








收藏了~阿里巴巴程序员常用的 15 款开发者工具
从人工到自动化,从重复到创新,技术演进的历程中,伴随着开发者工具类产品的发展。
阿里巴巴将自身在各类业务场景下的技术积淀,通过开源、云上实现或工具等形式对外开放,本文将精选了一些阿里巴巴的开发者工具,希望能帮助开发者们提高开发效率、更优雅的写代码。
由于开发者涉及的技术领域众多,笔者仅从自己熟悉的领域,以后端开发者的视角盘点平时可能用得到的工具。每个工具按照以下几点进行介绍:
工具名称和简介
使用场景
使用教程
获取方式
一、Java 线上诊断工具 Arthas
Arthas 阿里巴巴 2018 年 9 月开源的一款 Java 线上诊断工具。
工具的使用场景:
这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
是否有一个全局视角来查看系统的运行状况?
有什么办法可以监控到 JVM 的实时运行状态?
Arthas 支持 JDK 6+,支持 Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
使用教程:
基础教程:
https://alibaba.github.io/arthas/arthas-tutorials?language=cn&id=arthas-basics
进阶教程:
https://alibaba.github.io/arthas/arthas-tutorials?language=cn&id=arthas-advanced
获取方式:(免费)
开源地址:
https://github.com/alibaba/arthas
二、IDE 插件 Cloud Toolkit
Cloud Toolkit是一款 IDE 插件,可以帮助开发者更高效地开发、测试、诊断并部署应用。通过 Cloud Toolkit,开发者能够方便地将本地应用一键部署到任意机器(本地或云端),并内置 Arthas 诊断、高效执行终端命令和 SQL 等,提供 IntelliJ IDEA 版,Eclipse 版,PyCharm 版和 Maven 版。
工具的使用场景:
每次修改完代码后,是否正在经历反复地打包?
在 Maven 、Git 以及其他运维脚本和工具的之间频繁切换?
采用 SCP 工具上传?使用 XShell 或 SecureCRT 登陆服务器?替换部署包?重启?
文件上传到服务器指定目录,在各种 FTP、SCP 工具之间频繁切换 ?
使用教程:
IntelliJ IDEA 版:
https://help.aliyun.com/document_detail/98762.html
Eclipse 版:
https://help.aliyun.com/document_detail/29970.html
PyCharm 版:
https://help.aliyun.com/document_detail/112740.html
Maven 版:
https://help.aliyun.com/document_detail/108682.html
获取方式:(免费) 工具地址:
https://www.aliyun.com/product/cloudtoolkit
三、混沌实验注入工具 ChaosBlade
ChaosBlade是一款遵循混沌工程实验原理,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具,可实现底层故障的注入,提供了延迟、异常、返回特定值、修改参数值、重复调用和 try-catch 块异常等异常场景。
工具的使用场景:
微服务的容错能力不易衡量?
容器编排配置是否合理无法验证?
PaaS 层健壮性的测试工作无从入手?
使用教程:
https://github.com/chaosblade-io/chaosblade/wiki/ 新手指南
获取方式:(免费)
开源地址:
https://github.com/chaosblade-io/chaosblade/wiki/ 新手指南
四、Java 代码规约扫描插件
该插件用于检测 Java 代码中存在的不规范的位置,并给予提示。规约插件是采用 Kotlin 语言开发。
使用教程:
IDEA 插件使用文档:
https://github.com/alibaba/p3c/wiki/IDEA 插件使用文档
Eclipse 插件使用文档:
https://github.com/alibaba/p3c/wiki/Eclipse 插件使用文档
获取方式:(免费)
开源地址:
https://github.com/alibaba/p3c
五、应用实时监控工具 ARMS
ARMS是一款 APM 类的监控工具,提供前端、应用、自定义监控 3 类监控选项,可快速构建实时的应用性能和业务监控能力。
工具的使用场景:
晚上 10 点收到 37 条报警信息,你却无从下手?
当我们发现问题的时候,客户 / 业务方已经发起投诉?
每个月花几十万买服务器,却无法保障用户体验?
使用教程:
前端监控接入:
https://help.aliyun.com/documentdetail/106086.html
应用监控接入:
https://help.aliyun.com/documentdetail/63796.html
自定义监控:
https://help.aliyun.com/document_detail/47474.html
获取方式:(收费)
工具地址:
https://www.aliyun.com/product/arms
六、静态开源站点搭建工具 Docsite
Docsite一款集官网、文档、博客和社区为一体的静态开源站点的解决方案,具有简单易上手、上手不撒手的特质,同时支持 react 和静态渲染、PC 端和移动端、支持中英文国际化、SEO、markdown 文档、全局站点搜索、站点风格自定义、页面自定义等功能。
使用教程:
https://docsite.js.org/zh-cn/docs/installation.html
获取方式:(免费)
项目地址:
https://github.com/txd-team/docsite
七、Android 平台上的秒级编译方案 Freeline
Freeline 可以充分利用缓存文件,在几秒钟内迅速地对代码的改动进行编译并部署到设备上,有效地减少了日常开发中的大量重新编译与安装的耗时。Freeline 最快捷的使用方法就是直接安装 Android Studio 插件。
使用教程:
https://github.com/alibaba/freeline/blob/master/README-zh.md
获取方式:(免费)
项目地址:
https://github.com/alibaba/freeline
八、性能测试工具 PTS
PTS可以模拟大量用户访问业务的场景,任务随时发起,免去搭建和维护成本,支持 JMeter 脚本转化为 PTS 压测,同样支持原生 JMeter 引擎进行压测。
使用教程:
https://help.aliyun.com/document_detail/70290.html
获取方式:(收费)
工具地址:
https://www.aliyun.com/product/pts
九、云效开发者工具 KT
KT 可以简化在 Kubernetes 下进行联调测试的复杂度,提高基于 Kubernetes 的研发效率。
使用教程:
https://yq.aliyun.com/articles/690519
获取方式:(免费)
工具地址:
https://yq.aliyun.com/download/3393
十、架构可视化工具 AHAS
AHAS为 K8s 等容器环境提供了架构可视化的功能,同时,具有故障注入式高可用能力评测和一键流控降级等功能,可以快速低成本的提升应用可用性。
工具的使用场景:
服务化改造过程中,想精确的了解资源实例的构成和交互情况,实现架构的可视化?
想引入真实的故障场景和演练模型?
低门槛获得流控、降级功能?
使用教程:
https://help.aliyun.com/document_detail/90323.html
获取方式:(免费)
工具地址:
https://www.aliyun.com/product/ahas
十一、数据处理工具 EasyExcel
EasyExcel 是一个用来对 Java 进行解析、生成 Excel 的框架,它重写了 poi 对 07 版 Excel 的解析,原本一个 3M 的 Excel 用 POI sax 需要 100M 左右内存,EasyExcel 可降低到 KB 级别,并且再大的 excel 也不会出现内存溢出的情况。03 版依赖 POI 的 sax 模式。在上层做了模型转换的封装,让使用者更加简单方便。
使用教程:
https://github.com/alibaba/easyexcel/blob/master/quickstart.md
获取方式:(开源)
https://github.com/alibaba/easyexcel
十二、iOS 类工具 HandyJSON
HandyJSON 是一个用于 Swift 语言中的 JSON 序列化 / 反序列化库。
与其他流行的 Swift JSON 库相比,HandyJSON 的特点是,它支持纯 Swift 类,使用也简单。它反序列化时 (把 JSON 转换为 Model) 不要求 Model 从 NSObject 继承 (因为它不是基于 KVC 机制),也不要求你为 Model 定义一个 Mapping 函数。只要你定义好 Model 类,声明它服从 HandyJSON 协议,HandyJSON 就能自行以各个属性的属性名为 Key,从 JSON 串中解析值。
使用教程:
https://github.com/alibaba/HandyJSON/blob/master/README_cn.md
获取方式:(开源)
https://github.com/alibaba/HandyJSON
十三、云上资源和应用部署工具 EDAS Serverless
EDAS Serverless一款基于 Kubernetes,面向应用和微服务的 Serverless 平台。用户无需管理和维护集群与服务器,即可通过镜像、WAR 包和 JAR 包,快速创建原生支持 Kubernetes 的容器应用,同时支持 Spring Cloud 和 Dubbo 等主流微服务框架。
使用教程:
https://help.aliyun.com/document_detail/102048.html
获取方式:(公测期间免费)
https://help.aliyun.com/document_detail/97792.html
十四、数据库连接池 Druid
Druid 是 Java 语言下的数据库连接池,它能够提供强大的监控和扩展功能。
使用教程:
https://github.com/alibaba/druid/wiki/ 常见问题
获取方式:(开源)
http://central.maven.org/maven2/com/alibaba/druid/
十五、Java 工具集 Dragonwell
Alibaba Dragonwell 是阿里巴巴内部 OpenJDK 定制版 AJDK 的开源版本, AJDK 为在线电商,金融,物流做了结合业务场景的优化,运行在超大规模的,100,000+ 服务器的阿里巴巴数据中心。 Alibaba Dragonwell 与 Java SE 标准兼容,目前仅支持 Linux/x86_64 平台。
使用教程:
https://github.com/alibaba/dragonwell8/wiki/ 阿里巴巴 Dragonwell8 用户指南
获取方式:(开源)
https://github.com/alibaba/dragonwell8
上一篇: Java首度承认PK失败,愿永久服软Python!
收起阅读 »
阿里巴巴将自身在各类业务场景下的技术积淀,通过开源、云上实现或工具等形式对外开放,本文将精选了一些阿里巴巴的开发者工具,希望能帮助开发者们提高开发效率、更优雅的写代码。
由于开发者涉及的技术领域众多,笔者仅从自己熟悉的领域,以后端开发者的视角盘点平时可能用得到的工具。每个工具按照以下几点进行介绍:
工具名称和简介
使用场景
使用教程
获取方式
一、Java 线上诊断工具 Arthas
Arthas 阿里巴巴 2018 年 9 月开源的一款 Java 线上诊断工具。
工具的使用场景:
这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
是否有一个全局视角来查看系统的运行状况?
有什么办法可以监控到 JVM 的实时运行状态?
Arthas 支持 JDK 6+,支持 Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
使用教程:
基础教程:
https://alibaba.github.io/arthas/arthas-tutorials?language=cn&id=arthas-basics
进阶教程:
https://alibaba.github.io/arthas/arthas-tutorials?language=cn&id=arthas-advanced
获取方式:(免费)
开源地址:
https://github.com/alibaba/arthas
二、IDE 插件 Cloud Toolkit
Cloud Toolkit是一款 IDE 插件,可以帮助开发者更高效地开发、测试、诊断并部署应用。通过 Cloud Toolkit,开发者能够方便地将本地应用一键部署到任意机器(本地或云端),并内置 Arthas 诊断、高效执行终端命令和 SQL 等,提供 IntelliJ IDEA 版,Eclipse 版,PyCharm 版和 Maven 版。
工具的使用场景:
每次修改完代码后,是否正在经历反复地打包?
在 Maven 、Git 以及其他运维脚本和工具的之间频繁切换?
采用 SCP 工具上传?使用 XShell 或 SecureCRT 登陆服务器?替换部署包?重启?
文件上传到服务器指定目录,在各种 FTP、SCP 工具之间频繁切换 ?
使用教程:
IntelliJ IDEA 版:
https://help.aliyun.com/document_detail/98762.html
Eclipse 版:
https://help.aliyun.com/document_detail/29970.html
PyCharm 版:
https://help.aliyun.com/document_detail/112740.html
Maven 版:
https://help.aliyun.com/document_detail/108682.html
获取方式:(免费) 工具地址:
https://www.aliyun.com/product/cloudtoolkit
三、混沌实验注入工具 ChaosBlade
ChaosBlade是一款遵循混沌工程实验原理,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具,可实现底层故障的注入,提供了延迟、异常、返回特定值、修改参数值、重复调用和 try-catch 块异常等异常场景。
工具的使用场景:
微服务的容错能力不易衡量?
容器编排配置是否合理无法验证?
PaaS 层健壮性的测试工作无从入手?
使用教程:
https://github.com/chaosblade-io/chaosblade/wiki/ 新手指南
获取方式:(免费)
开源地址:
https://github.com/chaosblade-io/chaosblade/wiki/ 新手指南
四、Java 代码规约扫描插件
该插件用于检测 Java 代码中存在的不规范的位置,并给予提示。规约插件是采用 Kotlin 语言开发。
使用教程:
IDEA 插件使用文档:
https://github.com/alibaba/p3c/wiki/IDEA 插件使用文档
Eclipse 插件使用文档:
https://github.com/alibaba/p3c/wiki/Eclipse 插件使用文档
获取方式:(免费)
开源地址:
https://github.com/alibaba/p3c
五、应用实时监控工具 ARMS
ARMS是一款 APM 类的监控工具,提供前端、应用、自定义监控 3 类监控选项,可快速构建实时的应用性能和业务监控能力。
工具的使用场景:
晚上 10 点收到 37 条报警信息,你却无从下手?
当我们发现问题的时候,客户 / 业务方已经发起投诉?
每个月花几十万买服务器,却无法保障用户体验?
使用教程:
前端监控接入:
https://help.aliyun.com/documentdetail/106086.html
应用监控接入:
https://help.aliyun.com/documentdetail/63796.html
自定义监控:
https://help.aliyun.com/document_detail/47474.html
获取方式:(收费)
工具地址:
https://www.aliyun.com/product/arms
六、静态开源站点搭建工具 Docsite
Docsite一款集官网、文档、博客和社区为一体的静态开源站点的解决方案,具有简单易上手、上手不撒手的特质,同时支持 react 和静态渲染、PC 端和移动端、支持中英文国际化、SEO、markdown 文档、全局站点搜索、站点风格自定义、页面自定义等功能。
使用教程:
https://docsite.js.org/zh-cn/docs/installation.html
获取方式:(免费)
项目地址:
https://github.com/txd-team/docsite
七、Android 平台上的秒级编译方案 Freeline
Freeline 可以充分利用缓存文件,在几秒钟内迅速地对代码的改动进行编译并部署到设备上,有效地减少了日常开发中的大量重新编译与安装的耗时。Freeline 最快捷的使用方法就是直接安装 Android Studio 插件。
使用教程:
https://github.com/alibaba/freeline/blob/master/README-zh.md
获取方式:(免费)
项目地址:
https://github.com/alibaba/freeline
八、性能测试工具 PTS
PTS可以模拟大量用户访问业务的场景,任务随时发起,免去搭建和维护成本,支持 JMeter 脚本转化为 PTS 压测,同样支持原生 JMeter 引擎进行压测。
使用教程:
https://help.aliyun.com/document_detail/70290.html
获取方式:(收费)
工具地址:
https://www.aliyun.com/product/pts
九、云效开发者工具 KT
KT 可以简化在 Kubernetes 下进行联调测试的复杂度,提高基于 Kubernetes 的研发效率。
使用教程:
https://yq.aliyun.com/articles/690519
获取方式:(免费)
工具地址:
https://yq.aliyun.com/download/3393
十、架构可视化工具 AHAS
AHAS为 K8s 等容器环境提供了架构可视化的功能,同时,具有故障注入式高可用能力评测和一键流控降级等功能,可以快速低成本的提升应用可用性。
工具的使用场景:
服务化改造过程中,想精确的了解资源实例的构成和交互情况,实现架构的可视化?
想引入真实的故障场景和演练模型?
低门槛获得流控、降级功能?
使用教程:
https://help.aliyun.com/document_detail/90323.html
获取方式:(免费)
工具地址:
https://www.aliyun.com/product/ahas
十一、数据处理工具 EasyExcel
EasyExcel 是一个用来对 Java 进行解析、生成 Excel 的框架,它重写了 poi 对 07 版 Excel 的解析,原本一个 3M 的 Excel 用 POI sax 需要 100M 左右内存,EasyExcel 可降低到 KB 级别,并且再大的 excel 也不会出现内存溢出的情况。03 版依赖 POI 的 sax 模式。在上层做了模型转换的封装,让使用者更加简单方便。
使用教程:
https://github.com/alibaba/easyexcel/blob/master/quickstart.md
获取方式:(开源)
https://github.com/alibaba/easyexcel
十二、iOS 类工具 HandyJSON
HandyJSON 是一个用于 Swift 语言中的 JSON 序列化 / 反序列化库。
与其他流行的 Swift JSON 库相比,HandyJSON 的特点是,它支持纯 Swift 类,使用也简单。它反序列化时 (把 JSON 转换为 Model) 不要求 Model 从 NSObject 继承 (因为它不是基于 KVC 机制),也不要求你为 Model 定义一个 Mapping 函数。只要你定义好 Model 类,声明它服从 HandyJSON 协议,HandyJSON 就能自行以各个属性的属性名为 Key,从 JSON 串中解析值。
使用教程:
https://github.com/alibaba/HandyJSON/blob/master/README_cn.md
获取方式:(开源)
https://github.com/alibaba/HandyJSON
十三、云上资源和应用部署工具 EDAS Serverless
EDAS Serverless一款基于 Kubernetes,面向应用和微服务的 Serverless 平台。用户无需管理和维护集群与服务器,即可通过镜像、WAR 包和 JAR 包,快速创建原生支持 Kubernetes 的容器应用,同时支持 Spring Cloud 和 Dubbo 等主流微服务框架。
使用教程:
https://help.aliyun.com/document_detail/102048.html
获取方式:(公测期间免费)
https://help.aliyun.com/document_detail/97792.html
十四、数据库连接池 Druid
Druid 是 Java 语言下的数据库连接池,它能够提供强大的监控和扩展功能。
使用教程:
https://github.com/alibaba/druid/wiki/ 常见问题
获取方式:(开源)
http://central.maven.org/maven2/com/alibaba/druid/
十五、Java 工具集 Dragonwell
Alibaba Dragonwell 是阿里巴巴内部 OpenJDK 定制版 AJDK 的开源版本, AJDK 为在线电商,金融,物流做了结合业务场景的优化,运行在超大规模的,100,000+ 服务器的阿里巴巴数据中心。 Alibaba Dragonwell 与 Java SE 标准兼容,目前仅支持 Linux/x86_64 平台。
使用教程:
https://github.com/alibaba/dragonwell8/wiki/ 阿里巴巴 Dragonwell8 用户指南
获取方式:(开源)
https://github.com/alibaba/dragonwell8
上一篇: Java首度承认PK失败,愿永久服软Python!
收起阅读 »
手!慢!无!价值1980的数据分析教程,终终终于免费啦!!!
对比互联网各个岗位的裁员程度可以发现,数据分析相关岗位正在不断的扩招,已经成为了这波逆流中的黑马,什么原因导致的数据分析人才如此紧缺?
因为数据分析是大势所趋,未来的发展空间会大有可为。随着5G网络即将商用,企业每天将会产生海量的数据,BAT日均数据更是达到了PB的级别,数据分析相关岗位才会存在着巨大的需求缺口。
长此以往,企业要用尽可能少的人才,来满足尽可能多岗位的诉求,可以这么说,数据分析将会是每个程序员个人能力最重要的补充,也是BAT这类大公司急招人才的必备技能。
但是一提数据分析,很多人就觉得无从下手,知识点零散总是抓不住重点,学习起来相当吃力。这有一份廖雪峰大神历时3个月打磨出来的《数据分析必备技能》的视频学习资料,由浅入深系统化的讲解,内容详尽。基本囊括了平时学习工作中经常用到的分析方式,这份不可或缺的宝贵资料原价值1980元,现在,关注公众号cainiao_xueyuan就可以免费领取(仅限300名)。
学完这套资料可以给你将会得到哪些收获?
1. 总时长>48个小时的干货内容,每天2小时,20天掌握数据分析必备技能;
2. 对照自己掌握知识点进行查缺补漏,帮助你扫除知识盲区、重构知识体系。
具体详细的资料内容:
1 数学理论基础
01.数据挖掘之数学基础02.数学基础之微积分
03.机器学习之线性回归
04.机器学习之逻辑回归
05.朴素贝叶斯
06.机器学习之决策树
07.机器学习之集成学习
2 必备Python基础
01.Python语言介绍、发展、特色02.概念介绍:Python解释器
03.Python函数及高级特性
04.交互环境介绍:启动和退出交互环境
05.Python基础语法及模块
3 高效scrapy爬虫框架
01.scrapy简介02.scrapy选择器
03.创建scrapy爬虫
04.下载器与爬虫中间件
05.突破反爬虫机制与策略
06.使用管道 pipelines
4 Excel数据处理
01.认识数据表的字段和记录02.使用Excel制作数据表
03.指定常用数据类型
04.Excel导入网站数据、文本数据
05.Excel数据清洗、筛选
06.Excel数据抽样和计算
5 使用SQL实现数据操作
01SQL基础语法
02.SQL表连接
03.SQL普通函数
04.SQL窗口函数
05.SQL优化
长按扫码 添加微信,领取干货视频

Ps:学习资料由"开课吧"友情提供。 收起阅读 »
因为数据分析是大势所趋,未来的发展空间会大有可为。随着5G网络即将商用,企业每天将会产生海量的数据,BAT日均数据更是达到了PB的级别,数据分析相关岗位才会存在着巨大的需求缺口。
长此以往,企业要用尽可能少的人才,来满足尽可能多岗位的诉求,可以这么说,数据分析将会是每个程序员个人能力最重要的补充,也是BAT这类大公司急招人才的必备技能。
但是一提数据分析,很多人就觉得无从下手,知识点零散总是抓不住重点,学习起来相当吃力。这有一份廖雪峰大神历时3个月打磨出来的《数据分析必备技能》的视频学习资料,由浅入深系统化的讲解,内容详尽。基本囊括了平时学习工作中经常用到的分析方式,这份不可或缺的宝贵资料原价值1980元,现在,关注公众号cainiao_xueyuan就可以免费领取(仅限300名)。
学完这套资料可以给你将会得到哪些收获?
1. 总时长>48个小时的干货内容,每天2小时,20天掌握数据分析必备技能;
2. 对照自己掌握知识点进行查缺补漏,帮助你扫除知识盲区、重构知识体系。
具体详细的资料内容:
1 数学理论基础
01.数据挖掘之数学基础02.数学基础之微积分
03.机器学习之线性回归
04.机器学习之逻辑回归
05.朴素贝叶斯
06.机器学习之决策树
07.机器学习之集成学习
2 必备Python基础
01.Python语言介绍、发展、特色02.概念介绍:Python解释器
03.Python函数及高级特性
04.交互环境介绍:启动和退出交互环境
05.Python基础语法及模块
3 高效scrapy爬虫框架
01.scrapy简介02.scrapy选择器
03.创建scrapy爬虫
04.下载器与爬虫中间件
05.突破反爬虫机制与策略
06.使用管道 pipelines
4 Excel数据处理
01.认识数据表的字段和记录02.使用Excel制作数据表
03.指定常用数据类型
04.Excel导入网站数据、文本数据
05.Excel数据清洗、筛选
06.Excel数据抽样和计算
5 使用SQL实现数据操作
01SQL基础语法
02.SQL表连接
03.SQL普通函数
04.SQL窗口函数
05.SQL优化
长按扫码 添加微信,领取干货视频
Ps:学习资料由"开课吧"友情提供。 收起阅读 »
打击电信诈骗保障客户安全,环信客服云6大安全机制让骗子无所遁形!
近日,环信收到海淀网警和用户的反馈,部分不法分子通过注册环信客服云获取专业客服工具在各大论坛和二手交易平台:如百度贴吧、58同城“转转”等进行电信诈骗,不法分子冒充平台的专业客服人员诱导客户先行付款进行诈骗,造成了很恶劣的社会影响。

环信第一时间获悉即敏锐的采取行动,一期关停450个诈骗账号信息,同时推出6大安全机制让骗子无所遁形。
环信客服云防诈骗六大安全机制:
1.注册环节:单手机号15天内只能注册一个账号,以防反复账号行骗。
2.使用环节:关停H5聊天窗口,需申请审核后才能打开。
3.聊天环节:敏感词预警,在用户聊天记录过程中系统监控到提前设置的关键词,会触发预警给到运营人员,进行账户关停。
4.账号限制:实时操作异常账号关闭,一经发现,立即关停账号
5.黑名单机制:加入黑名单的注册手机号,永久无法再注册环信
6.报警机制:第一时间反馈所有诈骗信息至公安网警等相关部门
同时,环信也开通了反诈骗投诉信箱:Antifraud@easemob.com 和 400专线:400-622-1776,我们的工作人员会第一时间解决所有用户碰到的所有潜在欺诈问题。
维护网络安全繁荣是环信义不容辞的社会责任,环信会一如既往和网警网安等部门密切合作,打击电信诈骗,保护客户安全,环信客服云一直在路上! 收起阅读 »
环信第一时间获悉即敏锐的采取行动,一期关停450个诈骗账号信息,同时推出6大安全机制让骗子无所遁形。
环信客服云防诈骗六大安全机制:
1.注册环节:单手机号15天内只能注册一个账号,以防反复账号行骗。
2.使用环节:关停H5聊天窗口,需申请审核后才能打开。
3.聊天环节:敏感词预警,在用户聊天记录过程中系统监控到提前设置的关键词,会触发预警给到运营人员,进行账户关停。
4.账号限制:实时操作异常账号关闭,一经发现,立即关停账号
5.黑名单机制:加入黑名单的注册手机号,永久无法再注册环信
6.报警机制:第一时间反馈所有诈骗信息至公安网警等相关部门
同时,环信也开通了反诈骗投诉信箱:Antifraud@easemob.com 和 400专线:400-622-1776,我们的工作人员会第一时间解决所有用户碰到的所有潜在欺诈问题。
维护网络安全繁荣是环信义不容辞的社会责任,环信会一如既往和网警网安等部门密切合作,打击电信诈骗,保护客户安全,环信客服云一直在路上! 收起阅读 »
同一个网站,手机端跟电脑端显示不同是怎么实现的?
同一个网站,手机端跟电脑端不同是怎么实现的?
常见的方式有三种:
1,自适应网站
同一套代码,自动实现手机端和电脑端的布局自动调整。例如:openGPS.cn 网站现在大部分页面已经支持自适应展示,手机端电脑端都可以访问本站内容,正常阅读。自适应站点,往往是对CSS布局的重点考虑,本站使用的是BootStrap这个前端样式组件实现的自适应布局。
2,网站二级目录
这种是早期网站比较喜欢的做法,因为其实这是一个网站。早期网站往往是使用虚拟主机(也叫空间)发布,一个空间只能放一个网站,所以这种做法在早期特别流行。这种结构本质还是一个网站,但是针对手机电脑客户端单独做了往往对应的一套目录,例如:
电脑站点地址一般是:www.domain.com/xxxxxxx
手机站点地址往往是:www.domain.com/m/xxxxxxx
3,手机站点使用二级域名,电脑手机各一套2套站点代码
这种做法,工作量跟二级目录基本相似,严格来说代码量稍微多点。由于是2套代码,所以发布时候也得配备2套域名,不过要求两套站点连接同一个数据库来实现数据统一。例如:
电脑端网站域名是:www.domain.com
手机端网站域名是:m.domain.com
原文地址: https://www.opengps.cn/Blog/View.aspx?id=302 文章的更新编辑依此链接为准。欢迎关注源站原创文章!
收起阅读 »
常见的方式有三种:
1,自适应网站
同一套代码,自动实现手机端和电脑端的布局自动调整。例如:openGPS.cn 网站现在大部分页面已经支持自适应展示,手机端电脑端都可以访问本站内容,正常阅读。自适应站点,往往是对CSS布局的重点考虑,本站使用的是BootStrap这个前端样式组件实现的自适应布局。
2,网站二级目录
这种是早期网站比较喜欢的做法,因为其实这是一个网站。早期网站往往是使用虚拟主机(也叫空间)发布,一个空间只能放一个网站,所以这种做法在早期特别流行。这种结构本质还是一个网站,但是针对手机电脑客户端单独做了往往对应的一套目录,例如:
电脑站点地址一般是:www.domain.com/xxxxxxx
手机站点地址往往是:www.domain.com/m/xxxxxxx
3,手机站点使用二级域名,电脑手机各一套2套站点代码
这种做法,工作量跟二级目录基本相似,严格来说代码量稍微多点。由于是2套代码,所以发布时候也得配备2套域名,不过要求两套站点连接同一个数据库来实现数据统一。例如:
电脑端网站域名是:www.domain.com
手机端网站域名是:m.domain.com
原文地址: https://www.opengps.cn/Blog/View.aspx?id=302 文章的更新编辑依此链接为准。欢迎关注源站原创文章!
收起阅读 »
在微信小程序里实现聊天室
第一次搞小程序,老板让我实现一个聊天室功能,压力山大啊。
花了几天时间研究比较了一下方案,最后基于环信的小程序SDK 开发了一个聊天室。
准备工作
集成
收起阅读 »
花了几天时间研究比较了一下方案,最后基于环信的小程序SDK 开发了一个聊天室。
准备工作
- 下载环信 小程序demo+sdk
git clone https://github.com/easemob/webim-weixin-xcx
- 创建一个文件夹,将 demo 中的文件 comps、images、sdk、utils 拷贝到新的文件,文件目录说明

集成
- 登录环信没什么可说的,这里选择的是使用 username/password 登录,和demo中的一样,文件没有进行任何更改

- 在app.js 中注册的 WebIM.conn.listen, 然后在 登陆成功的回调 onOpened 设置的跳转页面,并将登陆的 username 赋给 myName,传到新的页面中使用

- 修改 roomlist.js 获取聊天室列表,是分页获取的,这里先偷个懒,获取了第一页 20 个聊天室

然后将listChatrooms() 分别在onLoad、onShow 内,更改下,将原有的 listGroups() 替换掉 - 然后在roomlist.wxml 修改对应的 变量绑定名称


- demo中的group.js 中,获取到的是当前登陆账号已加入的群组,咱们做的是聊天室功能,所以需要有一个加入的操作,找roomlist.js 中找到 into_room: function (event),然后填写加入聊天室的方法, 我是直接在当前这个里面加的跳转到聊天页面,并将当前登陆的IDmyName,聊天室IDgroupID,聊天室名称your 传给新页面

Ex:监听是否加入聊天室成功的回调是在 onPresence 中,type:memberJoinChatRoomSuccess,正常是监听这个回调跳转页面,有点麻烦就直接这样吧 - 到会话页面后,需要修改一下对应的消息格式,在comps/chat/suit 目录下,将里面的文件对应的 js 文件根据文档给聊天室发送消息 格式进行修改,聊天室消息和群组消息不同,所以我目前是直接将getSendToParam()、isGroupChat() 注释,改成下面这样,demo 中下面还有代码的,这里就用 …… 代替了


就这样了,简单集成聊天室功能,demo中的UI 是开源的,可以根据自己的需求更改~下面是具体实现过程。代码也放在github 上了,有需要的兄弟自取。demo下载地址:https://github.com/lizgDonkey/room-xcx
收起阅读 »
(客服云)iOS访客端集成常见问题(非报错)
1、UI上很多地方显示英文,比如聊天页面的工具栏

把客服demo中配置的国际化文件添加到您自己的工程中。拖之前要打开国际化文件,全部选中这三个,再进行拖入。

2、进入聊天页面没有加载聊天记录
这种情况一般出现在只使用了 HDMessageViewController 没有使用 HDChatViewController 的时候
在HDMessageViewController 的 viewDidLoad 方法中, 将 [self tableViewDidTriggerHeaderRefresh]; 的注释打开,再在这句代码之前加上 self.showRefreshHeader = YES;
3、发送表情却显示字符串

把下面这段代码添加到appdelegate中就可以了
[[HDEmotionEscape sharedInstance] setEaseEmotionEscapePattern:@"\\[[^\\[\\]]{1,3}\\]"];
[[HDEmotionEscape sharedInstance] setEaseEmotionEscapeDictionary:[HDConvertToCommonEmoticonsHelper emotionsDictionary]];
4、文本消息,收发双方的布局不一样,如图

参考一下截图修改即可

5、客服能收到访客的消息,访客收不到客服的消息
(1)客服和im同时使用的话,初始化sdk、登录、登出用的是im的api会出现这种情况。必须使用客服的api。
(2)IM sdk升级为客服sdk,不兼容导致的,这种情况可以线上发起会话咨询。
把客服demo中配置的国际化文件添加到您自己的工程中。拖之前要打开国际化文件,全部选中这三个,再进行拖入。
2、进入聊天页面没有加载聊天记录
这种情况一般出现在只使用了 HDMessageViewController 没有使用 HDChatViewController 的时候
在HDMessageViewController 的 viewDidLoad 方法中, 将 [self tableViewDidTriggerHeaderRefresh]; 的注释打开,再在这句代码之前加上 self.showRefreshHeader = YES;
3、发送表情却显示字符串
把下面这段代码添加到appdelegate中就可以了
[[HDEmotionEscape sharedInstance] setEaseEmotionEscapePattern:@"\\[[^\\[\\]]{1,3}\\]"];
[[HDEmotionEscape sharedInstance] setEaseEmotionEscapeDictionary:[HDConvertToCommonEmoticonsHelper emotionsDictionary]];
4、文本消息,收发双方的布局不一样,如图
参考一下截图修改即可
5、客服能收到访客的消息,访客收不到客服的消息
(1)客服和im同时使用的话,初始化sdk、登录、登出用的是im的api会出现这种情况。必须使用客服的api。
(2)IM sdk升级为客服sdk,不兼容导致的,这种情况可以线上发起会话咨询。
6、发送的消息,出现在聊天页面的左侧
一般是由于当前访客没有登录或者登录失败,断点仔细检查下。
一般是由于当前访客没有登录或者登录失败,断点仔细检查下。
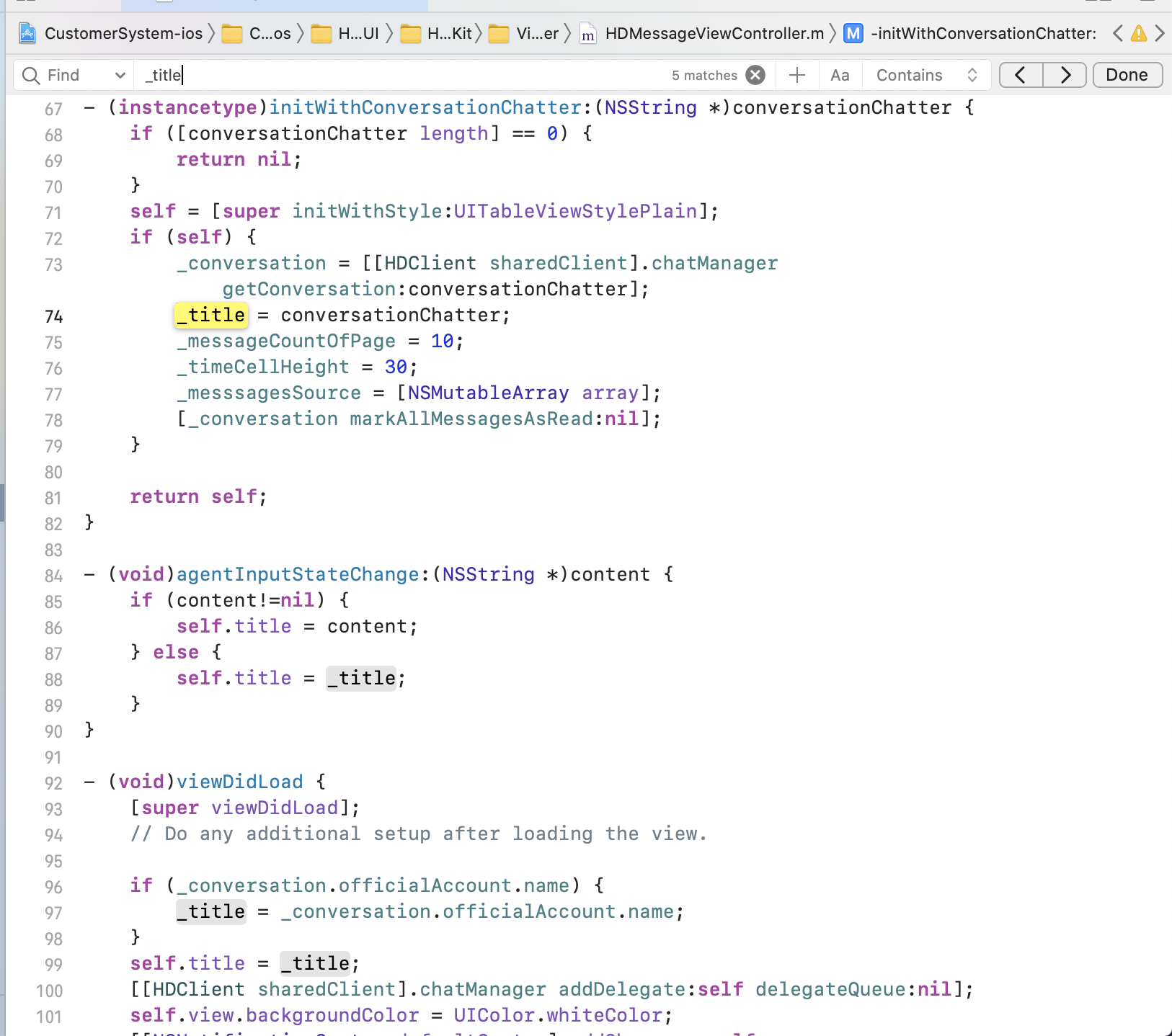
7、修改聊天页面导航栏标题
修改_title的值
(客服云)iOS访客端集成常见报错(总有一款适合你)
注意:向自己工程中添加环信SDK和UI文件的时候,不要直接向xcode中拖拽添加,先把SDK和UI文件粘贴到自己工程的finder目录中,再从finder中向xcode中拖拽添加,避免出现找不到SDK或者UI文件的情况。
1、很多同学在首次“导入SDK”或“更新SDK重新导入SDK”后,Xcode运行报以下的error:
dyld: Library not loaded: @rpath/Hyphenate.framework/Hyphenate
Referenced from: /Users/shenchong/Library/Developer/CoreSimulator/Devices/C768FE68-6E79-40C8-8AD1-FFFC434D51A9/data/Containers/Bundle/Application/41EA9A48-4DD5-4AA4-AB3F-139CFE036532/CallBackTest.app/CallBackTest
Reason: image not found
这个原因是工程未加载到 framework,正确的处理方式是在TARGETS → General → Embedded Binaries 中添加HelpDesk.framework和Hyphenate.framework依赖库,且 Linked Frameworks and Libraries中依赖库的Status必须是Required。

2、运行之后,自变量为nil,这就有可能是因为上面所说的依赖库的status设置为了Optional,需要改成Required。

3、打包后上传到appstore报错
(1)ERROR ITMS-90535: "Unexpected CFBundleExecutable Key. The bundle at 'Payload/toy.app/HelpDeskUIResource.bundle' does not contain a bundle executable. If this bundle intentionally does not contain an executable, consider removing the CFBundleExecutable key from its Info.plist and using a CFBundlePackageType of BNDL. If this bundle is part of a third-party framework, consider contacting the developer of the framework for an update to address this issue."
方法:把HelpDeskUIResource.bundle里的Info.plist删掉就即可。

(2)This bundle is invalid. The value for key CFBundleShortVersionString ‘1.2.2.1’in the Info.plist must be a period-separated list of at most three non-negative integers.

把sdk里的plist文件的版本号改成3位数即可

(3)Invalid Mach-O Format.The Mach-O in bundle “SMYG.app/Frameworks/Hyphenate.framework” isn’t consistent with the Mach-O in the main bundle.The main bundle Mach-O contains armv7(bitcode) and arm64(bitcode),while the nested bundle Mach-O contains armv7(machine code) and arm64(machine code).Verify that all of the targets for a platform have a consistent value for the ENABLE_BITCODE build setting.”

将TARGETS-Build Settings-Enable Bitcode改为NO

(4)还有很多同学打包失败,看不出什么原因

那么可以先看看有没有按照文档剔除x86_64 i386两个平台
文档链接:http://docs.easemob.com/cs/300visitoraccess/iossdk#%E4%B8%8A%E4%BC%A0appstore%E4%BB%A5%E5%8F%8A%E6%89%93%E5%8C%85ipa%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B9
4、那么剔除x86_64 i386时会遇到can't open input file的错误,这是因为cd的路径错误,把“/HelpDesk.framework”删掉。是cd到framework所在的路径,不是cd到framework

5、下图中的报错,需要创建一个pch文件,并且在pch文件添加如下判断,将环信的和自己的头文件都引入到#ifdef内部,参考文档:iOS访客端sdk集成准备工作
#ifdef __OBJC__
#endif
(swift项目也需这样操作)



6、集成环信HelpDeskUI的时候,由于HelpDeskUI内部使用了第三方库,如果与开发者第三方库产生冲突,可将HelpDeskUI中冲突的第三方库删除,如果第三方库中的接口有升级的部分,请酌情进行升级。

7、集成1.2.2版本demo中的HelpDeskUI,Masonry报错:Passing ‘CGFloat’(aka ‘double’) to parameter of incompatible type ‘__strong id’
需要在pch中添加#define MAS_SHORTHAND_GLOBALS
注意:要在#import "Masonry.h"之前添加此宏定义

8、Xcode11运行demo,PSTCollectionView第三方库会有如下报错

标明下类型就行了,如图

9、Xcode12.3编译报错(Building for iOS, but the linked and embedded framework......)

解决方案:
或者打开xcode,左上方点击File --- Workspace Settings,按照截图修改试下(不建议)

收起阅读 »
1、很多同学在首次“导入SDK”或“更新SDK重新导入SDK”后,Xcode运行报以下的error:
dyld: Library not loaded: @rpath/Hyphenate.framework/Hyphenate
Referenced from: /Users/shenchong/Library/Developer/CoreSimulator/Devices/C768FE68-6E79-40C8-8AD1-FFFC434D51A9/data/Containers/Bundle/Application/41EA9A48-4DD5-4AA4-AB3F-139CFE036532/CallBackTest.app/CallBackTest
Reason: image not found
这个原因是工程未加载到 framework,正确的处理方式是在TARGETS → General → Embedded Binaries 中添加HelpDesk.framework和Hyphenate.framework依赖库,且 Linked Frameworks and Libraries中依赖库的Status必须是Required。
2、运行之后,自变量为nil,这就有可能是因为上面所说的依赖库的status设置为了Optional,需要改成Required。
3、打包后上传到appstore报错
(1)ERROR ITMS-90535: "Unexpected CFBundleExecutable Key. The bundle at 'Payload/toy.app/HelpDeskUIResource.bundle' does not contain a bundle executable. If this bundle intentionally does not contain an executable, consider removing the CFBundleExecutable key from its Info.plist and using a CFBundlePackageType of BNDL. If this bundle is part of a third-party framework, consider contacting the developer of the framework for an update to address this issue."
方法:把HelpDeskUIResource.bundle里的Info.plist删掉就即可。
(2)This bundle is invalid. The value for key CFBundleShortVersionString ‘1.2.2.1’in the Info.plist must be a period-separated list of at most three non-negative integers.
把sdk里的plist文件的版本号改成3位数即可
(3)Invalid Mach-O Format.The Mach-O in bundle “SMYG.app/Frameworks/Hyphenate.framework” isn’t consistent with the Mach-O in the main bundle.The main bundle Mach-O contains armv7(bitcode) and arm64(bitcode),while the nested bundle Mach-O contains armv7(machine code) and arm64(machine code).Verify that all of the targets for a platform have a consistent value for the ENABLE_BITCODE build setting.”
将TARGETS-Build Settings-Enable Bitcode改为NO
(4)还有很多同学打包失败,看不出什么原因
那么可以先看看有没有按照文档剔除x86_64 i386两个平台
文档链接:http://docs.easemob.com/cs/300visitoraccess/iossdk#%E4%B8%8A%E4%BC%A0appstore%E4%BB%A5%E5%8F%8A%E6%89%93%E5%8C%85ipa%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B9
4、那么剔除x86_64 i386时会遇到can't open input file的错误,这是因为cd的路径错误,把“/HelpDesk.framework”删掉。是cd到framework所在的路径,不是cd到framework
5、下图中的报错,需要创建一个pch文件,并且在pch文件添加如下判断,将环信的和自己的头文件都引入到#ifdef内部,参考文档:iOS访客端sdk集成准备工作
#ifdef __OBJC__
#endif
(swift项目也需这样操作)
6、集成环信HelpDeskUI的时候,由于HelpDeskUI内部使用了第三方库,如果与开发者第三方库产生冲突,可将HelpDeskUI中冲突的第三方库删除,如果第三方库中的接口有升级的部分,请酌情进行升级。
7、集成1.2.2版本demo中的HelpDeskUI,Masonry报错:Passing ‘CGFloat’(aka ‘double’) to parameter of incompatible type ‘__strong id’
需要在pch中添加#define MAS_SHORTHAND_GLOBALS
注意:要在#import "Masonry.h"之前添加此宏定义
8、Xcode11运行demo,PSTCollectionView第三方库会有如下报错
标明下类型就行了,如图
9、Xcode12.3编译报错(Building for iOS, but the linked and embedded framework......)
或者打开xcode,左上方点击File --- Workspace Settings,按照截图修改试下(不建议)
(客服云)iOS访客端怎么判断会话是否结束
1、联系商务开通【会话创建、接起、结束】功能
2、在 cmdMessagesDidReceive 方法中做如下判断,返回ServiceSessionClosedEvent,则是会话已结束,如图:

代码:
if ([message.body isKindOfClass:[EMCmdMessageBody class]]) {
EMCmdMessageBody *_bb = (EMCmdMessageBody *)message.body;
if ([_bb.action isEqualToString:@"ServiceSessionCreatedEvent"]) {
NSLog(@"hhhhh--Creat");
} else if ([_bb.action isEqualToString:@"ServiceSessionOpenedEvent"]) {
NSLog(@"hhhhh--Open");
} else if ([_bb.action isEqualToString:@"ServiceSessionClosedEvent"]) {
NSLog(@"hhhhh--Close");
}
}
收起阅读 »
2、在 cmdMessagesDidReceive 方法中做如下判断,返回ServiceSessionClosedEvent,则是会话已结束,如图:
代码:
if ([message.body isKindOfClass:[EMCmdMessageBody class]]) {
EMCmdMessageBody *_bb = (EMCmdMessageBody *)message.body;
if ([_bb.action isEqualToString:@"ServiceSessionCreatedEvent"]) {
NSLog(@"hhhhh--Creat");
} else if ([_bb.action isEqualToString:@"ServiceSessionOpenedEvent"]) {
NSLog(@"hhhhh--Open");
} else if ([_bb.action isEqualToString:@"ServiceSessionClosedEvent"]) {
NSLog(@"hhhhh--Close");
}
}
收起阅读 »
(客服云)iOS访客端点击订单消息
1、在HDMessageCell.m 的
- (void)_setupSubviewsWithType:(EMMessageBodyType)messageType
isSender:(BOOL)isSender
model:(id)model
方法中给orderBgView 添加手势

2、在HDMessageCell.m 中添加手势点击事件

3、在HDMessageViewController的
- (void)messageCellSelected:(id)model 方法中添加订单消息的判断

- (void)_setupSubviewsWithType:(EMMessageBodyType)messageType
isSender:(BOOL)isSender
model:(id
方法中给orderBgView 添加手势
UITapGestureRecognizer *tapRecognizer3 = [[UITapGestureRecognizer alloc] initWithTarget:self action:@selector(orderImageViewTapAction:)];
[_bubbleView.orderBgView addGestureRecognizer:tapRecognizer3];
2、在HDMessageCell.m 中添加手势点击事件
- (void)orderImageViewTapAction:(UITapGestureRecognizer *)tapRecognizer
{
if ([_delegate respondsToSelector:@selector(messageCellSelected:)]) {
[_delegate messageCellSelected:_model];
}
}
3、在HDMessageViewController的
- (void)messageCellSelected:(id
代码:收起阅读 »
if ([HDMessageHelper getMessageExtType:model.message] == HDExtOrderMsg) {
// 订单消息携带的扩展
NSDictionary *dic = model.message.ext;
NSLog(@"点击了订单消息");
}
(客服云)IOS访客端设置访客昵称头像
1.在HDMessageViewController.h 中添加访客昵称、头像的属性

2.在HDMessageViewController.m - (NSArray *)formatMessages:(NSArray *)messages 方法中添加判断

3.在初始化聊天页面的时候,传入访客的昵称、头像即可。
(可选择url或者本地头像图片)

// 访客昵称
@property (nonatomic, strong) NSString *sendName;
// 访客头像(url)
@property (nonatomic, strong) NSString *sendAvatarUrl;
// 访客头像(本地图片)
@property (nonatomic, strong) UIImage *sendAvatarImage;
2.在HDMessageViewController.m - (NSArray *)formatMessages:(NSArray *)messages 方法中添加判断
if (isSender) {
if (self.sendName) {
model.nickname = self.sendName;
}
// 加载网络头像
if (self.sendAvatarUrl) {
model.avatarURLPath = self.sendAvatarUrl;
}
// 加载本地头像
if (self.sendAvatarImage) {
model.avatarImage = self.sendAvatarImage;
model.avatarURLPath = nil;
}
} 3.在初始化聊天页面的时候,传入访客的昵称、头像即可。
(可选择url或者本地头像图片)
ctrl.sendName = @"访客昵称";收起阅读 »
ctrl.sendAvatarImage = [UIImage imageNamed:@"测试图片"];
// chat.sendAvatarUrl = @"";
(客服云)iOS访客端设置客服系统头像(调度员消息显示企业logo)
0、在客服系统内 管理员模式--设置--企业基本信息 处上传企业logo

在 管理员模式--设置--系统开关--系统开关--访客端显示客服昵称 处打开开关

1、在HDIMessageModel.h 中添加客服系统头像url属性

2、在HDMessageModel.h 中添加客服系统头像url属性

3、在HDMessageModel.m类 - (instancetype)initWitMessage:(HDMessage *)message方法中添加

4、在HDBaseMessageCell.m类 - (void)setModel:(id)model方法中 修改代码
(“系统消息”要改成您自己客服系统中设置的调度员昵称)

在 管理员模式--设置--系统开关--系统开关--访客端显示客服昵称 处打开开关
1、在HDIMessageModel.h 中添加客服系统头像url属性
@property (strong, nonatomic) NSString *officialAccountURL;
2、在HDMessageModel.h 中添加客服系统头像url属性
@property (strong, nonatomic) NSString *officialAccountURL;
3、在HDMessageModel.m类 - (instancetype)initWitMessage:(HDMessage *)message方法中添加
NSDictionary *officialAccount = [NSDictionary dictionary];
if ([weichat objectForKey:@"official_account"]) {
officialAccount = [weichat valueForKey:@"official_account"];
if ([officialAccount objectForKey:@"img"]) {
self.officialAccountURL = [[@"https:" stringByAppendingString:[officialAccount objectForKey:@"img"]] stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
}
}
4、在HDBaseMessageCell.m类 - (void)setModel:(id
(“系统消息”要改成您自己客服系统中设置的调度员昵称)
if (model.avatarURLPath) {
if (model.nickname) {
if ([model.nickname isEqualToString:@"系统消息"]) {
if (model.officialAccountURL) {
[self.avatarView sd_setImageWithURL:[NSURL URLWithString:model.officialAccountURL] placeholderImage:model.avatarImage];
}
} else {
[self.avatarView sd_setImageWithURL:[NSURL URLWithString:model.avatarURLPath] placeholderImage:model.avatarImage];
}
}
} else {
self.avatarView.image = model.avatarImage;
} 收起阅读 »
(客服云)iOS访客端获取机器人欢迎语
注意:
0、代码中有两个拼接的url显示不全,我在评论有补充。
1、此文档只支持获取单机器人的欢迎语,多机器人会获取第一个机器人的欢迎语。
2、此文档暂不支持获取多媒体和图文消息类型的机器人欢迎语。
3、老版机器人与新版机器人集成方法不同,集成前需区分好。


一、先到客服系统配置机器人欢迎语
1、老版机器人设置方案:
管理员模式--智能机器人--机器人设置--自动回复--欢迎语,开启开关并添加欢迎语

2、新版(企业版)机器人设置方案:
(1)管理员模式--智能机器人--机器人设置--基础设置,点击“机器人管理”跳转到机器人管理页面
(2)机器人设置--自动回复--欢迎语,开启开关并添加欢迎语

二、iOS端获取、解析机器人欢迎语
在HDMessageViewController.m类的 -(void)viewDidLoad 方法最后调用robotWelcome或者newRobotWelcome 方法即可。其余客户端插入消息的逻辑自行处理
0、代码中有两个拼接的url显示不全,我在评论有补充。
1、此文档只支持获取单机器人的欢迎语,多机器人会获取第一个机器人的欢迎语。
2、此文档暂不支持获取多媒体和图文消息类型的机器人欢迎语。
3、老版机器人与新版机器人集成方法不同,集成前需区分好。
一、先到客服系统配置机器人欢迎语
1、老版机器人设置方案:
管理员模式--智能机器人--机器人设置--自动回复--欢迎语,开启开关并添加欢迎语
2、新版(企业版)机器人设置方案:
(1)管理员模式--智能机器人--机器人设置--基础设置,点击“机器人管理”跳转到机器人管理页面
(2)机器人设置--自动回复--欢迎语,开启开关并添加欢迎语
二、iOS端获取、解析机器人欢迎语
在HDMessageViewController.m类的 -(void)viewDidLoad 方法最后调用robotWelcome或者newRobotWelcome 方法即可。其余客户端插入消息的逻辑自行处理
//获取老版机器人欢迎语
- (void)robotWelcome
{
// kDefaultTenantId:租户id
// kDefaultCustomerName:IM服务号
NSString *urlStr = [NSString stringWithFormat:@"https://kefu.easemob.com/v1/Tenants/%@/robots/visitor/greetings/app", kDefaultTenantId];
NSString *newStr = [urlStr stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSURL *url = [NSURL URLWithString:newStr];
NSURLRequest *requst = [NSURLRequest requestWithURL:url cachePolicy:NSURLRequestReloadIgnoringLocalCacheData timeoutInterval:10];
//异步链接(形式1,较少用)
[NSURLConnection sendAsynchronousRequest:requst queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *connectionError) {
// 解析
NSString *result =[[ NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
//同样的可以替换字符
NSLog(@"result-----%@", result);
NSString *str = [result stringByReplacingOccurrencesOfString:@""" withString:@"\""];
NSString *str1 = [str stringByReplacingOccurrencesOfString:@"\"{" withString:@"{"];
NSString *str2 = [str1 stringByReplacingOccurrencesOfString:@"}\"" withString:@"}"];
// JSON字符串转字典
NSDictionary *dic = [self dictionaryWithJsonString:str2];
// 取消息的ext
NSLog(@"dic---%@",dic);
NSString *robotText = nil;
NSDictionary *dicExt = [NSDictionary dictionary];
if ([[dic objectForKey:@"greetingText"] isKindOfClass:[NSString class]]) {
robotText = [dic objectForKey:@"greetingText"];
} else {
dicExt = [[dic objectForKey:@"greetingText"] objectForKey:@"ext"];
}
//构建消息
EMTextMessageBody *bdy = [[EMTextMessageBody alloc] initWithText:robotText];
NSString *from = [[HDClient sharedClient] currentUsername];
HDMessage *message = [[HDMessage alloc] initWithConversationID:kDefaultCustomerName from:from to:kDefaultCustomerName body:bdy];
message.ext = dicExt;
message.direction = 1;
message.status = HDMessageStatusSuccessed;
// 消息添加到UI
[self addMessageToDataSource:message progress:nil];
// 消息插入到会话
HDError *pError;
[self.conversation addMessage:message error:&pError];
}];
}
//获取新版(企业版)机器人欢迎语
- (void)newRobotWelcome
{
[[HDClient sharedClient] accessToken];
// 以下信息换成自己的
// kDefaultTenantId:租户id
// kDefaultOrgName:appkey中#的前半部分
// kDefaultAppName:appkey中#的后半部分
// kDefaultCustomerName:IM服务号
NSString *imToken = [HDClient sharedClient].accessToken;
NSString *urlStr = [NSString stringWithFormat:@"https://kefu.easemob.com/v1/webimplugin/tenants/robots/welcome?channelType=easemob&originType=app&tenantId=%@&orgName=%@&appName=%@&userName=%@&token=%@",kDefaultTenantId, kDefaultOrgName, kDefaultAppName, kDefaultCustomerName, imToken];
NSString *newStr = [urlStr stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
NSLog(@"newStr---%@", newStr);
NSURL *url = [NSURL URLWithString:newStr];
NSURLRequest *requst = [NSURLRequest requestWithURL:url cachePolicy:NSURLRequestReloadIgnoringLocalCacheData timeoutInterval:10];
//异步链接(形式1,较少用)
[NSURLConnection sendAsynchronousRequest:requst queue:[NSOperationQueue mainQueue] completionHandler:^(NSURLResponse *response, NSData *data, NSError *connectionError) {
// 解析
NSString *result = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
//同样的可以替换字符
NSString *str = [result stringByReplacingOccurrencesOfString:@"&" withString:@"&"]; NSString *str1 = [str stringByReplacingOccurrencesOfString:@""" withString:@"\""];
NSString *str2 = [str1 stringByReplacingOccurrencesOfString:@"\"{" withString:@"{"];
NSString *str3 = [str2 stringByReplacingOccurrencesOfString:@"}\"" withString:@"}"];
// JSON字符串转字典
NSDictionary *dic = [self dictionaryWithJsonString:str3];
// 取消息的ext
NSString *robotText = nil;
NSDictionary *dicExt = [NSDictionary dictionary];
if ([[[dic objectForKey:@"entity"] objectForKey:@"greetingText"] isKindOfClass:[NSString class]]) {
robotText = [[dic objectForKey:@"entity"] objectForKey:@"greetingText"];
} else {
dicExt = [[[dic objectForKey:@"entity"] objectForKey:@"greetingText"] objectForKey:@"ext"];
}
//构建消息
NSLog(@"dicExt---%@",dicExt);
EMTextMessageBody *bdy = [[EMTextMessageBody alloc] initWithText:robotText];
NSString *from = [[HDClient sharedClient] currentUsername];
HDMessage *message = [[HDMessage alloc] initWithConversationID:kDefaultCustomerName from:from to:kDefaultCustomerName body:bdy];
message.ext = dicExt;
message.direction = 1;
message.status = HDMessageStatusSuccessed;
// 消息添加到UI
[self addMessageToDataSource:message progress:nil];
// 消息插入到会话
HDError *pError;
[self.conversation addMessage:message error:&pError];
}];
}
// JSON字符串转化为字典
- (NSDictionary *)dictionaryWithJsonString:(NSString *)jsonString
{
if (jsonString == nil) {
return nil;
}
NSData *jsonData = [jsonString dataUsingEncoding:NSUTF8StringEncoding];
NSError *err;
NSDictionary *dic = [NSJSONSerialization JSONObjectWithData:jsonData
options:NSJSONReadingMutableContainers
error:&err];
if(err)
{
NSLog(@"json解析失败:%@",err);
return nil;
}
return dic;
}
收起阅读 »
客服满意度评价设置
1、怎么设置会话结束时自动发送评价邀请
管理员模式----设置----满意度评价邀请设置 第一项:会话结束自动发送满意度评价邀请,勾选需要设置的访客渠道
2、访客是否能多次评价
访客的评价次数是不限制的,但是可以设置客服后台统计的评为为第一次还是最后一次,可以在管理员模式----设置---- 满意度评价邀请设置 第三项:多次满意度评价只取第一次
3、系统结束的会话是否自动发送满意度评价
管理员模式----设置----满意度评价邀请设置 开关打开时,因访客超时未回复、不活跃超时而自动结束的会话,系统不会自动推送满意度评价
4、如何设置满意度邀请提示语
管理员模式----设置----满意度评价邀请设置 第6项
收起阅读 »
android客服云如何获取机器人欢迎语
1.APP端要想获取到机器人菜单欢迎语,首先在移动客服管理员模式下,智能机器人,机器人设置——自动回复——欢迎语配置菜单欢迎语或者是欢迎语消息。
2、在会话分配规则中,渠道指定一定要指定机器人,APP端才能获取到机器人欢迎语,否则获取不到
具体的代码如下附件
图1中的
MyApplication.tenantId记得替换为自己的tenantId
new Thread(new Runnable() {
@Override
public void run() {
HttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet("http://kefu.easemob.com/v1/Tenants/"+MyApplication.tenantId+"/robots/visitor/greetings/app");
try {
HttpResponse response = httpClient.execute(httpGet);
int code = response.getStatusLine().getStatusCode();
if (code == 200) {
final String rev = EntityUtils.toString(response.getEntity());
JSONObject obj = new JSONObject(rev);
int type = obj.getInt("greetingTextType");
final String rob_welcome = obj.getString("greetingText");
//type为0代表是文字消息的机器人欢迎语
//type为1代表是菜单消息的机器人欢迎语
if(type == 0){
//把解析拿到的string保存在本地
shareUtil.saveRobot(rob_welcome);
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"rob_welcome="+rob_welcome,Toast.LENGTH_SHORT).show();
}
});
}else if(type == 1){
final String str = rob_welcome.replaceAll(""","\"");
JSONObject json = new JSONObject(str);
JSONObject ext = json.getJSONObject("ext");
final JSONObject msgtype = ext.getJSONObject("msgtype");
//把解析拿到的string保存在本地
shareUtil.saveRobot(msgtype.toString());
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"rob_welcome="+msgtype,Toast.LENGTH_SHORT).show();
}
});
}
}
}catch(final Exception e){
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"exception="+e.getMessage(),Toast.LENGTH_SHORT).show();
}
});
}
}
}).start();
图2中的:
//创建消息插入本地
Message message = Message.createReceiveMessage(Message.Type.TXT);
//从本地获取保存的string
String str = shareUtil.getRobot();
EMTextMessageBody body = null;
//判断是否是菜单消息的string,这是自己实现的一个方法
if(!isRobotMenu(str)){
//文字消息直接去设置给消息
body = new EMTextMessageBody(str);
}else{
//菜单消息需要设置给消息扩展
try{
body = new EMTextMessageBody("");
JSONObject msgtype = new JSONObject(str);
message.setAttribute("msgtype",msgtype);
}catch (Exception e){
Toast.makeText(this,"exception="+e.getMessage(),Toast.LENGTH_SHORT).show();
}
}
message.setFrom(MyApplication.imService);
message.addBody(body);
message.setMsgTime(System.currentTimeMillis());
message.setStatus(Message.Status.SUCCESS);
message.setMsgId(UUID.randomUUID().toString());
ChatClient.getInstance().chatManager().saveMessage(message);
图3中的:
private boolean isRobotMenu(String str){
try {
JSONObject json = new JSONObject(str);
JSONObject obj = json.getJSONObject("choice");
}catch (Exception e){
return false;
}
return true;
}
收起阅读 »
2、在会话分配规则中,渠道指定一定要指定机器人,APP端才能获取到机器人欢迎语,否则获取不到
具体的代码如下附件
图1中的
MyApplication.tenantId记得替换为自己的tenantId
new Thread(new Runnable() {
@Override
public void run() {
HttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet("http://kefu.easemob.com/v1/Tenants/"+MyApplication.tenantId+"/robots/visitor/greetings/app");
try {
HttpResponse response = httpClient.execute(httpGet);
int code = response.getStatusLine().getStatusCode();
if (code == 200) {
final String rev = EntityUtils.toString(response.getEntity());
JSONObject obj = new JSONObject(rev);
int type = obj.getInt("greetingTextType");
final String rob_welcome = obj.getString("greetingText");
//type为0代表是文字消息的机器人欢迎语
//type为1代表是菜单消息的机器人欢迎语
if(type == 0){
//把解析拿到的string保存在本地
shareUtil.saveRobot(rob_welcome);
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"rob_welcome="+rob_welcome,Toast.LENGTH_SHORT).show();
}
});
}else if(type == 1){
final String str = rob_welcome.replaceAll(""","\"");
JSONObject json = new JSONObject(str);
JSONObject ext = json.getJSONObject("ext");
final JSONObject msgtype = ext.getJSONObject("msgtype");
//把解析拿到的string保存在本地
shareUtil.saveRobot(msgtype.toString());
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"rob_welcome="+msgtype,Toast.LENGTH_SHORT).show();
}
});
}
}
}catch(final Exception e){
runOnUiThread(new Runnable() {
@Override
public void run() {
Toast.makeText(getApplicationContext(),"exception="+e.getMessage(),Toast.LENGTH_SHORT).show();
}
});
}
}
}).start();
图2中的:
//创建消息插入本地
Message message = Message.createReceiveMessage(Message.Type.TXT);
//从本地获取保存的string
String str = shareUtil.getRobot();
EMTextMessageBody body = null;
//判断是否是菜单消息的string,这是自己实现的一个方法
if(!isRobotMenu(str)){
//文字消息直接去设置给消息
body = new EMTextMessageBody(str);
}else{
//菜单消息需要设置给消息扩展
try{
body = new EMTextMessageBody("");
JSONObject msgtype = new JSONObject(str);
message.setAttribute("msgtype",msgtype);
}catch (Exception e){
Toast.makeText(this,"exception="+e.getMessage(),Toast.LENGTH_SHORT).show();
}
}
message.setFrom(MyApplication.imService);
message.addBody(body);
message.setMsgTime(System.currentTimeMillis());
message.setStatus(Message.Status.SUCCESS);
message.setMsgId(UUID.randomUUID().toString());
ChatClient.getInstance().chatManager().saveMessage(message);
图3中的:
private boolean isRobotMenu(String str){
try {
JSONObject json = new JSONObject(str);
JSONObject obj = json.getJSONObject("choice");
}catch (Exception e){
return false;
}
return true;
}
收起阅读 »
(客服云)知识库添加了附件,怎么发送的时候附件没有发送出去?
附件需要单独发送给访客。发送知识时,图文消息仅包含知识标题和知识内容,不包含知识的附件。若发送知识中的附件,需打开知识详情,并点击附件右上角的“发送”按钮。
(客服云)iOS访客端插入企业欢迎语
0、前提配置
(1)在客服系统内 管理员模式--设置--系统开关--企业欢迎语 处设置欢迎语,并开启开关

(2)联系商务开通会话创建、接起、结束的透传事件功能
1、在HDMessageViewController.m中添加企业欢迎语属性

2、在HDMessageViewController.m中的 viewdidload 方法的最后调用 [self judge];


3、在HDMessageViewController.m中的cmdMessagesDidReceive方法中调用 messageExtwithEventName

4、在cell中设置插入消息的昵称头像,根据插入消息ext中的key去判断。

效果图

收起阅读 »
(1)在客服系统内 管理员模式--设置--系统开关--企业欢迎语 处设置欢迎语,并开启开关
(2)联系商务开通会话创建、接起、结束的透传事件功能
1、在HDMessageViewController.m中添加企业欢迎语属性
// 企业欢迎语
@property (nonatomic, strong) NSString *companyWelcome;
2、在HDMessageViewController.m中的 viewdidload 方法的最后调用 [self judge];
// 这个方法是属于逻辑判断,用UD去记录参数,只有第一次进入聊天页面和会话结束之后再进入到聊天页面才插入消息。
- (void)judge
{
// 判断会话中是否有消息
if (self.conversation.latestMessage == nil) {
// 如果会话中没有消息,那么UD的值变成NO
[[NSUserDefaults standardUserDefaults] setBool:NO forKey:@"isGetWelcome"];
}
// 根据以前的判断,如果UD值为NO则插入消息欢迎语
if (![[NSUserDefaults standardUserDefaults] boolForKey:@"isGetWelcome"]) {
// 插入企业欢迎语
[self welcome];
}
[[NSUserDefaults standardUserDefaults] setBool:YES forKey:@"isGetWelcome"];
}
// 这个方法是构建消息以及向UI页面以及本地数据库插入消息
- (void)welcome
{
// 此方法是SDK获取企业欢迎语的
__weak typeof(self) weakself = self;
[[HDClient sharedClient].chatManager getEnterpriseWelcomeWithCompletion:^(NSString *welcome, HDError *error) {
// 判断客服系统中是否设置了企业欢迎语并且开关有没有打开,兼容误操作客服关闭了企业欢迎语开关,会插入一条空消息,那么自己选择是否插入一条默认的欢迎语,自行修改 ‘您好,欢迎光临!’ 的内容
if (![welcome isEqualToString:@""]) {
weakself.companyWelcome = welcome;
} else {
weakself.companyWelcome = @"您好,欢迎光临!";
}
// 构建消息
EMTextMessageBody *bdy = [[EMTextMessageBody alloc] initWithText:weakself.companyWelcome];
NSString *from = [[HDClient sharedClient] currentUsername];
// _converID就是IM服务号,可以自己替换下
HDMessage *message = [[HDMessage alloc] initWithConversationID:weakself.conversation.conversationId from:from to:weakself.conversation.conversationId body:bdy];
// 构建的消息用ext来标记此条消息是插入的欢迎语,然后在cell里面根据消息的ext来修改插入消息的昵称和头像
NSDictionary *welcomeExt = @{@"insertWelcome":@"插入的欢迎语"};
[message addAttributeDictionary:welcomeExt];
message.direction = 1;
message.status = HDMessageStatusSuccessed;
// 更新UI
dispatch_async(dispatch_get_main_queue(), ^{
// 消息添加到数据源,刷新UI
[weakself addMessageToDataSource:message progress:nil];
});
// 消息插入到会话
HDError *pError;
[weakself.conversation addMessage:message error:&pError];
}];
}
3、在HDMessageViewController.m中的cmdMessagesDidReceive方法中调用 messageExtwithEventName
// 这个方法是判断接收到客服消息的ext里面有没有ServiceSessionClosedEvent,如果有就把UD记录改变参数,下次进入聊天页面的时候插入欢迎语
// 如果是ServiceSessionOpenedEvent,客服系统接入了会话,那么就不插入欢迎语
// 这个方法是接收透传消息里面调用,客服系统会话被接入会给app端发送透传消息通知,如果没有接收到透传消息,那么找对接的环信商务开通这个功能
[self messageExtwithEventName:message];
- (void)messageExtwithEventName:(HDMessage *)message
{
if (![[[message.ext objectForKey:@"weichat"] objectForKey:@"event"] isKindOfClass:[NSNull class]]) {
NSDictionary *dict = [[message.ext objectForKey:@"weichat"] objectForKey:@"event"];
if ([[dict objectForKey:@"eventName"] isEqualToString:@"ServiceSessionClosedEvent"]) {
//如果接收到客服的消息ext中有 ServiceSessionClosedEvent,表示会话已经结束,那么UD的值变成NO
[[NSUserDefaults standardUserDefaults] setBool:NO forKey:@"isGetWelcome"];
}
if ([[dict objectForKey:@"eventName"] isEqualToString:@"ServiceSessionOpenedEvent"]) {
//如果接收到客服的消息ext中有 ServiceSessionClosedEvent,表示会话已经结束,那么UD的值变成NO
[[NSUserDefaults standardUserDefaults] setBool:YES forKey:@"isGetWelcome"];
}
}
}
4、在cell中设置插入消息的昵称头像,根据插入消息ext中的key去判断。
if (!self.model.isSender) {
if (![model.nickname isKindOfClass:[NSNull class]]) {
// 判断此条消息是否为插入的企业欢迎语,是的话赋值昵称和头像
if ([self.model.message.ext objectForKey:@"insertWelcome"]) {
_nameLabel.text = @"系统消息";
self.avatarView.image = [UIImage imageNamed:@"测试图片"];
}
}
}效果图
收起阅读 »
Android MVP架构从入门到精通-真枪实弹

一. 前言
你是否遇到过Activity/Fragment中成百上千行代码,完全无法维护,看着头疼?
你是否遇到过因后台接口还未写而你不能先写代码逻辑的情况?
你是否遇到过用MVC架构写的项目进行单元测试时的深深无奈?
如果你现在还是用MVC架构模式在写项目,请先转到MVP模式!
二. MVC架构
MVC架构模式最初生根于服务器端的Web开发,后来渐渐能够胜任客户端Web开发,再后来因Android项目由XML和Activity/Fragment组成,慢慢的Android开发者开始使用类似MVC的架构模式开发应用.
.jpeg")
M层:模型层(model),主要是实体类,数据库,网络等存在的层面,model将新的数据发送到view层,用户得到数据响应.
V层:视图层(view),一般指XML为代表的视图界面.显示来源于model层的数据.用户的点击操作等事件从view层传递到controller层.
C层:控制层(controller),一般以Activity/Fragment为代表.C层主要是连接V层和M层的,C层收到V层发送过来的事件请求,从M层获取数据,展示给V层.
从上图可以看出M层和V层有连接关系,而Activity有时候既充当了控制层又充当了视图层,导致项目维护比较麻烦.
1. MVC架构优缺点
A. 缺点
M层和V层有连接关系,没有解耦,导致维护困难.
Activity/Fragment中的代码过多,难以维护.
Activity中有很多关于视图UI的显示代码,因此View视图和Activity控制器并不是完全分离的,当Activity类业务过多的时候,会变得难以管理和维护.尤其是当UI的状态数据,跟持久化的数据混杂在一起,变得极为混乱.
B. 优点
控制层和View层都在Activity中进行操作,数据操作方便.
模块职责划分明确.主要划分层M,V,C三个模块.
三. MVP架构
.jpeg")
MVP,即是Model,View,Presenter架构模式.看起来类似MVC,其实不然.从上图能看到Model层和View层没有相连接,完全解耦.
用户触碰界面触发事件,View层把事件通知Presenter层,Presenter层通知Model层处理这个事件,Model层处理后把结果发送到Presenter层,Presenter层再通知View层,最后View层做出改变.这是一整套流程.
M层:模型层(Model),此层和MVC中的M层作用类似.
V层:视图层(View),在MVC中V层只包含XML文件,而MVP中V层包含XML,Activity和Fragment三者.理论上V层不涉及任何逻辑,只负责界面的改变,尽量把逻辑处理放到M层.
P层:通知层(Presenter),P层的主要作用就是连接V层和M层,起到一个通知传递数据的作用.
1. MVP架构优缺点
A. 缺点
MVP中接口过多.
每一个功能,相比于MVC要多写好几个文件.
如果某一个界面中需要请求多个服务器接口,这个界面文件中会实现很多的回调接口,导致代码繁杂.
如果更改了数据源和请求中参数,会导致更多的代码修改.
额外的代码复杂度及学习成本.
B. 优点
模块职责划分明显,层次清晰,接口功能清晰.
Model层和View层分离,解耦.修改View而不影响Model.
功能复用度高,方便.一个Presenter可以复用于多个View,而不用更改Presenter的逻辑.
有利于测试驱动开发,以前的Android开发是难以进行单元测试.
如果后台接口还未写好,但已知返回数据类型的情况下,完全可以写出此接口完整的功能.
四. MVP架构实战(真枪实弹)
1. MVP三层代码简单书写
接下来笔者从简到繁,一点一点的堆砌MVP的整个架构.先看一下XML布局,布局中一个Button按钮和一个TextView控件,用户点击按钮后,Presenter层通知Model层请求处理网络数据,处理后Model层把结果数据发送给Presenter层,Presenter层再通知View层,然后View层改变TextView显示的内容.

<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:layout_gravity="center"
android:gravity="center"
android:orientation="vertical"
tools:context=".view.SingleInterfaceActivity">
<Button
android:id="@+id/button"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="点击" />
<TextView
android:id="@+id/textView"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginTop="100px"
android:text="请点击上方按钮获取数据" />
</LinearLayout>
接下来是Activity代码,里面就是获取Button和TextView控件,然后对Button做监听,先简单的这样写,一会慢慢的增加代码.
public class SingleInterfaceActivity extends AppCompatActivity {
private Button button;
private TextView textView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_single_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
}
});
}
}下面是Model层代码.本次网络请求用的是wanandroid网站的开放api,其中的文章首页列表接口.SingleInterfaceModel文件里面有一个方法getData,第一个参数curPage意思是获取第几页的数据,第二个参数callback是Model层通知Presenter层的回调.
public class SingleInterfaceModel {
public void getData(int curPage, final Callback callback) {
NetUtils.getRetrofit()
.create(Api.class)
.getData(curPage)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Subscriber<ArticleListBean>() {
@Override
public void onCompleted() {
LP.w("completed");
}
@Override
public void onError(Throwable e) {
callback.onFail("出现错误");
}
@Override
public void onNext(ArticleListBean bean) {
if (null == bean) {
callback.onFail("出现错误");
} else if (bean.errorCode != 0) {
callback.onFail(bean.errorMsg);
} else {
callback.onSuccess(bean);
}
}
});
}
}Callback文件内容如下.里面一个成功一个失败的回调接口,参数全是泛型,为啥使用泛型笔者就不用说了吧.public interface Callback<K, V> {
void onSuccess(K data);
void onFail(V data);
}再接下来是Presenter层的代码.SingleInterfacePresenter类构造函数中直接new了一个Model层对象,用于Presenter层对Model层的调用.然后SingleInterfacePresenter类的方法getData用于与Model的互相连接.public class SingleInterfacePresenter {
private final SingleInterfaceModel singleInterfaceModel;
public SingleInterfacePresenter() {
this.singleInterfaceModel = new SingleInterfaceModel();
}
public void getData(int curPage) {
singleInterfaceModel.getData(curPage, new Callback<ArticleListBean, String>() {
@Override
public void onSuccess(ArticleListBean loginResultBean) {
//如果Model层请求数据成功,则此处应执行通知View层的代码
}
@Override
public void onFail(String errorMsg) {
//如果Model层请求数据失败,则此处应执行通知View层的代码
}
});
}
}至此,MVP三层简单的部分代码算是完成.那么怎样进行整个流程的相互调用呢.我们把刚开始的SingleInterfaceActivity代码改一下,让SingleInterfaceActivity持有Presenter层的对象,这样View层就可以调用Presenter层了.修改后代码如下.public class SingleInterfaceActivity extends AppCompatActivity {
private Button button;
private TextView textView;
private SingleInterfacePresenter singleInterfacePresenter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_single_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
singleInterfacePresenter = new SingleInterfacePresenter();
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
singleInterfacePresenter.getData(0);
}
});
}
}从以上所有代码可以看出,当用户点击按钮后,View层按钮的监听事件执行调用了Presenter层对象的getData方法,此时,Presenter层对象的getData方法调用了Model层对象的getData方法,Model层对象的getData方法中执行了网络请求和逻辑处理,把成功或失败的结果通过Callback接口回调给了Presenter层,然后Presenter层再通知View层改变界面.但此时SingleInterfacePresenter类中收到Model层的结果后无法通知View层,因为SingleInterfacePresenter未持有View层的对象.如下代码的注释中有说明.(如果此时点击按钮,下方代码LP.w()处会打印出网络请求成功的log)public class SingleInterfacePresenter {
private final SingleInterfaceModel singleInterfaceModel;
public SingleInterfacePresenter() {
this.singleInterfaceModel = new SingleInterfaceModel();
}
public void getData(int curPage) {
singleInterfaceModel.getData(curPage, new Callback<ArticleListBean, String>() {
@Override
public void onSuccess(ArticleListBean loginResultBean) {
//如果Model层请求数据成功,则此处应执行通知View层的代码
//LP.w()是一个简单的log打印
LP.w(loginResultBean.toString());
}
@Override
public void onFail(String errorMsg) {
//如果Model层请求数据失败,则此处应执行通知View层的代码
}
});
}
}代码写到这里,笔者先把这些代码提交到github(https://github.com/serge66/MVPDemo),github上会有一次提交记录,如果想看此时的代码,可以根据提交记录"第一次修改"克隆此时的代码.2. P层V层沟通桥梁
现在P层未持有V层对象,不能通知V层改变界面,那么就继续演变MVP架构.
在MVP架构中,我们要为每个Activity/Fragment写一个接口,这个接口需要让Presenter层持有,P层通过这个接口去通知V层更改界面.接口中包含了成功和失败的回调,这个接口Activity/Fragment要去实现,最终P层才能通知V层.
public interface SingleInterfaceIView {
void showArticleSuccess(ArticleListBean bean);
void showArticleFail(String errorMsg);
}一个完整的项目以后肯定会有许多功能界面,那么我们应该抽出一个IView公共接口,让所有的Activity/Fragment都间接实现它.IVew公共接口是用于给View层的接口继承的,注意,不是View本身继承.因为它定义的是接口的规范, 而其他接口才是定义的类的规范(这句话请仔细理解).public interface IView {
}这个接口中可以写一些所有Activigy/Fragment共用的方法,我们把SingleInterfaceIView继承IView接口.public interface SingleInterfaceIView extends IView {
void showArticleSuccess(ArticleListBean bean);
void showArticleFail(String errorMsg);
}同理Model层和Presenter层也是如此.public interface IModel {
}
public interface IPresenter {
}现在项目中Model层是一个SingleInterfaceModel类,这个类对象被P层持有,对于面向对象设计来讲,利用接口达到解耦目的已经人尽皆知,那我们就要对SingleInterfaceModel类再写一个可继承的接口.代码如下.public interface ISingleInterfaceModel extends IModel {
void getData(int curPage, final Callback callback);
}如此,SingleInterfaceModel类的修改如下.public class SingleInterfaceModel implements ISingleInterfaceModel {
@Override
public void getData(int curPage, final Callback callback) {
NetUtils.getRetrofit()
.create(Api.class)
.getData(curPage)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Subscriber<ArticleListBean>() {
@Override
public void onCompleted() {
LP.w("completed");
}
@Override
public void onError(Throwable e) {
callback.onFail("出现错误");
}
@Override
public void onNext(ArticleListBean bean) {
if (null == bean) {
callback.onFail("出现错误");
} else if (bean.errorCode != 0) {
callback.onFail(bean.errorMsg);
} else {
callback.onSuccess(bean);
}
}
});
}
}同理,View层持有P层对象,我们也需要对P层进行改造.但是下面的代码却没有像ISingleInterfaceModel接口继承IModel一样继承IPresenter,这点需要注意,笔者把IPresenter的继承放在了其他处,后面会讲解.public interface ISingleInterfacePresenter {
void getData(int curPage);
}然后SingleInterfacePresenter类的修改如下:
public class SingleInterfacePresenter implements ISingleInterfacePresenter {
private final ISingleInterfaceModel singleInterfaceModel;
public SingleInterfacePresenter() {
this.singleInterfaceModel = new SingleInterfaceModel();
}
@Override
public void getData(int curPage) {
singleInterfaceModel.getData(curPage, new Callback<ArticleListBean, String>() {
@Override
public void onSuccess(ArticleListBean loginResultBean) {
//如果Model层请求数据成功,则此处应执行通知View层的代码
//LP.w()是一个简单的log打印
LP.w(loginResultBean.toString());
}
@Override
public void onFail(String errorMsg) {
//如果Model层请求数据失败,则此处应执行通知View层的代码
LP.w(errorMsg);
}
});
}
}3. 生命周期适配至此,MVP三层每层的接口都写好了.但是P层连接V层的桥梁还没有搭建好,这个慢慢来,一个好的高楼大厦都是一步一步建造的.上面IPresenter接口我们没有让其他类继承,接下来就讲下这个.P层和V层相连接,V层的生命周期也要适配到P层,P层的每个功能都要适配生命周期,这里可以把生命周期的适配放在IPresenter接口中.P层持有V层对象,这里把它放到泛型中.代码如下.
public interface IPresenter<T extends IView> {
/**
* 依附生命view
*
* @param view
*/
void attachView(T view);
/**
* 分离View
*/
void detachView();
/**
* 判断View是否已经销毁
*
* @return
*/
boolean isViewAttached();
}
这个IPresenter接口需要所有的P层实现类继承,对于生命周期这部分功能都是通用的,那么就可以抽出来一个抽象基类BasePresenter,去实现IPresenter的接口.
public abstract class BasePresenter<T extends IView> implements IPresenter<T> {
protected T mView;
@Override
public void attachView(T view) {
mView = view;
}
@Override
public void detachView() {
mView = null;
}
@Override
public boolean isViewAttached() {
return mView != null;
}
}此时,SingleInterfacePresenter类的代码修改如下.泛型中的SingleInterfaceIView可以理解成对应的Activity,P层此时完成了对V层的通信.public class SingleInterfacePresenter extends BasePresenter<SingleInterfaceIView> implements ISingleInterfacePresenter {
private final ISingleInterfaceModel singleInterfaceModel;
public SingleInterfacePresenter() {
this.singleInterfaceModel = new SingleInterfaceModel();
}
@Override
public void getData(int curPage) {
singleInterfaceModel.getData(curPage, new Callback<ArticleListBean, String>() {
@Override
public void onSuccess(ArticleListBean loginResultBean) {
//如果Model层请求数据成功,则此处应执行通知View层的代码
//LP.w()是一个简单的log打印
LP.w(loginResultBean.toString());
if (isViewAttached()) {
mView.showArticleSuccess(loginResultBean);
}
}
@Override
public void onFail(String errorMsg) {
//如果Model层请求数据失败,则此处应执行通知View层的代码
LP.w(errorMsg);
if (isViewAttached()) {
mView.showArticleFail(errorMsg);
}
}
});
}
}此时,P层和V层的连接桥梁已经搭建,但还未搭建完成,我们需要写个BaseMVPActvity让所有的Activity继承,统一处理Activity相同逻辑.在BaseMVPActvity中使用IPresenter的泛型,因为每个Activity中需要持有P层对象,这里把P层对象抽出来也放在BaseMVPActvity中.同时BaseMVPActvity中也需要继承IView,用于P层对V层的生命周期中.代码如下.public abstract class BaseMVPActivity<T extends IPresenter> extends AppCompatActivity implements IView {
protected T mPresenter;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
initPresenter();
init();
}
protected void initPresenter() {
mPresenter = createPresenter();
//绑定生命周期
if (mPresenter != null) {
mPresenter.attachView(this);
}
}
@Override
protected void onDestroy() {
if (mPresenter != null) {
mPresenter.detachView();
}
super.onDestroy();
}
/**
* 创建一个Presenter
*
* @return
*/
protected abstract T createPresenter();
protected abstract void init();
}接下来让SingleInterfaceActivity实现这个BaseMVPActivity.public class SingleInterfaceActivity extends BaseMVPActivity<SingleInterfacePresenter> implements SingleInterfaceIView {
private Button button;
private TextView textView;
@Override
protected void init() {
setContentView(R.layout.activity_single_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
mPresenter.getData(0);
}
});
}
@Override
protected SingleInterfacePresenter createPresenter() {
return new SingleInterfacePresenter();
}
@Override
public void showArticleSuccess(ArticleListBean bean) {
textView.setText(bean.data.datas.get(0).title);
}
@Override
public void showArticleFail(String errorMsg) {
Toast.makeText(this, errorMsg, Toast.LENGTH_SHORT).show();
}
}到此,MVP架构的整个简易流程完成.代码写到这里,笔者先把这些代码提交到github(https://github.com/serge66/MVPDemo),github上会有一次提交记录,如果想看此时的代码,可以根据提交记录"第二次修改"克隆此时的代码.
4. 优化MVP架构
.jpeg")
上面是MVP的目录,从目录中我们可以看到一个功能点(网络请求)MVP三层各有两个文件需要写,相对于MVC来说写起来确实麻烦,这也是一些人不愿意写MVP,宁愿用MVC的原因.
这里我们可以对此优化一下.MVP架构中有个Contract的概念,Contract有统一管理接口的作用,目的是为了统一管理一个页面的View和Presenter接口,用Contract可以减少部分文件的创建,比如P层和V层的接口文件.
那我们就把P层的ISingleInterfacePresenter接口和V层的SingleInterfaceIView接口文件删除掉,放入SingleInterfaceContract文件中.代码如下.
public interface SingleInterfaceContract {
interface View extends IView {
void showArticleSuccess(ArticleListBean bean);
void showArticleFail(String errorMsg);
}
interface Presenter {
void getData(int curPage);
}
}此时,SingleInterfacePresenter和SingleInterfaceActivity的代码修改如下.public class SingleInterfacePresenter extends BasePresenter<SingleInterfaceContract.View>
implements SingleInterfaceContract.Presenter {
private final ISingleInterfaceModel singleInterfaceModel;
public SingleInterfacePresenter() {
this.singleInterfaceModel = new SingleInterfaceModel();
}
@Override
public void getData(int curPage) {
singleInterfaceModel.getData(curPage, new Callback<ArticleListBean, String>() {
@Override
public void onSuccess(ArticleListBean loginResultBean) {
//如果Model层请求数据成功,则此处应执行通知View层的代码
//LP.w()是一个简单的log打印
LP.w(loginResultBean.toString());
if (isViewAttached()) {
mView.showArticleSuccess(loginResultBean);
}
}
@Override
public void onFail(String errorMsg) {
//如果Model层请求数据失败,则此处应执行通知View层的代码
LP.w(errorMsg);
if (isViewAttached()) {
mView.showArticleFail(errorMsg);
}
}
});
}
}
public class SingleInterfaceActivity extends BaseMVPActivity<SingleInterfacePresenter>
implements SingleInterfaceContract.View {
private Button button;
private TextView textView;
@Override
protected void init() {
setContentView(R.layout.activity_single_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
mPresenter.getData(0);
}
});
}
@Override
protected SingleInterfacePresenter createPresenter() {
return new SingleInterfacePresenter();
}
@Override
public void showArticleSuccess(ArticleListBean bean) {
textView.setText(bean.data.datas.get(0).title);
}
@Override
public void showArticleFail(String errorMsg) {
Toast.makeText(this, errorMsg, Toast.LENGTH_SHORT).show();
}
}
代码写到这里,笔者先把这些代码提交到github(https://github.com/serge66/MVPDemo),github上会有一次提交记录,如果想看此时的代码,可以根据提交记录"第三次修改"克隆此时的代码.
5. 单页面多网络请求以及P层复用
上面的MVP封装只适用于单页面一个网络请求的情况,当一个界面有两个网络请求时,此封装已不适合.以及考虑到P层的复用.为此,我们再次新建一个MultipleInterfaceActivity来进行说明.XML中布局是两个按钮两个Textview,点击则可以进行网络请求.
.gif")
<?xml version="1.0" encoding="utf-8"?>MultipleInterfaceActivity类代码暂时如下.
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:layout_gravity="center"
android:gravity="center"
android:orientation="vertical"
tools:context=".view.MultipleInterfaceActivity">
<Button
android:id="@+id/button"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="点击" />
<TextView
android:id="@+id/textView"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginTop="50px"
android:text="请点击上方按钮获取数据" />
<Button
android:id="@+id/btn"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginTop="100px"
android:text="点击" />
<TextView
android:id="@+id/tv"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginTop="50px"
android:text="请点击上方按钮获取数据" />
</LinearLayout>
public class MultipleInterfaceActivity extends BaseMVPActivity {
private Button button;
private TextView textView;
private Button btn;
private TextView tv;
@Override
protected void init() {
setContentView(R.layout.activity_multiple_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
}
});
btn = findViewById(R.id.btn);
tv = findViewById(R.id.tv);
btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
}
});
}
@Override
protected IPresenter createPresenter() {
return null;
}
}此时我们可以想下,当一个页面中有多个网络请求时,Activity所继承的BaseMVPActivity的泛型中要写多个参数,那有没有上面代码的框架不变的情况下实现这个需求呢?答案必须有的.我们可以把多个网络请求的功能当做一个网络请求来看待,封装成一个MultiplePresenter,其继承至BasePresenter实现生命周期的适配.此MultiplePresenter类的作用就是容纳多个Presenter,连接同一个View.代码如下.public class MultiplePresenter<T extends IView> extends BasePresenter<T> {
private T mView;
private List<IPresenter> presenters = new ArrayList<>();
@SafeVarargs
public final <K extends IPresenter<T>> void addPresenter(K... addPresenter) {
for (K ap : addPresenter) {
ap.attachView(mView);
presenters.add(ap);
}
}
public MultiplePresenter(T mView) {
this.mView = mView;
}
@Override
public void detachView() {
for (IPresenter presenter : presenters) {
presenter.detachView();
}
}
}因MultiplePresenter类中需要有多个网络请求,现在举例说明时,暂时用两个网络请求接口.MultipleInterfaceActivity类中代码改造如下.public class MultipleInterfaceActivity extends BaseMVPActivity<MultiplePresenter>写到这里,MVP框架基本算是完成.如果想再次优化,其实还是有可优化的地方,比如当View销毁时,现在只是让P层中的View对象置为null,并没有继续对M层通知.如果View销毁时,M层还在请求网络中呢,可以为此再加入一个取消网络请求的通用功能.这里只是举一个例子,每个人对MVP的理解不一样,而MVP架构也并不是一成不变,适合自己项目的才是最好的.
implements SingleInterfaceContract.View, MultipleInterfaceContract.View {
private Button button;
private TextView textView;
private Button btn;
private TextView tv;
private SingleInterfacePresenter singleInterfacePresenter;
private MultipleInterfacePresenter multipleInterfacePresenter;
@Override
protected void init() {
setContentView(R.layout.activity_multiple_interface);
button = findViewById(R.id.button);
textView = findViewById(R.id.textView);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
singleInterfacePresenter.getData(0);
}
});
btn = findViewById(R.id.btn);
tv = findViewById(R.id.tv);
btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
multipleInterfacePresenter.getBanner();
}
});
}
@Override
protected MultiplePresenter createPresenter() {
MultiplePresenter multiplePresenter = new MultiplePresenter(this);
singleInterfacePresenter = new SingleInterfacePresenter();
multipleInterfacePresenter = new MultipleInterfacePresenter();
multiplePresenter.addPresenter(singleInterfacePresenter);
multiplePresenter.addPresenter(multipleInterfacePresenter);
return multiplePresenter;
}
@Override
public void showArticleSuccess(ArticleListBean bean) {
textView.setText(bean.data.datas.get(0).title);
}
@Override
public void showArticleFail(String errorMsg) {
Toast.makeText(this, errorMsg, Toast.LENGTH_SHORT).show();
}
@Override
public void showMultipleSuccess(BannerBean bean) {
tv.setText(bean.data.get(0).title);
}
@Override
public void showMultipleFail(String errorMsg) {
Toast.makeText(this, errorMsg, Toast.LENGTH_SHORT).show();
}
}
6. 完整项目地址
完整项目已提交到github(https://github.com/serge66/MVPDemo).点击下方阅读原文即可访问.
五. 参考资料
[一步步带你精通MVP](https://mp.weixin.qq.com/s/DuNbl3V4gZY-ZCETbhZGug)
[从0到1搭建MVP框架](https://mp.weixin.qq.com/s/QFpHhC-5JkAb4IlMP0nKug)
[Presenter层如何高度的复用](https://juejin.im/post/599ce8016fb9a0247e4255f4)
六. 后续
MVVM架构从入门到精通-真枪实弹 敬请期待~~~

微信公众号:IT大前端
关注可了解更多的大前端领域技术
收起阅读 »
React Native调用原生Android/iOS代码方案并实现拨号功能
一 前言
由于前几个月公司2.0项目开发技术选型为React Native,技术部相关人员开始学习React Native相关的技术,笔者是一名Android开发者,下文所描述的React Native调用Android/iOS模块中关于iOS的部分如有误的地方,请指出。为了让从Android或iOS学习React Native的同志更加清楚的了解另一移动端,笔者尽可能写的详细点。
二 效果
下面两张图分别为iOS和Android上效果图,其中iOS效果图中点击电话号码会打印log,并不会调起iOS拨号界面,因为iOS模拟器不支持此功能,所以要想看效果只能用真机查看。这里打印log是为了证明React Native成功调起了原生iOS模块功能。

.gif")
三 实现方案
关于调用拨号功能以及调用浏览器、短信、邮箱等功能,可有两种实现方案。
一种是按照React Native提供的调用原生的过程方案来调用,这种适合大部分React Native调用原生功能的需求,掌握这种后,基本以后再有调用原生需求即可按照此过程方案解决,此文也会选用这种方案进行描述。
另一种是React Native帮我们封装的Linking模块可以实现这类的需求,这种相比上一种来说相对简单,主要适用于调用原生的电话、短信、邮箱、浏览器等功能。
四 实现原生Android模块
1.在自己新建的Reacat Native项目中android/app/src/main/java/xxx(项目包名)/ 目录下(为了和其他文件分离,笔者又在此目录下新建一个native文件夹),需要新建一个java类文件,例如文件名为CallPhoneModule.java,这个java类一定要继承RN提供的ReactContextBaseJavaModule抽象类,然后实现其构造函数,其中的参数要为ReactApplicationContext reactContext。
2.然后实现NativeModule中定义的getName()方法,返回一个String类型字符串,这个返回结果将要在JavaScript中使用,例如返回“CallPhoneModule”,则可以在JavaScript中通过React.NativeModules.CallPhoneModule调用。
注意,如果返回的字符串中有RCT前缀,则会自动移除RCT前缀。例如返回“RCTCallPhoneModule”,则在JavaScript中依然可以通过React.NativeModules.CallPhoneModule调用。CallPhoneModule继承ReactContextBaseJavaModule,ReactContextBaseJavaModule继承BaseJavaModule,BaseJavaModule实现了NativeModule接口,这是CallPhoneModule与NativeModule的关系。
3.然后在CallPhoneModule类中写一个方法,这个方法提供给JavaScript调用,例如方法名为callPhone,里面传递String类型参数(非必须),特别的这个方法要使用@ReactMethod注解,以及返回类型必须为void。然后在callPhone方法中写入要实现的功能,这里写入了拨号功能的实现。
CallPhoneModule.java文件的全部代码如下:
4.新建一个java类文件,例如文件名为CallPhoneReactPackage.java,这个类必须实现ReactPackage接口,然后实现createViewManagers、createNativeModules两个方法,特别的要在createNativeModules方法的返回值中add进刚才新建的CallPhoneModule类。
CallPhoneReactPackage.java全部代码如下:
5.最后在MainApplication.java文件中的getPackages方法中加上刚才新建的CallPhoneReactPackage类。至此,原生Android模块书写完毕。关于JavaScript调用原生Android模块代码会在文末和调用原生iOS一起写出。
修改后的MainApplication.java文件代码如下:
五 实现原生iOS模块
1.在自己新建的Reacat Native项目中ios/xxx(项目包名)/ 目录下,需要新建一个后缀为m和一个后缀为h的文件。为了和其他文件分离以及和Android保持一致,笔者又在此目录下新建一个native文件夹。
在Xcode的此文件夹上右键New File,然后在弹出的页面中Cocoa Touch Class选项输入文件名,这样会建立出相同文件名的m和h文件。如果New File时,分别选择Objective-C File和Header File,则这两个文件名要相同。例如文件名称为CallPhoneModuleIos。
2.在CallPhoneModuleIos.h文件中,类要实现RN提供的RCTBridgeModule协议。RCT是ReaCT的缩写,React Native中Object-C相关的命名均以RCT开头。
RCTBridgeModule是定义好的protocol,实现该协议的类,会自动注册到Object-C对应的Bridge中。Object-C Bridge上层负责与Object-C通信,下层负责和JavaScript Bridge通信,而JavaScript Bridge负责和JavaScript通信。这样,通过Object-C Bridge和JavaScript Bridge就可以实现JavaScript和Object-C的相互调用。
CallPhoneModuleIos.h文件如下:
3.CallPhoneModuleIos.m文件中,类需要包含RCT_EXPORT_MODULE()宏,作用是自动注册一个module。这个宏可以添加一个参数,用来指定在JavaScript调用这个模块的名字,类似于上文中说的getName()方法。如果不添加这个参数,则默认就是这个类的名字。
4.然后需要在此类中写一个方法,提供给RN调用,方法通过RCT_EXPORT_METHOD()宏来实现。
CallPhoneModuleIos.m完整代码:
至此,则原生iOS代码书写完成,现在即将开始调用。
六 React Native调用Android、iOS原生模块
为了在JavaScript端同时访问Android、iOS原生模块更加方便,笔者把原生模块的调用封装在一个JavaScript文件中,例如文件名为CallPhone.js,这样在需要调用的地方直接调用此JavaScript文件既可,同时在此文件中,处理好Android、iOS、Web(若有)的分别调用。
然后在JavaScript文件中这样调用:
到这里,整篇文章就结束了,疑问、建议或者指教欢迎讨论。
七 参考资料
native-modules-ios (https://facebook.github.io/react-native/docs/native-modules-ios.html)
native-modules-android (https://facebook.github.io/react-native/docs/native-modules-android.html)

微信公众号:IT大前端
关注可了解更多的大前端领域技术 收起阅读 »
由于前几个月公司2.0项目开发技术选型为React Native,技术部相关人员开始学习React Native相关的技术,笔者是一名Android开发者,下文所描述的React Native调用Android/iOS模块中关于iOS的部分如有误的地方,请指出。为了让从Android或iOS学习React Native的同志更加清楚的了解另一移动端,笔者尽可能写的详细点。
二 效果
下面两张图分别为iOS和Android上效果图,其中iOS效果图中点击电话号码会打印log,并不会调起iOS拨号界面,因为iOS模拟器不支持此功能,所以要想看效果只能用真机查看。这里打印log是为了证明React Native成功调起了原生iOS模块功能。
三 实现方案
关于调用拨号功能以及调用浏览器、短信、邮箱等功能,可有两种实现方案。
一种是按照React Native提供的调用原生的过程方案来调用,这种适合大部分React Native调用原生功能的需求,掌握这种后,基本以后再有调用原生需求即可按照此过程方案解决,此文也会选用这种方案进行描述。
另一种是React Native帮我们封装的Linking模块可以实现这类的需求,这种相比上一种来说相对简单,主要适用于调用原生的电话、短信、邮箱、浏览器等功能。
四 实现原生Android模块
1.在自己新建的Reacat Native项目中android/app/src/main/java/xxx(项目包名)/ 目录下(为了和其他文件分离,笔者又在此目录下新建一个native文件夹),需要新建一个java类文件,例如文件名为CallPhoneModule.java,这个java类一定要继承RN提供的ReactContextBaseJavaModule抽象类,然后实现其构造函数,其中的参数要为ReactApplicationContext reactContext。
public class CallPhoneModule extends ReactContextBaseJavaModule {
public CallPhoneModule(ReactApplicationContext reactContext) {
super(reactContext);
}
}2.然后实现NativeModule中定义的getName()方法,返回一个String类型字符串,这个返回结果将要在JavaScript中使用,例如返回“CallPhoneModule”,则可以在JavaScript中通过React.NativeModules.CallPhoneModule调用。
注意,如果返回的字符串中有RCT前缀,则会自动移除RCT前缀。例如返回“RCTCallPhoneModule”,则在JavaScript中依然可以通过React.NativeModules.CallPhoneModule调用。CallPhoneModule继承ReactContextBaseJavaModule,ReactContextBaseJavaModule继承BaseJavaModule,BaseJavaModule实现了NativeModule接口,这是CallPhoneModule与NativeModule的关系。
@Override
public String getName() {
return "CallPhoneModule";
}
3.然后在CallPhoneModule类中写一个方法,这个方法提供给JavaScript调用,例如方法名为callPhone,里面传递String类型参数(非必须),特别的这个方法要使用@ReactMethod注解,以及返回类型必须为void。然后在callPhone方法中写入要实现的功能,这里写入了拨号功能的实现。
Intent intent = new Intent(Intent.ACTION_DIAL, Uri.parse("tel:" + phoneString));
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
this.reactContext.startActivity(intent);CallPhoneModule.java文件的全部代码如下:
package com.zhuku02;
import android.content.Intent;
import android.net.Uri;
import com.facebook.react.bridge.ReactApplicationContext;
import com.facebook.react.bridge.ReactContextBaseJavaModule;
import com.facebook.react.bridge.ReactMethod;
import java.lang.String;
public class CallPhoneModule extends ReactContextBaseJavaModule {
public ReactApplicationContext reactContext;
public CallPhoneModule(ReactApplicationContext reactContext) {
super(reactContext);
this.reactContext = reactContext;
}
@ReactMethod
public void callPhone(String phoneString) {
Intent intent = new Intent(Intent.ACTION_DIAL, Uri.parse("tel:" + phoneString));
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
this.reactContext.startActivity(intent);
}
@Override
public String getName() {
return "CallPhoneModule";
}
}
4.新建一个java类文件,例如文件名为CallPhoneReactPackage.java,这个类必须实现ReactPackage接口,然后实现createViewManagers、createNativeModules两个方法,特别的要在createNativeModules方法的返回值中add进刚才新建的CallPhoneModule类。
CallPhoneReactPackage.java全部代码如下:
package com.zhuku02;
import com.facebook.react.ReactPackage;
import com.facebook.react.bridge.NativeModule;
import com.facebook.react.bridge.ReactApplicationContext;
import com.facebook.react.uimanager.ViewManager;
import com.zhuku02.CallPhoneModule;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CallPhoneReactPackage implements ReactPackage {
@Override
public List<ViewManager> createViewManagers(ReactApplicationContext reactContext) {
return Collections.emptyList();
}
@Override
public List<NativeModule> createNativeModules(ReactApplicationContext reactContext) {
List<NativeModule> modules = new ArrayList<>();
modules.add(new CallPhoneModule(reactContext));
return modules;
}
}
5.最后在MainApplication.java文件中的getPackages方法中加上刚才新建的CallPhoneReactPackage类。至此,原生Android模块书写完毕。关于JavaScript调用原生Android模块代码会在文末和调用原生iOS一起写出。
修改后的MainApplication.java文件代码如下:
package com.zhuku02;
import android.app.Application;
import com.facebook.react.ReactApplication;
import com.facebook.react.ReactNativeHost;
import com.facebook.react.ReactPackage;
import com.facebook.react.shell.MainReactPackage;
import com.facebook.soloader.SoLoader;
import com.zhuku02.CallPhoneReactPackage;
import java.util.Arrays;
import java.util.List;
public class MainApplication extends Application implements ReactApplication {
private final ReactNativeHost mReactNativeHost = new ReactNativeHost(this) {
@Override
public boolean getUseDeveloperSupport() {
return BuildConfig.DEBUG;
}
@Override
protected List<ReactPackage> getPackages() {
return Arrays.<ReactPackage>asList(
new MainReactPackage(),
new CallPhoneReactPackage()
);
}
};
@Override
public ReactNativeHost getReactNativeHost() {
return mReactNativeHost;
}
@Override
public void onCreate() {
super.onCreate();
SoLoader.init(this, /* native exopackage */ false);
}
}
五 实现原生iOS模块
1.在自己新建的Reacat Native项目中ios/xxx(项目包名)/ 目录下,需要新建一个后缀为m和一个后缀为h的文件。为了和其他文件分离以及和Android保持一致,笔者又在此目录下新建一个native文件夹。
在Xcode的此文件夹上右键New File,然后在弹出的页面中Cocoa Touch Class选项输入文件名,这样会建立出相同文件名的m和h文件。如果New File时,分别选择Objective-C File和Header File,则这两个文件名要相同。例如文件名称为CallPhoneModuleIos。
2.在CallPhoneModuleIos.h文件中,类要实现RN提供的RCTBridgeModule协议。RCT是ReaCT的缩写,React Native中Object-C相关的命名均以RCT开头。
RCTBridgeModule是定义好的protocol,实现该协议的类,会自动注册到Object-C对应的Bridge中。Object-C Bridge上层负责与Object-C通信,下层负责和JavaScript Bridge通信,而JavaScript Bridge负责和JavaScript通信。这样,通过Object-C Bridge和JavaScript Bridge就可以实现JavaScript和Object-C的相互调用。
CallPhoneModuleIos.h文件如下:
#import <UIKit/UIKit.h>
#import <React/RCTBridgeModule.h>
#import <React/RCTLog.h>
@interface CallPhoneModuleIos : NSObject <RCTBridgeModule>
@end
3.CallPhoneModuleIos.m文件中,类需要包含RCT_EXPORT_MODULE()宏,作用是自动注册一个module。这个宏可以添加一个参数,用来指定在JavaScript调用这个模块的名字,类似于上文中说的getName()方法。如果不添加这个参数,则默认就是这个类的名字。
4.然后需要在此类中写一个方法,提供给RN调用,方法通过RCT_EXPORT_METHOD()宏来实现。
RCT_EXPORT_METHOD(callPhone: (NSString *)phone){
NSLog(@"======%@",phone);
}CallPhoneModuleIos.m完整代码:
#import "CallPhoneModuleIos.h"
#import <Foundation/Foundation.h>
@implementation CallPhoneModuleIos
RCT_EXPORT_MODULE(CallPhoneModuleIos);
RCT_EXPORT_METHOD(callPhone: (NSString *)phone){
NSLog(@"======%@",phone);
//去掉注释,下面代码就是实现拨号功能代码,但还未真机测试
// NSMutableString * str = [[NSMutableString alloc] initWithFormat:@"telprompt://%@",phone];
// [[UIApplication sharedApplication] openURL:[NSURL URLWithString:str]];
}
// -(dispath_queue_t)methodQueue{
// return dispath_get_main_queue();
// }
@end
至此,则原生iOS代码书写完成,现在即将开始调用。
六 React Native调用Android、iOS原生模块
为了在JavaScript端同时访问Android、iOS原生模块更加方便,笔者把原生模块的调用封装在一个JavaScript文件中,例如文件名为CallPhone.js,这样在需要调用的地方直接调用此JavaScript文件既可,同时在此文件中,处理好Android、iOS、Web(若有)的分别调用。
import {Platform, NativeModules} from 'react-native';
var module = null;
if (Platform.OS == 'ios') {
module = NativeModules.CallPhoneModuleIos;
} else if (Platform.OS == 'android') {
module = NativeModules.CallPhoneModule;
} else if (Platform.OS == 'web') {
//暂未实现web功能
}
export default module;然后在JavaScript文件中这样调用:
import CallPhone from '../../native/CallPhone';
CallPhone.callPhone('40077731xx');
到这里,整篇文章就结束了,疑问、建议或者指教欢迎讨论。
七 参考资料
native-modules-ios (https://facebook.github.io/react-native/docs/native-modules-ios.html)
native-modules-android (https://facebook.github.io/react-native/docs/native-modules-android.html)
微信公众号:IT大前端
关注可了解更多的大前端领域技术 收起阅读 »
EaseUI 3.5.3 DexArchiveMergerException
集成easeui3.5.3报错
【活动推荐】2019安卓巴士千人开发者大会-NEW●无界
本次将邀请到BAT等知名互联网公司的16位优秀演讲嘉宾坐镇,内容上除了主会场全天的Android技术干货分享,分会场还将覆盖到大数据、机器学习、跨平台开发以及小程序等方向内容。
三人行两人免单团购超便宜报名速戳https://www.hdb.com/dis/htn3yi6fpo
活动时间:2019年4月20号
活动地点:深圳南山区圣淘沙酒店
*入现场群说明:
购票成功后,请添加安卓巴士官方微信号 shzsbgbs ,备注【开发者大会】通过后提供购票成功截图,小编邀请您进入420开发者大会现场群。
备注【拼团】邀请您进入拼团群,和小伙伴一起享受超低团购价。
*付费说明:
本次活动经费用于场租、设备、物料、礼品、嘉宾交通住宿费等。
*退款说明:
由于本活动各项资源需提前采购,一经售出不接受退款,请确认后购买。



收起阅读 »
WIFI 考勤打卡 浅析
一、背景
最近产品部提出了在WEB端设置wifi考勤打卡新需求,根据管理员设置的wifi相关信息(主要是WIFI名称和MAC地址),员工用户利用移动端相连接的wifi进行wifi考勤打卡。
二、名词术语解释
下面的理解全是建立在无线路由器的基础上。如有错误请指出。
1、SS
SS(Service set)即服务集,是无线局域网中的一个术语,用以描述802.11无线网络的构成单位(一组互相有联系的无线设备),使用服务集标识符(SSID)作为识别。
可以分为独立基本服务集(IBSS)、基本服务集(BSS)和扩展服务集(ESS)三类。其中IBSS属于对等拓扑模式(又称Ad-Hoc模式、无线随意网络),而BSS和ESS属于基础架构模式。这些拓扑是原始的802.11规范中定义的,其他的如网桥、中继器等则是属于特定厂商的扩展或者WDS的拓扑模式。
2、SSID
SSID(Service Set Identifier)即服务集标识符,是一个或一组基础架构模式无线网络的标识,依照标识方式又可细分为两种:
基本服务集标识符(BSSID),表示的是AP的数据链路层的MAC地址。
扩展服务集标识符(ESSID),一个最长32字节区分大小写的字符串,ESSID标识与SSID相同的网络。术语SSID最常用。
在此可以理解为无线路由器发射的某个wifi的名称。(SSID=name of network)
3、BSS
BSS(Basic Service Set)即基本服务集,是一组能在PHY层相互通信的所有站。每个BSS都有一个称为BSSID的标识(ID),它是服务于BSS的接入点的MAC地址。
用在无线路由器发射出的wifi上可以这样理解:某一个无线路由器发射出的wifi信号所覆盖的范围可视为BSS。

4、BSSID
BSSID(Basic Service Set Identifier)即基本服务集标识符。
在上面的基础上可以这样理解:对某一个BSS基本服务集的唯一标识。例如,某无线路由器发射了一个名称为A的wifi热点,同一区域另一个无线路由器也发出了一个名称为A的wifi热点,当手机连接A热点时,如何辨别连接的是由哪一个路由器发射的wifi呢?
这时候就要用到BSSID了。一般情况下BSSID可以理解为无线路由器的MAC地址,通过查看手机连接wifi的MAC地址即可知道连接的是哪一个路由。(BSSID=AP MAC address)
其实准确来说手机得到的BSSID并不是路由器的基准(出厂)MAC地址。
例如,笔者公司的某款无线路由器B的出厂MAC地址为 XX:XX:XX:XX:XX:F1,当手机连接此wifi查看mac地址时发现是XX:XX:XX:XX:XX:F2,或者是XX:XX:XX:XX:XX:F3。
5、ESS ESSID
ESS(Extended Service Set )即扩展的基本服务集。
ESSID(Extended Service Set Identifier)即扩展的基本服务集标识符。
BSS+BSS+BSS+BSS+…=ESS。ESS为多个BSS的集合。ESS使用指定的ESSID作识别。
通过将多个BSS比邻安置,可以扩展网络的范围,如果这些BSS通过各种分布系统互联(无论是有线的还是无线的),拥有一致的ESSID,并且对于逻辑链路控制层来说可以认为是一个BSS的话,那么这些BSS可以被统一为一个ESS。
在同一个ESS中的不同BSS之间切换的过程称为漫游。一般而言,一个ESS中的BSS都会使用相同的SSID和安全机制以提供接近于无缝漫游的可能。两个BSS之间通常有15%左右的重叠范围来保证漫游时信号不会长时间丢失,并且设置在不同频段来防止相互干扰。

6、MAC
MAC地址采用十六进制数表示,共六个字节(48位)。(XX:XX:XX:XX:XX:XX )其中,前三个字节是由IEEE的注册管理机构RA负责给不同厂家分配的代码(高位24位),也称为“编制上唯一的标识符”(Organizationally Unique Identifier),后三个字节(低位24位)由各厂家自行指派给生产的适配器接口,称为扩展标识符(唯一性)。
三、历程
当产品部提出wifi考勤打卡需求时,普遍认为一个路由器有一个mac地址,手机连接wifi可以根据mac地址等信息进行打卡。当我们用多个手机连接公司名称为A(SSID)的wifi时,发现手机上展示的mac地址并不是一致的,这个就尴尬了,打翻了原有理念。
然后发现我们公司共有五个无线路由器,wifi名称都是A。哦,这时候才感觉到原来以前的知识还是靠谱的,可能是多个手机具体连接的路由器不是同一个。
然后把五个路由器wifi热点名称改为A、B、C、D、E,多个手机连接A热点时,发现手机得到的mac地址是一致的,到这里可以得出的结论是手机连接同一个wifi热点得到的mac地址是一致的。但是…..又尴尬了。
当多款手机连接B热点时,发现又出现了不一致的mac地址,查找原因发现,原来B无线路由器中可以设置2.4G Hz和5G Hz两个不同频段的wifi热点。B路由器中默认是开启2.4G Hz和5G Hz频段的wifi热点,并且wifi名称(SSID)是同一个。经过检查还有个问题是B路由器的出厂mac地址和手机连接得到的mac地址不一致。
例如上面举得例子:笔者公司的某款无线路由器B的出厂MAC地址为 XX:XX:XX:XX:XX:F1,当手机连接此wifi查看mac地址时发现是XX:XX:XX:XX:XX:F2,另一款手机连接时是XX:XX:XX:XX:XX:F3。由此可得出的结论是,路由器有一个基准(出厂)mac地址,然后发射出wifi的mac在基准mac地址上按照一定的算法进行变动,具体的变动算法不清楚,有清楚的请告知我,非常感谢。
另外还有一个问题是,C路由器设备后面所写的出厂说明mac地址是XX:XX:XX:XX:XX:56,但是通过路由器后台看到的出厂mac地址是XX:XX:XX:XX:XX:57,手机连接后得到的mac地址是XX:XX:XX:XX:XX:56。这就尴尬了,是厂家写错了还是根据特定的算法算的?
除了根据wifi设备分析外,我们也对具有wifi考勤打卡功能的软件进行了分析。比如现在比较火爆的由阿里团队研发的钉钉,以及纷享销客APP,在Android端,他们的处理都是获取周围wifi信息(并不是当前手机连接的wifi)进行打卡。在iOS端,他们的处理都是根据当前手机连接的wifi信息进行打卡。据iOS同事说,iOS获取周围wifi信息需要申请此功能,并最低支持版本是iOS 9。另外据可靠消息,分享逍客对mac地址的处理也是通过忽略低4位进行匹配。
四、结论
经过上述分析,手机获取的无线路由器MAC地址的低4位是变化的。那我们实现这个需求时,除了匹配虚拟位置、手机信息、wifi相关等其他信息外,只针对mac地址,我们可以忽略mac地址的低4位来做匹配。
五、参考资料
http://www.juniper.net/documentation/en_US/junos-space-apps12.3/network-director/topics/concept/wireless-ssid-bssid-essid.html

微信公众号:IT大前端
关注可了解更多的大前端领域技术 收起阅读 »
最近产品部提出了在WEB端设置wifi考勤打卡新需求,根据管理员设置的wifi相关信息(主要是WIFI名称和MAC地址),员工用户利用移动端相连接的wifi进行wifi考勤打卡。
二、名词术语解释
下面的理解全是建立在无线路由器的基础上。如有错误请指出。
1、SS
SS(Service set)即服务集,是无线局域网中的一个术语,用以描述802.11无线网络的构成单位(一组互相有联系的无线设备),使用服务集标识符(SSID)作为识别。
可以分为独立基本服务集(IBSS)、基本服务集(BSS)和扩展服务集(ESS)三类。其中IBSS属于对等拓扑模式(又称Ad-Hoc模式、无线随意网络),而BSS和ESS属于基础架构模式。这些拓扑是原始的802.11规范中定义的,其他的如网桥、中继器等则是属于特定厂商的扩展或者WDS的拓扑模式。
2、SSID
SSID(Service Set Identifier)即服务集标识符,是一个或一组基础架构模式无线网络的标识,依照标识方式又可细分为两种:
基本服务集标识符(BSSID),表示的是AP的数据链路层的MAC地址。
扩展服务集标识符(ESSID),一个最长32字节区分大小写的字符串,ESSID标识与SSID相同的网络。术语SSID最常用。
在此可以理解为无线路由器发射的某个wifi的名称。(SSID=name of network)
3、BSS
BSS(Basic Service Set)即基本服务集,是一组能在PHY层相互通信的所有站。每个BSS都有一个称为BSSID的标识(ID),它是服务于BSS的接入点的MAC地址。
用在无线路由器发射出的wifi上可以这样理解:某一个无线路由器发射出的wifi信号所覆盖的范围可视为BSS。
4、BSSID
BSSID(Basic Service Set Identifier)即基本服务集标识符。
在上面的基础上可以这样理解:对某一个BSS基本服务集的唯一标识。例如,某无线路由器发射了一个名称为A的wifi热点,同一区域另一个无线路由器也发出了一个名称为A的wifi热点,当手机连接A热点时,如何辨别连接的是由哪一个路由器发射的wifi呢?
这时候就要用到BSSID了。一般情况下BSSID可以理解为无线路由器的MAC地址,通过查看手机连接wifi的MAC地址即可知道连接的是哪一个路由。(BSSID=AP MAC address)
其实准确来说手机得到的BSSID并不是路由器的基准(出厂)MAC地址。
例如,笔者公司的某款无线路由器B的出厂MAC地址为 XX:XX:XX:XX:XX:F1,当手机连接此wifi查看mac地址时发现是XX:XX:XX:XX:XX:F2,或者是XX:XX:XX:XX:XX:F3。
5、ESS ESSID
ESS(Extended Service Set )即扩展的基本服务集。
ESSID(Extended Service Set Identifier)即扩展的基本服务集标识符。
BSS+BSS+BSS+BSS+…=ESS。ESS为多个BSS的集合。ESS使用指定的ESSID作识别。
通过将多个BSS比邻安置,可以扩展网络的范围,如果这些BSS通过各种分布系统互联(无论是有线的还是无线的),拥有一致的ESSID,并且对于逻辑链路控制层来说可以认为是一个BSS的话,那么这些BSS可以被统一为一个ESS。
在同一个ESS中的不同BSS之间切换的过程称为漫游。一般而言,一个ESS中的BSS都会使用相同的SSID和安全机制以提供接近于无缝漫游的可能。两个BSS之间通常有15%左右的重叠范围来保证漫游时信号不会长时间丢失,并且设置在不同频段来防止相互干扰。
6、MAC
MAC地址采用十六进制数表示,共六个字节(48位)。(XX:XX:XX:XX:XX:XX )其中,前三个字节是由IEEE的注册管理机构RA负责给不同厂家分配的代码(高位24位),也称为“编制上唯一的标识符”(Organizationally Unique Identifier),后三个字节(低位24位)由各厂家自行指派给生产的适配器接口,称为扩展标识符(唯一性)。
三、历程
当产品部提出wifi考勤打卡需求时,普遍认为一个路由器有一个mac地址,手机连接wifi可以根据mac地址等信息进行打卡。当我们用多个手机连接公司名称为A(SSID)的wifi时,发现手机上展示的mac地址并不是一致的,这个就尴尬了,打翻了原有理念。
然后发现我们公司共有五个无线路由器,wifi名称都是A。哦,这时候才感觉到原来以前的知识还是靠谱的,可能是多个手机具体连接的路由器不是同一个。
然后把五个路由器wifi热点名称改为A、B、C、D、E,多个手机连接A热点时,发现手机得到的mac地址是一致的,到这里可以得出的结论是手机连接同一个wifi热点得到的mac地址是一致的。但是…..又尴尬了。
当多款手机连接B热点时,发现又出现了不一致的mac地址,查找原因发现,原来B无线路由器中可以设置2.4G Hz和5G Hz两个不同频段的wifi热点。B路由器中默认是开启2.4G Hz和5G Hz频段的wifi热点,并且wifi名称(SSID)是同一个。经过检查还有个问题是B路由器的出厂mac地址和手机连接得到的mac地址不一致。
例如上面举得例子:笔者公司的某款无线路由器B的出厂MAC地址为 XX:XX:XX:XX:XX:F1,当手机连接此wifi查看mac地址时发现是XX:XX:XX:XX:XX:F2,另一款手机连接时是XX:XX:XX:XX:XX:F3。由此可得出的结论是,路由器有一个基准(出厂)mac地址,然后发射出wifi的mac在基准mac地址上按照一定的算法进行变动,具体的变动算法不清楚,有清楚的请告知我,非常感谢。
另外还有一个问题是,C路由器设备后面所写的出厂说明mac地址是XX:XX:XX:XX:XX:56,但是通过路由器后台看到的出厂mac地址是XX:XX:XX:XX:XX:57,手机连接后得到的mac地址是XX:XX:XX:XX:XX:56。这就尴尬了,是厂家写错了还是根据特定的算法算的?
除了根据wifi设备分析外,我们也对具有wifi考勤打卡功能的软件进行了分析。比如现在比较火爆的由阿里团队研发的钉钉,以及纷享销客APP,在Android端,他们的处理都是获取周围wifi信息(并不是当前手机连接的wifi)进行打卡。在iOS端,他们的处理都是根据当前手机连接的wifi信息进行打卡。据iOS同事说,iOS获取周围wifi信息需要申请此功能,并最低支持版本是iOS 9。另外据可靠消息,分享逍客对mac地址的处理也是通过忽略低4位进行匹配。
四、结论
经过上述分析,手机获取的无线路由器MAC地址的低4位是变化的。那我们实现这个需求时,除了匹配虚拟位置、手机信息、wifi相关等其他信息外,只针对mac地址,我们可以忽略mac地址的低4位来做匹配。
五、参考资料
http://www.juniper.net/documentation/en_US/junos-space-apps12.3/network-director/topics/concept/wireless-ssid-bssid-essid.html
微信公众号:IT大前端
关注可了解更多的大前端领域技术 收起阅读 »
2019年3月3日凌晨阿里云宕机引发事故公告
环信的小伙伴,您好,
首先,环信对2019年3月3日凌晨的事故为您造成的影响深表歉意,故障公告如下:
事故概述:
3月2日晚23:55,阿里云华北2地域ECS出现了大面积宕机,导致使用这些服务的环信即时通讯云北京集群和VIP6集群服务不可用。
环信客服云的用户,如果添加了受影响的IM集群上的APP Key作为APP渠道接入的关联并且使用环信IM SDK,也会出现收发消息失败的现象。
使用系统默认的APP渠道接入关联,支持第二通道的客户互动云访客端SDK和网页端的环信客户互动云用户均不受影响。
处理过程:
收起阅读 »
首先,环信对2019年3月3日凌晨的事故为您造成的影响深表歉意,故障公告如下:
事故概述:
3月2日晚23:55,阿里云华北2地域ECS出现了大面积宕机,导致使用这些服务的环信即时通讯云北京集群和VIP6集群服务不可用。
(阿里云事故公告)

环信客服云的用户,如果添加了受影响的IM集群上的APP Key作为APP渠道接入的关联并且使用环信IM SDK,也会出现收发消息失败的现象。
使用系统默认的APP渠道接入关联,支持第二通道的客户互动云访客端SDK和网页端的环信客户互动云用户均不受影响。
处理过程:
- 环信运维团队监控到异常后,第一时间联系了阿里云,在阿里云ECS服务全面恢复之前,利用少量可用的实例提前进行了服务恢复
- 3月3日凌晨3:10,环信即时通讯云的北京集群和VIP6集群服务全部恢复
- 我们会同阿里云一起排查事故原因,防止此类事故再次发生,对您造成的影响深表歉意,感谢您对环信的支持。
收起阅读 »
老司机带你一文读懂Android运行时权限
老司机发车了,未到终点请勿下车. 嘟嘟嘟~~~
运行时权限从Android 6.0版本开始的,如果你的项目中 targetSdkVersion/compileSdkVersion 大于等于23,那么你就必须要考虑动态权限了。
权限又分为普通权限和危险权限。
普通权限如下:
android.permission.ACCESS LOCATIONEXTRA_COMMANDS
android.permission.ACCESS NETWORKSTATE
android.permission.ACCESS NOTIFICATIONPOLICY
android.permission.ACCESS WIFISTATE
android.permission.ACCESS WIMAXSTATE
android.permission.BLUETOOTH
android.permission.BLUETOOTH_ADMIN
android.permission.BROADCAST_STICKY
android.permission.CHANGE NETWORKSTATE
android.permission.CHANGE WIFIMULTICAST_STATE
android.permission.CHANGE WIFISTATE
android.permission.CHANGE WIMAXSTATE
android.permission.DISABLE_KEYGUARD
android.permission.EXPAND STATUSBAR
android.permission.FLASHLIGHT
android.permission.GET_ACCOUNTS
android.permission.GET PACKAGESIZE
android.permission.INTERNET
android.permission.KILL BACKGROUNDPROCESSES
android.permission.MODIFY AUDIOSETTINGS
android.permission.NFC
android.permission.READ SYNCSETTINGS
android.permission.READ SYNCSTATS
android.permission.RECEIVE BOOTCOMPLETED
android.permission.REORDER_TASKS
android.permission.REQUEST INSTALLPACKAGES
android.permission.SET TIMEZONE
android.permission.SET_WALLPAPER
android.permission.SET WALLPAPERHINTS
android.permission.SUBSCRIBED FEEDSREAD
android.permission.TRANSMIT_IR
android.permission.USE_FINGERPRINT
android.permission.VIBRATE
android.permission.WAKE_LOCK
android.permission.WRITE SYNCSETTINGS
com.android.alarm.permission.SET_ALARM
com.android.launcher.permission.INSTALL_SHORTCUT
com.android.launcher.permission.UNINSTALL_SHORTCUT
普通权限是当需要用到时,只需要在清单文件中声明就可。危险权限除了需要在清单文件中声明外,还需在代码中动态进行判断申请。
危险权限如下:
android.permission-group.CALENDAR
android.permission.READ_CALENDAR
android.permission.WRITE_CALENDAR
android.permission-group.CAMERA
android.permission.CAMERA
android.permission-group.CONTACTS
android.permission.READ_CONTACTS
android.permission.WRITE_CONTACTS
android.permission.GET_ACCOUNTS
android.permission-group.LOCATION
android.permission.ACCESS_FINE_LOCATION
android.permission.ACCESS_COARSE_LOCATION
android.permission-group.MICROPHONE
android.permission.RECORD_AUDIO
android.permission-group.PHONE
android.permission.READ_PHONE_STATE
android.permission.CALL_PHONE
android.permission.READ_CALL_LOG
android.permission.WRITE_CALL_LOG
com.android.voicemail.permission.ADD_VOICEMAIL
android.permission.USE_SIP
android.permission.PROCESS_OUTGOING_CALLS
android.permission-group.SENSORS
android.permission.BODY_SENSORS
android.permission-group.SMS
android.permission.SEND_SMS
android.permission.RECEIVE_SMS
android.permission.READ_SMS
android.permission.RECEIVE_WAP_PUSH
android.permission.RECEIVE_MMS
android.permission.READ_CELL_BROADCASTS
android.permission-group.STORAGE
android.permission.READ_EXTERNAL_STORAGE
android.permission.WRITE_EXTERNAL_STORAGE
危险权限是按组划分的,每一组中当某一个权限被允许或者拒绝后,同一组的其他权限也相应的自动允许或者拒绝。
当targetSdkVersion/compileSdkVersion大于等于23时,我们用到危险权限时,应按照这样的逻辑去处理。先判断当前应用是否具有权限,如果没有就去申请,当用户允许或者拒绝后,会回调相应的方法,我们在回调中处理自己的逻辑。
申请单个权限
在Activity/Fragment中,判断是否具有权限的方法是 checkSelfPermission(),申请权限的方法是requestPermissions(),然后用户允许或者拒绝后会回调方法onRequestPermissionsResult()。
虽然Activity/Fragment提供了这些方法,如果我们用这些的话,要判断安卓版本是否大于等于23,代码如下:
if(Build.VERSION.SDK_INT >= Build.VERSION_CODES.M){
//动态请求权限
}else{
//直接去调用代码
}谷歌工程师当然考虑到了这些,于是给开发者提供了兼容包,在Activity/Fragment中用ContextCompat.checkSelfPermission()判断是否具有权限;
在Activity中用 ActivityCompat.requestPermissions()请求权限;
在Fragment中直接用 requestPermissions()请求权限,不要在前面加上ActivityCompat,否则会回调Fragment所在Activity的回调方法;
在Activity/Fragment中用户允许或者拒绝权限后会回调onRequestPermissionsResult()方法。
下面看一个平常的调用系统相机拍照功能的代码:
private void takePhoto() {
Intent photoIn = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
startActivityForResult(photoIn, TAKE_PHOTO_REQUEST);
}如果我们项目targetSdkVersion/compileSdkVersion大于等于23,那么就需要动态申请权限了:
if (ContextCompat.checkSelfPermission(MySetupActivity.this, Manifest.permission.CAMERA)!= PackageManager.PERMISSION_GRANTED) {
ActivityCompat.requestPermissions(MySetupActivity.this,new String[]{Manifest.permission.CAMERA}, 100);
} else {
takePhoto();
}先判断是否具有权限,如果有直接去执行相关代码,没有则去申请权限。
当用户点击允许或者拒绝权限时,会回调onRequestPermissionsResult方法,我们在此方法中进行处理:
@Override
public void onRequestPermissionsResult(int requestCode, String[] permissions, int[] grantResults) {
if (requestCode == 100) {//相机
if (grantResults.length > 0 && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
takePhoto();
} else {
// Permission Denied
AlertDialog mDialog = new AlertDialog.Builder(MySetupActivity.this)
.setTitle("友好提醒")
.setMessage("您已拒绝权限,请开启权限!")
.setPositiveButton("开启", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
ShowAppSetDetails.showInstalledAppDetails(MySetupActivity.this, "user.zhuku.com");
LogPrint.logILsj(TAG, "开启权限设置");
}
})
.setCancelable(true)
.create();
mDialog.show();
}
}
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
}
当用户允许权限后我们直接执行相关代码,若拒绝则提示用户,弹窗提示是否需要开启权限。其中的
ShowAppSetDetails.showInstalledAppDetails(MySetupActivity.this, "user.zhuku.com");
是开启当前app信息设置界面的代码。
具体代码如下:
import android.content.Context;
import android.content.Intent;
import android.net.Uri;
import android.os.Build;
import android.provider.Settings;
public class ShowAppSetDetails {
private static final String SCHEME = "package";
/**
* 调用系统InstalledAppDetails界面所需的Extra名称(用于Android 2.1及之前版本)
*/
private static final String APP_PKG_NAME_21 = "com.android.settings.ApplicationPkgName";
/**
* 调用系统InstalledAppDetails界面所需的Extra名称(用于Android 2.2)
*/
private static final String APP_PKG_NAME_22 = "pkg";
/**
* InstalledAppDetails所在包名
*/
private static final String APP_DETAILS_PACKAGE_NAME = "com.android.settings";
/**
* InstalledAppDetails类名
*/
private static final String APP_DETAILS_CLASS_NAME = "com.android.settings.InstalledAppDetails";
/**
* 调用系统InstalledAppDetails界面显示已安装应用程序的详细信息。 对于Android 2.3(Api Level
* 9)以上,使用SDK提供的接口; 2.3以下,使用非公开的接口(查看InstalledAppDetails源码)。
*
* @param context
* @param packageName 应用程序的包名
*/
public static void showInstalledAppDetails(Context context, String packageName) {
Intent intent = new Intent();
final int apiLevel = Build.VERSION.SDK_INT;
if (apiLevel >= 9) { // 2.3(ApiLevel 9)以上,使用SDK提供的接口
intent.setAction(Settings.ACTION_APPLICATION_DETAILS_SETTINGS);
Uri uri = Uri.fromParts(SCHEME, packageName, null);
intent.setData(uri);
} else { // 2.3以下,使用非公开的接口(查看InstalledAppDetails源码)
// 2.2和2.1中,InstalledAppDetails使用的APP_PKG_NAME不同。
final String appPkgName = (apiLevel == 8 ? APP_PKG_NAME_22
: APP_PKG_NAME_21);
intent.setAction(Intent.ACTION_VIEW);
intent.setClassName(APP_DETAILS_PACKAGE_NAME,
APP_DETAILS_CLASS_NAME);
intent.putExtra(appPkgName, packageName);
}
context.startActivity(intent);
}
}
当app申请权限时,如果用户点击了“不再提醒”,则会直接回调拒绝权限,为此谷歌工程师提供了shouldShowRequestPermissionRationale()方法。兼容包中方法是ActivityCompat.shouldShowRequestPermissionRationale(),如果是在Fragment中使用请直接用shouldShowRequestPermissionRationale()。
ActivityCompat.shouldShowRequestPermissionRationale()方法返回值是boolean类型,当第一次申请权限时,此方法会返回false,如果用户点击“不再提醒”,则此方法会返回true。
详细代码如下:
if (ContextCompat.checkSelfPermission(MySetupActivity.this, Manifest.permission.CAMERA)
!= PackageManager.PERMISSION_GRANTED) {
if (ActivityCompat.shouldShowRequestPermissionRationale(MySetupActivity.this, Manifest.permission.CAMERA)) {
//已经禁止提示了
mDialog = new AlertDialog.Builder(MySetupActivity.this)
.setTitle("友好提醒")
.setMessage("您已拒绝相机权限,此功能需要开启,是否开启?")
.setPositiveButton("是", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
ActivityCompat.requestPermissions(MySetupActivity.this,
new String[]{Manifest.permission.CAMERA},
100);
}
})
.setNegativeButton("否", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
}
})
.setCancelable(true)
.create();
mDialog.show();
} else {
ActivityCompat.requestPermissions(MySetupActivity.this,
new String[]{Manifest.permission.CAMERA},
100);
}
} else {
takePhoto();
}
如果是在Fragment中,则代码如下:
if (ContextCompat.checkSelfPermission(getActivity(), Manifest.permission.CAMERA)
!= PackageManager.PERMISSION_GRANTED) {
if (shouldShowRequestPermissionRationale(Manifest.permission.CAMERA)) {
//已经禁止提示了
mDialog = new AlertDialog.Builder(getContext())
.setTitle("友好提醒")
.setMessage("您已拒绝相机权限,此功能需要开启,是否开启?")
.setPositiveButton("是", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
requestPermissions(new String[]{Manifest.permission.CAMERA},
PERMISSIONS_CAMERA);
}
})
.setNegativeButton("否", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
}
})
.setCancelable(true)
.create();
mDialog.show();
} else {
requestPermissions(new String[]{Manifest.permission.CAMERA},
PERMISSIONS_CAMERA);
}
} else {
selectPicFromCamera();
}
特别要注意的是,如果在Fragment中请求权限,若在Activity中也重写了onRequestPermissionsResult(),则onRequestPermissionsResult()方法中一定要写
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
这句代码,若不写,则Activity不会分发执行Fragment中的权限回调方法。
因为Fragment中requestPermissions()源码如下:
public final void requestPermissions(@NonNull String[] permissions, int requestCode) {
if (mHost == null) {
throw new IllegalStateException("Fragment " + this + " not attached to Activity");
}
mHost.onRequestPermissionsFromFragment(this, permissions, requestCode);
}
其实在Fragment请求权限也是在它Activity中请求,只是把回调结果传递给了Fragment。
一次申请多个权限
例如需要申请的权限如下:
/**
* 需要进行检测的权限数组
*/
protected String[] permissionList = {
Manifest.permission.ACCESS_FINE_LOCATION,
Manifest.permission.ACCESS_COARSE_LOCATION,
Manifest.permission.ACCESS_LOCATION_EXTRA_COMMANDS,
Manifest.permission.READ_PHONE_STATE,
Manifest.permission.CAMERA,
Manifest.permission.WRITE_EXTERNAL_STORAGE,
Manifest.permission.READ_EXTERNAL_STORAGE
};
我们要先判断每一个权限是否已经允许或者拒绝,当有某一个权限未被允许时,则申请未被允许的权限。
protected void onStart() {
super.onStart();
if (PermissionUtils.checkSelfPermission(SplashActivity.this, permissionList)) {
PermissionUtils.checkPermissions(this, 0, permissionList);
} else {
//处理业务逻辑
}
}其中PermissionUtils类的代码如下:
import android.app.Activity;
import android.content.Context;
import android.content.pm.PackageManager;
import android.support.v4.app.ActivityCompat;
import android.support.v4.content.ContextCompat;
import java.util.ArrayList;
import java.util.List;
public class PermissionUtils {
/**
* 检查权限
*/
public static void checkPermissions(Activity activity, int permissRequestCode, String... permissions) {
List<String> needRequestPermissonList = findDeniedPermissions(activity, permissions);
if (null != needRequestPermissonList
&& needRequestPermissonList.size() > 0) {
ActivityCompat.requestPermissions(activity,
needRequestPermissonList.toArray(
new String[needRequestPermissonList.size()]),
permissRequestCode);
}
}
/**
* 获取权限中需要申请权限的列表
*/
public static List<String> findDeniedPermissions(Activity activity, String[] permissions) {
List<String> needRequestPermissonList = new ArrayList<String>();
for (String perm : permissions) {
if (ContextCompat.checkSelfPermission(activity,
perm) != PackageManager.PERMISSION_GRANTED) {
needRequestPermissonList.add(perm);
} else {
if (ActivityCompat.shouldShowRequestPermissionRationale(
activity, perm)) {
needRequestPermissonList.add(perm);
}
}
}
return needRequestPermissonList;
}
public static boolean checkSelfPermission(Context context, String[] permissions) {
for (String perm : permissions) {
if (ContextCompat.checkSelfPermission(context, perm) != PackageManager.PERMISSION_GRANTED) {
return true;
}
}
return false;
}
public static boolean checkSelfResult(int[] grantResults) {
for (int grantResult : grantResults) {
if (grantResult != PackageManager.PERMISSION_GRANTED) {
return false;
}
}
return true;
}
}
onRequestPermissionsResult回调方法中则这样处理:
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
if (requestCode == 0) {
if (PermissionUtils.checkSelfResult(grantResults)) {
// Permission Granted
//处理业务逻辑
} else {
// Permission Denied
if (null == mDialog)
mDialog = new AlertDialog.Builder(SplashActivity.this)
.setTitle("友好提醒")
.setMessage("没有权限将不能更好的使用,请开启权限!")
.setPositiveButton("开启", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
ShowAppSetDetails.showInstalledAppDetails(SplashActivity.this, "user.zhuku.com");
LogPrint.logILsj(TAG, "开启权限设置");
}
})
.setCancelable(false)
.create();
if (!mDialog.isShowing()) {
mDialog.show();
}
}
}
}
如果项目需要在页面可见时进行权限申请,请放在onStart()方法中,不要写在onResume()中。
可以想象一下,如果写在onResume()中,当用户同意了权限,则无碍,若是点击拒绝,则会回调权限拒绝的方法,这时系统申请权限的对话框消失不见,会再次调用onResume()请求权限显示对话框,若是还拒绝,则会再次调用onResume()方法,一直处于死循环。
因为系统请求权限的对话框其实一个开启了一个Activity。部分源码如下:
public final void requestPermissions(@NonNull String[] permissions, int requestCode) {
if (mHasCurrentPermissionsRequest) {
Log.w(TAG, "Can reqeust only one set of permissions at a time");
// Dispatch the callback with empty arrays which means a cancellation.
onRequestPermissionsResult(requestCode, new String[0], new int[0]);
return;
}
Intent intent = getPackageManager().buildRequestPermissionsIntent(permissions);
startActivityForResult(REQUEST_PERMISSIONS_WHO_PREFIX, intent, requestCode, null);
mHasCurrentPermissionsRequest = true;
}
至此,老司机本次发车已到终点,这一程体验,你还不会封装自己的运行时权限库吗?

微信公众号:IT大前端
关注可了解更多的大前端领域技术 收起阅读 »
2018,环信是如何C位出道的!(分享你和环信的故事赢千元奖励)
六年,筚路蓝缕,环信走过了一段从无至有的征程;
六年,栉风沐雨,见证了中国SaaS从0到1到1++的幸运;
六年,砥砺前行,从IM云1.0到IM云4.0,从移动客服到全媒体客服再到智能客服;
六年,峥嵘岁月,又一个全新的起点等待环信人去超越,从“心”出发;
六载春秋,陪伴是最长情的告白!感恩有你!!!










分享你和环信的故事赢千元奖励
欢迎在评论区分享你和环信的故事,评论区点赞前3名各送200元京东卡一张,第4-10名各送100元京东卡一张。(春节后第一个工作日2月11日公布获奖名单)
评论地址:https://mp.weixin.qq.com/s/Tij4kpquSUSeB04lkcepXQ 收起阅读 »







十六位互联网大咖,齐邀你共赴七麦【NextWorld2018】增长盛宴!
今年的 12 月 12 日,不仅有阿里的“双十二”购物日,还有一场属于你的互联网年末盛宴。
12 月 12 日 9:00 — 17:00。
北京 · 四季酒店 · 五层宴会厅。(朝阳区亮马桥路 48 号)
十六位互联网行业大咖,齐聚【NextWorld2018 新原力增长】峰会,邀你一起深度解锁用户增长新姿势!

最具价值峰会,齐聚大咖风采
清科集团联席总裁【袁润兵】,为你解读互联网资本浪潮下的新趋势。
数看全球:国内市场流量红利消失,全球市场近况如何?
AppsFlyer 大中华地区商务副总裁【徐宇】,带你揭秘全球移动应用市场现状和出海新机会。
OneSight CEO【李蕾】,解析出海营销新技术,助力移动产品新增长。
UMKA 俄罗斯电商平台中国区副总裁【Sofia Zhang】,分享如何实现用户本地化爆发式增长的宝贵经验。
游艺道副总裁【孙可】,评说出海新红利,快速崛起的跨境手游。
聚焦增长:产品增长乏力,如何为产品赋能,实现高速增长?
樊登读书会副总裁【孙向利】,分享关于知识付费时代,如何激发用户自传播力,助力产品增长。
十点读书 CTO【张峡】,解读十点读书如何通过矩阵式布局,一年涨粉上千万。
社群裂变:获客成本日益升高,产品如何通过裂变,零成本精准获客?
知乎商业市场经理【陈欣】,为你解析内容创意如何引爆产品病毒式增长。

创业家副总裁【易涛】,分享黑马营如何通过社群营销打造市值 50 亿的“创业基地”。

产业互联网:传统行业如何借力互联网实现新增长?
连咖啡合伙人【张洪基】,和你聊聊连咖啡的社交营销新模式。

Plum 平台创始人兼 CEO【徐薇】,解析 Plum 如何实现二手时尚平台交易量的几十倍增长。
拉勾招聘联合创始人&CMO【鲍艾乐】,带来拉勾年度大数据,俯瞰“增长er”的生存地图。

以为这就完事了?错!惊喜还远未结束!
新产品!
2018 年最值得期待的 App 出海推广平台全新重磅发布!七麦技术团队历时两年诚意巨献,让你出海有术!
加人脉!
峰会到场数十位移动互联网意见领袖,1000+ 精英创业、推广从业者到场,覆盖推广、营销、运营多领域从业人员,互联网最牛的人等你来撩~ 资源、人脉无压力!
有福利!
现场设“2018年度推广增长大礼包”,有料有趣高价值!
扫描下图二维码,马上报名参加吧!
和七麦一起,共赴年末增长盛宴!

NextWorld 2018新原力增长峰会了解详情 收起阅读 »
12 月 12 日 9:00 — 17:00。
北京 · 四季酒店 · 五层宴会厅。(朝阳区亮马桥路 48 号)
十六位互联网行业大咖,齐聚【NextWorld2018 新原力增长】峰会,邀你一起深度解锁用户增长新姿势!
最具价值峰会,齐聚大咖风采
清科集团联席总裁【袁润兵】,为你解读互联网资本浪潮下的新趋势。
数看全球:国内市场流量红利消失,全球市场近况如何?
AppsFlyer 大中华地区商务副总裁【徐宇】,带你揭秘全球移动应用市场现状和出海新机会。
OneSight CEO【李蕾】,解析出海营销新技术,助力移动产品新增长。
UMKA 俄罗斯电商平台中国区副总裁【Sofia Zhang】,分享如何实现用户本地化爆发式增长的宝贵经验。
游艺道副总裁【孙可】,评说出海新红利,快速崛起的跨境手游。
聚焦增长:产品增长乏力,如何为产品赋能,实现高速增长?
樊登读书会副总裁【孙向利】,分享关于知识付费时代,如何激发用户自传播力,助力产品增长。
十点读书 CTO【张峡】,解读十点读书如何通过矩阵式布局,一年涨粉上千万。
社群裂变:获客成本日益升高,产品如何通过裂变,零成本精准获客?
知乎商业市场经理【陈欣】,为你解析内容创意如何引爆产品病毒式增长。
创业家副总裁【易涛】,分享黑马营如何通过社群营销打造市值 50 亿的“创业基地”。
产业互联网:传统行业如何借力互联网实现新增长?
连咖啡合伙人【张洪基】,和你聊聊连咖啡的社交营销新模式。
Plum 平台创始人兼 CEO【徐薇】,解析 Plum 如何实现二手时尚平台交易量的几十倍增长。
拉勾招聘联合创始人&CMO【鲍艾乐】,带来拉勾年度大数据,俯瞰“增长er”的生存地图。
以为这就完事了?错!惊喜还远未结束!
新产品!
2018 年最值得期待的 App 出海推广平台全新重磅发布!七麦技术团队历时两年诚意巨献,让你出海有术!
加人脉!
峰会到场数十位移动互联网意见领袖,1000+ 精英创业、推广从业者到场,覆盖推广、营销、运营多领域从业人员,互联网最牛的人等你来撩~ 资源、人脉无压力!
有福利!
现场设“2018年度推广增长大礼包”,有料有趣高价值!
扫描下图二维码,马上报名参加吧!
和七麦一起,共赴年末增长盛宴!
NextWorld 2018新原力增长峰会了解详情 收起阅读 »
【活动推荐】ECUG Con 2018 拥抱下一个十年
国内云计算领域大咖 许式伟ECUG Con 2018
倾情发起的技术盛宴
引领国内云领域风向的高端峰会
ECUG Con 2018
2018 年 12 月 22-23 日 深圳
全新启程!
七牛云 CEO 许式伟
PingCAP CEO 刘奇
七牛云产品副总裁戴文军
Gopher 社区创始人 Asta Xie
阿里巴巴技术专家孙宏亮
《Kubernetes IN ACTION》作者 Marko Lukša
华为云 AI 推理平台&云搜索技术总监胡斐然
七牛云技术总监陈超
阿里云高级开发工程师严明明
京东云区块链实验室与数据库部负责人郭里靖
网易研究院云计算资深架构师朱剑峰
腾讯云高级工程师刘兆瑞
货拉拉数据分析负责人高遥
......
超豪华讲师阵容!
超有料精彩分享!
ECUG 历经十年蜕变
邀您共同开启下个十年
让我们坚持技术情怀,秉承技术精神
开启新的云计算布道篇章!
时 间
2018 年 12 月 22-23 日
地 点
深圳市南山区软件产业基地
更多详情请见下方海报~

扫描上方二维码 ,立即购买早鸟票
与大咖讲师共同探索云计算的下一个十年!
活动详情:了解更多 收起阅读 »
0 元福利手慢无 | 年尾盛会——2018 · 支付学院年会环信用户免费报名
文能提笔抒骚情
武能切图画交互

作为一个产品经理
学习不是忙里偷闲的充电
而是写进岗位职责里的日日功
公司一步步发展,业务一步步扩张
支付
一个熟悉又陌生的词映入眼帘
从 2014 年起,Ping++ 用 4 年的沉淀积累,化繁为简,实现「 7 行代码接入支付」的聚合支付、会员账户系统、多级商户系统等产品,首次提出「聚合支付」,在聚合支付领域树立标杆、建立规则。曾经踩过的无数坑,都成为了支付这一领域内宝贵的经验。所以说,不如为所有的产品经理们办一个「支付学院」吧!就这样,支付学院第一期款款而来。

「你们应该继续办下去啊!支持你们!」
「这次真的收获满满,老师讲得我还要再捋捋,太多了一下吸收不了。」
「可以私底下给秋秋老师打 Call 吗?请替我表白!」
「PPT 我打印出来学习,你们下次别用黑底白字了,打印起来反白很麻烦。」
「……」

受宠若惊,十分惶恐。因此,领域即便如此狭窄,架构即便大同小异,也要像宰相的女儿山鲁佐德一样,奉上个个迥异的故事,直到第一千零一夜。



于是就又举办了第二期、第三期,以及现在如约而至的 2018 年会。

❤ 作为一名严肃活泼认真可爱的支付从业者,你一定知道支付的前提是合规,监管即是这开头的 1 ;而后作为一个产品商业化的核心,支付系统与交易系统应为业务敞开怀抱,随着需求的变化而迭代以支撑业务十倍百倍的增长,0 是谦虚也是包容;在当今经济下行的处境下,很多企业为了寻求进一步的发展,纷纷选择了出海,去海外寻求新的增长点,因此跨境就像尾部的 1,代表了新的起点和开始。
❤ 1001 个支付故事,其实也是 4 个支付故事。2018 支付学院年会来为大家讲解关于交易系统、支付系统、监管和跨境支付的故事。
年会不同以往的是,大家热热闹闹开开心心相聚才是最重要的,因此这次人数应该远超以往,如果想要 0 元听老师讲课,那你就需要手快一些了。
0 元票兑换码
feqylt1
有道是,相逢即是有缘,有缘自会相逢。
我觉得我们已经很有缘了,故事也有了,来年会一起聊聊吧。
活动详情:免费报名 收起阅读 »
【我最喜爱的 Cloud Studio 插件评选大赛】终于开始了!

由 环信、腾讯云和 CODING 共同举办的 我最喜爱的 Cloud Studio 插件评选大赛正式开始了!在这场比赛里,将会有技术上的碰撞,大牛评委的专业点评,愉快的技术交流,好玩的插件尝试。

- 参赛者可以围绕 Git、实用小工具、腾讯云产品对接、UI 强化、语言支持等 14 个主题提交插件,再加上最具娱乐奖,代码最简单奖,设置功能最复杂奖等;
- 近 30 种奖项,超高中奖率;
- 插件只要提交上架,就有 50 元的话费相赠;
- 只要关注 CODING 公众号并转发活动讯息到朋友圈,即可获得手机充值小礼!
参与方式
注册并登陆腾讯云开发者平台(https://dev.tencent.com) -> 点击进入活动页面 -> 点击进行插件的编写与提交(需要选择参与评选的类别)-> 审核无误后即可上架自动参与评选。
赛程时间

环信特别奖

基于环信开发一款聊天插件,即有机会获得特别奖,根据作品还将获得环信提供的神秘奖品
更多活动信息,请浏览我们的活动页面。
进入活动页面> 收起阅读 »
NIUDAY 11.23 北京站 |环信CEO刘俊彦现场讲述人工智能赋能客户互动之现状与未来
2018 年是见证「奇迹」的一年。AI 从多年的热门话题中开始走下神坛,逐渐深入到了各个行业,加速经济结构优化及行业智慧化升级,AI 已不再是难以企及的神话而是可触摸的美好未来。 政策支持加上资本推动,无论是从新兴行业还是传统行业都出现了人工智能方面的布局者和佼佼者,智慧教育、移动社交、智能语音、智慧客服、传统媒体等行业都在突破技术上和流程上的难点和困惑。
11 月 23 日,一场由七牛云主办主题为「AI 产业技术的渗透与融合」的 NIUDAY 小牛汇共享日将在北京举行。会上,将邀请众多行业内知名企业及技术专家,针对当前 AI 在技术上以及行业中遇到的一些壁垒问题,进行深入探讨和分享。
智慧教育、移动未来,体验指尖上的 AI
在此次活动中,除行业专家的视点剖析之外,对于 AI 与行业的渗透与融合度是理论大于实践亦或是理论与实践已完美结合,已经应用的行业代表案例有哪些?对于这些问题,大家可以在此次活动中得以解惑。
刘俊彦

手机电商、手机软件系统的快速更迭让在线客服、移动客服有了更大的发展空间,成了市场中的一片蓝海,究竟现状如何、客户体验的真实反馈是什么?环信 CEO 刘俊彦先生带来的《人工智能赋能客户互动之现状与未来》让你更贴近生活,更能体会 AI 的无处不在。
谢华亮

科技发展教育先行,技术与教育的结合又将碰撞出怎样的火花,会上,将有好未来 SEG 智慧教育事业部技术总监谢华亮带来主题为《AI 在教育行业中的应用》的精彩演讲。
佘超杰

移动互联网的发展已影响到我们身边的每一个人,游戏、娱乐、社交等手机平台的火爆更是带来了巨大的信息流量。但如何应对这些突然爆发的信息流,如何让产品与技术更好地去结合以吸引更多的受众人群,成为人们关注的话题。以作为专注于移动互联网社交的知名企业 Blued 为例,实践与技术并重的技术专家佘超杰将分享给我们《AI 在 Blued 上的应用》。
连线行业专家,洞悉专业视点
人工智能技术在飞速发展过程中得到了国家以及政府的极大关注与大力支持,中国人工智能产业发展联盟作为国家发展改革委、科学技术部、工业和信息化部、中央网信办四部委共同指导下的人工智能产业权威联盟机构,也将加入到此次 NIUDAY 小牛汇共享日活动中来。
孙明俊

中国信息通信研究院人工智能部副主任,中国人工智能产业发展联盟总体组组长、数据中心联盟秘书长孙明俊女士将出席本次活动,并将从行业专家的角度带来主题为《人工智能产业发展水平分析》的演讲,向大家解析产业发展水平、分享行业利好政策等。
战略签约中国网 传统与创新的再突破
杨新华

值得一提的是,本次 NIUDAY 小牛汇共享日活动上七牛云将与中国互联网新闻中心举行战略合作签约仪式。届时,中国互联网新闻中心·中国网副总编辑杨新华先生将带来《AI 如何讲好中国故事》的演讲,介绍七牛云在未来媒体平台构建中发挥的作用,以及正处于变革中的媒体行业对 AI 的思考。
当然作为本次 NIUDAY 小牛汇活动的主办方,七牛云也准备了满满的干货带给大家。七牛云技术总监陈超《数据智能时代的智慧工厂实践》、七牛云人工智能实验室资深产品经理杨叶青《一站式审核助力无忧运营》带你体会七牛云两大重要产品线的技术与发展。
更多大咖嘉宾,请往下看~

关于环信机器人:
环信机器人已经在中通快递、新东方、天津农商行、宜家、环球捕手等头部企业的“双十一”中发挥着中流砥柱的作用,机器人可以帮助解决80%以上的常见问题,在售后环节能替代超90%的人工,轻松实现7*24无间断客户服务,AI从此让我们的客服人员告别苦逼,云淡风轻,笑对各种节假日促销、狂欢节。
目前,环信机器人已经广泛服务于包括保险、证券、银行、教育、物流、商旅、电商、汽车等行业的数万客户,日机器人会话超千万条。
活动报名地址:http://www.huodongxing.com/event/2464773427600 收起阅读 »
iOS 环信视频语音 细节处理(挂断电话逻辑处理)
对方挂断语言,可能要发送相应的消息(对方拒接 挂断等)在结束实时通话的回调中
- (void)callDidEnd:(EMCallSession *)aSession
reason:(EMCallEndReason)aReason
error:(EMError *)aError
根据EMCallEndReason这个枚举看通话结束的原因,去发送NSNotification通知
然后在聊天页面EaseMessageViewController.m中去监听这个通知,然后在通知方法中去插入消息,可参考以下代码:
NSString *insertStr = @"对方已挂断";
EMTextMessageBody *body = [[EMTextMessageBody alloc] initWithText:insertStr];
NSString *from = [[EMClient sharedClient] currentUsername];
//生成Message
EMMessage *message = [[EMMessage alloc] initWithConversationID:self.conversation.conversationId from:from to:self.conversation.conversationId body:body ext:nil];
message.chatType = EMChatTypeChat;// 设置为单聊消息
message.status = EMMessageStatusSucceed;
message.direction = callEnder;
[self addMessageToDataSource:message progress:nil];
[self.conversation insertMessage:message error:nil]; 收起阅读 »
- (void)callDidEnd:(EMCallSession *)aSession
reason:(EMCallEndReason)aReason
error:(EMError *)aError
根据EMCallEndReason这个枚举看通话结束的原因,去发送NSNotification通知
然后在聊天页面EaseMessageViewController.m中去监听这个通知,然后在通知方法中去插入消息,可参考以下代码:
NSString *insertStr = @"对方已挂断";
EMTextMessageBody *body = [[EMTextMessageBody alloc] initWithText:insertStr];
NSString *from = [[EMClient sharedClient] currentUsername];
//生成Message
EMMessage *message = [[EMMessage alloc] initWithConversationID:self.conversation.conversationId from:from to:self.conversation.conversationId body:body ext:nil];
message.chatType = EMChatTypeChat;// 设置为单聊消息
message.status = EMMessageStatusSucceed;
message.direction = callEnder;
[self addMessageToDataSource:message progress:nil];
[self.conversation insertMessage:message error:nil]; 收起阅读 »
2018 freeCodeConf 全国联动报名通道已正式开启
筹划已久的 freeCodeConf 终于和大家见面啦!React、Vue、Java、小程序开发、敏捷开发、区块链技术、开源项目维护......主题丰富,大咖云集,12个城市社区同步呈现。不管你是努力学习、热衷分享的开发者,还是技术粉、编程爱好者,都将收获满满!
freeCodeConf 是 freeCodeCamp 中国举办的每年一度大型联动技术大会,旨在联合 freeCodeCamp 各城市本地开发者社区,促进高度垂直、高度人才集中、高度明星企业集结的互联网与软件行业技术交流。
第一届 freeCodeConf 将于2018年11月10日在上海、天津、深圳、成都、西安、武汉、北京、杭州、广州、重庆、郑州、济南全国12个城市同期举办,诚邀广大开发者共享技术盛宴。
大会亮点
一.12城同期举办
12个城市社区同期举办,促进本地开发者技术分享与交流
二.与大咖面对面交流
与数十位前端、区块链等领域的优秀开发者和技术负责人面对面交流
三.优质企业现场招聘
部分城市设置现场招聘环节,为企业和开发者搭建沟通桥梁
四.丰厚的礼品
华为云体验券、IBM开发者纪念品、技术书籍、个性胸章......各种精美礼品等你来拿!
演讲嘉宾

报名通道
2018 freeCodeConf 成都站
【时间】2018.11.10 9:00-18:00
【地点】天府大道北段 966 号天府国际金融中心 4 号楼 1 层 1 号会议厅
演讲主题(成都站)
《How does freeCodeCamp help people learn to code for free and become developers》|《给 Node.js 插上 C++ 的翅膀》|《开源项目维护》|《敏捷中国史》|《高效 H5 动画开发方式》|《高可用React服务端渲染》|《打造 Vue 组件库》
报名通道(成都站)

扫描二维码报名
2018 freeCodeConf 天津站
【时间】2018 年11月10日(周六) 13:00-18:00
【地点】天津市大学软件学院天软微吧2楼(地铁三号线大学城站)
演讲主题(天津站)
《前端工程师的格局》| 《多租户Saas平台web实践》| 《Vue.js中的DOM和性能优化》| 《工程能力原子化的探索与实践》| 《数据可视化实践》| 《前端代码尺寸精简》
报名通道(天津站)

(扫描二维码报名)
2018 freeCodeConf 深圳站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】广东深圳深南大道10000号腾讯大厦
演讲主题(深圳站)
《Tencent Server Web 详解》| 《CSS GRIDS 终极探秘》| 《React Native 开发》等
报名通道(深圳站)

(扫描二维码报名)
2018 freeCodeConf 杭州站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】杭州市文一西路1818-2号中国人工智能小镇
演讲主题(杭州站)
《如何基于graphene开发智能合约》|《基于 VUE SSR 的前后端同构解决方案》等
报名通道(杭州站)

2018 freeCodeConf 上海站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】上海市静安区愚园路546号3号楼1层
演讲主题(上海站)
《从“零”做起的系统架构演进之路》| 《公有链开发技术分享:从共识算法到性能优化》等
报名通道(上海站)

2018 freeCodeConf 北京站
【时间】2018.11.10 下午 13:30 - 17:00
【地点】北京市朝阳区建国路108号海航实业大厦8、9层(氪空间-国贸海航实业大厦社区)
演讲主题(北京站)
《小程序对战功能实现及浅析排行榜》|《小程序的开发生态变迁》等
报名通道(北京站)

(扫描二维码报名)
2018 freeCodeConf 西安站
【时间】2018 年11月10日(周六) 14:00-18:00
【地点】西安市高新区沣惠南路36号橡树街区B-10101哈希屋HashHouse咖啡厅
演讲主题(西安站)
《Android 热修复背后的那些 Java 进阶知识》| 《Java 与未来发展职业规划》| 《如何阅读源代码》| 《可视化的遗留系统微服务改造》
报名通道(西安站)

(扫描二维码报名)
2018 freeCodeConf 广州站
【时间】2018.11.10 下午 13:30 - 17:00
【地点】广州市番禺区大学城青蓝街22号国家数字家庭应用示范产业基地B区(大学城北C出口)
报名通道(广州站)

(扫描二维码报名)
2018 freeCodeConf 济南站
【时间】2018 年11月10日(周六) 13:00-17:30
【地点】济南市高新区鑫盛大厦2号楼801
报名通道(济南站)

2018 freeCodeConf 郑州站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】上海市静安区愚园路546号3号楼1层
演讲主题(郑州站)
《互联网下半场产品核心竞争力--UED》| 《运营那点事儿》| 《如何成为一名合格的“接盘侠”》| 《VUE实践框架志iview》| 《大象圈到底是个什么圈?》
报名通道(郑州站)

(扫描二维码报名)
了解活动最新进展,请关注 freeCodeConf 大会官网 https://conf.freecodecamp.one

收起阅读 »
freeCodeConf 是 freeCodeCamp 中国举办的每年一度大型联动技术大会,旨在联合 freeCodeCamp 各城市本地开发者社区,促进高度垂直、高度人才集中、高度明星企业集结的互联网与软件行业技术交流。
第一届 freeCodeConf 将于2018年11月10日在上海、天津、深圳、成都、西安、武汉、北京、杭州、广州、重庆、郑州、济南全国12个城市同期举办,诚邀广大开发者共享技术盛宴。
大会亮点
一.12城同期举办
12个城市社区同期举办,促进本地开发者技术分享与交流
二.与大咖面对面交流
与数十位前端、区块链等领域的优秀开发者和技术负责人面对面交流
三.优质企业现场招聘
部分城市设置现场招聘环节,为企业和开发者搭建沟通桥梁
四.丰厚的礼品
华为云体验券、IBM开发者纪念品、技术书籍、个性胸章......各种精美礼品等你来拿!
演讲嘉宾
报名通道
2018 freeCodeConf 成都站
【时间】2018.11.10 9:00-18:00
【地点】天府大道北段 966 号天府国际金融中心 4 号楼 1 层 1 号会议厅
演讲主题(成都站)
《How does freeCodeCamp help people learn to code for free and become developers》|《给 Node.js 插上 C++ 的翅膀》|《开源项目维护》|《敏捷中国史》|《高效 H5 动画开发方式》|《高可用React服务端渲染》|《打造 Vue 组件库》
报名通道(成都站)
扫描二维码报名
2018 freeCodeConf 天津站
【时间】2018 年11月10日(周六) 13:00-18:00
【地点】天津市大学软件学院天软微吧2楼(地铁三号线大学城站)
演讲主题(天津站)
《前端工程师的格局》| 《多租户Saas平台web实践》| 《Vue.js中的DOM和性能优化》| 《工程能力原子化的探索与实践》| 《数据可视化实践》| 《前端代码尺寸精简》
报名通道(天津站)
(扫描二维码报名)
2018 freeCodeConf 深圳站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】广东深圳深南大道10000号腾讯大厦
演讲主题(深圳站)
《Tencent Server Web 详解》| 《CSS GRIDS 终极探秘》| 《React Native 开发》等
报名通道(深圳站)
(扫描二维码报名)
2018 freeCodeConf 杭州站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】杭州市文一西路1818-2号中国人工智能小镇
演讲主题(杭州站)
《如何基于graphene开发智能合约》|《基于 VUE SSR 的前后端同构解决方案》等
报名通道(杭州站)
2018 freeCodeConf 上海站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】上海市静安区愚园路546号3号楼1层
演讲主题(上海站)
《从“零”做起的系统架构演进之路》| 《公有链开发技术分享:从共识算法到性能优化》等
报名通道(上海站)
2018 freeCodeConf 北京站
【时间】2018.11.10 下午 13:30 - 17:00
【地点】北京市朝阳区建国路108号海航实业大厦8、9层(氪空间-国贸海航实业大厦社区)
演讲主题(北京站)
《小程序对战功能实现及浅析排行榜》|《小程序的开发生态变迁》等
报名通道(北京站)
(扫描二维码报名)
2018 freeCodeConf 西安站
【时间】2018 年11月10日(周六) 14:00-18:00
【地点】西安市高新区沣惠南路36号橡树街区B-10101哈希屋HashHouse咖啡厅
演讲主题(西安站)
《Android 热修复背后的那些 Java 进阶知识》| 《Java 与未来发展职业规划》| 《如何阅读源代码》| 《可视化的遗留系统微服务改造》
报名通道(西安站)
(扫描二维码报名)
2018 freeCodeConf 广州站
【时间】2018.11.10 下午 13:30 - 17:00
【地点】广州市番禺区大学城青蓝街22号国家数字家庭应用示范产业基地B区(大学城北C出口)
报名通道(广州站)
(扫描二维码报名)
2018 freeCodeConf 济南站
【时间】2018 年11月10日(周六) 13:00-17:30
【地点】济南市高新区鑫盛大厦2号楼801
报名通道(济南站)
2018 freeCodeConf 郑州站
【时间】2018 年11月10日(周六) 14:00-17:30
【地点】上海市静安区愚园路546号3号楼1层
演讲主题(郑州站)
《互联网下半场产品核心竞争力--UED》| 《运营那点事儿》| 《如何成为一名合格的“接盘侠”》| 《VUE实践框架志iview》| 《大象圈到底是个什么圈?》
报名通道(郑州站)
(扫描二维码报名)
了解活动最新进展,请关注 freeCodeConf 大会官网 https://conf.freecodecamp.one
收起阅读 »
据说这是18年最值得期待的产品经理大会@产品经理那些事

这是17年深圳产品经理大会。
这也是我们第一次,办这么大的线下活动。
一眨眼间一年过去了……
我们在北京、上海、广州、深圳、成都、杭州、厦门、武汉都建立了自己的分会,让全国各地产品伙伴都能连接在一起,提供产品人一个交流的平台。通过线上社区社群打卡学习、话题交流、发表文章、问答交流......
说出来你可能不相信,PMTalk2018年才一周岁呢!
那“周岁宴”我们要怎么过呢?
现在,我们想诚邀坐标深圳的各位产品经理们,欢聚一堂,一起倾(chī)心(dà)交(dàn)谈(gāo)!!
2018深圳产品经理大会,来了!!
私享级分享嘉宾、参会大咖云集、PMTalk创始故事大曝光、领到手软的礼品、超大型下午茶甜品盛宴、一起切超大的多层蛋糕、与PMTalk创始团队共进烛光晚餐……
这大概是PMTalk在今年举办的最最最最最最盛大的一次线下活动了!
那么这次的一周年盛会到底有什么看点,PMTalk产品经理社区又给各位小伙伴们邀请到了哪些大咖呢?请往下看!

让人看到就再也挪不动腿的下午茶

丰富的周边礼品
(只是冰山一角,神秘大奖我才不会现在就告诉你!)

礼品多到你抱不回家……
活动报名
2018深圳产品经理大会
报
名方式:点击活动报名即可报名。
平台含有限量早鸟票,可享受20元的优惠哦~拼手速赶紧抢啦!(截止时间:11月15日)
收起阅读 »
2018科大讯飞全球1024开发者节,来了!
10月24日-10月25日,安徽·合肥,2018届科大讯飞全球1024开发者节即将重磅开启,邀请MIT科技创新专家等大咖,还有10多场AI+分论坛、1000+AI产品等你体验。点击阅读原文,即刻进入官网抢票!

如果要用一样事物来形容科技,非光莫属。科技革新如光一般照亮我们的生活,让我们看到未来。
讯飞开放平台自2010年成立以来,目前已拥有83万开发者。我们一起在“追光之旅”中不断探索万物互联的缤纷世界,攀登AI之巅!
秉承“开放·合作·生态·共享”理念。2018届科大讯飞全球1024开发者节,我们为开发者们带来更多精彩。
今年1024,你将看到
1.AI领军人物齐聚前沿论坛
如果你想与AI商业化专家吴霁虹、斯坦福大学教授蒋里、科大讯飞董事长刘庆峰、AI大学校长胡郁、讯飞华南公司总裁杜兰、智慧医疗专家陶晓东、MIT35岁以下科技创新青年魏思等AI领袖面对面,请一定不要错过本届1024开发者节。
2.1024计划全新发布
2017届全球1024开发者节,“1024计划”重磅推出。从“AI教引”、“AI生态”、“AI公益”三个方面,辅导、赋能开发者,关注公益事业。
回顾:重磅 | 科大讯飞发布《1024计划》,AI点亮全球
今年开发者节,全新“1024计划”将现场公布,新的计划将:
更大规模:覆盖更宽广的领域,让更多用户感受到AI所带来的便捷!
更大力度:用更先进的AI科技,更全面的支持策略,赋能未来!
3.最强AI开发者现场终极PK
科大讯飞2018年面向全球正式发起首届“顶天立地”iFLYTEK AI开发者大赛。历时4个月,大赛吸引了1万余名世界各地的优秀开发者踊跃参加,共计收到全球3千多支团队提交参赛作品。
10月24日,应用开发AI挑战赛总决赛9支团队,方言种类识别AI挑战赛总决赛8支团队将在开发者节现场展开AI开发技能的巅峰对决和终极PK。
4.公益音乐节,以AI之名传递温暖
2018届科大讯飞全球1024开发者节,将延续“三声有幸”的公益主题,盛邀公益音乐人亲临,为AI献声!以歌声传达鼓舞人心的力量,用音乐唤醒人们对公益的认知。另外,现场还将有特别呈现的“公益天使”带来的的额外惊喜!
注:AI公益音乐节所有门票收入将全部用于讯飞“三声有幸”公益计划。
5.2大展区,50+展位,1000+黑科技
在AI体验区,我们准备了多个神秘环节,带给你突破想象力边界的AI旅程。我们用1000+AI黑科技展示对生活的思考。
在生态展区,科大讯飞集结自己的生态合作伙伴,在50多个展位上展示最前沿的AI落地产品和服务。覆盖企业服务、图像识别、健康医疗、公益、大数据、智能家居、机器人、智能营销、智能招聘……为你带来最in的场景化体验。
AIUI、讯飞医疗、AI大学、智慧城市……科技展区将带来科大讯飞各事业群的最新成果,从大型电信级应用到小型嵌入式应用;从手机到车载;从家电到玩具,你将体验能够满足不同应用环境的各种惊喜。
6.行业大咖做客,10+场AI细分领域论坛
医疗、客服、营销、家居、机器人、城市、AIoT……本届1024开发者节围绕等10多场AI+场景举行深度分论坛。
知名企业的资深大咖将与大家分享AI时代的见解,在圆桌互动交流彼此观点。我们将会展示讯飞和合作伙伴之间共创的各项核心赛道的AI风采,以科技之心为开发者赋能,用AI之光点亮全行业!
7.丰富互动,亲身参与“追光之旅”
你既可以与AI大咖零距离沟通,围绕AI发展进行思维碰撞,也可以现场与他人分享你对AI产品的使用体验。在2018届科大讯飞全球1024开发者节,你不仅是一名AI巅峰领域的见证者,更是追逐AI科技之光的参与者!
如何开启我的“追光之旅”?2018届全球1024开发者节购票通道已正式开启
贵宾票、嘉宾票、学生票、音乐节票任你选择
点击购买门票即刻抢票

想了解更多关于票务及优惠方面的信息,快添加AI小助手微信号:iFLYTEKAI

我们希望全球1024开发者节可以构建人工智能生态链接,打造科技文化独家品牌,影响全球人工智能开发者、爱好者,用人工智能共创美好世界!
2018届科大讯飞全球1024开发者节将用最新最全的人工智能技术和产品促进跨行业链接、多领域碰撞、新技术开发,以科技之光、生态之念,立足当下、放眼未来!
凡是过往,皆为序曲。AI+带来的无限可能,都在此刻埋下伏笔。1024,许你未来之光! 收起阅读 »
如果要用一样事物来形容科技,非光莫属。科技革新如光一般照亮我们的生活,让我们看到未来。
讯飞开放平台自2010年成立以来,目前已拥有83万开发者。我们一起在“追光之旅”中不断探索万物互联的缤纷世界,攀登AI之巅!
秉承“开放·合作·生态·共享”理念。2018届科大讯飞全球1024开发者节,我们为开发者们带来更多精彩。
今年1024,你将看到
1.AI领军人物齐聚前沿论坛
如果你想与AI商业化专家吴霁虹、斯坦福大学教授蒋里、科大讯飞董事长刘庆峰、AI大学校长胡郁、讯飞华南公司总裁杜兰、智慧医疗专家陶晓东、MIT35岁以下科技创新青年魏思等AI领袖面对面,请一定不要错过本届1024开发者节。
2.1024计划全新发布
2017届全球1024开发者节,“1024计划”重磅推出。从“AI教引”、“AI生态”、“AI公益”三个方面,辅导、赋能开发者,关注公益事业。
回顾:重磅 | 科大讯飞发布《1024计划》,AI点亮全球
今年开发者节,全新“1024计划”将现场公布,新的计划将:
更大规模:覆盖更宽广的领域,让更多用户感受到AI所带来的便捷!
更大力度:用更先进的AI科技,更全面的支持策略,赋能未来!
3.最强AI开发者现场终极PK
科大讯飞2018年面向全球正式发起首届“顶天立地”iFLYTEK AI开发者大赛。历时4个月,大赛吸引了1万余名世界各地的优秀开发者踊跃参加,共计收到全球3千多支团队提交参赛作品。
10月24日,应用开发AI挑战赛总决赛9支团队,方言种类识别AI挑战赛总决赛8支团队将在开发者节现场展开AI开发技能的巅峰对决和终极PK。
4.公益音乐节,以AI之名传递温暖
2018届科大讯飞全球1024开发者节,将延续“三声有幸”的公益主题,盛邀公益音乐人亲临,为AI献声!以歌声传达鼓舞人心的力量,用音乐唤醒人们对公益的认知。另外,现场还将有特别呈现的“公益天使”带来的的额外惊喜!
注:AI公益音乐节所有门票收入将全部用于讯飞“三声有幸”公益计划。
5.2大展区,50+展位,1000+黑科技
在AI体验区,我们准备了多个神秘环节,带给你突破想象力边界的AI旅程。我们用1000+AI黑科技展示对生活的思考。
在生态展区,科大讯飞集结自己的生态合作伙伴,在50多个展位上展示最前沿的AI落地产品和服务。覆盖企业服务、图像识别、健康医疗、公益、大数据、智能家居、机器人、智能营销、智能招聘……为你带来最in的场景化体验。
AIUI、讯飞医疗、AI大学、智慧城市……科技展区将带来科大讯飞各事业群的最新成果,从大型电信级应用到小型嵌入式应用;从手机到车载;从家电到玩具,你将体验能够满足不同应用环境的各种惊喜。
6.行业大咖做客,10+场AI细分领域论坛
医疗、客服、营销、家居、机器人、城市、AIoT……本届1024开发者节围绕等10多场AI+场景举行深度分论坛。
知名企业的资深大咖将与大家分享AI时代的见解,在圆桌互动交流彼此观点。我们将会展示讯飞和合作伙伴之间共创的各项核心赛道的AI风采,以科技之心为开发者赋能,用AI之光点亮全行业!
7.丰富互动,亲身参与“追光之旅”
你既可以与AI大咖零距离沟通,围绕AI发展进行思维碰撞,也可以现场与他人分享你对AI产品的使用体验。在2018届科大讯飞全球1024开发者节,你不仅是一名AI巅峰领域的见证者,更是追逐AI科技之光的参与者!
如何开启我的“追光之旅”?2018届全球1024开发者节购票通道已正式开启
贵宾票、嘉宾票、学生票、音乐节票任你选择
点击购买门票即刻抢票
想了解更多关于票务及优惠方面的信息,快添加AI小助手微信号:iFLYTEKAI
我们希望全球1024开发者节可以构建人工智能生态链接,打造科技文化独家品牌,影响全球人工智能开发者、爱好者,用人工智能共创美好世界!
2018届科大讯飞全球1024开发者节将用最新最全的人工智能技术和产品促进跨行业链接、多领域碰撞、新技术开发,以科技之光、生态之念,立足当下、放眼未来!
凡是过往,皆为序曲。AI+带来的无限可能,都在此刻埋下伏笔。1024,许你未来之光! 收起阅读 »
git push -f 是什么?应该怎么处理
我们的内网有使用gitlab作为我们的版本控制工具,最近组里出现了一次误操作,没有更新服务器的代码到本地仓库,直接使用git push -f 强制将本地的修改覆盖了远程仓库的版本,将其他人的commit都给冲掉了,而且无法使用通常的git reset方式回滚,因为使用 git log查看远程仓库的提交历史已经没有其他同事在这之前提交的commit记录了。
一般遇到这种情况,如果同事A将本地覆盖了远程,覆盖了同事B和同事C的commit,而同事B和C本地仓库依旧有他们的提交,这个时候同事B和C只需要同步一下远程,然后再git push -f一下他们的提交,这样就能将被覆盖的commit重新合并到远程仓库里面。
但是我遇到的情况比较特殊,因为当时同事B和同事C是在gitlab的网页版直接编辑的文件,并通过Gitlab提交,也就是说所有人本地都没有同事B和同事C提交的内容,这个时候同事A使用git push -f直接就冲掉了记录,所以就没办法通过上面的办法来回滚了。
废话那么多,下面记录下找回的过程:
1 场景
```bash
Original:
(remote origin:)
branch master -> commit 111111
(local)
branch master -> commit 22222
After git push -f:
(remote origin:)
branch master -> commit 22222
```
2 找回步骤
(1)这个方法的前提是你有权限登陆部署了Gitlab的服务器,我们需要找到Gitlab保存仓库的目录,首先通过ssh登陆上Gitlab的服务器,然后找到gitlab的存放仓库的地方,默认是在```/var/opt/gitlab/git-data/repositories```。
在这个目录下找到自己要回滚的仓库,并cd到该仓库。
(2)在执行回滚操作前一定要先进行仓库备份:
```bash
tar cvzf project-backup.tgz /path/to/project.git
```
备份好之后才可以进行下面的操作。
首先gitlab的仓库的目录是这样的:
```
config description HEAD hooks hooks.old.xxx info objects refs
```
在当前目录使用```git fsck```工具找回上次执行的危险操作,直接执行```git fsck```命令,该命令显示所有未被其他对象引用 (指向) 的所有对象,会有如下输出:
```bash
dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
```
ab1afef80fac8e34258ff41fc1b867c702daa24就是可能被丢弃的commit,也就是被冲掉的commit,具体是自己想要的哪个,可以:
```
git log ab1afef80fac8e34258ff41fc1b867c702daa24
```
查看在这之前的commit历史,找到自己想要回滚的commit。
(3)找到了想要回滚的commit 哈希值,是不是可以在本地仓库执行
```
git reset --HEAD ab1afef80fac8e34258ff41fc1b867c702daa24
```
实现回滚了呢?答案是不可以的,因为仓库关于被覆盖的对象已经被清除了,所以clone下来的仓库是没有被覆盖的对象可以回滚的,所以回滚操作还是需要在gitlab的实际仓库里操作。
```
echo ab1afef80fac8e34258ff41fc1b867c702daa24 > refs/heads/master
```
将commit 哈希值直接添加到refs/heads/master文件里,然后克隆远程仓库到本地,你会发现以前的commit又神奇的回来了。
具体的原理需要大家自己去了解git的原理,参考这几篇文章:
https://git-scm.com/book/zh/v1/Git-内部原理-维护及数据恢复
https://superuser.com/questions/297973/how-can-i-recover-from-an-accidental-git-push-f/298015#298015
希望对大家有所帮助。
Regards,
codjust
收起阅读 »
《AI企业级应用产品实力榜单》:环信机器人实力上榜
企服行业头条组织筹办的《AI企业级应用产品实力榜单》对外发榜,从众多报名的产品中,经过层层筛选及评审打分,“环信机器人”凭借深厚的AI技术沉淀以及在保险、教育等领域的大规模落地获得上榜。
作为企业服务领域的资深观察者,企服行业头条一直关注企服领域内的动态,这次组织筹办《AI企业级应用产品实力榜单》,希望寻找有价值的优秀企业级产品,传递企业服务的商业价值和趋势。
榜单综述
企服行业头条根据上榜产品在人工智能方面的特点,把产品划分为几个大类。包括例如商业智能和解决方案类、计算机视觉类、人机交互类等等。
现在,企服君又进一步标注出了这50个产品所处的细分行业,试图进一步挖掘榜单背后蕴藏的行业发展趋势。
在细分行业统计中:纯AI行业产品有25个;信息安全+AI有2个;大数据+AI有11个;云计算+AI有1个;行业SaaS+AI有7个;其他行业+AI有4个。

从行业分布比例图可以很明显看出,虽然此次企服行业头条评选的是企业级AI产品,但细分行业却并非100%全部来自人工智能领域。
不仅如此,榜单甚至一半(50%)的产品都来自非AI行业。而这也恰恰说明,现在越来越多企业开始主动拥抱人工智能技术,人工智能与各个行业的融合也越发紧密。
接下来,企服君就该榜单的典型产品“环信机器人”进行解读。
环信机器人:
AI1.0——4.0,环信机器人全貌展示AI客服发展史
近年,基于规则和传统机器学习的AI 1.0兴起,随着Google等科技大鳄以及资本的推波助澜,基于算法升级的深度学习AI 2.0时代慢慢开始改造客服行业,准确率和召回率(覆盖率)均取得了大幅度提升。到了AI 3.0时代,从单点的文字机器人产品出发实现了全工具链改造,这个阶段环信智能IVR、智能质检、人机协作、环信智能外呼机器人等产品和服务应运而生,到了AI 4.0大规模落地时代,环信又发布了以保险行业为首的四大行业解决方案,环信机器人产品的发展史很好的全貌展示了AI改造中国客服行业的发展历程。
作为自然语言理解技术最先实现商业化落地的领域,智能客服行业吸引了众多市场玩家争相布局。从传统呼叫中心厂商、到SaaS云客服公司、再到客服机器人公司,各类企业都在积极用AI为客服赋能。那么,现阶段什么样的智能客服产品真正实现了大规模落地,帮助企业规模化的优化了生产力结构,助力客服中心从成本中心往利润中心演变,环信机器人4.0似乎已经给出了答案。
对于智能客服赛道上的三类公司,环信CEO刘俊彦用“刀架”和“刀片”做了一个形象的比喻:基础客服系统是刀架,特点是高粘性业务系统,替换成本高,竞争激励毛利相对较低;AI是刀片,特点是技术壁垒高,毛利高,但不能脱离刀架单独存在。传统呼叫中心厂商缺乏一个多租户的、基于云架构的在线客服系统,因此刀架尚不完备;客服机器人厂商从做刀片起家,目前正在竭力补足刀架短板;而像环信这样的云客服厂商先有刀架,后磨砺刀片,能够为客户提供全套智能客服解决方案。
环信机器人4.0,低成本可持续运营的客服机器人解决方案
环信机器人4.0致力于为企业提供一套低成本可持续运营的客服机器人解决方案。4.0版本新推出了三大平台级应用(环信AIROOT运营平台、环信AIROOT Pro训练师平台、环信中文语义计算平台)和保险行业智能机器人解决方案,一举将AI在客服行业的传统单点型产品全面升级为体系化整体解决方案。
环信AIROOT运营平台是一个面向客服团队的简单、智能、低成本可持续运营的客服机器人运营平台。通过打造可快速上手的运营体系,建设快速落地的学习闭环。AIROOT提供了机器人运营环节所有涉及到的常用功能,包括:完整的服务数据产品、运维支撑产品、服务运营产品、机器人知识库、知识运营体系产品,使得平台拥有业界领先的知识构建、知识运营和服务交付能力,并且有效降低使用的难度与成本。
针对诸如100坐席+、日咨询会话1万+、知识点1000以上的大型客户,环信AIROOT可以帮助企业实现1-2周完成知识构建快速上线,并在后续的知识持续运营中实现“1天+1人+2小时”完成的运营工作量。保障广大企业真正实现智能客服机器人的“买得起、用得起”的愿望。
环信AIROOT Pro 训练师平台是一个面向专业知识训练师的专业、高效深度调优的客服机器人运营平台。AIROOT Pro通过完整专业的算法优化调优平台,全面打通从“数据清洗”数据标注””模型训练””效果评测””用户反馈”的完整学习闭环,使得能力调优环节中的大批量数据生产、训练以及模型迭代成为可能。并利用环信中文语义计算平台提供的AI能力,全面提升调优过程中的工具智能化程度,有效降低成本。
经实际落地评测,在无需机器人厂商的算法人员、软件工程师、数据工程师参与的情况下,基于AIROOT Pro的训练相较于普通算法平台的能力调优整体效率提升30%以上,客服机器人知识建设周期整体缩短20%。
环信中文语义计算平台是一个面向开发者的自然语言处理(NLP)的能力开放平台。环信中文语义计算平台在经过了近三年的核心算法能力提升和迭代后,在开放NLP基础算法能力的同时,也完整开放了在NLP领域经常使用的应用级别算法能力诸如:纠错、情感分析、意图识别、语义相似度计算等,帮助开发者们在NLP领域的应用环节具有更强的能力,快速应用落地在更多价值场景。
经实际落地评测,环信中文语义计算平台的基于深度学习的意图分类算法在多个测试集上达到了95%准确率的业界领先水平,语义相似度计算到达了93%准确率的业界领先水平。
环信一直秉承着AI必须通过行业解决方案落地帮助企业提能增效解决实际业务问题来体现生产力。基于环信在保险领域的深入积累,环信率先发布了环信机器人保险行业解决方案。环信机器人保险行业解决方案致力于为保险行业提供开箱可用的AI能力,针对寿险、财险保险智能客服、智能IVR、产品推荐、代理人支持等领域的提供了全套综合智能化保险解决方案。以环信机器人保险行业解决方案中的寿险机器人为例,环信的寿险机器人在业界领先的算法和工程能力基础上,还预装了全套寿险服务知识图谱,涵盖了从保险百科到理赔核保的数百个服务场景下的数千条知识图谱,并与业内主流保险核心业务系统预集成打通,真正做到了开箱可用的行业AI能力。
经过近三年的迭代发展,环信机器人已经在保险、证券、教育、物流、银行、电信运营商、航空等领域树立了一批标杆客户,包括新东方、泰康在线、中意人寿、中信证券、长江证券、天津农商行、南京银行、中通快递、厦门航空等。
客户服务作为现代企业和消费者沟通的核心环节,年产业规模高达5000亿元。对于企业来说,如何利用AI新技术、新产品最大化客服价值,如何把客服这个成本中心转化为利润中心,已成为当务之急,或许人工智能产业化改造整个客服行业的奇点已经来临!
收起阅读 »
环信机器人上榜《AI企业级应用产品实力榜单》

作为企业服务领域的资深观察者,企服行业头条一直关注企服领域内的动态,这次组织筹办《AI企业级应用产品实力榜单》,希望寻找有价值的优秀企业级产品,传递企业服务的商业价值和趋势。
榜单综述
企服行业头条根据上榜产品在人工智能方面的特点,把产品划分为几个大类。包括例如商业智能和解决方案类、计算机视觉类、人机交互类等等。
现在,企服君又进一步标注出了这50个产品所处的细分行业,试图进一步挖掘榜单背后蕴藏的行业发展趋势。
在细分行业统计中:纯AI行业产品有25个;信息安全+AI有2个;大数据+AI有11个;云计算+AI有1个;行业SaaS+AI有7个;其他行业+AI有4个。
从行业分布比例图可以很明显看出,虽然此次企服行业头条评选的是企业级AI产品,但细分行业却并非100%全部来自人工智能领域。
不仅如此,榜单甚至一半(50%)的产品都来自非AI行业。而这也恰恰说明,现在越来越多企业开始主动拥抱人工智能技术,人工智能与各个行业的融合也越发紧密。
接下来,企服君就该榜单的典型产品“环信机器人”进行解读。
环信机器人:
AI1.0——4.0,环信机器人全貌展示AI客服发展史
近年,基于规则和传统机器学习的AI 1.0兴起,随着Google等科技大鳄以及资本的推波助澜,基于算法升级的深度学习AI 2.0时代慢慢开始改造客服行业,准确率和召回率(覆盖率)均取得了大幅度提升。到了AI 3.0时代,从单点的文字机器人产品出发实现了全工具链改造,这个阶段环信智能IVR、智能质检、人机协作、环信智能外呼机器人等产品和服务应运而生,到了AI 4.0大规模落地时代,环信又发布了以保险行业为首的四大行业解决方案,环信机器人产品的发展史很好的全貌展示了AI改造中国客服行业的发展历程。
作为自然语言理解技术最先实现商业化落地的领域,智能客服行业吸引了众多市场玩家争相布局。从传统呼叫中心厂商、到SaaS云客服公司、再到客服机器人公司,各类企业都在积极用AI为客服赋能。那么,现阶段什么样的智能客服产品真正实现了大规模落地,帮助企业规模化的优化了生产力结构,助力客服中心从成本中心往利润中心演变,环信机器人4.0似乎已经给出了答案。
对于智能客服赛道上的三类公司,环信CEO刘俊彦用“刀架”和“刀片”做了一个形象的比喻:基础客服系统是刀架,特点是高粘性业务系统,替换成本高,竞争激励毛利相对较低;AI是刀片,特点是技术壁垒高,毛利高,但不能脱离刀架单独存在。传统呼叫中心厂商缺乏一个多租户的、基于云架构的在线客服系统,因此刀架尚不完备;客服机器人厂商从做刀片起家,目前正在竭力补足刀架短板;而像环信这样的云客服厂商先有刀架,后磨砺刀片,能够为客户提供全套智能客服解决方案。
环信机器人4.0,低成本可持续运营的客服机器人解决方案
环信机器人4.0致力于为企业提供一套低成本可持续运营的客服机器人解决方案。4.0版本新推出了三大平台级应用(环信AIROOT运营平台、环信AIROOT Pro训练师平台、环信中文语义计算平台)和保险行业智能机器人解决方案,一举将AI在客服行业的传统单点型产品全面升级为体系化整体解决方案。
环信AIROOT运营平台是一个面向客服团队的简单、智能、低成本可持续运营的客服机器人运营平台。通过打造可快速上手的运营体系,建设快速落地的学习闭环。AIROOT提供了机器人运营环节所有涉及到的常用功能,包括:完整的服务数据产品、运维支撑产品、服务运营产品、机器人知识库、知识运营体系产品,使得平台拥有业界领先的知识构建、知识运营和服务交付能力,并且有效降低使用的难度与成本。
针对诸如100坐席+、日咨询会话1万+、知识点1000以上的大型客户,环信AIROOT可以帮助企业实现1-2周完成知识构建快速上线,并在后续的知识持续运营中实现“1天+1人+2小时”完成的运营工作量。保障广大企业真正实现智能客服机器人的“买得起、用得起”的愿望。
环信AIROOT Pro 训练师平台是一个面向专业知识训练师的专业、高效深度调优的客服机器人运营平台。AIROOT Pro通过完整专业的算法优化调优平台,全面打通从“数据清洗”数据标注””模型训练””效果评测””用户反馈”的完整学习闭环,使得能力调优环节中的大批量数据生产、训练以及模型迭代成为可能。并利用环信中文语义计算平台提供的AI能力,全面提升调优过程中的工具智能化程度,有效降低成本。
经实际落地评测,在无需机器人厂商的算法人员、软件工程师、数据工程师参与的情况下,基于AIROOT Pro的训练相较于普通算法平台的能力调优整体效率提升30%以上,客服机器人知识建设周期整体缩短20%。
环信中文语义计算平台是一个面向开发者的自然语言处理(NLP)的能力开放平台。环信中文语义计算平台在经过了近三年的核心算法能力提升和迭代后,在开放NLP基础算法能力的同时,也完整开放了在NLP领域经常使用的应用级别算法能力诸如:纠错、情感分析、意图识别、语义相似度计算等,帮助开发者们在NLP领域的应用环节具有更强的能力,快速应用落地在更多价值场景。
经实际落地评测,环信中文语义计算平台的基于深度学习的意图分类算法在多个测试集上达到了95%准确率的业界领先水平,语义相似度计算到达了93%准确率的业界领先水平。
环信一直秉承着AI必须通过行业解决方案落地帮助企业提能增效解决实际业务问题来体现生产力。基于环信在保险领域的深入积累,环信率先发布了环信机器人保险行业解决方案。环信机器人保险行业解决方案致力于为保险行业提供开箱可用的AI能力,针对寿险、财险保险智能客服、智能IVR、产品推荐、代理人支持等领域的提供了全套综合智能化保险解决方案。以环信机器人保险行业解决方案中的寿险机器人为例,环信的寿险机器人在业界领先的算法和工程能力基础上,还预装了全套寿险服务知识图谱,涵盖了从保险百科到理赔核保的数百个服务场景下的数千条知识图谱,并与业内主流保险核心业务系统预集成打通,真正做到了开箱可用的行业AI能力。
经过近三年的迭代发展,环信机器人已经在保险、证券、教育、物流、银行、电信运营商、航空等领域树立了一批标杆客户,包括新东方、泰康在线、中意人寿、中信证券、长江证券、天津农商行、南京银行、中通快递、厦门航空等。
客户服务作为现代企业和消费者沟通的核心环节,年产业规模高达5000亿元。对于企业来说,如何利用AI新技术、新产品最大化客服价值,如何把客服这个成本中心转化为利润中心,已成为当务之急,或许人工智能产业化改造整个客服行业的奇点已经来临!
收起阅读 »
【环信征文】我做面试官的第三个故事
有一天Java主管江总拿着一份简历找我协助他面试一个自称既懂Java又懂Android的人
江总:你Android和Java都会?来面试Android还是Java?
他:(我猜他打量了6年经验的江总和4年经验的我之后选了一个好对付的)我最近今年都在搞Android,还是面试Android吧!
我:(看他的简历和面试登记表上面的信息出入有点大,心里就有底了)请简单介绍下自己吧
他:balah……balah……(就像《海贼王》有漫画版、动画版和国内百度贴吧版三种剧情一样,他的工作经历也有打印简历版、面试登记表手写版和面试口述版三种)
我:(知道他是什么牛鬼蛇神了,一上来就让他出丑)你能说说Fragment的生命周期吗?
他:Fragment的生命周期……emmm……就是和Activity的生命周期差不多嘛
我:这儿有纸笔,你默写Activity的生命周期吧
他:(边嘟囔边写)先是onCreate()……emmm……还有onResume()……onStart()和onDestroy()
我:Activity的生命周期不是写出来了吗?再好好想想Fragment的生命周期是啥样的
他:就是在Activity的onCreate()上边加上onActivityCreate()和onAttach()……emmm……onDestroy()下边再加上onDestroyView()吧~
我:在什么情况下Fragment的onResume()方法执行?
他:Fragment从不可见到可见的情况下
我:同一个Activity里,从A Fragment切换到B Fragment,然后从B切换到A,A执行了onResume()吗?
他:那当然执行咯~
我:我再问问你View事件分发机制吧
他:(感觉死耗子终于来找瞎猫了)这个我知道,就是从最外层的ViewGroup……
我:(打断他的话)ACTION_DOWN和ACTION_UP总是成对出现吗?换句话说,一个View触发了ACTION_DOWN之后,一定会触发ACTION_UP吗?反过来,一个View触发了ACTION_UP之前,它一定先触发ACTION_DOWN吗?
他:那是一定的,ACTION_UP是手指离开屏幕时触发的……
我:(打断他的话)按住A View,拖动到B View,松手,A和B也都触发了ACTION_UP和ACTION_DOWN吗?
他:这个……emmm……我不太清楚哈~
我:(偷偷看一眼江总,江总正在冷笑摇头)我再考考你Java基础吧,ArrayList和LinkedList,哪个线程安全?哪个线程不安全?
他:ArrayList线程不安全,LinkedList线程安全
我:那你知道线程池有哪几种吗?
他:有四种,就是有带缓存的……emmm……还有别的~
我:(看他简历上的银行项目负责人的工作经历)你长期从事银行、金融软件开发,记录存款和消费金额之类和钱账有关的数据用那种数据类型呀?
他:当然用float了,精确度比double高嘛
我:double精度比float低吗?
他:那当然啦,double只精确到小数点后两位嘛,double在英语里就是二的意思
我:你现在拿出手机查查
他:(用手机查了一会)emmm……我刚才口误,我们记钱账的数据类型是double
我:那你听说过BigDecimal吗?
江总:(此时的鄙夷表情已经和相亲时候拜金女听见“租房”关键词时候的表情一样了)你还想继续面Android吗?
他:不,不,我Java经验更丰富些,还是面Java吧
江总:拿你对Spring Cloud了解多少?
他:balah……balah……(说了一大堆驴唇不对马嘴的东西)
江总:好吧,今天的面试就到这里,有消息我们会通知你
我:(送他出去之后)你知道他简历造假的破绽有多明显吗?
江总:他简历上的毕业年份和填表上的不一样
我:我连他以前什么职业都知道,他是送外卖的或者工地上下苦力的,培训几个月出来骗人了
江总:你怎么知道的?
我:常年室内工作的人脸没那么黑
后记:他被我介绍给了一个“工资一开始没那么高,我看你做得好以后会给你股份”的“创业公司CEO”做技术扶贫去了,也不知道他俩到底谁坑了谁
往期推荐:
今天面试一个自称两年经验的Android
我又做了一次面试官 收起阅读 »
江总:你Android和Java都会?来面试Android还是Java?
他:(我猜他打量了6年经验的江总和4年经验的我之后选了一个好对付的)我最近今年都在搞Android,还是面试Android吧!
我:(看他的简历和面试登记表上面的信息出入有点大,心里就有底了)请简单介绍下自己吧
他:balah……balah……(就像《海贼王》有漫画版、动画版和国内百度贴吧版三种剧情一样,他的工作经历也有打印简历版、面试登记表手写版和面试口述版三种)
我:(知道他是什么牛鬼蛇神了,一上来就让他出丑)你能说说Fragment的生命周期吗?
他:Fragment的生命周期……emmm……就是和Activity的生命周期差不多嘛
我:这儿有纸笔,你默写Activity的生命周期吧
他:(边嘟囔边写)先是onCreate()……emmm……还有onResume()……onStart()和onDestroy()
我:Activity的生命周期不是写出来了吗?再好好想想Fragment的生命周期是啥样的
他:就是在Activity的onCreate()上边加上onActivityCreate()和onAttach()……emmm……onDestroy()下边再加上onDestroyView()吧~
我:在什么情况下Fragment的onResume()方法执行?
他:Fragment从不可见到可见的情况下
我:同一个Activity里,从A Fragment切换到B Fragment,然后从B切换到A,A执行了onResume()吗?
他:那当然执行咯~
我:我再问问你View事件分发机制吧
他:(感觉死耗子终于来找瞎猫了)这个我知道,就是从最外层的ViewGroup……
我:(打断他的话)ACTION_DOWN和ACTION_UP总是成对出现吗?换句话说,一个View触发了ACTION_DOWN之后,一定会触发ACTION_UP吗?反过来,一个View触发了ACTION_UP之前,它一定先触发ACTION_DOWN吗?
他:那是一定的,ACTION_UP是手指离开屏幕时触发的……
我:(打断他的话)按住A View,拖动到B View,松手,A和B也都触发了ACTION_UP和ACTION_DOWN吗?
他:这个……emmm……我不太清楚哈~
我:(偷偷看一眼江总,江总正在冷笑摇头)我再考考你Java基础吧,ArrayList和LinkedList,哪个线程安全?哪个线程不安全?
他:ArrayList线程不安全,LinkedList线程安全
我:那你知道线程池有哪几种吗?
他:有四种,就是有带缓存的……emmm……还有别的~
我:(看他简历上的银行项目负责人的工作经历)你长期从事银行、金融软件开发,记录存款和消费金额之类和钱账有关的数据用那种数据类型呀?
他:当然用float了,精确度比double高嘛
我:double精度比float低吗?
他:那当然啦,double只精确到小数点后两位嘛,double在英语里就是二的意思
我:你现在拿出手机查查
他:(用手机查了一会)emmm……我刚才口误,我们记钱账的数据类型是double
我:那你听说过BigDecimal吗?
江总:(此时的鄙夷表情已经和相亲时候拜金女听见“租房”关键词时候的表情一样了)你还想继续面Android吗?
他:不,不,我Java经验更丰富些,还是面Java吧
江总:拿你对Spring Cloud了解多少?
他:balah……balah……(说了一大堆驴唇不对马嘴的东西)
江总:好吧,今天的面试就到这里,有消息我们会通知你
我:(送他出去之后)你知道他简历造假的破绽有多明显吗?
江总:他简历上的毕业年份和填表上的不一样
我:我连他以前什么职业都知道,他是送外卖的或者工地上下苦力的,培训几个月出来骗人了
江总:你怎么知道的?
我:常年室内工作的人脸没那么黑
后记:他被我介绍给了一个“工资一开始没那么高,我看你做得好以后会给你股份”的“创业公司CEO”做技术扶贫去了,也不知道他俩到底谁坑了谁
往期推荐:
今天面试一个自称两年经验的Android
我又做了一次面试官 收起阅读 »
基操!坐下!勿6!5分钟搭建小程序直播
今天你看直播了吗?拥有10亿微信生态用户的小程序已经成为了继移动互联后的又一个现象级风口,随着微信小程序对外开放实时音视频录制及播放等更多连接能力,小程序与直播强强联合,在各行各业找到了非常多的玩法,小程序直播相比微信直播和APP直播更加简洁、流畅、低延时、多入口等众多优势迅速向商业直播领域及泛娱乐直播领域蔓延。从小游戏、内容付费、工具、大数据、社交电商创业者到传统品牌商们,都在努力搭上小程序直播这辆快车,以免错过微信生态里新的流量洼地。

作为一名环信生态圈资深开发者,本着对技术的热衷,对环信的眷恋和对党的忠诚,基于环信即时通讯云写了这个“直播购物小程序”,目前项目源码已全部免费开放,希望对有需求的企业和开发者提供一个思路和参考。
直播购物小程序运行GIF效果图

小程序体验指南(仅需三步):
1.下载小程序直播源码:github源码
2.下载微信小程序开发工具:小程序开发工具下载地址
3.导入源码:将附件的源码解压直接导入
就是这么简单,还有问题?我们准备了视频教程!
手把手教学直播小程序开发【环信公开课35期】:公开课回放地址

公开课视频截图
课程大纲:
环信直播技术流程
1、【环信账号准备】注册、认证。
2、【直播间创建】环信后台创建及api 方式创建
3、【房间主播及推拉流地址设置】创建直播,主播绑定房间,房间设置直播地址。
小程序技术分享
1、【创建小程序项目】创建好已有UI的小程序项目。
2、【环信小程序sdk集成】基于webIM sdk 开发的小程序版本SDK集成配置。
3、【配置小程序进行直播推拉流测试】模拟直播间,使用推流工具进行推流测试。
4、【开发直播间聊天功能及特效】利用小程序SDK进行直播聊天室聊天开发。弹幕、特效延时处理。
附:环信小程序直播开发文档文档地址
关于环信直播聊天室:
1、采用支持高并发的异步架构,轻松应对千万级并发请求; 各项基础服务集群化,确保系统高可用性; 系统冗余度高,容量评估体系完善,弹性扩容应对流量峰值;
2、支持各种消息格式:文字、表情、图片、声音、视频、附件、位置、扩展消息;
3、支持实时配置的消息分级策略,确保重要消息优先必达;
4、支持直播聊天室后台管理及审核功能,提供直播相关数据统计;
5、提供智能反垃圾和自定义敏感词过滤功能;
6、快速集成,demo提供高质量代码示例,可根据运营情况随时扩展;
7、聊天室人数无上限 收起阅读 »
环信公开课35期回放:手把手教学直播小程序开发
微信小程序越来越多的新功能不断上线,流量入口的不断增加,俨然成为互联网公司“必争之地”。 传统的公众号第三方直播由于入口较深,用户次使用路径复杂,很难培养用户的使用习惯;微信小程序入口便捷使用方便,极大提升了用户体验。公开课第35期视频回放
直播商业化最困扰的地方在于哪里?流量!微信有庞大的低成本的流量可以帮助商家获取和转化用户。小程序直播可以说是商业化用户最好的工具。直播和购物的结合就是其中一个较好的表现形式。
8月8日,环信公开课邀请了小程序开发业界大牛席海江老师,分享了全国首个小程序直播源码,在公开课上手把手教学从零开始搭建一套基于环信的小程序直播平台。
公开课回放视频
直播购物小程序运行GIF效果图

席海江老师演示集成环信小程序直播

课程回顾:
环信直播技术流程
1、【环信账号准备】注册、认证。
2、【直播间创建】环信后台创建及api 方式创建
3、【房间主播及推拉流地址设置】创建直播,主播绑定房间,房间设置直播地址。
小程序技术分享
1、【创建小程序项目】创建好已有UI的小程序项目。
2、【环信小程序sdk集成】基于webIM sdk 开发的小程序版本SDK集成配置。
3、【配置小程序进行直播推拉流测试】模拟直播间,使用推流工具进行推流测试。
4、【开发直播间聊天功能及特效】利用小程序SDK进行直播聊天室聊天开发。弹幕、特效延时处理。
课程亮点:全国首个直播购物小程序源码分享,手把手搭建基于环信的直播购物小程序。
课程形式:网络直播 全国各地区、联网电脑、联网手机均可免费参与。
感谢合作伙伴APICLloud,APKBUS,码客,七牛云,客户世界对本期环信公开课的大力支持,环信公开课合作、课程订阅请添加公开课小助手微信:huanixn-hh
强烈推荐:每周三下午3点环信IM在线培训,工程师现场答疑,还有定制T恤送出,观看地址环信公开课 收起阅读 »
环信 ios 发不了录音
发送block 返回 code 401 描述是 录音文件地址+ too small 接手别人的代码 一步一个坑 环信还没技术支持 以前还有在线支持的 求解
2018安卓巴士开发者大会【技术之声 改变世界】
2018安卓巴士开发者大会,是中国最具前沿性、专业性的安卓技术会议。由安卓巴士技术社区首次发起并组织的安卓线下交流大会,集结500位安卓开发,与你一起交流学习,探讨行业动态。
本次上海作为首站,将盛邀数位业内技术大咖为开发者们带来最高质量的技术分享和丰富的现场互动体验项目,让参会者在得到业务成长的同时还能知晓行业动态、结识同僚并享受活动带来的特别体验。
报名链接:http://www.hdb.com/dis/fmjhe7y02o

付费说明:
本次活动经费用于场租、设备、物料、礼品等。
早鸟票¥199,享受活动五折优惠。
标准票¥399,购此票种开发者凭大会当天凭二维码签到可得安卓开发书籍一本。
团购票¥798,此票为套票3张,即三人成行一人免单,经济实惠。
VIP票¥599,此票座位为会场前排、赠高级礼品、有提问机会、可加入讲师群。
活动须知:
请各位小伙伴认真填写所有的报名资料用于审核使用,由于场地位置有限和为了保证活动质量,活动当天拒绝空降,现场签到凭报名成功二维码,谢谢配合!
活动路线:
地铁路线:地铁9号线金桥站2号口骑行1公里。
公交:1045路、浦东27路、上川专线新金桥路唐陆路站下步行418米。
驾车路线:收费停车场位于唐陆公路与新金桥路交叉口西南150米。(前40名可拥有免费停车券)

收起阅读 »
本次上海作为首站,将盛邀数位业内技术大咖为开发者们带来最高质量的技术分享和丰富的现场互动体验项目,让参会者在得到业务成长的同时还能知晓行业动态、结识同僚并享受活动带来的特别体验。
报名链接:http://www.hdb.com/dis/fmjhe7y02o
付费说明:
本次活动经费用于场租、设备、物料、礼品等。
早鸟票¥199,享受活动五折优惠。
标准票¥399,购此票种开发者凭大会当天凭二维码签到可得安卓开发书籍一本。
团购票¥798,此票为套票3张,即三人成行一人免单,经济实惠。
VIP票¥599,此票座位为会场前排、赠高级礼品、有提问机会、可加入讲师群。
活动须知:
请各位小伙伴认真填写所有的报名资料用于审核使用,由于场地位置有限和为了保证活动质量,活动当天拒绝空降,现场签到凭报名成功二维码,谢谢配合!
活动路线:
地铁路线:地铁9号线金桥站2号口骑行1公里。
公交:1045路、浦东27路、上川专线新金桥路唐陆路站下步行418米。
驾车路线:收费停车场位于唐陆公路与新金桥路交叉口西南150米。(前40名可拥有免费停车券)
收起阅读 »
环信即时通讯云V3.5.0更新--多版本实时音视频发布,总有一款适合你
摘要: 为满足不同场景需求,3.5.0版本开始将实时音视频会议划分了不同的类型,不同类型对应了不同场景,使你能够轻松地将实时音视频功能集成到你的应用或者网站中。

iOS SDK 更新日志
版本 V3.5.0 2018-08-13
新功能:
- 为满足不同场景需求,3.5.0版本开始将实时音视频会议划分了不同的类型,不同类型对应了不同场景,使你能够轻松地将实时音视频功能集成到你的应用或者网站中。在创建会议时可以传入以下几种类型:
- 优化实时音视频多人会议功能
- 为满足不同场景需求,3.5.0版本开始将实时音视频会议划分了不同的类型,不同类型对应了不同场景,使你能够轻松地将实时音视频功能集成到你的应用或者网站中。类型如下:
1. Communication:普通通信会议,最多支持参会者6人,会议里的每个参会者都可以自由说话和发布视频,该会议类型在服务器不做语音的再编码,音质最好,适用于远程医疗,在线客服等场景;
2. Large Communication:大型通信会议,最多参会者30人,会议里的每个参会者都可以自由说话,最多支持6个人发布视频,该会议模式在服务器做混音处理,支持更多的人说话,适用于大型会议等场景;
3. Live:互动视频会议,会议里支持最多6个主播和600个观众,观众可以通过连麦与主播互动,该会议类型适用于在线教育,互动直播等场景。
版本历史:Android SDK更新日志 ios SDK更新日志
下载地址:SDK下载 收起阅读 »
最近开发的即时通讯软件,有ios和安卓






有不足之之处,还请大家多多指教哈,可以加我q使用交流一下 249793044
图解View测量、布局及绘制原理
来自https://www.jianshu.com/p/3d2c49315d68
Android中自定义View一直是一个高级的技能,入门比较难,看起来很高大上。想要学会自定义View,当然要理解View的测量、布局及绘制原理,本篇文章将以图表的形式讲解View的测量、布局及绘制原理。
一、View绘制的流程框架

View的绘制是从上往下一层层迭代下来的。DecorView-->ViewGroup(--->ViewGroup)-->View ,按照这个流程从上往下,依次measure(测量),layout(布局),draw(绘制)。关于DecorView,可以看这篇文章。

二、Measure流程
顾名思义,就是测量每个控件的大小。
调用measure()方法,进行一些逻辑处理,然后调用onMeasure()方法,在其中调用setMeasuredDimension()设定View的宽高信息,完成View的测量操作。
如果有了widthMeasureSpec, heightMeasureSpec,通过一定的处理(可以重写,自定义处理步骤),从中获取View的宽/高,调用setMeasuredDimension()方法,指定View的宽高,完成测量工作。
MeasureSpec的确定
先介绍下什么是MeasureSpec?

MeasureSpec由两部分组成,一部分是测量模式,另一部分是测量的尺寸大小。
其中,Mode模式共分为三类
UNSPECIFIED :不对View进行任何限制,要多大给多大,一般用于系统内部
EXACTLY:对应LayoutParams中的match_parent和具体数值这两种模式。检测到View所需要的精确大小,这时候View的最终大小就是SpecSize所指定的值,
AT_MOST :对应LayoutParams中的wrap_content。View的大小不能大于父容器的大小。
那么MeasureSpec又是如何确定的?
对于DecorView,其确定是通过屏幕的大小,和自身的布局参数LayoutParams。
这部分很简单,根据LayoutParams的布局格式(match_parent,wrap_content或指定大小),将自身大小,和屏幕大小相比,设置一个不超过屏幕大小的宽高,以及对应模式。
对于其他View(包括ViewGroup),其确定是通过父布局的MeasureSpec和自身的布局参数LayoutParams。
这部分比较复杂。以下列图表表示不同的情况:

当子View的LayoutParams的布局格式是wrap_content,可以看到子View的大小是父View的剩余尺寸,和设置成match_parent时,子View的大小没有区别。为了显示区别,一般在自定义View时,需要重写onMeasure方法,处理wrap_content时的情况,进行特别指定。从这里看出MeasureSpec的指定也是从顶层布局开始一层层往下去,父布局影响子布局。
View的测量流程:

三、Layout流程
测量完View大小后,就需要将View布局在Window中,View的布局主要通过确定上下左右四个点来确定的。
其中布局也是自上而下,不同的是ViewGroup先在layout()中确定自己的布局,然后在onLayout()方法中再调用子View的layout()方法,让子View布局。在Measure过程中,ViewGroup一般是先测量子View的大小,然后再确定自身的大小。
setOpticalFrame()内部也是调用了setFrame(),所以具体看setFrame()怎么确定自身的位置布局。
如果当前View是一个ViewGroup,就需要实现onLayout方法,该方法的实现个自定义ViewGroup时其特性有关,必须自己实现。
由此便完成了一层层的的布局工作。
View的布局流程:

四、Draw过程
View的绘制过程遵循如下几步:
①绘制背景 background.draw(canvas)
②绘制自己(onDraw)
③绘制Children(dispatchDraw)
④绘制装饰(onDrawScrollBars)
从源码中可以清楚地看出绘制的顺序。

五、总结
从View的测量、布局和绘制原理来看,要实现自定义View,根据自定义View的种类不同,可能分别要自定义实现不同的方法。但是这些方法不外乎:onMeasure()方法,onLayout()方法,onDraw()方法。
onMeasure()方法:单一View,一般重写此方法,针对wrap_content情况,规定View默认的大小值,避免于match_parent情况一致。ViewGroup,若不重写,就会执行和单子View中相同逻辑,不会测量子View。一般会重写onMeasure()方法,循环测量子View。
onLayout()方法:单一View,不需要实现该方法。ViewGroup必须实现,该方法是个抽象方法,实现该方法,来对子View进行布局。
onDraw()方法:无论单一View,或者ViewGroup都需要实现该方法,因其是个空方法
收起阅读 »
Android中自定义View一直是一个高级的技能,入门比较难,看起来很高大上。想要学会自定义View,当然要理解View的测量、布局及绘制原理,本篇文章将以图表的形式讲解View的测量、布局及绘制原理。
一、View绘制的流程框架
View的绘制是从上往下一层层迭代下来的。DecorView-->ViewGroup(--->ViewGroup)-->View ,按照这个流程从上往下,依次measure(测量),layout(布局),draw(绘制)。关于DecorView,可以看这篇文章。
二、Measure流程
顾名思义,就是测量每个控件的大小。
调用measure()方法,进行一些逻辑处理,然后调用onMeasure()方法,在其中调用setMeasuredDimension()设定View的宽高信息,完成View的测量操作。
public final void measure(int widthMeasureSpec, int heightMeasureSpec) {
}measure()方法中,传入了两个参数 widthMeasureSpec, heightMeasureSpec 表示View的宽高的一些信息。protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
setMeasuredDimension(getDefaultSize(getSuggestedMinimumWidth(), widthMeasureSpec),
getDefaultSize(getSuggestedMinimumHeight(), heightMeasureSpec));
}
由上述流程来看Measure流程很简单,关键点是在于widthMeasureSpec, heightMeasureSpec这两个参数信息怎么获得?如果有了widthMeasureSpec, heightMeasureSpec,通过一定的处理(可以重写,自定义处理步骤),从中获取View的宽/高,调用setMeasuredDimension()方法,指定View的宽高,完成测量工作。
MeasureSpec的确定
先介绍下什么是MeasureSpec?
MeasureSpec由两部分组成,一部分是测量模式,另一部分是测量的尺寸大小。
其中,Mode模式共分为三类
UNSPECIFIED :不对View进行任何限制,要多大给多大,一般用于系统内部
EXACTLY:对应LayoutParams中的match_parent和具体数值这两种模式。检测到View所需要的精确大小,这时候View的最终大小就是SpecSize所指定的值,
AT_MOST :对应LayoutParams中的wrap_content。View的大小不能大于父容器的大小。
那么MeasureSpec又是如何确定的?
对于DecorView,其确定是通过屏幕的大小,和自身的布局参数LayoutParams。
这部分很简单,根据LayoutParams的布局格式(match_parent,wrap_content或指定大小),将自身大小,和屏幕大小相比,设置一个不超过屏幕大小的宽高,以及对应模式。
对于其他View(包括ViewGroup),其确定是通过父布局的MeasureSpec和自身的布局参数LayoutParams。
这部分比较复杂。以下列图表表示不同的情况:
当子View的LayoutParams的布局格式是wrap_content,可以看到子View的大小是父View的剩余尺寸,和设置成match_parent时,子View的大小没有区别。为了显示区别,一般在自定义View时,需要重写onMeasure方法,处理wrap_content时的情况,进行特别指定。从这里看出MeasureSpec的指定也是从顶层布局开始一层层往下去,父布局影响子布局。
View的测量流程:
三、Layout流程
测量完View大小后,就需要将View布局在Window中,View的布局主要通过确定上下左右四个点来确定的。
其中布局也是自上而下,不同的是ViewGroup先在layout()中确定自己的布局,然后在onLayout()方法中再调用子View的layout()方法,让子View布局。在Measure过程中,ViewGroup一般是先测量子View的大小,然后再确定自身的大小。
public void layout(int l, int t, int r, int b) {
// 当前视图的四个顶点
int oldL = mLeft;
int oldT = mTop;
int oldB = mBottom;
int oldR = mRight;
// setFrame() / setOpticalFrame():确定View自身的位置
// 即初始化四个顶点的值,然后判断当前View大小和位置是否发生了变化并返回
boolean changed = isLayoutModeOptical(mParent) ?
setOpticalFrame(l, t, r, b) : setFrame(l, t, r, b);
//如果视图的大小和位置发生变化,会调用onLayout()
if (changed || (mPrivateFlags & PFLAG_LAYOUT_REQUIRED) == PFLAG_LAYOUT_REQUIRED) {
// onLayout():确定该View所有的子View在父容器的位置
onLayout(changed, l, t, r, b);
...
}
上面看出通过 setFrame() / setOpticalFrame():确定View自身的位置,通过onLayout()确定子View的布局。setOpticalFrame()内部也是调用了setFrame(),所以具体看setFrame()怎么确定自身的位置布局。
protected boolean setFrame(int left, int top, int right, int bottom) {
...
// 通过以下赋值语句记录下了视图的位置信息,即确定View的四个顶点
// 即确定了视图的位置
mLeft = left;
mTop = top;
mRight = right;
mBottom = bottom;
mRenderNode.setLeftTopRightBottom(mLeft, mTop, mRight, mBottom);
}
确定了自身的位置后,就要通过onLayout()确定子View的布局。onLayout()是一个可继承的空方法。protected void onLayout(boolean changed, int left, int top, int right, int bottom) {
}如果当前View就是一个单一的View,那么没有子View,就不需要实现该方法。如果当前View是一个ViewGroup,就需要实现onLayout方法,该方法的实现个自定义ViewGroup时其特性有关,必须自己实现。
由此便完成了一层层的的布局工作。
View的布局流程:
四、Draw过程
View的绘制过程遵循如下几步:
①绘制背景 background.draw(canvas)
②绘制自己(onDraw)
③绘制Children(dispatchDraw)
④绘制装饰(onDrawScrollBars)
从源码中可以清楚地看出绘制的顺序。
public void draw(Canvas canvas) {
// 所有的视图最终都是调用 View 的 draw ()绘制视图( ViewGroup 没有复写此方法)
// 在自定义View时,不应该复写该方法,而是复写 onDraw(Canvas) 方法进行绘制。
// 如果自定义的视图确实要复写该方法,那么需要先调用 super.draw(canvas)完成系统的绘制,然后再进行自定义的绘制。
...
int saveCount;
if (!dirtyOpaque) {
// 步骤1: 绘制本身View背景
drawBackground(canvas);
}
// 如果有必要,就保存图层(还有一个复原图层)
// 优化技巧:
// 当不需要绘制 Layer 时,“保存图层“和“复原图层“这两步会跳过
// 因此在绘制的时候,节省 layer 可以提高绘制效率
final int viewFlags = mViewFlags;
if (!verticalEdges && !horizontalEdges) {
if (!dirtyOpaque)
// 步骤2:绘制本身View内容 默认为空实现, 自定义View时需要进行复写
onDraw(canvas);
......
// 步骤3:绘制子View 默认为空实现 单一View中不需要实现,ViewGroup中已经实现该方法
dispatchDraw(canvas);
........
// 步骤4:绘制滑动条和前景色等等
onDrawScrollBars(canvas);
..........
return;
}
...
}
无论是ViewGroup还是单一的View,都需要实现这套流程,不同的是,在ViewGroup中,实现了 dispatchDraw()方法,而在单一子View中不需要实现该方法。自定义View一般要重写onDraw()方法,在其中绘制不同的样式。五、总结
从View的测量、布局和绘制原理来看,要实现自定义View,根据自定义View的种类不同,可能分别要自定义实现不同的方法。但是这些方法不外乎:onMeasure()方法,onLayout()方法,onDraw()方法。
onMeasure()方法:单一View,一般重写此方法,针对wrap_content情况,规定View默认的大小值,避免于match_parent情况一致。ViewGroup,若不重写,就会执行和单子View中相同逻辑,不会测量子View。一般会重写onMeasure()方法,循环测量子View。
onLayout()方法:单一View,不需要实现该方法。ViewGroup必须实现,该方法是个抽象方法,实现该方法,来对子View进行布局。
onDraw()方法:无论单一View,或者ViewGroup都需要实现该方法,因其是个空方法
收起阅读 »
环信公开课第35期-手把手教学开发直播小程序
微信小程序,依托微信,已经越来越多的新功能不断上线,流量入口的不断增加,俨然成为互联网公司“必争之地”。 传统的公众号第三方直播由于入口较深,用户每次使用都有较复杂的路径,很难培养用户的使用习惯,而小程序呢?使用之后有永久留存,用户下次再使用可以瞬间找到入口,大大提升用户使用直播的习惯。直播商业化最难的地方在于哪里?在于流量,微信有庞大的低成本的流量可以帮助你去获得用户,转化用户。小程序直播可以说是你商业化用户最好的工具,同样也是你客户商业化微信流量的最好的工具。直播和购物的结合比较经典的,也是我们课程主要剖析的一个项目就是“超级购物台”——直播购物小程序。

公开课参与
开课时间:2018年8月8日15:00
课程时长:40分钟
课程亮点:全国首个小程序直播购物Demo分享。手把手搭建基于环信的小程序直播购物平台
课程形式:网络直播 全国各地区、联网电脑、联网手机均可免费参与
课程大纲:
环信直播技术流程
1、【环信账号准备】注册、认证。
2、【直播间创建】包括环信后台创建及api 方式创建。
3、【房间主播及推流拉流地址设置】创建直播。主播绑定房间,房间设置直播地址。
小程序技术分享
1、【创建小程序项目】创建好已有UI的小程序项目。
2、【环信小程序sdk集成】基于webIM sdk 开发的小程序版本SDK集成配置。
3、【配置已有房间到小程序进行直播推流拉流测试】模拟直播间,使用推流工具进行推流测试。
4、【开发直播间聊天功能及聊天功能特殊情况处理】利用小程序SDK进行直播聊天室聊天开发。弹幕、特效等的一些延时。
答疑送奖品:
从提问中抽5名同学送出环信定制T恤,大家多多提问互动

公开参与:报名听课 收起阅读 »
公开课参与
开课时间:2018年8月8日15:00
课程时长:40分钟
课程亮点:全国首个小程序直播购物Demo分享。手把手搭建基于环信的小程序直播购物平台
课程形式:网络直播 全国各地区、联网电脑、联网手机均可免费参与
课程大纲:
环信直播技术流程
1、【环信账号准备】注册、认证。
2、【直播间创建】包括环信后台创建及api 方式创建。
3、【房间主播及推流拉流地址设置】创建直播。主播绑定房间,房间设置直播地址。
小程序技术分享
1、【创建小程序项目】创建好已有UI的小程序项目。
2、【环信小程序sdk集成】基于webIM sdk 开发的小程序版本SDK集成配置。
3、【配置已有房间到小程序进行直播推流拉流测试】模拟直播间,使用推流工具进行推流测试。
4、【开发直播间聊天功能及聊天功能特殊情况处理】利用小程序SDK进行直播聊天室聊天开发。弹幕、特效等的一些延时。
答疑送奖品:
从提问中抽5名同学送出环信定制T恤,大家多多提问互动
公开参与:报名听课 收起阅读 »
滴滴!“全村的希望”环信T恤已发出,收到的同学打个卡
千呼万唤!经过与工厂沟通无数沟通,环信T恤量产到货啦!中奖同学收到了吗?
实物图

希望款:
环信机器人,正面是我们美女设计师设计的三个机器人,扛着“全镇的希望”,“全县的希望”,“全环信的希望”三个小旗,背面印有“全村的希望”
IM款:
正面:IM
背面:IM (即时通讯)
活动回顾:【有奖调查】环信T恤文案征集,你来我们就送!
中奖名单:
- 楼层6:Eternally(额外奖励,提建议被采纳)
- 楼层8:°﹏D.X.F.VIP
- 楼层18:空谷幽兰
- 楼层28:skoxe
- 楼层38.咚咚
欢迎大家以后多参加我们活动,除了T恤还有更多礼品送出,感谢继续支持环信! 收起阅读 »
【开源项目】全国首个开源直播小程序源码
今天你看直播了吗?拥有10亿微信生态用户的小程序已经成为了继移动互联后的又一个现象级风口,随着微信小程序对外开放实时音视频录制及播放等更多连接能力,小程序与直播强强联合,在各行各业找到了非常多的玩法,小程序直播相比微信直播和APP直播更加简洁、流畅、低延时、多入口等众多优势迅速向商业直播领域及泛娱乐直播领域蔓延。从小游戏、内容付费、工具、大数据、社交电商创业者到传统品牌商们,都在努力搭上小程序直播这辆快车,以免错过微信生态里新的流量洼地。

作为一名环信生态圈资深开发者,本着对技术的热衷,对环信的眷恋和对党的忠诚,基于环信即时通讯云写了“直播购物小程序”,目前项目源码已全部免费开放,希望对有需求的企业和开发者提供一个思路和参考。
直播购物小程序源码github地址:https://github.com/YuTongNetworkTechnology/wechat_live/tree/master
git打不开可直接点下面链接下载

直播购物小程序运行预览图
小程序体验指南(仅需两步):
1、下载微信小程序开发工具,下载地址:https://developers.weixin.qq.com/miniprogram/dev/devtools/download.html
.jpg")
2、导入源码:将附件的源码解压直接导入
.jpg")
环信小程序直播技术文档
一、 使用的技术
1、 环信IM直播室。
2、 微信小程序实时音视频播放组件live-player。
3、 推流软件(obs、易推流)等推流。
4、 视频流服务器(UCLOUD、七牛、腾讯)等视频流服务器。
二、 系统使用流程。
1、 视频推流软件将视频流推到流服务器。
2、 打开视频直播demo小程序注册环信账号。
3、 进入软件直播室进行测试。
三、 技术流程及使用的SDk
1、 注册环信账号
打开https://www.easemob.com/ 环信官网,点击右上角注册按钮,选择[注册即时通讯云]

填写对相关信息进行注册

注册成功后进行登录

注:新注册用户需进行账号的认证。
2、 直播应用创建
登录成功点击应用列表选择创建应用

输入应用名称等信息

创建成功后点击应用进入

需要注意的是应用的OrgName 和AppName这两个是以后都需要用到的两个参数变量

3、 直播创建
1)在创建直播之前需要对应用进行设置首先需要设置应用的直播流地址
第一步获取应用管理员的Token
curl -X POST "https://a1.easemob.com/[应用OrgName]/[应用AppName]/token" -d '{"grant_type":"client_credentials","client_id":"[应用client_id]","client_secret":"[应用] client_secret"}'返回格式
{
"access_token":"YWMtWY779DgJEeS2h9OR7fw4QgAAAUmO4Qukwd9cfJSpkWHiOa7MCSk0MrkVIco",
"expires_in":5184000,
"application":"c03b3e30-046a-11e4-8ed1-5701cdaaa0e4"
第二步设置直播流地址curl -X POST -H "Authorization: Bearer [管理员Token]" " https://a1.easemob.com/[应用OrgName]/[应用AppName]/liverooms/stream_url -d '{"pc_pull":"[pc拉流地址]","pc_push":"[pc推流地址]","mobile_pull":"[手机拉流地址]","mobile_push":"[手机推流地址]"}'"成功返回格式:
{
"action": "post",
"application": "e1a09de0-0e03-11e7-ad8e-a1d913615409",
"uri": "http://127.0.0.1:8080/easemob-demo/chatdemoui/liverooms/stream_url",
"entities": [ ],
"data": {
"pc_pull": true,
"mobile_push": true,
"mobile_pull": true,
"pc_push": true
},
"timestamp": 1494084474885,
"duration": 1,
"organization": "easemob-demo",
"applicationName": "chatdemoui"
}
2)创建主播点击IM用户

点击注册IM用户

填写用户信息

创建用户的过程同样也可以通过REST API形式进行
curl -X POST -i " https://a1.easemob.com/[应用OrgName]/[应用AppName]/users" -d '{"username":"[用户名]","password":"[密码]"}'
注:应用必须为开放注册

将注册的用户添加为主播
curl -X POST -H "Authorization: [管理员Token]" https://a1.easemob.com/[应用OrgName]/[应用AppName]/super_admin -d'{"superadmin":"[IM用户名]"}'返回结果示例:
{
"action": "post",
"application": "4d7e4ba0-dc4a-11e3-90d5-e1ffbaacdaf5",
"uri": "http://127.0.0.1:8080/easemob-demo/chatdemoui/chatrooms/super_admin",
"entities": [ ],
"data": {
"result": "success"
},
"timestamp": 1496236798886,
"duration": 0,
"organization": "easemob-demo",
"applicationName": "chatdemoui"
}
3)创建直播点击直播

点击新建房间

填写房间信息

创建房间同时也可以使用REST API形式进行详情可以查看http://docs.easemob.com/im/live/server-integration环信官方文档。
4、 小程序demo集成使用
小程序直播购物demo集成官方WebIM SDK详情请查看https://github.com/easemob/webim-weixin-xcx
Demo具体配置如下
打开demo 下sdk配置文件

修改appkey为自己应用的appkey

打开pages/live/index.js修改房间默认拉流地址及直播间房间号

四、 扩展说明
Demo中房间为固定测试房间,实际使用中应获取环信直播的房间信息及房间列表。具体如下:
获取直播间列表:
curl -X GET -H "Authorization: Bearer [用户Token]" https://a1.easemob.com/[应用OrgName]/[应用AppName]/liverooms?ongoing=true&limit=[获取数量]&cursor=[游标地址(不填写为充开始查询)]
响应:
{
"action": "get",
"application": "4d7e4ba0-dc4a-11e3-90d5-e1ffbaacdaf5",
"params": {
"cursor": [
"ZGNiMjRmNGY1YjczYjlhYTNkYjk1MDY2YmEyNzFmODQ6aW06Y2hhdHJvb206ZWFzZW1vYi1kZW1vI2NoYXRkZW1vdWk6MzE"
],
"ongoing": [
"true"
],
"limit": [
"2"
]
},
"uri": "http://127.0.0.1:8080/easemob-demo/chatdemoui/liverooms",
"entities": [ ],
"data": [
{
"id": "1924",
"chatroom_id": "17177265635330",
"title": "具体了",
"desc": "就咯",
"startTime": 1495779917352,
"endTime": 1495779917352,
"anchor": "wuls",
"gift_count": 0,
"praise_count": 0,
"current_user_count": 8,
"max_user_count": 9,
"status": "ongoing",
"cover_picture_url": "",
"pc_pull_url": "rtmp://vlive3.rtmp.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1924_1",
"pc_push_url": "rtmp://publish3.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1924_1",
"mobile_pull_url": "rtmp://vlive3.rtmp.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1924_1",
"mobile_push_url": "rtmp://publish3.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1924_1"
},
{
"id": "1922",
"chatroom_id": "17175003856897",
"title": "香山",
"desc": "随便",
"startTime": 1495777760957,
"endTime": 1495777760957,
"anchor": "sx001",
"gift_count": 0,
"praise_count": 8,
"current_user_count": 1,
"max_user_count": 3,
"status": "ongoing",
"cover_picture_url": "http://127.0.0.1:8080/easemob-demo/chatdemoui/chatfiles/43a62c20-41d6-11e7-a88e-df409c88cf66",
"pc_pull_url": "rtmp://vlive3.rtmp.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1922_1",
"pc_push_url": "rtmp://publish3.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1922_1",
"mobile_pull_url": "rtmp://vlive3.rtmp.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1922_1",
"mobile_push_url": "rtmp://publish3.cdn.ucloud.com.cn/ucloud/easemob-demo_chatdemoui_1922_1"
}
],
"timestamp": 1496303336669,
"duration": 0,
"organization": "easemob-demo",
"applicationName": "chatdemoui",
"cursor": "ZGNiMjRmNGY1YjczYjlhYTNkYjk1MDY2YmEyNzFmODQ6aW06Y2hhdHJvb206ZWFzZW1vYi1kZW1vI2NoYXRkZW1vdWk6NDk",
"count": 2
}
获取直播间详情:curl -X GET -H "Authorization: Bearer [用户Token]" " https://a1.easemob.com/[应用OrgName]/[应用AppName]/[房间id]/status"响应:
{
"action": "get",
"application": "4d7e4ba0-dc4a-11e3-90d5-e1ffbaacdaf5",
"uri": "http://127.0.0.1:8080/easemob-demo/chatdemoui/liverooms/1946/status",
"entities": [ ],
"data": {
"liveRoomID": "1946",
"status": "ongoing"
},
"timestamp": 1496234759930,
"duration": 0,
"organization": "easemob-demo",
"applicationName": "chatdemoui",
"count": 0
}
使用环信直播购物小程序遇到任何问题欢迎跟帖讨论。 收起阅读 »
环信客户互动云v5.37已发布,新增客户中心日志
新增客户中心日志:在客户中心日志页面下,可查看到客户中心的操作日志,目前记录范围为黑名单操作日志。
进入“管理员模式 > 客户中心 > 客户中心日志”页面,可以查看到黑名单操作日志,点击【筛选排序】按钮可进行自定义筛选,点击操作日志记录可显示客户资料、互动详情及黑名单操作详情。

客服模式
历史会话和质检页面iframe标签页支持拖动移动左右位置
历史会话和质检记录详情,会话聊窗右侧iframe标签页支持拖动移动左右位置。
进入“客服模式 > 历史会话”页面,打开历史会话记录详情,选中聊窗右侧iframe标签页,待鼠标变成小手状时,左右拖动可移动位置。
“客服模式 > 质量检查 > 质检记录”页面,以上优化适用。
注:管理员模式下,历史会话/质量检查页面记录详情页,同样支持iframe标签页拖动移动左右位置。
历史会话和质检页面会话标签可显示所有层级
历史会话和质检页面记录详情,会话标签可显示所有层级。
进入“客服模式 > 历史会话”页面,打开历史会话记录详情,可看到聊窗会话标签显示效果优化并可显示所有层级。
“客服模式 > 质量检查 > 质检记录”页面,“客服模式 > 搜索”页面,以上优化适用。
注:管理员模式下,历史会话/质检/搜索页面,以上优化适用。
历史会话满意度标签页替换为满意度图标显示
历史会话详情,原满意度标签页取消,右上角增加满意度图标,显示满意度评价信息。
进入“客服模式 > 历史会话”页面,打开历史会话记录详情,可看到聊窗右侧满意度标签页取消显示,右上角增加满意度图标,鼠标点击可弹窗显示满意度评价详情。
“客服模式 > 质量检查 > 质检记录”页面,以上优化适用。
注:管理员模式下,历史会话/质检页面,以上优化适用。
管理员模式
新增【客户中心日志】功能
在客户中心日志页面下,可查看到客户中心的操作日志,目前记录范围为黑名单操作日志。
进入“管理员模式 > 客户中心 > 客户中心日志”页面,可以查看到黑名单操作日志,点击【筛选排序】按钮可进行自定义筛选,点击操作日志记录可显示客户资料、互动详情及黑名单操作详情。
新增自定义业务规则模拟测试功能
自定义业务规则新增模拟测试功能,可通过测试,判断规则是否可用。
进入“管理员模式 > 设置 > 自定义业务规则”页面,可点击 图标对指定规则进行模拟测试。点击 ,弹出规则测试详细参数窗口,设定参数后,可点击测试按钮,进行测试。若测试成功,则说明规则可用。
注:自定义业务规则功能为标准版增值服务、旗舰版基础功能。如需开通,请提供租户ID并联系环信商务经理。
权限管理中客服模式-历史会话增加数据权限
自定义角色权限,客服模式-历史会话增加数据权限。
进入“管理员模式 > 设置 > 权限管理”页面,编辑自定义角色权限(或添加自定义角色),找到客服模式下历史会话权限,可查看到右边新增数据权限,下拉列表可选择“客服/技能组/租户”3个选项,可根据需要进行自定义设置。
【优化】客户中心导航菜单优化
管理员模式下,【客户中心】导航菜单优化。
进入“管理员模式 > 客户中心”页面,可看到客户中心下二级菜单项优化。其中包括:
原“客户中心”一级菜单更改为【客户中心】下“客户信息”二级菜单。
原“设置-客户标签”“设置-客户中心设置”二级菜单 更改为【客户中心】下二级菜单。
新增【客户中心日志】功能,详情可参考新增【客户中心日志】功能章节。
【优化】访客端消息关键字匹配后行为设置
关键字匹配功能下,新增访客消息端行为配置选项。
进入“管理员模式 > 设置 > 关键字匹配”页面,点击关键字过滤(或添加关键字匹配规则),在弹出窗口中,消息来源选择“访客消息”,满足以下条件选择“关键字匹配”,可查看到执行下拉列表新增2项“在坐席端提示消息 / 在坐席和访客端提示消息”;
弹出窗口中,消息来源选择“访客消息”,满足以下条件选择“正则表达式”,可查看到执行下拉列表新增1项“发送事件到告警记录面板”。
注:关键字匹配功能为标准版增值服务、旗舰版基础功能。如需开通,请提供租户ID并联系环信商务经理。
【优化】客户标签数量限制增大至100
优化会话窗口客户标签显示问题,数量限制40增大至100。新建及导入客户标签时,支持最大数量为100。
【优化】机器人自定义菜单操作提示统一交互
优化机器人设置页面,自定义菜单标签页操作的交互提示,与其他交互保持一致。
进入“管理员模式 > 智能机器人 > 机器人设置”页面,打开自定义菜单页签,添加/编辑/删除菜单项时,回车或点击输入框以外的其他区域可保存,并在右上角给出保存反馈提示。
【优化】公共常用语新增及导入字符数限制统一为1000
优化了公共常用语新增及导入字符数限制问题,统一为1000字符。1个字母或1个汉字均算作1个字符。
修复历史会话/待接入页面数据权限问题
“管理员模式 > 设置 > 权限管理”,修复如下问题:
- 管理员角色-客服模式-待接入,默认数据权限为“技能组”。
- 坐席角色-客服模式-历史会话,默认数据权限为“客服”。
- 坐席角色-客服模式-待接入,默认数据权限为“技能组”。
并修复了相关前端数据显示问题。
环信客户互动云更新日志:更新日志
环信客户互动云登陆地址:登陆地址 收起阅读 »
环信即时通讯云新版本发布-不在群聊天也能参加多人实时音视频会议!
环信即时通讯云V3.4.2已发布,新增消息邀请参加会议接口,被邀请方不在群聊天也能加入多人音视频会议。
- Android SDK 更新日志
- iOS SDK 更新日志
版本 V3.4.2 2018-06-15
新功能:
通过消息邀请参加其他人参加多人实时音视频会议
修复:
1v1视频通话,iOS端接收视频后,偶尔会不显示视频画面
请注意:为提供高质量且一致的音视频体验,从3.4.1版本开始,1v1 通话不再与3.1.5及以前版本兼容,请及时升级。
SDK更新日志:Android SDK更新日志 ios SDK更新日志
最新SDK下载:下载地址 收起阅读 »


