
多线程爬虫案例
多线程爬虫的使用主要是为了提高网络爬虫的效率和性能。以下是几个关键原因:
- 提高速度:
- 并行处理:多线程爬虫可以同时处理多个请求,从而大大减少总的爬取时间。例如,如果一个单线程爬虫需要10秒来下载一个网页,而一个多线程爬虫可以同时下载10个网页,那么在同样的时间内,多线程爬虫可以完成更多的任务。
- 资源利用:
- 充分利用CPU和网络带宽:现代计算机通常具有多核CPU和高速网络连接,多线程爬虫可以更好地利用这些资源,避免单线程爬虫中的空闲等待时间(如等待网络响应)。
- 容错性:
- 任务隔离:多线程爬虫中,每个线程可以独立运行,即使某个线程出现错误或被阻塞,其他线程仍然可以继续工作,提高了整个爬虫系统的稳定性和可靠性。
- 复杂任务管理:
- 任务分配:对于复杂的爬虫任务,可以将不同的任务分配给不同的线程,例如,一个线程负责下载页面,另一个线程负责解析页面内容,还有一个线程负责存储数据。
- 适应动态环境:
- 灵活调整:多线程爬虫可以根据实际情况动态调整线程数量,例如,在网络状况良好时增加线程数以加快爬取速度,而在网络拥塞时减少线程数以避免对目标网站造成过大压力。
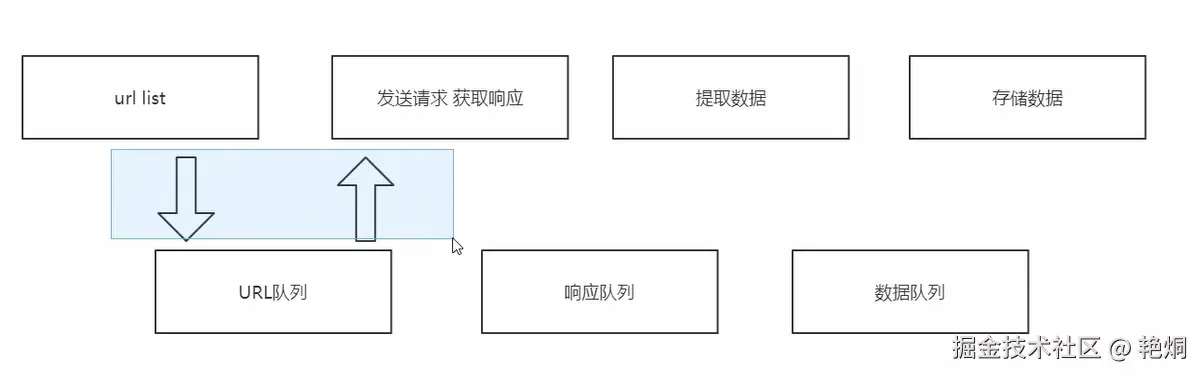
多线程爬取网站案例
# -*- coding: UTF-8 -*-
'''
@Project :网络爬虫
@File :11-多线程爬虫案例.py
@IDE :PyCharm
@Author :慕逸
@Date :09/11/2024 19:54
'''
# https://www.doutupk.com/search?type=photo&more=1&keyword=%E9%9D%93%E4%BB%94&page=3
import requests
from urllib import request
from lxml import etree
import threading
from queue import Queue
import winsound
class Producer(threading.Thread):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers)
text = response.text
# print(text)
html = etree.HTML(text)
imgs = html.xpath("//div[@class='pic-content text-center']//img[@class!='gif']")
img_names = html.xpath(
"//div[@class='pic-content text-center']//img[@class!='gif']/following-sibling::p/text()")
for img, img_name in zip(imgs, img_names):
img_url = img.get('data-original')
# request.urlretrieve(img_url, 'E:/Study/code/Python/图片爬取/斗图啦/{}'.format(img_name) + str(random.randint(1, 10000)) + '.jpg')
# print(img_name + "-下载完成~~" + img_url)
self.img_queue.put((img_url, img_name))
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img = self.img_queue.get()
img_url, file_name = img
file_name = file_name.replace('.','').replace('?','')
request.urlretrieve(img_url, 'E:/Study/code/Python/图片爬取/斗图啦/{}.jpg'.format(file_name))
print(file_name + "-下载完成~~" + img_url)
def main():
winsound.Beep(1500, 500)
page_queue = Queue(100)
img_queue = Queue(500)
for i in range(1, 18):
url = "https://www.doutupk.com/search?type=photo&more=1&keyword=%E9%9D%93%E4%BB%94&page={}".format(i)
# parse_page(url)
page_queue.put(url)
# break
# 创建5个线程
for i in range(5):
t = Producer(page_queue, img_queue)
t.start()
for i in range(5):
t = Consumer(page_queue, img_queue)
t.start()
if __name__ == '__main__':
main()
winsound.Beep(1000, 500)
- 生产者类负责从队列中获取页面 URL,解析页面并提取图片信息,然后将图片信息放入图片队列中。
- 消费者类负责从图片队列中获取图片信息,下载图片并保存到本地。
作者:艳烔
来源:juejin.cn/post/7435257934344798248
来源:juejin.cn/post/7435257934344798248
