
锁的原理(一):@synchronized
一、性能分析
网上很多对比八大锁性能的文章,时间大部分比较早。苹果对某些锁内部进行了优化。这篇文章找中会以10万次数据做对比对主流锁性能进行分析。
1.1 调用情况模拟
OSSpinLockOSSpinLock在iOS 10以后废弃了,不过还可以调用。需要导入头文件<libkern/OSAtomic.h>:
int hp_runTimes = 100000;
/** OSSpinLock 性能 */
{
OSSpinLock hp_spinlock = OS_SPINLOCK_INIT;
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
OSSpinLockLock(&hp_spinlock);//解锁
OSSpinLockUnlock(&hp_spinlock);
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("OSSpinLock: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}信号量是
GCD提供的:/** dispatch_semaphore_t 性能 */
{
dispatch_semaphore_t hp_sem = dispatch_semaphore_create(1);
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
dispatch_semaphore_wait(hp_sem, DISPATCH_TIME_FOREVER);
dispatch_semaphore_signal(hp_sem);
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("dispatch_semaphore_t: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}os_unfair_lock是iOS10推出的新类型的锁需要导入头文件<os/lock.h>:/** os_unfair_lock_lock 性能 */
{
os_unfair_lock hp_unfairlock = OS_UNFAIR_LOCK_INIT;
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
os_unfair_lock_lock(&hp_unfairlock);
os_unfair_lock_unlock(&hp_unfairlock);
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent() ;
printf("os_unfair_lock_lock: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}pthread_mutex_t
pthread_mutex_t是linux下提供的锁,需要导入头文件<pthread/pthread.h>:/** pthread_mutex_t 性能 */
{
pthread_mutex_t hp_metext = PTHREAD_MUTEX_INITIALIZER;
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
pthread_mutex_lock(&hp_metext);
pthread_mutex_unlock(&hp_metext);
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("pthread_mutex_t: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}NSLock是Foundation框架提供的锁:/** NSlock 性能 */
{
NSLock *hp_lock = [NSLock new];
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
[hp_lock lock];
[hp_lock unlock];
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("NSlock: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}/** NSCondition 性能 */
{
NSCondition *hp_condition = [NSCondition new];
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
[hp_condition lock];
[hp_condition unlock];
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("NSCondition: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}pthread_mutex_t(recursive)
/** PTHREAD_MUTEX_RECURSIVE 性能 */
{
pthread_mutex_t hp_metext_recurive;
pthread_mutexattr_t attr;
pthread_mutexattr_init (&attr);
pthread_mutexattr_settype (&attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init (&hp_metext_recurive, &attr);
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
pthread_mutex_lock(&hp_metext_recurive);
pthread_mutex_unlock(&hp_metext_recurive);
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("PTHREAD_MUTEX_RECURSIVE: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}/** NSRecursiveLock 性能 */
{
NSRecursiveLock *hp_recursiveLock = [NSRecursiveLock new];
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
[hp_recursiveLock lock];
[hp_recursiveLock unlock];
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("NSRecursiveLock: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}/** NSConditionLock 性能 */
{
NSConditionLock *hp_conditionLock = [NSConditionLock new];
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
[hp_conditionLock lock];
[hp_conditionLock unlock];
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent() ;
printf("NSConditionLock: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}@synchronized
/** @synchronized 性能 */
{
double_t hp_beginTime = CFAbsoluteTimeGetCurrent();
for (int i = 0 ; i < hp_runTimes; i++) {
@synchronized(self) {}
}
double_t hp_endTime = CFAbsoluteTimeGetCurrent();
printf("@synchronized: %f ms\n",(hp_endTime - hp_beginTime) * 1000);
}锁内部没有处理任何逻辑,都执行的空操作,在10万次循环后计算时间差值。
1.2 验证
iPhone 12 pro max 14.3真机测试数据如下:
OSSpinLock: 1.366019 ms
dispatch_semaphore_t: 1.923084 ms
os_unfair_lock_lock: 1.502037 ms
pthread_mutex_t: 1.694918 ms
NSlock: 2.384901 ms
NSCondition: 2.082944 ms
PTHREAD_MUTEX_RECURSIVE: 3.449082 ms
NSRecursiveLock: 3.075957 ms
NSConditionLock: 7.895947 ms
@synchronized: 3.794074 msiPhone 12 pro max 14.3模拟器测试数据如下:
OSSpinLock: 1.199007 ms
dispatch_semaphore_t: 1.991987 ms
os_unfair_lock_lock: 1.762986 ms
pthread_mutex_t: 2.611995 ms
NSlock: 2.719045 ms
NSCondition: 2.544045 ms
PTHREAD_MUTEX_RECURSIVE: 4.145026 ms
NSRecursiveLock: 5.039096 ms
NSConditionLock: 8.215070 ms
@synchronized: 10.205030 ms
大部分锁在真机上性能表现更好,@synchronized在真机与模拟器中表现差异巨大。也就是说苹果在真机模式下优化了@synchronized的性能。与之前相比目前@synchronized的性能基本能满足要求。
判断一把锁的性能好坏,一般情况下是与pthread_mutex_t做对比(因为底层都是对它的封装)。
二、@synchronized
由于@synchronized使用比较简单,并且目前真机性能也不错。所以先分析它。
2.1售票案例
有如下代码:
@property (nonatomic, assign) NSUInteger ticketCount;
- (void)testTicket {
self.ticketCount = 10;
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 2; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 3; i++) {
[self saleTicket];
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 5; i++) {
[self saleTicket];
}
});
}
- (void)saleTicket {
if (self.ticketCount > 0) {
self.ticketCount--;
sleep(0.1);
NSLog(@"当前余票还剩:%lu张",(unsigned long)self.ticketCount);
} else {
NSLog(@"当前车票已售罄");
}
}模拟了多线程售票请款,输出如下:
当前余票还剩:6张
当前余票还剩:7张
当前余票还剩:7张
当前余票还剩:7张
当前余票还剩:4张
当前余票还剩:4张
当前余票还剩:3张
当前余票还剩:2张
当前余票还剩:1张
当前余票还剩:0张
当前车票已售罄
当前车票已售罄
当前车票已售罄
当前车票已售罄
当前车票已售罄saleTicket加上@synchronized就能解决问题:- (void)saleTicket {
@synchronized(self) {
if (self.ticketCount > 0) {
self.ticketCount--;
sleep(0.1);
NSLog(@"当前余票还剩:%lu张",(unsigned long)self.ticketCount);
} else {
NSLog(@"当前车票已售罄");
}
}
}一般参数传递self。那么有以下疑问:
- 为什么要传
self呢?传nil行不行? @synchronized是怎么实现加锁的效果的呢?{}代码块究竟是什么呢?- 是否可以递归呢?
- 底层是什么数据结构呢?
2.2 clang 分析 @synchronized
@synchronized是个系统关键字,那么通过clang还原它的底层实现,为了方便实现在main函数中调用它:
int main(int argc, char * argv[]) {
NSString * appDelegateClassName;
@autoreleasepool {
appDelegateClassName = NSStringFromClass([AppDelegate class]);
@synchronized(appDelegateClassName) {
}
}
return UIApplicationMain(argc, argv, nil, appDelegateClassName);
}clang还原后代码如下:
int main(int argc, char * argv[]) {
NSString * appDelegateClassName;
{ __AtAutoreleasePool __autoreleasepool;
appDelegateClassName = NSStringFromClass(((Class (*)(id, SEL))(void *)objc_msgSend)((id)objc_getClass("AppDelegate"), sel_registerName("class")));
{
id _rethrow = 0;
id _sync_obj = (id)appDelegateClassName;
objc_sync_enter(_sync_obj);
try {
struct _SYNC_EXIT {
_SYNC_EXIT(id arg) : sync_exit(arg) {}
~_SYNC_EXIT() {
objc_sync_exit(sync_exit);
}
id sync_exit;
} _sync_exit(_sync_obj);
}
catch (id e) {
_rethrow = e;
}
{
struct _FIN {
_FIN(id reth) : rethrow(reth) {}
~_FIN() {
if (rethrow) objc_exception_throw(rethrow);
}
id rethrow;
} _fin_force_rethow(_rethrow);
}
}
}
return UIApplicationMain(argc, argv, __null, appDelegateClassName);
}异常处理不关心,所以核心就是try的逻辑,精简后如下:
id _sync_obj = (id)appDelegateClassName;
objc_sync_enter(_sync_obj);
struct _SYNC_EXIT {
_SYNC_EXIT(id arg) : sync_exit(arg) {}
~_SYNC_EXIT() {
objc_sync_exit(sync_exit);
}
id sync_exit;
} _sync_exit(_sync_obj);_SYNC_EXIT是个结构体的定义,_sync_exit析构的实现是objc_sync_exit(sync_exit),所以@synchronized本质上等价于enter + exit://@synchronized(appDelegateClassName) {}
//等价
objc_sync_enter(appDelegateClassName);
objc_sync_exit(appDelegateClassName);它们是定义在objc中的。当然也可以通过对@synchronized打断点查看汇编定位:

2.3 源码分析
2.3.1 objc_sync_enter
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
//obj存在的情况下 获取 SyncData
SyncData* data = id2data(obj, ACQUIRE);
ASSERT(data);
//加锁
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
//不存在调用objc_sync_nil
objc_sync_nil();
}
return result;
}obj存在的情况下通过id2data获取SyncData,参数是obj与ACQUIRE。- 然后通过
mutex.lock()加锁。
- 然后通过
obj为nil的情况下调用objc_sync_nil,根据注释does nothing是一个空实现。
mutexmutex是recursive_mutex_t mutex类型,本质上是recursive_mutex_tt:
using recursive_mutex_t = recursive_mutex_tt<LOCKDEBUG>;
class recursive_mutex_tt : nocopy_t {
os_unfair_recursive_lock mLock;
......
}
typedef struct os_unfair_recursive_lock_s {
os_unfair_lock ourl_lock;
uint32_t ourl_count;
} os_unfair_recursive_lock, *os_unfair_recursive_lock_t;os_unfair_recursive_lock是对os_unfair_lock的封装。所以 @synchronized 是对os_unfair_lock 的封装。
objc_sync_nilobjc_sync_nil的定义如下:
BREAKPOINT_FUNCTION(
void objc_sync_nil(void)
);
# define BREAKPOINT_FUNCTION(prototype) \
OBJC_EXTERN __attribute__((noinline, used, visibility("hidden"))) \
prototype { asm(""); }替换还原后如下:
OBJC_EXTERN __attribute__((noinline, used, visibility("hidden")))
void objc_sync_nil(void) {
asm("");
}也就是一个空实现。
2.3.2 objc_sync_exit
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;//0
if (obj) {
//获取 SyncData
SyncData* data = id2data(obj, RELEASE);
if (!data) {//没有输出返回错误code - 1
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
//获取到数据先解锁
bool okay = data->mutex.tryUnlock();
if (!okay) {//解锁失败返回-1
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {
// @synchronized(nil) does nothing
}
return result;
}obj存在的情况下通过id2data获取SyncData,参数是obj与RELEASE。- 获取到数据进行解锁,解锁成功返回
0,失败返回-1。
2.3.3 SyncData 数据结构
SyncData是一个结构体:
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;//下一个节点
DisguisedPtr<objc_object> object;//obj,@synchronized的参数
int32_t threadCount; // number of THREADS using this block 线程数量
recursive_mutex_t mutex;//锁
} SyncData;nextData指向下一个节点,SyncData是一个单向链表。object存储的是@synchronized的参数,只不过进行了包装。threadCount代表线程数量。支持多线程访问。mutex创建的锁。递归锁只能递归使用不能多线程使用。
三、id2data
objc_sync_enter与objc_sync_exit中都调用了id2data获取数据,区别是第二个参数,显然id2data就是数据处理的核心了。
进行代码块折叠后有如下逻辑:
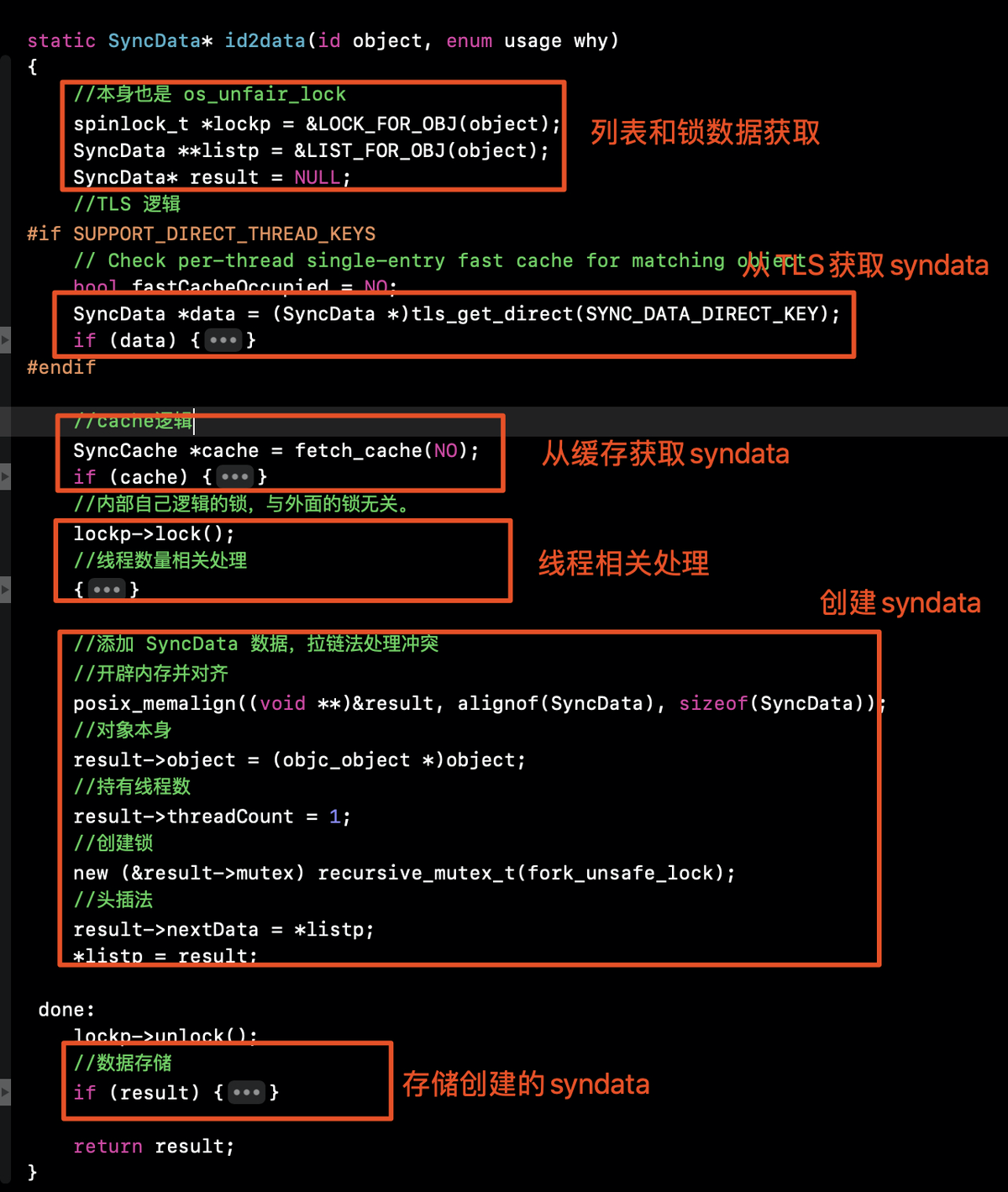
syndata要么从TLS获取,要么从cache获取。都没有的情况下进行创建。