








cURL开源作者怒怼“白嫖”企业:我不删库跑路,但答疑得付钱!
cURL 作者 Daniel Stenberg 在 1 月 21 日收到了一家美国《财富》500 强企业发来的电子邮件,要求 Stenberg 回答关于 cURL 是否受到 Log4Shell 漏洞影响以及如何处理等问题。随后,他将邮件内容截图发到了推特上,并写道:
如果你是一家价值数十亿美元的公司还关注 Log4j,怎么不直接给那些你从未支付过任何费用的 OSS 作者发邮件,要求他们 24 小时内免费回复你这么多问题?
这件事迅速引发了网友们的关注。
把开源当成供应商
根据公开的邮件内容,这家《财富》500 强企业(暂且称为“NNNN”)将 Daniel 团队当成了产品供应商,并要求其 24 小时内免费提供关于 Log4j 漏洞的解决方案。下面是 NNNN 要求 Stenberg 回答的问题:
- 如果您在应用程序中使用了 Java 日志库,那么正在运行的是哪些 Log4j 版本?
- 贵公司是否发生过任何已确认的安全事件?
- 如果是,哪些应用程序、产品、服务和相关版本会受到影响?
- 哪些 NNNN 产品和服务受到影响?
- NNNN 的非公开或个人信息是否会受到影响?
- 如果是,请立即向 NNNN 提供详细信息。
- 什么时候完成修复?列出每个步骤,包括每个步骤的完成日期。
- NNNN 需要采取什么行动来完成此修复?

cURL(client URL 请求库的简称)是一个命令行接口,用于检索可通过计算机网络访问资源的内容。资源由 URL 指定,并且必须是软件支持的类型。cURL 程序实现了用户界面,基于用 C 语言开发的 libcurl 软件库。
Apache Log4j 日志库被 Java/J2EE 应用开发项目和基于 Java/J2EE 的现成软件解决方案的供应商大量使用。去年 12 月 9 日,Log4j 中被发现了一个漏洞,攻击者通过该漏洞能够进行远程代码执行,具体包括通过受影响的设备或应用程序访问整个网络、运行任何代码、访问受影响设备或应用程序上的所有数据、删除或加密文件等。可以说,cURL 开源代码与 Log4j 漏洞事件毫不相干。
虽然 Stenberg 从未参与过任何 Log4j 的开发工作,也没有任何使用了 Log4j 代码的版权产品,但 Stenberg 还是回复道,“你不是我们的客户,我们也不是你的客户。”并略带调侃地表示,只要双方签了商业合同就很乐意回答所有的问题。
“发邮件”只是例行公事?
“这封电子邮件显示出来的无知和无能程度令人难以置信。”Stenberg 在博文里写道,“很奇怪他们现在才发送关于 Log4j 的查询邮件,这似乎有点晚了。”
“这很可能只是一封发送给数十或数百个其他软件供应商 / 开发人员的模板电子邮件。如果确实来自像我过去工作过的那些大型企业,他们很可能会要求各种 IT 支持和开发团队编制一份企业使用的所有软件 / 工具的列表以及每个软件 / 工具的电子邮件地址。所以,很大可能只是有人按照项目计划中的要求向供应商发送电子邮件以延缓问题,并勾选他们的方框,说明已联系该供应商 / 开发人员。”有网友猜测道。
网友“Jack0r”介绍,其所在公司规定要有一个记载依赖项的 Excel 列表,列表里大多数是开源软件,还有一些封闭源代码和付费产品。开发人员要为每个依赖项设置一个联系人,因此与某软件相关的电子邮件可能会被放入列表中。但这个列表通常非常过时,也没有人专门更新。
“我曾经被要求填写一份 3 页关于 Oracle 数据库的详细资料表,但我们从未使用过 Oracle。有的软件运行在 Postgres 上,有的运行在 MySQL 上,有的运行在 NoSQL 上,但他们说,‘MySQL 是从 Oracle 来的,不是吗?’”网友现身说法。
而当出现严重安全漏洞时,负责 Excel 工作表的人员(非开发人员,也不知道这些依赖项如何使用,甚至不知道它们是什么)必须联系每个依赖项的所有者并向他们提出相同的问题。他们这样做不是为了做有用的事情,只是为了告诉他们的客户“我们正在竭尽全力修复这个漏洞”。大多数情况下,这些甚至要被写进合同中。
Reddit 上也有网友表示,Stenberg 收到的邮件来自对计算机或开源一无所知的律师助理。他只是有一长串的名字要联系,这样就可以为公司建立防御,防止因黑客攻击而被起诉。他甚至不在乎公司是否被黑,也不在乎会不会被起诉,他只关心自己的工作,那就是做好准备,以防万一。
因此,有人庆幸道,这就是为什么开源许可证非常重要的原因。开源许可证保护了作者的权益,同时确保了治理到位是企业的责任。
“只盖房子而不关心地基”
“我认为,这可能是开源金字塔的一个很好例证,上层用户根本不考虑底层设施的维护。只盖房子而不关心地基。”Stenberg 写道。

开源金字塔的最底部是基础组件、操作系统和库,上面所有的东西都是在此基础上建立的。
越往上走,产品更多是面向终端用户,企业能赚更多的钱,同时产品迭代更快、语言要求层次更高,开放源码的份额也不断减少。在最上面,很多东西已经不是开源的了。反之,越往下走,产品使用寿命更长,语言要求不好,但 bug 的影响更大,修复需要的时间更长,因此维护比重构更重要。在最底部,几乎所有的东西都是开源的,每个组件都被无数的用户所依赖。
只要有可能在不为“公共基础设施”付出很多就能赚到很多钱,那么企业就没有什么动力去投资或支付某些东西的维护费用。但足够好的软件组件也会偶尔出现 bug,但只要这些漏洞没有真正威胁到赚钱的人,这种情况就不会改变。
Stenberg 认为,为依赖项的维护付费有助于降低未来在周末早上过早发出警报的风险。底层组件的开发者们的工作就是要让依赖其组件功能的用户相信,如果他们购买支持,就能更加放心,避免任何隐藏的陷阱。
根据 Linux 基金会和学术研究人员对 FOSS(免费和开源软件)贡献者进行的调查,开发者们花在安全问题上时间低于 3%,同时受访者并不希望增加花在安全上的时间。“安全事业是一项令人沮丧的苦差事”“安全是令人难以忍受的无聊程序障碍”。有足够的资金让工程师将时间花在代码维护上,或许可以降低严重故障的发生率。
与此同时,底层开发者与上层使用者之间的矛盾日益加深。1 月 11 日, Apache PLC4X 的创建者 Christofer Dutz 在 GitHub 发文称,由于得不到任何形式的回报,他将停止对 PLC4X 的企业用户提供免费的社区支持。若后续仍无企业愿意站出来资助项目,他将停止对 PLC4X 的维护和任何形式的支持。
有的组件可能被成千上万家公司用于一项很小而重要的任务,有的是与 Apache PLC4x 一样,可能只有一个少数组织形成的自然市场。但目前没有具体办法来衡量使用组件给企业带来的收益,更没有一个通用方案可以用来收集和分配企业对开源项目的捐款。
开源可持续性问题的解决已经迫在眉睫。
作者:褚杏娟
来源:https://mp.weixin.qq.com/s/G_47x6D8-KXozSy8XWGXbg
这才是Yaml的语法精髓, 不要再只有字符串了
文章目录
什么是YAML
基本语法
数据类型
标量
对象
数组
文本块
显示指定类型
引用
单文件多配置
什么是YAML
YAML是"YAML Ain’t a Markup Language"(YAML不是一种标记语言)的递归缩写。YAML的意思其实是:“Yet Another Markup Language”(仍是一种标记语言)。主要强度这种语音是以数据为中心,而不是以标记语音为重心,例如像xml语言就会使用大量的标记。
YAML是一个可读性高,易于理解,用来表达数据序列化的格式。它的语法和其他高级语言类似,并且可以简单表达清单(数组)、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件等。
YAML的配置文件后缀为 .yml,例如Springboot项目中使用到的配置文件 application.yml 。
基本语法
YAML使用可打印的Unicode字符,可使用UTF-8或UTF-16。
数据结构采用键值对的形式,即
键名称: 值,注意冒号后面要有空格。每个清单(数组)成员以单行表示,并用短杠+空白(- )起始。或使用方括号([]),并用逗号+空白(, )分开成员。
每个散列表的成员用冒号+空白(: )分开键值和内容。或使用大括号({ }),并用逗号+空白(, )分开。
字符串值一般不使用引号,必要时可使用,使用双引号表示字符串时,会转义字符串中的特殊字符(例如\n)。使用单引号时不会转义字符串中的特殊字符。
大小写敏感
使用缩进表示层级关系,缩进不允许使用tab,只允许空格,因为有可能在不同系统下tab长度不一样
缩进的空格数可以任意,只要相同层级的元素左对齐即可
在单一文件中,可用连续三个连字号(—)区分多个文件。还有选择性的连续三个点号(…)用来表示文件结尾。
'#'表示注释,可以出现在一行中的任何位置,单行注释
在使用逗号及冒号时,后面都必须接一个空白字符,所以可以在字符串或数值中自由加入分隔符号(例如:5,280或http://www.wikipedia.org)而不需要使用引号。
数据类型
纯量(scalars):单个的、不可再分的值
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
标量
标量是最基础的数据类型,不可再分的值,他们一般用于表示单个的变量,有以下七种:
字符串
布尔值
整数
浮点数
Null
时间
日期
# 字符串
string.value: Hello!我是陈皮!
# 布尔值,true或false
boolean.value: true
boolean.value1: false
# 整数
int.value: 10
int.value1: 0b1010_0111_0100_1010_1110 # 二进制
# 浮点数
float.value: 3.14159
float.value1: 314159e-5 # 科学计数法
# Null,~代表null
null.value: ~
# 时间,时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
datetime.value: !!timestamp 2021-04-13T10:31:00+08:00
# 日期,日期必须使用ISO 8601格式,即yyyy-MM-dd
date.value: !!timestamp 2021-04-13这样,我们就可以在程序中引入了,如下:
@RestController
@RequestMapping("demo")
public class PropConfig {
@Value("${string.value}")
private String stringValue;
@Value("${boolean.value}")
private boolean booleanValue;
@Value("${boolean.value1}")
private boolean booleanValue1;
@Value("${int.value}")
private int intValue;
@Value("${int.value1}")
private int intValue1;
@Value("${float.value}")
private float floatValue;
@Value("${float.value1}")
private float floatValue1;
@Value("${null.value}")
private String nullValue;
@Value("${datetime.value}")
private Date datetimeValue;
@Value("${date.value}")
private Date datevalue;
}对象
我们知道单个变量可以用键值对,使用冒号结构表示 key: value,注意冒号后面要加一个空格。可以使用缩进层级的键值对表示一个对象,如下所示:
person:
name: 陈皮
age: 18
man: true然后在程序对这几个属性进行赋值到Person对象中,注意Person类要加get/set方法,不然属性会无法正确取到配置文件的值。使用@ConfigurationProperties注入对象,@value不能很好的解析复杂对象。
package com.nobody;
import lombok.Getter;
import lombok.Setter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
/**
* @Description
* @Author Mr.nobody
* @Date 2021/4/13
* @Version 1.0.0
*/
@Configuration
@ConfigurationProperties(prefix = "my.person")
@Getter
@Setter
public class Person {
private String name;
private int age;
private boolean man;
}当然也可以使用 key:{key1: value1, key2: value2, ...}的形式,如下:
person: {name: 陈皮, age: 18, man: true}数组
可以用短横杆加空格 -开头的行组成数组的每一个元素,如下的address字段:
person:
name: 陈皮
age: 18
man: true
address:
- 深圳
- 北京
- 广州也可以使用中括号进行行内显示形式,如下:
person:
name: 陈皮
age: 18
man: true
address: [深圳, 北京, 广州]在代码中引入方式如下:
package com.nobody;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* @Description
* @Author Mr.nobody
* @Date 2021/4/13
* @Version 1.0.0
*/
@Configuration
@ConfigurationProperties(prefix = "person")
@Getter
@Setter
@ToString
public class Person {
private String name;
private int age;
private boolean man;
private List<String> address;
}如果数组字段的成员也是一个数组,可以使用嵌套的形式,如下:
person:
name: 陈皮
age: 18
man: true
address: [深圳, 北京, 广州]
twoArr:
-
- 2
- 3
- 1
-
- 10
- 12
- 30
package com.nobody;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
@ConfigurationProperties(prefix = "person")
@Getter
@Setter
@ToString
public class Person {
private String name;
private int age;
private boolean man;
private List<String> address;
private List<List<Integer>> twoArr;
}如果数组成员是一个对象,则用如下两种形式形式:
childs:
-
name: 小红
age: 10
-
name: 小王
age: 15
childs: [{name: 小红, age: 10}, {name: 小王, age: 15}]文本块
如果你想引入多行的文本块,可以使用|符号,注意在冒号:和 |符号之间要有空格。
person:
name: |
Hello Java!!
I am fine!
Thanks! GoodBye!它和加双引号的效果一样,双引号能转义特殊字符:
person:
name: "Hello Java!!\nI am fine!\nThanks! GoodBye!"显示指定类型
有时我们需要显示指定某些值的类型,可以使用 !(感叹号)显式指定类型。!单叹号通常是自定义类型,!!双叹号是内置类型,例如:
# 指定为字符串
string.value: !!str HelloWorld!
# !!timestamp指定为日期时间类型
datetime.value: !!timestamp 2021-04-13T02:31:00+08:00内置的类型如下:
!!int:整数类型
!!float:浮点类型
!!bool:布尔类型
!!str:字符串类型
!!binary:二进制类型
!!timestamp:日期时间类型
!!null:空值
!!set:集合类型
!!omap,!!pairs:键值列表或对象列表
!!seq:序列
!!map:散列表类型
引用
引用会用到 &锚点符合和 *星号符号,&用来建立锚点,<< 表示合并到当前数据,* 用来引用锚点。
xiaohong: &xiaohong
name: 小红
age: 20
dept:
id: D15D8E4F6D68A4E88E
<<: *xiaohong上面最终相当于如下:
xiaohong:
name: 小红
age: 20
dept:
id: D15D8E4F6D68A4E88E
name: 小红
age: 20还有一种文件内引用,引用已经定义好的变量,如下:
base.host: https://chenpi.com
add.person.url: ${base.host}/person/add单文件多配置
可以在同一个文件中,实现多文档分区,即多配置。在一个yml文件中,通过 — 分隔多个不同配置,根据spring.profiles.active 的值来决定启用哪个配置
#公共配置
spring:
profiles:
active: pro # 指定使用哪个文档块
---
#开发环境配置
spring:
profiles: dev # profiles属性代表配置的名称
server:
port: 8080
---
#生产环境配置
spring:
profiles: pro
server:
port: 8081作者:陈皮的JavaLib
来源:https://blog.csdn.net/chenlixiao007/article/details/115654824
程序员连相7天亲:规划有多重要!
近日,北京一程序员小伙提前放假,避开了连上7天班,不料被家人安排了7场相亲,每天一场。他结合相亲对象性格、爱好等认真制作了规划,并准备了不同年货礼物,感叹好累…

人家程序员相7个亲都有个规划,身为凡事皆是项目,凡事皆有规划的项目经理,你呢?有相亲对象吗? 相亲必备SOP流程,直接拿走不谢
第一步: 明确问题
找到自己的爱人 项目在立项之前,最重要的是,先明确做这个项目是为了要解决的问题是什么。要不然这个项目本身就是不成立的。
项目在立项之前,最重要的是,先明确做这个项目是为了要解决的问题是什么。要不然这个项目本身就是不成立的。
现在你要解决的问题就是:找对象。而立之年,恋爱结婚是你当前的一大任务!(注:那些本身就不想结婚的人不在我们讨论范围之内。)
第二步:了解现状
好感度等级
我们在做计划之前必须进行一些分析和定义,这样我们才能有针对性的制定计划首先我们对“潜在对象对你的好感度”做等级划分如下:
第三步:设定目标
在一年之内将T对我好感由1星提升为8星

第四步: 把握真因
了解自己和对方真实需求
项目经理在跟甲方对接需求的时候,一定要先了解对方的真实原因。
找对象也一样。下面这个四句口诀,请牢记:
了解自己的优势,扬长避短;
了解目标的界定,聚焦战略;
了解对方的全况,知己知彼;
了解对方的需求,对症下药;
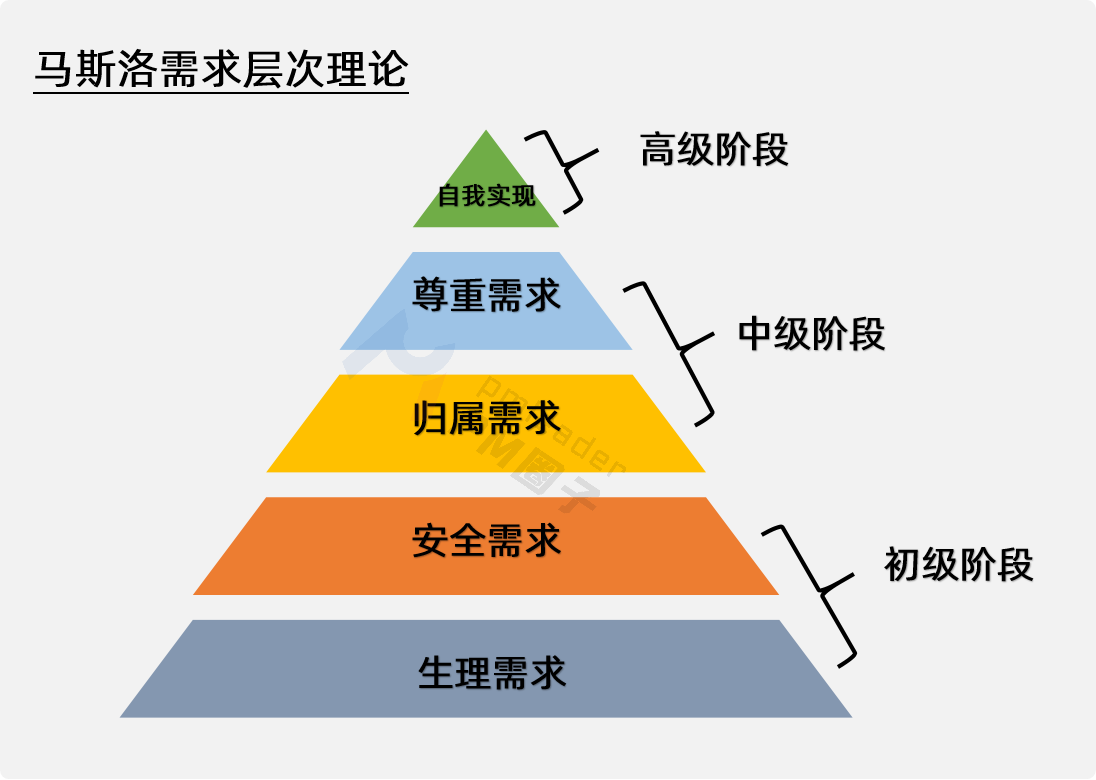
第五步: 制定对策
了解一切的可能,制造机缘
首先,确定T的日常作息。这个可以直接问本人,如果认识T的朋友同学会更好。比如,有的姑娘每周五下班会去超市采购,你就可以也在同样的时间点去偶遇。
其次,了解对方的兴趣爱好。比如T喜欢打篮球,跟他朋友打听一下T经常去什么地方打篮球;如果T喜欢看书,那就去看看T喜欢什么类型的书,增加以后聊天的话题。
总之,就是寻找突破口,制造更多在一起的时间增进彼此了解。
举个例子:
第六步:实施对策
用逻辑树来进行归纳整理以便更好的实施

注:以上只是作为举例,具体实践请根据你们交往发展情况而定。
第七步: 评价结果和过程
关注实施方案,随时修正
在采取行动的过程中,要保持警惕,用思维导图分析不良效果的原因,时刻注意对方的变化,采取相应对策化解,修正自己的行为。
使用思维导图进行原因分析:
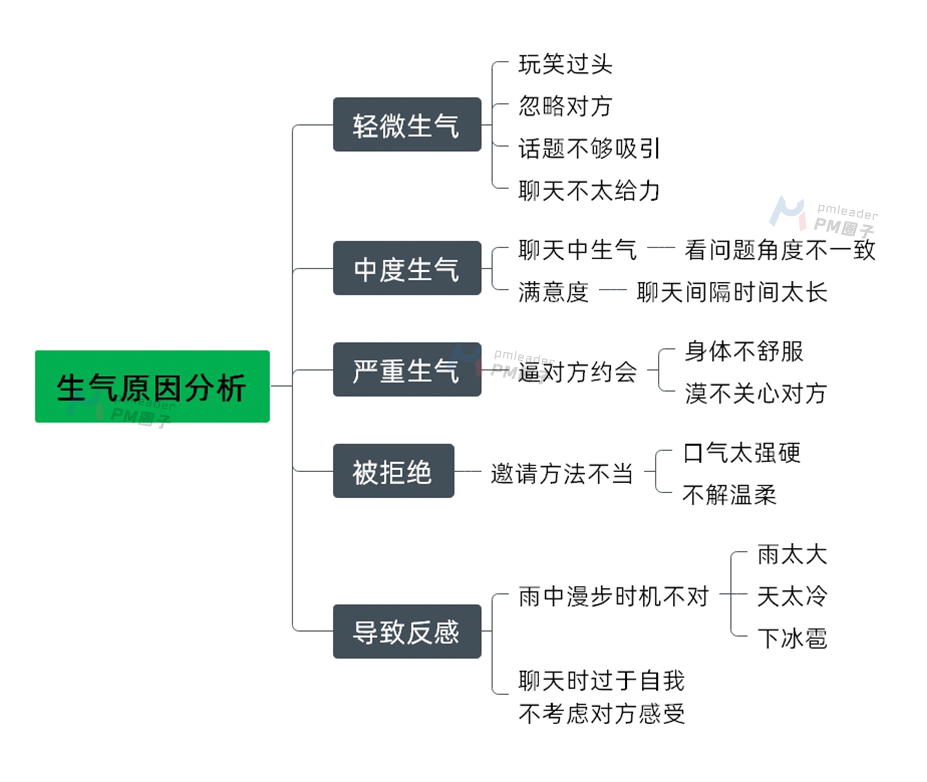
针对问题列出措施改进方法:
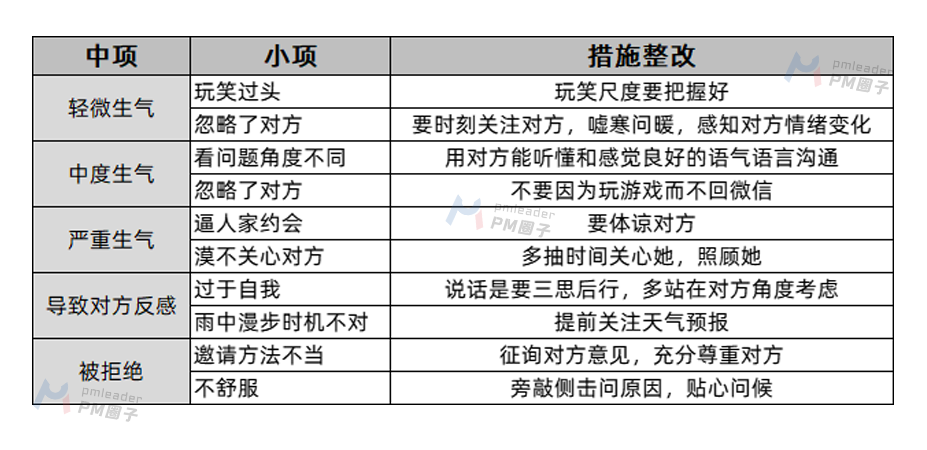
第八步: 评估方法并标准化
了解力量的消长,成功或退出
理性的三个关键词:
敏感:上帝存在于细节之中,如果是你要怎么把握对方的话。
关爱:爱胜在付出,每个人都在为爱播种,是否结果看你照顾多少。
尊严:人最后的防线就是自尊,不要为了恋爱却失去了尊严。
作者:圈圈
来源:https://mp.weixin.qq.com/s/GNPVc5qgOpMgnAeeQlAwrw
研究生写脚本抢HPV九价疫苗:被采取强制措施,后果严重
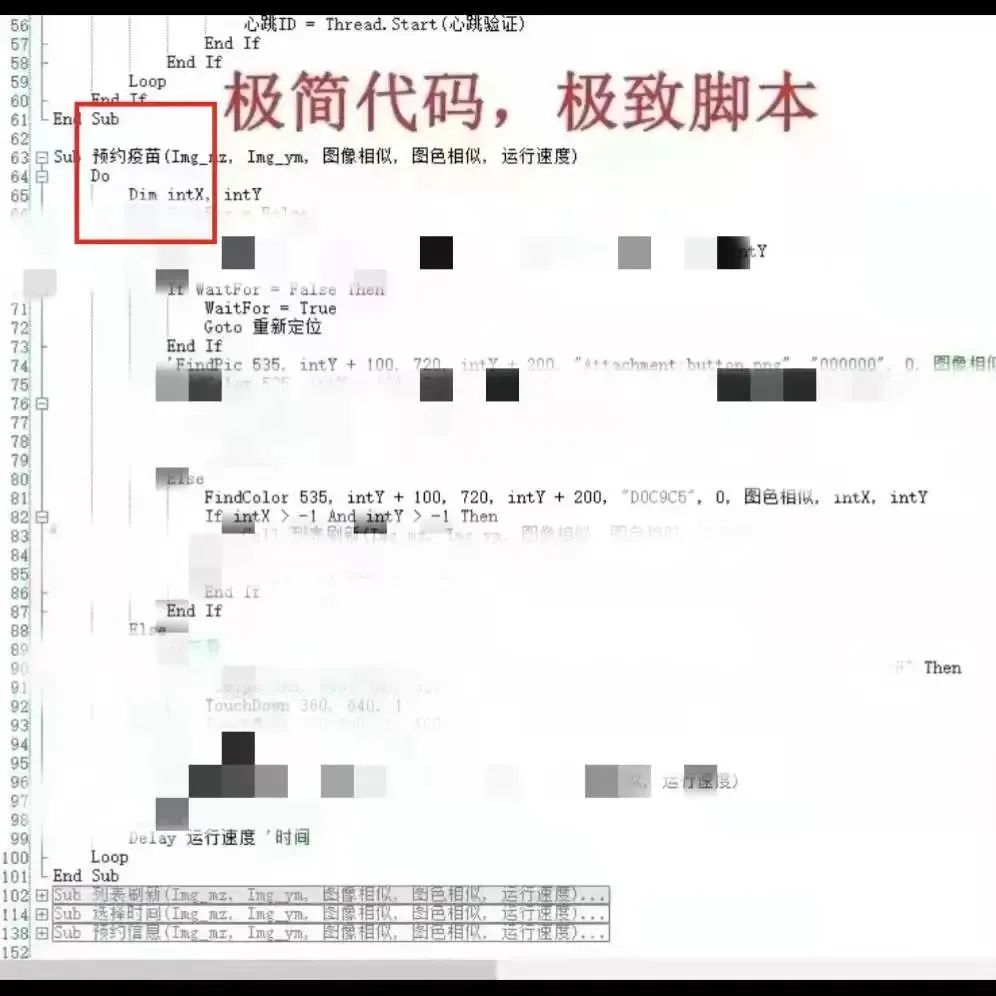
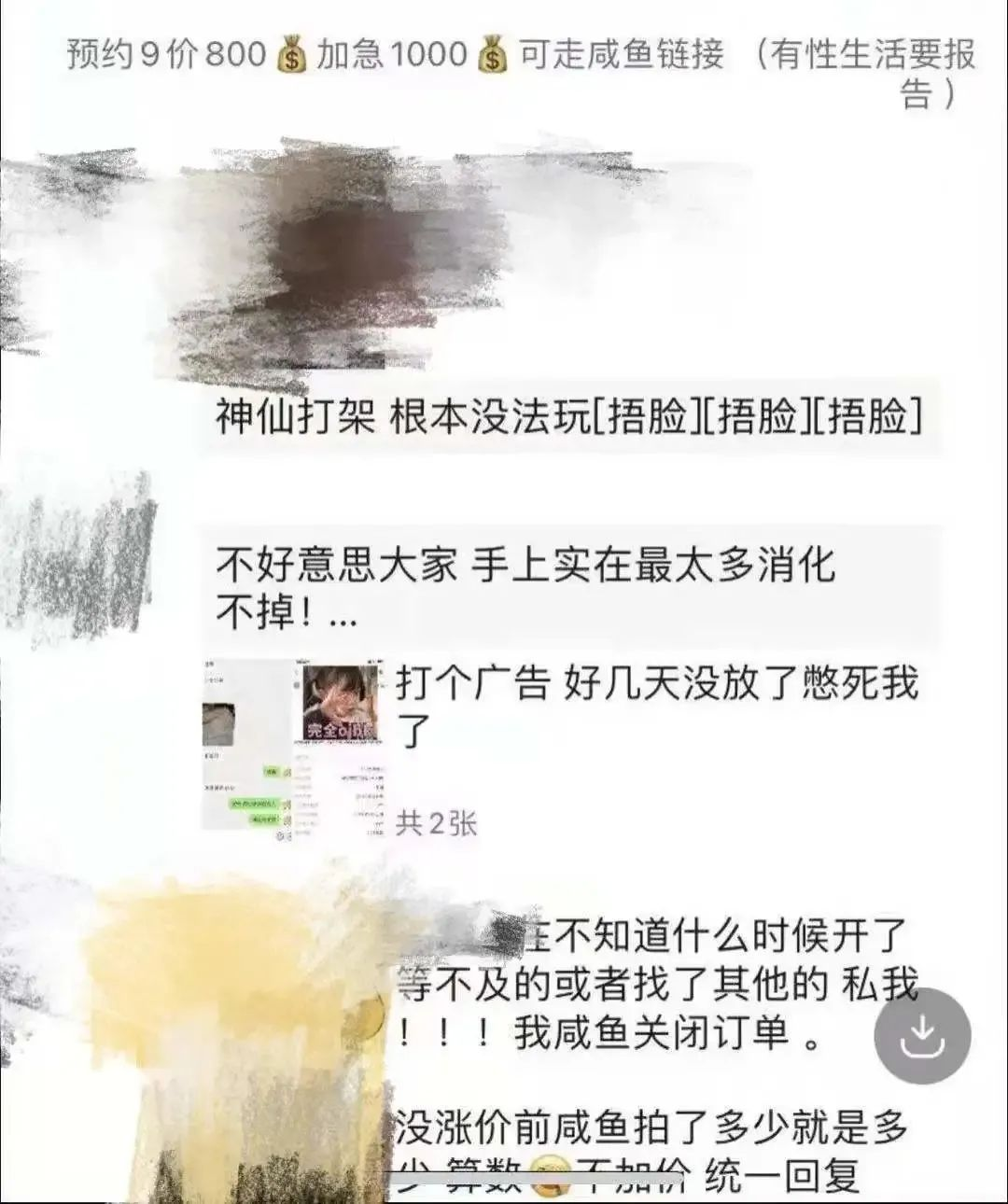

参考链接:
https://mp.weixin.qq.com/s/Umq6UjeKD0kwgyZgVA28zA
https://weibo.com/5044281310/LbhRgewXz
整理 | 王晓曼
收起阅读 »掉了两根头发,可算是把volatile整明白了
本来想着快过年了偷个懒休息下,没想到被兄弟们连续催更,没办法,博主暖男嘛,掐着人中也要更,兄弟们卷起来
volatile关键字可以说是Java虚拟机提供的最轻量级的同步机制,但对于为什么它只能保证可见性,不保证原子性,它又是如何禁用指令重排的,还有很多同学没彻底理解
相信我,坚持看完这篇文章,你将牢牢掌握一个Java核心知识点
先说它的两个作用:
保证变量在内存中对线程的可见性
禁用指令重排
每个字都认识,凑在一起就麻了
这两个作用通常很不容易被我们Java开发人员正确、完整地理解,以至于许多同学不能正确地使用volatile
关于可见性
不多bb,码来
public class VolatileTest {
private static volatile int count = 0;
private static void increase() {
count++;
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 10000; j++) {
increase();
}
}).start();
}
// 所有线程累加完成后输出
while (Thread.activeCount() > 2) Thread.yield();
System.out.println(count);
}
}代码很好理解,开了十个线程对同一个共享变量count做累加,每个线程累加1w次
count我们已经用volatile修饰,已经保证了count对十个线程在内存中的可见性,按理说十个线程执行完毕count的值应该10w
然鹅,运行多次,结果都远小于期望值
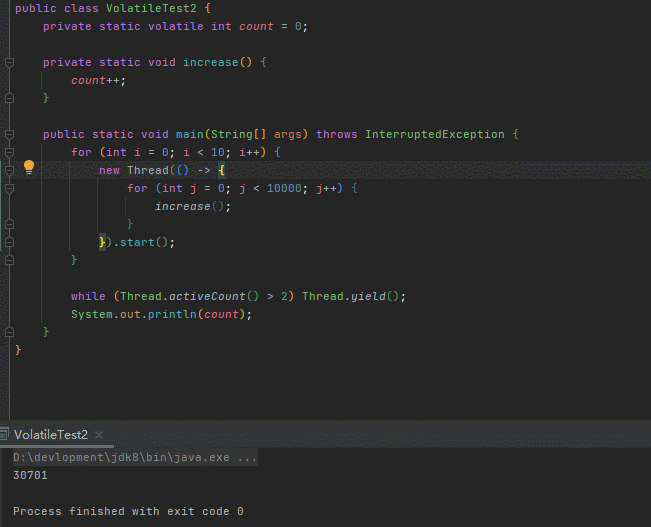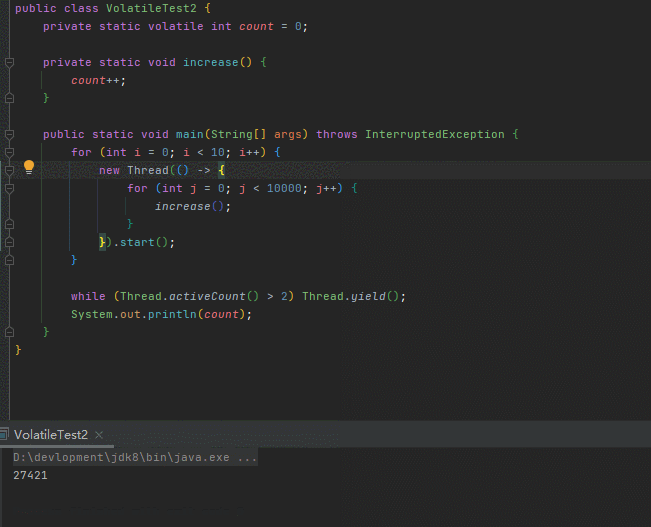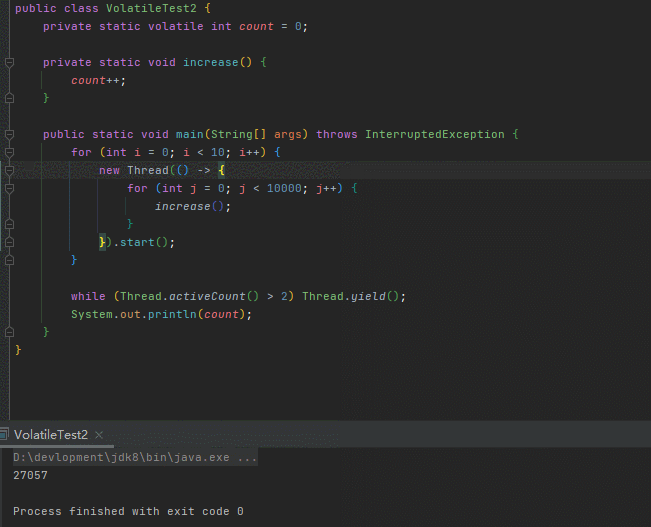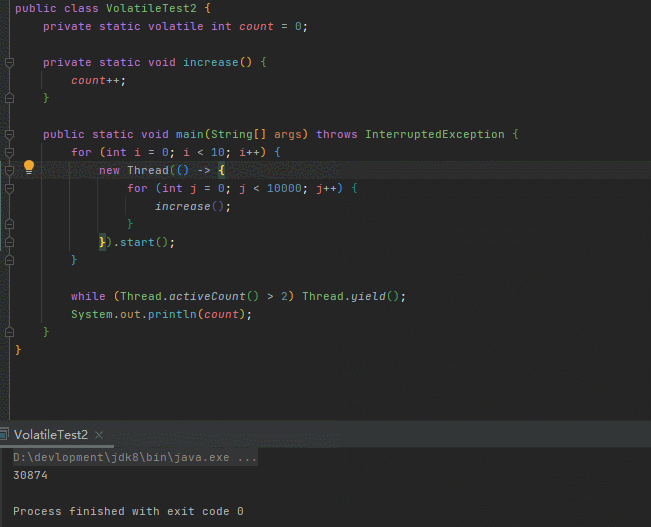
是哪个环节出了问题?

你肯定听过一句话:volatile只保证可见性,不保证原子性
这句话就是答案,但是依旧很多人没搞懂其中的奥秘
说来话长我长话短说,简单来讲就是 count++这个操作不是原子的,它是分三步进行
从内存读取 count 的值
执行 count + 1
将 count 的新值写回
要彻底搞懂这个问题,我们得从字节码入手
下面是increase方法编译后的字节码
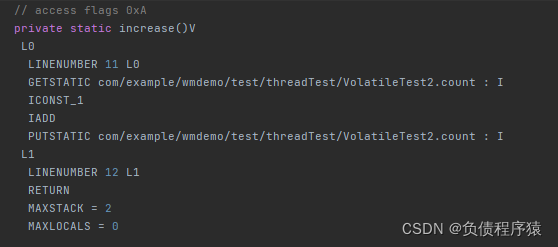
看不懂没关系,我们一行一行来看:
GETSTATIC:读取 count 的当前值
ICONST_1:将常量 1 加载到栈顶
IADD:执行+1
PUTSTATIC:写入count最新值
ICONST_1和IADD其实就是真正的++操作
关键点来了,volatile只能保证线程在GETSTATIC这一步拿到的值是最新的,但当该线程执行到下面几行指令时,这期间可能就有其它线程把count的值修改了,最终导致旧值把真正的新值覆盖
懂我意思吗
所以,并发编程中,只靠volatile修饰共享变量是不可靠的,最终还是要通过对关键方法加锁来保证线程安全
就如上面的demo,稍加修改就能实现真正的线程安全
最简单的,给increase方法加个synchronized (synchronized怎么实现线程安全的我就不啰嗦了,我以前讲过 synchronized底层实现原理)
private synchronized static void increase() {
++count;
}run几下
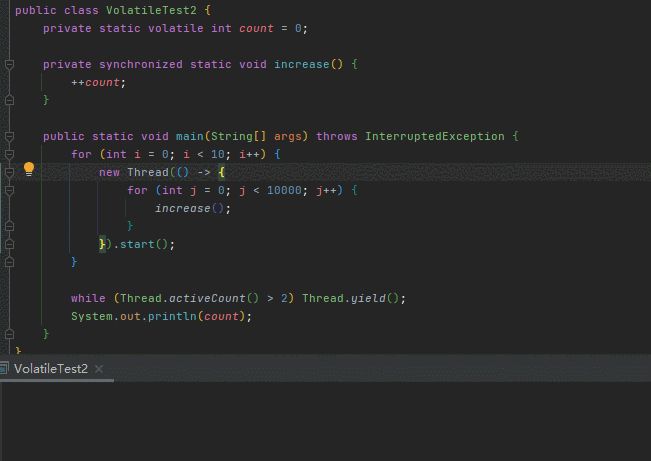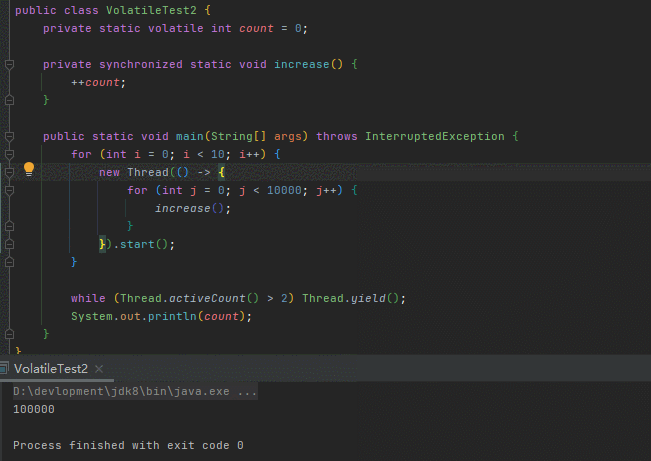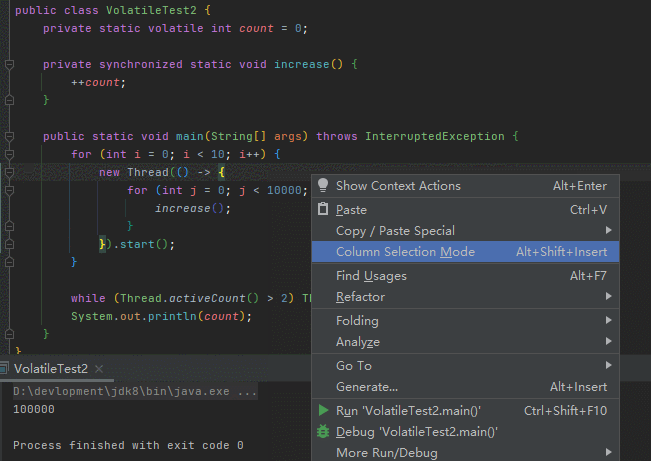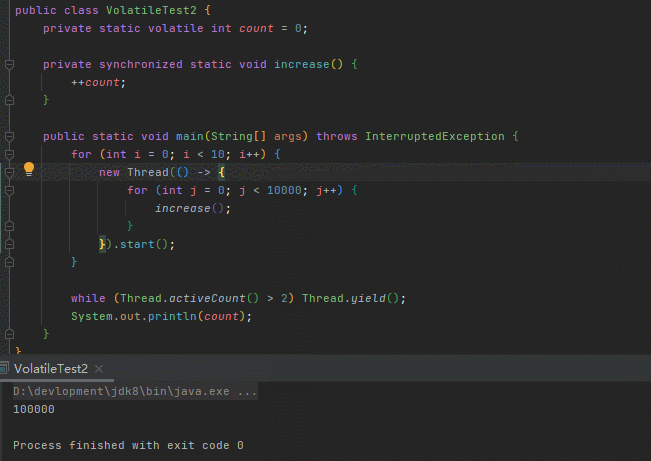
这不就妥了嘛
到现在,对于以下两点你应该有了新的认知
volatile保证变量在内存中对线程的可见性
volatile只保证可见性,不保证原子性
关于指令重排
并发编程中,cpu自身和虚拟机为了提高执行效率,都会采用指令重排(在保证不影响结果的前提下,将某些代码乱序执行)
关于cpu:为了从分利用cpu,实际执行指令时会做优化;
关于虚拟机:在HotSpot vm中,为了提升执行效率,JIT(即时编译)模式也会做指令优化
指令重排在大部分场景下确实能提升执行效率,但有些场景对代码执行顺序是强依赖的,此时我们需要禁用指令重排,如下面这个场景

伪代码取自《深入理解Java虚拟机》:
其描述的场景是开发中常见配置读取过程,只是我们在处理配置文件时一般不会出现并发,所以没有察觉这会有问题。
试想一下,如果定义initialized变量时没有使用volatile修饰,就可能会由于指令重排序的优化,导致位于线程A中最后一条代码“initialized=true”被提前执行(这里虽然使用Java作为伪代码,但所指的重排序优化是机器级的优化操作,提前执行是指这条语句对应的汇编代码被提前执行),这样在线程B中使用配置信息的代码就可能出现错误,而volatile通过禁止指令重排则可以避免此类情况发生
禁用指令重排只需要将变量声明为volatile,是不是很神奇
我们来看看volatile是如何实现禁用指令重排的
也借用《深入理解Java虚拟机》的一个例子吧,比较好理解

这是个单例模式的实现,下面是它的部分字节码,红框中 mov%eax,0x150(%esi) 是对instance赋值
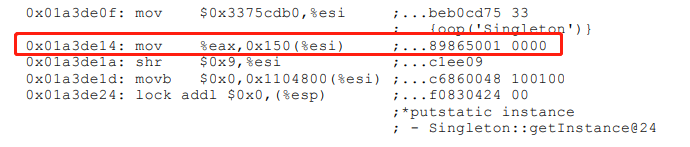
可以看到,在赋值后,还执行了 lock addl$0x0,(%esp) 指令,关键点就在这儿,这行指令相当于此处设置了个 内存屏障 ,有了内存屏障后,cpu或虚拟机在指令重排时就不能把内存屏障后面的指令提前到内存屏障前面,好好捋一下这段话
最后,留一个能加深大家对volatile理解的问题,兄弟们好好思考下:
Java代码明明是从上往下依次执行,为什么会出现指令重排这个问题?
ok我话说完
————————————————
作者:负债程序猿
来源:https://blog.csdn.net/qq_33709582/article/details/122415754
什么样的问题应该使用动态规划
说起动态规划,我不知道你有没有这样的困扰,在掌握了一些基础算法和数据结构之后,碰到一些较为复杂的问题还是无从下手,面试时自然也是胆战心惊。如果我说动态规划是个玄幻的问题其实也不为过。究其原因,我觉得可以归因于这样两点:
你对动态规划相关问题的套路和思想还没有完全掌握;
你没有系统地总结过究竟有哪些问题可以用动态规划解决。
知己知彼,你想把动态规划作为你的面试武器之一,就得足够了解它;而应对面试,总结、归类问题其实是个不错的选择,这在我们刷题的时候其实也能感觉得到。那么,我们就针对以上两点,系统地谈一谈究竟什么样的问题可以用动态规划来解。
一、动态规划是一种思想
动态规划算法,这种叫法我想你应该经常听说。嗯,从道理上讲这么叫我觉得也没错,首先动态规划它不是数据结构,这一点毋庸置疑,并且严格意义上来说它就是一种算法。但更加准确或者更加贴切的提法应该是说动态规划是一种思想。那算法和思想又有什么区别呢?
一般来说,我们都会把算法和数据结构放一起来讲,这是因为它们之间密切相关,而算法也往往是在特定数据结构的基础之上对解题方案的一种严谨的总结。
比如说,在一个乱序数组的基础上进行排序,这里的数据结构指的是什么呢?很显然是数组,而算法则是所谓的排序。至于排序算法,你可以考虑使用简单的冒泡排序或效率更高的快速排序方法等等来解决问题。
没错,你应该也感觉到了,算法是一种简单的经验总结和套路。那什么是思想呢?相较于算法,思想更多的是指导你我来解决问题。
比如说,在解决一个复杂问题的时候,我们可以先将问题简化,先解决简单的问题,再解决难的问题,那么这就是一种指导解决问题的思想。另外,我们常说的分治也是一种简单的思想,当然它在诸如归并排序或递归算法当中会常常被提及。
而动态规划就是这样一个指导我们解决问题的思想:你需要利用已经计算好的结果来推导你的计算,即大规模问题的结果是由小规模问题的结果运算得来的。
总结一下:算法是一种经验总结,而思想则是用来指导我们解决问题的。既然动态规划是一种思想,那它实际上就是一个比较抽象的概念了,也很难和实际的问题关联起来。所以说,弄清楚什么样的问题可以使用动态规划来解就显得十分重要了。
二、动态规划问题的特点
动态规划作为运筹学上的一种最优化解题方法,在算法问题上已经得到广泛应用。接下来我们就来看一下动归问题所具备的一些特点。
2.1 最优解问题
除非你碰到的问题是简单到找出一个数组中最大的值这样,对这种问题来说,你可以对数组进行排序,然后取数组头或尾部的元素,如果觉得麻烦,你也可以直接遍历得到最值。不然的话,你就得考虑使用动态规划来解决这个问题了。这样的问题一般都会让你求最大子数组、求最长递增子数组、求最长递增子序列或求最长公共子串、子序列等等。
如果碰到求最值问题,我们可以使用下面的套路来解决问题:
优先考虑使用贪心算法的可能性;
然后是暴力递归进行穷举,针对数据规模不大的情况;
如果上面两种都不适合,那么再选择动态规划。
可以看到,求解动态规划的核心问题其实就是穷举。当然了,动态规划问题也不会这么简单了事,我们还需要考虑待解决的问题是否存在重叠子问题、最优子结构等特性。
清楚了动态规划算法的特点,接下来我们就来看一下哪些问题适合用动态规划思想来解题。
1. 乘积最大子数组
给你一个整数数组 numbers,找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),返回该子数组的乘积。
示例1:
输入: [2,7,-2,4]
输出: 14
解释: 子数组 [2,7] 有最大乘积 14。
示例2:
输入: [-5,0,3,-1]
输出: 3
解释: 结果不能为 15, 因为 [-5,3,-1] 不是子数组,是子序列。首先,很明显这个题目当中包含一个“最”字,使用动态规划求解的概率就很大。这个问题的目的就是从数组中寻找一个最大的连续区间,确保这个区间的乘积最大。由于每个连续区间可以划分成两个更小的连续区间,而且大的连续区间的结果是两个小连续区间的乘积,因此这个问题还是求解满足条件的最大值,同样可以进行问题分解,而且属于求最值问题。同时,这个问题与求最大连续子序列和比较相似,唯一的区别就是你需要在这个问题里考虑正负号的问题,其它就相同了。
对应实现代码:
class Solution {
public:
int maxProduct(vector<int>& nums) {
if(nums.empty()) return 0;
int curMax = nums[0];
int curMin = nums[0];
int maxPro = nums[0];
for(int i=1; i<nums.size(); i++){
int temp = curMax; // 因为curMax在下一行可能会被更新,所以保存下来
curMax = max(max(curMax*nums[i], nums[i]), curMin*nums[i]);
curMin = min(min(curMin*nums[i], nums[i]), temp*nums[i]);
maxPro = max(curMax, maxPro);
}
return maxPro;
}
};2. 最长回文子串
问题:给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例1:
输入: "babad"
输出: "bab"
示例2:
输入: "cbbd"
输出: "bb"【回文串】是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。这个问题依然包含一个“最”字,同样由于求解的最长回文子串肯定包含一个更短的回文子串,因此我们依然可以使用动态规划来求解这个问题。
对应实现代码:
class Solution {
public boolean isPalindrome(String s, int b, int e){//判断s[b...e]是否为回文字符串
int i = b, j = e;
while(i <= j){
if(s.charAt(i) != s.charAt(j)) return false;
++i;
--j;
}
return true;
}
public String longestPalindrome(String s) {
if(s.length() <=1){
return s;
}
int l = 1, j = 0, ll = 1;
for(int i = 1; i < s.length(); ++i){
//下面这个if语句就是用来维持循环不变式,即ll恒表示:以第i个字符为尾的最长回文子串的长度
if(i - 1 - ll >= 0 && s.charAt(i) == s.charAt(i-1-ll)) ll += 2;
else{
while(true){//重新确定以i为边界,最长的回文字串长度。确认范围为从ll+1到1
if(ll == 0||isPalindrome(s,i-ll,i)){
++ll;
break;
}
--ll;
}
}
if(ll > l){//更新最长回文子串信息
l = ll;
j = i;
}
}
return s.substring(j-l+1, j+1);//返回从j-l+1到j长度为l的子串
}
}3. 最长上升子序列
问题:给定一个无序的整数数组,找到其中最长上升子序列的长度。可能会有多种最长上升子序列的组合,你只需要输出对应的长度即可。
示例:
输入: [10,9,2,5,3,7,66,18]
输出: 4
解释: 最长的上升子序列是 [2,3,7,66],它的长度是 4。这个问题依然是一个最优解问题,假设我们要求一个长度为 5 的字符串中的上升自序列,我们只需要知道长度为 4 的字符串最长上升子序列是多长,就可以根据剩下的数字确定最后的结果。
对应实现代码:
class Solution {
public int lengthOfLIS(int[] nums) {
if(nums.length == 0) return 0;
int[] dp = new int[nums.length];
int res = 0;
Arrays.fill(dp, 1);
for(int i = 0; i < nums.length; i++) {
for(int j = 0; j < i; j++) {
if(nums[j] < nums[i]) dp[i] = Math.max(dp[i], dp[j] + 1);
}
res = Math.max(res, dp[i]);
}
return res;
}
}2.2 求可行性
如果有这样一个问题,让你判断是否存在一条总和为 x 的路径(如果找到了,就是 True;如果找不到,自然就是 False),或者让你判断能否找到一条符合某种条件的路径,那么这类问题都可以归纳为求可行性问题,并且可以使用动态规划来解。
1. 凑零兑换问题
问题:给你 k 种面值的硬币,面值分别为 c1, c2 … ck,每种硬币的数量无限,再给一个总金额 amount,问你最少需要几枚硬币凑出这个金额,如果不可能凑出,算法返回 -1 。
示例1:
输入: c1=1, c2=2, c3=5, c4=7, amount = 15
输出: 3
解释: 11 = 7 + 7 + 1。
示例2:
输入: c1=3, amount =7
输出: -1
解释: 3怎么也凑不到7这个值。这个问题显而易见,如果不可能凑出我们需要的金额(即 amount),最后算法需要返回 -1,否则输出可能的硬币数量。这是一个典型的求可行性的动态规划问题。
对于示例代码:
class Solution {
public int coinChange(int[] coins, int amount) {
if(coins.length == 0)
return -1;
//声明一个amount+1长度的数组dp,代表各个价值的钱包,第0个钱包可以容纳的总价值为0,其它全部初始化为无穷大
//dp[j]代表当钱包的总价值为j时,所需要的最少硬币的个数
int[] dp = new int[amount+1];
Arrays.fill(dp,1,dp.length,Integer.MAX_VALUE);
for (int coin : coins) {
for (int j = coin; j <= amount; j++) {
if(dp[j-coin] != Integer.MAX_VALUE) {
dp[j] = Math.min(dp[j], dp[j-coin]+1);
}
}
}
if(dp[amount] != Integer.MAX_VALUE)
return dp[amount];
return -1;
}
}2. 字符串交错组成问题
问题:给定三个字符串 s1, s2, s3, 验证 s3 是否是由 s1 和 s2 交错组成的。
示例1:
输入: s1="aabcc",s2 ="dbbca",s3="aadbbcbcac"
输出: true
解释: 可以交错组成。
示例2:
输入: s1="aabcc",s2="dbbca",s3="aadbbbaccc"
输出: false
解释:无法交错组成。这个问题稍微有点复杂,但是我们依然可以通过子问题的视角,首先求解 s1 中某个长度的子字符串是否由 s2 和 s3 的子字符串交错组成,直到求解整个 s1 的长度为止,也可以看成一个包含子问题的最值问题。
对应示例代码:
class Solution {
public boolean isInterleave(String s1, String s2, String s3) {
int length = s3.length();
// 特殊情况处理
if(s1.isEmpty() && s2.isEmpty() && s3.isEmpty()) return true;
if(s1.isEmpty()) return s2.equals(s3);
if(s2.isEmpty()) return s1.equals(s3);
if(s1.length() + s2.length() != length) return false;
int[][] dp = new int[s2.length()+1][s1.length()+1];
// 边界赋值
for(int i = 1;i < s1.length()+1;i++){
if(s1.substring(0,i).equals(s3.substring(0,i))){
dp[0][i] = 1;
}
}
for(int i = 1;i < s2.length()+1;i++){
if(s2.substring(0,i).equals(s3.substring(0,i))){
dp[i][0] = 1;
}
}
for(int i = 2;i <= length;i++){
// 遍历 i 的所有组成(边界除外)
for(int j = 1;j < i;j++){
// 防止越界
if(s1.length() >= j && i-j <= s2.length()){
if(s1.charAt(j-1) == s3.charAt(i-1) && dp[i-j][j-1] == 1){
dp[i-j][j] = 1;
}
}
// 防止越界
if(s2.length() >= j && i-j <= s1.length()){
if(s2.charAt(j-1) == s3.charAt(i-1) && dp[j-1][i-j] == 1){
dp[j][i-j] = 1;
}
}
}
}
return dp[s2.length()][s1.length()]==1;
}
}2.3 求总数
除了求最值与可行性之外,求方案总数也是比较常见的一类动态规划问题。比如说给定一个数据结构和限定条件,让你计算出一个方案的所有可能的路径,那么这种问题就属于求方案总数的问题。
1. 硬币组合问题
问题:英国的英镑硬币有 1p, 2p, 5p, 10p, 20p, 50p, £1 (100p), 和 £2 (200p)。比如我们可以用以下方式来组成 2 英镑:1×£1 + 1×50p + 2×20p + 1×5p + 1×2p + 3×1p。问题是一共有多少种方式可以组成 n 英镑? 注意不能有重复,比如 1 英镑 +2 个 50P 和 50P+50P+1 英镑是一样的。
示例1:
输入: 2
输出: 73682 这个问题本质还是求满足条件的组合,只不过这里不需要求出具体的值或者说组合,只需要计算出组合的数量即可。
public class Main {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
int coin[] = { 1, 5, 10, 20, 50, 100 };
// dp[i][j]表示用前i种硬币凑成j元的组合数
long[][] dp = new long[7][n + 1];
for (int i = 1; i <= n; i++) {
dp[0][i] = 0; // 用0种硬币凑成i元的组合数为0
}
for (int i = 0; i <= 6; i++) {
dp[i][0] = 1; // 用i种硬币凑成0元的组合数为1,所有硬币均为0个即可
}
for (int i = 1; i <= 6; i++) {
for (int j = 1; j <= n; j++) {
dp[i][j] = 0;
for (int k = 0; k <= j / coin[i - 1]; k++) {
dp[i][j] += dp[i - 1][j - k * coin[i - 1]];
}
}
}
System.out.print(dp[6][n]);
}
sc.close();
}
}2. 路径规划问题
问题:一个机器人位于一个 m x n 网格的左上角。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角,共有多少路径?
示例1:
输入: 2 2
输出: 2
示例1:
输入: 3 3
输出: 6这个问题还是一个求满足条件的组合数量的问题,只不过这里的组合变成了路径的组合。我们可以先求出长宽更小的网格中的所有路径,然后再在一个更大的网格内求解更多的组合。这和硬币组合的问题相比没有什么本质区别。
这里有一个规律或者说现象需要强调,那就是求方案总数的动态规划问题一般都指的是求“一个”方案的所有具体形式。如果是求“所有”方案的具体形式,那这种肯定不是动态规划问题,而是使用传统递归来遍历出所有方案的具体形式。
为什么这么说呢?因为你需要把所有情况枚举出来,大多情况下根本就没有重叠子问题给你优化。即便有,你也只能使用备忘录对遍历进行一个简单加速。但本质上,这类问题不是动态规划问题。
对应示例代码:
package com.qst.Tesst;
import java.util.Scanner;
public class Test12 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
int x = scanner.nextInt();
int y = scanner.nextInt();
//设置路径
long[][] path = new long[x + 1][y + 1];
//设置领导数量
int n = scanner.nextInt();
//领导位置
for (int i = 0; i < n; i++) {
int a = scanner.nextInt();
int b = scanner.nextInt();
path[a][b] = -1;
}
for (int i = 0; i <= x; i++) {
path[i][0] = 1;
}
for (int j = 0; j <= y; j++) {
path[0][j] = 1;
}
for (int i = 1; i <= x; i++) {
for (int j = 1; j <= y; j++) {
if (path[i][j] == -1) {
path[i][j] = 0;
} else {
path[i][j] = path[i - 1][j] + path[i][j - 1];
}
}
}
System.out.println(path[x][y]);
}
}
}三、 如何确认动态规划问题
从前面我所说来看,如果你碰到了求最值、求可行性或者是求方案总数的问题的话,那么这个问题就八九不离十了,你基本可以确定它就需要使用动态规划来解。但是,也有一些个别情况需要注意:
3.1 数据不可排序
假设我们有一个无序数列,希望求出这个数列中最大的两个数字之和。很多初学者刚刚学完动态规划会走火入魔到看到最优化问题就想用动态规划来求解,事实上,这个问题不是简单做一个排序或者做一个遍历就可以求解出来的。对于这种问题,我们应该先考虑一下能不能通过排序来简化问题,如果不能,才极有可能是动态规划问题。
最小的 k 个数
问题:输入整数数组 arr ,找出其中最小的 k 个数。例如,输入 4、5、1、6、2、7、3、8 这 8 个数字,则最小的 4 个数字是 1、2、3、4。
示例1:
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
示例2:
输入:arr = [0,1,2,1], k = 1
输出:[0]我们发现虽然这个问题也是求“最”值,但其实只要通过排序就能解决,所以我们应该用排序、堆等算法或者数据结构就可以解决,而不应该用动态规划。
对应的示例代码:
public class Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) {
int t;
boolean flag;
ArrayList result = new ArrayList();
if(k>input.length){
return result;
}
for(int i =0;i<input.length;i++){
flag = true;
for(int j = 0; j < input.length-i;j++)
if(j<input.length-i-1){
if(input[j] > input[j+1]) {
t = input[j];
input[j] = input[j+1];
input[j+1] = t;
flag = false;
}
}
if(flag)break;
}
for(int i = 0; i < k;i++){
result.add(input[i]);
}
return result;
}
}3.2 数据不可交换
还有一类问题,可以归类到我们总结的几类问题里去,但是不存在动态规划要求的重叠子问题(比如经典的八皇后问题),那么这类问题就无法通过动态规划求解。
全排列
问题:给定一个没有重复数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]这个问题虽然是求组合,但没有重叠子问题,更不存在最优化的要求,因此可以使用回溯方法处理。
对应的示例代码:
public class Main {
public static void main(String[] args) {
perm(new int[]{1,2,3},new Stack<>());
}
public static void perm(int[] array, Stack<Integer> stack) {
if(array.length <= 0) {
//进入了叶子节点,输出栈中内容
System.out.println(stack);
} else {
for (int i = 0; i < array.length; i++) {
//tmepArray是一个临时数组,用于就是Ri
//eg:1,2,3的全排列,先取出1,那么这时tempArray中就是2,3
int[] tempArray = new int[array.length-1];
System.arraycopy(array,0,tempArray,0,i);
System.arraycopy(array,i+1,tempArray,i,array.length-i-1);
stack.push(array[i]);
perm(tempArray,stack);
stack.pop();
}
}
}
}总结一下,哪些问题可以使用动态规划呢,通常含有下面情况的一般都可以使用动态规划来解决:
求最优解问题(最大值和最小值);
求可行性(True 或 False);
求方案总数;
数据结构不可排序(Unsortable);
算法不可使用交换(Non-swappable)。
如果面试题目出现这些特征,那么在 90% 的情况下你都能断言它就是一个动归问题。除此之外,还需要考虑这个问题是否包含重叠子问题与最优子结构,在这个基础之上你就可以 99% 断言它是否为动归问题,并且也顺势找到了大致的解题思路。
作者:xiangzhihong来源:https://segmentfault.com/a/1190000041300090
Flutter线上监控说明
概要
移动端Apm系统作用:
1、我们可以快速定位到线上App的实际使用情况,了解到App的奔溃、异常数据,从而针对潜在的风险问题进行预警,并进行相应的处理。
2、了解App的真实使用信息,提高用户使用黏性。
一、移动端常用apm指标
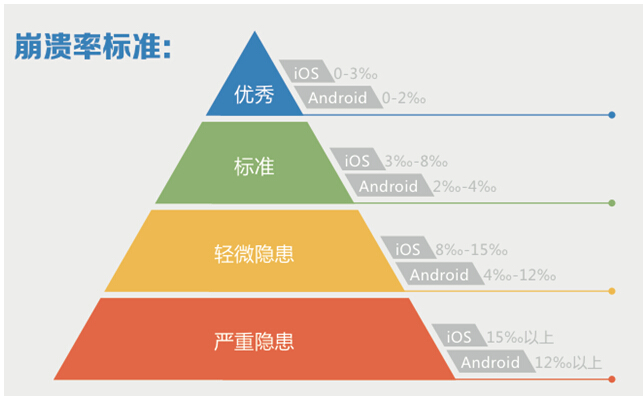
1、崩溃率
崩溃分析,是将 Android 和 iOS 平台常见的 APP 崩溃问题进行归类分析,帮助企业根据崩溃指标快速发现、定位问题。
2、UI卡顿
拿Android来说:大多数用户感知到的卡顿等性能问题的最主要根源都是因为渲染性能。Android系统每隔大概16.6ms发出VSYNC信号,触发对UI进行渲染,如果每次渲染都成功,这样就能够达到流畅的画面所需要的60fps,为了能够实现60fps,这意味着程序的大多数操作都必须在16ms内完成。
3、线上日志
可以快速定位某个用户的日志数据,及时根据用户反馈的情况进行快速排查。
4、网络监控
由于网络环境错综复杂,对于网络接口性能方面需要关注 接口响应时间,网络错误,http状态码,网络劫持等
三、Flutter apm现状
闲鱼自研(未开方源码)
再无其他第三方
Flow 操作符 shareIn 和 stateIn 使用须知
Flow.shareIn 与 Flow.stateIn 操作符可以将冷流转换为热流: 它们可以将来自上游冷数据流的信息广播给多个收集者。这两个操作符通常用于提升性能: 在没有收集者时加入缓冲;或者干脆作为一种缓存机制使用。
注意 : 冷流 是按需创建的,并且会在它们被观察时发送数据;热流 则总是活跃,无论是否被观察,它们都能发送数据。
本文将会通过示例帮您熟悉 shareIn 与 stateIn 操作符。您将学到如何针对特定用例配置它们,并避免可能遇到的常见陷阱。
底层数据流生产者
继续使用我 之前文章 中使用过的例子——使用底层数据流生产者发出位置更新。它是一个使用 callbackFlow 实现的 冷流。每个新的收集者都会触发数据流的生产者代码块,同时也会将新的回调加入到 FusedLocationProviderClient。
class LocationDataSource(
private val locationClient: FusedLocationProviderClient
) {
val locationsSource: Flow<Location> = callbackFlow<Location> {
val callback = object : LocationCallback() {
override fun onLocationResult(result: LocationResult?) {
result ?: return
try { offer(result.lastLocation) } catch(e: Exception) {}
}
}
requestLocationUpdates(createLocationRequest(), callback, Looper.getMainLooper())
.addOnFailureListener { e ->
close(e) // in case of exception, close the Flow
}
// 在 Flow 结束收集时进行清理
awaitClose {
removeLocationUpdates(callback)
}
}
}让我们看看在不同的用例下如何使用 shareIn 与 stateIn 优化 locationsSource 数据流。
shareIn 还是 stateIn?
我们要讨论的第一个话题是 shareIn 与 stateIn 之间的区别。shareIn 操作符返回的是 SharedFlow 而 stateIn 返回的是 StateFlow。
注意 : 要了解有关
StateFlow与SharedFlow的更多信息,可以查看 我们的文档 。
StateFlow 是 SharedFlow 的一种特殊配置,旨在优化分享状态: 最后被发送的项目会重新发送给新的收集者,并且这些项目会使用 Any.equals 进行合并。您可以在 StateFlow 文档 中查看更多相关信息。
两者之间的最主要区别,在于 StateFlow 接口允许您通过读取 value 属性同步访问其最后发出的值。而这不是 SharedFlow 的使用方式。
提升性能
通过共享所有收集者要观察的同一数据流实例 (而不是按需创建同一个数据流的新实例),这些 API 可以为我们提升性能。
在下面的例子中,LocationRepository 消费了 LocationDataSource 暴露的 locationsSource 数据流,同时使用了 shareIn 操作符,从而让每个对用户位置信息感兴趣的收集者都从同一数据流实例中收集数据。这里只创建了一个 locationsSource 数据流实例并由所有收集者共享:
class LocationRepository(
private val locationDataSource: LocationDataSource,
private val externalScope: CoroutineScope
) {
val locations: Flow<Location> =
locationDataSource.locationsSource.shareIn(externalScope, WhileSubscribed())
}
WhileSubscribed 共享策略用于在没有收集者时取消上游数据流。这样一来,我们便能在没有程序对位置更新感兴趣时避免资源的浪费。
Android 应用小提醒! 在大部分情况下,您可以使用 WhileSubscribed(5000),当最后一个收集者消失后再保持上游数据流活跃状态 5 秒钟。这样在某些特定情况 (如配置改变) 下可以避免重启上游数据流。当上游数据流的创建成本很高,或者在 ViewModel 中使用这些操作符时,这一技巧尤其有用。
缓冲事件
在下面的例子中,我们的需求有所改变。现在要求我们保持监听位置更新,同时要在应用从后台返回前台时在屏幕上显示最后的 10 个位置:
class LocationRepository(
private val locationDataSource: LocationDataSource,
private val externalScope: CoroutineScope
) {
val locations: Flow<Location> =
locationDataSource.locationsSource
.shareIn(externalScope, SharingStarted.Eagerly, replay = 10)
}
我们将参数 replay 的值设置为 10,来让最后发出的 10 个项目保持在内存中,同时在每次有收集者观察数据流时重新发送这些项目。为了保持内部数据流始终处于活跃状态并发送位置更新,我们使用了共享策略 SharingStarted.Eagerly,这样就算没有收集者,也能一直监听更新。
缓存数据
我们的需求再次发生变化,这次我们不再需要应用处于后台时 持续 监听位置更新。不过,我们需要缓存最后发送的项目,让用户在获取当前位置时能在屏幕上看到一些数据 (即使数据是旧的)。针对这种情况,我们可以使用 stateIn 操作符。
class LocationRepository(
private val locationDataSource: LocationDataSource,
private val externalScope: CoroutineScope
) {
val locations: Flow<Location> =
locationDataSource.locationsSource.stateIn(externalScope, WhileSubscribed(), EmptyLocation)
}
Flow.stateIn 可以缓存最后发送的项目,并重放给新的收集者。
注意!不要在每个函数调用时创建新的实例
切勿 在调用某个函数调用返回时,使用 shareIn 或 stateIn 创建新的数据流。这样会在每次函数调用时创建一个新的 SharedFlow 或 StateFlow,而它们将会一直保持在内存中,直到作用域被取消或者在没有任何引用时被垃圾回收。
class UserRepository(
private val userLocalDataSource: UserLocalDataSource,
private val externalScope: CoroutineScope
) {
// 不要像这样在函数中使用 shareIn 或 stateIn
// 这将在每次调用时创建新的 SharedFlow 或 StateFlow,而它们将不会被复用。
fun getUser(): Flow<User> =
userLocalDataSource.getUser()
.shareIn(externalScope, WhileSubscribed())
// 可以在属性中使用 shareIn 或 stateIn
val user: Flow<User> =
userLocalDataSource.getUser().shareIn(externalScope, WhileSubscribed())
}
需要入参的数据流
需要入参 (如 userId) 的数据流无法简单地使用 shareIn 或 stateIn 共享。以开源项目——Google I/O 的 Android 应用 iosched 为例,您可以在 源码中 看到,从 Firestore 获取用户事件的数据流是通过 callbackFlow 实现的。由于其接收 userId 作为参数,因此无法简单使用 shareIn 或 stateIn 操作符对其进行复用。
class UserRepository(
private val userEventsDataSource: FirestoreUserEventDataSource
) {
// 新的收集者会在 Firestore 中注册为新的回调。
// 由于这一函数依赖一个 `userId`,所以在这个函数中
// 数据流无法通过调用 shareIn 或 stateIn 进行复用.
// 这样会导致每次调用函数时,都会创建新的 SharedFlow 或 StateFlow
fun getUserEvents(userId: String): Flow<UserEventsResult> =
userLocalDataSource.getObservableUserEvents(userId)
}
如何优化这一用例取决于您应用的需求:
- 您是否允许同时从多个用户接收事件?如果答案是肯定的,您可能需要为
SharedFlow或StateFlow实例创建一个 map,并在subscriptionCount为 0 时移除引用并退出上游数据流。 - 如果您只允许一个用户,并且收集者需要更新为观察新的用户,您可以向一个所有收集者共用的
SharedFlow或StateFlow发送事件更新,并将公共数据流作为类中的变量。
shareIn 与 stateIn 操作符可以与冷流一同使用来提升性能,您可以使用它们在没有收集者时添加缓冲,或者直接将其作为缓存机制使用。小心使用它们,不要在每次函数调用时都创建新的数据流实例——这样会导致资源的浪费及预料之外的问题!
作者:Android_开发者
链接:https://juejin.cn/post/6998066384290709518
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
同一个app不同activity显示多任务(仿微信小程序切换效果)
如题,这种效果类似微信小程序显示的效果,就是打开微信跳一跳后,切换安卓多任务窗口(就是清理内存窗口),会看到如下页面
微信小程序会在其中显示两个单独的页面,点击跳一跳会进入跳一跳小程序,点击后面的微信,即会进入微信聊天主页面。
在安卓中如何实现呢?
这里有两种方法实现:
第一种:代码动态实现
Intent intent = new Intent(this, SecondActivity.class);
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_DOCUMENT);
intent.addFlags(Intent.FLAG_ACTIVITY_MULTIPLE_TASK);
startActivity(intent);
添加上面的两个Flag即可,有些文章说关闭的时候要使用
finishAndRemoveTask();
方法,我这边没使用该方法也没发现问题,如果存在潜在问题,知道的人麻烦告知下,谢谢!!!
第二种:在AndroidManifest.xml中配置属性
参考链接:在近期任务列表显示单个APP的多个Activity
第二种方法由于需要写死配置,可能对于我来说作用不大,所以也没有测试,需要了解的人可以查看上面地址。
注意:这里来说下处理第一种方法的问题
使用上面的方法确实是实现了微信小程序多任务窗口的效果,但你会发现两个窗口在文章开头的图中的地方显示的是相同的名字,即你APP的名字,这里就跟小程序有区别了,下面来说下如何实现这种效果:
首先:经过测试,在manifest.xml中给要显示的activity设置android:lable,这种方法是可行的,但会相当于是固定了,不可变了。
然后:在manifest.xml中给该activity设置android:icon也是可以的,这样就实现了显示"跳一跳"文字和logo了。
最后:当然还是同样需要在代码中动态设置,不然固定死对于程序员来说有瑕疵。
在需要显示的activity中调用下面的代码即可显示不同文字
setTaskDescription(new ActivityManager.TaskDescription("跳一跳"));
聪明的程序员都会看下该方法的源码以及需要参数的构造方法,所以同时显示图片和文字以及需要适配就需要用下面的代码了
if( Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP){
setTaskDescription(new ActivityManager.TaskDescription("跳一跳", mBitmap));
}
没错,需要5.0以上才能实现,参数的构造就需要传入bitmap才能显示图片了。
最终效果图:
存在的问题:当添加flag打开activity之后,如果切换了任务窗口,这时返回是不能返回到之前调用startActivity的方法的页面了,如果没有切换就不会存在这个问题,微信也是一样,像微信大佬都没有解决(也可能没这个需求),反正我是没有办法滴。
作者:ling9400
链接:https://juejin.cn/post/7055466828365037575
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android Activity Result API
最近准备开始新的项目,在编写base类复写onActivityResult方法时,发现已经提示deprecation了。于是去官网查找了一下,发现现在官方推荐做法是使用 Activity Result API。
本篇文章用来记录一下 Activity Result API 如何使用。
以往的实现方式
以往,A Activity获取B Activity的返回值的实现方法是,A通过startActivityForResult()来启动B,然后B在finish()之前通过setResult()方法来设置结果值,A就可以在onActivityResult()方法中获取到B在setResult()方法中设置的参数。简单示例如下:
class A : Activity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
startActivityForResult(Intent(this,B::class.java))
}
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
//从B返回后这里就可以获取到resultCode为Activity.RESULT_OK
}
}
class B: Activity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setResult(Activity.RESULT_OK)
finish()
}
}
Activity Result API
现在,在Activity和Fragment中,Activity Result API提供了registerForActivityResult()方法,该方法用于注册获取结果的回调。
registerForActivityResult可以传入ActivityResultContract、ActivityResultRegistry、ActivityResultCallback等3个参数,并返回ActivityResultLauncher。
- ActivityResultContract:ActivityResult合约,约定输入的参数和输出的参数。包含默认合约和自定义合约。
- ActivityResultRegistry:存储已注册的ActivityResultCallback的记录表,可以在非Activity和Fragment的类中借用此类获取ActivityResult。
- ActivityResultCallback:ActivityResult回调,用于获取返回结果。
- ActivityResultLauncher:启动器,根据合约规定的输入参数来启动页面。
Activity Result API的简单使用示例:
class A : Activity() {
//默认合约
var forActivityResultLauncher = registerForActivityResult(ActivityResultContracts.StartActivityForResult()) { activityResult ->
launcher?.text="lanuncher callback value : resultCode:$resultCode data$data"
}
//自定义合约(输入输出类型均为String)
var forActivityResultLauncher1 = registerForActivityResult(object : ActivityResultContract<String, String>() {
override fun createIntent(context: Context, input: String?): Intent {
return Intent(this@AActivity, B::class.java).apply {
putExtra("inputParams", input)
}
}
override fun parseResult(resultCode: Int, intent: Intent?): String {
return if (resultCode == Activity.RESULT_OK) {
intent?.getStringExtra("result") ?: "empty result"
} else {
""
}
}
}) { resultString ->
launcher1?.text = "lanuncher1 callback value : reslutString:$reslutString"
}
var launcher: TextView? = null
var launcher1: TextView? = null
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.layout_a_activity)
launcher = findViewById(R.id.tv_launcher_callback)
launcher1 = findViewById(R.id.tv_launcher_callback1)
val btnLauncher = findViewById<Button>(R.id.launcher)
val btnLauncher1 = findViewById<Button>(R.id.launcher1)
btnLauncher.setOnClickListener {
//默认合约
forActivityResultLauncher.launch(Intent(this@AActivity, B::class.java))
}
btnLauncher1.setOnClickListener {
//自定义合约
forActivityResultLauncher1.launch("inputParams from A")
}
}
}
class B: Activity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.layout_b_activity)
val btnBack = findViewById<Button>(R.id.back)
val inputParams = intent.getStringExtra("inputParams")
btnBack.setOnClickListener {
if (TextUtils.isEmpty(inputParams)) {
setResult(Activity.RESULT_OK, Intent())
} else {
setResult(Activity.RESULT_OK, Intent().apply {
putExtra("result", "result from A")
})
}
finish()
}
}
}
示例效果图:
在非Activity和Fragment的类中接收ActivityResult
示例代码如下:
class A : Activity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
val myActivityResultObserver = MyActivityResultObserver(activityResultRegistry)
lifecycle.addObserver(myActivityResultObserver)
}
}
class MyActivityResultObserver(private val registry: ActivityResultRegistry) : DefaultLifecycleObserver {
override fun onCreate(owner: LifecycleOwner) {
super.onCreate(owner)
registry.register("MyActivityResultReceiver", owner, ActivityResultContracts.StartActivityForResult()) {
}
}
}
作者:ChenYhong
链接:https://juejin.cn/post/7055971438767357965
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android LiveData原理分析
前言
官方介绍:LiveData 是一种可观察的数据存储器类。与常规的可观察类不同,LiveData 具有生命周期感知能力,意指它遵循其他应用组件(如 Activity、Fragment 或 Service)的生命周期。这种感知能力可确保 LiveData 仅更新处于活跃生命周期状态的应用组件观察者。 它有以下的优势:
- 确保界面符合数据状态
- 不会发生内存泄露
- 不会因Activity停止而导致崩溃
- 不再需要手动处理生命周期
- 数据始终保持最新状态
- 适当的配置修改
- 共享资源
接下来我们通过基本使用,一步一步的探究LiveData是如何实现这些优势的。
使用
创建 LiveData 对象
public class CoursePreviewModel extends ViewModel {
/**
* view状态
*/
private MutableLiveData<List<CoursePreviewBean.DataBean>> mStateLiveData;
public MutableLiveData<List<CoursePreviewBean.DataBean>> viewStateLive() {
if (mStateLiveData == null) {
mStateLiveData = new MutableLiveData<>();
}
return mStateLiveData;
}
}
观察 LiveData 对象
class CoursePreviewActivity : AppCompatActivity() {
// Use the 'by viewModels()' Kotlin property delegate
// from the activity-ktx artifact
private val mViewModel: CoursePreviewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 监听
mViewModel.viewStateLive().observe(this, target -> {
});
}
}
原理分析
这里我们先提出几个问题:
- LiveData怎么绑定到应用组件的生命周期呢
- 为什么不需要我们手动处理生命周期,为什么不会因Activity停止而导致崩溃
- 数据变化又是怎么触发的呢
带着这些问题,我们逐步往里看
一、应用组件生命周期的绑定
当我们需要观察数据变化时,需要调用LiveData的observe接口,这也是LiveData与Activity或Fragment产生关联的地方:
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<? super T> observer) {
assertMainThread("observe");
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}
这个方法需要接收两个参数:
- LifecycleOwner:生命周期所有者
- Observer:观察者,用于观察获取变化后的数据
通常我们在Activity或Fragment中使用LiveData,看下androidx包提供的AppCompatActivity和Fragment都是实现了LifecycleOwner接口。所以直接将this作为第一个参数即可。
继续分析上边的observe方法
- 这里会首先判断是否在主线程执行,假如不是即会抛出异常
assertMainThread("observe");
static void assertMainThread(String methodName) {
if (!ArchTaskExecutor.getInstance().isMainThread()) {
throw new IllegalStateException("Cannot invoke " + methodName + " on a background"
+ " thread");
}
}
- 假如是应用组件的生命周期已经是destory的状态,即不会继续往下执行
if (owner.getLifecycle().getCurrentState() == DESTROYED) {
// ignore
return;
}
- 通过LifecycleBoundObserver进行真正的逻辑处理,这里我们继续往下走,待会再回头分析这块
- 判断相同的observer不能被不同的LifecycleOwner处理
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
这里主要用到SafeIterableMap这个结构保存owner和observer的关系:
// put之前先判断是否已经包含了该key,假如是则直接返回相应的value
public V putIfAbsent(@NonNull K key, @NonNull V v) {
Entry<K, V> entry = get(key);
if (entry != null) {
return entry.mValue;
}
put(key, v);
return null;
}
- 最后,将生命周期所有者与observer绑定起来,这样子observer即可接收到相应的生命周期
owner.getLifecycle().addObserver(wrapper);
可以看到,这里不是直接add传递进来的Observer,而是上边提到的包装了owner和Observer的LifecycleBoundObserver。所以接下来我们好好分析下它:
class LifecycleBoundObserver extends ObserverWrapper implements LifecycleEventObserver {
@NonNull
final LifecycleOwner mOwner;
LifecycleBoundObserver(@NonNull LifecycleOwner owner, Observer<? super T> observer) {
super(observer);
mOwner = owner;
}
@Override
boolean shouldBeActive() {
return mOwner.getLifecycle().getCurrentState().isAtLeast(STARTED);
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (mOwner.getLifecycle().getCurrentState() == DESTROYED) {
removeObserver(mObserver);
return;
}
activeStateChanged(shouldBeActive());
}
@Override
boolean isAttachedTo(LifecycleOwner owner) {
return mOwner == owner;
}
@Override
void detachObserver() {
mOwner.getLifecycle().removeObserver(this);
}
}
可以看到,LifecycleBoundObserver是实现了LifecycleEventObserver接口,而LifecycleEventObserver接口是继承于LifecycleObserver接口的,因此可以看出主要是在LifecycleBoundObserver这里完成生命周期的处理。
二、为什么不需要手动处理生命周期
经过上边的分析,我们发现其实主要的生命周期处理工作是在LifecycleBoundObserver里边完成的。我们继续看它的源码,有这么两个方法:
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (mOwner.getLifecycle().getCurrentState() == DESTROYED) {
removeObserver(mObserver);
return;
}
activeStateChanged(shouldBeActive());
}
@Override
void detachObserver() {
mOwner.getLifecycle().removeObserver(this);
}
我们先看detachObserver,这里明显就是用于解除绑定的。我们找下哪里调用了这个方法:
@MainThread
public void removeObserver(@NonNull final Observer<? super T> observer) {
assertMainThread("removeObserver");
ObserverWrapper removed = mObservers.remove(observer);
if (removed == null) {
return;
}
removed.detachObserver();
removed.activeStateChanged(false);
}
主要是在LiveData的removeObserver,那继续找下该方法的调用。发现又回到了LifecycleBoundObserver本身,不错就是在onStateChanged里边,它会接收生命周期的变化通知,当发现mOwner.getLifecycle().getCurrentState() == DESTROYED即组件处于destory状态时,自动移除相应的观察者,这样子当activity或fragment销毁时,不会再收到相应的事件通知
三、数据变化怎么触发的
我们继续将核心放在LifecycleBoundObserver的onStateChanged方法上。当组件还没销毁,即会继续往下跑activeStateChanged(shouldBeActive());,该方法定义在ObserverWrapper类里边(LifecycleBoundObserver继承于它)
void activeStateChanged(boolean newActive) {
if (newActive == mActive) {
return;
}
// immediately set active state, so we'd never dispatch anything to inactive
// owner
mActive = newActive;
boolean wasInactive = LiveData.this.mActiveCount == 0;
LiveData.this.mActiveCount += mActive ? 1 : -1;
if (wasInactive && mActive) {
onActive();
}
if (LiveData.this.mActiveCount == 0 && !mActive) {
onInactive();
}
if (mActive) {
dispatchingValue(this);
}
}
当处于活跃状态,即mActive为true时,会走到dispatchingValue(this);。我们继续看
void dispatchingValue(@Nullable ObserverWrapper initiator) {
if (mDispatchingValue) {
mDispatchInvalidated = true;
return;
}
mDispatchingValue = true;
do {
mDispatchInvalidated = false;
if (initiator != null) {
considerNotify(initiator);
initiator = null;
} else {
for (Iterator<Map.Entry<Observer<? super T>, ObserverWrapper>> iterator =
mObservers.iteratorWithAdditions(); iterator.hasNext(); ) {
considerNotify(iterator.next().getValue());
if (mDispatchInvalidated) {
break;
}
}
}
} while (mDispatchInvalidated);
mDispatchingValue = false;
}
核心在于considerNotify方法
private void considerNotify(ObserverWrapper observer) {
if (!observer.mActive) {
return;
}
// Check latest state b4 dispatch. Maybe it changed state but we didn't get the event yet.
//
// we still first check observer.active to keep it as the entrance for events. So even if
// the observer moved to an active state, if we've not received that event, we better not
// notify for a more predictable notification order.
if (!observer.shouldBeActive()) {
observer.activeStateChanged(false);
return;
}
if (observer.mLastVersion >= mVersion) {
return;
}
observer.mLastVersion = mVersion;
observer.mObserver.onChanged((T) mData);
}
直接看到最后一句,这里直接调用了observer.mObserver.onChanged((T) mData);,这里就会触发数据变化回调。而这里的mObserver即是我们在刚开始传递进来的。
其他
一、observeForever
其实,LiveData除了提供observe用于方法,还提供了一个observeForever方法
@MainThread
public void observeForever(@NonNull Observer<? super T> observer) {
assertMainThread("observeForever");
AlwaysActiveObserver wrapper = new AlwaysActiveObserver(observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing instanceof LiveData.LifecycleBoundObserver) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
wrapper.activeStateChanged(true);
}
这里可以看到,没有跟生命周期绑定,也不再使用LifecycleBoundObserver进行包装,而是使用AlwaysActiveObserver:
private class AlwaysActiveObserver extends ObserverWrapper {
AlwaysActiveObserver(Observer<? super T> observer) {
super(observer);
}
@Override
boolean shouldBeActive() {
return true;
}
}
AlwaysActiveObserver和LifecycleBoundObserver都继承于ObserverWrapper,但是前者没有重写它的detachObserver方法,因此它不会被自动移除监听。只能通过手动调用removeObserver进行移除。
二、postValue和setValue
两个方法都可以用于更新值,分析下区别:
protected void postValue(T value) {
boolean postTask;
synchronized (mDataLock) {
postTask = mPendingData == NOT_SET;
mPendingData = value;
}
if (!postTask) {
return;
}
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}
@MainThread
protected void setValue(T value) {
assertMainThread("setValue");
mVersion++;
mData = value;
dispatchingValue(null);
}
- setValue必须在主线程调用,否则会抛出异常
- postValue用于在其他线程更新值,核心在:
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);,这会切回到主线程执行。 - 由于postValue是通过handler的消息派发进行处理,而setValue直接设值,因此这种情况需要注意:
// 源码提示
Posts a task to a main thread to set the given value. So if you have a following code executed in the main thread:
liveData.postValue("a");
liveData.setValue("b");
The value "b" would be set at first and later the main thread would override it with the value "a".
- 如果在主线程执行已发布任务之前多次调用此方法,则只会调度最后一个值。这个是怎么实现的呢?我们看下postValue里边的处理
protected void postValue(T value) {
boolean postTask;
synchronized (mDataLock) {
postTask = mPendingData == NOT_SET;
mPendingData = value;
}
if (!postTask) {
return;
}
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}
private final Runnable mPostValueRunnable = new Runnable() {
@SuppressWarnings("unchecked")
@Override
public void run() {
Object newValue;
synchronized (mDataLock) {
newValue = mPendingData;
mPendingData = NOT_SET;
}
setValue((T) newValue);
}
};
第一次,mPendingData的值为NOT_SET,因此postTask为true,而mPendingData为设置的value。直到mPostValueRunnable被执行时,mPendingData才被重新赋值为NOT_SET。假如在主线程执行前,不断的调用postValue,postTask一直为false,mPendingData会被更新到最新设置的值,但是mPostValueRunnable不会被重复执行。
作者:PG_KING
链接:https://juejin.cn/post/7056651781874548773
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 中的contract 到底有什么用?
我们在开发中肯定会经常用Kotlin提供的一些通用拓展函数,当我们进去看源码的时候会发现许多函数里面有contract {}包裹的代码块,那么这些代码块到底有什么作用呢??
测试
接下来用以下两个我们常用的拓展函数作为例子
public inline fun <T, R> T.run(block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block()
}
public inline fun CharSequence?.isNullOrEmpty(): Boolean {
contract {
returns(false) implies (this@isNullOrEmpty != null)
}
return this == null || this.length == 0
}
run和isNullOrEmpty我相信大家在开发中是经常见到的。
不知道那些代码有什么作用,那么我们就把那几行代码去掉,然后看看函数使用起来有什么区别。
public inline fun <T, R> T.runWithoutContract(block: T.() -> R): R {
return block()
}
public inline fun CharSequence?.isNullOrEmptyWithoutContract(): Boolean {
return this == null || this.length == 0
}
上面是去掉了contract{}代码块后的两个函数 调用看看
fun test() {
var str1: String = ""
var str2: String = ""
runWithoutContract {
str1 = "jayce"
}
run {
str2 = "jayce"
}
println(str1) //jayce
println(str2) //jayce
}
经过测试发现,看起来好像没什么问题,run代码块都能都正常执行,做了赋值的操作。
那么如果是这样呢
将str的初始值去掉,在run代码块里面进行初始化操作
@Test
fun test() {
var str1: String
var str2: String
runWithoutContract {
str1 = "jayce"
}
run {
str2 = "jayce"
}
println(str1) //编译不通过 (Variable 'str1' must be initialized)
println(str2) //编译通过
}
??????
我们不是在runWithoutContract做了初始化赋值的操作了吗?怎么IDE还报错,难道是IDE出了什么问题?好 有问题就重启,我去,重启还没解决。。。。好重装。不不不!!别急 会不会Contract代码块就是干这个用的?是不是它悄悄的跟IDE说了什么话 以至于它能正常编译通过?
好 这个问题先放一放 我们再看看没contract版本的isNullOrEmpty对比有contract的有什么区别
fun test() {
val str: String? = "jayce"
if (!str.isNullOrEmpty()) {
println(str) //jayce
}
if (!str.isNullOrEmptyWithoutContract()) {
println(str) //jayce
}
}
发现好像还是没什么问题。相信大家根据上面遇到的问题可以猜测,这其中肯定也有坑。
比如这种情况
fun test() {
val str: String? = "jayce"
if (!str.isNullOrEmpty()) {
println(str.length) // 编译通过
}
if (!str.isNullOrEmptyWithoutContract()) {
println(str.length) // 编译不通过(Only safe (?.) or non-null asserted (!!.) calls are allowed on a nullable receiver of type String?)
}
}
根据错误提示可以看出,在
isNullOrEmptyWithoutContract判断为flase之后的代码块,str这个字段还是被IDE认为是一个可空类型,必须要进行空检查才能通过。然而在isNullOrEmpty返回flase之后的代码块,IDE认为str其实已经是非空了,所以使用前就不需要进行空检查。
查看 contract 函数
public inline fun contract(builder: ContractBuilder.() -> Unit) { }
点进去源码,我们可以看到
contract是一个内联函数,接收一个函数类型的参数,该函数是ContractBuilder的一个拓展函数(也就是说在这个函数体里面拥有ContractBuilder的上下文)
看看ContractBuilder给我们提供了哪些函数(主要就是依靠这些函数来约定我们自己写的lambda函数)
public interface ContractBuilder {
//描述函数正常返回,没有抛出任何异常的情况。
@ContractsDsl public fun returns(): Returns
//描述函数以value返回的情况,value可以取值为 true|false|null。
@ContractsDsl public fun returns(value: Any?): Returns
//描述函数以非null值返回的情况。
@ContractsDsl public fun returnsNotNull(): ReturnsNotNull
//描述lambda会在该函数调用的次数,次数用kind指定
@ContractsDsl public fun <R> callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN): CallsInPlace
}
returns
其中 returns() returns(value) returnsNotNull() 都会返回一个继承于SimpleEffect的Returns 接下来看看SimpleEffect
public interface SimpleEffect : Effect {
//接收一个Boolean值的表达式 改函数用来表示当SimpleEffect成立之后 保证Boolean值的表达式返回值为true
//表达式可以传判空代码块(`== null`, `!= null`)判断实例语句 (`is`, `!is`)。
public infix fun implies(booleanExpression: Boolean): ConditionalEffect
}
可以看到SimpleEffect里面有一个中缀函数implies 。可以使用ContractBuilder的函数指定某种返回的情况 然后用implies来声明传入的表达式为true。
看到这里 那么我们应该就知道 isNullOrEmpty() 加的contract是什么意思了
public inline fun CharSequence?.isNullOrEmpty(): Boolean {
contract {
//返回值为false的情况 returns(false)
//意味着 implies
//调用该函数的对象不为空 (this@isNullOrEmpty != null)
returns(false) implies (this@isNullOrEmpty != null)
}
return this == null || this.length == 0
}
因为isNullOrEmpty里面加了contract代码块,告诉IDE说:返回值为false的情况意味着调用该函数的对象不为空。所以我们就可以直接在判断语句后直接使用非空的对象了。
有些同学可能还是不理解,这里再举一个没什么用的例子(运行肯定会crash哈。。。)
@ExperimentalContracts //因为该特性还在试验当中 所以需要加上这个注解
fun CharSequence?.isNotNull(): Boolean {
contract {
//返回值为true returns(true)
//意味着implies
//调用该函数的对象是StringBuilder (this@isNotNull is StringBuilder)
returns(true) implies (this@isNotNull is StringBuilder)
}
return this != null
}
fun test() {
val str: String? = "jayce"
if (str.isNotNull()) {
str.append("")//String可是没有这个函数的,因为我们用contract让他强制转换成StringBuilder了 所以才有了这个函数
}
}
是的 这样IDE居然没有报错,因为经过我们contract的声明,只要这个函数返回true,调用函数的对象就是一个StringBuilder。
callsInPlace
//描述lambda会在该函数调用的次数,次数用kind指定
@ContractsDsl public fun <R> callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN): CallsInPlace
可以知道callsInPlace是用来指定lambda函数调用次数的
kind有四种取值
- InvocationKind.AT_MOST_ONCE:最多调用一次
- InvocationKind.AT_LEAST_ONCE:最少调用一次
- InvocationKind.EXACTLY_ONCE:调用一次
- InvocationKind.UNKNOWN:未知,不指定的默认值
我们再看回去之前run函数里面的contract声明了什么
public inline fun <T, R> T.run(block: T.() -> R): R {
contract {
//block这个函数,刚好调用一次
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block()
}
看到这里 应该就知道为什么我们自己写的
runWithoutContract会报错(Variable 'str1' must be initialized),而系统的run却不会报错了,因为run声明了lambda会调用一次,所以就一定会对str2做初始化操作,然而runWithoutContract却没有声明,所以IDE就会报错(因为有可能不会调用,所以就不会做初始化操作了)。
总结
- Kotlin提供了一些自动转换的功能,例如平时判空和判断是否为某个实例的时候,Kotlin都会为我们自动转换。但是如果这个判断被提取到其他函数的时候,这个转换会失效。所以提供了
contract给我们在函数体添加声明,编译器会遵守我们的约定。 - 当使用一个高阶函数的时候,可以使用
callsInPlace指定该函数会被调用的次。例如在函数体里面做初始化,如果申明为EXACTLY_ONCE的时候,IDE就不会报错,因为编译器会遵守我们的约定。
作者:JayceonDu
链接:https://juejin.cn/post/7051907516380217374
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
在开发过程中,我们经常会用到网络请求,在flutter框架中,dio框架非常不错,所以今天的文章在dio的基础上搭建一套网络持久化框架,那么在flutter项目中如何搭建一套,高可用性,维护性较高的dio公共请求参数框架呢?
搭建前夕准备
一、基本认知
- 要持久化那么必然要有存储设备
- 持久化的数据在app启动后要即使填充到项目中
- 由于项目中网络请求地址繁多,类型不同,需要持久化的位置不同
二、基于基本认知来找合适的工具&必要点
2.1 持久化的工具:
我的推荐
- mmkv
- share_prefresence
今天主要用讲解mmkv版本
2.2必要点:
dio拦截器
拦截器是搭建这套持久化的关键
三、准备好如上技能,我们来搭建这套持久化网络框架吧
1、首先要知道有几种类型的公共
//请求中url后追加公共请求
static const int urlPresistent = 1;
//请求头中追加公共请求
static const int headerPresistent = 2;
//全部都追加公共请求
static const int allPresistent = 3;
2、构建缓存参数(为了快速获取)
static Map> headerPersistent = Map();
static Map> urlPersistent = Map();
3、构建mmkv存储结构(加密存储)
static MMKV _store(String baseUrl, int type) => MMKVStore.sysSafeMMKV(name: '${SysConfig.sysPersistent}${baseUrl}_${type.toString()}');
4、构建基本函数
单健值对存储
static void setPersistent(String baseUrl,String key,String? value,{int type = allPresistent}){
if (type == allPresistent || type == headerPresistent) {
if (!headerPersistent.containsKey(baseUrl)) {
headerPersistent[baseUrl] = Map();
}
var keyMap = headerPersistent[baseUrl]!;
keyMap[key] = value;
_store(baseUrl, headerPresistent).encodeString(key, value??"");
}
if (type == allPresistent || type == urlPresistent) {
if (!urlPersistent.containsKey(baseUrl)) {
urlPersistent[baseUrl] = Map();
}
var keyMap = urlPersistent[baseUrl]!;
keyMap[key] = value;
_store(baseUrl, urlPresistent).encodeString(key, value??"");
}
}
多健值对存储
static void setPersistentMap(String baseUrl,Map map,{int type = allPresistent}){
if (type == allPresistent || type == headerPresistent) {
if (!headerPersistent.containsKey(baseUrl)) {
headerPersistent[baseUrl] = Map();
}
var keyMap = headerPersistent[baseUrl]!;
keyMap.addAll(map);
keyMap.forEach((key, value) {
_store(baseUrl, headerPresistent).encodeString(key, value??"");
});
}
if (type == allPresistent || type == urlPresistent) {
if (!urlPersistent.containsKey(baseUrl)) {
urlPersistent[baseUrl] = Map();
}
var keyMap = urlPersistent[baseUrl]!;
keyMap.addAll(map);
keyMap.forEach((key, value) {
_store(baseUrl, urlPresistent).encodeString(key, value??"");
});
}
}
参数获取:
static Map? getPersistent(String baseUrl, {int type = allPresistent}) {
Map? map;
if (type == allPresistent || type == headerPresistent) {
Map? headerMap;
if (headerPersistent.containsKey(baseUrl)) {
headerMap = headerPersistent[baseUrl];
} else {
headerMap = null;
}
if (headerMap != null) {
if (map == null) {
map = Map();
}
map.addAll(headerMap);
}
}
if (type == allPresistent || type == urlPresistent) {
Map? urlMap;
if (urlPersistent.containsKey(baseUrl)) {
urlMap = urlPersistent[baseUrl];
} else {
urlMap = null;
}
if (urlMap != null) {
if (map == null) {
map = Map();
}
map.addAll(urlMap);
}
}
return map;
}
刷新当前缓存(应用启动刷新)
static Map _all(String baseurl, int type) {
var mmkv= _store(baseurl, type);
var keys = mmkv.allKeys;
var map = Map();
keys.forEach((element) {
var value = mmkv.decodeString(element);
map[element] = value;
});
return map;
}
static void flushPersistent(String baseurl, {int type = allPresistent}) {
if (type == allPresistent || type == headerPresistent) {
var map = _all(baseurl, headerPresistent);
headerPersistent[baseurl]?.clear();
if (!headerPersistent.containsKey(baseurl)) {
headerPersistent[baseurl] = Map();
}
var keyMap = headerPersistent[baseurl]!;
keyMap.addAll(map);
}
if (type == allPresistent || type == urlPresistent) {
var map = _all(baseurl, urlPresistent);
urlPersistent[baseurl]?.clear();
if (!urlPersistent.containsKey(baseurl)) {
urlPersistent[baseurl] = Map();
}
var keyMap = urlPersistent[baseurl]!;
keyMap.addAll(map);
}
}
退出登陆移除持久化
static void removeAllPersistent(String baseurl, {int type = allPresistent}) {
if (type == allPresistent || type == headerPresistent) {
headerPersistent[baseurl]?.clear();
_store(baseurl, headerPresistent).clearAll();
}
if (type == allPresistent || type == urlPresistent) {
urlPersistent[baseurl]?.clear();
_store(baseurl, urlPresistent).clearAll();
}
}
拦截器实现(dio请求拦截管理)
class PresistentInterceptor extends Interceptor {
@override
void onRequest(RequestOptions options, RequestInterceptorHandler handler) {
var urlPersitents = HttpPersistent.getPersistent(options.baseUrl,type: HttpPersistent.urlPresistent);
var headerPersitents = HttpPersistent.getPersistent(options.baseUrl,
type: HttpPersistent.headerPresistent);
headerPersitents?.forEach((key, value) {
options.headers[key] = value;
});
urlPersitents?.forEach((key, value) {
options.queryParameters[key] = value;
});
super.onRequest(options, handler);
}
}
四、整体代码&事件调用逻辑
整体代码
class HttpPersistent{
static const int urlPresistent = 1;
static const int headerPresistent = 2;
static const int allPresistent = 3;
static MMKV _store(String baseUrl, int type) => MMKVStore.sysSafeMMKV(name: '${SysConfig.sysPersistent}${baseUrl}_${type.toString()}');
static Map> headerPersistent = Map();
static Map> urlPersistent = Map();
static void setPersistent(String baseUrl,String key,String? value,{int type = allPresistent}){
if (type == allPresistent || type == headerPresistent) {
if (!headerPersistent.containsKey(baseUrl)) {
headerPersistent[baseUrl] = Map();
}
var keyMap = headerPersistent[baseUrl]!;
keyMap[key] = value;
_store(baseUrl, headerPresistent).encodeString(key, value??"");
}
if (type == allPresistent || type == urlPresistent) {
if (!urlPersistent.containsKey(baseUrl)) {
urlPersistent[baseUrl] = Map();
}
var keyMap = urlPersistent[baseUrl]!;
keyMap[key] = value;
_store(baseUrl, urlPresistent).encodeString(key, value??"");
}
}
static void setPersistentMap(String baseUrl,Map map,{int type = allPresistent}){
if (type == allPresistent || type == headerPresistent) {
if (!headerPersistent.containsKey(baseUrl)) {
headerPersistent[baseUrl] = Map();
}
var keyMap = headerPersistent[baseUrl]!;
keyMap.addAll(map);
keyMap.forEach((key, value) {
_store(baseUrl, headerPresistent).encodeString(key, value??"");
});
}
if (type == allPresistent || type == urlPresistent) {
if (!urlPersistent.containsKey(baseUrl)) {
urlPersistent[baseUrl] = Map();
}
var keyMap = urlPersistent[baseUrl]!;
keyMap.addAll(map);
keyMap.forEach((key, value) {
_store(baseUrl, urlPresistent).encodeString(key, value??"");
});
}
}
static Map? getPersistent(String baseUrl, {int type = allPresistent}) {
Map? map;
if (type == allPresistent || type == headerPresistent) {
Map? headerMap;
if (headerPersistent.containsKey(baseUrl)) {
headerMap = headerPersistent[baseUrl];
} else {
headerMap = null;
}
if (headerMap != null) {
if (map == null) {
map = Map();
}
map.addAll(headerMap);
}
}
if (type == allPresistent || type == urlPresistent) {
Map? urlMap;
if (urlPersistent.containsKey(baseUrl)) {
urlMap = urlPersistent[baseUrl];
} else {
urlMap = null;
}
if (urlMap != null) {
if (map == null) {
map = Map();
}
map.addAll(urlMap);
}
}
return map;
}
static Map _all(String baseurl, int type) {
var mmkv= _store(baseurl, type);
var keys = mmkv.allKeys;
var map = Map();
keys.forEach((element) {
var value = mmkv.decodeString(element);
map[element] = value;
});
return map;
}
static void flushPersistent(String baseurl, {int type = allPresistent}) {
if (type == allPresistent || type == headerPresistent) {
var map = _all(baseurl, headerPresistent);
headerPersistent[baseurl]?.clear();
if (!headerPersistent.containsKey(baseurl)) {
headerPersistent[baseurl] = Map();
}
var keyMap = headerPersistent[baseurl]!;
keyMap.addAll(map);
}
if (type == allPresistent || type == urlPresistent) {
var map = _all(baseurl, urlPresistent);
urlPersistent[baseurl]?.clear();
if (!urlPersistent.containsKey(baseurl)) {
urlPersistent[baseurl] = Map();
}
var keyMap = urlPersistent[baseurl]!;
keyMap.addAll(map);
}
}
static void removeAllPersistent(String baseurl, {int type = allPresistent}) {
if (type == allPresistent || type == headerPresistent) {
headerPersistent[baseurl]?.clear();
_store(baseurl, headerPresistent).clearAll();
}
if (type == allPresistent || type == urlPresistent) {
urlPersistent[baseurl]?.clear();
_store(baseurl, urlPresistent).clearAll();
}
}
}
class PresistentInterceptor extends Interceptor {
@override
void onRequest(RequestOptions options, RequestInterceptorHandler handler) {
var urlPersitents = HttpPersistent.getPersistent(options.baseUrl,type: HttpPersistent.urlPresistent);
var headerPersitents = HttpPersistent.getPersistent(options.baseUrl,
type: HttpPersistent.headerPresistent);
headerPersitents?.forEach((key, value) {
options.headers[key] = value;
});
urlPersitents?.forEach((key, value) {
options.queryParameters[key] = value;
});
super.onRequest(options, handler);
}
}
1、登陆后,调用存储 HttpPersistent.setPersistent("http://www.baidu.com","token","123",HttpPersistent.headerPresistent)
2、退出登陆后,调用移除 HttpPersistent.removeAllPersistent("http://www.baidu.com",,type: HttpPersistent.headerPresistent);
3、应用启动后刷新缓存
HttpPersistent.flushPersistent("http://www.baidu.com", type: HttpPersistent.headerPresistent);
五、大功告成
如上就构建出一套可靠性高,维护性高的网络持久化框架
更多flutter教程请关注我的IMGeek:http://www.imgeek.org/people/3369…
熬夜再战Android之修炼Kotlin-【Kotlin的static是什么】
👉关于作者
众所周知,人生是一个漫长的流程,不断克服困难,不断反思前进的过程。在这个过程中会产生很多对于人生的质疑和思考,于是我决定将自己的思考,经验和故事全部分享出来,以此寻找共鸣!!!
专注于Android/Unity和各种游戏开发技巧,以及各种资源分享(网站、工具、素材、源码、游戏等)
欢迎关注公众号【空名先生】获取更多资源和交流!
👉前提
前面我们学了Kotlin语言,趁热打铁我们试试Kotlin在Android中的应用。
如果是新手,请先学完Android基础。
推荐先看小空之前写的熬夜Android系列,再来尝试。
👉实践过程
😜方式一
Java中有static关键字,而且我们常用,在Kotlin中是伴生对象,使用方式如下:
class LoginFragment : Fragment() {
companion object {
//默认无权限修饰符的话,就public类型
const val APP_Name = "空名先生"
var APP_Name_Change = "空名先生"
private const val APP_Author = "芝麻粒儿"
}
}
class MainActivity : AppCompatActivity(), View.OnClickListener {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
Log.e("TAG", "onCreate: " + LoginFragment.APP_Name)
// Log.e("TAG", "onCreate: "+LoginFragment.APP_Author ) //无法调用,因为是私有类型private
LoginFragment.APP_Name_Change="我修改了你的名字"
Log.e("TAG", "onCreate: " + LoginFragment.APP_Name_Change)
}
}
输出结果:
2021-10-19 16:04:26.574 22369-22369/cn.appstudy E/TAG: onCreate: 空名先生
2021-10-19 16:04:26.577 22369-22369/cn.appstudy E/TAG: onCreate: 我修改了你的名字
上面是关于变量的使用,那方法呢?Java中方法加上【static】关键字就是静态再加上public就是公开的了,哪都能用。Kotlin呢?
companion object {
fun myWork() {
Log.e("TAG", "方法:我的工作是研发")
}
//默认无权限修饰符的话,就public类型
const val APP_Name = "空名先生"
var APP_Name_Change = "空名先生"
private const val APP_Author = "芝麻粒儿"
}
如上在里面正常些函数,其他的kt文件中就能调用。
难道就这么简单?
注意,重点来了。如果在Java中调用Kotlin呢?
我们创建个【TextActivity】,调用下:
public class TextActivity extends AppCompatActivity {
public static String myName = "";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_text);
//LoginFragment.myWork(); //无法调用
//LoginFragment.setAPP_Name_Change("修改名字"); //无法调用
LoginFragment.Companion.myWork();
LoginFragment.Companion.setAPP_Name_Change("修改名字");
}
}
从实践中我们得知,在KT的companion object中做的任何声明,在Java中不能直接调用,而是利用【Companion】实体调用出来的,这就相当于new个类,调用实例方法了,而非静态方法。
所以需要这样:
companion object {
@JvmStatic
fun myWork() {
Log.e("TAG", "方法:我的工作是研发")
}
//默认无权限修饰符的话,就public类型
const val APP_Name = "空名先生"
@JvmStatic
var APP_Name_Change = "空名先生"
private const val APP_Author = "芝麻粒儿"
//非const类型的常量 val修饰的,要想Java中作为静态引用需要@JvmField
@JvmField
val MY_APP = "我的作品"
}
public class TextActivity extends AppCompatActivity {
public static String myName = "";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_text);
//LoginFragment.myWork(); //无法调用
//LoginFragment.setAPP_Name_Change("修改名字"); //无法调用
Log.e("TAG", "onCreate: " + LoginFragment.APP_Name);
//这些使用均正常,即使添加了@JvmStatic,仍然可以用Companion实例形式调用
LoginFragment.Companion.myWork();
LoginFragment.Companion.setAPP_Name_Change("修改名字");
LoginFragment.myWork();
LoginFragment.getAPP_Name_Change();
Log.e("TAG", "onCreate: " + LoginFragment.MY_APP);
Log.e("TAG", "onCreate: " + LoginFragment.APP_Name);
}
}
运行后你再试试,会发现,哎?真的,没有那么多吐司了,真的好啊。
要想实现Java中直接点出来的静态形式
- var类型的要添加@JvmStatic
- const修饰的不用管
- 方法使用@JvmStatic
- 非const修饰却为val类型的使用@JvmField
作者:芝麻粒儿
链接:https://juejin.cn/post/7021682280808579085
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter进阶-key的原理
在之前的篇幅介绍中,我们在构造函数中都没有使用key,只要继承于Widget的都默认有这个key属性,这是一个可选属性。下面我们通过案例来研究一个key的作用。
const MyApp({Key? key}) : super(key: key);
StatefulWidget中的key
先搭建一个页面,在页面的中间位置随机创建不同颜色的正方形
class _MyHomePageState extends State<MyHomePage> {
List<SquareItem1> list = [
const SquareItem1('上上上', key: ValueKey(111),),
const SquareItem1('中中中', key: ValueKey(222),),
const SquareItem1('下下下', key: ValueKey(333),)
];
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: list,
),
),
floatingActionButton: FloatingActionButton(
onPressed: () {
setState(() {
list.removeAt(0);
});
},
child: const Icon(Icons.add),
), // This trailing comma makes auto-formatting nicer for build methods.
);
}
}
其中SquareItem1的构造方法如下:const SquareItem1(this.title, {Key? key}) : super(key: key);
import 'dart:math';
import 'package:flutter/material.dart';
class SquareItem1 extends StatefulWidget {
final String title;
const SquareItem1(this.title, {Key? key}) : super(key: key);
@override
_SquareItem1State createState() => _SquareItem1State();
}
class _SquareItem1State extends State<SquareItem1> {
final color = Color.fromRGBO(
Random().nextInt(256), Random().nextInt(256), Random().nextInt(256), 1.0);
@override
Widget build(BuildContext context) {
return Container(
width: 100,
height: 100,
color: color,
child: Text(widget.title),
);
}
}
在点击按钮的时候,一次删除数组中的第一个元素 仔细看,通过实验对比可以明显的发现,此时顺序似乎是有点问题,那么问题出在哪里?
- 先看文字:文字的话似乎顺序没有问题,每一次都删除最上面的
- 再看颜色:颜色话倒像从是后面开始删除的,每次把最后一个删掉
带着这个疑问,我们再来看看StatelessWidget中的key
StatelessWidget中的key
这次继承的是StatelessWidget,其中SquareItem1的构造方法如下:SquareItem(this.title, {Key? key}) : super(key: key);
import 'dart:math';
import 'package:flutter/material.dart';
class SquareItem extends StatelessWidget {
final String title;
SquareItem(this.title, {Key? key}) : super(key: key);
final color = Color.fromRGBO(
Random().nextInt(256), Random().nextInt(256), Random().nextInt(256), 1.0);
@override
Widget build(BuildContext context) {
return Container(
width: 100,
height: 100,
color: color,
child: Text(title),
);
}
}
经过观察发现,此次的remove的顺序没有问题,颜色和文字都能一一对应上。通过两边的代码对比发现唯一的差别可能就是color初始化的位置区别,一个是在State中初始化,一个是在Widget中初始化,那是不是就是这个原因呢,我们接着研究。
key的使用
在StatefulWidget中我们可以通过给key赋值来区分不同的Widget,示例
List<SquareItem1> list = [
const SquareItem1(
'上上上',
key: ValueKey(111),
),
const SquareItem1(
'中中中',
key: ValueKey(222),
),
const SquareItem1(
'下下下',
key: ValueKey(333),
)
];
此时再运行发现颜色+文字删除的顺序正确了。所以我们有理由合理大胆的猜测,之所以在Stateful中数据紊乱是因为对应关系出了问题,那么到底是不是呢,我们看下API。StatelessWidget -> Widget 这里有一个方法canUpdate
static bool canUpdate(Widget oldWidget, Widget newWidget) {
return oldWidget.runtimeType == newWidget.runtimeType
&& oldWidget.key == newWidget.key;
}
Flutter是增量渲染,哪些需要更新的通过上面的那个方法来判断。所以当两个Widget都StatefulWidget的时候,如果不指定key的话,如果结构一样那么此时这个方法就会返回True
- 在
Widget中保存的是Text - 在
Element中保存的是Color - 在删除的时候,虽然我们删除了文字,但是由于没有指定key,所以
canUpdate = true所以此时第一个Element的颜色指向了Widget的第二个,这也就是示例一中出现的问题。
当然如果再新增一个跟上面一模一样的小部件,此时没有用到了Element下有了新的指向就不会删除了。也就是说新增的color= Element下的颜色
Key的原理
Key本身是一个抽象类,有一个工厂构造方法,创建ValueKey,其直接子类主要有:LocalKey和GlobalKey
GlobalKey:帮助访问某一个Widget的信息LocalKey: 用来区别哪个Element需要保留const ValueKey(this.value);// 以值作为参数,数字、字符串const ObjectKey(this.value);// 以对象作为参数UniqueKey();// 创建唯一标识
GlobalKey的使用
import 'package:flutter/material.dart';
class GlobalDemo extends StatelessWidget {
const GlobalDemo({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Home Page'),
),
body: const BodyCenter(),
floatingActionButton: FloatingActionButton(
onPressed: () {
//外层需要调用内层的count++
},
child: const Icon(Icons.add),
),
);
}
}
class BodyCenter extends StatefulWidget {
const BodyCenter({Key? key}) : super(key: key);
@override
_BodyCenterState createState() => _BodyCenterState();
}
class _BodyCenterState extends State<BodyCenter> {
int count = 0;
String title = 'hello';
@override
Widget build(BuildContext context) {
return Center(
child: Column(
children: [Text(count.toString()), Text(title)],
mainAxisAlignment: MainAxisAlignment.center,
),
);
}
}
在下面的设计中,外层是一个StatelessWidget中间的body是一个StatefulWidget,我们在外层onPress的时候,正常情况是无法更新内存的count的,此时用GlobalKey可以解决
- 在外层初始化一个
GlobalKey同时指定需要跟哪个State绑定final GlobalKey<_BodyCenterState> _globalKey = GlobalKey(); - 内存小部件初始化的时候同步绑定
body: BodyCenter(key: _globalKey), - 使用方式:
onPressed: () {
_globalKey.currentState!.setState(() {
_globalKey.currentState!.title =
'上一次count=' + _globalKey.currentState!.count.toString();
_globalKey.currentState!.count++;
});
},
只要是属于当前子部件的树状结构中,这种方式都管用,都可以拿到子部件的数据。
作者:weak_PG
链接:https://juejin.cn/post/7051452170385752078
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
哪怕不学Gradle,这些常见操作,你也值得掌握
Gradle是每个Android同学都逃不开的一个话题。你是否看到别人的
Gradle文件干净又卫生?而自己的又是一团乱麻🏷不用怕,本篇将结合我的开发日常,将一些常用的操作分享出来,希望可以帮到像我一样不怎么会[玩]
Gradle的同学,相信会对大家有所帮助。
模板代码提取
这是最基础的操作了,对于一个普通 model.gradle ,默认的配置如下:
如果我们每个 model 都这样写,那岂不是很麻烦,那么让我们提取通用代码:
优化步骤
新建一个 gradle 文件,命名为 xxx.gradle ,复制上述 model 里的配置,放到你的项目中,可以自定义修改一些通用内容,在其他model 中依赖即可,如下所示:
这是一个播放器model
// 这就是刚才新建的默认gradle文件,
// 注意:如果你的default.gradle是在项目目录下,请使用../,如果仅在app下,请使用./
apply from: "../default.gradle"
import xxx.*
android {
// 用于隔离不同model的资源文件
resourcePrefix "lc_play_"
}
dependencies {
compileOnly project(path: ':common')
api xxx
}
上述的 android{} , dependencies{}
其内部的内容都会在
default.gradle的基础上叠加,对于唯一的键值对,会进行替换。
定义统一的config配置
在项目中,你是如何去写你的版本号等其他默认配置呢?
对于一个新项目,其默认的配置如下所示,每次新创建 model ,也需要定义其默认参数,如果每次都直接在这里去改动,那么如果版本变化,意味着我们需要修改多次,这并不是我们想看到的效果。
优化步骤
新建 config.gradle ,内容如下:
// 一些配置文件的保存
// 使用git的commit记录当做versionCode
static def gitVersionCode() {
def cmd = 'git rev-list HEAD --count'
return cmd.execute().text.trim().toInteger()
}
static def releaseBuildTime() {
return new Date().format("yyyy.MM.dd", TimeZone.getTimeZone("UTC"))
}
ext {
android = [compileSdkVersion: 30,
applicationId : "com.xxx.xxx",
minSdkVersion : 21,
targetSdkVersion : 30,
buildToolsVersion: "30.0.2",
buildTime : releaseBuildTime(),
versionCode : gitVersionCode(),
versionName : "1.x.x"]
}
使用时:
android {
def android = rootProject.ext.android
defaultConfig {
multiDexEnabled true
minSdk android.minSdkVersion
compileSdk android.compileSdkVersion
targetSdk android.targetSdkVersion
versionCode android.versionCode
versionName android.versionName
}
}
配置你的build
配置不同build类型
在开发中,我们一般会有多个环境,比如 开发环境 ,测试环境,线上环境:
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
dev{
// initWith代表的是允许从其他build类型进行复制操作,然后配置我们想更改的设置
// 这里代表的是从release复制build配置
initWith release
// 清单占位符
manifestPlaceholders = [hostName:"com.petterp.testgradle.dev"]
// 会在你原包名后面新增.test
applicationIdSuffix ".dev"
}
}
如上所述,dev 是我们新增的 build类型 ,当新增之后,我们就可以在命令行使用如下匹配的指令,或者点击As 最右侧,gradle图标,选择app(根据自己build的配置位置而定,一般默认是app-model),选择other,即可看到多了如下几个指令:
当然你也可以选择如下命令行执行,以便在 Jenkins 或者 CI 下 build 时执行:
gradlew buildDev
gradlew assembleDev
注意,mac下是gradlew开头,windows下可能是./gradlew
配置变体
对于开发中,我们一般都有多渠道的需求,一般而言,如果仅仅是多渠道我们可以选择使用第三方 walle 去做,如果我们可能还有更精细的设置,比如针对这个 build类型,我们很可能对应了不同的默认配置等,比如配置不同的 applicationId ,资源。
如下所示:
// 变体风味名,如果只设置一个,则所有变体会自动使用,如果存在两个及以上,需要在变体中指定,并且变体需要与分组匹配。
// 风味名,类似于风格,分组的意思。
flavorDimensions "channel"
// flavorDimensions ("channel","api")
productFlavors {
demo1 {
// 每一个变体都必须存在一个风味,默认使用flavorDimensions(仅限其为单个时)的值,否则如果没提供,则会报错。
dimension "channel"
// appid后缀,会覆盖了我们build类型中的applicationIdSuffix
applicationIdSuffix ".demo"
// 版本后缀
versionNameSuffix "-demo"
}
demo2 {
dimension "channel"
applicationIdSuffix ".demo2"
versionNameSuffix "-demo2"
}
}
然后查看我们的 build Variants:
Gradle 会根据我们的 变体 和 build类型 自动创建多个build变种,按照 变体名-build类型名 方式命名。
在配置变体时,我们也可以替换在
build类型中设置的所有默认值,具体原因是,在添加build类型时,默认的defaultConfig配置其实是属于ProductFlavors类,所以我们也可以在任意变体中替换所有默认值。
组合多个变体
在某些场景下,我们可能想将多个产品的变体组合在一起,比如我们想增加一个 api30 的变体,并且针对这个变体,我们想让demo1和demo2与分别也能与其组合在一起 ,即也就是当channel是demo1时api30下对应的包。
理解起来有些拗口,示例如下所示,我们更改上面的配置:
flavorDimensions("channel", "api")
productFlavors {
demo1 {
dimension "channel"
applicationIdSuffix ".demo"
versionNameSuffix "-demo"
}
demo2 {
dimension "channel"
applicationIdSuffix ".demo2"
versionNameSuffix "-demo2"
}
minApi23 {
dimension "api"
minSdk 23
applicationIdSuffix ".minapi23"
versionNameSuffix "-minapi23"
}
}
最终如下所示,左侧是 gralde 生成的 build变种 ,右侧对应其中 demo1MinApi23Debug 打包后的产物具体信息:
所以我们可以总结为:
最终我们在打包时,我们的包名和版本名会根据多个变体混合生成,具体如上图所示,然后分别使用了两者都具有的配置,当配置出现重复时,优先以开头的变体配置作为基准。
比如如果我们给demo1变体也配置了最低sdk版本是21,那么最终打出来的包minSdk也会是21,而不是minApi23中的minSdk配置,这点需要注意。
解疑
那么 变体 和 build类型 两者到底应该怎么选?似乎两者好像很是相似?
其实不难理解,如下所示:
比如你新增了一个变体 firDev ,那么默认情况下就会有如下的 build命令 生成
firDevDebug
firDevRelase
firDevXXX(xxx是你自定义的build类型)
需要注意的是
debug和relase是默认就会存在的,我们可以选择覆盖,否则就算移除,其也会选择默认设置存在
即也就是最终 gradle 会帮我们每个变体都生成相应的 build类型 对应的命令,变体就相当于不同的渠道,而 build类型 就相当于针对这个渠道,存在着多种环境,比如 debug,relase,你自定义的更多build类型。
- 所以如果你的场景仅仅是想对应几个不同环境,那么直接配置 build类型 即可;
- 如果你可能希望区分不同的包下的依赖项或者资源配置,那么配置变体即可。
过滤变体
Gradle 会为我们配置的 所有变体 和 build类型 每一种可能组合都创建一个 build变种 。当然有些变种,我们并不需要,所以我们可以在相应模块的 build.gradle 中创建 变体过滤器 ,以便移除某些不需要的变体配置。
android{
...
variantFilter { variant ->
def names = variant.flavors*.name
if (names.contains("demo2")) {
setIgnore(true)
}
}
...
}
效果如下:
针对变体配置依赖项
我们也可以针对上面这些变体,进行不同的依赖。比如:
demo1Implementation xxx
minApi23Implementation xxxx
常见技巧
关于依赖管理
对于一些环境下,我们并不想在线上依赖某些库或者 model ,如果是三方库,一般都会有 relase 下依赖的版本。
如果是本地model,目前已经引用到了,所以就需要对于线上环境做null包处理,只留有相应的包名与入口,具体的实现都为null.
限制依赖条件为build类型
debugImplementation project(":dev")
releaseImplementation project(":dev_noop")
有一点需要注意,当我们使用默认的 debugImplementation 和 releaseImplementation 进行依赖时,最终打包时是否会依赖其中,取决于我们 使用的build命令中build类型是不是debug或者relase ,如果使用的是自定义的 dev ,那么上述的两个 model 也都不会依赖,很好理解。
限制依赖条件为变体
相应的,如果我们希望当前的依赖的库或者model 不受 build类型 限制,仅受 变体 限制,我们也可以使用我们的 变体-Implementation 进行依赖,如下所示:
demo1Implementation project(":dev")
这个意思是,如果我们打包时使用demo1相应的gradle命令,比如assembleDemo1Debug,那么无论当前build类型是debug还是release或者其他,其都会参与依赖。
排除传递的依赖项
开发中,我们经常会遇见依赖冲突,对于第三方库导致的依赖冲突,比较好解决,我们只需要使用 exclude 解决即可,如下所示:
dependencies {
implementation("androidx.lifecycle:lifecycle-extensions:2.2.0") {
exclude group: 'androidx.lifecycle', module: 'lifecycle-process'
}
}
统一全局的依赖版本
有时候,某些库会存在好多个版本,虽然 Gradle 会默认选用最高的版本,但是依然不免有时候还是会提示报错,此时我们就可以通过配置全局统一的版本限制:
android{
defaultConfig {
configurations.all {
resolutionStrategy {
force AndroidX.Core
force AndroidX.Ktx.Core
force AndroidX.Work_Runtime
}
}
}
}
简化你的BuildConfig配置
开发中,我们常见的都会将一些配置信息,写入到 BuildConfig 中,以便我们在开发中使用,这也是最常用的手段之一了。
配置方式1
最简单的方式就是,我们可以在执行 applicationVariants task任务时,将我们的 config 写入配置中,示例如下:
app/ build.gradle
android.applicationVariants.all { variant ->
if ("release" == variant.buildType.getName()) {
variant.buildConfigField "String", "baseUrl", "\"xxx\""
} else if ("preReleaseDebug" == variant.buildType.getName()) {
variant.buildConfigField "String", "baseUrl", "\"xxx\""
} else {
variant.buildConfigField "String", "baseUrl", "\"xxx\""
}
variant.buildConfigField "String", "buglyAppId", "\"xx\""
variant.buildConfigField "String", "xiaomiAppId", "\"xx\""
...
}
在写入时,我们也可以通过判断当前的 build类型 从而决定到底写入哪些。
优化配置
如果配置很少的话,上述方式写还可以接收,那如果配置参数很多,成百呢?此时就需要我们将其抽离出来了。
所以我们可以新建一个 build_config.gradle ,将上述代码复制到其中。
然后在需要的 模块 里,依赖一下即可。
apply from: "build_config.gradle"
这样做的好处就是,可以减少我们 app-build.gradle 里的逻辑,通过增加统一的入口,来提高效率和可读性。
配置方式2
当然也有另一种方式,相当于我们自己定义两个方法,在 buildType 里自行调用,相应的我们将 config配置 按照规则写入一个文件中去管理。
示例代码:
app/ build.gradle
buildTypes {
// 读取 ./build_extras 下的所有配置
def configBuildExtras = { com.android.build.gradle.internal.dsl.BuildType type ->
// This closure reads lines from "build_extras" file and feeds its content to BuildConfig
// Nothing but a better way of storing magic numbers
def buildExtras = new FileInputStream(file("./build_extras"))
buildExtras.eachLine {
def keyValue = it == null ? null : it.split(" -> ")
if (keyValue != null && keyValue.length == 2) {
type.buildConfigField("String", keyValue[0].toUpperCase(), "\"${keyValue[1]}\"")
}
}
}
release {
...
configBuildExtras(delegate)
...
}
debug{
...
configBuildExtras(delegate)
...
}
}
build_extras
...
baseUrl -> xxx
buglyId -> xxx
...
上述两种配置方式,我们可以根据需要自行决定,我个人是比较喜欢方式1,毕竟看着更简单,但其实两者的实现方式也是大差不大,具体看个人习惯吧。
管理全局插件的依赖
某些时候,我们所有的model,可能都需要集成一个插件,此时我们就可以通过在 项目build.gradle 里全局统一管理,而避免到每一个Gradle 下去集成:
// 管理全局插件的依赖
subprojects { subproject ->
// 默认应用所有子项目中
apply plugin: xxx
// 如果想应用到某个子项目中,可以通过 subproject.name 来判断应用在哪个子项目中
// subproject.name 是你子项目的名字,示例如下
// 官方文档地址:https://guides.gradle.org/creating-multi-project-builds/#add_documentation
// if (subproject.name == "app") {
// apply plugin: 'com.android.application'
// apply plugin: 'kotlin-android'
// apply plugin: 'kotlin-android-extensions'
// }
}
动态调整你的组件开关
对于一些组件,在 debug 开发时如果依赖,对我们的编译时间可能会有影响,那么此时,如果我们增加相应的开关控制,就会比较好:
buildscript {
ext.enableBooster = flase
ext.enableBugly = flase
if (enableBooster)
classpath "com.didiglobal.booster:booster-gradle-plugin:$booster_version"
}
如果每次都是静态控制,那么当我们使用 CI 来打包时,就会没法操作。所以相应的,我们可以更改一下逻辑:
我们创建一个文件夹,里面放的是相应的忽略文件,如下所示:
然后我们更改一下相应的 buildscript 逻辑:
buildscript {
ext.enableBooster = !file("ignore/.boosterignore").exists()
ext.enableBugly = !file("ignore/.buglyignore").exists()
if (enableBooster)
classpath "com.didiglobal.booster:booster-gradle-plugin:$booster_version"
}
通过判断相应的插件对应的文件是否存在,来决定插件在CI打包时的启用状态。在CI打包时,我们只需要通过shell删除相应的配置ignore文件或者通过gradle执行相应命令即可。因为本篇是讲gradle的一些操作,所以我们就主要演示一下gradle的命令示例。
定义自己的gradle插件
我们先简单写一个最入门的插件,用来移除相应的文件,来达到开关插件的目的。
task checkIgnore {
println "-------checkIgnore--------开始->"
removeIgnore("enableBugly", ".buglyignore")
removeIgnore("enableGms", ".gmsignore")
removeIgnore("enableByteTrack", ".bytedancetrackerignore")
removeIgnore("enableSatrack", ".satrackerignore")
removeIgnore("enableBooster", ".boosterignore")
removeIgnore("enableHms", ".hmsignore")
removeIgnore("enablePrivacy", ".privacyignore")
println "-------checkIgnore--------结束->"
}
def removeIgnore(String name, ignoreName) {
if (project.hasProperty(name)) {
delete "../ignore/$ignoreName"
def sdkName = name.replaceAll("enable", "")
println "--------已打开$sdkName" + "组件"
}
}
这个插件的作用很简单,就是通过我们 Gradle 命令 携带的参数 来移除相应的插件文件。
gradlew app:assembleRoyalFinalDebug -PenableBugly=true
具体如图所示:在 CI-build 时,我们就可以通过传递相应的值,来动态决定是否启用某插件。
优化版
上述方式虽然方便,但是看着依然很麻烦,那么有没有更简单,单纯利用 Gradle 即可。其实如果稍微懂一点 Gradle 生命周期,这个问题就能轻松解决。
我们可以在 settings.gradle 里监听一下 Gradle 的 生命周期 ,然后在项目结构加载完成时,也就是 projectsLoaded 执行时,去判断一下,如果存在某个参数,那么就打开相应的组件,否则关闭。
示例:
settings.gradle
gradle.projectsLoaded { proj ->
println 'projectsLoaded()->项目结构加载完成(初始化阶段结束)'
def rootProject = proj.gradle.rootProject
rootProject.ext.enableBugly = rootProject.findProperty("enableBugly") ?: false
rootProject.ext.enableBooster = rootProject.findProperty("enableBooster") ?: false
rootProject.ext.enableGms = rootProject.findProperty("enableGms") ?: false
rootProject.ext.enableBytedance = rootProject.findProperty("enableBytedance") ?: false
rootProject.ext.enableSadance = rootProject.findProperty("enableSadance") ?: false
rootProject.ext.enableHms = rootProject.findProperty("enableHms") ?: false
rootProject.ext.enablePrivacy = rootProject.findProperty("enablePrivacy") ?: false
}
执行build命令时携带相应参数即可:
gradlew assembleDebug -PenablePrivacy=true
参考
我是Petterp,一个三流开发,如果本文对你有所帮助,欢迎点赞支持。
作者:Petterp
链接:https://juejin.cn/post/7053985196906905636
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
超实用的算法小技巧
本篇文章我们将介绍一些超级实用的算法小技巧,灵活使用这些算法小技巧可以帮助我们更好的解决遇到的问题,让我们的时间复杂度,空间复杂度大大降低,有效的提高我们的编程能力。
1 严格定义函数名称,出入参
我们在一开始拿到算法题,读懂题之后,就需要根据题意定义我们的函数名称,以及入参,函数的返回类型。日常的企业项目开发也是一样,我们在拿到需求之后,需要去定义接口,入参,出参。
我们一定要给处理函数起一个能够明确表达函数功能的名字比如:排序sort,搜索search,统一用英文表示(入参也是如此)。
leetcode技巧: 变量名称定义简单,可以提高算法执行速度,这也是在好多人在刷leetcode参数定义不那么规范的原因,往往在周赛或者一些比赛中一点点优势,就能助我们取得胜利。
2 严进宽出,边界判断
严进宽出就是说我们要对算法的入参进行严格的验证,比如我们经常要对数组、字符串进行非空校验,还有一些需要对边界值进行校验。
对于不符合规范的直接返回,很好的把控边界也可提升我们的算法效率。
笔试小技巧: 优雅严格的边界值判断,往往能给面试官留下很好的印象。
// 入参校验
if (nums == null || nums.length == 0) {
return -1;
}
// 边界值(不相等时,我们让左边指针移动到二分处,并且+1就很细节,因为中间点已经不符合,所以我们+1可以少循环一次)
while (l <= r) {
mid = l + (r - l) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
l = mid + 1;
} else if (nums[mid] > target) {
r = mid - 1;
}
}
3 暴力解法
没有经过算法训练的同学,一般在解决算法问题时,只能想到暴力解法,常常就是多层嵌套函数,定义额外的空间。
往往时间复杂度都是O(N)、O(N²) 虽然也能解决算法问题,但是往往因为算法的执行效率过低,代码不够优雅让Offer与我们失之交臂。
不过暴力解法虽然效率不高,但是是我们必须掌握的,写出来永远比什么都写不出来要强的多,暴力解法就要求我们灵活应用每种数据结构的遍历,并加入条件判断逻辑。
以下几个技巧则可以帮助我们优化算法,提供算法的执行效率。
4 双指针(Two Pointers)
双指针是一种算法小套路,我们在好多地方可以见到双指针的妙用,比如二分查找,确定链表是否成环等,接下来我们就来一起探究一下双指针的妙用。
双指针一般有以下几种形式。
普通双指针
两个指针往同一个方向移动
/**
* 冒泡排序
* @param nums
*/
public static void sort(int [] nums) {
if (nums == null || nums.length == 0) {
return;
}
int temp = 0;
for (int i = 0; i < nums.length - 1; i++) {
for (int j = i + 1; j < nums.length; j++) {
if (nums[i] > nums[j]) {
temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
}
}对撞双指针
两个指针从两端向对方移动
/**
* 力扣704 二分查找
* 二分查找算法是借助二分的思想,结合双指针来实现的一种搜索算法
* @author zhj
*/
public class Test704 {
public static void main(String[] args) {
int[] nums = {-1, 0, 3, 5, 9, 12};
int index = search(nums, 5);
System.out.println(index);
}
private static int search(int[] nums, int target) {
if (nums == null || nums.length == 0) {
return -1;
}
int l = 0;
int r = nums.length - 1;
int mid;
while (l <= r) {
mid = l + (r - l) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
l = mid + 1;
} else if (nums[mid] > target) {
r = mid - 1;
}
}
return -1;
}
}快慢双指针
慢指针+快指针 解决环形链表问题
/**
* 力扣 141 环形链表
* 给定一个链表,判断链表中是否有环
* @author zhj
*/
public class Test141 {
public static void main(String[] args) {
ListNode node = new ListNode(1);
ListNode node1 = new ListNode(2);
ListNode node2 = new ListNode(3);
ListNode node3 = new ListNode(4);
ListNode node4 = new ListNode(5);
node.next = node1;
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node2;
System.out.println(isRing(node));
}
private static boolean isRing(ListNode node) {
if (node == null || node.next == null) {
return false;
}
ListNode s = node;
ListNode f = node;
while (f != null && f.next != null) {
s = s.next;
f = f.next.next;
if (s == f) {
return true;
}
}
return false;
}
}
5 滑动窗口
滑动窗口也是一种算法小技巧,可以极大的减少重叠部分计算量,尤其是当重叠部分比较大的时候,效果格外明显。滑动窗口主要解决的是连续定长子数组的问题,但是有一些非定长的也可以通过滑动窗口的思想来解决。
当我们移动窗口时只需要排除移除的一个数据,在加入移入的一个数据,窗口内其它数据是不需要做出改变的。
非定长一般需要通过加入内层循环来解决。
/**
* 力扣209 长度最小的子数组
* @author zhj
*/
public class Test209 {
public static void main(String[] args) {
int[] nums = {2,3,1,2,4,3};
System.out.println(mumsLength(nums, 7));
}
private static int mumsLength(int[] nums, int sum) {
if (nums == null || nums.length == 0) {
return 0;
}
int res = nums.length + 1;
int total = 0;
int i = 0;
int j = 0;
while (j < nums.length) {
total = total + nums[j];
j++;
while (total >= sum) {
res = res < j-i ? res : j-i;
total = total - nums[i];
i = i + 1;
}
}
if (res == nums.length + 1) {
return 0;
}
return res;
}
}
6 递归
一些复杂的问题,我们往往可以通过递归去简化。
特点:自己调自己,根据特点条件可以返回,不会陷入死循环。
递归的四个要素:
- 参数
- 返回值
- 终止条件
- 递归拆解
经典问题斐波那契数列
0,1,1,2,3,5... f(0) = 0 f(1) = 1 f(n) = f(n-1) + f(n-2)
int recursion(int n) {
if (n < 2) {
return n == 1 ? 1 : 0;
}
return recursion(n-1) + recursion(n-2);
}
7 高阶算法
除了上边一些简单的小技巧之外,还有许多高阶的算法,比如由递归引发的分治法、回溯法;还有树和图的遍历方法,深度优先遍历,广度优先遍历;还有经典的算法贪心算法、动态规划等等,本文将不做讲解,后续会单独更新在算法这一专栏中,希望大家持续关注。
作者:CoderJie
链接:https://juejin.cn/post/7056632496032579620
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
揭秘 Kotlin 中的 == 和 ===
这篇文章我们主要来分析 Kotlin 中的操作符 == 和 === 的区别,以及它们分别在什么场景下使用。这些操作符在实际项目和开源项目中,使用的频率非常的高。主要包含以下内容:
- Java 中的
==和equals的区别? - Kotlin 提供的操作符
==和===分别做什么用?- 比较对象的结构是否相等 (
==或者equals) - 比较对象的引用是否相等 (
===)
- 比较对象的结构是否相等 (
- Kotlin 中的操作符在以下场景中的使用
- 基本数据类型
- 包装类
- 普通类
- 数据类
在开始分析之前,我们先来简单回顾一下 Java 中的操作符 == 和 equals 的区别。
Java 中的操作符 == 和 equals 的区别
操作符 ==
- 如果是基本数据类型比较的是值
- 如果是引用数据类型比较的是地址
操作符 equals
- 默认情况下在不重写
equals方法时,等价于==,比较的是地址
public boolean equals(Object obj) {
return (this == obj);
}
- 重写
equals方法时,一般用于比较结构是否相等,例如String
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
但是需要注意的是重写 equals 方法时,需要重写 hashCode() 方法,否则无法和 hash 集合类一起正常工作,可以通过快捷键自动生成 equals() 、hashCode() 、 toString() 等等方法。
- Mac: Cmd + N
- Win/Linux: Alt+Insert
更多 AndroidStudio 快捷键使用技巧查看下列文章:
关于 Java 的操作符介绍就到这里了,接下来重点来分析 Kotlin 中的操作符。
Kotlin 中的操作符 == 和 === 及 equals
Kotlin 提供了两种方式用于对象的比较。
比较对象的结构是否相等(
==或者equals)Kotlin 中的操作符
==等价于equals用于比较对象的结构是否相等, 很多情况下使用的是==,因为对于浮点类型 Float 和 Double,其实现方法equals不遵循 IEEE 754 浮点运算标准。比较对象的引用是否相等 (
===)Kotlin 中的操作符
===用于比较对象的引用是否指向同一个对象,运行时如果是基本数据类型===等价于==。
我们知道了基本概念之后,接下来一起来看一下这些操作符( == 和 === 及 equals ),在以下场景中的使用。
- 基本数据类型
- 包装类
- 普通类
- 数据类
基本数据类型
我们先来看一个例子:
val a1 = -0
val a2 = 0
println(a1 == a2) // true
println(a1.equals(a2)) // true
println(a1 === a2) // true
a1 = 100
a2 = 100
println(a1 == a2) // true
println(a1.equals(a2)) // true
println(a1 === a2) // true
运行时,对于基本数据类型 === 等价于 == 比较的是值(即对象的结构是否相等),如果比较基本数据类型时使用 ===,编译器就会给出一个警告,不建议使用。
但是 equals 比较特殊, 对于浮点类型 Float 和 Double 却有不同的表现,代码如下所示。
val a3 = -0f
val a4 = 0f
println(a3 == a4) // true
println(a3.equals(a4)) // false
println(a3 === a4) // true
正如你所看到的 a3.equals(a4) 结果为 false,那么为什么会这样呢,一起来查看反编译后的 Java 代码都做了什么。Tools → Kotlin → Show Kotlin Bytecode 。
float a3 = -0.0F;
float a4 = 0.0F;
boolean var2 = Float.valueOf(a3).equals(a4);
boolean var3 = false;
System.out.println(var2);
将 float 转换为包装类型 Float,调用其 equals 方法来进行比较,来看一下 equals 方法。
运行结果正如源码注释高亮部分一样,使用 equals 方法比较 +0.0f 和 -0.0f 其结果为 false, 如果使用操作符 ==结果为 true。
在 equals 方法中调用了 floatToIntBits 方法,在这个方法中是根据 IEEE 754 浮点算法标准,返回指定浮点值的表示形式,结果是一个整数,如下所示:
System.out.println(Float.floatToIntBits(-0f)); // -2147483648
System.out.println(Float.floatToIntBits(0f)); // 0
正如你所见,Float.floatToIntBits(-0f) 计算出来的结果,是整数的最小值 -2147483648,从结果来看它不遵循 IEEE 754 浮点运算标准,一起来看一下官方是如何解释的,更多信息点击查看 IEEE 754 浮点运算标准
对于浮点类型 Float 和 Double,其实现方法 equals 不遵循 IEEE 754 浮点运算标准:
NaN被认为和它自身相等NaN被认为比包括正无穷在内的任何其他元素都大-0.0小于+0.0
因此在 Kotlin 中如果使用 equals 方法进行比较的时候,需要注意这个情况。
包装类
无论是 Java 还是 Kotlin 每一种基本类型都会对应一个唯一的包装类,只不过它们的区分方式不一样。
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
val a5 = Integer(10)
val a6 = Integer(10)
println(a5 == a6) // true
println(a5.equals(a6)) // true
println(a5 === a6) // false
因为包装类重写了 equals 方法,所以使用操作符 == 和 equals 比较的是对象的结构是否相等,所以结果为 true。而操作符 === 比较的是对象的引用,是否指向同一个对象,因为是不同的对象,所以结果为 false。
普通的类
普通的类其实就是我们自己新建的类,并没有重写 equals 方法,一起来看一下这三种操作符的运行结果。
class Person1(val name: String, val age: Int)
val p1 = Person1(name = "hi-dhl", age = 10)
val p2 = Person1(name = "hi-dhl", age = 10)
println(p1 == p2) // false
println(p1.equals(p2)) // false
println(p1 === p2) // false
println(p1.name == p2.name) // true
println(p1.name.equals(p2.name)) // true
println(p1.name === p2.name) // true
因为普通的类 Person1 并没有实现 equals 方法,所以使用操作符 == 和 equals 比较的结果为 false,而 p1 和 p2 是不同的对象所以操作符 === 的结果为 false。
参数 name 是 String 类型,在上文分析过了 String 重写了 equals 方法,操作符 == 和 equals 比较的结果为 true。而 p1.name === p2.name 结果为 true , 是因为会先去常量池中查找是否存在 "hi-dhl",如果存在直接返回常量池中的引用。
数据类
最后我们在来看一下这三种操作符在数据类中的表现。
data class Person2(val name: String, val age: Int)
val p3 = Person2(name = "ByteCode", age = 10)
val p4 = Person2(name = "ByteCode", age = 10)
println(p3 == p4) // true
println(p3.equals(p4)) // true
println(p3 === p4) // false
println(p3.name == p4.name) // true
println(p3.name.equals(p4.name))// true
println(p3.name === p4.name) // true
因为编译器会根据数据类中的参数,自动生成 equals 、 hashCode 、 toString 等等方法,编译后的代码如下所示。
public int hashCode() {
String var10000 = this.name;
return (var10000 != null ? var10000.hashCode() : 0) * 31 + Integer.hashCode(this.age);
}
public boolean equals(@Nullable Object var1) {
if (this != var1) {
if (var1 instanceof Person2) {
Person2 var2 = (Person2)var1;
if (Intrinsics.areEqual(this.name, var2.name) && this.age == var2.age) {
return true;
}
}
return false;
} else {
return true;
}
}
所以使用操作符 == 和 equals,输出结果为 true,但是 p3 和 p4 是不同的对象所以操作符 === 的结果为 false。
总结
Java 中的操作符
操作符 ==
- 如果是基本数据类型比较的是值
- 如果是引用数据类型比较的是地址
操作符 equals
- 默认情况下在不重写
equals方法时,等价于==,比较的是地址 - 重写
equals方法时,常用于比较结构是否相等,可以通过快捷键自动生成equals()、hashCode()、toString()等等方法。- Mac: Cmd + N
- Win/Linux: Alt+Insert
Kotlin 中的操作符
Kotlin 提供了两种方式用于对象的比较。
比较对象的结构是否相等(
==或者equals)Kotlin 中的操作符
==等价于equals用于比较对象的结构是否相等, 很多情况下使用的是==,因为对于浮点类型 Float 和 Double,其实现方法equals不遵循 IEEE 754 浮点运算标准。比较对象的引用是否相等 (
===)Kotlin 中的操作符
===用于比较对象的引用是否指向同一个对象,运行时如果是基本数据类型===等价于==。
全文到这里就结束了,最后附上文章的精简示例,你能够在不运行程序的情况下,说出下面代码的运行结果吗?
class Person1(val name: String, val age: Int)
data class Person2(val name: String, val age: Int)
fun main() {
val a1 = -0
val a2 = 0
println(a1 == a2)
println(a1.equals(a2)
val a3 = -0f
val a4 = 0f
println(a3 == a4)
println(a3.equals(a4))
//-------------
val p1 = Person1(name = "hi-dhl", age = 10)
val p2 = Person1(name = "hi-dhl", age = 10)
println(p1 == p2)
println(p1.equals(p2))
println(p1 === p2)
println(p1.name === p2.name)
//-------------
val p3 = Person2(name = "ByteCode", age = 10)
val p4 = Person2(name = "ByteCode", age = 10)
println(p3 == p4)
println(p3.equals(p4))
println(p3 === p4)
println(p3.name === p4.name)
}
运行结果如下所示:
a1 == a2 true
a1.equals(a2) true
a3 == a4 true
a3.equals(a4) false
--------------------------
p1 == p2 false
p1.equals(p2) false
p1 === p2 false
p1.name === p2.name true
--------------------------
p3 == p4 true
p3.equals(p4) true
p3 === p4) false
p3.name === p4.name true
作者:DHL
链接:https://juejin.cn/post/6984606151845363743
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
李纳斯是个怎样的人?
李纳斯,更常用的翻译是林纳斯,下文保留作者的写法。
我对生命的意义有种理论。我们可以在第一章里对人们解释生命的意义何在。这样可以吸引住他们。一旦他们被吸引住,并且付钱买了书,剩下的章节里我们就可以胡扯了。
虽然李纳斯戏谑的称自己是在胡扯,但是如果你看到后面,了解李纳斯的为人,了解李纳斯的生活,了解李纳斯的故事之后,再来看这句话,你心里会嘀咕:这是在胡扯吗?其实还好啦。
也许真正的大佬才能懂得生命的意义,当李纳斯说"有三件事具有生命的意义。它们是你生活当中所有事情的动机,包括你所做的任何事情和一个生命体该做的所有事情。第一是生存,第二是社会秩序,第三是娱乐。生活中所有的事情都是按这个顺序发展的。娱乐之后便一无所有。因此从某种意义上说,这意味着生活的意义就是要达到第三个阶段。你一旦达到了第三个阶段,就算成功了。但首先要越过前两个阶段。"
反观我们生活的世界,这三个道理却具有普适性意义。也许马斯洛需求理论根本不存在,该理论提出最底层就是人的生存需求,上一层就是社会秩序、安全需求,再往上什么归属于爱的需求、尊重需求、求知需求、审美需求、自我实现等等都是可以归为娱乐。
吃得饱穿得暖是人的天性,而爱玩娱乐也是人的天性。但是娱乐这个范围非常却是广泛的,李纳斯抱着 CommodoreVIC-20 在芬兰严冬中的屋内编程玩游戏是一种娱乐;我们在北方的地暖屋里躺在床上刷着短视频也是一种娱乐,只不过后者无法创造出现实价值来罢了。
李纳斯是很简单的。他的妈妈对她的一些朋友们说,"我是个非常好养的孩子。她只要把我放在一个黑咕隆咚的储藏柜里,再配上一台电脑,偶尔朝里扔一些意大利面条,我就会感到格外高兴了。她的话不无道理。"其实我们也是很简单的,当你在玩游戏上瘾的时候,我相信给你一根网线,一瓶水,一碗面条,一个瓶子(用来装什么大家可以猜测)你也能熬两天,不要问我怎么知道的,因为我这么熬过,只不过我有洗手间。。。。。。
我写文章已经两年多了,这段时间以来我确实也有许多次能体会到李纳斯的那种快乐,单纯地快乐,喜欢写作,发自内心的喜欢,对象找我去逛街我觉得麻烦,领导让我开发新功能我觉得麻烦,甚至我家狗子拉的屎我都不愿意收。。。。。。
但是我非常佩服的就是李纳斯在暑假只做两件事情,第一件事是什么都没做。第二件事是读完了719页的《操作系统:设计和执行》。放在现如今的学生时代,我想恐怕鲜有人能够做到,反正我在上学时候的暑假,要么就是写作业,要么就是玩游戏。
李纳斯编写的 Linux 操作系统确实花费了他大量的时间和精力,"编程――睡觉――编程――睡觉――编程――吃饭(饼干)――编程――睡觉――编程――洗澡(冲冲了事)――编程。" 阿基米德说过给我一根杠杆我就能撬动地球,我却想说,给我六个月,我能把游戏玩明白了。
不管李纳斯编写出来的 Linux 系统多么耀眼和辉煌,他却从不在家人面前过多谈论自己,他只是想在家人面前表现出:"这就是一个喜欢捣鼓电脑的老实孩子"。
毫不夸张的说,开源创造了整个软件行业,无私分享的精神真是人类进步的阶梯和推动力,这也是为什么开源精神如此崇高的原因,即站在巨人的肩膀上看世界。
最让我觉得李纳斯特别尊敬的一点就是他对版权的看法:如果一个人每月只能挣五十美元,他可能会为一个软件花费二百五十美元吗?如果花一点钱买非法拷贝软件,而把五个月的工资用于吃饱肚子,我一点不觉得他不道德。这种侵权是道义上可以接受的。去追捕这种“侵权者”是不道德的,更不要说简直就是愚蠢的。科技向善,科技最终的目标就是让我们的生活更加方便和便利,而不是驱逐一些人。
我觉得那些能在各种领域构建一个小型世界的人真的很酷,比如海贼王这部作品就构筑了一个海上世界,世界格局和世界秩序相辅相成,同样的,李纳斯也构建了一个世界,这个世界是属于操作系统的,他自己制定了操作系统的运行规则,他决定了进程和线程的生死,他决定了内存的分配规则,他构建了一切应用软件的基础规则。
在这本自传中,让我很能体会到李纳斯一个非常显著的特点就是:当懒人,编程是一项创造性的工作,而 Linux的发明从来不是靠牺牲宝贵的睡眠时间换来的。事实上相比创造 Linux,他更喜欢睡觉。
也许程序员都是直率的,李纳斯也是一样,因为直率的人善于解决问题,这类人遇到问题时想的不是拐弯抹角想方设法逃避问题,而是直接上手解决,这样才会节省出来时间做更多的事儿。但是直率的人怼人也非常直率,我相信大家都遇到过被上司无情痛批或是在 Code View 时代码被无情的 diss。李纳斯在回复安德鲁塔南鲍姆(MINIX 的作者)的质疑时也显现出了直率的一面,只不过他怼人的语气相较于国内来说,还是温柔太多了。
李纳斯和塔芙育有三个孩子,塔芙最开始是李纳斯所讲的《计算机科学入门》这门课程的学生,后来李纳斯在给学生布置作业时说到:今天的家庭作业是给我发一个邮件(这在通讯如此发达的现代看起来有点傻),其他人都在问候,只有塔芙在请李纳斯出去约会。只有塔芙让李纳斯将近两周都没有使用计算机。
Linux 被创建出来,轰动了全世界,但是作为 Linux 的作者,却奉行了开源的思想,我想这就是为什么李纳斯在程序员眼里被看做是神一样的男人,这种看似离经叛道的行为,这种和资本主义金钱主义背道而驰的行为,在大多数人看起来都是不可理喻的,但是也许只有他自己知道,Just For Fun。
还有一句话我觉得很有意思,就是他在和盖茨的比较中说的话:"在这场操作系统之争中,一方是庞大而邪恶的微软公司与刻毒、贪婪却他妈富得流油的比尔盖茨,另一方则是以无私的爱心致力于自由软件的谦逊的民间英雄李纳斯·托沃兹。" 当 Linux 有足够和微软抗衡的资本后:"于是,有些加盟微软的朋友告诉我,他们曾见到我的头像被钉在了微软公司里的飞镖靶心上,我对此唯一的评论是:我的大鼻子实在太好瞄准了。"
作者:cxuan
来源:https://mp.weixin.qq.com/s/wyUUyf9cEKgr7s51EQYF9w
10 个让人头疼的 bug
那个谁,今天又写 bug 了,没错,他说的好像就是我。。。。。。
作为 Java 开发,我们在写代码的过程中难免会产生各种奇思妙想的 bug ,有些 bug 就挺让人无奈的,比如说各种空指针异常,在 ArrayList 的迭代中进行删除操作引发异常,数组下标越界异常等。
如果你不小心看到同事的代码出现了我所描述的这些 bug 后,那你就把我这篇文章甩给他!!!你甩给他一篇文章,并让他关注了一波 cxuan,你会收获他在后面像是如获至宝并满眼崇拜大神的目光。
废话不多说,下面进入正题。
错误一:Array 转换成 ArrayList
Array 转换成 ArrayList 还能出错?这是哪个笨。。。。。。
等等,你先别着急说,先来看看是怎么回事。
如果要将数组转换为 ArrayList,我们一般的做法会是这样
List<String> list = Arrays.asList(arr);Arrays.asList() 将返回一个 ArrayList,它是 Arrays 中的私有静态类,它不是 java.util.ArrayList 类。如下图所示
Arrays 内部的 ArrayList 只有 set、get、contains 等方法,但是没有能够像是 add 这种能够使其内部结构进行改变的方法,所以 Arrays 内部的 ArrayList 的大小是固定的。
如果要创建一个能够添加元素的 ArrayList ,你可以使用下面这种创建方式:
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arr));因为 ArrayList 的构造方法是可以接收一个 Collection 集合的,所以这种创建方式是可行的。
错误二:检查数组是否包含某个值
检查数组中是否包含某个值,部分程序员经常会这么做:
Set<String> set = new HashSet<String>(Arrays.asList(arr));
return set.contains(targetValue);
这段代码虽然没错,但是有额外的性能损耗,正常情况下,不用将其再转换为 set,直接这么做就好了:
return Arrays.asList(arr).contains(targetValue);或者使用下面这种方式(穷举法,循环判断)
for(String s: arr){
if(s.equals(targetValue))
return true;
}
return false;
上面第一段代码比第二段更具有可读性。
错误三:在 List 中循环删除元素
这个错误我相信很多小伙伴都知道了,在循环中删除元素是个禁忌,有段时间内我在审查代码的时候就喜欢看团队的其他小伙伴有没有犯这个错误。
说到底,为什么不能这么做(集合内删除元素)呢?且看下面代码
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
for (int i = 0; i < list.size(); i++) {
list.remove(i);
}
System.out.println(list);
这个输出结果你能想到么?是不是蠢蠢欲动想试一波了?
答案其实是 [b,d]
为什么只有两个值?我这不是循环输出的么?
其实,在列表内部,当你使用外部 remove 的时候,一旦 remove 一个元素后,其列表的内部结构会发生改变,一开始集合总容量是 4,remove 一个元素之后就会变为 3,然后再和 i 进行比较判断。。。。。。所以只能输出两个元素。
你可能知道使用迭代器是正确的 remove 元素的方式,你还可能知道 for-each 和 iterator 这种工作方式类似,所以你写下了如下代码
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
for (String s : list) {
if (s.equals("a"))
list.remove(s);
}
然后你充满自信的 run xxx.main() 方法,结果。。。。。。ConcurrentModificationException
为啥呢?
那是因为使用 ArrayList 中外部 remove 元素,会造成其内部结构和游标的改变。
在阿里开发规范上,也有不要在 for-each 循环内对元素进行 remove/add 操作的说明。
所以大家要使用 List 进行元素的添加或者删除操作,一定要使用迭代器进行删除。也就是
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String s = iter.next();
if (s.equals("a")) {
iter.remove();
}
}
.next() 必须在 .remove() 之前调用。在 foreach 循环中,编译器会在删除元素的操作后调用 .next(),导致ConcurrentModificationException。
错误四:Hashtable 和 HashMap
这是一条算法方面的规约:按照算法的约定,Hashtable 是数据结构的名称,但是在 Java 中,数据结构的名称是 HashMap,Hashtable 和 HashMap 的主要区别之一就是 Hashtable 是同步的,所以很多时候你不需要 Hashtable ,而是使用 HashMap。
错误五:使用原始类型的集合
这是一条泛型方面的约束:
在 Java 中,原始类型和无界通配符类型很容易混合在一起。以 Set 为例,Set 是原始类型,而 Set<?> 是无界通配符类型。
比如下面使用原始类型 List 作为参数的代码:
public static void add(List list, Object o){
list.add(o);
}
public static void main(String[] args){
List<String> list = new ArrayList<String>();
add(list, 10);
String s = list.get(0);
}
这段代码会抛出 java.lang.ClassCastException 异常,为啥呢?
使用原始类型集合是比较危险的,因为原始类型会跳过泛型检查而且不安全,Set、Set<?> 和 Set<Object> 存在巨大的差异,而且泛型在使用中很容易造成类型擦除。
大家都知道,Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java 的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
如在代码中定义List<Object>和List<String>等类型,在编译后都会变成List,JVM 看到的只是List,而由泛型附加的类型信息对 JVM 是看不到的。Java 编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法在运行时刻出现的类型转换异常的情况,类型擦除也是 Java 的泛型与 C++ 模板机制实现方式之间的重要区别。
比如下面这段示例
public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<String>();
list1.add("abc");
ArrayList<Integer> list2 = new ArrayList<Integer>();
list2.add(123);
System.out.println(list1.getClass() == list2.getClass());
}
}
在这个例子中,我们定义了两个ArrayList数组,不过一个是ArrayList<String>泛型类型的,只能存储字符串;一个是ArrayList<Integer>泛型类型的,只能存储整数,最后,我们通过list1对象和list2对象的getClass()方法获取他们的类的信息,最后发现结果为true。说明泛型类型String和Integer都被擦除掉了,只剩下原始类型。
所以,最上面那段代码,把 10 添加到 Object 类型中是完全可以的,然而将 Object 类型的 "10" 转换为 String 类型就会抛出类型转换异常。
错误六:访问级别问题
我相信大部分开发在设计 class 或者成员变量的时候,都会简单粗暴的直接声明 public xxx,这是一种糟糕的设计,声明为 public 就很容易赤身裸体,这样对于类或者成员变量来说,都存在一定危险性。
错误七:ArrayList 和 LinkedList
哈哈哈,ArrayList 是我见过程序员使用频次最高的工具类,没有之一。
当开发人员不知道 ArrayList 和 LinkedList 的区别时,他们经常使用 ArrayList(其实实际上,就算知道他们的区别,他们也不用 LinkedList,因为这点性能不值一提),因为看起来 ArrayList 更熟悉。。。。。。
但是实际上,ArrayList 和 LinkedList 存在巨大的性能差异,简而言之,如果添加/删除操作大量且随机访问操作不是很多,则应首选 LinkedList。如果存在大量的访问操作,那么首选 ArrayList,但是 ArrayList 不适合进行大量的添加/删除操作。
错误八:可变和不可变
不可变对象有很多优点,比如简单、安全等。但是不可变对象需要为每个不同的值分配一个单独的对象,对象不具备复用性,如果这类对象过多可能会导致垃圾回收的成本很高。在可变和不可变之间进行选择时需要有一个平衡。
一般来说,可变对象用于避免产生过多的中间对象。比如你要连接大量字符串。如果你使用一个不可变的字符串,你会产生很多可以立即进行垃圾回收的对象。这会浪费 CPU 的时间和精力,使用可变对象是正确的解决方案(例如 StringBuilder)。如下代码所示:
String result="";
for(String s: arr){
result = result + s;
}
所以,正确选择可变对象还是不可变对象需要慎重抉择。
错误九:构造函数
首先看一段代码,分析为什么会编译不通过?
发生此编译错误是因为未定义默认 Super 的构造函数。在 Java 中,如果一个类没有定义构造函数,编译器会默认为该类插入一个默认的无参数构造函数。如果在 Super 类中定义了构造函数,在这种情况下 Super(String s),编译器将不会插入默认的无参数构造函数。这就是上面 Super 类的情况。
要想解决这个问题,只需要在 Super 中添加一个无参数的构造函数即可。
public Super(){
System.out.println("Super");
}
错误十:到底是使用 "" 还是构造函数
考虑下面代码:
String x = "abc";
String y = new String("abc");
上面这两段代码有什么区别吗?
可能下面这段代码会给出你回答
String a = "abcd";
String b = "abcd";
System.out.println(a == b); // True
System.out.println(a.equals(b)); // True
String c = new String("abcd");
String d = new String("abcd");
System.out.println(c == d); // False
System.out.println(c.equals(d)); // True
这就是一个典型的内存分配问题。
后记
今天我给你汇总了一下 Java 开发中常见的 10 个错误,虽然比较简单,但是很容易忽视的问题,细节成就完美,看看你还会不会再犯了,如果再犯,嘿嘿嘿。
作者:cxuan
来源:https://mp.weixin.qq.com/s/uF0p8MGDhfvke4gdRv44iA
leetcode-零钱兑换
周末一直在下雨,甚至看天气预报,年前就一直是这样的天气了。不过这样的天气也有好处,反正哪儿也去不了,就在家看看书,也算是难得精心。
题目
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出: -1
示例 3:
输入:coins = [1], amount = 0
输出: 0
示例 4:
输入:coins = [1], amount = 11
输出: 1
示例 5:
输入:coins = [1], amount = 2
输出: 2
思路
这也是一个背包问题,要求刚好把背包装满,选用尽量少的件数。
定义一个一维数组dp,dp[n]代表总金额为n的情况下,最少的硬币个数,如果无法刚好凑成n,那么可以用一个特殊的固定值。dp[n] = min(dp[n-coin[k]]) + 1
怎么理解呢?
我们可以这么考虑:刚好组成总金额n的硬币中,可能包含coin[0]~coin[len-1]各有ci枚,当然,ci可以是0。如果ci > 0,那么我们可以先去掉这一枚,这样,dp[n] = dp[n-coin[k]] + 1;因为有len枚硬币,这里就可能存在len种情况,所以,dp[n] = min(dp[n-coin[0]]+1...dp[n-coin[len-1]]+1),整理一下,就得到了上面的状态转移方程。
边界条件,amount为0的时候,我们可以不用任何1枚硬币,所以dp[0] = 0。
另外,对于n无法刚好凑成的情况,本来我们可以初始化dp[n] = Integer.MAX_VALUE,由于有+1这个操作,会导致溢出,所以我们选择把dp[n]初始化成amount+1,因为面值是整数,至少是1,所以对于能凑成的n,硬币个数一定小于amount+1,等于amount+1的,就代表无法凑成。
Java版本代码
class Solution {
public int coinChange(int[] coins, int amount) {
int[] dp = new int[amount+1];
Arrays.fill(dp, amount + 1);
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
for (int coin : coins) {
if (i >= coin) {
dp[i] = Integer.min(dp[i], dp[i-coin] + 1);
}
}
}
if (dp[amount] > amount) {
return -1;
}
return dp[amount];
}
}作者:podongfeng
链接:https://juejin.cn/post/7056389501618225165
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不知不觉到了 Hero 动画
其实在我们的开发过程中,我们可能已经看见过 Hero 动画了,比如像电商类 App 的一个典型场景,商品列表页到商品详情页,列表页的缩略图需要带到详情页,并且带的过程中可能有大小,位置等的变化。在 Flutter 中,这种页面简直共有元素的动画就叫做 Hero 动画 ,有的时候也叫做 共享元素动画。
Flutter 官方的每周组件也介绍了 Hero 组件:👉 Hero 组件介绍
本文就演示如何构建标准的 Hero 动画,以及在页面过渡过程中将图像从圆形转换为方形的 Hero 动画。
可以使用 Hero 组件来创建这种动画。随着Hero动画从源路由到目标路由,目标路由也会在这一过程中淡入到视图上。一般来说,Hero 组件是两个页面 UI 的一部分,比如图片等等。从用户体验的角度来说,Hero 组件是从源路由飞到了目标路由。我们就用代码实现下面的 Hero 效果。
Standard hero animations
标准的 Hero 动画是 Hero 元素从一个页面飞到另一个页面,并且一般情况下位置和尺寸会有变化。比如是这样的:
第一个页面图片是在中间的,到了第二个蓝色页面,图片的位置和大小都发生了变化。从第二个页面到第一个页面,图片又还原到最初的样子。
Radial hero animations
在 radial hero 动画中, 随着页面的过渡,Hero的形状会发生变化从圆形到矩形。比如下面的效果:
上面的效果就是一个radial hero 动画,底部的三个元素,依次展示到第二个页面的中间,并且形状从圆形到矩形。从第二个页面回到第一个页面,图片元素还原到最初的样子。
Hero 动画的基本结构
- 在不同的 Route 声明两个 Hero 组件,两个 Hero 组件的 tag 要一致。
- Navigator 管理应用的路由栈
- 路由的 Push 或者 Pop 触发 Hero 动画
- 边框效果是由
RectTween实现的,从源路由到目标路由的过程中,这个效果值会变化。也许你可能会有疑问,为啥第二个路由还没显示呢,作为页面的一部分的 Hero 却可以显示? 因为在过渡期间,Hero 是放在应用的 Overlay 上的,所以它才可以显示在所有的 Route 上。
Hero 动画是由两个 Hero 组件实现的,一个在源路由中,一个在目标路由中。虽然从用户体验的角度,两个 UI 是共享的,只是样子变化了。这都不重要,因为只需要我们程序知道怎么计算的就可以了😭。
这里注意一点,Hero 动画不能加到 Dialog 上
Hero 动画主要是下面几部分:
在源路由定义一个 Hero 组件,这个组件叫做 源 hero,需要给 源hero 设置两个参数,待添加动画的组件,比如图片等等,和动画的唯一标示 tag
在目标路由定义一个 Hero 组件,这个组件叫做目标 hero,这个目标Hero需要和源Hero的tag一样,这也是最重要的一点,并且目标Hero也需要包裹一个带添加动画的组件。为了动画的效果达到最佳,目标Hero和源Hero包裹的内容最好一样
创建一个包含 目标Hero 的路由,路由定义的树会在动画结束时渲染出来
Navigator 的 push 或者 pop 操作会触发 Hero 动画,会去匹配 Hero 动画的 tag
Flutter 会计算 Hero 动画从开始到结束的补间,补间就是效果比如尺寸大小和位置摆放。真正承载动画效果的是在 overlay 中,而不是源或者目标路由中。
幕后工作
下面我们就介绍 Flutter 是怎么执行 Hero 的。
在执行动画之前,源 Hero 在 源路由的 Widget 树上。目标路由还不存在,Overlay 也是空的。
我们使用 Navigator Push 一个 路由,就会触发动画的执行。在动画开始的时刻,也就是 t=0.0, Flutter 就会执行下面的动作:
现在 Flutter 已经知道 Hero 动画到哪里停止,它会计算 Hero 动画的路径,动画的效果是 Material 运动的设计规范,这里注意一点,动画是不依附任何页面的
把 目标Hero 和 源Hero 都放在 Overlay 上,他们的大小和尺寸都是我们给他设置的。在Overlay 上进行动画效果,所以可以在页面之上显示效果
页面之上进行动画
当 Hero 动画移动的时候,边框效果使用 Tween ,具体的实现是 Hero 刻的 createRectTween 方法。默认情况下,Flutter 使用的 MaterialRectArcTween 效果。
动画完成之后:
- Flutter 会把 Overlay 上的目标Hero,移动到目标路由(页面)上,Overlay 就是空的了。
- 目标Hero 就出现在了页面上最终的位置
- 源Hero就存储在了页面上
Push 页面 Hero 动画会前进,Pop 页面会让 Hero 动画反向执行。
关键类
Hero 动画的实现需要使用到下面的类:
Hero是一个动画组件,会让子组件从源路由动画到目标路由,使用的时候需要指定相同的tag属性。Flutter 会用 tag 匹对 Hero。
Inkwell用于手势识别,onTap()的执行的时候 push 个新的页面,触发 Hero 动画。
Navigator管理路由栈,可以 Push 或者 Pop。
Route承载一个页面,一般情况下,一个Route代表了 一个页面。大多数应用都是多路由的。
标准的 Hero 动画
关键点
使用
MaterialPageRoute、CupertinoPageRoute、 自定义PageRouteBuilder指定路由,案例用的是 MaterialPageRoute
使用
SizedBox组件包裹 Image 组件,实现页面切换时,尺寸动画的效果
把图片组件放在目标页面的 Widget 树上,源页面和目标页面的 Widget 树不同,Image 组件在树中的位置也不同。
继续写代码
从一个页面到另一页面的动画可以使用 Flutter 的 Hero 组件,如果目标路由是 MaterialPageRoute ,那么动画的效果会使用 👉Material的效果。
Create a new Flutter example 使用代码👉 hero_animation.
按着下面的步骤运行:
点击主页页面的图片,会打开新页面,新页面会呈现一个不同尺寸和位置的图片
点击图像或者物理返回会返回到前一个路由
可以使用
timeDilation属性让动画的速度降下来
PhotoHero 类
自定义的 PhotoHero 类维护这个 Hero、尺寸、图片和点击的行为,代码如下:
class PhotoHero extends StatelessWidget {
const PhotoHero({ Key key, this.photo, this.onTap, this.width }) : super(key: key);
final String photo;
final VoidCallback onTap;
final double width;
Widget build(BuildContext context) {
return SizedBox(
width: width,
child: Hero(
tag: photo,
child: Material(
color: Colors.transparent,
child: InkWell(
onTap: onTap,
child: Image.asset(
photo,
fit: BoxFit.contain,
),
),
),
),
);
}
}
代码的关键信息:
InkWell包裹了 Image 组件,让源路由和目标路由的手势添加变得简单了。- 代码中的
Material和Colors.transparent的效果是,当图片动画到目的地之后,图像可以从背景中 “pop out” (弹出来)。 SizedBox的含义是指定Hero的大小- Image 的
fit属性是为了让图片在容器内尽可能大,这个尽可能大是指不改变宽高比。可以看这里👉图文组件
PhotoHero 的树结构是:
HeroAnimation 类
PhotoHero 类是显示类,HeroAnimation 类是动画类,这个类创建了源路由和目标路由,并且关联了动画。
代码如下:
class HeroAnimation extends StatelessWidget {
Widget build(BuildContext context) {
timeDilation = 5.0; // 1.0 means normal animation speed.
return Scaffold(
appBar: AppBar(
title: const Text('Basic Hero Animation'),
),
body: Center(
child: PhotoHero(
photo: 'images/flippers-alpha.png',
width: 300.0,
onTap: () {
Navigator.of(context).push(MaterialPageRoute(
builder: (BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Flippers Page'),
),
body: Container(
// The blue background emphasizes that it's a new route.
color: Colors.lightBlueAccent,
padding: const EdgeInsets.all(16.0),
alignment: Alignment.topLeft,
child: PhotoHero(
photo: 'images/flippers-alpha.png',
width: 100.0,
onTap: () {
Navigator.of(context).pop();
},
),
),
);
}
));
},
),
),
);
}
}
关键信息:
用户点击图片创建一个
MaterialPageRoute的路由,并且使用Navigator把路由添加到栈中
Container容器让PhotoHero放置在页面的左上角,当然在AppBar的下面
onTap()触发页面切换和动画
timeDilation属性让动画变慢了
动画的效果:
Radial hero animations
关键点
radial 效果是把圆形的边框动画成方形边框
从源路由到目标路由,Hero 执行径向的转换。
MaterialRectCenterArcTween 定义了径向效果
使用
PageRouteBuilder定义目标路由
进行页面跳转的同时进行形状的变化,会让动画更加的流畅。为了实现这一效果,代码会动画两个形状的交集:圆形和正方形。在整个动画过程中,圆形的裁剪从 minRadius 到 maxRadius,方形的裁剪始终保持同一个大小。同时,图片也从源路由动画到目标路由的指定位置。
动画可能看起来很复杂(确实很复杂),但开发者可以根据需要定制所提供的示例。一般性的代码已经完成了。
继续写代码
下面的算法展示了图片的裁剪过程,从开始的(t = 0.0)到结束的(t = 1.0)。
蓝色的渐变代表图片,表示裁剪形状的交点。在动画的开始,相交的结果是一个圆形。在动画过程中,ClipOval 从 minRadius 缩放到 maxRadius,而 ClipRect 保持恒定的大小。在动画的最后,圆形和矩形的交集会生成一个矩形,这个矩形与 Hero 组件的大小相同。也就是说,在动画结束时,图像不再被裁剪。
动画的代码在这里👉radial_hero_animation
按着下面的步骤操作:
点击三个圆形缩略图中的一个,使图像动画到一个更大的正方形,正方形在目标路由的中间
点击图像返回到上一个源路由,也可以物理返回
使用
timeDilation属性慢放动画
Photo class
The Photo class builds the widget tree that holds the image:
content_copy
class Photo extends StatelessWidget {
Photo({ Key key, this.photo, this.color, this.onTap }) : super(key: key);
final String photo;
final Color color;
final VoidCallback onTap;
Widget build(BuildContext context) {
return Material(
// Slightly opaque color appears where the image has transparency.
color: Theme.of(context).primaryColor.withOpacity(0.25),
child: InkWell(
onTap: onTap,
child: Image.asset(
photo,
fit: BoxFit.contain,
)
),
);
}
}
关键点:
Inkwell组件捕捉点击事件,执行的动作是构造方法传进来的回调
动画期间,
InkWell会使用第一个 Material 祖先节点的效果,比如水波纹等等
Material 组件有一个稍微不透明的背景色,这样即使是图片透明的部分也会有一个背景色。确保了圆形到方形的过渡很容易被看到。
Photo类中没有包含Hero组件,为了让动画生效,Hero 包装了RadialExpansion组件。
RadialExpansion class
RadialExpansion 组件是 Demo 的核心,构建了 裁剪图片的 Widget树。裁剪的形状是圆形和矩形的交集,圆形是随着动画正向变大,反向变小的,矩形的大小是不变的。
代码如下:
class RadialExpansion extends StatelessWidget {
RadialExpansion({
Key key,
this.maxRadius,
this.child,
}) : clipRectSize = 2.0 * (maxRadius / math.sqrt2),
super(key: key);
final double maxRadius;
final clipRectSize;
final Widget child;
@override
Widget build(BuildContext context) {
return ClipOval(
child: Center(
child: SizedBox(
width: clipRectSize,
height: clipRectSize,
child: ClipRect(
child: child, // Photo
),
),
),
);
}
}
上面代码形成的节点树:
关键点:
Hero 组件包裹了
RadialExpansion组件
在动画的过程中,它的尺寸和
RadialExpansion的尺寸都会改变
RadialExpansion动画是被两个重叠的裁剪组件创建的
案例使用
MaterialRectCenterArcTween定义了补间的插值,默认的动画路径使用 Hero 角度的计算值(sqrt)来进行插值。这种方法会在径向变化期间会影响Hero的长宽比。因此径向动画使用 MaterialRectCenterArcTween 来使用 Hero的中心点和角度计算进行差值。
代码如下:
static RectTween _createRectTween(Rect begin, Rect end) {
return MaterialRectCenterArcTween(begin: begin, end: end);
}
完成的代码是这样的:
import 'dart:math' as math;
import 'package:flutter/material.dart';
import 'package:flutter/scheduler.dart' show timeDilation;
class Photo extends StatelessWidget {
const Photo({Key? key, required this.photo, this.onTap}) : super(key: key);
final String photo;
final VoidCallback? onTap;
@override
Widget build(BuildContext context) {
return Material(
// Slightly opaque color appears where the image has transparency.
color: Theme.of(context).primaryColor.withOpacity(0.25),
child: InkWell(
onTap: onTap,
child: LayoutBuilder(
builder: (BuildContext context, BoxConstraints size) {
return Image.asset(
photo,
fit: BoxFit.contain,
);
},
),
),
);
}
}
class RadialExpansion extends StatelessWidget {
const RadialExpansion({
Key? key,
required this.maxRadius,
this.child,
}) : clipRectSize = 2.0 * (maxRadius / math.sqrt2),
super(key: key);
final double maxRadius;
final double clipRectSize;
final Widget? child;
@override
Widget build(BuildContext context) {
return ClipOval(
child: Center(
child: SizedBox(
width: clipRectSize,
height: clipRectSize,
child: ClipRect(
child: child,
),
),
),
);
}
}
class RadialExpansionDemo extends StatelessWidget {
const RadialExpansionDemo({Key? key}) : super(key: key);
static double kMinRadius = 32.0;
static double kMaxRadius = 128.0;
static Interval opacityCurve =
const Interval(0.0, 0.75, curve: Curves.fastOutSlowIn);
static RectTween _createRectTween(Rect? begin, Rect? end) {
return MaterialRectCenterArcTween(begin: begin, end: end);
}
static Widget _buildPage(
BuildContext context, String imageName, String description) {
return Container(
color: Theme.of(context).canvasColor,
child: Center(
child: Card(
elevation: 8.0,
child: Column(
mainAxisSize: MainAxisSize.min,
children: [
SizedBox(
width: kMaxRadius * 2.0,
height: kMaxRadius * 2.0,
child: Hero(
createRectTween: _createRectTween,
tag: imageName,
child: RadialExpansion(
maxRadius: kMaxRadius,
child: Photo(
photo: imageName,
onTap: () {
Navigator.of(context).pop();
},
),
),
),
),
Text(
description,
style: const TextStyle(fontWeight: FontWeight.bold),
textScaleFactor: 3.0,
),
const SizedBox(height: 16.0),
],
),
),
),
);
}
Widget _buildHero(
BuildContext context, String imageName, String description) {
return SizedBox(
width: kMinRadius * 2.0,
height: kMinRadius * 2.0,
child: Hero(
createRectTween: _createRectTween,
tag: imageName,
child: RadialExpansion(
maxRadius: kMaxRadius,
child: Photo(
photo: imageName,
onTap: () {
Navigator.of(context).push(
PageRouteBuilder(
pageBuilder: (BuildContext context,
Animation animation,
Animation secondaryAnimation) {
return AnimatedBuilder(
animation: animation,
builder: (BuildContext context, Widget? child) {
return Opacity(
opacity: opacityCurve.transform(animation.value),
child: _buildPage(context, imageName, description),
);
});
},
),
);
},
),
),
),
);
}
@override
Widget build(BuildContext context) {
timeDilation = 5.0; // 1.0 is normal animation speed.
return Scaffold(
appBar: AppBar(
title: const Text('Radial Transition Demo'),
),
body: Container(
padding: const EdgeInsets.all(32.0),
alignment: FractionalOffset.bottomLeft,
child: Row(
mainAxisAlignment: MainAxisAlignment.spaceBetween,
children: [
_buildHero(context, 'images/chair-alpha.png', 'Chair'),
_buildHero(context, 'images/binoculars-alpha.png', 'Binoculars'),
_buildHero(context, 'images/beachball-alpha.png', 'Beach ball'),
],
),
),
);
}
}
void main() {
runApp(
const MaterialApp(
home: RadialExpansionDemo(),
),
);
} 作者:Time_sun
链接:https://juejin.cn/post/7051933760702382094
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
每个 Flutter 开发者都应该知道的框架总览
本篇文章翻译自官方的👉总览文章,这篇文章基本上把 Flutter 介绍清楚了,如果想从总体上知道 Flutter 是咋回事,本篇文章是最好的教程了。
以下是正文
本文旨在从高层级提供一个 Flutter 框架结构的总体概览,介绍一些其设计上的核心原则和概念。
Flutter 是一个跨平台的 UI 工具包,目的是一份代码可以运行在不同的操作系统上,比如 Android、IOS等等,同时也可以让应用直接和底层的平台服务交互。我们的目标是:尽量用一份代码,开发者就可以在不用的平台上开发出高性能、高保真的 APP。拥抱差异,更少代码,更高性能。
在开发阶段,Flutter 运行在虚拟机上,虚拟机提供了 hot reload 的功能,可以加载每次开发者改动的差异代码,而不需要全代码的编译。在正式版本上,Flutter 应用是直接编译成了机器码:Intel x64、ARM、JavaScript等等。这里说的开发阶段和正式版本是指 Flutter 产物的模式,Flutter 的产物有三种模式 debug、release、profile。Flutter 的 framework 是开源的,开源的协议是 BSD 协议,并且有活跃繁荣的第三方库社区,这些优秀的第三方库很好的补充了 Flutter 的能力。
本文的总览分为以下几个部分:
- 分层模型: Flutter 的组成部分
- 响应式 UI : Flutter UI 开发的核心概念
- Widgets 介绍: Flutter UI 代码构建的基础
- 渲染流程: Flutter 是如何将 UI 代码转化为屏幕像素点的
- 平台嵌入 的总览: 让移动端和桌面系统运行 Flutter 应用
- 用其他代码集成 Flutter: 介绍 Flutter 可用的不同的技术信息
- Web 的支持: 总结 Flutter 在浏览器环境中的特点
框架分层
从设计上来看,Flutter 框架是可扩展的、分层的。Flutter 由一系列的单独的依赖包组成,而且这些依赖包依赖底层。上层没有权限访问下层,并且框架层的每个部分都是可插拔的。
对于底层的操作系统来说,Flutter 应用被打成的应用包和其他的 Native 应用是一样。平台特定的嵌入层提供了一个入口:协调底层操作系统来访问一些底层的服务,比如渲染桌面、可访问性、输入等,管理事件循环。这个嵌入层是被特定的平台语言开发的,Android 系统是 Java 和 C++,iOS 和 macOS 系统是 Objective-C/Objective-C++,Windows 和 Linux 系统是 C++。正是由于这一层的存在,Flutter 代码可以集成进已经存在的应用,也可以直接使用 Flutter 代码打包整个应用。Flutter 为通用的平台提供了一些嵌入器,其他的嵌入器也是存在的。
Flutter 的核心是 Flutter engine,engine 是 C++ 开发的,并且 Flutter 应用提供最
原始的支持,比如协议、通道等等。当新的一帧需要被绘制的时候,Flutter engine 就会栅格化代码合成的绘制信息。Engine 也为上层封装了访问底层的 API:图形图像化、文本布局、文件和网络 I/O、访问性支持、插件架构、Dart运行时、Dart编译工具链等等。
Flutter engine 暴漏是通过 dart:ui 这个库来暴漏给上一层的,这个库用 Dart 类包装了底层的 C++ 代码。像上面说的 engine 的功能,这个库包含了驱动输入、图形化、文本渲染系统等功能。
Typically, developers interact with Flutter through the Flutter framework, which provides a modern, reactive framework written in the Dart language. It includes a rich set of platform, layout, and foundational libraries, composed of a series of layers. Working from the bottom to the top, we have:
一般来说,开发者通过 Flutter framework 来和 Flutter 交互,这一层是 Dart 代码,提供了现代的、响应式的 Flutter 框架。这一层包括了和平台、布局、基础相关的库,并且也是分层的,自底向上以次有:
必要的基础类以及常用的底层代码块的抽象,比如动画、绘制和手势。
处理布局的rendering layer,在这一层,可以构建一棵渲染对象的节点树,你也可以动态的操作这些节点,那么布局就会自动响应你的改变。
合成抽象的 widgets layer,渲染层的每一个渲染对象在 Widget 层都会有一个 Widget 对象与之对应。另外,在这一层开发者也可以定义一些可以复用的组合类,就是这这一层引入了响应式框架。
[Material] 和 [Cupertino] 库, 提供了全套的 Material和 iOS 风格的原始组件。
Flutter 框架是相对来说比较小的,一些开发者用到的高级功能大多是以包的形式实现的,比如像 camera 和 webview 这样的平台插件,像 characters、http、animations 这样的平台无关的包,平台无关的包可以完全依赖 Dart 和 Flutter依赖。这些高级包有一些是生态共建的,比如支付、苹果证书、动画等等。
下面就从响应式 UI 编程以此向下层展开描述。主要内容有,介绍 Widget 是怎么结合到一起的,Widget 是怎么转化为渲染对象的,介绍 Flutter 是怎么集成以及互操作平台代码的,最后简要总结Flutter 的 Web支持。
响应式 UI
总体上来说,Flutter 是一个响应式的非声明式的UI 框架,这意味着开发者仅仅需要提供程序状态与程序 UI 的映射,框架会在应用状态改变的时候自动完成 UI 的刷新。这种设计的灵感得益于 Facebook 的 React 框架,React 框架对很多传统的设计原则进行了重新思考。
在大多数传统的 UI 框架中,UI 的初始化状态只被描述一次,然后为了响应各种事件会单独的更新。这种方法的一个痛点是,随着应用复杂性的增长,开发者需要时刻注意状态的改变是怎么层叠地贯穿整个 UI 的。比如,考虑下面的 UI:
上面有许多状态可以改变的地方:Color box、色带 Slider、Radio按钮等等。只要用户和 UI 交互,那么改变必须被响应到每一个地方。更麻烦的是,页面一个很小的改动,比如拖动一下色带,可能会导致一系列连锁的反应,进而影响到很多看似不相干的代码。比如色带的拖动,文本框里面也要改变。
一种解决的方案是像 MVC 这样的代码开发架构,通过 controller 将数据的改变推送到 model,然后,model 通过 controller 将新的状态 推送给 view。但是,这样的方式其实也是有瑕疵的,因为创建和更新 UI 元素是两个单独的步骤,可能会导致不同步。
沿着其他响应式框架的脚步👣,Flutter 通过 UI 与底层状态彻底的解耦来解决这个问题。在响应式的 API 开发背景下,开发者仅仅创建 UI 的描述,framework 会在运行时使用我们的描述创建或者更新界面。
在 Flutter 中,我们所说的组件是 Widget,并且 Widget 是不可变的,可以形成 Widget 树形结构。这些组件用于管理独立的布局对象树,布局树用与管理独立的合成对象树。Widget 树到布局树再到合成树。Flutter的核心就是,确保可以有效的修改树中部分节点:把上层树转化成低层级的树(Widget到布局),并且在这些树上传递改变。
在Flutter中,小部件(类似于React中的组件)由用于配置对象树的不可变类表示。这些小部件用于管理用于布局的独立对象树,然后用于管理用于合成的独立对象树。Flutter的核心是一系列机制,可以有效地在树的修改部分行走,将对象树转换为较低级的对象树,并在这些树之间传播变化。
开发者需要在 Widget 的 build() 方法中将状态转化为 UI:
UI = f(state)
在 Flutter 设计中,build() 方法执行起来会很快,并且没啥副作用,framework 会在需要调用的时候调用它。
这种响应式的框架需要一些特定的语言特征(对象快速实例化和删除),而 Dart 就很符合干这件事。
Widgets
正如前面所提,Flutter 着重强调 Widget 是合成的一个单元。Flutter 应用的 UI 就是 Widget 构建块,并且每一个 Widget 都是一份不可变的描述。
Widget 在组合的基础上形成一个体系结构。每一个 Widget 都嵌套在它的父节点里面,并且从父节点接受上下文。这种结构一直延伸到根 Widget,像下面的简单代码:
import 'package:flutter/material.dart';
void main() => runApp(const MyApp());
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('My Home Page'),
),
body: Center(
child: Builder(
builder: (BuildContext context) {
return Column(
children: [
const Text('Hello World'),
const SizedBox(height: 20),
ElevatedButton(
onPressed: () {
print('Click!');
},
child: const Text('A button'),
),
],
);
},
),
),
),
);
在这个代码中,所有的类都是 Widget。
用户交互的时候会生成事件,App会更新 UI 来响应事件。更新的方式是告诉 framework 用另一个 Widget 来替换 Widget。framework 就会比较 新的和旧的 Widget,并且有效的更新 UI。
Flutter 有其自己的实现机制来控制 UI,而不是按照系统所提供的方式:比如说,这段代码是iOS Switch control和Android control纯 Dart 的实现。
这种方式有以下几点好处:
无限的可扩展性。比如开发者想要一个 Switch 组件,那么可以用任意的方式来创建,不需要局限于操作系统所提供的
避免性能瓶颈。这种方式运行 Flutter 一次就合成整个屏幕信息,而不需要在 Flutter 代码和 平台代码之间来回切换
将应用的执行和操作系统的依赖解耦。Flutter 应用在操作系统的所有版本上运行的效果是一样的,即使操作系统改变了他自己的一些控件实现。
组合先与继承
Widget 通常由许多更小的 、用途更单一的 Widget 组成,组合起来的 Widget 往往可以产生更加有力的效果。
理想的效果,设计上概念的数量尽可能少,然而实际的总量表要尽可能大。比如说,在 Widget 层,概念只有一个,那就是 Widget,表示屏幕绘制、布局、用户交互、状态管理、主题定制、动画、路由导航等等。在动画层,只有两个概念:Animation 和 Tween。在渲染层,只有一个概念 RenderObject,用于描述布局、绘制、点击、可访问。而这些层级中,每一层都有大量的具体实现来具化概念,比如有几百个 widget 和 render对象,几十个动画和插值类型。
Flutter 有意地将类的继承体系设计的浅而宽,目的是最大化组合的数量。每一个小粒度的 可组合的Widget尽量聚焦做好自己的功能。核心的功能是抽象的,即使是像间距、对齐这样的基础功能,也被设计成具体的 Widget,而不是把这些功能添加到基础的 Widget 中。因此,假如我们想要居中一个组件,不是添加 Align 属性,而是使用 Center 组件包裹。
间距、对齐、横向排列、竖向排列,表格等等都是 Widget,布局类型的 Widget 并没有它自己本身可视的样子。但是呢,它们就是控制其他组件的布局。Flutter 也包括了一些功能性组件,这些功能组件也利用这种组合的方法。
比如,Container 是非常常用的组件,它本身是有负责布局、绘制、定位、尺寸的几个小 Widget 组成,具体来说,Container 由 LimitedBox、ConstrainedBox、Align、Padding、DecoratedBox 和 Transform 组成。Flutter 的一个很明显的特征是,我们可以深入源码,去看去检查源码。因此,我们不需要泛化一个 Container 来实现自定义的效果,我们可以把它和另外一些 Widget 进行组合,或者参考 Container 写一个新的 Widget。
构建 Widget
正如前面提到的,build() 方法返回的内容就是页面上显示的内容,返回的元素会形成一颗 Widget 树,这个树以更具体的方式来表示 UI 的一部分。比如说,toolbar Widget 的 build 方法 构建了横向的布局,包括了 文本、按钮等等。根据需要,framework 会递归的 build 每一个 Widget 直到 Widget 树可以被更具化的渲染对象完全描述下来。framework 会将渲染对象拼合成一颗渲染树。
Widget 的 build 方法应该是无副作用的。只要方法被调用了,那么不管旧的 Widget 树是什么,一颗新的 Widget 树都会被创建。framework 做了大量的工作,来决定哪一个 Widget 的 build 方法需要被执行。具体的过程可以参考Inside Flutter topic。
在每一个渲染帧,Flutter 仅仅会再次创建 UI 中需要创建的部分,这一部分就是状态变化的地方,创建的方式是执行 build 方法。所以,build 方法耗时应该非常小。一些比较重的计算应该放在异步中,将计算的结果作为状态的一部分,build 方法只是用数据。
虽然这种方式相对有点直白,但是这种自动比较的方式很高效,能够保正高性能、高保真。而且,build 方法的这种设计可以简化代码,让开发者聚焦在 Widget 的声明上,脱离状态与 UI 复杂的交互。
Widget state
框架里面有两个最主要的 Widget 类:StatefulWidget 和 StatelessWidget。
许多 Widget 都是无状态的:它们的属性不随着时间改变。这样的 Widget 是 StatelessWidget 的子类。
但是呢,如果 Widget 的某个特征需要根据用户交互或者其他因素发生改变,那么这种 Widget 是 StatefulWidget。比如说,如果一个 Widget 有一个计数器,当用户点击按钮的时候,计数器需要变化,那么计数器就是 Widget 的 State。当值改变的时候,Widget 需要被重新构建来更新部分 UI(显示数字的那部分)。这样的 Widget 就是 StatefulWidget,因为 Widget 本身是不可变的,所以把状态存储在 可变的 State 子类中。StatefulWidget 没有 build 方法,相反,它的 UI 构建放到了 State 对象中。
只要想要改变 State 对象的状态,那么就调用 setState() 方法来告诉 framework : 你应该调用我的 build 方法来更新 UI 来。
虽然 StatefulWidget 既有 State 对象又有Widget 对象,但是其他 Widget 可以像使用 StatelessWidget 一样使用 StatefulWidget,担心状态丢失等问题。父节点在需要的时候可以随时创建子组件,不需要保留前一个 state 对象,framework 做了查找和重用状态对象的所有工作。
状态管理
因此,如果保持状态的 Widget 非常的多,那么状态是怎么管理的呢?是怎么更好的在应用内传递呢?
像其他的类一样,开发者可以在 Widget 构造方法中初始化它的数据, build() 方法可以确保其用的数据已经初始化了:
@override
Widget build(BuildContext context) {
return ContentWidget(importantState);
}
随着节点树越来越深,状态的向上向下查找就变的十分糟糕了。因此,另一种类型的 Widget —— InheritedWidget 就应运而生了。这种类型的 Widget 提供了一个很容易的方式来获取祖先节点的数据。可以使用 InheritedWidget 来创建一个 StatefulWidget 祖先节点,就像下面一样:
Whenever one of the ExamWidget or ExamWidget objects needs data from StudentState, it can now access it with a command such as:
只要 ExamWidget 或者 ExamWidget 需要 StudentState 的数据,那么可以使用下面的方式:
final studentState = StudentState.of(context);
of(context) 从 context 开始向上查找,找到最近的指定类型的祖先节点。这里的类型是StudentState。InheritedWidget 也提供了一个 updateShouldNotify() 方法,这个方法决定了当状态改变的时候,是否来触发使用数据的子节点的更新重建。
Flutter 本身就广泛的使用 InheritedWidget 来共享状态,比如我们熟知的主题。MaterialApp 的 build() 方法中插入了一个 theme 节点,并为 theme 填充了数据,这样 比theme 节点更深的节点就可以通过 .of() 来找到 theme 节点,并使用数据。比如:
Container(
color: Theme.of(context).secondaryHeaderColor,
child: Text(
'Text with a background color',
style: Theme.of(context).textTheme.headline6,
),
);
Navigator 也用了这种方式,我们经常使用 Navigator 的 of 方法来 push 或者 pop 路由。MediaQuery 也用这种方式让开发者可以很快捷的获取屏幕相关信息,尺寸、方向、密度、模式等等。
随着应用的增长,更加先进高级的状态管理方案更加符合生产环境的开发,可以减少 StatefulWidget 的使用。许多 Flutter 应用使用 provider 这样的开源库。前面提到 Flutter 的分层结构可以无限扩展,flutter_hooks 这个第三方库提供了另外一种将状态转为 UI 的方式。
渲染与布局
这一节主要描述渲染管线,渲染管线包括了几个重要的步骤,将 Widget 真正的转化为实际的绘制像素。
Flutter 渲染模型
你可能会好奇:既然 Flutter 是一个跨平台的框架,它是怎么做到和单平台框架相当的性能效果呢?
我们先想一下传统的 Android app 是怎么运行的。当需要绘制的时候,开发者需要首先调用 Android 框架的 Java 代码。Android 系统提供的组件负责在 Canvas 对象中绘制,Android 使用 Skia 进行渲染。Skia 是 C/C++ 开发的图形库,会调用 CPU 或者 GPU 完成设备屏幕的绘制。
跨平台框架通常的做法是:在原生的 Android and iOS UI 层上创建一个抽象层,来尝试磨平每个平台的差异性。应用的代码一般是解释语言——JavaScript,必须和Java/Objective-C反复的交互来显示 UI。这些都增加了高额的负担,尤其是 UI 层和逻辑层有大量交互的时候。
Flutter 另辟蹊径,Flutter 最小化了这些抽象,避开系统提供的 UI,它自己有丰富的 Widget 库。绘制 Flutter 的 Dart 代码最终转为 native 代码,而这些 native 代码会使用 Skia 进行渲染。 Flutter 把 Skia 作为 引擎的一部分,这样开发者可以始终让应用保持到最新版本,而 Android 设备不需要更新。IOS等其他的设备也是相同的道理。
从用户输入到 GPU
Flutter 渲染管线的总原则是:简单就是快,Flutter 有一个简单明了的数据传输管道,沿着这个通道用户的输入流到了系统。正如下面所示:
下面我们来看更多的细节。
Build: 从 Widget 到 Element
Consider this code fragment that demonstrates a widget hierarchy:
思考一下下面的 Widget 体系代码片段:
Container(
color: Colors.blue,
child: Row(
children: [
Image.network('https://www.example.com/1.png'),
const Text('A'),
],
),
);
当 Flutter 需要渲染这个片段的时候,会调用 build 方法,返回了反应当前程序状态的 Widget 树,然后去渲染 UI。在这个过程中,build() 方法可能会构造新的 Widget。比如,前面的代码中,
Container 有 color 和 child 属性。但是在 Container 的源码中,如果 color 不是null,那么会插入一个代表颜色的 ColoredBox 组件:
if (color != null)
current = ColoredBox(color: color!, child: current);
同样地,Image 和 Text 组件也插入了 RawImage 和 RichText 组件在 build 过程中。所以最终的 Widget 树可能会比代码更深,比如:
这就解释了为啥我们在 Flutter inspector 看到的节点要远远深于我们的原始代码。
在 build 阶段,Flutter 会将 widget 树 转为 element 树,每一个 Element 都对应一个 Widget。每一个 Element 表示一个指定位置的特定 Widget 实例。有两个不同类型的 Element:
ComponentElement, 承载其他 Element 的 ElementRenderObjectElement, 参与布局和绘制阶段的 Element
RenderObjectElement 是它的 Widget 和 背后的 RenderObject 的中介,这个后面再说。
Widget 的 Element 可以通过 BuildContext 来引用到,同时 BuildContext 也表示树的位置信息。比如 Theme.of(context) 的参数就是 BuildContext,并且 BuildContext 是 build 方法的参数。
因为 Widget 是不变的,所以 Widget 树的任意改变都会导致一组新的 Widget 要被创建,即使是像 Text('A') 到 Text('B') 这样的变化。但是,Widget 的重新构建,并不意味着背后的 Element、RenderObject 也要重新构建。Element 树是持久化的在帧与帧之间,Flutter 的高性能很大一原因就是这个持久化的设计。Flutter 会缓存 Element等背后的对象,所以完全舍弃旧的Widget 也没啥问题。通过只遍历已经修改的 Widget,Flutter可以仅仅重建需要重建的 Element 树。
布局和渲染
仅仅绘制一个 Widget 的应用几乎是不存在的。因此,框架需要高效的布局 Widget 层次树,并且在渲染在屏幕上之前,也要高效的计算 Element 的尺寸,标定 Element 的位置。
渲染对象的基类是 RenderObject,这个类定义了布局和绘制的通用抽象模型,像多维、极坐标这样的需要自定义渲染模型。每个 RenderObject 知道它的父节点是谁,但是子节点的信息知道的很少,仅仅知道怎么去 visit 子节点和子节点布局约束。但是对于抽象来说这就够了,RenderObject 可以处理各种用例。
在 build 阶段,Flutter 会创建或者更新 element 树上每一个 RenderObjectElement 背后的 RenderObject 对象。
RenderObject 是原始的抽象类:RenderParagraph 渲染文本,RenderImage 渲染图像,RenderTransform 会在子节点绘制之前应用位置等信息。
大多数 Flutter Widget 背后的渲染对象是 RenderBox 的子类,RenderBox 将模型定义为盒子模型——固定大小的二维笛卡尔坐标。RenderBox 提供基本的 盒子约束,每一个 Widget 都放在由最大最小宽度、最大最小高度限制的盒子内。
为了执行布局过程,Flutter 向下👇传递约束。向上👆传递尺寸。父节点设置位置。
布局的遍历完成之后,每个对象都有了符合父节点约束的尺寸,就会调用 paint() 方法进行绘制。
盒子约束模型非常棒,布局的过程时间复杂度仅是*O(n)*的:
父节点可以将最大值和最小值设置为相同的,这样子节点的大小就是固定的了。比如说,最根部的节点就强制其子节点为屏幕大小。(子节点可以选择如何使用这一部分空间,比如,子节点可以在空间内居中摆放)
父节点可以让设置子节点的宽度,但是让高度灵活可变。或者设置高度,让宽度灵活可变。比如文本组件,文本组件的宽度是灵活可变的,高度是固定的。
除了上述描述:子节点要根据可用空间的多少来展示自己的显示也是可行的。使用 LayoutBuilder 可以达到这样的效果,子节点检查父节点传进来的约束,然后使用约束的信息来展示自己的内容,比如:
Widget build(BuildContext context) {
return LayoutBuilder(
builder: (context, constraints) {
if (constraints.maxWidth < 600) {
return const OneColumnLayout();
} else {
return const TwoColumnLayout();
}
},
);
}
布局和约束更加详细的内容可以看这一篇文章👉深入理解Flutter布局约束
所有 RenderObject 的根节点是 RenderView,它就代表一颗渲染树。当平台决定绘制新的一帧时,就会调用 RenderView 的 compositeFrame() 方法,方法内部创建了 SceneBuilder 去更新 scene。当 scene 准备完成之后,RenderView 对象会将合成的 scene 传递给
dart:ui 内的 Window.render() 方法,然后 GPU 就会渲染合成信息。
合成和光栅化阶段的更多细节可以参考 👉Flutter 渲染管线
Platform embedding
正如我们所示,Flutter 不像 React Native,把自己的组件转为 OS 的组件,让 OS 去渲染,它 是自己完成 build、布局、合成、绘制。获取纹理和 App 生命周期的机制也会因为平台的原因有所不同,比如 Android 的纹理和 IOS 的纹理在实现上就有所不同。Flutter 引擎是平台无关的,表现出来是 👉应用二进制接口,提供了一种平台嵌入器,可以安装和使用 Flutter。
平台嵌入器是一个原生系统的应用程序,承载着 Flutter 的所有的内容,并且充当了原生操作系统与 Flutter 之间的粘合剂。当我们打开 Flutter 应用的时候,嵌入器提供了一个入口:初始化 Flutter 引擎,获得 UI 线程和 光栅,创建 Flutter 纹理。嵌入器也负责:应用的生命周期、手势输入、窗口尺寸、线程管理和平台消息。Flutter 包含了 Android、iOS、Windows、macOS、Linux。开发者也可以自定义平台嵌入器,有两个比较不错的案例 👉 案例1 和 👉 案例2——Raspberry Pi。
每一个平台尤其本身的API和约束。一些简明的平台原则如下:
在 iOS 和 macOS,Flutter 是作为
UIViewController或者NSViewController而被加载进嵌入器的。平台嵌入器创建了FlutterEngine,而引擎可以当作 Dart VM 和 Flutter 运行时的宿主。FlutterViewController和FlutterEngine相绑定,将 UIKit 或者 Cocoa 输入事件传递给 Flutter,并且使用 Metal 或者 OpenGL 来渲染帧。
在 Android 上,Flutter 默认加载到
Activity中,视图就是FlutterView,FlutterView可以渲染 Flutter 的内容(ui 或者 纹理,取决于合成信息和 z 轴顺序),
在 Windows 上,Flutter 被装载在传统的 Win32 应用中。Flutter 内容使用 ANGLE 渲染,
这个库可以将 OpenGL API 转为与之等价的 DirectX 11。目前正在做的事情是,提供一个使用 UWP 应用模型的 Windows 嵌入器,以及使用更加高效直接的方式将 DirectX 12 到 GPU,替换现有的 ANGLE。
集成其他代码
Flutter 提供了一些互操作的机制,访问 Kotlin 或者 Swift 编写的代码,调用 基于 C 的本地 API,在 Flutter 中嵌入原生组件,在既有应用中嵌入 Flutter。
Platform channels
对于移动端和桌面 App,通过 platform channel 机制,Flutter 可以让开发者调用自定义代码。platform channel 是 Dart 代码和 App 宿主平台代码通信的机制。通过创建一个通用的 channel (指定名字和编解码器),开发者能够在 Dart 和平台之间发送和接受消息。数据会被序列化,比如 Dart 的 Map 就是 Kotlin 中的 HashMap,Swift 的 Dictionary。
下面是简单的事件处理器的代码,Android 是 Kotlin,iOS 是 Swift,Dart 调用原生的方法,并获取数据:
// Dart side
const channel = MethodChannel('foo');
final String greeting = await channel.invokeMethod('bar', 'world');
print(greeting);
// Android (Kotlin)
val channel = MethodChannel(flutterView, "foo")
channel.setMethodCallHandler { call, result ->
when (call.method) {
"bar" -> result.success("Hello, ${call.arguments}")
else -> result.notImplemented()
}
}
// iOS (Swift)
let channel = FlutterMethodChannel(name: "foo", binaryMessenger: flutterView)
channel.setMethodCallHandler {
(call: FlutterMethodCall, result: FlutterResult) -> Void in
switch (call.method) {
case "bar": result("Hello, (call.arguments as! String)")
default: result(FlutterMethodNotImplemented)
}
}
像这样的 channel 代码,可以在 flutter/plugins 仓库中找到,里面也有响应的 macOS 的实现。一些通用的场景大概有几千个可用插件,从广告到相机、蓝牙这样的硬件设备。
外部方法接口
对于 C基础的 API(包含 Rust、Go 生产的代码),Dart 也提供了直接的调用机制,可以使用 dart:ffi 依赖库来绑定 native 代码。Foreign function interface (FFI) 模型 没有数据数据序列化过程,所以它比上面的 channel 更快。Dart 运行时提供了在堆内存上分配内存的能力,堆上的内存是 Dart 对象内存,并且可以调用静态和动态的链接库。FFI 可用在除 web 之外的所有平台上,因为 js package 提供了相同的能力。
要使用 FFI 的话,可以创建一个 typedef 为每一个 Dart 的非管理的方法签名,并且指定 Dart VM 做了映射。下面是一个案例,调用 Win32 MessageBox() 的 API:
typedef MessageBoxNative = Int32 Function(
IntPtr hWnd,
Pointer lpText,
Pointer lpCaption,
Int32 uType,
);
typedef MessageBoxDart = int Function(
int hWnd,
Pointer lpText,
Pointer lpCaption,
int uType,
);
void exampleFfi() {
final user32 = DynamicLibrary.open('user32.dll');
final messageBox =
user32.lookupFunction('MessageBoxW');
final result = messageBox(
0, // No owner window
'Test message'.toNativeUtf16(), // Message
'Window caption'.toNativeUtf16(), // Window title
0, // OK button only
);
}
在 Flutter 应用中渲染原生组件
因为 Flutter 内容是被绘制在纹理上的,并且 组件树完全是内部的。像 Android view 存在在 Flutter 内部模型中,或者在 Flutter 组件交错渲染,这些情况我们咩有看到。如果不能支持的话,是有问题的,比如一些原生组件不能用的话,就很麻烦。比如 WebView。
Flutter 解决这种问题是通过平台视图 Widget 的方式(AndroidView 和 UiKitView)。这些组件可以嵌入平台原生组件。Platform Widget 可以和其他的 Flutter 内容一起集成,并且充当着与底层操作系统的中介。比如,在Android上,AndroidView 有三个主要的功能:
复制原生视图的图形纹理,并把纹理作为 Flutter 合成渲染的一部分,所以在每一帧的时候都会进行这样的合成绘制。
响应手势,并且把手势转为等价于 Native 的输入。
创建一个可访问性树的模拟,并且在原生和 Flutter 层之间传递和响应命令
显而易见的,每帧的合成都是相当耗时的,像音视频也非常耗内存。所以,这种方法一般会在复杂交互的时候采用,比如 Google Maps 这样的,Flutter 不太具有生产实践意义的。
通常,一个 Flutter 应用也是在 build() 方法中实例化这些组件,比如,google_maps_flutter创建了地图插件:
if (defaultTargetPlatform == TargetPlatform.android) {
return AndroidView(
viewType: 'plugins.flutter.io/google_maps',
onPlatformViewCreated: onPlatformViewCreated,
gestureRecognizers: gestureRecognizers,
creationParams: creationParams,
creationParamsCodec: const StandardMessageCodec(),
);
} else if (defaultTargetPlatform == TargetPlatform.iOS) {
return UiKitView(
viewType: 'plugins.flutter.io/google_maps',
onPlatformViewCreated: onPlatformViewCreated,
gestureRecognizers: gestureRecognizers,
creationParams: creationParams,
creationParamsCodec: const StandardMessageCodec(),
);
}
return Text(
'$defaultTargetPlatform is not yet supported by the maps plugin');
AndroidView 或者 UiKitView 使用的我们前面提到的 platform channel 机制来和 原生代码交互。
目前,Platform Widget 在桌面平台上是不可用的,但是这不是架构上的限制,后面可能会添加。
宿主 App 接入 Flutter
和前面Flutter 嵌入 native 相反,这一节介绍 既有应用中嵌入 Flutter。前面我们提到了 Flutter 是被 Android 的 Activity,iOS 的 UIViewController 承载的,Flutter 的内容可以用相同的方式被嵌入。
Flutter module 模版很容易被嵌入,开发者可以使用 Gradle 或者 Xcode 进行源码依赖,也可以产物依赖。产物依赖的方式的好处就是项目组的成员不需要每个人都安装 Flutter 环境。
Flutter 引擎需要一点的时间初始化,因为需要加载 Flutter 依赖库,初始化 Dart 运行时,创建和运行 Dart 线程,绑定渲染 surface 到 UI。为了最小化上面提到的时间,减少呈现 Flutter UI 的延迟,最好的处理方式是在程序初始化的时候,初始化 Flutter 引擎,至少在第一个 第一个Flutter屏幕之前,这样用户不就会在显示 Flutter 第一个页面的时候,出现短暂的白屏或者黑屏。
关于接入的更多信息,可以在 👉Load sequence, performance and memory topic找到。
Flutter web support
一些通用的框架概念适用于 Flutter 支持的所有平台,但是呢,Flutter’s web 有一些值得讨论的独特的点。
自JavaScript语言存在以来,Dart就一直在编译JavaScript,并为开发和生产目的优化了工具链。许多重要的应用程序从Dart编译到JavaScript,并在今天的生产中运行,包括谷歌Ads的广告商工具。因为Flutter框架是用Dart编写的,所以将它编译成JavaScript相对简单。
从 Dart 语言面世以来,Dart 就一直在支持编译成 JavaScript,并且持续的为开发和生产优化工具链。许多重要的程序从 Dart 编译成 JavaScript,并在今天一直在运行,比如 👉advertiser tooling for Google Ads。因为 Flutter 框架是 Dart 开发的,把 Dart 编译成 JavaScript 相对来说是简单直接的。
However, the Flutter engine, written in C++, is designed to interface with the underlying operating system rather than a web browser. A different approach is therefore required. On the web, Flutter provides a reimplementation of the engine on top of standard browser APIs. We currently have two options for rendering Flutter content on the web: HTML and WebGL. In HTML mode, Flutter uses HTML, CSS, Canvas, and SVG. To render to WebGL, Flutter uses a version of Skia compiled to WebAssembly called CanvasKit. While HTML mode offers the best code size characteristics, CanvasKit provides the fastest path to the browser’s graphics stack, and offers somewhat higher graphical fidelity with the native mobile targets5.
然而,C++ 开发的 Flutter 引擎是操作系统底层的接口,而不是浏览器。因此,需要采取一个不同的方法。在 web 上,Flutter 在标准浏览器 API 之上 提供了重新实现。目前,在 Web 上渲染 Flutter 有两个方案:HTML 和 WebGL。HTML 模式下,Flutter 使用 HTML、 CSS、
Canvas 和 SVG。WebGL 模式下,Flutter 使用 CanvasKit 编译成 WebAssembly。
HTML 模式的包体积会很小,而 CanvasKit 的渲染会更快、渲染效果更佳高保真。
Web 版本的架构图是下面的:
和其他 Flutter 平台相比,最显著的区别是:不需要提供一个 Dart 的运行时。相反,Flutter 的framework 被编译成了 JavaScript。在 Dart 的众多模式中,比如 JIT、AOT、native、web,语言语义上的差别很小,开发者也不会在开发的过程中体验到差异。
在开发期间,Flutter web 使用 dartdevc,它支持增量编译,这就可以 hot restart 了。相反,如果想要创建一个线上正式版本的 web,就会使用 dart2js 编译器,这是一款高性能的 JavaScript 编译器,会将 Flutter 核心和框架与应用程序打包为可部署到任何 web 服务器的小型源文件。deferred imports 可以将代码封装为一个文件,或者分割为多个文件。
展望
如果想要更加深入了解 Flutter 内部的机制,那么可以看 Inside Flutter 文章。
作者:Time_sun
链接:https://juejin.cn/post/7054817076073988127
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
业务开发时,接口不能对外暴露怎么办?
0 - 前言
在业务开发的时候,经常会遇到某一个接口不能对外暴露,只能内网服务间调用的实际需求。面对这样的情况,我们该如何实现呢?今天,我们就来理一理这个问题,从几个可行的方案中,挑选一个来实现。
1 - 可行方案
目前,想到的方案有三种:内外网接口通过微服务隔离、redis配合网关实现接口白名单机制、网关加AOP在业务侧判断访问权限。
1.1 方案一 内外网接口微服务隔离
将对外暴露的接口和对内暴露的接口分别放到两个微服务上,一个服务里所有的接口均对外暴露,另一个服务的接口只能内网服务间调用。
该方案需要额外编写一个只对内部暴露接口的微服务,将所有只能对内暴露的业务接口聚合到这个微服务里,通过这个聚合的微服务,分别去各个业务侧获取资源。
该方案,新增一个微服务做请求转发,增加了系统的复杂性,增大了调用耗时以及后期的维护成本。
1.2 方案二 网关 + redis 实现白名单机制
在 redis 里维护一套接口白名单列表,外部请求到达网关时,从 redis 获取接口白名单,在白名单内的接口放行,反之拒绝掉。
该方案的好处是,对业务代码零侵入,只需要维护好白名单列表即可;
不足之处在于,白名单的维护是一个持续性投入的工作,在很多公司,业务开发无法直接触及到 redis,只能提工单申请,增加了开发成本;另外,每次请求进来,都需要判断白名单,增加了系统响应耗时,考虑到正常情况下外部进来的请求大部分都是在白名单内的,只有极少数恶意请求才会被白名单机制所拦截,所以该方案的性价比很低。
1.3 方案三 网关 + AOP
相比于方案二对接口进行白名单判断而言,方案三是对请求来源进行判断,并将该判断下沉到业务侧。避免了网关侧的逻辑判断,从而提升系统响应速度。
我们知道,外部进来的请求一定会经过网关再被分发到具体的业务侧,内部服务间的调用是不用走外部网关的(走 k8s 的 service)。根据这个特点,我们可以对所有经过网关的请求的header里添加一个字段,业务侧接口收到请求后,判断header里是否有该字段,如果有,则说明该请求来自外部,没有,则属于内部服务的调用,再根据该接口是否属于内部接口来决定是否放行该请求。
该方案将内外网访问权限的处理分布到各个业务侧进行,消除了由网关来处理的系统性瓶颈;同时,开发者可以在业务侧直接确定接口的内外网访问权限,提升开发效率的同时,增加了代码的可读性。
当然该方案会对业务代码有一定的侵入性,不过可以通过注解的形式,最大限度的降低这种侵入性。
2 - 具体实操
下面就方案三,进行具体的代码演示。
首先在网关侧,需要对进来的请求header添加外网标识符: from=public
@Component
public class AuthFilter implements GlobalFilter, Ordered {
@Override
public Mono < Void > filter ( ServerWebExchange exchange, GatewayFilterChain chain ) {
return chain.filter(
exchange.mutate().request(
exchange.getRequest().mutate().header("id", "").header("from", "public").build())
.build()
);
}
@Override
public int getOrder () {
return 0;
}
}
接着,编写内外网访问权限判断的AOP和注解
@Aspect
@Component
@Slf4j
public class OnlyIntranetAccessAspect {
@Pointcut ( "@within(org.openmmlab.platform.common.annotation.OnlyIntranetAccess)" )
public void onlyIntranetAccessOnClass () {}
@Pointcut ( "@annotation(org.openmmlab.platform.common.annotation.OnlyIntranetAccess)" )
public void onlyIntranetAccessOnMethed () {
}
@Before ( value = "onlyIntranetAccessOnMethed() || onlyIntranetAccessOnClass()" )
public void before () {
HttpServletRequest hsr = (( ServletRequestAttributes ) RequestContextHolder.getRequestAttributes()) .getRequest ();
String from = hsr.getHeader ( "from" );
if ( !StringUtils.isEmpty( from ) && "public".equals ( from )) {
log.error ( "This api is only allowed invoked by intranet source" );
throw new MMException ( ReturnEnum.C_NETWORK_INTERNET_ACCESS_NOT_ALLOWED_ERROR);
}
}
}
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface OnlyIntranetAccess {
}
最后,在只能内网访问的接口上加上@OnlyIntranetAccess注解即可
@GetMapping ( "/role/add" )
@OnlyIntranetAccess
public String onlyIntranetAccess() {
return "该接口只允许内部服务调用";
}
以上。
作者:arkMon
链接:https://juejin.cn/post/7055862842540425223
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
为什么ConcurrentHashMap是线程安全的?
ConcurrentHashMap 是 HashMap 的多线程版本,HashMap 在并发操作时会有各种问题,比如死循环问题、数据覆盖等问题。而这些问题,只要使用 ConcurrentHashMap 就可以完美解决了,那问题来了,ConcurrentHashMap 是如何保证线程安全的?它的底层又是如何实现的?接下来我们一起来看。
JDK 1.7 底层实现
ConcurrentHashMap 在不同的 JDK 版本中实现是不同的,在 JDK 1.7 中它使用的是数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。 大数组 Segment 可以理解为 MySQL 中的数据库,而每个数据库(Segment)中又有很多张表 HashEntry,每个 HashEntry 中又有多条数据,这些数据是用链表连接的,如下图所示:
JDK 1.7 线程安全实现
了解了 ConcurrentHashMap 的底层实现,再看它的线程安全实现就比较简单了。
接下来,我们通过添加元素 put 方法,来看 JDK 1.7 中 ConcurrentHashMap 是如何保证线程安全的,具体实现源码如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 Segment 写入前,先确保获取到锁
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// Segment 内部数组
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有值...
}
else {
// 放置 HashEntry 到特定位置,如果超过阈值则进行 rehash
// 忽略其他代码...
}
}
} finally {
// 释放锁
unlock();
}
return oldValue;
}
复制代码从上述源码我们可以看出,Segment 本身是基于 ReentrantLock 实现的加锁和释放锁的操作,这样就能保证多个线程同时访问 ConcurrentHashMap 时,同一时间只有一个线程能操作相应的节点,这样就保证了 ConcurrentHashMap 的线程安全了。
也就是说 ConcurrentHashMap 的线程安全是建立在 Segment 加锁的基础上的,所以我们把它称之为分段锁或片段锁,如下图所示:
JDK 1.8 底层实现
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的,因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下:
链表升级为红黑树的规则:当链表长度大于 8,并且数组的长度大于 64 时,链表就会升级为红黑树的结构。
PS:ConcurrentHashMap 在 JDK 1.8 虽然保留了 Segment 的定义,但这仅仅是为了保证序列化时的兼容性,不再有任何结构上的用处了。
JDK 1.8 线程安全实现
在 JDK 1.8 中 ConcurrentHashMap 使用的是 CAS + volatile 或 synchronized 的方式来保证线程安全的,它的核心实现源码如下:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 节点为空
// 利用 CAS 去进行无锁线程安全操作,如果 bin 是空的
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
}
}
// 如果超过阈值,升级为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
从上述源码可以看出,在 JDK 1.8 中,添加元素时首先会判断容器是否为空,如果为空则使用 volatile 加 CAS 来初始化。如果容器不为空则根据存储的元素计算该位置是否为空,如果为空则利用 CAS 设置该节点;如果不为空则使用 synchronize 加锁,遍历桶中的数据,替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
我们把上述流程简化一下,我们可以简单的认为在 JDK 1.8 中,ConcurrentHashMap 是在头节点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度,具体加锁示意图如下:
总结
ConcurrentHashMap 在 JDK 1.7 时使用的是数据加链表的形式实现的,其中数组分为两类:大数组 Segment 和小数组 HashEntry,而加锁是通过给 Segment 添加 ReentrantLock 锁来实现线程安全的。而 JDK 1.8 中 ConcurrentHashMap 使用的是数组+链表/红黑树的方式实现的,它是通过 CAS 或 synchronized 来实现线程安全的,并且它的锁粒度更小,查询性能也更高。
作者:Java中文社群
链接:https://juejin.cn/post/7056572041511567367
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

687亿美元 微软史上最大一笔收购是为了元宇宙?
微软公司1月18日发布声明称,微软将以每股95美元的价格全现金收购动视暴雪,包括动视暴雪的净现金在内,交易价值687亿美元。

据有关美媒报道,这将是微软公司史上最大规模的一笔收购。
微软表示,交易完成后,微软将成为世界上收入第三高的游戏公司,仅次于腾讯和索尼。计划中的收购包括动视暴雪和子公司King的知名作品,如《魔兽系列》、《暗黑破坏神》、《守望先锋》、《使命召唤》和 《糖果粉碎传奇》等。
声明还指出,Bobby Kotick将继续担任动视暴雪CEO,交易完成后,动视暴雪业务将向微软游戏部CEO Phil Spencer汇报。
动视暴雪是全球最大的游戏开发商和发行商,于2008年由美国视频游戏发行商动视公司合并维旺迪游戏后更名而来。
有分析称,微软此举或是为元宇宙布局。此次微软的元宇宙平台分别为Mesh for Teams 和Dynamics 365 Connected Spaces,意在将办公软件功能发挥到极致,立足于各领域生产、办公的需求,将沉浸式办公落到实际应用。而在加码游戏之后,微软的元宇宙平台将如虎添翼。
HiCare数字健康管理系统

“HiCare数字健康管理系统”是面向智慧社区、智慧家庭提供的集:健康数据采集、管理及运营于一体的综合健康管理系统,包含:HiCare数字健康管理平台 + HiCare健康主机 + 健康检测设备组成;
从最基础的健康数据采集入手,融合智能终端+云平台+APP+大数据分析+顾问咨询,可提供持续的健康监测和健康管理服务。
作者:万物智能视界
来源:https://mp.weixin.qq.com/s/xeQF_SH-HRUQ9crqh9k76Q
对雪花算法的初识到热恋
分库分表常见主键id生产策略讲解
引入什么技术都是会存在一定的风险,分库分表也不会是例外。在不同的数据节点生成一个唯一主键是一个难题,一张逻辑表x_order会被拆分成多个真实表x_order_n,然后这些表又被分散到不同的库中db_0、db1、db2各个表自增键由于没有办法相互的感应会产生重复的主键,这就没有办法满足分库分表对主键的全局唯一的要求了。
尽管可以使用分片表的自增主键初始值和步长来解决,但是这样会导致运维成本提高,可扩展性差,这种方式不太可取。
业界常用ID解决方案
UUID: 性能非常高,没有网络消耗。缺点就是无序的字符串,不具备有趋势自增的特性,UUID太长也不便于存储,浪费存储空间,所以很多的场景是不使用的
Redsi发号器: 利用Redis的INCR和INCRBY来实现,原子操作,线程安全,性能比Mysql强劲。缺点就是需要占用网络资源,增加系统复杂度。
Snowflake雪花算法: 它是twitter开源式的分布式ID生成算法,代码实现简单,而且不占用宽带,数据的迁移不会受到影响,生成的id里包含有时间戳,所以生成的id按照时间进行递增,部署多台服务器的话,需要保证系统时间是一样的。缺点就是依赖系统时钟。
UUID
进入UUID的主键生成实现类,发现它只有一个规则,那就是UUID.randomUUID(),可以看出是多么的牛啊。UUID虽然可以做到全局的唯一性,但还是不推荐作为主键,因为我们知道,在实际业务中主键一般为整型,而UUID是生成32位的字符串。它对MYSQL的性能消耗会比较大,而且MYSQL也建议主键要尽量的短,UUID主键的无序性还会导致数据位置的频繁变动,严重的影响了性能。
public final class UUIDShardingKeyGenerator implements ShardingKeyGenerator {
private Properties properties = new Properties();
public UUIDShardingKeyGenerator() {
}
public String getType() {
return "UUID";
}
public synchronized Comparable<?> generateKey() {
return UUID.randomUUID().toString().replaceAll("-", "");
}
public Properties getProperties() {
return this.properties;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
}
Snowflake(雪花算法)
雪花算法是默认使用主键生成方案,生成一个64bit的长整型数据。sharding-jdbc中雪花算法生成的主键主要是由四个部分组成,1bit符号位、41bit时间戳位、10bit机器id,12bit序列号。
符号位(1bit)
在Java当中,Long型最高的位是符号位,也就是正数是0,负数是1,一般id生成都为正数,所以的话默认是0。
时间戳位(41bit)
41位的时间戳占41个bit,毫秒数是2的41次幂,而一年的总毫秒数就为1000L * 60 * 60 * 24 * 365,为服务上线的时间毫秒级时间戳(当前时间-服务第一次上线的时间)。
工作机器id(10bit)
表示一个唯一的工作进程,它的默认值是0,可以通过key-generator.props.worker.id来进行设置
序列号位(12bit)
可以允许同一毫秒生成2^12=4096个id,理论上一秒就可以生成400万个id。
时钟回拨
了解了雪花算法主键的组成后可以发现,这是一种严重的依赖服务器的时间算法,这时候依赖服务器时间就会遇到一个棘手的问题就是-时钟回拨。
为啥会出现时钟回拨这种现象
据我们所知,在互联网中有一种网络的时间协议叫ntp,专门是用来进行同步或者是用来校准网络计算机的时间。这就是手机现在不用手动校对时间的原因。
当硬件因为某一些原因导致时间快或者是慢了,这个时候就需要使用ntp服务来对时间进行校准,在做校准的时候就有可能发生服务器时钟的跳跃或者是回拨这些问题。
雪花算法怎么样解决时钟回拨问题
上面提到服务器时钟回拨问题可能会导致重复的id产生,所以在SNOWFLAKE方案对雪花算法进行了改进,添加了一个最大的容忍时钟回拨毫秒数。
当时钟回拨的时间超过最大容忍毫秒数的阀值的话,就直接程序报错。如果在可以容忍的范围内的话,就默认使用了分布式的主键生成器,等待时钟同步到最后一次生成主键时间后才继续开始工作。
最大容忍的时钟回拨毫秒数默认是0,max.tolerate.time.difference.milliseconds来设置。
public final class SnowflakeShardingKeyGenerator implements ShardingKeyGenerator{
@Getter
@Setter
private Properties properties = new Properties();
public String getType() {
return "SNOWFLAKE";
}
public synchronized Comparable<?> generateKey() {
/**
* 当前系统时间毫秒数
*/
long currentMilliseconds = timeService.getCurrentMillis();
/**
* 判断是否需要等待容忍时间差,如果需要,则等待时间差过去,然后再获取当前系统时间
*/
if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
/**
* 如果最后一次毫秒与 当前系统时间毫秒相同,即还在同一毫秒内
*/
if (lastMilliseconds == currentMilliseconds) {
/**
* &位与运算符:两个数都转为二进制,如果相对应位都是1,则结果为1,否则为0
* 当序列为4095时,4095+1后的新序列与掩码进行位与运算结果是0
* 当序列为其他值时,位与运算结果都不会是0
* 即本毫秒的序列已经用到最大值4096,此时要取下一个毫秒时间值
*/
if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {
currentMilliseconds = waitUntilNextTime(currentMilliseconds);
}
} else {
/**
* 上一毫秒已经过去,把序列值重置为1
*/
vibrateSequenceOffset();
sequence = sequenceOffset;
}
lastMilliseconds = currentMilliseconds;
/**
* XX......XX XX000000 00000000 00000000 时间差 XX
* XXXXXX XXXX0000 00000000 机器ID XX
* XXXX XXXXXXXX 序列号 XX
* 三部分进行|位或运算:如果相对应位都是0,则结果为0,否则为1
*/
return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence;
}
/**
* 判断是否需要等待容忍时间差
*/
@SneakyThrows
private boolean waitTolerateTimeDifferenceIfNeed(final long currentMilliseconds) {
/**
* 如果获取ID时的最后一次时间毫秒数小于等于当前系统时间毫秒数,属于正常情况,则不需要等待
*/
if (lastMilliseconds <= currentMilliseconds) {
return false;
}
/**
* ===>时钟回拨的情况(生成序列的时间大于当前系统的时间),需要等待时间差
*/
/**
* 获取ID时的最后一次毫秒数减去当前系统时间毫秒数的时间差
*/
long timeDifferenceMilliseconds = lastMilliseconds - currentMilliseconds;
/**
* 时间差小于最大容忍时间差,即当前还在时钟回拨的时间差之内
*/
Preconditions.checkState(timeDifferenceMilliseconds < getMaxTolerateTimeDifferenceMilliseconds(),
"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastMilliseconds, currentMilliseconds);
/**
* 线程休眠时间差
*/
Thread.sleep(timeDifferenceMilliseconds);
return true;
}
// 配置的机器ID
private long getWorkerId() {
long result = Long.valueOf(properties.getProperty("worker.id", String.valueOf(WORKER_ID)));
Preconditions.checkArgument(result >= 0L && result < WORKER_ID_MAX_VALUE);
return result;
}
private int getMaxTolerateTimeDifferenceMilliseconds() {
return Integer.valueOf(properties.getProperty("max.tolerate.time.difference.milliseconds", String.valueOf(MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS)));
}
private long waitUntilNextTime(final long lastTime) {
long result = timeService.getCurrentMillis();
while (result <= lastTime) {
result = timeService.getCurrentMillis();
}
return result;
}
}
可以看出最后的主键生成时间(lastMilliseconds)与当前(currentMilliseconds)做比较,如果生成的时间大于当前时间的话,这就说明了时钟回调了。那么这时会接着判断两个时间的差,看下是否在设置在最大的容忍时间范围内,在范围内就睡眠差值的时间,大于差值那就直接报异常。
百度UidGenerator
UidGenerator算法是对雪花算法的改进版。UidGenerator组成是由:sign(1bit)+delta seconds(28bits)+worker node id(22bits)+sequence(13bits)。
UidGenerator可以保证指定的机器同一时间某一并发序列是唯一的,并由此生成一个64bits的唯一id。
UidGenerator跟雪花算法不一样,它可以自定义时间戳,工作机器id与序列号各部位的位数,用于不同的场景。
1.sign:固定的符号标识,生成的UID为正数。
2.delta seconds:当前的时间
3.worker id:机器id,内置实现是在启动的时候由数据库分配,默认分配策略为:用后就弃掉。
4.sequence:每秒下的并发序列,13bits可以支持每一秒8192个并发。
UidGenerator两种方式
DefaultUidGenerator: 通过DefaultUidGenerator来实现的,对于时钟回拨问题比较的简单,根据业务情况来调整字段占用的位数。
CachedUidGenerator: CachedUidGenerator是在DefaultUidGenerator进行改进的,利用了RingBuffer,它的本质是一个数组,数组里的每一个项都叫slot。而CachedUidGenerator是设计两个RingBuffer,一个是用于保存唯一id,一个保存flag。
CachedUidGenerator主要是通过以下的集中方式规避了时钟的问题和增强了唯一性
1、自增列:在每一次重启的时候workerid都会初始化,且它就是数据库自增的id,这样完美的实现每一个实例获取到的workerid都不一样,不会造成冲突
2、RingBuffer:不需要在每次取得ID都要计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID来保存
3、时间递增:像雪花算法都是通过currentTimeMillis来获取时间,并比较,这样的话是很依赖服务器的时间,但是CachedUidGenerator的时间类型是AtomicLong,通过incrementAndGet方法来获取下一次的时间,这样就避免了对服务器时间的依赖,也就是时钟回拨的问题可以得到解决。
CachedUidGenerator通过缓存的这种方式来预先生成唯一ID列表,这种可以解决唯一ID所消耗的时间,但是也有不好的点就是,需要耗费内存来缓存这一部分ID的数据,如果访问量不是很大的情况下,提前生成的UID的时间戳可能是很早以前的。
作者:零零后程序员小三
链接:https://juejin.cn/post/7056214824010645535
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
flutter架构:Repository设计模式
在软件开发中,我们可以使用设计模式有效的解决我们软件设计中的常见问题。而在app的架构中,structural设计模式可以帮助我们很好的划分应用结构。
在本文,我们将使用Repository设计模式,访问各种来源的数据,如后端的API,蓝牙等等。并将这些数据转化成类型安全的实体类提供给上层(领域层),即我们业务逻辑所在的位置。
本文中我们将详细讲解Repository设计模式,包含以下部分:
- Repository设计模式是什么以及何时使用它
- 使用具体和抽象类的实现以及如何权衡使用
- 如何使用Repository设计模式单元测试
1.什么是Repository设计模式
为了帮助我们理解,我们先看看下面的app架构设计图:
在这张图中,repositories位于 数据层(data layer),它的作用是:
- 将领域模型(或实体)与数据源(data sources)的实现细节隔离开来。
- 将数据源的数据对象转换为领域层(domain layer)中使用的实体或模型
- (可选)执行数据缓存等操作。
上图仅展示了构建APP的其中一种架构模式。如果使用其他的架构模式,例如 MVC、MVVM 或 Clean Architecture,虽然看起来不一样,但repository设计模式的应用都一样。
还要注意在**表示层(UI或Presentation)**中,widget是需要与业务逻辑或网络等是无关的。
如果在Widget中直接使用来自REST API 或远程数据库的key-value,这样做是有很大风险的。换句话说:不要将业务逻辑与您的 UI 代码混合,这会使你的代码更难测试、调试和推理。
2.什么时候使用Repository设计模式
如果你的APP有一个复杂的数据层,包含许多不同的数据来源,并且这些来源返回非结构化数据(例如 JSON),这样需要将其与其他部分隔离,这时候使用Repository设计模式非常方便。
如果说更具体的话,下面这些场景我认为Repository设计模式更合适:
- 与 REST API 交互
- 与本地或远程数据库(例如 Sembast、Hive、Firestore 等)交互
- 与设备的 API(例如权限、摄像头、位置等)交互
这样做的最大的好处是,如果任何第三方API 发生重大更改,我们只需要更新Repository的代码。
仅仅这一点就我就觉得使Repository模式 是100% 值得我们在实际中使用的。💯
下面我们就看看如何使用吧!🚀
3.Repository设计模式在实际中的使用
我们以OpenWeatherMap(https://openweathermap.org/api)提供的天气查询API为例,做一个简单的天气查询APP。
我们先看看API 文档(openweathermap.org/current),先了解需要如何调用 API,以及响应数据的JSON 格式。
我们通过Repository设计模式能非常快速的抽象出所有网络相关和 JSON 序列化代码。下面,我们就来具体实现吧。
首先,我们为repository定义一个抽象类:
abstract class WeatherRepository {
Future<Weather> getWeather({required String city});
}
复制代码我们的WeatherRepository现在只添加了一个方法,但是在实际应用中我们可能会有很多个,根据需求决定。
接下来,我们还需要一个具体的实现类,来实现API调用以及数据出局等:
import 'package:http/http.dart' as http;
class HttpWeatherRepository implements WeatherRepository {
HttpWeatherRepository({required this.api, required this.client});
// custom class defining all the API details
final OpenWeatherMapAPI api;
// client for making calls to the API
final http.Client client;
// implements the method in the abstract class
Future<Weather> getWeather({required String city}) {
// TODO: send request, parse response, return Weather object or throw error
}
}
这些具体的细节在data layer实现,其他层就不需要关心数据是如何来的。
3.1数据解析
我们需要定义一个具体的model(或者entity),用来接收和解析api返回的json数据。
class Weather {
// TODO: declare all the properties we need
factory Weather.fromJson(Map<String, dynamic> json) {
// TODO: parse JSON and return validated Weather object
}
}
api返回的字段可能很多,我们这里只需要解析我们使用到的字段。
json解析有很多方法,ide(vscode、android studio)提供了很多插件,帮助我们快速的实现fromJson,感兴趣的同学可以自己去找找。
3.2 初始化repository
repository定义后,我们需要在一个合适的时机进行初始化,以便app其他层能够访问。
如何进行repository的初始化,我们需要根据我们选择的状态管理工具来决定。
例如,我们使用get_it(pub.dev/packages/ge…)来进行管理:
import 'package:get_it/get_it.dart';
GetIt.instance.registerLazySingleton<WeatherRepository>(
() => HttpWeatherRepository(api: OpenWeatherMapAPI(), client: http.Client(),
);
或者也可使用Riverpod
import 'package:flutter_riverpod/flutter_riverpod.dart';
final weatherRepositoryProvider = Provider<WeatherRepository>((ref) {
return HttpWeatherRepository(api: OpenWeatherMapAPI(), client: http.Client());
});
或者是使用bloc:
import 'package:flutter_bloc/flutter_bloc.dart';
RepositoryProvider<WeatherRepository>(
create: (_) => HttpWeatherRepository(api: OpenWeatherMapAPI(), client: http.Client()),
child: MyApp(),
))
不管使用哪种方式,我们的目的是repository初始化一次全局都可以使用。
4.抽象还是具体?
当创建一个repository的时候,我们也许会有疑惑,我们需要创建一个抽象类吗?还是只需要一个具体类?如果添加的方法越来越多,可能会觉得工作越来越多,如下:
abstract class WeatherRepository {
Future<Weather> getWeather({required String city});
Future<Forecast> getHourlyForecast({required String city});
Future<Forecast> getDailyForecast({required String city});
// and so on
}
class HttpWeatherRepository implements WeatherRepository {
HttpWeatherRepository({required this.api, required this.client});
// custom class defining all the API details
final OpenWeatherMapAPI api;
// client for making calls to the API
final http.Client client;
Future<Weather> getWeather({required String city}) { ... }
Future<Forecast> getHourlyForecast({required String city}) { ... }
Future<Forecast> getDailyForecast({required String city}) { ... }
// and so on
}
到底需不需要,答案就像软件设计中的给出的一样:视情况而定。那么,我们就来分析下两种方法的优缺点。
4.1 使用抽象类
- 优点:提供了统一的接口,不关心具体实现,使用时比较统一。
- 优点 : 完全可以使用不同的实现 ****,替换时只需要更改初始化时的一行代码。
- 缺点**:**当我们在IDE点击“跳转到引用”时只能到抽象类中的方法定义而不是具体类中的实现。
- 缺点:会写更多代码。
4.2只有具体类
- 优点:更少的代码。
- 优点:IDE中点击“跳转到引用”能跳转到正确的方法。
- 缺点:如果我们repository名字,需要多处修改。
但是呢,具体如何选择,我们还有一个重要的参考标准,就是我们需要为它添加单元测试。
5.repository的单元测试
单元测试时,我们需要mock掉网络调用的部分,是我们的测试更快更准确。
这样的话,我们使用抽象类就没有任何优势,因为在Dart中所有类都有一个隐式接口,如下,我们可以这样mock数据:
// note: in Dart we can always implement a concrete class
class FakeWeatherRepository implements HttpWeatherRepository {
// just a fake implementation that returns a value immediately
Future<Weather> getWeather({required String city}) {
return Future.value(Weather(...));
}
}
所以在单元测试中,我们完全没必要需要抽象类。我们在单测中,可以使用mocktail这样的包:
import 'package:mocktail/mocktail.dart';
class MockWeatherRepository extends Mock implements HttpWeatherRepository {}
final mockWeatherRepository = MockWeatherRepository();
when(() => mockWeatherRepository.getWeather('London'))
.thenAnswer((_) => Future.value(Weather(...)));
在测试里,我们可以mock HttpWeatherRepository,也可以mock HttpClient,
import 'package:http/http.dart' as http;
import 'package:mocktail/mocktail.dart';
class MockHttpClient extends Mock implements http.Client {}
void main() {
test('repository with mocked http client', () async {
// setup
final mockHttpClient = MockHttpClient();
final api = OpenWeatherMapAPI();
final weatherRepository =
HttpWeatherRepository(api: api, client: mockHttpClient);
when(() => mockHttpClient.get(api.weather('London')))
.thenAnswer((_) => Future.value(/* some valid http.Response */));
// run
final weather = await weatherRepository.getWeather(city: 'London');
// verify
expect(weather, Weather(...));
});
}
具体的是mock Repository还是HttpClient,可以根据你需要测试的内容来定。
最后,对于Repository到底需不需要抽象类,我觉得是没必要的,对于Repository我们只需要一个具体的实现,而且每个Repository是不一样的。
Repository的扩展
这里我们只实例了一个库,但是随着业务的增长,我们的应用功能越来越多,在一个Repository里添加所有api显然不是一个明智的选择。
所有,我们可以根据场景划分不同的Repository,将相关的方法放在同一个Repository中。比如在电商app中,我们划分为产品列表、购物车、订单管理、身份验证、结算等Repository。
总结
所有事情保持简单是最好的,我希望这篇概述能够激发大家更清晰地去思考App的架构,以及分层(UI层、领域和数据层)的重要性。
作者:AaronLei
链接:https://juejin.cn/post/7053426006312845325
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin协程,我学“废”了
Kotlin协程
Kotlin协程(本文讲解的协程都是基于Kotlin讲解的,其他语言的协程不在本文章的讨论范围)目前很流行的一款用于异步任务处理的库,都知道它处理异步任务特别好用,但是很少人去探究它背后的原理。还有一点,由于它是用于处理异步任务的,很多人将协程与线程做对比,也有一些人将协程与Rxjava做对比。这篇文章将从最简单的用法开始,层层递进的讲解以下知识点:
- 如何使用使用协程,以及协程中的一些重要概念
- 协程怎么处理异步任务和并发任务
- 挂起函数是什么
- 协程底层是怎么实现挂起-恢复的
- 协程是怎么做线程切换的
如何使用使用协程,以及协程中的一些重要概念
首先先介绍一下怎么开启一个协程,在Android开发中,如果是在Activity或者Fragment中,那么可以通过以下这种方式开启一个协程。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
//这里面就是协程
}
}
}
然而我们肯定不止在Activity或者Fragment中去使用协程,那么其他地方怎么去开启协程呢?要搞清楚这一点,就要知道lifecycleScope是什么,lifecycleScope是一个实现了CoroutineScope类的一个实例。CoroutineScope翻译过来就是协程作用域,到这里我们就清楚了,要开启一个协程,首先就要有一个协程作用域。通过协程作用域的实例去启动一个协程。 在Android开发中呢,很多时候不需要我们自己创建协程作用域,因为android中有很多拓展属性。比方上面说的Activity和Fragment中有lifecycleScope,ViewModel中有viewModelScope,可以直接使用这些拓展属性去开启一个协程。那其他地方怎么去创建一个协程作用域呢?首先就是可以通过MainScope()去创建一个主线程下协程作用域,还有可以通过CoroutineScope(Dispatchers.IO)去创建一个IO线程下的协程作用域。如下
// demo1
val scope = MainScope()
scope.launch{
Log.d(TAG,Thread.currentThread().name) // 打印main
}
// demo2
val scope2 = CoroutineScope(Dispatchers.IO)
scope2.launch {
Log.d(TAG,Thread.currentThread().name) // 打印DefaultDispatcher-worker-1
}
上面的这段代码还有一个地方没有讲清楚CoroutineScope(Dispatchers.IO)里面的参数是什么?其实CoroutineScope(context: CoroutineContext)接收的是一个CoroutineContext实例,CoroutineContext翻译过来就是协程的上下文的意思。
协程上下文是各种不同元素的集合。其中元素包含了了一个CoroutineDispatcher,即协程调度器。它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。 比如上述的例子通过demo1里面的MainScope()协程作用域开启的协程,协程是运行在主线程里面的。demo2的协程就是运行在io线程里面的。即使是在通过MainScope()开启的协程,依旧可以指定线程。啥意思,看如下这个例子,launch里面多了Dispatchers.IO这个参数
val scope = MainScope()
val job = scope.launch(Dispatchers.IO){
Log.d(TAG,Thread.currentThread().name) //打印 DefaultDispatcher-worker-1
}
这里面打印的就不是主线程了,而是IO线程了。看到这里明白了吗?协程调度器才是真正决定协程在哪个线程运行的关键,而协程作用域只是给这个协程提供了一个生命周期的管理而已。它并不能真正决定协程运行在哪一个线程。那么demo1打印main的现象怎么解释?因为launch函数如果不传协程的上下文,它就默认是协程作用域里面的上下文,而MainScope()默认的上下文里面的调度器就是Dispatchers.Main.
总结对比一下上面讲述的几个概念: 协程作用域:主要负责管理协程的生命周期。 协程上下文:由各种元素组成,其中一个元素是协程调度器。 协程调度器:定了相关的协程在哪个线程或哪些线程上执行。
协程如何处理异步任务和并发任务
上面说了这么多概念,好像很厉害的样子,但是听完之后也就听完了,啥也没学会。比如他如何处理异步任务?就一个普通的场景,去网络上请求数据,然后在前台显示。协程里面该怎么做,如下
class MainActivity : AppCompatActivity() {
val TAG = MainActivity::class.java.name
var text = "hello"
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 步骤一,通过lifecycleScope开启一个协程
lifecycleScope.launch{
//步骤二 调用耗时任务
changeText()
//步骤三 打印结果
Log.d(TAG,text) // 最终打印结果 hello Coroutine,这段代码在Main线程
}
}
// changeText 在IO线程模拟一个耗时任务,注意这里的suspend关键字,标识这个函数是挂起函数,什么是挂起函数后面会讲
private suspend fun changeText(){
// 通过withContext将协程运行的线程切换到IO线程,然后在IO线程里面做耗时处理,并改变text
withContext(Dispatchers.IO){
delay(1000)
text = "$text Coroutine"
}
}
}
以上就是简单处理一个耗时任务的例子。看上去是不是很神奇,明明切换了线程,Log.d(TAG,text)这段代码不会先执行吗?可以肯定的告诉你,不会。这就是协程相比于线程的优势,用同步的代码方式去完成异步任务。而能完成这一切都与挂起函数有关。这是简单的任务,如果是多任务呢?比如说,任务一在IO线程任务二在UI线程,任务三又在IO线程任务四又回来了UI线程:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
task1() // io线程执行耗时任务
task2() // ui线程执行界面更新
task3() // io线程执行耗时任务
task4() // ui线程执行界面更新
}
}
private suspend fun task1(){
withContext(Dispatchers.IO){
delay(1000)
}
}
private suspend fun task2(){
withContext(Dispatchers.Main){
}
}
private suspend fun task3(){
withContext(Dispatchers.IO){
delay(1000)
}
}
private suspend fun task4(){
withContext(Dispatchers.Main){
}
}
task1->task2->task3->task4会依次按照顺序执行。没有回调函数,直接明了。
还有一种比较复杂的情况就是,如果a,b,c三个任务,a,b任务的结果用于c任务的参数,那应该怎么做?我们先想一下如果是不用协程我们改怎么做,很多人说用rxjava。确实rxjava可以比较简单的实现我们上面的功能。如果只用线程来做的话是不是很麻烦,因为我们不知道任务a,b哪一个更快或者哪一个更忙,这样的任务用线程来管控的话,会非常麻烦,所以我们在代码里面可以会先a执行完,在执行b,然后再执行c,这样做的话,效率就会很低了。而且任务如果有10个呢(这当然是比较极端的情况了)。那么当当是用线程写起来可读性就很差了,这不是要写10次回调?
那么在协程中如何去做呢?如下:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
val time = measureTimeMillis{
// ① 通过async启动一个协程,async 返回一个 Deferred —— 一个轻量级的非阻塞 future, 这代表了一个将会在稍后提供结果的 promise。你可以使用 .await() 在一个延期的值上得到它的最终结果
val firstName = async(Dispatchers.IO) { getFirstName() }
val second = async(Dispatchers.IO) { getSecondName() }
// 通过await()得到结果,getFirstName() 与getSecondName()是并发的
val name = firstName.await() + " - " +second.await()
val friend = withContext(Dispatchers.IO){
getFriend(name)
}
Log.d(TAG,friend) // John - Tom Amy
}
Log.d(TAG,"$time") // 2000ms右一般2050左右,不到3000ms
}
}
private suspend fun getFirstName():String{
delay(1000)
return "John"
}
private suspend fun getSecondName():String{
delay(1000)
return "Tom"
}
private suspend fun getFriend(name:String):String{
delay(1000)
return "$name Amy"
}
以上就是协程中如何处理异步和做并发了。
总结:
1、在Android中,可以开启一个主线程作用域的协程,然后需要切线程的时候通过withContext去切换线程,耗时任务放到IO线程中去执行,并且将耗时任务通过suspend声明为挂起函数。完成以上步骤就可以在协程中,用同步方式的代码去实现简单的异步任务了。
2、如果要并发任务,可以通过async关键字开启一个新的协程,然后之后通过.await()拿到结果。
挂起函数是什么
通过以上的讲解,我们仅仅是知道怎么使用协程,怎么去使用协程完成并发任务,我们还不知道协程为什么能够用同步的代码方式去完成异步任务。要想知道这个,就从一个关键字说起,那就是suspend关键字,被suspend关键字标记的函数叫挂起函数。
首先先来看一下什么是CPS。Suspending functions are implemented via Continuation-Passing-Style (CPS). Every suspending function and suspending lambda has an additional Continuation parameter that is implicitly passed to it when it is invoked.
这段话什么意思呢?它的意思是说挂起函数都会经过CPS转换的,CPS转换之后呢会有一个额外的参数Continuation,当调用这个挂起函数的时候,会传递给这个挂起函数。
什么意思呢?来看代码:
// 注释1
private suspend fun getFirstName():String //kotlin代码
//注释2
private fun <T> getFirstName(continuation: Continuation<T>):Any? //经过CPS转化后的代码,多了一个Continuation类型的参数,而这个参数就类似一个callback接口的作用
/** 这是Continuation的定义
*Here is the definition of the standard library interface Continuation
*(defined in kotlinx.coroutines package), which represents a generic callback:
*/
interface Continuation<in T> {
val context: CoroutineContext
fun resumeWith(result: Result<T>)
}
从注释1到注释2的过程,就是CPS的过程。函数类型由原来的 suspend()->String 变成了Continuation->Any?
那么Continuation是什么,它是一个类似于callback的东西,里面的resumeWith函数,就类似于callBack里面的回调函数,那么这个
Continuation指的是哪一部分呢?
它大概会转换成下面这个样子
lifecycleScope.launch{
task1(object: Continuation<Unit>{
override fun resumeWith(result: Result<Unit>) {
// 也就是说,等到task1,执行完成之后才会执行到task2,task3与task4
task2() // ui线程执行界面更新
task3() // io线程执行耗时任务
task4() // ui线程执行界面更新
}
override val context: CoroutineContext
get() = TODO("Not yet implemented")
}) // io线程执行耗时任务
}
以上大概就是有关挂起函数的讲解了。
简单总结一下:在kotlin中,如果用suspend声明的函数,称为挂起函数。挂起函数的原理其实就是CPS转换。挂起函数并没有切换线程的功能,将函数声明为挂起函数,只是做一个标记,让编译器去做CPS转换,这个CPS转换对开发者来说是无感知的,所以我们能以同步的方式去实现异步的任务。
协程如何去实现挂起-恢复的
通过以上的讲解,我们知道了协程是如何工作了,但是我们还是不知道协程如果去实现这些功能的,首先看一段代码,跟着这一段代码,我们一步一步去讲解协程是如何实现挂起-恢复的。
fun testCoroutine() {
lifecycleScope.launch {
val firstName = getFirstName()
Log.d(TAG, firstName)
}
Log.d(TAG, "主线程继续执行")
}
private suspend fun getFirstName(): String {
var name = ""
withContext(Dispatchers.IO) {
delay(1000)
name = "hello"
}
return name
}
以上代码的执行步骤如下: 1、在主线程中开启一个协程
2、通过withContext切换了线程去做耗时任务,同时主线程打印“主线程继续执行”
3、耗时任务执行完成,并且在主线程将值赋给firstName,主线程打印firstname
如下:
在执行代码1的时候,在IO线程做耗时任务,这时候主线程的代码块2是不执行的,代码块2被挂起了,但是主线程的代码块3这时候是执行的,代码块1里面的耗时任务执行完成之后,主线程2里面的代码会被恢复,然后继续执行完成
现在的难点在于:
协程如何做挂起和恢复。
首先我们将delay()(这个delay()只是代表了耗时任务,但是他会增加我们阅读反编译代码的难度)这段代码删除,然后反编译一下。这里我就不直接贴反编译的代码了,因为直接贴反编译的代码,它的可读性太差了。它反编译之后大概如下:
public final void testCoroutine() {
BuildersKt.launch$default((CoroutineScope)LifecycleOwnerKt.getLifecycleScope(this), (CoroutineContext)null, (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object result) { // 状态机状态的切换
suspendLable = IntrinsicsKt.getCOROUTINE_SUSPENDED(); // 是否要挂起
switch(this.label) {
case 0:
this.label = 1;
funtionSuspend = var4.getFirstName(this); //是否为挂起函数,注意这里的this
if (suspendLable == funtionSuspend) {
return suspendLable; //如果是挂起函数,那么直接return,return之后就可以执行 这段代码 Log.d(this.TAG, "主线程继续执行");
}
break;
case 1:
finalResult = result;
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
String firstName = (String)finalResult;
return Unit.INSTANCE;
}
}), 3, (Object)null);
Log.d(this.TAG, "主线程继续执行");
}
private final Object getFirstName(Continuation var1) {
Object $result = ((<undefinedtype>)$continuation).result;
Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
final ObjectRef name;
switch(label) {
case 0:
name = "";
CoroutineContext var10000 = (CoroutineContext)Dispatchers.getIO(); //切换线程
Function2 var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object var1) {
switch(this.label) {
case 0:
name= "hello";
return Unit.INSTANCE;
}
}
});
break;
case 1:
name = (ObjectRef)((<undefinedtype>)$continuation).L$0;
ResultKt.throwOnFailure($result);
break;
}
return name;
}
编译后的代码大概就是这样,这种利用label进行状态判断的代码,也叫状态机机制,其实协程就是通过状态机去实现挂起恢复的一个过程。在testCoroutine,我们能够清楚的看到,如果在线程中执行了一个挂起函数,那么他就会直接return掉。这里也解释了为什么在执行挂起函数的时候,协程外的主线程会执行了。
if (suspendLable == funtionSuspend) {
return suspendLable; //如果是挂起函数,那么直接return,return之后就可以执行 这段代码 Log.d(this.TAG, "主线程继续执行");
}
那怎么办恢复呢?恢复的代码在反编译的代码中是没有呈现出来的,他其实是通过执行了invokeSuspend函数来进行恢复的。再一次执行invokeSuspend的时候,这时候它的label就不是0了,而是1了,所以他会执行- finalResult = result;然后跳出switch语句,并且执行String firstName = (String)finalResult;语句。这样一整个流程就结束了。协程的挂起与恢复。
总结:协程的挂起与恢复是通过状态机去实现的。每一个挂起点都是一种状态,协程恢复只是跳转到下一个状态,挂起点将执行过程分割成多个片段,利用状态机的机制保证各个片段按顺序执行。
协程是如何做线程切换的:
那么现在还剩下最后一个问题,协程的底层是怎么做线程切换的呢?其实在刚刚的反编译代码中就可以看出,协程它的底层是通过Dispatchers去切换线程的,那么它是怎么切换的呢?要研究这个问题就要从最开始的launch{}的源码开始了,今天当然不会去纠结源码的实现细节,我们知道底层切换线程是怎么做的就好了。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
第一个参数 context 是协程上下文,在讲述协程概念的时候有提到过 第二个参数 start 此处我们没有传值则使用默认值,代表启动方式默认值为立即执行。 第三个参数 block 是协程真正执行的代码块,即launch{}花括号中的代码块。
launch{}里面做了什么?
1、创建一个新的协程上下文。
2、再创建一个Continuation,默认情况下是StandaloneCoroutine
3、启动Continuation
首先来看:newCoroutineContext
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = coroutineContext + context // 将launch方法传入的context与CoroutineScope中的context组合起来
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug // 如果combined中没有拦截器,会传入一个默认的拦截器,即Dispatchers.Default
}
再来看启动Continuation
coroutine.start(start, coroutine, block)
->AbstractCoroutine.start()
->CoroutineStart.invoke()
->block.startCoroutineCancellable()
->createCoroutineUnintercepted(receiver, completion).intercepted().resumeCancellableWith(Result.success(Unit), onCancellation)
最终会执行到我们的最后一行最后一行也是分析的重点。
首先创建一个协程,并链式调用intercepted()和resumeCancellableWith()方法。createCoroutineUnintercepted()这个方法目前看不到源码的实现,不过不影响我们后面的分析,先看intercepted()
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
(this as? ContinuationImpl)?.intercepted() ?: this
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
//上面讲解newCoroutineContext的时候,讲解到有一个默认的Dispatchers.Default是CoroutineDispatcher,所以这里最终会调用到CoroutineDispatcher的interceptContinuation()
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
所以,我们可以发现这里其实就是创建的一个DispatchedContinuation,并且将原来的协程放入的DispatchedContinuation中。
最后看一下resumeCancellableWith这里很明显了,调用的是DispatchedContinuation的resumeCancellableWith。
@Suppress("NOTHING_TO_INLINE")
inline fun resumeCancellableWith(
result: Result<T>,
noinline onCancellation: ((cause: Throwable) -> Unit)?
) {
val state = result.toState(onCancellation)
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_CANCELLABLE
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_CANCELLABLE) {
if (!resumeCancelled(state)) {
resumeUndispatchedWith(result)
}
}
}
}
来看一下这段代码,如果需要切换线程,那么调用dispatcher.dispatch方法,如果不需要,直接运行在原来的线程上。
那么接下来就是要看一下dispatcher是怎么切换线程的了,DispatchedContinuation提供了四种实现,我们接下来只看Dispatchers.IO
最终会调用的ExperimentalCoroutineDispatcher的dispatch方法
override fun dispatch(context: CoroutineContext, block: Runnable): Unit =
try {
coroutineScheduler.dispatch(block)
} catch (e: RejectedExecutionException) {
// CoroutineScheduler only rejects execution when it is being closed and this behavior is reserved
// for testing purposes, so we don't have to worry about cancelling the affected Job here.
DefaultExecutor.dispatch(context, block)
}
而这里的coroutineScheduler是一个Executor。看到这里,我们就大概知道协程是怎么做一个线程切换了,它的底层是通过线程池去做线程的切换的。这是Dispatchers.IO的实现,如果是Dispatchers.Main的,它的底层是通过handler去做的一个线程切换。
Android Hook告诉你 如何启动未注册的Activity
前言
Android Hook 插件化其实已经不是什么新鲜的技术了,不知你有没有想过,支付宝中那么多小软件:淘票票 ,火车票等软件,难道是支付宝这个软件自己编写的吗?那不得写个十年,软件达到几十G,但是并没有,玩游戏时那么多的皮肤包肯定时用户使用哪个就下载哪个皮肤包。
一 未在配置文件中注册的Activity可以启动吗?
从0学的时候就知道Activity必须在配置文件中注册,否则无法启动且报错。但是Hook告诉你的是,未在配置文件中注册Activity是可以启动的,惊不惊喜?意不意外?
通过本文你可以学到:
1.通过对startActivity方法进行Hook,实现为startActivity方法添加日志。
1.1 通过对Instrumentation进行Hook
1.2 通过对AMN进行Hook
2.如何启动一个未在配置文件中注册的Activity实现插件化
本片文章基础建立在 Java反射机制和App启动流程解析,建议不太了解的小伙伴可以先移步至这两篇文章。
二 对startActivity方法进行Hook
通过对查阅startActivity的源码可以看出startActivity最终都会走到startActivityFoResult方法中
public void startActivityForResult(Intent intent, int requestCode, Bundle options) {
if(this.mParent == null) {
ActivityResult ar = this.mInstrumentation.execStartActivity(this, this.mMainThread.getApplicationThread(), this.mToken, this, intent, requestCode, options);
if(ar != null) {
this.mMainThread.sendActivityResult(this.mToken, this.mEmbeddedID, requestCode, ar.getResultCode(), ar.getResultData());
}
if(requestCode >= 0) {
this.mStartedActivity = true;
}
} else if(options != null) {
this.mParent.startActivityFromChild(this, intent, requestCode, options);
} else {
this.mParent.startActivityFromChild(this, intent, requestCode);
}
}
通过mInstrumentation.execStartActivity调用(ps:详细的源码解析已在上篇文章中讲解),再看mInstrumentation.execStartActivity方法源码如下:
public Instrumentation.ActivityResult execStartActivity(Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) {
IApplicationThread whoThread = (IApplicationThread)contextThread;
if(this.mActivityMonitors != null) {
Object e = this.mSync;
synchronized(this.mSync) {
int N = this.mActivityMonitors.size();
for(int i = 0; i < N; ++i) {
Instrumentation.ActivityMonitor am = (Instrumentation.ActivityMonitor)this.mActivityMonitors.get(i);
if(am.match(who, (Activity)null, intent)) {
++am.mHits;
if(am.isBlocking()) {
return requestCode >= 0?am.getResult():null;
}
break;
}
}
}
}
try {
intent.setAllowFds(false);
intent.migrateExtraStreamToClipData();
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
checkStartActivityResult(var16, intent);
} catch (RemoteException var14) {
;
}
return null;
}
最终会交给 int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent,...处理,所以如果我们想对startActivity方法进行Hook,可以从这两个地方入手(其实不止这两个地方,我们只讲解着两个地方,下面使用的反射封装类也在上篇文章中给出)。
- 2.1 对mInstrumentation进行Hook
在Activity.class类中定义了私有变量
private Instrumentation mInstrumentation;
我们首先要做的就是修改这个私有变量的值,在执行方法前打印一行日志,首先我们通过反射来获取这一私有变量。
Instrumentation instrumentation = (Instrumentation) Reflex.getFieldObject(Activity.class,MainActivity.this,"mInstrumentation");
我们要做的是将这个Instrumentation替换成我们自己的Instrumentation,所以下面我们新建MyInstrumentation继承自Instrumentation,并且MyInstrumentation的execStartActivity方法不变。
public class MyInstrumentation extends Instrumentation {
private Instrumentation instrumentation;
public MyInstrumentation(Instrumentation instrumentation) {
this.instrumentation = instrumentation;
}
public ActivityResult execStartActivity(Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) {
Log.d("-----","啦啦啦我是hook进来的!");
Class[] classes = {Context.class,IBinder.class,IBinder.class,Activity.class,Intent.class,int.class,Bundle.class};
Object[] objects = {who,contextThread,token,target,intent,requestCode,options};
Log.d("-----","啦啦啦我是hook进来的!!");
return (ActivityResult) Reflex.invokeInstanceMethod(instrumentation,"execStartActivity",classes,objects);
}
我们直接通过反射调用这个方法 参数就是 Class[] classes = {Context.class,IBinder.class,IBinder.class,Activity.class,Intent.class,int.class,Bundle.class}与方法名中一致
(ActivityResult) Reflex.invokeInstanceMethod(instrumentation,"execStartActivity",classes,objects)
如果我们这里不调用它本身的execStartActivity方法的话,那么startActivity就无效了。
然后我们将自定义的替换为原来的Instrumentation
Reflex.setFieldObject(Activity.class,this,"mInstrumentation",instrumentation1);
完整代码就是
Instrumentation instrumentation = (Instrumentation) Reflex.getFieldObject(Activity.class,MainActivity.this,"mInstrumentation");
MyInstrumentation instrumentation1 = new MyInstrumentation(instrumentation);
Reflex.setFieldObject(Activity.class,this,"mInstrumentation",instrumentation1);
运行日志如下:
这个时候我们就成功的Hook了startActivity方法
2.2 对AMN进行Hook
execStartActivity方法最终会走到ActivityManagerNative.getDefault().startActivity方法
try {
intent.setAllowFds(false);
intent.migrateExtraStreamToClipData();
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
checkStartActivityResult(var16, intent);
} catch (RemoteException var14) {
;
}
你可能会说上面说过了啊,替换ActivityManagerNative.getDefault(),重写startActivity方法,我们来看ActivityManagerNative.getDefault()
public static IActivityManager getDefault() {
return (IActivityManager)gDefault.get();
}
public final T get() {
synchronized(this) {
if(this.mInstance == null) {
this.mInstance = this.create();
}
return this.mInstance;
}
}
可以看出IActivityManager是一个接口,gDefault.get()返回的是一个泛型,上述方案我们无法入手,所以我们这里要用动态代理方案
我们定义一个AmsHookHelperUtils类,在AmsHookHelperUtils类中处理反射代码
gDefault是个final静态类型的字段,首先我们获取gDefault字段
Object gDefault = Reflex.getStaticFieldObject("android.app.ActivityManagerNative","gDefault");
gDefault是 Singleton<IActivityManager>类型的对象,Singleton是一个单例模式
public abstract class Singleton<T> {
private T mInstance;
public Singleton() {
}
protected abstract T create();
public final T get() {
synchronized(this) {
if(this.mInstance == null) {
this.mInstance = this.create();
}
return this.mInstance;
}
}
}
接下里我们来取出mInstance字段
Object mInstance = Reflex.getFieldObject("android.util.Singleton",gDefault,"mInstance");
然后创建一个代理对象
Class<?> classInterface = Class.forName("android.app.IActivityManager");
Object proxy = Proxy.newProxyInstance(classInterface.getClassLoader(),
new Class<?>[]{classInterface},new AMNInvocationHanlder(mInstance));
我们的代理对象就是new AMNInvocationHanlder(mInstance),(ps:代理模式分为静态代理和动态代理,如果对代理模式不了解可以百度一波,也可以关注我,等待我的代理模式相关文章)
public class AMNInvocationHanlder implements InvocationHandler {
private String actionName = "startActivity";
private Object target;
public AMNInvocationHanlder(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals(actionName)){
Log.d("---","啦啦啦我是hook AMN进来的");
return method.invoke(target,args);
}
return method.invoke(target,args);
}
}
所有的代理类都要实现InvocationHandler接口,在invoke方法中method.invoke(target,args);表示的就是 执行被代理对象所对应的方法。因为AMN Singleton做的事情比较多,所以这里只对startActivity方法hook
if (method.getName().equals(actionName)){
Log.d("---","啦啦啦我是hook AMN进来的");
return method.invoke(target,args);
}
然后我们将gDefault字段替换为我们的代理类
Reflex.setFieldObject("android.util.Singleton",gDefault,"mInstance",proxy);
AmsHookHelperUtils方法整体如下:
public class AmsHookHelperUtils {
public static void hookAmn() throws ClassNotFoundException {
Object gDefault = Reflex.getStaticFieldObject("android.app.ActivityManagerNative","gDefault");
Object mInstance = Reflex.getFieldObject("android.util.Singleton",gDefault,"mInstance");
Class<?> classInterface = Class.forName("android.app.IActivityManager");
Object proxy = Proxy.newProxyInstance(classInterface.getClassLoader(),
new Class<?>[]{classInterface},new AMNInvocationHanlder(mInstance));
Reflex.setFieldObject("android.util.Singleton",gDefault,"mInstance",proxy);
}
}
我们调用AmsHookHelperUtils.hookAmn();然后启动一个新的Activity,运行日志如下:
这样我们就成功Hook了AMN的getDefault方法。
2.3 如何启动一个未注册的Activity
如何启动一个未注册的Activity,首先我们了解Activity的启动流程,App的启动流程已经在上篇文章中讲解了,APP启动流程解析,还不了解的小伙伴,可先移步至上篇文章。假设现在MainActivity,Main2Activity,Main3Activity,其中Main3Activity未注册,我们在MainActivity中启动Main3Activity,当启动Main3Activity的时候,AMS会在配置文件中检查,是否有Main3Activity的配置信息如果不存在则报错,存在则启动Main3Activity。
所以我们可以做的是,将要启动的Activity发送给AMS之前,将要启动的Activity替换未已经注册Activity Main2Activity,这样AMS就可以检验通过,当AMS要启动目标Activity的时候再将Main2Activity替换为真正要启动的Activity。
首先我们按照上面逻辑先对startActivity方法进行Hook,这里采用对AMN Hook的方式。和上述代码一样,不一样的地方在于mInstance的代理类不同。
新建一个AMNInvocationHanlder1对象同样继承自InvocationHandler,只拦截startActivity方法。
if (method.getName().equals(actionName)){}
在这里我们要做的就是将要启动的Main3Activity替换为Main2Activity,这样能绕过AMS的检验,首先我们从目标方法中取出目标Activity。
Intent intent;
int index = 0;
for (int i = 0;i<args.length;i++){
if (args[i] instanceof Intent){
index = i;
break;
}
}
你可能会问你怎么知道args中一定有intent类的参数,因为invoke方法中最终会执行
return method.invoke(target,args);
表示会执行原本的方法,而我们来看原本的startActivity方法如下:
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
所以我们说args中肯定有个intent类型的参数,获取真实目标Activity之后,我们获取目标的包名
intent = (Intent) args[index];
String packageName = intent.getComponent().getPackageName();
新建一个Intent 将intent设置为 冒充者Main2Activity的相关信息
Intent newIntent = new Intent();
ComponentName componentName = new ComponentName(packageName,Main2Activity.class.getName());
newIntent.setComponent(componentName);
args[index] = newIntent;
这样目标Activity就被替换成了Main2Activity,不过这个冒充者还要将原本的目标携带过去,等待真正打开的时候再替换回来,否则就真的启动这个冒充者了
newIntent.putExtra(AmsHookHelperUtils.TUREINTENT,intent);
这个时候我们调用这个方法什么都不做,这个时候启动Main3Activity
startActivity(new Intent(this,Main3Activity.class));
显示的其实是Main2Activity,如图所示:
这样说明我们的冒充者已经成功替换了真实目标,所以我们接下来要在启动的时候,将冒充者再重新替换为目标者,ActivityThread通过mH发消息给AMS
synchronized(this) {
Message msg = Message.obtain();
msg.what = what;
msg.obj = obj;
msg.arg1 = arg1;
msg.arg2 = arg2;
this.mH.sendMessage(msg);
}
AMS收到消息后进行处理
public void handleMessage(Message msg) {
ActivityThread.ActivityClientRecord data;
switch(msg.what) {
case 100:
Trace.traceBegin(64L, "activityStart");
data = (ActivityThread.ActivityClientRecord)msg.obj;
data.packageInfo = ActivityThread.this.getPackageInfoNoCheck(data.activityInfo.applicationInfo, data.compatInfo);
ActivityThread.this.handleLaunchActivity(data, (Intent)null);
Trace.traceEnd(64L);
mH是Handler类型的消息处理类,所以sendMessage方法会调用callback,Handler消息处理机制可看我之前一篇博客
深入理解Android消息机制,所以我们可以对callback字段进行Hook。如果不明白怎么办?关注我!
新建hookActivityThread方法,首先我们获取当前的ActivityThread对象
Object currentActivityThread = Reflex.getStaticFieldObject("android.app.ActivityThread", "sCurrentActivityThread");
然后获取对象的mH对象
Handler mH = (Handler) Reflex.getFieldObject(currentActivityThread, "mH");
将mH替换为我们的自己自定义的MyCallback。
Reflex.setFieldObject(Handler.class, mH, "mCallback", new MyCallback(mH));
自定义MyCallback首先 Handler.Callback接口,重新处理handleMessage方法
@Override
public boolean handleMessage(Message msg) {
switch (msg.what) {
case 100:
handleLaunchActivity(msg);
break;
default:
break;
}
mBase.handleMessage(msg);
return true;
}
我们获取传递过来的目标对象
Object obj = msg.obj;
Intent intent = (Intent) Reflex.getFieldObject(obj, "intent");
然后从目标对象中取出携带过来的真实对象,并将intent修改为真实目标对象的信息,这样就可以启动真实的目标Activity
Intent targetIntent = intent.getParcelableExtra(AmsHookHelperUtils.TUREINTENT);
intent.setComponent(targetIntent.getComponent());
MyCallbackt如下
**
* Created by Huanglinqing on 2019/4/30.
*/
public class MyCallback implements Handler.Callback {
Handler mBase;
public MyCallback(Handler base) {
mBase = base;
}
@Override
public boolean handleMessage(Message msg) {
switch (msg.what) {
case 100:
handleLaunchActivity(msg);
break;
default:
break;
}
mBase.handleMessage(msg);
return true;
}
private void handleLaunchActivity(Message msg) {
Object obj = msg.obj;
Intent intent = (Intent) Reflex.getFieldObject(obj, "intent");
Intent targetIntent = intent.getParcelableExtra(AmsHookHelperUtils.TUREINTENT);
intent.setComponent(targetIntent.getComponent());
}
}
这个时候再启动未注册的Main3Activity,就可以成功启动了
startActivity(new Intent(this,Main3Activity.class));
这样我们就成功的启动了未注册Activity
作者:黄林晴_阿黄哥
链接:https://juejin.cn/post/7052520889379880968
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CTO 说了,用错 @Autowired 和 @Resource 的人可以领盒饭了
介绍
今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?
@Autowire
private JdbcTemplate jdbcTemplate;
提示的警告信息
Field injection is not recommended Inspection info: Spring Team recommends: "Always use constructor based dependency injection in your beans. Always use assertions for mandatory dependencies".
这段是Spring工作组的建议,大致翻译一下:
属性字段注入的方式不推荐,检查到的问题是:Spring团队建议:"始终在bean中使用基于构造函数的依赖项注入,始终对强制性依赖项使用断言"
如图
Field注入警告
注入方式
虽然当前有关Spring Framework(5.0.3)的文档仅定义了两种主要的注入类型,但实际上有三种:
基于构造函数的依赖注入
public class UserServiceImpl implents UserService{
private UserDao userDao;
@Autowire
public UserServiceImpl(UserDao userDao){
this.userDao = userDao;
}
}
基于Setter的依赖注入
public class UserServiceImpl implents UserService{
private UserDao userDao;
@Autowire
public serUserDao(UserDao userDao){
this.userDao = userDao;
}
}
基于字段的依赖注入
public class UserServiceImpl implents UserService{
@Autowire
private UserDao userDao;
}
基于字段的依赖注入方式会在Idea当中吃到黄牌警告,但是这种使用方式使用的也最广泛,因为简洁方便.您甚至可以在一些Spring指南中看到这种注入方法,尽管在文档中不建议这样做.(有点执法犯法的感觉)
如图
Spring自己的文档
基于字段的依赖注入缺点
对于有final修饰的变量不好使
Spring的IOC对待属性的注入使用的是set形式,但是final类型的变量在调用class的构造函数的这个过程当中就得初始化完成,这个是基于字段的依赖注入做不到的地方.只能使用基于构造函数的依赖注入的方式
掩盖单一职责的设计思想
我们都知道在OOP的设计当中有一个单一职责思想,如果你采用的是基于构造函数的依赖注入的方式来使用Spring的IOC的时候,当你注入的太多的时候,这个构造方法的参数就会很庞大,类似于下面.
当你看到这个类的构造方法那么多参数的时候,你自然而然的会想一下:这个类是不是违反了单一职责思想?.但是使用基于字段的依赖注入不会让你察觉,你会很沉浸在@Autowire当中
public class VerifyServiceImpl implents VerifyService{
private AccountService accountService;
private UserService userService;
private IDService idService;
private RoleService roleService;
private PermissionService permissionService;
private EnterpriseService enterpriseService;
private EmployeeService employService;
private TaskService taskService;
private RedisService redisService;
private MQService mqService;
public SystemLogDto(AccountService accountService,
UserService userService,
IDService idService,
RoleService roleService,
PermissionService permissionService,
EnterpriseService enterpriseService,
EmployeeService employService,
TaskService taskService,
RedisService redisService,
MQService mqService) {
this.accountService = accountService;
this.userService = userService;
this.idService = idService;
this.roleService = roleService;
this.permissionService = permissionService;
this.enterpriseService = enterpriseService;
this.employService = employService;
this.taskService = taskService;
this.redisService = redisService;
this.mqService = mqService;
}
}
与Spring的IOC机制紧密耦合
当你使用基于字段的依赖注入方式的时候,确实可以省略构造方法和setter这些个模板类型的方法,但是,你把控制权全给Spring的IOC了,别的类想重新设置下你的某个注入属性,没法处理(当然反射可以做到).
本身Spring的目的就是解藕和依赖反转,结果通过再次与类注入器(在本例中为Spring)耦合,失去了通过自动装配类字段而实现的对类的解耦,从而使类在Spring容器之外无效.
隐藏依赖性
当你使用Spring的IOC的时候,被注入的类应当使用一些public类型(构造方法,和setter类型方法)的方法来向外界表达:我需要什么依赖.但是基于字段的依赖注入的方式,基本都是private形式的,private把属性都给封印到class当中了.
无法对注入的属性进行安检
基于字段的依赖注入方式,你在程序启动的时候无法拿到这个类,只有在真正的业务使用的时候才会拿到,一般情况下,这个注入的都是非null的,万一要是null怎么办,在业务处理的时候错误才爆出来,时间有点晚了,如果在启动的时候就暴露出来,那么bug就可以很快得到修复(当然你可以加注解校验).
如果你想在属性注入的时候,想根据这个注入的对象操作点东西,你无法办到.我碰到过的例子:一些配置信息啊,有些人总是会配错误,等到了自己测试业务阶段才知道配错了,例如线程初始个数不小心配置成了3000,机器真的是狂叫啊!这个时候就需要再某些Value注入的时候做一个检测机制.
结论
通过上面,我们可以看到,基于字段的依赖注入方式有很多缺点,我们应当避免使用基于字段的依赖注入.推荐的方法是使用基于构造函数和基于setter的依赖注入.对于必需的依赖项,建议使用基于构造函数的注入,以使它们成为不可变的,并防止它们为null。对于可选的依赖项,建议使用基于Setter的注入
作者:MarkerHub
链接:https://juejin.cn/post/7053664705507753991
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Ngnix之父突然离职,程序员巅峰一代落幕
当地时间 1 月 18 日,Nginx 公司副总裁兼总经理 Rob Whiteley 在 Nginx 官网发布了一篇「告别信」,正式宣告 Nginx 的作者和 Nginx Inc. 的联合创始人 Igor Sysoev 退出 Nginx 和 F5 Networks。
此事很快登上 Hacker News 的热搜榜,有网友留言道:
我看过 Igor 参加某个会议的视频,他一说:“你好,我是 Nginx 的创建者 Igor Sysoev ”,观众席就会‘爆发’绵延不绝的掌声。他甚至不得不告诉他们“Come on guys, 你们还没听我的讲演呢。”。
不少开发者对 Igor 所做出的贡献表达了崇敬和感谢,也有网友感慨“巅峰一代落幕”。从 2002 年发展至今日,Nginx 已经成为全球最受欢迎的 Web 服务器。据 W3Techs 统计,截至 2022 年 1 月上旬,Nginx 占据了全球 Web 服务器市场 33% 的份额。排在第二位的是 Apache,份额为 31%。

一直以来,Nginx 常被拿来跟 Apache 对比,也有观点认为,Nginx 和 Apache 不算真正意义上的竞争者,很多地方会同时使用两者。但无论如何,Igor 和 Nginx 的成功确实鼓舞了不少开源人。
作为一名开源开发者和商业 OSS 初创公司创始人,Nginx 给了我很大的挑战现状的信心。Apache 是如此受人尊敬,以至于你会认为可以改进它的想法是很疯狂的,但他( Igor )做到了,这对我产生了真正的影响。——yesimahuman
Igor 早期曾在采访中分享对于开源和商业产品找平衡的观点,他表示不想创建单独的商业产品,而是希望对 Nginx 的主要开源产品进行商业扩展,社区想要的新功能将出现在其中。商业扩展更多的是有助于处理数千个实例、添加扩展性能监控、托管、云和 CDN 基础设施的附加功能等。
很多客户会说愿意付钱让 Igor 增加他们所需要的新功能,而 Igor 等人收集此类请求后会将其与从用户社区收到的需求进行比较,并寻找交叉点——“如果我们意识到每个人都需要某些功能,而不仅仅是某些公司,我们会将这些功能包含在开源版本中。我们从中了解我们可以销售什么,而不会惹恼开源产品的支持者,也不会损害整个项目的信誉。”
Nginx 如今归属于 F5 Networks。2019 年 3 月,F5 Networks 宣布将以 6.7 亿美元收购 Nginx,根据交易条款,Nginx 品牌被保留,而 Igor 和 合伙人 Konovalov 作为 F5 的一部分继续致力于该项目。但这笔交易很快就触发了利益纷争,同年 12 月,Igor 陷入版权纠纷,前东家 Rambler 集团对 NGINX Inc. 提出了侵犯版权的诉讼,声称拥有 Nginx Web 服务器代码的全部所有权,但 Igor 辩称是在业余时间开发了 Nginx。
此事随即引发热议,业余项目究竟属于开发者个人、还是属于开发者所在的企业,目前没有明确的统一的法律来判定。2020 年 4 月,Rambler 驳回针对 Nginx 的刑事诉讼。但 Rambler 并未就此停下,只是不再是以刑事诉讼的方式,而是通过民事法院,并于 2020 年 6 月初宣布授权旗下 Lynwood Investments 在美国对 F5 Networks、Igor 本人发起民事诉讼,要求索赔 7.5 亿美元。6 月末,俄罗斯内政部因缺乏犯罪记录证据,结案了有关 Nginx 版权的案件。
告别信有提到 Igor 从 Nginx 离职后将从事个人项目,目前我们尚不清楚他具体会涉及哪些项目。
以下是「告别信」全文:
挥别 Igor:
感谢你为 Nginx 付出的一切
怀着深深的感激之情,我们今天宣布,Nginx 的作者和 Nginx 公司联合创始人 Igor Sysoev 选择退出 Nginx 和 F5,以便花更多的时间与他的朋友和家人在一起,并追求个人项目。
2002 年的春天,Igor Sysoev 开始开发 Nginx。互联网的早期飞速发展让他萌生出一个念头:用一套全新架构改进网络流量的处理方式,帮助高流量网站从容应对数万个并发连接,并将照片、视频等各类可能严重拖慢页面加载速度的内容统统塞进缓存。
二十年过去,Igor 写下的代码已经在为世界上大部分网站提供支持。除了直接使用外,也被作为 Cloudflare、OpenResty、Tengine 等流行服务器的底层软件。很多人认为,Igor 最初的梦想就是把 Web 塑造成如今的样貌。Igor 所秉持的意志与价值观则汇聚成 Nginx 公司,结合开源与技术社区之力成就高透明度、质量卓越的代码,最终转化为客户喜闻乐见的商业产品。
但其中的平衡往往很难把握。Igor 之所以受到开发者、企业客户以及 Nginx 工程师们的高度赞扬,依靠的正是他谦逊的内心、不断探索的激情以及在开发工作中勇攀高峰的意志。
Igor 的成长与 Nginx 的诞生
Igor 的人生起点不高。他出生于苏联时期的一个哈萨克斯坦小镇,父亲是一名军官。一岁时,他们全家迁往首都阿拉木图。Igor 从小痴迷计算机,1980 年代中期就在 Yamaha MSX 上写下了人生第一行代码。而伴随着早期互联网产业的快速发展,Igor 也从著名的鲍曼莫斯科国立技术大学计算机科学系顺利毕业。
Igor 毕业后先找了份系统管理员工作,但写代码的好习惯一直没有丢下。1999 年,他用汇编语言开发出自己的第一个程序,这款反病毒软件能抵御当时最常见的十种计算机病毒。Igor 免费开放了程序的二进制文件,这款工具也在俄罗斯国内风靡一时。之后,敏感的他发觉 Apache HTTP 服务器的连接处理方式过于原始,根本无法满足不断发展的万维网需求。于是他决定开展相关研究,这也正是后来 Nginx 项目的雏形。
彼时,Igor 将目光投向了 C10k 问题,即如何在单一服务器上处理 10000 个并发连接。此外,他还希望让自己的 Web 服务器更快、更高效地处理照片或者音乐文件等极占传输带宽的元素。在获得俄罗斯国内外多家公司的肯定和采用之后,Igor 于 2004 年 10 月 4 日(即苏联发射全球首颗人造卫星「斯普特尼克」号的四十七周年纪念日)对这个名为 Nginx 的项目进行了许可开源。
七年来,Igor 一直是唯一的开发者。他独力写下数十万行代码,并把 Nginx 从简单的 Web 服务器加反向代理工具,扩展成一把能满足各类 Web 应用与服务需求的“瑞士军刀”。随着项目发展,负载均衡、缓存、安全和内容加速等关键功能也在他的指尖一一成形。
没有队伍的 Igor 当时自然没精力宣传项目,甚至连说明文档也不够完备。但 Nginx 仍然凭借着出色的表现迅速占领了市场。更神奇的是,新用户发现就算没有全面的使用指南、自己仍然能轻松玩转 Nginx,于是项目就在口口相传之下普及开来。越来越多的开发者和系统管理员利用 Nginx 解决自己面对的现实问题,提升网站响应速度。对于 Igor 的贡献,我们已经不需要刻意赞美或者宣扬,他的代码已经说明了一切。
Nginx 开启商业化之路,但开源定位永不动摇
2011 年,Igor 与 Maxim Konovalov、Andrew Alexeev 两位联合创始人共同成立了 Nginx 公司,希望借众人之力加快项目开发速度。但 Igor 也很清楚,从这一刻起他和团队得想办法赚钱了。不过他们坚持发布 Nginx 完整开源版本、恪守开源许可的承诺不会动摇。君子一诺值千金,自公司成立以来,Igor 引领 Nginx 通过 140 多个版本不断完善自我,始终以开源姿态为全球数亿网站提供支持。

奔波在为 Nginx 公司筹集风险投资的路上——(右起)Igor、公司 CEO Gus Robertson、联合创始人 Andrew Alexeev 以及 Maxim Konovalov
2011 年的时候,以专有模块的形式向商业版本中添加新功能的想法还属于开时代之先河。但如今,很多开源后起之秀已经可以站在巨人的肩膀上享受这种商业模式。在商业版 Nginx Plus 于 2013 年首次推出时,市场立刻抱以热烈欢迎。四年之后,Nginx 已经拥有超过 1000 家付费客户和数千万收入,Nginx 开源项目与技术社区的规模也在同步发展壮大。截至 2019 年底,Nginx 已经在为全球超过 4.75 亿个网站提供支持;到 2021 年,Nginx 正式成为世界上应用范围最广的 Web 服务器方案。
着眼于未来需求,Igor 还一路打造出多个 Nginx 相关项目,包括 Nginx JavaScript(njs)与 Nginx Unit。他还为 sendfile(2)系统调用设计了全新实现,将其整合到开源 FreeBSD 操作系统当中。随着 Nginx 工程师队伍的壮大和 Nginx 公司正式加入 F5,Igor 一直是团队背后稳健的领导者,保证 Nginx 始终方向明确、斗志坚定。
接过 Igor 手中的旗帜
今天,Igor 希望退居幕后享受生活,独余我们继续前行。但 Igor 的精神和他一路塑造的文化不会消失。伟大的企业、产品和项目中,创始人的 DNA 是永恒不变的。我们对于产品、社区、透明度、开源和创新的态度皆继承自 Igor,我们也将继续在 Maxim 和 Nginx 领导团队的指引下接过这面旗帜、发挥这份传统。
Igor 在 Nginx 与 F5 时代的奋斗与付出凝结成了我们今天所看到的项目代码,多年以来一直默默支撑起整个互联网世界。时间会考验我们、鞭策我们,证明我们能否像 Igor 那样创造出历久弥新、影响深远的产品。这当然是一条极高的标准,但 Igor 也用实际行动为我们指明了达成目标的方法。感恩多年来的指引与教导,Igor,祝你在人生的新阶段写下新的传奇故事。
来源:https://mp.weixin.qq.com/s/GANdlnXt1_vuUm3j97Njg
收起阅读 »城市数字孪生标准化白皮书(2022版)
当 前,城市数字孪生已经发展成为支撑智慧城市的重要技术手段。

全文共计3026字,预计阅读时间8分钟
来源| 全国信标委智慧城市标准工作组
编辑 | 蒲蒲
城市数字孪生通过在数字空间对城市物理空间和社会空间进行全要素表达、全过程呈现、全周期可溯,实现城市全面感知、虚实交互、智能决策、精准控制,推动城市智能化、智慧化发展。
当前,城市数字孪生已经发 展成为支撑智慧城市的重要技术手段。 为做好城市数字孪生标准化工作整体规划,有序推动相关标准制定与应用实施工作,全国信标 委智慧城市标准工作组组建了城市数字孪生专题组,并联合相关单位编制了《城市数字孪生标准化白皮书(2022版)》。
白皮书在系统研究城市数字孪生内涵、典型特征、相关方等基础上,构建了城市数字孪生技术参考架构,梳理了城市数字孪生关键技术和典型应用场景,总结了城市数字孪生发展现状、发展趋势、面临的问题与挑战及国际国内标准化现状。在此基础上,白皮书探索形成了“城市数字孪生标准体系总体框架(1.0版)”,并提出了拟研制标准建议和标准化工作建议。白皮书构建了城市数字孪生标准化路线图,为后续相关标准研制、应用实施指明了方向。
城市数字孪生典型特征
全面感知:城市数字孪生以全面感知为前提。城市是一个复杂巨系统,时刻处于发展变化中,必须时刻掌握物理城市的全局发展与精细变化,实现孪生环境下的数字城市与物理城市同步运行。
精准映射是构建数字世界并建立数字世界与物理世界紧密关系的过程。
智能推演是城市数字孪生具备智慧能力的体现,是实现对物理城市进行科学预测、指导与优化的关键。
动态可视:指通过将感知的多源数据进行数字化建模和可视化渲染,城市数字孪生提供了全要素、全范围、全精度真实的渲染效果,实现全空间信息和城市实时运行
虚实互动:指物理空间与数字空间的互操作和双向互动,借助物联网、图形/图像、AR/VR、人机交互等领域技术的协同和融合,实现城市级虚实空间融合、控制与反馈等能力。态势的动态展示。
协同演进是城市数字孪生具有高阶智慧能力的体现。城市数字孪生过程中,物理城市与数字城市在城市运行、数据、技术、机制等方面存在长期协同关系,长期相互反馈、相互影响。

多维度构建参考架构,立体刻画城市数字孪生内涵
白皮书对“城市数字孪生”概念进行了系统地梳理和分析,创新性地从概念、技术、相关方等不同视角构建了城市数字孪生参考架构。
白皮书认为,城市数字孪生是利用数字孪生技术,以数字化方式创建城市物理实体的虚拟映射,借助历史数据、实时数据、空间数据以及算法模型等,仿真、预测、交互、控制城市物理实体全生命周期过程的技术手段,可以实现城市物理空间和社会空间中物理实体对象以及关系、活动等在数字空间的多维映射和连接。
从概念视角,城市数字孪生以城市物理空间、社会空间以及数字空间在时间维度和空间维度更加精准的映射、更加紧密的联接和更加多维的联动,实现三元空间的协同演进和共生共智,满足“人”在城市生活、生产、生态的各类需求,服务“以人为本”的智慧城市建设初心。

图1 城市数字孪生概念模型
从技术视角,需对物理空间以及社会空间中的物理实体对象、事件对象以及关系对象进行数字空间的虚拟表达以及映射,通过信息基础设施的转化传输以及处理形成数据资源,在通用服务能力的支撑下进一步融合数字孪生技术形成能够对外提供的数字孪生服务,并通过交互服务实现与上层应用场景的融合。同时,需提供立体化安全管理以及全生命周期的运营管理,保障数字空间各类资产以及服务的安全高效运行。
 图2 城市数字孪生技术参考架构
图2 城市数字孪生技术参考架构
从相关方视角,城市数字孪生由城市数字孪生咨询服务提供方、建设技术提供方、运营服务方三方多类主体联动构建。
 图3 城市数字孪生相关方
图3 城市数字孪生相关方

梳理发展现状,总结城市数字孪生趋势与问题
白皮书梳理了城市数字孪生国家及地方相关政策,分析了产业生态发展现状。同时,提出了城市数字孪生发展的总体发展趋势及面临的主要问题和挑战。
 图4 城市数字孪生产业生态
图4 城市数字孪生产业生态
随着各地城市数字孪生探索与落地,智慧城市建设也将进入新的发展阶段。随供需双发力,城市数字孪生的技术创新、产业发展、标准规范等将快速发展,呈现物理城市和数字城市并行共生的新发展格局。
- 城市数字孪生将成为智慧城市建设技术底座。城市数字孪生将成为智慧城市发展新阶段的核心底座,为城市构建虚实共生的数字基础设施能力。
- 城市数字孪生将在智慧城市中迎来深度应用。城市数字孪生相关产业快速发展,市场规模不断扩大,以城市大脑、城运中心、城市信息模型、城市数字孪生运营管理为主的相关领域市场迅速升温。
- 城市数字孪生将形成跨行业协作生态共融。数据融合、技术融合和业务融合推动城市数字孪生产业链上下游的多元主体在竞争中发展出共生关系,生态共融正成为行业共识。
城市数字孪生从概念培育逐步走向建设实施,各项支撑技术日渐成熟,但仍面临着供应链安全性不足、数据支撑不足、应用深度不足、产业联动不足和标准支撑不足等问题与挑战。

构建标准体系,以标准化助力高质量发展
当前,城市数字孪生标准化处于起步阶段,亟需开展标准体系顶层设计。白皮书探索构建了“城市数字孪生标准体系总体框架(1.0版)”,将城市数字孪生标准划分为“01总体”“02数据”“03技术与平台”“04安全”“05运维/运营”“06应用”六大类。
 图5 城市数字孪生标准体系总体框架(1.0版)
图5 城市数字孪生标准体系总体框架(1.0版)
 图6 城市数字孪生标准体系结构
图6 城市数字孪生标准体系结构
为充分发挥标准基础性、引领性作用,助力城市数字孪生相关产业高质量发展,白皮书建议城市数字孪生标准化工作主要从四方面开展。
- 完善工作机制,强化统筹与协同。城市数字孪生涉及技术、应用、相关方众多,是复杂的系统工程,其标准化工作开展需统筹布局、协同各方。
- 研制重点标准,完善标准体系建设。以“规划引领、需求牵引”为原则,推动重点标准研制工作,不断完善城市数字孪生标准体系。
- 挖掘优秀案例,发挥示范引领作用。建立城市数字孪生典型案例与标准的良性互动机制,充分发挥先进性、代表性案例的引领与示范作用。
- 强化国际交流,推动国际标准制定。城市数字孪生承载了一系列关键技术和核心产业,要借助国际标准带动我国产品和方案走出去。
下一步,全国信标委智慧城市标准工作组将以此白皮书为基础,与各界共同推动城市数字孪生技术、理论、标准研究与制定工作,凝共识、聚合力,助力城市数字孪生产业生态培育,推动“以人为本”的智慧城市向智能化、智慧化迈进。
具体内容如下



























































 来源:全国信标委智慧城市标准工作组
来源:全国信标委智慧城市标准工作组
元宇宙报告(2021-2022)
元宇宙并非仅仅像扎克伯格这样的技术公司高管的逐利梦想,而且还是一个伟大的技术和工程上的创新,如果它得到正确的应用,也是一个能为我们实现世界带来确实好处的有益工具。它的应用场景不仅仅在社会和娱乐,而是对制造业、城市规划、零售业、教育、医疗乃至整个人类世界有着广泛和深远的意义。

全文共计929字,预计阅读时间10分钟
来源| 五道口供应链研究院(转载请注明来源)
编辑 | 赵超
元宇宙的应用场景可分为核心层、技术层和环境层。核心层是元宇宙最基本最普及的应用场景,具有用户覆盖面广、技术实现度高与生活最贴近的特点,满足用户基本的元宇宙生活需求;技术层是元宇宙的领先场景,具有技术创新性、概念引领性、话语斗争性的特点,是大型企业与跨国公司角逐的关键领域,也是元宇由的重要支撑;环境层是元宇宙发展的综合应用场景,具有复合性、生态性特征,“元宇宙+”生态大量涌现,对用户注意力的争夺常态化。
面向元宇宙的各项技术和应用还在快速发展中,对元宇宙未来发展的趋势预测可以结合技术性与社会变革性展开讨论,并且按照元宇宙率的程度高低进行未来趋势排序。在未来几年,元宇宙的核心维度将越来越强,包括算力、响应力、逼真性、沉浸性、互动性、用户自主性、数字财产保护、数字货币支付等,它在制造业、城市规划、零售业、教育、医疗、娱乐和社交等方面的应用也将越来越多。
元宇宙是现实世界延伸,而不是现实世界的替代。它将深刻地影响我们对时间、空间、真实身体、关系、伦理、工作、学习、教育等的认知。
具体内容如下
































































来源:五道口供应链研究院
收起阅读 »中美程序员不完全对比

我是在美国工作过两年,回国经历了逆文化冲击,现在勉强算是适应了国内互联网公司的节奏。随便聊聊,没有崇洋媚外的意图,只是刚好最近被剥削得很不爽,趁机吐槽一下。
1.年龄
美国公司:
同事里 20 多到 70 多岁的都有,众数是三四十的中年人,大部分工作目标都是为了早日退休,攒够钱就随时办退休 party。也有些纯粹因为热爱工作、热爱写代码选择不退休的。 我们组的核心成员之一,是位 72 岁的老头,他每天 4 点多起床到公司写一会儿代码,等天全亮就戴上头盔去骑山地车锻炼,9 点多回公司继续工作。对这老头印象深刻,是因为他逻辑清晰、思路锐利,他是 code review 小组的成员,经常在邮件里破口大骂其他人写的代码写得有多烂,被投诉,只好在邮件里道歉,过几天继续骂,在我工作的两年里一直循环。 我的另一位资深同事,是位 68 岁的架构师,热爱工作,每天都乐呵呵的,对我这种新毕业生也很友好,有人问他什么时候退休,他回答说他死的那天。
我国公司:
回国之后我现在工作的公司,员工平均年龄在 30 岁以下。年纪大的都去哪里了呢?极少数在管理层。
2. 加班
美国公司:
从没加过班,晚上发版除外(会默认第二天调休)。 经常正开着会,时间到了 5 点半,产品打断领导说到点了他要回去喂狗(他是一个 50 岁的不婚族,养了一院子狗),然后就散会下班了。 加班需要申请,有次我申请工作日晚上加班,没批准只好回家了。因为加班费会比较高,需要从项目预算走,领导控制预算不给批。 偶尔周末去办公室取东西,几层停车场只有两三辆车。
我国公司:
996 是常事了。 印象比较深的是我司之前有个清华本科+美国硕士的小伙子,每天 7 点半准时下班,结果试用期被辞退了,原因是工作态度不积极,据说后来还和公司打了官司,不知输赢。
3. 代码质量
美国公司:
项目在前期花的时间是最多的,比如说需求分析、架构讨论、技术讨论。 写代码会考虑得比较长远,比较有时间去考虑开发原则、维护成本,领导也会乐意去安排版本来解决技术债务。
我国公司:
国内互联网节奏会要快得多,讲究小步快跑,就几天的开发时间,不管三七二十一先上线再说,刚开始我都惊呆了。
4.工作氛围
美国公司:
老美的公司确实比较尊重员工,在员工关怀上做得比较好。我可以感受到,和领导职位不同,但是我们人格是平等的,彼此尊重。 记得有一次发版前几天,组里程序员说他压力太大,领导给他假期让他放松调整,版本被延迟上线。 美国有 family first 的文化。有个老印同事,家里老人身体不好,公司同意他回印度工作照顾家人,远程跨国工作。经常有同事因为要看孩子比赛请假。领导自己也会偶尔周五请假,因为要去和女儿一起参加学校的公益活动。 对差异性接受度也比较高。同事有变性人、残疾人,大家相处得都很好。
我国公司:
绝大部分领导高高在上(我遇到的),官威很大。请个假,和求他借钱似的,组长还提醒我让我请假原因不要写“旅游”不然可能会不给批假。 记得有个需求,大家都认为不合理没必要,我去找领导沟通,刚提了一句还没展开,领导直接甩脸色“你是领导还是我是领导”。 有个同事因为耿直,和领导不和,被各种排挤冷暴力,逼他自己辞职拒给赔偿金。 开个线上事故复盘会,做 root cause 分析,就像要把人钉在耻辱柱一样,我不理解这对解决问题有什么帮助。
5.工作之外
美国公司:
很注重对健康的投资。至少 1/3 同事有每天早上去健身房的习惯。公司很多球场,晚上下班能看到很多同事在楼下踢足球、打排球。健身不只是为了锻炼,还是很多同事的爱好。看起来平平无奇的程序员,可能都是隐藏的运动高手,多年马拉松选手、山地车骑手遍地都是,还有不少极限运动爱好者。 喜欢看牙医。喜欢看各种体育比赛。喜欢旅游,基本上每年至少一次家庭旅游,游轮是热门项目。 一部分同事热衷慈善回馈社会,小到捐血捐钱做公益,大到组织慈善拍卖会。 据我观察都没啥夜生活,下了班就开车直接回家两点一线,偶尔聚餐也是和同事朋友。可能是我自己的感觉,人和人之间的链接比较淡薄,所以华人码农也会经常吐槽空虚无聊。 已婚同事的其他时间和我国的一样,花在养孩子和投资上。
我国公司:
办公室的好多同事,不敢看体检报告。都是 20 多岁的年轻人,检查出来啥的都有,胆囊炎、结石、痛风。。。前几天还有一个要好的同事请假去做痔疮手术的(捂脸),据他说是因为久坐,加班经常吃小龙虾。 相比之下离职率高太多了,每个月都有几个认识的同事离职,跳槽的、转行的、回老家躺平的。 除了领导们,几乎每个人看起来都很焦虑,都想着退路,想着搞点什么副业。
我为大家带来了二十张登录界面?!!!
我为大家带来了二十张登录界面😎!!!这次给大家带来了20张Web登录界面,真的是辛辛苦苦收集了好久,如果有喜欢的不妨给我点个赞吧,感谢!
以下所有设计图均来自网络,如有侵权,请联系我删除,感谢各位分享~
本人最喜欢的一张😎:(大家在评论区投票选出最喜欢的一张吧)
按钮的圆角让我看了真的是身心愉悦,简约却又不是高雅!
其他的十九张😍:
1.这一款我也是吹爆,层次非常明显,颜色令人舒适,各位觉得怎么样呢?
2.这张就是经典款,左侧突出自己网页的主题,右侧是一个简约的登录,这张非常实用,只需将左侧的图片一换即可!
3. 这就很像校园的网站,这样的配色突出校园青春气息,登录框与背景的交叠凸显层次
4.这一款可是上榜2020年6月的设计榜,层次相当丰富,主题也很突出,不愧是上榜的作品
5.哇塞当时看到这一款的时候,我是惊讶到的,这款色彩和层次是真的丰富🤩!!!
6.这款也是相当的好,一款卡通风格的旅游网页,用于游戏的官网也可以(例如原神),个人很喜欢
7.这篇也是很通用的网页,不过右边的圆角登录框也是比较有特色的
8.这一款乍一看很普通,但是当你关注到了细节时,它的背景分块真的是很好,爱了爱了
9.这一款是相较于其他有很大不同的,它更多的是在展示自己的界面美,没有去注意功能的突出,这样别具一格的其实也很不错!
10.以蓝色为底色,利用圆角层次分明,也突出了功能,很适合电商网页
11.这一款除了背景有点留白太多,其他还是很不错的,换一下背景就可以直接商用了~
12.也是一如往常的好,乍一看是很常规,但是当你细看的时候,它对于输入框的处理还是很到位的
13.这一款就比较有特色的,左侧一个轮播图用于展示网页与业务的特点,右侧的输入框与背景交叠丰富了层次,很棒的作品!
14.这款就是介绍自己app的一个网页,也是很不错,但是不知道为啥图片有点糊😭
15.这款黑色与紫色交融,满满的高级感!
16.这一款也在设计榜上,不过,我水平不够,没有欣赏到它的美,蓝色的底色(好了我真是编不下去啦哈哈,原作者看到的话不要打我,这只能证明我的审美不够)
17.漫威蜘蛛侠咱就不用多说了吧,懂得都懂,5星通过👌
18.唯美风格,相当舒服了,很适合一些助睡眠的网页🌙
19.外星风格,我觉得可以卖玩具了哈哈😝
每一张都是设计师辛辛苦苦设计的,每一张都很棒,感谢!!!
作者:阿Tya
链接:https://juejin.cn/post/7015042594396700709
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【Flutter App】GetX框架的实践
正在做的这款App是一个打卡软件,旨在让用户能够更好地坚持自己所设置的目标,坚持自己的初心。
由于项目还只是在前期阶段,目前根据需要建立了以下结构:
参考了部分官方插件以及结合官方getX文档中建议的目录:
暂时没有对state分离出来一层的想法。 以下是各层详细内容:
在使用GetX的时候,往往每次都是用需要手动实例化一个控制器final controller = Get.put(CounterController());,如果每个界面都要实例化一次,有些许麻烦。使用Binding 能解决上述问题,可以在项目初始化时把所有需要进行状态管理的控制器进行统一初始化,直接使用Get.find()找到对应的GetxController使用。
- 可以将路由、状态管理器和依赖管理器完全集成
- 这里介绍2种使用方式,推荐第一种使用getx的命名路由的方式
- 不使用binding,不会对功能有任何的影响。
- 第一种:使用命名路由进行Binding绑定
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
/// 这里使用 GetMaterialApp
/// 初始化路由
return GetMaterialApp(
initialRoute: RouteConfig.onePage,
getPages: RouteConfig.getPages,
);
}
}
/// 路由配置
class RouteConfig {
static const String onePage = "/onePage";
static const String twoPage = "/twoPage";
static final List<GetPage> getPages = [
GetPage(
name: onePage,
page: () => const OnePage(),
binding: OnePageBinding(),
),
// GetPage(
// name: twoPage,
// page: () => TwoPage(),
// binding: TwoPageBinding(),
// ),
];
}
/// binding层
class OnePageBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
}
}
/// 逻辑层
class CounterController extends GetxController{
var count = 0;
/// 自增方法
void increase(){
count++;
update();
}
}
- 第二种:使用initialBinding初始化所有的Binding
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return GetMaterialApp(
/// 初始化所有的Binding
initialBinding: AllControllerBinding(),
home: const OnePage(),
);
}
}
/// 所有的Binding层
class AllControllerBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
///Get.lazyPut(() => OneController());
///Get.lazyPut(() => TwoController());
}
}
作者:_Archer
链接:https://juejin.cn/post/7042904386799927332
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
android Handler架构思考
前言
写这篇文章不是为了分析Handler怎么使用,目的是想从设计的角度来看Handler的演进过程,以及为什么会出现Looper,MessageQueue,Handler,Message这四个类。
一.线程通信的本质?
线程区别于进程的主要因素在于,线程之间是共享内存的。在android系统中,堆中的对象可以被所有线程访问。因此无论是哪种线程通信方式,考虑到性能问题,一定会选用持有对方线程的某个对象来实现通信。
1.1 AsyncTask
public AsyncTask(@Nullable Looper callbackLooper) {
mHandler = callbackLooper == null || callbackLooper == Looper.getMainLooper()
? getMainHandler()
: new Handler(callbackLooper);
mWorker = new WorkerRunnable() {
public Result call() throws Exception {
mTaskInvoked.set(true);
Result result = null;
try {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
result = doInBackground(mParams);
Binder.flushPendingCommands();
} catch (Throwable tr) {
mCancelled.set(true);
throw tr;
} finally {
postResult(result);
}
return result;
}
};
mFuture = new FutureTask(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult(this, result));
message.sendToTarget();
return result;
}
从用法可以看出,AsyncTask也是间接通过handler机制实现从当前线程给Looper所对应线程发送消息的,如果不传,默认选的就是主线程的Looper。
1.2 Handler
借助ThreadLocal获取thread的Looper,传输message进行通信。本质上也是持有对象线程的Looper对象。
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
1.3 View.post(Runnable)
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
// Postpone the runnable until we know on which thread it needs to run.
// Assume that the runnable will be successfully placed after attach.
getRunQueue().post(action);
return true;
}
getRunQueue().post(action)仅仅是在没有attachToWindow之前缓存了Runnable到数组中
private HandlerAction[] mActions;
public void postDelayed(Runnable action, long delayMillis) {
final HandlerAction handlerAction = new HandlerAction(action, delayMillis);
synchronized (this) {
if (mActions == null) {
mActions = new HandlerAction[4];
}
mActions = GrowingArrayUtils.append(mActions, mCount, handlerAction);
mCount++;
}
}
等到attachToWindow时执行,因此本质上也是handler机制进行通信。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
....
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
....
}
1.4 runOnUiThread
public final void runOnUiThread(Runnable action) {
if (Thread.currentThread() != mUiThread) {
mHandler.post(action);
} else {
action.run();
}
}
通过获取UIThread的handler来通信。
从以上分析可以看出,android系统的四种常见通信方式本质上都是通过Handler技术进行通信。
二.handler解决什么问题?
handler解决线程通信问题,以及线程切换问题。本质上还是共享内存,通过持有其他线程的Looper来发送消息。
我们常提的Handler技术通常包括以下四部分
- Handler
- Looper
- MessageQueue
- Message
三.从架构的演进来看Handler
3.1 原始的线程通信
String msg = "hello world";
Thread thread = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread1.start();
3.2 结构化数据支持
为了发送结构化数据,因此设计了Message
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
super.run();
msg.content = "hello";
System.out.println(msg);
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread1.start();
3.3 持续通信支持
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
for (;;){
msg.content = "hello";
}
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
for (;;){
System.out.println(msg.content);
}
}
};
thread1.start();
通过无限for循环阻塞线程,Handler中对应的是Looper。
3.4 线程切换支持
上述方法都只能是thread1接受改变,而无法通知thread。因此设计了Handler, 同时封装了发送和接受消息的方法.
class Message{
String content = "123";
String from = "hch";
}
abstract class Handler{
public void sendMessage(Message message){
handleMessage(message);
}
public abstract void handleMessage(Message message);
}
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
for (;;){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
msg.content = "hello";
if (handler != null){
handler.sendMessage(msg);
}
}
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
handler = new Handler(){
@Override
public void handleMessage(Message message) {
System.out.println(message.content);
}
};
}
};
thread1.start();
3.5 对于线程消息吞吐量的支持
abstract class Handler{
BlockingDeque messageQueue = new LinkedBlockingDeque<>();
public void sendMessage(Message message){
messageQueue.add(message);
}
public abstract void handleMessage(Message message);
}
...
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
handler = new Handler(){
@Override
public void handleMessage(Message message) {
if (!handler.messageQueue.isEmpty()){
System.out.println(messageQueue.pollFirst().content);
}
}
};
}
};
thread1.start();
增加消息队列MessageQueue来缓存消息,处理线程按顺序消费。形成典型的生产者消费者模型。
3.6 对于多线程的支持
上述模型最大的不便之后在于Handler的申明和使用,通信线程双方必须能够非常方便的获取到相同的Handler。
同时考虑到使用线程的便利性,我们不能限制Handler在某个固定的地方申明。如果能够非常方便的获取到对应线程的消息队列,然后往里面塞我们的消息,那该多么美好。
因此Looper和ThreadLocal闪亮登场。
- Looper抽象了无限循环的过程,并且将MessageQueue从Handler中移到Looper中。
- ThreadLocal将每个线程通过ThreadLocalMap将Looper与Thread绑定,保证能够通过任意Thread获取到对应的Looper对象,进而获取到Thread所需的关键MessageQueue.
//ThreadLocal获取Looper
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
//Looper写入到ThreadLocal
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
// 队列抽象
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
//Handler获取Looper
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
3.7 google对于Handler的无奈妥协
思考一个问题,由于Handler可以在任意位置定义,sendMessage到对应的线程可以通过线程对应的Looper--MessageQueue来执行,那handleMessage的时候,如何能找到对应的Handler来处理呢?我们可没有好的办法能直接检索到每个消息对应的Handler
两种解决思路
- 通过公共总线,比如定义Map
- 通过消息带Message来携带属性target到对应线程,当消息被消费后,可以通过Message来获得Handler.
第一种方式的问题比较明显,公共总线需要手动维护它的生命周期,google采用的是第二种方式。
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
3.8.妥协造成Handler泄露问题的根源
由于Message持有了Handler的引用,当我们通过内部类的形式定义Handler时,持有链为
Thread->MessageQueue->Message->Handler->Activity/Fragment
长生命周期的Thread持有了短生命周期的Activity.
解决方式: 使用静态内部类定义Handler,静态内部类不持有外部类的引用,所以使用静态的handler不会导致activity的泄露。
四.总结
- 1.线程通信本质上通过共享内存来实现
- 2.android系统常用的四种通信方式,实际都采用Handler实现
- 3.Handler机制包含四部分Handler,MessageQueue,Message,Looper,它是架构演进的结果。
- 4.Handler泄露本质是由于长生命周期的对象Thead间接持有了短生命周期的对象造成。
作者:八道
链接:https://juejin.cn/post/7045473726929829918
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android架构学习之路一-漫谈
架构是什么
对于架构,我也有些一知半解,读了一些架构相关的文章,结合实际项目经历,有了自己的一些理解。
关于架构是什么?这点可以顾名思义去看,架构=架+构,即整体的一个架子和各个组件之间的组合结构。当然可能不同的程序员对于项目架构的风格和习惯不一样,但是底层的思想应该都是类似的,诸如我们可能听到起了茧子的“关注点分离”,“低耦合高内聚”,“可扩展可复用易维护”等等,听完这些话,感觉自己懂了,又感觉啥也不懂,好像有所收获了,准备开始写代码的时候,脑子里想的可能又是“工期太赶了,就这样写吧,反正干完这几票就跑路了”。
架构离我们并不远,反而在我们的实际开发中无处不在,它是一个很笼统的概念,上至框架选型,组件化等,下至业务代码,设计模式都能称为架构的一部分。对于架构学习而言,我觉得首先得对面向对象(抽象,继承,多态等)及设计原则有一定的理解,进而结合 Android 常用的一些架构如 MVVM, MVP, MVI 等思想,基础与理论理解清楚了,架构就在日常的开发中,多思考,多结合理论与实际,一点一点地积累起来了。
一起吐槽
我想每个程序员在写代码的时候可能都有这些历程(夸张):
- 这坨代码谁写的,怎么要这样写啊,我这个需求该怎么加代码!
- (尝试在shit山上小心地走,并添加新代码)写的好难受,shit越改越chou了...
- 算了,爷来重构一下,结束掉一切吧!
- 重构的一天:我曰,这个地方怎么埋了个雷,我来排一下;哇,怎么这里还有奇怪的逻辑,哼哧哼哧问了之前的同事说是PM改的需求;哎,爱咋地咋地。
- Several days later -> git revert -> 下班
- 在原来的shit山上再拉一坨,OK,很稳定,提测。
新员工整天都想着重构,而经验丰富的老人早就知道能不动别人的代码就不动的(doge),shit都是互相的,你来我往才能生生不息。写代码嘛,就讲究一个礼尚往来~
背后的原因令人XX
吐槽不是针对某个人,这种现象其实也挺正常的,因为技术在发展和迭代,业务也在丰富和重构,所以在当时看起来,这块代码是很优秀的,只不过由于一步一步的发展,以及一些历史包袱(PM: ??),慢慢的原先的架构可能就跟不上业务需求了,毕竟,架构不是一成不变的,业务在发展,技术在迭代,熵增很正常。到了一定的地步,评估好成本和收入,老老实实提需求重构吧。
当然,虽说随着业务的发展,熵增是必然情况,但是也得注意自己的代码质量呀,毕竟大家应该都不想被后面的同事接手的时候偷偷吐槽你的shit太chou了吧,除非真的抱着干完这一票就溜溜球的想法(doge)。
简而言之原因可以分为两种:
- 产品的发展,技术的更新迭代
- 每个人的代码习惯可能不一样,比较参差
怎么做
学好面向对象
听说即使是许多年的老 Java 人,可能在开发中也不怎么注意面向对象的思想,我也经常疏忽这点,啊不对,我不算老 Java 人(囧)。
关于面向对象和面向过程的区别,网上很多介绍的,随便抄了一份:
- 面向对象:面向对象是一种风格,会以类作为代码的基本单位,通过对象访问,并拥有
封装、继承、抽象、多态四种特性作为基石,可让其更为智能。 - 面向过程:分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了,更侧重于功能的设计。
在开始做需求的时候,先别急着写代码,思考一下这个需求的本质是干嘛,用面向对象的思想去抽象这个过程,不是直接搞几个类就可以了的。
举个栗子,之前在老东家的时候做过后台启动的需求,当时的情况是这样子的:针对不同的 Android 版本,可能有一种或者多种不同的启动方式,需要分版本挨个尝试。直截了当的方式是 if else 从头到尾一路火花带闪电,但是觉得这样子肯定是比较难以维护的,所以就把每种启动方式都抽象成了一个 Starter 类:
abstract class Starter {
// 做后台启动的事情
abstract fun handle(context: Context, intent: Intent)
// 是否满足特定Android版本和业务场景等
abstract fun satisfy(): Boolean
}
然后把这些启动方式串起来,通过类似责任链的设计模式去工作,具体代码不贴了,有兴趣可以看看之前的文章: 实战|Android后台启动Activity实践之路。可能现在看当时的代码,会觉得有些稚嫩,但程序员不就是得一直进步的嘛~
接着就是那些常用的面向对象设计模式了,讲道理这些设计模式是很有用的,另外还有面向对象的六大设计原则,这些网上应该很多很多的文章都会讲,此处就不赘述了。
设计架构
前面已经提过随着技术和业务的发展,架构也在一步一步迭代,比如说一开始的单体架构,把用户界面,业务逻辑,数据管理都糅合到一起,到后面根据业务和技术拆分结构,如 MVC, MVP, MVVM, MVI 这些,以及模块化和组件化,服务注册和发现等等,另外还有比较复杂的 Clean 架构,Android 版的 Redux 架构之类的等等。多的一批,哎,好卷。
有时候会产生疑问,这么多新的东西冒出来到底是技术必需的迭代还是由于 OKR, KPI 太卷了(doge)。但能怎么着哦,还是得哼哧哼哧学习。这些文章计划在后面慢慢整理,就当给我年初补充的flag 两年半,加油Android|2021年终总结 吧!
不过架构再多,也都是为业务服务的,没有什么完美的架构,适合当前需求的才是最好的。
写在最后
写代码的时候,记得三思而后行,想一想你写的代码是不是在它该在的位置,是不是以该有的形式存在的。
架构不是一蹴而就的,希望我们有一天的时候,能够从自己写的代码中找到架构的成就感,而不是干几票就跑路的想法,这个系列应该会一直更新,记录我在架构之路上学习的脚印儿,一件一件扒开架构神秘的面纱。
作者:苍耳叔叔
链接:https://juejin.cn/post/7052201118092230669
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
丢掉丑陋的 toast,会动的 toast 更有趣!
前言
我们通常会用 toast(也叫吐司)来显示提示信息,例如网络请求错误,校验错误等等。大多数 App的 toast 都很简单,简单的半透明黑底加上白色文字草草了事,比如下面这种. 说实话,这种toast 的体验很糟糕。假设是新手用户,他们并不知道 toast 从哪里出来,等出现错误的时候,闪现出来的时候,可能还没抓住内容的重点就消失了(尤其是想截屏抓错误的时候,更抓狂)。这是因为一个是这种 toast 一般比较小,而是动效非常简单,用来提醒其实并不是特别好。怎么破?本篇来给大家介绍一个非常有趣的 toast 组件 —— motion_toast。
motion_toast 介绍
从名字就知道,motion_toast 是支持动效的,除此之外,它的颜值还很高,下面是它的一个示例动图,仔细看那个小闹钟图标,是在跳动的哦。这种提醒效果比起常用的 toast 来说醒目多了,也更有趣味性。 下面我们看看 motion_toast 的特性:
- 可以通过动画图标实现动效;
- 内置了成功、警告、错误、提醒和删除类型;
- 支持自定义;
- 支持不同的主题色;
- 支持 null safety;
- 心跳动画效果;
- 完全自定义的文本内容;
- 内置动画效果;
- 支持自定义布局(LTR 和 RTL);
- 自定义持续时长;
- 自定义展现位置(居中,底部或顶部);
- 支持长文本显示;
- 自定义背景样式;
- 自定义消失形式。
可以看到,除了能够开箱即用之外,我们还可以通过自定义来丰富 toast 的样式,使之更有趣。
示例
介绍完了,我们来一些典型的示例吧,首先在 pubspec.yaml 中添加依赖motion_toast: ^2.0.0(最低Dart版本需要2.12)。
最简单用法
只需要一行代码搞定!其他参数在 success 的命名构造方法中默认了,因此使用非常简单。
MotionToast.success(description: '操作成功!').show(context);
复制代码其他内置的提醒
内置的提醒也支持我们修改默认参数进行样式调整,如标题、位置、宽度、显示位置、动画曲线等等。
// 错误提示
MotionToast.error(
description: '发生错误!',
width: 300,
position: MOTION_TOAST_POSITION.center,
).show(context);
//删除提示
MotionToast.delete(
description: '已成功删除',
position: MOTION_TOAST_POSITION.bottom,
animationType: ANIMATION.fromLeft,
animationCurve: Curves.bounceIn,
).show(context);
// 信息提醒(带标题)
MotionToast.info(
description: '这是一条提醒,可能会有很多行。toast 会自动调整高度显示',
title: '提醒',
titleStyle: TextStyle(fontWeight: FontWeight.bold),
position: MOTION_TOAST_POSITION.bottom,
animationType: ANIMATION.fromBottom,
animationCurve: Curves.linear,
dismissable: true,
).show(context);
不过需要注意的是,一个是 dismissable 参数只对显示位置在底部的有用,当在底部且dismissable为 true 时,点击空白处可以让 toast 提前消失。另外就是显示位置 position 和 animationType 是存在某些互斥关系的。从源码可以看到底部显示的时候,animationType不能是 fromTop,顶部显示的时候 animationType 不能是 fromBottom。
void _assertValidValues() {
assert(
(position == MOTION_TOAST_POSITION.bottom &&
animationType != ANIMATION.fromTop) ||
(position == MOTION_TOAST_POSITION.top &&
animationType != ANIMATION.fromBottom) ||
(position == MOTION_TOAST_POSITION.center),
);
}
自定义 toast
自定义其实就是使用 MotionToast 构建一个实例,其中,description,icon 和 primaryColor参数是必传的。自定义的参数很多,使用的时候建议看一下源码注释。
MotionToast(
description: '这是自定义 toast',
icon: Icons.flag,
primaryColor: Colors.blue,
secondaryColor: Colors.green[300],
descriptionStyle: TextStyle(
color: Colors.white,
),
position: MOTION_TOAST_POSITION.center,
animationType: ANIMATION.fromRight,
animationCurve: Curves.easeIn,
).show(context);
下面对自定义的一些参数做一下解释:
icon:图标,IconData 类,可以使用系统字体图标;primaryColor:主颜色,也就是大的背景底色;secondaryColor:辅助色,也就是图标和旁边的竖条的颜色;descriptionStyle:toast 文字的字体样式;title:标题文字;titleStyle:标题文字样式;toastDuration:显示时长;backgroundType:背景类型,枚举值,共三个可选值,transparent,solid和lighter,默认是lighter。lighter其实就是加了一层白色底色,然后再将原先的背景色(主色调)加上一定的透明度叠加到上面,所以看起来会泛白。onClose:关闭时回调,可以用于出现多个错误时依次展示,或者是关闭后触发某些动作,如返回上一页。
总结
看完之后,是不是觉得以前的 toast 太丑了?用 motion_toast来一个更有趣的吧。另外,整个 motion_toast 的源码并不多,有兴趣的可以读读源码,了解一下toast 的实现也是不错的。
作者:岛上码农
链接:https://juejin.cn/post/7042301322376265742
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2022年为什么要使用Flutter构建应用程序?
今天每个人都想构建一个应用程序,但是谁又能责怪他们呢?事实上,如今每个人都拥有智能手机,它已迅速成为我们白天最常使用的工具。当我们没有它们时,我们会感到缺少一些东西,我们甚至把它们带到洗手间,我们甚至想不出没有它们,如何出门。无论我们喜欢与否,它对我们生活都在进行最快,最积极的影响,而这要归功于应用程序。
应用有一种特殊的方式来吸引用户,而其他事物则没有。这里给大家顺便带一下,我之前写过的一篇文章你想好,如何为你的应用做推广了吗?这可能是由于其漂亮的用户界面,经过深思熟虑的用户体验或完美的可用性。这就是为什么编程可以被认为是一门艺术的全部原因,而Flutter在这里为我们提供了这条道路。
什么是Flutter?
"Flutter是Google的UI工具包,用于从单个代码库为移动,Web和桌面构建美观,可以的应用程序。
Flutter是一个跨平台框架,使开发人员能够从单个代码库在不同的平台上编程。 这为桌面带来了很多优势。
以下是关于Flutter的一些最特点:
- 它是开源的
- 它有一个清晰的文档和一个伟大的社区
- 由谷歌开发
- 它有一个适合一切的小部件
- 提高开发人员的工作效率
- 一个单一的代码库来统治它们
为什么跨平台如此重要?
跨平台开发允许创建与多个操作系统兼容的软件应用程序。通过这种方式,该技术克服了为每个平台构建唯一代码的原始开发困难。
当然,今天开发一个应用程序意味着出现在两个相关操作系统上:Android和iOS。 在过去,这意味着拥有两个代码,两个团队和两倍的成本。多亏了跨平台,我们可以让一个团队从一个代码库为多个平台创建一个应用程序。
毫无疑问,Flutter并不是唯一的跨平台解决方案,我们可以继续讨论其他人如何尝试采取不同的方向,但这是另一篇文章。但是,有一件事是肯定的,那就是:跨平台将继续存在。 这也是2022年为什么要学习Flutter的理由
单个代码库,单个技术栈。
为了继续我要去的地方,如果管理应用程序的开发是困难的,想象一下管理两种不同技术的开发。每个更改都必须在两种不同的技术中编码和批准。团队必须分为两个,iOS团队和Android团队。这就是为什么让一个团队在单个代码库中工作更有益的原因。
Flutter 擅长的地方
*任何软件开发人员都熟悉这个概念,因为我们做出的每一个选择都决定了优点和缺点。因此,再次选择Flutter在您的项目中有利有弊。
在本文中,我想提供有关它的信息,以便在适合您的项目时进行权衡。以下是它的一些好处:
缩短上市时间
Flutter 是一项出色的原型设计技术 - 不仅是 MVP ,还包括具有实际产品功能的应用程序。通过使用Flutter,您将为两个平台(iOS和Android)构建一个应用程序,这可以大大减少开发时间,从而可以更快地将您推向市场。此外,基本上将小部件用于所有内容的可能性以及具有大量可用库的可能性是加快速度的另一个重要因素。
单个开发团队
通过使用Flutter,你可以拥有一个开发团队,而不需要有两个iOS和Android专家团队。您不必担心同步两台计算机,两个代码库,您可以简单地同时在两个平台上发布。
降低开发成本
拥有一个开发团队还有其他好处 ,例如大大降低成本。 这对任何想要构建应用程序的人来说都非常有吸引力,因为进入应用程序市场的经济门槛较低。使其具有成本效益
但是等等,上面说了这么多好处,有什么不利吗
什么时候使用Flutter不方便?
当然,在某些情况下,Flutter并不完全适合您的项目。当这种情况发生时,我们必须简单地接受它,并选择原生开发或其他选择。
例如,如果你的应用需要并且完全依赖于某些特定的硬件设备密集型功能,你可能想要找出是否存在某种Flutter插件。但是,由于它非常新,我强烈建议您进行概念验证,需求分析,以降低技术不是障碍的风险。
此外,还有一些Flutter尚未到达的地方,例如增强现实和3D游戏。在这些情况下,Unity 可能更适合您的项目。请记住,您始终可以尽可能使用 Flutter,然后对于特定的事情使用 native 或 Unity。请记住,将 Flutter 与原生集成始终是一个可用的选项。
想学习另一个技术?
如果你对学习另一种技术有想法,我明白了。但是,请在这里继续等我,让我向您展示它到目前为止是如何演变的:
Flutter的测试版于2018年3月推出,并于2018年12月首次上线。从那时起 ,Flutter稳固了其在市场上的地位,并继续高速崛起。
Flutter社区也在不断发展。Flutter受到大型市场参与者和顶级公司的信任 ,如Google Ads,丰田,还有国内的很多大厂等等。 ,
关于这点你可以去检查你的手机的应用程序,相信会发现很多关于Flutter的踪迹。
最后:
自信地迁移到 Flutter
可以肯定地说,Flutter 有着光明的未来。所以,如果你一直生活在一块石头下并且还没有听说过它,现在就去看看。这是官网flutter.dev/
就我的使用来说,Flutter 不仅达到了我的期望,而且超出了我的期望。这无疑是一项我们从头到尾都爱上的技术。它使我们能够在创纪录的时间内高效地构建应用程序。
这就是我信任 Flutter 的原因。我相信它的未来。我也愿意为此推广Flutter。
作者:大前端之旅
链接:https://juejin.cn/post/7051828127227609124
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我们对 DiffUtil 的使用可能被带偏了
我们对 DiffUtil 的使用可能被带偏了
前面都是我的流水账, 觉得看起来很没劲的, 可以直接跳转到本质小节,.
DiffUtil 的优势
我在最初接触 DiffUtil 时, 心中便对它有颇多的好感, 包括:
- 算法听提来就很nb, 一定是个好东西;
- 简化了
RecyclerView的刷新逻辑, 无须关心该调用notifyItemInserted还是notifyItemChanged, 一律submitList就完事了(虽然notifyDataSetChanged也能做到, 但是性能拉胯, 而且没有动画); LiveData或者Flow监听单一List数据源时, 往往很难知道, 整个List中到底哪些数据项被更新了, 只能调用notifyDataSetChanged方法, 而DiffUtil恰好就能解决这个问题, 无脑submitList就完事了.
DiffUtil 代码示例
使用 DiffUtil 时, 代码大致如下:
data class Item (
var id: Long = 0,
var data: String = ""
)
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
// AsyncListDiffer 类位于 androidx.recyclerview.widget 包下
// 这里以 AsyncListDiffer 的使用来举例, 使用 ListAdapter 或者直接用 DiffUtil, 也存在后面的问题
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
// Kotlin中的 == 运算符, 相当于 Java 中调用 equals 方法
return oldItem == newItem
}
private val payloadResult = Any()
override fun getChangePayload(oldItem: Item, newItem: Item): Any {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult
}
})
class MyViewHolder(val view: View):RecyclerView.ViewHolder(view){
private val dataTv:TextView by lazy{ view.findViewById(R.id.dataTv) }
fun bind(item: Item){
dataTv.text = item.data
}
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): MyViewHolder {
return MyViewHolder(LayoutInflater.from(parent.context).inflate(
R.layout.item_xxx,
parent,
false
))
}
override fun onBindViewHolder(holder: MyViewHolder, position: Int) {
holder.bind(differ.currentList[position])
}
override fun getItemCount(): Int {
return differ.currentList.size
}
public fun submitList(newList: List<Item>) {
differ.submitList(newList)
}
}
val dataList = mutableListOf<Item>(item1, item2)
differ.submitList(dataList)
以上代码的关键在于以下两个方法的实现, 作用分别是:
areItemsTheSame(oldItem: Item, newItem: Item):比较两个 Item 是否表示同一项数据;areContentsTheSame(oldItem: Item, newItem: Item):比较两个 Item 的数据是否相同.
DiffUtil 的踩坑过程
上述示例代码很看起来简单, 也比较好理解, 当我们尝试添加一条数据时:
val dataList = mutableListOf<Item>(item1, item2)
differ.submitList(dataList)
// 增加数据
dataList.add(item3)
differ.submitList(dataList)
发现 item3 并未在界面上显示出来, 怎么回事呢? 我们来看 AsyncListDiffer 关键代码的实现:
public void submitList(@Nullable final List<T> newList) {
submitList(newList, null);
}
public void submitList(@Nullable final List<T> newList, @Nullable final Runnable commitCallback) {
// ...省略无关代码
// 注意这里是 Java 代码, 正在比较 newList 与 mList 是否为同一个引用
if (newList == mList) {
// nothing to do (Note - still had to inc generation, since may have ongoing work)
if (commitCallback != null) {
commitCallback.run();
}
return;
}
// ...省略无关代码
mConfig.getBackgroundThreadExecutor().execute(new Runnable() {
@Override
public void run() {
final DiffUtil.DiffResult result = DiffUtil.calculateDiff(new DiffUtil.Callback() {
// ...省略 newList 和 mList 的 Diff 算法比较代码
});
// ...省略无关代码
mMainThreadExecutor.execute(new Runnable() {
@Override
public void run() {
if (mMaxScheduledGeneration == runGeneration) {
latchList(newList, result, commitCallback);
}
}
});
}
});
}
void latchList(
@NonNull List<T> newList,
@NonNull DiffUtil.DiffResult diffResult,
@Nullable Runnable commitCallback) {
// ...省略无关代码
mList = newList;
// 将结果更新到具体的
diffResult.dispatchUpdatesTo(mUpdateCallback);
// ...省略无关代码
}
可以看到, 单参数的 submitList 方法会调用 双参数的 submitList 方法, 重点在于双参数的submitList 方的实现:
- 首先检查新提交的
newList与内部持有的mList的引用是否相同, 如果相同, 就直接返回; - 如果不同的引用, 就对
newList和mList做Diff算法比较, 并生成比较结果DiffUtil.DiffResult; - 最后通过
latchList方法将newList赋值给mList, 并将Diff算法的结果DiffUtil.DiffResult应用给mUpdateCallback.
最后的
mUpdateCallback, 其实就是上述示例代码中, 创建AsyncListDiffer对象时, 传入的RecyclerView.Adapter对象, 这里就不贴代码了.
浅拷贝
分析代码后, 我们可以知道, 每次 submitList 时, 必须传入不同的 List 对象, 否者方法内部不会做 Diff 算法比较, 而是直接返回, 界面也不会刷新. 需要要不同的 List 是吧? 哪还不简单, 我创建一个新的 List 不就行了?
于是我们修改一下 submitList 方法:
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem == newItem
}
})
// ...省略无关代码
public fun submitList(newList: List<Item>) {
// 创建一个新的 List, 再调用 submitList
differ.submitList(newList.toList())
}
}
相应的测试代码也变成了:
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 增加数据
dataList.add(item3)
diffAdapter.submitList(dataList)
// 删除数据
dataList.removeAt(0)
diffAdapter.submitList(dataList)
// 更新数据
dataList[1].data = "最新的数据"
diffAdapter.submitList(dataList)
运行代码后发现, 单独运行"增加数据"和"删除数据"的测试代码, 表现都是正常的, 唯独"更新数据"单独运行时, 界面毫无反应.
其实仔细想想也能明白, 虽然我们调用 differ.submitList(newList.toList()) 方法时, 确实对 List 做了一份拷贝, 但却是浅拷贝, 真正在运行 Diff 算法比较时, 其实是同一个 Item 对象在自己和自己比较(areContentsTheSame 方法参数的 oldItem 和 newItem 为同一个对象引用), 也就判定为没有数据更新.
data class 的 copy
有的同学,可能有话要说: "你应该在更新 data 字段时, 应该调用 copy 方法, 拷贝一个新的对象, 更新新的值后, 再把原始的 Item 替换掉!".
于是就有了以下代码:
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
dataList[0] = dataList[0].copy(data = "最新的数据")
diffAdapter.submitList(dataList)
运行代码后, "更新数据"也变得正常了, 当业务比较简单时, 也就到此为止了, 没有新的坑来踩了. 但如果业务比较复杂时, 更新数据的代码可能是这样的:
data class InnerItem(
val innerData: String = ""
)
data class Item(
val id: Long = 0,
val data: String = "",
val innerItem: InnerItem = InnerItem()
)
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
val item = dataList[0]
// 内部的数据也不能直接赋值, 需要拷贝一份, 否者和上面的情况类似了
val innerNewItem = item.innerItem.copy(innerData = "内部最新的数据")
dataList[0] = item.copy(innerItem = innerNewItem)
diffAdapter.submitList(dataList)
好像稍微有些复杂的样子, 那如果我们嵌套再深一些呢? 我里面还嵌套了一个List呢? 就要依次递归copy, 代码好像就比较复杂了.
此时我们再回想起开篇提到的 DiffUtil 第 2 点优势要打个疑问了. 本来以为会简化代码, 反而使代码变得更复杂了, 我还不如手动赋值, 然后自己去调用 notifyItemXxx , 代码怕是要简单一些.
深拷贝
于是乎, 为了避免递归copy, 导致更新数据的代码变得过于复杂, 就有了深拷贝的方案. 我管你套了几层, 我先深拷贝一份, 我直接对深拷贝的数据进行修改, 然后直接设置回去, 代码如下:
data class InnerItem(
var innerData: String = ""
)
data class Item(
val id: Long = 0,
var data: String = "",
var innerItem: InnerItem = InnerItem()
)
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
dataList[0] = dataList[0].deepCopy().apply {
innerItem.innerData = "内部最新的数据"
}
diffAdapter.submitList(dataList)
代码看上去又变得简洁了许多, 我们的关注点又来到了深拷贝的如何实现:
利用 Serializable 或者 Parcelable 即可实现对象深拷贝, 具体可自行搜索.
- 使用
Serializable, 代码看起来比较简单, 但是性能稍差; - 使用
Parcelable, 性能好, 但是需要生成更多额外的代码, 看起来不够简洁;
其实选择 Serializable 或者 Parcelable 都无所谓, 看个人喜好即可. 关键在于实现了 Serializable 或者 Parcelable 接口后, Item 中的数据类型会被限制, 要求 Item 中所有的直接或间接字段也必须实现 Serializable Parcelable 接口, 否者就会序列化失败.
比如说, Item 中就不能声明类型为 android.text.SpannableString 的字段(用于显示富文本), 因为 SpannableString 既没有实现 Serializable 接口, 也没有实现 Parcelable 接口.
本质
回过头去, 我们再来审视一下 DiffUtil 两个核心方法:
areItemsTheSame(oldItem: Item, newItem: Item): 比较两个 Item 是否表示同一项数据;
areContentsTheSame(oldItem: Item, newItem: Item): 比较两个 Item 的数据是否相同.
先问个问题, 这两个方法分别为了实现什么目的呢, 或者说他们在算法中起的作用是什么?
简单, 就算不懂 DiffUtil 算法实现(其实是我不懂 o( ̄▽ ̄)o ), 也能猜到, 仅凭 areItemsTheSame 方法我们就能实现以下三种操作:
- itemRemove
- itemInsert
- itemMove
而最后一种 itemChange 操作, 需要 areItemsTheSame 方法先返回 true, 然后调用 areContentsTheSame 方法返回 false, 才能判定为 itemChange 操作, 这也和此方法的注释说明相对应:
This method is called only if {@link #areItemsTheSame(T, T)} returns {@code true} for these items.
所以, areContentsTheSame 方法的作用, 仅仅是为了判定 Item 用于界面显示的部分是否有更新, 而不一定需要调用 equals 方法来全量比较两个item的所有字段. 其实 areContentsTheSame 方法的代码注释也有说明:
This method to check equality instead of {@link Object#equals(Object)} so that you can change its behavior depending on your UI.
For example, if you are using DiffUtil with a {@link RecyclerView.Adapter RecyclerView.Adapter}, you should return whether the items' visual representations are the same.
你会发现, 网上很多教程的代码示例就是用的 equals 来判定数据是否被修改, 然后基于 equals 的比较前提, 更新数据的时候, 又是递归copy, 又是深拷贝, 其实是被带偏了, 思想被限制住了.
改进办法
既然 areItemsTheSame 方法仅用于判定 Item 用于显示的部分是否有更新, 从而判定 itemChange 操作, 那我们完全可以新起一个 contentId 字段, 用于标识内容的唯一性, areItemsTheSame 方法的实现也仅比较 contentId , 代码看起来像这样:
private val contentIdCreator = AtomicLong()
abstract class BaseItem(
open val id: Long,
val contentId: Long = contentIdCreator.incrementAndGet()
)
data class InnerItem(
var innerData: String = ""
)
data class ItemImpl(
override val id: Long,
var data: String = "",
var innerItem: InnerItem = InnerItem()
) : BaseItem(id)
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
// contentId不一致时, 就认为此Item数据有更新
return oldItem.contentId == newItem.contentId
}
private val payloadResult = Any()
override fun getChangePayload(oldItem: Item, newItem: Item): Any {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult
}
})
// ... 省略无关代码
public fun submitList(newList: List<Item>) {
// 创建新的List的浅拷贝, 再调用submitList
differ.submitList(newList.toList())
}
}
val diffAdapter: DiffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
// 仅需copy外层的数据,保证contentId不一致即可, 内部嵌套的数据仅需直接赋值即可
// 由于ItemImpl继承自BaseItem, 当执行ItemImpl.copy方法时, 会调用父类BaseItem的构造方法, 生成新的contentId
dataList[0] = dataList[0].copy().apply {
data = "最新的数据"
innerItem.innerData = "内部最新的数据"
}
diffAdapter.submitList(dataList)
因为 areContentsTheSame 方法执行时,需要不同的两个对象比较,所以有字段更新时,还是需要通过 copy 方法生成新的对象.
这种方式存在误判的可能, 因为
ItemImpl中的一些字段的更新可能不会影响到界面的显示, 此时areContentsTheSame方法应该返回false. 但个人认为这种情况是少数, 误判是可以接受的, 代价仅仅只会额外多更新了一次界面 item 而已.
其实, 了解了本质后, 我们还可以根据自己的业务需求按自己的方式来定制. 比如说用Java该怎么办? 我们也许可以这么做:
class Item{
int id;
boolean isUpdate; // 此字段用于标记此Item是否有更新
String data;
}
class JavaDiffAdapter extends RecyclerView.Adapter<JavaDiffAdapter.MyViewHolder>{
public void submitList(List<Item> dataList){
differ.submitList(new ArrayList<>(dataList));
}
@NonNull
@Override
public MyViewHolder onCreateViewHolder(@NonNull ViewGroup parent, int viewType) {
return new MyViewHolder(LayoutInflater.from(parent.getContext()).inflate(
R.layout.item_xxx,
parent,
false
));
}
@Override
public void onBindViewHolder(@NonNull MyViewHolder holder, int position) {
// 绑定一次数据后, 将需要更新的标识赋值为false
differ.getCurrentList().get(position).isUpdate = false;
holder.bind(differ.getCurrentList().get(position));
}
@Override
public int getItemCount() {
return differ.getCurrentList().size();
}
class MyViewHolder extends RecyclerView.ViewHolder{
private TextView dataTv;
public MyViewHolder(View itemView) {
super(itemView);
dataTv = itemView.findViewById(R.id.dataTv);
}
private void bind(Item item){
dataTv.setText(item.data);
}
}
private AsyncListDiffer<Item> differ = new AsyncListDiffer<Item>(this, new DiffUtil.ItemCallback<Item>() {
@Override
public boolean areItemsTheSame(@NonNull Item oldItem, @NonNull Item newItem) {
return oldItem.id == newItem.id;
}
@Override
public boolean areContentsTheSame(@NonNull Item oldItem, @NonNull Item newItem) {
// 通过读取isUpdate来确定数据是否有更新
return !newItem.isUpdate;
}
private final Object payloadResult = new Object();
@Nullable
@Override
public Object getChangePayload(@NonNull Item oldItem, @NonNull Item newItem) {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult;
}
});
}
// 更新数据
List<Item> dataList = ...;
Item target = dataList.get(0);
// 标识数据有更新
target.isUpdate = true;
target.data = "新的数据";
adapter.submitList(dataList);
最后
其实, 如果我们的 List<Item> 来源于 Room, 其实没有这么多麻烦事, 直接调用 submitList 即可, 不用考虑这里提到的问题, 因为 Room 数据有更新时, 会自动生成新的 List<Item>, 里面的每项 Item 也是新的, 具体代码示例可参考 AsyncListDiffer 或者 ListAdapter 类的顶部的注释. 需要注意的是数据更新太频繁时, 会不会生成了太多的临时对象.
作者:水花DX
链接:https://juejin.cn/post/7054930375675478023
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
快速实现分布式session?厉害了
我们在开发一个项目时通常需要登录认证,常用的登录认证技术实现框架有Spring Security和shiro
Spring Security
Spring Security是一个功能强大且高度可定制的身份验证和访问控制框架。它是保护基于spring的应用程序的事实上的标准。
Spring Security是一个专注于为Java应用程序提供身份验证和授权的框架。与所有Spring项目一样,Spring Security的真正强大之处在于它可以很容易地扩展以满足定制需求,并且Spring Security和spring更加适配贴合,我们工作中常常使用到Spring Security。
Apache Shiro
Apache Shiro 是 Java 的一个安全框架。目前,使用 Apache Shiro 的人越来越多,因为它相当简单,对比Spring Security,可能没有 Spring Security 做的功能强大,但是在实际工作时可能并不需要那么复杂的东西,所以使用小而简单的 Shiro 就足够了。
不足:
这些都是认证技术框架,在单体应用中都是常用的技术框架,但是在分布式中,应用可能要部署多份,这时通过nginx分发请求,但是每个单体应用都要可能重复验证,因为他们的seesion数据是放在他们自己服务中的。
Session作用
Session是客户端与服务器通讯会话跟踪技术,服务器与客户端保持整个通讯的会话基本信息。
客户端在第一次访问服务端的时候,服务端会响应一个sessionId并且将它存入到本地cookie中,在之后的访问会将cookie中的sessionId放入到请求头中去访问服务器。
spring-session
Spring Session是Spring的项目之一,Spring Session把servlet容器实现的httpSession替换为spring-session,专注于解决session管理问题。
Spring Session提供了集群Session(Clustered Sessions)功能,默认采用外置的Redis来存储Session数据,以此来解决Session共享的问题。
spring-session提供对用户session管理的一系列api和实现。提供了很多可扩展、透明的封装方式用于管理httpSession/WebSocket的处理。
支持功能
- 轻易把session存储到第三方存储容器,框架提供了redis、jvm的map、mongo、gemfire、hazelcast、jdbc等多种存储session的容器的方式。这样可以独立于应用服务器的方式提供高质量的集群。
- 同一个浏览器同一个网站,支持多个session问题。 从而能够很容易地构建更加丰富的终端用户体验。
- Restful API,不依赖于cookie。可通过header来传递jessionID 。控制session id如何在客户端和服务器之间进行交换,这样的话就能很容易地编写Restful API,因为它可以从HTTP 头信息中获取session id,而不必再依赖于cookie
- WebSocket和spring-session结合,同步生命周期管理。当用户使用WebSocket发送请求的时候
分布式seesion实战
步骤1:依赖包
因为是web应用。我们加入springboot的常用依赖包web,加入SpringSession、redis的依赖包,移支持把session存储在redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
这里因为是把seesion存储在redis,这样每个服务登录都是去查看redis中数据进行验证的,所有是分布式的。
这里要引入spring-session-data-redis和spring-boot-starter-redis
步骤2:配置文件
spring.application.name=spring-boot-redis
server.port=9090
# 设置session的存储方式,采用redis存储
spring.session.store-type=redis
# session有效时长为15分钟
server.servlet.session.timeout=PT15M
## Redis 配置
## Redis数据库索引
spring.redis.database=1
## Redis服务器地址
spring.redis.host=127.0.0.1
## Redis服务器连接端口
spring.redis.port=6379
## Redis服务器连接密码(默认为空)
spring.redis.password=
步骤3:实现逻辑
初始化用户数据
@Slf4j
@RestController
@RequestMapping(value = "/user")
public class UserController {
Map<String, User> userMap = new HashMap<>();
public UserController() {
//初始化1个用户,用于模拟登录
User u1=new User(1,"user1","user1");
userMap.put("user1",u1);
}
}
这里就不用使用数据库了,初始化两条数据代替数据库,用于模拟登录
登录
@GetMapping(value = "/login")
public String login(String username, String password, HttpSession session) {
//模拟数据库的查找
User user = this.userMap.get(username);
if (user != null) {
if (!password.equals(user.getPassword())) {
return "用户名或密码错误!!!";
} else {
session.setAttribute(session.getId(), user);
log.info("登录成功{}",user);
}
} else {
return "用户名或密码错误!!!";
}
return "登录成功!!!";
}
登录接口,根据用户名和密码登录,这里进行验证,如果验证登录成功,使用 session.setAttribute(session.getId(), user);把相关信息放到session中。
查找用户
/**
* 通过用户名查找用户
*/
@GetMapping(value = "/find/{username}")
public User find(@PathVariable String username) {
User user=this.userMap.get(username);
log.info("通过用户名={},查找出用户{}",username,user);
return user;
}
模拟通过用户名查找用户
获取session
/**
*拿当前用户的session
*/
@GetMapping(value = "/session")
public String session(HttpSession session) {
log.info("当前用户的session={}",session.getId());
return session.getId();
}
退出登录
/**
* 退出登录
*/
@GetMapping(value = "/logout")
public String logout(HttpSession session) {
log.info("退出登录session={}",session.getId());
session.removeAttribute(session.getId());
return "成功退出!!";
}
这里退出时,要把session中的用户信息删除。
步骤4:编写session拦截器
session拦截器的作用:验证当前用户发来的请求是否有携带sessionid,如果没有携带,提示用户重新登录。
@Configuration
public class SecurityInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws IOException {
HttpSession session = request.getSession();
//验证当前session是否存在,存在返回true true代表能正常处理业务逻辑
if (session.getAttribute(session.getId()) != null){
log.info("session拦截器,session={},验证通过",session.getId());
return true;
}
//session不存在,返回false,并提示请重新登录。
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json; charset=utf-8");
response.getWriter().write("请登录!!!!!");
log.info("session拦截器,session={},验证失败",session.getId());
return false;
}
}
步骤5:把拦截器注入到拦截器链中
@Slf4j
@Configuration
public class SessionCofig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new SecurityInterceptor())
//排除拦截的2个路径
.excludePathPatterns("/user/login")
.excludePathPatterns("/user/logout")
//拦截所有URL路径
.addPathPatterns("/**");
}
}
步骤6:测试
登录user1用户:http://127.0.0.1:9090/user/login?username=user1&password=user1
查询user1用户session:http://127.0.0.1:9090/user/session
退出登录: http://127.0.0.1:9090/user/logout
登录后查看redis中数据:
seesion数据已经保存到redis了,到这里我们就整合了使用spring-seesion实现分布式seesion功能。
作者:小伙子vae
链接:https://juejin.cn/post/7054913351503052813
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
你真的了解反射吗?
1. 啥是反射
1.初识反射
刚开始学反射的时候,我是一脸懵逼的,这玩意真的是“抽象的妈妈给抽象开门-抽象到家了。”
为什么创建对象要先获取 Class 对象?这不多此一举吗?我直接 new 一下不是更简单吗?
什么是程序运行时获取类的属性和方法?平时都是程序编译出错了再修改代码,我为什么要考虑程序运行时的状态?
我平时开发也用不到,学这玩意有啥用?
后来学了注解、spring、SpringMVC 等技术之后,发现反射无处不在。
2.JVM 加载类
我们写的 java 程序要放到 JVM 中运行,所以要学习反射,首先需要了解 JVM 加载类的过程。
1.我们写的 .java 文件叫做源代码。
2.我们在一个类中写了一个 main 方法,然后点击 IDEA 的 run 按钮,JVM 运行时会触发 jdk 的 javac 指令将源代码编译成 .class 文件,这个文件又叫做字节码文件。
3.JVM 的类加载器(你可以理解成一个工具)通过一个类的全限定名来获取该类的二进制字节流,然后将该 class 文件加载到 JVM 的方法区中。
4.类加载器加载一个 .class 文件到方法区的同时会在堆中生成一个唯一的 Class 对象,这个 Class 包含这个类的成员变量、构造方法以及成员方法。
5.这个 Class 对象会创建与该类对应的对象实例。
所以表面上你 new 了一个对象,实际上当 JVM 运行程序的时候,真正帮你创建对象的是该类的 Class 对象。
也就是说反射其实就是 JVM 在运行程序的时候将你创建的所有类都封装成唯一一个 Class 对象。这个 Class 对象包含属性、构造方法和成员方法。你拿到了 Class 对象,也就能获取这三个东西。
你拿到了反射之后(Class)的属性,就能获取对象的属性名、属性类别、属性值,也能给属性设置值。
你拿到了反射之后(Class)的构造方法,就能创建对象。
你拿到了反射之后(Class)的成员方法,就能执行该方法。
3.反射的概念
JAVA 反射机制是在程序运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为 java 语言的反射机制。
知道了 JVM 加载类的过程,相信你应该更加深入的了解了反射的概念。
反射:JVM 运行程序 --> .java 文件 --> .class 文件 --> Class 对象 --> 创建对象实例并操作该实例的属性和方法
接下来我就讲一下反射中的相关类以及常用方法。
2. Class 对象
获取 Class 对象
先建一个 User 类:
public class User {
private String name = "知否君";
public String sex = "男";
public User() {
}
public User(String name, String sex) {
this.name = name;
this.sex = sex;
}
public void eat(){
System.out.println("人要吃饭!");
}
private void run(){
System.out.println("人要跑步!");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}获取 Class 对象的三种方式:
1. Class.forName("全类名")
全类名:包名+类名
Class userClass = Class.forName("com.xxl.model.User");
2. 类名.class
Class userClass = User.class;
3. 对象.getClass()
User user = new User();
Class userClass = user.getClass();
尽管有三种方式获取 Class 对象,但是我们一般采用上述第一种方式。
拿到 Class 对象之后,我们就可以操作与它相关的方法了。
3. 获取类名
1.获取完整类名:包名+类名
getName()
Class userClass = Class.forName("com.xxl.model.User");
String name = userClass.getName();
System.out.println(name);
打印结果:
2.获取简单类名:不包括包名
getSimpleName()
Class userClass = Class.forName("com.xxl.model.User");
String simpleName = userClass.getSimpleName();
System.out.println(simpleName);
打印结果:
4. 属性
4.1 获取属性
1.获取所有公有属性:public 修饰
getFields()
Class userClass = Class.forName("com.xxl.model.User");
Field[] fields = userClass.getFields();
for (Field field : fields) {
System.out.println(field);
}
打印结果:
2.获取单个公有属性
getField("属性名")
Class userClass = Class.forName("com.xxl.model.User");
Field field = userClass.getField("sex");
System.out.println(field);
打印结果:
3.获取所有属性:公有+私有
getDeclaredFields()
Class userClass = Class.forName("com.xxl.model.User");
Field[] fields = userClass.getDeclaredFields();
for (Field field : fields) {
System.out.println(field);
}
打印结果:
4.获取单个属性:公有或者私有
getDeclaredField("属性名")
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
Field sexField = userClass.getDeclaredField("sex");
System.out.println(nameField);
System.out.println(sexField);
打印结果:
4.2 操作属性
1.获取属性名称
getName()
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
System.out.println(nameField.getName());
打印结果:
2.获取属性类型
getType()
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
System.out.println(nameField.getType());
打印结果:
3.获取属性值
get(object)
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("sex");
User user = new User();
System.out.println(nameField.get(user));
打印结果:
注: 通过反射不能直接获取私有属性的值,但是可以通过修改访问入口来获取私有属性的值。
设置允许访问私有属性:
field.setAccessible(true);
例如:
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
nameField.setAccessible(true);
User user = new User();
System.out.println(nameField.get(user));
打印方法:
4.设置属性值
set(object,"属性值")
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
nameField.setAccessible(true);
User user = new User();
nameField.set(user,"张无忌");
System.out.println(nameField.get(user));
打印结果:
5. 构造方法
1.获取所有公有构造方法
getConstructors()
Class userClass = Class.forName("com.xxl.model.User");
Constructor[] constructors = userClass.getConstructors();
for (Constructor constructor : constructors) {
System.out.println(constructor);
}
打印结果:
2.获取与参数类型匹配的构造方法
getConstructor(参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Constructor constructor = userClass.getConstructor(String.class, String.class);
System.out.println(constructor);
打印结果:
6. 成员方法
6.1获取成员方法
1.获取所有公共方法
getMethods()
Class userClass = Class.forName("com.xxl.model.User");
Method[] methods = userClass.getMethods();
for (Method method : methods) {
System.out.println(method);
}
打印结果:
我们发现,打印结果除了自定义的公共方法,还有继承自 Object 类的公共方法。
2.获取某个公共方法
getMethod("方法名", 参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getMethod("setName", String.class);
System.out.println(method);
打印结果:
3.获取所有方法:公有+私有
getDeclaredMethods()
Class userClass = Class.forName("com.xxl.model.User");
Method[] declaredMethods = userClass.getDeclaredMethods();
for (Method method : declaredMethods) {
System.out.println(method);
}
打印结果:
4.获取某个方法:公有或者私有
getDeclaredMethod("方法名", 参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getDeclaredMethod("run");
System.out.println(method);
打印结果:
6.2 执行成员方法
invoke(object,"方法参数")
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getDeclaredMethod("eat");
User user = new User();
method.invoke(user);
打印结果:
注: 通过反射不能直接执行私有成员方法,但是可以设置允许访问。
设置允许执行私有方法:
method.setAccessible(true);
7. 注解
1.判断类上或者方法上时候包含某个注解
isAnnotationPresent(注解名.class)
例如:
Class userClass = Class.forName("com.xxl.model.User");
if(userClass.isAnnotationPresent(Component.class)){
Component annotation = (Component)userClass.getAnnotation(Component.class);
String value = annotation.value();
System.out.println(value);
};
2.获取注解
getAnnotation(注解名.class)
例如:
Class userClass = Class.forName("com.xxl.model.User");
// 获取类上的注解
Annotation annotation1 = userClass.getAnnotation(Component.class);
Method method = userClass.getMethod("eat");
// 获取方法上的某个注解
Annotation annotation2 = userClass.getAnnotation(Component.class);
8. 创建类的实例
1.通过 Class 实例化对象
Class.newInstance()
Class userClass = Class.forName("com.xxl.model.User");
User user = (User)userClass.newInstance();
System.out.println("姓名:"+user.getName()+" 性别:"+user.getSex());
打印结果:
2.通过构造方法实例化对象
constructor.newInstance(参数值)
Class userClass = Class.forName("com.xxl.model.User");
Constructor constructor = userClass.getConstructor(String.class, String.class);
User user = (User)constructor.newInstance\("李诗情", "女"\);
System.out.println("姓名:"+user.getName()+" 性别:"+user.getSex());
打印结果:
9. 反射案例
有一天技术总监对张三说:"张三,听说你最近学反射了呀。那你设计一个对象的工厂类给我看看。"
张三心想:"哟,快过年了,领导这是要给我涨工资啊。这次我一定好好表现一次。"
5分钟过后,张三提交了代码:
public class ObjectFactory {
public static User getUser() {
User user = null;
try {
Class userClass = Class.forName("com.xxl.model.User");
user = (User) userClass.newInstance();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
return user;
}
public static UserService getUserService() {
UserService userService = null;
try {
Class userClass = Class.forName("com.xxl.service.impl.UserServiceImpl");
userService = (UserService) userClass.newInstance();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
return userService;
}
}
技术总监瞄了一眼代码,对张三说:"你这个工厂类存在两个问题。"
1.代码存在大量冗余。如果有一万个类,你是不是要写一万个静态方法?
2.代码耦合度太高。如果这些类存放的包路径发生改变,你再用 forName()获取 Class 对象是不是就会有问题?你还要一个个手动改代码,然后再编译、打包、部署。。你不觉得麻烦吗?
“发散你的思维想一下,能不能只设计一个静态类,通过传参的方式用反射创建对象,传递的参数要降低和工厂类的耦合度。顺便提醒你一下,可以参考一下 JDBC 获取数据库连接参数的方式。”
张三一听:"不愧是总监啊,醍醐灌顶啊!等我 10 分钟。"
10 分钟后,张三再次提交了代码:
object.properties
user=com.xxl.model.User
userService=com.xxl.service.impl.UserServiceImpl
ObjectFactory
public class ObjectFactory {
private static Properties objectProperty = new Properties();
// 静态方法在类初始化时执行,且只执行一次
static{
try {
InputStream inputStream = ObjectFactory.class.getResourceAsStream("/object.properties");
objectProperty.load(inputStream);
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static Object getObject(String key){
Object object = null;
try {
Class objectClass = Class.forName(objectProperty.getProperty(key));
object = objectClass.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return object;
}
}
测试方法:
@Test
void testObject() {
User user = (User)ObjectFactory.getObject("user");
UserService userService = (UserService)ObjectFactory.getObject("userService");
System.out.println(user);
System.out.println(userService);
}
执行结果:
总监看后连连点头,笑着对张三说:“用 properties 文件存放类的全限定名降低了代码的耦合度,通过传参的方式使用反射创建对象又降低了代码的冗余性,这次改的可以。"
"好啦,今晚项目要上线,先吃饭去吧,一会还要改 bug。”
张三:"..........好的总监。"
10. 反射的作用
我们或多或少都听说过设计框架的时候会用到反射,例如 Spring 的 IOC
就用到了工厂模式和反射来创建对象,BeanUtils 的底层也是使用反射来拷贝属性。所以反射无处不在。
尽管我们日常开发几乎用不到反射,但是我们必须要搞懂反射的原理,因为它能帮我们理解框架设计的原理。
作者:知否技术
链接:https://juejin.cn/post/7055090668619694094
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
HashMap除了死循环之外,还有什么问题?
本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类:
- 程序问题:比如 HashMap 在 JDK 1.7 中,并发插入时可能会发生死循环或数据覆盖的问题。
- 业务问题:比如 HashMap 无序性造成查询结果和预期结果不相符的问题。
接下来我们一个一个来看。
1.死循环问题
死循环问题发生在 JDK 1.7 版本中,形成的原因是 JDK 1.7 HashMap 使用的是头插法,那么在并发扩容时可能就会导致死循环的问题,具体产生的过程如下流程所示。
HashMap 正常情况下的扩容实现如下图所示:
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?
1.1 死循环执行流程一
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,如下图所示:
1.2 死循环执行流程二
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示:
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
1.3 死循环执行流程三
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示:
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
1.4 解决方案
使用线程安全的容器来替代 HashMap,比如 ConcurrentHashMap 或 Hashtable,因为 ConcurrentHashMap 的性能远高于 Hashtable,因此推荐使用 ConcurrentHashMap 来替代 HashMap。
2.数据覆盖问题
数据覆盖问题发生在并发添加元素的场景下,它不止出现在 JDK 1.7 版本中,其他版本中也存在此问题,数据覆盖产生的流程如下:
- 线程 T1 进行添加时,判断某个位置可以插入元素,但还没有真正的进行插入操作,自己时间片就用完了。
- 线程 T2 也执行添加操作,并且 T2 产生的哈希值和 T1 相同,也就是 T2 即将要存储的位置和 T1 相同,因为此位置尚未插入值(T1 线程执行了一半),于是 T2 就把自己的值存入到当前位置了。
- T1 恢复执行之后,因为非空判断已经执行完了,它感知不到此位置已经有值了,于是就把自己的值也插入到了此位置,那么 T2 的值就被覆盖了。
具体执行流程如下图所示。
2.1 数据覆盖执行流程一
线程 T1 准备将数据 k1:v1 插入到 Null 处,但还没有真正的执行,自己的时间片就用完了,进入休眠状态了,如下图所示:
2.2 数据覆盖执行流程二
线程 T2 准备将数据 k2:v2 插入到 Null 处,因为此处现在并未有值,如果此处有值的话,它会使用链式法将数据插入到下一个没值的位置上,但判断之后发现此处并未有值,那么就直接进行数据插入了,如下图所示:
2.3 数据覆盖执行流程三
线程 T2 执行完成之后,线程 T1 恢复执行,因为线程 T1 之前已经判断过此位置没值了,所以会直接插入,此时线程 T2 插入的值就被覆盖了,如下图所示:
2.4 解决方案
解决方案和第一个解决方案相同,使用 ConcurrentHashMap 来替代 HashMap 就可以解决此问题了。
3.无序性问题
这里的无序性问题指的是 HashMap 添加和查询的顺序不一致,导致程序执行的结果和程序员预期的结果不相符,如以下代码所示:
HashMap<String, String> map = new HashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
我们添加的顺序:
我们期望查询的顺序和添加的顺序是一致的,然而以上代码输出的结果却是:
执行结果和我们预期结果不相符,这就是 HashMap 的无序性问题。我们期望输出的结果是 Hello,Java 1、2、3、4、5,而得到的顺序却是 2、1、4、3、5。
解决方案
想要解决 HashMap 无序问题,我们只需要将 HashMap 替换成 LinkedHashMap 就可以了,如下代码所示:
LinkedHashMap<String, String> map = new LinkedHashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});以上程序的执行结果如下图所示:
总结
本文演示了 3 个 HashMap 的经典问题,其中死循环和数据覆盖是发生在并发添加元素时,而无序问题是添加元素的顺序和查询的顺序不一致的问题,这些问题本质来说都是对 HashMap 使用不当才会造成的问题,比如在多线程情况下就应该使用 ConcurrentHashMap,想要保证插入顺序和查询顺序一致就应该使用 LinkedHashMap,但刚开始时我们对 HashMap 不熟悉,所以才会造成这些问题,不过了解了它们之后,就能更好的使用它和更好的应对面试了。
作者:Java中文社群
链接:https://juejin.cn/post/7055084070790758436
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
还在用策略模式解决 if-else?Map+函数式接口方法才是YYDS!
本文介绍策略模式的具体应用以及Map+函数式接口如何 “更完美” 的解决 if-else的问题。
需求
最近写了一个服务:根据优惠券的类型resourceType和编码resourceId来 查询 发放方式grantType和领取规则
实现方式:
根据优惠券类型resourceType -> 确定查询哪个数据表
根据编码resourceId -> 到对应的数据表里边查询优惠券的派发方式grantType和领取规则
优惠券有多种类型,分别对应了不同的数据库表:
红包 —— 红包发放规则表
购物券 —— 购物券表
QQ会员
外卖会员
实际的优惠券远不止这些,这个需求是要我们写一个业务分派的逻辑
第一个能想到的思路就是if-else或者switch case:
switch(resourceType){
case "红包":
查询红包的派发方式
break;
case "购物券":
查询购物券的派发方式
break;
case "QQ会员" :
break;
case "外卖会员" :
break;
......
default : logger.info("查找不到该优惠券类型resourceType以及对应的派发方式");
break;
}如果要这么写的话, 一个方法的代码可就太长了,影响了可读性。(别看着上面case里面只有一句话,但实际情况是有很多行的)
而且由于 整个 if-else的代码有很多行,也不方便修改,可维护性低。
策略模式
策略模式是把 if语句里面的逻辑抽出来写成一个类,如果要修改某个逻辑的话,仅修改一个具体的实现类的逻辑即可,可维护性会好不少。
以下是策略模式的具体结构(详细可看这篇博客: 策略模式.):

策略模式在业务逻辑分派的时候还是if-else,只是说比第一种思路的if-else 更好维护一点。。。
switch(resourceType){
case "红包":
String grantType=new Context(new RedPaper()).ContextInterface();
break;
case "购物券":
String grantType=new Context(new Shopping()).ContextInterface();
break;
......
default : logger.info("查找不到该优惠券类型resourceType以及对应的派发方式");
break;但缺点也明显:
如果 if-else的判断情况很多,那么对应的具体策略实现类也会很多,上边的具体的策略实现类还只是2个,查询红包发放方式写在类RedPaper里边,购物券写在另一个类Shopping里边;那资源类型多个QQ会员和外卖会员,不就得再多写两个类?有点麻烦了
没法俯视整个分派的业务逻辑
Map+函数式接口
用上了Java8的新特性lambda表达式
判断条件放在key中
对应的业务逻辑放在value中
这样子写的好处是非常直观,能直接看到判断条件对应的业务逻辑
需求: 根据优惠券(资源)类型resourceType和编码resourceId查询派发方式grantType
上代码:
@Service
public class QueryGrantTypeService {
@Autowired
private GrantTypeSerive grantTypeSerive;
private Map<String, Function<String,String>> grantTypeMap=new HashMap<>();
/**
* 初始化业务分派逻辑,代替了if-else部分
* key: 优惠券类型
* value: lambda表达式,最终会获得该优惠券的发放方式
*/
@PostConstruct
public void dispatcherInit(){
grantTypeMap.put("红包",resourceId->grantTypeSerive.redPaper(resourceId));
grantTypeMap.put("购物券",resourceId->grantTypeSerive.shopping(resourceId));
grantTypeMap.put("qq会员",resourceId->grantTypeSerive.QQVip(resourceId));
}
public String getResult(String resourceType){
//Controller根据 优惠券类型resourceType、编码resourceId 去查询 发放方式grantType
Function<String,String> result=getGrantTypeMap.get(resourceType);
if(result!=null){
//传入resourceId 执行这段表达式获得String型的grantType
return result.apply(resourceId);
}
return "查询不到该优惠券的发放方式";
}
}如果单个 if 语句块的业务逻辑有很多行的话,我们可以把这些 业务操作抽出来,写成一个单独的Service,即:
//具体的逻辑操作
@Service
public class GrantTypeSerive {
public String redPaper(String resourceId){
//红包的发放方式
return "每周末9点发放";
}
public String shopping(String resourceId){
//购物券的发放方式
return "每周三9点发放";
}
public String QQVip(String resourceId){
//qq会员的发放方式
return "每周一0点开始秒杀";
}
}入参String resourceId是用来查数据库的,这里简化了,传参之后不做处理。
用http调用的结果:
@RestController
public class GrantTypeController {
@Autowired
private QueryGrantTypeService queryGrantTypeService;
@PostMapping("/grantType")
public String test(String resourceName){
return queryGrantTypeService.getResult(resourceName);
}
}
用Map+函数式接口也有弊端:
你的队友得会lambda表达式才行啊,他不会让他自己百度去
最后捋一捋本文讲了什么:
策略模式通过接口、实现类、逻辑分派来完成,把 if语句块的逻辑抽出来写成一个类,更好维护。
Map+函数式接口通过
Map.get(key)来代替 if-else的业务分派,能够避免策略模式带来的类增多、难以俯视整个业务逻辑的问题。————————————————
作者:zhongh Jim
来源:https://blog.csdn.net/qq_44384533/article/details/109197926
DDD划分领域、子域、核心域、支撑域的目的
名词解释
在DDD兴起的原因以及与微服务的关系中曾举了一个研究桃树的例子,如果要研究桃树,将桃树根据器官分成根、茎、叶、花、果实、种子,这每一种器官都可以认为是一个研究领域,而领域又有更加具体的细分,分成子域、核心域、通用域、支撑域等,下面回顾桃树这个例子

看上面这张图 ,如果研究桃树是我们的业务,那么如何更加快速有效的研究桃树呢? 根据回忆,初中课本是这样研究的:
第一步: 确定研究的对象,即研究领域 ,这里是一棵桃树。
第二步: 根据研究对象的某些维度,对其进行进一步的拆分,例如拆分成器官,而器官又可以分成营养器官,生殖器官,其中营养器官包括根、茎、叶,生殖器官包括花、果实、种子,那么这些就是我们要研究的子域。
第三步: 现在就可以最子域进行划分了,找出核心域,通用域,支撑域,至于为什么要这么划分,后面再解释,当我们找到核心域之后,再各个子域进行深一步的划分,划分成组织,例如分成保护组织,营养组织,疏导组织,这就儿也可以理解成将领域继续划分为子域的过程。
第四步:对组织进行进一步的划分,可以分成细胞,例如根毛细胞、导管细胞等等
我们有没有必要继续拆分细胞呢?这个取决于我们研究的业务,例如在之前光学显微镜时,研究到细胞也就截止了,具体到其他业务,也是研究到某一步就不需要继续拆分,而这最小层次的领域,通常就是我们所说的实体,聚合、聚合根、实体以及值对象等内容会在后面深入了解。

下面归纳一下上面提到的几个名词的概念 :
领域: 往往就是业务的某一个部分 , 例如电商的销售部分、物流部分、供应链部分等, 这些对于电商来说就是各个领域(模块),领域主要作用就是用来驱动范围, DDD 会将问题范围限定在特定的边界内,在这个边界内建立领域模型,进而用代码实现该领域模型,解决相应的业务问题。简言之,DDD 的领域就是这个边界内要解决的业务问题域。
子域:相对的一个概念, 我们可以将领域进行进一步的划分 , 这时候就是子域, 甚至可以对子域继续划分形成 子子域(依旧叫子域),就好比当我们研究植物时,如果研究的对象是桃树,那么果实根茎叶是领域,可是如果不仅仅要研究果实,还要研究组织甚至细胞,那么研究的就是果实的子域、组织的子域。
核心域:所有领域中最关键的部分 , 什么意思呢, 就是最核心的部分, 对于业务来说, 核心域是企业根本竞争力, 也是创造利润里最关键的部分 , 例如电商里面那么多领域, 最重要的是什么? 就是销售系统, 无论你是2B还是2C, 还是PDD ,这些核心模块就是核心域。
通用域:除了核心域之外, 还需要自己做的一些领域, 例如鉴权、日志等, 特点是可能被多个领域公用的部分。
支撑域:系统中业务分析阶段最不重点关注的领域, 也就是非核心域非通用域的领域, 例如电商里面的支付、物流,仅仅是为了支撑业务的运转而存在, 甚至可以去购买别人的服务, 这类的领域就是支撑域。
需要注意的是,这些名词在实际的微服务设计和开发过程中不一定用得上,但是可以帮助理解DDD的核心设计思想以及理念,而这些思想和理念在实际的IT战略设计业务建模和微服务设计上都是可以借鉴的。
为什么要划分核心域、通用域、支撑域 ?
通过上面可以知道,决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。没有太多个性化的诉求,同时被多个子域使用的通用功能子域是通用域。还有一种功能子域是必需的,但既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,它就是支撑域。
这三类子域相较之下,核心域是最重要的,我们下面讲目的的时候还会以核心域为例详细介绍。通用域和支撑域如果对应到企业系统,举例来说的话,通用域则是你需要用到的通用系统,比如认证、权限等等,这类应用很容易买到,没有企业特点限制,不需要做太多的定制化。而支撑域则具有企业特性,但不具有通用性,例如数据代码类的数据字典等系统。
那么为什么要划分出这些新的名词呢? 先想一个问题,对于桃树而言,根、茎、叶、花、果实、种子六个领域哪一个是核心域?
是不是有不同的理解? 有人说是种子,有人说是根,有人说是叶子,也有人说是茎等等,为什么会有这种情况呢?
因为每个人站的角度不一样,你如果是果农,那么果实就是核心域,你的大部分操作应该都是围绕提高果实产量进行,如果你是景区管理员,那么芳菲四月桃花盛开才是你重点关注,如果比是林场工作人员,那么树干才应该是你重点关注的领域,看到没,对于同一个领域划分的子域,每个人都有不同的理解,那么要通过讨论确定核心域,确保大家认同一致,对于实际业务开发来说,参与的人员众多,有业务方面的,有架构师,有后端开发人员,营销市场等等,势必要最开始就确定我们的核心域,除了统一大家的认识之外还有什么好处呢?
对于一个企业来说,预算以及时间是有限的,也就意味着时间以及精力甚至金钱要尽可能多的花在核心的的地方。就好比电商,电商企业那么多,每一家核心域都有所差别,造成的市场结果也千差万别,那么公司战略重点和商业模式应该找到核心域,且重点关注核心域。
总的来说,核心域、支撑域和通用域的主要目标是:通过领域划分,区分不同子域在公司内的不同功能
属性和重要性,从而公司可对不同子域采取不同的资源投入和建设策略,其关注度也会不一样。
作者:等不到的口琴
来源:https://www.cnblogs.com/Courage129/p/14853600.html
Android 启动优化杂谈 | 另辟蹊径
新年快乐
新年伊始,万象更新,虾哥开卷,天下无敌。
首先感谢各位大佬的支持,今年终于喜提掘金优秀作者了。
给各位大佬跪了,祝各位安卓同学新年快乐啊。
开篇
先介绍下徐公大佬的文章,如果有前置需要的话建议看下这个系列。
启动优化这个系列都可以好好看看,感谢徐公大佬。
本文将不发表任何关于 有向无环图(DAG) 相关,会更细致的说一些我自己的奇怪的观点,以及从一些问题出发,介绍如何做一些有意思的调整。
当前仓库还处于一个迭代状态中,并不是一个特别稳定的状态,所以文章更多的是给大家打开一些小思路。
有想法的同学可以留言啊,我个人感觉一个迭代库才是可以持续演进的啊。
demo 地址 AndroidStartup
demo中很多代码参考了android-startup,感谢这位大佬,u1s1这位大佬很强啊。
Task粒度
这一点其实蛮重要的,相信很多人在接入启动框架之后,更多的事情是把原来可以用的代码,直接用几个Task的把之前的代码包裹起来,之后然后这样就相当于完成了简单的启动框架接入了。
其实这个基本算是违背了启动框架设计的初衷了。我先抛出一个观点,启动框架并不会真实帮你加快多少启动速度,他解决的场景只是让你的sdk的初始化更加的有序,让你可以在长时间的迭代过程中,可以更加稳妥的添加一些新的sdk。
举个栗子,当你的埋点框架依赖了网络库,abtest配置中心也依赖了网络库,然后网络库则依赖了dns等等,之后所有的业务依赖了埋点配置中心图片库等等sdk的初始化完成之后。
当然还是有极限情况下会出现依赖成环问题,这个时候可能就需要开发同学手动的把这个依赖问题给解决了 比如特殊情况网络库需要唯一id,上报库依赖了网络库,而上报库又依赖了唯一id,唯一id又需要进行数据上报
所以我个人的看法启动框架的粒度应该细化到每个sdk的初始化,如果粒度可以越细致当然就越好了。其实一般的启动框架都会对每个task的耗时进行统计的,这样我们后续在跟进对应的问题也会变的更简便,比如查看某些的任务耗时是否增加了啊之类的。
当前我们在设计的时候可能会把一个sdk的初始化拆分成三个部分去做,就是为了去解决这种依赖成环的问题。
子线程间的等待
之前发现项目内的启动框架只保证了放入线程的时候的顺序是按照dag执行的。如果只有主线程和池子大小为1线程池的情况下,这种是ok的。但是如果多线程并发的情况下,这个就变成了一个危险操作了。
所以我们需要在并发场景下加上一个等待的情况下,一定要等到依赖的任务完成了之后,才能继续向下执行初始化代码。
机制的话还是使用CountDownLatch,当依赖的任务都执行完成之后,await会被释放,继续向下执行。而设计上我还是采取了装饰者,不需要使用方更改原始的逻辑就能继续使用了。
代码如下,主要就是一次任务完成的分发,之后发现当前的依赖是有该任务的则latch-1. 当latch到0的情况下就会释放当前线程了。
class StartupAwaitTask(val task: StartupTask) : StartupTask {
private var dependencies = task.dependencies()
private lateinit var countDownLatch: CountDownLatch
private lateinit var rightDependencies: List
var awaitDuration: Long = 0
override fun run(context: Context) {
val timeUsage = SystemClock.elapsedRealtime()
countDownLatch.await()
awaitDuration = (SystemClock.elapsedRealtime() - timeUsage) / 1000
KLogger.i(
TAG, "taskName:${task.tag()} await costa:${awaitDuration} "
)
task.run(context)
}
override fun dependencies(): MutableList {
return dependencies
}
fun allTaskTag(tags: HashSet) {
rightDependencies = dependencies.filter { tags.contains(it) }
countDownLatch = CountDownLatch(rightDependencies.size)
}
fun dispatcher(taskName: String) {
if (rightDependencies.contains(taskName)) {
countDownLatch.countDown()
}
}
override fun mainThread(): Boolean {
return task.mainThread()
}
override fun await(): Boolean {
return task.await()
}
override fun tag(): String {
return task.tag()
}
override fun onTaskStart() {
task.onTaskStart()
}
override fun onTaskCompleted() {
task.onTaskCompleted()
}
override fun toString(): String {
return task.toString()
}
companion object {
const val TAG = "StartupAwaitTask"
}
}
这个算是一个能力的补充完整,也算是多线程依赖必须要完成的一部分。
同时将依赖模式从class变更成tag的形式,但是这个地方还没完成最后的设计,当前还是有点没想好的。主要是解决组件化情况下,可以更随意一点。
线程池关闭
这里是我个人考虑哦,当整个启动流程结束之后,默认情况下是不是应该考虑把线程池关闭了呢。我发现很多都没有写这些的,会造成一些线程使用的泄漏问题。
fun dispatcherEnd() {
if (executor != mExecutor) {
KLogger.i(TAG, "auto shutdown default executor")
mExecutor.shutdown()
}
}
代码如上,如果当前线程池并不是传入的线程池的情况下,考虑执行完毕之后关闭线程池。
dsl + 锚点
因为我既是开发人员,同时也是框架的使用方。所以我自己在使用的过程中发现原来的设计上问题还是很多的,我自己想要插入一个在所有sdk完成之后的任务非常不方便。
然后我就考虑这部分通过dsl的方式去写了动态添加task。kotlin是真的很香,如果后续开发没糖我估计就是个废人了。
我就是死从这里跳下去,卧槽语法糖真香。
fun Application.createStartup(): Startup.Builder = run {
startUp(this) {
addTask {
simpleTask("taskA") {
info("taskA")
}
}
addTask {
simpleTask("taskB") {
info("taskB")
}
}
addTask {
simpleTask("taskC") {
info("taskC")
}
}
addTask {
simpleTaskBuilder("taskD") {
info("taskD")
}.apply {
dependOn("taskC")
}.build()
}
addTask("taskC") {
info("taskC")
}
setAnchorTask {
MyAnchorTask()
}
addTask {
asyncTask("asyncTaskA", {
info("asyncTaskA")
}, {
dependOn("asyncTaskD")
})
}
addAnchorTask {
asyncTask("asyncTaskB", {
info("asyncTaskB")
}, {
dependOn("asyncTaskA")
await = true
})
}
addAnchorTask {
asyncTaskBuilder("asyncTaskC") {
info("asyncTaskC")
sleep(1000)
}.apply {
await = true
dependOn("asyncTaskE")
}.build()
}
addTaskGroup { taskGroup() }
addTaskGroup { StartupTaskGroupApplicationKspMain() }
addMainProcTaskGroup { StartupTaskGroupApplicationKspAll() }
addProcTaskGroup { StartupProcTaskGroupApplicationKsp() }
}
}
这种DSL写法适用于插入一些简单的任务,可以是一些没有依赖的任务,也可以是你就是偷懒想这么写。好处就是可以避免自己用继承等的形式去写过多冗余的代码,然后在这个启动流程内能看到自己做了些什么事情。
一般等到项目稳定之后,会设立几个锚点任务。他们的作用是后续任务只要挂载到锚点任务之后执行即可,定下一些标准,让后续的同学可以更快速的接入。
我们会把这些设置成一些任务组设置成基准,比如说是网络库,图片库,埋点框架,abtest等等,等到这些任务完成之后,别的业务代码就可以在这里进行初始化了。这样就不需要所有人都写一些基础的依赖关系,也可以让开发同学舒服一点点。
怎么又成环了
在之前的排序阶段,存在一个非常鬼畜的问题,如果你依赖的任务并不在当前的图中存在,就会报出依赖成环问题,但是你并不知道是因为什么原因成环的。
这个就非常不方便开发同学调试问题了,所以我增加了前置任务有效性判断,如果不存在的则会直接打印Log日志,也增加了debugmode,如果测试情况下可以直接已任务不存在的崩溃结束。
ksp
我想偷懒所以用ksp生成了一些代码,同时我希望我的启动框架也可以应用于项目的组件化和插件化中,这样反正就是牛逼啦。
启动任务分组
当前完成的一个功能就是通过注解+ksp生成一个启动任务的分组,这次ksp的版本我们采用的是1.5.30的版本,同时api也有了一些变更。
之前在ksp的文章说过process死循环的问题,最近和米忽悠乌蝇哥交流(吹牛)的时候发现,系统提供一个finish方法,因为process的时候只要有类生成就会重新出发process方法,导致stackoverflow,所以后续代码生成可以考虑迁移到新方法内。
class StartupProcessor(
val codeGenerator: CodeGenerator,
private val logger: KSPLogger,
val moduleName: String
) : SymbolProcessor {
private lateinit var startupType: KSType
private var isload = false
private val taskGroupMap = hashMapOf>()
private val procTaskGroupMap =
hashMapOf>>>()
override fun process(resolver: Resolver): List {
logger.info("StartupProcessor start")
val symbols = resolver.getSymbolsWithAnnotation(StartupGroup::class.java.name)
startupType = resolver.getClassDeclarationByName(
resolver.getKSNameFromString(StartupGroup::class.java.name)
)?.asType() ?: kotlin.run {
logger.error("JsonClass type not found on the classpath.")
return emptyList()
}
symbols.asSequence().forEach {
add(it)
}
return emptyList()
}
private fun add(type: KSAnnotated) {
logger.check(type is KSClassDeclaration && type.origin == Origin.KOTLIN, type) {
"@JsonClass can't be applied to $type: must be a Kotlin class"
}
if (type !is KSClassDeclaration) return
//class type
val routerAnnotation = type.findAnnotationWithType(startupType) ?: return
val groupName = routerAnnotation.getMember("group")
val strategy = routerAnnotation.arguments.firstOrNull {
it.name?.asString() == "strategy"
}?.value.toString().toValue() ?: return
if (strategy.equals("other", true)) {
val key = groupName
if (procTaskGroupMap[key] == null) {
procTaskGroupMap[key] = mutableListOf()
}
val list = procTaskGroupMap[key] ?: return
list.add(type.toClassName() to (routerAnnotation.getMember("processName")))
} else {
val key = "${groupName}${strategy}"
if (taskGroupMap[key] == null) {
taskGroupMap[key] = mutableListOf()
}
val list = taskGroupMap[key] ?: return
list.add(type.toClassName())
}
}
private fun String.toValue(): String {
var lastIndex = lastIndexOf(".") + 1
if (lastIndex <= 0) {
lastIndex = 0
}
return subSequence(lastIndex, length).toString().lowercase().upCaseKeyFirstChar()
}
// 开始代码生成逻辑
override fun finish() {
super.finish()
// logger.error("className:${moduleName}")
try {
taskGroupMap.forEach { it ->
val generateKt = GenerateGroupKt(
"${moduleName.upCaseKeyFirstChar()}${it.key.upCaseKeyFirstChar()}",
codeGenerator
)
it.value.forEach { className ->
generateKt.addStatement(className)
}
generateKt.generateKt()
}
procTaskGroupMap.forEach {
val generateKt = GenerateProcGroupKt(
"${moduleName.upCaseKeyFirstChar()}${it.key.upCaseKeyFirstChar()}",
codeGenerator
)
it.value.forEach { pair ->
generateKt.addStatement(pair.first, pair.second)
}
generateKt.generateKt()
}
} catch (e: Exception) {
logger.error(
"Error preparing :" + " ${e.stackTrace.joinToString("\n")}"
)
}
}
}
class StartupProcessorProvider : SymbolProcessorProvider {
override fun create(
environment: SymbolProcessorEnvironment
): SymbolProcessor {
return StartupProcessor(
environment.codeGenerator,
environment.logger,
environment.options[KEY_MODULE_NAME] ?: "application"
)
}
}
fun String.upCaseKeyFirstChar(): String {
return if (Character.isUpperCase(this[0])) {
this
} else {
StringBuilder().append(Character.toUpperCase(this[0])).append(this.substring(1)).toString()
}
}
const val KEY_MODULE_NAME = "MODULE_NAME"
其中processor被拆分成两部分,SymbolProcessorProvider负责构造,SymbolProcessor则负责处理ast逻辑。以前的initapi 被移动到SymbolProcessorProvider中了。
逻辑也比较简单,收集注解,然后基于注解的入参生成一个taskGroup逻辑。这个组会被我手动加入到启动流程内。
未完成
另外我想做的一件事就是通过注解来去生成一个Task任务,然后通过不同的注解的排列组合,组合出一个新的task任务。
这部分功能还在设计中,后续完成之后再给大家水一篇好了。
调试组件
这部分是我最近设计的重中之重了。当接了启动框架这个活之后,更多的时候你是需要去追溯启动变慢的问题的,我们把这种情况叫做劣化。如何快速定位劣化问题也是启动框架所需要关心的。
一开始我们打算通过日志上报,之后在版本发布之后重新推导线上的任务耗时,但是因为计算出来的是平均值,而且我们的自动化测试同学每个版本发布前都会跑自动化case,观察启动时间的状况,如果时间均值变长就会来通知我们,这个时候看埋点数据其实挺难发现问题的。
核心原因还是我想偷懒,因为排查问题必须要基于之前的版本和当前版本进行对比,比较各个task之间的耗时状况,我们当前大概应该有30+的启动任务,这尼玛不是要了我老命了吗。
所以我和我大佬沟通了下,就对这部分进行了立项,打算折腾一个调试工具,可以记录下启动任务的耗时,还有启动任务的列表,通过本地对比的形式,可以快速推导出出现问题任务,方便我们快速定位问题。
小贴士 调试工具的开发最好不要有太多的依赖 然后通过debug 的buildtype来加入 所以使用了contentprovider来初始化
启动时间轴
江湖上一直流传着我的外号-ui大湿,在下也不是浪得虚名,ui大湿画出来的图形那叫一个美如画啊。
这部分原理比较简单,我们把当前启动任务的数据进行了收集,然后根据线程名进行分发,记录任务开始和结束的节点,然后通过图形化进行展示。
如果你第一时间看不懂,可以参考下自选股列表,每一列都是代表一个线程执行的时间轴。
启动顺序是否变更
我们会在每次启动的时候将当前启动的顺序进行数据库记录,然后通过数据库找出和当前hashcode不一样的任务,然后比对下用textview的形式展示出来,方便测试同学反馈问题。
这个地方的原理的,我是将整个启动任务通过字符串拼接,然后生成一个字符串,之后通过字符串的hashcode作为唯一标识符,不同字符串生成的hashcode也是不同的。
这里有个傻事就是我一开始对比的是stringbuilder的hashcode,然后发现一样的任务竟然值变更了,我真傻真的。
别问,问就是ui大湿,textview不香?
平均任务耗时
这个地方的数据库设计让我思考了好一会,之后我按照天为维度,之后记录时间和次数,然后在渲染的时候取出均值。
之后把之前的历史数据取出来,然后进行汇总统计,之后重新生成list,一个当前task下面跟随一个历史的task。然后进行牛逼的ui渲染。
这个时候你要喷了啊,为什么你全部都是textview还自称ui大湿啊。
虾扯蛋你听过吗,没错就是这样的。
总结
卷来,天不生我逮虾户,卷道万古长如夜。
与诸君共勉。
真的总结
UI方面我后续还是会进行迭代的,毕竟第一个版本丑陋不堪主要是想完成数据的手机,而且开发看起来也不是特别显眼,后面可能会把差异部分直接输出。
做大做强,搞一波大新闻。
作者:究极逮虾户
链接:https://juejin.cn/post/7048516748768706567
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
SpringBoot 三大开发工具,你都用过么?
1、SpringBoot Dedevtools
他是一个让SpringBoot支持热部署的工具,下面是引用的方法
要么在创建项目的时候直接勾选下面的配置:
要么给springBoot项目添加下面的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
idea修改完代码后再按下 ctrl + f9 使其重新编译一下,即完成了热部署功能
eclipse是按ctrl + s保存 即可自动编译
如果你想一修改代码就自动重新编译,无需按ctrl+f9。只需要下面的操作:
1.在idea的setting中把下面的勾都打上
2.进入pom.xml,在build的反标签后给个光标,然后按Alt+Shift+ctrl+/
3.然后勾选下面的东西,接着重启idea即可
2、Lombok
Lombok是简化JavaBean开发的工具,让开发者省去构造器,getter,setter的书写。
在项目初始化时勾选下面的配置,即可使用Lombok
或者在项目中导入下面的依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
使用时,idea还需要下载下面的插件:
下面的使用的例子
@AllArgsConstructor
//全参构造器
@NoArgsConstructor
//无参构造器
@Data//getter + setterpublic
class User {
private Long id;
private String name;
private Integer age;
private String email;
}
3、Spring Configuration Processor
该工具是给实体类的属性注入开启提示,自我感觉该工具意义不是特别大!
因为SpringBoot存在属性注入,比如下面的实体类:
@Component
@ConfigurationProperties(prefix = "mypet")
public class Pet {
private String nickName;
private String strain;
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public String getStrain() {
return strain;
}
public void setStrain(String strain) {
this.strain = strain;
}
@Override public String toString() {
return "Pet [nickName=" + nickName + ", strain=" + strain + "]";
}
}
想要在application.properties和application.yml中给mypet注入属性,却没有任何的提示,为了解决这一问题,我们在创建SpringBoot的时候勾选下面的场景:
或者直接在项目中添加下面的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
并在build的标签中排除对该工具的打包:(减少打成jar包的大小)
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins></build>
作者:终码一生
链接:https://juejin.cn/post/7054436849804132382
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »


