
姚期智:人类本身就是世界上相当理想的具身智能体
60s要点速读:
1、人类本身就是世界上相当理想的一个具身智能体。它基本上具备三个方面,三个成分:第一方面是身体,第二方面是小脑,第三方面是大脑。身体的部分具身必须要有足够的硬件,具有传感器和执行器,小脑会主导视觉、触觉各种感知来控制身体,完成复杂的任务,最后大脑部分,它主导上层的逻辑推理、决策、长时间的规划以用自然语言能够和其他的智能体、环境交流。
2、ChatGPT主要是对于语言的处理能力,如果真正的想要让通用人工智能发挥出它的力量,未来的AGI需要有具身的实体,同真实的物理世界相交互来完成各种任务,这样才能给产业带来真正更大的价值。
3、具身机器人目前遇到的主要有四大挑战:第一,机器人不能够像大语言模型一样有一个基础大模型直接一步到位,做到最底层的控制。第二,计算能力的挑战。即使谷歌研发的Robotics Transformer模型,要做到机器人控制,距离实际需要的控制水平仍有许多事情要做。第三,如何把机器人多模态的感官感知全部融合起来,仍面临诸多难题需要解决。第四,机器人的发展需要收集很多数据,其中也面临很多安全隐私等方面的问题。
正文:
最近,ChatGPT的出现,在人工智能在学术上是一个突破,同时它为各行各业也创造了许多新价值。所以人工智能的下一步是什么呢?ChatGPT主要是对于语言的处理能力,如果真正的想要让通用人工智能发挥出它的力量,未来的AGI需要有具身的实体,让它能够同真实的物理世界相交互来完成各种任务,这样才能够带来真正更大的一个价值。那么,具身智能体长的应该是什么样子呢?人类本身就是世界上相当理想的一个具身智能体。它基本上具备三个方面,三个成分:第一方面是身体,第二方面是小脑,第三方面是大脑。身体的部分具身必须要有足够的硬件,具有传感器和执行器,小脑会主导视觉、触觉各种感知来控制身体,完成复杂的任务,最后大脑部分,它主导上层的逻辑推理、决策、长时间的规划以用自然语言能够和其他的智能体、环境交流。目前,清华大学交叉信研究院里有八九位老师近年来的工作都是在关于具身智能的方方面面。接下来我想从这些团队的一些进展和思考方面,和大家分享。第一,关于身体部分。具身AGI最理想身体的形式,我们认为应该就是人形机器人。因为人类的社会环境主要是为人类而定制的,比如说楼梯的结构、门把手的高度、被子的形状等等,这些都是为了人类的形状而定制,所以如果我们能够打造一个有泛应用的通用机器人,人形是最好最适合的一个形态,人形机器人能够适应人类的各种环境。在清华大学交叉信息研究院里,我们自主研发了人形机器人初步的造型,这个工作主要由陈建宇团队所完成的。目前我们已经有了两个形式的机器人,其中有一个是前几个月在世界人工智能大会上亮相的“小星”。它的高度是1米2,而这次我们在这个机器人大会里面亮相的是“小星MAX”,它的身高达到了1米6,这两款机器人在展区有进行展示。
关于它的技术:它所用的是新一代的本体感知驱动器技术方案,在算法方面采用了动态的双足行走,是世界上为数不多的,能够走通整个软硬件技术的团队之一。
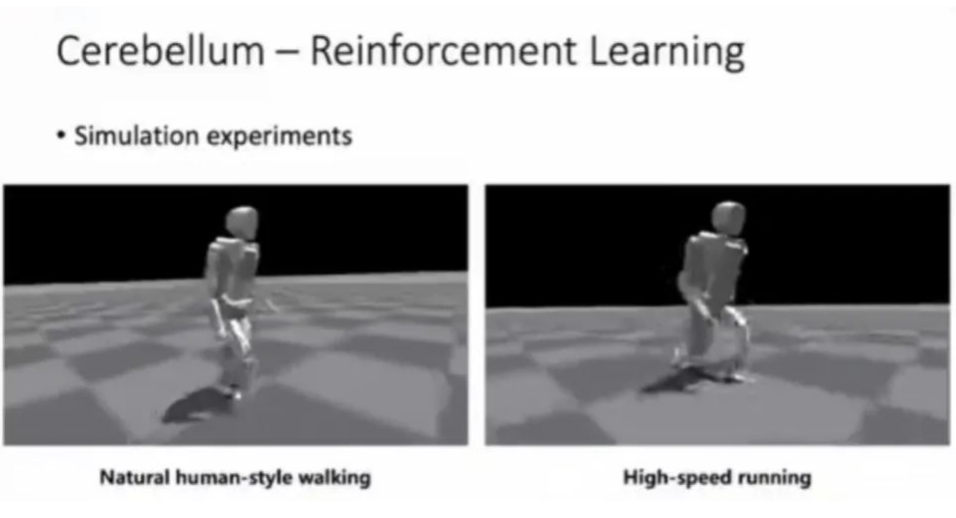
其次,关于具身智能体第二方面的小脑如何体现呢?比如小星机器人实体上是一套机器人运动控制的算法,分成两层:上一层是固态规划层,下一层是基于动力学的实时全身运动控制,它用来计算发给电机关节精确的指令。我们再展示一下这几个机器人在户外运动的画面,可以看到左边小星可以在水泥地上很灵活的快速行走,在右边也可以在比较复杂的一个树林里面走,它具有一定的抗干扰的能力——在草地里、石子路上走的也具有稳定性。在构建小脑的算法端,我们想到在未来需要给机器人更好的功能、更好的控制,所以我们也在研究灵活度更高的,利用人工智能、强化学习的方法去运用和强化学习框架。它的好处是没有一个模型的限制,所以它能够对于复杂的环境跟不确定的环境,能够展现出更强的适应的能力。另外还有一个方法来学习,就是能够利用人体运动实际的数据,我们把它放到这个框架里,给予强化学习更好的引导。我们可以看到,通过强化学习,机器人能够用一种自然的方式来模拟人态的行走,在设计上我们可以使它消耗更低的能耗,我们把这个硬件参数代入仿真里,能够实现更高度的运动形态,比如在仿真里能够走到4米/秒。而除了这种方法以外,强化学习方面,清华大学交叉信息研究院里的队伍也来研究一些基础的核心技术,尤其是在机器人研究方面,能够使得强化学习更加有效。
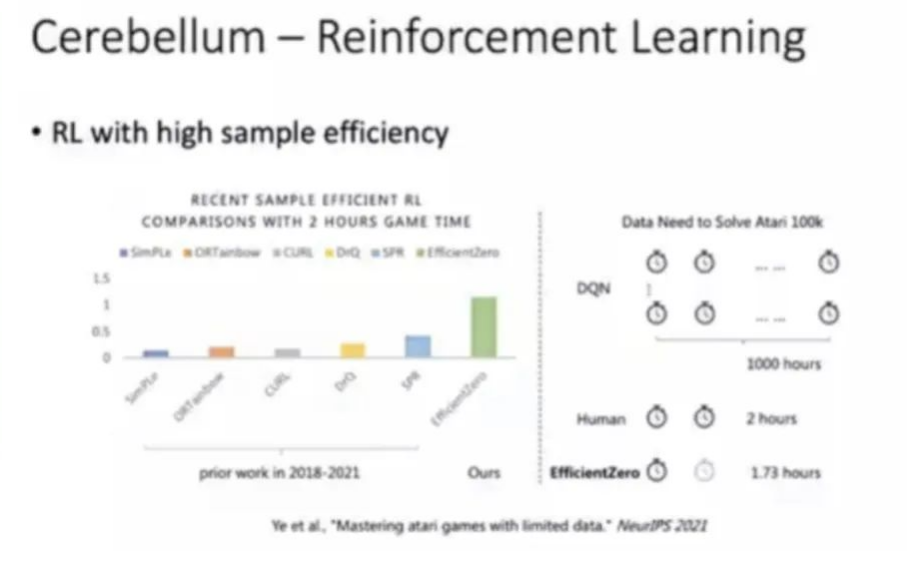
第一是有关样本的效率方面,目前一直困扰着强化学习应用的难题它所需要的样本非常多。在这方面我们做了一些工作。比如Atari游戏作为标准测试的指标,Deepmind在2015年在自然上发表了DQN算法,需要花一千个小时去进行学习,才能够达到人类的水平,这在当时已经非常了不起,而高阳队伍提出了一个新的算法叫Efficient Zero,它能够在两小时时间里能够达到超过人类平均水平,比DQN提高了500倍的样本效率。另外一个困扰着强化学习的难题是泛化性,就是对于这些任务及其环境中间的不确定性和干扰,能不能够泛化的更好,许华哲团队围绕着这个问题提出了一系列解决方案,比如应用到机器人包饺子的演示,我们可以看到在这个物理过程里面有些非常复杂的动作,使得算法适应性高,即使有人为干扰下也能够达到任务。我们再看小脑方面。除了走路以外别的功能,其中一个重要的任务是视觉处理,赵行团队有一些最新工作:基于视觉机器人跑酷,在这里面四足机器人基于视觉信号能够识别路障,能够匍匐前进,能够跳高台,同时请注意到当这些跳跃失败的时候,这个机器人会不停的来尝试,一直到成功为主,未来我们也会把这类跑酷功能放到人形机器人来实现。

清华大学交叉信研究院赵行团队四足机器人还有一个比较高端的感知就是触觉。人的皮肤吸收了很多的触觉信号,能够完成非常精细的物体抓取的动作来回避危险,所以我们希望给机器人能够有好的触觉的传感器,让它们能够触摸感受到这个世界。对此,许华哲队伍运用到一些非常好的材料,他设计了一个触觉传感器低成本、易操作,能够精确的感觉得到接触到物体三维的几何,还有能够捕捉到物体很细小的纹理,它和人工算法能够结合,能够达到物体的分割和最终的效果。并且,我们也做了一些下游的关于触觉物体操纵的触觉工作,希望机器人将来对于更小的物体能够操作。此外比较难的事情,就如何打造机器人灵活的双手,需要自由度非常高,接触和物件非常复杂,所以机器人想要做这些动作非常困难。弋力团队提出新的算法,可以用自动的方式来创建场景和建模仿真,使得机器人在仿真里学习到这些技术。最后我们谈一谈关于机器人第三方面关于大脑。这一部分谷歌做了大量的工作,特别是Palm-e多模态的大语言,能够对机器人的任务进行规划,大语言模型就把他所做的事情调用到下沉的控制器,去按照这个顺序来做任务,这也是一个非常重要的,尤其是谷歌在具身大模型方面主要的技术路线。不过,这个框架有一个主要的问题:它的下层不一定能够很好执行上一层的规划,尤其是中间如果发生一些意外的干扰。对此,陈建宇团队提出一个新的方案和新的框架,比如是否可以在任务执行中能够自动的判断是不是有异常,如果有异常的话怎么样解决,这些都是有一个语言模型和视觉模型自动的完成的。我们把这个方法用在了人形机器人上。首先我们需要像大语言模型一样,给这个机器人描述一下他所需要的任务,机器人按照任务来执行。在场景工作中,如果机器人做搬箱子的工作,它的视觉语言模型通过视角检测是否有意外发生,如果有的话如何能够纠正,如果看到这个箱子掉到地上,机器人能够想出一个方法最后把它捡起来,最后完成任务。
