
GCD底层分析 - 队列、同步异步函数
一、GCD 简介
1.1 GCD
GCD(Grand Central Dispatch)本质是 将任务添加到队列,并且指定执行任务的函数。
GCD是纯C语言实现,提供了非常强大的函数。GCD的优势:
- 是苹果公司为多核的并行运算提出的解决方案。
- 会自动利用更多的
CPU内核(比如双核、四核)。 - 会自动管理线程的生命周期(创建线程、调度任务、销毁线程)。
- 程序员只需要告诉
GCD想要执行什么任务,不需要编写任何线程管理代码。
最简单的一个例子:
dispatch_block_t block = ^{
NSLog(@"Hello GCD");
};
//串行队列
dispatch_queue_t quene = dispatch_queue_create("com.HotpotCat.zai", NULL);
//函数
dispatch_async(quene, block);- 任务使用
block封装,这个block块就是任务。任务的block没有参数也没有返回值 quene是创建的串行队列。- 通过函数将任务和队列关联在一起。
1.2 GCD 的作用

二、函数与队列
2.1 同步与异步
dispatch_async异步执行任务的函数。- 不用等待当前语句执行完毕,就可以执行下一条语句。
- 会开启线程执行
block的任务。 - 异步是多线程的代名词。
dispatch_sync同步函数。- 必须等待当前语句执行完毕,才会执行下一条语句。
- 不会开启线程。
- 在当前执行
block任务。
block块是在函数内部执行的。
有如下案例:
- (void)test {
CFAbsoluteTime time = CFAbsoluteTimeGetCurrent();
dispatch_queue_t queue = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{
NSLog(@"1: %f",CFAbsoluteTimeGetCurrent() - time);
method();
});
dispatch_sync(queue, ^{
NSLog(@"2: %f",CFAbsoluteTimeGetCurrent() - time);
method();
});
method();
NSLog(@"3: %f",CFAbsoluteTimeGetCurrent() - time);
}
void method() {
sleep(3);
}输出:
1: 0.000055
2: 3.000264
3: 9.001459说明同步异步是一个耗时的操作。
2.2 串行队列与并发队列
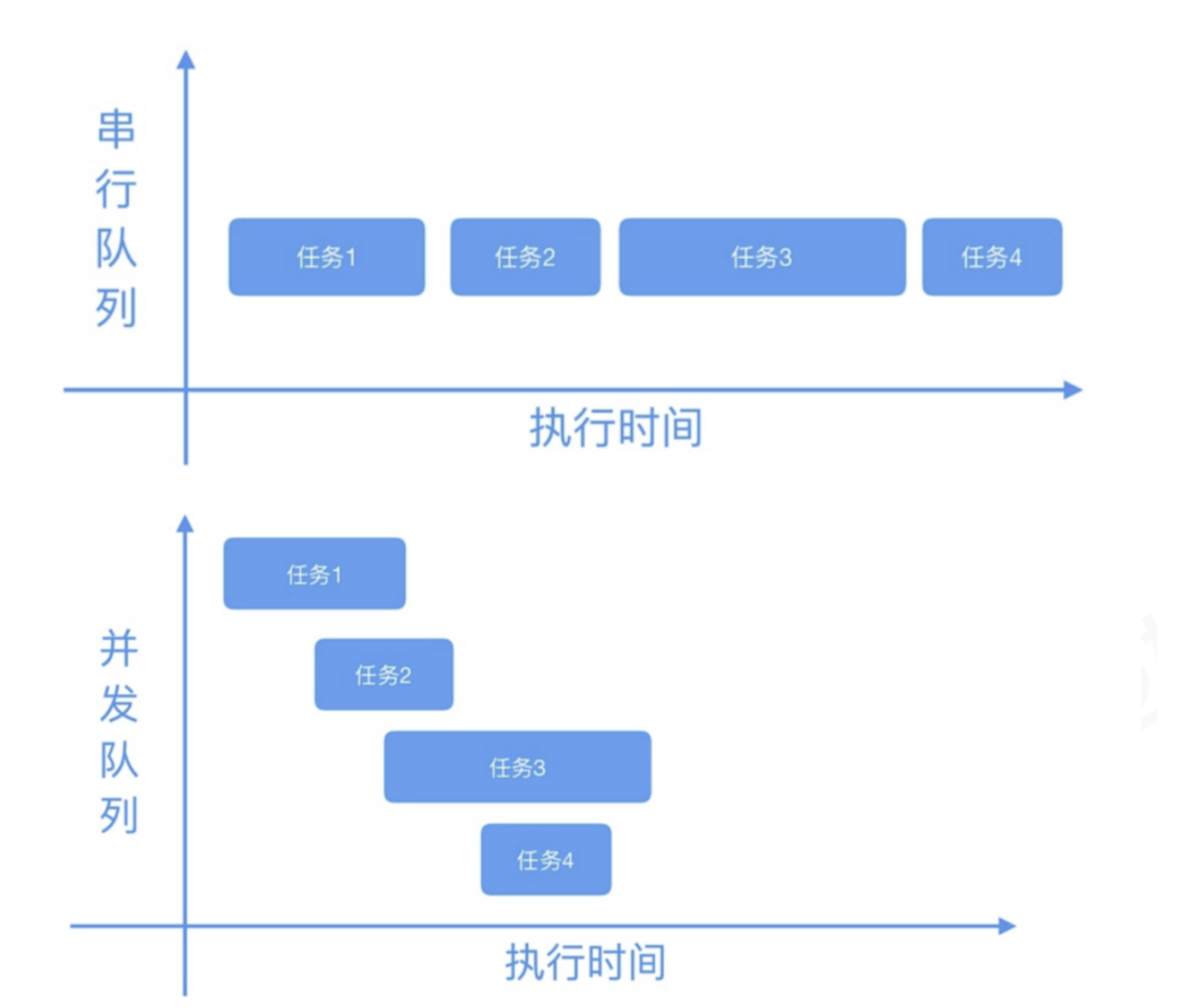
- 队列:是一种数据结构,支持
FIFO原则。 - 串行队列:一次只能进一个任务,任务之间需要排队,
DFQ_WIDTH = 1。在上图中任务一比任务二先执行,队列中的任务按顺序执行。 - 并发队列:一次能调度多个任务(调度多个并不是执行多个,队列不具备执行任务能力,线程才能执行任务),任务一先调度不一定比任务二先执行,得看线程池的调度情况(先调度不一定先执行)。
⚠️ 队列与线程没有任何关系,队列存储任务,线程执行任务。
2.2.1 案例1
有如下代码:
dispatch_queue_t queue = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_CONCURRENT);
NSLog(@"1");
dispatch_async(queue, ^{
NSLog(@"2");
dispatch_sync(queue, ^{
NSLog(@"3");
});
NSLog(@"4");
});
NSLog(@"5");输出:1 5 2 3 4。
分析:queue是并发队列,dispatch_async是异步函数。所以先执行1 5, 在dispatch_async的block内部先执行2,由于dispatch_sync同步函数导致3执行完才能执行4。 所以输出1 5 2 3 4。
2.2.2 案例2
将上面的例子中DISPATCH_QUEUE_CONCURRENT改为NULL(DISPATCH_QUEUE_SERIAL):
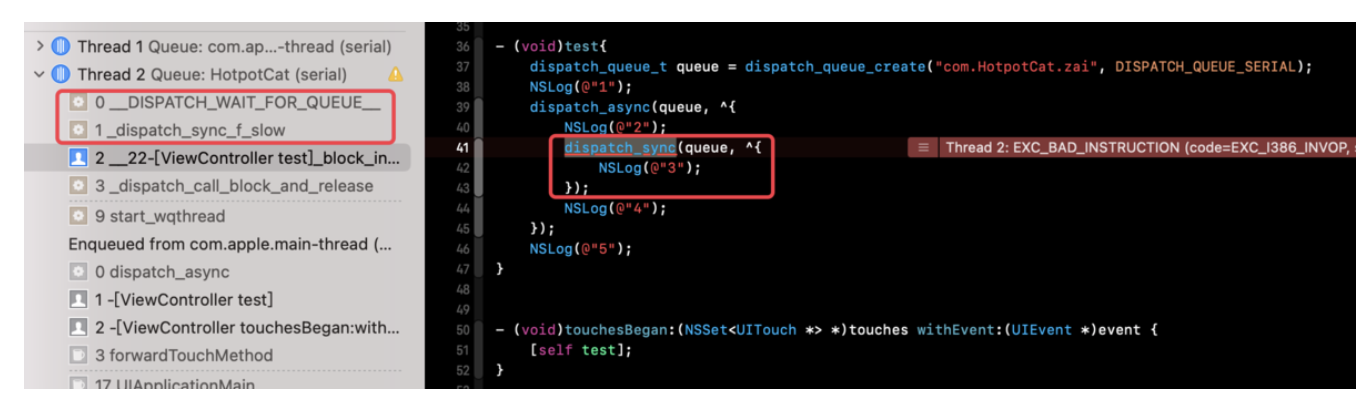
dispatch_sync的时候发生了死锁。对于同步函数会进行护犊子,堵塞的是
block之后的代码。queue中的任务如下(这里为了简单没有写外层异步函数的任务块):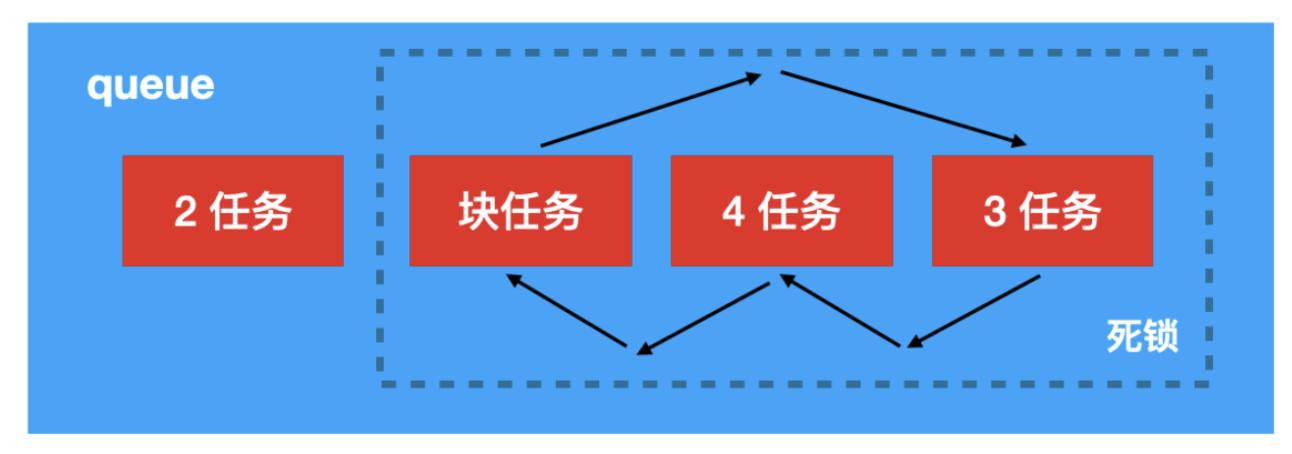
queue是串行队列并且支持FIFO,在queue中块任务为同步函数需要保证任务3执行,但是queue是串行队列,任务3的执行依赖于任务4,而任务4以来块任务所以发生了循环等待,造成死锁。如果改为并发队列(3和4可以一起执行)或者任务3为异步函数调用则就不会发生死锁了。2.2.3 案例3
继续修改代码,将任务4删除,代码如下:
- (void)test{
dispatch_queue_t queue = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_SERIAL);
NSLog(@"1");
dispatch_async(queue, ^{
NSLog(@"2");
dispatch_sync(queue, ^{
NSLog(@"3");
});
});
NSLog(@"5");
}这个时候仍然发生了死锁。对于queue而言有两个任务块以及一个任务2。
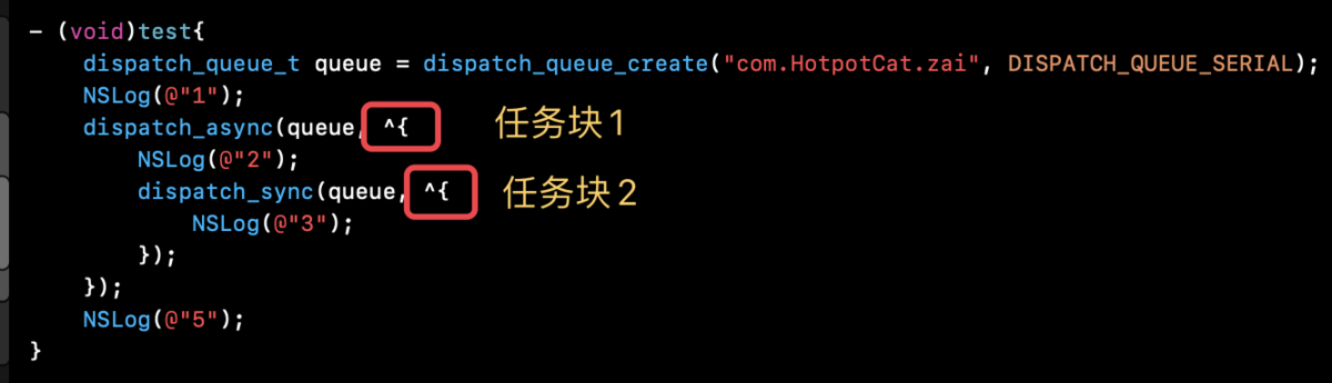
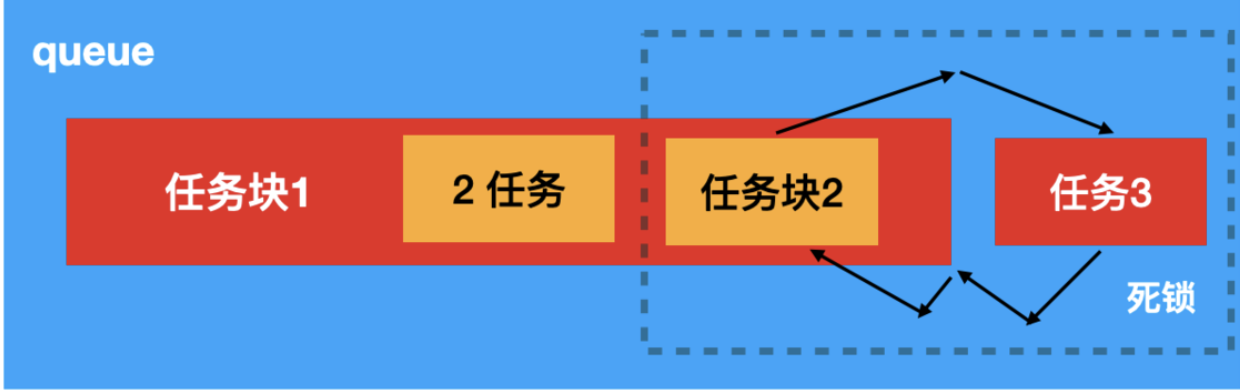
任务块
2阻塞了任务块1的执行完毕,任务块2的执行依赖于任务3的执行,任务3的执行完毕以来于任务块1。这样就造成了死锁。2.2.4 案例4
- (void)test {
dispatch_queue_t queue = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
NSLog(@"1");
});
dispatch_async(queue, ^{
NSLog(@"2");
});
dispatch_sync(queue, ^{ NSLog(@"3"); });
NSLog(@"0");
dispatch_async(queue, ^{
NSLog(@"7");
});
dispatch_async(queue, ^{
NSLog(@"8");
});
dispatch_async(queue, ^{
NSLog(@"9");
});
}输出选项:
A: 1230789
B: 1237890
C: 3120798
D: 2137890queue是并发队列,任务3是同步函数执行的。所以任务3后面的任务会被阻塞。那么任务0肯定在任务3之后执行,任务7、8、9肯定在任务0之后执行。所以就有1、 2、 3 — 0 — 7、 8、 9。而由于本身是并发队列,所以1、2、3之间是无序的,7、8、9之间也是无序的。所以A、C符合。
dispatch_async中增加耗时操作,修改如下:
- (void)test {
dispatch_queue_t queue = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
sleep(8);
NSLog(@"1");
});
dispatch_async(queue, ^{
sleep(7);
NSLog(@"2");
});
dispatch_sync(queue, ^{
sleep(1);
NSLog(@"3");
});
NSLog(@"0");
dispatch_async(queue, ^{
sleep(3);
NSLog(@"7");
});
dispatch_async(queue, ^{
sleep(2);
NSLog(@"8");
});
dispatch_async(queue, ^{
sleep(1);
NSLog(@"9");
});
}当任务中有耗时操作时1、2就不一定在0之前执行了,核心点在于dispatch_sync只能保证任务3先执行不能保证1、2先执行。而0仍然在7、8、9之前。
所以只能保证:3在0之前执行。0在7、8、9之前执行(1、2、7、8、9无序,3与1、2之间无序)。此时上面的代码输出3098721。
修改queue为串行队列DISPATCH_QUEUE_SERIAL后,1、2、3以及7、8、9就是按顺序执行了1230789就选A了。
小结:
- 同步函数串行队列:
- 不会开启线程,在当前线程执行任务。
- 任务串行执行,一个接着一个。
- 会产生阻塞。
- 同步函数并发队列:
- 不会开启线程,在当前线程执行任务。
- 任务一个接着一个。
- 异步函数串行队列:
- 开启线程,一条新线程。
- 任务一个接着一个。
- 异步函数并发队列:
- 开启线程,在当前线程执行任务。
- 任务异步执行,没有顺序,与
CPU调用有关。
三、主队列与全局并发队列
通过GCD创建队列,一般有以下4种方式:
- (void)test {
//串行队列
dispatch_queue_t serial = dispatch_queue_create("com.HotpotCat.cat", DISPATCH_QUEUE_SERIAL);
//并发队列
dispatch_queue_t concurrent = dispatch_queue_create("com.HotpotCat.zai", DISPATCH_QUEUE_CONCURRENT);
//主队列
dispatch_queue_t mainQueue = dispatch_get_main_queue();
//全局队列
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
NSLog(@"serial:%@\nconcurrent:%@\nmainQueue:%@\nglobalQueue:%@",serial,concurrent,mainQueue,globalQueue);
}3.1 主队列
dispatch_get_main_queue声明如下:
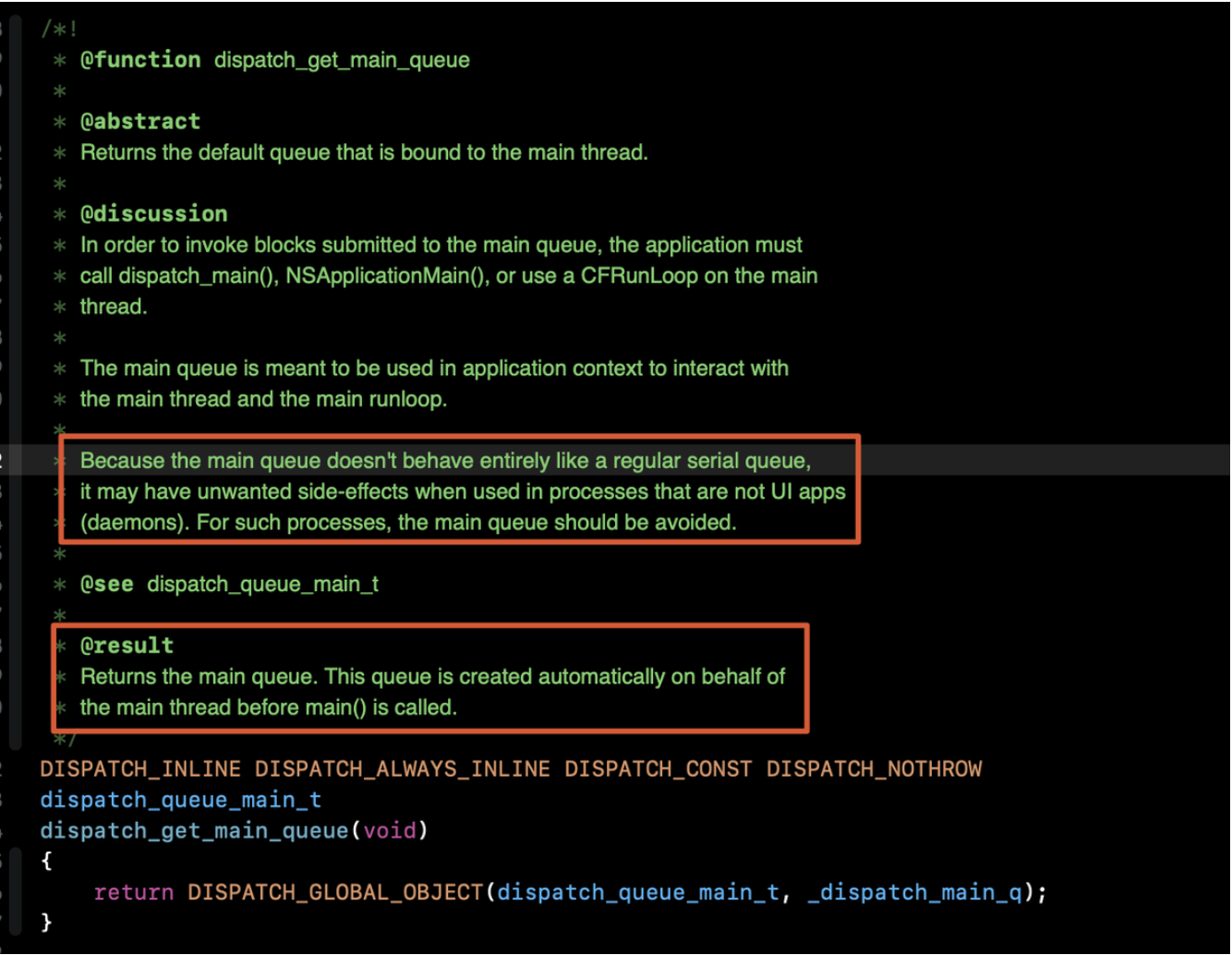
3.1.1 dispatch_get_main_queue 源码分析
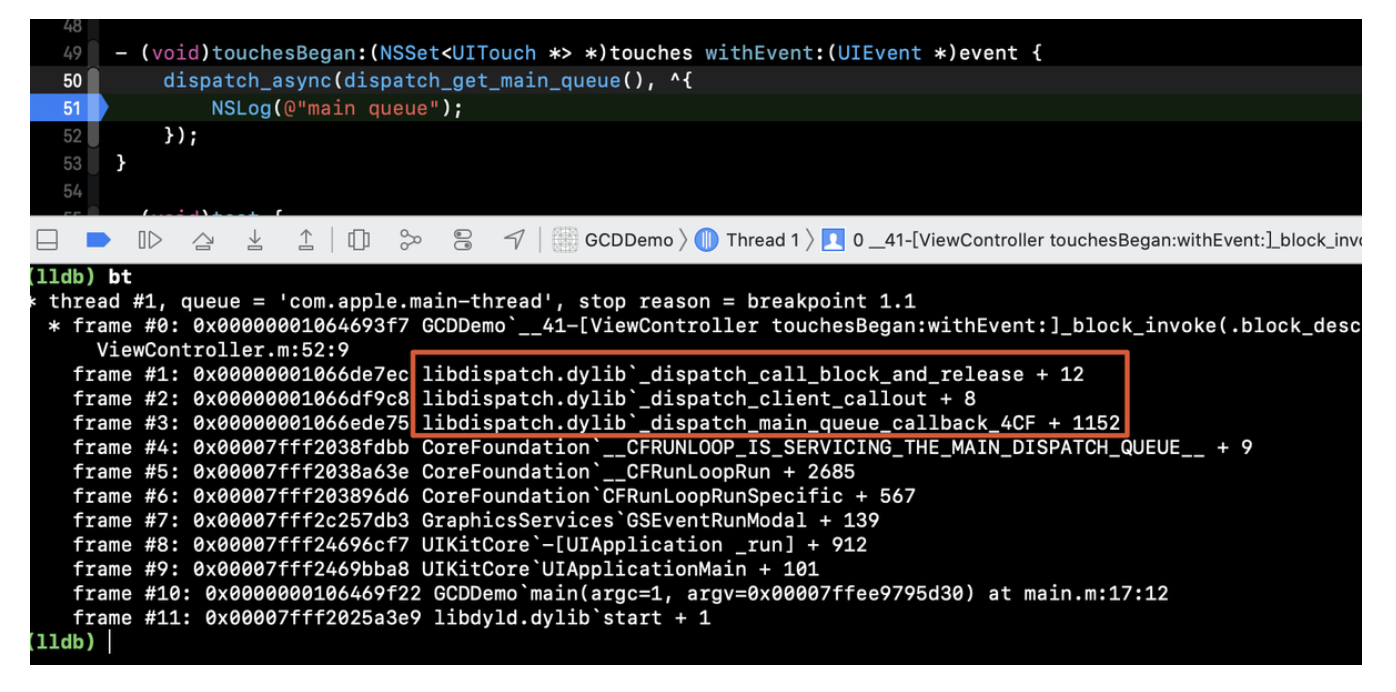
那么dispatch_get_main_queue具体是在什么时机创建的呢?
在main_queue的block中打断点bt查看堆栈定位到调用是在libdispatch中:
dispatch_get_main_queue定义如下:dispatch_queue_main_t
dispatch_get_main_queue(void)
{
//dispatch_queue_main_t 是类型,真正的对象是_dispatch_main_q
return DISPATCH_GLOBAL_OBJECT(dispatch_queue_main_t, _dispatch_main_q);
}dispatch_get_main_queue返回了DISPATCH_GLOBAL_OBJECT,参数是dispatch_queue_main_t以及_dispatch_main_q。
DISPATCH_GLOBAL_OBJECT的宏定义如下:
#define DISPATCH_GLOBAL_OBJECT(type, object) ((OS_OBJECT_BRIDGE type)&(object))可以看到dispatch_queue_main_t是一个类型,真正的对象是object也就是_dispatch_main_q
_dispatch_main_q_dispatch_main_q的函数搜索不到,此时通过赋值可以直接定位到:
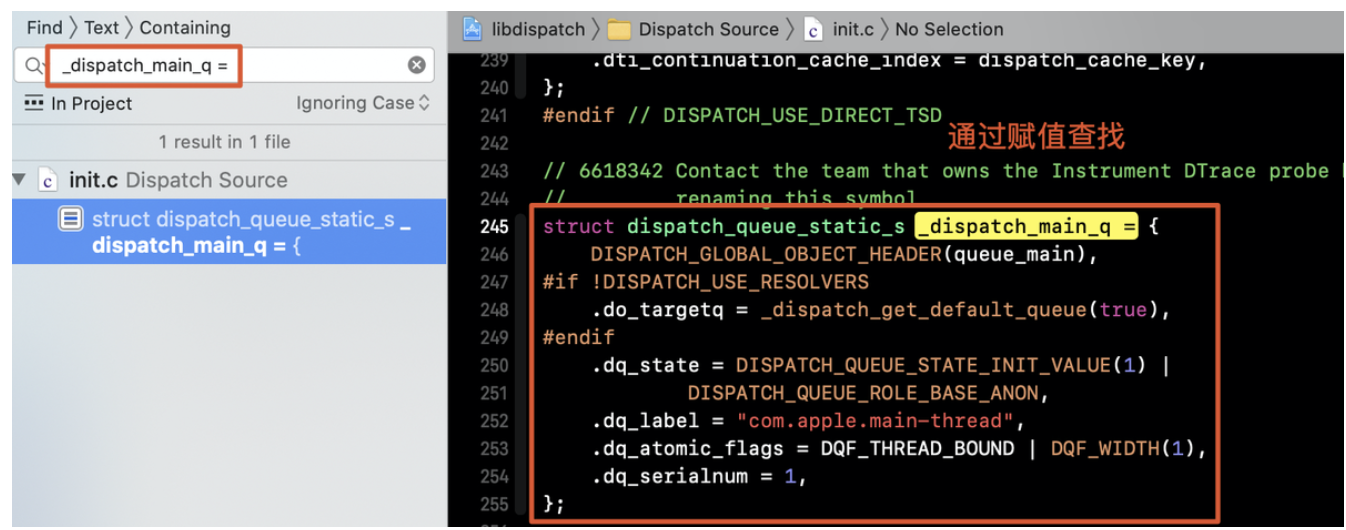
当然也可以通过
labelcom.apple.main-thread搜索定位到。
struct dispatch_queue_static_s _dispatch_main_q = {
DISPATCH_GLOBAL_OBJECT_HEADER(queue_main),
#if !DISPATCH_USE_RESOLVERS
.do_targetq = _dispatch_get_default_queue(true),
#endif
.dq_state = DISPATCH_QUEUE_STATE_INIT_VALUE(1) |
DISPATCH_QUEUE_ROLE_BASE_ANON,
.dq_label = "com.apple.main-thread",
//DQF_WIDTH(1) 串行队列
.dq_atomic_flags = DQF_THREAD_BOUND | DQF_WIDTH(1),
.dq_serialnum = 1,
};DISPATCH_GLOBAL_OBJECT_HEADER(queue_main)传递的参数是queue_main。DQF_WIDTH区分串行并行队列。并不是通过serialnum。- 最终返回的类型是
dispatch_queue_main_t。在使用过程中都是使用dispatch_queue_t接收的。
dispatch_queue_static_s定义如下:
typedef struct dispatch_lane_s {
DISPATCH_LANE_CLASS_HEADER(lane);
/* 32bit hole on LP64 */
} DISPATCH_ATOMIC64_ALIGN *dispatch_lane_t;
// Cache aligned type for static queues (main queue, manager)
struct dispatch_queue_static_s {
struct dispatch_lane_s _as_dl[0]; \
DISPATCH_LANE_CLASS_HEADER(lane);
} DISPATCH_CACHELINE_ALIGN;内部实际上是dispatch_lane_s。
3.2 全局队列
dispatch_get_global_queue的实现如下:
dispatch_queue_global_t
dispatch_get_global_queue(intptr_t priority, uintptr_t flags)
{
dispatch_assert(countof(_dispatch_root_queues) ==
DISPATCH_ROOT_QUEUE_COUNT);
//过量使用直接返回0
if (flags & ~(unsigned long)DISPATCH_QUEUE_OVERCOMMIT) {
return DISPATCH_BAD_INPUT;
}
//根据优先级返回qos
dispatch_qos_t qos = _dispatch_qos_from_queue_priority(priority);
#if !HAVE_PTHREAD_WORKQUEUE_QOS
if (qos == QOS_CLASS_MAINTENANCE) {
qos = DISPATCH_QOS_BACKGROUND;
} else if (qos == QOS_CLASS_USER_INTERACTIVE) {
qos = DISPATCH_QOS_USER_INITIATED;
}
#endif
if (qos == DISPATCH_QOS_UNSPECIFIED) {
return DISPATCH_BAD_INPUT;
}
//调用 _dispatch_get_root_queue
return _dispatch_get_root_queue(qos, flags & DISPATCH_QUEUE_OVERCOMMIT);
}- 返回
dispatch_queue_global_t。 - 通过
_dispatch_get_root_queue获取队列。
_dispatch_get_root_queue实现:
static inline dispatch_queue_global_t
_dispatch_get_root_queue(dispatch_qos_t qos, bool overcommit)
{
if (unlikely(qos < DISPATCH_QOS_MIN || qos > DISPATCH_QOS_MAX)) {
DISPATCH_CLIENT_CRASH(qos, "Corrupted priority");
}
return &_dispatch_root_queues[2 * (qos - 1) + overcommit];
}- 先对优先级进行验证。
- 去
_dispatch_root_queues集合中取数据。
_dispatch_root_queues实现:
//静态变量集合,随时调用随时取。
struct dispatch_queue_global_s _dispatch_root_queues[] = {
#define _DISPATCH_ROOT_QUEUE_IDX(n, flags) \
((flags & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) ? \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS_OVERCOMMIT : \
DISPATCH_ROOT_QUEUE_IDX_##n##_QOS)
#define _DISPATCH_ROOT_QUEUE_ENTRY(n, flags, ...) \
[_DISPATCH_ROOT_QUEUE_IDX(n, flags)] = { \
DISPATCH_GLOBAL_OBJECT_HEADER(queue_global), \
.dq_state = DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE, \
.do_ctxt = _dispatch_root_queue_ctxt(_DISPATCH_ROOT_QUEUE_IDX(n, flags)), \
.dq_atomic_flags = DQF_WIDTH(DISPATCH_QUEUE_WIDTH_POOL), \
.dq_priority = flags | ((flags & DISPATCH_PRIORITY_FLAG_FALLBACK) ? \
_dispatch_priority_make_fallback(DISPATCH_QOS_##n) : \
_dispatch_priority_make(DISPATCH_QOS_##n, 0)), \
__VA_ARGS__ \
}
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, 0,
.dq_label = "com.apple.root.maintenance-qos",
.dq_serialnum = 4,
),
_DISPATCH_ROOT_QUEUE_ENTRY(MAINTENANCE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.maintenance-qos.overcommit",
.dq_serialnum = 5,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, 0,
.dq_label = "com.apple.root.background-qos",
.dq_serialnum = 6,
),
_DISPATCH_ROOT_QUEUE_ENTRY(BACKGROUND, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.background-qos.overcommit",
.dq_serialnum = 7,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, 0,
.dq_label = "com.apple.root.utility-qos",
.dq_serialnum = 8,
),
_DISPATCH_ROOT_QUEUE_ENTRY(UTILITY, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.utility-qos.overcommit",
.dq_serialnum = 9,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT, DISPATCH_PRIORITY_FLAG_FALLBACK,
.dq_label = "com.apple.root.default-qos",
.dq_serialnum = 10,
),
_DISPATCH_ROOT_QUEUE_ENTRY(DEFAULT,
DISPATCH_PRIORITY_FLAG_FALLBACK | DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.default-qos.overcommit",
.dq_serialnum = 11,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, 0,
.dq_label = "com.apple.root.user-initiated-qos",
.dq_serialnum = 12,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INITIATED, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-initiated-qos.overcommit",
.dq_serialnum = 13,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, 0,
.dq_label = "com.apple.root.user-interactive-qos",
.dq_serialnum = 14,
),
_DISPATCH_ROOT_QUEUE_ENTRY(USER_INTERACTIVE, DISPATCH_PRIORITY_FLAG_OVERCOMMIT,
.dq_label = "com.apple.root.user-interactive-qos.overcommit",
.dq_serialnum = 15,
),
};- 根据下标取对应的队列。
_dispatch_root_queues是一个静态变量集合,随时调用随时获取。- 在使用过程中都是使用
dispatch_queue_t接收。 DISPATCH_GLOBAL_OBJECT_HEADER(queue_global)传递的参数是queue_global。
小结:
主队列(dispatch_get_main_queue())
- 专⻔用来在主线程上调度任务的串行队列。
- 不会开启线程。
- 如果当前主线程正在有任务执行,那么无论主队列中当前被添加了什么任务,都不会被调度。
全局并发队列
- 为了方便使用,提供了全局队列
dispatch_get_global_queue(0, 0)。 - 全局队列是一个并发队列。
- 在使用多线程开发时,如果对队列没有特殊需求,在执行异步任务时,可以直接使用全局队列。
四、dispatch_queue_create
普通的串行队列以及并发队列是通过dispatch_queue_create创建的,它的实现如下
dispatch_queue_t
dispatch_queue_create(const char *label, dispatch_queue_attr_t attr)
{
return _dispatch_lane_create_with_target(label, attr,
DISPATCH_TARGET_QUEUE_DEFAULT, true);
}返回dispatch_queue_t类型,内部直接调用_dispatch_lane_create_with_target。
4.1 _dispatch_lane_create_with_target
_dispatch_queue_attr_to_info根据dqa(串行/并行)创建dqai。- 返回的
dqai进行优先级相关的处理,进行准备工作。 - 初始化队列
- 根据
dqai_concurrent串行并行获取vtable(class name)。参数是queue_concurrent或者queue_serial。 _dispatch_object_alloc开辟空间。_dispatch_queue_init初始化,根据dqai_concurrent传递DISPATCH_QUEUE_WIDTH_MAX或者1区分是串行还是并行。label赋值。- 优先级设置。
- 根据
_dispatch_trace_queue_create追踪返回_dq,重点在dq。
这里创建
queue并不是通过queue相关对象进行创建和接收。
4.2 _dispatch_queue_attr_to_info
- 串行队列(
dqa为空)直接返回。 - 并行队列进行一系列配置。
4.3 _dispatch_object_alloc
_dispatch_object_alloc传递的参数是vtable以及sizeof(struct dispatch_lane_s),那么意味着实际上也是dispatch_lane_s类型。
void *
_dispatch_object_alloc(const void *vtable, size_t size)
{
#if OS_OBJECT_HAVE_OBJC1
const struct dispatch_object_vtable_s *_vtable = vtable;
dispatch_object_t dou;
dou._os_obj = _os_object_alloc_realized(_vtable->_os_obj_objc_isa, size);
dou._do->do_vtable = vtable;
return dou._do;
#else
return _os_object_alloc_realized(vtable, size);
#endif
}- 调用
_os_object_alloc_realized申请开辟内存。
4.3.1 _os_object_alloc_realized
inline _os_object_t
_os_object_alloc_realized(const void *cls, size_t size)
{
_os_object_t obj;
dispatch_assert(size >= sizeof(struct _os_object_s));
while (unlikely(!(obj = calloc(1u, size)))) {
_dispatch_temporary_resource_shortage();
}
obj->os_obj_isa = cls;
return obj;
}内部直接调用calloc开辟空间。
4.4 _dispatch_queue_init
根据是否并行队列传递DISPATCH_QUEUE_WIDTH_MAX与1。
#define DISPATCH_QUEUE_WIDTH_FULL 0x1000ull
#define DISPATCH_QUEUE_WIDTH_POOL (DISPATCH_QUEUE_WIDTH_FULL - 1)
#define DISPATCH_QUEUE_WIDTH_MAX (DISPATCH_QUEUE_WIDTH_FULL - 2)- 根据
width配置状态。 - 根据
width配置队列串行/并行以及dq_serialnum标识。dq_serialnum通过_dispatch_queue_serial_numbers赋值。
unsigned long volatile _dispatch_queue_serial_numbers =
DISPATCH_QUEUE_SERIAL_NUMBER_INIT;
// skip zero
// 1 - main_q
// 2 - mgr_q
// 3 - mgr_root_q
// 4,5,6,7,8,9,10,11,12,13,14,15 - global queues
// 17 - workloop_fallback_q
// we use 'xadd' on Intel, so the initial value == next assigned
#define DISPATCH_QUEUE_SERIAL_NUMBER_INIT 17
extern unsigned long volatile _dispatch_queue_serial_numbers;0跳过。1主队列。2管理队列。3管理队列的目标队列。4~15全局队列。根据qos优先级指定不同队列。17自动创建相关返回队列。
os_atomic_inc_orig传递的参数是_dispatch_queue_serial_numbers(p)以及relaxed(m):
#define os_atomic_inc_orig(p, m) \
os_atomic_add_orig((p), 1, m)
#define os_atomic_add_orig(p, v, m) \
_os_atomic_c11_op_orig((p), (v), m, add, +)
//##是连接符号,编译后会被去掉
#define _os_atomic_c11_op_orig(p, v, m, o, op) \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), v, \
memory_order_##m)atomic_fetch_add_explicit(_os_atomic_c11_atomic(17), 1, memory_order_relaxed)。原子替换(p + 1 -> p), 并返回p之前的值。也就相当于是i++这是原子操作。这里多层宏定义处理是为了兼容不同的c/c++版本。C atomic_fetch_add_explicit(volatile A * obj,M arg,memory_order order);
enum memory_order {
memory_order_relaxed, //不对执行顺序做保证,只保证此操作是原子的
memory_order_consume, // 本线程中,所有后续的有关本原子类型的操作,必须>在本条原子操作完成之后执行
memory_order_acquire, //本线程中,所有后续的读操作必须在本条原子操作完>成后执行
memory_order_release, //本线程中,所有之前的写操作完成后才能执行本条原子操作
memory_order_acq_rel, //同时包含 memory_order_acquire 和 memory_order_release
memory_order_seq_cst //全部存取都按顺序执行
};4.5 _dispatch_trace_queue_create
#define _dispatch_trace_queue_create _dispatch_introspection_queue_create
dispatch_queue_class_t
_dispatch_introspection_queue_create(dispatch_queue_t dq)
{
dispatch_queue_introspection_context_t dqic;
size_t sz = sizeof(struct dispatch_queue_introspection_context_s);
if (!_dispatch_introspection.debug_queue_inversions) {
sz = offsetof(struct dispatch_queue_introspection_context_s,
__dqic_no_queue_inversion);
}
dqic = _dispatch_calloc(1, sz);
dqic->dqic_queue._dq = dq;
if (_dispatch_introspection.debug_queue_inversions) {
LIST_INIT(&dqic->dqic_order_top_head);
LIST_INIT(&dqic->dqic_order_bottom_head);
}
dq->do_introspection_ctxt = dqic;
_dispatch_unfair_lock_lock(&_dispatch_introspection.queues_lock);
LIST_INSERT_HEAD(&_dispatch_introspection.queues, dqic, dqic_list);
_dispatch_unfair_lock_unlock(&_dispatch_introspection.queues_lock);
DISPATCH_INTROSPECTION_INTERPOSABLE_HOOK_CALLOUT(queue_create, dq);
if (DISPATCH_INTROSPECTION_HOOK_ENABLED(queue_create)) {
_dispatch_introspection_queue_create_hook(dq);
}
return upcast(dq)._dqu;
}五、dispatch_queue_t
由于所有的队列都是通过dispatch_queue_t来接收的,直接研究dispatch_queue_t是一个不错的入口。dispatch_queue_t的点击会跳转到:
DISPATCH_DECL(dispatch_queue);5.1 DISPATCH_DECL 源码分析
DISPATCH_DECL宏定义:
#define DISPATCH_DECL(name) OS_OBJECT_DECL_SUBCLASS(name, dispatch_object)OS_OBJECT_DECL_SUBCLASS,在源码中它的定义有两个,一个是针对objc的,定义如下:#define OS_OBJECT_DECL_SUBCLASS(name, super) \
OS_OBJECT_DECL_IMPL(name, NSObject, <OS_OBJECT_CLASS(super)>)OS_OBJECT_DECL_IMPL定义如下:
#define OS_OBJECT_DECL_IMPL(name, adhere, ...) \
OS_OBJECT_DECL_PROTOCOL(name, __VA_ARGS__) \
typedef adhere<OS_OBJECT_CLASS(name)> \
* OS_OBJC_INDEPENDENT_CLASS name##_t
OS_OBJECT_DECL_PROTOCOL定义如下:
#define OS_OBJECT_DECL_PROTOCOL(name, ...) \
@protocol OS_OBJECT_CLASS(name) __VA_ARGS__ \
@end- 也就是定义了一个
@protocol。
OS_OBJC_INDEPENDENT_CLASS定义如下:
#if __has_attribute(objc_independent_class)
#define OS_OBJC_INDEPENDENT_CLASS __attribute__((objc_independent_class))
#endif // __has_attribute(objc_independent_class)
#ifndef OS_OBJC_INDEPENDENT_CLASS
#define OS_OBJC_INDEPENDENT_CLASS
#endif为了方便分析,这里假设它走的是OS_OBJC_INDEPENDENT_CLASS为空。
OS_OBJECT_CLASS定义如下:
#define OS_OBJECT_CLASS(name) OS_##name- 本质上是
OS_拼接。
在整个宏定义中参数 name: dispatch_queue super: dispatch_object,整个宏定义替换完成后如下:
@protocol OS_dispatch_queue <OS_dispatch_object>
@end
typedef NSObject<OS_dispatch_queue> *dispatch_queue_t当然在源码中搜索#define DISPATCH_DECL可以搜到多个,其中有一个定义如下:
#define DISPATCH_DECL(name) \
typedef struct name##_s : public dispatch_object_s {} *name##_t替换后如下:
typedef struct dispatch_queue_s : public dispatch_object_s {} *dispatch_queue_tdispatch_queue_t是一个结构体来自于dispatch_queue_s。dispatch_queue_s继承自dispatch_object_s。dispatch_queue_t -> dispatch_queue_s -> dispatch_object_s类似于class -> objc_class -> objc_object。- 本质上
dispatch_queue_t是dispatch_queue_s结构体类型。
5.2 dispatch_queue_s 分析
要研究dispatch_queue_t那么就要研究它的类型dispatch_queue_s。dispatch_queue_s定义如下:
struct dispatch_queue_s {
DISPATCH_QUEUE_CLASS_HEADER(queue, void *__dq_opaque1);
/* 32bit hole on LP64 */
} DISPATCH_ATOMIC64_ALIGN;内部继承于_DISPATCH_QUEUE_CLASS_HEADER:
_DISPATCH_QUEUE_CLASS_HEADER内部又继承自DISPATCH_OBJECT_HEADER:
- 这里就对接到了
dispatch_object_s类型。
DISPATCH_OBJECT_HEADER内部又使用_DISPATCH_OBJECT_HEADER:
#define _DISPATCH_OBJECT_HEADER(x) \
struct _os_object_s _as_os_obj[0]; \
OS_OBJECT_STRUCT_HEADER(dispatch_##x); \
struct dispatch_##x##_s *volatile do_next; \
struct dispatch_queue_s *do_targetq; \
void *do_ctxt; \
union { \
dispatch_function_t DISPATCH_FUNCTION_POINTER do_finalizer; \
void *do_introspection_ctxt; \
}也就是最终使用的是_os_object_s类型。
OS_OBJECT_STRUCT_HEADER类型:
#define OS_OBJECT_STRUCT_HEADER(x) \
_OS_OBJECT_HEADER(\
const struct x##_vtable_s *__ptrauth_objc_isa_pointer do_vtable, \
do_ref_cnt, \
do_xref_cnt)
#endif_OS_OBJECT_HEADER有3个成员变量:
#define _OS_OBJECT_HEADER(isa, ref_cnt, xref_cnt) \
isa; /* must be pointer-sized and use __ptrauth_objc_isa_pointer */ \
int volatile ref_cnt; \
int volatile xref_cnt至此整个继承链为:dispatch_queue_t -> dispatch_queue_s -> dispatch_object_s -> _os_object_s。
5.3 dispatch_object_s 分析
dispatch_object_t是一个联合体,那么意味着它可以是里面数据类型的任意一种。- 其中有
dispatch_object_s类型,那么意味者它底层实际上是dispatch_object_t类型。 _os_object_s也与上面的分析相对应。
总结: 整个继承链为:dispatch_queue_t -> dispatch_queue_s -> dispatch_object_s -> _os_object_s -> dispatch_object_t。
作者:HotPotCat
链接:https://www.jianshu.com/p/1b2202ecb964
