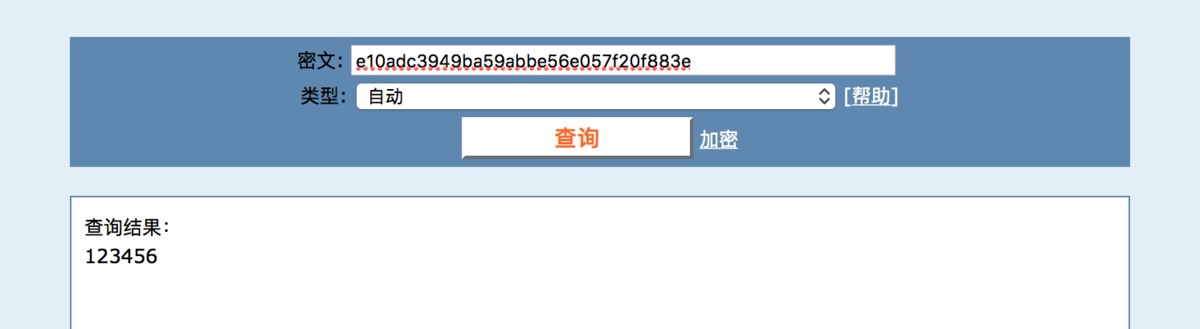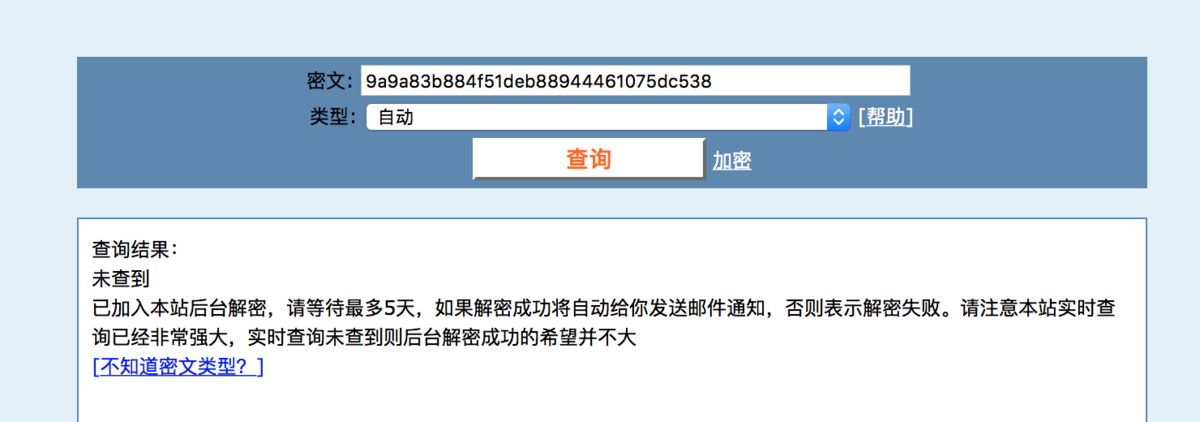


 冯·诺依曼最大的贡献是现代计算机,他采用了图灵奠定的卓越理论框架,并实际提出了为几乎所有数字计算机提供动力的架构:冯·诺依曼架构。 更有争议的是,冯·诺依曼在二战期间对曼哈顿计划做出了重大贡献,包括完善原子弹本身的设计和对其功能至关重要的机制。
冯·诺依曼最大的贡献是现代计算机,他采用了图灵奠定的卓越理论框架,并实际提出了为几乎所有数字计算机提供动力的架构:冯·诺依曼架构。 更有争议的是,冯·诺依曼在二战期间对曼哈顿计划做出了重大贡献,包括完善原子弹本身的设计和对其功能至关重要的机制。  与曼哈顿计划的其他一些老兵不同,冯·诺依曼从未对自己在该计划中的角色表示遗憾,甚至在冷战期间推动了「同归于尽」的政策。 至少可以说,约翰·冯·诺依曼是一个复杂的人物,但他在20世纪几乎无人能及,可以说他对现代世界的责任比他同时代的任何人都大。
与曼哈顿计划的其他一些老兵不同,冯·诺依曼从未对自己在该计划中的角色表示遗憾,甚至在冷战期间推动了「同归于尽」的政策。 至少可以说,约翰·冯·诺依曼是一个复杂的人物,但他在20世纪几乎无人能及,可以说他对现代世界的责任比他同时代的任何人都大。
 冯·诺伊曼11岁时与表妹 Katalin Alcsuti在一起 六岁时,他就开始在头脑中进行两个八位数的除法,八岁时,他已经掌握了微积分。
冯·诺伊曼11岁时与表妹 Katalin Alcsuti在一起 六岁时,他就开始在头脑中进行两个八位数的除法,八岁时,他已经掌握了微积分。  他的父亲认为,他所有的孩子都需要说除母语匈牙利语以外的欧洲主要语言,所以冯·诺依曼学习了英语、法语、意大利语和德语。 小时候,他对历史也有很深的兴趣,并阅读了德国历史学家威廉·昂肯的整部46卷专著《通史》。
他的父亲认为,他所有的孩子都需要说除母语匈牙利语以外的欧洲主要语言,所以冯·诺依曼学习了英语、法语、意大利语和德语。 小时候,他对历史也有很深的兴趣,并阅读了德国历史学家威廉·昂肯的整部46卷专著《通史》。

 1928年,他成为柏林大学的一名私 人教师,也是柏林大学历史上获得该职位最年轻的人。 这个职位使他能够在大学里讲课,直到1929年他成为汉堡大学的一名私人教师。 冯·诺依曼在父亲于1929年去世后,皈依了天主教。1930年元旦,约翰·冯·诺依曼与布达佩斯大学经济学学生玛丽埃塔·科维西结婚,并于1935年与她生下了他唯一的孩子玛丽娜。 虽然冯·诺依曼似乎注定要在德国科学院从事一个有前途的职业,但在1929年10月,他获得了新泽西州普林斯顿大学的一个职位,他最终接受了这个职位,并于1930年与妻子一起前往美国。
1928年,他成为柏林大学的一名私 人教师,也是柏林大学历史上获得该职位最年轻的人。 这个职位使他能够在大学里讲课,直到1929年他成为汉堡大学的一名私人教师。 冯·诺依曼在父亲于1929年去世后,皈依了天主教。1930年元旦,约翰·冯·诺依曼与布达佩斯大学经济学学生玛丽埃塔·科维西结婚,并于1935年与她生下了他唯一的孩子玛丽娜。 虽然冯·诺依曼似乎注定要在德国科学院从事一个有前途的职业,但在1929年10月,他获得了新泽西州普林斯顿大学的一个职位,他最终接受了这个职位,并于1930年与妻子一起前往美国。 1937年,冯·诺依曼成为美国公民,1939年,他的母亲、兄弟姐妹和姻亲也都移民到了美国(他的父亲早些时候去世了)。
1937年,冯·诺依曼成为美国公民,1939年,他的母亲、兄弟姐妹和姻亲也都移民到了美国(他的父亲早些时候去世了)。 这使他与美国军方,特别是美国海军进行了相当多的定期磋商。当曼哈顿计划在20世纪40年代初开始工作时,冯·诺依曼因其专业知识而被招募。 1943年,冯·诺依曼对曼哈顿计划产生了最重大、最持久的影响。
这使他与美国军方,特别是美国海军进行了相当多的定期磋商。当曼哈顿计划在20世纪40年代初开始工作时,冯·诺依曼因其专业知识而被招募。 1943年,冯·诺依曼对曼哈顿计划产生了最重大、最持久的影响。  曼哈顿计划成员 当时,设计原子弹的洛斯阿拉莫斯实验室发现,钚-239(该项目使用的裂变材料之一)与实验室的工作炸弹设计不兼容。 实验室的物理学家塞斯·尼德迈尔一直在研究一种独立的内爆型炸弹设计,这种设计很有希望,但许多人认为它不可行。
曼哈顿计划成员 当时,设计原子弹的洛斯阿拉莫斯实验室发现,钚-239(该项目使用的裂变材料之一)与实验室的工作炸弹设计不兼容。 实验室的物理学家塞斯·尼德迈尔一直在研究一种独立的内爆型炸弹设计,这种设计很有希望,但许多人认为它不可行。

 三位一体试验 与曼哈顿计划中同时代的一些人不同,冯·诺依曼似乎没有任何反思的痛苦、遗憾,甚至对他在原子弹方面的工作也没有一丝怀疑。 事实上,冯·诺依曼是核武器发展和相互保证毁灭(MAD)理论的最有力支持者之一,认为这是防止另一场灾难性世界大战的唯一方法。
三位一体试验 与曼哈顿计划中同时代的一些人不同,冯·诺依曼似乎没有任何反思的痛苦、遗憾,甚至对他在原子弹方面的工作也没有一丝怀疑。 事实上,冯·诺依曼是核武器发展和相互保证毁灭(MAD)理论的最有力支持者之一,认为这是防止另一场灾难性世界大战的唯一方法。 冯·诺依曼在上世纪30年代初遇到了艾伦·图灵,当时图灵正在普林斯顿攻读博士学位。1937年,图灵发表了具有里程碑意义的论文《论可计算数》,奠定了现代计算的理论基础。
冯·诺依曼在上世纪30年代初遇到了艾伦·图灵,当时图灵正在普林斯顿攻读博士学位。1937年,图灵发表了具有里程碑意义的论文《论可计算数》,奠定了现代计算的理论基础。 冯·诺依曼很快认识到了图灵这一发现的重要性,并在30年代推动了计算机科学的发展。在普林斯顿大学,他和图灵围绕人工智能的思想曾进行了长时间的讨论。 作为一名数学家,冯·诺依曼从更抽象的角度研究计算机科学,另一个原因也是因为在30年代时,并没有真正可以工作的计算机。 在二战结束后,这种情况很快就改变了。
冯·诺依曼很快认识到了图灵这一发现的重要性,并在30年代推动了计算机科学的发展。在普林斯顿大学,他和图灵围绕人工智能的思想曾进行了长时间的讨论。 作为一名数学家,冯·诺依曼从更抽象的角度研究计算机科学,另一个原因也是因为在30年代时,并没有真正可以工作的计算机。 在二战结束后,这种情况很快就改变了。  冯·诺依曼深入参与了第一台可编程电子计算机「ENIAC」的开发,这台计算机能够识别和决定其他数据操作规则集,而不是最初使用的规则集。是冯诺依曼将 ENIAC 修改为作为存储程序机器运行。 后者让使我们今天理解的现代程序成为可能。冯·诺依曼本人编写了几个在 ENIAC 上运行的首批程序,并用这些程序模拟原子能委员会的部分核武器研究。 毫无疑问,冯·诺依曼对计算机科学领域最持久的贡献是在当今运行的每台计算机中使用的两个基本概念:冯·诺依曼体系架构和存储程序概念。
冯·诺依曼深入参与了第一台可编程电子计算机「ENIAC」的开发,这台计算机能够识别和决定其他数据操作规则集,而不是最初使用的规则集。是冯诺依曼将 ENIAC 修改为作为存储程序机器运行。 后者让使我们今天理解的现代程序成为可能。冯·诺依曼本人编写了几个在 ENIAC 上运行的首批程序,并用这些程序模拟原子能委员会的部分核武器研究。 毫无疑问,冯·诺依曼对计算机科学领域最持久的贡献是在当今运行的每台计算机中使用的两个基本概念:冯·诺依曼体系架构和存储程序概念。  冯·诺依曼架构涉及构成计算机的物理电子电路的组织方式。按照这种方式构建的计算机被称为「冯·诺依曼机」。该架构由算术和逻辑单元 (ALU)、控制单元和临时存储器寄存器组成,它们共同构成了中央处理器 (CPU)。 CPU 连接到内存单元,该内存单元包含将要由CPU处理和操作的所有数据。CPU还连接到输入和输出设备,以根据需要更改数据,并检索运行程序的结果。 自 1945 年冯诺依曼提出这一架构以来,直到今天,它基本上仍是当今大多数通用计算机的运行方式,几乎没有改变。 另一项重大创新与冯·诺依曼架构有关,即存储程序概念,也就是说,被操作或处理的数据,以及描述如何操纵和处理该数据的程序,都存储在计算机的内存中。 这两项相互交织的创新实现了图灵机的理论框架,实际上将它们变成了可以用来计算工资、火炮轨迹、游戏、互联网等几乎所有一切数据的机器。
冯·诺依曼架构涉及构成计算机的物理电子电路的组织方式。按照这种方式构建的计算机被称为「冯·诺依曼机」。该架构由算术和逻辑单元 (ALU)、控制单元和临时存储器寄存器组成,它们共同构成了中央处理器 (CPU)。 CPU 连接到内存单元,该内存单元包含将要由CPU处理和操作的所有数据。CPU还连接到输入和输出设备,以根据需要更改数据,并检索运行程序的结果。 自 1945 年冯诺依曼提出这一架构以来,直到今天,它基本上仍是当今大多数通用计算机的运行方式,几乎没有改变。 另一项重大创新与冯·诺依曼架构有关,即存储程序概念,也就是说,被操作或处理的数据,以及描述如何操纵和处理该数据的程序,都存储在计算机的内存中。 这两项相互交织的创新实现了图灵机的理论框架,实际上将它们变成了可以用来计算工资、火炮轨迹、游戏、互联网等几乎所有一切数据的机器。 1932年,他和保罗·狄拉克在《量子力学的数学基础》一书中发表了狄拉克-冯·诺依曼公理,这是该领域的第一个完整的数学框架。在这本书中,他还提出了量子逻辑的形式系统,也是同类体系中的首创。 冯·诺依曼还将博弈论确立为一门严谨的数学学科,这无疑影响了他后来关于MAD理论的地缘政治战略工作。
1932年,他和保罗·狄拉克在《量子力学的数学基础》一书中发表了狄拉克-冯·诺依曼公理,这是该领域的第一个完整的数学框架。在这本书中,他还提出了量子逻辑的形式系统,也是同类体系中的首创。 冯·诺依曼还将博弈论确立为一门严谨的数学学科,这无疑影响了他后来关于MAD理论的地缘政治战略工作。  冯·诺依曼的博弈论中包含这样一个观点,即在广泛的博弈类别中,总是有可能找到一个平衡,任何参与者都不应单方面偏离这个平衡。 在生命科学领域,冯·诺依曼对元胞自动机的自我复制进行了彻底的数学分析,主要是构造函数、正在构建的事物以及构造函数构建所讨论事物所遵循的蓝图之间的关系。该分析描述了一种自我复制的机器,它是在40年代设计的,没有使用计算机。 冯·诺依曼的数学造诣也惠及气候科学。1950年,他编写了第一个气候建模程序,并使用 ENIAC 使用数值数据进行了世界上第一个气象预测。 冯·诺依曼预计,全球变暖是人类活动的结果,他在1955年写道: 「工业燃烧煤和石油释放到大气中的二氧化碳,可能已经充分改变了大气的成分,导致全球普遍变暖约1华氏度。」 冯·诺依曼也被认为是第一个描述「技术奇点」的人。冯·诺依曼的朋友斯坦·乌拉姆 (Stan Ulam) 后来描述了与他的一次对话,这次对话在今天听起来非常有先见之明。
冯·诺依曼的博弈论中包含这样一个观点,即在广泛的博弈类别中,总是有可能找到一个平衡,任何参与者都不应单方面偏离这个平衡。 在生命科学领域,冯·诺依曼对元胞自动机的自我复制进行了彻底的数学分析,主要是构造函数、正在构建的事物以及构造函数构建所讨论事物所遵循的蓝图之间的关系。该分析描述了一种自我复制的机器,它是在40年代设计的,没有使用计算机。 冯·诺依曼的数学造诣也惠及气候科学。1950年,他编写了第一个气候建模程序,并使用 ENIAC 使用数值数据进行了世界上第一个气象预测。 冯·诺依曼预计,全球变暖是人类活动的结果,他在1955年写道: 「工业燃烧煤和石油释放到大气中的二氧化碳,可能已经充分改变了大气的成分,导致全球普遍变暖约1华氏度。」 冯·诺依曼也被认为是第一个描述「技术奇点」的人。冯·诺依曼的朋友斯坦·乌拉姆 (Stan Ulam) 后来描述了与他的一次对话,这次对话在今天听起来非常有先见之明。  斯坦·乌拉姆、理查德·费曼和冯·诺依曼在一起 乌拉姆回忆说:「有一次谈话集中在不断加速的技术进步和人类生活方式的变化上,这让我们看到了人类历史上一些本质上的奇点。一旦超越了这些奇点,我们所熟知的人类事务就将无法继续下去了。」
斯坦·乌拉姆、理查德·费曼和冯·诺依曼在一起 乌拉姆回忆说:「有一次谈话集中在不断加速的技术进步和人类生活方式的变化上,这让我们看到了人类历史上一些本质上的奇点。一旦超越了这些奇点,我们所熟知的人类事务就将无法继续下去了。」 「当冯·诺依曼意识到自己病入膏肓时,他的逻辑迫使他意识到,自己即将不复存在,因此也不再有思想……亲眼目睹这一过程是令人心碎的,所有的希望都消失了,即将到来的命运尽管难以接受,但已经不可避免。」 冯·诺依曼的病情在1956年持续恶化,最终被送进了华盛顿特区的沃尔特里德陆军医疗中心。为防止泄密,军方对他实施了特殊的安全措施。 冯·诺依曼邀请一位天主教神父在他临终前商量,并接受了他的临终仪式安排。不过这位神父本人表示,冯诺依曼看上去似乎并没有从仪式中得到安慰。 1957年2月8日,冯·诺依曼因癌症逝世,享年53岁,他被安葬在新泽西州的普林斯顿公墓。 关于冯·诺依曼的癌症是否与他在「曼哈顿计划」期间遭受辐射有关,人们一直存在争议,但毫无争议的是,人类过早地失去了当代最伟大的科学巨人之一。
「当冯·诺依曼意识到自己病入膏肓时,他的逻辑迫使他意识到,自己即将不复存在,因此也不再有思想……亲眼目睹这一过程是令人心碎的,所有的希望都消失了,即将到来的命运尽管难以接受,但已经不可避免。」 冯·诺依曼的病情在1956年持续恶化,最终被送进了华盛顿特区的沃尔特里德陆军医疗中心。为防止泄密,军方对他实施了特殊的安全措施。 冯·诺依曼邀请一位天主教神父在他临终前商量,并接受了他的临终仪式安排。不过这位神父本人表示,冯诺依曼看上去似乎并没有从仪式中得到安慰。 1957年2月8日,冯·诺依曼因癌症逝世,享年53岁,他被安葬在新泽西州的普林斯顿公墓。 关于冯·诺依曼的癌症是否与他在「曼哈顿计划」期间遭受辐射有关,人们一直存在争议,但毫无争议的是,人类过早地失去了当代最伟大的科学巨人之一。  冯·诺依曼的助手 P.R. Halmos 在1973年写道: 「人类的英雄有两种:一种和我们所有人一样,但更加相似,另一种显然具有一些「超人」的特质。 我们都可以跑步,我们中的一些人可以在不到4分钟的时间内跑完一英里。但有些事,我们大多数人一辈子都无法做到。冯·诺依曼的伟大贡献是惠及全人类的。在某些时候,我们或多或少都能清晰地思考,但冯·诺依曼的清晰思维始终比我们大多数人高出好几个数量级。」 冯·诺依曼的才华是毋庸置疑的,尽管他留下的遗产,尤其是核武器方面的贡献,比他的朋友和崇拜者愿意承认的要复杂得多。 无论我们最终如何看待冯·诺依曼和他的成就,我们都可以肯定地说,在未来一代人甚至几代人的时间里,都不太可能出现像他一样,对人类历史产生如此重大影响的人了。
冯·诺依曼的助手 P.R. Halmos 在1973年写道: 「人类的英雄有两种:一种和我们所有人一样,但更加相似,另一种显然具有一些「超人」的特质。 我们都可以跑步,我们中的一些人可以在不到4分钟的时间内跑完一英里。但有些事,我们大多数人一辈子都无法做到。冯·诺依曼的伟大贡献是惠及全人类的。在某些时候,我们或多或少都能清晰地思考,但冯·诺依曼的清晰思维始终比我们大多数人高出好几个数量级。」 冯·诺依曼的才华是毋庸置疑的,尽管他留下的遗产,尤其是核武器方面的贡献,比他的朋友和崇拜者愿意承认的要复杂得多。 无论我们最终如何看待冯·诺依曼和他的成就,我们都可以肯定地说,在未来一代人甚至几代人的时间里,都不太可能出现像他一样,对人类历史产生如此重大影响的人了。








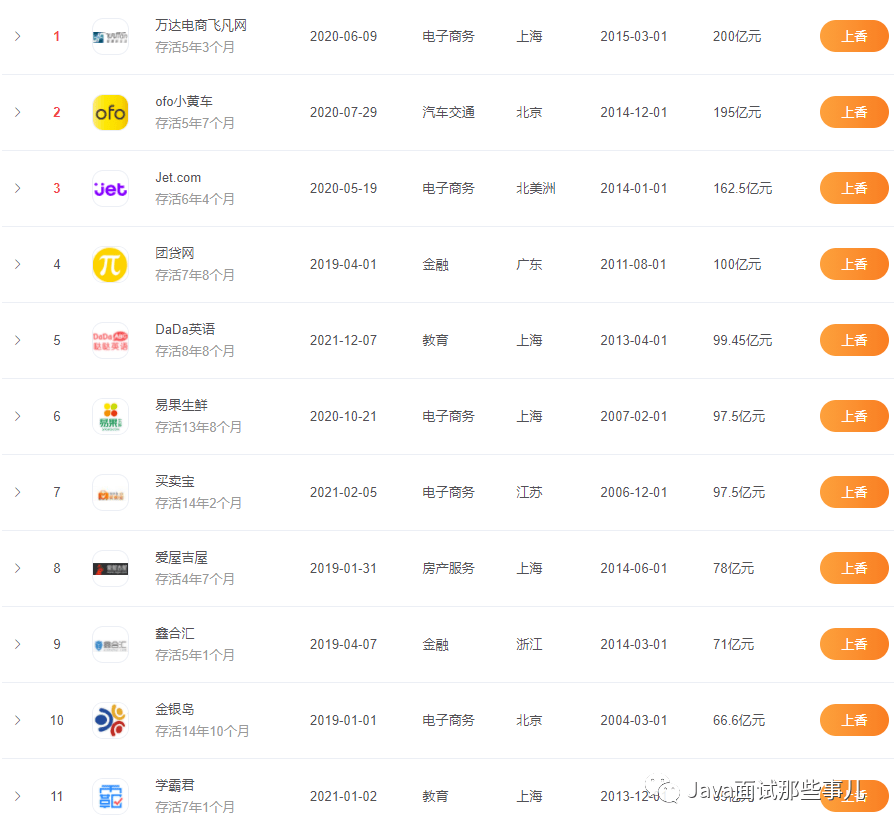
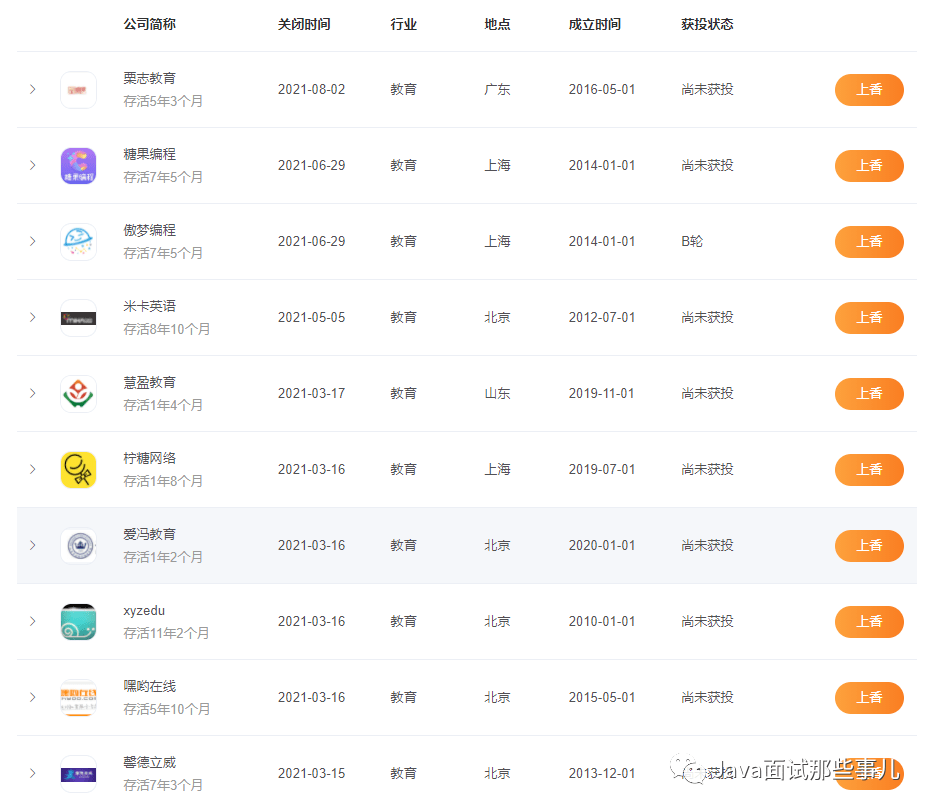
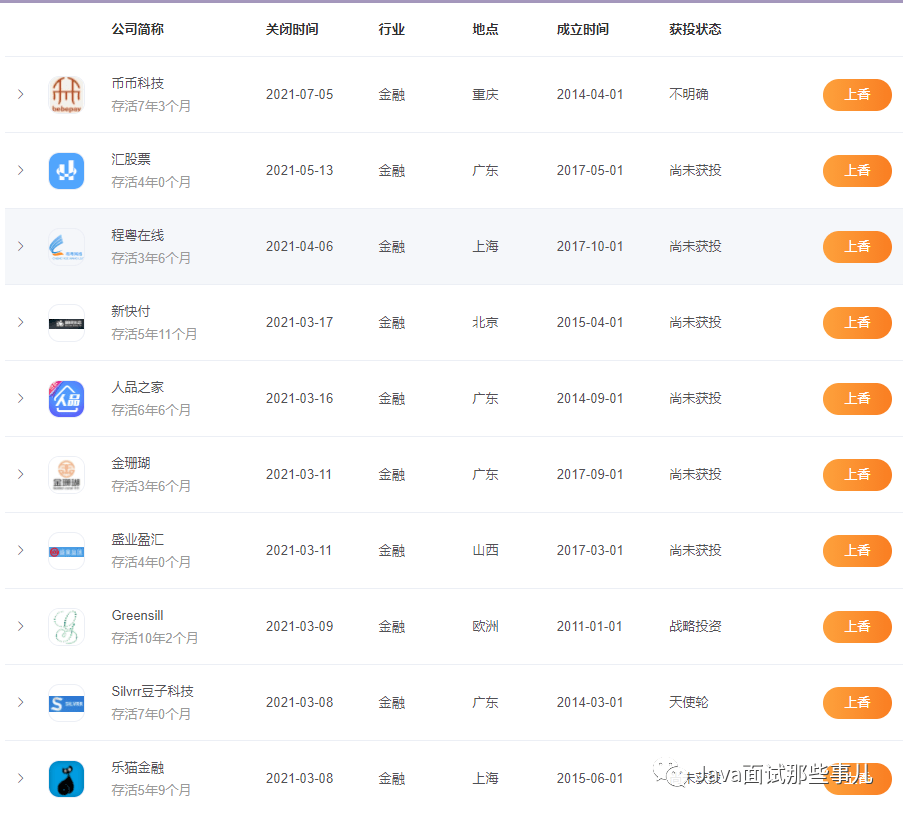
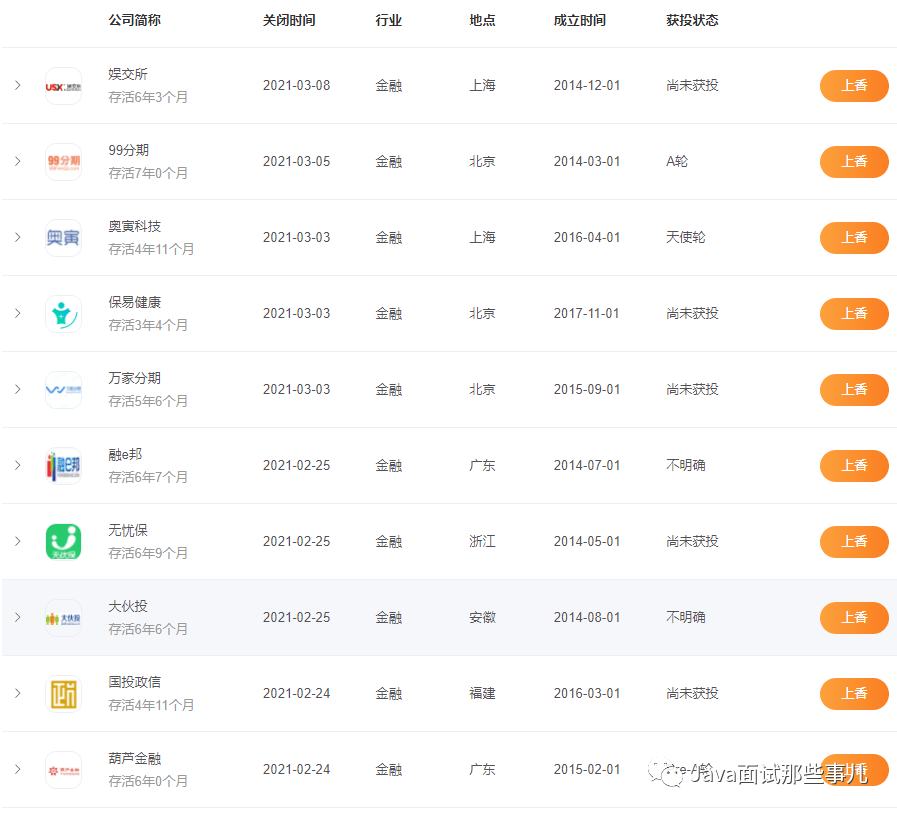
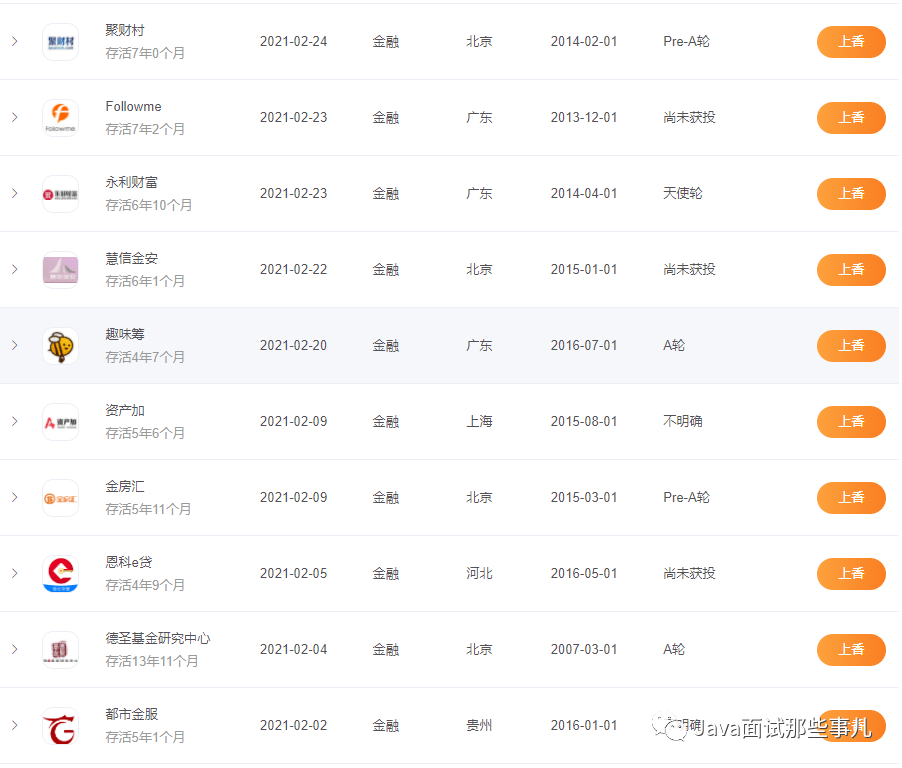
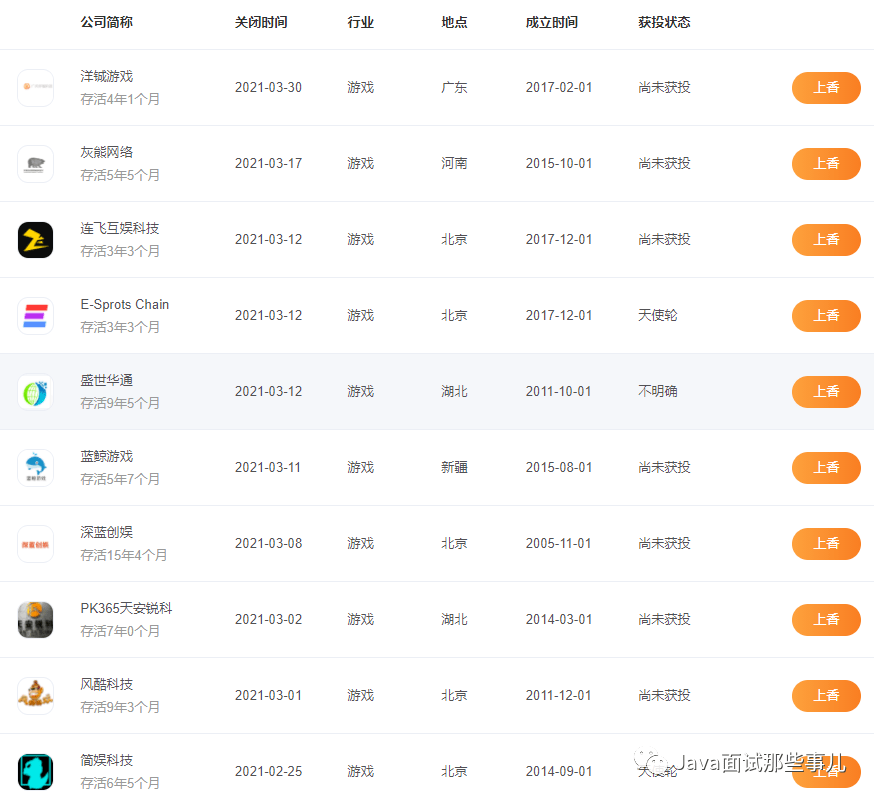
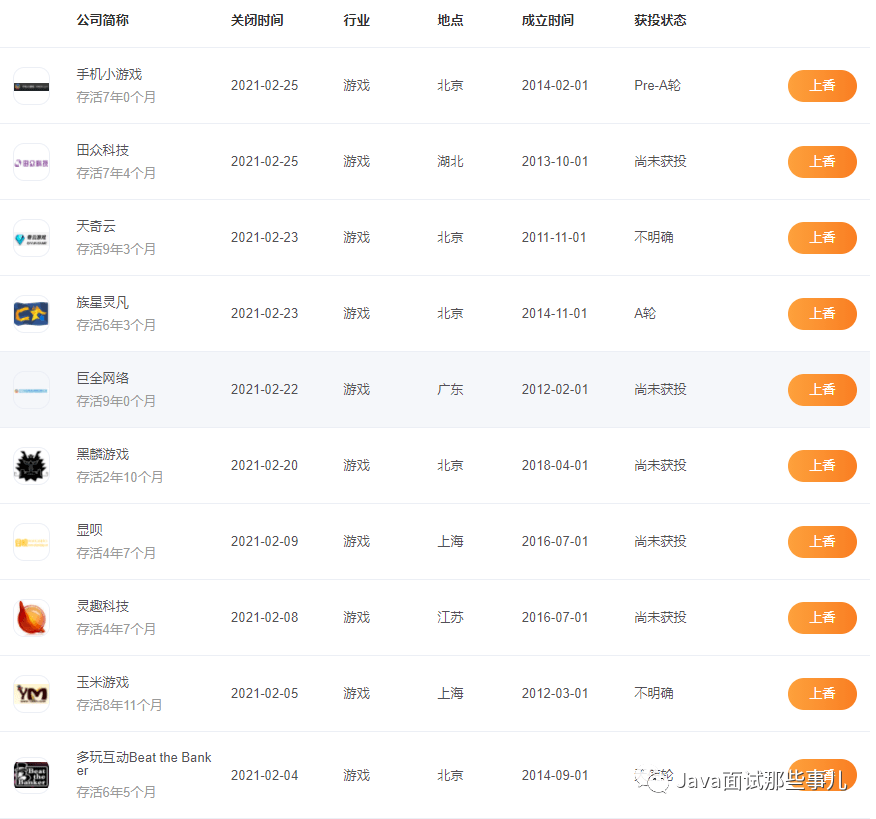
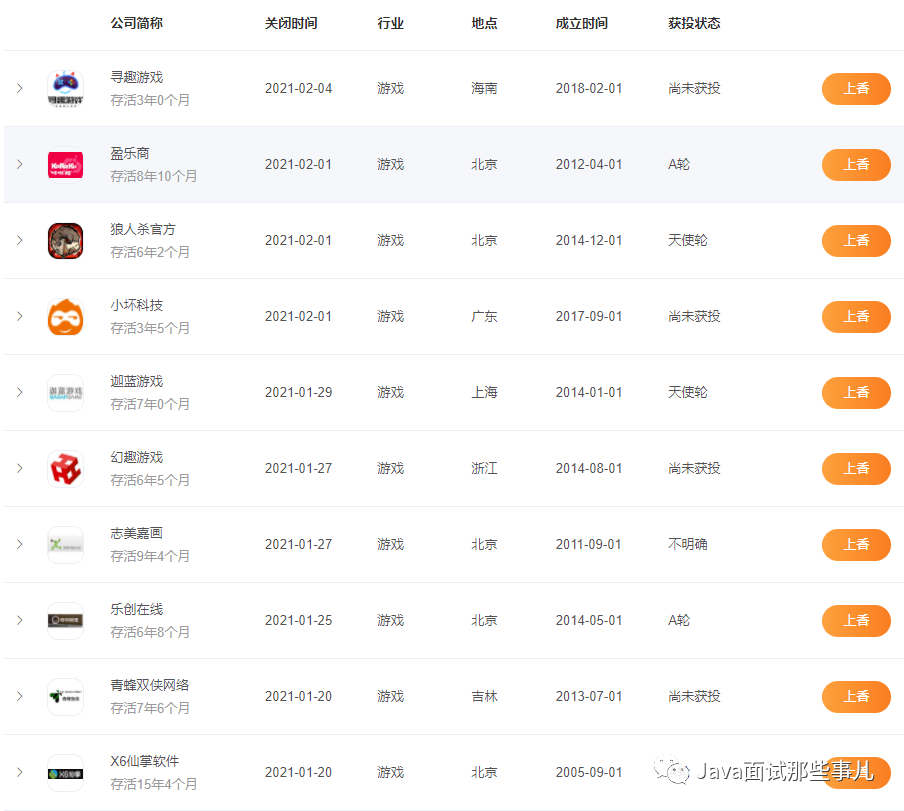
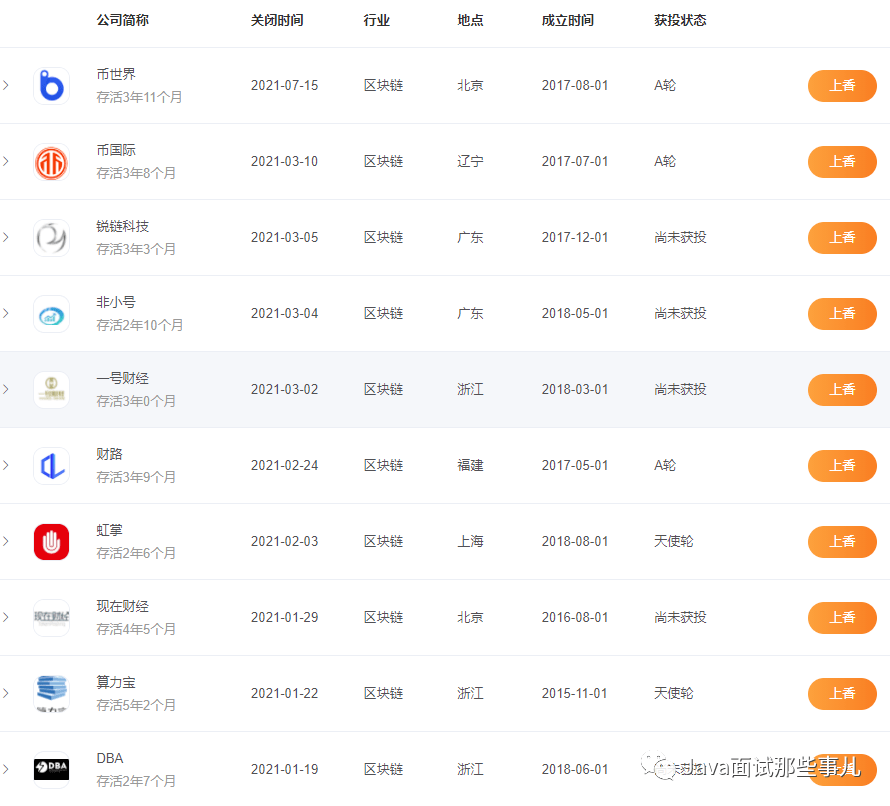
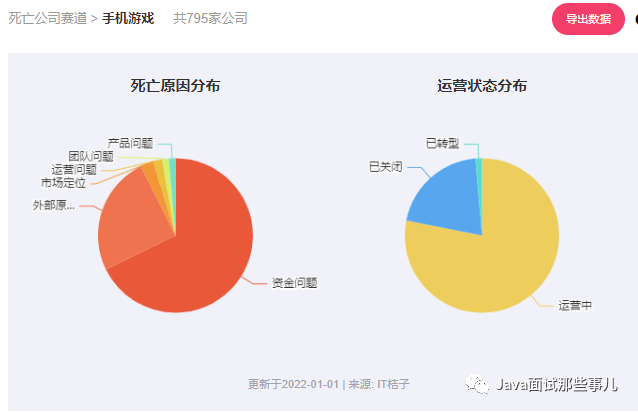











































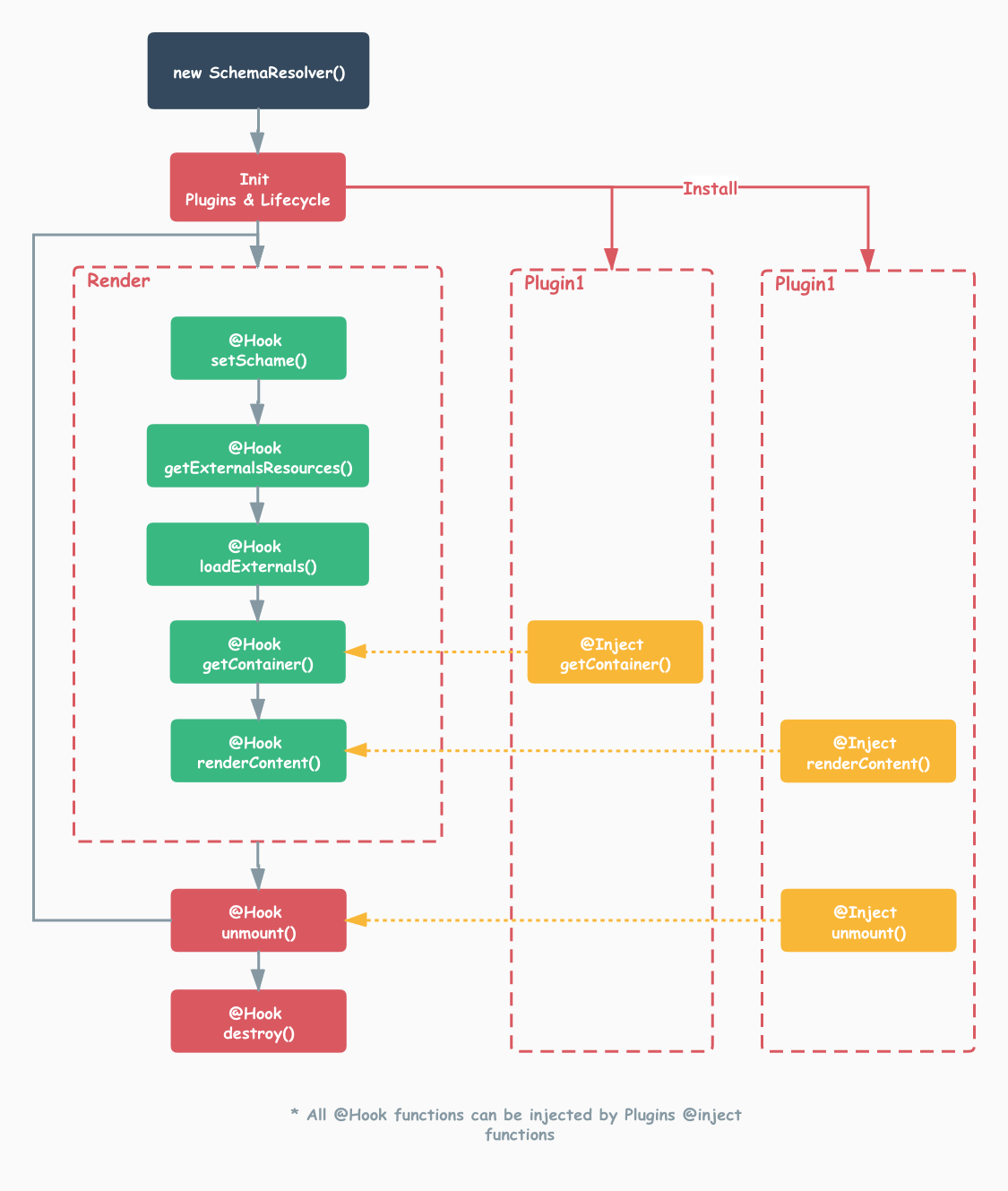

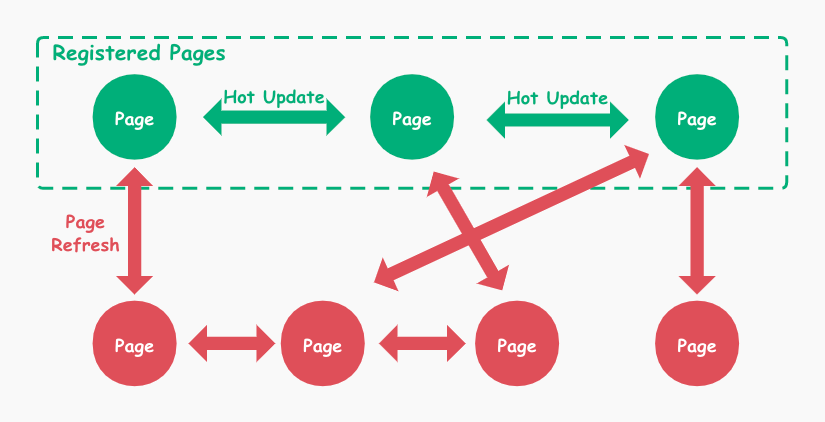
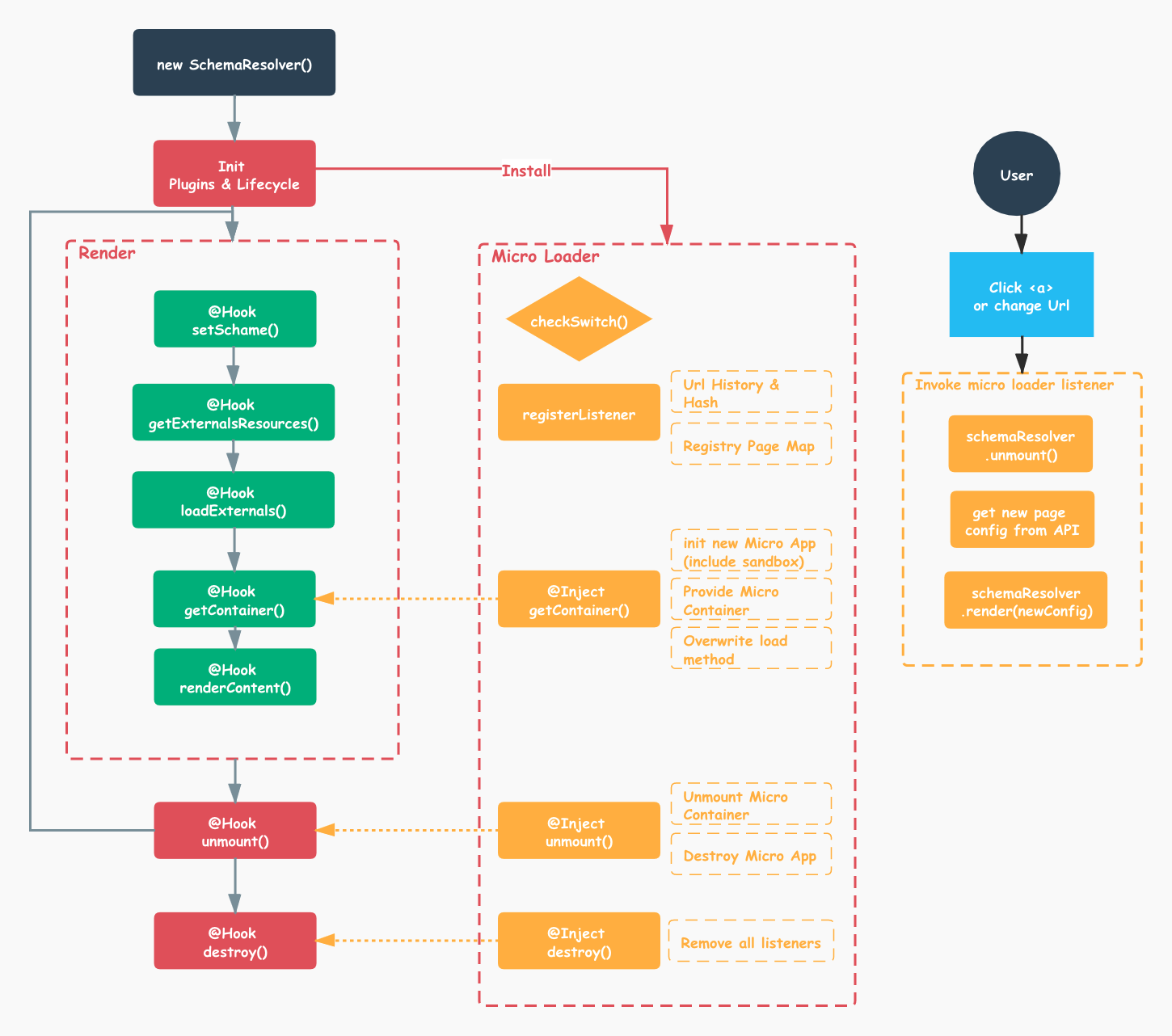
前端框架的数据流
前端框架实现了数据驱动视图变化的功能,我们用 template 或者 jsx 描述好了数据和视图的绑定关系,然后就只需要关心数据的管理了。
数据在组件和组件之间、组件和全局 store 之间传递,叫做前端框架的数据流。
一般来说,除了某部分状态数据是只有某个组件关心的,我们会把状态数据放在组件内以外,业务数据、多个组件关心的状态数据都会放在 store 里面。组件从 store 中取数据,当交互的时候去通知 store 改变对应的数据。
这个 store 不一定是 redux、mobox 这些第三方库,其实 react 内置的 context 也可以作为 store。但是 context 做为 store 有一个问题,任何组件都能从 context 中取出数据来修改,那么当排查问题的时候就特别困难,因为并不知道是哪个组件把数据改坏的,也就是数据流不清晰。
正是因为这个原因,我们几乎见不到用 context 作为 store,基本都是搭配一个 redux。
所以为什么 redux 好呢?第一个原因就是数据流清晰,改变数据有统一的入口。
组件里都是通过 dispatch 一个 action 来触发 store 的修改,而且修改的逻辑都是在 reducer 里面,组件再监听 store 的数据变化,从中取出最新的数据。
这样数据流动是单向的,清晰的,很容易管理。
这就像为什么我们在公司里想要什么权限都要走审批流,而不是直接找某人,一样的道理。集中管理流程比较清晰,而且还可以追溯。
异步过程的管理
很多情况下改变 store 数据都是一个异步的过程,比如等待网络请求返回数据、定时改变数据、等待某个事件来改变数据等,那这些异步过程的代码放在哪里呢?
组件?
放在组件里是可以,但是异步过程怎么跨组件复用?多个异步过程之间怎么做串行、并行等控制?
所以当异步过程比较多,而且异步过程与异步过程之间也不独立,有串行、并行、甚至更复杂的关系的时候,直接把异步逻辑放组件内不行。
不放组件内,那放哪呢?
redux 提供的中间件机制是不是可以用来放这些异步过程呢?
redux 中间件
先看下什么是 redux 中间件:
redux 的流程很简单,就是 dispatch 一个 action 到 store, reducer 来处理 action。那么如果想在到达 store 之前多做一些处理呢?在哪里加?
改造 dispatch!中间件的原理就是层层包装 dispatch。
下面是 applyMiddleware 的源码,可以看到 applyMiddleware 就是对 store.dispatch 做了层层包装,最后返回修改了 dispatch 之后的 store。
function applyMiddleware(middlewares) {
let dispatch = store.dispatch
middlewares.forEach(middleware =>
dispatch = middleware(store)(dispatch)
)
return { ...store, dispatch}
}
所以说中间件最终返回的函数就是处理 action 的 dispatch:
function middlewareXxx(store) {
return function (next) {
return function (action) {
// xx
};
};
};
}
中间件会包装 dispatch,而 dispatch 就是把 action 传给 store 的,所以中间件自然可以拿到 action、拿到 store,还有被包装的 dispatch,也就是 next。
比如 redux-thunk 中间件的实现:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
它判断了如果 action 是一个函数,就执行该函数,并且把 store.dispath 和 store.getState 传进去,否则传给内层的 dispatch。
通过 redux-thunk 中间件,我们可以把异步过程通过函数的形式放在 dispatch 的参数里:
const login = (userName) => (dispatch) => {
dispatch({ type: 'loginStart' })
request.post('/api/login', { data: userName }, () => {
dispatch({ type: 'loginSuccess', payload: userName })
})
}
store.dispatch(login('guang'))
但是这样解决了组件里的异步过程不好复用、多个异步过程之间不好做并行、串行等控制的问题了么?
没有,这段逻辑依然是在组件里写,只不过移到了 dispatch 里,也没有提供多个异步过程的管理机制。
解决这个问题,需要用 redux-saga 或 redux-observable 中间件。
redux-saga
redux-saga 并没有改变 action,它会把 action 透传给 store,只是多加了一条异步过程的处理。
redux-saga 中间件是这样启用的:
import { createStore, applyMiddleware } from 'redux'
import createSagaMiddleware from 'redux-saga'
import rootReducer from './reducer'
import rootSaga from './sagas'
const sagaMiddleware = createSagaMiddleware()
const store = createStore(rootReducer, {}, applyMiddleware(sagaMiddleware))
sagaMiddleware.run(rootSaga)
要调用 run 把 saga 的 watcher saga 跑起来:
watcher saga 里面监听了一些 action,然后调用 worker saga 来处理:
import { all, takeLatest } from 'redux-saga/effects'
function* rootSaga() {
yield all([
takeLatest('login', login),
takeLatest('logout', logout)
])
}
export default rootSaga
redux-saga 会先把 action 透传给 store,然后判断下该 action 是否是被 taker 监听的:
function sagaMiddleware({ getState, dispatch }) {
return function (next) {
return function (action) {
const result = next(action);// 把 action 透传给 store
channel.put(action); //触发 saga 的 action 监听流程
return result;
}
}
}
当发现该 action 是被监听的,那么就执行相应的 taker,调用 worker saga 来处理:
function* login(action) {
try {
const loginInfo = yield call(loginService, action.account)
yield put({ type: 'loginSuccess', loginInfo })
} catch (error) {
yield put({ type: 'loginError', error })
}
}
function* logout() {
yield put({ type: 'logoutSuccess'})
}
比如 login 和 logout 会有不同的 worker saga。
login 会请求 login 接口,然后触发 loginSuccess 或者 loginError 的 action。
logout 会触发 logoutSuccess 的 action。
redux saga 的异步过程管理就是这样的:先把 action 透传给 store,然后判断 action 是否是被 taker 监听的,如果是,则调用对应的 worker saga 进行处理。
redux saga 在 redux 的 action 流程之外,加了一条监听 action 的异步处理的流程。
其实整个流程还是比较容易理解的。理解成本高一点的就是 generator 的写法了:
比如下面这段代码:
function* xxxSaga() {
while(true) {
yield take('xxx_action');
//...
}
}
它就是对每一个监听到的 xxx_action 做同样的处理的意思,相当于 takeEvery:
function* xxxSaga() {
yield takeEvery('xxx_action');
//...
}
但是因为有一个 while(true),很多同学就不理解了,这不是死循环了么?
不是的。generator 执行后返回的是一个 iterator,需要另外一个程序调用 next 方法才会继续执行。所以怎么执行、是否继续执行都是由另一个程序控制的。
在 redux-saga 里面,控制 worker saga 执行的程序叫做 task。worker saga 只是告诉了 task 应该做什么处理,通过 call、fork、put 这些命令(这些命令叫做 effect)。
然后 task 会调用不同的实现函数来执行该 worker saga。
为什么要这样设计呢?直接执行不就行了,为啥要拆成 worker saga 和 task 两部分,这样理解成本不就高了么?
确实,设计成 generator 的形式会增加理解成本,但是换来的是可测试性。因为各种副作用,比如网络请求、dispatch action 到 store 等等,都变成了 call、put 等 effect,由 task 部分控制执行。那么具体怎么执行的就可以随意的切换了,这样测试的时候只需要模拟传入对应的数据,就可以测试 worker saga 了。
redux saga 设计成 generator 的形式是一种学习成本和可测试性的权衡。
还记得 redux-thunk 有啥问题么?多个异步过程之间的并行、串行的复杂关系没法处理。那 redux-saga 是怎么解决的呢?
redux-saga 提供了 all、race、takeEvery、takeLatest 等 effect 来指定多个异步过程的关系:
比如 takeEvery 会对多个 action 的每一个做同样的处理,takeLatest 会对多个 action 的最后一个做处理,race 会只返回最快的那个异步过程的结果,等等。
这些控制多个异步过程之间关系的 effect 正是 redux-thunk 所没有的,也是复杂异步过程的管理必不可少的部分。
所以 redux-saga 可以做复杂异步过程的管理,而且具有很好的可测试性。
其实异步过程的管理,最出名的是 rxjs,而 redux-observable 就是基于 rxjs 实现的,它也是一种复杂异步过程管理的方案。
redux-observable
redux-observable 用起来和 redux-saga 特别像,比如启用插件的部分:
const epicMiddleware = createEpicMiddleware();
const store = createStore(
rootReducer,
applyMiddleware(epicMiddleware)
);
epicMiddleware.run(rootEpic);
和 redux saga 的启动流程是一样的,只是不叫 saga 而叫 epic。
但是对异步过程的处理,redux saga 是自己提供了一些 effect,而 redux-observable 是利用了 rxjs 的 operator:
import { ajax } from 'rxjs/ajax';
const fetchUserEpic = (action$, state$) => action$.pipe(
ofType('FETCH_USER'),
mergeMap(({ payload }) => ajax.getJSON(`/api/users/${payload}`).pipe(
map(response => ({
type: 'FETCH_USER_FULFILLED',
payload: response
}))
)
);
通过 ofType 来指定监听的 action,处理结束返回 action 传递给 store。
相比 redux-saga 来说,redux-observable 支持的异步过程的处理更丰富,直接对接了 operator 的生态,是开放的,而 redux-saga 则只是提供了内置的几个 effect 来处理。
所以做特别复杂的异步流程处理的时候,redux-observable 能够利用 rxjs 的操作符的优势会更明显。
但是 redux-saga 的优点还有基于 generator 的良好的可测试性,而且大多数场景下,redux-saga 提供的异步过程的处理能力就足够了,所以相对来说,redux-saga 用的更多一些。
总结
前端框架实现了数据到视图的绑定,我们只需要关心数据流就可以了。
相比 context 的混乱的数据流,redux 的 view -> action -> store -> view 的单向数据流更清晰且容易管理。
前端代码中有很多异步过程,这些异步过程之间可能有串行、并行甚至更复杂的关系,放在组件里并不好管理,可以放在 redux 的中间件里。
redux 的中间件就是对 dispatch 的层层包装,比如 redux-thunk 就是判断了下 action 是 function 就执行下,否则就是继续 dispatch。
redux-thunk 并没有提供多个异步过程管理的机制,复杂异步过程的管理还是得用 redux-saga 或者 redux-observable。
redux-saga 透传了 action 到 store,并且监听 action 执行相应的异步过程。异步过程的描述使用 generator 的形式,好处是可测试性。比如通过 take、takeEvery、takeLatest 来监听 action,然后执行 worker saga。worker saga 可以用 put、call、fork 等 effect 来描述不同的副作用,由 task 负责执行。
redux-observable 同样监听了 action 执行相应的异步过程,但是是基于 rxjs 的 operator,相比 saga 来说,异步过程的管理功能更强大。
不管是 redux-saga 通过 generator 来组织异步过程,通过内置 effect 来处理多个异步过程之间的关系,还是 redux-observable 通过 rxjs 的 operator 来组织异步过程和多个异步过程之间的关系。它们都解决了复杂异步过程的处理的问题,可以根据场景的复杂度灵活选用。
原文:https://juejin.cn/post/7011835078594527263