu, View v, ContextMenuInfo menuInfo) {
getActivity().getMenuInflater().inflate(R.menu.em_delete_message, menu);
}
@Override
public boolean onContextItemSelected(MenuItem item) {
boolean deleteMessage = false;
if (item.getItemId() == R.id.delete_message) {
deleteMessage = true;
} else if (item.getItemId() == R.id.delete_conversation) {
deleteMessage = false;
}
EMConversation tobeDeleteCons = conversationListView.getItem(((AdapterContextMenuInfo) item.getMenuInfo()).position);
if (tobeDeleteCons == null) {
return true;
}
if(tobeDeleteCons.getType() == EMConversationType.GroupChat){
EaseAtMessageHelper.get().removeAtMeGroup(tobeDeleteCons.conversationId());
}
try {
// delete conversation
EMClient.getInstance().chatManager().deleteConversation(tobeDeleteCons.conversationId(), deleteMessage);
InviteMessgeDao inviteMessgeDao = new InviteMessgeDao(getActivity());
inviteMessgeDao.deleteMessage(tobeDeleteCons.conversationId());
} catch (Exception e) {
e.printStackTrace();
}
refresh();
// update unread count
((MainActivity) getActivity()).updateUnreadLabel();
return true;
}
}
public class ConversationListFragment extends EaseConversationListFragment来,我们还是得先去找他爹算账。
public class EaseConversationListFragment extends EaseBaseFragment哎呀,我们再去找他爷爷。
public abstract class EaseBaseFragment extends Fragment爷爷终于正常点是从Android系统类继承下来的了,我们看具体的代码
EaseBaseFragment
package com.hyphenate.easeui.ui;我们还是挨个来看代码,研究他的功能。
import android.content.Context;
import android.os.Bundle;
import android.support.v4.app.Fragment;
import android.view.View;
import android.view.WindowManager;
import android.view.inputmethod.InputMethodManager;
import com.hyphenate.easeui.R;
import com.hyphenate.easeui.widget.EaseTitleBar;
public abstract class EaseBaseFragment extends Fragment{
protected EaseTitleBar titleBar;
protected InputMethodManager inputMethodManager;
@Override
public void onActivityCreated(Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
inputMethodManager = (InputMethodManager) getActivity().getSystemService(Context.INPUT_METHOD_SERVICE);
//noinspection ConstantConditions
titleBar = (EaseTitleBar) getView().findViewById(R.id.title_bar);
initView();
setUpView();
}
public void showTitleBar(){
if(titleBar != null){
titleBar.setVisibility(View.VISIBLE);
}
}
public void hideTitleBar(){
if(titleBar != null){
titleBar.setVisibility(View.GONE);
}
}
protected void hideSoftKeyboard() {
if (getActivity().getWindow().getAttributes().softInputMode != WindowManager.LayoutParams.SOFT_INPUT_STATE_HIDDEN) {
if (getActivity().getCurrentFocus() != null)
inputMethodManager.hideSoftInputFromWindow(getActivity().getCurrentFocus().getWindowToken(),
InputMethodManager.HIDE_NOT_ALWAYS);
}
}
protected abstract void initView();
protected abstract void setUpView();
}
@Override隐藏输入法
public void onActivityCreated(Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
inputMethodManager = (InputMethodManager) getActivity().getSystemService(Context.INPUT_METHOD_SERVICE);
//noinspection ConstantConditions
titleBar = (EaseTitleBar) getView().findViewById(R.id.title_bar);
initView();
setUpView();
}
看到inputmethdManager要干嘛啊,隐藏键盘。果不其然。
protected void hideSoftKeyboard() {
if (getActivity().getWindow().getAttributes().softInputMode != WindowManager.LayoutParams.SOFT_INPUT_STATE_HIDDEN) {
if (getActivity().getCurrentFocus() != null)
inputMethodManager.hideSoftInputFromWindow(getActivity().getCurrentFocus().getWindowToken(),
InputMethodManager.HIDE_NOT_ALWAYS);
}
}然后呢?初始化标题头
//noinspection ConstantConditions最后初始化标题头,并且让子孙们去实现抽象方法initView和setUpView().
titleBar = (EaseTitleBar) getView().findViewById(R.id.title_bar);
隐藏和显示标题头
其中还提供了两个方法,隐藏和显示标题头
public void showTitleBar(){
if(titleBar != null){
titleBar.setVisibility(View.VISIBLE);
}
}
public void hideTitleBar(){
if(titleBar != null){
titleBar.setVisibility(View.GONE);
}
}好了,爷爷的帐算完了,我们来找他儿子。EaseConversationListFragment
我们来看代码
package com.hyphenate.easeui.ui;填充布局
import android.content.Context;
import android.os.Bundle;
import android.os.Handler;
import android.text.Editable;
import android.text.TextWatcher;
import android.util.Pair;
import android.view.LayoutInflater;
import android.view.MotionEvent;
import android.view.View;
import android.view.View.OnClickListener;
import android.view.View.OnTouchListener;
import android.view.ViewGroup;
import android.view.WindowManager;
import android.view.inputmethod.InputMethodManager;
import android.widget.AdapterView;
import android.widget.AdapterView.OnItemClickListener;
import android.widget.EditText;
import android.widget.FrameLayout;
import android.widget.ImageButton;
import com.hyphenate.EMConnectionListener;
import com.hyphenate.EMConversationListener;
import com.hyphenate.EMError;
import com.hyphenate.chat.EMClient;
import com.hyphenate.chat.EMConversation;
import com.hyphenate.easeui.R;
import com.hyphenate.easeui.widget.EaseConversationList;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
/**
* conversation list fragment
*
*/
public class EaseConversationListFragment extends EaseBaseFragment{
private final static int MSG_REFRESH = 2;
protected EditText query;
protected ImageButton clearSearch;
protected boolean hidden;
protected List<EMConversation> conversationList = new ArrayList<EMConversation>();
protected EaseConversationList conversationListView;
protected FrameLayout errorItemContainer;
protected boolean isConflict;
protected EMConversationListener convListener = new EMConversationListener(){
@Override
public void onCoversationUpdate() {
refresh();
}
};
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
return inflater.inflate(R.layout.ease_fragment_conversation_list, container, false);
}
@Override
public void onActivityCreated(Bundle savedInstanceState) {
if(savedInstanceState != null && savedInstanceState.getBoolean("isConflict", false))
return;
super.onActivityCreated(savedInstanceState);
}
@Override
protected void initView() {
inputMethodManager = (InputMethodManager) getActivity().getSystemService(Context.INPUT_METHOD_SERVICE);
conversationListView = (EaseConversationList) getView().findViewById(R.id.list);
query = (EditText) getView().findViewById(R.id.query);
// button to clear content in search bar
clearSearch = (ImageButton) getView().findViewById(R.id.search_clear);
errorItemContainer = (FrameLayout) getView().findViewById(R.id.fl_error_item);
}
@Override
protected void setUpView() {
conversationList.addAll(loadConversationList());
conversationListView.init(conversationList);
if(listItemClickListener != null){
conversationListView.setOnItemClickListener(new OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
EMConversation conversation = conversationListView.getItem(position);
listItemClickListener.onListItemClicked(conversation);
}
});
}
EMClient.getInstance().addConnectionListener(connectionListener);
query.addTextChangedListener(new TextWatcher() {
public void onTextChanged(CharSequence s, int start, int before, int count) {
conversationListView.filter(s);
if (s.length() > 0) {
clearSearch.setVisibility(View.VISIBLE);
} else {
clearSearch.setVisibility(View.INVISIBLE);
}
}
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
public void afterTextChanged(Editable s) {
}
});
clearSearch.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
query.getText().clear();
hideSoftKeyboard();
}
});
conversationListView.setOnTouchListener(new OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
hideSoftKeyboard();
return false;
}
});
}
protected EMConnectionListener connectionListener = new EMConnectionListener() {
@Override
public void onDisconnected(int error) {
if (error == EMError.USER_REMOVED || error == EMError.USER_LOGIN_ANOTHER_DEVICE || error == EMError.SERVER_SERVICE_RESTRICTED) {
isConflict = true;
} else {
handler.sendEmptyMessage(0);
}
}
@Override
public void onConnected() {
handler.sendEmptyMessage(1);
}
};
private EaseConversationListItemClickListener listItemClickListener;
protected Handler handler = new Handler(){
public void handleMessage(android.os.Message msg) {
switch (msg.what) {
case 0:
onConnectionDisconnected();
break;
case 1:
onConnectionConnected();
break;
case MSG_REFRESH:
{
conversationList.clear();
conversationList.addAll(loadConversationList());
conversationListView.refresh();
break;
}
default:
break;
}
}
};
/**
* connected to server
*/
protected void onConnectionConnected(){
errorItemContainer.setVisibility(View.GONE);
}
/**
* disconnected with server
*/
protected void onConnectionDisconnected(){
errorItemContainer.setVisibility(View.VISIBLE);
}
/**
* refresh ui
*/
public void refresh() {
if(!handler.hasMessages(MSG_REFRESH)){
handler.sendEmptyMessage(MSG_REFRESH);
}
}
/**
* load conversation list
*
* @return
+ */
protected List<EMConversation> loadConversationList(){
// get all conversations
Map<String, EMConversation> conversations = EMClient.getInstance().chatManager().getAllConversations();
List<Pair<Long, EMConversation>> sortList = new ArrayList<Pair<Long, EMConversation>>();
/**
* lastMsgTime will change if there is new message during sorting
* so use synchronized to make sure timestamp of last message won't change.
*/
synchronized (conversations) {
for (EMConversation conversation : conversations.values()) {
if (conversation.getAllMessages().size() != 0) {
sortList.add(new Pair<Long, EMConversation>(conversation.getLastMessage().getMsgTime(), conversation));
}
}
}
try {
// Internal is TimSort algorithm, has bug
sortConversationByLastChatTime(sortList);
} catch (Exception e) {
e.printStackTrace();
}
List<EMConversation> list = new ArrayList<EMConversation>();
for (Pair<Long, EMConversation> sortItem : sortList) {
list.add(sortItem.second);
}
return list;
}
/**
* sort conversations according time stamp of last message
*
* @param conversationList
*/
private void sortConversationByLastChatTime(List<Pair<Long, EMConversation>> conversationList) {
Collections.sort(conversationList, new Comparator<Pair<Long, EMConversation>>() {
@Override
public int compare(final Pair<Long, EMConversation> con1, final Pair<Long, EMConversation> con2) {
if (con1.first.equals(con2.first)) {
return 0;
} else if (con2.first.longValue() > con1.first.longValue()) {
return 1;
} else {
return -1;
}
}
});
}
protected void hideSoftKeyboard() {
if (getActivity().getWindow().getAttributes().softInputMode != WindowManager.LayoutParams.SOFT_INPUT_STATE_HIDDEN) {
if (getActivity().getCurrentFocus() != null)
inputMethodManager.hideSoftInputFromWindow(getActivity().getCurrentFocus().getWindowToken(),
InputMethodManager.HIDE_NOT_ALWAYS);
}
}
@Override
public void onHiddenChanged(boolean hidden) {
super.onHiddenChanged(hidden);
this.hidden = hidden;
if (!hidden && !isConflict) {
refresh();
}
}
@Override
public void onResume() {
super.onResume();
if (!hidden) {
refresh();
}
}
@Override
public void onDestroy() {
super.onDestroy();
EMClient.getInstance().removeConnectionListener(connectionListener);
}
@Override
public void onSaveInstanceState(Bundle outState) {
super.onSaveInstanceState(outState);
if(isConflict){
outState.putBoolean("isConflict", true);
}
}
public interface EaseConversationListItemClickListener {
/**
* click event for conversation list
* @param conversation -- clicked item
*/
void onListItemClicked(EMConversation conversation);
}
/**
* set conversation list item click listener
* @param listItemClickListener
*/
public void setConversationListItemClickListener(EaseConversationListItemClickListener listItemClickListener){
this.listItemClickListener = listItemClickListener;
}
}
首先onCreateView(),正常的填充了布局
return inflater.inflate(R.layout.ease_fragment_conversation_list, container, false);继续看代码
判断冲突标志位
@Override
public void onActivityCreated(Bundle savedInstanceState) {
if(savedInstanceState != null && savedInstanceState.getBoolean("isConflict", false))
return;
super.onActivityCreated(savedInstanceState);
}
@OverrideinitView()
protected void initView() {
inputMethodManager = (InputMethodManager) getActivity().getSystemService(Context.INPUT_METHOD_SERVICE);
conversationListView = (EaseConversationList) getView().findViewById(R.id.list);
query = (EditText) getView().findViewById(R.id.query);
// button to clear content in search bar
clearSearch = (ImageButton) getView().findViewById(R.id.search_clear);
errorItemContainer = (FrameLayout) getView().findViewById(R.id.fl_error_item);
}
覆写爷爷的家规,初始化View输入法管理器
- 会话列表List
- 查找联系人的输入框
- 清除搜索的按钮
- errorItemContainer 错误标签容器
conversationList.addAll(loadConversationList());conversationListView.init(conversationList);if(listItemClickListener != null){ conversationListView.setOnItemClickListener(new OnItemClickListener() { @Override public void onItemClick(AdapterView<?> parent, View view, int position, long id) { EMConversation conversation = conversationListView.getItem(position); listItemClickListener.onListItemClicked(conversation); } });}EMClient.getInstance().addConnectionListener(connectionListener);query.addTextChangedListener(new TextWatcher() { public void onTextChanged(CharSequence s, int start, int before, int count) { conversationListView.filter(s); if (s.length() > 0) { clearSearch.setVisibility(View.VISIBLE); } else { clearSearch.setVisibility(View.INVISIBLE); } } public void beforeTextChanged(CharSequence s, int start, int count, int after) { } public void afterTextChanged(Editable s) { }});clearSearch.setOnClickListener(new OnClickListener() { @Override public void onClick(View v) { query.getText().clear(); hideSoftKeyboard(); }});conversationListView.setOnTouchListener(new OnTouchListener() { @Override public boolean onTouch(View v, MotionEvent event) { hideSoftKeyboard(); return false; }});我们一句句的看conversationList.addAll(loadConversationList()); conversationListView.init(conversationList);会话列表添加全部以及数据填充初始化。我们来看具体的方法
/** * load conversation list * * @return */protected List<EMConversation> loadConversationList(){ // get all conversations Map<String, EMConversation> conversations = EMClient.getInstance().chatManager().getAllConversations(); List<Pair<Long, EMConversation>> sortList = new ArrayList<Pair<Long, EMConversation>>(); /** * lastMsgTime will change if there is new message during sorting * so use synchronized to make sure timestamp of last message won't change. */ synchronized (conversations) { for (EMConversation conversation : conversations.values()) { if (conversation.getAllMessages().size() != 0) { sortList.add(new Pair<Long, EMConversation>(conversation.getLastMessage().getMsgTime(), conversation)); } } } try { // Internal is TimSort algorithm, has bug sortConversationByLastChatTime(sortList); } catch (Exception e) { e.printStackTrace(); } List<EMConversation> list = new ArrayList<EMConversation>(); for (Pair<Long, EMConversation> sortItem : sortList) { list.add(sortItem.second); } return list;}loadConversationList()返回一个EMConversation对象List。// get all conversationsMap<String, EMConversation> conversations = EMClient.getInstance().chatManager().getAllConversations();List<Pair<Long, EMConversation>> sortList = new ArrayList<Pair<Long, EMConversation>>();通过封装的chatManager拿到所有的会话列表
/** * lastMsgTime will change if there is new message during sorting * so use synchronized to make sure timestamp of last message won't change. */synchronized (conversations) { for (EMConversation conversation : conversations.values()) { if (conversation.getAllMessages().size() != 0) { sortList.add(new Pair<Long, EMConversation>(conversation.getLastMessage().getMsgTime(), conversation)); } }}lastMsgTime会随着新消息的到来排序发生改变,所以我们用同步方法确保最新消息的时间戳不发生改变。英文不好,大致是这么个意思。 try { // Internal is TimSort algorithm, has bug sortConversationByLastChatTime(sortList); } catch (Exception e) { e.printStackTrace(); } List<EMConversation> list = new ArrayList<EMConversation>(); for (Pair<Long, EMConversation> sortItem : sortList) { list.add(sortItem.second); } return list;其中还特地注释了一把,算法有点bug。 /** * sort conversations according time stamp of last message * * @param conversationList */ private void sortConversationByLastChatTime(List<Pair<Long, EMConversation>> conversationList) { Collections.sort(conversationList, new Comparator<Pair<Long, EMConversation>>() { @Override public int compare(final Pair<Long, EMConversation> con1, final Pair<Long, EMConversation> con2) { if (con1.first.equals(con2.first)) { return 0; } else if (con2.first.longValue() > con1.first.longValue()) { return 1; } else { return -1; } } });根据最新的会话时间戳来排序。我们接着看 List<EMConversation> list = new ArrayList<EMConversation>();for (Pair<Long, EMConversation> sortItem : sortList) { list.add(sortItem.second);}return list;添加完了返回list。conversationListView.init(conversationList);接着就初始化了。
if(listItemClickListener != null){ conversationListView.setOnItemClickListener(new OnItemClickListener() { @Override public void onItemClick(AdapterView<?> parent, View view, int position, long id) { EMConversation conversation = conversationListView.getItem(position); listItemClickListener.onListItemClicked(conversation); } });}然后便是连接接听EMClient.getInstance().addConnectionListener(connectionListener);添加了一个连接的监听。
protected EMConnectionListener connectionListener = new EMConnectionListener() { @Override public void onDisconnected(int error) { if (error == EMError.USER_REMOVED || error == EMError.USER_LOGIN_ANOTHER_DEVICE || error == EMError.SERVER_SERVICE_RESTRICTED) { isConflict = true; } else { handler.sendEmptyMessage(0); } } @Override public void onConnected() { handler.sendEmptyMessage(1); }};在断开连接时判断用户是否移除,是否在其他设备登陆,或者服务端的服务受到限制,是的话则标记冲突。不是则发送handler空消息。protected Handler handler = new Handler(){ public void handleMessage(android.os.Message msg) { switch (msg.what) { case 0: onConnectionDisconnected(); break; case 1: onConnectionConnected(); break; case MSG_REFRESH: { conversationList.clear(); conversationList.addAll(loadConversationList()); conversationListView.refresh(); break; } default: break; } }};干嘛啊?调用 onConnectionDisconnected 即连接断开的处理方法 /** * disconnected with server */protected void onConnectionDisconnected(){ errorItemContainer.setVisibility(View.VISIBLE);}即显示错误条。我们再接着看代码query.addTextChangedListener(new TextWatcher() { public void onTextChanged(CharSequence s, int start, int before, int count) { conversationListView.filter(s); if (s.length() > 0) { clearSearch.setVisibility(View.VISIBLE); } else { clearSearch.setVisibility(View.INVISIBLE); } } public void beforeTextChanged(CharSequence s, int start, int count, int after) { } public void afterTextChanged(Editable s) { }});clearSearch.setOnClickListener(new OnClickListener() { @Override public void onClick(View v) { query.getText().clear(); hideSoftKeyboard(); }});conversationListView.setOnTouchListener(new OnTouchListener() { @Override public boolean onTouch(View v, MotionEvent event) { hideSoftKeyboard(); return false; }});干了些什么啊?查询、清除搜索、会话列表点击监听。其他方法 /** * connected to server */protected void onConnectionConnected(){ errorItemContainer.setVisibility(View.GONE);}连接后将错误条隐藏case MSG_REFRESH: { conversationList.clear(); conversationList.addAll(loadConversationList()); conversationListView.refresh(); break; }服务器告诉要刷新了,那么我们就去清楚列表,然后去服务器拿并排序,然后刷新listview。其中该listview为自定义的EaseConversationList。那么儿子齐活了,我们再看孙子ConversationListFragmentpackage com.hyphenate.chatuidemo.ui;import android.content.Intent;import android.view.ContextMenu;import android.view.ContextMenu.ContextMenuInfo;import android.view.MenuItem;import android.view.View;import android.widget.AdapterView;import android.widget.AdapterView.AdapterContextMenuInfo;import android.widget.AdapterView.OnItemClickListener;import android.widget.LinearLayout;import android.widget.TextView;import android.widget.Toast;import com.easemob.redpacketsdk.constant.RPConstant;import com.hyphenate.chat.EMClient;import com.hyphenate.chat.EMConversation;import com.hyphenate.chat.EMConversation.EMConversationType;import com.hyphenate.chat.EMMessage;import com.hyphenate.chatuidemo.Constant;import com.hyphenate.chatuidemo.R;import com.hyphenate.chatuidemo.db.InviteMessgeDao;import com.hyphenate.easeui.model.EaseAtMessageHelper;import com.hyphenate.easeui.ui.EaseConversationListFragment;import com.hyphenate.easeui.widget.EaseConversationList.EaseConversationListHelper;import com.hyphenate.util.NetUtils;public class ConversationListFragment extends EaseConversationListFragment{ private TextView errorText; @Override protected void initView() { super.initView(); View errorView = (LinearLayout) View.inflate(getActivity(),R.layout.em_chat_neterror_item, null); errorItemContainer.addView(errorView); errorText = (TextView) errorView.findViewById(R.id.tv_connect_errormsg); } @Override protected void setUpView() { super.setUpView(); // register context menu registerForContextMenu(conversationListView); conversationListView.setOnItemClickListener(new OnItemClickListener() { @Override public void onItemClick(AdapterView<?> parent, View view, int position, long id) { EMConversation conversation = conversationListView.getItem(position); String username = conversation.conversationId(); if (username.equals(EMClient.getInstance().getCurrentUser())) Toast.makeText(getActivity(), R.string.Cant_chat_with_yourself, Toast.LENGTH_SHORT).show(); else { // start chat acitivity Intent intent = new Intent(getActivity(), ChatActivity.class); if(conversation.isGroup()){ if(conversation.getType() == EMConversationType.ChatRoom){ // it's group chat intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_CHATROOM); }else{ intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_GROUP); } } // it's single chat intent.putExtra(Constant.EXTRA_USER_ID, username); startActivity(intent); } } }); //red packet code : 红包回执消息在会话列表最后一条消息的展示 conversationListView.setConversationListHelper(new EaseConversationListHelper() { @Override public String onSetItemSecondaryText(EMMessage lastMessage) { if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_RED_PACKET_ACK_MESSAGE, false)) { String sendNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_SENDER_NAME, ""); String receiveNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_RECEIVER_NAME, ""); String msg; if (lastMessage.direct() == EMMessage.Direct.RECEIVE) { msg = String.format(getResources().getString(R.string.msg_someone_take_red_packet), receiveNick); } else { if (sendNick.equals(receiveNick)) { msg = getResources().getString(R.string.msg_take_red_packet); } else { msg = String.format(getResources().getString(R.string.msg_take_someone_red_packet), sendNick); } } return msg; } else if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_TRANSFER_PACKET_MESSAGE, false)) { String transferAmount = lastMessage.getStringAttribute(RPConstant.EXTRA_TRANSFER_AMOUNT, ""); String msg; if (lastMessage.direct() == EMMessage.Direct.RECEIVE) { msg = String.format(getResources().getString(R.string.msg_transfer_to_you), transferAmount); } else { msg = String.format(getResources().getString(R.string.msg_transfer_from_you),transferAmount); } return msg; } return null; } }); super.setUpView(); //end of red packet code } @Override protected void onConnectionDisconnected() { super.onConnectionDisconnected(); if (NetUtils.hasNetwork(getActivity())){ errorText.setText(R.string.can_not_connect_chat_server_connection); } else { errorText.setText(R.string.the_current_network); } } @Override public void onCreateContextMenu(ContextMenu menu, View v, ContextMenuInfo menuInfo) { getActivity().getMenuInflater().inflate(R.menu.em_delete_message, menu); } @Override public boolean onContextItemSelected(MenuItem item) { boolean deleteMessage = false; if (item.getItemId() == R.id.delete_message) { deleteMessage = true; } else if (item.getItemId() == R.id.delete_conversation) { deleteMessage = false; } EMConversation tobeDeleteCons = conversationListView.getItem(((AdapterContextMenuInfo) item.getMenuInfo()).position); if (tobeDeleteCons == null) { return true; } if(tobeDeleteCons.getType() == EMConversationType.GroupChat){ EaseAtMessageHelper.get().removeAtMeGroup(tobeDeleteCons.conversationId()); } try { // delete conversation EMClient.getInstance().chatManager().deleteConversation(tobeDeleteCons.conversationId(), deleteMessage); InviteMessgeDao inviteMessgeDao = new InviteMessgeDao(getActivity()); inviteMessgeDao.deleteMessage(tobeDeleteCons.conversationId()); } catch (Exception e) { e.printStackTrace(); } refresh(); // update unread count ((MainActivity) getActivity()).updateUnreadLabel(); return true; }}initView() @Overrideprotected void initView() { super.initView(); View errorView = (LinearLayout) View.inflate(getActivity(),R.layout.em_chat_neterror_item, null); errorItemContainer.addView(errorView); errorText = (TextView) errorView.findViewById(R.id.tv_connect_errormsg);}添加了错误的容器、初始化错误消息控件。registerForContextMenu(conversationListView);注册上下文菜单
conversationListView.setOnItemClickListener(new OnItemClickListener() { @Override public void onItemClick(AdapterView<?> parent, View view, int position, long id) { EMConversation conversation = conversationListView.getItem(position); String username = conversation.conversationId(); if (username.equals(EMClient.getInstance().getCurrentUser())) Toast.makeText(getActivity(), R.string.Cant_chat_with_yourself, Toast.LENGTH_SHORT).show(); else { // start chat acitivity Intent intent = new Intent(getActivity(), ChatActivity.class); if(conversation.isGroup()){ if(conversation.getType() == EMConversationType.ChatRoom){ // it's group chat intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_CHATROOM); }else{ intent.putExtra(Constant.EXTRA_CHAT_TYPE, Constant.CHATTYPE_GROUP); } } // it's single chat intent.putExtra(Constant.EXTRA_USER_ID, username); startActivity(intent); } }});条目的点击监听其中做了这么些事情:- 判断用户名是否等于当前登陆用户,是则提示不能跟自己聊天
- 如果是群聊的话,则继续判断是聊天室还是群组,并带值给ChatActivity即聊天界面
- 最后将用户名带上,跳转ChatActivity。
//red packet code : 红包回执消息在会话列表最后一条消息的展示最后是红包回执信息。
conversationListView.setConversationListHelper(new EaseConversationListHelper() {
@Override
public String onSetItemSecondaryText(EMMessage lastMessage) {
if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_RED_PACKET_ACK_MESSAGE, false)) {
String sendNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_SENDER_NAME, "");
String receiveNick = lastMessage.getStringAttribute(RPConstant.EXTRA_RED_PACKET_RECEIVER_NAME, "");
String msg;
if (lastMessage.direct() == EMMessage.Direct.RECEIVE) {
msg = String.format(getResources().getString(R.string.msg_someone_take_red_packet), receiveNick);
} else {
if (sendNick.equals(receiveNick)) {
msg = getResources().getString(R.string.msg_take_red_packet);
} else {
msg = String.format(getResources().getString(R.string.msg_take_someone_red_packet), sendNick);
}
}
return msg;
} else if (lastMessage.getBooleanAttribute(RPConstant.MESSAGE_ATTR_IS_TRANSFER_PACKET_MESSAGE, false)) {
String transferAmount = lastMessage.getStringAttribute(RPConstant.EXTRA_TRANSFER_AMOUNT, "");
String msg;
if (lastMessage.direct() == EMMessage.Direct.RECEIVE) {
msg = String.format(getResources().getString(R.string.msg_transfer_to_you), transferAmount);
} else {
msg = String.format(getResources().getString(R.string.msg_transfer_from_you),transferAmount);
}
return msg;
}
return null;
}
});
super.setUpView();
我们接着看其他的方法
端口网络则提示没网标签。
@Override
protected void onConnectionDisconnected() {
super.onConnectionDisconnected();
if (NetUtils.hasNetwork(getActivity())){
errorText.setText(R.string.can_not_connect_chat_server_connection);
} else {
errorText.setText(R.string.the_current_network);
}
}
创建上下文菜单
@Override
public void onCreateContextMenu(ContextMenu menu, View v, ContextMenuInfo menuInfo) {
getActivity().getMenuInflater().inflate(R.menu.em_delete_message, menu);
}
@Override上下文菜单选择的处理方法
public boolean onContextItemSelected(MenuItem item) {
boolean deleteMessage = false;
if (item.getItemId() == R.id.delete_message) {
deleteMessage = true;
} else if (item.getItemId() == R.id.delete_conversation) {
deleteMessage = false;
}
EMConversation tobeDeleteCons = conversationListView.getItem(((AdapterContextMenuInfo) item.getMenuInfo()).position);
if (tobeDeleteCons == null) {
return true;
}
if(tobeDeleteCons.getType() == EMConversationType.GroupChat){
EaseAtMessageHelper.get().removeAtMeGroup(tobeDeleteCons.conversationId());
}
try {
// delete conversation
EMClient.getInstance().chatManager().deleteConversation(tobeDeleteCons.conversationId(), deleteMessage);
InviteMessgeDao inviteMessgeDao = new InviteMessgeDao(getActivity());
inviteMessgeDao.deleteMessage(tobeDeleteCons.conversationId());
} catch (Exception e) {
e.printStackTrace();
}
refresh();
// update unread count[url=http://www.imgeek.org/article/825308690]环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面[/url]
((MainActivity) getActivity()).updateUnreadLabel();
return true;
}
删除消息并更新未读消息。
好,至此,第一个界面,会话界面到此结束。
我们再来看通讯录界面。
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面 收起阅读 »
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
上文我们在已经登录的情况下来到的MainActivity,那么我们在没有登录情况下呢,当然是来登陆页面。下面我们来看登录页。
LoginActivity
自动登录
用户名文本变动监听
下面我们来看登录逻辑
登录逻辑
首先判断当前是否有网络连接
接着往下看
来看比较有意思的
然后就是在登陆之前重新设置下当前登陆的用户名
下面就是具体的登陆实现了
三个接口:
我们看onSuccess中的代码
然后跳转到主界面
那么我们看完了这些Activity了,接着看啥呢?啰嗦了这么久,我们终于可以看具体的主界面的三个Fragment了。
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
上文我们在已经登录的情况下来到的MainActivity,那么我们在没有登录情况下呢,当然是来登陆页面。下面我们来看登录页。
LoginActivity
/**我们挨个来阅读
* Copyright (C) 2016 Hyphenate Inc. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.hyphenate.chatuidemo.ui;
import android.app.ProgressDialog;
import android.content.DialogInterface;
import android.content.DialogInterface.OnCancelListener;
import android.content.Intent;
import android.os.Bundle;
import android.text.Editable;
import android.text.TextUtils;
import android.text.TextWatcher;
import android.util.Log;
import android.view.View;
import android.widget.EditText;
import android.widget.Toast;
import com.hyphenate.EMCallBack;
import com.hyphenate.chat.EMClient;
import com.hyphenate.chatuidemo.DemoApplication;
import com.hyphenate.chatuidemo.DemoHelper;
import com.hyphenate.chatuidemo.R;
import com.hyphenate.chatuidemo.db.DemoDBManager;
import com.hyphenate.easeui.utils.EaseCommonUtils;
/**
* Login screen
*
*/
public class LoginActivity extends BaseActivity {
private static final String TAG = "LoginActivity";
public static final int REQUEST_CODE_SETNICK = 1;
private EditText usernameEditText;
private EditText passwordEditText;
private boolean progressShow;
private boolean autoLogin = false;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// enter the main activity if already logged in
if (DemoHelper.getInstance().isLoggedIn()) {
autoLogin = true;
startActivity(new Intent(LoginActivity.this, MainActivity.class));
return;
}
setContentView(R.layout.em_activity_login);
usernameEditText = (EditText) findViewById(R.id.username);
passwordEditText = (EditText) findViewById(R.id.password);
// if user changed, clear the password
usernameEditText.addTextChangedListener(new TextWatcher() {
@Override
public void onTextChanged(CharSequence s, int start, int before, int count) {
passwordEditText.setText(null);
}
@Override
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
@Override
public void afterTextChanged(Editable s) {
}
});
if (DemoHelper.getInstance().getCurrentUsernName() != null) {
usernameEditText.setText(DemoHelper.getInstance().getCurrentUsernName());
}
}
/**
* login
*
* @param view
*/
public void login(View view) {
if (!EaseCommonUtils.isNetWorkConnected(this)) {
Toast.makeText(this, R.string.network_isnot_available, Toast.LENGTH_SHORT).show();
return;
}
String currentUsername = usernameEditText.getText().toString().trim();
String currentPassword = passwordEditText.getText().toString().trim();
if (TextUtils.isEmpty(currentUsername)) {
Toast.makeText(this, R.string.User_name_cannot_be_empty, Toast.LENGTH_SHORT).show();
return;
}
if (TextUtils.isEmpty(currentPassword)) {
Toast.makeText(this, R.string.Password_cannot_be_empty, Toast.LENGTH_SHORT).show();
return;
}
progressShow = true;
final ProgressDialog pd = new ProgressDialog(LoginActivity.this);
pd.setCanceledOnTouchOutside(false);
pd.setOnCancelListener(new OnCancelListener() {
@Override
public void onCancel(DialogInterface dialog) {
Log.d(TAG, "EMClient.getInstance().onCancel");
progressShow = false;
}
});
pd.setMessage(getString(R.string.Is_landing));
pd.show();
// After logout,the DemoDB may still be accessed due to async callback, so the DemoDB will be re-opened again.
// close it before login to make sure DemoDB not overlap
DemoDBManager.getInstance().closeDB();
// reset current user name before login
DemoHelper.getInstance().setCurrentUserName(currentUsername);
final long start = System.currentTimeMillis();
// call login method
Log.d(TAG, "EMClient.getInstance().login");
EMClient.getInstance().login(currentUsername, currentPassword, new EMCallBack() {
@Override
public void onSuccess() {
Log.d(TAG, "login: onSuccess");
// ** manually load all local groups and conversation
EMClient.getInstance().groupManager().loadAllGroups();
EMClient.getInstance().chatManager().loadAllConversations();
// update current user's display name for APNs
boolean updatenick = EMClient.getInstance().pushManager().updatePushNickname(
DemoApplication.currentUserNick.trim());
if (!updatenick) {
Log.e("LoginActivity", "update current user nick fail");
}
if (!LoginActivity.this.isFinishing() && pd.isShowing()) {
pd.dismiss();
}
// get user's info (this should be get from App's server or 3rd party service)
DemoHelper.getInstance().getUserProfileManager().asyncGetCurrentUserInfo();
Intent intent = new Intent(LoginActivity.this,
MainActivity.class);
startActivity(intent);
finish();
}
@Override
public void onProgress(int progress, String status) {
Log.d(TAG, "login: onProgress");
}
@Override
public void onError(final int code, final String message) {
Log.d(TAG, "login: onError: " + code);
if (!progressShow) {
return;
}
runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getApplicationContext(), getString(R.string.Login_failed) + message,
Toast.LENGTH_SHORT).show();
}
});
}
});
}
/**
* register
*
* @param view
*/
public void register(View view) {
startActivityForResult(new Intent(this, RegisterActivity.class), 0);
}
@Override
protected void onResume() {
super.onResume();
if (autoLogin) {
return;
}
}
}
自动登录
if (DemoHelper.getInstance().isLoggedIn()) {
autoLogin = true;
startActivity(new Intent(LoginActivity.this, MainActivity.class));
return;
}如果已经登录那么设置自动标志位为true,跳到主界面去。用户名文本变动监听
// if user changed, clear the password简单的文本变化监听,用户名变化了就把密码给清空一下。
usernameEditText.addTextChangedListener(new TextWatcher() {
@Override
public void onTextChanged(CharSequence s, int start, int before, int count) {
passwordEditText.setText(null);
}
@Override
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
@Override
public void afterTextChanged(Editable s) {
}
});
if (DemoHelper.getInstance().getCurrentUsernName() != null) {
usernameEditText.setText(DemoHelper.getInstance().getCurrentUsernName());
}
下面我们来看登录逻辑
登录逻辑
首先判断当前是否有网络连接
if (!EaseCommonUtils.isNetWorkConnected(this)) {
Toast.makeText(this, R.string.network_isnot_available, Toast.LENGTH_SHORT).show();
return;
}我们来看看这个工具类是怎么写的/**大家常用的通用判断网络连接方法。
* check if network avalable
*
* @param context
* @return
*/
public static boolean isNetWorkConnected(Context context) {
if (context != null) {
ConnectivityManager mConnectivityManager = (ConnectivityManager) context.getSystemService(Context.CONNECTIVITY_SERVICE);
NetworkInfo mNetworkInfo = mConnectivityManager.getActiveNetworkInfo();
if (mNetworkInfo != null) {
return mNetworkInfo.isAvailable() && mNetworkInfo.isConnected();
}
}
return false;
}
接着往下看
String currentUsername = usernameEditText.getText().toString().trim();正常的取值,弹个进度框。
String currentPassword = passwordEditText.getText().toString().trim();
if (TextUtils.isEmpty(currentUsername)) {
Toast.makeText(this, R.string.User_name_cannot_be_empty, Toast.LENGTH_SHORT).show();
return;
}
if (TextUtils.isEmpty(currentPassword)) {
Toast.makeText(this, R.string.Password_cannot_be_empty, Toast.LENGTH_SHORT).show();
return;
}
progressShow = true;
final ProgressDialog pd = new ProgressDialog(LoginActivity.this);
pd.setCanceledOnTouchOutside(false);
pd.setOnCancelListener(new OnCancelListener() {
@Override
public void onCancel(DialogInterface dialog) {
Log.d(TAG, "EMClient.getInstance().onCancel");
progressShow = false;
}
});
pd.setMessage(getString(R.string.Is_landing));
pd.show();
来看比较有意思的
// After logout,the DemoDB may still be accessed due to async callback, so the DemoDB will be re-opened again.英文不好,大致的意思就是注销以后,DemoDB可能会依然在执行一些异步回调,所以DemoDB会再次重新打开,所以我们要在登陆之前确保DemoDB不会被Overlap。所以我们关闭一下数据库。
// close it before login to make sure DemoDB not overlap
DemoDBManager.getInstance().closeDB();
// reset current user name before login
DemoHelper.getInstance().setCurrentUserName(currentUsername);
然后就是在登陆之前重新设置下当前登陆的用户名
下面就是具体的登陆实现了
EMClient.getInstance().login(currentUsername, currentPassword, new EMCallBack() {
@Override
public void onSuccess() {
Log.d(TAG, "login: onSuccess");
// ** manually load all local groups and conversation
EMClient.getInstance().groupManager().loadAllGroups();
EMClient.getInstance().chatManager().loadAllConversations();
// update current user's display name for APNs
boolean updatenick = EMClient.getInstance().pushManager().updatePushNickname(
DemoApplication.currentUserNick.trim());
if (!updatenick) {
Log.e("LoginActivity", "update current user nick fail");
}
if (!LoginActivity.this.isFinishing() && pd.isShowing()) {
pd.dismiss();
}
// get user's info (this should be get from App's server or 3rd party service)
DemoHelper.getInstance().getUserProfileManager().asyncGetCurrentUserInfo();
Intent intent = new Intent(LoginActivity.this,
MainActivity.class);
startActivity(intent);
finish();
}
@Override
public void onProgress(int progress, String status) {
Log.d(TAG, "login: onProgress");
}
@Override
public void onError(final int code, final String message) {
Log.d(TAG, "login: onError: " + code);
if (!progressShow) {
return;
}
runOnUiThread(new Runnable() {
public void run() {
pd.dismiss();
Toast.makeText(getApplicationContext(), getString(R.string.Login_failed) + message,
Toast.LENGTH_SHORT).show();
}
});
}
});我们看到环信封装了自己实现的登陆方法,并做了回调。三个接口:
- onSuccess() 成功了
- onError() 嗝屁了
- onProgress 处理中
我们看onSuccess中的代码
我们看到跳转到MainActivity之前通用做了相同的群组加载
// ** manually load all local groups and conversation
EMClient.getInstance().groupManager().loadAllGroups();
EMClient.getInstance().chatManager().loadAllConversations();
// update current user's display name for APNs
boolean updatenick = EMClient.getInstance().pushManager().updatePushNickname(
DemoApplication.currentUserNick.trim());
if (!updatenick) {
Log.e("LoginActivity", "update current user nick fail");
}
if (!LoginActivity.this.isFinishing() && pd.isShowing()) {
pd.dismiss();
}
// get user's info (this should be get from App's server or 3rd party service)
DemoHelper.getInstance().getUserProfileManager().asyncGetCurrentUserInfo();
Intent intent = new Intent(LoginActivity.this,
MainActivity.class);
startActivity(intent);
finish();
// ** manually load all local groups and conversation
EMClient.getInstance().groupManager().loadAllGroups();
EMClient.getInstance().chatManager().loadAllConversations();
// update current user's display name for APNs更新当前的推送昵称。
boolean updatenick = EMClient.getInstance().pushManager().updatePushNickname(
DemoApplication.currentUserNick.trim());
if (!updatenick) {
Log.e("LoginActivity", "update current user nick fail");
}
if (!LoginActivity.this.isFinishing() && pd.isShowing()) {
pd.dismiss();
}
异步的从App后台或者三方库中获取用户信息,想想我们之前看他的分包的时候,是不是见到过parse这个包。就是这玩意。
// get user's info (this should be get from App's server or 3rd party service)
DemoHelper.getInstance().getUserProfileManager().asyncGetCurrentUserInfo();
Intent intent = new Intent(LoginActivity.this,
MainActivity.class);
startActivity(intent);
finish();
然后跳转到主界面
然后便是注册了,是直接跳到注册界面去。onResume中如果已经登录直接return掉。
/**
* register
*
* @param view
*/
public void register(View view) {
startActivityForResult(new Intent(this, RegisterActivity.class), 0);
}
@Override
protected void onResume() {
super.onResume();
if (autoLogin) {
return;
}
}
那么我们看完了这些Activity了,接着看啥呢?啰嗦了这么久,我们终于可以看具体的主界面的三个Fragment了。
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
ChatDemoUI3.0
代码结构及逻辑分析
既然上面提到首先分析ChatDemoUI 3.0,那么我们来看看其目录结构

mainfests 清单文件我们稍后来看具体内容
java 具体的代码部分,其包名为com.hyphenate.chatuidemo.
有如下子包:

解决sdk定义版本声明的问题,我们在后面如果使用到了红包的ui,出现了一些sdk的错误可以加上。

SDK常见的一大坨权限。其中Google Cloud Messaging还是别用吧,身在何处,能稳定么?然后就是各种各样的界面声明总共这么些个界面(Tips:由于本文是现阅读现写,所有未中文指出部分,后面代码阅读会去补上):[list=1]开屏页 登陆页 注册 聊天 添加好友 群组邀请 群组列表 聊天室详情 新建群组 退出群组提示框 群组选人 PickAtUserActivity 地图 新的朋友邀请消息页面 转发消息用户列表页面 自定义的contextmenu 显示下载大图页面 下载文件 黑名单 公开的群聊列表 PublicChatRoomsActivity 语音通话 视频通话 群聊简单信息 群组黑名单用户列表 GroupBlacklistActivity GroupSearchMessageActivity PublicGroupsSeachActivity EditActivity EaseShowVideoActivity ImageGridActivity RecorderVideoActivity DiagnoseActivity OfflinePushNickActivity robots list RobotsActivity UserProfileActivity SetServersActivity OfflinePushSettingsActivity CallOptionActivity 发红包 红包详情 红包记录 WebView 零钱 绑定银行卡 群成员列表 支付宝h5支付页面 转账页面 转账详情页面 再往下就是相关的一些广播接收者,服务,以及杂七杂八的东西了。有如下部分:开机自启动[list=1]GCM 小米推送 华为推送 友盟 EMChat服务 EMJob服务 EMMonitor Receiver 百度地图服务 其中比较重要的项目中的Application类继承MultiDexApplication。 在自己的Application类的attachBaseContext方法中调用MultiDex.install(this);。 然后又做了几件事[list=1]初始化DemoHelper 初始化红包并开启日志输出 Application就这样没了,我们继续看SplashActivity。SplashActivity我们来看代码:

我们来看官方文档中关于此isLoggedInBefore()的解释。

我们再回头来看刚才的代码,代码中有句注释,是这么写到。

这里做了等待和判断如果栈顶的ActivityName不为空而且顶栈的名字为语音通话的Activity或者栈顶的名字等于语音通话的Activity。毛线都不做。这个地方猜测应该是指语音通话挂起,重新调起界面的过程。否则,跳到主界面。那么我们接着看主界面。MainActivity那么这个时候,我们应该怎样去看主界面的代码呢?首先看Demo的界面,然后看代码的方法,再一一对应。来,我们来看界面,界面是这个样子的。

三个界面会话、通讯录、设置有了直观的认识以后,我们再来看代码。 我们来一段一段看代码BaseActivityMainActivity继承自BaseActivity。

这段代码其实是用来解决重复实例化Launch Activity的问题。喜欢打破砂锅问到底的,可以自己去google。至于hideSoftKeyboard则是常见的隐藏软键盘其中有一句

说实话自己英文水平不是太好,没搞懂为毛国人写的代码要用英文注释,难道是外国人开发的?注释本身不就是让人简单易懂代码逻辑的。可能跟这个公司大了,这个心理上有些关系吧。

确保当你在其他设备登陆或者登出的时候,界面不在后台。大概我只能翻译成这样了。但是看代码的意思应该是当你再其他设备登陆的时候啊,你的app又在后台,那么这个时候呢,咱啊就你在当前设备点击进来的时候,我就判断你这个saveInstanceState是不是为空。如果不为空而且得到账号已经remove 标识位为true的话,咱就把你当前的界面结束掉。跳到登陆页面去。否则的话,如果savedInstanceState不为空,而且得到isConflict标识位为true的话,也退出去跳到登陆页面。权限请求我们继续看下面的,封装了请求权限的代码。


继续,之后就是常规的界面初始化及其他设置了。

初始化界面方法initView()友盟的更新没用过友盟的东西

从字面上意思来看来应该是当账号冲突,移除,禁止的时候去显示异常。其中用到了showExceptionDialog()方法来显示我们来看看一下代码

当用户遇到一些异常的时候显示对话框,例如在其他设备登陆,账号被移除或者禁止。数据库相关操作
接受了消息了以后调用了updateUnreadLabel();和updateUnreadAddressLable();方法
未读消息数更新
如果为群红包更新意图则调用的converstationListFragment的refersh()方法

添加联系人监听

我们发现是MyContactListener是继承自EMContactListener的,我们再来看看EMContactListener和其官方文档的解释。

我们发现其定义了5个接口,这5个接口根据文档释义分别是如下含义:

如果你正在和这个删除你的人聊天就提示你这个人已把你从他好友列表里移除并且结束掉聊天界面。
测试用广播监听
其他方法
接下来我们来捡漏,看看还有剩余哪些方法没有去看。

判断当前账号是否移除
requestPermission()
initView()
界面切换方法
unregisterBroadcastReceiver();反注册广播接收者。
updateUnreadAddressLable()
getUnreadAddressCountTotal()
getUnreadMsgCountTotal()
getExceptionMessageId() 判断异常的种类
getUnreadAddressCountTotal()
getUnreadMsgCountTotal()
onResume() 中做了一些例如更新未读应用事件消息,并且push当前Activity到easui的ActivityList中
onSaveInstanceState
onKeyDown();判断按了回退的时候。 moveTaskToBack(false);仅当前Activity为task根时,将activity退到后台而非finish();
showExceptionDialog()
showExceptionDialogFromIntent()
onNewIntent() Activity在singleTask模式下重用该实例,onNewIntent()->onResart()->onStart()->onResume()这么个顺序原地复活。
至此,我们的MainActivity就全部阅读完毕了。
我们是在已经登录的情况下来到的MainActivity,那么我们在没有登录情况下呢,当然是来登陆页面。下面我们来看登录页。
环信官方Demo源码分析及SDK简单应用-LoginActivity 收起阅读 »
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现
ChatDemoUI3.0
代码结构及逻辑分析
既然上面提到首先分析ChatDemoUI 3.0,那么我们来看看其目录结构
mainfests 清单文件我们稍后来看具体内容
java 具体的代码部分,其包名为com.hyphenate.chatuidemo.
有如下子包:
- adapter 适配器
- db 数据库相关
- domain 实体相关
- parse 第三方库 parse(用于存储 Demo 中用户的信息)管理包
- receiver 广播接收者
- runtimepermissions 运行时权限相关
- ui 界面部分
- utils 工具类
- video.util 视频录制工具包
- widget 自定义view
- Constant 常量类
- DemoApplication application
- DemoHelper Demo的帮助类
- DemoModel 逻辑相关类
- DemoApplication:继承于系统的 Application 类,其 onCreate() 为整个程序的入口,相关的初始化操作都在这里面;
- DemoHelper: Demo 全局帮助类,主要功能为初始化 EaseUI、环信 SDK 及 Demo 相关的实例,以及封装一些全局使用的方法;
- MainActivity: 主页面,包含会话列表页面(ConversationListFragment)、联系人列表页(ContactListFragment)、设置页面(SettingsFragment),前两个继承自己 EaseUI 中的 fragment;
- ChatActivity: 会话页面,这个类代码很少,主要原因是大部分逻辑写在 ChatFragment 中。ChatFragment 继承自 EaseChatFragment,做成 fragment 的好处在于用起来更灵活,可以单独作为一个页面使用,也可以和其他 fragment 一起放到一个 Activity 中;
- GroupDetailsActivity: 群组详情页面
- 分包挺清晰
- 抓住了DemoHelper和DemoModel也就抓住了整个的纲领
- 其他的你就自己扯吧。
- AndroidMainfest.xml
- DemoApplication
- SplashActivity
- 各流程类
解决sdk定义版本声明的问题,我们在后面如果使用到了红包的ui,出现了一些sdk的错误可以加上。
SDK常见的一大坨权限。其中Google Cloud Messaging还是别用吧,身在何处,能稳定么?然后就是各种各样的界面声明总共这么些个界面(Tips:由于本文是现阅读现写,所有未中文指出部分,后面代码阅读会去补上):[list=1]
<!-- 设置环信应用的appkey --> <meta-data android:name="EASEMOB_APPKEY" android:value="你自己的环信Key" />这样,我们基本AndroidMainfest就阅读完了。因为Androidmainfest.xml指出主Activity为ui包下的SplashActivity。按理说我们应该接着来看SplashActivity。但是别忘了App启动后DemoApplication是在主界面之前的。我们将在阅读完Application后再来看SplashActivity。DemoApplication上代码:
/** * Copyright (C) 2016 Hyphenate Inc. All rights reserved. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * http://www.apache.org/licenses/LICENSE-2.0 * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package com.hyphenate.chatuidemo;import android.app.Application;import android.content.Context;import android.support.multidex.MultiDex;import com.easemob.redpacketsdk.RedPacket;public class DemoApplication extends Application { public static Context applicationContext; private static DemoApplication instance; // login user name public final String PREF_USERNAME = "username"; /** * nickname for current user, the nickname instead of ID be shown when user receive notification from APNs */ public static String currentUserNick = ""; @Override public void onCreate() { MultiDex.install(this); super.onCreate(); applicationContext = this; instance = this; //init demo helper DemoHelper.getInstance().init(applicationContext); //red packet code : 初始化红包上下文,开启日志输出开关 RedPacket.getInstance().initContext(applicationContext); RedPacket.getInstance().setDebugMode(true); //end of red packet code } public static DemoApplication getInstance() { return instance; } @Override protected void attachBaseContext(Context base) { super.attachBaseContext(base); MultiDex.install(this); }}第一句是分包,我们知道分包有以下两种方式:[list=1] package com.hyphenate.chatuidemo.ui;import android.content.Intent;import android.os.Bundle;import android.view.animation.AlphaAnimation;import android.widget.RelativeLayout;import android.widget.TextView;import com.hyphenate.chat.EMClient;import com.hyphenate.chatuidemo.DemoHelper;import com.hyphenate.chatuidemo.R;import com.hyphenate.util.EasyUtils;/** * 开屏页 * */public class SplashActivity extends BaseActivity { private static final int sleepTime = 2000; @Override protected void onCreate(Bundle arg0) { setContentView(R.layout.em_activity_splash); super.onCreate(arg0); RelativeLayout rootLayout = (RelativeLayout) findViewById(R.id.splash_root); TextView versionText = (TextView) findViewById(R.id.tv_version); versionText.setText(getVersion()); AlphaAnimation animation = new AlphaAnimation(0.3f, 1.0f); animation.setDuration(1500); rootLayout.startAnimation(animation); } @Override protected void onStart() { super.onStart(); new Thread(new Runnable() { public void run() { if (DemoHelper.getInstance().isLoggedIn()) { // auto login mode, make sure all group and conversation is loaed before enter the main screen long start = System.currentTimeMillis(); EMClient.getInstance().chatManager().loadAllConversations(); EMClient.getInstance().groupManager().loadAllGroups(); long costTime = System.currentTimeMillis() - start; //wait if (sleepTime - costTime > 0) { try { Thread.sleep(sleepTime - costTime); } catch (InterruptedException e) { e.printStackTrace(); } } String topActivityName = EasyUtils.getTopActivityName(EMClient.getInstance().getContext()); if (topActivityName != null && (topActivityName.equals(VideoCallActivity.class.getName()) || topActivityName.equals(VoiceCallActivity.class.getName()))) { // nop // avoid main screen overlap Calling Activity } else { //enter main screen startActivity(new Intent(SplashActivity.this, MainActivity.class)); } finish(); }else { try { Thread.sleep(sleepTime); } catch (InterruptedException e) { } startActivity(new Intent(SplashActivity.this, LoginActivity.class)); finish(); } } }).start(); } /** * get sdk version */ private String getVersion() { return EMClient.getInstance().VERSION; }}UI部分我们不关心,我们来看下代码逻辑部分 new Thread(new Runnable() { public void run() { if (DemoHelper.getInstance().isLoggedIn()) { // auto login mode, make sure all group and conversation is loaed before enter the main screen long start = System.currentTimeMillis(); EMClient.getInstance().chatManager().loadAllConversations(); EMClient.getInstance().groupManager().loadAllGroups(); long costTime = System.currentTimeMillis() - start; //wait if (sleepTime - costTime > 0) { try { Thread.sleep(sleepTime - costTime); } catch (InterruptedException e) { e.printStackTrace(); } } String topActivityName = EasyUtils.getTopActivityName(EMClient.getInstance().getContext()); if (topActivityName != null && (topActivityName.equals(VideoCallActivity.class.getName()) || topActivityName.equals(VoiceCallActivity.class.getName()))) { // nop // avoid main screen overlap Calling Activity } else { //enter main screen startActivity(new Intent(SplashActivity.this, MainActivity.class)); } finish(); }else { try { Thread.sleep(sleepTime); } catch (InterruptedException e) { } startActivity(new Intent(SplashActivity.this, LoginActivity.class)); finish(); } } }).start();在这里,我们看到了这个DemoHelper帮助类,起了个线程,判断是否已经登录。我们来看看他是如何判断的。我们来看官方文档中关于此isLoggedInBefore()的解释。
我们再回头来看刚才的代码,代码中有句注释,是这么写到。
// auto login mode, make sure all group and conversation is loaed before enter the main screen自动登录模式,请确保进入主页面后本地回话和群组都load完毕。那么代码中有两句话就是干这个事情的
EMClient.getInstance().chatManager().loadAllConversations();EMClient.getInstance().groupManager().loadAllGroups();这里部分代码最好是放在SplashActivity因为如果登录过,APP 长期在后台再进的时候也可能会导致加载到内存的群组和会话为空。
这里做了等待和判断如果栈顶的ActivityName不为空而且顶栈的名字为语音通话的Activity或者栈顶的名字等于语音通话的Activity。毛线都不做。这个地方猜测应该是指语音通话挂起,重新调起界面的过程。否则,跳到主界面。那么我们接着看主界面。MainActivity那么这个时候,我们应该怎样去看主界面的代码呢?首先看Demo的界面,然后看代码的方法,再一一对应。来,我们来看界面,界面是这个样子的。
三个界面会话、通讯录、设置有了直观的认识以后,我们再来看代码。 我们来一段一段看代码BaseActivityMainActivity继承自BaseActivity。
/** * Copyright (C) 2016 Hyphenate Inc. All rights reserved. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * http://www.apache.org/licenses/LICENSE-2.0 * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package com.hyphenate.chatuidemo.ui;import android.annotation.SuppressLint;import android.os.Bundle;import com.hyphenate.easeui.ui.EaseBaseActivity;import com.umeng.analytics.MobclickAgent;@SuppressLint("Registered")public class BaseActivity extends EaseBaseActivity { @Override protected void onCreate(Bundle arg0) { super.onCreate(arg0); } @Override protected void onResume() { super.onResume(); // umeng MobclickAgent.onResume(this); } @Override protected void onStart() { super.onStart(); // umeng MobclickAgent.onPause(this); }}只有友盟的一些数据埋点,我们继续往上挖看他爹。EaseBaseActivity/** * Copyright (C) 2016 Hyphenate Inc. All rights reserved. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * http://www.apache.org/licenses/LICENSE-2.0 * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package com.hyphenate.easeui.ui;import android.annotation.SuppressLint;import android.content.Context;import android.content.Intent;import android.os.Bundle;import android.support.v4.app.FragmentActivity;import android.view.View;import android.view.WindowManager;import android.view.inputmethod.InputMethodManager;import com.hyphenate.easeui.controller.EaseUI;@SuppressLint({"NewApi", "Registered"})public class EaseBaseActivity extends FragmentActivity { protected InputMethodManager inputMethodManager; @Override protected void onCreate(Bundle arg0) { super.onCreate(arg0); //http://stackoverflow.com/questions/4341600/how-to-prevent-multiple-instances-of-an-activity-when-it-is-launched-with-differ/ // should be in launcher activity, but all app use this can avoid the problem if(!isTaskRoot()){ Intent intent = getIntent(); String action = intent.getAction(); if(intent.hasCategory(Intent.CATEGORY_LAUNCHER) && action.equals(Intent.ACTION_MAIN)){ finish(); return; } } inputMethodManager = (InputMethodManager) getSystemService(Context.INPUT_METHOD_SERVICE); } @Override protected void onResume() { super.onResume(); // cancel the notification EaseUI.getInstance().getNotifier().reset(); } protected void hideSoftKeyboard() { if (getWindow().getAttributes().softInputMode != WindowManager.LayoutParams.SOFT_INPUT_STATE_HIDDEN) { if (getCurrentFocus() != null) inputMethodManager.hideSoftInputFromWindow(getCurrentFocus().getWindowToken(), InputMethodManager.HIDE_NOT_ALWAYS); } } /** * back * * @param view */ public void back(View view) { finish(); }}这段代码其实是用来解决重复实例化Launch Activity的问题。喜欢打破砂锅问到底的,可以自己去google。至于hideSoftKeyboard则是常见的隐藏软键盘其中有一句
EaseUI.getInstance().getNotifier().reset();其中Notifier()为新消息提醒类,reset()方法调用了resetNotificationCount()和cancelNotificaton()。重置消息提醒数和取消提醒。
public void reset(){ resetNotificationCount(); cancelNotificaton(); } void resetNotificationCount() { notificationNum = 0; fromUsers.clear(); } void cancelNotificaton() { if (notificationManager != null) notificationManager.cancel(notifyID); }耗电优化首先判断系统版本是否大于6.0,如果是,则判断是否忽略电池耗电的优化。说实话自己英文水平不是太好,没搞懂为毛国人写的代码要用英文注释,难道是外国人开发的?注释本身不就是让人简单易懂代码逻辑的。可能跟这个公司大了,这个心理上有些关系吧。
确保当你在其他设备登陆或者登出的时候,界面不在后台。大概我只能翻译成这样了。但是看代码的意思应该是当你再其他设备登陆的时候啊,你的app又在后台,那么这个时候呢,咱啊就你在当前设备点击进来的时候,我就判断你这个saveInstanceState是不是为空。如果不为空而且得到账号已经remove 标识位为true的话,咱就把你当前的界面结束掉。跳到登陆页面去。否则的话,如果savedInstanceState不为空,而且得到isConflict标识位为true的话,也退出去跳到登陆页面。权限请求我们继续看下面的,封装了请求权限的代码。
继续,之后就是常规的界面初始化及其他设置了。
初始化界面方法initView()友盟的更新没用过友盟的东西
MobclickAgent.updateOnlineConfig(this);UmengUpdateAgent.setUpdateOnlyWifi(false);UmengUpdateAgent.update(this);看字面意思第一句应该是点击数据埋起点,后面应该是设置仅wifi更新为false以及设置更新。异常提示从Intent中获取的异常标志位进行一个弹窗提示
从字面上意思来看来应该是当账号冲突,移除,禁止的时候去显示异常。其中用到了showExceptionDialog()方法来显示我们来看看一下代码
当用户遇到一些异常的时候显示对话框,例如在其他设备登陆,账号被移除或者禁止。数据库相关操作
inviteMessgeDao = new InviteMessgeDao(this);UserDao userDao = new UserDao(this);初始化Fragment
conversationListFragment = new ConversationListFragment(); contactListFragment = new ContactListFragment(); SettingsFragment settingFragment = new SettingsFragment(); fragments = new Fragment { conversationListFragment, contactListFragment, settingFragment}; getSupportFragmentManager().beginTransaction().add(R.id.fragment_container, conversationListFragment) .add(R.id.fragment_container, contactListFragment).hide(contactListFragment).show(conversationListFragment) .commit();注册广播接收者//register broadcast receiver to receive the change of group from DemoHelperregisterBroadcastReceiver();从英文注释来看,字面意思来看是用DemoHelper来注册广播接收者来接受群变化通知。我们来看具体的代码
private void registerBroadcastReceiver() { broadcastManager = LocalBroadcastManager.getInstance(this); IntentFilter intentFilter = new IntentFilter(); intentFilter.addAction(Constant.ACTION_CONTACT_CHANAGED); intentFilter.addAction(Constant.ACTION_GROUP_CHANAGED); intentFilter.addAction(RPConstant.REFRESH_GROUP_RED_PACKET_ACTION); broadcastReceiver = new BroadcastReceiver() { @Override public void onReceive(Context context, Intent intent) { updateUnreadLabel(); updateUnreadAddressLable(); if (currentTabIndex == 0) { // refresh conversation list if (conversationListFragment != null) { conversationListFragment.refresh(); } } else if (currentTabIndex == 1) { if(contactListFragment != null) { contactListFragment.refresh(); } } String action = intent.getAction(); if(action.equals(Constant.ACTION_GROUP_CHANAGED)){ if (EaseCommonUtils.getTopActivity(MainActivity.this).equals(GroupsActivity.class.getName())) { GroupsActivity.instance.onResume(); } } //red packet code : 处理红包回执透传消息 if (action.equals(RPConstant.REFRESH_GROUP_RED_PACKET_ACTION)){ if (conversationListFragment != null){ conversationListFragment.refresh(); } } //end of red packet code } }; broadcastManager.registerReceiver(broadcastReceiver, intentFilter); } LocalBroadcastManager是Android Support包提供了一个工具,是用来在同一个应用内的不同组件间发送Broadcast的。使用LocalBroadcastManager有如下好处:发送的广播只会在自己App内传播,不会泄露给其他App,确保隐私数据不会泄露 其他App也无法向你的App发送该广播,不用担心其他App会来搞破坏 比系统全局广播更加高效 拦截了这么几种广播,按字面意思,应该是这么几类- Constant.ACTION_CONTACT_CHANAGED 联系人变化广播
- Constant.ACTION_GROUP_CHANAGED 群组变化广播
- RPConstant.REFRESH_GROUP_RED_PACKET_ACTION 刷新群红包广播
接受了消息了以后调用了updateUnreadLabel();和updateUnreadAddressLable();方法
未读消息数更新
更新总计未读数量
/**
* update unread message count
*/
public void updateUnreadLabel() {
int count = getUnreadMsgCountTotal();
if (count > 0) {
unreadLabel.setText(String.valueOf(count));
unreadLabel.setVisibility(View.VISIBLE);
} else {
unreadLabel.setVisibility(View.INVISIBLE);
}
}
/**然后判断广播类型,如果当前的栈顶为主界面,则调用GroupsActivity的onResume方法。
* update the total unread count
*/
public void updateUnreadAddressLable() {
runOnUiThread(new Runnable() {
public void run() {
int count = getUnreadAddressCountTotal();
if (count > 0) {
unreadAddressLable.setVisibility(View.VISIBLE);
} else {
unreadAddressLable.setVisibility(View.INVISIBLE);
}
}
});
}
如果为群红包更新意图则调用的converstationListFragment的refersh()方法
添加联系人监听
EMClient.getInstance().contactManager().setContactListener(new MyContactListener());我们来看下这个MyContactListener()监听方法。
我们发现是MyContactListener是继承自EMContactListener的,我们再来看看EMContactListener和其官方文档的解释。
我们发现其定义了5个接口,这5个接口根据文档释义分别是如下含义:
void onContactAdded (String username)//增加联系人时回调此方法从而我们得知,我们demo中的自定义监听接口在被删除回调时,做了如下操作:
void onContactDeleted (String username)//被删除时回调此方法
void onContactInvited (String username, String reason)/**收到好友邀请 参数 username 发起加为好友用户的名称 reason 对方发起好友邀请时发出的文字性描述*/
void onFriendRequestAccepted (String username)//对方同意好友请求
void onFriendRequestDeclined (String username)//对方拒绝好友请求
如果你正在和这个删除你的人聊天就提示你这个人已把你从他好友列表里移除并且结束掉聊天界面。
测试用广播监听
//debug purpose only
registerInternalDebugReceiver();
/**至此MainActivity的OnCreate方法中所有涉及到的代码我们均已看完。
* debug purpose only, you can ignore this
*/
private void registerInternalDebugReceiver() {
internalDebugReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
DemoHelper.getInstance().logout(false,new EMCallBack() {
@Override
public void onSuccess() {
runOnUiThread(new Runnable() {
public void run() {
finish();
startActivity(new Intent(MainActivity.this, LoginActivity.class));
}
});
}
@Override
public void onProgress(int progress, String status) {}
@Override
public void onError(int code, String message) {}
});
}
};
IntentFilter filter = new IntentFilter(getPackageName() + ".em_internal_debug");
registerReceiver(internalDebugReceiver, filter);
}
其他方法
接下来我们来捡漏,看看还有剩余哪些方法没有去看。
判断当前账号是否移除
/**oncreate()
* check if current user account was remove
*/
public boolean getCurrentAccountRemoved() {
return isCurrentAccountRemoved;
}
requestPermission()
initView()
界面切换方法
/**消息刷新
* on tab clicked
*
* @param view
*/
public void onTabClicked(View view) {
switch (view.getId()) {
case R.id.btn_conversation:
index = 0;
break;
case R.id.btn_address_list:
index = 1;
break;
case R.id.btn_setting:
index = 2;
break;
}
if (currentTabIndex != index) {
FragmentTransaction trx = getSupportFragmentManager().beginTransaction();
trx.hide(fragments[currentTabIndex]);
if (!fragments[index].isAdded()) {
trx.add(R.id.fragment_container, fragments[index]);
}
trx.show(fragments[index]).commit();
}
mTabs[currentTabIndex].setSelected(false);
// set current tab selected
mTabs[index].setSelected(true);
currentTabIndex = index;
}
private void refreshUIWithMessage() {
runOnUiThread(new Runnable() {
public void run() {
// refresh unread count
updateUnreadLabel();
if (currentTabIndex == 0) {
// refresh conversation list
if (conversationListFragment != null) {
conversationListFragment.refresh();
}
}
}
});
}registerBroadcastReceiver()unregisterBroadcastReceiver();反注册广播接收者。
onDestory()
private void unregisterBroadcastReceiver(){
broadcastManager.unregisterReceiver(broadcastReceiver);
}
@Override异常的弹窗disimiss及置空,反注册广播接收者。
protected void onDestroy() {
super.onDestroy();
if (exceptionBuilder != null) {
exceptionBuilder.create().dismiss();
exceptionBuilder = null;
isExceptionDialogShow = false;
}
unregisterBroadcastReceiver();
try {
unregisterReceiver(internalDebugReceiver);
} catch (Exception e) {
}
}
updateUnreadAddressLable()
getUnreadAddressCountTotal()
getUnreadMsgCountTotal()
getExceptionMessageId() 判断异常的种类
showExceptionDialog()
private int getExceptionMessageId(String exceptionType) {
if(exceptionType.equals(Constant.ACCOUNT_CONFLICT)) {
return R.string.connect_conflict;
} else if (exceptionType.equals(Constant.ACCOUNT_REMOVED)) {
return R.string.em_user_remove;
} else if (exceptionType.equals(Constant.ACCOUNT_FORBIDDEN)) {
return R.string.user_forbidden;
}
return R.string.Network_error;
}
getUnreadAddressCountTotal()
getUnreadMsgCountTotal()
onResume() 中做了一些例如更新未读应用事件消息,并且push当前Activity到easui的ActivityList中
onStop();
@Override
protected void onResume() {
super.onResume();
if (!isConflict && !isCurrentAccountRemoved) {
updateUnreadLabel();
updateUnreadAddressLable();
}
// unregister this event listener when this activity enters the
// background
DemoHelper sdkHelper = DemoHelper.getInstance();
sdkHelper.pushActivity(this);
EMClient.getInstance().chatManager().addMessageListener(messageListener);
}
@Override做了一些销毁的活。
protected void onStop() {
EMClient.getInstance().chatManager().removeMessageListener(messageListener);
DemoHelper sdkHelper = DemoHelper.getInstance();
sdkHelper.popActivity(this);
super.onStop();
}
onSaveInstanceState
@Override存一下冲突和账户移除的标志位
protected void onSaveInstanceState(Bundle outState) {
outState.putBoolean("isConflict", isConflict);
outState.putBoolean(Constant.ACCOUNT_REMOVED, isCurrentAccountRemoved);
super.onSaveInstanceState(outState);
}
onKeyDown();判断按了回退的时候。 moveTaskToBack(false);仅当前Activity为task根时,将activity退到后台而非finish();
@OverridegetExceptionMessageId()
public boolean onKeyDown(int keyCode, KeyEvent event) {
if (keyCode == KeyEvent.KEYCODE_BACK) {
moveTaskToBack(false);
return true;
}
return super.onKeyDown(keyCode, event);
}
showExceptionDialog()
showExceptionDialogFromIntent()
onNewIntent() Activity在singleTask模式下重用该实例,onNewIntent()->onResart()->onStart()->onResume()这么个顺序原地复活。
至此,我们的MainActivity就全部阅读完毕了。
我们是在已经登录的情况下来到的MainActivity,那么我们在没有登录情况下呢,当然是来登陆页面。下面我们来看登录页。
环信官方Demo源码分析及SDK简单应用-LoginActivity 收起阅读 »
ios V2.3.1 已发布,增加获取日志压缩文件路径接口
ios版本:V2.3.1 2016-02-17

新功能/改进:
版本历史:ios 2.x更新日志
下载地址:SDK下载 收起阅读 »
新功能/改进:
- 修改HttpsOnly参数默认值,默认设置为NO(由于苹果强制ATS政策延缓, 所以SDK默认关闭httpsOnly)
[[EaseMob sharedInstance].chatManager setIsUseHttpsOnly:YES];//设置httpsonly,YES开启,NO关闭
- 增加获取日志压缩文件路径接口(具体上传日志方式可由开发者决定, Demo是通过邮件的形式上报日志)
- 优化群组过多时重连卡顿问题
- 修复离线已读回执有时丢失问题
- 修复SDK收到特殊消息闪退问题
版本历史:ios 2.x更新日志
下载地址:SDK下载 收起阅读 »
Web IM V1.4.10已发布,新增语音呼叫

新功能:
[sdk] webrtc新增语音呼叫
Bug修复:
[sdk] webrtc:Firefox在结束通话后的问题
[sdk] webrtc:多次接通挂断之后,逻辑功能混乱
[sdk] webrtc:正常挂断不应该提醒offline
[sdk] webrtc:重连后无法处理音视频IQ消息
webim体验:https://webim.easemob.com
版本历史:更新日志
SDK下载:下载地址 收起阅读 »
Android 依赖EaseUI联系人列表显示昵称 修改之前的发起的那篇文章
在设置时要说明 好友数据由app的服务器提供的 所以服务端也要集成
注意 我的页面以及类都是从Demo中复制过来的
我们必须要知道好友数据是在什么位置进行数据适配的
在UserDao中有一个方法是saveContactList这个就是进行好友数据保存的操作了
之前我自己创建了一个数据库 进行操作发现出现很多问题 修改的地方也比较多 走了很多弯路
这次经过观察 Demo已经为我们创建了数据库和表 我们只需要在正确的位置把我们获取的数据保存起来就可以了
那么我们的任务就是定位这个方法是在哪调用的,经过代码的跟踪,最终定位到这个位置在
DemoHelper中asyncFetchContactsFromServer()方法
这个方法在没有修改的情况下是从环信服务器获取的好友数据
为了方便我把代码贴出来
//这里就是开始从自己app的服务器获取好友数据了
//这是关键的地方
//报讯联系人的数据就是在这了
以上就是我的代码了 希望有用 我已经解决昵称的问题了 至于头像也是一样的道理了
之前的文章有很多问题 这里给小伙们说声对不起了 收起阅读 »
注意 我的页面以及类都是从Demo中复制过来的
我们必须要知道好友数据是在什么位置进行数据适配的
在UserDao中有一个方法是saveContactList这个就是进行好友数据保存的操作了
之前我自己创建了一个数据库 进行操作发现出现很多问题 修改的地方也比较多 走了很多弯路
这次经过观察 Demo已经为我们创建了数据库和表 我们只需要在正确的位置把我们获取的数据保存起来就可以了
那么我们的任务就是定位这个方法是在哪调用的,经过代码的跟踪,最终定位到这个位置在
DemoHelper中asyncFetchContactsFromServer()方法
这个方法在没有修改的情况下是从环信服务器获取的好友数据
为了方便我把代码贴出来
public void asyncFetchContactsFromServer(final EMValueCallBack<List<String>> callback) {
if (isSyncingContactsWithServer) {
return;
}
isSyncingContactsWithServer = true;
new Thread() {
@Override public void run() {
List<String> usernames = null;
try {
usernames = EMClient.getInstance().contactManager().getAllContactsFromServer(); // in case that logout already before server returns, we should return immediately
if (!isLoggedIn()) {
isContactsSyncedWithServer = false;
isSyncingContactsWithServer = false;
notifyContactsSyncListener(false); return;
}
//这里就是开始从自己app的服务器获取好友数据了
Map<String, EaseUser> userlist = new HashMap<String, EaseUser>();
String url = AppConfig.BASE_URL+AppConfig.GETFRIENDS;
HashMap<String, String> map = new HashMap<>(); map.put("userName",PreforenceUtils.getStringData("userInfo","hxid"));
Log.e(TAG,url);
MyHttpUtils myHttpUtils = new MyHttpUtils();
String s = myHttpUtils.httpPost(url, "", "&user", map.toString());
Log.e(TAG,s);
JSONArray jarr = new JSONArray(s);
if(jarr.length()!=0||jarr != null){
for (int i = 0; i < jarr.length(); i++) {
JSONObject jobj = (JSONObject) jarr.get(i);
EaseUser easeUser = new EaseUser(jobj.getString("FRIENDID")); easeUser.setNick(jobj.getString("FRIENDNICKNAME"));
easeUser.setAvatar("");
Log.e(TAG,easeUser.toString());
EaseCommonUtils.setUserInitialLetter(easeUser);
//这是关键的地方
userlist.put(jobj.getString("FRIENDID"), easeUser);
}
//这是就是将数据转换成Easeuser对象 的原有方式 已经注释掉了 其他代码没有做修改
/*for (String username : usernames) {
EaseUser user = new EaseUser(username);
EaseCommonUtils.setUserInitialLetter(user);
userlist.put(username, user); }*/
// save the contact list to cache getContactList().clear(); getContactList().putAll(userlist); // save the contact list to database
UserDao dao = new UserDao(appContext);
List<EaseUser> users = new ArrayList<EaseUser>(userlist.values());
Log.e(TAG,"获取联系人");//报讯联系人的数据就是在这了
dao.saveContactList(users);
demoModel.setContactSynced(true);
EMLog.d(TAG, "set contact syn status to true");
isContactsSyncedWithServer = true; isSyncingContactsWithServer = false;
//notify sync success notifyContactsSyncListener(true); getUserProfileManager().asyncFetchContactInfosFromServer(usernames, new EMValueCallBack<List<EaseUser>>() {
@Override public void onSuccess(List<EaseUser> uList) {
updateContactList(uList);
getUserProfileManager().notifyContactInfosSyncListener(true);
}
@Override public void onError(int error, String errorMsg) { } });
if (callback != null) { callback.onSuccess(usernames); } } }
catch (HyphenateException e) { d
emoModel.setContactSynced(false);
isContactsSyncedWithServer = false;
isSyncingContactsWithServer = false;
notifyContactsSyncListener(false);
e.printStackTrace();
if (callback != null) {
callback.onError(e.getErrorCode(), e.toString()); } }
catch (JSONException e) { e.printStackTrace(); } } }.start(); }
以上就是我的代码了 希望有用 我已经解决昵称的问题了 至于头像也是一样的道理了
之前的文章有很多问题 这里给小伙们说声对不起了 收起阅读 »
让IVR具备“判断”的能力

任何一个呼叫中心都离不开IVR(Interactive Voice Response),即互动式语音应答系统。它作为呼叫中心的门户,最初被赋予的作用有两点:一是初步甄别客户的需求,通过不同的按键设置导流客户需求;二是通过提供自动语音服务来降低日益增加的人工成本。
从IVR进入呼叫中心领域到2012年约二十多年的时间里,所有的呼叫中心管理者都是按照以上两点考虑去规划和设计自己的IVR架构,这期间呼叫中心的管理水平以及客户体验也因此而产生飞速的发展,一方面对于客户而言,很多业务都可以通过自助方式办理,真正体验到了呼叫中心全天候的业务优势;另一方面对于呼叫中心的管理者而言,大量相对简单、适合人机对话的业务被自动方式取代,所需要的人工服务成本大大降低,节省下来的人力资源可以用于更有价值的业务,同时诸如“自助服务占比”等KPI指标也应运而生,被列入呼叫中心管理和考核体系。这样的情况一方面促进了客户体验和呼叫中心管理水平的提高;另一方面随着时间的推进,它的负面作用也逐渐显现,那就是IVR的结构越来越复杂、层级越来越深。现在你拨打任何一个客服中心,无论他是银行业、保险业、电信业或其他行业,大概都会听到一个庞杂的IRV语音提示系统,注意这里我用了“系统”这个词。之所以用这个词,一方面是说明它的复杂性,如果你不是一个经常拨打的老手,你真的很不容易找到自己想要找的东西;另一方面如果抛开客户体验单纯从呼叫中心业务管理层面去看,这样的IVR真的非常完美,它承载了很多自助功能,具备完美的逻辑体系和严谨的语音提示。这时IVR的应用似乎走入了一个误区,即自身不断增加的复杂性和客户体验之间产生了不可调和的矛盾,这样的IVR对客户、对客户体验而言成了一个深不可测的黑匣子,这个黑匣子的完美逻辑让客户产生了莫大的迷惘甚至是恐惧:客户开始不知道如何找到自己需要的东西了,大量的客户因为不愿意在IVR中漫游而重新选择人工服务。
2012—2103年是个更大的分水岭,这一时期移动互联网方兴未艾,给人们的生活、工作产生巨大的、革命性的影响的同时也对社会的普遍风气产生了深远影响。时间进一步碎片化,越来越崇尚随时随地,生活工作节奏进一步加快,人们的容忍度似乎也在降低:去营业厅办理业务,对排队等候时间没法容忍;拨打客服热线,对人工服务等候时间没法容忍。这种情况下对于呼叫中心的IVR而言就会走入一个死胡同:无论怎么优化、怎么搞扁平化,客户都会认为它是如此复杂。道理很简单,业务种类的多样性以及呼叫中心管理者对IVR作用的定位都决定了IVR不可能太简单,而客户早就失去了耐性。
在这期间,IVR的整体架构其实也在不断演进,从最初适用于所有客户的通用架构细分到可以分别对不同客户群体设置的灵活的架构体系。可这样的细分方式大多数情况下是基于一个相对静态的状况,例如客户的品牌、客户使用产品的类型等,和互联网渠道“千人千面”的接触规划相比,细分和个性化的程度显然是大大的落后了。
面对客户需求的这种变化,呼叫中心的运营管理者应该如何应对?
笔者认为要对IVR的能力有清醒的认识。虽然互联网渠道异常活跃,可对于诸如银行、保险、电信等行业而言呼叫中心仍然是主要渠道,既然是这样,IVR的作用就不能被替代,关键在于怎样改变从而让用户自己在庞杂的IVR体系中进行选择的现状,也就是说让呼叫中心的IVR具备一定的“判断”能力,把客户需要的主动推给客户,降低客户满足需求的成本。
试想一想,客户拨打呼叫中心,绝大多数情况下他都会有一个或几个明确的目的,比如说查手机话费、查银行卡交易情况等,如果在客户接通呼叫中心时系统就能够知道客户的拨打目的从而直接把他需要的结果或者查询路径告诉他,是不是很神奇?客户体验是不是会爆棚呢?
这是一个寻找和确定客户需求并匹配产品或者功能的过程,也是通常所说的场景化思考和设计过程。举一个电信行业的具体的、最简单的应用场景来说明整个过程:
第一步,发现客户需求。
通过分析呼叫中心人工话务量发现每月23—24日都有大量客户来电咨询自己手机的欠费情况,而IVR中虽然有当月欠费查询的功能,但和进入人工台的咨询量相比自助使用量非常少,而且大多数客户就是查询欠费,需求非常简单。
第二步,分析客户需求的合理性。
该公司每月从20日开始对欠费客户进行催缴,25日开始陆续进行停机,因此客户在23—24日这个期间准备缴费,所以了解自己的欠费情况属于刚需,而IVR中虽然有查询欠费的自助功能,但因为涉及架构原因层级较深,对于不熟悉的客户而言难以准确找到。
第三步,设计业务场景。
针对以上客户需求进行业务场景设计:客户拨打热线——客服系统获取主叫号码——客服通过支撑系统判断客户是否欠 费——如果欠费就获取客户欠费数据——IVR直接向用户语音播报:您的当月应缴费用为**元,缴费请按1,其他服务请按2。
这是一个非常简单的业务流程,它把过去要由客户在IVR中寻找有关功能的成本或等待转入人工座席、和座席人员沟通的成本转嫁给系统之间通过的数据交互,有效提高了获取答案的效率,给客户体验带来极大提升,同时又有效控制了该类问题的人工话务量,这样的思路可以应用于很多更加复杂的场景。
通过分析客户业务状态的变化,判断客户此次拨打呼叫中心的具体需求,并且有针对性地提供有关功能,这样的IVR已经初步具备了“判断”的能力,在客户体验的层面已经在智能化改造的路上跨出了关键一步!
本文刊载于《客户世界》2016年1-2月刊文章;原文作者陈直,本文作者为山东联通客服中心。 收起阅读 »
环信移动客服走向国际化,提供多语言版本-环信移动客服v5.10发布
国际化
为适应快速增长的国际市场需要,同时为国内客户提供更好的国际化服务,环信推出移动客服的国际化版本,提供多语言版本支持。系统目前支持中/英无缝切换,功能及代码设计能够处理不同语言,与国际行业标准保持统一,方便您更好地进行国际交流。
该多语言版本也为将来支持更多国家的语言打下坚实的基础。
界面介绍
环信移动客服系统中,客服模式和管理员模式下的各个页面均制作了英文版,英文界面与中文界面结构一致,不影响现有使用习惯。登录时和登录后均可以进行语言切换,消息中心的新通知与登录后的语言保持一致。

语言设置
语言设置支持两种方式:
1. 在登录页面,可以在右上角选择使用中文或English登录环信移动客服。

2. 在客服模式下,进入“客服信息”页面,选择语言为English,并保存,即可切换至英文界面。
同样,在英文界面下,进入Personal页面,选择Language为中文,并保存,即可切换回中文界面。

环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.10
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
为适应快速增长的国际市场需要,同时为国内客户提供更好的国际化服务,环信推出移动客服的国际化版本,提供多语言版本支持。系统目前支持中/英无缝切换,功能及代码设计能够处理不同语言,与国际行业标准保持统一,方便您更好地进行国际交流。
该多语言版本也为将来支持更多国家的语言打下坚实的基础。
界面介绍
环信移动客服系统中,客服模式和管理员模式下的各个页面均制作了英文版,英文界面与中文界面结构一致,不影响现有使用习惯。登录时和登录后均可以进行语言切换,消息中心的新通知与登录后的语言保持一致。
语言设置
语言设置支持两种方式:
1. 在登录页面,可以在右上角选择使用中文或English登录环信移动客服。
2. 在客服模式下,进入“客服信息”页面,选择语言为English,并保存,即可切换至英文界面。
同样,在英文界面下,进入Personal页面,选择Language为中文,并保存,即可切换回中文界面。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.10
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
环信IM 开发遇到两个小问题以及解决办法
环信IM 开发遇到两个小问题以及解决办法
1.消息已读提示 默认是英文“Read” 改为中文“已读”
2.消息长按操作 默认NO 改为YES 系统默认只能进行删除,复制操作 提示方式为英文 改为中文“复制”“删除”
环信Insight.io: 这才是环信开源代码正确的打开方式!
环信作为国内领先的企业级服务软件提供商,截至2016年上半年,环信即时通讯云共服务了82149家App客户,SDK覆盖手机终端5.64亿,平台日发送消息5.57亿条。 为了让开发者能够更快速的使用环信API开发应用,环信在Github上开源了自己诸如easeUI, sdkdemoapp3.0_android, emchat-server-examples等项目,阅读这些官方开源项目的源代码无疑是上手环信API最快的方式。
Github虽然是优秀的开源项目协作工具,但是对于源代码本身一直停留在将源代码作为纯文本处理的阶段,搜索和浏览都没有代码智能(Code Intelligence)信息,对于开发者深入了解源代码本身形成了很大的障碍。为了解决这个问题,来自硅谷的Lambda Lab团队为我们带来了Codatlas,一款能让开发者在网页端也能像用IDE一样浏览和搜索源代码的工具,下面让我们一起来看看Codatlas如何让你获得Web端的终极代码浏览体验吧。
1. 跳转到定义
想快速看到代码中的类,变量或者方法是如何定义的?没问题,点击类,变量或者方法被使用的地方就会跳转到相应定义的地方。不仅可以在项目内部跳转,跨项目也同样可以实现跳转。

2. 查找应用
同样的,如果想知道代码中的类,变量或者方法在代码库中哪些地方被使用了,可以点击类,变量或者方法的定义处来显示所有被引用的地方。引用会被进一步分成Referenced At Inherit Override等子类型方便开发者进一步缩小查找范围。

3. 类结构
通过类结构可以把一个类中的所有成员变量和方法列出来,并且点击跳到相应行

4. 语意搜索
基于对源代码的语意分析,在搜索时开发者可以直接按照类名,方法名,变量名等搜索,并且Codatlas提供自动补全功能。

除了上述基于代码智能(Code Intelligence)的功能之外,Codatlas也提供切换版本,显示Commit历史,逐行标注最近Commit信息,树状目录结构等功能。相信有了Codatlas的帮助,开发者们能够更快的上手环信SDK,也欢迎有经验的环信SDK开发者将自己开源的项目提交到Codatlas,让更多的开发者找到。
5. 在问答社区提供代码链接
在IMGeek社区的提问或者回答需要涉及到源代码?用Insight.io可以更迅速的让其他人理解你提问回答中代码的上下文:

除了上述基于代码智能(Code Intelligence)的功能之外,Insight.io也提供切换版本,显示Commit历史,逐行标注最近Commit信息,树状目录结构等功能。
如果你也有优秀的基于环信SDK开发的开源项目希望分享给大家,欢迎联系insight@insight.io让我们收录你的项目,让更多的开发者学习使用环信SDK的最佳实践。
下面是示例中涉及到的开源项目在Insight.io上的访问地址:
如果使用Codatlas有任何的问题或者反馈,欢迎邮件至lambdalab@lambdalab.io 收起阅读 »
Github虽然是优秀的开源项目协作工具,但是对于源代码本身一直停留在将源代码作为纯文本处理的阶段,搜索和浏览都没有代码智能(Code Intelligence)信息,对于开发者深入了解源代码本身形成了很大的障碍。为了解决这个问题,来自硅谷的Lambda Lab团队为我们带来了Codatlas,一款能让开发者在网页端也能像用IDE一样浏览和搜索源代码的工具,下面让我们一起来看看Codatlas如何让你获得Web端的终极代码浏览体验吧。
1. 跳转到定义
想快速看到代码中的类,变量或者方法是如何定义的?没问题,点击类,变量或者方法被使用的地方就会跳转到相应定义的地方。不仅可以在项目内部跳转,跨项目也同样可以实现跳转。
2. 查找应用
同样的,如果想知道代码中的类,变量或者方法在代码库中哪些地方被使用了,可以点击类,变量或者方法的定义处来显示所有被引用的地方。引用会被进一步分成Referenced At Inherit Override等子类型方便开发者进一步缩小查找范围。
3. 类结构
通过类结构可以把一个类中的所有成员变量和方法列出来,并且点击跳到相应行
4. 语意搜索
基于对源代码的语意分析,在搜索时开发者可以直接按照类名,方法名,变量名等搜索,并且Codatlas提供自动补全功能。
除了上述基于代码智能(Code Intelligence)的功能之外,Codatlas也提供切换版本,显示Commit历史,逐行标注最近Commit信息,树状目录结构等功能。相信有了Codatlas的帮助,开发者们能够更快的上手环信SDK,也欢迎有经验的环信SDK开发者将自己开源的项目提交到Codatlas,让更多的开发者找到。
5. 在问答社区提供代码链接
在IMGeek社区的提问或者回答需要涉及到源代码?用Insight.io可以更迅速的让其他人理解你提问回答中代码的上下文:
除了上述基于代码智能(Code Intelligence)的功能之外,Insight.io也提供切换版本,显示Commit历史,逐行标注最近Commit信息,树状目录结构等功能。
如果你也有优秀的基于环信SDK开发的开源项目希望分享给大家,欢迎联系insight@insight.io让我们收录你的项目,让更多的开发者学习使用环信SDK的最佳实践。
下面是示例中涉及到的开源项目在Insight.io上的访问地址:
- http://www.insight.io/v3/github.com/easemob/sdkdemoapp3.0_android
- http://www.insight.io/v3/github.com/easemob/easeui
- http://www.insight.io/v3/github.com/easemob/emchat-server-examples
如果使用Codatlas有任何的问题或者反馈,欢迎邮件至lambdalab@lambdalab.io 收起阅读 »
环信官方Demo源码分析及SDK简单应用
前言
环信官方Android版本的Demo,还算是功能齐全的.日常工作中我们如果只是为App加个im模块基本的界面和逻辑也出不了Demo多少。
所以如果你的公司有这方面的需求,为了能顺利拿到银子,少些波澜,我们还是一起来研究下其官方Demo吧。
感谢有环信这样强力的三方IM解决方案,并提供了简单易用而又强大的SDK,方便了我们广大中小开发者集成IM相关功能。
有缘的话,我们后面再来分析IOS版本的环信官方Demo源代码。
由于时间仓促,错误及不足之处,欢迎指正。
准备工作
我们说拿到一份代码,要想分析下内容。先看目录再看AndroidMainfest,抽丝剥茧一步步的去理解和分析。
当然这只是个人的习惯,其他有更好的方法或建议,可以留言一起讨论。
废话不多说,我们来看目录。

有三个Moudle
那么我们首先分析哪个库呢?自然是主Demo库,单单的去分析EaseUI库,或者红包库并没有任何意义和连贯性。下面就来进入我们的环信官方Demo源码分析,在文章的最后会教大家一些SDK的简单应用,同时分享一个我做的基于环信开发项目。
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现 收起阅读 »
环信官方Android版本的Demo,还算是功能齐全的.日常工作中我们如果只是为App加个im模块基本的界面和逻辑也出不了Demo多少。
所以如果你的公司有这方面的需求,为了能顺利拿到银子,少些波澜,我们还是一起来研究下其官方Demo吧。
感谢有环信这样强力的三方IM解决方案,并提供了简单易用而又强大的SDK,方便了我们广大中小开发者集成IM相关功能。
有缘的话,我们后面再来分析IOS版本的环信官方Demo源代码。
由于时间仓促,错误及不足之处,欢迎指正。
准备工作
我们说拿到一份代码,要想分析下内容。先看目录再看AndroidMainfest,抽丝剥茧一步步的去理解和分析。
当然这只是个人的习惯,其他有更好的方法或建议,可以留言一起讨论。
废话不多说,我们来看目录。
有三个Moudle
- ChatDemoUI3.0 //主Demo模块
- EaseUI //UI库
- redpacketlibrary //红包库
那么我们首先分析哪个库呢?自然是主Demo库,单单的去分析EaseUI库,或者红包库并没有任何意义和连贯性。下面就来进入我们的环信官方Demo源码分析,在文章的最后会教大家一些SDK的简单应用,同时分享一个我做的基于环信开发项目。
环信官方Demo源码分析及SDK简单应用
环信官方Demo源码分析及SDK简单应用-ChatDemoUI3.0
环信官方Demo源码分析及SDK简单应用-LoginActivity
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-会话界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-通讯录界面
环信官方Demo源码分析及SDK简单应用-主界面的三个fragment-设置界面
环信官方Demo源码分析及SDK简单应用-EaseUI
环信官方Demo源码分析及SDK简单应用-IM集成开发详案及具体代码实现 收起阅读 »
2017年SaaStr大会:AI正吃掉软件?
文章摘要:硅谷著名的投资人马克·安德森说过一句话“软件正在吃掉世界”。在2017SaaStr上,红点的合伙人Tomasz Tunguz做了一场演讲,讲述了AI是如何正在吃掉软件。作者:环信创始人 刘俊彦
硅谷著名的投资人马克·安德森说过一句话“软件正在吃掉世界”。在2017SaaStr上,红点的合伙人Tomasz Tunguz做了一场关于AI正在变成SaaS的基础平台的演讲。我们深刻的感到,下一场革命已经到来了,AI正在吃掉软件。

Tomasz首先简单介绍了他看到的在工作流,保险,建筑,医疗,农业,交通这6个行业的AI投资案例和AI所产生的价值。当然,以Tomasz一向的干货风格,他很快进入在座的SaaS企业最关心的问题:SaaS企业的AI怎么做,投资人会投什么样的AI企业:





1.企业一定要有自己的私有数据来源:
所谓私有数据,就不是你随便可以从百度下载到的数据或者从微博上爬下来的数据,而一定是只有你才能获取的独特数据。
关于怎样获得私有数据来源,这对很多初创企业都是一个难事。Tomasz有2个建议:
a. 创建自己的工作流工具。比如你可以先去做一个CRM软件,当大家都在用你的软件的时候,你就有了数据。当然这个过程可能会很慢,你要有耐心。
B.找到那些全球500强企业。告诉他们,这是你们现在面对的问题,你们自己搞不定,我们可以用AI帮你们搞定。得到500强企业的授权后,你就能接触到大量的数据。
2.这个企业一定是做end-to-end的应用的,而不是做AI平台的。
一定不要告诉我,你要做一个通用的AI平台。很明显,和巨头公司是无法在这个层面竞争的。
对创业企业来说,你要回答的问题是,你在巨头的平台上做工作,你能在这个平台上增加什么额外的价值,可以带来什么额外的竞争优势?
3.要有基于AI的很强的go-to-market的策略。
光有AI不行,还要想好怎么推向市场。
4.一定要有特定领域的行业专家
光有AI科学家和AI工程师是不行的,还要有领域知识和领域经验,要把这些领域知识翻译成AI。
5.如果有AI算法优势那就更好
这也是为什么有自己的NLP引擎的公司比完全用公用的NLP引擎的公司可能要更值钱的原因
最后,AI创业公司向VC介绍自己时,最好的AI公司是那些可以不用提机器学习,不用提深度学习,不用提任何AI的公司。你听明白了吗?
AI正在吃掉软件,也正在深刻的影响着SaaS客服行业,在客服领域AI正逐渐发挥着重要的作用,有望成为一股颠覆性的力量从而被整个行业寄予厚望。随着全媒体客服的普及和广泛应用导致企业和消费者多点接触,同时用户体验得到了企业的重视,导致客服咨询量暴增,企业有限的客服人力资源与日益增加的客服请求之间的矛盾日益尖锐,如何用有限的客服资源服务不断增长的海量客服请求需要一个颠覆型的技术来解决。相比人工客服,AI客服机器人将提供极大的效率优势。Gartner报告指出智能客服机器人(VCA-virtual customer assistance)的使用正处于临界点。大幅改进的自然语言处理技术,以聊天为中心的移动渠道与客户互动的应用,以及客户对机器人技术的接受程度,这些因素使得人们对VCA的兴趣越來越大。从被动的被人类编程出来的可以在结构化和非结构化内容库中找到问题答案的虚拟助手,到主动的有时候是机器学习得到的VCA的转变,其考察个人的特征并代表他们行动。虚拟助手正在经历从被动的被人类编程出来在结构化和非结构化内容库中找到问题答案到主动的通过机器学习能够理解用户个性化的需求并且随之采取灵活应对行为的转变。
环信作为智能客服企业的践行者,基于自然语言处理和机器学习技术推出了环信智能客服机器人,辅助或代替人工客服精准回答常见或高频问题,降低企业客服人力成本。截止2016年上半年,环信已经在客服领域服务了29000多家标杆客户,积累了人工智能在客户服务行业落地的大量最佳实践。
收起阅读 »
电商直播模式爆发,未来如何赢胜?
如日中天的直播业务正在与不同互联网行业快速结合起来,形成“直播+经济”。“直播+电商”模式爆发,成为网络零售的下一个风口
直播+娱乐已很成熟,如今还有一个正迅速崛起的商业模式—— “直播+电商”。
2016年被称作“直播+电商”的元年,今年“双十一”各大电商直播很火爆,直播平台数量呈井喷式爆发,“直播+电商”作为连接用户和商品销售的一种愈来愈重要的新模式,让业界直呼“直播+电商”已成为网络零售的下一个风口,而随着诸如AR/VR等直播的技术升级,“直播+电商”更是让业界产生无限的的想象空间。
传统电商流量红利期已过,电商布局直播的目的都是为了获取新的大量的流量入口以营造新利基,而随着资本进一步加持,今年以来国内直播平台数量持续增加,市场规模飙长。2016年春节时,国内直播平台大概有八十多家,5月份骤增至四五百家,年底更是飙到快接近一千家。艾瑞机构统计数据显示去年国内移动直播行业的市场份额为120亿元,到2020年预计将会突破1000亿元,而“直播+电商”将成为其中一支重要的生力军。
今年5月淘宝正式推出淘宝直播,至今已经有超过千万的用户观看过直播内容,超过1000人在淘宝上做过主播。在成功运营了半年之后,阿里巴巴也将电商直播栏目化植入到今年的“双十一”大促。蘑菇街9.0版本上线了全球街拍和美妆视频两项PGC(专业生产内容),用户可以在蘑菇街APP里看到每日更新的街拍图和专业的美妆视频,边看美妆边购物,效果很好。
同时,消费升级的趋势让跨境电商也加入直播阶段。去年7月第一家确立PGC直播的跨境电商菠萝蜜上线,仅两个月,波罗蜜创收1000多万;今年3月亚马逊也开始尝试网络直播服务,推送其海外商品,交易规模飙涨5倍;8月,网易考拉海购则与虎牙直播、斗鱼直播和花椒直播签订战略合作框架……
“电商+直播”,机遇与挑战并存
我们知道传统电商平台存在的痛点有二:一是商品展现形式单一,图文信息对消费者的购物决策不再充分;二是缺乏社交行为,尽管用户足不出户就能购物但还是不能互动、互视交流。而基于视频直播的电商融入一定的社交属性并承载传播商品信息方式,视频的信息维度更为丰富,可以在很大程度上打破消费者对货物看不见、摸不着、感受不到的现状,为消费者提供更全面的产品或服务信息,可以较大地提升购物体验,降低试错成本,促进了用户的有效决策,降低售前咨询的负担,同时通过网红、明星等方式聚集人气营造团购氛围,进而提高成交转化效率。尤其是那些难于现场体验、大件复杂、技术性较强的商品往往有很多问题,而通过与主播的直面互动基本可以立刻得到解答甚至能实现和明星、网红一起逛街的梦想,享受边看边买、边聊边买的体验。波罗蜜全球购的创始人张振栋说过,直播能对销售转化大幅度提升是因为在观看直播的群体内产生了从众效应。在一个强交互的场景下,屏幕两端都在向着购买的方向拉动,人群决策的效果影响了每个个体。
当前直播与电商结合的大趋势正在向三种模式发展。一是电商平台增加直播功能;二是新型“直播+电商”模式平台的出现;三是直播平台通过商品链接倒流至第三方电商平台。三种模式各有特色,但最终脱颖而出的很可能是第二种模式,并且在这种模式下会形成多强格局。
第一种模式,以天猫直播、淘宝直播为代表的大电商平台增加直播功能。从天猫直播最引以为傲的案例来看,2016年4月14日AngelaBaby在天猫直播两小时,美宝莲新品卖出10000支;4月26日杜蕾斯3小时直播,几十万用户付费观看,20%的用户引导进店。以上营销案例代表了以网红、明星、品牌直播内容为流量入口迅速打造爆款的营销方式。
第二种模式,以小红唇和波罗蜜为代表的“直播+电商”新模式的创业公司。波罗蜜是2015年初成立的主打“视频互动直播”的自营跨境电商平台,用户打开APP可以真切感受到当地购物的场景,看到各种商品在世界各地的商场店铺热卖,并能通过聊天室与现场团队实时互动。小红唇是国内针对15-25岁年轻女孩的“美妆网红”视频电商平台,网红在平台分享如何化妆护肤、如何选择化妆品等视频和直播,该公司正在通过快速融资进一步打造网红及增强变现渠道,强化直播内容+流量及品牌双向导流,粉丝有数百万。
第三种模式,直播平台通过商品链接的方式倒流到第三方电商平台。目前这种模式尚未有代表公司,原因在于转型电商的风险大、成本高,这不是目前直播平台想要看到的结果。
然而,“直播+电商”模式井喷同时也遭遇不少挑战与问题。
“直播+电商”的形式不同于传统直播平台中靠收取虚拟礼物折现,除了网店给的基本工资外主播们的收入主要靠“卖货”拿提成盈利。然而许多网红主播在推荐产品时并不专业,效果大打折扣,购买转化率低。据悉艾瑞媒体在某电商直播平台观察统计,一个平均18万粉丝的主播、2500人左右观看的直播通常一场下来只有寥寥几十单的转化,转化率为零的情况也不罕见,流量难以变现成为传统电商的切肤之痛。专家认为商家花高价请来明星和网红只能是“赚吆喝不赚钱”的尴尬局面。
可以说直播说到底拼的还是内容和玩法,虽然明星、网红或小鲜肉在直播期间短期能带来巨大的流量,但鉴于电商直播的经济属性、消费性,多数普通粉丝很难沉淀在电商平台,关键是要有对口的受众体。电商直播的营销面向的是广义人群,但也要根据消费类型、产品定位对普通观众、核心受众做精准细分、渗透,不然只有人气没有买气。观众和受众(潜在消费者)还是不一样的概念,只有针对重点、关键的受众体做出高性价比的产品平台及相应的精确宣传动作,才会有推广效果,不是有了明星、网红或小鲜肉就能带来大量购买行为。诚如京东直播负责人所说,直播实质上是一个新的内容形式,和传统媒体类似,重点还是在内容、精确对口的商品,还是靠比拼实力,未来随着直播内容数量的指数级增长,只有真正有价值、大众化、对口的内容平台才能被用户关注。
不过令人忧虑的是,当前电商直播平台公布的直播资质门槛表明店铺需拥有4万以上粉丝才有资格开通电商直播,也才能转化成一定的购买量,但庞大的粉丝基数对于白手起家的绝大多数中小卖家而言无疑是望而兴叹。
还有,有业界人士认为 “直播+电商”本质就是电视+电商,即所谓的T2O模式(TV to Online)模式,连电视这么强势的媒体都玩不转,更别说手机或PC直播。直播只是宣传方式,跟文字、图片等没有本质区别,而电商的商业本质并没有变化,过去并不存在着“文字+电商”、“图片+电商”的说法,“直播+电商”只是一个拼造的新概念,因此认为“直播还是为数很少的大玩家大平台才能玩得起”。
另外对电商直播来说,以出售为主、直播为辅,直播只是作为一种展示商品的工具,这并不能撕掉网络零售长期以来存在的某些负面标签,如数据造假、平台刷单、价格欺诈、涉黄等现象也不时隐藏在 “直播+电商”中,若不“悔改”,加了直播也未必能在多大程度上改善营销局面。
最为关键的是随着最严监管潮的来临,国内直播平台正遭遇一轮大洗牌,电商直播能否避免“殃及池鱼”并撑得住?未来电商直播格局又会发生怎样的变化?
短期内多个新政密集出台,电商直播业洗牌加快
2016年9月起,直播领域的监管骤然收紧。9月9日,新闻出版广电总局下发《关于加强网络视听节目直播服务管理有关问题的通知》,重申互联网视听节目服务机构开展直播服务必须符合《互联网视听节目服务管理规定》和《互联网视听节目服务业务分类目录》的有关规定。11月4日,国家网信办发布了《互联网直播服务管理规定》,该规定主要实行“主播实名制登记”、“黑名单制度”等强力措施,且明确提出 “双资质”的要求。12月12日,文化部又印发《互联网直播管理办法》,对网络表演单位、表演者和表演内容进行了进一步的细致规定。
在大量新规三令五申背后反映出的是直播行业加速整合、自我净化提升的现状,一系列新规的出台对大直播平台来说是利好,而对小直播平台来说则是一道迈不过去的门槛,准入门槛和从业门槛的提高将使直播行业产生重大的洗牌效应。
同样,短期内多个新政密集出台也给才露出苗头的电商直播业泼了冷水。
目前中小电商直播平台用户积累较为单薄,缺乏足够内容及内容生产能力,资源置换能力较弱,与此同时受单一商业模式影响,营收收入逐渐难以覆盖成本,未来生存压力较大。未来电商直播业强者恒强弱者恒弱的格局将愈来愈明显,中小平台数量的减少将加快。而当相关政策全部落实到位后,电商直播行业才能将逐渐建立起良性竞争的健康市场氛围。
电商直播未来之路何在?如何赢胜?
没有规矩不成方圆。可以说未来电商直播业只有合乎产业政策,守法经营才能生存,才有前途。同时,电商直播想要长久发展、弯道超车,还需解决以下几个重大问题:
1、如何持续保持高流量
未来一个阶段电商平台方需要着力解决的仍是流量问题,高流量的平台如何持续保持高流量,低流量的平台如何提升流量,都是各家需要着力解决的问题。和更加成熟的平台合作、与更具知名度的网红合作都或将成为更加主流的方式,同时直播的内容也需要加以斟酌和推敲,如何巧打“政策边球”,如何雅俗共赏,如何以更高性价比打动用户,从而刺激更多的用户参与其中,保持提升高流量,是重要的生存战略。
2、如何实现高效转化并带来高销量
直播是在做娱乐,但是“电商+直播”最重要的还是要解决买卖的生意问题,不能娱乐化,也不能商业味过浓。无论是何种营销方式,电商直播的目的有二:一是增加曝光度提升品牌美誉度;二是带来更多的销量,促使人气转化为买气。因此在直播过程中,电商直播平台更需要促成用户对商品的了解、兴趣,最后达到购买下单,这主要要着力解决高转化、高销量的问题,主要措施包括深入定制到内容层面、增加更多的互动成分、看直播有奖、积分返利等等都是可以尝试采用的方式。
3、如何解决高成本的问题
虽然电商获取新用户的成本近200元,但直播+电商模式本身的费用并不比传统方式低,或许更高。
一般情况下电商直播大抵是与国内的直播平台合作,而要更有名气更有流量,这意味着需要采用直播平台+网红这种模式来提升人气,甚至+明星,而这均需要支付很高的费用,而直播+明星对大多数平台来说更是遥不可及,所以如果要想有高流量就必然需要支付高开销,如何办? 这就需要电商直播业脑洞大开,殚精竭力了。有一个最简单办法就是美女+直播,因为美女是网红一个基本前提,而且找一个美女容易也不贵,同时可采取各种办法炒红所聘请的美女。
4、最大难题是技术问题,就是如何让用户直播时有更好的购物体验,这需要有更好的购物技术,将直播与电商结合得更顺畅,增加消费转化效率。
(1)语音技术:在主播讲解说到某个商品时,就能出现商品链接,用户可方便地加入购物车,眼下还没有直播平台做到这一点。聚划算的做法提供了新思路:通过语音口令帮助用户快速购买,在主播公布语音口令之后用户可通过聚划算App“喊出”口令进而获得优惠、购买商品,这让用户在直播中有消费欲时购物更便捷,提升了转化效率,丰富了互动方式。
(2)图像技术:在主播展示某个商品或到达某个地方时可通过图像识别技术探测对应商品,进而给用户推荐,便于用户下单,实现真正的边看边买。已有创业团队尝试在视频上实现类似技术,比如观众看到《欢乐颂》里面刘涛的衣服不错,如何方便将其加入购物车下单、如何将图像识别技术与直播结合起来是接下来的难点,要做到实时识别并不容易。
(3)VR技术:直播+VR结合将是大势所趋,VR能够让观众、消费者更全面、多维、生动地了解世界各地的商品。之于直播电商,有了VR(虚拟现实)或AR(增强现实)技术,消费者就能更好地了解商品信息或者跟明星或视频内的商品互动。比如戴上头盔让你到达一个虚拟的商场,里面有导购员(主播)正在讲解,还有一群人在围观(社交),还有琳琅满目的商品如真实般扑面而来,甚至还有声响、气味,让你有真实美妙的购物感觉,这是一种前所未有的购物体验。淘宝愚人节发布了BUY+计划就是类似理念,阿里巴巴还宣布要做VR内容平台,打造VR交互技术,直播+VR+电商打通为时不远,那时直播电商或真的爆发了,因此未来谁掌握最新最先进的直播技术,谁就能引领电商直播业的未来。
瑕瑜并现,瑕并不掩瑜,任何事物不是只有光鲜的一面。在电商与直播碰撞的第一个“双十一”,电商直播到底是网络零售的下一个风口还是无意义的流量争夺泡沫?面对直播的火爆与直播的一些乱象,电商直播是风口还是烫手的山芋?电商直播业如何应对越来越严厉的直播监管?如何快速提升直播平台人气、人脉?如何有效提升直播技术水平,让自己脱颖而出弯道超车?让我们拭目以待以察!
本文刊载于《客户世界》2016年1-2月刊文章;原文作者吴勇毅,本文作者为厦门智者恒通管理顾问机构总监。 收起阅读 »
环信头像和昵称显示的详细、详细、详细教程!
写在前边:本文由江南大神的环信集成demo衍生而来!
附上大神的集成链接: http://www.imgeek.org/article/825307886
通过官方的文档我们知道有两种显示头像和昵称的方式(http://docs.easemob.com/im/490integrationcases/10nickname 官方文档)
这里主要讲方式二!(通过扩展消息传递显示)
这里主要有三个类需要改,分别是:
EaseMessageViewController
EaseBaseMessageCell
chatUIhelper
首先我们需要在发送消息的时候添加扩展字段,在EaseMessageViewController.m里。可以看到有以下方法:
有发送各种消息的,我们要每个里边都加扩展字段么?那恐怕要累死咯! 仔细看会发现发送消息的方法最后都会走一个方法:
好的,就是这里了,添加扩展字段,包含用户的头像地址,昵称和环信ID。 找到保存用户信息的类UserCacheInfo,找到相应的字段,在这个方法里添加如下代码:
这样第一步就完成了!
接下来我们要在接收消息的方法里保存传过来的扩展消息里的头像、昵称和环信ID,这就用到chatUIhelper.m这个类,这个方法里:
关键就是这句话:
[UserCacheManager saveInfo:message.ext];// 通过消息的扩展属性传递昵称和头像时,需要调用这句代码缓存!!!
到这里头像和昵称的问题就基本解决了!
上两步完成后你会惊奇的发现头像和昵称正常显示了,然而当你换个头像测试的时候,你会发现很不美妙,头像没有更换,这是什么问题呢? 这就要用到开始讲到的第一个类EaseBaseMessageCell.m,我们仔细看代码会发现它是怎么赋值的,如下:
看到这里就明白了是头像缓存了,直接用的是缓存里的头像,我们需要更新的话直接设置一下缓存策略就可以了,代码修改如下:
然后运行一下你会发现世界如此美好,大功告成!
对各位小伙伴you有没有帮助呢?
如有任何问题,请咨询【环信IM互帮互助群】,群号:340452063 (进群记得改名片哦!江南大神也在群里!)
本人群里的名片:上海-iOS-小码农 。 收起阅读 »
附上大神的集成链接: http://www.imgeek.org/article/825307886
通过官方的文档我们知道有两种显示头像和昵称的方式(http://docs.easemob.com/im/490integrationcases/10nickname 官方文档)
这里主要讲方式二!(通过扩展消息传递显示)
这里主要有三个类需要改,分别是:
EaseMessageViewController
EaseBaseMessageCell
chatUIhelper
首先我们需要在发送消息的时候添加扩展字段,在EaseMessageViewController.m里。可以看到有以下方法:
#pragma mark - send message
- (void)_refreshAfterSentMessage:(EMMessage*)aMessage
{
if ([self.messsagesSource count] && [EMClient sharedClient].options.sortMessageByServerTime) {
NSString *msgId = aMessage.messageId;
EMMessage *last = self.messsagesSource.lastObject;
if ([last isKindOfClass:[EMMessage class]]) {
__block NSUInteger index = NSNotFound;
index = NSNotFound;
[self.messsagesSource enumerateObjectsWithOptions:NSEnumerationReverse usingBlock:^(EMMessage *obj, NSUInteger idx, BOOL *stop) {
if ([obj isKindOfClass:[EMMessage class]] && [obj.messageId isEqualToString:msgId]) {
index = idx;
*stop = YES;
}
}];
if (index != NSNotFound) {
[self.messsagesSource removeObjectAtIndex:index];
[self.messsagesSource addObject:aMessage];
//格式化消息
self.messageTimeIntervalTag = -1;
NSArray *formattedMessages = [self formatMessages:self.messsagesSource];
[self.dataArray removeAllObjects];
[self.dataArray addObjectsFromArray:formattedMessages];
[self.tableView reloadData];
[self.tableView scrollToRowAtIndexPath:[NSIndexPath indexPathForRow:[self.dataArray count] - 1 inSection:0] atScrollPosition:UITableViewScrollPositionBottom animated:YES];
return;
}
}
}
[self.tableView reloadData];
}
- (void)_sendMessage:(EMMessage *)message
{
if (self.conversation.type == EMConversationTypeGroupChat){
message.chatType = EMChatTypeGroupChat;
}
else if (self.conversation.type == EMConversationTypeChatRoom){
message.chatType = EMChatTypeChatRoom;
}
[self addMessageToDataSource:message
progress:nil];
__weak typeof(self) weakself = self;
[[EMClient sharedClient].chatManager sendMessage:message progress:nil completion:^(EMMessage *aMessage, EMError *aError) {
if (!aError) {
[weakself _refreshAfterSentMessage:aMessage];
}
else {
[weakself.tableView reloadData];
}
}];
}
- (void)sendTextMessage:(NSString *)text
{
NSDictionary *ext = nil;
if (self.conversation.type == EMConversationTypeGroupChat) {
NSArray *targets = [self _searchAtTargets:text];
if ([targets count]) {
__block BOOL atAll = NO;
[targets enumerateObjectsUsingBlock:^(NSString *target, NSUInteger idx, BOOL *stop) {
if ([target compare:kGroupMessageAtAll options:NSCaseInsensitiveSearch] == NSOrderedSame) {
atAll = YES;
*stop = YES;
}
}];
if (atAll) {
ext = @{kGroupMessageAtList: kGroupMessageAtAll};
}
else {
ext = @{kGroupMessageAtList: targets};
}
}
}
[self sendTextMessage:text withExt:ext];
}
- (void)sendTextMessage:(NSString *)text withExt:(NSDictionary*)ext
{
EMMessage *message = [EaseSDKHelper sendTextMessage:text
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:ext];
[self _sendMessage:message];
}
- (void)sendLocationMessageLatitude:(double)latitude
longitude:(double)longitude
andAddress:(NSString *)address
{
EMMessage *message = [EaseSDKHelper sendLocationMessageWithLatitude:latitude
longitude:longitude
address:address
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:nil];
[self _sendMessage:message];
}
- (void)sendImageMessageWithData:(NSData *)imageData
{
id progress = nil;
if (_dataSource && [_dataSource respondsToSelector:@selector(messageViewController:progressDelegateForMessageBodyType:)]) {
progress = [_dataSource messageViewController:self progressDelegateForMessageBodyType:EMMessageBodyTypeImage];
}
else{
progress = self;
}
EMMessage *message = [EaseSDKHelper sendImageMessageWithImageData:imageData
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:nil];
[self _sendMessage:message];
}
- (void)sendImageMessage:(UIImage *)image
{
id progress = nil;
if (_dataSource && [_dataSource respondsToSelector:@selector(messageViewController:progressDelegateForMessageBodyType:)]) {
progress = [_dataSource messageViewController:self progressDelegateForMessageBodyType:EMMessageBodyTypeImage];
}
else{
progress = self;
}
EMMessage *message = [EaseSDKHelper sendImageMessageWithImage:image
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:nil];
[self _sendMessage:message];
}
- (void)sendVoiceMessageWithLocalPath:(NSString *)localPath
duration:(NSInteger)duration
{
id progress = nil;
if (_dataSource && [_dataSource respondsToSelector:@selector(messageViewController:progressDelegateForMessageBodyType:)]) {
progress = [_dataSource messageViewController:self progressDelegateForMessageBodyType:EMMessageBodyTypeVoice];
}
else{
progress = self;
}
EMMessage *message = [EaseSDKHelper sendVoiceMessageWithLocalPath:localPath
duration:duration
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:nil];
[self _sendMessage:message];
}
- (void)sendVideoMessageWithURL:(NSURL *)url
{
id progress = nil;
if (_dataSource && [_dataSource respondsToSelector:@selector(messageViewController:progressDelegateForMessageBodyType:)]) {
progress = [_dataSource messageViewController:self progressDelegateForMessageBodyType:EMMessageBodyTypeVideo];
}
else{
progress = self;
}
EMMessage *message = [EaseSDKHelper sendVideoMessageWithURL:url
to:self.conversation.conversationId
messageType:[self _messageTypeFromConversationType]
messageExt:nil];
[self _sendMessage:message];
}
有发送各种消息的,我们要每个里边都加扩展字段么?那恐怕要累死咯! 仔细看会发现发送消息的方法最后都会走一个方法:
- (void)_sendMessage:(EMMessage *)message
{
if (self.conversation.type == EMConversationTypeGroupChat){
message.chatType = EMChatTypeGroupChat;
}
else if (self.conversation.type == EMConversationTypeChatRoom){
message.chatType = EMChatTypeChatRoom;
}
[self addMessageToDataSource:message
progress:nil];
__weak typeof(self) weakself = self;
[[EMClient sharedClient].chatManager sendMessage:message progress:nil completion:^(EMMessage *aMessage, EMError *aError) {
if (!aError) {
[weakself _refreshAfterSentMessage:aMessage];
}
else {
[weakself.tableView reloadData];
}
}];
}
好的,就是这里了,添加扩展字段,包含用户的头像地址,昵称和环信ID。 找到保存用户信息的类UserCacheInfo,找到相应的字段,在这个方法里添加如下代码:
NSMutableDictionary *Muext = [NSMutableDictionary dictionaryWithDictionary:message.ext];
UserCacheInfo *info = [UserCacheManager currUser];
[Muext setObject:kCurrEaseUserId forKey:kChatUserId];
[Muext setObject:info.NickName forKey:kChatUserNick];
[Muext setObject:info.AvatarUrl forKey:kChatUserPic];
message.ext = Muext;
这样第一步就完成了!
接下来我们要在接收消息的方法里保存传过来的扩展消息里的头像、昵称和环信ID,这就用到chatUIhelper.m这个类,这个方法里:
- (void)didReceiveMessages:(NSArray *)aMessages
{
BOOL isRefreshCons = YES;
for(EMMessage *message in aMessages){
[UserCacheManager saveInfo:message.ext];// 通过消息的扩展属性传递昵称和头像时,需要调用这句代码缓存
BOOL needShowNotification = (message.chatType != EMChatTypeChat) ? [self _needShowNotification:message.conversationId] : YES;
#ifdef REDPACKET_AVALABLE
/**
* 屏蔽红包被抢消息的提示
*/
NSDictionary *dict = message.ext;
needShowNotification = (dict && [dict valueForKey:RedpacketKeyRedpacketTakenMessageSign]) ? NO : needShowNotification;
#endif
UIApplicationState state = [[UIApplication sharedApplication] applicationState];
if (needShowNotification) {
#if !TARGET_IPHONE_SIMULATOR
switch (state) {
case UIApplicationStateActive:
[self playSoundAndVibration];
break;
case UIApplicationStateInactive:
[self playSoundAndVibration];
break;
case UIApplicationStateBackground:
[self showNotificationWithMessage:message];
break;
default:
break;
}
#endif
}
if (_chatVC == nil) {
_chatVC = [self _getCurrentChatView];
}
BOOL isChatting = NO;
if (_chatVC) {
isChatting = [message.conversationId isEqualToString:_chatVC.conversation.conversationId];
}
if (_chatVC == nil || !isChatting || state == UIApplicationStateBackground) {
[self _handleReceivedAtMessage:message];
if (self.conversationListVC) {
[_conversationListVC refresh];
}
if (self.mainVC) {
NOTIFY_POST(kSetupUnreadMessageCount);
}
return;
}
if (isChatting) {
isRefreshCons = NO;
}
}
if (isRefreshCons) {
if (self.conversationListVC) {
[_conversationListVC refresh];
}
if (self.mainVC) {
NOTIFY_POST(kSetupUnreadMessageCount);
}
}
}
关键就是这句话:
[UserCacheManager saveInfo:message.ext];// 通过消息的扩展属性传递昵称和头像时,需要调用这句代码缓存!!!
到这里头像和昵称的问题就基本解决了!
- 重要的总是留在最后!!! 不看后悔哦!!!
上两步完成后你会惊奇的发现头像和昵称正常显示了,然而当你换个头像测试的时候,你会发现很不美妙,头像没有更换,这是什么问题呢? 这就要用到开始讲到的第一个类EaseBaseMessageCell.m,我们仔细看代码会发现它是怎么赋值的,如下:
#pragma mark - setter
- (void)setModel:(id<IMessageModel>)model
{
[super setModel:model];
if (model.avatarURLPath) {
[self.avatarView sd_setImageWithURL:[NSURL URLWithString:model.avatarURLPath] placeholderImage:model.avatarImage];
} else {
self.avatarView.image = model.avatarImage;
}
_nameLabel.text = model.nickname;
if (self.model.isSender) {
_hasRead.hidden = YES;
switch (self.model.messageStatus) {
case EMMessageStatusDelivering:
{
_statusButton.hidden = YES;
[_activity setHidden:NO];
[_activity startAnimating];
}
break;
case EMMessageStatusSuccessed:
{
_statusButton.hidden = YES;
[_activity stopAnimating];
if (self.model.isMessageRead) {
_hasRead.hidden = NO;
}
}
break;
case EMMessageStatusPending:
case EMMessageStatusFailed:
{
[_activity stopAnimating];
[_activity setHidden:YES];
_statusButton.hidden = NO;
}
break;
default:
break;
}
}
}
看到这里就明白了是头像缓存了,直接用的是缓存里的头像,我们需要更新的话直接设置一下缓存策略就可以了,代码修改如下:
把 [self.avatarView sd_setImageWithURL:[NSURL URLWithString:model.avatarURLPath] placeholderImage:model.avatarImage];
改成 [self.avatarView sd_setImageWithURL:[NSURL URLWithString:model.avatarURLPath] placeholderImage:model.avatarImage options:EMSDWebImageRefreshCached];
然后运行一下你会发现世界如此美好,大功告成!
对各位小伙伴you有没有帮助呢?
如有任何问题,请咨询【环信IM互帮互助群】,群号:340452063 (进群记得改名片哦!江南大神也在群里!)
本人群里的名片:上海-iOS-小码农 。 收起阅读 »
技术选型最怕的是什么?

昨天聊聊架构发布了一篇关于技术选型的文章,文章作者介绍了目前流行的技术选型方式,比如有微博驱动、技术会议驱动、嗓门驱动、领导驱动.....不少读者都表示深有体会,并在评论区贴出了自己的经历。今天再推荐一篇由环信首席架构师一乐所撰写的关于技术选型的文章(旧文),希望能帮到各位。另推荐一乐的个人微信一乐来了,id是yilecoming,欢迎关注。这也许是我上半年最大的欠账,在去普吉的飞机上突发无聊,想想还了这债吧。
去年的时候,我们使用Cassandra出了一次问题,定位加修复用了一晚上。当我把经历发出来的时候,收到了下面一段话:
“一个开源产品,连官方文档都没看完大半,然后匆匆忙忙上生产环境,出了问题团团转。若是不能掌控就先不要玩,说回这Cassandra的例子,在对它不了解的情况下,仅通过Google就能解决问题,不正说明它不难掌握有大量资料可查吗,实在不行还能翻代码。”
我现在都不知道这位神仙从哪里看到的匆匆忙忙上和团团转,当时我还是忍了,因为实在太忙,口水又没那么多。当然我思考了很多,这就是你现在看到的文章。我相信它会有一些价值,毕竟有些事情有的人你不告诉他,他永远不可能知道。比如个体认知的局限,比如口无遮拦的损失,比如做事之人才会有的思考角度。
本文讲的是技术选型。
大多数技术都存在选型问题,因为技术的发展已经让一件事情可以有多种解决方案,选型问题就自然出现。前段时间也有人说过语言选型,这里举的例子是在组件、框架、服务的范畴。其中有相通之处,各位可以自行领会。
选型最怕什么
怕失败么?那肯定的。你的服务崩溃,用户愤而投诉,客户电话打到老板那里,明天你要洗干净到办公室去一趟(笑...)。而所有对失败的无法容忍,最终都会变成一句话,为什么你要选这个型?
你总要回答这个问题,所以选型一怕随意,公鸡头母鸡头,选上哪头是哪头;二怕凭感觉,某某已经在用听起来还不错。你需要真正的思考,而且尽可能的全面。我下文会详细讲解,但这还不是最怕的。
最怕的是什么?看看本文开头引用的那句话,你体会一下。
嗯,最怕的是喷子。怕任意总结,如果再加上一些诋毁,一次选型失败足以让人心碎一万次。
失败不可怕,可怕的是没有总结,因为没有总结就没有提高。而比没有总结更可怕的是乱总结。
为了方便理解,我再帮你换个角度。你天天在河边走,一次不小心湿了鞋。如果是本文说的这种人,那肯定要说:
一条公共的河,你连旱季旺季都没搞清楚,就匆匆忙忙跑过来散步,湿了鞋还到处讲。若是脚不行就别在这玩,说回这条河,湿了鞋就能爬上来,不正说明他水不深么。
这种人实在不算少见。他说的每一句话都有一点道理,但都跟事情的本质毫无关系,每一句话又都掺加了嘲讽,来体现那无处安放的莫名优越感。而所有的这些,对于解决问题和后续提高通常毫无帮助。
想想也真遗憾,人生本是如此美好,有的人却硬生生地活成了奇葩。
选型需要什么
言归正传,我认为有三点不可或缺:分析、实验和胆量。
- 分析
分析主要有定性分析和定量分析。实际操作中,前者主要针对的是模型维度的估计,用来考虑一个组件是否有可能达到它宣称的目的,后者主要用来验证,用来确认它是否在真的做到了。
比如在语言选型时,你要考虑它的范型、内存模型和并发设计;数据库选型时你要考虑存储模型、支撑量级、成本开销;开源项目要考虑它的社区发展、文档完善程度;如果是库或者中间件,还要考虑他的易用性、灵活性以及可替代性,等等。
需要说明的一点是,我个人并不觉得阅读全部源码或者文档这种事情是必须的,这不局限在OS、VM层面。不仅因为这样的事情会耗费过多精力,而且受制于代码以及文档质量,就算真正阅读完毕也未必意味着完全领会。
这些都是定性的,而定性的东西就有可能存在理解偏差。一个库可以完成工作,并不代表它在高并发压力下依然表现正常;一个语言做到了自动管理内存,并不代表他能做得很好没有副作用;一件事情设计者觉得达到了目标并不代表能够满足使用者期望。因此我们还需要量化分析,也就是一直口口相传的,用数据说话。
量化分析需要你构建或使用现成的工具和数据集,对服务进行特定场景下的分析。通过提高压力、增加容量或者针对性的测试,来验证之前的定性分析是否达到预期,并分析不同技术之间的差异和表现。
- 实验
量化分析可以为真正的实验做一些准备和帮助,但是实验要走的明显更远。到了这一步,意味着要在真正的业务场景下进行验证,这跟量化分析中通用性场景有所不同。
在真正的业务中采用需要很多细致和琐碎的工作,除此之外,还要构建自己的测试工具集,这需要非常扎实的业务理解能力和勤奋的工作。而所有这些,你需要在开发环境做一次,在沙箱环境做一次,然后在仿真环境再做一次。
这几步经常被简化,但经验告诉我们,如果你想做一个高可用的系统,你就不应该少走任何一步。
步子大了,容易扯到蛋。
- 胆量
实验做完,剩下的就是上线,但这一步有很多人跨不过去。因为就算做了再多准备,你依然不敢说百分百保证没问题。现实情况是,80%的线上问题都是升级或者上线引起的。
你需要胆量。
这不是说要硬着头皮做,人家都是艺高才胆大。所以为了让胆子大一点,你首先需要考虑降级和开关。从最悲观的角度来重新审视整个方案,如果升级出现问题怎么办,如何才能让出现的问题影响最小化。
而只要弄完了这些,也就只要再记住一句话就行:
你行你上啊!
对技术服务的提醒
- 得到认可
刚才在胆量里没说的一点。我们经常会看到,一项新技术在公司内久久难以推行,因为业务主管百般阻挠。即使排除利益纠葛,仍然会发现一种发自心底的不信任存在。而这种不信任,又往往来源于对同事工作的不认可。
这个问题原因很多,也许没有通用的解决方案,但我说一个例子。
我们最近开始使用Codis,就是@goroutine 和几个家伙之前搞过的玩意儿。虽然他们最近已经独立开搞像Google Spanner但拥有更高级特性的TiDB(就是太牛了的意思)。由于我对他们比较熟悉和认可,所以在Codis尝试方面也多出很多底气。这种信任并非完全来自于出问题之后的直接电话支持,而是真心觉得活儿好。
反过来,这对很多服务也是一个提醒,特别是云服务。也许只要你得到合作伙伴的认可,或者至少让他们觉得,自己动手不会比你做得更好,你基本也就成功了。
对于大多数理性创业公司来讲,他们还是更愿意把精力放在自己的主要业务上,不会希望所有的服务都自己做,因为这个年代,唯快不破,创业等不起一辈子。
- 产品意识
回到开始那句话,“在对它不了解的情况下,仅通过google就能解决问题,不正说明它不难掌握有大量资料可查吗,实在不行还能翻代码。” 这话有些道理,然而却存在一个问题,这个问题就是:
作为一个使用者,是否有能力解决遇到的问题,与是否有意愿去遇到并解决问题,是两回事。
你有本CPU设计手册,你可以说处理器很简单,但我只想看个电影啊?给你Linux内核的源码,你可以说内核设计不难掌握,但我只想跑个游戏啊?何况他们是否因此就变得不难了,也是值得怀疑的。
这其实反映了技术人的产品意识。
很多技术人员喜欢玩酷的东西,他们愿意去探索新的领域,把不可能的变为可能。但是很多时候,他们做出来的东西却很难使用。
有的库可以增加很多参数,参数之间却有耦合,导致你在采用的时候需要写很多设置代码,而有点库却只需要一行代码;有的服务功能众多,却需要用户学习繁杂的步骤,而有的服务却可以开箱即用;有的服务功能可以实现,却会有很多不稳定甚至崩溃的情况出现,等等。
对于实现的工程师来讲,可能最大的区别在于,你是否考虑从用户的角度审视过自己的东西。即使这个服务也许只是为其他技术人员使用的。
技术人员可以,也应该,让技术人员更幸福。
最后,聊聊架构为大家送上一个关于技术选型的小漫画。其实技术并没有错,错的也许是我们.....

收起阅读 »
用户的满意是检验服务流程的唯一标准
写这个话题,源于本人的一次亲身经历,一个典型的案例。

某日上午,致电当地10000号开通ADSL上网服务,CSR认真地讲解该项业务的办理流程以及每个环节的服务承诺,包括致电后24小时内查线,48小时内上门安装。我欣然接受。
当日下午,很快接到CSR的安装预约电话,告知次日便可以为我上门安装,同时询问我是上午方便还是下午方便。如此快速的响应令我很高兴,并约定次日上午,同时将自己的活动安排在下午。
次日午后,仍然不见有人前来安装,也再没有人与我联系。于是我再次致电客服,讲明情况后,客服代表建议我自己与安装人员联系,并给我了一个电话号码。由于这本应该是电信公司内部协调处理的事情,所以我希望这位客服代表能够直接为我处理,CSR却“严格”地根据他们的工作流程拒绝了我。客服代表给我的解释是:如果由她下工单,要在3个工作日后能才上门给我安装,如果想要尽快安装的话,就需要我自己与安装人员联系。
可能是感觉到我有些不满意,这名CSR又问我是否需要投诉?我说:“不必了,我只是希望能够兑现今天为我上门安装的承诺。”
结束通话,我不禁深思:单从流程上讲,这是一个标准的操作流程,由CSR下工单,工单流转到安装人员处,安装人员上门安装。同时该流程也有明确的KPI指标(3天内完成)。从这一点来看,似乎这流程没有什么问题,CSR的服务也完全符合标准。但试问,这个流程的执行能够令用户满意吗?不会!因为:用户的感受是检验流程的唯一标准。
流程有四个关键因素:“目标”、“输入”、“输出”以及“活动”。我们先看“目标”这个重要因素:对于客服中心来讲,目标无疑应该是让用户满意。所以,客服中心的各个业务受理流程,每一个流程都应该是基于为用户服务并获得用户满意的这个原则。一旦流程的执行不能够实现这一目标,则无论该流程的执行多么好,都已经失去了流程本身的意义。
所以,客服中心在制定以及执行流程的过程中,需要定期的对现有流程进行目标校正,针对在流程的执行过程中用户不同的需求,以实现目标为宗旨梳理并调整现有流程。结合上面的这个case,从用户对该流程的不满可以看出,对现有流程进行修改已经具备了必要性。
第二个因素是“输入”。在上面这个案例中,当我再次致电时,实际上如果仍然按照原来的流程执行,那么已经无法再令我感到满意了。最初,我的需求是希望尽快开通上网服务,并且也接受电信的服务标准。当第二次联系客服中心时,需求已经变为要求能够兑现之前的承诺------当日完成上门安装。很明显,此时用户需求已经变更,但CSR仍然执行新业务开通的标准流程,当然无法得到用户的满意。原因很简单,我的服务需求已经发生了变化,对于该流程来讲,其“输入”已经由“新用户安装需求”转变为“兑现安装服务承诺”。“输入”已经改变,而CSR仍按固有流程受理,自然无法令用户满意。此时,用户的感受已经检验出该流程已经需要“优化”了。
再来看一下“输出”这个因素。根据该客服中心的流程,输出结果有两种:一种是由CSR下工单,然后三天内安排安装;一种是用户自行联系安装人员。但无论是哪种输出结果,都不能够获得用户的满意。第一种超出了用户能够接受的服务时效,第二种将本不该用户完成的“工作”转移给了用户。
最后关注一下“活动”这个因素。CSR对原有流程的执行可谓一丝不苟,而且也不存在“活动”不畅的情况。但是不是这样的执行就是合理的呢?我们知道,要使一个服务流程达到预期的效果,要求在流程的执行过程中,每一个“活动”都应该有其既定的“执行”步骤以及标准(流程KPI),但这不代表因此就禁锢了CSR为用户提供服务的主动性。客服中心在设计流程以及规范流程执行标准时,同时需要考虑到流程应有的“弹性”,即在用户需求发生改变时,应有紧急受理流程供CSR执行。这样,才能真正实现流程为用户服务的最终目的。
从上面流程图的对比中很容易看到,这本不是一个很复杂的流程,而且优化后的流程也更加的简单,更重要的是能够减少用户的不满,最终获得用户的满意。
结合这个Case,必须强调一个重要的问题:谁是这个流程中的关键角色?
对于客服中心来讲,当受理了用户的需求时,CSR与用户便成了服务流程中的关键角色,安装人员只是CSR的一个协作角色(内部流程下游角色)。如果在为用户提供服务过程中,将安装人员“引入”流程中,无疑将影响流程的执行效果。另外,让用户代替CSR去联系“安装人员”这更加影响用户的感受。
由于“安装人员”只是CSR的协作角色,并非是这个流程中的关键角色,所以应该采用“安装人员”相对CSR的悬挂流程模式。相关的流程模型可参照下面的流程模型对比图:
通过对比,很明显后者减少了流程中的关键角色,提高了流程的执行效率。CSR直接为用户提供了“一站式服务”,用户只需要通过一个电话便能解决问题,而至于CSR与安装人员的工作协调,完全不需要用户去介入。
上面的案例中,我更多的相信这并不全是CSR的责任,作为客服中心则应该在设计服务流程的同时考虑到特殊情况的处理流程,作好各种“预备方案”,以此指引CSR更有效、更灵活地为用户提供服务。而设计与优化流程的原则只有一个:用户的满意是检验流程的唯一标准。 收起阅读 »
某日上午,致电当地10000号开通ADSL上网服务,CSR认真地讲解该项业务的办理流程以及每个环节的服务承诺,包括致电后24小时内查线,48小时内上门安装。我欣然接受。
当日下午,很快接到CSR的安装预约电话,告知次日便可以为我上门安装,同时询问我是上午方便还是下午方便。如此快速的响应令我很高兴,并约定次日上午,同时将自己的活动安排在下午。
次日午后,仍然不见有人前来安装,也再没有人与我联系。于是我再次致电客服,讲明情况后,客服代表建议我自己与安装人员联系,并给我了一个电话号码。由于这本应该是电信公司内部协调处理的事情,所以我希望这位客服代表能够直接为我处理,CSR却“严格”地根据他们的工作流程拒绝了我。客服代表给我的解释是:如果由她下工单,要在3个工作日后能才上门给我安装,如果想要尽快安装的话,就需要我自己与安装人员联系。
可能是感觉到我有些不满意,这名CSR又问我是否需要投诉?我说:“不必了,我只是希望能够兑现今天为我上门安装的承诺。”
结束通话,我不禁深思:单从流程上讲,这是一个标准的操作流程,由CSR下工单,工单流转到安装人员处,安装人员上门安装。同时该流程也有明确的KPI指标(3天内完成)。从这一点来看,似乎这流程没有什么问题,CSR的服务也完全符合标准。但试问,这个流程的执行能够令用户满意吗?不会!因为:用户的感受是检验流程的唯一标准。
流程有四个关键因素:“目标”、“输入”、“输出”以及“活动”。我们先看“目标”这个重要因素:对于客服中心来讲,目标无疑应该是让用户满意。所以,客服中心的各个业务受理流程,每一个流程都应该是基于为用户服务并获得用户满意的这个原则。一旦流程的执行不能够实现这一目标,则无论该流程的执行多么好,都已经失去了流程本身的意义。
所以,客服中心在制定以及执行流程的过程中,需要定期的对现有流程进行目标校正,针对在流程的执行过程中用户不同的需求,以实现目标为宗旨梳理并调整现有流程。结合上面的这个case,从用户对该流程的不满可以看出,对现有流程进行修改已经具备了必要性。
第二个因素是“输入”。在上面这个案例中,当我再次致电时,实际上如果仍然按照原来的流程执行,那么已经无法再令我感到满意了。最初,我的需求是希望尽快开通上网服务,并且也接受电信的服务标准。当第二次联系客服中心时,需求已经变为要求能够兑现之前的承诺------当日完成上门安装。很明显,此时用户需求已经变更,但CSR仍然执行新业务开通的标准流程,当然无法得到用户的满意。原因很简单,我的服务需求已经发生了变化,对于该流程来讲,其“输入”已经由“新用户安装需求”转变为“兑现安装服务承诺”。“输入”已经改变,而CSR仍按固有流程受理,自然无法令用户满意。此时,用户的感受已经检验出该流程已经需要“优化”了。
再来看一下“输出”这个因素。根据该客服中心的流程,输出结果有两种:一种是由CSR下工单,然后三天内安排安装;一种是用户自行联系安装人员。但无论是哪种输出结果,都不能够获得用户的满意。第一种超出了用户能够接受的服务时效,第二种将本不该用户完成的“工作”转移给了用户。
最后关注一下“活动”这个因素。CSR对原有流程的执行可谓一丝不苟,而且也不存在“活动”不畅的情况。但是不是这样的执行就是合理的呢?我们知道,要使一个服务流程达到预期的效果,要求在流程的执行过程中,每一个“活动”都应该有其既定的“执行”步骤以及标准(流程KPI),但这不代表因此就禁锢了CSR为用户提供服务的主动性。客服中心在设计流程以及规范流程执行标准时,同时需要考虑到流程应有的“弹性”,即在用户需求发生改变时,应有紧急受理流程供CSR执行。这样,才能真正实现流程为用户服务的最终目的。
从上面流程图的对比中很容易看到,这本不是一个很复杂的流程,而且优化后的流程也更加的简单,更重要的是能够减少用户的不满,最终获得用户的满意。
结合这个Case,必须强调一个重要的问题:谁是这个流程中的关键角色?
对于客服中心来讲,当受理了用户的需求时,CSR与用户便成了服务流程中的关键角色,安装人员只是CSR的一个协作角色(内部流程下游角色)。如果在为用户提供服务过程中,将安装人员“引入”流程中,无疑将影响流程的执行效果。另外,让用户代替CSR去联系“安装人员”这更加影响用户的感受。
由于“安装人员”只是CSR的协作角色,并非是这个流程中的关键角色,所以应该采用“安装人员”相对CSR的悬挂流程模式。相关的流程模型可参照下面的流程模型对比图:
通过对比,很明显后者减少了流程中的关键角色,提高了流程的执行效率。CSR直接为用户提供了“一站式服务”,用户只需要通过一个电话便能解决问题,而至于CSR与安装人员的工作协调,完全不需要用户去介入。
上面的案例中,我更多的相信这并不全是CSR的责任,作为客服中心则应该在设计服务流程的同时考虑到特殊情况的处理流程,作好各种“预备方案”,以此指引CSR更有效、更灵活地为用户提供服务。而设计与优化流程的原则只有一个:用户的满意是检验流程的唯一标准。 收起阅读 »
天津电视台采访环信天津研发中心
环信天津研发中心赵贵斌接受采访

环信天津滨海新区研发中心负责人赵贵斌表示环信代表了中国企业级服务的新生力量,将把环信在企业级服务的优势经验带到新区,服务好新区的众多金融和外贸客户。现阶段天津研发中心是北京中心的有益补充,未来将立足天津辐射世界,更希望有志于用技术改变世界的工程师们加入环信落户天津,一起把环信天津研发中心做大做强,用卓越的技术连接人与人,连接人与商业来改变每个人的生活和工作!
环信天津滨海新区研发中心热招职位
收起阅读 »

基于环信的仿QQ即时通讯的简单实现
之前一直想实现聊天的功能,但是感觉有点困难,今天看了环信的API,就利用下午的时间动手试了试,然后做了一个小Demo。
因为没有刻意去做聊天软件,花的时间也不多,然后界面就很简单,都是一些基本知识,如果觉得功能简单,可以自行添加,我这就不多介绍了。
照例先来一波动态演示:

功能很简单,注册用户 --> 用户登录 --> 选择聊天对象 --> 开始聊天
使用到的知识点:
首先是看了郭神的《第二行代码》做了聊天界面,用的是RecyclerView
a. 消息类的封装

c. RecyclerView适配器
RecyclerView初始化
就是一些基本的初始化,我就不赘述了,讲一下添加数据的细节处理
2. 环信API的简单应用
官网有详细的API介绍 环信即时通讯云V3.0,我这里就简单介绍如何简单集成
a. 环信开发账号的注册
环信官网

b. SDK导入
你可以直接下载然后拷贝工程的libs目录下
Android Studio可以直接添加依赖
将以下代码放到项目根目录的build.gradle文件里
在自定义Application的onCreate中初始化
注册要在子线程中执行
到此,一个简单的即时聊天Demo已经完成,功能很简单,如果需要添加额外功能的话,可以自行参考官网,官网给出的教程还是很不错的!
最后希望大家能多多支持我,需要你们的支持喜欢!!
作者:环信开发者下位子 收起阅读 »
因为没有刻意去做聊天软件,花的时间也不多,然后界面就很简单,都是一些基本知识,如果觉得功能简单,可以自行添加,我这就不多介绍了。
照例先来一波动态演示:
功能很简单,注册用户 --> 用户登录 --> 选择聊天对象 --> 开始聊天
使用到的知识点:
RecyclerView依赖的库
CardView
环信的API的简单使用
compile 'com.android.support:appcompat-v7:24.2.1'1、聊天页面
compile 'com.android.support:cardview-v7:24.1.1'
compile 'com.android.support:recyclerview-v7:24.0.0'
首先是看了郭神的《第二行代码》做了聊天界面,用的是RecyclerView
a. 消息类的封装
public class MSG {
public static final int TYPE_RECEIVED = 0;//消息的类型:接收
public static final int TYPE_SEND = 1; //消息的类型:发送
private String content;//消息的内容
private int type; //消息的类型
public MSG(String content, int type) {
this.content = content;
this.type = type;
}
public String getContent() {
return content;
}
public int getType() {
return type;
}
}b. RecyclerView子项的布局<LinearLayout这是左边的部分,至于右边应该也就简单了。我用CardView把ImageView包裹起来,这样比较好看。效果如下:
android:id="@+id/ll_msg_left"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
<!-- 设置点击效果为水波纹(5.0以上) -->
android:background="?android:attr/selectableItemBackground"
android:clickable="true"
android:focusable="true"
android:orientation="horizontal"
android:padding="2dp">
<android.support.v7.widget.CardView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:cardCornerRadius="20dp"
app:cardPreventCornerOverlap="false"
app:cardUseCompatPadding="true">
<ImageView
android:layout_width="50dp"
android:layout_height="50dp"
android:scaleType="centerCrop"
android:src="@mipmap/man" />
</android.support.v7.widget.CardView>
<LinearLayout
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:background="@drawable/message_left"
android:orientation="horizontal">
<TextView
android:id="@+id/tv_msg_left"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center"
android:layout_margin="10dp"
android:textColor="#fff" />
</LinearLayout>
</LinearLayout>
c. RecyclerView适配器
public class MsgAdapter extends RecyclerView.Adapter<MsgAdapter.MyViewHolder> {
private List<MSG> mMsgList;
public MsgAdapter(List<MSG> mMsgList) {
this.mMsgList = mMsgList;
}
@Override
public MyViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View view = View.inflate(parent.getContext(), R.layout.item_msg, null);
MyViewHolder holder = new MyViewHolder(view);
return holder;
}
@Override
public void onBindViewHolder(MyViewHolder holder, int position) {
MSG msg = mMsgList.get(position);
if (msg.getType() == MSG.TYPE_RECEIVED){
//如果是收到的消息,显示左边布局,隐藏右边布局
holder.llLeft.setVisibility(View.VISIBLE);
holder.llRight.setVisibility(View.GONE);
holder.tv_Left.setText(msg.getContent());
} else if (msg.getType() == MSG.TYPE_SEND){
//如果是发送的消息,显示右边布局,隐藏左边布局
holder.llLeft.setVisibility(View.GONE);
holder.llRight.setVisibility(View.VISIBLE);
holder.tv_Right.setText(msg.getContent());
}
}
@Override
public int getItemCount() {
return mMsgList.size();
}
static class MyViewHolder extends RecyclerView.ViewHolder{
LinearLayout llLeft;
LinearLayout llRight;
TextView tv_Left;
TextView tv_Right;
public MyViewHolder(View itemView) {
super(itemView);
llLeft = (LinearLayout) itemView.findViewById(R.id.ll_msg_left);
llRight = (LinearLayout) itemView.findViewById(R.id.ll_msg_right);
tv_Left = (TextView) itemView.findViewById(R.id.tv_msg_left);
tv_Right = (TextView) itemView.findViewById(R.id.tv_msg_right);
}
}
}这部分应该也没什么问题,就是适配器的创建,我之前的文章也讲过 传送门:简单粗暴----RecyclerViewd. RecyclerView初始化
就是一些基本的初始化,我就不赘述了,讲一下添加数据的细节处理
btSend.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
String content = etInput.getText().toString().trim();
if (!TextUtils.isEmpty(content)){
...//环信部分的发送消息
MSG msg = new MSG(content, MSG.TYPE_SEND);
mList.add(msg);
//当有新消息时,刷新RecyclerView中的显示
mAdapter.notifyItemInserted(mList.size() - 1);
//将RecyclerView定位到最后一行
mRecyclerView.scrollToPosition(mList.size() - 1);
etInput.setText("");
}
}
});至此界面已经结束了,接下来就是数据的读取2. 环信API的简单应用
官网有详细的API介绍 环信即时通讯云V3.0,我这里就简单介绍如何简单集成
a. 环信开发账号的注册
环信官网
b. SDK导入
你可以直接下载然后拷贝工程的libs目录下
Android Studio可以直接添加依赖
将以下代码放到项目根目录的build.gradle文件里
repositories {
maven { url "https://raw.githubusercontent.com/HyphenateInc/Hyphenate-SDK-Android/master/repository" }
}在你的module的build.gradle里加入以下代码android {
//use legacy for android 6.0
useLibrary 'org.apache.http.legacy'
}
dependencies {
compile 'com.android.support:appcompat-v7:23.4.0'
//Optional compile for GCM (Google Cloud Messaging).
compile 'com.google.android.gms:play-services-gcm:9.4.0'
compile 'com.hyphenate:hyphenate-sdk:3.2.3'
}如果想使用不包含音视频通话的sdk,用compile 'com.hyphenate:hyphenate-sdk-lite:3.2.3'c. 清单文件配置
<?xml version="1.0" encoding="utf-8"?>APP打包混淆
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="Your Package"
android:versionCode="100"
android:versionName="1.0.0">
<!-- Required -->
<uses-permission android:name="android.permission.VIBRATE" />
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.RECORD_AUDIO" />
<uses-permission android:name="android.permission.CAMERA" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.ACCESS_MOCK_LOCATION" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS"/>
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<uses-permission android:name="android.permission.GET_TASKS" />
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
<uses-permission android:name="android.permission.CHANGE_WIFI_STATE" />
<uses-permission android:name="android.permission.WAKE_LOCK" />
<uses-permission android:name="android.permission.MODIFY_AUDIO_SETTINGS" />
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
<uses-permission android:name="android.permission.RECEIVE_BOOT_COMPLETED" />
<application
android:icon="@drawable/ic_launcher"
android:label="@string/app_name"
android:name="Your Application">
<!-- 设置环信应用的AppKey -->
<meta-data android:name="EASEMOB_APPKEY" android:value="Your AppKey" />
<!-- 声明SDK所需的service SDK核心功能-->
<service android:name="com.hyphenate.chat.EMChatService" android:exported="true"/>
<service android:name="com.hyphenate.chat.EMJobService"
android:permission="android.permission.BIND_JOB_SERVICE"
android:exported="true"
/>
<!-- 声明SDK所需的receiver -->
<receiver android:name="com.hyphenate.chat.EMMonitorReceiver">
<intent-filter>
<action android:name="android.intent.action.PACKAGE_REMOVED"/>
<data android:scheme="package"/>
</intent-filter>
<!-- 可选filter -->
<intent-filter>
<action android:name="android.intent.action.BOOT_COMPLETED"/>
<action android:name="android.intent.action.USER_PRESENT" />
</intent-filter>
</receiver>
</application>
</manifest>
-keep class com.hyphenate.** {*;}
-dontwarn com.hyphenate.**d. 初始化SDK在自定义Application的onCreate中初始化
public class MyApplication extends Application {
private Context appContext;
@Override
public void onCreate() {
super.onCreate();
EMOptions options = new EMOptions();
options.setAcceptInvitationAlways(false);
appContext = this;
int pid = android.os.Process.myPid();
String processAppName = getAppName(pid);
// 如果APP启用了远程的service,此application:onCreate会被调用2次
// 为了防止环信SDK被初始化2次,加此判断会保证SDK被初始化1次
// 默认的APP会在以包名为默认的process name下运行,如果查到的process name不是APP的process name就立即返回
if (processAppName == null || !processAppName.equalsIgnoreCase(appContext.getPackageName())) {
Log.e("--->", "enter the service process!");
// 则此application::onCreate 是被service 调用的,直接返回
return;
}
//初始化
EMClient.getInstance().init(getApplicationContext(), options);
//在做打包混淆时,关闭debug模式,避免消耗不必要的资源
EMClient.getInstance().setDebugMode(true);
}
private String getAppName(int pID) {
String processName = null;
ActivityManager am = (ActivityManager) this.getSystemService(ACTIVITY_SERVICE);
List l = am.getRunningAppProcesses();
Iterator i = l.iterator();
PackageManager pm = this.getPackageManager();
while (i.hasNext()) {
ActivityManager.RunningAppProcessInfo info = (ActivityManager.RunningAppProcessInfo) (i.next());
try {
if (info.pid == pID) {
processName = info.processName;
return processName;
}
} catch (Exception e) {
// Log.d("Process", "Error>> :"+ e.toString());
}
}
return processName;
}
}e. 注册和登陆注册要在子线程中执行
//注册失败会抛出HyphenateExceptionf. 发送消息
EMClient.getInstance().createAccount(username, pwd);//同步方法
EMClient.getInstance().login(userName,password,new EMCallBack() {//回调
@Override
public void onSuccess() {
EMClient.getInstance().groupManager().loadAllGroups();
EMClient.getInstance().chatManager().loadAllConversations();
Log.d("main", "登录聊天服务器成功!");
}
@Override
public void onProgress(int progress, String status) {
}
@Override
public void onError(int code, String message) {
Log.d("main", "登录聊天服务器失败!");
}
});
//创建一条文本消息,content为消息文字内容,toChatUsername为对方用户或者群聊的id,后文皆是如此g. 接收消息
EMMessage message = EMMessage.createTxtSendMessage(content, toChatUsername);
//发送消息
EMClient.getInstance().chatManager().sendMessage(message);
msgListener = new EMMessageListener() {
@Override
public void onMessageReceived(List<EMMessage> messages) {
//收到消息
String result = messages.get(0).getBody().toString();
String msgReceived = result.substring(5, result.length() - 1);
Log.i(TAG, "onMessageReceived: " + msgReceived);
final MSG msg = new MSG(msgReceived, MSG.TYPE_RECEIVED);
runOnUiThread(new Runnable() {
@Override
public void run() {
mList.add(msg);
mAdapter.notifyDataSetChanged();
mRecyclerView.scrollToPosition(mList.size() - 1);
}
});
}
@Override
public void onCmdMessageReceived(List<EMMessage> messages) {
//收到透传消息
}
@Override
public void onMessageRead(List<EMMessage> list) {
}
@Override
public void onMessageDelivered(List<EMMessage> list) {
}
@Override
public void onMessageChanged(EMMessage message, Object change) {
//消息状态变动
}
};接收消息的监听器分别需要在OnResume()和OnDestory()方法中注册和取消注册EMClient.getInstance().chatManager().addMessageListener(msgListener);//注册需要注意的是,当接收到消息,需要在主线程中更新适配器,否则会不能及时刷新出来
EMClient.getInstance().chatManager().removeMessageListener(msgListener);//取消注册
到此,一个简单的即时聊天Demo已经完成,功能很简单,如果需要添加额外功能的话,可以自行参考官网,官网给出的教程还是很不错的!
最后希望大家能多多支持我,需要你们的支持喜欢!!
作者:环信开发者下位子 收起阅读 »
是对单位的认可、对领导的眷恋、对事业的追求,环信工程师们春节前3天发布了环信移动客服v5.9!!!
2017年1月24日,离中国农历新年还有3天,环信工程师们本着对单位的认可、对领导的眷恋、对事业的追求、对党的忠诚以及对所有环信客户成功的承诺,发布了环信移动客服v5.9版本,谱写了一曲忠诚的赞歌!本次版本新增了黑名单、支持查看位置消息、添加会话标签时支持对会话标签进行搜索等新的特性,以及若干优化。虽然只是一次普通的更新,但是凝结的是所有环信工程师们的勤恳和汗水,环信移动客服在整个2016年度始终保持了最少两周发布一个大版本的速度,力求产品和服务一直能够满足大中型企业用户的业务增长需求,特别是在2016年8月份环信移动客服5.0旗舰版发布以后,整个中国的SaaS客服市场欣欣向荣,全媒体智能云客服的大时代从而正式拉开大幕!
在整个2016年环信全媒体智能云客服平台的经营数据也取得了长足的进步和发展,不管是新增服务企业数、日服务用户数、还是营收都取得了爆发式的增长,环信也拿下了诸如国美在线、中信证券、新浪微博、泰康在线、神州专车等众多标杆企业用户,在2017年,环信也将一如既往秉承以客户成功为己任,以产品和技术驱动,用卓越的技术服务好包括金融、电商、教育、医疗、旅游、O2O、制造业等领域的每一位小伙伴们!
客服模式
支持查看位置消息
在会话、历史会话、客户中心等页面,可以查看客户发送的位置消息。点击位置图标,可以查看图片形式的位置消息。

新接入的会话增加颜色提醒
在会话页面,为新接入的会话增加背景颜色,使客服能够优先关注到新会话,及时回复访客,提升首次响应速度。客服手动回复消息后,背景颜色消失,客户再次发送消息时,背景颜色不再变化。

添加会话标签时,支持对会话标签进行搜索
在会话、历史会话等页面添加会话标签时,支持对会话标签的叶结点进行搜索。搜索完成后,直接选择叶结点,即可添加会话标签。

黑名单功能
新增黑名单功能,在会话进行中,如果客户恶意骚扰,客服可以手动将其加入黑名单,加入黑名单后,会话立即自动结束。客服还可以在“历史会话”和“客户中心”,将客户手动加入黑名单,或移除黑名单。黑名单中的客户可以再次发送消息,但系统不会为其创建会话;客户被移除黑名单后,再次发送消息时可以成功创建会话。
1. 加入黑名单:
在会话过程中,客服可以点击“资料”页签下方的“加入黑名单”按钮,填写加入黑名单的理由,将客户加入黑名单。

或者,客服可以在“历史会话”或“客户中心”页面找到需要加入黑名单的客户,点击该客户,在详情页点击“加入黑名单”按钮,将客户加入黑名单。
注意:管理员需要在“管理员模式 > 设置 > 系统开关”页面打开“客服可以使用访客中心功能”开关,客服才能使用“客户中心”页面。

2. 移除黑名单:
客服可以在“历史会话”或“客户中心”页面找到已经加入黑名单的客户,点击该客户,在详情页点击“移除黑名单”按钮,将客户移除黑名单。
支持从消息中心跳转至客户中心
在消息中心页面,收到与客户有关的系统消息时(如不活跃会话自动结束),可以在消息详情页点击“查看详情”按钮,进入客户中心页面查看客户的详情。

【优化】支持查看客服同事的头像
与客服同事聊天时,以及将会话转接给客服同事时,可以查看客服同事的头像。
【优化】在历史会话中显示微信/微博网友发送的表情
在历史会话页面,支持显示微信/微博网友发送的表情,和会话页面的显示保持一致。
【优化】接到呼叫中心来电时,客服状态自动置为忙碌
接到呼叫中心来电时,如果客服在线状态为空闲,则自动置为忙碌,此时不会自动分配会话,进行中会话可以继续处理。挂断电话后,客服状态自动恢复空闲。如果接到呼叫中心来电时,客服状态为忙碌、离开、隐身,则不改变原来的状态。接听电话过程中,依然可以手动修改在线状态。
呼叫中心为增值服务,如需开通,请提供租户ID并联系环信商务经理。

管理员模式
管理黑名单
管理员可以在“客户中心”对黑名单进行管理,包括将客户加入黑名单,查看黑名单中的客户,将客户移除黑名单等。黑名单中的客户可以再次发送消息,但系统不会为其创建会话;客户被移除黑名单后,再次发送消息时可以成功创建会话。
1. 加入黑名单:
在“历史会话”或“客户中心”页面,可以将客户加入黑名单。以“客户中心”为例,点击任意客户,进入详情页。通过“互动记录”鉴定需要将该客户加入黑名单后,进入“基本资料”tab页签,点击“加入黑名单”按钮,在对话框中填写加入黑名单的理由,并保存。

2. 查看黑名单:
在“客户中心”页面,点击右上角的“黑名单”按钮,切换至“黑名单”页面,可以查看黑名单中的客户及加入黑名单的原因。

3. 移除黑名单:
在“黑名单”页面,点击删除按钮,可以快速将客户移除黑名单。
或者,在“历史会话”或“客户中心”页面,通过“访客ID”找到黑名单中的客户,进入详情页,点击“移除黑名单”按钮,将客户移除黑名单。
访客新消息排在会话列表顶端
新增“访客新消息排在会话列表顶端”开关,开关打开时,访客发送新消息,该会话主动排在客服的“进行中”会话列表顶端。
进入“设置 > 系统开关”页面,可以打开这个开关。

微信渠道向Iframe传递微信公众号的原始ID
可以使用移动客服提供的Iframe集成CRM系统,环信默认向Iframe传递两个参数:easemobId和visitorImId(访客ID),用于向CRM系统查询详细的客户资料。对于微信渠道,额外传递参数to,该参数的值为微信公众号的原始ID。
进入移动客服的“管理员模式 > 设置 > 自定义信息接口”页面可以配置CRM系统的服务器地址,详情请查看环信文档:CRM系统对接。
进入微信公众平台,在“公众号设置”页面,可以查看微信公众号的“原始ID”。
【优化】当前会话页面固定显示“刷新”按钮
当前会话页面的“刷新”按钮改为固定显示,管理员可以随时点击“刷新”,查看最新的进行中会话列表。但是,进行中会话的最新消息内容不会一起更新。

Android客服工作台
当前版本:V2.6
优化推送栏提醒频率
Android客服工作台对推送栏提醒频率进行了优化,减少推送次数,使提醒更合理。
关于更多Android客服工作台的更新日志,请查看Android客服工作台更新日志。
iOS客服工作台
当前版本:V2.1
支持设置最大接待人数
iOS客服工作台支持设置最大接待人数。最大接待人数的上限为100,登录客服工作台后可以查看自己的最大接待人数,并根据需要做出调整。
【优化】减少不必要的推送
iOS客服工作台对离线推送进行分类处理,减少不必要的推送。
关于更多iOS客服工作台的更新日志,请查看iOS客服工作台更新日志。
商城Demo
通过扫描二维码获取关联配置
“商城Demo”支持通过扫描移动客服“管理员模式 > 渠道管理 > 手机APP”页面任意关联的二维码获取关联配置,包括该关联的AppKey和IM服务号以及该租户的租户ID和留言ID。
获取关联配置后,可以使用“商城Demo”直接发起会话或留言,操作更便捷。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.9
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
环信移动客服v5.8已发布-实时监控页面新增“平均响应时长”以及技能组数据
管理员模式
实时监控页面新增技能组数据和平均响应时长
实时监控页面,将原来的客服排名变更为全部客服的排序,增加“平均响应时长”,并且为“接起会话数”、“平均首次响应时长”、“满意度”、“平均响应时长”模块增加技能组数据。
以“平均响应时长”模块为例,该模块显示所有客服或技能组今天参与会话期间的平均响应时长,并进行排名。当客服数量较多时,可以下拉查看更多客服的名次和数据。点击“技能组”,可以切换为技能组的“平均响应时长”排名。

【优化】工作量报表“会话数分布”扩展维度
工作量报表中,扩展“会话数分布”图形的横坐标维度,覆盖更多指标区间。
会话数分布(按会话时长维度):增加会话时长“5分钟-10分钟”和“10分钟”以上。

【优化】工作质量导出报表增加“有效人工会话占比”个数
工作质量导出报表中,“有效人工会话占比”增加有效会话和无效会话的个数。

环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.8
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
实时监控页面新增技能组数据和平均响应时长
实时监控页面,将原来的客服排名变更为全部客服的排序,增加“平均响应时长”,并且为“接起会话数”、“平均首次响应时长”、“满意度”、“平均响应时长”模块增加技能组数据。
以“平均响应时长”模块为例,该模块显示所有客服或技能组今天参与会话期间的平均响应时长,并进行排名。当客服数量较多时,可以下拉查看更多客服的名次和数据。点击“技能组”,可以切换为技能组的“平均响应时长”排名。
【优化】工作量报表“会话数分布”扩展维度
工作量报表中,扩展“会话数分布”图形的横坐标维度,覆盖更多指标区间。
- 会话数分布(按会话消息数维度):增加消息数量“30-60”与“60以上”。
会话数分布(按会话时长维度):增加会话时长“5分钟-10分钟”和“10分钟”以上。
【优化】工作质量导出报表增加“有效人工会话占比”个数
工作质量导出报表中,“有效人工会话占比”增加有效会话和无效会话的个数。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.8
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
保险业客服进化论,看泰康在线的SaaS客服进阶之路!
嘿,你以为保险公司还是当年那些“卖保险的”吗?不厌其烦地打电话、上门推销,这是我们印象中传统保险公司的做法。然而数据表明,早已有超过65%的保险公司已经向互联网+转型,截至2016年3月,互联网保险用户已经超过3.3亿,同比增长42.5%,互联网保民的人数已经是股民的3倍,基民的1.5倍。在互联网平台上,保险与消费正展现出一种互相促进的“共生效应”。保险行业的全面“触网”不仅带来了更加丰富的保险产品,也使得这个视客户服务为生命线的行业更加需要重视用户体验和精细化用户运营。


图1. 环信全渠道客服工作台界面 基于庞大的粉丝积累和逐渐提升的客服咨询量,平台稳定性也是必须要考虑的因素。以千万级并发IM业务起家的环信移动客服平台运行稳定,通过了多次线上活动的峰值考验。

图2.不同渠道对应不同技能组示意图 2.丰富客户画像,让转化更精准 大数据如今对于更深入理解客户、挖掘客户需求的意义无需多说,泰康结合环信提供的一套灵活的标签体系,针对从客户和会话两个维度进行标签分类,能够更有效地帮助积累话术经验,进行精准客服。同时,结合轻营销的能力,对客户进行个性化的消息推送、回呼等行为,营销效率得到提升。

图3.客户标签示意图

图4.会话标签示意图 3.轨迹跟踪,了解访客来源及历史行为。 如果能知道客户在网页或APP上看了啥,从哪个入口进来的,那是再好不过了,这些信息可以帮助企业更好地判断是否有销售机会、在哪些方面有销售机会以及从哪入手去和客户接触。在泰康的APP渠道中就集成了轨迹跟踪的功能,不论你在哪一款保险产品页面进入客服,都会自动带上对应产品的访问轨迹,方便客服人员判断,你可能感兴趣的是哪款产品,从而做到有的放矢。

图5.APP端访问轨迹示意图
随着人工智能的兴起,保险行业使用客服机器人也并非新鲜事。然而智能机器人的选型才是真正的难中之难。首先不能选机器人和客服平台分属两家公司的,一旦出现问题容易互相踢皮球;其次,要评估机器人厂家在单轮会话,多轮会话,人机协助这3个核心功能上的表现和指标。最重要的是要选拥有自主知识产权,真正能够基于语义分析和深度学习混合计算进行服务的机器人。泰康选择与环信合作,机器人对这些条件的达成,自然不言而喻,目前已在人工客服下班时间为泰康在线保驾护航,目前业务问答正确率达到行业领先水平。
智能机器人除了本身对自动回复、单轮/多轮会话、自主学习等功能的支持,现阶段一般都需要人工的参与才能够达到最佳客服效果。泰康在这方面的策略也堪称实践典范:在知识库中配置了以30多个核心业务咨询场景为核心的智能文字IVR菜单,并在欢迎语、默认回复等引导语中,尽量将用户问题范围收敛到已有知识规则上,大幅提升了机器人工作效率。

图6.客服机器人体验示意图
自此,泰康在线联手环信率先在互联网保险行业实现了包括电话坐席、网页端、APP端、微信端等全渠道打通的全媒体客服接入,引领了保险业智能客服的潮流,实现了服务渠道的一体化,通过精准营销实现了业务增长,实实在在给用户打造了一套用户体验为王的一站式智能互联网保险服务。
泰康在线客服主管童娜表示:“环信智能客服平台适用多业务场景,一站式后台提高客服效率的同时,也给客户带来更好的咨询体验。”
下一步泰康将在呼叫中心融合、智能营销和大数据分析方面做更多的创新和尝试。环信也将一如既往的秉承以客户成功为己任,通过自身优秀的产品技术和服务实力在推动包括保险、金融、教育、医疗、旅游等各大行业全媒体智能SaaS客服解决方案上发挥更大的价值。
关于泰康在线
- 互联网+时代,保险行业面临5大客服痛点亟需解决
- 全渠道客服是趋势,泰康在线先从微信客服单点突破!
图1. 环信全渠道客服工作台界面 基于庞大的粉丝积累和逐渐提升的客服咨询量,平台稳定性也是必须要考虑的因素。以千万级并发IM业务起家的环信移动客服平台运行稳定,通过了多次线上活动的峰值考验。
- 从服务中挖掘销售机会,泰康在线三招玩转精准营销!
图2.不同渠道对应不同技能组示意图 2.丰富客户画像,让转化更精准 大数据如今对于更深入理解客户、挖掘客户需求的意义无需多说,泰康结合环信提供的一套灵活的标签体系,针对从客户和会话两个维度进行标签分类,能够更有效地帮助积累话术经验,进行精准客服。同时,结合轻营销的能力,对客户进行个性化的消息推送、回呼等行为,营销效率得到提升。
图3.客户标签示意图
图4.会话标签示意图 3.轨迹跟踪,了解访客来源及历史行为。 如果能知道客户在网页或APP上看了啥,从哪个入口进来的,那是再好不过了,这些信息可以帮助企业更好地判断是否有销售机会、在哪些方面有销售机会以及从哪入手去和客户接触。在泰康的APP渠道中就集成了轨迹跟踪的功能,不论你在哪一款保险产品页面进入客服,都会自动带上对应产品的访问轨迹,方便客服人员判断,你可能感兴趣的是哪款产品,从而做到有的放矢。
图5.APP端访问轨迹示意图
- 智能客服机器人的诀窍,在机器也在人!
随着人工智能的兴起,保险行业使用客服机器人也并非新鲜事。然而智能机器人的选型才是真正的难中之难。首先不能选机器人和客服平台分属两家公司的,一旦出现问题容易互相踢皮球;其次,要评估机器人厂家在单轮会话,多轮会话,人机协助这3个核心功能上的表现和指标。最重要的是要选拥有自主知识产权,真正能够基于语义分析和深度学习混合计算进行服务的机器人。泰康选择与环信合作,机器人对这些条件的达成,自然不言而喻,目前已在人工客服下班时间为泰康在线保驾护航,目前业务问答正确率达到行业领先水平。
智能机器人除了本身对自动回复、单轮/多轮会话、自主学习等功能的支持,现阶段一般都需要人工的参与才能够达到最佳客服效果。泰康在这方面的策略也堪称实践典范:在知识库中配置了以30多个核心业务咨询场景为核心的智能文字IVR菜单,并在欢迎语、默认回复等引导语中,尽量将用户问题范围收敛到已有知识规则上,大幅提升了机器人工作效率。
图6.客服机器人体验示意图
自此,泰康在线联手环信率先在互联网保险行业实现了包括电话坐席、网页端、APP端、微信端等全渠道打通的全媒体客服接入,引领了保险业智能客服的潮流,实现了服务渠道的一体化,通过精准营销实现了业务增长,实实在在给用户打造了一套用户体验为王的一站式智能互联网保险服务。
泰康在线客服主管童娜表示:“环信智能客服平台适用多业务场景,一站式后台提高客服效率的同时,也给客户带来更好的咨询体验。”
下一步泰康将在呼叫中心融合、智能营销和大数据分析方面做更多的创新和尝试。环信也将一如既往的秉承以客户成功为己任,通过自身优秀的产品技术和服务实力在推动包括保险、金融、教育、医疗、旅游等各大行业全媒体智能SaaS客服解决方案上发挥更大的价值。
关于泰康在线
2015年11月18日,泰康在线财产保险股份有限公司作为行业内首家由国内大型保险企业发起成立的互联网保险公司,正式在武汉挂牌成立,注册资本金人民币10亿元。其前身是2000年8月成立的泰康人寿的官方网站.经过十多年的发展,目前已经已形成互联网产寿险结合的保险产品体系,产品线涵盖互联网财产险、旅行险、健康险、意外险、养老金和理财险等。收起阅读 »
如何通过呼叫中心发现客户变化?
我们如何更好的以客户为中心?一种方法是听完所有客户通话记录,阅读所有客户邮件,从客户角度看待问题并理解客户意见,之后直接询问客户问题。很明显,企业无法听完所有通话记录,并且客户调查涉及许多方法,每种方法都各有利弊。
客户分析能够通过为语音分析、文本分析和客户反馈调查提供软件应用来解决这些问题。这些应用是人力资源优化战略的组成部分,这个战略是由分析驱动的,能提供关键的、全新的客户中心视角。因为它们基于公用的人力资源优化平台,可以分享数据,你的组织能够从数据的协同效益中受益。
`8K~ORA~A(M_Y(_QCRKN.png")
语音分析
语音分析是当下的热门话题,这种兴奋很容易理解。呼叫中心记录了不计其数的客户通话,但是只有一小部分能被听完。此外,他们更注意坐席人员的表现,而非客户。就算组织有意识把关注的重点转移到客户身上,但是只听如此少的谈话记录也不足以充分了解客户的话语和感受,很容易产生误解。
如果你愿意,语音分析解决方案可以“听”到所有通话记录。这个方案使用了多种技术和算法来索引和记录谈话,让所有谈话都能被搜到。使用索引技术,语音分析就能把记录下的对话按照兴趣的类别进行分类——投诉电话、转移呼叫和情感呼叫。接着,语音分析用算法把与兴趣相类似的单词或短语分门别类,提示呼叫的根本原因。
除了区分原因,语音分析还自动跟踪趋势和变化。按照日、周甚至更长的时间间隔,语音分析可以提醒你它所监测到的相关类别、措辞和短语的变化。
有个关于德国外包商为他的客户提供语音分析的例子。一天,外包商的语音分析解决方案显示电话数量急剧增加——从零飙升至几百——且含有以下词语“blah, blah, blah”。更为奇怪的是,这些通话的平均时长是一般通话的3倍。分析结果十分骇人。起初,他们认为是一些坐席人员在使用奇怪的词语。但在检查了一些新类别中的通话记录之后,他们很快发现,客户收到了一封来自于市场部的信,解释了服务合同中的一些新特点。这封信十分晦涩难懂,促使很多客户打来电话说:“我收到了一封信,说我的服务发生了变化blah, blah, blah,我不明白这封信到底是什么意思。”外包商立刻通知市场部,这些问题很快就得到了澄清。

文本分析
如今,客户的“声音”并非仅限于呼叫中心。越来越多的客户通过智能手机发送文本信息(SMS)。在反复尝试解决问题而未果后,他们就会沮丧,进而转向社交网站,如Facebook和专业投诉网站
重点是,客户不仅仅是在谈论你的公司;他们写信给你的同时还在写关于你的事。了解顾客写出来的“声音”就需要使用专注于内部和外部的文本通讯分析工具。这正是文本分析的职责。这些解决方案使用自然的语言处理算法和方法以采集和分析电子邮件、网络聊天和社交媒体网站上的帖子。
虽然监视公共网站和需要密码的网站很有趣并且很具话题性,但是大部分内容都无关具体的某个企业。网络是一个浩瀚的海洋,深邃无比,耗费大量时间进行分析也不一定可以获得有益的见解。
相反,组织自身的文本档案仓库就像是一个大湖泊,是有限的。它存有许多来自客户的邮件、调查、网络反馈对话等等文本。所有这些,尽管数量也十分庞大,但都集中关注于你自己的企业,是了解客户的很丰富的资源。文本分析——特别是与语音分析共同使用时——能让组织把从客户邮件和语音记录中获得的有用信息结合起来,得到许多可操作性的信息。

客户反馈调查
在高度竞争化的时代,征求客户反馈意见非常重要,不能被忽视,也不能执行不力。客户分析解决方案使用简短的、对文本十分敏感的动态的调查来捕捉客户对产品、流程和员工表现的意见。它能提供十分有价值的“由外之内”的观点评估客户的意见,让呼叫中心和市场部门通过电话和网络获得客户的看法。如果能被正确执行,这些调查就能够取得很好的效果,提供关于员工、流程和情绪的宝贵信息。在把衡量坐席人员业绩表现的调查结果与内部质量监控进行比对时,客户反馈调查会特别有帮助。

客户分析的附加价值主张
虽然客户分析提供了以上价值,但是还有其他两个特殊的益处。越来越多的公司希望能更好的处理与他们相关的评论。如果能把文本和语音分析结合起来使用,就可以提供各种各样早期的预警系统。公司可以标记出新出现的问题,及时解决,避免负面信息的爆发。
另一种特殊的价值主张通过语音分析和质量监控的集成来实现。当语音分析处理并把录音分类保存在数据库中时,质量监控和指导就可以启动——甚至能够超额进行。为什么呢?因为通过高密度的对通话的分类,主管和坐席人员能够准确找到典型的或者涉及工作所需技巧和行为的记录。无论哪种方式,拥有实在的例子能让呼叫中心采取高针对性的指导和培训,进而带来很好的效果。
最终,客户分析可以提供深刻的洞察力以推动更好的决策。通过把这种洞察力和其他措施相结合,就能获得对客户服务、体验和满意度的360度全方位视角——在不断变化的客户人口统计数据和情绪变动中更有效地发展。
本文转自:天华东航运营中心 收起阅读 »
客户分析能够通过为语音分析、文本分析和客户反馈调查提供软件应用来解决这些问题。这些应用是人力资源优化战略的组成部分,这个战略是由分析驱动的,能提供关键的、全新的客户中心视角。因为它们基于公用的人力资源优化平台,可以分享数据,你的组织能够从数据的协同效益中受益。
语音分析
语音分析是当下的热门话题,这种兴奋很容易理解。呼叫中心记录了不计其数的客户通话,但是只有一小部分能被听完。此外,他们更注意坐席人员的表现,而非客户。就算组织有意识把关注的重点转移到客户身上,但是只听如此少的谈话记录也不足以充分了解客户的话语和感受,很容易产生误解。
如果你愿意,语音分析解决方案可以“听”到所有通话记录。这个方案使用了多种技术和算法来索引和记录谈话,让所有谈话都能被搜到。使用索引技术,语音分析就能把记录下的对话按照兴趣的类别进行分类——投诉电话、转移呼叫和情感呼叫。接着,语音分析用算法把与兴趣相类似的单词或短语分门别类,提示呼叫的根本原因。
除了区分原因,语音分析还自动跟踪趋势和变化。按照日、周甚至更长的时间间隔,语音分析可以提醒你它所监测到的相关类别、措辞和短语的变化。
有个关于德国外包商为他的客户提供语音分析的例子。一天,外包商的语音分析解决方案显示电话数量急剧增加——从零飙升至几百——且含有以下词语“blah, blah, blah”。更为奇怪的是,这些通话的平均时长是一般通话的3倍。分析结果十分骇人。起初,他们认为是一些坐席人员在使用奇怪的词语。但在检查了一些新类别中的通话记录之后,他们很快发现,客户收到了一封来自于市场部的信,解释了服务合同中的一些新特点。这封信十分晦涩难懂,促使很多客户打来电话说:“我收到了一封信,说我的服务发生了变化blah, blah, blah,我不明白这封信到底是什么意思。”外包商立刻通知市场部,这些问题很快就得到了澄清。
文本分析
如今,客户的“声音”并非仅限于呼叫中心。越来越多的客户通过智能手机发送文本信息(SMS)。在反复尝试解决问题而未果后,他们就会沮丧,进而转向社交网站,如Facebook和专业投诉网站
重点是,客户不仅仅是在谈论你的公司;他们写信给你的同时还在写关于你的事。了解顾客写出来的“声音”就需要使用专注于内部和外部的文本通讯分析工具。这正是文本分析的职责。这些解决方案使用自然的语言处理算法和方法以采集和分析电子邮件、网络聊天和社交媒体网站上的帖子。
虽然监视公共网站和需要密码的网站很有趣并且很具话题性,但是大部分内容都无关具体的某个企业。网络是一个浩瀚的海洋,深邃无比,耗费大量时间进行分析也不一定可以获得有益的见解。
相反,组织自身的文本档案仓库就像是一个大湖泊,是有限的。它存有许多来自客户的邮件、调查、网络反馈对话等等文本。所有这些,尽管数量也十分庞大,但都集中关注于你自己的企业,是了解客户的很丰富的资源。文本分析——特别是与语音分析共同使用时——能让组织把从客户邮件和语音记录中获得的有用信息结合起来,得到许多可操作性的信息。
客户反馈调查
在高度竞争化的时代,征求客户反馈意见非常重要,不能被忽视,也不能执行不力。客户分析解决方案使用简短的、对文本十分敏感的动态的调查来捕捉客户对产品、流程和员工表现的意见。它能提供十分有价值的“由外之内”的观点评估客户的意见,让呼叫中心和市场部门通过电话和网络获得客户的看法。如果能被正确执行,这些调查就能够取得很好的效果,提供关于员工、流程和情绪的宝贵信息。在把衡量坐席人员业绩表现的调查结果与内部质量监控进行比对时,客户反馈调查会特别有帮助。
客户分析的附加价值主张
虽然客户分析提供了以上价值,但是还有其他两个特殊的益处。越来越多的公司希望能更好的处理与他们相关的评论。如果能把文本和语音分析结合起来使用,就可以提供各种各样早期的预警系统。公司可以标记出新出现的问题,及时解决,避免负面信息的爆发。
另一种特殊的价值主张通过语音分析和质量监控的集成来实现。当语音分析处理并把录音分类保存在数据库中时,质量监控和指导就可以启动——甚至能够超额进行。为什么呢?因为通过高密度的对通话的分类,主管和坐席人员能够准确找到典型的或者涉及工作所需技巧和行为的记录。无论哪种方式,拥有实在的例子能让呼叫中心采取高针对性的指导和培训,进而带来很好的效果。
最终,客户分析可以提供深刻的洞察力以推动更好的决策。通过把这种洞察力和其他措施相结合,就能获得对客户服务、体验和满意度的360度全方位视角——在不断变化的客户人口统计数据和情绪变动中更有效地发展。
本文转自:天华东航运营中心 收起阅读 »
单技能专席与多技能普席的策略选择
《孙子兵法》中有一句脍炙人口的话:“凡战者,以正合,以奇胜。”奇正之用,由2500多年前流传至今,已经成为中国式谋略的一个重要手段,而且备受当今的商业社会推崇。兵法原意是,在以正兵与敌人交战的时候,永远要多埋伏一支多出来的兵力,谓之奇兵。奇兵能出其不意,战斗中突然打乱敌人的部署,是致胜的关键,这也是“分战法”的基本法则。
纵观目前客户服务中心,通常会设有单技能的专席和多技能的普通座席,设置专席的理由也很简单,就是为了集中部分专业人员去解决一些普通座席无法做得更好的事情,或为某类特殊客户群体提供专门服务,如通信行业的话费专席、金融行业的理财专席等。但是设立专席也往往出现共性的问题,就是专席利用率不高,不如全技能普通座席复用方式,可以满足任何时期的服务资源不足的问题,于是原单技能的专席变成了加载多技能的普席,以应对资源不足情况,这种做法貌似是解决了资源不足的问题,但又出现了专席不专的情况,甚至慢慢的专席被撤离,重新回到大而全的多技能普席状况。带着这些问题,笔者尝试进一步剖析单技能专席与多技能普通座席的策略利弊,并阐述两种模式技能座席如何进行切换。
一、专席设立的目的与原则 (奇正之用)
正本溯源,首先我们从专席设立的目的和方式着手研究。专席的设立是客户联络中心运营策略的重要组成部分,核心是“合适的时间选择合适的人做合适的事情”。大多数企业在业务规模不大或建立之初,一般选择组建全技能普通座席作为生产运营的主力,可称之为“正兵”。
全技能普通座席的建立可以实现全员识业务、懂系统的运营需求,也可在短时间内调用生产资源,来满足服务资源不足的问题。但随着业务量的增长、服务规模的扩大,多技能普通座席的运营弊端开始显现。
以通信运营商的客户联络中心为例,多技能普通座席存在的弊端如下:
1、业务量增长迅速,人员需掌握的知识内容多:电信运营商业务种类量级都有数百个或上千个,每个业务再细分不同的知识点,需要上万个文档进行汇编。如果采用复合型普通座席承接,人员需掌握的知识数量过于庞大,因而很难精通全部业务内容,无法成为万能的“专家”。
2、团队流失率较高,人员职业素质良莠不齐:一般呼叫中心话务员平均流失率在3%-5%,年流失率在20%-30%之间,如果不考虑业务萎缩或新增情况,人员流失后需要补充新的资源进来,而一名新员工从入职到熟练过程需要6个月到12月时间,由于“生手”的存在一定会导致客户的服务感知存在偏差。
3、客户需求呈多样化,快速响应要求高:现在客户需求明显呈多层次化,他们开始关注品质服务、尊享服务、增值服务、延伸服务等精神上的需求,普通座席由于服务对象较多,即使目前已经可以实现大数据标签筛选,再通过弹窗方式识别客户,但很难在技能上完全匹配客户需求,或服务成效不明显。
此时,就如同用兵作战,我们需要用奇兵取胜,组建一支装备精良的突击队伍(专席),为新形势下产生的新问题或新产品提供服务,进而解决多技能普通座席所面临的“不专”问题。
首先,我们在组建专席后,可以通过人员集中培训、问题集中反馈推进,快速打造作战队伍,在其作战(服务)方式成熟顺畅后,通过经验模板的沉淀,再传递给作战的主力军即普通座席,进而形成有效的服务配合体系。
当然,专席的建立因需要有独立的生产资源,会对客户联络中心的整体运营产生一定的资源耗损,但笔者认为,如果专席的建立能有效支持公司核心战略业务发展或重要客户保障工作,提供更专业更优质的服务,那搭建专席就是有价值且值得投入资源运营的。专席的核心价值,在于集中精力快速解决客户问题,我们称之为运营策略中的“奇兵”,但是,正奇是会随着时间推演而发生变化,比如专席数量越来越庞大,后面会再做进一步的阐述。
其次,要打造具备有战斗力的奇兵,不是简单的圈一堆人就可以了,需要在业务界定、运作流程、人员选拔等方面进行思考,以便更好的支撑专席运作。
1、圈业务:专席承接业务内容的圈定,首先要考虑公司内外部环境的变化情况,内部环境需要考虑公司战略发展方向,外部环境需要考虑市场竞争形势及客户需求的变化;其次要从业务角度考虑,优先解决复杂、长流程或客户群体较重要的业务。另外,在业务圈定的过程中,需确保被筛选的话务类型便于识别,进而降低一线识别难度及客户的入线门槛。
2、定流程:武器装备是发挥作战效能的关键,专席需要在具备常规装备的基础上,同时具备更为精良、丰富的作战武器。具体在运营上可体现为以下三个方面:其一,专席人员使用的支撑系统及人员操作权限上需更加完备,用于支撑人员解决普席无法解决的各类疑难杂症;其二,专席需与业务管理等后台部门建立更为完善、顺畅的跨部门沟通流程,以便高效开展各类服务运营工作;其三,专席需具备更加丰富、有力的客户声音传递渠道,便于有效解决客户反馈的业务服务短板。
3、选专人:专席承接的是业务难度大、客户咨询细致的高端业务,要求专席代表具备较强的业务素质和学习能力,因此专席代表的选拔不建议采用新人,而是通过对人员绩效、工作年限、实操能力及对专席兴趣的考量,在多技能普通座席人员中选拔。另外,人员在培养阶段,需要有一套完善的培训体系及认证标准,使之与专席定位高度匹配,让专席成为优秀普席代表晋升的途径之一。
二、专席与普席的衔接关系(奇正之变)
用兵作战注重的是战略部署的灵活多变,客户联络中心的运营也需要做动态调整,其实专席运营策略也是如此,存在奇正之变。
以笔者所在的广东移动客户服务中心为例,在专席运营过程中,角色定位也发生了三个阶段的演进。
1、引入阶段,专席为奇
初级的服务策略1.0时期,专席是作战的奇兵,该时期客户需求量少,服务入口识别方便性、座席配置均处于基础搭建阶段,为了保障客户接入感知,一般会采用多技能普通座席转接专席的方式。如广东移动客户服务中心宽带专席,业务发展初期,客户需求通过10086主服务入口进入,通过在线转接的方式传递给专席,此时普席为服务的第一窗口,而专席就是服务的后备奇兵。
2、成长阶段,专席为正
随着业务发展,客户需求量逐步增加,专席需要从后台走向前台,成为作战的主力军,由“奇兵”成长为“正兵”,也就进入了专席服务策略2.0时期。此阶段,专席人员服务流程较为顺畅、各类运营策略趋于成熟、服务经验也在逐步沉淀,专席处于飞速成长时期。还是以广东移动宽带专席为例,在服务提升时期,我们建立了移动光宽带服务热线1008616,并在10086主渠道下增加宽带服务入口,通过IVR服务策略的配置,实现全量宽带需求直接进入专席,成为面向客户提供服务的第一窗口。
3、成熟阶段,奇正之和
当业务进入成熟期后,专席数量越来越庞大,由于规模过大出现专席投入资源不足或知识点不断扩大的问题,也就意味着,此时专席充当主力的作战(服务)模式需要做进一步调整,专席服务策略将进入精耕细作的3.0时期,即专席与普席为奇正之和的协同作战(服务)模式。
当客户拨打服务热线时,通过IVR入线策略将客户的需求进行第一层的辨别,简单服务需求通过路由配置进入普通座席,更高服务技能的复杂服务需求(如故障处理、投诉等)则进入专家专席。同时如普通座席客服代表在服务过程中遇到无法解决的问题,可在线转接至专家座席,由专家团队给予支撑。

席服务策略演进的三个阶段
当然,做好专席与普席的衔接,除了有精准客户识别能力以外,重点要打通专席与普席话务转接功能,可查看双方资源闲置状态,避免转接失败和等待给客户带来的不良感知。在话务协同方面,需要在业务管理、投诉管理、营销管理、系统支撑、业务流程优化等方面有明确的协同规范,以更好的支持两种运营模式的衔接。
综合所述,我们可以看到单技能专席与多技能普通座席的策略选择问题,其实是一个不断变化调整的过程,是所有客户联络中心需要注重运营的动态平衡问题,也是兵法所说的“诡”,即能根据实际情况而随时变化。
三、未来展望
笔者认为,专席的建立,肩负的不仅仅是普通座席的职能,更应该向着“更专业、更优质、更标杆”的目标前进。
随着人工智能技术的兴起,未来客户联络中心不但是人工专席与普席之间的策略选择问题,更多是在于前端智能机器人与后端人工服务的区别方式,但智能机器人方式解决更多是原有普通座席简单可以处理的问题,相信在未来,对于人工专席的要求会更高,如何让人工价值更加显性,需要我们更多的关注和研究。
本文刊载于《客户世界》2016年12月刊文章;原文作者李俊凡、李雪梅,本文作者单位为中国移动广东公司 客户服务(佛山)中心。 收起阅读 »
纵观目前客户服务中心,通常会设有单技能的专席和多技能的普通座席,设置专席的理由也很简单,就是为了集中部分专业人员去解决一些普通座席无法做得更好的事情,或为某类特殊客户群体提供专门服务,如通信行业的话费专席、金融行业的理财专席等。但是设立专席也往往出现共性的问题,就是专席利用率不高,不如全技能普通座席复用方式,可以满足任何时期的服务资源不足的问题,于是原单技能的专席变成了加载多技能的普席,以应对资源不足情况,这种做法貌似是解决了资源不足的问题,但又出现了专席不专的情况,甚至慢慢的专席被撤离,重新回到大而全的多技能普席状况。带着这些问题,笔者尝试进一步剖析单技能专席与多技能普通座席的策略利弊,并阐述两种模式技能座席如何进行切换。
一、专席设立的目的与原则 (奇正之用)
正本溯源,首先我们从专席设立的目的和方式着手研究。专席的设立是客户联络中心运营策略的重要组成部分,核心是“合适的时间选择合适的人做合适的事情”。大多数企业在业务规模不大或建立之初,一般选择组建全技能普通座席作为生产运营的主力,可称之为“正兵”。
全技能普通座席的建立可以实现全员识业务、懂系统的运营需求,也可在短时间内调用生产资源,来满足服务资源不足的问题。但随着业务量的增长、服务规模的扩大,多技能普通座席的运营弊端开始显现。
以通信运营商的客户联络中心为例,多技能普通座席存在的弊端如下:
1、业务量增长迅速,人员需掌握的知识内容多:电信运营商业务种类量级都有数百个或上千个,每个业务再细分不同的知识点,需要上万个文档进行汇编。如果采用复合型普通座席承接,人员需掌握的知识数量过于庞大,因而很难精通全部业务内容,无法成为万能的“专家”。
2、团队流失率较高,人员职业素质良莠不齐:一般呼叫中心话务员平均流失率在3%-5%,年流失率在20%-30%之间,如果不考虑业务萎缩或新增情况,人员流失后需要补充新的资源进来,而一名新员工从入职到熟练过程需要6个月到12月时间,由于“生手”的存在一定会导致客户的服务感知存在偏差。
3、客户需求呈多样化,快速响应要求高:现在客户需求明显呈多层次化,他们开始关注品质服务、尊享服务、增值服务、延伸服务等精神上的需求,普通座席由于服务对象较多,即使目前已经可以实现大数据标签筛选,再通过弹窗方式识别客户,但很难在技能上完全匹配客户需求,或服务成效不明显。
此时,就如同用兵作战,我们需要用奇兵取胜,组建一支装备精良的突击队伍(专席),为新形势下产生的新问题或新产品提供服务,进而解决多技能普通座席所面临的“不专”问题。
首先,我们在组建专席后,可以通过人员集中培训、问题集中反馈推进,快速打造作战队伍,在其作战(服务)方式成熟顺畅后,通过经验模板的沉淀,再传递给作战的主力军即普通座席,进而形成有效的服务配合体系。
当然,专席的建立因需要有独立的生产资源,会对客户联络中心的整体运营产生一定的资源耗损,但笔者认为,如果专席的建立能有效支持公司核心战略业务发展或重要客户保障工作,提供更专业更优质的服务,那搭建专席就是有价值且值得投入资源运营的。专席的核心价值,在于集中精力快速解决客户问题,我们称之为运营策略中的“奇兵”,但是,正奇是会随着时间推演而发生变化,比如专席数量越来越庞大,后面会再做进一步的阐述。
其次,要打造具备有战斗力的奇兵,不是简单的圈一堆人就可以了,需要在业务界定、运作流程、人员选拔等方面进行思考,以便更好的支撑专席运作。
1、圈业务:专席承接业务内容的圈定,首先要考虑公司内外部环境的变化情况,内部环境需要考虑公司战略发展方向,外部环境需要考虑市场竞争形势及客户需求的变化;其次要从业务角度考虑,优先解决复杂、长流程或客户群体较重要的业务。另外,在业务圈定的过程中,需确保被筛选的话务类型便于识别,进而降低一线识别难度及客户的入线门槛。
2、定流程:武器装备是发挥作战效能的关键,专席需要在具备常规装备的基础上,同时具备更为精良、丰富的作战武器。具体在运营上可体现为以下三个方面:其一,专席人员使用的支撑系统及人员操作权限上需更加完备,用于支撑人员解决普席无法解决的各类疑难杂症;其二,专席需与业务管理等后台部门建立更为完善、顺畅的跨部门沟通流程,以便高效开展各类服务运营工作;其三,专席需具备更加丰富、有力的客户声音传递渠道,便于有效解决客户反馈的业务服务短板。
3、选专人:专席承接的是业务难度大、客户咨询细致的高端业务,要求专席代表具备较强的业务素质和学习能力,因此专席代表的选拔不建议采用新人,而是通过对人员绩效、工作年限、实操能力及对专席兴趣的考量,在多技能普通座席人员中选拔。另外,人员在培养阶段,需要有一套完善的培训体系及认证标准,使之与专席定位高度匹配,让专席成为优秀普席代表晋升的途径之一。
二、专席与普席的衔接关系(奇正之变)
用兵作战注重的是战略部署的灵活多变,客户联络中心的运营也需要做动态调整,其实专席运营策略也是如此,存在奇正之变。
以笔者所在的广东移动客户服务中心为例,在专席运营过程中,角色定位也发生了三个阶段的演进。
1、引入阶段,专席为奇
初级的服务策略1.0时期,专席是作战的奇兵,该时期客户需求量少,服务入口识别方便性、座席配置均处于基础搭建阶段,为了保障客户接入感知,一般会采用多技能普通座席转接专席的方式。如广东移动客户服务中心宽带专席,业务发展初期,客户需求通过10086主服务入口进入,通过在线转接的方式传递给专席,此时普席为服务的第一窗口,而专席就是服务的后备奇兵。
2、成长阶段,专席为正
随着业务发展,客户需求量逐步增加,专席需要从后台走向前台,成为作战的主力军,由“奇兵”成长为“正兵”,也就进入了专席服务策略2.0时期。此阶段,专席人员服务流程较为顺畅、各类运营策略趋于成熟、服务经验也在逐步沉淀,专席处于飞速成长时期。还是以广东移动宽带专席为例,在服务提升时期,我们建立了移动光宽带服务热线1008616,并在10086主渠道下增加宽带服务入口,通过IVR服务策略的配置,实现全量宽带需求直接进入专席,成为面向客户提供服务的第一窗口。
3、成熟阶段,奇正之和
当业务进入成熟期后,专席数量越来越庞大,由于规模过大出现专席投入资源不足或知识点不断扩大的问题,也就意味着,此时专席充当主力的作战(服务)模式需要做进一步调整,专席服务策略将进入精耕细作的3.0时期,即专席与普席为奇正之和的协同作战(服务)模式。
当客户拨打服务热线时,通过IVR入线策略将客户的需求进行第一层的辨别,简单服务需求通过路由配置进入普通座席,更高服务技能的复杂服务需求(如故障处理、投诉等)则进入专家专席。同时如普通座席客服代表在服务过程中遇到无法解决的问题,可在线转接至专家座席,由专家团队给予支撑。
席服务策略演进的三个阶段
当然,做好专席与普席的衔接,除了有精准客户识别能力以外,重点要打通专席与普席话务转接功能,可查看双方资源闲置状态,避免转接失败和等待给客户带来的不良感知。在话务协同方面,需要在业务管理、投诉管理、营销管理、系统支撑、业务流程优化等方面有明确的协同规范,以更好的支持两种运营模式的衔接。
综合所述,我们可以看到单技能专席与多技能普通座席的策略选择问题,其实是一个不断变化调整的过程,是所有客户联络中心需要注重运营的动态平衡问题,也是兵法所说的“诡”,即能根据实际情况而随时变化。
三、未来展望
笔者认为,专席的建立,肩负的不仅仅是普通座席的职能,更应该向着“更专业、更优质、更标杆”的目标前进。
随着人工智能技术的兴起,未来客户联络中心不但是人工专席与普席之间的策略选择问题,更多是在于前端智能机器人与后端人工服务的区别方式,但智能机器人方式解决更多是原有普通座席简单可以处理的问题,相信在未来,对于人工专席的要求会更高,如何让人工价值更加显性,需要我们更多的关注和研究。
本文刊载于《客户世界》2016年12月刊文章;原文作者李俊凡、李雪梅,本文作者单位为中国移动广东公司 客户服务(佛山)中心。 收起阅读 »
Android V2.3.4 已发布,客户端支持修改群描述

Android 版本:V2.3.4 2017-1-12
新功能/改进:
- 增加修改群描述方法EMGroupManager::changeGroupDescription()
- EMChat::setServerAddress()方法支持设置https地址
- EMContactManager增加addContactListener(EMContactListener contactListener)方法,方便app在不同类里监听好友变动
- 修复REST短时间内发多条相同内容的消息,客户端只显示一条的bug
- 修复搜索有时候返回结果不对的bug
- 修复上个版本出现的个别情况下堆栈溢出的问题
版本历史:Android 2.X更新日志
下载地址:SDK下载 收起阅读 »
环信移动客服v5.7已发布-十余项更新,更丰富的统计和报表
客服模式
支持客服查看自己的统计数据
客服模式下,新增“统计数据”页面,显示当前客服的核心统计数据,包含接起会话数、结束会话数、平均响应时间、平均首次响应时间、满意度评价、消息/会话数趋势。并支持按日期进行筛选。
选择“统计查询”页面即可查看。统计指标解释如下:

【优化】输入框支持Shift+Enter发送消息“会话”页面的输入框支持选择使用Enter或Shift+Enter发送消息。

【优化】进行中会话列表显示消息发送失败提示当客服的消息发送失败时,在原有的消息前提示的基础上,增加进行中会话列表的提示。

【优化】实时更新客服同事的在线状态“会话”页面的客服同事列表实时更新客服同事的状态,使内部沟通更方便。【优化】支持播放移动端客服工作台发送的语音消息在移动端客服工作台发送的语音消息,支持在web版客服工作台进行播放。【优化】客服可以看到所接待客户的满意度评价客服可以在“客户中心”的互动记录中查看所接待客户的满意度评价。 管理员模式工作量报表优化,区分客服的工作量数据,新增技能组的工作量数据优化工作量报表,在原有的会话维度的基础上,增加以客服和技能组为维度的工作量数据统计。如果会话发生了转接,不同客服之间不再共享会话数和消息数。如下图所示,会话创建后,首先被客服A接入,之后转接给客服B,该会话的指标为:

优化工作量筛选项支持按照渠道、关联、客服、技能组对工作量数据进行筛选,并且,支持同时选择多个客服或技能组,方便管理员进行数据查询和分类。在管理员模式下,选择“统计查询 > 工作量”,点击“筛选排序”,可以对工作量数据进行筛选。客服的工作量详情在管理员模式下,选择“统计查询 > 工作量”,可以直接查看客服的工作量详情数据。优化后的报表对客服的以下指标进行了调整:会话接入至结束之间的时长(无转接) 会话接入至转出之间的时长(有转接) 会话转入至转出之间的时长(有转接) 会话转入至结束之间的时长(有转接)

工作质量报表优化,区分客服的工作质量数据,新增技能组的工作质量数据优化工作质量报表,在原有的会话维度的基础上,增加以客服和技能组为维度的工作质量数据统计。如果会话发生了转接,不同客服之间不再共享首次响应时长和响应时长。如下图所示,会话首先被客服A接入,之后转接给客服B,该会话的指标为:

优化工作质量筛选项支持按照渠道、关联、客服、技能组对工作质量数据进行筛选,并且,支持同时选择多个客服或技能组,方便管理员进行数据查询和分类。在管理员模式下,选择“统计查询 > 工作量”,点击“筛选排序”,可以对工作量数据进行筛选。客服的工作质量详情在管理员模式下,选择“统计查询 > 工作质量”,可以直接查看客服的工作质量详情数据。优化后的报表对客服的以下指标进行了调整:首次响应时长:该客服接起会话后,客服的首条人工消息时间减去接起(接入/转入)时间。响应时长:该客服参与会话期间,多次响应时间的平均值。

技能组的工作质量详情在管理员模式下,选择“统计查询 > 工作质量”,点击“筛选排序”,选择“技能组”,可以查看技能组的工作质量详情数据。技能组的指标算法和客服的指标算法类似,仅举例说明:
注意:如果一条会话在技能组内转接,统计首次响应时长时,计算多次接入的首次响应时长平均值。

新增客服工作时长统计
新增“客服时长统计”页面,支持根据日期和时间、客服昵称查看客服的在线(空闲、忙碌、隐身、离开)和离线时长,并导出客服状态详情。显示的在线和离线时长总和为选择的时间段的长度。
点击任意一名客服的记录,可以查看该客服的登录详情,包含每次登录使用的IP地址。

新增排队次数分布
在“排队统计”页面,新增按会话标签维度的排队次数分布,展示不同会话标签的会话曾经在客服系统中的排队次数,便于定位不同类型的会话的排队情况。

精确统计技能组数据
新增“精确统计技能组数据”开关,开关打开时,会话转接页面调整为以技能组分类的窗格,可以将会话转接给技能组或技能组下的客服,保证技能组数据统计更精准。 如果您需要更准确的技能组数据,可以进入管理员模式,选择“设置 > 系统开关”,打开此开关。

计算客服当前会话工作台显示的时长,最后一条消息可以是访客或客服
新增开关“计算客服当前会话工作台显示的时长,最后一条消息可以是访客或客服”。该开关默认关闭。关闭时,进行中会话列表显示访客最后一次发送消息的时间与当前时间的差异;开关打开时,显示访客或客服最后一条消息的时间与当前时间的差异。
如果您希望改变进行中会话列表的时间显示方式,可以进入管理员模式,选择“设置 > 系统开关”,打开此开关。

客服维度的会话质检
优化“质量检查”功能,将基于会话的质检更改为基于客服的质检。
质量检查页面的列表显示参与会话的每位客服的首次响应时长、会话时长、平均响应时长这些指标,以及会话整体的满意度评价指标。质检员可以基于每位客服参与会话期间的表现分别给予评分。

搜索、历史会话快速质检
为了满足不同场景下的会话质检需求,新增多入口快速质检功能,在管理员模式的“搜索”和“历史会话”页面均可以对会话进行快速质检。
以“历史会话”为例,点击一条历史会话,进入该会话的详情页。点击“质检”页签,可以查看该会话的首次响应时长、会话时长、平均响应时长、满意度评价这些指标。如果会话经过转接,可以查看经手的每位客服的上述指标。您可以根据历史消息记录和这些指标进行会话的快速质检。

【优化】管理技能组成员时,支持搜索当前成员
在“成员管理 > 技能组”页面,管理技能组成员时,支持对当前成员进行搜索,快速定位客服。
【优化】APP关联支持使用“商城”demo扫码
APP关联的详情页新增二维码,使用手机扫码工具扫描并在浏览器打开后,可以下载新版“商城”demo,而使用新版“商城”demo扫码时,将自动配置租户ID、IM服务号等信息,无需手动填写。
之后,可以用“商城”demo向客服发起聊天或留言,测试移动客服的会话和留言功能。
【优化】支持导出机器人的知识规则
支持导出机器人的知识规则,导出后,可以在本地编辑并重新导入,方便批量整理知识规则。
进入“智能机器人 > 机器人设置 > 知识规则”页签,点击“导出知识规则”按钮,即可导出全部知识规则。
【优化】客户之声支持导出关键词的消息详情
在“客户之声”页面,查看关键词的相关消息列表时,可以点击任意一条会话,进入详情页,导出该条会话的消息内容。导出文件可在“导出管理”页面进行下载。
“客户之声”功能为增值服务,请联系环信商务经理开通哦。
Web访客端
支持Web端客户发送文件
环信移动客服的web插件支持发送文件,客户使用PC聊天窗口和H5网页联系客服时,均可以向客服发送文件。客服在客服工作台收到文件后,可以下载到本地进行查看。
该功能属于Webim plugin V43.12,如果您正在使用定制开发版,请更新到最新版本。
多租户管理后台
多租户管理后台进一步完善了租户的统计数据。
支持查看、筛选、并导出所有租户的统计数据
在多租户管理后台,可以查看平台下所有租户的统计数据,支持按照租户ID、日期、会话时长平均值、首次响应时长平均值、响应时长平均值、满意度评价对租户进行筛选以及质检,并导出筛选结果。
进入“统计”页面,可以查看、筛选、导出这些统计数据。在页面内进行左右滑动,以查看更多项目。

在“导出管理”页面,可以下载导出文件。

支持查看单个租户的当前会话列表及消息内容
在“租户管理”页面,选择某个租户,在租户详情页点击“当前会话”,可以查看该租户的当前会话列表。点击任意一条会话,可以查看该会话的消息详情。

环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.7
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
支持客服查看自己的统计数据
客服模式下,新增“统计数据”页面,显示当前客服的核心统计数据,包含接起会话数、结束会话数、平均响应时间、平均首次响应时间、满意度评价、消息/会话数趋势。并支持按日期进行筛选。
选择“统计查询”页面即可查看。统计指标解释如下:
- 接起会话数:该客服参与的呼入和回呼会话数量总和,包括已结束和进行中会话。
- 结束会话数:该客服参与的会话中,由该客服结束的会话数量总和。
- 平均响应时间:该客服参与会话过程中,所有响应时间的平均值。
- 平均首次响应时间:该客服参与会话过程中,所有首次响应时间的平均值。
- 满意度评价:该客服参与的会话获得的满意度评价的平均值。如果某条会话经过转接,所有参与客服共享该会话的满意度评价。
- 消息/会话数趋势:该客服参与会话过程中,每天的消息数和会话数趋势。会话数:该客服的接起会话数;消息数:该客服参与会话期间,客服、访客、系统消息数总和。如果客服A将会话转接给客服B,转接前的消息数属于客服A;转接后的消息数属于客服B。
【优化】输入框支持Shift+Enter发送消息“会话”页面的输入框支持选择使用Enter或Shift+Enter发送消息。
【优化】进行中会话列表显示消息发送失败提示当客服的消息发送失败时,在原有的消息前提示的基础上,增加进行中会话列表的提示。
【优化】实时更新客服同事的在线状态“会话”页面的客服同事列表实时更新客服同事的状态,使内部沟通更方便。【优化】支持播放移动端客服工作台发送的语音消息在移动端客服工作台发送的语音消息,支持在web版客服工作台进行播放。【优化】客服可以看到所接待客户的满意度评价客服可以在“客户中心”的互动记录中查看所接待客户的满意度评价。 管理员模式工作量报表优化,区分客服的工作量数据,新增技能组的工作量数据优化工作量报表,在原有的会话维度的基础上,增加以客服和技能组为维度的工作量数据统计。如果会话发生了转接,不同客服之间不再共享会话数和消息数。如下图所示,会话创建后,首先被客服A接入,之后转接给客服B,该会话的指标为:
- 会话时长:系统的会话时长为,会话接入至会话结束之间的时长;客服A的会话时长为,会话接入至会话转出之间的时长;客服B的会话时长为,会话转入至会话结束之间的时长。
- 消息数:系统的消息数为,会话开始到结束期间,客服、访客、系统消息数量之和;客服A的消息数为,会话转出之前,客服A、访客、系统消息数量之和;客服B的消息数为,会话转出之后,客服B、访客、系统消息数量之和。
优化工作量筛选项支持按照渠道、关联、客服、技能组对工作量数据进行筛选,并且,支持同时选择多个客服或技能组,方便管理员进行数据查询和分类。在管理员模式下,选择“统计查询 > 工作量”,点击“筛选排序”,可以对工作量数据进行筛选。客服的工作量详情在管理员模式下,选择“统计查询 > 工作量”,可以直接查看客服的工作量详情数据。优化后的报表对客服的以下指标进行了调整:
- 接入/转入会话数:该客服接起会话的方式,分为第一次接入的会话数和接起的转入会话数。
- 转出/结束会话数:该客服完成会话的方式,分为转出的会话数和结束的会话数。
- 客服/访客/系统消息数:该客服参与会话期间(会话转出前/转出后),客服、访客、系统分别的消息数。
- 会话时长:该客服参与会话的时长,包括以下几种情况:
- 单会话消息数:会话过程中,属于该客服的消息条目数量,包含客服、访客、系统消息。

- 接入/转入会话数:该技能组的客服接起会话的方式,分为第一次接入的会话数和收到的转入会话数。
- 转出/结束会话数:该技能组完成会话的方式,分为转出的会话数和结束的会话数。
工作质量报表优化,区分客服的工作质量数据,新增技能组的工作质量数据优化工作质量报表,在原有的会话维度的基础上,增加以客服和技能组为维度的工作质量数据统计。如果会话发生了转接,不同客服之间不再共享首次响应时长和响应时长。如下图所示,会话首先被客服A接入,之后转接给客服B,该会话的指标为:
- 首次响应时长:系统的首次响应时长为,客服首次回复消息的时间减去会话接入时间;客服A的首次响应时长为,客服A首次回复消息的时间减去会话接入时间;客服B的首次响应时长为,客服B首次回复消息的时间减去会话转入时间。
- 响应时长:系统的响应时长为,所有客服的响应时间的平均值;客服A的响应时长为,客服A的所有响应时间的平均值;客服B的响应时长为,客服B的所有响应时间的平均值。
优化工作质量筛选项支持按照渠道、关联、客服、技能组对工作质量数据进行筛选,并且,支持同时选择多个客服或技能组,方便管理员进行数据查询和分类。在管理员模式下,选择“统计查询 > 工作量”,点击“筛选排序”,可以对工作量数据进行筛选。客服的工作质量详情在管理员模式下,选择“统计查询 > 工作质量”,可以直接查看客服的工作质量详情数据。优化后的报表对客服的以下指标进行了调整:首次响应时长:该客服接起会话后,客服的首条人工消息时间减去接起(接入/转入)时间。响应时长:该客服参与会话期间,多次响应时间的平均值。
技能组的工作质量详情在管理员模式下,选择“统计查询 > 工作质量”,点击“筛选排序”,选择“技能组”,可以查看技能组的工作质量详情数据。技能组的指标算法和客服的指标算法类似,仅举例说明:
- 首次响应时长:该技能组的客服接起会话后,首条人工客服消息时间减去接起(接入/转入)时间。
- 响应时长:该技能组参与会话期间,多次响应时间的平均值。
注意:如果一条会话在技能组内转接,统计首次响应时长时,计算多次接入的首次响应时长平均值。
新增客服工作时长统计
新增“客服时长统计”页面,支持根据日期和时间、客服昵称查看客服的在线(空闲、忙碌、隐身、离开)和离线时长,并导出客服状态详情。显示的在线和离线时长总和为选择的时间段的长度。
点击任意一名客服的记录,可以查看该客服的登录详情,包含每次登录使用的IP地址。
新增排队次数分布
在“排队统计”页面,新增按会话标签维度的排队次数分布,展示不同会话标签的会话曾经在客服系统中的排队次数,便于定位不同类型的会话的排队情况。
精确统计技能组数据
新增“精确统计技能组数据”开关,开关打开时,会话转接页面调整为以技能组分类的窗格,可以将会话转接给技能组或技能组下的客服,保证技能组数据统计更精准。 如果您需要更准确的技能组数据,可以进入管理员模式,选择“设置 > 系统开关”,打开此开关。
计算客服当前会话工作台显示的时长,最后一条消息可以是访客或客服
新增开关“计算客服当前会话工作台显示的时长,最后一条消息可以是访客或客服”。该开关默认关闭。关闭时,进行中会话列表显示访客最后一次发送消息的时间与当前时间的差异;开关打开时,显示访客或客服最后一条消息的时间与当前时间的差异。
如果您希望改变进行中会话列表的时间显示方式,可以进入管理员模式,选择“设置 > 系统开关”,打开此开关。
客服维度的会话质检
优化“质量检查”功能,将基于会话的质检更改为基于客服的质检。
质量检查页面的列表显示参与会话的每位客服的首次响应时长、会话时长、平均响应时长这些指标,以及会话整体的满意度评价指标。质检员可以基于每位客服参与会话期间的表现分别给予评分。
搜索、历史会话快速质检
为了满足不同场景下的会话质检需求,新增多入口快速质检功能,在管理员模式的“搜索”和“历史会话”页面均可以对会话进行快速质检。
以“历史会话”为例,点击一条历史会话,进入该会话的详情页。点击“质检”页签,可以查看该会话的首次响应时长、会话时长、平均响应时长、满意度评价这些指标。如果会话经过转接,可以查看经手的每位客服的上述指标。您可以根据历史消息记录和这些指标进行会话的快速质检。
【优化】管理技能组成员时,支持搜索当前成员
在“成员管理 > 技能组”页面,管理技能组成员时,支持对当前成员进行搜索,快速定位客服。
【优化】APP关联支持使用“商城”demo扫码
APP关联的详情页新增二维码,使用手机扫码工具扫描并在浏览器打开后,可以下载新版“商城”demo,而使用新版“商城”demo扫码时,将自动配置租户ID、IM服务号等信息,无需手动填写。
之后,可以用“商城”demo向客服发起聊天或留言,测试移动客服的会话和留言功能。
【优化】支持导出机器人的知识规则
支持导出机器人的知识规则,导出后,可以在本地编辑并重新导入,方便批量整理知识规则。
进入“智能机器人 > 机器人设置 > 知识规则”页签,点击“导出知识规则”按钮,即可导出全部知识规则。
【优化】客户之声支持导出关键词的消息详情
在“客户之声”页面,查看关键词的相关消息列表时,可以点击任意一条会话,进入详情页,导出该条会话的消息内容。导出文件可在“导出管理”页面进行下载。
“客户之声”功能为增值服务,请联系环信商务经理开通哦。
Web访客端
支持Web端客户发送文件
环信移动客服的web插件支持发送文件,客户使用PC聊天窗口和H5网页联系客服时,均可以向客服发送文件。客服在客服工作台收到文件后,可以下载到本地进行查看。
该功能属于Webim plugin V43.12,如果您正在使用定制开发版,请更新到最新版本。
多租户管理后台
多租户管理后台进一步完善了租户的统计数据。
支持查看、筛选、并导出所有租户的统计数据
在多租户管理后台,可以查看平台下所有租户的统计数据,支持按照租户ID、日期、会话时长平均值、首次响应时长平均值、响应时长平均值、满意度评价对租户进行筛选以及质检,并导出筛选结果。
进入“统计”页面,可以查看、筛选、导出这些统计数据。在页面内进行左右滑动,以查看更多项目。
在“导出管理”页面,可以下载导出文件。
支持查看单个租户的当前会话列表及消息内容
在“租户管理”页面,选择某个租户,在租户详情页点击“当前会话”,可以查看该租户的当前会话列表。点击任意一条会话,可以查看该会话的消息详情。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.7
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
环信及时通信iOS SDK的一些看法和建议
先说下环境:我使用的是HyphenateLite,3.2.3版本
1,关于bitcode
终于看到3.2.3版本有说:sdk支持bitcode拉,赶紧下载组装。编译时提示:
libopencore-amrnb.a(wrapper.o)' does not contain bitcode. You must rebuild it with bitcode enabled (Xcode setting ENABLE_BITCODE), obtain an updated library from the vendor, or disable bitcode for this target. for architecture arm64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
看来官方给出的sdk支持bitcode还真是仅限于“sdk”了,EaseUI里的libopencore-amrnb不是环信出品的,就不管了??可这对开发者来说有什么用呢?我们需要sdk提供的全部组件都支持bicode才行呢!!!
另外:跟iOS SDK客服沟通了下,似乎没有搞明白开启bitcode时什么意思。
强调一遍:必须在TARGET中设置bitcode为YES,然后真机运行,真机运行!!!!
麻烦官方再仔细检查一遍给我们开发者一个真正能用的bitcode版本!!!
2,关于文档
这次3.2.3说使用了动态framework,嗯,对官方的这种与时俱进赞一个。但你们能仔细看看给的文档吗:
然后呢?如何操作?能再简洁一点吗?
熟悉开发的肯定都知道用lipo操作,但是刚入门的是还需要查询的呀。能直接说下怎么操作岂不是更好!
3,一些建议
1,做SDK不像平常开发个app,自己的一亩三分地想怎么搞就怎么搞,sdk是拿出来给大家用的,对象都是开发者,需要开发sdk的同学本身就非常精通。一个建议,对于暴漏的.h文件最好都引用:
#import <Foundation/Foundation.h>
#import <UIKit/UIKit.h>//如何有UI
2,并且文档什么的要尽量细化。看到官方推出了不少视频的开发文档,这个虽然很好,降低了门槛,可是sdk总是在升级的在变动的,视频的内容往往发出来不久就落后于实际的代码了。建议多些文字文档,重要步骤尽量详细,文字能快速传达信息,没人有希望集成个sdk都要花费很多时间。
以上是我个人的浅见,不是纯粹是发牢骚,大家都是开发者,都希望作品精益求精,希望共同进步!
匆促中难免有错字,望理解!谢谢!
收起阅读 »
1,关于bitcode
终于看到3.2.3版本有说:sdk支持bitcode拉,赶紧下载组装。编译时提示:
libopencore-amrnb.a(wrapper.o)' does not contain bitcode. You must rebuild it with bitcode enabled (Xcode setting ENABLE_BITCODE), obtain an updated library from the vendor, or disable bitcode for this target. for architecture arm64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
看来官方给出的sdk支持bitcode还真是仅限于“sdk”了,EaseUI里的libopencore-amrnb不是环信出品的,就不管了??可这对开发者来说有什么用呢?我们需要sdk提供的全部组件都支持bicode才行呢!!!
另外:跟iOS SDK客服沟通了下,似乎没有搞明白开启bitcode时什么意思。
强调一遍:必须在TARGET中设置bitcode为YES,然后真机运行,真机运行!!!!
麻烦官方再仔细检查一遍给我们开发者一个真正能用的bitcode版本!!!
2,关于文档
这次3.2.3说使用了动态framework,嗯,对官方的这种与时俱进赞一个。但你们能仔细看看给的文档吗:
注: 由于 iOS 编译的特殊性,为了方便开发者使用,我们将 i386 x86_64 armv7 arm64 几个平台都合并到了一起,所以使用动态库上传appstore时需要将i386 x86_64两个平台删除后,才能正常提交
然后呢?如何操作?能再简洁一点吗?
熟悉开发的肯定都知道用lipo操作,但是刚入门的是还需要查询的呀。能直接说下怎么操作岂不是更好!
3,一些建议
1,做SDK不像平常开发个app,自己的一亩三分地想怎么搞就怎么搞,sdk是拿出来给大家用的,对象都是开发者,需要开发sdk的同学本身就非常精通。一个建议,对于暴漏的.h文件最好都引用:
#import <Foundation/Foundation.h>
#import <UIKit/UIKit.h>//如何有UI
2,并且文档什么的要尽量细化。看到官方推出了不少视频的开发文档,这个虽然很好,降低了门槛,可是sdk总是在升级的在变动的,视频的内容往往发出来不久就落后于实际的代码了。建议多些文字文档,重要步骤尽量详细,文字能快速传达信息,没人有希望集成个sdk都要花费很多时间。
以上是我个人的浅见,不是纯粹是发牢骚,大家都是开发者,都希望作品精益求精,希望共同进步!
匆促中难免有错字,望理解!谢谢!
收起阅读 »
项目整合环信中遇到的问题
在项目开发过程中,有聊天社区的需求,经过研究后,最终选择环信,因为环信的服务真的很不错,无论是技术还是服务,都很到位,客服人员和技术人员都会耐心地解答开发中遇到的问题,只不过在开发的过程中发现demo中的有些代码并未及时更新,并且部分接口功能有些限制,不过还是由衷的感谢,希望环信发展越来越好!
整合过程中遇到的相关问题:
1、在配置文件中配置在环信中注册app的相关信息,如:API_PROTOCAL、API_HOST、API_ORG、API_APP、APP_CLIENT_ID、APP_CLIENT_SECRET等;
2、api接口实现类中的发送请求时请求的方法(demo中的代码可能没及时更新)
3、公共类中的部分body类的get方法(demo中表示的都是同一代码,但实际应用中并不这样)
4、聊天记录信息需要保存在本地服务器(环信的服务器保存期限是3天)
感恩环信,希望环信早日上市!
收起阅读 »
整合过程中遇到的相关问题:
1、在配置文件中配置在环信中注册app的相关信息,如:API_PROTOCAL、API_HOST、API_ORG、API_APP、APP_CLIENT_ID、APP_CLIENT_SECRET等;
2、api接口实现类中的发送请求时请求的方法(demo中的代码可能没及时更新)
3、公共类中的部分body类的get方法(demo中表示的都是同一代码,但实际应用中并不这样)
4、聊天记录信息需要保存在本地服务器(环信的服务器保存期限是3天)
感恩环信,希望环信早日上市!
收起阅读 »
环信Android SDK的些许建议
由于公司应用业务需要集成即时通信框架,对比多方后选择了环信,从应用上线到现在,可以说看着环信一点一点不断的改变完善,从原来的2.x到现在的3.x,功能越来越完善,接口分离封装的越来越好,不过使用过程中还是会碰到一些问题,总结总结提一点建议
1、社区问题讨论不够活跃,大部分碰到的问题在社区中找不到,很多问题没有官方解答,相反QQ群的技术支持反而更好,解决问题很及时,解答也很专业,这里感谢下QQ群的小伙伴们
2、文档不够完善,由于做Android的开发,所以这点仅限于Android文档,文档比起以前要好很多,但是说明还是太过宽泛,一些具体的设置及解决方案还要去demo中寻找,这就相当费时间了
3、上面说到了有些东西要去demo中找,下面就不得不吐槽下Android demo了,真是看到让人头大,一个类中放了一堆的东西,虽然有继承和封装,感觉看着真心累,尤其是当碰到一些问题需要再demo找解决方法的时候,真是生无可恋,感觉现在的demo一直从2.X时代继承过来,只是把新功能添加了进去,没有像SDK一样,重新规划来一版新的demo,相信这个demo也让不少小伙伴心有同感
不管怎么说,瑕不掩瑜,环信作为即时通信领域的佼佼者,为广大开发者提供了很多帮助和便捷,希望环信能越来越好,开放给广大开发者的接口或资源越来越多一些,在新的一年里一起加油!!! 收起阅读 »
1、社区问题讨论不够活跃,大部分碰到的问题在社区中找不到,很多问题没有官方解答,相反QQ群的技术支持反而更好,解决问题很及时,解答也很专业,这里感谢下QQ群的小伙伴们
2、文档不够完善,由于做Android的开发,所以这点仅限于Android文档,文档比起以前要好很多,但是说明还是太过宽泛,一些具体的设置及解决方案还要去demo中寻找,这就相当费时间了
3、上面说到了有些东西要去demo中找,下面就不得不吐槽下Android demo了,真是看到让人头大,一个类中放了一堆的东西,虽然有继承和封装,感觉看着真心累,尤其是当碰到一些问题需要再demo找解决方法的时候,真是生无可恋,感觉现在的demo一直从2.X时代继承过来,只是把新功能添加了进去,没有像SDK一样,重新规划来一版新的demo,相信这个demo也让不少小伙伴心有同感
不管怎么说,瑕不掩瑜,环信作为即时通信领域的佼佼者,为广大开发者提供了很多帮助和便捷,希望环信能越来越好,开放给广大开发者的接口或资源越来越多一些,在新的一年里一起加油!!! 收起阅读 »
喜大奔普,环信IM Demo登录苹果应用商店!
据环信社报道,环信IM Demo于2017年1月9日正式登录苹果AppStore,意味着小伙伴们可以在AppStore上直接下载到环信最新IM Demo啦。目前在苹果应用商店的版本为最新的IOS3.2.3,未来也将于环信官网同步更新,同时Android的IM demo也陆续上传到各大应用市场,方便小伙伴们下载使用,大家在使用过程中遇到问题可以在imgeek社区(http://www.imgeek.org) 反馈,我们将第一时间处理。
环信IM Demo登录苹果应用商店

环信即时通讯云作为国内最早也是全球最大的即时通讯云PaaS平台,为开发者提供基于移动互联网的即时通讯能力,如单聊、群聊、发语音、发图片、发位置、实时音频、实时视频等,让开发者摆脱繁重的移动IM通讯底层开发,24小时即可让App拥有内置IM能力,帮助APP轻松实现社交功能。近期也上线了包括环信红包、环信直播等明星产品,深受开发者喜爱。
截至2016年上半年,环信共服务了82149家App客户,SDK覆盖手机终端5.64亿,平台日发送消息5.57亿条。典型用户包括快牙、国美在线、猎聘同道、百合相亲、宝宝树、迪信通等。
本次上线苹果AppStore的环信IM Demo展示了如何使用环信SDK创建一个完整的即时通讯APP,主要功能包括:用户注册和登录,好友管理,单聊/群聊,支持包括文字、表情、语音、图片、地理位置等消息类型,用户也可以通过Demo进行实时音视频通话等。 收起阅读 »
我要上周刊!欢迎推荐内容到技术周刊!
如果你发现了好内容希望分享更多的朋友们,
如果你觉得你的文章很赞需要推送,欢迎联系我们......
历史技术周报合集:http://www.easemob.com/weekly
技术周报是精选了一周的优质内容的集合,欢迎各位按照如下格式推荐精品内容:
1. 推荐内容:标题
2. 推荐链接:XXX
3. 推荐理由:XXXXX 收起阅读 »
将环信集成到已有的业务体系,后台用php写的接口
我做的是一个普通资讯类app,需要集成即时通讯,在比较以后,还是选择了环信。
首先讲下版本,开始开始集成环信的应用的时间比较早,用的是2.1.6版本。
后台接口用的php和mysql。
下面,我就将应用本身的注册,登陆和环信的想结合的逻辑分享下。
1.登陆的逻辑是,先在app里面调用服务器接口,接口里面判断账号密码是否正确,(注意:在做环信的登陆的时候,为了安全,我并不是直接使用用户的账号密码登陆,而是用户唯一uid和加密后的密码)。
代码如下:
2.这里要说下关于用户昵称和头像,官方给出了两个解决方案,我选择的就是第一个方案。在登陆成功的回掉里面,you有这样的代码
UserUtils内容
HXIMUserDao内容
3.关于注册,由于环信的提倡的是用REST API 注册,不是在app里面,所以注册接口逻辑是,当用户提交账号 和密码我就在自己的数据库中添加一条记录并且返回uid,然后用uid和经过加密后的密码 去向环信提交注册。
注意,如果在环信上如果注册失败,则要在本地删除这条记录,以免用处再次cha尝试注册的时候 ,提示已经注册,但其实环信没有注册成功所以无法登陆。修改密码也是这样的 。
建议:在sdk里面,好像没有将该会话置顶的方法。而是统一按照最后消息排序
最后感谢下环信,不管从消息下发,文档,sdk,以及客服各个方面来说都做的不错。最后提交一张我自己集成会话的页面截图。
收起阅读 »
首先讲下版本,开始开始集成环信的应用的时间比较早,用的是2.1.6版本。
后台接口用的php和mysql。
下面,我就将应用本身的注册,登陆和环信的想结合的逻辑分享下。
1.登陆的逻辑是,先在app里面调用服务器接口,接口里面判断账号密码是否正确,(注意:在做环信的登陆的时候,为了安全,我并不是直接使用用户的账号密码登陆,而是用户唯一uid和加密后的密码)。
代码如下:
EMChatManager.getInstance().login(username, password,
new EMCallBack() {
#####
});
2.这里要说下关于用户昵称和头像,官方给出了两个解决方案,我选择的就是第一个方案。在登陆成功的回掉里面,you有这样的代码
try {
// ** 第一次登录或者之前logout后再登录,加载所有本地群和回话
// 处理好友和群组
processContactsAndGroups();
}
我就是在这里去出来头像和昵称的,用sqlite来保存。在保存的时候,异步通过用户list的username去后台请求昵称和头像,然后保存到sqlite。然后再messageAdapter中设置。
MessageAdapter中
/**
* 显示用户头像
*
* @param message
* @param imageView
*/
private void setUserAvatar(EMMessage message, ImageView imageView) {
if (message.direct == Direct.SEND) {
// // 显示自己头像
UserUtils.setSendAvatar(context, imageView);
} else {
UserUtils.setDirectAvatar(context, message, imageView);
}
}UserUtils内容
/**
* 设置对方头像
*
* @param username
*/
public static void setDirectAvatar(Context context, EMMessage message,
ImageView imageView) {
AppContext appContext = (AppContext) context.getApplicationContext();
HXIMUserDao hximUserDao = appContext.getHXIMUserDao();
String dbface = hximUserDao.viewItem(HXIMUserDao.COLUMN_NAME_NAME
+ "=?", new String { message.getFrom() });
if (dbface != null&&dbface.length()>0) {
Picasso.with(context).load(dbface)
.placeholder(R.drawable.default_avatar).into(imageView);
} else {
IMUser user = getUserInfo(message.getFrom());
Picasso.with(context).load(user.getAvatar())
.placeholder(R.drawable.default_avatar).into(imageView);
}
}
HXIMUserDao内容
@Override
public String viewItem(String selection, String selectionArgs) {
SQLiteDatabase database = null;
Cursor cursor = null;
Map<String, String> map = new HashMap<String, String>();
try {
database = hximusersqlhelper.getWritableDatabase();
cursor = database.query(false, TABLE_NAME, null, selection,
selectionArgs, null, null, null, null);
int cols_len = cursor.getColumnCount();
while (cursor.moveToNext()) {
for (int i = 0; i < cols_len; i++) {
String cols_name = cursor.getColumnName(i);
String cols_values = cursor.getString(cursor
.getColumnIndex(cols_name));
if (cols_values == null) {
cols_values = "";
}
map.put(cols_name, cols_values);
}
}
} catch (Exception e) {
// TODO: handle exception
} finally {
if (database != null) {
database.close();
}
}
return map.get(COLUMN_NAME_FACE);
}
3.关于注册,由于环信的提倡的是用REST API 注册,不是在app里面,所以注册接口逻辑是,当用户提交账号 和密码我就在自己的数据库中添加一条记录并且返回uid,然后用uid和经过加密后的密码 去向环信提交注册。
//$result为0注册失败
//注册成功后再取hx注册 ,成功则返回result为true
//否则返回false同时删除再app服务器上的注册
if ($result) {
$registcondition['user_id']=$result;
$User=$this->model->table('user');
$registinfo=$User->where($registcondition)->find();
$hxoptions['username']=$registinfo['user_id'];
$hxoptions['password']=$registinfo['user_userpass'];
$mooptions['client_id']=$this->config['CLIENT_ID'];
$mooptions['client_secret']=$this->config['CLIENT_SECRET'];
$mooptions['org_name']=$this->config['ORG_NAME'];
$mooptions['app_name']=$this->config['APP_NAME'];
require_once('Easemob.class.php');
$Easemob = new Easemob($mooptions);
$hxregisterresult= $Easemob->accreditRegister($hxoptions);
if ($hxregisterresult['status']==200) {
$result=true;
}else{
$deleteuser['user_id']=$result;
$deleteresult=$User->where($deleteuser)->delete();
$result=false;
}
}
注意,如果在环信上如果注册失败,则要在本地删除这条记录,以免用处再次cha尝试注册的时候 ,提示已经注册,但其实环信没有注册成功所以无法登陆。修改密码也是这样的 。
建议:在sdk里面,好像没有将该会话置顶的方法。而是统一按照最后消息排序
最后感谢下环信,不管从消息下发,文档,sdk,以及客服各个方面来说都做的不错。最后提交一张我自己集成会话的页面截图。
收起阅读 »
集成环信时遇到的问题
"_ASN1_INTEGER_get",
referenced from:
_get_cert_info in
libEaseMobClientSDKLite.a(ssl_sock_ossl.o)
今天集成环信,可能是因为之前导入过多第三方静态库的原因,导致出现以上75个错去,貌似说编译的时候不能找到.a文件,在真机上可以跑,但在模拟器上就出现此错误,现将我出现错误的原因及解决方法晒出,希望可以帮助将来跟我一样遇到困难的人.
原因如下:在Build Settings下Linking 下的other Linker Flags中添加了-ObjC、-all_load或-force_load从而导致出现上述问题
在Build Settings下Linking 下的other Linker Flags 只保留-ObjC即可
收起阅读 »
关于集成环信即时通讯的文章
环信的Web IM即时通讯聊天室的聊天记录不能保存,有的用户想要翻看以前的聊天记录看,找不到当时的聊天记录,调用环信Web IM的相关api也只能调取一部分,不能充分的满足开发的需求。
iOS 环信 集成 详细步骤图文
环信的教程:
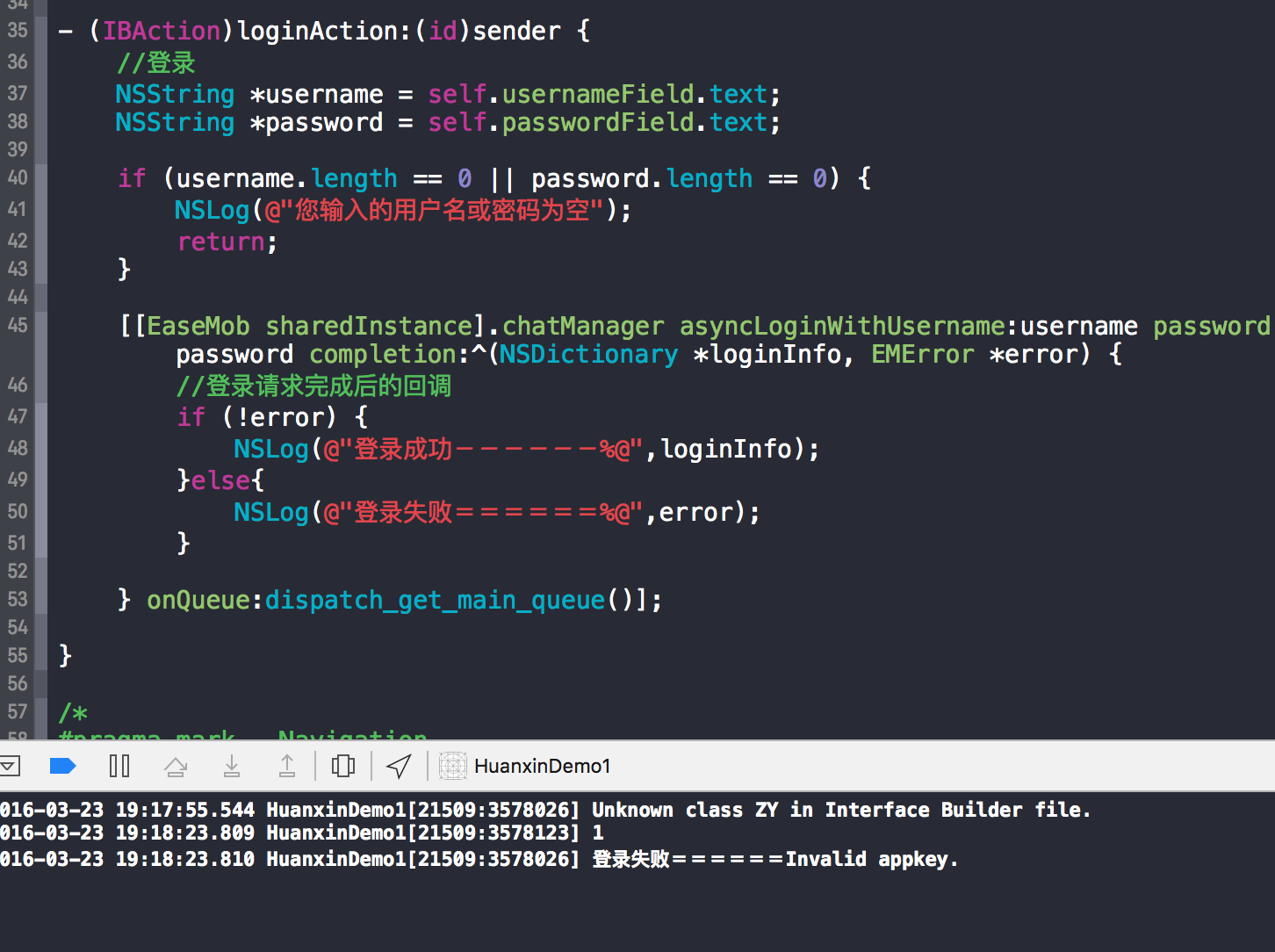
没有初始化SDK
去AppDelegate里面初始化
密码
User not exist ??????????
每一个应用都有自己的注册用户 去你的后台管理 去看你的注册的用户数
为什么demo的可以跑起来????????
是在它的应用下注册的
怎么去注册用户 -注册用户
用户名字可以相同 不同的应用
那个打印的loginInfo 是这个字典的也就是用户的登录信息
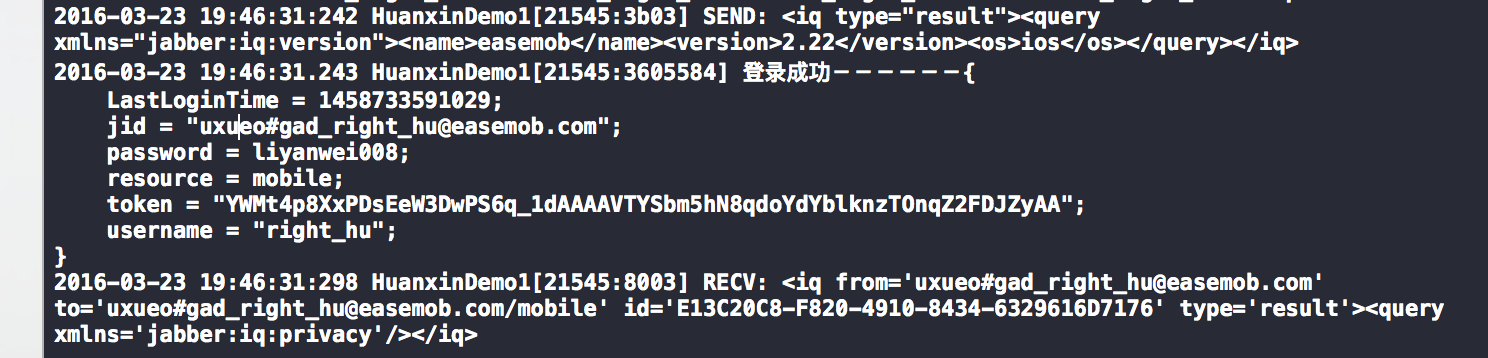
你会发现打印的loginInfo上面还有一坨恶心的东西,那个是环信SDK自己打印的日志信息
SEND 和 RECV 使用的是XMPP协议 所以 数据的格式是XML 一般的HTTP协议的话他就是JSON格式的
这个是app把客户端登录的信息发给环信服务器后打印出来的日志 是不是很烦
如何去在哪儿隐藏它的控制台的日志信息 ?????????
去初始化的时候把它隐藏 有一个otherConfig的东西 右键-jump to Define
进去瞅瞅--

复制它的key 给他设置为NO

这个时候它的控制台的日志信息就被屏蔽了
跟环信交互的所有类都有这个
[EaseMob sharedInstance].chatManager
注册的时候代码:
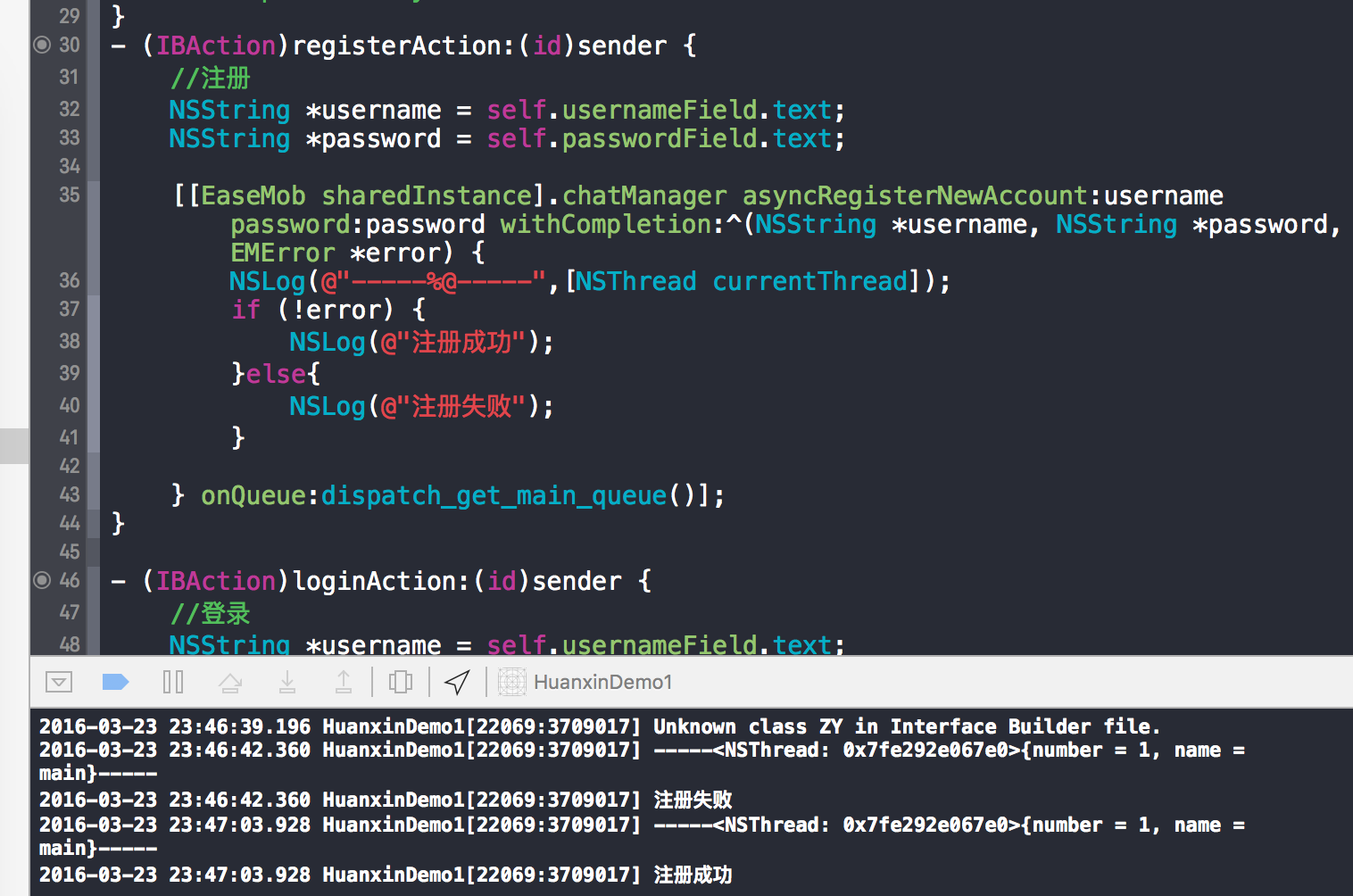
如果你把这onQueue改为nil的话他默认也是在主线程的
然后你在去环信的开发中心刷新IM用户 你会发现他多了一个

发送给的数据给服务器的时候还是XML格式,里面的SDK帮你封装了,不用你自己去接触
---自动登录------------------------------------
看到它的主界面只有三个tabbar
进去 mainstoryboard里面 删除原始的viewcontroller 拖入一个 tabbarController 去掉原始的tabbar 的两个子控制器 记得给它的isinitial 那个选项钩上 然后拖入三个navigationcontroller(这个根据你的界面而定)
选中给每个的Item 的title属性可以更改
然后在登录成功中写上加载storyboard的方法

你会发现你已经跳转进去
 如何实现自动登录?????????????????
如何实现自动登录?????????????????
实现原理:把你的登录信息保存在沙盒中 程序启动时候发送登录请求
只要你在第一次登录成功后发送环信自带登录的网络请求去实现、
环信自己帮你实现上面的东西
具体实现
在登录成功的下面写上
[[EaseMob sharedInstance].chatManager setIsAutoLoginEnabled:YES]
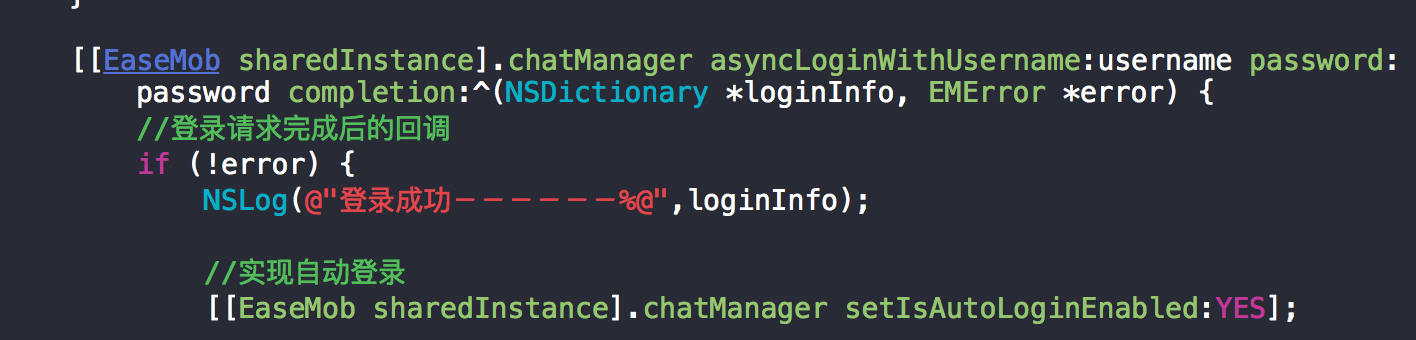
然后去在AppDelegte里面把他的沙盒路径拿到
 然后再控制台你可以看到这些信息,其中的账号密码信息你会发现他被加密了,有没有?
然后再控制台你可以看到这些信息,其中的账号密码信息你会发现他被加密了,有没有?
 如何监听是否是已经处于登录状态了这个地方有个代理 环信的代理方法
如何监听是否是已经处于登录状态了这个地方有个代理 环信的代理方法
在AppDelegate方法里面进去 在启动方法里面写
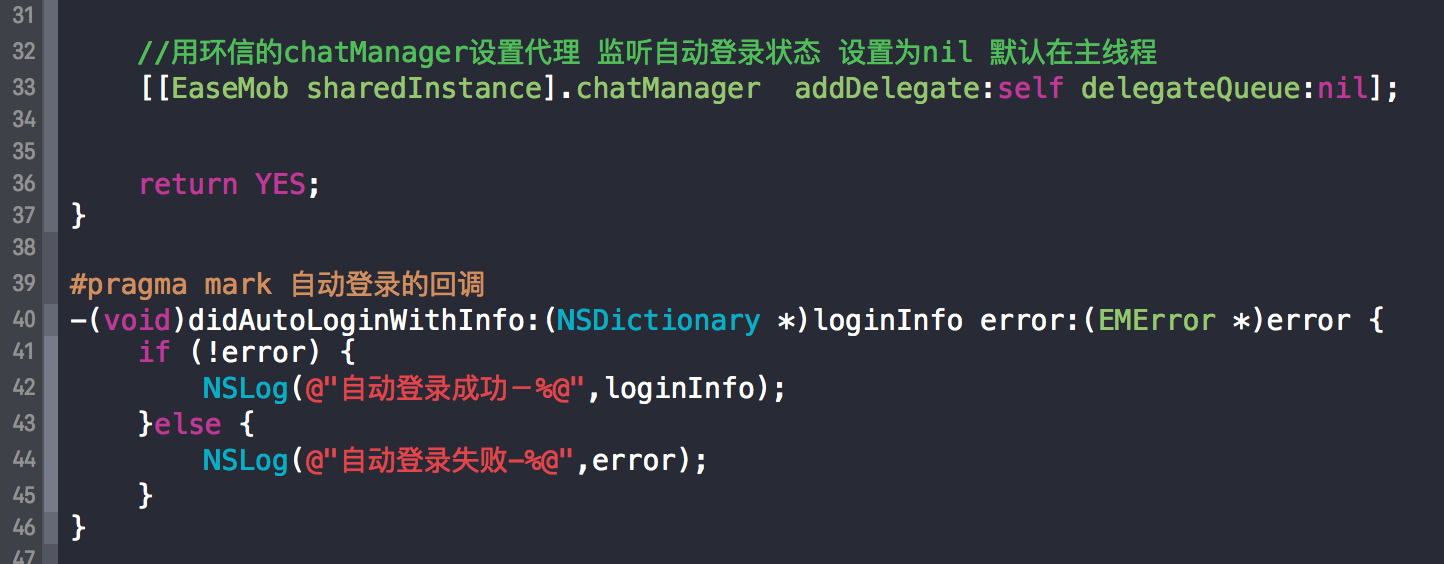 你会发现它的那个啥没有完成界面的跳转 但是控制台却是带那个登陆成功了
你会发现它的那个啥没有完成界面的跳转 但是控制台却是带那个登陆成功了
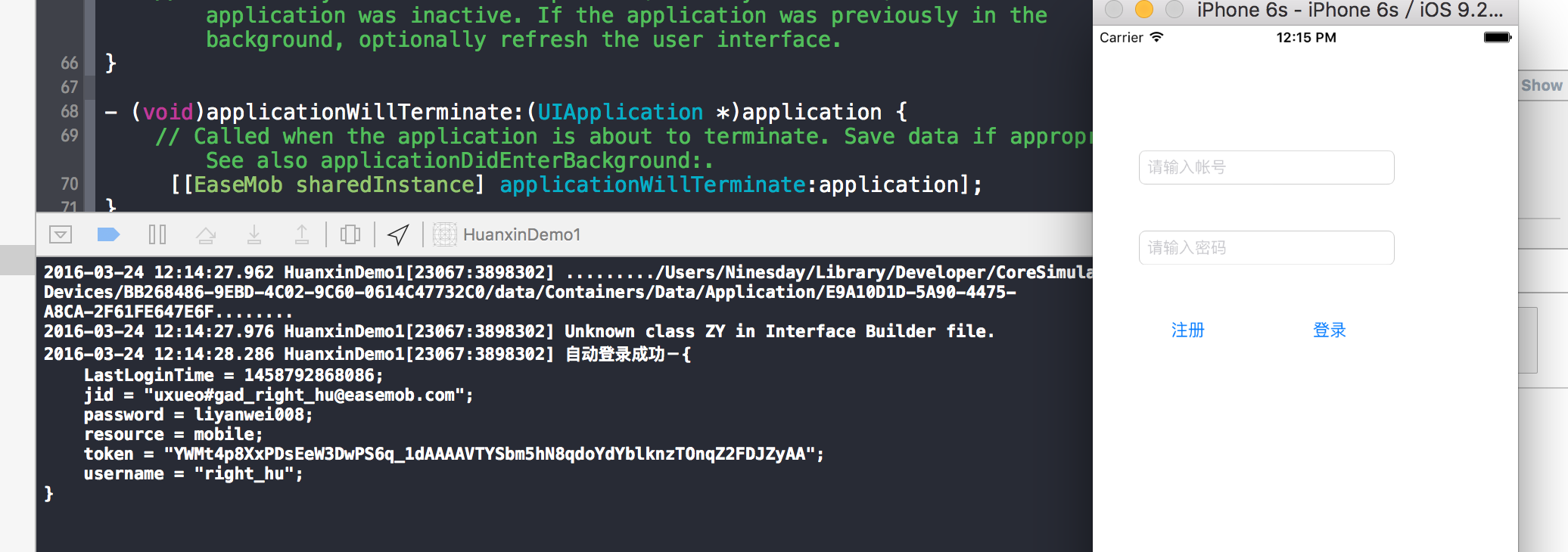 这个时候我们还缺一步骤 之前我们在自动登录时候我们调用的是set方法
这个时候我们还缺一步骤 之前我们在自动登录时候我们调用的是set方法
这个时候我们要实现它的 get方法 写在监听登录状态的下面
//如果登录过直接来到主界面
 if([[EaseMob sharedInstance].chatManager isAutoLoginEnabled]){
if([[EaseMob sharedInstance].chatManager isAutoLoginEnabled]){
self.window.rootViewController = [UIStoryboard storyboardWithName:@"Main" bundle:nil].instantiateInitialViewController;
}
=------------自动连接--------------------------
网络通不通的时候类似微信那种网络不通的实现
去那个main.storyboard里面把那会话的导航控制器跳转的那个类继承改为你自己创建的那个UItableViewController
1.在会话里面监听的网络的状态 环信的有很多个代理
去那个.m文件里面去实现
 点击那个EMChatManagerDelegate 里面去实现 EMChatManagerUtilDelegate里面的这个方法就OK了
点击那个EMChatManagerDelegate 里面去实现 EMChatManagerUtilDelegate里面的这个方法就OK了
- (void)didConnectionStateChanged:(EMConnectionState)connectionState;
 在真机上面测试的时候 网络连接成功不代表客户端和服务器端连接成功
在真机上面测试的时候 网络连接成功不代表客户端和服务器端连接成功
还有自动连接的状态的监听 也是加上他的代理方法就行了
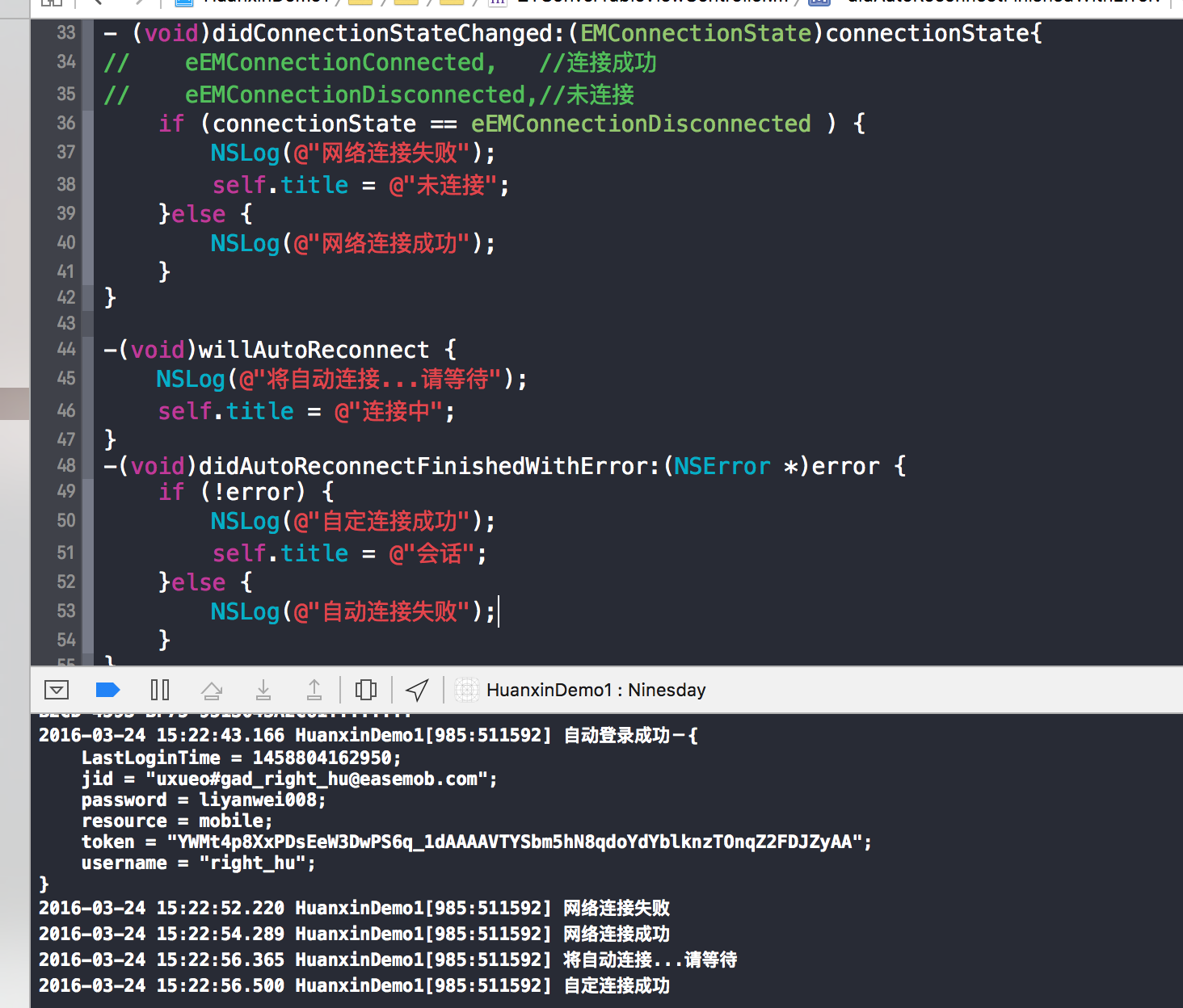
--------添加好友请求-----------------------------
1.是用环信的思想
所有的网络请求 [EaseMob sharedInstance].chatManager 由这个管理器发起的
2.所有结果(自动登录 自动连接)通过代理来回调完成
[EaseMob sharedInstance].chatManager的addDelegate来完成
3.EMChatManagerBuddyDelegate 这个代理实现了对用户的基本操作
1.添加好友 2.从本地获取好友 3.从服务器列表获取最新的好友 4.接受好友添加请求
5.删除好友 6.被好友从名单上面删除
在navigation 的第二个控制器上面加上一个UIbarbarItem 选择自定义 然后+
再去创建一个UIviewController 然后再去实现用个+号去拖一个线
可以在上面加上navigationItem 上改为添加好友
再去新建一个控制器AdressBooking 通讯录 这个类是继承于UIviewController
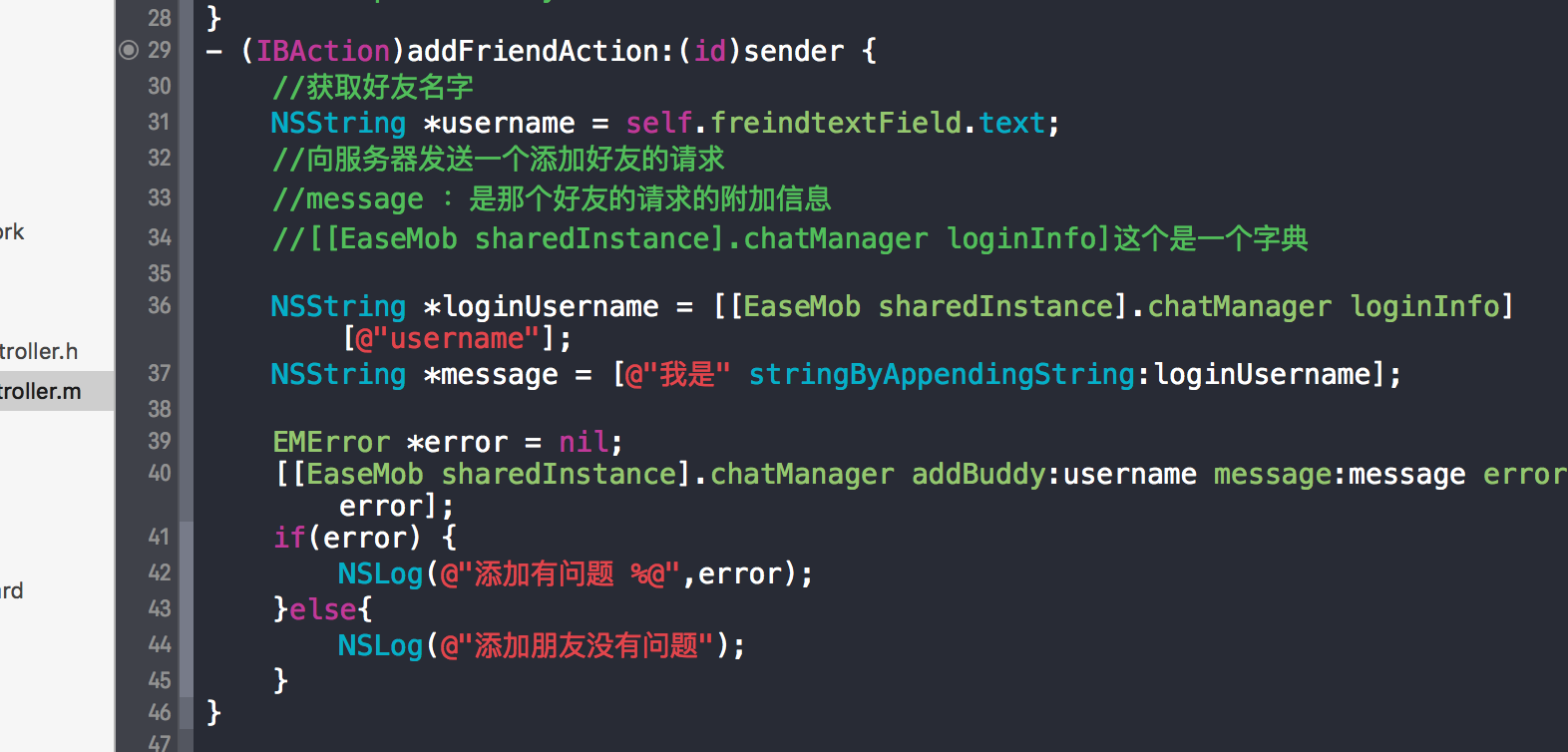 是用环信最简单的方法 ,把官方的Demo直接拿过来用 直接跟改它的Appdelegate里面的APPKey
是用环信最简单的方法 ,把官方的Demo直接拿过来用 直接跟改它的Appdelegate里面的APPKey
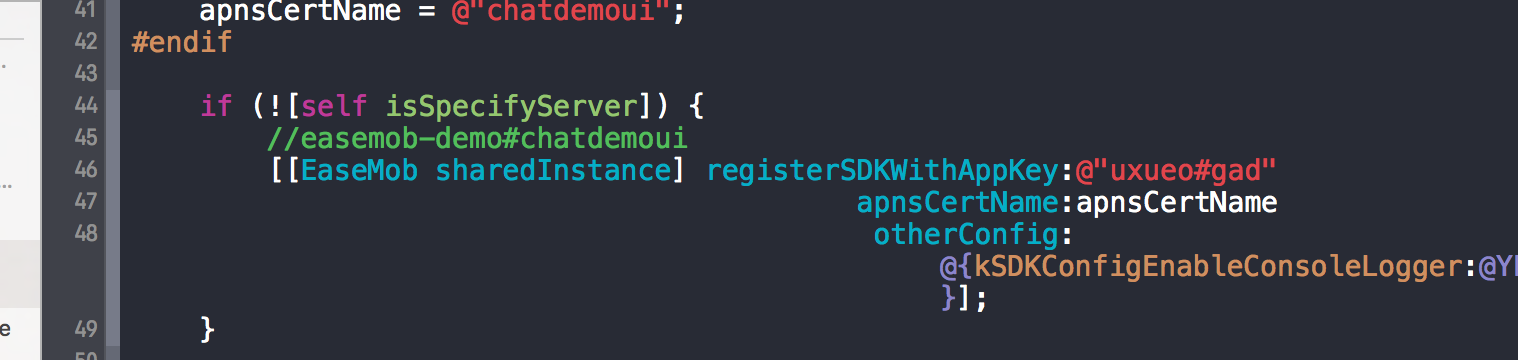
这样你就收到了申请 注意 这是最简单的方式
还有一点 你要在每个控制器里面写上你环信的代理方法
这样就能保证你下面写的环信 的每一个方法会被自动调用了
 代理方法:
代理方法:
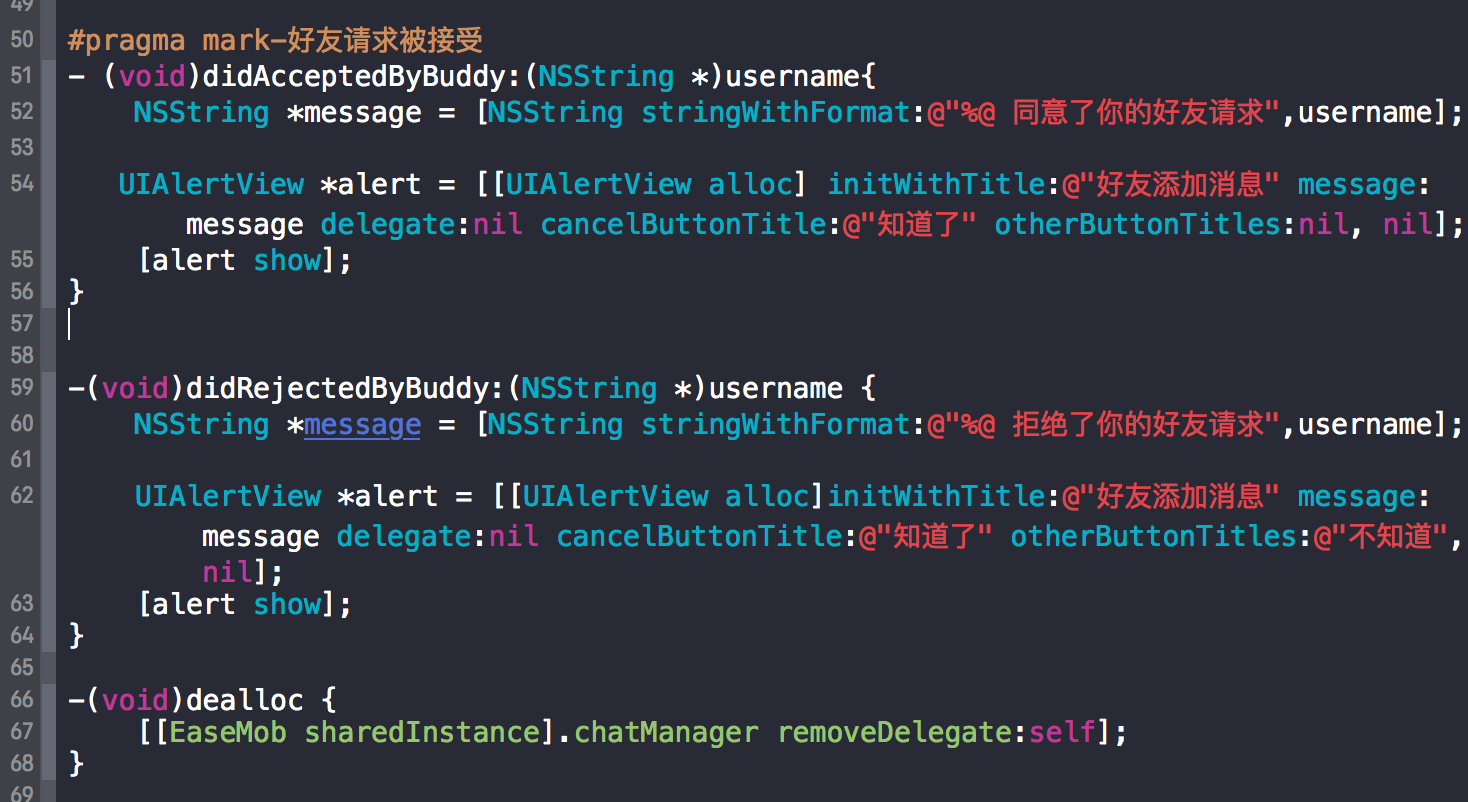
代理的销毁
好友请求消息反馈写在什么地方 因为你进去那个会话的控制器里面了的话就会被销毁了。我们可以把它的好友请求写在会话控制器 这样他每个控制器都可以收到了 也没有必要写在AppDelegate里面 可以去尝试一下
---------现实好友界面列表------------------
1.新建一个tableViewcontroller 修改那个tableView的继承
2.给他的cell添加一个Identifier
 下面打印的就是他的好友列表
下面打印的就是他的好友列表
#pragma mark - Tableview datasource
- (NSInteger)tableView:(UITableView *)tableView numberOfRowsInSection:(NSInteger)section {
return self.buddyList.count;
}
-(UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath {
static NSString *ID = @"BuddyCell";
UITableViewCell *cell = [tableView dequeueReusableCellWithIdentifier:ID];
//获取好友列表名称 EMBuddy是环信封装的好友模型
EMBuddy *buddy = self.buddyList[indexPath.row];
//显示头像 和名字
cell.imageView.image = [UIImage imageNamed:@"chatListCellHead"];
cell.textLabel.text = buddy.username;
return cell;
}
注意一个bug在网速很慢的时候话或者用户的手速很快的情况下(遇到单身30年的手速)用户的时候 你会发现好友列表但是没有值的 因为它的好友列表是在你用户登录策划国内恭候才会有值
buddyList是从本地获取的数据 本地有个数据库你可以去里面看看
// buddyList
如果删除了应用或者饿用户第一次登陆的时候 buddyList是没有数据记录的
就要从服务区获取好友列表纪录
在网络登陆之前我们去从服务器获取那个 好友列表并把它写到本地的数据库里面去,注意一下这个方法写在哪个地方 切记切记
 ----------------好友请求同意后的列表刷新----------------------------
----------------好友请求同意后的列表刷新----------------------------
当接收到后有的同意后要刷新好友的列表数据 去通讯录控制器监听
 产生了一个问题?
产生了一个问题?
我发送了请求 对方接受了 没有刷新好友列表
环信发送的话一定调用了
#pragma mark-好友列表的请求被更新,然而并没什么卵用
-(void)didUpdateBuddyList:(NSArray *)buddyList changedBuddies:(NSArray *)changedBuddies isAdd:(BOOL)isAdd{
// NSLog(@"好友列表被更新%@", buddyList);
NSLog(@"%@",buddyList);
self.buddyList = buddyList;
[self.tableView reloadData];
}
加上这句话就可以解决这个问题
============删除好友==========================
获取移除好友的名字
还有一种删除了是互相删除还是只是将一方的删除
#pragma mark--删除好友的代理方法
-(void)tableView:(UITableView *)tableView commitEditingStyle:(UITableViewCellEditingStyle)editingStyle forRowAtIndexPath:(nonnull NSIndexPath *)indexPath {
if(editingStyle == UITableViewCellEditingStyleDelete) {
//获取要移除的好友的名字
EMBuddy *buddy =self.buddyList[indexPath.row];
NSString *deleteusername = buddy.username;
//删除好友
[[EaseMob sharedInstance].chatManager removeBuddy:deleteusername removeFromRemote:YES error:nil];
}
}
———--------被好友删除的监听-----------------------------
1.在会话里面:
//被好友删除
#pragma mark-监听被好友删除
-(void)didRemovedByBuddy:(NSString *)username {
NSString *message = [username stringByAppendingString:@"把你删除"];
UIAlertView *alert = [[UIAlertView alloc]initWithTitle:@"好友删除提醒" message:message delegate:nil cancelButtonTitle:@"知道了" otherButtonTitles:nil, nil];
[alert show];
}
在同叙录里面:
//监听被删除去会话里面
#pragma mark-被好友删除了刷新一遍列表
-(void)didRemovedByBuddy:(NSString *)username {
[self loadDataFromServer];
}
--------------退出登录--------------------------
选中table View 的然后给他选static cell
2.然后连线去实现它的方法
-重点-------------聊天界面的实现----------------------------
1.拖入一个UIviewController 在上面在取拖入一个navagationBar 去设置他的标题
2.把cell的脱线 show
3.拖入一个View 拖到最下面 你会发现被tabbar 给盖住了 怎么去隐藏他呢?
选中他 有个 Bottom Bar 改为None
4.给这个View设置约束的时候注意 不要给她设置底部距Bottom 选择View
layout后 选择 Hidden Bottom Bar
5.往上面添加button button也要设置约束 要他举例底部的位子不变
否者的话 他会随着聊天的界面文字的的增加 而那个上升
还要加上一个textfield
通过代码监听键盘 如果底部
 千万不要把键盘关闭了 不然神仙也救不了你
千万不要把键盘关闭了 不然神仙也救不了你
具体代码:
-(void)viewDidLoad {
[super viewDidLoad];
//1.监听键盘的弹出,把inputToolbar往上移
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(kbWillShow:) name:UIKeyboardWillShowNotification object:nil];
}
#pragma mark-键盘显示的时候会触发方法
-(void)kbWillShow:(NSNotification *)notification {
//获取键盘的高度
//1.获取键盘结束的位子
CGRect kbEndFrame = [notification.userInfo[UIKeyboardFrameEndUserInfoKey] CGRectValue];
CGFloat kbHeight = kbEndFrame.size.height;
//更改inputToolBar的底部约束
self.inputToolBarBottonConstraint.constant = kbHeight;
//添加动画
[UIView animateWithDuration:0.25 animations:^{
[self.view layoutIfNeeded];
}];
}
//移除通知
-(void)dealloc {
[[NSNotificationCenter defaultCenter] removeObserver:self];
}
///////////////////
再加上一个tableView在它的上面 如何实现在拖动tableview 的时候让键盘隐藏
或者去监听tableView滚动的方法
tableView 有一个属性 Keyboard Dismiss on drag
在键盘推出的时候 让inputToolBarView 恢复原位
也要监听他
-----------cell有三种类型的 左边 中间 右边 -------------------------
1.往那个tableView里面去添加cell的时候我们可以 在里面加上图片
思路:在你设置好了头像之后再去设置文本的时候怎么设置
UILabel 设置背景图片的时候 我们可以先去给UILabel设置约束
再去设置那个背景图片,让他去拉伸
设置约束的时候注意头像要写死 但是lable只需要设置他的左边和 上面就行
如何加上测试数据:
1.自定一一个cell 在给他对用的类 和 对应的cell 绑定一个改类名
在。h文件里面给label加上一个属性 , 在给他的cell绑定一cell
最后别忘了在给tableview 右键往那个UIviewController上面加上数据源和代理
也就是自定义cell
------如何去让他显示的换行
1.吧label的Lines设置为0;
2.设置她的最大宽度:选择 Preferred width 这个选项242;
----最后给他设置那个背景图片
吧那个UIimage添加到那个Label上面
如何给那个这个ImageView 和Label 设置左上角对其?????????????
选中他们两个,然后把选择设置约束右下角的正向第2个 然后把4个Edge选择对其
最后别忘了去吧label 设置为clear
怎么去把ImageView的背景图片拉伸???????
选择背景图片 第4个属性倒立的脚 有一个strecting属性 设置为0.5 0.5 0 0
那个时候你会发现它的那个啥的没有那个左边图片的角的属性,什么原因呢?
这是因为你的这个时候的Y值拉升的不够可以把他的Y方向上面改成 0.7
这个时候还缺最后一步,要把它的那个背景ImagView改动一下,让它在上下左右 都往外面
拉伸一下??????//
可以选中它的那个约束,更改它的那个Constant 左边和上面的都是 加10 下边和右边是减10
最后别忘了跟新约束
-----------发送方的cell排布----------------------
先拖入一tableViewCell 然后改他的名字 在去拖入一个Imageview 在去实现它的那个
5 5 35 35
2.拖入一个Label 上面15 右边20 宽和高就不要添加了
3.如何让两个自定义的cell指向同一个的cell 新思想 :两个View公用一个cell
连线的时候又一个选择 选择senderCell 再给SenderCell一个identifier标示符号
在渲染cell的方法中加入一个加载哪一个cell的判断
4.最后设置它的Lines = 0 和 那个Preferred Width的宽度 让它实现自动换行
5.添加一个ImageView然后再去设置它的背景图片和 那个边距的对其
6.更改Image的Stretching
7.最后去把ImageView 的各个边距都改一下 上 10 左 10 下 -10 右边 -15 最后跟新
8 重点----如何去根据label里面的文字的高度去自动计算那个文字的高度?????
1.实现它的给他添加了一个测试的数据源方法
9--重点----还有一个问题 怎么去更改的它的自动计算那个行高呢??????
cell的高度取决于label文字的高度和它的字体的大小决定的、
思想: 去获取那个cell里面的label的高度再去加上一个固定的高度就是cell的高度了
怎么去获取那个label的高度呢???
上面的额头像距上为5 加上那个上面label距离上面的10的高度 再加上label自己 的高度self.label.hight +下面的那个10,再去加上那个固定的高度就是cell的高度了
10.--重点----我们专门搞一个计算高度的属性(他是一个返回cell的方法,然后去返回cell高度的方法里面去给他完成一下赋值的操作,最后去实现)
//还少了一步 ,一定要加上去设置那个label的数据
self.chatCellTool.messageLabel.text = self.dataSources[indexPath.row];
return [self.chatCellTool cellHeight];
/** 计算高度的cell的属性*/
@property (nonatomic,strong)UXZYChatCell *chatCellTool;
//给计算cell高度的对象完成一个赋值
//他返回的是一个cell 这个cell只是在那个返回高度的方法里面去用到了,其他的地方没有用到
记得最好把它的方法static NSString *Indentifier = @"ReceiveCell";写在那个cell的.h文件中
tableview记得再拖一次线 为什么任何一个的Identifier:都可以呢?????
因为你在返回高度的方法里面都是一样的执行的,不获去细分你是哪一个cell的方法 so。。。
self.chatCellTool = [self.tableView dequeueReusableCellWithIdentifier:SenderCell];
--------------发送聊天消息---------------------
1.首先要做的是把那个 textView的发送框改成send属性 第四个选项里面的有一个
Return Key 选项 改成那个Send选项
2.怎么去发送按钮的事件呢?????
1.把那个textView 的代理的线连上 2.然后去那个tableView里面的那个去遵守textView代理
在textView的方法里面去监听他最后的字符有没有换行,如果有换行的字符的话我就代表说他是发送sender的按钮]
3.怎么去发送文字呢???????
#pragma mark-UITextView的代理
-(void)textViewDidChange:(UITextView *)textView {
if([textView.text hasSuffix:@"\n"] ) {
NSLog(@"这是一个发送事件");
//发送文字
[self sendMessage:textView.text];
//清空文字
textView.text = nil;
}
}
-(void)sendMessage:(NSString *)text {
//创建一个消息对象实例
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:nil bodies:nil];
//发送消息
[[EaseMob sharedInstance].chatManager asyncSendMessage:msgObj progress:nil prepare:^(EMMessage *message, EMError *error) {
NSLog(@"消息准备发送");
} onQueue:nil completion:^(EMMessage *message, EMError *error) {
NSLog(@"消息完成发送");
} onQueue:nil];
}
还缺少一个参数 就是把消息发送给谁? 我们就缺少一个参数传递
initWithReceiver:要去拿到那个参数好友列表的参数 EMBuddy
#warning 每一种消息类型对象不同的消息体
//EMTextMessageBody
//EMVoiceMessageBody
//EMVideoMessageBody
// EMLocationMessageBody
// EMImageMessageBody
//创建一个聊天的文本对象
EMChatText *chatText = [[EMChatText alloc]initWithText:text];
//创建一个文本消息体
EMTextMessageBody *textBody = [[EMTextMessageBody alloc]initWithChatObject:chatText];
//创建一个消息对象实例 bodies是一个数组
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:self.buddy.username bodies:@[textBody]];
//发送消息
[[EaseMob sharedInstance].chatManager asyncSendMessage:msgObj progress:nil prepare:^(EMMessage *message, EMError *error) {
NSLog(@"消息准备发送");
} onQueue:nil completion:^(EMMessage *message, EMError *error) {
NSLog(@"消息完成发送");
} onQueue:nil];
注意点 : 加上一个return;去测试
把选中的好友列表正向传递进去
最后别忘了把那个return打开;
--------------显示好友的名字---------------------
1.在那个聊天的控制器的viewdidload里面写上
self.titlte = self.buddy.username
——————-------加载本地的聊天数据--------------------
有封装好的东西,先去内存的会话列表中去获取会话 如果没有找到就去数据库中去获取会话
没有找到就会出发现的会话
#pragma mark-加载本地的聊天数据
-(void)loadLocalChatrecords {
//获取本地聊天记录 会话对象
EMConversation *conversation = [[EaseMob sharedInstance].chatManager conversationForChatter:self.buddy.username conversationType: eConversationTypeChat];
//加载当前来哦天用户所有的聊天记录
NSArray *messages = [conversation loadAllMessages];
for(id obj in messages) {
NSLog(@"%@",[obj class]);
}
[self.dataSources addObject:messages];
}
[self.dataSources addObject:messages];加上了就报错了,她的原因是什么呢?
tableView:heightForRowAtIndexPath 错了
跳进设置高度的方法里面去 去吧里面改动一下
//改进后的cell高度的获取
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
// EMMessage *msg = self.dataSources[indexPath.row];
// id body = msg.messageBodies[0];
// if([body isKindOfClass:[EMTextMessageBody class]]) {//如果是文本消息
// EMTextMessageBody *textBody = body;
// cell.messageLabel.text = textBody;
// }
最后是用一个set方法去代替他们
-(CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath {
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
EMMessage *msg = self.dataSources[indexPath.row];
//改进后的cell高度的获取
// id body = msg.messageBodies[0];
//
// if([body isKindOfClass:[EMTextMessageBody class]]) {//如果是文本消息
// EMTextMessageBody *textBody = body;
// cell.messageLabel.text = textBody;
// }
self.chatCellTool.message = msg;
return [self.chatCellTool cellHeight];
//还少了一步 ,一定要加上去设置那个label的数据
// self.chatCellTool.messageLabel.text = self.dataSources[indexPath.row];
// return [self.chatCellTool cellHeight];
}
最后别忘了去那个tableviewcell的模型里面去改,
————为了计算高度我们建立了一个模型——----------
-(CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath {
//改进后的cell高度的获取
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
EMMessage *msg = self.dataSources[indexPath.row];
self.chatCellTool.message = msg;
return [self.chatCellTool cellHeight];
}
重写了模型的set方法 ,然后去调用了他的set方法
最后别忘了在显示的时候去调用他渲染那个方法
我的这个msg是一个消息模型
msg.messageBodies[0]
这样才能拿到消息体
msg.messageBodies[0].text才正确
-------------
[Pasted Graphic.tiff]
----------这样还不对-------------------------
你会看到你发出去的消息会在左边能看到
如何让它只能在右边显示呢??????????/
EMmessage有两个属性 from to
from是发送方也就是自己 from是好友的话自己就是接受方
所以我们得在现实渲染的方法里面去先去获取消息模型
然后再去做一个from的判断
UXZYChatCell *cell = nil;
//先去获取消息模型然后去在去判断是发送方还是接收方
EMMessage *msg = self.dataSources[indexPath.row];
if([msg.from isEqualToString:self.buddy.username]) {//自己接收方
cell = [tableView dequeueReusableCellWithIdentifier:Indentifier];
}else {
cell = [tableView dequeueReusableCellWithIdentifier:SenderCell];
}
--------怎么让你的消息立马显示-----------------------
去这个方法里面
-(void)sendMessage:(NSString *)text { }
msgObj是你自己创建一个消息对象实例 bodies是一个数组
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:self.buddy.username bodies:@[textBody]];
//把消息添加到数据源 再刷新表格
[self.dataSources addObject:msgObj];
[self.tableView reloadData];
------怎么让你的消息自己滚动到最上面的一行----
//4.把消息显示在顶部
[self scrollToBottom];
}
-(void)scrollToBottom {
//获取最后一行
if(self.dataSources.count == 0){
return;
}
NSIndexPath *lastIndex = [NSIndexPath indexPathForRow:self.dataSources.count-1 inSection:0];
[self.tableView scrollToRowAtIndexPath:lastIndex atScrollPosition:UITableViewScrollPositionBottom animated:YES];
}
—————仔细的你到这一步了发没发现你那个你发出去的消息子啊框里面都会多出一行---
原因:是你在点击发送的时候他换了一下行,换行字符只展占用一个字节
如何去清除那个换行的字符,在发消息的放里面去实现
text = [text substringToIndex:text.length-1];
-----------怎么去监听消息的回复--------------------
1.设置代理方法 并遵循它的 代理方法
2.有一个那个mesage的方法去实现一下
------对输入框的完善,即在你输入的时候那个输入框的高速会自动增加-------------------------
1.得定义输入框的一个最小的高度和最大的高度
2.textView是继承于UIscrollView scrollView有一个属性 contensize 属性
这个是计算那个做一个判断 不同情况下面的高度
3.我们再去拿到那个的InputView 的高度的约束 再去连线使它成为一个属性 然后像之前一样去约束它,找到他,然后给他连线 使它成为一个属性
//获取contentsize的高度
CGFloat contentHeight = textView.contentSize.height;
if (contentHeight <minHeight) {
textViewH = minHeight;
}else if (contentHeight >maxHeight) {
textViewH = maxHeight;
}else {
textViewH = contentHeight;
}
self.inputToolBarHeightConstrains.constant = 5 + 8 + textViewH;
4.还是有一个问题,就是在你输入完了一之后发送了 之后textView还是有一个换行的空格
所以还得有一个在发送完了后的判断语句
if([textView.text hasSuffix:@"\n"] ) {
NSLog(@"这是一个发送事件");
//发送文字
[self sendMessage:textView.text];
//清空文字
textView.text = nil;
// 发送时textView的高速为最小的高度
textViewH = minHeight;
}
self.inputToolBarHeightConstrains.constant = 5 + 8 + textViewH;
5.设置textView的背景图片 在SB中去设置 拖入一个IMageView 然后把它拿到那个textView的上面去 然后改透明 设置背景图片 把图片拉伸 streching 别忘了给背景图片加约束 不然的话他会随着那个的高度的增加他不会随着拉伸 最后去加个动画
6.——————---发送完了后发现光标不见了 发大模拟器看在左上角???
原因???scrollView有一个contentOffset.y的值会随着你的那个的光标的contensize的而向上拖动而拖送
NSStringFromCGSize(textView.contentSet)可以打印出来看看
contentOffset一开始为(0,0)之后它的y值为正数了,为什么呢,因为他要显示的下面的文字内容的话它的那个轴必须下移动 所以为正
如何解决 哪次发送完了 让它的contentset恢复到原位
环信遇到的bug1:真机上面不能跑 模拟器可以
[Pasted Graphic_1.tiff]
把那个bitcode 设置为NO bitcode是被编译程序的一种中间形式的代码。包含bitcode配置的程序将会在App store上被编译和链接
默认是yes
storyboard作为控制器的复习
1.拖入一导航控制器 ,更改尺寸 去掉后一个
2.拖入一个viewControler 然后去把它的那个root viewcontroller 设置一下
3.创建一个控制器UIviewcontroller 第三个选项 class里面更改继承关系
4.拖线 连线 1.去改掉main 2。去那个第4个 is initial View Controller 的钩上
登录提供了三种方法
1.同步 2.block的异步 3.代理的回调
注释的方法提示在图表
方式一:/// 点在图标
方式二:
/*!
* @brief 点在图标
*/ 收起阅读 »
没有初始化SDK
去AppDelegate里面初始化
密码
User not exist ??????????
每一个应用都有自己的注册用户 去你的后台管理 去看你的注册的用户数
为什么demo的可以跑起来????????
是在它的应用下注册的
怎么去注册用户 -注册用户
用户名字可以相同 不同的应用
那个打印的loginInfo 是这个字典的也就是用户的登录信息
你会发现打印的loginInfo上面还有一坨恶心的东西,那个是环信SDK自己打印的日志信息
SEND 和 RECV 使用的是XMPP协议 所以 数据的格式是XML 一般的HTTP协议的话他就是JSON格式的
这个是app把客户端登录的信息发给环信服务器后打印出来的日志 是不是很烦
如何去在哪儿隐藏它的控制台的日志信息 ?????????
去初始化的时候把它隐藏 有一个otherConfig的东西 右键-jump to Define
进去瞅瞅--
复制它的key 给他设置为NO
这个时候它的控制台的日志信息就被屏蔽了
跟环信交互的所有类都有这个
[EaseMob sharedInstance].chatManager
注册的时候代码:
如果你把这onQueue改为nil的话他默认也是在主线程的
然后你在去环信的开发中心刷新IM用户 你会发现他多了一个
发送给的数据给服务器的时候还是XML格式,里面的SDK帮你封装了,不用你自己去接触
---自动登录------------------------------------
看到它的主界面只有三个tabbar
进去 mainstoryboard里面 删除原始的viewcontroller 拖入一个 tabbarController 去掉原始的tabbar 的两个子控制器 记得给它的isinitial 那个选项钩上 然后拖入三个navigationcontroller(这个根据你的界面而定)
选中给每个的Item 的title属性可以更改
然后在登录成功中写上加载storyboard的方法
你会发现你已经跳转进去
如何实现自动登录?????????????????实现原理:把你的登录信息保存在沙盒中 程序启动时候发送登录请求
只要你在第一次登录成功后发送环信自带登录的网络请求去实现、
环信自己帮你实现上面的东西
具体实现
在登录成功的下面写上
[[EaseMob sharedInstance].chatManager setIsAutoLoginEnabled:YES]
然后去在AppDelegte里面把他的沙盒路径拿到
然后再控制台你可以看到这些信息,其中的账号密码信息你会发现他被加密了,有没有?如何监听是否是已经处于登录状态了这个地方有个代理 环信的代理方法在AppDelegate方法里面进去 在启动方法里面写
你会发现它的那个啥没有完成界面的跳转 但是控制台却是带那个登陆成功了这个时候我们还缺一步骤 之前我们在自动登录时候我们调用的是set方法这个时候我们要实现它的 get方法 写在监听登录状态的下面
//如果登录过直接来到主界面
if([[EaseMob sharedInstance].chatManager isAutoLoginEnabled]){self.window.rootViewController = [UIStoryboard storyboardWithName:@"Main" bundle:nil].instantiateInitialViewController;
}
=------------自动连接--------------------------
网络通不通的时候类似微信那种网络不通的实现
去那个main.storyboard里面把那会话的导航控制器跳转的那个类继承改为你自己创建的那个UItableViewController
1.在会话里面监听的网络的状态 环信的有很多个代理
去那个.m文件里面去实现
点击那个EMChatManagerDelegate 里面去实现 EMChatManagerUtilDelegate里面的这个方法就OK了- (void)didConnectionStateChanged:(EMConnectionState)connectionState;
在真机上面测试的时候 网络连接成功不代表客户端和服务器端连接成功还有自动连接的状态的监听 也是加上他的代理方法就行了
--------添加好友请求-----------------------------
1.是用环信的思想
所有的网络请求 [EaseMob sharedInstance].chatManager 由这个管理器发起的
2.所有结果(自动登录 自动连接)通过代理来回调完成
[EaseMob sharedInstance].chatManager的addDelegate来完成
3.EMChatManagerBuddyDelegate 这个代理实现了对用户的基本操作
1.添加好友 2.从本地获取好友 3.从服务器列表获取最新的好友 4.接受好友添加请求
5.删除好友 6.被好友从名单上面删除
在navigation 的第二个控制器上面加上一个UIbarbarItem 选择自定义 然后+
再去创建一个UIviewController 然后再去实现用个+号去拖一个线
可以在上面加上navigationItem 上改为添加好友
再去新建一个控制器AdressBooking 通讯录 这个类是继承于UIviewController
是用环信最简单的方法 ,把官方的Demo直接拿过来用 直接跟改它的Appdelegate里面的APPKey这样你就收到了申请 注意 这是最简单的方式
还有一点 你要在每个控制器里面写上你环信的代理方法
这样就能保证你下面写的环信 的每一个方法会被自动调用了
代理方法:代理的销毁
好友请求消息反馈写在什么地方 因为你进去那个会话的控制器里面了的话就会被销毁了。我们可以把它的好友请求写在会话控制器 这样他每个控制器都可以收到了 也没有必要写在AppDelegate里面 可以去尝试一下
---------现实好友界面列表------------------
1.新建一个tableViewcontroller 修改那个tableView的继承
2.给他的cell添加一个Identifier
下面打印的就是他的好友列表#pragma mark - Tableview datasource
- (NSInteger)tableView:(UITableView *)tableView numberOfRowsInSection:(NSInteger)section {
return self.buddyList.count;
}
-(UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath {
static NSString *ID = @"BuddyCell";
UITableViewCell *cell = [tableView dequeueReusableCellWithIdentifier:ID];
//获取好友列表名称 EMBuddy是环信封装的好友模型
EMBuddy *buddy = self.buddyList[indexPath.row];
//显示头像 和名字
cell.imageView.image = [UIImage imageNamed:@"chatListCellHead"];
cell.textLabel.text = buddy.username;
return cell;
}
注意一个bug在网速很慢的时候话或者用户的手速很快的情况下(遇到单身30年的手速)用户的时候 你会发现好友列表但是没有值的 因为它的好友列表是在你用户登录策划国内恭候才会有值
buddyList是从本地获取的数据 本地有个数据库你可以去里面看看
// buddyList
如果删除了应用或者饿用户第一次登陆的时候 buddyList是没有数据记录的
就要从服务区获取好友列表纪录
在网络登陆之前我们去从服务器获取那个 好友列表并把它写到本地的数据库里面去,注意一下这个方法写在哪个地方 切记切记
----------------好友请求同意后的列表刷新----------------------------当接收到后有的同意后要刷新好友的列表数据 去通讯录控制器监听
产生了一个问题?我发送了请求 对方接受了 没有刷新好友列表
环信发送的话一定调用了
#pragma mark-好友列表的请求被更新,然而并没什么卵用
-(void)didUpdateBuddyList:(NSArray *)buddyList changedBuddies:(NSArray *)changedBuddies isAdd:(BOOL)isAdd{
// NSLog(@"好友列表被更新%@", buddyList);
NSLog(@"%@",buddyList);
self.buddyList = buddyList;
[self.tableView reloadData];
}
加上这句话就可以解决这个问题
============删除好友==========================
获取移除好友的名字
还有一种删除了是互相删除还是只是将一方的删除
#pragma mark--删除好友的代理方法
-(void)tableView:(UITableView *)tableView commitEditingStyle:(UITableViewCellEditingStyle)editingStyle forRowAtIndexPath:(nonnull NSIndexPath *)indexPath {
if(editingStyle == UITableViewCellEditingStyleDelete) {
//获取要移除的好友的名字
EMBuddy *buddy =self.buddyList[indexPath.row];
NSString *deleteusername = buddy.username;
//删除好友
[[EaseMob sharedInstance].chatManager removeBuddy:deleteusername removeFromRemote:YES error:nil];
}
}
———--------被好友删除的监听-----------------------------
1.在会话里面:
//被好友删除
#pragma mark-监听被好友删除
-(void)didRemovedByBuddy:(NSString *)username {
NSString *message = [username stringByAppendingString:@"把你删除"];
UIAlertView *alert = [[UIAlertView alloc]initWithTitle:@"好友删除提醒" message:message delegate:nil cancelButtonTitle:@"知道了" otherButtonTitles:nil, nil];
[alert show];
}
在同叙录里面:
//监听被删除去会话里面
#pragma mark-被好友删除了刷新一遍列表
-(void)didRemovedByBuddy:(NSString *)username {
[self loadDataFromServer];
}
--------------退出登录--------------------------
选中table View 的然后给他选static cell
2.然后连线去实现它的方法
-重点-------------聊天界面的实现----------------------------
1.拖入一个UIviewController 在上面在取拖入一个navagationBar 去设置他的标题
2.把cell的脱线 show
3.拖入一个View 拖到最下面 你会发现被tabbar 给盖住了 怎么去隐藏他呢?
选中他 有个 Bottom Bar 改为None
4.给这个View设置约束的时候注意 不要给她设置底部距Bottom 选择View
layout后 选择 Hidden Bottom Bar
5.往上面添加button button也要设置约束 要他举例底部的位子不变
否者的话 他会随着聊天的界面文字的的增加 而那个上升
还要加上一个textfield
通过代码监听键盘 如果底部
千万不要把键盘关闭了 不然神仙也救不了你具体代码:
-(void)viewDidLoad {
[super viewDidLoad];
//1.监听键盘的弹出,把inputToolbar往上移
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(kbWillShow:) name:UIKeyboardWillShowNotification object:nil];
}
#pragma mark-键盘显示的时候会触发方法
-(void)kbWillShow:(NSNotification *)notification {
//获取键盘的高度
//1.获取键盘结束的位子
CGRect kbEndFrame = [notification.userInfo[UIKeyboardFrameEndUserInfoKey] CGRectValue];
CGFloat kbHeight = kbEndFrame.size.height;
//更改inputToolBar的底部约束
self.inputToolBarBottonConstraint.constant = kbHeight;
//添加动画
[UIView animateWithDuration:0.25 animations:^{
[self.view layoutIfNeeded];
}];
}
//移除通知
-(void)dealloc {
[[NSNotificationCenter defaultCenter] removeObserver:self];
}
///////////////////
再加上一个tableView在它的上面 如何实现在拖动tableview 的时候让键盘隐藏
或者去监听tableView滚动的方法
tableView 有一个属性 Keyboard Dismiss on drag
在键盘推出的时候 让inputToolBarView 恢复原位
也要监听他
-----------cell有三种类型的 左边 中间 右边 -------------------------
1.往那个tableView里面去添加cell的时候我们可以 在里面加上图片
思路:在你设置好了头像之后再去设置文本的时候怎么设置
UILabel 设置背景图片的时候 我们可以先去给UILabel设置约束
再去设置那个背景图片,让他去拉伸
设置约束的时候注意头像要写死 但是lable只需要设置他的左边和 上面就行
如何加上测试数据:
1.自定一一个cell 在给他对用的类 和 对应的cell 绑定一个改类名
在。h文件里面给label加上一个属性 , 在给他的cell绑定一cell
最后别忘了在给tableview 右键往那个UIviewController上面加上数据源和代理
也就是自定义cell
------如何去让他显示的换行
1.吧label的Lines设置为0;
2.设置她的最大宽度:选择 Preferred width 这个选项242;
----最后给他设置那个背景图片
吧那个UIimage添加到那个Label上面
如何给那个这个ImageView 和Label 设置左上角对其?????????????
选中他们两个,然后把选择设置约束右下角的正向第2个 然后把4个Edge选择对其
最后别忘了去吧label 设置为clear
怎么去把ImageView的背景图片拉伸???????
选择背景图片 第4个属性倒立的脚 有一个strecting属性 设置为0.5 0.5 0 0
那个时候你会发现它的那个啥的没有那个左边图片的角的属性,什么原因呢?
这是因为你的这个时候的Y值拉升的不够可以把他的Y方向上面改成 0.7
这个时候还缺最后一步,要把它的那个背景ImagView改动一下,让它在上下左右 都往外面
拉伸一下??????//
可以选中它的那个约束,更改它的那个Constant 左边和上面的都是 加10 下边和右边是减10
最后别忘了跟新约束
-----------发送方的cell排布----------------------
先拖入一tableViewCell 然后改他的名字 在去拖入一个Imageview 在去实现它的那个
5 5 35 35
2.拖入一个Label 上面15 右边20 宽和高就不要添加了
3.如何让两个自定义的cell指向同一个的cell 新思想 :两个View公用一个cell
连线的时候又一个选择 选择senderCell 再给SenderCell一个identifier标示符号
在渲染cell的方法中加入一个加载哪一个cell的判断
4.最后设置它的Lines = 0 和 那个Preferred Width的宽度 让它实现自动换行
5.添加一个ImageView然后再去设置它的背景图片和 那个边距的对其
6.更改Image的Stretching
7.最后去把ImageView 的各个边距都改一下 上 10 左 10 下 -10 右边 -15 最后跟新
8 重点----如何去根据label里面的文字的高度去自动计算那个文字的高度?????
1.实现它的给他添加了一个测试的数据源方法
9--重点----还有一个问题 怎么去更改的它的自动计算那个行高呢??????
cell的高度取决于label文字的高度和它的字体的大小决定的、
思想: 去获取那个cell里面的label的高度再去加上一个固定的高度就是cell的高度了
怎么去获取那个label的高度呢???
上面的额头像距上为5 加上那个上面label距离上面的10的高度 再加上label自己 的高度self.label.hight +下面的那个10,再去加上那个固定的高度就是cell的高度了
10.--重点----我们专门搞一个计算高度的属性(他是一个返回cell的方法,然后去返回cell高度的方法里面去给他完成一下赋值的操作,最后去实现)
//还少了一步 ,一定要加上去设置那个label的数据
self.chatCellTool.messageLabel.text = self.dataSources[indexPath.row];
return [self.chatCellTool cellHeight];
/** 计算高度的cell的属性*/
@property (nonatomic,strong)UXZYChatCell *chatCellTool;
//给计算cell高度的对象完成一个赋值
//他返回的是一个cell 这个cell只是在那个返回高度的方法里面去用到了,其他的地方没有用到
记得最好把它的方法static NSString *Indentifier = @"ReceiveCell";写在那个cell的.h文件中
tableview记得再拖一次线 为什么任何一个的Identifier:都可以呢?????
因为你在返回高度的方法里面都是一样的执行的,不获去细分你是哪一个cell的方法 so。。。
self.chatCellTool = [self.tableView dequeueReusableCellWithIdentifier:SenderCell];
--------------发送聊天消息---------------------
1.首先要做的是把那个 textView的发送框改成send属性 第四个选项里面的有一个
Return Key 选项 改成那个Send选项
2.怎么去发送按钮的事件呢?????
1.把那个textView 的代理的线连上 2.然后去那个tableView里面的那个去遵守textView代理
在textView的方法里面去监听他最后的字符有没有换行,如果有换行的字符的话我就代表说他是发送sender的按钮]
3.怎么去发送文字呢???????
#pragma mark-UITextView的代理
-(void)textViewDidChange:(UITextView *)textView {
if([textView.text hasSuffix:@"\n"] ) {
NSLog(@"这是一个发送事件");
//发送文字
[self sendMessage:textView.text];
//清空文字
textView.text = nil;
}
}
-(void)sendMessage:(NSString *)text {
//创建一个消息对象实例
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:nil bodies:nil];
//发送消息
[[EaseMob sharedInstance].chatManager asyncSendMessage:msgObj progress:nil prepare:^(EMMessage *message, EMError *error) {
NSLog(@"消息准备发送");
} onQueue:nil completion:^(EMMessage *message, EMError *error) {
NSLog(@"消息完成发送");
} onQueue:nil];
}
还缺少一个参数 就是把消息发送给谁? 我们就缺少一个参数传递
initWithReceiver:要去拿到那个参数好友列表的参数 EMBuddy
#warning 每一种消息类型对象不同的消息体
//EMTextMessageBody
//EMVoiceMessageBody
//EMVideoMessageBody
// EMLocationMessageBody
// EMImageMessageBody
//创建一个聊天的文本对象
EMChatText *chatText = [[EMChatText alloc]initWithText:text];
//创建一个文本消息体
EMTextMessageBody *textBody = [[EMTextMessageBody alloc]initWithChatObject:chatText];
//创建一个消息对象实例 bodies是一个数组
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:self.buddy.username bodies:@[textBody]];
//发送消息
[[EaseMob sharedInstance].chatManager asyncSendMessage:msgObj progress:nil prepare:^(EMMessage *message, EMError *error) {
NSLog(@"消息准备发送");
} onQueue:nil completion:^(EMMessage *message, EMError *error) {
NSLog(@"消息完成发送");
} onQueue:nil];
注意点 : 加上一个return;去测试
把选中的好友列表正向传递进去
最后别忘了把那个return打开;
--------------显示好友的名字---------------------
1.在那个聊天的控制器的viewdidload里面写上
self.titlte = self.buddy.username
——————-------加载本地的聊天数据--------------------
有封装好的东西,先去内存的会话列表中去获取会话 如果没有找到就去数据库中去获取会话
没有找到就会出发现的会话
#pragma mark-加载本地的聊天数据
-(void)loadLocalChatrecords {
//获取本地聊天记录 会话对象
EMConversation *conversation = [[EaseMob sharedInstance].chatManager conversationForChatter:self.buddy.username conversationType: eConversationTypeChat];
//加载当前来哦天用户所有的聊天记录
NSArray *messages = [conversation loadAllMessages];
for(id obj in messages) {
NSLog(@"%@",[obj class]);
}
[self.dataSources addObject:messages];
}
[self.dataSources addObject:messages];加上了就报错了,她的原因是什么呢?
tableView:heightForRowAtIndexPath 错了
跳进设置高度的方法里面去 去吧里面改动一下
//改进后的cell高度的获取
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
// EMMessage *msg = self.dataSources[indexPath.row];
// id body = msg.messageBodies[0];
// if([body isKindOfClass:[EMTextMessageBody class]]) {//如果是文本消息
// EMTextMessageBody *textBody = body;
// cell.messageLabel.text = textBody;
// }
最后是用一个set方法去代替他们
-(CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath {
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
EMMessage *msg = self.dataSources[indexPath.row];
//改进后的cell高度的获取
// id body = msg.messageBodies[0];
//
// if([body isKindOfClass:[EMTextMessageBody class]]) {//如果是文本消息
// EMTextMessageBody *textBody = body;
// cell.messageLabel.text = textBody;
// }
self.chatCellTool.message = msg;
return [self.chatCellTool cellHeight];
//还少了一步 ,一定要加上去设置那个label的数据
// self.chatCellTool.messageLabel.text = self.dataSources[indexPath.row];
// return [self.chatCellTool cellHeight];
}
最后别忘了去那个tableviewcell的模型里面去改,
————为了计算高度我们建立了一个模型——----------
-(CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath {
//改进后的cell高度的获取
//1.获取消息的模型 这样代码风格不好我们可以去cell的属性里面去创建一个cell的模型
EMMessage *msg = self.dataSources[indexPath.row];
self.chatCellTool.message = msg;
return [self.chatCellTool cellHeight];
}
重写了模型的set方法 ,然后去调用了他的set方法
最后别忘了在显示的时候去调用他渲染那个方法
我的这个msg是一个消息模型
msg.messageBodies[0]
这样才能拿到消息体
msg.messageBodies[0].text才正确
-------------
[Pasted Graphic.tiff]
----------这样还不对-------------------------
你会看到你发出去的消息会在左边能看到
如何让它只能在右边显示呢??????????/
EMmessage有两个属性 from to
from是发送方也就是自己 from是好友的话自己就是接受方
所以我们得在现实渲染的方法里面去先去获取消息模型
然后再去做一个from的判断
UXZYChatCell *cell = nil;
//先去获取消息模型然后去在去判断是发送方还是接收方
EMMessage *msg = self.dataSources[indexPath.row];
if([msg.from isEqualToString:self.buddy.username]) {//自己接收方
cell = [tableView dequeueReusableCellWithIdentifier:Indentifier];
}else {
cell = [tableView dequeueReusableCellWithIdentifier:SenderCell];
}
--------怎么让你的消息立马显示-----------------------
去这个方法里面
-(void)sendMessage:(NSString *)text { }
msgObj是你自己创建一个消息对象实例 bodies是一个数组
EMMessage *msgObj = [[EMMessage alloc]initWithReceiver:self.buddy.username bodies:@[textBody]];
//把消息添加到数据源 再刷新表格
[self.dataSources addObject:msgObj];
[self.tableView reloadData];
------怎么让你的消息自己滚动到最上面的一行----
//4.把消息显示在顶部
[self scrollToBottom];
}
-(void)scrollToBottom {
//获取最后一行
if(self.dataSources.count == 0){
return;
}
NSIndexPath *lastIndex = [NSIndexPath indexPathForRow:self.dataSources.count-1 inSection:0];
[self.tableView scrollToRowAtIndexPath:lastIndex atScrollPosition:UITableViewScrollPositionBottom animated:YES];
}
—————仔细的你到这一步了发没发现你那个你发出去的消息子啊框里面都会多出一行---
原因:是你在点击发送的时候他换了一下行,换行字符只展占用一个字节
如何去清除那个换行的字符,在发消息的放里面去实现
text = [text substringToIndex:text.length-1];
-----------怎么去监听消息的回复--------------------
1.设置代理方法 并遵循它的 代理方法
2.有一个那个mesage的方法去实现一下
------对输入框的完善,即在你输入的时候那个输入框的高速会自动增加-------------------------
1.得定义输入框的一个最小的高度和最大的高度
2.textView是继承于UIscrollView scrollView有一个属性 contensize 属性
这个是计算那个做一个判断 不同情况下面的高度
3.我们再去拿到那个的InputView 的高度的约束 再去连线使它成为一个属性 然后像之前一样去约束它,找到他,然后给他连线 使它成为一个属性
//获取contentsize的高度
CGFloat contentHeight = textView.contentSize.height;
if (contentHeight <minHeight) {
textViewH = minHeight;
}else if (contentHeight >maxHeight) {
textViewH = maxHeight;
}else {
textViewH = contentHeight;
}
self.inputToolBarHeightConstrains.constant = 5 + 8 + textViewH;
4.还是有一个问题,就是在你输入完了一之后发送了 之后textView还是有一个换行的空格
所以还得有一个在发送完了后的判断语句
if([textView.text hasSuffix:@"\n"] ) {
NSLog(@"这是一个发送事件");
//发送文字
[self sendMessage:textView.text];
//清空文字
textView.text = nil;
// 发送时textView的高速为最小的高度
textViewH = minHeight;
}
self.inputToolBarHeightConstrains.constant = 5 + 8 + textViewH;
5.设置textView的背景图片 在SB中去设置 拖入一个IMageView 然后把它拿到那个textView的上面去 然后改透明 设置背景图片 把图片拉伸 streching 别忘了给背景图片加约束 不然的话他会随着那个的高度的增加他不会随着拉伸 最后去加个动画
6.——————---发送完了后发现光标不见了 发大模拟器看在左上角???
原因???scrollView有一个contentOffset.y的值会随着你的那个的光标的contensize的而向上拖动而拖送
NSStringFromCGSize(textView.contentSet)可以打印出来看看
contentOffset一开始为(0,0)之后它的y值为正数了,为什么呢,因为他要显示的下面的文字内容的话它的那个轴必须下移动 所以为正
如何解决 哪次发送完了 让它的contentset恢复到原位
环信遇到的bug1:真机上面不能跑 模拟器可以
[Pasted Graphic_1.tiff]
把那个bitcode 设置为NO bitcode是被编译程序的一种中间形式的代码。包含bitcode配置的程序将会在App store上被编译和链接
默认是yes
storyboard作为控制器的复习
1.拖入一导航控制器 ,更改尺寸 去掉后一个
2.拖入一个viewControler 然后去把它的那个root viewcontroller 设置一下
3.创建一个控制器UIviewcontroller 第三个选项 class里面更改继承关系
4.拖线 连线 1.去改掉main 2。去那个第4个 is initial View Controller 的钩上
登录提供了三种方法
1.同步 2.block的异步 3.代理的回调
注释的方法提示在图表
方式一:/// 点在图标
方式二:
/*!
* @brief 点在图标
*/ 收起阅读 »
java集成环信
1、项目环境描述
项目是一个关于教育的项目,主要的架构是Spring,Struts2,Hibernate,前端页面是Jsp。
手机端:Android,IOS
2.项目需求描述
项目中有一个需求是聊天的功能,主要有好友聊天,陌生人聊天,同班同学群聊三种。
3.集成步骤
1)、服务器集成文档
http://docs.easemob.com/im/100serverintegration/10intro

在页面中点击"示例代码"栏中的“这里”
2)、服务器端代码下载
https://github.com/easemob/emchat-server-examples

在页面中选择对应的语言版本进行下载,本项目需要的是java版本emchat-server-java
4)、将下载的代码引入项目中
将libs下边的jar导入项目。
将代码加入项目并调试不报错,主要注意配置文件中的内容。文件里内容有:
API_PROTOCAL = https //协议
API_HOST = a1.easemob.com //ip
API_ORG = 1193161011115832 //组织信息
API_APP = testapp //应用名称
APP_CLIENT_ID = YXA6Gj8v8KAIEea4-ukHSS2iNQ
APP_CLIENT_SECRET = YXA6pSzVILsRgv9Wu2cRsVhJxoAz924
上述参数要根据具体的环信应用得到
5)、注册环信,登录后创建应用。应用的参数信息主要用于上述的配置文件中。
4、应用步骤
1)、分工
服务器端负责注册/删除环信用户,推送系统消息。手机端负责登录,退出,消息管理。
2)、数据库
1、用户信息
保存项目用户的基本注册信息,一般通过手机号进行注册,环信用户的用户名为手机号,密码和系统保持一致。保证手机端在登录系统后登录环信。保持统一在线。
2、好友
好友表中记录用户之间的关系,关系分为:发送好友请求,同意好友,拒绝好友,黑名单,陌生人。
3)、服务封装
1、登录时先查看用户是否注册环信IM用户,如果没有则先注册然后登录。
2、删除用户时,查看是否注册IM用户,如果有则一起删除。
3、退出时,通过环信的退出提醒在手机端提醒用户退出。
4、添加好友,判断是否是好友,同时对黑名单进行处理。
5、用户的头像,性别,名称等进本信息都是通过系统查询得到。
6、好友列表,陌生人列表通过对好友表查询得到用户的具体信息,然后展示好友/陌生人列表信息
7、同班同学是通过班级表来确认用户的班集体,进而查询得到所有同班同学的信息,展示同班同学列表。
8、聊天时,直接向用户手机号的IM用户发送消息即可。
项目只是用到了环信最基本的聊天功能,环信有更丰富的内容。比如:好友管理,上线下线管理,群聊,批量注册,手机端信息推送,环信客服等功能。
跟多信息请到环信官网查询:http://www.easemob.com/
收起阅读 »
项目是一个关于教育的项目,主要的架构是Spring,Struts2,Hibernate,前端页面是Jsp。
手机端:Android,IOS
2.项目需求描述
项目中有一个需求是聊天的功能,主要有好友聊天,陌生人聊天,同班同学群聊三种。
3.集成步骤
1)、服务器集成文档
http://docs.easemob.com/im/100serverintegration/10intro
在页面中点击"示例代码"栏中的“这里”
2)、服务器端代码下载
https://github.com/easemob/emchat-server-examples
在页面中选择对应的语言版本进行下载,本项目需要的是java版本emchat-server-java
4)、将下载的代码引入项目中
将libs下边的jar导入项目。
将代码加入项目并调试不报错,主要注意配置文件中的内容。文件里内容有:
API_PROTOCAL = https //协议
API_HOST = a1.easemob.com //ip
API_ORG = 1193161011115832 //组织信息
API_APP = testapp //应用名称
APP_CLIENT_ID = YXA6Gj8v8KAIEea4-ukHSS2iNQ
APP_CLIENT_SECRET = YXA6pSzVILsRgv9Wu2cRsVhJxoAz924
上述参数要根据具体的环信应用得到
5)、注册环信,登录后创建应用。应用的参数信息主要用于上述的配置文件中。
4、应用步骤
1)、分工
服务器端负责注册/删除环信用户,推送系统消息。手机端负责登录,退出,消息管理。
2)、数据库
1、用户信息
保存项目用户的基本注册信息,一般通过手机号进行注册,环信用户的用户名为手机号,密码和系统保持一致。保证手机端在登录系统后登录环信。保持统一在线。
2、好友
好友表中记录用户之间的关系,关系分为:发送好友请求,同意好友,拒绝好友,黑名单,陌生人。
3)、服务封装
1、登录时先查看用户是否注册环信IM用户,如果没有则先注册然后登录。
2、删除用户时,查看是否注册IM用户,如果有则一起删除。
3、退出时,通过环信的退出提醒在手机端提醒用户退出。
4、添加好友,判断是否是好友,同时对黑名单进行处理。
5、用户的头像,性别,名称等进本信息都是通过系统查询得到。
6、好友列表,陌生人列表通过对好友表查询得到用户的具体信息,然后展示好友/陌生人列表信息
7、同班同学是通过班级表来确认用户的班集体,进而查询得到所有同班同学的信息,展示同班同学列表。
8、聊天时,直接向用户手机号的IM用户发送消息即可。
项目只是用到了环信最基本的聊天功能,环信有更丰富的内容。比如:好友管理,上线下线管理,群聊,批量注册,手机端信息推送,环信客服等功能。
跟多信息请到环信官网查询:http://www.easemob.com/
收起阅读 »
环信SDK3.0时遇到的问题及解决办法汇总
1.先直接根据官方文档集成SDK,在集成之前如果是第一次接触环信,建议备份工程.
注:官方下载的包里会有两个静态库,一个是包含实时语音的库,另一个则不包含,根据业务需求,记得删除掉一个库,直接move to trash就可以.切记要删除!否则在后边的步骤会报重复引用链接错误.
2.根据官方文档导入依赖库的时候,dylib后缀没有的直接用tbd就可以(Xcode 7之后改为tbd).
加入系统SDK依赖库:
CoreMedia.framework
AudioToolbox.framework
AVFoundation.framework
MobileCoreServices.framework
ImageIO.framework
SystemConfiguration.framework
libc++.a
libresolv.dylib
libz.dylib
libstdc++.6.0.9.dylib
libsqlite3.dylib
libHyphenateSDK.a
如果报错:"_iconv", referenced from: _avcodec_decode_subtitle2 in libHyphenateFullSDK.a(utils.o),则另外要加入libiconv.tbd依赖库.
官方依赖库导入之后编译,此处编译会遇到的坑:
1).报重复引用静态库错误(没删官方两个静态库中的一个)
2).报与-all_load 冲突错误 根据文档改为-ObjC即可 如果改为-ObjC还有错 可按照文档改为 -force_load
注:项目如果用了友盟分享,改为-force_load之后 会与友盟有冲突,具体原因也不清楚,项目直接crash在分享新浪微博,此处求解惑. 改为-ObjC即可
到此步骤直到编译没错的时候就说明导入SDK 配环境成功.
3.环信官方提供了easeUI这个快速集成单聊界面,在集成easeUI之前建议不要用cocoapods来集成,因为会报一些莫名的错误.
集成easeUI:
1).将EaseUI工程下载下来之后,直接拖入EaseUI文件夹,EaseUIResource里面的Resource文件夹,export文件夹里的resource文件夹下的EaseUIResource.bundle 包,到工程中.
2).新建一个pch文件,设置好路径之后,在pch文件中添加引用:EaseUI-Prefix.pch 、ChatDemo-UI3.0-Prefix.pch 这两个pch中的代码.
此时编译会报一个 NSObject + EaseMob类别错误 (该类别是2.0demo中的,根本没有用) 可以选择注释,或者直接删除该类别.将该类别注释掉之后,如果报更多的错误,错误定在NSString或其他系统类上,在你新建的pch文件里,你所包含的头文件开始加上: #ifdef __OBJC__ 结尾处加上: #endif 如下图:450A4D8A-1D3D-463A-8012-D75920068558.png此时编译如果还报错并且错误定在NSLocalizedString, 在你的pch文件里添上如下宏:
#define NSEaseLocalizedString(key, comment) [[NSBundle bundleWithURL:[[NSBundle mainBundle] URLForResource:@"EaseUIResource"withExtension:@"bundle"]] localizedStringForKey:(key) value:@"" table:nil]
3).下载官方提供的ChatDemo-3.0 拖入demo中3rdparty文件夹,因EaseUI本身集成了几个常用三方库,因此会与工程中你所用的重复,此时编译会报错.本身所包含的常用三方如下:MBProgressHUD、VoiceConvert、MJRefresh、SDWebImage. 如果有冲突,切记删除ChatDemo中的三方库,然后改掉相关报错的代码.
此时编译如果还报错,错误为Setting文件夹下的BackUp类,直接删除掉或注释即可,该类用处不大.
至此,编译成功则EaseUI的集成也完毕了.
环信的EaseUI其实只是做到一个展示的作用,包括一些控件的布局,排版都没有处理,因此我们可以直接用ChatDemo3.0中的ChatViewController这个界面,附上集成视频地址:http://v.youku.com/v_show/id_XMTQxOTgyNjU1Mg==.html?from=y1.2-1-87.3.6-2.1-1-1-5-0
好了,到此当你把ChatViewController也集成完毕,一个初步成型的单聊界面就出来了.ps:环信支持非好友之间的聊天,你只要知道对方的环信id即可.
那么你会疑问了,头像和昵称还没有搞定.因为环信服务器不存储用户的头像和昵称,因此需要你与自己app的服务器交互,聊天界面的头像和昵称在如下方法中修改:
- (id<IMessageModel>)messageViewController:(EaseMessageViewController *)viewController
modelForMessage:(EMMessage *)message
如果因业务需求用到会话列表,官方并没有非常完善的文档,可以参考demo中的ConversationListViewController.
转自:http://docs.easemob.com/doku.php?id=im:start 收起阅读 »
注:官方下载的包里会有两个静态库,一个是包含实时语音的库,另一个则不包含,根据业务需求,记得删除掉一个库,直接move to trash就可以.切记要删除!否则在后边的步骤会报重复引用链接错误.
2.根据官方文档导入依赖库的时候,dylib后缀没有的直接用tbd就可以(Xcode 7之后改为tbd).
加入系统SDK依赖库:
CoreMedia.framework
AudioToolbox.framework
AVFoundation.framework
MobileCoreServices.framework
ImageIO.framework
SystemConfiguration.framework
libc++.a
libresolv.dylib
libz.dylib
libstdc++.6.0.9.dylib
libsqlite3.dylib
libHyphenateSDK.a
如果报错:"_iconv", referenced from: _avcodec_decode_subtitle2 in libHyphenateFullSDK.a(utils.o),则另外要加入libiconv.tbd依赖库.
官方依赖库导入之后编译,此处编译会遇到的坑:
1).报重复引用静态库错误(没删官方两个静态库中的一个)
2).报与-all_load 冲突错误 根据文档改为-ObjC即可 如果改为-ObjC还有错 可按照文档改为 -force_load
注:项目如果用了友盟分享,改为-force_load之后 会与友盟有冲突,具体原因也不清楚,项目直接crash在分享新浪微博,此处求解惑. 改为-ObjC即可
到此步骤直到编译没错的时候就说明导入SDK 配环境成功.
3.环信官方提供了easeUI这个快速集成单聊界面,在集成easeUI之前建议不要用cocoapods来集成,因为会报一些莫名的错误.
集成easeUI:
1).将EaseUI工程下载下来之后,直接拖入EaseUI文件夹,EaseUIResource里面的Resource文件夹,export文件夹里的resource文件夹下的EaseUIResource.bundle 包,到工程中.
2).新建一个pch文件,设置好路径之后,在pch文件中添加引用:EaseUI-Prefix.pch 、ChatDemo-UI3.0-Prefix.pch 这两个pch中的代码.
此时编译会报一个 NSObject + EaseMob类别错误 (该类别是2.0demo中的,根本没有用) 可以选择注释,或者直接删除该类别.将该类别注释掉之后,如果报更多的错误,错误定在NSString或其他系统类上,在你新建的pch文件里,你所包含的头文件开始加上: #ifdef __OBJC__ 结尾处加上: #endif 如下图:450A4D8A-1D3D-463A-8012-D75920068558.png此时编译如果还报错并且错误定在NSLocalizedString, 在你的pch文件里添上如下宏:
#define NSEaseLocalizedString(key, comment) [[NSBundle bundleWithURL:[[NSBundle mainBundle] URLForResource:@"EaseUIResource"withExtension:@"bundle"]] localizedStringForKey:(key) value:@"" table:nil]
3).下载官方提供的ChatDemo-3.0 拖入demo中3rdparty文件夹,因EaseUI本身集成了几个常用三方库,因此会与工程中你所用的重复,此时编译会报错.本身所包含的常用三方如下:MBProgressHUD、VoiceConvert、MJRefresh、SDWebImage. 如果有冲突,切记删除ChatDemo中的三方库,然后改掉相关报错的代码.
此时编译如果还报错,错误为Setting文件夹下的BackUp类,直接删除掉或注释即可,该类用处不大.
至此,编译成功则EaseUI的集成也完毕了.
环信的EaseUI其实只是做到一个展示的作用,包括一些控件的布局,排版都没有处理,因此我们可以直接用ChatDemo3.0中的ChatViewController这个界面,附上集成视频地址:http://v.youku.com/v_show/id_XMTQxOTgyNjU1Mg==.html?from=y1.2-1-87.3.6-2.1-1-1-5-0
好了,到此当你把ChatViewController也集成完毕,一个初步成型的单聊界面就出来了.ps:环信支持非好友之间的聊天,你只要知道对方的环信id即可.
那么你会疑问了,头像和昵称还没有搞定.因为环信服务器不存储用户的头像和昵称,因此需要你与自己app的服务器交互,聊天界面的头像和昵称在如下方法中修改:
- (id<IMessageModel>)messageViewController:(EaseMessageViewController *)viewController
modelForMessage:(EMMessage *)message
如果因业务需求用到会话列表,官方并没有非常完善的文档,可以参考demo中的ConversationListViewController.
转自:http://docs.easemob.com/doku.php?id=im:start 收起阅读 »
集成的单聊界面不能下拉加载更多的问题
只需要在EaseMessageViewController 的viewDidLoad方法里底部加上[self tableViewDidTriggerHeaderRefresh];即可解决。
祝环信越来越好!
祝环信越来越好!
环信receive的本地封装
使用环信一年多来,由于iOS环信的长链本地接收通过的是单例对象EaseMob的代理来实现的,但是由于OC中代理单一指向问题,导致多个使用环信的界面都需要设置代理,并且要在viewwillappear方法中设置,这样虽然能够实现需求,但很不友好。
最近在重构环信的本地封装,思路如下:
经实测以上方法可行,并避免了在viewwillappear方法中加入冗余代码,影响效率。 收起阅读 »
最近在重构环信的本地封装,思路如下:
- 建立一个新的单例对象(该对象是EaseMob的Receive的进一步抽象)
- 新的单例对象是EaseMob单例的delegate
- 新的单例对象使用block来实现长链消息的本地handle
- 针对每一个接收代理方法建立private一个数组属性,每个数组的成员变量都是block(当delegate被调用,便利数组回执block)
经实测以上方法可行,并避免了在viewwillappear方法中加入冗余代码,影响效率。 收起阅读 »
环信小程序 Demo源码发布,集成视频手把手教你玩转小程序!
1月9日,向乔布斯致敬的张小龙如约发布了微信小程序,首批上线的小程序就有300多家,一时刷爆朋友圈,如果不转发一两条有关小程序的内容,你都不好意思自称挨踢人。从效率看,小程序成功给APP瘦身,节省了系统资源。以往用户经常面临APP安装繁琐、加载缓慢、吃运存、占空间等痛点,有了小程序,这些问题可以迎刃而解,同时,几乎所有的API可以移植在小程序上,这在很大程度上节约了开发成本和时间,所以小程序的前期投入并不高。
为了让大家的小程序都能顺利“聊”起来,环信小程序Demo源码也于今日正式发布,也许在“用完即走”基础上“聊两句再走”也是极好的哦!同时,环信工程师们还贴心的为大家准备好了集成使用教程视频,手把手教你玩转小程序。
环信小程序运行视频在线观看
微信小程序 Demo
环信准备了微信小程序 Demo,该 Demo 基于 Web IM SDK,并在其基础之上进行了修改。如果您想在您的微信小程序中添加即时通讯的功能,可以参考以下方式集成。
小程序运行效果

Demo源码下载
GitHub下载地址:https://github.com/easemob/webim-weixin-xcx.git
或者,执行如下命令:
进入微信公众平台的官网下载“开发者工具”,并安装。目前支持 windows 64、windows 32、mac 版本。
打开“微信web开发者工具”,使用微信扫一扫授权登录。 选择“本地小程序项目 → 添加项目”。 填写AppID、项目名称(自定义)、项目目录(本地代码路径),并点击“添加项目”。
进入“微信小程序Demo”项目后,可以对项目进行编辑、调试。
收起阅读 »
为了让大家的小程序都能顺利“聊”起来,环信小程序Demo源码也于今日正式发布,也许在“用完即走”基础上“聊两句再走”也是极好的哦!同时,环信工程师们还贴心的为大家准备好了集成使用教程视频,手把手教你玩转小程序。
环信小程序运行视频在线观看
微信小程序 Demo
环信准备了微信小程序 Demo,该 Demo 基于 Web IM SDK,并在其基础之上进行了修改。如果您想在您的微信小程序中添加即时通讯的功能,可以参考以下方式集成。
小程序运行效果
Demo源码下载
GitHub下载地址:https://github.com/easemob/webim-weixin-xcx.git
或者,执行如下命令:
git clone https://github.com/easemob/webim-weixin-xcx.git安装IDE
进入微信公众平台的官网下载“开发者工具”,并安装。目前支持 windows 64、windows 32、mac 版本。
- 微信开发者文档:https://mp.weixin.qq.com/debug/wxadoc/dev/index.html
- “开发者工具”下载地址:https://mp.weixin.qq.com/debug/wxadoc/dev/devtools/download.html?t=201715
- request合法域名 https://a1.easemob.com
- socket合法域名 wss://im-api.easemob.com
- uploadFile合法域名 https://a1.easemob.com
进入“微信小程序Demo”项目后,可以对项目进行编辑、调试。
收起阅读 »
感谢环信这么几年来的免费支持。
在开发过程中遇到的问题,环信客服都会耐心的回答,从刚入门时的小白,到现在的游刃有余。一直以来都有环信客服的陪伴。
祝愿环信早日上市,拥有美好的未来。
祝愿环信早日上市,拥有美好的未来。
环信动态库sdk上架问题解决方案
环信发布了动态库sdk:

但是也会有一些问题,这里讲下关于这个上架的问题。
1.先把Hyphenate.framework放到桌面上;
2.终端位置cd到桌面;
3.运行:lipo Hyphenate.framework/Hyphenate -thin armv7 -output Hyphenate_armv7
4.运行后没有输出提示,直接运行下一个命令:lipo Hyphenate.framework/Hyphenate -thin arm64 -output Hyphenate_arm64
5.运行后一样没有输出提示,直接运行下一个命令:lipo -create Hyphenate_armv7 Hyphenate_arm64 -output Hyphenate
6.运行后一样没有输出提示,直接运行最后一个命令:mv Hyphenate Hyphenate.framework/

得到的Hyphenate.framework就是最后的结果,拖进工程,编译打包上架。
作者:环信ios工程师张磊 收起阅读 »
但是也会有一些问题,这里讲下关于这个上架的问题。
1.先把Hyphenate.framework放到桌面上;
2.终端位置cd到桌面;
3.运行:lipo Hyphenate.framework/Hyphenate -thin armv7 -output Hyphenate_armv7
4.运行后没有输出提示,直接运行下一个命令:lipo Hyphenate.framework/Hyphenate -thin arm64 -output Hyphenate_arm64
5.运行后一样没有输出提示,直接运行下一个命令:lipo -create Hyphenate_armv7 Hyphenate_arm64 -output Hyphenate
6.运行后一样没有输出提示,直接运行最后一个命令:mv Hyphenate Hyphenate.framework/
得到的Hyphenate.framework就是最后的结果,拖进工程,编译打包上架。
作者:环信ios工程师张磊 收起阅读 »
Web IM V1.4.8已发布,刷新页面保持登陆状态

新功能:
[demo] 增加webrtc视频聊天的声音开关
[demo] 动态创建chatWindow,提高网页性能
[demo] 切换leftbar时会给chatWindow添加遮罩,返回之前的leftbar时会直接跳到之前选中的cate和chatWindow
[demo] 登录成功后,刷新页面不会再回到登录页
Bug修复:
[sdk] 移除sdk中所有log方法
[sdk] 退出muc group room 时,追加发送一条unavailable的presence stanza
webim体验:https://webim.easemob.com/
版本历史:更新日志
SDK下载:点击下载 收起阅读 »
数据驱动下的在线旅游新生态——易观数聚论(旅游专场)
2016年中国在线度假旅游市场目前处于市场高速发展阶段。
纵观2016年中国的在线度假旅游的市场发展状况;线上线下融合程度提升。2016年中国在线度假旅游市场竞争向全产业链深入,在线度假旅游企业对资源端的渗透能力和用户细分需求的精细化响应是市场竞争核心,行业整合将向产业链上游不断深入;同时线下旅游企业对于互联网平台重视程度提升,线上线下企业通过战略合作、投资入股等方式加强资源端与渠道端协同,出现海航与途牛联姻、众信与携程联姻、万达与同程联姻等案例,说明市场整合不断深入,线上线下一体化加速,互联网正成为串联渠道和资源等产业链多环节的基础平台。
1月14日,易观邀您一起探讨在线旅游市场在大数据的驱动下将如何完成2017年的新突破。
▎活动背景
“易观数聚论”是面向互联网+垂直领域关于大数据应用相关内容的线下研讨会。旨在为企业衡量数字用户资产价值,产品精细化运营,用户转化与变现等问题。
“易观数聚论”将嘉宾架构更新为 “1位易观产品规划师+1位垂直领域知名企业领袖分享+2位该领域有实战案例嘉宾分享+话题互动”的模式,为互联网企业和在职人员提供相关领域的大数据应用干货。
用户运营将成为所有类型企业的核心命题,如何进行数字用户资产管理和经营,是企业未来最重要的竞争力之一。数字用户资产四大价值,市值管理(企业第四张表)、获客、提高忠诚度、提供用户ARPU交相辉映,方法论倾囊相授,企业实践案例分析解读,一站式融会贯通数字用户资产运营方法论,学会经营用户。
数据是新能源,易观是加油站。面对行业的机遇和挑战,易观将助力企业学习用户数字资产管理方法,提高用户转化与精准变现。
▎活动信息
时间:2017.1.14(周六)13:30-16:00
规模:100人(现场座位有限,按照报名顺序安排留座)
地点:上海市静安区愚园东路20号东海广场3号楼(具体地址电话/短信告知)
▎报名须知
为保证参会人员质量与留座到场率,本次活动为收费形式;报名者可在1月10日之前通过本平台购买“早鸟票”(单人:68元;套票双人:88元);1月10日之后即恢复原价100元/人。报名后凭审核短信签到入场,未报名者一概不予进场。以此带来不便,敬请谅解!
注:活动无任何盈利目的,报名参会者可现场领取Linckia现磨咖啡一杯(大杯,种类可选)。
▎联系方式
活动联系人:许宏运 13120751039
▎活动详情

▎活动议程
13:30-13:55——签到
13:55-14:00——主持人开场
14:00-14:30——主题:中国在线旅游行业发展现状与趋势预测
——嘉宾:易观旅游行业中心资深分析师姜昕蔚
14:30-15:00——主题:旅游产品的用户转化与价值变现
——嘉宾:驴妈妈旅游网CMO黄春香
15:00-15:30——主题:个性化定制旅行产品的新风口
——嘉宾:指南猫创始人兼CEO任静
15:30-16:00——圆桌:旅游企业的新风口与新生态
16:00-16:20——交流/提问
(提问者有机会获得价值880元的《互联网产业发展年鉴》一本)
▎合作单位


——感谢以上平台对本次活动的大力支持!
▎往期回顾

我要报名:http://www.huodongxing.com/event/4368713124800 收起阅读 »
纵观2016年中国的在线度假旅游的市场发展状况;线上线下融合程度提升。2016年中国在线度假旅游市场竞争向全产业链深入,在线度假旅游企业对资源端的渗透能力和用户细分需求的精细化响应是市场竞争核心,行业整合将向产业链上游不断深入;同时线下旅游企业对于互联网平台重视程度提升,线上线下企业通过战略合作、投资入股等方式加强资源端与渠道端协同,出现海航与途牛联姻、众信与携程联姻、万达与同程联姻等案例,说明市场整合不断深入,线上线下一体化加速,互联网正成为串联渠道和资源等产业链多环节的基础平台。
1月14日,易观邀您一起探讨在线旅游市场在大数据的驱动下将如何完成2017年的新突破。
▎活动背景
“易观数聚论”是面向互联网+垂直领域关于大数据应用相关内容的线下研讨会。旨在为企业衡量数字用户资产价值,产品精细化运营,用户转化与变现等问题。
“易观数聚论”将嘉宾架构更新为 “1位易观产品规划师+1位垂直领域知名企业领袖分享+2位该领域有实战案例嘉宾分享+话题互动”的模式,为互联网企业和在职人员提供相关领域的大数据应用干货。
用户运营将成为所有类型企业的核心命题,如何进行数字用户资产管理和经营,是企业未来最重要的竞争力之一。数字用户资产四大价值,市值管理(企业第四张表)、获客、提高忠诚度、提供用户ARPU交相辉映,方法论倾囊相授,企业实践案例分析解读,一站式融会贯通数字用户资产运营方法论,学会经营用户。
数据是新能源,易观是加油站。面对行业的机遇和挑战,易观将助力企业学习用户数字资产管理方法,提高用户转化与精准变现。
▎活动信息
时间:2017.1.14(周六)13:30-16:00
规模:100人(现场座位有限,按照报名顺序安排留座)
地点:上海市静安区愚园东路20号东海广场3号楼(具体地址电话/短信告知)
▎报名须知
为保证参会人员质量与留座到场率,本次活动为收费形式;报名者可在1月10日之前通过本平台购买“早鸟票”(单人:68元;套票双人:88元);1月10日之后即恢复原价100元/人。报名后凭审核短信签到入场,未报名者一概不予进场。以此带来不便,敬请谅解!
注:活动无任何盈利目的,报名参会者可现场领取Linckia现磨咖啡一杯(大杯,种类可选)。
▎联系方式
活动联系人:许宏运 13120751039
▎活动详情
▎活动议程
13:30-13:55——签到
13:55-14:00——主持人开场
14:00-14:30——主题:中国在线旅游行业发展现状与趋势预测
——嘉宾:易观旅游行业中心资深分析师姜昕蔚
14:30-15:00——主题:旅游产品的用户转化与价值变现
——嘉宾:驴妈妈旅游网CMO黄春香
15:00-15:30——主题:个性化定制旅行产品的新风口
——嘉宾:指南猫创始人兼CEO任静
15:30-16:00——圆桌:旅游企业的新风口与新生态
16:00-16:20——交流/提问
(提问者有机会获得价值880元的《互联网产业发展年鉴》一本)
▎合作单位
——感谢以上平台对本次活动的大力支持!
▎往期回顾
我要报名:http://www.huodongxing.com/event/4368713124800 收起阅读 »
我要回归了
换了一份工作,需要使用即时通讯,那就比较尴尬了,我就直接确定环信了,毕竟老客户了^_^
美团热更方案ASM实践
美团热更新的文章已经讲了,他们用的是Instant Run的方案。
这篇文章主要讲美团热更方案中没讲到的部分,包含几个方面:
方案选择:
我们公司提供及时通讯服务,同时需要提供给用户方便集成的及时通讯的SDK,每次SDK发布的同时也面临SDK发布后紧急bug的修复问题。 现在市面上的热更新方案通常不适用SDK提供方使用。 以阿里的andFix和微信的tinker为例,都是直接修改并合成新的apk。这样做对于普通app没有问题,但是对于sdk提供方是不可以的,SDK发布者不能够直接修改apk,这个事情只能由app开发者来做。
tinker方案如图:

女娲方案,由大众点评Jason Ross实现并开源,他们是在classLoader过程中,將自己的修改后的patch类所在的dex, 插入到dex队列前面,这样在classloader按照类名字加载的时候会优先加载patch类。
女娲方案如图:

女娲方案有一个条件约束,就是每个类都要插桩,插入一个类的引用,并且这个被引用类需要打包到单独的dex文件中,这样保证每个类都没有被打上CLASS_ISPREVERIFIED标志。 具体详细描述在早期的hotpatch方案 安卓App热补丁动态修复技术介绍
作为SDK提供者,只能提供jar包给用户,无法约束用户的dex生成过程,所以女娲方案无法直接应用。 女娲方案是开源的,而且其中提供了asm插桩示例,对于后面应用美团方案有很好参考意义。
美团&&Instant Run方案
美团方案 也就是Instant Run的方案基本思路就是在每个函数都插桩,如果一个类存在bug,需要修复,就将插桩点类的changeRedirect字段从null值变成patch类。 基本原理在美团方案中有讲述,但是美团文中没有讲最重要的一个问题,就是如何在每一个函数前面插桩,下面会详细讲一下。 Patch应用部分,这里忽略,因为是java代码,大家可以反编译Instant Run.jar,看一下大致思路,基本都能写出来。
插桩
插桩的动作就是在每一个函数前面都插入PatchProxy.isSupport...PatchProxy.accessDisPatch这一系列代码(参看美团方案)。插桩工作直接修改class文件,因为这样不影响正常代码逻辑,只有最后打包发布的时候才进行插桩。
插桩最常用的是asm.jar。接下来的部分需要用户先了解asm.jar的大致使用流程。了解这个过程最好是找个实例实践一下,光看介绍文章是看不懂的。
asm有两种方式解析class文件,一种是core API, provides an event based representation of classes,类似解析xml的SAX的事件触发方式,遍历类,以及类的字段,类中的方法,在遍历的过程中会依次触发相应的函数,比如遍历类函数时,触发visitMethod(name, signature...),用户可以在这个方法中修改函数实现。 另外一种 tree API, provides an object based representation,类似解析xml中的DOM树方式。本文中,这里使用了core API方式。asm.jar有对应的manual asm4-guide.pdf,需要仔细研读,了解其用法。
使用asm.jar把java class反编译为字节码
反编译为字节码对应的命令是
插入前代码:
需要将全部入參传递给patch方法,插入的代码因此会根据入參进行调整,同时也要处理返回值.
可以观察上面代码,上面的例子显示了一个int型入參a,装箱变成Integer,放在一个Object[]数组中,先后调用isSupport和accessDispatch,传递给patch类的对应方法,patch返回类型是Long,然后调用longValue,拆箱变成long类型。
对于普通的java对象,因为均派生自Object,所以对象的引用直接放在数组中;对于primitive类型(包括int, long, float....)的处理,需要先调用Integer, Boolean, Float等java对象的构造函数,将primitive类型装箱后作为object对象放在数组中。
如果原来函数返回结果的是primitive类型,需要插桩代码将其转化为primitive类型。还要处理数组类型,和void类型。 java的primitive类型在 java virtual machine specification中有定义。
这个插入过程有两个关键问题,一个是函数signature的解析,另外一个是适配这个参数变化插入代码。下面详细解释下:
关于java字节码的理解,汇编指令主要是看 Java bytecode instruction listings
理解java字节码,需要理解jvm中的栈的结构。JVM是一个基于栈的架构。方法执行的时候(包括main方法),在栈上会分配一个新的帧,这个栈帧包含一组局部变量。这组局部变量包含了方法运行过程中用到的所有变量,包括this引用,所有的方法参数,以及其它局部定义的变量。对于类方法(也就是static方法)来说,方法参数是从第0个位置开始的,而对于实例方法来说,第0个位置上的变量是this指针。引自: Java字节码浅析
分析中间部分字节码实现,
坑:
ClassVisitor.visitMethod()中access如果是ACC_SYNTHETIC或者ACC_BRIDGE,插桩后无法正常运行。ACC_SYNTHETIC表示函数由javac自动生成的,enum类型就会产生这种类型的方法,不需要插桩,直接略过。因为观察到模版类也会产生ACC_SYNTHETIC,所以插桩过程跳过了模版类。
ClassVisitor.visit()函数对应遍历到类触发的事件,access如果是ACC_INTERFACE或者ACC_ENUM,无需插桩。简单说就是接口和enum不涉及方法修改,无需插桩。
静态方法的实现和普通类成员函数略有出入,对于汇编程序来说,本地栈的第一个位置,如果是普通方法,会存储this引用,static方法没有this,这里稍微调整一下就可以实现的。
不定参数由于要求连续输入的参数类型相同,被编译器直接变成了数组,所以对本程序没有造成影响。
大小:
插桩因为对每个函数都插桩,反编译后看实际上增加了大量代码,甚至可以说插入的代码比原有的代码还要多。但是实际上最终生成的jar包增长了大概20%多一点,并没有想的那么多,在可接受范围内。因为class所占的空间不止是代码部分,还包括类描述,字段描述,方法描述,const-pool等,代码段只占其中的不到一半。可以参考[The class File Format](link @http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html)
讨论
前面代码插桩的部分和美团热更文章中保持一致,实际上还有些细节还可以调整。isSupport这个函数的参数可以调整如下if (PatchProxy.isSupport(“getIndex”, "(I)J", false)) {这样能减小插桩部分代码,而且可以区分名字相同的函数。
PatchProxy.isSupport最后一个参数表示是普通类函数还是static函数,这个是方便java应用patch的时候处理。
源码地址
https://github.com/easemob/empatch
作者:李楠
公司:环信
关注领域:Android开发
文章署名: greenmemo 收起阅读 »
这篇文章主要讲美团热更方案中没讲到的部分,包含几个方面:
- 作为云服务提供厂商,需要提供给客户SDK,SDK发布后同样要考虑bug修复问题。这里讲一下作为sdk发布者的热更新方案选型,也就是为什么用美团方案&Instant Run方案。
- 美团方案实现的大致结构
- 最后讲一下asm插桩的过程,字节码导读,以及遇到的各种坑。
方案选择:
我们公司提供及时通讯服务,同时需要提供给用户方便集成的及时通讯的SDK,每次SDK发布的同时也面临SDK发布后紧急bug的修复问题。 现在市面上的热更新方案通常不适用SDK提供方使用。 以阿里的andFix和微信的tinker为例,都是直接修改并合成新的apk。这样做对于普通app没有问题,但是对于sdk提供方是不可以的,SDK发布者不能够直接修改apk,这个事情只能由app开发者来做。
tinker方案如图:
女娲方案,由大众点评Jason Ross实现并开源,他们是在classLoader过程中,將自己的修改后的patch类所在的dex, 插入到dex队列前面,这样在classloader按照类名字加载的时候会优先加载patch类。
女娲方案如图:
女娲方案有一个条件约束,就是每个类都要插桩,插入一个类的引用,并且这个被引用类需要打包到单独的dex文件中,这样保证每个类都没有被打上CLASS_ISPREVERIFIED标志。 具体详细描述在早期的hotpatch方案 安卓App热补丁动态修复技术介绍
作为SDK提供者,只能提供jar包给用户,无法约束用户的dex生成过程,所以女娲方案无法直接应用。 女娲方案是开源的,而且其中提供了asm插桩示例,对于后面应用美团方案有很好参考意义。
美团&&Instant Run方案
美团方案 也就是Instant Run的方案基本思路就是在每个函数都插桩,如果一个类存在bug,需要修复,就将插桩点类的changeRedirect字段从null值变成patch类。 基本原理在美团方案中有讲述,但是美团文中没有讲最重要的一个问题,就是如何在每一个函数前面插桩,下面会详细讲一下。 Patch应用部分,这里忽略,因为是java代码,大家可以反编译Instant Run.jar,看一下大致思路,基本都能写出来。
插桩
插桩的动作就是在每一个函数前面都插入PatchProxy.isSupport...PatchProxy.accessDisPatch这一系列代码(参看美团方案)。插桩工作直接修改class文件,因为这样不影响正常代码逻辑,只有最后打包发布的时候才进行插桩。
插桩最常用的是asm.jar。接下来的部分需要用户先了解asm.jar的大致使用流程。了解这个过程最好是找个实例实践一下,光看介绍文章是看不懂的。
asm有两种方式解析class文件,一种是core API, provides an event based representation of classes,类似解析xml的SAX的事件触发方式,遍历类,以及类的字段,类中的方法,在遍历的过程中会依次触发相应的函数,比如遍历类函数时,触发visitMethod(name, signature...),用户可以在这个方法中修改函数实现。 另外一种 tree API, provides an object based representation,类似解析xml中的DOM树方式。本文中,这里使用了core API方式。asm.jar有对应的manual asm4-guide.pdf,需要仔细研读,了解其用法。
使用asm.jar把java class反编译为字节码
反编译为字节码对应的命令是
java -classpath "asm-all.jar" org.jetbrains.org.objectweb.asm.util.ASMifier State.class这个地方有一个坑,官方版本asm.jar 在执行ASMifier命令的时候总是报错,后来在Android Stuidio的目录下面找一个asm-all.jar替换再执行就不出问题了。但是用asm.jar插桩的过程,仍然使用官方提供的asm.jar。
插入前代码:
class State {
long getIndex(int val) {
return 100;
}
}ASMifier反编译后字节码如下mv = cw.visitMethod(0, "getIndex", "(I)J", null, null);插桩后代码:
mv.visitCode();
mv.visitLdcInsn(new Long(100L));
mv.visitInsn(LRETURN);
mv.visitMaxs(2, 2);
mv.visitEnd();
long getIndex(int a) {
if ($patch != null) {
if (PatchProxy.isSupport(new Object[0], this, $patch, false)) {
return ((Long) com.hyphenate.patch.PatchProxy.accessDispatch(new Object[] {a}, this, $patch, false)).longValue();
}
}
return 100;
}ASMifier反编译后代码如下:mv = cw.visitMethod(ACC_PUBLIC, "getIndex", "(I)J", null, null);对于插桩程序来说,需要做的就是把差异部分插桩到代码中
mv.visitCode();
mv.visitFieldInsn(GETSTATIC, "com/hyphenate/State", "$patch", "Lcom/hyphenate/patch/PatchReDirection;");
Label l0 = new Label();
mv.visitJumpInsn(IFNULL, l0);
mv.visitInsn(ICONST_0);
mv.visitTypeInsn(ANEWARRAY, "java/lang/Object");
mv.visitVarInsn(ALOAD, 0);
mv.visitFieldInsn(GETSTATIC, "com/hyphenate/State", "$patch", "Lcom/hyphenate/patch/PatchReDirection;");
mv.visitInsn(ICONST_0);
mv.visitMethodInsn(INVOKESTATIC, "com/hyphenate/patch/PatchProxy", "isSupport", "([Ljava/lang/Object;Ljava/lang/Object;Lcom/hyphenate/patch/PatchReDirection;Z)Z", false);
mv.visitJumpInsn(IFEQ, l0);
mv.visitIntInsn(BIPUSH, 1);
mv.visitTypeInsn(ANEWARRAY, "java/lang/Object");
mv.visitInsn(DUP);
mv.visitIntInsn(BIPUSH, 0);
mv.visitVarInsn(ILOAD, 1);
mv.visitMethodInsn(INVOKESTATIC, "java/lang/Integer", "valueOf", "(I)Ljava/lang/Integer;", false);
mv.visitInsn(AASTORE);
mv.visitVarInsn(ALOAD, 0);
mv.visitFieldInsn(GETSTATIC, "com/hyphenate/State", "$patch", "Lcom/hyphenate/patch/PatchReDirection;");
mv.visitInsn(ICONST_0);
mv.visitMethodInsn(INVOKESTATIC, "com/hyphenate/patch/PatchProxy", "accessDispatch", "([Ljava/lang/Object;Ljava/lang/Object;Lcom/hyphenate/patch/PatchReDirection;Z)Ljava/lang/Object;", false);
mv.visitTypeInsn(CHECKCAST, "java/lang/Long");
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/Long", "longValue", "()J", false);
mv.visitInsn(LRETURN);
mv.visitLabel(l0);
mv.visitFrame(Opcodes.F_SAME, 0, null, 0, null);
mv.visitLdcInsn(new Long(100L));
mv.visitInsn(LRETURN);
mv.visitMaxs(4, 2);
mv.visitEnd();
需要将全部入參传递给patch方法,插入的代码因此会根据入參进行调整,同时也要处理返回值.
可以观察上面代码,上面的例子显示了一个int型入參a,装箱变成Integer,放在一个Object[]数组中,先后调用isSupport和accessDispatch,传递给patch类的对应方法,patch返回类型是Long,然后调用longValue,拆箱变成long类型。
对于普通的java对象,因为均派生自Object,所以对象的引用直接放在数组中;对于primitive类型(包括int, long, float....)的处理,需要先调用Integer, Boolean, Float等java对象的构造函数,将primitive类型装箱后作为object对象放在数组中。
如果原来函数返回结果的是primitive类型,需要插桩代码将其转化为primitive类型。还要处理数组类型,和void类型。 java的primitive类型在 java virtual machine specification中有定义。
这个插入过程有两个关键问题,一个是函数signature的解析,另外一个是适配这个参数变化插入代码。下面详细解释下:
@Override这个函数是asm.jar访问类函数时触发的事件,desc变量对应java jni中的signature,比如这里是'(I)J', 需要解析并转换成primitive类型,类,数组,void。这部分代码参考了android底层的源码libcore/luni/src/main/java/libcore/reflect,和sun java的SignatureParser.java,都有反映了这个遍历过程。
public MethodVisitor visitMethod(int access, String name, String desc,
String signature, String[] exceptions) {
关于java字节码的理解,汇编指令主要是看 Java bytecode instruction listings
理解java字节码,需要理解jvm中的栈的结构。JVM是一个基于栈的架构。方法执行的时候(包括main方法),在栈上会分配一个新的帧,这个栈帧包含一组局部变量。这组局部变量包含了方法运行过程中用到的所有变量,包括this引用,所有的方法参数,以及其它局部定义的变量。对于类方法(也就是static方法)来说,方法参数是从第0个位置开始的,而对于实例方法来说,第0个位置上的变量是this指针。引自: Java字节码浅析
分析中间部分字节码实现,
com.hyphenate.patch.PatchProxy.accessDispatch(new Object[] {a}, this, $patch, false))对应字节码如下,请对照Java bytecode instruction listings中每条指令观察对应栈帧的变化,下面注释中'[]'中表示栈帧中的内容。mv.visitIntInsn(BIPUSH, 1); # 数字1入栈,对应new Object[1]数组长度1。 栈:[1]熟悉上面的字节码以及对应的栈帧变化,也就掌握了插桩过程。
mv.visitTypeInsn(ANEWARRAY, "java/lang/Object"); # ANEWARRY:count(1) → arrayref, 栈:[arr_ref]
mv.visitInsn(DUP); # 栈:[arr_ref, arr_ref]
mv.visitIntInsn(BIPUSH, 0); # 栈:[arr_ref, arr_ref, 0]
mv.visitVarInsn(ILOAD, 1); # 局部变量位置1的内容入栈, 栈:[arr_ref, arr_ref, 0, a]
mv.visitMethodInsn(INVOKESTATIC, "java/lang/Integer", "valueOf", "(I)Ljava/lang/Integer;", false); # 调用Integer.valueOf, INVOKESTATIC: [arg1, arg2, ...] → result, 栈:[arr_ref, arr_ref, 0, integerObjectOf_a]
mv.visitInsn(AASTORE); # store a reference into array: arrayref, index, value →, 栈:[arr_ref]
mv.visitVarInsn(ALOAD, 0); # this入栈,栈:[arr_ref, this]
mv.visitFieldInsn(GETSTATIC, "com/hyphenate/State", "$patch", "Lcom/hyphenate/patch/PatchReDirection;"); #$patch入栈,栈:[arr_ref, this, $patch]
mv.visitInsn(ICONST_0); #false入栈, # 栈:[arr_ref, this, $patch, false]
mv.visitMethodInsn(INVOKESTATIC, "com/hyphenate/patch/PatchProxy", "accessDispatch", "([Ljava/lang/Object;Ljava/lang/Object;Lcom/hyphenate/patch/PatchReDirection;Z)Ljava/lang/Object;", false); # 调用accessDispatch, 栈包含返回结果,栈:[longObject]
坑:
ClassVisitor.visitMethod()中access如果是ACC_SYNTHETIC或者ACC_BRIDGE,插桩后无法正常运行。ACC_SYNTHETIC表示函数由javac自动生成的,enum类型就会产生这种类型的方法,不需要插桩,直接略过。因为观察到模版类也会产生ACC_SYNTHETIC,所以插桩过程跳过了模版类。
ClassVisitor.visit()函数对应遍历到类触发的事件,access如果是ACC_INTERFACE或者ACC_ENUM,无需插桩。简单说就是接口和enum不涉及方法修改,无需插桩。
静态方法的实现和普通类成员函数略有出入,对于汇编程序来说,本地栈的第一个位置,如果是普通方法,会存储this引用,static方法没有this,这里稍微调整一下就可以实现的。
不定参数由于要求连续输入的参数类型相同,被编译器直接变成了数组,所以对本程序没有造成影响。
大小:
插桩因为对每个函数都插桩,反编译后看实际上增加了大量代码,甚至可以说插入的代码比原有的代码还要多。但是实际上最终生成的jar包增长了大概20%多一点,并没有想的那么多,在可接受范围内。因为class所占的空间不止是代码部分,还包括类描述,字段描述,方法描述,const-pool等,代码段只占其中的不到一半。可以参考[The class File Format](link @http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html)
讨论
前面代码插桩的部分和美团热更文章中保持一致,实际上还有些细节还可以调整。isSupport这个函数的参数可以调整如下if (PatchProxy.isSupport(“getIndex”, "(I)J", false)) {这样能减小插桩部分代码,而且可以区分名字相同的函数。
PatchProxy.isSupport最后一个参数表示是普通类函数还是static函数,这个是方便java应用patch的时候处理。
源码地址
https://github.com/easemob/empatch
作者:李楠
公司:环信
关注领域:Android开发
文章署名: greenmemo 收起阅读 »


