
高级线程应用之栅栏、信号量、调度组以及source(一)
一、栅栏函数
CPU的乱序执行能力让我们对多线程的安全保障的努力变得异常困难。因此要保证线程安全,阻止CPU换序是必需的。遗憾的是,现在并不存在可移植的阻止换序的方法。通常情况下是调用CPU提供的一条指令,这条指令常常被称为barrier。一条barrier指令会阻止CPU将该指令之前的指令交换到barrier之后,反之亦然。换句话说,barrier指令的作用类似于一个拦水坝,阻止换序穿透这个大坝。
栅栏函数最直接的作用:控制任务执行顺序,导致同步效果。
有两个函数:
dispatch_barrier_async:前面的任务执行完毕才会执行barrier中的逻辑,以及barrier后加入队列的任务。dispatch_barrier_sync:作用相同,但是会堵塞线程,影响后面的任务执行 。
⚠️:栅栏函数只能控制同一队列并发,相当于针对队列而言。
1.1 应用
1.1.1 dispatch_barrier_async 与 dispatch_barrier_sync 效果
有如下案例:
- (void)test {
dispatch_queue_t concurrentQueue = dispatch_queue_create("HotpotCat", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(concurrentQueue, ^{
sleep(3);
NSLog(@"1");
});
dispatch_async(concurrentQueue, ^{
NSLog(@"2");
});
dispatch_barrier_async(concurrentQueue, ^{
NSLog(@"3:%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
NSLog(@"4");
});
NSLog(@"5");
}分析:barrier阻塞的是自己以及concurrentQueue队列中在它后面加入的任务。由于这里使用的是异步函数所以任务1,2,5顺序不定,3在4之前。
输出:
GCDDemo[49708:5622304] 5
GCDDemo[49708:5622437] 2
GCDDemo[49708:5622434] 1
GCDDemo[49708:5622434] 3:<NSThread: 0x600003439040>{number = 6, name = (null)}
GCDDemo[49708:5622434] 4如果将dispatch_barrier_async改为dispatch_barrier_sync同步函数,则任务5会被阻塞。1、2(顺序不定)在3之前执行,4和5(顺序不定)在之后。
1.1.2 栅栏函数存在的问题
1.1.2.1 栅栏函数与全局队列
将concurrentQueue改为全局队列:
dispatch_queue_t concurrentQueue = dispatch_get_global_queue(0, 0);
dispatch_async(concurrentQueue, ^{
NSLog(@"1");
});
dispatch_async(concurrentQueue, ^{
NSLog(@"2");
});
dispatch_barrier_async(concurrentQueue, ^{
NSLog(@"3:%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
NSLog(@"4");
});
NSLog(@"5");输出:
GCDDemo[49872:5632760] 5
GCDDemo[49872:5632979] 1
GCDDemo[49872:5633673] 2
GCDDemo[49872:5633675] 4
GCDDemo[49872:5633674] 3:<NSThread: 0x600001160240>{number = 10, name = (null)}这个时候栅栏函数无论同步还是异步都无效了(有可能系统调度刚好符合预期)。
这也就意味着全局并发队列不允许使用栅栏函数,一定是自定义队列才能使用。
1.1.2.1 栅栏函数与不同队列
将任务2和4放入另外一个队列:
dispatch_queue_t concurrentQueue = dispatch_queue_create("Hotpot", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t concurrentQueue2 = dispatch_queue_create("Cat", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(concurrentQueue, ^{
sleep(3);
NSLog(@"1");
});
dispatch_async(concurrentQueue2, ^{
NSLog(@"2");
});
dispatch_barrier_async(concurrentQueue, ^{
NSLog(@"3:%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue2, ^{
NSLog(@"4");
});
NSLog(@"5");输出:
GCDDemo[49981:5639766] 5
GCDDemo[49981:5640003] 2
GCDDemo[49981:5639998] 4
GCDDemo[49981:5639997] 1
GCDDemo[49981:5639998] 3:<NSThread: 0x600003761500>{number = 5, name = (null)}这个时候concurrentQueue2中的任务先执行了,它并不受栅栏函数的影响。那么说明 栅栏函数只对同一个队列中的任务起作用。
1.1.3 栅栏函数作为锁使用
有如下代码:
NSMutableArray *array = [NSMutableArray array];
dispatch_queue_t concurrentQueue = dispatch_queue_create("Hotpot", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i < 1000; i++) {
dispatch_async(concurrentQueue, ^{
[array addObject:@(i)];
});
}- 多个线程同时操作
array。 - 在
addObject的时候有可能存在同一时间对同一块内存空间写入数据。
比如写第3个数据的时候,当前数组中数据是(1、2)这个时候有2个线程同时写入数据就存在了(1、2、3)和(1、2、4)`这个时候数据就发生了混乱造成了错误。
在运行的时候由于线程不安全(可变数组线程不安全),发生了写入错误直接报错:
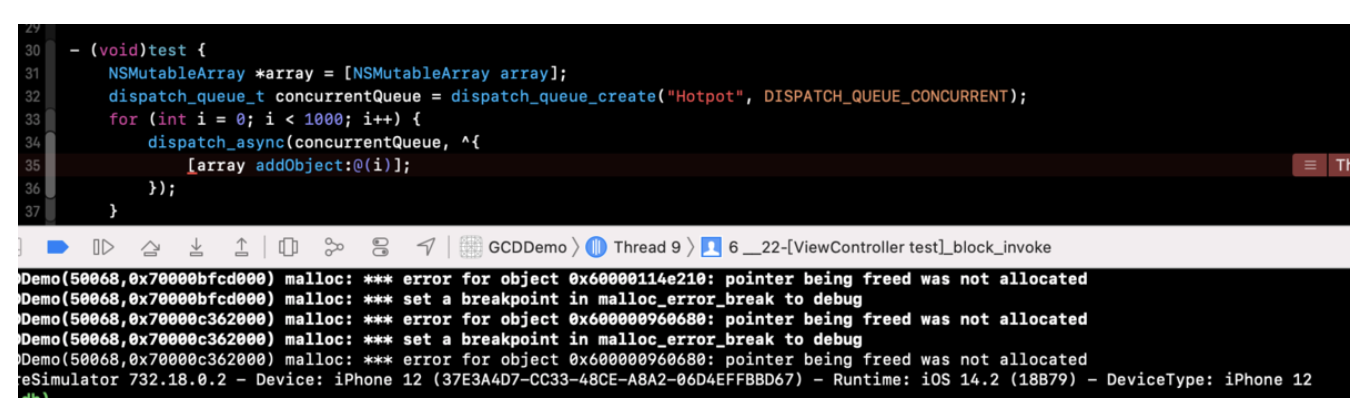
将数组添加元素的操作放入dispatch_barrier_async中:
NSMutableArray *array = [NSMutableArray array];
dispatch_queue_t concurrentQueue = dispatch_queue_create("Hotpot", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i < 1000; i++) {
dispatch_async(concurrentQueue, ^{
dispatch_barrier_async(concurrentQueue , ^{
[array addObject:@(i)];
});
});
}这样就没问题了,加入栅栏函数写入数据的时候相当于加了锁。
1.2 原理分析
根据1.1中的案例有3个问题:
- 1.为什么栅栏函数能起作用?
- 2.为什么全局队列无效?
- 3.为什么任务必须在同一队列才有效?
1.2.1 dispatch_barrier_sync
dispatch_barrier_sync源码如下:
void
dispatch_barrier_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BARRIER | DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_barrier_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}直接调用_dispatch_barrier_sync_f:
static void
_dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
_dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags);
}仍然是对_dispatch_barrier_sync_f_inline的调用:
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {
//死锁走这里的逻辑,同步栅栏函数也走这里
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,
DC_FLAG_BARRIER | dc_flags);
}
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));
}栅栏函数这个时候走的也是_dispatch_sync_f_slow逻辑:
static void
_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_class_t dqu, uintptr_t dc_flags)
{
dispatch_queue_t top_dq = top_dqu._dq;
dispatch_queue_t dq = dqu._dq;
if (unlikely(!dq->do_targetq)) {
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
......
_dispatch_trace_item_push(top_dq, &dsc);
//死锁报错
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);
if (dsc.dsc_func == NULL) {
// dsc_func being cleared means that the block ran on another thread ie.
// case (2) as listed in _dispatch_async_and_wait_f_slow.
dispatch_queue_t stop_dq = dsc.dc_other;
return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);
}
_dispatch_introspection_sync_begin(top_dq);
_dispatch_trace_item_pop(top_dq, &dsc);
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags
DISPATCH_TRACE_ARG(&dsc));
}断点调试走的是_dispatch_sync_complete_recurse:
static void
_dispatch_sync_complete_recurse(dispatch_queue_t dq, dispatch_queue_t stop_dq,
uintptr_t dc_flags)
{
bool barrier = (dc_flags & DC_FLAG_BARRIER);
do {
if (dq == stop_dq) return;
if (barrier) {
//唤醒执行
//_dispatch_lane_wakeup
dx_wakeup(dq, 0, DISPATCH_WAKEUP_BARRIER_COMPLETE);
} else {
//已经执行完成没有栅栏函数
_dispatch_lane_non_barrier_complete(upcast(dq)._dl, 0);
}
dq = dq->do_targetq;
barrier = (dq->dq_width == 1);
} while (unlikely(dq->do_targetq));
}- 这里进行了递归调用,循环条件是
dq->do_targetq也就是 仅对当前队列有效。 - 唤醒执行栅栏前任务执行
_dispatch_lane_wakeup逻辑。 - 当栅栏前的任务执行完毕走
_dispatch_lane_non_barrier_complete逻辑。这也就是为什么栅栏起作用的原因。
dx_wakeup在全局队列是_dispatch_root_queue_wakeup,在自定义并行队列是_dispatch_lane_wakeup。
1.2.1.1 _dispatch_lane_wakeup
void
_dispatch_lane_wakeup(dispatch_lane_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE;
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
//barrier完成了就走这里的逻辑,barrier之前的任务执行完毕。
return _dispatch_lane_barrier_complete(dqu, qos, flags);
}
if (_dispatch_queue_class_probe(dqu)) {
target = DISPATCH_QUEUE_WAKEUP_TARGET;
}
//走这里
return _dispatch_queue_wakeup(dqu, qos, flags, target);
}- 在栅栏函数执行完毕后才走
_dispatch_lane_barrier_complete与_dispatch_lane_non_barrier_complete中的逻辑就汇合了。 - 没有执行完毕的时候执行
_dispatch_queue_wakeup。
_dispatch_queue_wakeup源码如下:
void
_dispatch_queue_wakeup(dispatch_queue_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
......
if (likely((old_state ^ new_state) & enqueue)) {
......
//_dispatch_queue_push_queue 断点断不住,走这里。
return _dispatch_queue_push_queue(tq, dq, new_state);
}
......
}最终走的是_dispatch_queue_push_queue逻辑:
static inline void
_dispatch_queue_push_queue(dispatch_queue_t tq, dispatch_queue_class_t dq,
uint64_t dq_state)
{
#if DISPATCH_USE_KEVENT_WORKLOOP
if (likely(_dq_state_is_base_wlh(dq_state))) {
_dispatch_trace_runtime_event(worker_request, dq._dq, 1);
return _dispatch_event_loop_poke((dispatch_wlh_t)dq._dq, dq_state,
DISPATCH_EVENT_LOOP_CONSUME_2);
}
#endif // DISPATCH_USE_KEVENT_WORKLOOP
_dispatch_trace_item_push(tq, dq);
//_dispatch_lane_concurrent_push
return dx_push(tq, dq, _dq_state_max_qos(dq_state));
}内部是对_dispatch_lane_concurrent_push的调用:
void
_dispatch_lane_concurrent_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
if (dq->dq_items_tail == NULL &&
!_dispatch_object_is_waiter(dou) &&
!_dispatch_object_is_barrier(dou) &&
_dispatch_queue_try_acquire_async(dq)) {
return _dispatch_continuation_redirect_push(dq, dou, qos);
}
_dispatch_lane_push(dq, dou, qos);
}这里直接调用_dispatch_lane_push:
void
_dispatch_lane_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
......
if (flags) {
//栅栏函数走这里。
//#define dx_wakeup(x, y, z) dx_vtable(x)->dq_wakeup(x, y, z)
//dx_wakeup 对应 dq_wakeup 自定义全局队列对应 _dispatch_lane_wakeup,全局队列对应 _dispatch_root_queue_wakeup
return dx_wakeup(dq, qos, flags);
}
}又调用回了_dispatch_lane_wakeup,相当于一直扫描。
